Comparative Studies of Vertebrate Platelet Glycoprotein 4 (CD36)

Abstract
:
1. Introduction
2. Results and Discussion
2.1. Alignments of Vertebrate CD36 Amino Acid Sequences

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CD36 Gene | Species | RefSeq ID ¹Ensembl/NCBI | GenBank ID | UNIPROT ID | Amino acids | Chromosome location | Coding Exons (strand) | Gene Size bps | Gene Expression Level |
|---|---|---|---|---|---|---|---|---|---|
| Human | Homo sapiens | NM_001001547 | BC008406 | P16671 | 472 | 7:80,275,645-80,303,732 | 12 (+ve) | 72,231 | 6.6 |
| Chimpanzee | Pan troglodytes | ¹XP_519573 | na | na | 472 | 7:81,142,402-81,169,764 | 12 (+ve) | #27,363 | na |
| Orangutan | Pongo abelii | ¹XP_002818343 | na | na | 472 | 7:95,750,733-95,779,630 | 12 (-ve) | #28,898 | na |
| Gibbon | Nomascus leucogenys | ¹XP_003252221 | na | na | 472 | *GL397261:11,570,433-11,598,114 | 12 (+ve) | #27,682 | na |
| Rhesus | Macaca mulatta | NP_001028085 | na | na | 472 | 3:136,626,102-136,653,066 | 12 (+ve) | #27,682 | na |
| Mouse | Mus musculus | NM_001159555.1 | BC010262 | Q08857 | 472 | 5:17,291,543-17,334,712 | 12 (-ve) | 43,170 | 4.2 |
| Rat | Rattus norvegicus | NP_113749 | L19658 | Q07969 | 472 | 4:13,472,534-13,522,334 | 12 (+ve) | 49,801 | 0.3 |
| Guinea Pig | Cavia porcellus | ¹XP_003469862 | na | na | 472 | *31:20,074,611-20,098,210 | 12 (+ve) | #23,600 | na |
| Cow | Bos taurus | NM_17410 | BC103112 | P26201 | 472 | 4:40,585,624-40,614,621 | 12 (-ve) | #28,998 | na |
| Dog | Canis familaris | NM_001177734 | ADE58431 | na | 472 | 18:23,334,171-23,360,045 | 12 (+ve) | #25,875 | na |
| Pig | Sus scrofa | NP_001038087 | AK400585 | Q3HUX1 | 472 | 9:93,204,848-93,241,842 | 12 (-ve) | #36,995 | na |
| Rabbit | Oryctolagus cuniculus | ¹XP_002712062 | na | na | 472 | 7:35,303,111-35,333,630 | 12 (-ve) | #30,520 | na |
| Horse | Equus caballus | ¹XP_001487957 | na | na | 472 | 4:6730,96-698,607 | 12 (-ve) | #25,512 | na |
| Elephant | Loxodonta africana | ¹XP_003407226 | na | na | 472 | 5: 69,036,730-69,073,879 | 12 (-ve) | #37,150 | na |
| Opossum | Monodelphis domestica | ¹XP_001364375 | na | na | 471 | 8:149,041,138-149,075,533 | 12 (-ve) | #34,396 | na |
| Platypus | Ornithorhynchus anatinus | ¹XP_001506583 | na | na | 471 | *Ultra5:3,505,963-3,536,963 | 12 (-ve) | #31,001 | na |
| Chicken | Gallus gallus | ¹ENSGALG8439 | AJ719746 | F1NER9 | 471 | 1:12,077,308-12,107,415 | 12 (-ve) | 30,108 | na |
| Lizard | Anolis carolinensis | ¹XP_003221568 | na | na | 472 | 5:93,087,943-93,120,933 | 12 (-ve) | #32,991 | na |
| Frog | Xenopus tropicalis | NP_001107151 | na | na | 470 | *GL172681:663,550-679,762 | 12 (-ve) | #16,213 | na |
| Zebrafish | Danio rerio | NP_001002363.1 | BC076048 | Q6DHC7 | 465 | 4:21,594,449-21,606,961 | 12 (-ve) | 12,513 | na |
| SCARB1 Gene | Species | RefSeq ID ¹Ensembl/NCBI | GenBank ID | UNIPROT ID | Amino acids | Chromosome location | Coding Exons (strand) | Gene Size bps | Gene Expression Level |
| Human | Homo sapiens | NM_00505 | BC022087 | Q8WVT0 | 509 | 12:125,267,232-125,348,266 | 12 (-ve) | 81,035 | 13.7 |
| Mouse | Mus musculus | NM_001205082.1 | BC004656 | Q61009 | 509 | 5:125,761,478-125,821,252 | 12 (-ve) | 63,985 | 5.1 |
| Chicken | Gallus gallus | ¹XP_415106 | na | na | 503 | 15:4,543,054-4,558,954 | 12 (+ve) | 15,901 | na |
| Zebrafish | Danio rerio | NM_198121 | BC044516 | E7FB50 | 496 | 11:21,526,513-21,572,478 | 12 (-ve) | 45,684 | na |
| SCARB2 Gene | |||||||||
| Human | Homo sapiens | NM_005506 | BT006939 | Q53Y63 | 478 | 4:77,084,378-77,134,696 | 12 (-ve) | 50,316 | 3.2 |
| Mouse | Mus musculus | NM_007644 | BC029073 | O35114 | 478 | 5:92,875,330-92,934,334 | 12 (-ve) | 59,005 | 3.6 |
| Chicken | Gallus gallus | ¹XP_42093.1 | BX931548 | na | 481 | 4:51,411,268-51,429,620 | 12 (+ve) | 18,353 | na |
| Zebrafish | Danio rerio | NM_173259.1 | BC162407 | Q8JQR8 | 531 | 5: 63,942,096-63,955,449 | 13 (+ve) | 13,354 | na |
| CD36 Gene | |||||||||
| Lancelet | Branchiostoma floridae | ¹XP_002609178.1 | na | na | 480 | Un:534,334,234-534,343,082 | 12 (+ve) | 8,849 | na |
| Sea squirt | Ciona intestinalis | ¹XP_002127015.1 | na | na | 523 | 09p:2,872,362-2,873,903 | 1 (-ve) | 1,542 | na |
| Nematode | Caenorhabditis elegans | NM_067224 | na | Q9XTT3 | 534 | III:12,453,609-12,456,726 | 8 (+ve) | 3,118 | 4.6 |
| Fruit fly | Drosophila melanogaster | NP_523859 | na | na | 520 | 2R:20,864,606-20,867,116 | 6 (-ve) | #2,511 | na |
 ; predicted transmembrane residues are shown in
; predicted transmembrane residues are shown in  ; N-glycosylated and potential N-glycosylated Asn sites are in
; N-glycosylated and potential N-glycosylated Asn sites are in  ; exoplasmic Thr92, which is phosphorylated by pyruvate kinase alpha, is shown in
; exoplasmic Thr92, which is phosphorylated by pyruvate kinase alpha, is shown in  ; predicted disulfide bond Cys residues are shown in
; predicted disulfide bond Cys residues are shown in  ; predicted α-helices for vertebrate CD36 are in
; predicted α-helices for vertebrate CD36 are in  and numbered in sequence from the start of the predicted exoplasmic domain; predicted β-sheets are in
and numbered in sequence from the start of the predicted exoplasmic domain; predicted β-sheets are in  and also numbered in sequence; bold underlined font shows residues corresponding to known or predicted exon start sites; exon numbers refer to human CD36 gene exons;
and also numbered in sequence; bold underlined font shows residues corresponding to known or predicted exon start sites; exon numbers refer to human CD36 gene exons;  residues refer to conserved glycines in the N- and C-terminal oligomerisation domains of the trans-membrane sequence [49]; CD36 binding domains are identified: THP-refers to binding region for low-density lipoproteins [6,7,8]; neutrophil phagocytosis domain designated by [3,7]; PE binding refers to cytoadherence region of Plasmodium falciparum-parasitized erythrocytes (PE) to endothelial cells [4].
; predicted transmembrane residues are shown in ; N-glycosylated and potential N-glycosylated Asn sites are in ; exoplasmic Thr92, which is phosphorylated by pyruvate kinase alpha, is shown in ; predicted disulfide bond Cys residues are shown in ; predicted α-helices for vertebrate CD36 are in and numbered in sequence from the start of the predicted exoplasmic domain; predicted β-sheets are in and also numbered in sequence; bold underlined font shows residues corresponding to known or predicted exon start sites; exon numbers refer to human CD36 gene exons; residues refer to conserved glycines in the N- and C-terminal oligomerisation domains of the trans-membrane sequence [49]; CD36 binding domains are identified: THP-refers to binding region for low-density lipoproteins [6,7,8]; neutrophil phagocytosis domain designated by [3,7]; PE binding refers to cytoadherence region of Plasmodium falciparum-parasitized erythrocytes (PE) to endothelial cells [4].
residues refer to conserved glycines in the N- and C-terminal oligomerisation domains of the trans-membrane sequence [49]; CD36 binding domains are identified: THP-refers to binding region for low-density lipoproteins [6,7,8]; neutrophil phagocytosis domain designated by [3,7]; PE binding refers to cytoadherence region of Plasmodium falciparum-parasitized erythrocytes (PE) to endothelial cells [4].
