
Controlling Fleets of Autonomous Mobile Robots with Reinforcement Learning: A Brief Survey


Abstract
:1. Introduction
2. Related Literature
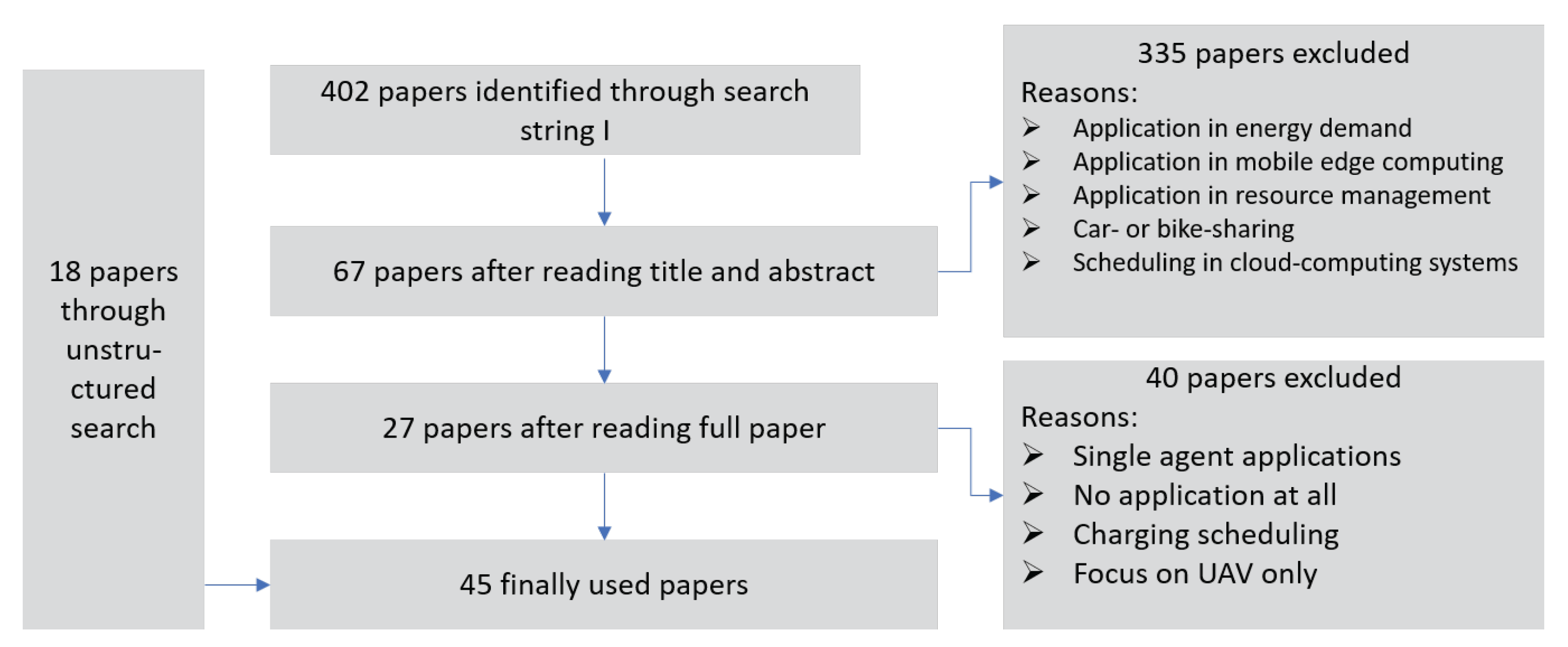
3. Survey Methodology
4. Approaches for Reinforcement Learning
4.1. Basic Idea of Reinforcement Learning
4.2. Q-Learning
4.3. Deep Q-Learning
4.4. Proximal Policy Optimization
5. Type of Control of Autonomous Fleets
5.1. Centralized Control
5.2. Decentralized Control
6. Subproblems of Fleet Control
6.1. Collision Avoidance
6.2. Path Planning
6.3. Dispatching and Scheduling
6.4. Orientation in Dynamic Environments
6.5. Combining Different Problems
7. Discussion
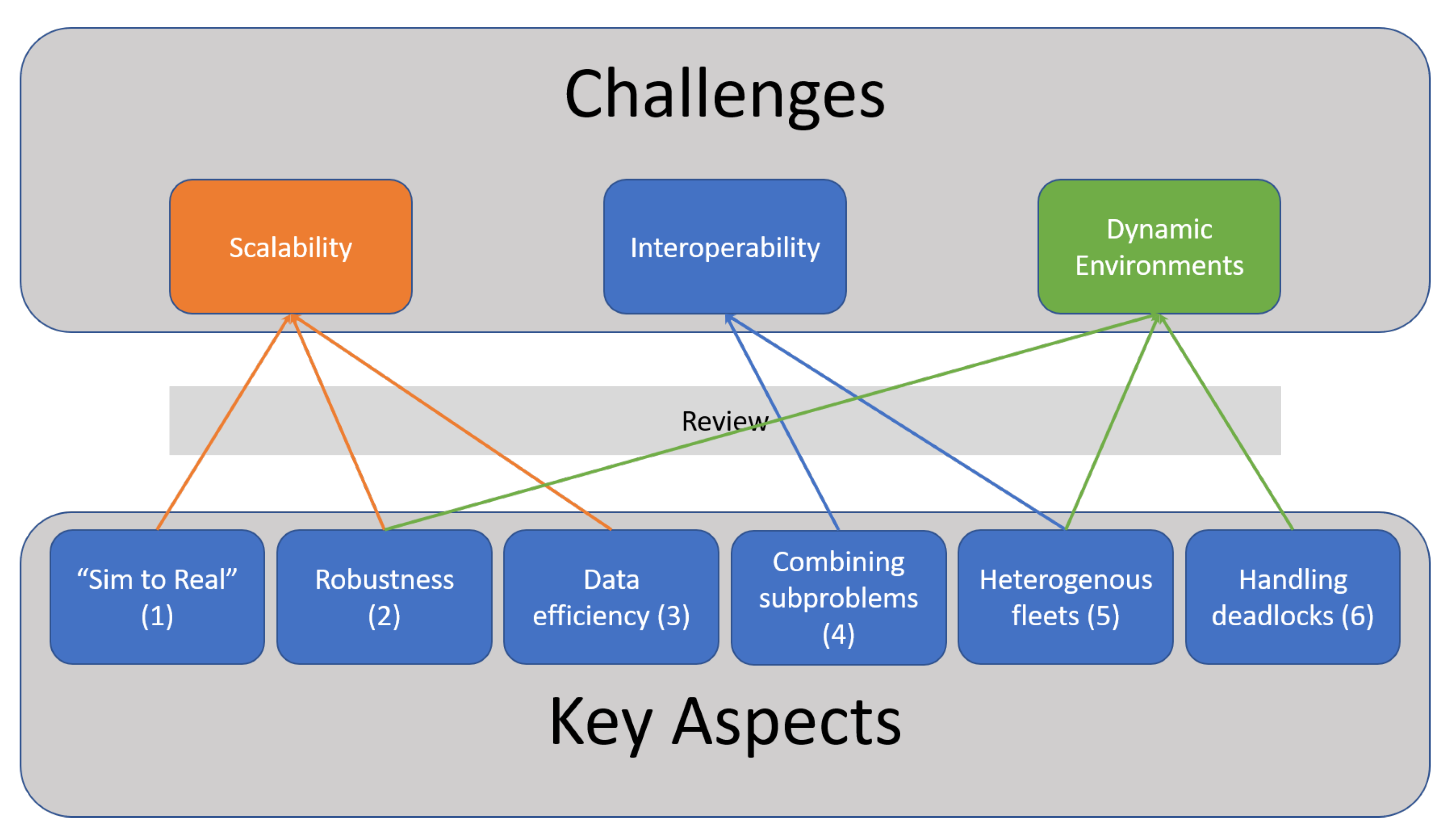
7.1. Challenges
7.1.1. Scalability
7.1.2. Interoperability
7.1.3. Dynamic Environments
7.2. Solutions
- 1.
- Overcoming the “sim-to-real gap”
- (a)
- Domain RandomizationIt is necessary to increase the randomization of the training to better prepare the algorithm for random events that may occur in reality with increased probability. The more the training scenario is randomized, the lower is the chance the algorithm will experience a scenario in reality that it has not yet experienced in training. In order to implement this, there are different approaches, ranging from simple (active ) domain randomization of the training environment [77,78] to noise in the data [79] in order to simulate errors from sensors, latencies or other influences.
- (b)
- Real data and real applicationsAnother important step is the use of real data beyond laboratory settings. It is necessary to generate scenarios, which are also performed in reality [80]. For this purpose, detailed process data must be generated within a simulation that represent reality as closely as possible. This data must be as close as to reality that the gap between simulation and reality is as small as possible. In order to achieve this, a close cooperation with the industry is necessary to integrate data from already existing systems into the training. Alternatively, it is possible to use real scenarios whose complexity are increased depending on the success rate within the scenario. The aim for this approach is to increase the complexity step by step beyond that of a laboratory setting to enable use in a real-world context.
- (c)
- State space reductionAs a further step to enable the transfer of the simulation into a real use case, one could adjust the state space. For example, one could create a grid within the agents move with the help of motion primitives [81,82]. Depending on the fineness of the grid, this would reduce the complexity of the environment on the one hand, and on the other hand reduce movement sensitivity, since the motion primitives could be programmed in advance. Another possibility to limit the state space is to change the observations. Compared to a camera-based input, a laser-based or distance-based input is much smaller and can reduce the reality gap [83]. If additional localization information is used, a better result can probably be achieved with less computing power.
