
A Multi-Label Classifier for Predicting the Most Appropriate Instrumental Method for the Analysis of Contaminants of Emerging Concern

 ,
,  , , and
, , and 
Abstract
:
1. Introduction
2. Results
2.1. Comparison between Feature Sets
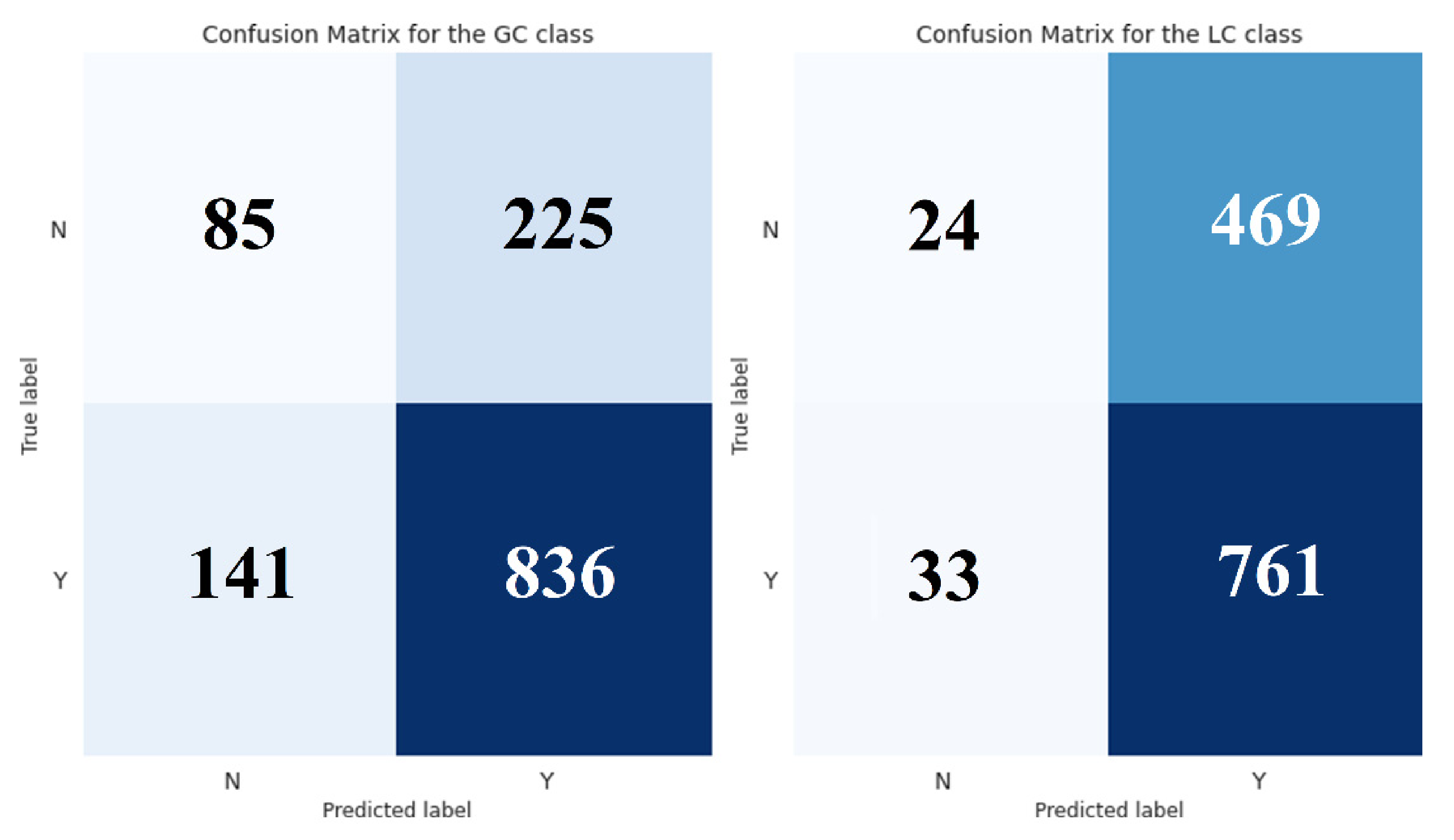
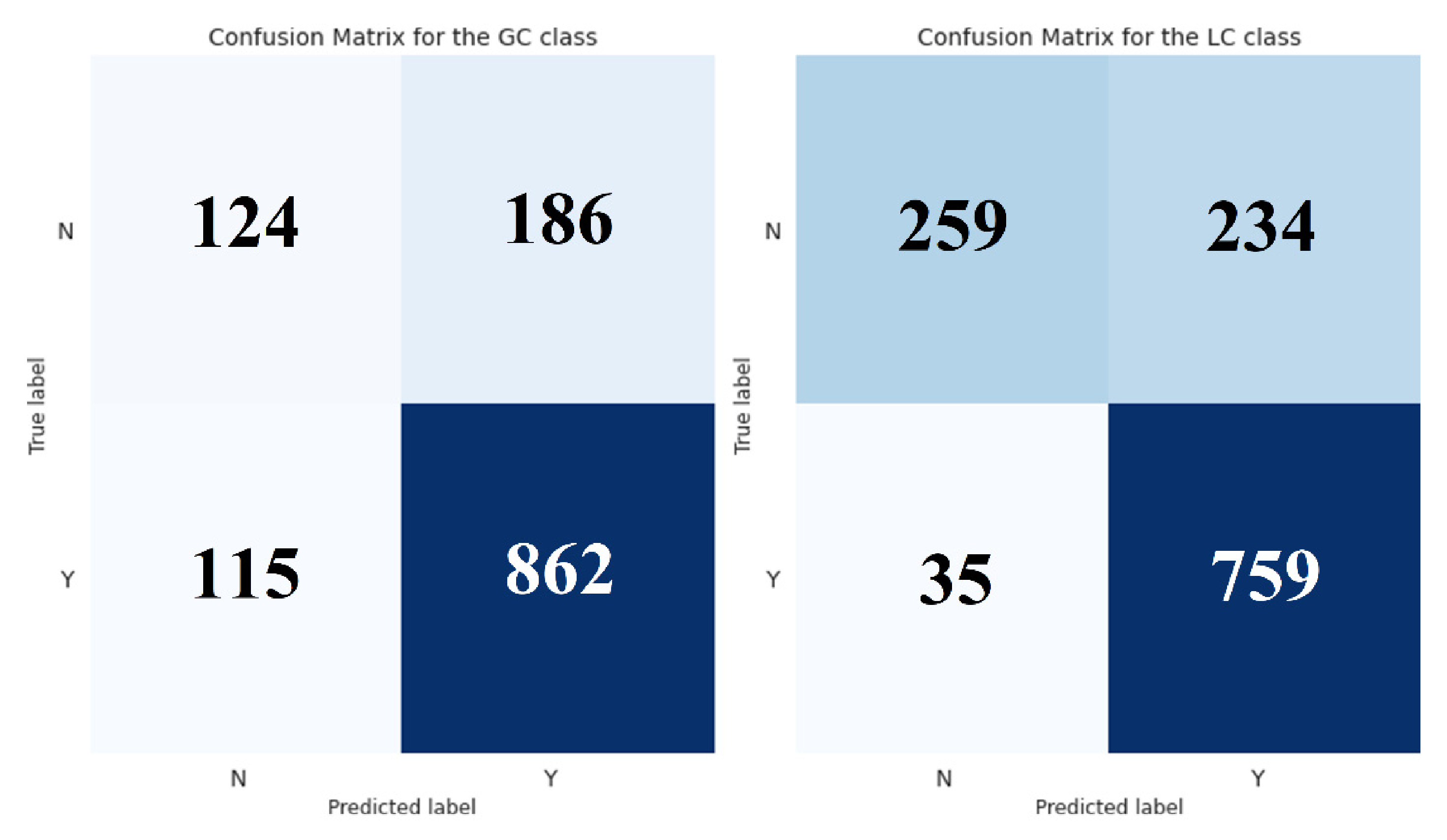
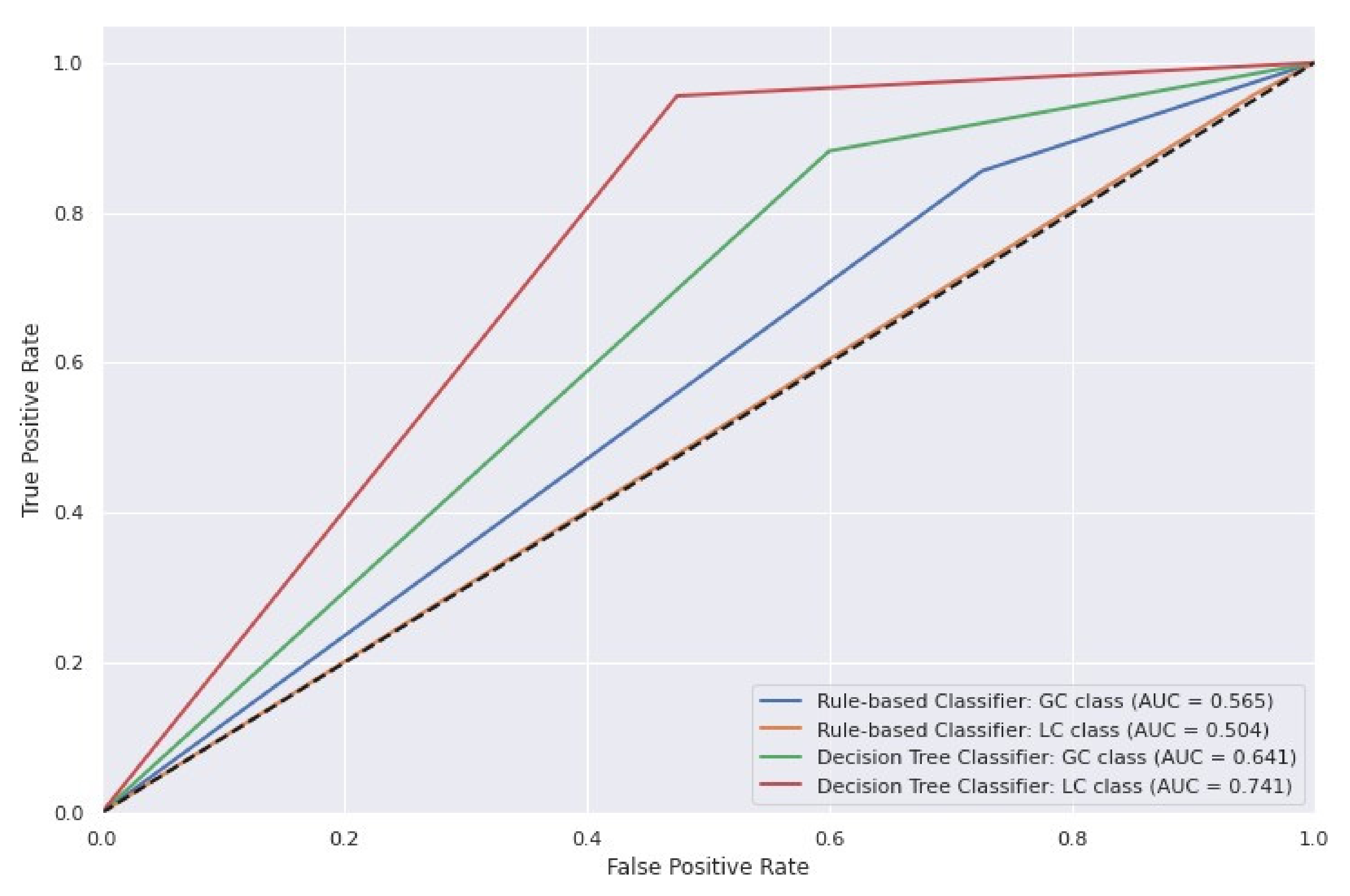
2.2. Comparison with Baseline
3. Discussion
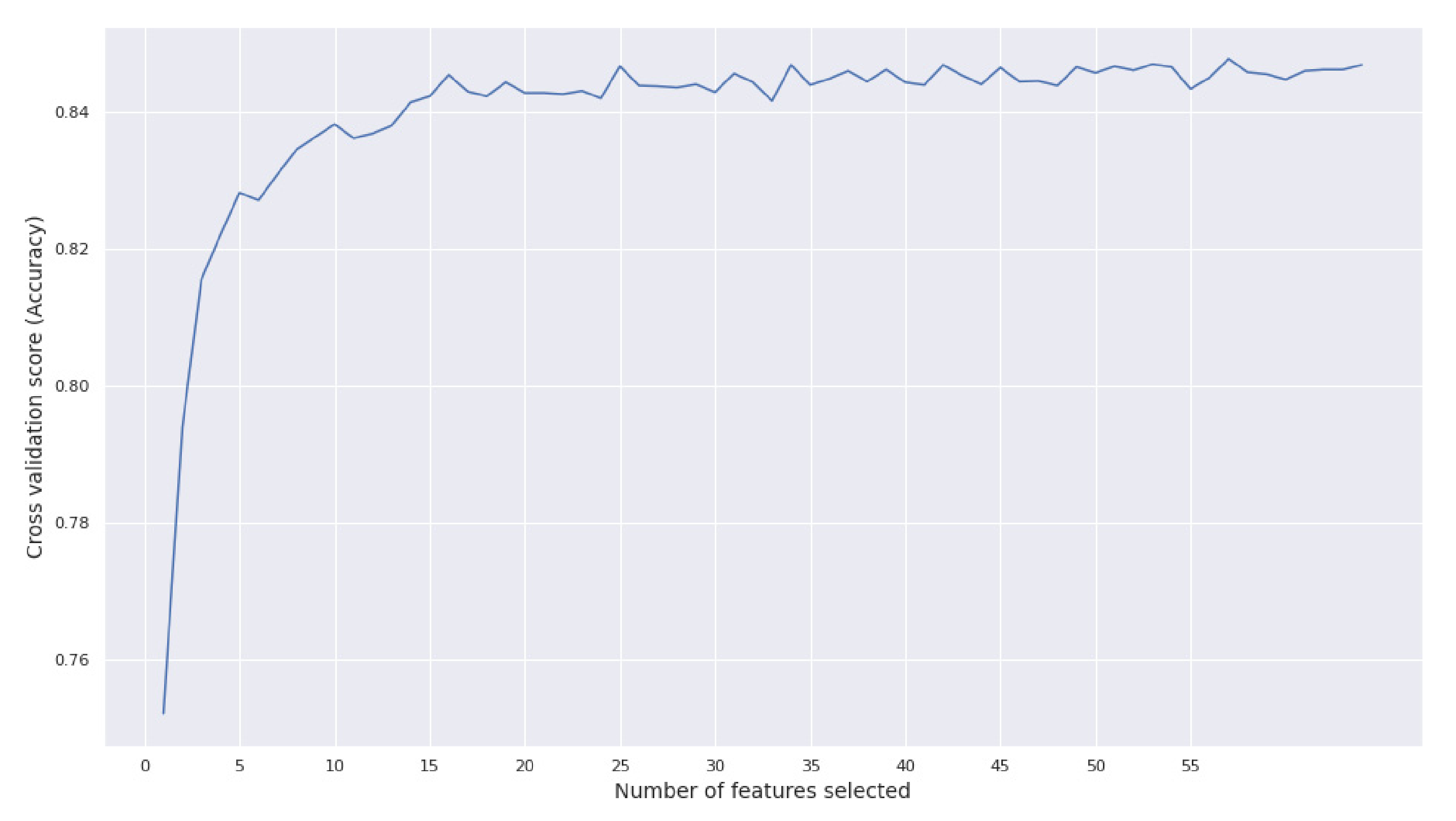
3.1. Feature Selection (FS)
3.2. Superiority of the Decision Tree Model against the Baseline Rule-Based Classification
3.3. Application of the Decision Tree Model
4. Materials and Methods
4.1. Data Collection and Processing
4.2. Baseline Implementation
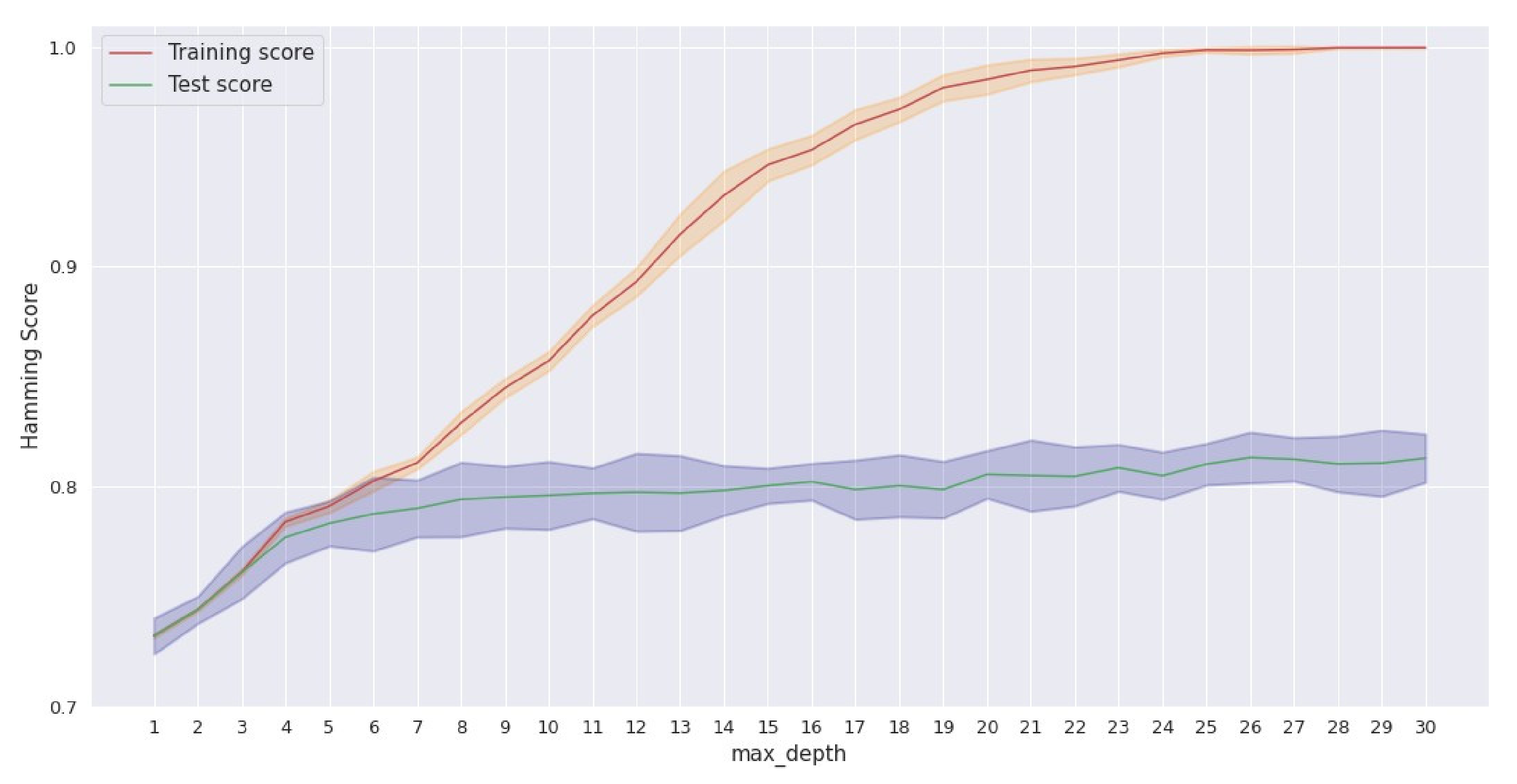
4.3. Model Construction
4.3.1. Filter Methods
4.3.2. Random Forest Feature Importance (RFFI)
4.3.3. Recursive Feature Elimination Methods
4.3.4. Sequential Feature Selection Methods
4.3.5. Manual Feature Selection
- Minimum E-State—gmin;
- Topological polar surface area—TopoPSA;
- Boiling Point—BoilingPoint;