; predicted transmembrane residues are shown in ; N-glycosylated and potential N-glycosylated Asn sites are in ; exoplasmic Thr92, which is phosphorylated by pyruvate kinase alpha, is shown in ; predicted disulfide bond Cys residues are shown in ; predicted α-helices for vertebrate CD36 are in and numbered in sequence from the start of the predicted exoplasmic domain; predicted β-sheets are in and also numbered in sequence; bold underlined font shows residues corresponding to known or predicted exon start sites; exon numbers refer to human CD36 gene exons; residues refer to conserved glycines in the N- and C-terminal oligomerisation domains of the trans-membrane sequence [49]; CD36 binding domains are identified: THP-refers to binding region for low-density lipoproteins [6,7,8]; neutrophil phagocytosis domain designated by [3,7]; PE binding refers to cytoadherence region of Plasmodium falciparum-parasitized erythrocytes (PE) to endothelial cells [4].
2.2. Comparative Sequences for Vertebrate CD36 N-Glycosylation Sites
2.3. Conserved Glycines in the N-Terminal Domain of the CD36 Trans-Membrane Sequence
| Vertebrate | Species | Site 1 | Site 2* | Site 3 | Site 4 | Site 5 | Site 6 | Site 7 | Site 8 | Site 9 | Site 10 | Site 11 | Site12 | Site 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CD36 | ||||||||||||||
| Human | Homo sapiens | 79NSSN | 102NVTQ | 134NFTV | 163NKSK | |||||||||
| Chimp | Pan troglodytes | 79NSSN | 102NVTQ | 134NFTV | 163NKSK | |||||||||
| Orangutan | Pongo abelii | 79NSSN | 102NVTQ | 134NFTV | 163NKSK | |||||||||
| Gibbon | Nomascus leucogenys | 79NSSN | 102NVTQ | 134NFTV | 163NKSK | |||||||||
| Rhesus | Macaca mulatta | 79NSSN | 102NITQ | 134NFTV | 163NKSK | |||||||||
| Marmoset | Callithrix jacchus | 79NSSN | 102NVTQ | 134NFTV | ||||||||||
| Mouse | Mus musculus | 79NSSK | 102NITQ | 134NFTV | ||||||||||
| Rat | Rattus norvegicus | 79NSSK | 102NITQ | 134NFTV | ||||||||||
| Guinea Pig | Cavia porcellus | 79NSSN | 102NVTQ | 132NDTF | 172NRTL | |||||||||
| Cow | Bos taurus | 79NSSK | 102NITQ | 172NRTL | ||||||||||
| Horse | Equus caballus | 79NSSK | 102NITH | 109NHTV | 134NDTF | |||||||||
| Dog | Canis familaris | 79NSSK | 102NITH | 172NRTV | ||||||||||
| Pig | Sus scrofa | 79NSSV | 102NITQ | 132NDTF | ||||||||||
| Rabbit | Oryctolagus cuniculus | 79NSSN | 102NVTQ | 132NDTF | ||||||||||
| Elephant | Loxodonta africana | 79NSSN | 102NITQ | 132NDTF | ||||||||||
| Panda | Ailuropoda melanoleuca | 79NSSA | 102NITH | 132NDTL | ||||||||||
| Opossum | Monodelphis domestica | 79NSTK | 102NLTQ | 131NDSF | ||||||||||
| Platypus | Ornithorhynchus anatinus | 79NNSK | 102NITK | |||||||||||
| Chicken | Gallus gallus | 46NGTI | 72NPSD | 102NITE | 108NGTI | 131NDTI | 171NRTV | |||||||
| Zebra finch | Taeniopygia guttata | 46NGGT | 72NPSE | 102NVTE | 108NGTI | 131NDTL | 171NRTV | |||||||
| Lizard | Anolis carolensis | 46NGTI | 79NGSQ | 102NITH | 131NDTF | |||||||||
| Frog | Xenopus tropicalis | 101NITQ | 107NNTV | 162NSSL | ||||||||||
| Zebrafish | Danio rerio | 47NGTL | 103NITF | 109NNTV | 168NRTV | |||||||||
| Tetraodon | Tetraodon nigroviridis | 77NGTT | 100NVTY | 105NDST | 162NSSL | |||||||||
| Sea squirt | Ciona intestinalis | 74NVTN | 120NKTY | 143NGSE | ||||||||||
| Lancelet | Branchiostoma floridae | 100NITF | 106NGTV | 122NMSF | 129NDTF | |||||||||
| Fruit fly | Drosophila melanogaster | 80NVTN | 90NGSK | 118NGTL | ||||||||||
| Vertebrate | Species | Site 14 | Site 15 | Site 16 | Site 17 | Site 18 | Site 19 | Site 20 | Site 21 | Site 22 | Site 23 | Site 24 | Site 25 | No of |
| CD36 | Sites | |||||||||||||
| Human | Homo sapiens | 205NNTA | 220NISK | 235NLSY | 247NGTD | 321NCTS | 417NETG | 10 | ||||||
| Chimp | Pan troglodytes | 205NNTA | 220NISK | 235NLSY | 247NGTD | 321NCTS | 417NETG | 10 | ||||||
| Orangutan | Pongo abelii | 205NNTA | 235NLSY | 247NGTD | 321NCTS | 417NETG | 9 | |||||||
| Gibbon | Nomascus leucogenys | 205NNTA | 235NLSY | 247NGTD | 321NCTS | 417NETG | 9 | |||||||
| Rhesus | Macaca mulatta | 205NNTA | 235NLSY | 247NGTD | 321NCTS | 417NETG | 9 | |||||||
