1. Introduction
In cryo-electron tomography (cryo-ET), frozen-hydrated cell samples are mounted on a rotating specimen holder to capture multiple views of biological cells in their native environment. After 3D reconstruction, the resulting tomograms provide 3–5 nm resolution views of the cell’s ultrastructure, down to the level of macromolecular assemblies and individual molecules. However, even after image processing, the tomograms exhibit considerable noise because the electron dose is limited to prevent radiation damage.
There are also blurring artifacts visible in the 3D reconstruction because of the limited tilt range of the specimen holder that masks out a wedge of the transformed image data in Fourier space [
1]. In recent years, several computational groups have focused on automatically detecting and segmenting biomolecular shapes in such tomograms by using techniques such as deep learning [
2,
3,
4]. Furthermore, a number of toolboxes have been developed for tomography analysis [
5,
6,
7]. These efforts have mainly been aimed at improving the signal-to-noise ratio by averaging multiple particles in subtomogram averaging [
8]; however, the averaging approach is unsuitable for long cytoskeletal filaments that exhibit variable shapes.
Our own work over the past decade has mainly focused on developing specialized techniques for the automated detection and modeling of cytoskeletal filaments such as actin [
1,
9,
10]. The orientation of actin filaments within cells is of considerable biological importance because the filaments organize the structure of functional cell appliances such as focal adhesions, bacterial comet tails, hair cell stereocilia, lamellipodia, and filopodia. Actin filament detection and analysis has become the focus of optical microscopy in 2D [
11,
12] and cryo-ET in 3D [
13,
14,
15,
16].
Given the noise, missing-wedge artifacts, and large volume of cryo-ET reconstructions, computational tracing methods often require manual intervention [
17]. Furthermore, a manual tracing of cytoskeletal filaments is labor intensive [
18]. To achieve a more reproducible and efficient analysis, we have developed several fully automated approaches over the past decade that do not require manual intervention. These approaches were motivated by the biological application requirements of our experimental collaborators.
For example, in
Dictyostelium discoideum filopodia, the packing density is relatively low, meaning that individual actin filaments are well separated and show random orientation. We developed the
voltrac tool to find the seed locations of filaments using a genetic algorithm-based search of a population of cylindrical templates [
9]. The filaments can then be traced, starting from the seeds, by using a bidirectional search that can follow curved paths, as long as the filaments are separated. In contrast, the shaft region of hair cell stereocilia is comprised of densely packed bundles that can be traced with
bundletrac [
10], starting from user-provided seed points, here by taking advantage of the hexagonal packing symmetry orthogonal to the filament axis.
In this work, we analyze the taper region of hair cell stereocilia [
18]. Actin bundles in this region exhibit an intermediate density that imposes a certain regularity and mean direction; however, individual filaments can deviate from this mean direction. Moreover, because of the proximity of the filaments, the missing-wedge effect fuses adjacent densities, seemingly impeding their direct tracing. This problem led us to earlier developing a template-based deconvolution [
1] to correct the missing-wedge artifacts prior to the tracing; however, this approach required expensive numerical techniques (up to a week of run time), and it came at the price of interpreting the entire tomogram (including membranes, other biomolecules, and noise) as filaments, leading to false-positive predictions.
In a recent workshop paper [
19], we showed that it is possible to achieve a significantly faster tracing of dense, semiregular filaments (as in the challenging intermediate density case of the stereocilia taper region [
18]) by combining denoising with tracing in a single dynamic programming (DP)–based framework. This approach was particularly promising because of the small number of false-positive predictions. However, earlier work has called for additional tests and optimizations, which we provide in the present paper. For example, the DP approach relied on a novel design of a bipyramidal path density (
PD) accumulation scheme, and thus we also tested a more conventional straight-line
PD accumulation to demonstrate the need for our innovation.