- 2.
- Robust algorithms
- (a)
- Reward shapingOne way to increase robustness is through reward shaping. By reward shaping, problems like dense rewards can be solved. For example, the reward structure could be revised in such a way that there are additional rewards for approaching goals or staying away from obstacles as well as the use of customized reward functions. However, adapting the reward function also takes away some of the generalizability of the algorithm, which is why a certain expertise is necessary to develop such a concept in the best possible way. In order to this and automate reward shaping, an approach has been developed by [84].
- (b)
- Imitational learningAnother way to improve the robustness of the algorithm is to use expert knowledge. With the help of imitational learning, as it is used in [41] among others, data generated by experts can be used for training the algorithm. This is also a support for data efficiency (3) and enables the algorithm to learn, how to act correctly in particularly error-prone situations.
- 3.
- Data efficiency
- (a)
- Improving memory/knowledgeOne possibility to increase data efficiency is to improve the memory of the algorithm. While many methods already have simple experience replay or use LSTM, there is still a high potential for improvement. In this case, one could fall back on procedures like the double experience replay [85], as well as prioritized experience replay [86] or making use of prior knowledge like the authors of [38]. With the help of such methods a higher generalizability is possible even with less data.
- (b)
- Curriculum learningCL [43] is a method which is used to give an algorithm step by step more complex tasks to enable a faster and better training success. Especially for sparse rewards this method is useful. Since the probability of completing a simple task is significantly higher than for a complex one, the algorithm learns the necessary correlations much faster. This knowledge can be transferred back to more complex scenarios, ensuring faster learning and more data-efficient training.
- 4.
- Combining different fields of application
- (a)
- Tuning the reward structureAs simple as it may sound, the best way to combine different applications is to integrate them into the training. In doing so, it is necessary that the algorithmic architecture is designed at the beginning of the training in such a way that two or more problems can be solved with it simultaneously. The reward structure is one of the biggest challenges. Since each sub-problem has its own reward structure, it must be ensured that the rewards are set to such a degree that the overall problem is solved optimally and not one of the sub-problems.
- (b)
- Reducing redundant information in problemsAnother method to improve the combination of different problems is to choose the correct input information. In order to combine several problems, they must be interdependent at first. However, this dependency on each other ensures that the information, that can be obtained from each problem also has dependencies on each other. For example, similar variables are of interest for scheduling and routing in a warehouse, such as the position of the object to be collected, the position to which it should be delivered and the layout of the warehouse itself. Accordingly, the algorithm needs this information only once and not once for each sub-problem. In the conceptual design of the algorithm it is necessary to find these dependencies and exclude redundant information. Due to the increasing complexity of the whole problem, it is especially important to avoid high computational efforts.
- 5.
- Enabling heterogeneous fleets
- (a)
- Decentralized TrainingAs already mentioned in the paper, decentralized training is particularly flexible, which results in a better scalability for multiple agents (see Table 2) and an easy integration of different agents. Consequently for the implementation of heterogeneous fleets, decentralized training of different agents is a central concept and necessary to enable the easy integration of additional vehicles.
- (b)
- Communication standardThe decentralized training of individual agents also requires a central communication interface that follows a standard [73]. Since different agents are combined in heterogeneous fleets, consideration must be given to the fact that these also bring different fundamentals. In addition to different transport characteristics and dimensions, the agents have different drive procedures and localization methods. In order to enable a common use of such agents, it is necessary to create a communication standard in which the information received from the agents can be processed in such a standardized way that an easy integration of the agents as well as a successful completion of tasks is possible.
- (c)
- Standard for better comparabilityIn order to develop such a standard [73], a certain comparability of the agents is necessary. During the research of this paper, it was noticed that different algorithms have been trained in different scenarios. Accordingly, a comparability of the individual algorithms among each other is hardly possible in most cases. In order to enable a heterogeneous fleet in the best possible way and to be able to integrate a communication standard, such comparability is necessary. Therefore, a further solution for the implementation of heterogeneous fleets is the development and definition of a training standard. With the help of this standard different agents are on the same level (experience wise) and an integration into the system is simplified.
- 6.
- Handling deadlocks
- (a)
- Deadlock detection and communicationOne technique to better handle deadlocks is not only to detect them, but also to communicate within the fleet [45,54]. In the event that an agent detects a deadlock or other disturbance within the test area, the information should be distributed within the fleet. However, only to the agents that are affected by this disturbance, in order to save unnecessary computing effort. This allows other agents to adjust their route early and thus reduces the chance that a deadlock will cause a significant delay in the completion of orders.
