
Indoor Emergency Path Planning Based on the Q-Learning Optimization Algorithm

Abstract
:1. Introduction
- Aimed at the path planning problem of indoor complex environments in disaster scenarios, a grid environment model is established, and the Q-learning algorithm is adopted to implement the path planning problem of the grid environment.
- Aimed at the problems of slow convergence speed and low accuracy of the Q-learning algorithm in a large-scale grid environment, the exploration factor in the ε-greedy strategy is dynamically adjusted, and the discount rate variable of the exploration factor is introduced. Before random actions are selected, the discount rate of the exploration factor is calculated to optimize the Q-learning algorithm in the grid environment.
- An indoor emergency path planning experiment based on the Q-learning optimization algorithm is carried out using simulated data and real indoor environment data of an office building. The results show that the Q-learning optimization algorithm is better than both the SARSA algorithm and the Q-learning algorithm in terms of solving time and convergence when planning the shortest path in a grid environment. The Q-learning optimization algorithm has a convergence speed that is approximately five times faster than that of the classic Q-learning algorithm. In the grid environment, the Q-learning optimization algorithm can successfully plan the shortest path to avoid obstacles in a short time.
2. Indoor Emergency Path Planning Method
2.1. Grid Environment Modeling
2.2. Q-Learning Optimization Algorithm
2.2.1. Q-Learning Algorithm
- Observe the status at this time;
- Select the action to perform next;
- Continue to observe the next step ;
- Get immediate reward ;
- Update the value;
- goes to the next moment.
- Initialize Q value;
- Select the status at time ;
- Update ;
- Select the next action according to the updated ;
- Perform action , obtain the new state and immediate reward value ;
- Calculate ;
- Adjust the weight of the Q network to minimize error , as shown in Equation (8):
- Go to 2.
2.2.2. Path Planning Strategy
- 1.
- Action and state of agent
- 2.
- Set the reward function
- 3.
- Action strategy selection
- 4.
- Q Value Table
2.2.3. Dynamic Adjustment of Exploration Factors
2.3. Algorithm Flow
3. Experiment and Analysis
3.1. Parameter Settings
3.2. Algorithm Simulation Experimental Analysis
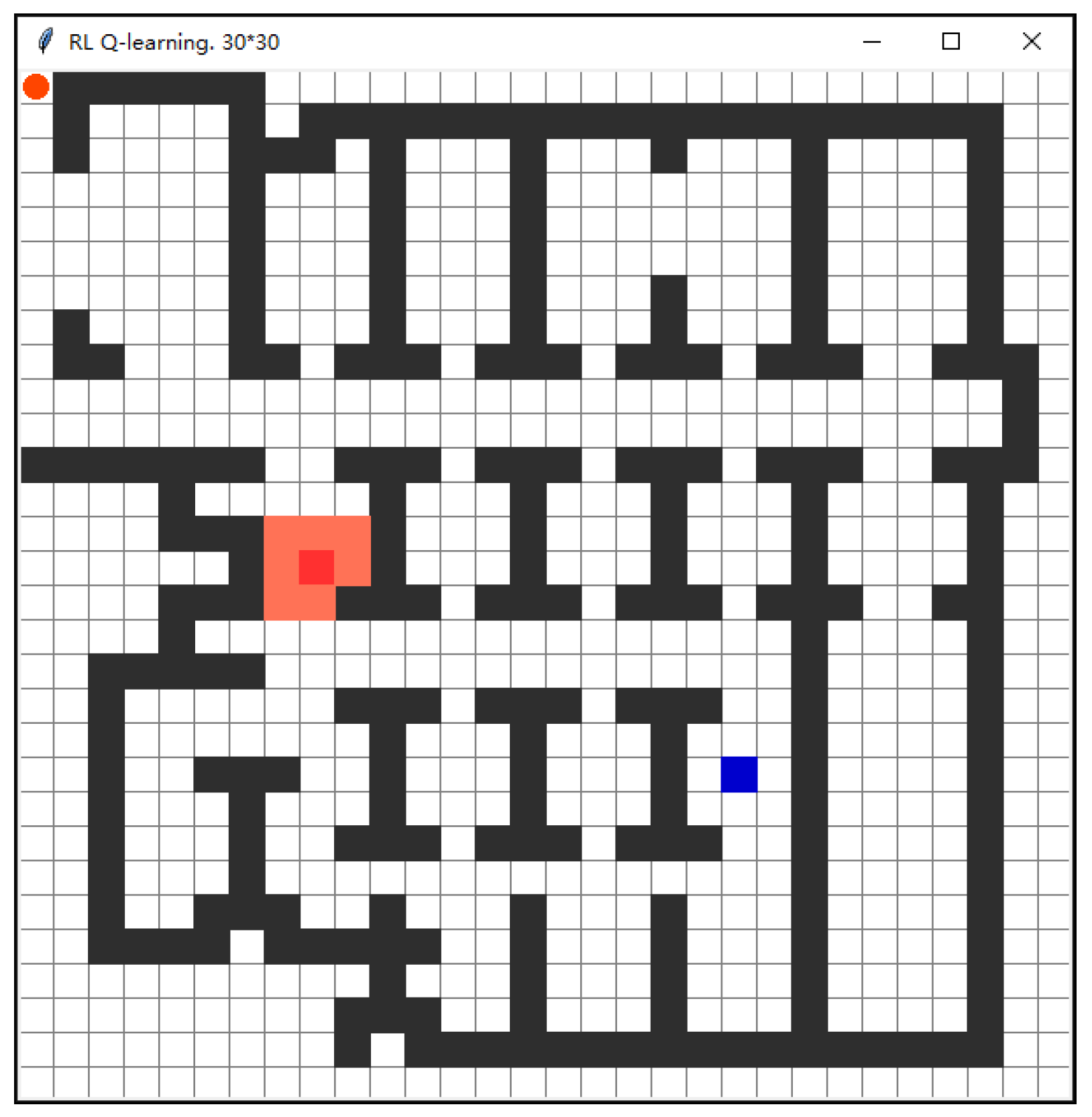