For the noisy density maps arising in cryo-ET, we recommended in [
19] a denoising filter as a preprocessing step; the filter was based on the same DP algorithm that we developed for the filament tracing (
Figure 1). Although computationally more expensive than the later tracing, the preprocessing can strengthen the underlying filamentous structures against the noise for better visualization and automatic extraction [
19]. Enhancement techniques have also been proposed by other groups as well [
20,
21]. To provide further justification for its inclusion in the workflow (
Figure 1), we investigated the filament-tracing performance at various noise levels in the presence and absence of this preprocessing step.
The denoising filter relies on the most efficient blending of the forward and backward accumulated
s. We empirically found that the filament contrast can be enhanced when requiring both
s to be simultaneously of a high value. The simplest way to implement this in [
19] was by multiplying the
s (essentially, using the square of the geometric mean). A squared density, however, has no biological meaning. Furthermore, it was not clear if the product offered the most discriminating performance against the noise. Therefore, we have explored three additional blending functions in this paper that do not yield a squared density: the arithmetic mean, geometric mean, and minimum.
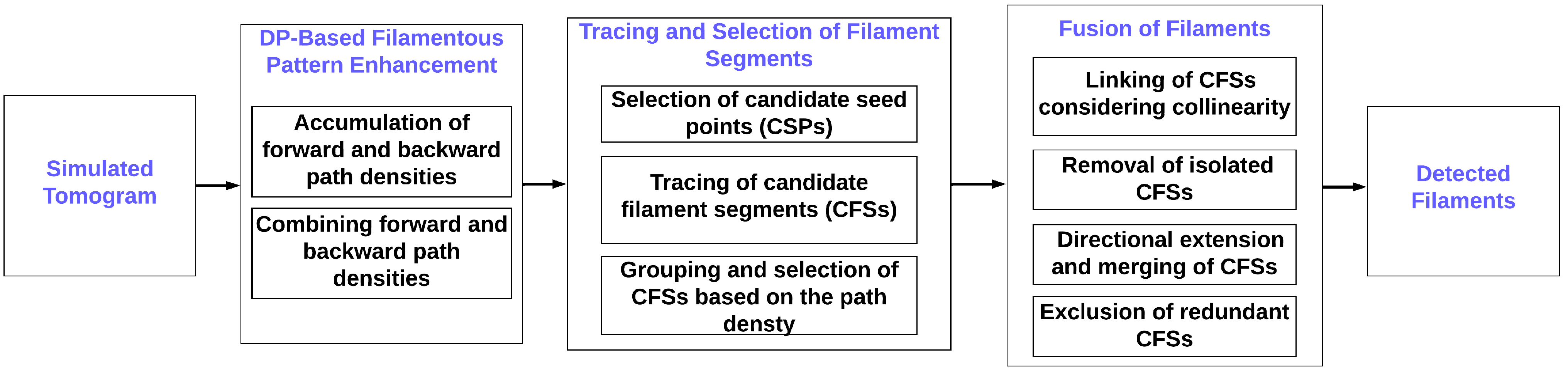
We introduced a new automatic method for seed point generation based on a spatial decomposition of the volume that specifically designed for our semiregular filament bundles [
19]. These seeds provide the starting points for the traces grown from the seeds. The nascent filaments are processed in various groupings, screenings, and fusion stages (
Figure 1), eventually yielding the final interpretation.
The filament predictions can then be evaluated in terms of true and false positives or negatives and statistical criteria, such as recall, precision, and F1 score. The statistical validation requires a known ground truth; therefore, we used only simulated tomograms modeled to closely match the noise level, noise color, and missing-wedge effects of an experimental tomogram. The results provide a quantitative justification and optimization of the various algorithmic modifications we have explored.
2. Methods
This section first introduces how our simulated tomograms were built from an existing manual tracing and how the map noise levels for our validation tests were calibrated against the existing experimental map. The simulated tomograms were then subjected to the main filament-tracing framework, which was developed in [
19] and is depicted in
Figure 1. The framework consists of several denoising, seed generation, tracing, refinement, and fusion steps, which will be described in the following.