- nhigh lowest partial charge weighted BCUTS—BCUTc-1l;
- Number of nitrogen atoms—nN;
- Number of basic groups—nBase;
- Overall or summation solute hydrogen bond acidity—MLFER_A;
- Maximum H E-State—hmax.
- criterion: [gini, entropy];
- max_features: [auto, sqrt, None];
- min_samples_split: [2, 3, 5, 8, 10, 20, 40];
- max_depth: range (3, 30);
- min_samples_leaf: [1–5, 10, 20, 40].
4.4. Evaluation Metrics
4.5. Statistical Significance
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Diaz-Cruz, M.S.; Lopez de Alda, M.J.; Lopez, R.; Barcelo, D. Determination of estrogens and progestogens by mass spectrometric techniques (GC/MS, LC/MS and LC/MS/MS). J. Mass Spectrom. 2003, 38, 917–923. [Google Scholar] [CrossRef] [PubMed]
- Barreca, S.; Orecchio, S.; Pace, A. Photochemical sample treatment for extracts clean up in PCB analysis from sediments. Talanta 2013, 103, 349–354. [Google Scholar] [CrossRef] [Green Version]
- Barreca, S.; Busetto, M.; Colzani, L.; Clerici, L.; Daverio, D.; Dellavedova, P.; Balzamo, S.; Calabretta, E.; Ubaldi, V. Determination of estrogenic endocrine disruptors in water at sub-ng L−1 levels in compliance with Decision 2015/495/EU using offline-online solid phase extraction concentration coupled with high performance liquid chromatography-tandem mass spectrometry. Microchem. J. 2019, 147, 1186–1191. [Google Scholar] [CrossRef]
- Krauss, M.; Singer, H.; Hollender, J. LC-high resolution MS in environmental analysis: From target screening to the identification of unknowns. Anal. Bioanal. Chem. 2010, 397, 943–951. [Google Scholar] [CrossRef] [Green Version]
- Bletsou, A.A.; Jeon, J.; Hollender, J.; Archontaki, E.; Thomaidis, N.S. Targeted and non-targeted liquid chromatography-mass spectrometric workflows for identification of transformation products of emerging pollutants in the aquatic environment. TrAC Trends Anal. Chem. 2015, 66, 32–44. [Google Scholar] [CrossRef] [Green Version]
- Vinaixa, M.; Schymanski, E.L.; Neumann, S.; Navarro, M.; Salek, R.M.; Yanes, O. Mass spectral databases for LC/MS- and GC/MS-based metabolomics: State of the field and future prospects. TrAC Trends Anal. Chem. 2016, 78, 23–35. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Carver, J.J.; Phelan, V.V.; Sanchez, L.M.; Garg, N.; Peng, Y.; Nguyen, D.D.; Watrous, J.; Kapono, C.A.; Luzzatto-Knaan, T.; et al. Sharing and community curation of mass spectrometry data with Global Natural Products Social Molecular Networking. Nat. Biotechnol. 2016, 34, 828–837. [Google Scholar] [CrossRef] [Green Version]
- Chiaia-Hernandez, A.C.; Schymanski, E.L.; Kumar, P.; Singer, H.P.; Hollender, J. Suspect and nontarget screening approaches to identify organic contaminant records in lake sediments. Anal. Bioanal. Chem. 2014, 406, 7323–7335. [Google Scholar] [CrossRef] [Green Version]
- Creusot, N.; Casado-Martinez, C.; Chiaia-Hernandez, A.; Kiefer, K.; Ferrari, B.J.D.; Fu, Q.; Munz, N.; Stamm, C.; Tlili, A.; Hollender, J. Retrospective screening of high-resolution mass spectrometry archived digital samples can improve environmental risk assessment of emerging contaminants: A case study on antifungal azoles. Environ. Int. 2020, 139, 105708. [Google Scholar] [CrossRef] [PubMed]
- Slobodnik, J.; Dulio, V. NORMAN Association: A Network Approach to Scientific Collaboration on Emerging Contaminants and their Transformation Products in Europe. In Transformation Products of Emerging Contaminants in the Environment; John Wiley and Sons Ltd.: The Atrium, Sothern Gate, Chichester, West Sussex, UK, 2014; pp. 903–916. [Google Scholar]
- NORMAN Network. NORMAN Database System. 2022. Available online: https://www.norman-network.com/nds/ (accessed on 17 February 2022).
- Dulio, V.; Koschorreck, J.; van Bavel, B.; van den Brink, P.; Hollender, J.; Munthe, J.; Schlabach, M.; Aalizadeh, R.; Agerstrand, M.; Ahrens, L.; et al. The NORMAN Association and the European Partnership for Chemicals Risk Assessment (PARC): Let’s cooperate! Environ. Sci. Eur. 2020, 32, 100. [Google Scholar] [CrossRef]
- Lowe, C.N.; Isaacs, K.K.; McEachran, A.; Grulke, C.M.; Sobus, J.R.; Ulrich, E.M.; Richard, A.; Chao, A.; Wambaugh, J.; Williams, A.J. Predicting compound amenability with liquid chromatography-mass spectrometry to improve non-targeted analysis. Anal. Bioanal. Chem. 2021, 413, 7495–7508. [Google Scholar] [CrossRef]
- Tomczak, M.; Tomczak, E. The need to report effect size estimates revisited an overview of some recommended measures of effect size. Trends Sport Sci. 2014, 21, 19–25. [Google Scholar]
- Kerby, D.S. The simple difference formula: An approach to teaching nonparametric correlation. Compr. Psychol. 2014, 3. [Google Scholar] [CrossRef]
- McGraw, K.O.; Wong, S.P. A common language effect size statistic. Psychol. Bull. 1992, 111, 361. [Google Scholar] [CrossRef]
- Japkowicz, N.; Shah, M. Evaluating Learning Algorithms: A Classification Perspective; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Olivier, J.; Bell, M.L. Effect sizes for 2 × 2 contingency tables. PLoS ONE 2013, 8, e58777. [Google Scholar] [CrossRef] [Green Version]
- NORMAN Network; Aalizadeh, R.; Alygizakis, N.; Schymanski, E.; Slobodnik, J.; Fischer, S.; Cirka, L. S0|SUSDAT| Merged NORMAN Suspect List: SusDat. 2020. Available online: https://zenodo.org/record/3900203#.YhM9ZOhByUk (accessed on 22 February 2022).