3.2.1. Environmental Spatial Modeling
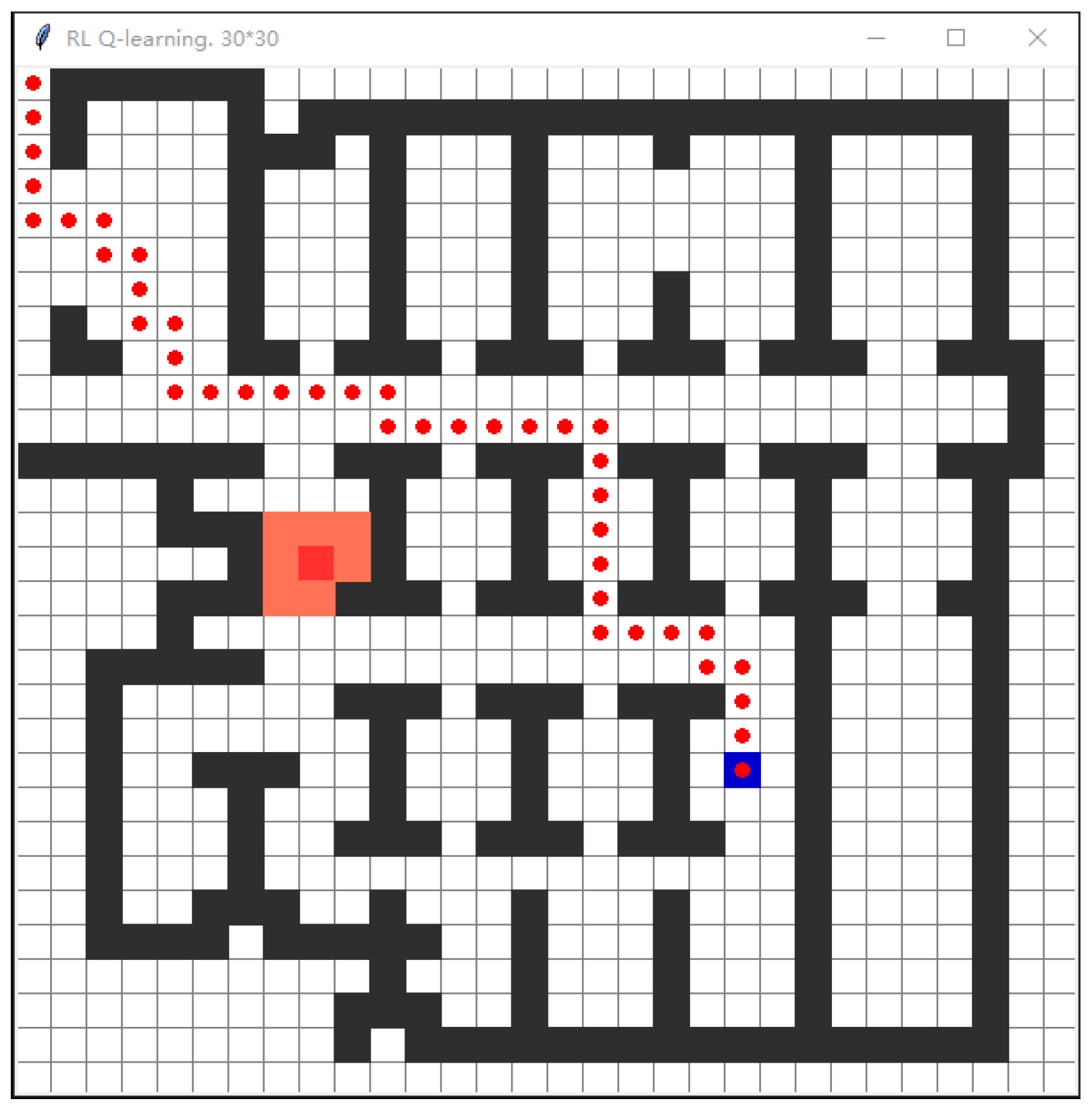
3.2.2. Comparison and Analysis of Experimental Results
3.3. Simulation Scene Experiment Analysis
3.3.1. Experimental Data and Scene Construction
3.3.2. Analysis of Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mao, J.H. Research on Emergency Rescue Organization under Urban Emergency. Master’s Thesis, Chang’an University, Xi’an, China, 2019. [Google Scholar]
- Wu, Q.H. Severity of the fire status and the impendency of establishing the related courses. Fire Sci. Technol. 2005, 2, 145–152. [Google Scholar]
- Meng, H.L. Security question in the fire evacuation. China Public Secur. 2005, 1, 71–74. [Google Scholar]
- Zhu, Q.; Hu, M.Y.; Xu, M.Y. 3D building information model for facilitating dynamic analysis of indoor fire emergency. Geomat. Inf. Sci. Wuhan Univ. 2014, 39, 762–766+872. [Google Scholar]
- Ni, W. Research on Emergency Evacuation Algorithm Based on Urban Traffic Network. Master’s Thesis, Hefei University of Technology, Hefei, China, 2018. [Google Scholar]
- Zhang, Y.H. Research on Path Planning Algorithm of Emergency Rescue Vehicle in Vehicle-Road Cooperative Environment. Master’s Thesis, Beijing Jiaotong University, Beijing, China, 2019. [Google Scholar]
- Wang, J. Research and Simulation of Dynamic Route Recommendation Method Based on Traffic Situation Cognition. Master’s Thesis, Beijing University of Posts and Telecommunications, Beijing, China, 2019. [Google Scholar]
- Li, C. Research on Intelligent Transportation Forecasting and Multi-Path Planning Based on Q-Learning. Master’s Thesis, Central South University, Changsha, China, 2014. [Google Scholar]
- Lu, J.; Xu, L.; Zhou, X.P. Research on reinforcement learning and its application to mobile robot. J. Harbin Eng. Univ. 2004, 25, 176–179. [Google Scholar]
- He, D.F.; Sun, S.D. Fuzzy logic navigation of mobile robot with on-line self-learning. J. Xi’an Technol. Univ. 2007, 4, 325–329. [Google Scholar]
- Bae, H.; Kim, G.; Kim, J.; Qian, D.; Lee, S. Multi-Robot Path Planning Method Using Reinforcement Learning. Appl. Sci. 2019, 9, 3057. [Google Scholar] [CrossRef] [Green Version]
- Aye, M.A.; Maxim, T.; Anh, N.T.; JaeWoo, L. iADA*-RL: Anytime Graph-Based Path Planning with Deep Reinforcement Learning for an Autonomous UAV. Appl. Sci. 2021, 11, 3948. [Google Scholar]
