

Multi-Scale Flood Mapping under Climate Change Scenarios in Hexagonal Discrete Global Grids


Abstract
:1. Introduction
2. Flood Modeling Techniques
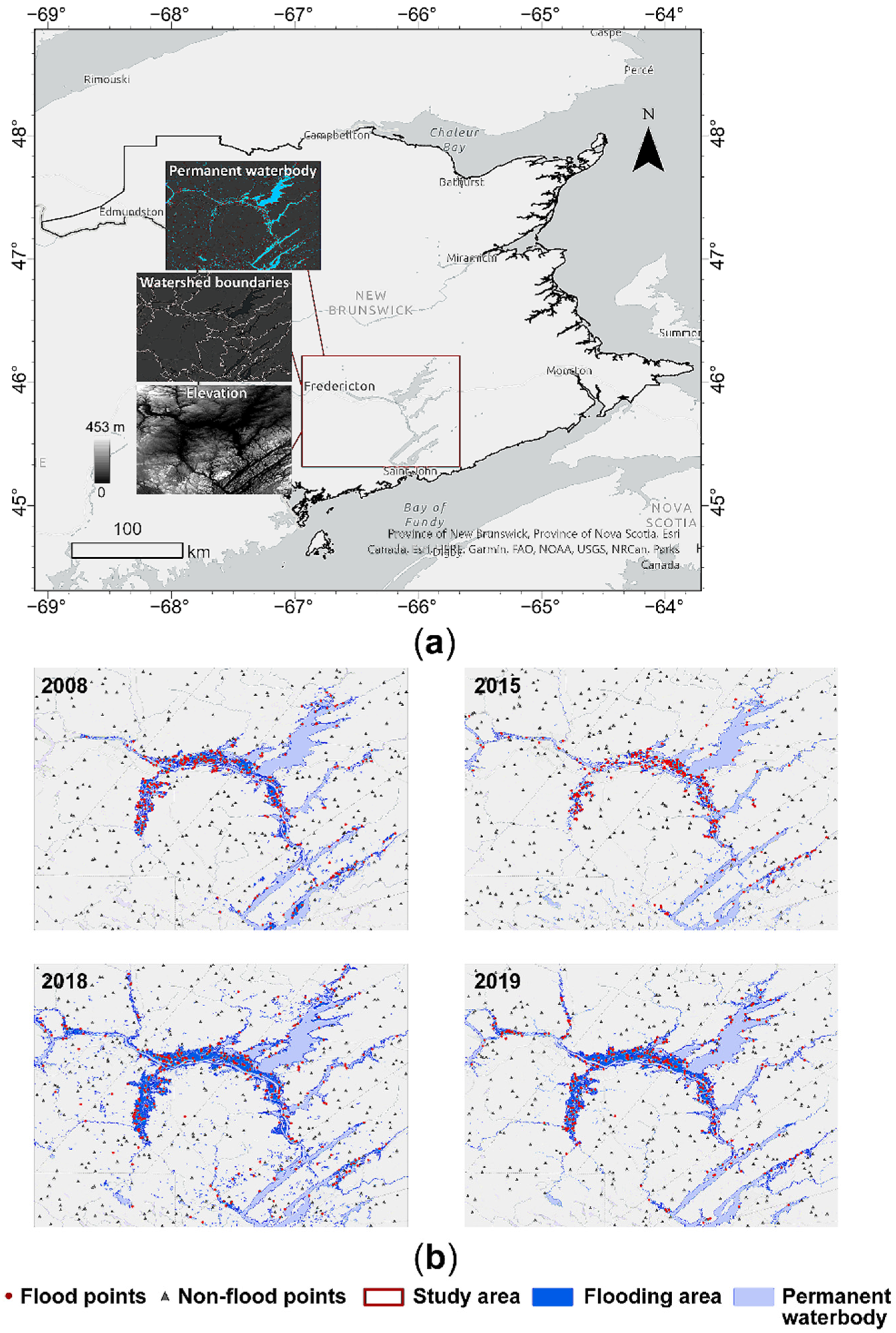
3. Study Area and Data Sources
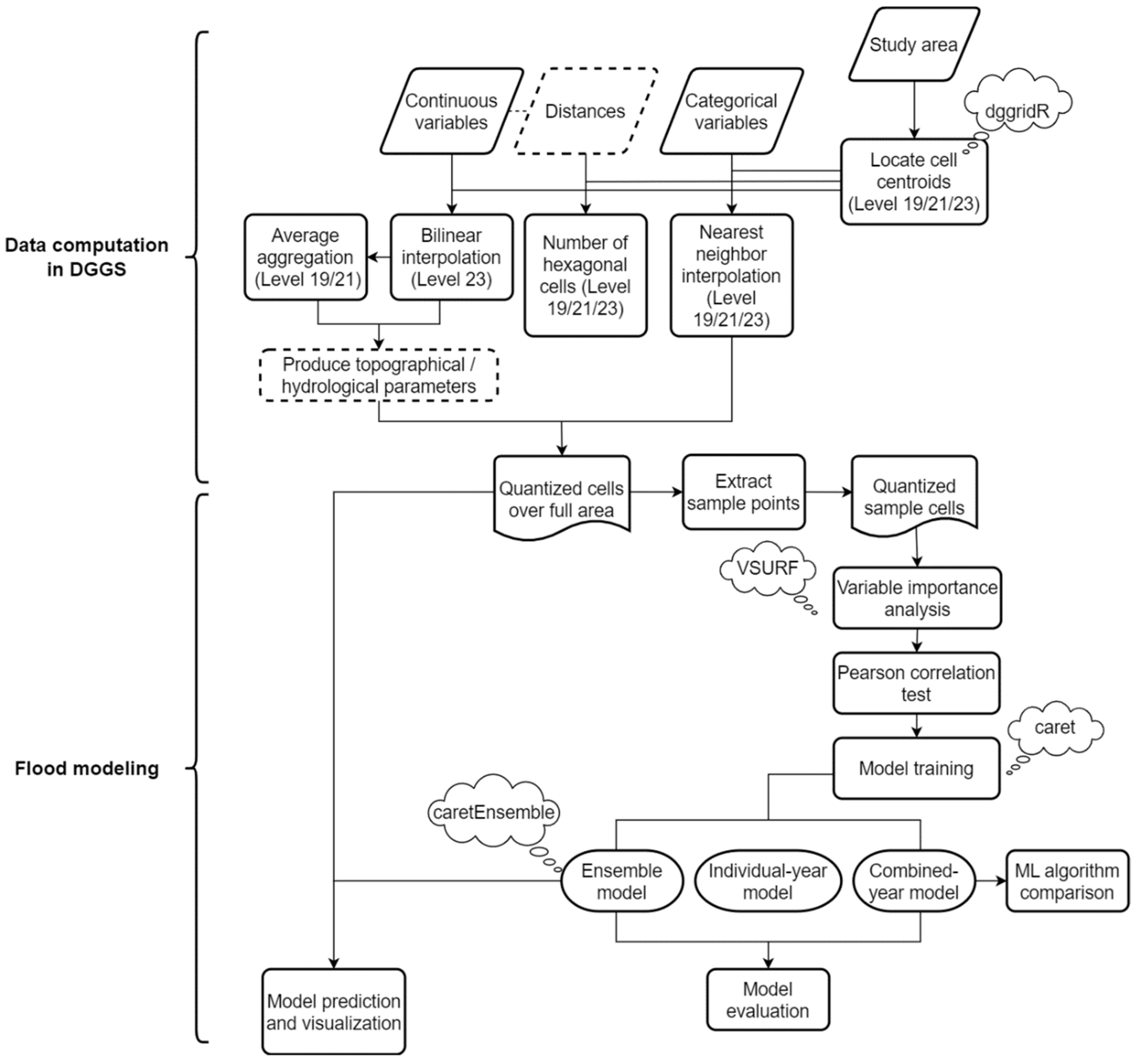
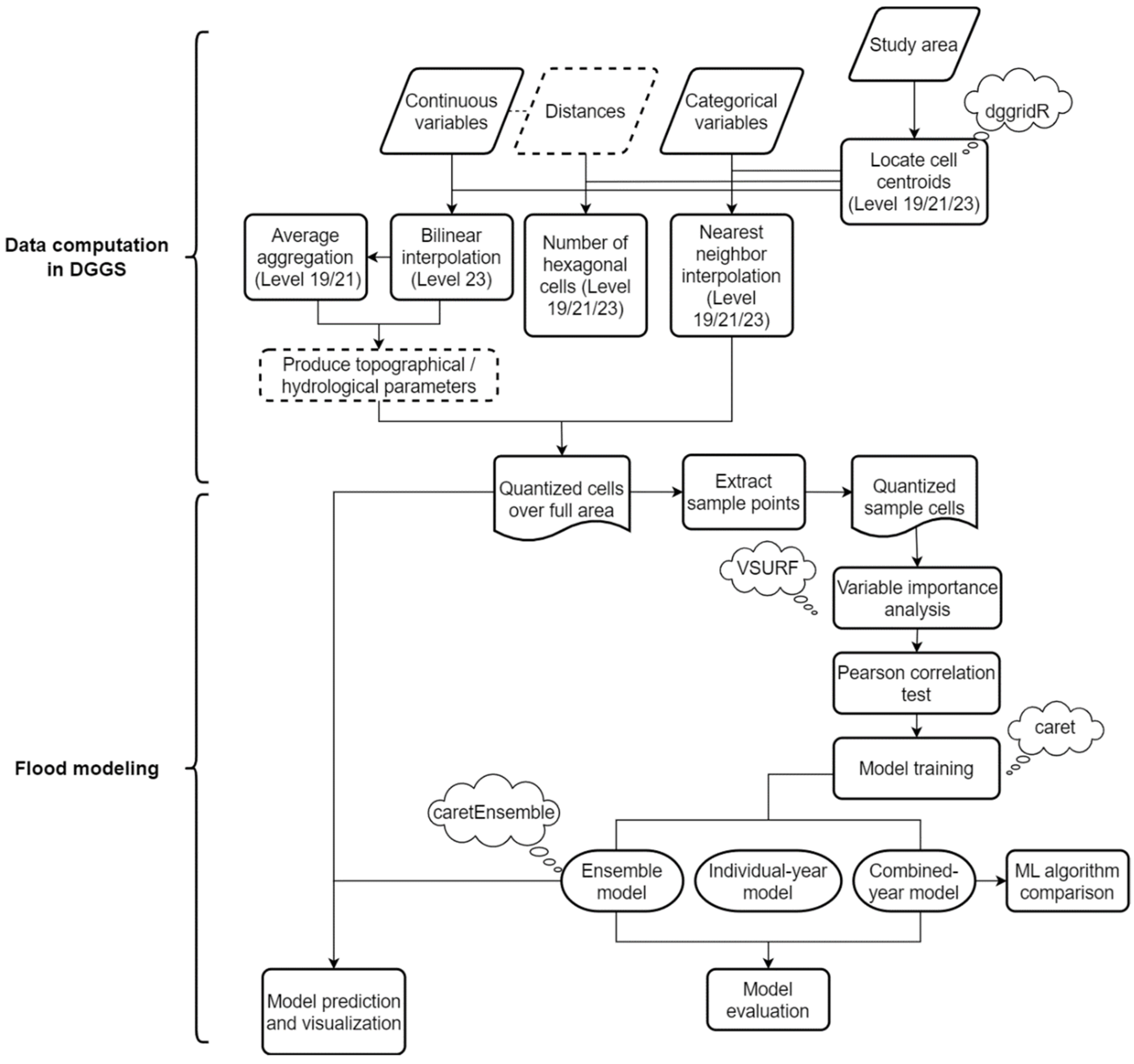
4. Data Computation in DGGS
4.1. DGGS Configuration
4.2. Variable Quantization
4.3. Topographical and Hydrological Parameters Computation
5. Flood Modeling
5.1. Variable Importance Analysis
5.2. Model Training, Evaluation, and Comparison
- RF (“rf”): “ntree” = 500, and “mtry” = square roots of number of predictor variables;
- ANN (“nnet”): “size” = 5, and “decay” = 0;
- MLP (“mlp”): “size” = 5;