- Alygizakis, N.A.; Oswald, P.; Thomaidis, N.S.; Schymanski, E.L.; Aalizadeh, R.; Schulze, T.; Oswaldova, M.; Slobodnik, J. NORMAN digital sample freezing platform: A European virtual platform to exchange liquid chromatography high resolution-mass spectrometry data and screen suspects in “digitally frozen” environmental samples. TrAC Trends Anal. Chem. 2019, 115, 129–137. [Google Scholar] [CrossRef]
- Schymanski, E.L.; Singer, H.P.; Slobodnik, J.; Ipolyi, I.M.; Oswald, P.; Krauss, M.; Schulze, T.; Haglund, P.; Letzel, T.; Grosse, S.; et al. Non-target screening with high-resolution mass spectrometry: Critical review using a collaborative trial on water analysis. Anal. Bioanal. Chem. 2015, 407, 6237–6255. [Google Scholar] [CrossRef]
- Gago-Ferrero, P.; Bletsou, A.A.; Damalas, D.E.; Aalizadeh, R.; Alygizakis, N.A.; Singer, H.P.; Hollender, J.; Thomaidis, N.S. Wide-scope target screening of >2000 emerging contaminants in wastewater samples with UPLC-Q-ToF-HRMS/MS and smart evaluation of its performance through the validation of 195 selected representative analytes. J. Hazard. Mater. 2020, 387, 121712. [Google Scholar] [CrossRef]
- Massei, R.; Byers, H.; Beckers, L.M.; Prothmann, J.; Brack, W.; Schulze, T.; Krauss, M. A sediment extraction and cleanup method for wide-scope multitarget screening by liquid chromatography-high-resolution mass spectrometry. Anal. Bioanal. Chem. 2018, 410, 177–188. [Google Scholar] [CrossRef]
- Yap, C.W. PaDEL-descriptor: An open source software to calculate molecular descriptors and fingerprints. J. Comput. Chem. 2011, 32, 1466–1474. [Google Scholar] [CrossRef]
- Shi, C.; Borchardt, T.B. JRgui: A Python Program of Joback and Reid Method. ACS Omega 2017, 2, 8682–8688. [Google Scholar] [CrossRef] [PubMed]
- USEPA. Mpbpnt.exe Included in Ecological Structure Activity Relationships. 2022. Available online: https://www.epa.gov/tsca-screeningtools/ecological-structure-activity-relationships-ecosar-predictive-model (accessed on 22 February 2022).
- Lehman, A. Jmp for basic univariate and multivariate statistics: A step-by-step guide. Math. Stat. Multivar. Anal. 2005, 1, 123. [Google Scholar]
- Sorower, M.S. A literature survey on algorithms for multi-label learning. Comput. Sci. 2010, 18, 1–25. [Google Scholar]
- Godbole, S.; Sarawagi, S. Discriminative methods for multi-labeled classification. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 26–28 May 2004. [Google Scholar]
- Demsar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- NORMAN Network. NORMAN Suspect List Exchange (SLE). 2022. Available online: https://www.norman-network.com/nds/SLE/ (accessed on 22 February 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initial (1446) | Variance (1074) | Correlation (439) | RF Importance (64) | RFECV (57) | Final (8) | |
|---|---|---|---|---|---|---|
| 1st 10-Fold | 80.06 ± 1.49 | 80.25 ± 2.17 | 80.18 ± 1.67 | 80.34 ± 1.05 | 80.2 ± 0.89 | 80.94 ± 1.07 |
| 2nd 10-Fold | 80.67 ± 2.08 | 80.26 ± 1.87 | 80.56 ± 2.08 | 80.2 ± 3.01 | 80.58 ± 2.7 | 81.23 ± 2.04 |
| 3rd 10-Fold | 80.81 ± 1.17 | 80.64 ± 1.83 | 79.48 ± 0.96 | 80.54 ± 2.04 | 80.33 ± 2.34 | 81.02 ± 1.86 |