- Junior, A.G.D.S.; Santos, D.; Negreiros, A.; Boas, J.; Gonalves, L. High-Level Path Planning for an Autonomous Sailboat Robot Using Q-Learning. Sensors 2020, 20, 1550. [Google Scholar] [CrossRef] [Green Version]
- Jaradat, M.A.K.; Al-Rousan, M.; Quadan, L. Reinforcement based mobile robot navigation in dynamic environment. Robot. Comput. Integr. Manuf. 2010, 27, 135–149. [Google Scholar] [CrossRef]
- Hao, W.Y.; Li, T.S.; Jui, L.C. Backward Q-learning: The combination of Sarsa algorithm and Q-learning. Eng. Appl. Artif. Intell. 2013, 26, 2184–2193. [Google Scholar]
- Zeng, J.Y.; Liang, Z.H. Research on the application of supervised reinforcement learning in path planning. Comput. Appl. Softw. 2018, 35, 185–188+244. [Google Scholar]
- Min, F.; Hao, L.; Zhang, X. A Heuristic Reinforcement Learning Based on State Backtracking Method. In Proceedings of the 2012 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Macau, China, 4–7 December 2012. [Google Scholar]
- Song, Y.; Li, Y.-b.; Li, C.-h.; Zhang, G.-f. An efficient initialization approach of Q-learning for mobile robots. Int. J. Control Autom. Syst. 2012, 10, 166–172. [Google Scholar] [CrossRef]
- Song, J.J. Research on Reinforcement Learning Problem Based on Memory in Partial Observational Markov Decision Process. Master’s Thesis, Tiangong University, Tianjin, China, 2017. [Google Scholar]
- Wang, Z.Z.; Xing, H.C.; Zhang, Z.Z.; Ni, Q.J. Twoclasses of abstract modes about matkov decision processes. Comput. Sci. 2008, 35, 6–14. [Google Scholar]
- Lieping, Z.; Liu, T.; Shenglan, Z.; Zhengzhong, W.; Xianhao, S.; Zuqiong, Z. A Self-Adaptive Reinforcement-Exploration Q-Learning Algorithm. Symmetry 2021, 13, 1057. [Google Scholar]
- Hongchao, Z.; Kailun, D.; Yuming, Q.; Ning, W.; Lei, D. Multi-Destination Path Planning Method Research of Mobile Robots Based on Goal of Passing through the Fewest Obstacles. Appl. Sci. 2021, 11, 7378. [Google Scholar]
- Ee, S.L.; Ong, P.; Kah, C.C. Solving the optimal path planning of a mobile robot using improved Q-learning. Robot. Auton. Syst. 2018, 115, 143–161. [Google Scholar]
- Li, C.; Li, M.J.; Du, J.J. A modified method to reinforcement learning action strategy ε-greedy. Comput. Technol. Autom. 2019, 38, 5. [Google Scholar]
- Yang, T.; Qin, J. Adaptive ε-greedy strategy based on average episodic cumulative reward. Comput. Eng. Appl. 2021, 57, 148–155. [Google Scholar]
- Li, D.; Sun, X.; Peng, J.; Sun, B. A Modified Dijkstra’s Algorithm Based on Visibility Graph. Electron. Opt. Control 2010, 17, 40–43. [Google Scholar]