| Marmoset | Callithrix jacchus | 205NNTA | 235NLSY | 247NGTD | 321NCTS | 417NETG | 9 | |||||||
| Mouse | Mus musculus | 205NDTV | 220NISK | 235NLSY | 247NGTD | 321NCTS | 417NETG | 9 | ||||||
| Rat | Rattus norvegicus | 205NNTV | 220NISK | 235NLSY | 247NGTD | 321NCTS | 417NETG | 9 | ||||||
| Guinea Pig | Cavia porcellus | 205NNTA | 220NISK | 235NLSY | 247NGTD | 321NCTS | 417NETG | 10 | ||||||
| Cow | Bos taurus | 205NNTA | 235NLSY | 247NGTD | 321NCTS | 417NETG | 8 | |||||||
| Horse | Equus caballus | 205NNTV | 220NISK | 235NLSY | 247NGTD | 321NCTS | 417NETG | 10 | ||||||
| Dog | Canis familaris | 205NNTV | 220NVSQ | 235NLSY | 247NGTD | 321NCTS | 417NETG | 9 | ||||||
| Pig | Sus scrofa | 205NNTS | 206NTSD | 235NLSY | 247NGTD | 321NCTS | 417NETG | 9 | ||||||
| Rabbit | Oryctolagus cuniculus | 205NNTV | 220NISK | 235NLSY | 247NGTD | 321NCTS | 417NETG | 9 | ||||||
| Elephant | Loxodonta africana | 205NNTV | 235NLSY | 247NGTD | 321NCTS | 417NETG | 8 | |||||||
| Panda | Ailuropoda melanoleuca | 208NNTA | 238NLSY | 250NGTD | 324NCTS | 420NETG | 8 | |||||||
| Opossum | Monodelphis domestica | 204NNTV | 234NLSF | 246NGTD | 320NCTS | 416NETG | 8 | |||||||
| Platypus | Ornithorhynchus anatinus | 204NNTA | 234NLSY | 246NGTD | 320NCTS | 416NETG | 7 | |||||||
| Chicken | Gallus gallus | 204NGTS | 234NLSY | 246NGTD | 320NCTL | 416NETA | 10 | |||||||
| Zebra finch | Taeniopygia guttata | 205NGTS | 247NGTD | 321NCTI | 417NESA | 9 | ||||||||
| Lizard | Anolis carolensis | 205NETL | 232NKSM | 247NTGD | 321NCTG | 417NETA | 9 | |||||||
| Frog | Xenopus tropicalis | 202NGTA | 245NGTD | 319NCTA | 415NETA | 7 | ||||||||
| Zebrafish | Danio rerio | 194NGTV | 229NDSY | 237NGSD | 311NCTL | 406NETA | 9 | |||||||
| Tetraodon | Tetraodon nigroviridis | 200NGTA | 228NRTV | 243NGTD | 317NCTL | 416NETA | 9 | |||||||
| Sea squirt | Ciona intestinalis | 232NQSR | 260NMSE | 276NGTD | 346NHTV | 7 | ||||||||
| Lancelet | Branchiostoma floridae | 182NDSL | 211NGTD | 255NGTD | 333NISI | 420NEST | 9 | |||||||
| Fruit fly | Drosophila melanogaster | 223NGTS | 347NVSL | 5 |
2.4. Conserved Vertebrate CD36 Cysteine Residues
2.5. Predicted Secondary Structures for Vertebrate CD36
2.6. Conserved Proline, Glycine and Charged Amino Acid Residues within the CD36 Exoplasmic Domain
2.7. Alignments of Human CD36, SCARB1 and SCARB2
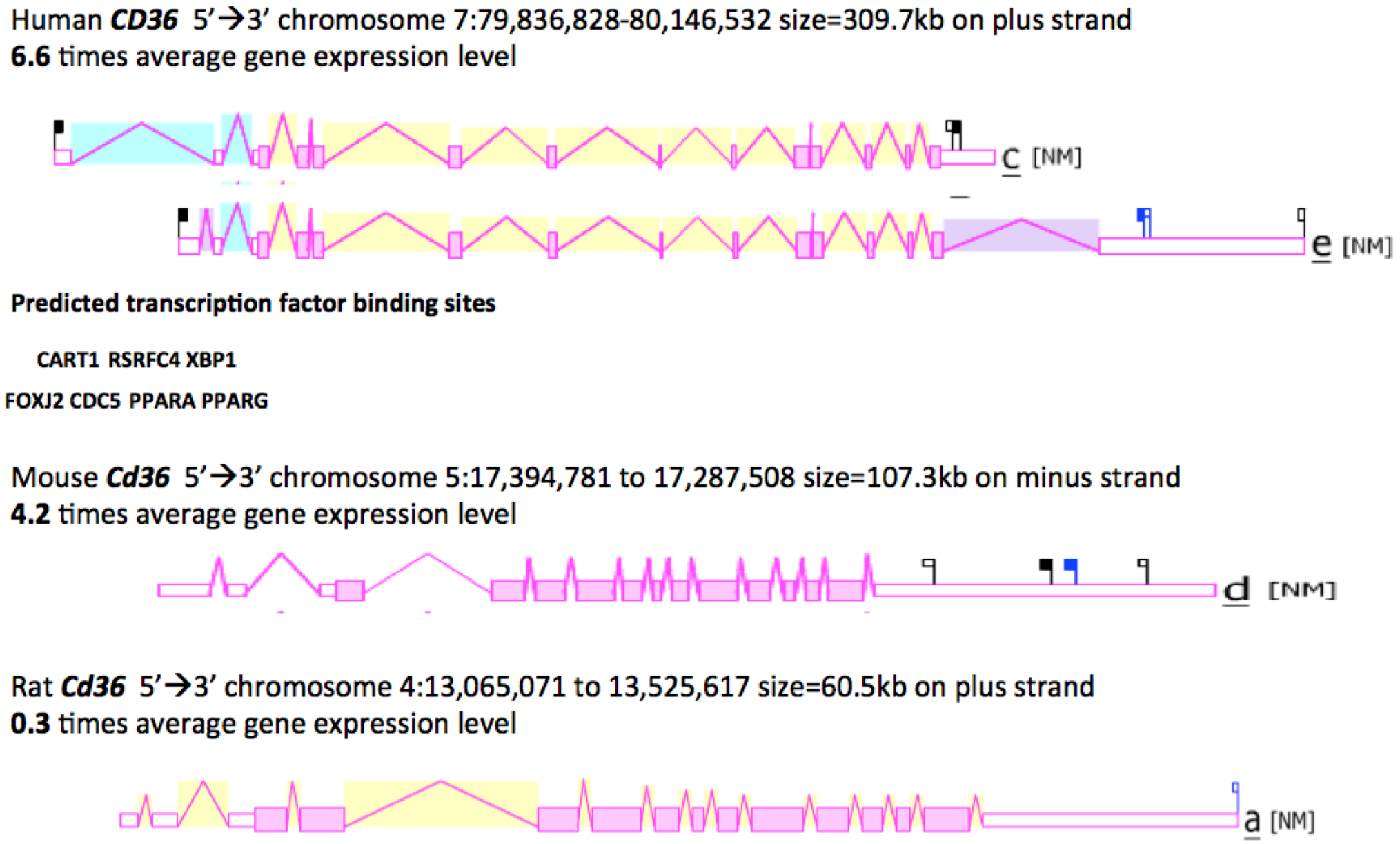
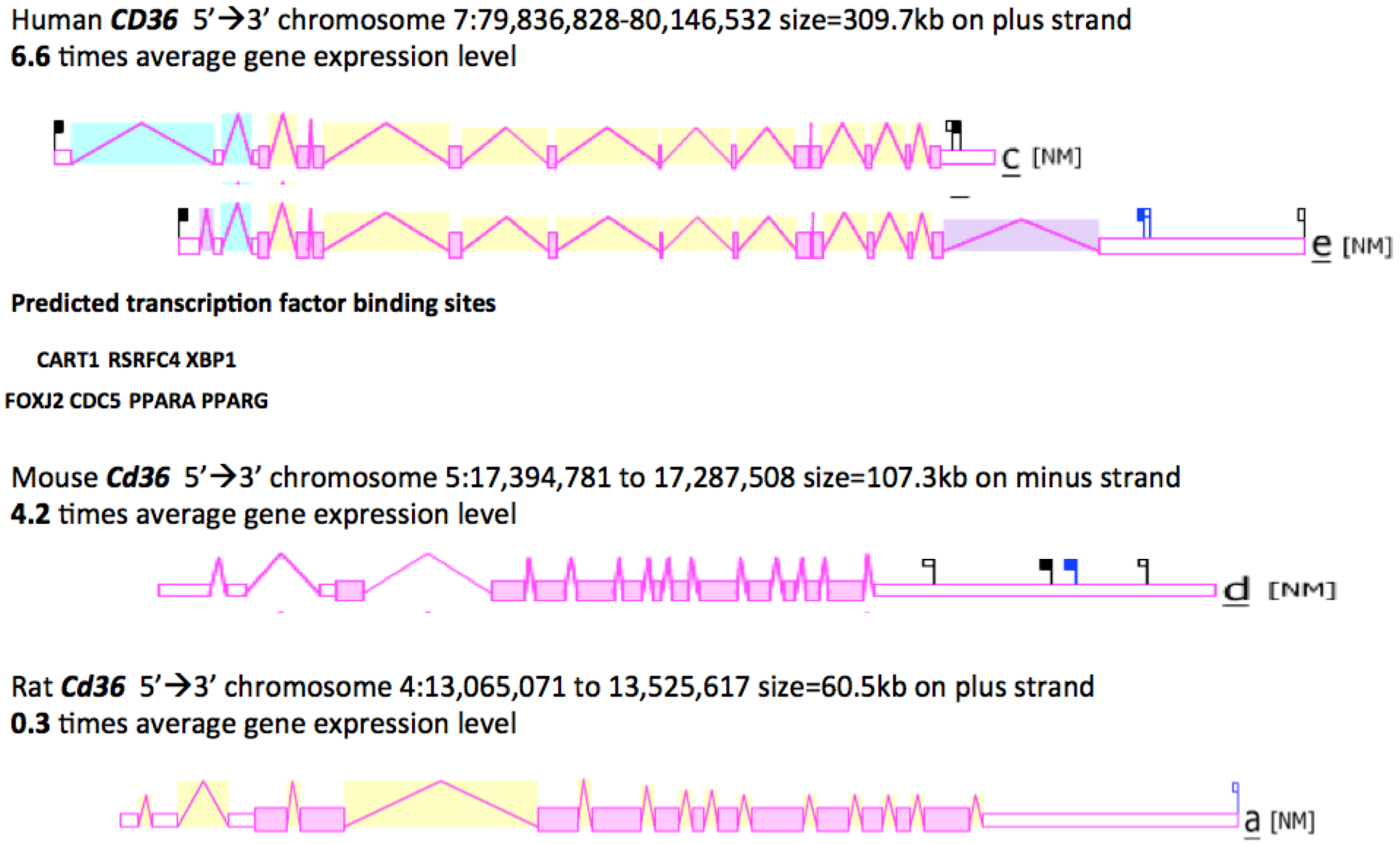
2.8. Gene Locations and Exonic Structures for Vertebrate CD36 Genes
; predicted trans-membrane residues are shown in ; N-glycosylated and potential N-glycosylated Asn sites are shown in ; free-SH Cys involved in lipid transfer for human SCARB1 is shown in ; predicted disulfide bond Cys residues are shown in ; predicted α-helices for CD36-like sequences are in and numbered in sequence from the start of the predicted exoplasmic domain; predicted β-sheets are in and also numbered in sequence; bold underlined font shows residues corresponding to known or predicted exon start sites; exon numbers are shown; residues refer to conserved glycines in the N- and C-terminal oligomerisation domains of the trans-membrane sequence [49]; C-terminal SCARB1  residues refer to PDZ-binding domain sequences [18,19].
; predicted trans-membrane residues are shown in ; N-glycosylated and potential N-glycosylated Asn sites are shown in ; free-SH Cys involved in lipid transfer for human SCARB1 is shown in ; predicted disulfide bond Cys residues are shown in ; predicted α-helices for CD36-like sequences are in and numbered in sequence from the start of the predicted exoplasmic domain; predicted β-sheets are in and also numbered in sequence; bold underlined font shows residues corresponding to known or predicted exon start sites; exon numbers are shown; residues refer to conserved glycines in the N- and C-terminal oligomerisation domains of the trans-membrane sequence [49]; C-terminal SCARB1 residues refer to PDZ-binding domain sequences [18,19].
residues refer to PDZ-binding domain sequences [18,19].