2.1. Noise Calibration and Simulation of Tomograms
We recently developed a software tool,
TomoSim, for the realistic simulation of tomograms [
22]. The simulation will allow us to test the filament-tracing performance based on a known filament model (
Figure 2) and its corresponding experimental tomogram. The initial model can be a manually obtained interpretation of an experimental density map (
Figure 2) or automated tracing generated by a computational tracing approach described in the next section. As described in more detail in [
22], the simulation aims to faithfully recreate the noise and missing-wedge Fourier space artifacts typically found in cryo-ET. The simulations created for the current paper do not include nonfilamentous biological features, such as membranes.
We started the simulation approach by interpolating the existing model filaments and rasterizing them onto the cubic grid of an experimental map corresponding to the start model. The grid indices and k correspond to the , and Z axes, respectively. We also retained the size and dimensions of the experimental reference map grid in our simulations.
The projected filament traces were then enlarged by convolving the voxel densities
with a Gaussian-shaped kernel whose dimensions (full width at half maximum 5 nm with a voxel spacing of 0.947 nm, ∼2.01 voxels) were matched to the width of an actin filament. Color-filtered noise was added from a noise map that matched the radial power spectral density (noise color) and the signal-to-noise ratio of an experimental reference tomogram [
22]. In a second step, we also matched the noise level in the experimental map by visual appearance by applying an amplification factor of 1.85 to the filament voxels prior to volumization. This additional manual amplification can be seen as subjective, but it helped provide a better visual match to the experimental data than our present automated noise matching, as described in [
22]. The manual adjustment accounted mainly for discrepancies between the model and experimental map. For example, the manual tracing might not perfectly match the experimental tomogram positions (which we called the “alignment error” in [
22]) or the tomogram might exhibit an inhomogeneous density distribution across the volume due to gaps or helical twist in the actin [
18] (whereas our simulated filament densities were perfectly homogeneous along the filament length). In such situations, the automatically calibrated filament signal strength can be weaker than a visual inspection suggests. After noise was added, a wedge was masked out in Fourier space to emulate the missing views from the limited tilt range of the microscope specimen holder.
To validate the performance of our proposed tracing framework, we have considered simulated tomograms with varying degrees of noise (
Figure 3). In our simulations, we used four noise levels ranging from 0.4 to 1.0 (
Figure 3). The manually amplified noise level (factor 1.85) was used as an upper bound (worst case experimental noise), which was normalized as a noise level of 1.0 in the current paper. Lower levels were used as an additional scale factor. For example, the 0.6 noise level would be the closest to the automatically matched experimental noise. The lowest 0.4 level might help identify improvements that could be afforded by better quality data in future work.
In summary, the main advantages of using simulated maps were as follows: (i) to provide us with a needed ground truth for validation and (ii) to free us from the above subjective amplification uncertainty (the manual matching is only used once to set the reference level 1.0). Consequently, we can consider a reasonable range of noise levels that we would expect to encounter in experimental maps. The noise level (global scale factor) did not affect the noise color calibration or missing-wedge modeling.