- Yan, J.F.; Tao, S.H.; Xia, F.Y. Breadth First P2P Search Algorithm Based on Unit Tree Structure. Comput. Eng. 2011, 37, 135–137. [Google Scholar]
- Li, G.; Shi, H. Path planning for mobile robot based on particle swarm optimization. In Proceedings of the 2008 Chinese Control and Decision Conference, Yantai, China, 2–4 July 2008. [Google Scholar]
- Ge, W.; Wang, B.; University, H.N. Global Path Planning Method for Mobile Logistics Robot Based on Raster Graph Method. Bull. Sci. Technol. 2019, 35, 72–75. [Google Scholar]
- Zhou, X.; Bai, T.; Gao, Y.; Han, Y. Vision-Based Robot Navigation through Combining Unsupervised Learning and Hierarchical Reinforcement Learning. Sensors 2019, 19, 1576. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tan, C.; Han, R.; Ye, R.; Chen, K. Adaptive Learning Recommendation Strategy Based on Deep Q-learning. Appl. Psychol. Meas. 2020, 44, 251–266. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Liu, Y.; Chen, W.; Ma, Z.-M.; Liu, T.-Y. Target transfer Q-learning and its convergence analysis. Neurocomputing 2020, 392, 11–22. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.Y. Research on Navigation of Autonomous Mobile Robot Based on Reinforcement Learning. Master’s Thesis, Northeast Normal University, Shenyang, China, 2009. [Google Scholar]
- Liu, Z.G.; Yin, X.C.; Hu, Y. CPSS LR-DDoS Detection and Defense in Edge Computing Utilizing DCNN Q-Learning. IEEE Access 2020, 8, 42120–42130. [Google Scholar] [CrossRef]
- Roozegar, M.; Mahjoob, M.J.; Esfandyari, M.J.; Panahi, M.S. XCS-based reinforcement learning algorithm for motion planning of a spherical mobile robot. Appl. Intell. 2016, 45, 736–746. [Google Scholar] [CrossRef]
- Qu, Z.; Hou, C.; Hou, C.; Wang, W. Radar Signal Intra-Pulse Modulation Recognition Based on Convolutional Neural Network and Deep Q-Learning Network. IEEE Access 2020, 8, 49125–49136. [Google Scholar] [CrossRef]
- Alshehri, A.; Badawy, A.; Huang, H. FQ-AGO: Fuzzy Logic Q-Learning Based Asymmetric Link Aware and Geographic Opportunistic Routing Scheme for MANETs. Electronics 2020, 9, 576. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.N. Research on Path Planning Based on Reinforcement Learning. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2017. [Google Scholar]
- Chen, L. Research on Reinforcement Learning Algorithm of Moving Vehicle Path Planning in Special Traffic Environment. Master’s Thesis, Beijing Jiaotong University, Beijing, China, 2019. [Google Scholar]