- SVM (“svmRadial”): “sigma” = 0.5, and “C” = 1.
5.3. Ensemble Model and Predictions
6. Results
6.1. Top Predictor Variables
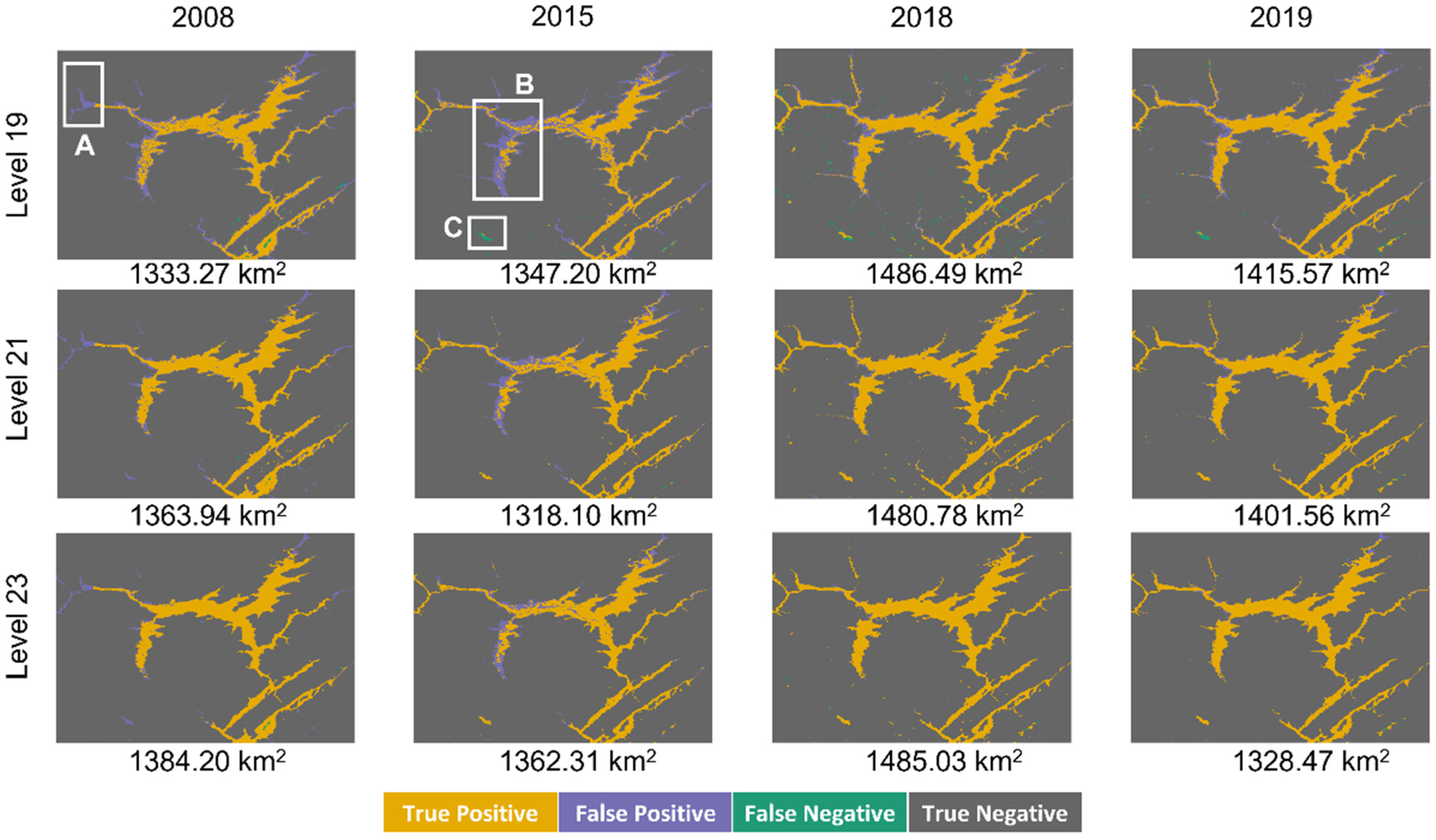
6.2. Individual-Year Models and Combined-Year Models
6.3. Predicted Floods by Ensemble Models with Historical Meteorological Data
6.4. Predicted Floods by Ensemble Models with Future Meteorological Conditions
7. Discussion
7.1. Influencing Factors and Forecasts of Flood Risks
7.2. Effects of Modeling Resolutions
7.3. Flood Modeling in Hexagonal DGGS
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Acronyms | Description |
| ANN | Artificial Neural Networks |
| ANUSPLIN | Australian National University Spline |
| BCCAQv2 | Bias Correction/Constructed Analogues with Quantile delta mapping reordering |