2.2. Density Map Preprocessing: Accumulation of Forward and Backward Path Densities
For cryo-ET maps, we recommended in [
19] a denoising filter as a preprocessing step. Our approach assumes that filaments have a mean direction, which, in the current work, is in the
Y direction, the same as the experimental map [
18]. Individual filaments may deviate from the mean direction, so we allowed for an up to a 45
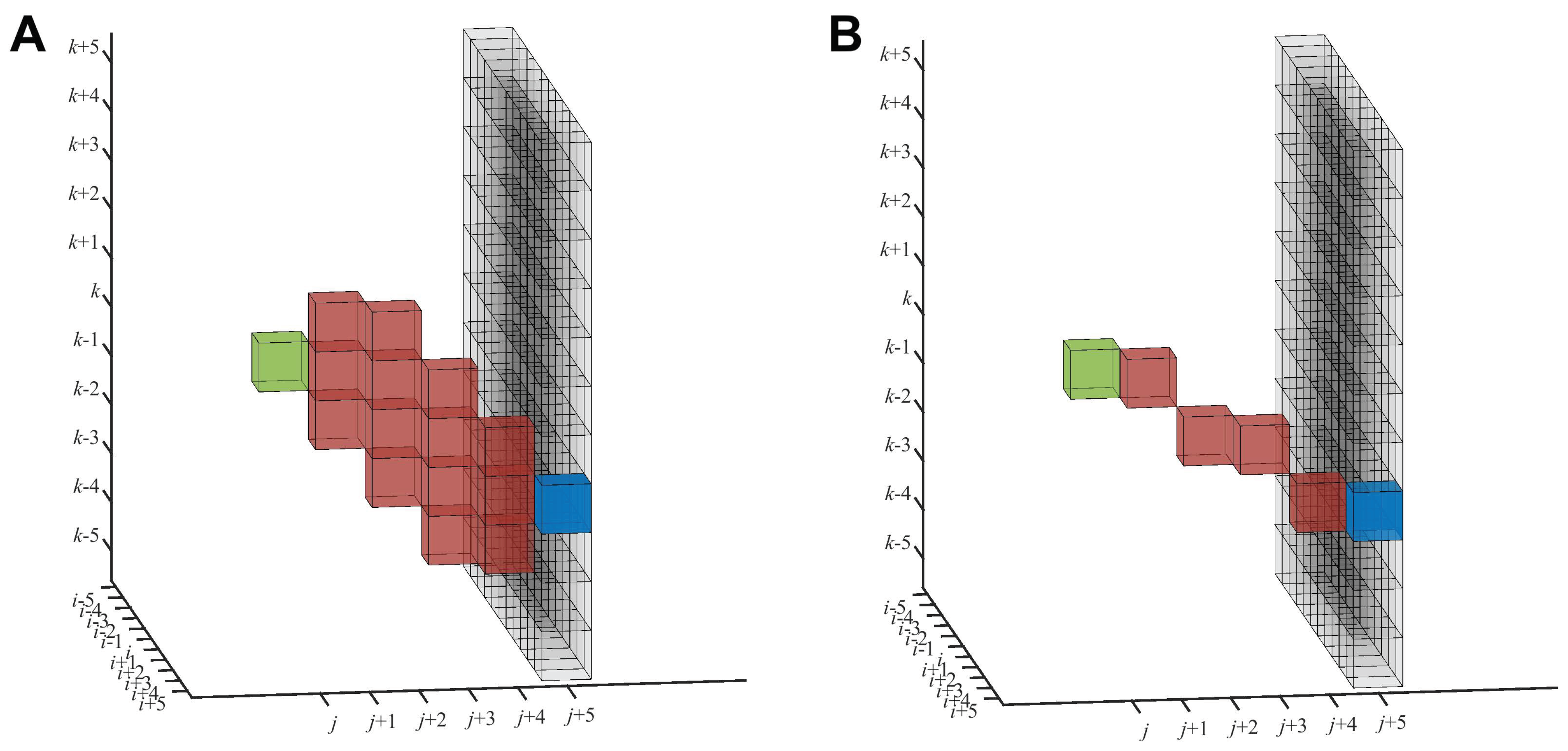
deviation from the dominant axis. For each voxel (
), here represented in green in
Figure 4, the preprocessing step assigns the path density values accumulated following a search window, starting from (
). This search window originating from (
) has a pyramidal shape in both directions constrained by the 45
limiting angle. The end points of the search window in the forward direction (fully shown in Figure 3 of [
19]) are represented in
Figure 4 by the black voxels (the base of the pyramid).