- (b)
- Subgoal IntegrationBy integrating sub-goals [57] into the flow of the algorithm, the route to the destination can be planned in a more fine-grained way. Such fine-grained planning subsequently makes it possible to easily bypass blocked driving areas and adjust the route accordingly. If, for example, a single route is disrupted, the algorithm does not need to re-plan the entire route, but can simply find a alternative route for the blocked location and then return to the original route. This also ensures that the route change has less impact on the rest of the fleet.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
References
- International Federation of Robotics. World Robotics Report 2020; International Federation of Robotics: Frankfurt am Main, Germany, 2020. [Google Scholar]
- International Federation of Robotics. Robot Sales Rise again; International Federation of Robotics: Frankfurt am Main, Germany, 2021. [Google Scholar]
- The Logistics IQ. AGV-AMR Market Map 2021; The Logistics IQ: New Delhi, India, 2021. [Google Scholar]
- Steeb, R.; Cammarata, S.; Hayes-Roth, F.A.; Thorndyke, P.W.; Wesson, R.B. Distributed Intelligence for Air Fleet Control. In Readings in Distributed Artificial Intelligence; Elsevier: Amsterdam, The Netherlands, 1981; pp. 90–101. [Google Scholar] [CrossRef]
- Naumov, V.; Kubek, D.; Więcek, P.; Skalna, I.; Duda, J.; Goncerz, R.; Derlecki, T. Optimizing Energy Consumption in Internal Transportation Using Dynamic Transportation Vehicles Assignment Model: Case Study in Printing Company. Energies 2021, 14, 4557. [Google Scholar] [CrossRef]
- Alexovič, S.; Lacko, M.; Bačík, J.; Perduková, D. Introduction into Autonomous Mobile Robot Research and Multi Cooperation; Springer: Cham, Switzerland, 2021; pp. 326–336. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Akkaya, I.; Andrychowicz, M.; Chociej, M.; Litwin, M.; McGrew, B.; Petron, A.; Paino, A.; Plappert, M.; Powell, G.; Ribas, R.; et al. Solving Rubik’s Cube with a robot hand. arXiv 2019, arXiv:1910.07113. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Kiumarsi, B.; Vamvoudakis, K.G.; Modares, H.; Lewis, F.L. Optimal and Autonomous Control Using Reinforcement Learning: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2042–2062. [Google Scholar] [CrossRef]
- Vázquez-Canteli, J.R.; Nagy, Z. Reinforcement learning for demand response: A review of algorithms and modeling techniques. Appl. Energy 2019, 235, 1072–1089. [Google Scholar] [CrossRef]
- Pandey, A.; Pandey, S.; Parhi, D.R. Mobile Robot Navigation and Obstacle Avoidance Techniques: A Review. Int. Robot. Autom. J. 2017, 2, 96–105. [Google Scholar] [CrossRef]
- Panchpor, A.A.; Shue, S.; Conrad, J.M. A survey of methods for mobile robot localization and mapping in dynamic indoor environments. In Proceedings of the 2018 Conference on Signal Processing and Communication Engineering Systems (SPACES), Vaddeswaram, India, 4–5 January 2018; pp. 138–144. [Google Scholar] [CrossRef]
- Shabbir, J.; Anwer, T. A Survey of Deep Learning Techniques for Mobile Robot Applications. arXiv 2018, arXiv:1803.07608. [Google Scholar]
- Farazi, N.P.; Ahamed, T.; Barua, L.; Zou, B. Deep Reinforcement Learning and Transportation Research: A Comprehensive Review. arXiv 2020, arXiv:2010.06187. [Google Scholar]
- Singh, P.; Tiwari, R.; Bhattacharya, M. Navigation in Multi Robot system using cooperative learning: A survey. In Proceedings of the 2016 International Conference on Computational Techniques in Information and Communication Technologies (ICCTICT), New Delhi, India, 11–13 March 2016; pp. 145–150. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef]
- OroojlooyJadid, A.; Hajinezhad, D. A Review of Cooperative Multi-Agent Deep Reinforcement Learning. arXiv 2019, arXiv:1908.03963. [Google Scholar]
- Rizk, Y.; Awad, M.; Tunstel, E.W. Decision Making in Multiagent Systems: A Survey. IEEE Trans. Cogn. Dev. Syst. 2018, 10, 514–529. [Google Scholar] [CrossRef]
- Madridano, Á.; Al-Kaff, A.; Martín, D. Trajectory Planning for Multi-Robot Systems: Methods and Applications. Expert Syst. Appl. 2021, 173, 114660. [Google Scholar] [CrossRef]