| DGGS | Discrete Global Grid Systems |
| DTM | Digital Terrain Model |
| GIS | Geographic Information Systems |
| ISEA3H | Icosahedral Snyder Equal Area Aperture 3 Hexagonal Grid |
| LiDAR | Light Detection and Ranging |
| MARS | Multivariate Adaptive Regression Splines |
| MAXENT | Maximum Entropy |
| MLP | Multilayer Perceptron |
| NRCan | Natural Resources Canada |
| PAVICS | Power Analytics and Visualization for Climate Science |
| Q2DI | Quadrilateral 2-Dimensional Integer |
| RCP | Representative Concentration Pathway |
| RF | Random Forest |
| ROC | Receiver Operating Characteristic |
| SAR | Synthetic Aperture Radar |
| SVM | Support Vector Machine |
| XGBoost | Extreme Gradient Boosting |
References
- Goodchild, M.F. Reimagining the history of GIS. Ann. GIS 2018, 24, 1–8. [Google Scholar] [CrossRef]
- Dutton, G. Modelling locational uncertainty via hierarchical tessellation. In Accuracy of Spatial Databases; Goodchild, M.F., Gopal, S., Eds.; Taylor & Francis: Abingdon, UK, 1989; pp. 81–91. [Google Scholar]
- Alderson, T.; Purss, M.; Du, X.; Mahdavi-Amiri, A.; Samavati, F. Digital earth platforms. In Manual of Digital Earth; Guo, H., Goodchild, M., Annoni, A., Eds.; Springer: Singapore, 2020; pp. 25–54. [Google Scholar]
- OGC. Topic 21: Discrete Global Grid System Abstract Specification. Available online: http://www.opengis.net/doc/AS/dggs/1.0 (accessed on 15 November 2019).