The forward path density
(
Figure 4A) and backward path density
(similar, not shown) are accumulated along certain paths (red) of a fixed length
l. In this paper, the term “length” is used for the extent in the
Y direction (mean direction), not the Euclidean length. The length
l can be tuned to the nominal resolution of the tomogram or separation of the desired features, or it can be used to control the straightness of the filaments. In this work, we set the length of
l to five voxels, here considering the trade-off between the noise present in the tomogram and shape of the filaments. The originally proposed accumulation scheme (fully shown in Figure 4 of [
19]) adds up intensity values within a zone of influence that forms a reverse pyramid with its tip at the target voxel, (
) (blue in
Figure 4). The
is then defined as the maximum
among all the target voxels in the base of the pyramid.
Therefore, the voxels contributing to the
form the intersection of two pyramids, the forward-facing search pyramid (
Figure 4A), and the reverse influence pyramid with its tip at the blue target voxel (Figure 4 of [
19]). This intersection is the accumulation zone, as shown in red in
Figure 4A. The accumulation zone is confined to a relatively localized volume reaching from the green origin (
) to the potential blue target (
). This localized zone inspired us to also test a simpler approach, where the path densities are accumulated directly along a thin straight line of voxels, as shown in
Figure 4B (see below).
For mathematical completeness, we again provide the details of the DP implementation (described above and shown in
Figure 4A). Readers familiar with the workshop proceedings [
19] may skip the following equations.
2.2.1. Pyramidal Search Window and Maximum Path Density Selection
The voxel densities
(normalized between 0 and 1) are accumulated as follows toward the base of the forward pyramid (
; black in
Figure 4) and, similarly, in the backward direction (
; not shown), from which the maximum values can be selected:
where
is initialized with the value of its normalized density
2.2.2. Accumulation and Reverse Pyramid Influence Zone
The accumulation proceeds iteratively through intermediate voxels
, whose
is updated from immediately adjacent voxels in the previous
Y-slice (i.e.,
for the forward direction or
for the backward direction) according to
where ∓ denotes the minus for Equation (
1) and plus for Equation (2) and only neighbors
within the above search pyramid are contributing (see Figure 4 of [
19] for an illustration). This scheme allows only voxels in a reverse pyramid to influence the blue target (
). The “if-contributing” condition in Equation (
4) forces an intersection of the reverse influence pyramid with the above search pyramid, yielding the red accumulation zone in
Figure 4A.
2.3. Combining Forward and Backward Path Densities for Filament Pattern Enhancement
In the second preprocessing stage, the and values are combined to form a single map, where acts as the center point and and are sampled from the two opposite directions. It is expected that if voxel is located on a filament segment, it will have high values for both and .
The two directional
s can be combined using a blending function. In our original approach [
19], we used a simple product for this purpose (first in the following list), but in the present paper, we also explored three additional alternative blending functions. Consequently, one of the following four equations was used in the present paper:
The
values are also normalized to a range from 0 to 1 for an easier way of classifying them in subsequent stages of the workflow (
Figure 1). Therefore, no normalization constants appear on the right side of the equations.
The original multiplication (Equation (
5)) provides a heuristic score to ensure a logical conjunction (
and gate); only if both
and
are large will
be large as well. In this type of blending, the product of the two densities in the filtered map
no longer corresponds to the density of the biological specimen (e.g., the larger dynamic range might amplify inhomogeneous density variations).
The addition (Equation (6)) is identical to the arithmetic mean (we ignore any normalization constants). It appears to be a more natural way to combine accumulated (summed) densities and . Moreover, the filtered map has the advantage of being proportional to the physical density of the specimen. Addition is similar to a logical disjunction (or gate), so filament voxels (with simultaneously high and ) are rewarded less than by multiplication.
Because Equation (
5) is essentially the square of the geometric mean (ignoring normalization), we can take its square root (Equation (7)). The geometric mean (Equation (7)), much like the arithmetic mean (Equation (6)), is a physical density (not density squared), but like Equation (
5), it acts as a logical conjunction because filament voxels with simultaneously high
and
are rewarded more than surrounding noise (albeit at a compressed dynamic range because of the use of the square root).