| 4th 10-Fold | 81.19 ± 1.81 | 80.14 ± 1.67 | 79.64 ± 1.51 | 80.35 ± 1.22 | 80.12 ± 1.52 | 80.52 ± 1.7 |
| 5th 10-Fold | 80.66 ± 1.18 | 81.17 ± 1.23 | 79.55 ± 1.33 | 81.29 ± 1.2 | 81.13 ± 1.28 | 80.98 ± 1.59 |
| 6th 10-Fold | 80.41 ± 1.12 | 80.13 ± 1.22 | 80.82 ± 1.59 | 81.15 ± 1.3 | 80.64 ± 1.05 | 81.36 ± 1.46 |
| 7th 10-Fold | 81.42 ± 0.58 | 80.92 ± 1.61 | 80.67 ± 1.73 | 80.12 ± 1.55 | 80.85 ± 1.59 | 81.18 ± 1.19 |
| 8th 10-Fold | 80.63 ± 1.53 | 81.02 ± 1.15 | 80.95 ± 0.87 | 80.58 ± 1.61 | 80.61 ± 2.34 | 81.01 ± 1.6 |
| 9th 10-Fold | 81.13 ± 1.28 | 80.25 ± 1.43 | 80.43 ± 1.44 | 79.86 ± 1.11 | 79.76 ± 1.1 | 81.04 ± 0.96 |
| 10th 10-Fold | 80.54 ± 1.08 | 80.24 ± 1.74 | 80.52 ± 0.92 | 80.68 ± 1.29 | 80.68 ± 1.32 | 81.03 ± 1.12 |
| Initial (1446) | Variance (1074) | Correlation (439) | RF Importance (64) | RFECV (57) | Final (8) | |
|---|---|---|---|---|---|---|
| Initial | 1.000 | 0.658 | 0.042 | 0.386 | 0.636 | 0.458 |
| Variance | 0.658 | 1.000 | 0.679 | 0.900 | 0.900 | 0.013 |
| Correlation | 0.042 | 0.679 | 1.000 | 0.900 | 0.701 | 0.001 |
| RF Importance | 0.386 | 0.900 | 0.900 | 1.000 | 0.900 | 0.003 |
| RFECV | 0.636 | 0.900 | 0.701 | 0.900 | 1.000 | 0.011 |
| Final | 0.458 | 0.013 | 0.001 | 0.003 | 0.011 | 1.000 |
| Precision | Recall | F1-Score | Accuracy | |
|---|---|---|---|---|
| GC class | 78.79 | 85.57 | 82.04 | 71.56 |
| LC class | 61.87 | 95.84 | 75.2 | 60.99 |
| Micro average | 69.71 | 90.18 | 78.63 | |
| Macro average | 70.33 | 90.71 | 78.62 | |
| Weighted average | 71.21 | 90.18 | 78.97 | |
| Samples average | 69.77 | 90.13 | 75.34 |
| Precision | Recall | F1-Score | Accuracy | |
|---|---|---|---|---|
| GC class | 82.25 | 88.23 | 85.14 | 76.61 |
| LC class | 76.44 | 95.59 | 84.95 | 79.10 |
| Micro average | 79.42 | 91.53 | 85.05 | |
| Macro average | 79.34 | 91.91 | 85.04 | |
| Weighted average | 79.64 | 91.53 | 85.05 | |
| Samples average | 81.86 | 92.35 | 84.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alygizakis, N.; Konstantakos, V.; Bouziotopoulos, G.; Kormentzas, E.; Slobodnik, J.; Thomaidis, N.S. A Multi-Label Classifier for Predicting the Most Appropriate Instrumental Method for the Analysis of Contaminants of Emerging Concern. Metabolites 2022, 12, 199. https://doi.org/10.3390/metabo12030199
Alygizakis N, Konstantakos V, Bouziotopoulos G, Kormentzas E, Slobodnik J, Thomaidis NS. A Multi-Label Classifier for Predicting the Most Appropriate Instrumental Method for the Analysis of Contaminants of Emerging Concern. Metabolites. 2022; 12(3):199. https://doi.org/10.3390/metabo12030199
Chicago/Turabian StyleAlygizakis, Nikiforos, Vasileios Konstantakos, Grigoris Bouziotopoulos, Evangelos Kormentzas, Jaroslav Slobodnik, and Nikolaos S. Thomaidis. 2022. "A Multi-Label Classifier for Predicting the Most Appropriate Instrumental Method for the Analysis of Contaminants of Emerging Concern" Metabolites 12, no. 3: 199. https://doi.org/10.3390/metabo12030199
APA StyleAlygizakis, N., Konstantakos, V., Bouziotopoulos, G., Kormentzas, E., Slobodnik, J., & Thomaidis, N. S. (2022). A Multi-Label Classifier for Predicting the Most Appropriate Instrumental Method for the Analysis of Contaminants of Emerging Concern. Metabolites, 12(3), 199. https://doi.org/10.3390/metabo12030199