- Robertson, C.; Chaudhuri, C.; Hojati, M.; Roberts, S.A. An integrated environmental analytics system (IDEAS) based on a DGGS. ISPRS J. Photogramm. Remote Sens. 2020, 162, 214–228. [Google Scholar] [CrossRef]
- Rawson, A.; Sabeur, Z.; Brito, M. Intelligent geospatial maritime risk analytics using the Discrete Global Grid System. Big Earth Data 2022, 6, 294–322. [Google Scholar] [CrossRef]
- Bousquin, J. Discrete Global Grid Systems as scalable geospatial frameworks for characterizing coastal environments. Environ. Model. Softw. 2021, 146, 105210. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; McGrath, H.; Stefanakis, E. Integration of heterogeneous terrain data into Discrete Global Grid Systems. Cartogr. Geogr. Inf. Sci. 2021, 48, 546–564. [Google Scholar] [CrossRef]
- Chen, A.S.; Evans, B.; Djordjević, S.; Savić, D.A. A coarse-grid approach to representing building blockage effects in 2D urban flood modelling. J. Hydrol. 2012, 426–427, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Chaudhuri, C.; Gray, A.; Robertson, C. InundatEd-v1.0: A height above nearest drainage (HAND)-based flood risk modeling system using a discrete global grid system. Geosci. Model Dev. 2021, 14, 3295–3315. [Google Scholar] [CrossRef]
- Wang, L.; Ai, T.; Shen, Y.; Li, J. The isotropic organization of DEM structure and extraction of valley lines using hexagonal grid. Trans. GIS 2020, 24, 483–507. [Google Scholar] [CrossRef]
- Liao, C.; Tesfa, T.; Duan, Z.; Leung, L.R. Watershed delineation on a hexagonal mesh grid. Environ. Model. Softw. 2020, 128, 104702. [Google Scholar] [CrossRef]
- Liao, C.; Zhou, T.; Xu, D.; Barnes, R.; Bisht, G.; Li, H.-Y.; Tan, Z.; Tesfa, T.; Duan, Z.; Engwirda, D.; et al. Advances in hexagon mesh-based flow direction modeling. Adv. Water Resour. 2022, 160, 104099. [Google Scholar] [CrossRef]
- Douass, S.; Kbir, M.A. Flood zones detection using a runoff model built on hexagonal shape based cellular automata. Int. J. Eng. Trends Technol. 2020, 68, 68–74. [Google Scholar] [CrossRef]
- Li, M.; McGrath, H.; Stefanakis, E. Multi-resolution topographic analysis in hexagonal Discrete Global Grid Systems. Int. J. Appl. Earth Obs. Geoinf. 2022, 113, 102985. [Google Scholar] [CrossRef]
- Li, M.; McGrath, H.; Stefanakis, E. Geovisualization of hydrological flow in hexagonal grid systems. Geographies 2022, 2, 227–244. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Jones, S.; Shabani, F. Identifying the essential flood conditioning factors for flood prone area mapping using machine learning techniques. Catena 2019, 175, 174–192. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Xu, L. Assessment of urban flood susceptibility using semi-supervised machine learning model. Sci. Total Environ. 2019, 659, 940–949. [Google Scholar] [CrossRef]
- McGrath, H.; Gohl, P.N. Accessing the impact of meteorological variables on machine learning flood susceptibility mapping. Remote Sens. 2022, 14, 1656. [Google Scholar] [CrossRef]
- GNB. New Brunswick’s Flood Risk Reduction Strategy. Available online: https://www2.gnb.ca/content/dam/gnb/Departments/env/pdf/Flooding-Inondations/NBFloodRiskReductionStrategy.pdf (accessed on 14 September 2022).
- Mosavi, A.; Ozturk, P.; Chau, K.-W. Flood prediction using machine learning models: Literature review. Water 2018, 10, 1536. [Google Scholar] [CrossRef] [Green Version]
- Abdullah, M.F.; Siraj, S.; Hodgett, R.E. An overview of multi-criteria decision analysis (MCDA) application in managing water-related disaster events: Analyzing 20 years of literature for food and drought events. Water 2021, 13, 1358. [Google Scholar] [CrossRef]
- Lin, L.; Di, L.; Yu, E.G.; Kang, L.; Shrestha, R.; Rahman, M.S.; Tang, J.; Deng, M.; Sun, Z.; Zhang, C.; et al. A review of remote sensing in flood assessment. In Proceedings of the 2016 Fifth International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Tianjin, China, 2016, 18–20 July 2016; p. 4. [Google Scholar]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Lohani, A.K.; Kumar, R.; Singh, R.D. Hydrological time series modeling: A comparison between adaptive neuro-fuzzy, neural network and autoregressive techniques. J. Hydrol. 2012, 442–443, 23–35. [Google Scholar] [CrossRef]
- Kim, S.; Singh, V.P. Flood forecasting using neural computing techniques and conceptual class segregation. JAWRA J. Am. Water Resour. Assoc. 2013, 49, 1421–1435. [Google Scholar] [CrossRef]