Finally, we also tested the minimum function (Equation (8)). Like the geometric mean (Equation (7)), it is a density and acts as a logical conjunction (because filament voxels with simultaneously high and are rewarded more). However, the dynamic range of the minimum function is not immediately obvious and requires further testing on actual density maps.
2.4. Candidate Seed Point Selection
It is often convenient to initiate automatic tracing from a given set of seed points. For example, Sazzed et al. [
10] required the user to provide a seed point for each filament in a highly regular (hexagonally packed) actin bundle. Rusu et al. [
9] used a genetic algorithm to find seeds for bidirectional tracing of isolated, irregular filaments. In particular, the manual placement of seeds is a tedious process and is only feasible when a small number of filaments are present. For hundreds of actin filaments forming loosely organized bundles with variable spacing among them (
Figure 2), a manual seed point selection is not practical (and it is also subjective and not reproducible). The automated genetic algorithm search uses cylindrical templates that require the filaments to be well separated [
9] and, therefore, is not applicable to our case of intermediate packing density.
The newly developed CSP generation stage of our workflow (
Figure 1) involves a spatial subdecomposition of the map into cubes of a user-defined size. For each cube, the voxel with the highest density value is considered a CSP. Here, we used cubes of 5 × 5 × 5 voxels. (The CSP cube length was identical to the path length,
l, hence providing a natural length scale for coarse-grained seed placement.)
All the local high-density voxels in the spatial decomposition are initially considered CSPs; however, it is not yet known whether any CFS generated from them constitute true filaments because the final traces are determined later (
Figure 1). A direct determination of true seed points and corresponding true filament traces is computationally out of reach because of the low signal-to-noise ratio and missing-wedge artifacts present in tomograms [
1]. Therefore, as described in the next section, the algorithm first generates a large number of CFSs from all the CSPs. Later, the CFSs pass through several rounds of screening to determine the true filaments (
Figure 1).
2.5. Tracing of Candidate Filament Segments
From each CSP, we can trace a path of length l (the same length as above) in the dominant forward direction ( axis in this work) to generate a set of short CFSs. Longer filaments will be fused from the short CFSs, if indicated, at a later stage. A CFS is represented by , where is the start voxel (i.e., the CSP), is the end voxel (i.e., the voxel with the maximum FPD after tracing a path of length l from along the forward pyramid), and .
The CFS tracing can use either one of the forward processing algorithms shown in
Figure 4. We have already explained the DP method (
Figure 4A) above (Equations (
1), (
3) and (
4)) because it is used in the preprocessing of the map. In the current paper, the relatively narrow width of the accumulation zone, as shown in
Figure 4A, inspired us to test an alternative straight-line density accumulation (
Figure 4B) that is simpler to implement. In this alternative approach, instead of considering the density of the neighbor voxels (Equations (
3) and (
4)) for creating the CFS (
) of length
l, we can consider straight lines, where lines are drawn from each of the seed points
to the target points
. For a specific seed, the target point
is the point on the base of the search pyramid,
and
, that exhibits the maximum
(Equation (
1)) among all the base points. The intermediate voxels of each straight line are determined by interpolation of the
and
indices, here using first-order Lagrange interpolating polynomials in
Y, rounded to the nearest integer.
In both approaches, we compute the
, and we also identify the corresponding CFS end voxels
. For each CFS, we finally obtain its
(normalized
) score, with a range between 0 and 1. (The
values range from 0 to (
) because the densities
were normalized between 0 and 1, so we divide by (
) to obtain the
; this revised formula supersedes the earlier calculation [
19]).
2.6. Grouping and Selection of Candidate Filament Segments
Based on their scores, the generated CFSs were grouped into 10 bins of a width of 0.1. Therefore, the bin numbers reflect the first floating point digit of the values (e.g., bin 10 contains CFSs with scores ranging from 0.9 to 1.0).