- Ibarz, J.; Tan, J.; Finn, C.; Kalakrishnan, M.; Pastor, P.; Levine, S. How to Train Your Robot with Deep Reinforcement Learning; Lessons We’ve Learned. Int. J. Robot. Res. 2021, 7, 027836492098785. [Google Scholar] [CrossRef]
- Xiao, X.; Liu, B.; Warnell, G.; Stone, P. Motion Control for Mobile Robot Navigation Using Machine Learning: A Survey. arXiv 2020, arXiv:2011.13112. [Google Scholar] [CrossRef]
- Jiang, H.; Wang, H.; Yau, W.Y.; Wan, K.W. A Brief Survey: Deep Reinforcement Learning in Mobile Robot Navigation. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; pp. 592–597. [Google Scholar] [CrossRef]
- Aradi, S. Survey of Deep Reinforcement Learning for Motion Planning of Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 740–759. [Google Scholar] [CrossRef]
- Zhu, K.; Zhang, T. Deep reinforcement learning based mobile robot navigation: A review. Tsinghua Sci. Technol. 2021, 26, 674–691. [Google Scholar] [CrossRef]
- Tranfield, D.; Denyer, D.; Smart, P. Towards a Methodology for Developing Evidence-Informed Management Knowledge by Means of Systematic Review. Br. J. Manag. 2003, 14, 207–222. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Cassandra, A.R. Planning and acting in partially observable stochastic domains. Artif. Intell. 1998, 101, 99–134. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lu, C.; Long, J.; Xing, Z.; Wu, W.; Gu, Y.; Luo, J.; Huang, Y. Deep Reinforcement Learning for Solving AGVs Routing Problem. In Verification and Evaluation of Computer and Communication Systems; Springer: Cham, Switzerland, 2020; Volume 12519, pp. 222–236. [Google Scholar]
- Liu, H.; Hyodo, A.; Akai, A.; Sakaniwa, H.; Suzuki, S. Action-limited, Multimodal Deep Q Learning for AGV Fleet Route Planning. In Proceedings of the Proceedings of the 5th International Conference on Control Engineering and Artificial Intelligence, Sanya, China, 14–16 January 2021; Zhang, D., Ed.; Association for Computing Machinery: New York, NY, USA, 2021; pp. 57–62. [Google Scholar] [CrossRef]
- He, C.; Wan, Y.; Gu, Y.; Lewis, F.L. Integral Reinforcement Learning-Based Multi-Robot Minimum Time-Energy Path Planning Subject to Collision Avoidance and Unknown Environmental Disturbances. IEEE Control. Syst. Lett. 2021, 5, 983–988. [Google Scholar] [CrossRef]
- Zhi, J.; Lien, J.M. Learning to Herd Agents Amongst Obstacles: Training Robust Shepherding Behaviors Using Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2021, 6, 4163–4168. [Google Scholar] [CrossRef]
- Meerza, S.I.A.; Islam, M.; Uzzal, M.M. Q-Learning Based Particle Swarm Optimization Algorithm for Optimal Path Planning of Swarm of Mobile Robots. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT 2019), Dhaka, Bangladesh, 3–5 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Wu, J.; Song, C.; Ma, J.; Wu, J.; Han, G. Reinforcement Learning and Particle Swarm Optimization Supporting Real-Time Rescue Assignments for Multiple Autonomous Underwater Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6807–6820. [Google Scholar] [CrossRef]
- Wang, M.; Zeng, B.; Wang, Q. Research on Motion Planning Based on Flocking Control and Reinforcement Learning for Multi-Robot Systems. Machines 2021, 9, 77. [Google Scholar] [CrossRef]
- Vitolo, E.; Miguel, A.S.; Civera, J.; Mahulea, C. Performance Evaluation of the Dyna-Q algorithm for Robot Navigation. In Proceedings of the 2018 IEEE 14th International Conference on Automation Science and Engineering (CASE), Munich, Germany, 20–24 August 2018; Vogel-Heuser, B., Ed.; IEEE: New York, NY, USA, 2018; pp. 322–327. [Google Scholar] [CrossRef]
- Li, B.; Liang, H. Multi-Robot Path Planning Method Based on Prior Knowledge and Q-learning Algorithms. J. Physics Conf. Ser. 2020, 1624, 042008. [Google Scholar] [CrossRef]
- Bae, H.; Kim, G.; Kim, J.; Qian, D.; Lee, S. Multi-Robot Path Planning Method Using Reinforcement Learning. Appl. Sci. 2019, 9, 3057. [Google Scholar] [CrossRef]
- Sartoretti, G.; Kerr, J.; Shi, Y.; Wagner, G.; Kumar, T.K.S.; Koenig, S.; Choset, H. PRIMAL: Pathfinding via Reinforcement and Imitation Multi-Agent Learning. IEEE Robot. Autom. Lett. 2019, 4, 2378–2385. [Google Scholar] [CrossRef]