; predicted trans-membrane residues are shown in ; N-glycosylated and potential N-glycosylated Asn sites are shown in ; free-SH Cys involved in lipid transfer for human SCARB1 is shown in ; predicted disulfide bond Cys residues are shown in ; predicted α-helices for CD36-like sequences are in and numbered in sequence from the start of the predicted exoplasmic domain; predicted β-sheets are in and also numbered in sequence; bold underlined font shows residues corresponding to known or predicted exon start sites; exon numbers are shown; residues refer to conserved glycines in the N- and C-terminal oligomerisation domains of the trans-membrane sequence [49]; C-terminal SCARB1 residues refer to PDZ-binding domain sequences [18,19]. 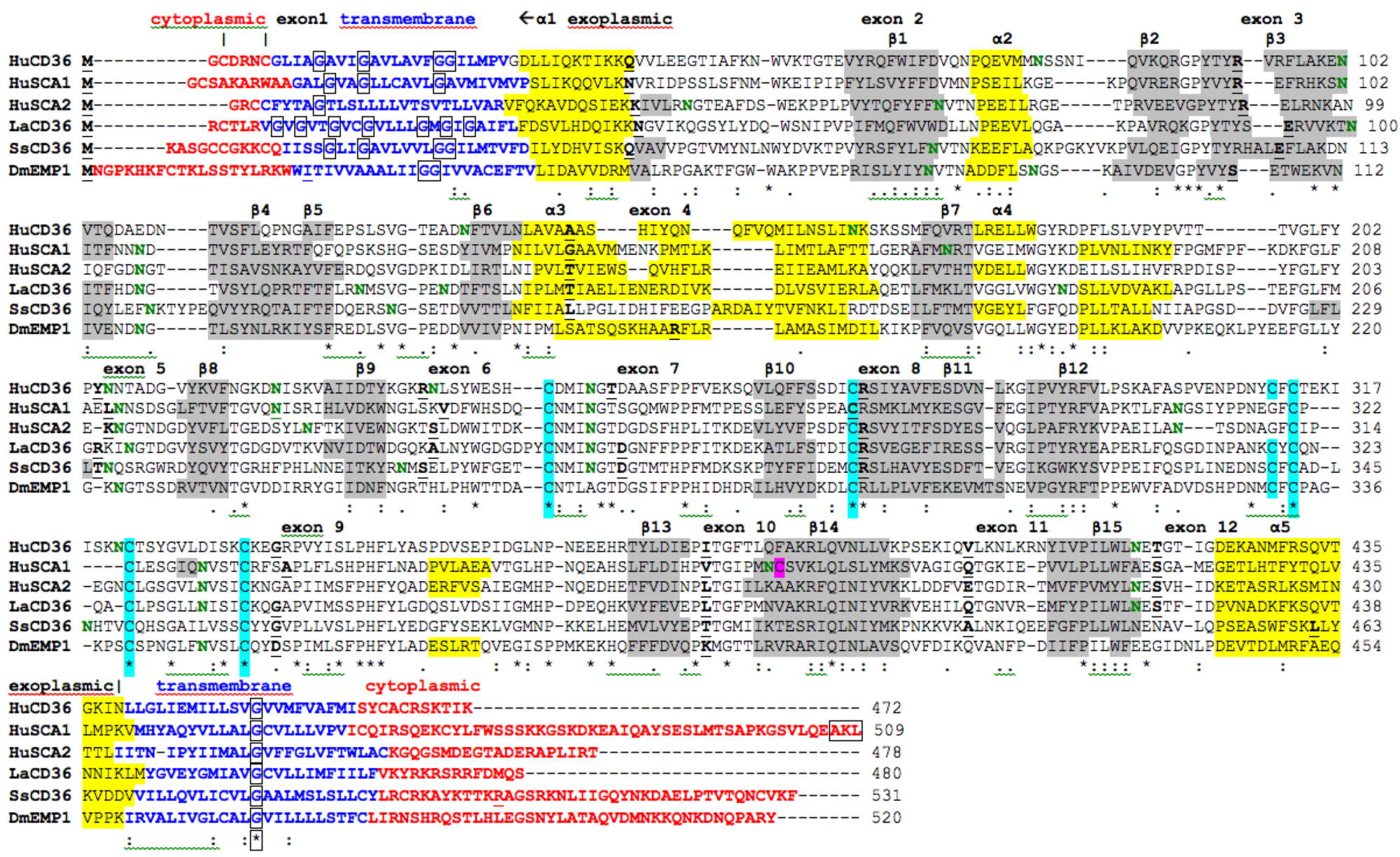
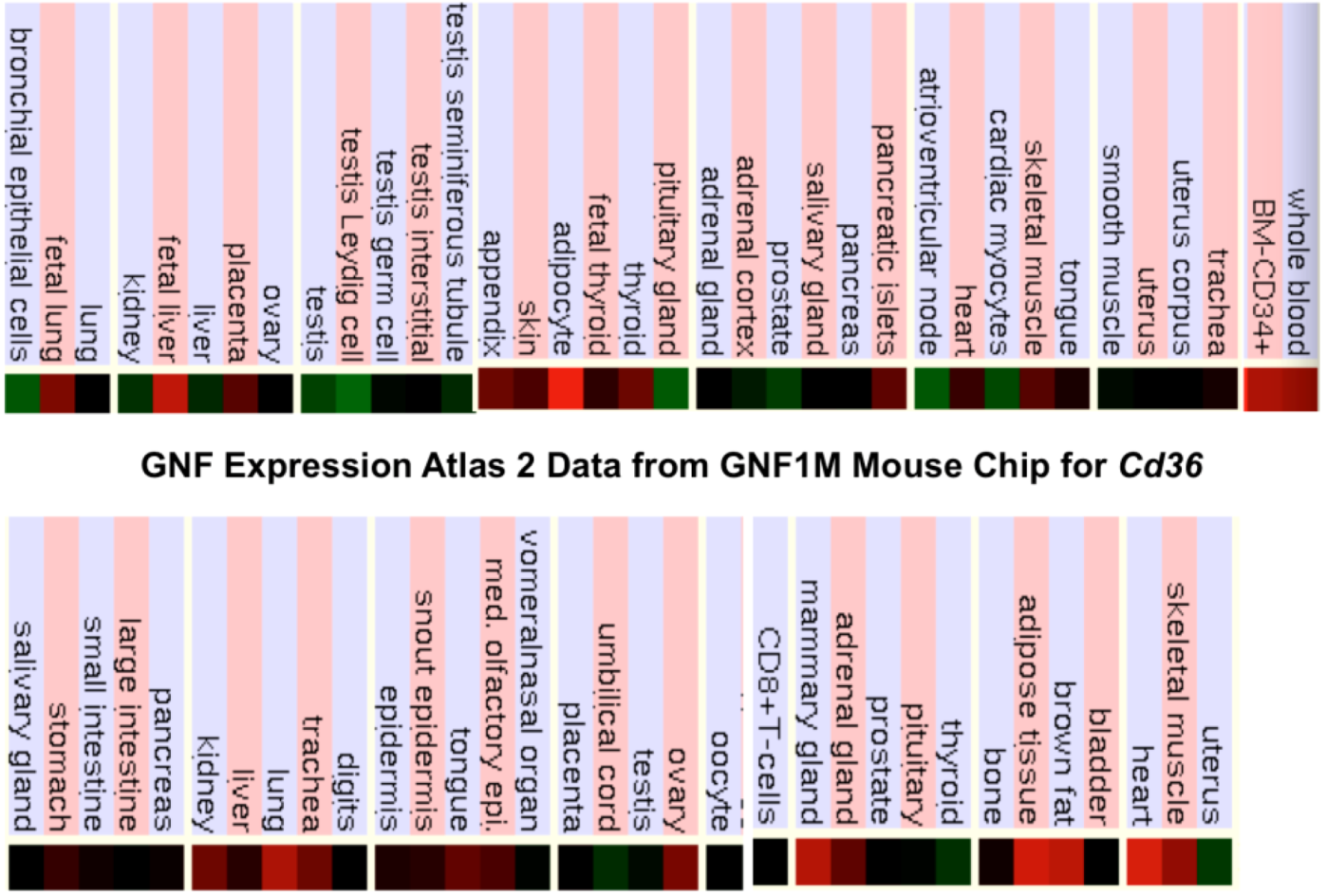
2.9. Comparative Human and Mouse CD36 Tissue Expression
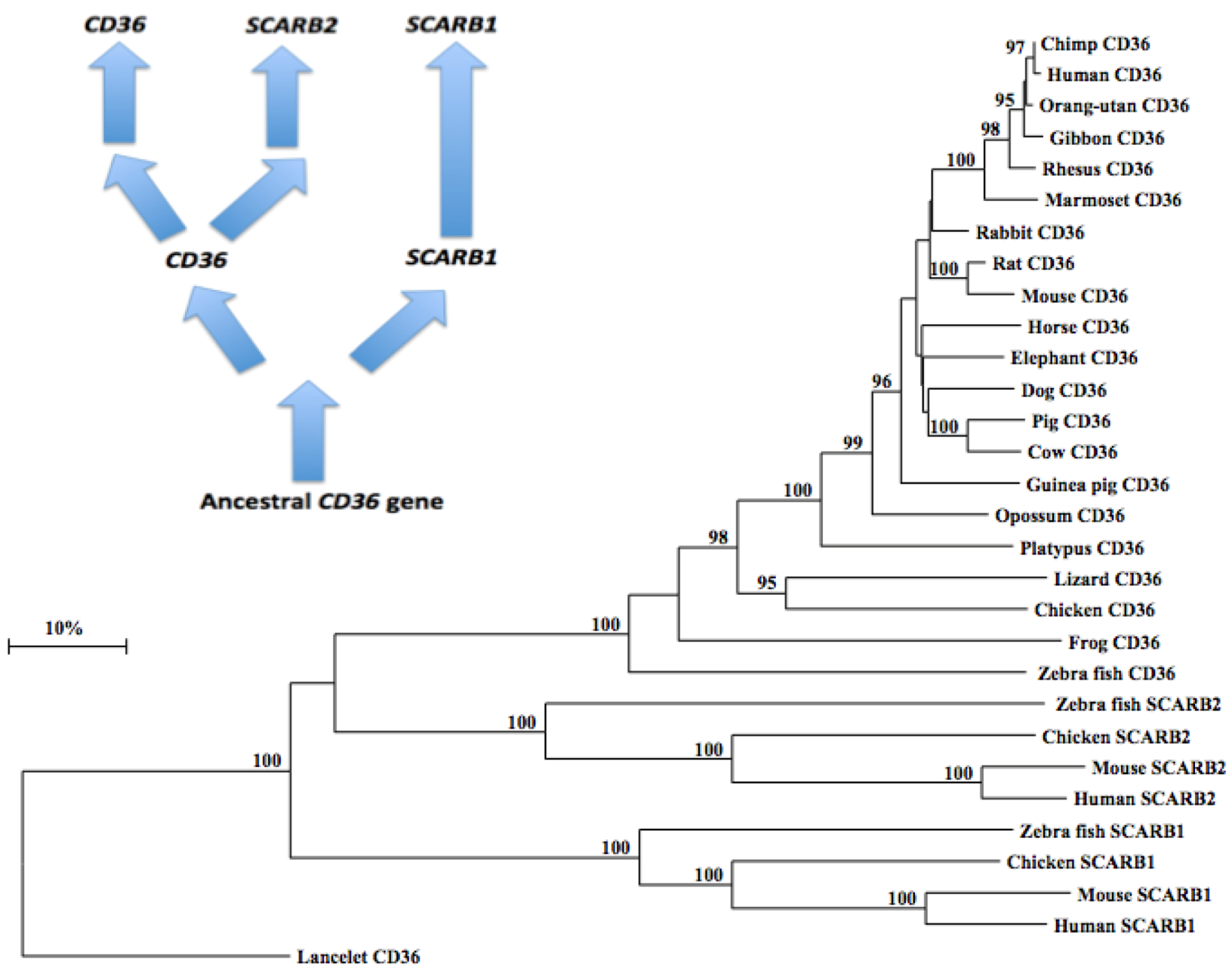
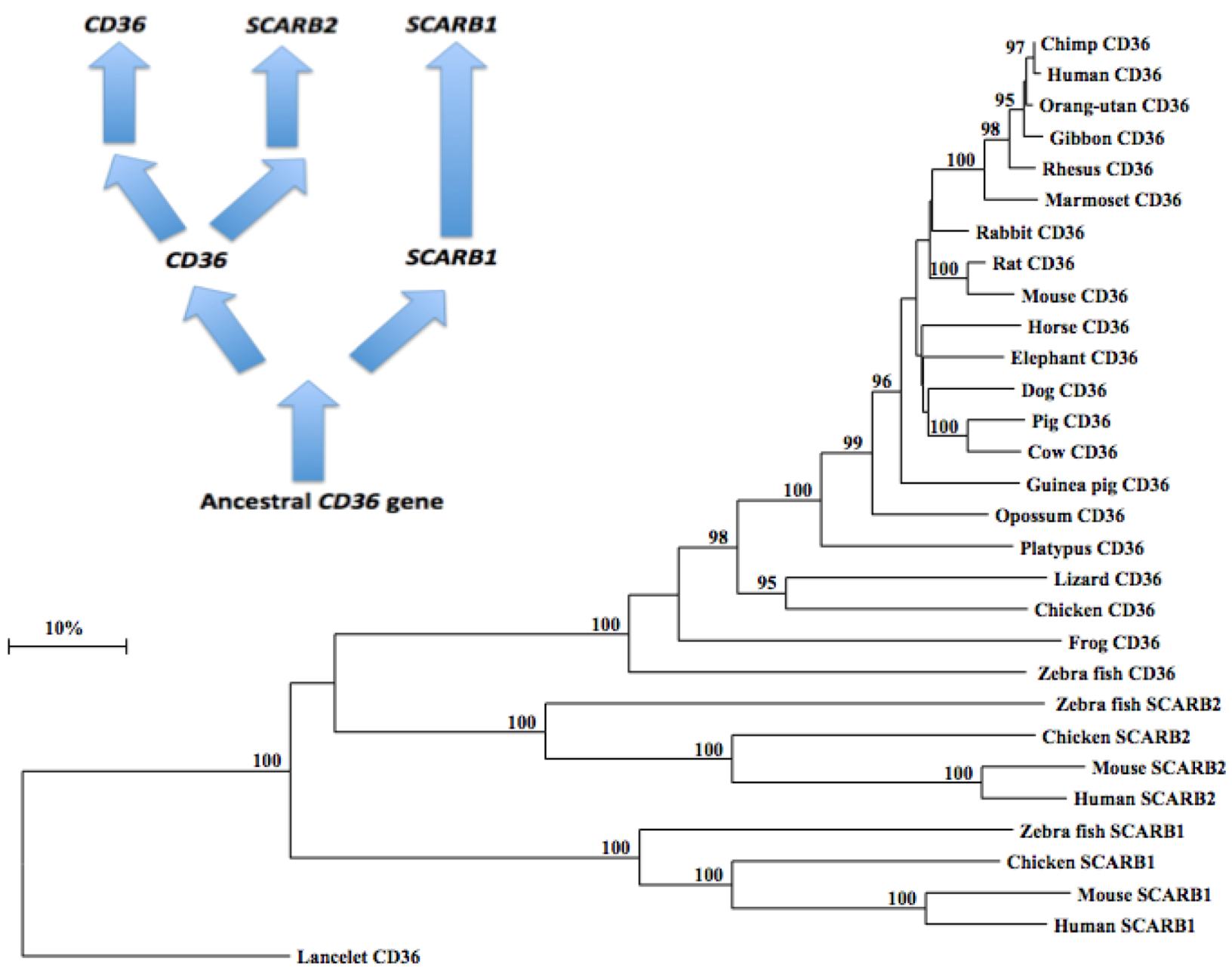
2.10. Phylogeny of Vertebrate CD36-Like Sequences
3. Methods
3.1. Vertebrate CD36 Gene and Protein Identification
3.2. Predicted Structures and Properties of Vertebrate CD36
3.3. Comparative Human and Mouse CD36 Gene Expression
3.4. Phylogeny Studies and Sequence Divergence
4. Conclusions
Supplementary

| CD36 Gene | Species | Subunit MW | % Identity with human | % Identity with human | % Identity with human |
|---|---|---|---|---|---|
| SCARB1 | SCARB2 | CD36 | |||
| Human | Homo sapiens | 53,053 | 31 | 30 | 100 |
| Chimpanzee | Pan troglodytes | 53,064 | 31 | 30 | 100 |
| Orangutan | Pongo abelii | 53,039 | 32 | 30 | 97 |
| Gibbon | Nomascus leucogenys | 53,161 | 32 | 30 | 96 |
| Rhesus | Macaca mulatta | 53,041 | 32 | 31 | 94 |
| Mouse | Mus musculus | 52,698 | 30 | 31 | 83 |
| Rat | Rattus norvegicus | 52,731 | 31 | 30 | 86 |
| Guinea Pig | Cavia porcellus | 53,085 | 32 | 32 | 81 |
| Cow | Bos taurus | 52,940 | 32 | 30 | 82 |
| Dog | Canis familaris | 52,549 | 31 | 30 | 82 |
| Pig | Sus scrofa | 53,085 | 31 | 30 | 82 |
| Rabbit | Oryctolagus cuniculus | 52,729 | 31 | 31 | 88 |
| Horse | Equus caballus | 52,789 | 31 | 31 | 83 |
| Elephant | Loxodonta africana | 52,873 | 31 | 31 | 80 |
| Opossum | Monodelphis domestica | 53,017 | 30 | 30 | 73 |
| Platypus | Ornithorhynchus anatinus | 52,807 | 31 | 30 | 73 |
| Chicken | Gallus gallus | 52,624 | 30 | 32 | 61 |
| Lizard | Anolis carolinensis | 52,890 | 31 | 31 | 61 |
| Frog | Xenopus tropicalis | 52,696 | 30 | 29 | 55 |
| Zebrafish | Danio rerio | 51,590 | 31 | 31 | 53 |
| SCARB1 Gene | Species | Subunit MW | % Identity with human | % Identity with human | % Identity with human |
| SCARB1 | SCARB2 | CD36 | |||
| Human | Homo sapiens | 56,973 | 100 | 29 | 31 |
| Mouse | Mus musculus | 56,754 | 79 | 29 | 29 |
| Chicken | Gallus gallus | 55,918 | 57 | 28 | 31 |
| Zebrafish | Danio rerio | 55,742 | 51 | 28 | 30 |
| SCARB2 Gene | |||||
| Human | Homo sapiens | 54,290 | 29 | 100 | 30 |
| Mouse | Mus musculus | 54,044 | 29 | 85 | 31 |
| Chicken | Gallus gallus | 53,907 | 30 | 59 | 33 |
| Zebrafish | Danio rerio | 60,234 | 31 | 43 | 33 |
| CD36 Gene | |||||
| Lancelet | Branchiostoma floridae | 54,141 | 34 | 35 | 35 |
| Sea squirt | Ciona intestinalis | 58,009 | 26 | 33 | 31 |
| Nematode | Caenorhabditis elegans | 60,182 | 21 | 26 | 24 |
| Fruit fly | Drosophila melanogaster | 58,663 | 20 | 23 | 26 |
Acknowledgements
References
- Oquendo, P.; Hundt, E.; Lawler, J.; Seed, B. CD36 directly mediates cytoadherence of Plasmodium falciparum parasitized erythrocytes. Cell 1989, 58, 95–101. [Google Scholar] [CrossRef]
- Asch, A.S.; Silbiger, S.; Heimer, E.; Nachman, R.L. Thrombospondin sequence motif (CSVTCG) is responsible for CD36 binding. Biochem. Biophys. Res. Commun. 1992, 182, 1208–1217. [Google Scholar] [CrossRef]
- Navazo, M.D.; Daviet, L.; Savill, J.; Ren, Y.; Leung, L.L.; McGregor, J.L. Identification of a domain (155-183) on CD36 implicated in the phagocytosis of apoptotic neutrophils. J. Biol. Chem. 1996, 271, 15381–15385. [Google Scholar]
- Serghides, L.; Crandall, I.; Hull, E.; Kain, K.C. The Plasmodium falciparum-CD36 interaction is modified by a single amino acid substitution in CD36. Blood 1998, 92, 1814–1819. [Google Scholar]
- Simantov, R.; Silverstein, R.L. CD36: A critical anti-angiogenic receptor. Front. Biosci. 2003, 8, s874–s882. [Google Scholar] [CrossRef]
- Adachi, H.; Tsujimoto, M. Endothelial scavenger receptors. Prog. Lipid Res. 2006, 45, 379–404. [Google Scholar] [CrossRef]
- Collot-Teixeira, S.; Martin, J.; McDermott-Roe, C.; Poston, R.; McGregor, J.L. CD36 and macrophages in atherosclerosis. Cardiovasc. Res. 2007, 75, 468–477. [Google Scholar] [CrossRef]
- Martin, C.A.; Longman, E.; Wooding, C.; Hoosdally, S.J.; Ali, S.; Aitman, T.J.; Gutmann, D.A.; Freemont, P.S.; Byrne, B.; Linton, K.J. Cd36, a class B scavenger receptor, functions as a monomer to bind acetylated and oxidized low-density lipoproteins. Protein Sci. 2007, 16, 2531–2541. [Google Scholar] [CrossRef]
