1. Introduction
Twenty years ago, if asked what the most popular aspect of geographic information studies was, many people would have answered, ‘the increasing use of geographic information systems’ (GIS). Now, similarly, volunteered geographic information impels the geoinformation society to comprehend geospatial datasets created by volunteers. Crowdsourced platforms involving spatial data generation by volunteer participants are called volunteered geographical information (VGI) projects. Each of the independent volunteers has an equal right to generate spatial data and update existing data. In other words, volunteer participants have the facility to provide unlimited geographic data and to edit each other’s contributions. However, there is no requirement for cartographic qualifications among participants in VGI platforms. Therefore, there is always a possibility that one can be a non-expert cartographer. Volunteers whose expertise is not confirmed as sufficient can create geographic data through online interfaces [
1,
2]. Spatial data consistency is achieved only after any detected conflicts have been resolved manually [
3]. Therefore, various scientific studies have been carried out to determine whether or not the geographic data generated through VGI can be used for professional purposes, like other maps produced by cartographers. Most studies have focused on evaluating the accuracy and completeness of semantic and geometric data in VGI. Only a few studies have directly investigated volunteers’ behavior [
4,
5,
6,
7,
8]. Briefly, they examined the geometric and semantic contributions and assessed the activities of volunteers.
This section firstly gives a general introduction to OpenStreetMap, the most popular VGI platform. Secondly, the quality assessment studies of VGI data are summarized, as they are one of the most common research interests on VGI data. Then, previous studies that shape the motivation of this paper and the scope of the investigation of contributors’ behavior are presented. Finally, the motivation and a brief outline of the study are introduced.
OSM, Wheelmap, Wikimapia, and WorldMap are some of the significant VGI projects. The Wheelmap project is carried out for individuals with walking disabilities to identify geographical objects on the map suitable for wheelchair use [
9]. WorldMap is a project that rapidly initiated the generation of geographic data for Africa [
10], before expanding to other continents. The Wikimapia project was established in 2006 [
11] with the aim of creating a geographic data encyclopedia inspired by Wikipedia. One of the pioneering VGI projects is OSM. It is used for all geographical entities that are predominantly located close to or related to roads; however, there is no limit on geographic data diversity in the project [
12]. Participants can freely contribute geometric and semantic information for any location in the world. Data are made available weekly at planet.osm. At the beginning of the OSM project, while some of the participants were active, many of them only became members, abstaining from any editing. Neis and Zipf [
13] mentioned that only 38% of the volunteers made at least one contribution, and just 5% actively contributed as OSM volunteers in real terms. Over the years, with the increase in member participation, the compressed version of the planet data available for sharing on 31 December 2020 has grown to 54.5 GB and the extracted version in XML format, 1338.4 GB [
14]. There is no geometric, semantic, or cartographic internal control mechanism except the authority of volunteers to regulate each other’s contributions, and there are no restrictive rules that enable the evaluation of this large geographic data source. Therefore, Mooney and Corcoran [
5] remark that it is necessary for users to evaluate the quality of the OSM data, especially for map applications that require high geometric accuracy and precision. Basiri et al. [
15] mentioned the problems of OSM contributions as arising from volunteers’ lack of GIS experience, insufficient knowledge of the area contributed, interpretations of similar attributes with different tags for the same objects, and additions of different numbers of tags to similar objects.
Early studies to evaluate OSM data focused on determining accuracy and completeness using reference data. Haklay [
16] focused on a quality analysis based on comparing the UK’s OSM data with large-scale data produced by Ordnance Survey. The author determined that the OSM geometric data accuracy is approximately 6 m. In France, Girres and Touya [
17] used evaluation measures for OSM data that determine spatial data quality, such as geometric, attribute, semantic and temporal accuracy, logical consistency, and completeness. Mondzech and Sester [
18] evaluated OSM quality in terms of pedestrian navigation by comparing ATKIS and OSM data. They analyzed some cities in Germany and determined that the datasets where long routes were formed consisted of incomplete data. Da Costa [
19] evaluated the completeness of OSM buildings by comparing them with official building datasets. The study showed that completeness was relatively high in town centers but decreased further away from urban areas. Zhang and Malczewski [
20] evaluated the quality of OSM road data in Canada. As a result of their analysis using spatial data evaluation measures such as completeness, spatial, attribute, and semantic accuracy, they found that there was more participation in urban road networks than in rural areas. Mobasheri et al. [
21] conducted an initial assessment of sidewalk data in OSM to increase the awareness and engagement of the crowd for enriching sidewalk information in different European cities. In Iran, Mohammadi and Sedaghat [
22] proposed a framework to estimate VGI quality using an index to classify them based on the users’ needs by using an integrated approach consisting of a matching process and a neural network classifier.