- Lin, J.; He, P.; Yang, L.; He, X.; Lu, S.; Liu, D. Predicting future urban waterlogging-prone areas by coupling the maximum entropy and FLUS model. Sustain. Cities Soc. 2022, 80, 103812. [Google Scholar] [CrossRef]
- Siahkamari, S.; Haghizadeh, A.; Zeinivand, H.; Tahmasebipour, N.; Rahmati, O. Spatial prediction of flood-susceptible areas using frequency ratio and maximum entropy models. Geocarto Int. 2018, 33, 927–941. [Google Scholar] [CrossRef]
- Abedi, R.; Costache, R.; Shafizadeh-Moghadam, H.; Pham, Q.B. Flash-flood susceptibility mapping based on XGBoost, random forest and boosted regression trees. Geocarto Int. 2022, 37, 5479–5496. [Google Scholar] [CrossRef]
- Bui, D.T.; Hoang, N.D.; Pham, T.D.; Ngo, P.T.T.; Hoa, P.V.; Minh, N.Q.; Tran, X.T.; Samui, P. A new intelligence approach based on GIS-based Multivariate Adaptive Regression Splines and metaheuristic optimization for predicting flash flood susceptible areas at high-frequency tropical typhoon area. J. Hydrology 2019, 575, 314–326. [Google Scholar] [CrossRef]
- Berger, A.; Della Pietra, S.A.; Della Pietra, V.J. A maximum entropy approach to natural language processing. Comput. Linguist. 1996, 22, 39–71. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition 1995, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar] [CrossRef]
- Wang, Z.; Lai, C.; Chen, X.; Yang, B.; Zhao, S.; Bai, X. Flood hazard risk assessment model based on random forest. J. Hydrol. 2015, 527, 1130–1141. [Google Scholar] [CrossRef]
- Jain, A.; Prasad Indurthy, S. Closure to “comparative analysis of event-based rainfall-runoff modeling techniques—Deterministic, statistical, and artificial neural networks” by ASHU JAIN and SKV prasad indurthy. J. Hydrol. Eng. 2004, 9, 551–553. [Google Scholar] [CrossRef]
- Kar, A.K.; Lohani, A.K.; Goel, N.K.; Roy, G.P.J. Development of flood forecasting system using statistical and ANN techniques in the downstream catchment of mahanadi basin, india. J. Water Resour. Prot. 2010, 2, 880. [Google Scholar]
- Taormina, R.; Chau, K.W.; Sethi, R. Artificial neural network simulation of hourly groundwater levels in a coastal aquifer system of the Venice lagoon. Eng. Appl. Artif. Intell. 2012, 25, 1670–1676. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Riad, S.; Mania, J.; Bouchaou, L.; Najjar, Y. Rainfall-runoff model usingan artificial neural network approach. Math. Comput. Model. 2004, 40, 839–846. [Google Scholar] [CrossRef]
- Senthil Kumar, A.R.; Sudheer, K.P.; Jain, S.K.; Agarwal, P.K. Rainfall-runoff modelling using artificial neural networks: Comparison of network types. Hydrol. Process. 2005, 19, 1277–1291. [Google Scholar] [CrossRef]
- Vapnik, V.; Mukherjee, S. Support vector method for multivariate density estimation. Adv. Neural Inf. Process. Syst. 2000, 4, 659–665. [Google Scholar]
- Dibike, Y.B.; Velickov, S.; Solomatine, D.; Abbott, M.B. Model induction with support vector machines: Introduction and applications. J. Comput. Civ. Eng. 2001, 15, 208–216. [Google Scholar] [CrossRef]
- NRCan. Floods in Canada—Archive. Available online: https://open.canada.ca/data/en/dataset/74144824-206e-4cea-9fb9-72925a128189 (accessed on 5 March 2022).
- NRCan. High Resolution Digital Elevation Model Mosaic (HRDEM Mosaic)—CanElevation Series. Available online: https://open.canada.ca/data/en/dataset/0fe65119-e96e-4a57-8bfe-9d9245fba06b (accessed on 4 March 2022).
- Hutchinson, M.F.; McKenney, D.W.; Lawrence, K.; Pedlar, J.H.; Hopkinson, R.F.; Milewska, E.; Papadopol, P. Development and testing of Canada-wide interpolated spatial models of daily minimum–maximum temperature and precipitation for 1961–2003. J. Appl. Meteorol. Climatol. 2009, 48, 725–741. [Google Scholar] [CrossRef]
- Cannon, A.J.; Sobie, S.R.; Murdock, T.Q. Bias correction of GCM precipitation by quantile mapping: How well do methods preserve changes in quantiles and extremes? J. Clim. 2015, 28, 6938–6959. [Google Scholar] [CrossRef]
- Bush, E.; Lemmen, D.S. Canada’s Changing Climate Report; Government of Canada: Ottawa, ON, Canada, 2019; p. 444. [Google Scholar]
- NRCan. New Brunswick Hydrographic Network (NBHN). Available online: https://open.canada.ca/data/en/dataset/56345831-3fdd-0e11-8a7a-3b009876bf86 (accessed on 4 March 2022).