- Gautam, S.; Banerjee, M. The macrophage Ox-LDL receptor, CD36 and its association with type II diabetes mellitus. Mol. Genet. Metab. 2011, 102, 389–398. [Google Scholar] [CrossRef]
- Ren, Y. Peroxisome proliferator-activator receptor γ: A link between macrophage CD36 and inflammation in malaria infection. PPAR Res. 2012, 640769. [Google Scholar]
- Smith, B.K.; Jain, S.S.; Rimbaud, S.; Dam, A.; Quadrilatero, J.; Ventura-Clapier, R.; Bonen, A.; Holloway, G.P. FAT/CD36 is located on the outer mitochondrial membrane, upstream of long-chain acyl-CoA synthetase, and regulates palmitate oxidation. Biochem. J. 2011, 437, 125–134. [Google Scholar] [CrossRef]
- Baranova, I.N.; Bocharov, A.V.; Vishnyakova, T.G.; Kurlander, R.; Chen, Z.; Fu, D.; Arias, I.M.; Csako, G.; Patterson, A.P.; Eggerman, T.L. CD36 is a novel serum amyloid A (SAA) receptor mediating SAA binding and SAA-induced signaling in human and rodent cells. J. Biol. Chem. 2010, 285, 8492–8506. [Google Scholar]
- Park, L.; Wang, G.; Zhou, P.; Zhou, J.; Pitstick, R.; Previti, M.L.; Younkin, L.; Younkin, S.G.; Van Nostrand, W.E.; Cho, S.; et al. Scavenger receptor CD36 is essential for the cerebrovascular oxidative stress and neurovascular dysfunction induced by amyloid-beta. Proc. Natl. Acad. Sci. USA 2011, 108, 5063–5068. [Google Scholar]
- Martin, C.; Chevrot, M.; Poirier, H.; Passilly-Degrace, P.; Niot, I.; Besnard, P. CD36 as a lipid sensor. Physiol. Behav. 2011, 105, 36–42. [Google Scholar] [CrossRef]
- Chen, K.; Li, W.; Silverstein, R.L. A specific CD36-dependent signaling pathway is required for platelet activation by oxidized low-density lipoprotein. Circ. Res. 2008, 102, 1512–1519. [Google Scholar] [CrossRef]
- Acton, S.; Osgood, D.; Donoghue, M.; Corella, D.; Pocovi, M.; Cenarro, A.; Mozas, P.; Keilty, J.; Squazzo, S.; Woolf, E.A.; et al. Association of polymorphisms at the SR-BI gene locus with plasma lipid levels and body mass index in a white population. Arterioscler. Thromb. Vasc. Biol. 1999, 19, 1734–1743. [Google Scholar] [CrossRef]
- Bultel-Brienne, S.; Lestavel, S.; Pilon, A.; Laffont, I.; Tailleux, A.; Fruchart, J.C.; Siest, G.; Clavey, V. Lipid free apolipoprotein E binds to the class B Type I scavenger receptor I (SR-BI) and enhances cholesteryl ester uptake from lipoproteins. J. Biol. Chem. 2002, 277, 36092–36099. [Google Scholar]
- Marsche, G.; Zimmermann, R.; Horiuchi, S.; Tandon, N.N.; Sattler, W.; Malle, E. Class B scavenger receptors CD36 and SR-BI are receptors for hypochlorite-modified low density lipoprotein. J. Biol. Chem. 2003, 278, 47562–47570. [Google Scholar]
- Connelly, M.A.; Williams, D.L. Scavenger receptor BI: A scavenger receptor with a mission to transport high density lipoprotein lipids. Curr. Opin. Lipid. 2004, 5, 287–295. [Google Scholar]
- Kent, A.P.; Stylianou, I.M. Scavenger receptor class B member 1 protein: Hepatic regulation and its effects on lipids, reverse cholesterol transport, and atherosclerosis. Hep. Med.: Evid. Res. 2011, 3, 29–44. [Google Scholar]
- Fujita, H.; Takata, Y.; Kono, A.; Tanaka, Y.; Takahashi, T.; Himeno, M.; Kato, K. Isolation and sequencing of a cDNA clone encoding the 85 kDa human lysosomal sialoglycoprotein (hLGP85) in human metastatic pancreas islet tumor cells. Biochem. Biophys. Res. Commun. 1992, 184, 604–611. [Google Scholar] [CrossRef]
- Ogata, S.; Fukuda, M. Lysosomal targeting of Limp II membrane glycoprotein requires a novel Leu-Ile motif at a particular position in its cytoplasmic tail. J. Biol. Chem. 1994, 269, 5210–5217. [Google Scholar]
- Tabuchi, N.; Akasaki, K.; Sasaki, T.; Kanda, N.; Tsuji, H. Identification and characterization of a major lysosomal membrane glycoprotein, LGP85/LIMP II in mouse liver. J. Biochem. 1997, 122, 756–763. [Google Scholar] [CrossRef]
- Kuronita, T.; Eskelinen, E.L.; Fujita, H.; Saftig, P.; Himeno, M.; Tanaka, Y. A role for the lysosomal membrane protein LGP85 in the biogenesis and maintenance of endosomal and lysosomal morphology. J. Cell Sci. 2002, 115, 4117–4131. [Google Scholar] [CrossRef]
- Lin, Y.W.; Lin, H.Y.; Tsou, Y.L.; Chitra, E.; Hsiao, K.N.; Shao, H.Y.; Liu, C.C.; Sia, C.; Chong, P.; Chow, Y.H. Human SCARB2-Mediated Entry and Endocytosis of EV71. PLoS One 2012, 7, e30507. [Google Scholar]
- Taylor, K.T.; Tang, Y.; Sobieski, D.A.; Lipsky, R.H. Characterization of two alternatively spliced 5'-untranslated exons of the human CD36 gene in different cell types. Gene 1993, 33, 205–212. [Google Scholar]
- Fernández-Ruiz, E.; Armesilla, A.L.; Sánchez-Madrid, F.; Vega, M.A. Gene encoding the collagen type I and thrombospondin receptor CD36 is located on chromosome 7q11.2. Genomics 1993, 17, 759–761. [Google Scholar] [CrossRef]
- Armesilla, A.L.; Vega, M.A. Structural organization of the gene for human CD36 glycoprotein. J. Biol. Chem. 1994, 269, 18985–18991. [Google Scholar]