We observed earlier that CFSs of very high-numbered bins usually represent segments of true filaments. As we gradually move toward the lower-level bins, many false filament segments appear. For example, in our simulated map, we can see that the CFSs belonging to bins 6–9 are primarily true filament segments, whereas the CFSs of bins 5 and lower exhibit false filament segments that are no longer localized in the expected filament region of the map (see Figure 6 in [
19]).
To identify the bin that starts introducing false CFSs, which we refer to as the threshold bin, we take advantage of the fact that false CFSs in the threshold bin spread to the full volume (Figure 6 in [
19]) because they are mainly picking up noise. By iterating from high to low numbered bins, we automatically detect at which bin value the CFSs are no longer localized and spread to the full volume. We decompose the tomogram into 100 × 100 × 100 voxel cubes, which is an intermediate level of detail between the fine CSP grid and global map size. If we find that at least 15% of the cubes contain less than 10 CFS midpoints, we deem that the CFSs do not yet occupy the entire volume, and we proceed to test the next lower bin. In this way, the approach selects the top bins that represent mostly true CFSs. Note that the threshold bin number is not a static value; it may vary based on the density distribution of the map. For example, in our simulated tomograms, we have observed various threshold bin indices when different levels of noise are added.
Subsequently, in another refinement step, the CFSs of the selected bins are further screened based on backward tracing. Backward tracing helps determine whether a CFS truly represents a filament segment because it is expected that the traces of a filament should be similar in both directions. Specifically, we select the CFS endpoint from forward tracing and retrace it backward using . False CFSs are then excluded based on their dissimilar forward and backward trace orientations (angle tolerance: 30). Because the algorithm is sufficiently fast to generate CFSs, this retracing step does not introduce any significant computational overhead.
2.7. Fusion of Filaments
The final stage of filament formation employs multiple strategies to fuse surviving CFSs into longer individual filaments:
Connecting CFS by collinearity: This step considers the collinearity to connect adjacent filaments that exhibit the same orientation and represent fragments of the same filament. A pair of CFS that are collinear or nearly collinear (0 to 6 angle) and are very close (or connected) along the primary axis of the filament (distance between 0 to 10 voxels) are assumed to represent the same filament and are consequently merged to generate a single, longer CFS.
Removal of isolated CFS: An additional screening step automatically excludes spatially distant CFSs that are arbitrarily generated because of the presence of noise in the tomogram. A small number of false CFSs can exhibit moderate to high
scores. If these CFSs are indeed caused by erratic, local noise and not by nearby filaments (that are populated by other CFSs), these spurious CFSs can be detected and excluded by considering the mutual separation of CFSs in a local region (Figure 7 in [
19]). To determine whether a CFS is false (isolated), its center is first computed, and then, the number of other CFSs present within a sphere of a radius of 20 voxels are determined. If the number of neighboring CFSs is less than three, the CFS is considered false and excluded accordingly.
Extending and fusing the CFS: Because of the noise present in the cryo-ET map, a filament may not exhibit a homogeneous density distribution along its length. Therefore, it is possible that the fragments of the filament (i.e., CFSs) fall into multiple bins; some may even fall below the threshold density and are excluded in the above screening. To bridge between such weaker segments of the same filament, we extend the surviving CFSs as follows: Each CFS of length l is gradually extended in the forward direction by repeatedly adding a new segment of length l but only if this new segment has an score of at least that of the threshold bin. This process continues until the value of the newly generated segment falls below that of the threshold bin or until a maximum length of is reached (this empirical limit caps the number of overlapping traces, which will need to be reduced below, but the exact multiplier of l has little effect on the final results).