- Shannon, C.E. Communication in the presence of noise. In Proceedings of the IRE; Institute of Radio Engineers: New York, NY, USA, 1949; pp. 10–21. [Google Scholar]
- Barnes, R.; Sahr, K. dggridR: Discrete Global Grids for R. R Package Version 2.0.4. Available online: https://github.com/r-barnes/dggridR (accessed on 5 March 2020).
- Guisan, A.; Weiss, S.B.; Weiss, A.D. GLM versus CCA spatial modeling of plant species distribution. Plant Ecol. 1999, 143, 107–122. [Google Scholar] [CrossRef]
- Riley, S.J.; DeGloria, S.D.; Elliot, R. Index that quantifies topographic heterogeneity intermountain. J. Sci. 1999, 5, 23–27. [Google Scholar]
- Hodgson, M.E. Comparison of angles from surface slope/aspect algorithms. Cartogr. Geogr. Inf. Syst. 1998, 25, 173–185. [Google Scholar] [CrossRef]
- Barnes, R. Parallel Priority-Flood depression filling for trillion cell digital elevation models on desktops or clusters. Comput. Geosci. 2016, 96, 56–68. [Google Scholar] [CrossRef] [Green Version]
- Barnes, R.; Lehman, C.; Mulla, D. Priority-flood: An optimal depression-filling and watershed-labeling algorithm for digital elevation models. Comput. Geosci. 2014, 62, 117–127. [Google Scholar] [CrossRef] [Green Version]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Beven, K.J.; Kirkby, M.J. A physically based, variable contributing area model of basin hydrology / Un modèle à base physique de zone d’appel variable de l’hydrologie du bassin versant. Hydrol. Sci. Bull. 1979, 24, 43–69. [Google Scholar] [CrossRef] [Green Version]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. VSURF: An R package for variable selection using random forests. R J. 2015, 7, 19–33. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Deane-Mayer, Z.A.; Knowles, J.E. Ensembles of Caret Models. Available online: https://github.com/zachmayer/caretEnsemble (accessed on 6 May 2022).
- NRCan. Floods in Canada/International Floods Product Specifications. Available online: https://open.canada.ca/data/en/dataset/74144824-206e-4cea-9fb9-72925a128189/resource/3d2e0b75-1546-4617-8bbb-ec65321b6c28 (accessed on 12 September 2022).
- Sahr, K. Location coding on icosahedral aperture 3 hexagon discrete global grids. Comput. Environ. Urban Syst. 2008, 32, 174–187. [Google Scholar] [CrossRef]
- Kiester, A.R.; Sahr, K. Planar and spherical hierarchical, multi-resolution cellular automata. Comput. Environ. Urban Syst. 2008, 32, 204–213. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Abbreviation | Description | Raw Format |
|---|---|---|---|
| Terrain-derived | dtm 1 | Digital Terrain Model (i.e., elevations) | GeoTIFF |
| asp | Aspect | ||
| slp | Slope | ||
| curv | Curvature | ||
| rgh | Roughness | ||
| tri | Terrain roughness index | ||
| tpi | Topographic position index | ||
| Hydrological | fldir | Flow direction | |
| flacc | Flow accumulation | ||
| msi 2 | Probability of the annual minimum snow and ice | GeoTIFF | |
| nhn 3 | Distance to the nearest permanent waterbodies | Geodatabase | |
| wl 4 | Wetland | Shapefile | |
| spi | Stream power index | ||
| twi | Topographic wetness index | ||
| Geomorphic | lc 5 | Land cover classes | GeoTIFF |
| scc 6 | Stand crown closure | GeoTIFF | |
| tfv 7 | Total forest volume | GeoTIFF | |
| ndvi 8 | Normalized difference vegetation index | GeoTIFF | |
| sol 9 | Soil types | Geodatabase | |
| geo 10 | Surficial geology types | Geodatabase | |
| Meteorological 11 | fprcptot | Total precipitation in last fall | NetCDF |
| ftgmean | Mean temperature in last fall | ||
| ftnmean | Mean of daily min temperature in last fall | ||
| wprcptot | Total precipitation in winter | ||
| wtgmean | Mean temperature in winter | ||
| sprcptot | Total precipitation in spring | ||
| stgmean | Mean temperature in spring | ||