- Rać, M.E.; Safranow, K.; Poncyljusz, W. Molecular basis of human CD36 gene mutations. Mol. Med. 2007, 13, 288–296. [Google Scholar]
- Simantov, R.; Febbraio, M.; Silverstein, R.L. The antiangiogenic effect of thrombospondin-2 is mediated by CD36 and modulated by histidine-rich glycoprotein. Matrix Biol. 2005, 24, 27–34. [Google Scholar] [CrossRef]
- Seimon, T.A.; Nadolski, M.J.; Liao, X.; Magallon, J.; Nguyen, M.; Feric, N.T.; Koschinsky, M.L.; Harkewicz, R.; Witztum, J.L.; Tsimikas, S.; et al. Atherogenic lipids and lipoproteins trigger CD36-TLR2-dependent apoptosis in macrophages undergoing endoplasmic reticulum stress. Cell Metab. 2010, 12, 467–482. [Google Scholar] [CrossRef]
- Nergiz-Unal, R.; Rademakers, T.; Cosemans, J.M.; Heemskerk, J.W. CD36 as a multiple-ligand signaling receptor in atherothrombosis. Cardiovasc. Hematol. Agents Med. Chem. 2011, 9, 42–55. [Google Scholar] [CrossRef]
- Ruiz-Valasco, N.; Dominguez, A.; Vega, M.A. Statins upregulated CD36 expression in human monocytes, an effect strengthened when combined with PPAR-gamma ligands. Putative contribution of Rho GTPases in statin-induced expression. Biochem. Pharmacol. 2004, 67, 303–313. [Google Scholar]
- Liu, H.; Liu, Q.; Lei, H.; Li, X.; Chen, X. Inflammatory stress promotes lipid accumulation in the aorta and liver of SR-A/CD36 double knock-out mice. Mol. Med. Rep. 2010, 3, 1053–1061. [Google Scholar]
- Steinbusch, L.K.; Luiken, J.J.; Vlasblom, R.; Chabowski, A.; Hoebers, N.T.; Coumans, W.A.; Vroegrijk, I.O.; Voshol, P.J.; Ouwens, D.M.; Glatz, J.F.; et al. Absence of fatty acid transporter CD36 protects against Western-type diet-related cardiac dysfunction following pressure overload in mice. Am. J. Physiol. Endocrinol. Metab. 2011, 301, E618–E627. [Google Scholar] [CrossRef]
- Kennedy, D.J.; Kashyap, S.R. Pathogenic role of scavenger receptor CD36 in the metabolic syndrome and diabetes. Metab. Syndr. Relat. Disord. 2011, 9, 239–245. [Google Scholar] [CrossRef]
- Lally, J.S.; Jain, S.S.; Han, X.X.; Snook, L.A.; Glatz, J.F.; Luiken, J.J.; McFarlan, J.; Holloway, G.P.; Bonen, A. Caffeine-stimulated fatty acid oxidation is blunted in CD36 null mice. Acta Physiol. 2011. [Google Scholar] [CrossRef]
- Ma, X.; Bacci, S.; Mlynarski, W.; Gottardo, L.; Soccio, T.; Menzaghi, C.; Iori, E.; Lager, R.A.; Shroff, A.R.; Gervino, E.V.; et al. A common haplotype at the CD36 locus is associated with high free fatty acid levels and increased cardiovascular risk in Caucasians. Hum. Mol. Genet. 2004, 13, 2197–2205. [Google Scholar] [CrossRef]
- Yuasa-Kawase, M.; Masuda, D.; Yamashita, T.; Kawase, R.; Nakaoka, H.; Inagaki, M.; Nakatani, K.; Tsubakio-Yamamoto, K.; Ohama, T.; Matsuyama, A.; et al. Patients with CD36 Deficiency Are Associated with Enhanced Atherosclerotic Cardiovascular Diseases. J. Atheroscler. Thromb. 2011, 19, 263–275. [Google Scholar]
- Keller, K.L.; Liang, L.C.; Sakimura, J.; May, D.; van Belle, C.; Breen, C.; Driggin, E.; Tepper, B.J.; Lanzano, P.C.; Deng, L.; et al. Common Variants in the CD36 Gene Are Associated With Oral Fat Perception, Fat Preferences, and Obesity in African Americans. Obesity 2012. [Google Scholar] [CrossRef]
- Pain, A.; Urban, B.C.; Kai, O.; Casals-Pascual, C.; Shafi, J.; Marsh, K.; Roberts, D.J. A non-sense mutation in Cd36 gene is associated with protection from severe malaria. Lancet 2001, 357, 1502–1503. [Google Scholar]
- Omi, K.; Ohashi, J.; Patarapotikul, J.; Hananantachai, H.; Naka, I.; Looareesuwan, S.; Tokunaga, K. CD36 polymorphism is associated with protection from cerebral malaria. Am. J. Hum. Genet. 2003, 72, 364–374. [Google Scholar] [CrossRef]
- Miquilena-Colina, M.E.; Lima-Cabello, E.; Sánchez-Campos, S.; García-Mediavilla, M.V.; Fernández-Bermejo, M.; Lozano-Rodríguez, T.; Vargas-Castrillón, J.; Buqué, X.; Ochoa, B.; Aspichueta, P.; et al. Hepatic fatty acid translocase CD36 upregulation is associated with insulin resistance, hyperinsulinaemia and increased steatosis in non-alcoholic steatohepatitis and chronic hepatitis C. Gut 2011, 60, 1394–1402. [Google Scholar]
- Ashraf, M.Z.; Gupta, N. Scavenger receptors: Implications in atherothrombotic disorders. Int. J. Biochem. Cell Biol. 2011, 43, 697–700. [Google Scholar] [CrossRef]
- Tandon, N.N.; Lipsky, R.H.; Burgess, W.H.; Jamieson, G.A. Isolation and characterization of platelet glycoprotein IV (CD36). J. Biol. Chem. 1989, 264, 7570–7575. [Google Scholar]
- Wyler, B.; Daviet, L.; Bortkiewicz, H.; Bordet, J.C.; McGregor, J.L. Cloning of the cDNA encoding human platelet CD36: Comparison to PCR amplified fragments of monocyte, endothelial and HEL cells. Thromb. Haemost. 1993, 70, 500–505. [Google Scholar]
- Tao, N.; Wagner, S.J.; Lublin, D.M. CD36 is palmitoylated on both N- and C-terminal cytoplasmic tails. J. Biol. Chem. 1996, 271, 22315–22320. [Google Scholar] [CrossRef]