Reference data can provide information on whether geometric or semantic data is correct, but it does not provide information on volunteers’ choice of tag type or general drawing trends [
5]. Studies without reference data generally assess OSM objects with the help of geometric and semantic measures and make inferences about the evolution of data or the behavior of contributors. Some of the studies conducted without reference data have been focused on the evolution and automated generation of OSM data. Corcoran et al. [
23] analyzed the temporal evolution of three OSM road networks in Ireland. They evaluated the results by densification and exploration in urban areas. Zhao et al. [
24] examined the evolution of Beijing’s OSM road networks between 2009 and 2012 in terms of geometric, topological, and centrality measures; in the study area, it was determined that OSM volunteers started to contribute from the city boundaries and that their drawings were directed towards the city center. Hacar et al. [
25] examined the evolution of the OSM road networks in Ankara between 2007 and 2017 by using centrality measures. They measured the temporal completeness parameter, the sinuosity of the roads, and the activation density of volunteers over the years. It was observed that as the experience of contributors increased, they made more detailed contributions. Basiri et al. [
26] analyzed trajectories of movement to extract some patterns and rules, which help to detect anomalies and errors within OSM data. In addition, Basiri et al. [
15] conducted a study with the assumption that some characteristics of raw trajectory data may be related to the geometry and attributes of the objects. They proposed an approach to generating new objects or editing existing data by using data mining techniques, which include cartographic generalization, and matching steps. Hacar [
27] suggested a semi-automated approach to identify the values of leisure tags. The approach uses geometric (rectangularity, density, area, and distances to bus stop and shop) and semantic (amenity) data and estimates the key values using a random forest classifier.
Creating geographical objects and converting them into map features is the specialty of cartographers. As in many engineering branches, this field requires extensive knowledge of analytical geometry. There are many cartographic rules that are defined by graphic and geometric resolution limits during the creation of drawings. Moreover, when the act of drawing is considered an artistic activity, it can be recognized that subjective actions are also performed [
28]. These actions are habits shaped by the experience of cartographers over time, and there are no specific common standards. For example, there is no objective rule for determining where to start drawing a road network, forest border, lake, or building. It may not be meaningful to scientifically investigate the subjective drawing habits of cartographers in projects consisting of several cartographers. However, volunteers contributing to crowdsourced VGI data should be considered outside this scope. In VGI projects, unlike others, it is necessary to talk about the behavior of hundreds of thousands of people, rather than individual habits. Scientific research on crowdsourced contribution behavior has been conducted using both geometric and semantic approaches. Mooney et al. [
4] evaluated the quality of OSM data by examining the creation of polygons representing hydrography and forested areas. They stated that it was easier for the volunteers to draw hydrographic features and boundaries from satellite images than to draw the boundaries of the forest area.
However, most of the quality assessment studies of OSM were designed to evaluate the semantic tags and their values. Mooney and Corcoran [
5,
29] examined frequently updated data (at least 15 times) by country. Although frequently changed objects have certain common points, it was observed that they did not have a correlation. They found that more than 90% of the OSM data changed less than three times and there was no strong relationship between the number of contributors and the number of tags. Jilani et al. [
6] developed a machine learning (ML) model to predict the “highway = *” tag values that refer to OSM road classes. They took some of the relatively reliable London OSM road data as a reference. As a result of the experiment, while more than 50% of residential, pedestrian, primary, motorway, primarylink, and motorwaylink were predicted correctly, less than 40% of the cycleway, bridleway, path, secondary, and secondarylink were correct. Due to the density of data in urban areas, the use of the ‘Map Features’ guide on the OSM Wiki website helps to make more careful and accurate contributions [
30]. In the manual, tag names that are especially preferred and accepted by users over several years are listed with their definitions. Contributors can select tags suitable for a characteristic of a geographic object from the list and enter data compatible with other users. Davidovic et al. [
7] investigated how often OSM volunteers in 30 different urban areas took the OSM Wiki web page into consideration. They found that the volunteers were in general agreement with the guideline on the ‘Map Features’ page, but that the same types of geographic objects were created with different tags in different cities. Hacar [
8] examined the planet.osm data, comparing the tags belonging to the roads and studying the tag adding trends of the volunteers. He stated that while surface, source, and oneway tags were added in residential roads at a similar rate to other road types, name tags were added more frequently. It was also found that in 81% of residential road drawings, the source used is not specified. He remarked that while OSM is a good data source in terms of tag diversity, it has deficiencies in terms of data completeness.