- Damani, M.; Luo, Z.; Wenzel, E.; Sartoretti, G. PRIMAL2: Pathfinding Via Reinforcement and Imitation Multi-Agent Learning—Lifelong. IEEE Robot. Autom. Lett. 2021, 6, 2666–2673. [Google Scholar] [CrossRef]
- Wang, B.; Liu, Z.; Li, Q.; Prorok, A. Mobile Robot Path Planning in Dynamic Environments through Globally Guided Reinforcement Learning. IEEE Robot. Autom. Lett. 2020, 5, 6932–6939. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, B.; Zhou, H.; Koushik, G.; Hebert, M.; Zhao, D. MAPPER: Multi-Agent Path Planning with Evolutionary Reinforcement Learning in Mixed Dynamic Environments. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 11748–11754. [Google Scholar]
- Ma, Z.; Luo, Y.; Pan, J. Learning Selective Communication for Multi-Agent Path Finding. IEEE Robot. Autom. Lett. 2022, 7, 1455–1462. [Google Scholar] [CrossRef]
- Ma, Z.; Luo, Y.; Ma, H. Distributed Heuristic Multi-Agent Path Finding with Communication. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar] [CrossRef]
- Hu, J.; Niu, H.; Carrasco, J.; Lennox, B.; Arvin, F. Voronoi-Based Multi-Robot Autonomous Exploration in Unknown Environments via Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2020, 69, 14413–14423. [Google Scholar] [CrossRef]
- Portugal, D.; Rocha, R.P. Cooperative multi-robot patrol with Bayesian learning. Auton. Robot. 2016, 40, 929–953. [Google Scholar] [CrossRef]
- Ajabshir, V.B.; Guzel, M.S.; Bostanci, E. A Low-Cost Q-Learning-Based Approach to Handle Continuous Space Problems for Decentralized Multi-Agent Robot Navigation in Cluttered Environments. IEEE Access 2022, 10, 35287–35301. [Google Scholar] [CrossRef]
- Chen, Y.F.; Liu, M.; Everett, M.; How, J.P. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 285–292. [Google Scholar] [CrossRef]
- Fan, T.; Long, P.; Liu, W.; Pan, J. Distributed multi-robot collision avoidance via deep reinforcement learning for navigation in complex scenarios. Int. J. Robot. Res. 2020, 39, 856–892. [Google Scholar] [CrossRef]
- Yao, S.; Chen, G.; Pan, L.; Ma, J.; Ji, J.; Chen, X. Multi-Robot Collision Avoidance with Map-based Deep Reinforcement Learning. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020. [Google Scholar]
- Fan, T.; Long, P.; Liu, W.; Pan, J. Fully Distributed Multi-Robot Collision Avoidance via Deep Reinforcement Learning for Safe and Efficient Navigation in Complex Scenarios. arXiv 2018, arXiv:1808.03841. [Google Scholar]
- Long, P.; Fan, T.; Liao, X.; Liu, W.; Zhang, H.; Pan, J. Towards Optimally Decentralized Multi-Robot Collision Avoidance via Deep Reinforcement Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018. [Google Scholar] [CrossRef]
- Zhai, Y.; Ding, B.; Liu, X.; Jia, H.; Zhao, Y.; Luo, J. Decentralized Multi-Robot Collision Avoidance in Complex Scenarios With Selective Communication. IEEE Robot. Autom. Lett. 2021, 6, 8379–8386. [Google Scholar] [CrossRef]
- Semnani, S.H.; Liu, H.; Everett, M.; de Ruiter, A.; How, J.P. Multi-Agent Motion Planning for Dense and Dynamic Environments via Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2020, 5, 3221–3226. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Zhou, S.; Pan, Z.; Zheng, H.; Liu, Y. Mapless Collaborative Navigation for a Multi-Robot System Based on the Deep Reinforcement Learning. Appl. Sci. 2019, 9, 4198. [Google Scholar] [CrossRef]
- Brito, B.; Everett, M.; How, J.P.; Alonso-Mora, J. Where to go Next: Learning a Subgoal Recommendation Policy for Navigation in Dynamic Environments. IEEE Robot. Autom. Lett. 2021, 6, 4616–4623. [Google Scholar] [CrossRef]
- Han, R.; Chen, S.; Hao, Q. Cooperative Multi-Robot Navigation in Dynamic Environment with Deep Reinforcement Learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar]
- Vera, J.M.; Abad, A.G. Deep Reinforcement Learning for Routing a Heterogeneous Fleet of Vehicles. In Proceedings of the 2019 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Guayaquil, Ecuador, 11–15 November 2019; pp. 1–6. [Google Scholar]