- Chu, L.Y.; Silverstein, R.L. CD36 Ectodomain Phosphorylation Blocks Thrombospondin-1 Binding: Structure-Function Relationships and Regulation by Protein Kinase C. Arterioscler. Thromb. Vasc. Biol. 2012, 32, 760–767. [Google Scholar] [CrossRef]
- Rasmussen, J.T.; Berglund, L.; Rasmussen, M.S.; Petersen, T.E. Assignment of disulfide bridges in bovine CD36. Eur. J. Biochem. 1998, 257, 488–494. [Google Scholar]
- Lewandrowski, U.; Moebius, J.; Walter, U.; Sickmann, A. Elucidation of N-glycosylation sites on human platelet proteins: A glycoproteomic approach. Mol. Cell Proteomics 2006, 5, 226–233. [Google Scholar]
- Gupta, R.; Brunak, S. Prediction of glycosylation across the human proteome and the correlation to protein function. Pac. Symp. Biocomput. 2002, 7, 310–322. [Google Scholar]
- Lauzier, B.; Merlen, C.; Vaillant, F.; McDuff, J.; Bouchard, B.; Beguin, P.C.; Dolinsky, V.W.; Foisy, S.; Villeneuve, L.R.; Labarthe, F.; et al. Post-translational modifications, a key process in CD36 function: Lessons from the spontaneously hypertensive rat heart. J. Mol. Cell Cardiol. 2011, 51, 99–108. [Google Scholar] [CrossRef]
- Gaidukov, L.; Nager, A.R.; Xu, S.; Penman, M.; Krieger, M. Glycine dimerization motif in the N-terminal transmembrane domain of the high density lipoprotein receptor SR-BI required for normal receptor oligomerization and lipid transport. J. Biol. Chem. 2011, 286, 18452–18464. [Google Scholar]
- Salaun, C.; Greaves, J.; Chamberlain, L.H. The intracellular dynamic of protein palmitoylation. J. Cell Biol. 2010, 191, 1229–1238. [Google Scholar] [CrossRef]
- Holmes, R.S.; Cox, L.A. Comparative studies of vertebrate scavenger receptor class B type 1 (SCARB1): A high density lipoprotein (HDL) binding protein. Res. Reports Biochem. 2012, 2012, 9–24. [Google Scholar] [CrossRef]
- Papale, G.A.; Hanson, P.J.; Sahoo, D. Extracellular disulfide bonds support scavenger receptor class B type I-mediated cholesterol transport. Biochemistry 2011, 50, 6245–6254. [Google Scholar] [CrossRef]
- Yua, M.; Romera, K.A.; Nielanda, T.J.F.; Xua, S.; Saenz-Vashb, V.; Penmana, M.; Yesilaltaya, A.; Carrb, S.A.; Kriegera, M. Exoplasmic cysteine Cys384 of the HDL receptor SR-BI is critical for its sensitivity to a small-molecule inhibitor and normal lipid transport activity. Proc. Natl. Acad. Sci. USA 2011, 108, 12243–12248. [Google Scholar]
- Kashiwagi, H.; Tomiyama, Y.; Honda, S.; Kosugi, S.; Shiraga, M.; Nagao, N.; Sekiguchi, S.; Kanayama, Y.; Kurata, Y.; Matsuzawa, Y. Molecular basis of CD36 deficiency. Evidence that a 478C-->T substitution (proline90-->serine) in CD36 cDNA accounts for CD36 deficiency. J. Clin. Invest. 1995, 95, 1040–1046. [Google Scholar]
- Yanai, H.; Chiba, H.; Fujiwara, H.; Morimoto, M.; Takahashi, Y.; Hui, S.P.; Fuda, H.; Akita, H.; Kurosawa, T.; Kobayashi, K.; Matsuno, K. Metabolic changes in human CD36 deficiency displayed by glucose loading. Thromb. Haemost. 2001, 86, 995–999. [Google Scholar]
- MacArthur, M.W.; Thornton, J.M. Influence of proline residues on protein conformation. J. Mol. Biol. 1991, 218, 397–412. [Google Scholar] [CrossRef]
- Krieger, A.; Möglich, A.; Kiefhaber, T. Effect of proline and glycine residues on dynamics and barriers of loop formation in polypeptide F. J. Am. Chem. Soc. 2005, 127, 3346–3352. [Google Scholar] [CrossRef]
- Kay, B.K.; Williamson, M.P.; Sudol, M. The importance of being proline: The interaction of proline-rich motifs in signaling proteins with their cognate domains. FASEB. J. 2000, 14, 231–241. [Google Scholar]
- Coleman, M.D.; Bass, R.B.; Mehan, R.S.; Falke, J.J. Conserved glycine residues in the cytoplasmic domain of the aspartate receptor play essential roles in kinase coupling and on-off switching. Biochemistry 2005, 44, 7687–7695. [Google Scholar]
- Kent, W.J.; Sugnet, C.W.; Furey, T.S. The human genome browser at UCSC. Genome Res. 2003, 12, 994–1006. [Google Scholar]
- Armesilla, A.L.; Calvo, D.; Vega, M.A. Structural and functional characterization of the human CD36 gene promoter: Identification of a proximal PEBP2/CBF site. J. Biol. Chem. 1996, 271, 7781–7787. [Google Scholar] [CrossRef]
- Thierry-Mieg, D.; Thierry-Mieg, J. AceView: A comprehensive cDNA-supported gene and transcripts annotation. Genome Biol. 2006, 7, S12. [Google Scholar] [CrossRef]
- Sato, O.; Kuriki, C.; Fukui, Y.; Motojima, K. Dual promoter structure of mouse and human fatty acid translocase/CD36 genes and unique transcriptional activation by peroxisome proliferator-activated receptor alpha and gamma ligands. J. Biol. Chem. 2002, 277, 15703–15711. [Google Scholar]
- Olagnier, D.; Lavergne, R.A.; Meunier, E.; Lefèvre, L.; Dardenne, C.; Aubouy, A.; Benoit-Vical, F.; Ryffel, B.; Coste, A.; Berry, A.; et al. Nrf2, a PPARγ alternative pathway to promote CD36 expression on inflammatory macrophages: Implication for malaria. PLoS Pathog. 2011, 7, e1002254. [Google Scholar]