| stxmean | Mean of daily max temperature in spring | ||
| sr10 | Spring wet-days > 10 mm | ||
| sr20 | Spring wet-days > 20 mm | ||
| Anthropogenic | ia | Impervious areas | |
| nrn 12 | Distance to the nearest major roads | Shapefile |
| Level | Model Year | Step | Selected Variables 1 |
|---|---|---|---|
| Level 19 | Year 2008 | interp 2 | dtm, ftgmean, stgmean, nhn, rgh, twi |
| pred 3 | dtm, ftgmean, stgmean, nhn, rgh, twi | ||
| Year 2015 | interp | dtm, ftgmean, nhn, stgmean, tri | |
| pred | dtm, ftgmean, nhn | ||
| Year 2018 | interp | dtm, nhn, twi, stgmean, flacc, lc | |
| pred | dtm, nhn, twi, stgmean | ||
| Year 2019 | interp | dtm, nhn, twi, slp, msi, geo, tri, stgmean, rgh, stxmean, tfv, flacc, curv, ndvi | |
| pred | dtm, nhn, twi, msi, geo, stgmean | ||
| Combined-year | interp | dtm, nhn, twi, rgh, tri, slp, stgmean, msi, geo, stxmean, flacc, lc, tpi, wtgmean, curv, spi, tfv, ndvi, fprcptot | |
| pred | dtm, nhn, twi, stgmean, rgh | ||
| Level 21 | Year 2008 | interp | dtm, ftgmean, nhn, stgmean, rgh |
| pred | dtm, ftgmean, nhn, stgmean, rgh | ||
| Year 2015 | interp | dtm, ftgmean, nhn, rgh, slp, stgmean, tri, ftnmean, tfv, lc, ndvi, msi, wtgmean, stxmean, scc | |
| pred | dtm, ftgmean, nhn, stgmean, tfv | ||
| Year 2018 | interp | dtm, nhn, stgmean | |
| pred | dtm, nhn, stgmean | ||
| Year 2019 | interp | dtm, nhn, stgmean, geo, rgh, msi | |
| pred | dtm, nhn, stgmean | ||
| Combined-year | interp | dtm, nhn, rgh, tri, stgmean, geo, slp, twi, msi, stxmean, wtgmean, curv, spi, tpi, fprcptot, ndvi, tfv, wprcoptot | |
| pred | dtm, nhn, rgh, tri, stgmean, twi, stxmean, ndvi, wprcptot | ||
| Level 23 | Year 2008 | interp | dtm, ftgmean, nhn, stgmean, slp, geo, rgh, sr10 |
| pred | dtm, ftgmean, nhn, stgmean, slp, rgh, sr10 | ||
| Year 2015 | interp | dtm, nhn, ftgmean | |
| pred | dtm, nhn, ftgmean | ||
| Year 2018 | interp | dtm, nhn, stgmean | |
| pred | dtm, nhn, stgmean | ||
| Year 2019 | interp | dtm, nhn, stgmean, geo, stxmean, msi, tfv | |
| pred | dtm, nhn, stgmean, tfv | ||
| Combined-year | interp | dtm, nhn, stgmean, rgh, slp, geo, tri, msi, stxmean, spi, wtgmean, tfv, wprcptot, fprcptot, twi, ftgmean, ndvi, lc, sprcptot, scc | |
| pred | dtm, nhn, stgmean, rgh, geo, stxmean, spi, tfv, ndvi |
| Level | Model Year | Selected Variables 1 |
|---|---|---|
| Level 19 | Year 2008 | dtm, ftgmean, nhn, rgh, twi |
| Year 2015 | dtm, ftgmean, nhn | |
| Year 2018 | dtm, nhn, stgmean, twi | |
| Year 2019 | dtm, nhn, twi, msi, geo, stgmean | |
| Combined-year | dtm, nhn, twi, stgmean, rgh | |
| Level 21 | Year 2008 | dtm, ftgmean, nhn, rgh |
| Year 2015 | dtm, ftgmean, nhn, tfv | |
| Year 2018 | dtm, nhn, stgmean | |
| Year 2019 | dtm, nhn, stgmean | |
| Combined-year | dtm, nhn, rgh, stgmean, twi, ndvi | |
| Level 23 | Year 2008 | dtm, ftgmean, nhn, slp, geo, sr10 |
| Year 2015 | dtm, nhn, ftgmean | |
| Year 2018 | dtm, nhn, stgmean | |
| Year 2019 | dtm, nhn, stgmean, tfv | |
| Combined-year | dtm, nhn, stgmean, rgh, geo, spi, tfv, ndvi |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; McGrath, H.; Stefanakis, E. Multi-Scale Flood Mapping under Climate Change Scenarios in Hexagonal Discrete Global Grids. ISPRS Int. J. Geo-Inf. 2022, 11, 627. https://doi.org/10.3390/ijgi11120627
Li M, McGrath H, Stefanakis E. Multi-Scale Flood Mapping under Climate Change Scenarios in Hexagonal Discrete Global Grids. ISPRS International Journal of Geo-Information. 2022; 11(12):627. https://doi.org/10.3390/ijgi11120627
Chicago/Turabian StyleLi, Mingke, Heather McGrath, and Emmanuel Stefanakis. 2022. "Multi-Scale Flood Mapping under Climate Change Scenarios in Hexagonal Discrete Global Grids" ISPRS International Journal of Geo-Information 11, no. 12: 627. https://doi.org/10.3390/ijgi11120627