- Google Inc. Google’s Optimization Tools (Or-Tools); Google Inc.: Mountain View, CA, USA, 2019. [Google Scholar]
- Schperberg, A.; Tsuei, S.; Soatto, S.; Hong, D. SABER: Data-Driven Motion Planner for Autonomously Navigating Heterogeneous Robots. IEEE Robot. Autom. Lett. 2021, 6, 8086–8093. [Google Scholar] [CrossRef]
- Zhang, Y.; Qian, Y.; Yao, Y.; Hu, H.; Xu, Y. Learning to Cooperate: Application of Deep Reinforcement Learning for Online AGV Path Finding. Auton. Agents Multiagent Syst. 2020, 2077–2079. [Google Scholar]
- Lin, K.; Zhao, R.; Xu, Z.; Zhou, J. Efficient Large-Scale Fleet Management via Multi-Agent Deep Reinforcement Learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1774–1783. [Google Scholar]
- Köksal Ahmed, E.; Li, Z.; Veeravalli, B.; Ren, S. Reinforcement learning-enabled genetic algorithm for school bus scheduling. J. Intell. Transp. Syst. 2022, 26, 269–283. [Google Scholar] [CrossRef]
- Qi, Q.; Zhang, L.; Wang, J.; Sun, H.; Zhuang, Z.; Liao, J.; Yu, F.R. Scalable Parallel Task Scheduling for Autonomous Driving Using Multi-Task Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2020, 69, 13861–13874. [Google Scholar] [CrossRef]
- Zhang, L.; Qi, Q.; Wang, J.; Sun, H.; Liao, J. Multi-task Deep Reinforcement Learning for Scalable Parallel Task Scheduling. In Proceedings of the 2019 IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; Baru, C., Ed.; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Xue, T.; Zeng, P.; Yu, H. A reinforcement learning method for multi-AGV scheduling in manufacturing. In Proceedings of the 2018 IEEE International Conference on Industrial Technology (ICIT), Lyon, France, 20–22 February 2018; pp. 1557–1561. [Google Scholar] [CrossRef]
- Zhang, C.; Odonkor, P.; Zheng, S.; Khorasgani, H.; Serita, S.; Gupta, C.; Wang, H. Dynamic Dispatching for Large-Scale Heterogeneous Fleet via Multi-agent Deep Reinforcement Learning. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020. [Google Scholar] [CrossRef]
- Elfakharany, A.; Ismail, Z.H. End-to-End Deep Reinforcement Learning for Decentralized Task Allocation and Navigation for a Multi-Robot System. Appl. Sci. 2021, 11, 2895. [Google Scholar] [CrossRef]
- Li, M.P.; Sankaran, P.; Kuhl, M.E.; Ptucha, R.; Ganguly, A.; Kwasinski, A. Task Selection by Autonomous Moblie Rrobots in a warhouse using Deep Reinforcement Learning. In Proceedings of the 2019 Winter Simulation Conference (WSC)E, National Harbor, MD, USA, 8–11 December 2019; pp. 680–689. [Google Scholar]
- Agrawal, A.; Won, S.J.; Sharma, T.; Deshpande, M.; McComb, C. A multi-agent reinforcement learning framework for intelligent manufactoring with autonomous mobile robots. Proc. Des. Soc. 2021, 1, 161–170. [Google Scholar] [CrossRef]
- Lütjens, B.; Everett, M.; How, J.P. Certified Adversarial Robustness for Deep Reinforcement Learning. In Proceedings of the Conference on Robot Learning, Virtual, 16–18 November 2020; Kaelbling, L.P., Kragic, D., Sugiura, K., Eds.; PMLR: Cambridge, MA, USA, 2020; Volume 100, pp. 1328–1337. [Google Scholar]
- Verband der Automobilindustrie. Interface for the Communication between Automated Guided Vehicles (AGV) and a Master Control: VDA5050; VDA: Berlin, Germany, 2020. [Google Scholar]
- Weinstock, C.B.; Goodenough, J.B. On System Scalability; Defense Technical Information Center: Fort Belvoir, VA, USA, 2006. [Google Scholar] [CrossRef]
- Wegner, P. Interoperability. ACM Comput. Surv. 1996, 28, 285–287. [Google Scholar] [CrossRef]
- Qin, W.; Zhuang, Z.; Huang, Z.; Huang, H. A novel reinforcement learning-based hyper-heuristic for heterogeneous vehicle routing problem. Comput. Ind. Eng. 2021, 156, 107252. [Google Scholar] [CrossRef]
- Mehta, B.; Diaz, M.; Golemo, F.; Pal, C.J.; Paull, L. Active Domain Randomization. Conf. Robot. Learn. 2020, 100, 1162–1176. [Google Scholar]
- Vuong, Q.; Vikram, S.; Su, H.; Gao, S.; Christensen, H.I. How to Pick the Domain Randomization Parameters for Sim-to-Real Transfer of Reinforcement Learning Policies? arXiv 2019, arXiv:1903.11774. [Google Scholar]