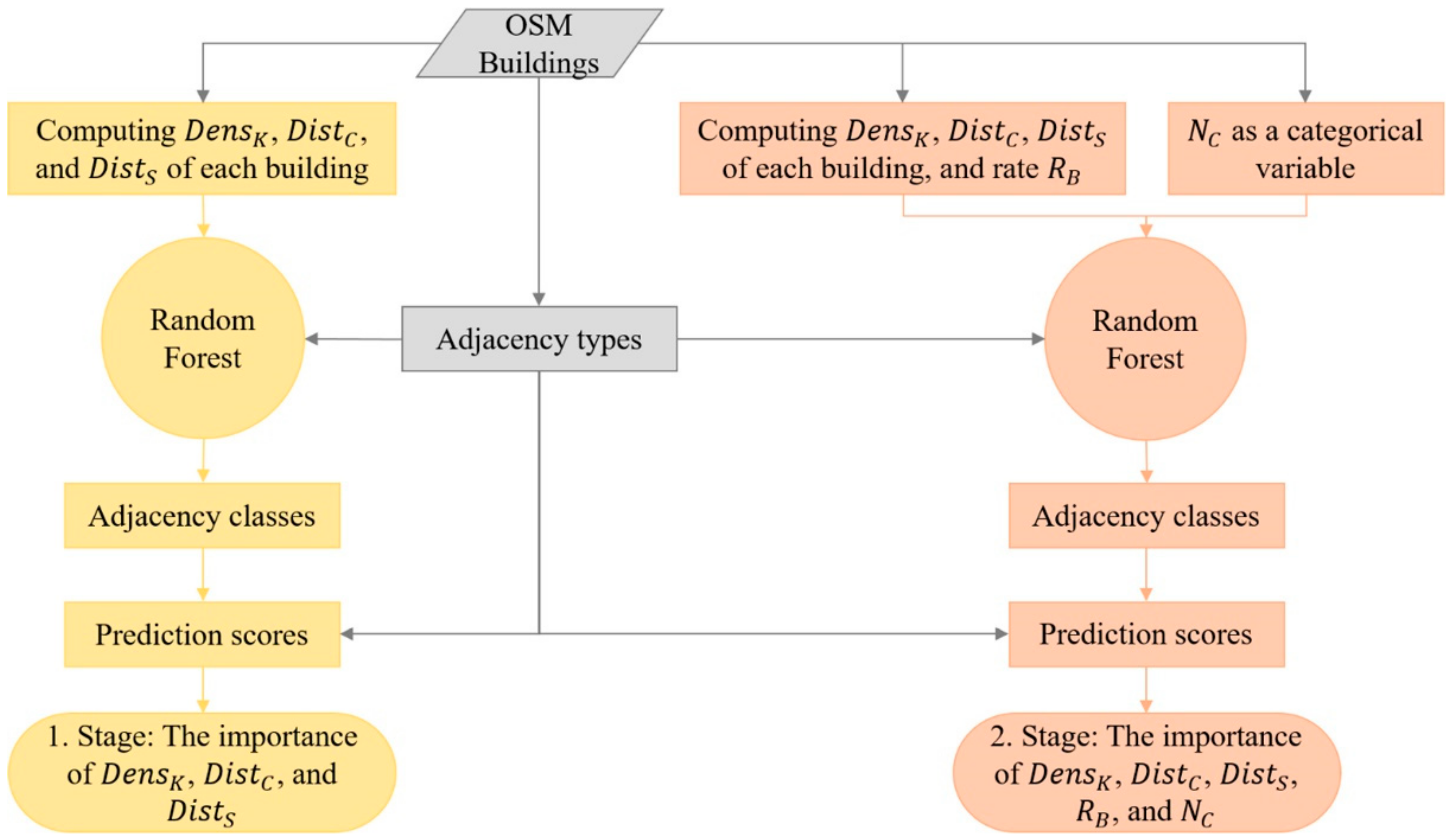
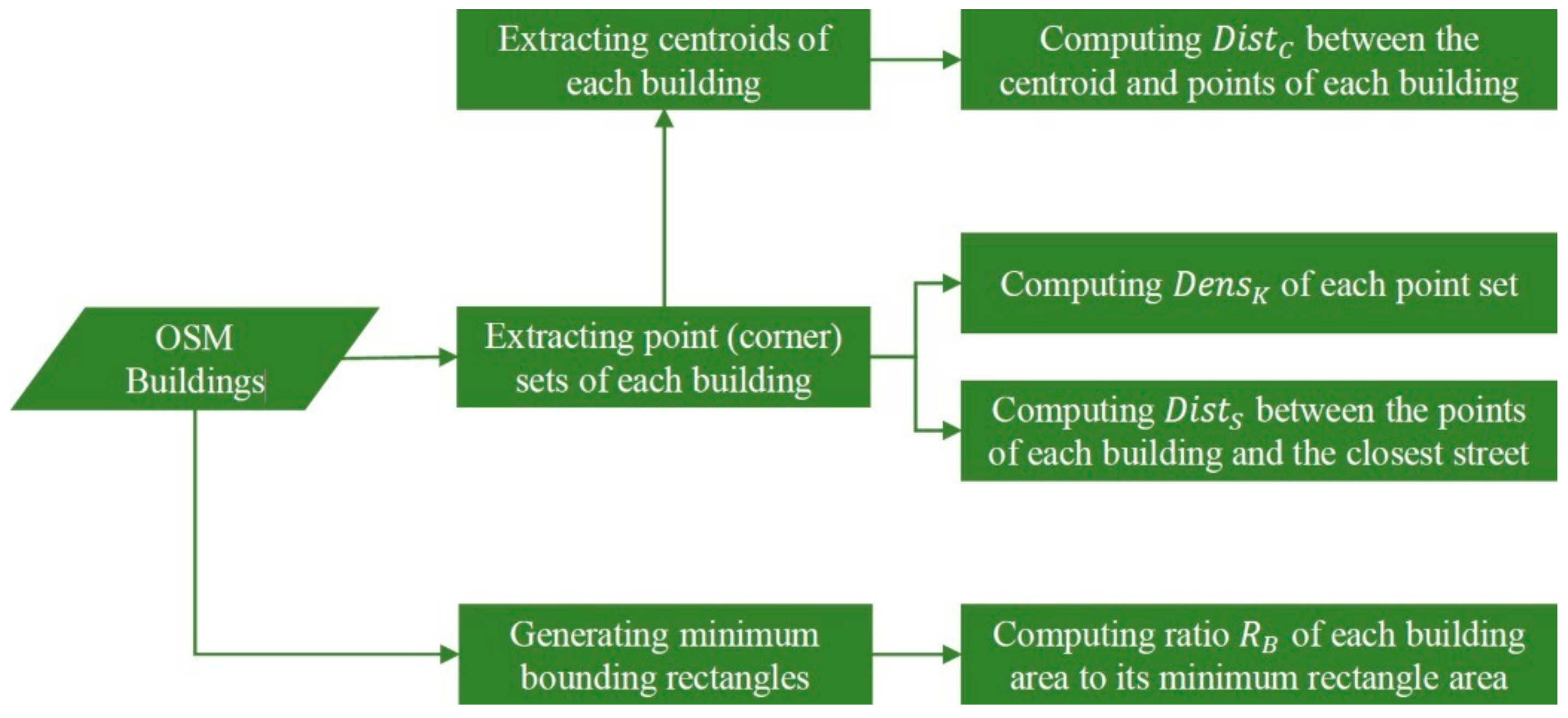
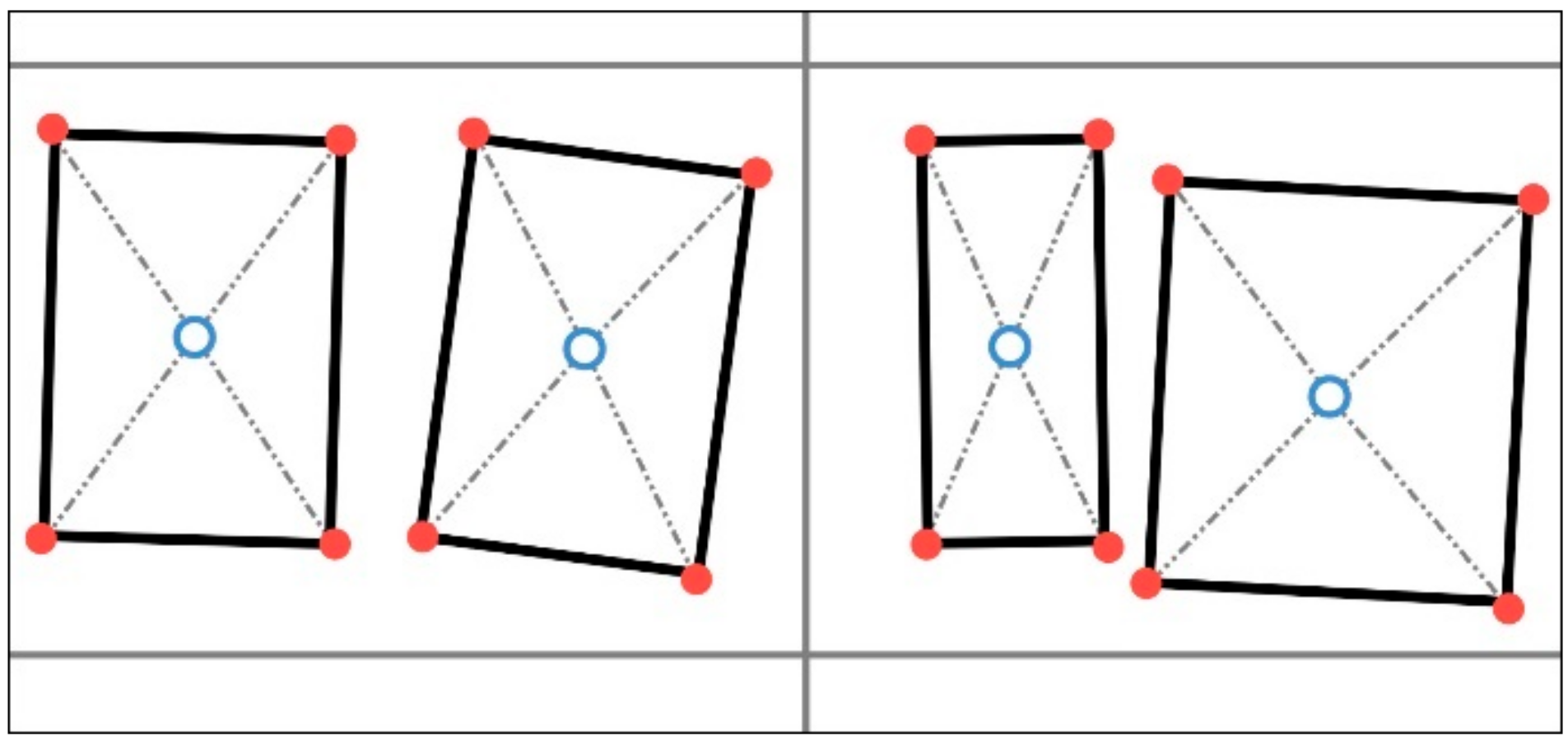
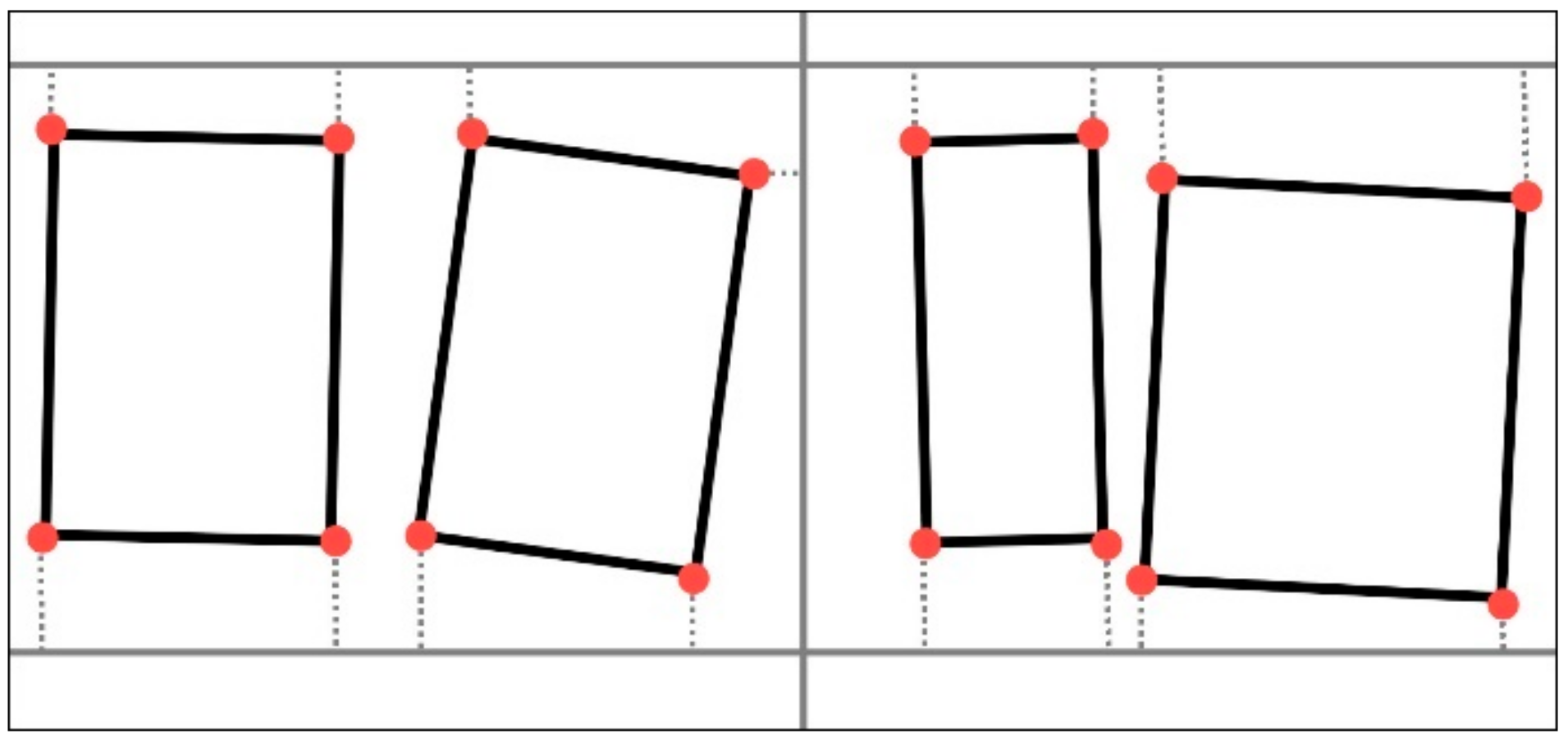
The research question of this study is inspired by the limited study of crowdsourced trends in cartographic drawing. Until now, researchers have had the opportunity to discover what the volunteers draw, but had insufficient information about how they draw. This study aims to find a common direction or trend among OSM contributors when mapping building polygons. Various properties of buildings’ corner points are used to measure possible distinctions among the points. The proposed approach evaluates how salient