- Motojima, K.; Passilly, P.; Peters, J.M.; Gonzalez, F.J.; Latruffe, N. Expression of putative fatty acid transporter genes are regulated by peroxisome proliferator-activated receptor alpha and gamma activators in a tissue- and inducer-specific manner. J. Biol. Chem. 1998, 273, 16710–16714. [Google Scholar]
- Sharrocks, A.D.; von Hesler, F.; Shaw, P.E. The identification of elements determining the different DNA binding specificities of the MADS box proteins p67SRF and RSRFC4. Nucleic Acids Res. 1993, 21, 215–221. [Google Scholar] [CrossRef]
- Cai, R.L. Human CART1, a paired-class homeodomain protein, activates transcription through palindromic binding sites. Biochem. Biophys. Res. Commun. 1998, 250, 305–311. [Google Scholar] [CrossRef]
- Gómez-Ferrería, M.A.; Rey-Campos, J. Functional domains of FOXJ2. J Mol Biol. 2003, 329, 631–644. [Google Scholar] [CrossRef]
- He, Y.; Sun, S.; Sha, H.; Liu, Z.; Yang, L.; Xue, Z.; Chen, H.; Qi, L. Emerging roles for XBP1, a sUPeR transcription factor. Gene Expr. 2010, 15, 13–25. [Google Scholar] [CrossRef]
- Dyczkowski, J.; Vingron, M. Comparative analysis of cell cycle regulated genes in eukaryotes. Genome Inform. 2005, 16, 125–131. [Google Scholar]
- Su, A.I.; Wiltshire, T.; Batalov, S.; Lapp, H.; Ching, K.R.; Block, D.; Zhang, J.; Soden, R.; Hayakawa, M.; Kreiman, G.; et al. A gene atlas of the human and mouse protein encoding transcriptomes. Proc. Natl. Acad. Sci. USA 2004, 101, 6062–6067. [Google Scholar]
- Eguez, L.; Lee, A.; Chavez, J.A.; Miinea, C.P.; Kane, S.; Lienhard, G.E.; McGraw, T.E. Full intracellular retention of GLUT4 requires AS160 Rab GTPase activating protein. Cell Metab. 2005, 2, 263–272. [Google Scholar] [CrossRef]
- Thong, F.S.; Bilan, P.J.; Klip, A. The Rab GTPase-activating protein AS160 integrates Akt, protein kinase C, and AMP-activated protein kinase signals regulating GLUT4 traffic. Diabetes 2007, 56, 414–423. [Google Scholar] [CrossRef]
- Samovski, D.; Su, X.; Xu, Y.; Abumrad, N.A.; Stahl, P.D. Insulin and AMPK regulate fatty acid translocase/CD36 plasma membrane recruitment in cardiomyocytes via RabGAP AS160 and Rab8a Rab GTPase. J. Lipid Res. 2012. [Epub ahead of print]. [Google Scholar]
- Sano, H.; Kane, S.; Sano, E.; Mîinea, C.P.; Asara, J.M.; Lane, W.S.; Garner, C.W.; Lienhard, G.E. Insulin-stimulated phosphorylation of a Rab GTPase-activating protein regulates GLUT4 translocation. J. Biol. Chem. 2003, 278, 14599–14602. [Google Scholar]
- Yuasa, T.; Uchiyama, K.; Ogura, Y.; Kimura, M.; Teshigawara, K.; Hosaka, T.; Tanaka, Y.; Obata, T.; Sano, H.; Kishi, K.; et al. The Rab GTPase-activating protein AS160 as a common regulator of insulin- and Galphaq-mediated intracellular GLUT4 vesicle distribution. Endocr. J. 2009, 56, 345–359. [Google Scholar] [CrossRef]
- Liani, R.; Halvorsen, B.; Sestili, S.; Handberg, A.; Santilli, F.; Vazzana, N.; Formoso, G.; Aukrust, P.; Davì, G. Plasma levels of soluble CD36, platelet activation, inflammation, and oxidative stress are increased in type 2 diabetic patients. Free Radic. Biol. Med. 2012. [Epub ahead of print]. [Google Scholar]
- Mitchell, R.W.; On, N.H.; Del Bigio, M.R.; Miller, D.W.; Hatch, G.M. Fatty acid transport protein expression in human brain and potential role in fatty acid transport across human brain microvessel endothelial cells. J. Neurochem. 2011, 117, 735–746. [Google Scholar]
- Donoghue, P.C.J.; Benton, M.J. Rocks and clocks: Calibrating the tree of life using fossils and molecules. Trends Genet. 2007, 22, 424–431. [Google Scholar]
- Bentley, A.A.; Adams, J.C. The evolution of thrombospondins and their ligand-binding activities. Mol. Biol. Evol. 2010, 27, 2187–2197. [Google Scholar] [CrossRef]
- Altschul, F.; Vyas, V.; Cornfield, A.; Goodin, S.; Ravikumar, T.S.; Rubin, E.H.; Gupta, E. Basic local alignment search tool. J. Mol. Biol. 1997, 215, 403–410. [Google Scholar]
- McGuffin, L.J.; Bryson, K.; Jones, D.T. The PSIPRED protein structure prediction server. Bioinform. 2000, 16, 404–405. [Google Scholar] [CrossRef]
- Hall, T.A. BioEdit: A user-friendly biological sequence alignment editor and analysis program for Windows 95/98/NT. Nucleic Acids Symp. Ser. 1999, 41, 95–99. [Google Scholar]
- Felsenstein, J. Confidence limits on phylogenies: An approach using the bootstrap. Evolution 1986, 39, 783–789. [Google Scholar] [CrossRef]
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Holmes, R.S. Comparative Studies of Vertebrate Platelet Glycoprotein 4 (CD36). Biomolecules 2012, 2, 389-414. https://doi.org/10.3390/biom2030389
Holmes RS. Comparative Studies of Vertebrate Platelet Glycoprotein 4 (CD36). Biomolecules. 2012; 2(3):389-414. https://doi.org/10.3390/biom2030389
Chicago/Turabian StyleHolmes, Roger S. 2012. "Comparative Studies of Vertebrate Platelet Glycoprotein 4 (CD36)" Biomolecules 2, no. 3: 389-414. https://doi.org/10.3390/biom2030389
APA StyleHolmes, R. S. (2012). Comparative Studies of Vertebrate Platelet Glycoprotein 4 (CD36). Biomolecules, 2(3), 389-414. https://doi.org/10.3390/biom2030389