The current set of CFSs is then fused using a directional traversing algorithm. Specifically, we labeled all voxels on the CFSs that survived the previous steps as filament voxels (FVs). Starting from one FV as a seed, we iteratively traverse in the main filament direction (+Y in this work) by considering that the possible range of movement along the X-axis and Z-axis is half of the Y-axis movement. For example, using relative grid indices for an FV (0,0,0) and connection range of value 2, the algorithm first checks whether voxel (0,1,0) is an FV; if not, it checks whether any of the voxels (0,2,0), (0,2,1), (0,2,−1), (1,2,1), (1,2,−1), (−1,2,−1), (1,2,0), or (−1,2,0) are FVs. If a new FV is found, it is selected as a second voxel of the FS, and the search continues until no FV is found, which marks the end point of that FS. Then, we initiate traversing again from another FV, which does not belong to any of the existing FSs yet, and follow the same procedure. This process continues until all FVs are assigned to their final FSs.
Excluding redundant filament segments: This final refinement step excludes short FSs that overlap with a longer FS along the dominant axis of filaments. By discarding the spurious FS, this step can also help distinguish true filaments from noise artifacts. FSs that have more than 90% voxels in common with a longer FS are automatically discarded (Figure 8 in [
19]).
4. Discussion and Conclusions
In the current work, we have optimized a fully automatic and fast framework for tracing filaments in an semiregular actin bundle. Our DP-based approach is a spatial domain technique that operates directly on the voxels of the 3D tomogram. The use of simulated maps based on a known model has allowed us to validate the algorithm performance quantitatively. The main result of the statistical analysis is that the earlier approach described in a previous workshop paper [
19] is robust, and it would take some considerable effort to match or surpass its performance.
The neighborhood-based density accumulation scheme (
Figure 4A) enables robustness in tracing because we do not observe clean filament densities that could be picked up by a thin line accumulation (
Figure 4B). The pyramidal search window ensures that the
s are large when filaments pass through the tip of the pyramid while providing some robustness against noise because individual voxel densities are replaced with
s. The tracing assumes that filaments are oriented in a mean direction and bundled, even though individual filaments may deviate up to 45
from the main direction because of the search pyramid. The main advantage of the current approach is its applicability to dense filament bundles while still being able to follow individual curved filaments.
Among the various blending functions, the multiplication of forward and backward path densities provides for an efficient filter lifting the filament density above the noise level. Our results (
Table 1) show that such a denoising is crucial for the detection of filaments in lower quality maps. There are alternative denoising filters already in use in tomography [
26,
27,
28], but generally, the earlier filters have made no assumptions about the shape of the biological structures. For example, the earlier work of Starosolski et al. [
26] also considered a path density–based filtering, but numerically expensive random walks were required to sample the density map isotropically. In contrast, our bidirectional filter is designed for filaments that are mainly oriented in the mean direction of the bundle, and we could take advantage of this known direction to develop a more efficient approach.
The tracing stage of our framework is several orders of magnitude faster than our earlier methods and only takes minutes (facilitated by the spatial coarse graining of the CSPs). However, the denoising of all tomogram voxels is a current bottleneck and still takes several hours on a standard computer. Note that in both the forward and backward directions, density is accumulated from the origin (initialized in Equation (
3)). Therefore, DP is performed only locally for each voxel, and the full density map needs to be processed exhaustively, which is expensive. We will explore further speed up in the future.
Prospective experimental applications [
1,
10,
18] of our
Spaghetti Tracer framework call for a modeling of filament gaps, as described in Figure 2 of [
18], and for a more detailed analysis of filament curvature. Another future application of our framework would be the tracing of irregular filaments that do not exhibit a mean direction [
9]. The future DP algorithm we envisioned [
29] would be able to identify high-density filament segments in any arbitrary orientation by combining the above DP search pyramids in
,
, and
directions into an omnidirectional search cube. To enable future work on more complete cellular tomograms, we have already developed a spatial subdecomposition [
1] scheme for handling large 3D maps in memory, and we have taken the first steps to generalize the tracing to the detection of other cellular components besides actin bundles [
1,
18].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}