the properties of a point are in making it the first point of OSM buildings. In order to examine the trends, several measures of the points constituting buildings (e.g., distance, density, and rectangularity) are used as independent variables. In addition, the adjacency types of the buildings are used as dependent variables. In order to examine the drawing trends, the proposed approach performs a classification study using a random forest classifier. The reason for the classification is to implement the assumption that ‘if a successful classification (attached/detached) is possible with the measures computed using the first points, there is some common behavior in mapping the first points of attached, or detached buildings’. In other words, each class helps to understand the specific trends for the buildings within it. The drawing trends were interpreted using the results of the test data. In the next section, the proposed approach is explained in detail. OSM data and the study area are also presented. In the third section, the results of the experiment are evaluated by measure importance. Finally, this study is concluded by discussing the drawing trends of the contributors and the perspective of future research.
3. Results and Evaluation
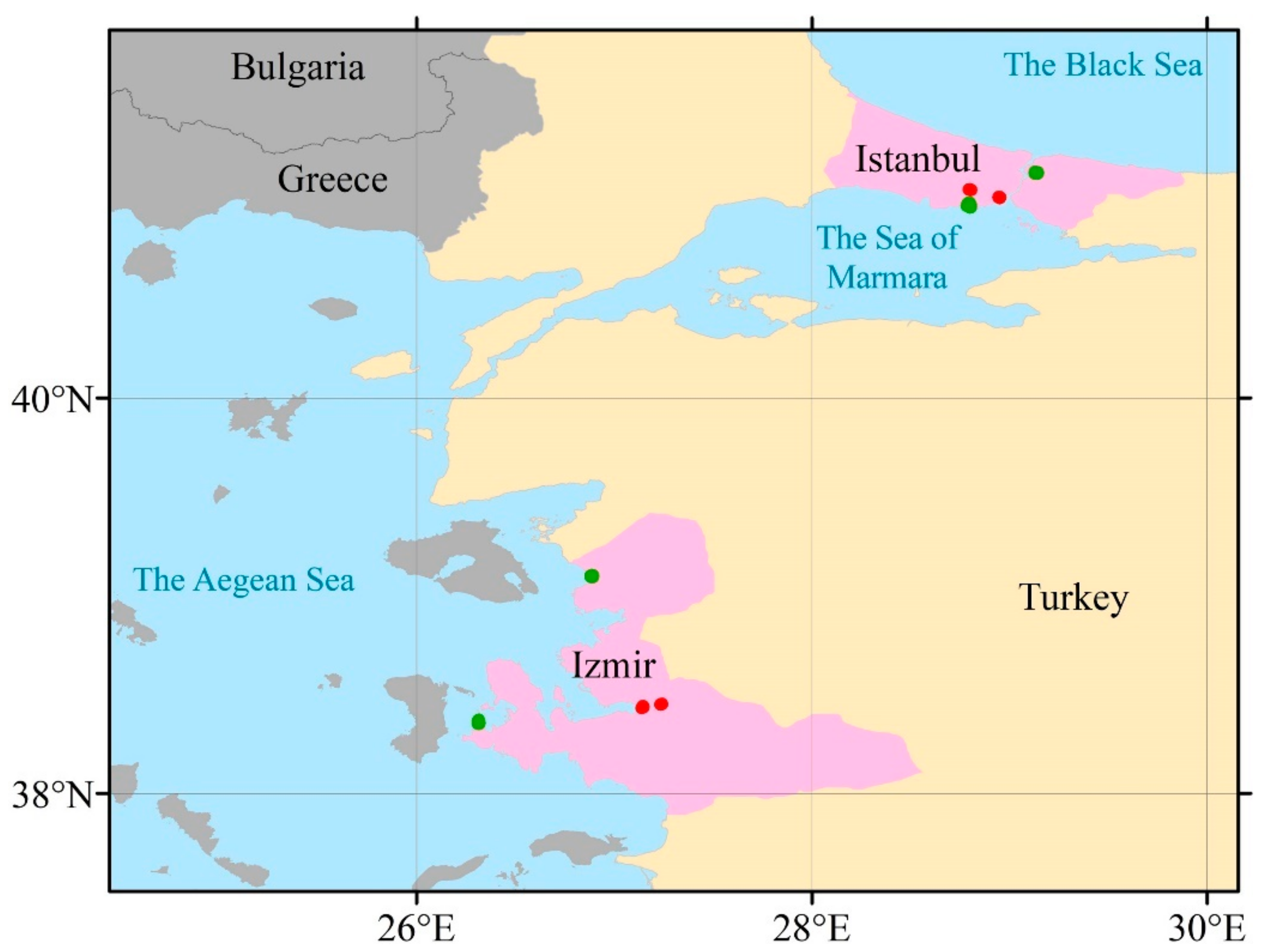
This study was conducted with the building groups in Istanbul and Izmir (
Table 1 and
Figure 2). While 5600 buildings were used randomly as training data, the adjacency types of the remaining 1400 buildings have been predicted. The prediction scores of the test data were obtained by comparing the predicted classes and real adjacency types. While precision can be defined as the positive predictive value or the ability of the classifier, recall is the sensitivity and ability of the classifier to find all the positive samples [
41]. F-score represents the balance between precision and recall. It is a weighted harmonic mean of the precision and recall, where the score reaches its best value at 1 and its worst at 0 [
41].