- Zhao, H.B.; Yan, S.Y. Global sliding mode control experiment of Arneodo Chaotic System based on Tkinter. Sci. Technol. Innov. Her. 2020, 17, 3. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantages | Disadvantages |
|---|---|---|
| Viewable method | The algorithm principle is simple and easy to implement | Inefficient and inflexible |
| Cell tree method | Close attention to details | Not suitable for environments with small volume and large number of obstacles |
| Link graph method | Flexible, and the model does not need to be rebuilt when changing the starting and ending point | When the number of obstacles is large, the algorithm becomes complex |
| Grid graph method | Simple theory, easy to implement | The timeliness of the algorithm decreases as the number of grids increases |
| Algorithm Performance | SARSA Algorithm | Q-Learning Algorithm | Proposed Q-Learning Optimization Algorithm |
|---|---|---|---|
| Shortest path steps | 102 | 42 | 42 |
| Longest path steps | 3682 | 1340 | 1227 |
| Convergence | No convergence trend after 5000 iterations | Approximately 2500 iterations tend to converge | Basically converged after 500 iterations |
| Computational time | 164.86 s | 68.692 s | 13.738 s |
| Cumulative rewards | Has been hovering around 0 value | Approximately 5000 iterations converge to 10 | About 3000 iterations converged to 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Gu, Y.; Li, X.; Chen, C.; Hu, Y.; Sang, Y.; Jiang, W. Indoor Emergency Path Planning Based on the Q-Learning Optimization Algorithm. ISPRS Int. J. Geo-Inf. 2022, 11, 66. https://doi.org/10.3390/ijgi11010066
Xu S, Gu Y, Li X, Chen C, Hu Y, Sang Y, Jiang W. Indoor Emergency Path Planning Based on the Q-Learning Optimization Algorithm. ISPRS International Journal of Geo-Information. 2022; 11(1):66. https://doi.org/10.3390/ijgi11010066
Chicago/Turabian StyleXu, Shenghua, Yang Gu, Xiaoyan Li, Cai Chen, Yingyi Hu, Yu Sang, and Wenxing Jiang. 2022. "Indoor Emergency Path Planning Based on the Q-Learning Optimization Algorithm" ISPRS International Journal of Geo-Information 11, no. 1: 66. https://doi.org/10.3390/ijgi11010066
APA StyleXu, S., Gu, Y., Li, X., Chen, C., Hu, Y., Sang, Y., & Jiang, W. (2022). Indoor Emergency Path Planning Based on the Q-Learning Optimization Algorithm. ISPRS International Journal of Geo-Information, 11(1), 66. https://doi.org/10.3390/ijgi11010066