- He, Z.; Rakin, A.S.; Fan, D. Certified Adversarial Robustness with Additive Noise. In Proceedings of the 32th Conference Advances in neural information processing systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: A Survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 737–744. [Google Scholar] [CrossRef]
- Stulp, F.; Theodorou, E.A.; Schaal, S. Reinforcement Learning With Sequences of Motion Primitives for Robust Manipulation. IEEE Trans. Robot. 2012, 28, 1360–1370. [Google Scholar] [CrossRef]
- Sledge, I.J.; Bryner, D.W.; Principe, J.C. Annotating Motion Primitives for Simplifying Action Search in Reinforcement Learning. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 1–20. [Google Scholar] [CrossRef]
- Shi, H.; Shi, L.; Xu, M.; Hwang, K.S. End-to-End Navigation Strategy With Deep Reinforcement Learning for Mobile Robots. IEEE Trans. Ind. Inform. 2020, 16, 2393–2402. [Google Scholar] [CrossRef]
- Chiang, H.T.L.; Faust, A.; Fiser, M.; Francis, A. Learning Navigation Behaviors End-to-End With AutoRL. IEEE Robot. Autom. Lett. 2019, 4, 2007–2014. [Google Scholar] [CrossRef]
- Wu, J.; Wang, R.; Li, R.; Zhang, H.; Hu, X. Multi-critic DDPG Method and Double Experience Replay. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018. [Google Scholar] [CrossRef]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2016, arXiv:1511.05952. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Algorithm | Application | Control |
|---|---|---|
| Reinforcement Learning | Scheduling | fleet |
| RL | Path planning | Multi robot |
| Deep Q Learning | Path finding | Multi agent |
| DQL | collision avoidance | Swarm |
| Ref. | App. | Control Type | Algorithm | Agents | Input | Data Efficiency |
|---|---|---|---|---|---|---|
| [30] | PP | c | asynchronous DQN | 22 | totally | LSTM |
| [31] | PP | c | actionlimited multimodal DQN | 50 | totally | action replay |
| [32] | CA | c | Integrated RL | 3 | totally | none |
| [33] | PP | c | DQN | 4 | partially | none |
| [34] | PP | c | PSO + QL | 10 | totally | none |
| [35] | S | c | PSO + QL | 3 | totally | none |
| [36] | CA | c | FC + RL | 4 | totally | none |
| [46] | PP + CA | d | VP + QL | 3 | partially | none |
| [43] | PP | d | Evolutionary RL | 20 | partially | none |
| [42] | PP | d | G2RL | 128 | partially | LSTM |
| [38] | PP | d | QL | 3 | totally | prior knowledge |
| [39] | PP | d | DQN | 4 | totally | none |
| [40] | PP | d | PRIMAL | 1024 | partially | LSTM |
| [41] | PP | d | PRIMAL2 | 2048 | partially | LSTM |
| [37] | PP | d | DynaQ | 3 | totally | none |
| [57] | PP | d | DRL + MPC | 10 | totally | subgoal planning |
| [69] | PP + S | d | PPO + DQN | 4 | partially | none |
| [53] | CA | d | PPO | 100 | partially | none |
| [50] | CA | d | PPO + PID | 100 | partially | none |
| [62] | PP | d | AC + TS | 150 | totally | post- processing |
| [54] | CA | d | AC + PPO | 24 | totally | selective communication |
| [51] | CA | d | Map-based PPO | 10 | partially | none |
| [55] | CA | d | GA3C-CARDL-NSL | 10 | partially | none |
| [45] | PP | d | QL | 128 | partially | selective communication |
| [48] | PP | d | QL | 4 | partially | sample efficient QL |
| [65] | S | d | MDTS | 8 | totally | partial data input for A3C |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wesselhöft, M.; Hinckeldeyn, J.; Kreutzfeldt, J. Controlling Fleets of Autonomous Mobile Robots with Reinforcement Learning: A Brief Survey. Robotics 2022, 11, 85. https://doi.org/10.3390/robotics11050085
Wesselhöft M, Hinckeldeyn J, Kreutzfeldt J. Controlling Fleets of Autonomous Mobile Robots with Reinforcement Learning: A Brief Survey. Robotics. 2022; 11(5):85. https://doi.org/10.3390/robotics11050085
Chicago/Turabian StyleWesselhöft, Mike, Johannes Hinckeldeyn, and Jochen Kreutzfeldt. 2022. "Controlling Fleets of Autonomous Mobile Robots with Reinforcement Learning: A Brief Survey" Robotics 11, no. 5: 85. https://doi.org/10.3390/robotics11050085
APA StyleWesselhöft, M., Hinckeldeyn, J., & Kreutzfeldt, J. (2022). Controlling Fleets of Autonomous Mobile Robots with Reinforcement Learning: A Brief Survey. Robotics, 11(5), 85. https://doi.org/10.3390/robotics11050085