Table 2 and
Table 3 present the results of the first and second stages, respectively.
In the first stage of the study, the adjacency type of the buildings was predicted using only
,
,
,
,
, and
measures. The F-score of the experiment was determined as 77% (
Table 2). In the second stage,
and
were added to the existing measures for second training. As a result, the score increased to 83% when all variables were used.
Table 2 and
Table 3 show that most of the classes have been predicted. However, the prediction scores do not demonstrate how the measures affect the results. Therefore, an additional evaluation is necessary to comprehend which measure is most effective in prediction.
Generally, the importance of a measure is computed as the (normalized) total reduction of the criterion brought about by that measure [
41]. The importance comes from the base formula of Gini impurity [
42]. After determining the importance of each measure in the prediction process (PP), the measure importance in predicting the relevant class (i.e., adjacency type) was also calculated by (1).
where
is the importance of measure
i in predicting the specific adjacency type,
is the scaled value of measure
i, and
is the importance of measure
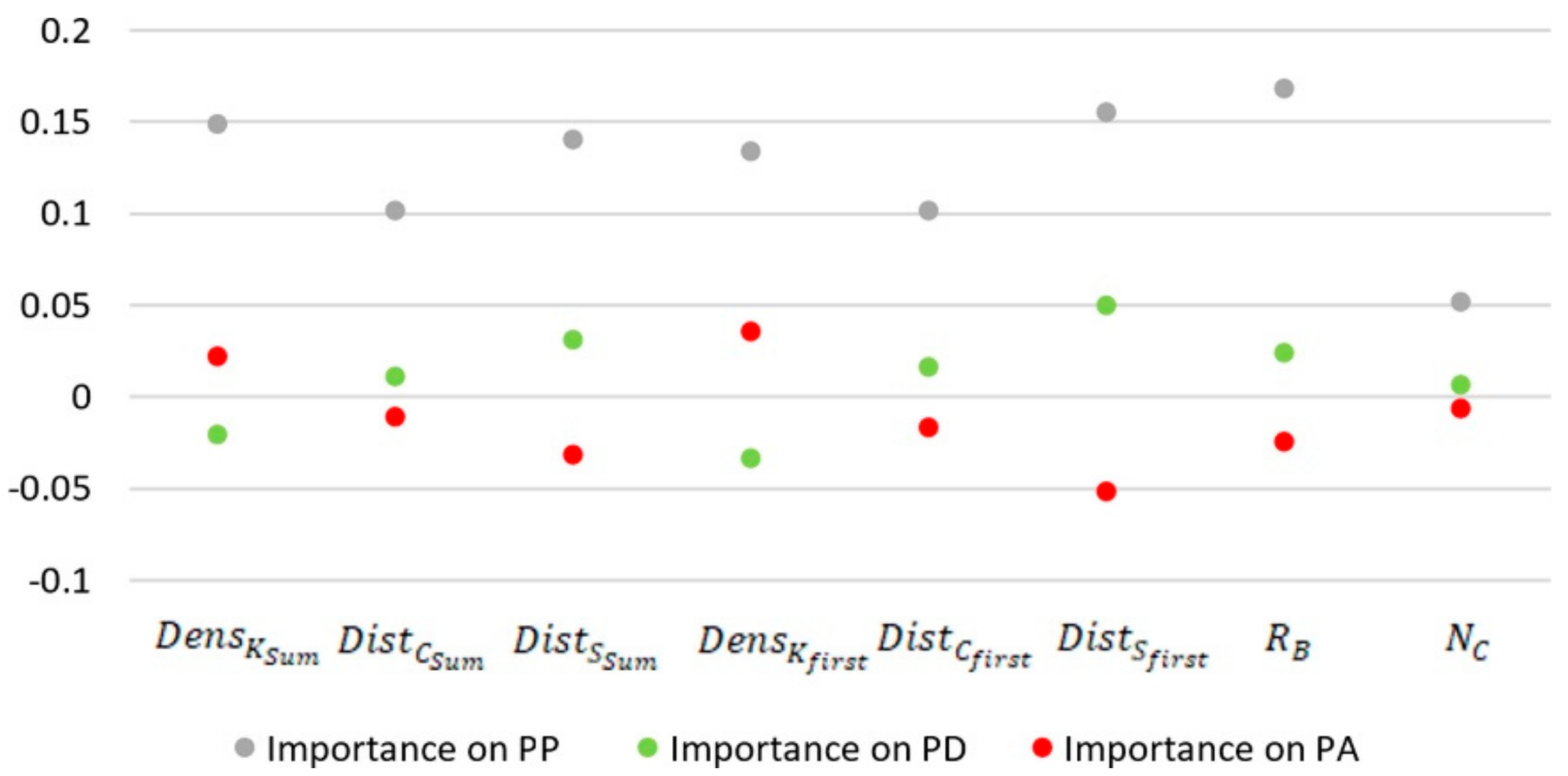
i in PP. The formula finds the importance by multiplying the mean value of each measure in each predicted adjacency type by the corresponding measure importance. As a result, the graph below summarizes the importance of each of the measures in predicting attached (PA in
Figure 7) and detached (PD in
Figure 7) types. The sign of the importance value in the graph helps us to interpret how much more (+) or less (−) important the relevant value is. The higher the kernel density of both the first point (
) and all points (
), the more important the kernel density is in estimating attached buildings because the sign is positive in the graph (
Figure 7). Conversely, we can say that the lower the density, the more effective it is in predicting detached buildings because the sign is negative. Similarly, in predicting the detached buildings it is more effective if the first point is far from the street, while it is more effective to have the first point closer to the street in predicting the attached buildings. Additionally, in the attached buildings it is more important that the first point is closer to the centroid, while it is more important that it is farther away in the detached. These results comprise a trend showing that the first points of attached buildings have greater density and are closer to the street and the centroid. The detached buildings have the opposite trend. It is possible to order the importance of the measures. The distance values and kernel density of the first point are more important than the total distances and kernel density of all points. Moreover, a lower rectangularity value is more significant in the attached buildings, whereas the opposite is the case for the detached. Finally, the city names have little effect on PA and PD; therefore, making inferences about the adjacency types according to the name measure requires additional experiments in different cities.
4. Conclusions
Assessing the drawing trends among OSM buildings is challenging because buildings are constituted by a limited number of points compared to other geographical features, such as roads, streams, land use, or sea. This study used an ML classifier to interpret the building geometry contributions in OSM. Four geometric measures (, , , and ) and one semantic measure () were used to assess the drawing behavior of the volunteers. Common trends were determined among the OSM drawings, which were generated by crowdsourced contributions in Istanbul and Izmir. It was observed that there are relationships between the adjacency type of the building and the first drawing action of OSM volunteers. For attached buildings, there is a trend towards drawing the first point where point density is large and close to the street and the centroid. This is the opposite in the detached buildings. It was also possible to determine an order of importance among the measures. Distance to the street is more important than kernel density, and density is more important than distance to the building centroid. In other words, for attached buildings, the volunteers focused on drawing the first point of the building in the parts closest to the street, and, among the alternatives, they decided to draw it in the place at which point density is higher and the distance to centroid is smaller. The results also enabled the inference that, for detached buildings, OSM volunteers paid more attention to open spaces when drawing the first points because the first-drawn points have lower density and are further both from streets and building centroids than for the attached ones.
This study shows that an ML classifier and feature importance based on prediction results can be used to determine the drawing trends of OSM contributors. The novelty of the study is that it reveals common drawing trends in building-mapping actions.
It appeared that adding the city name at the second stage had little effect (rather than no effect) in predicting the adjacency classes, even though equal numbers of buildings were used in both cities. This means that volunteers may have specific drawing habits in a particular region. However, to substantiate the assumption, buildings in more than two cities should be studied in the future.
The experimental test presents the drawing characteristics of the volunteers who contributed to OSM in the study areas. Both Istanbul and Izmir are metropolitan cities. Therefore, different types of urban or rural areas may give different results.
The main limitation of the study is the measures used as the independent variables in PP. Apart from the measures, the tags contributed by OSM volunteers can also be evaluated as independent variables and a similar study may be conducted. Thus, possible crowdsourced trends can be interpreted with geometric properties and tags.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}