
A Point-of-Interest Recommendation Method Exploiting Sequential, Category and Geographical Influence


Abstract
:1. Introduction
- 1.
- In this paper, we propose a new POI recommendation framework for exploiting sequential, category, and geographical influence (named SCGM) and get the user’s preference probability computed from the linear combination of CF and KDE.
- 2.
- A new user similarity computation method is proposed based on the constructed virtual common access sequence of users and category differentiation of POI.
- 3.
- Specifically, we introduce CBOW to capture the contextual influence of POI in the sequence, and obtain the users’ preference for POI.
- 4.
- A large number of experiments performed on two LBSN datasets show that our proposed method performs significantly better than other methods in terms of precision, recall, and F1 score.
2. Related Work
2.1. Temporal and Sequential Information
2.2. Category Information
2.3. Geographic Information
3. Preliminaries
3.1. Definitions
3.2. Word Embedding
4. Proposed Method
4.1. Framework of SCGM
| Algorithm 1: SCGM method. |
| Input: The target user , all check-in records and parameter |
| Output: Top-k list of POIs |
| 1: |
| 2: for each do |
| 3: |
| 4: Construct a virtual common access sequence according to Algorithm 2 |
| 5: Obtain according to Algorithm 3 |
| 6: end for |
| 7: for each do |
| 8: Obtain user behavioral preference probability according to Algorithm 4 |
| 9: Obtain user geographical preference probability based on KDE |
| 10: Calculate user preference probability according to Equation (3) |
| 11: end for |
| 12: Select the top-k POIs that descending sort by user preference probability. return Top-k list. |
| 13: return Top-k list. |
| Algorithm 2: The method of constructing a virtual common access sequence. |
| Input: check-in records |
| Output:, , |
| 1: divide a day into four time periods |
| 2: |
| 3: for each in T do |
| 4: generate check-in sequences and |
| 5: |
| 6: |
| 7: for each do |
| 8: |
| 9: − |
| 10: 0 |
| 11: end for |
| 12: for each do |
| 13: |
| 14: − |
| 15: 0 |
| 16: end for |
| 17: for each do |
| 18: |
| 19: end for |
| 20: for each do |
| 21: for each do |
| 22: |
| 23: end for |
| 24: find the minimum value of |
| 25: |
| 26: end for |
| 27: end for |
| Algorithm 3: The similarity computation of two users. |
| Input:, , |
| Output: |
| 1: for each do |
| 2: for each do |
| 3: |
| 4: end for |
| 5: Calculate the category differentiation according to Equation (5) |
| 6: Calculate according to Equation (6) |
| 7: end for |
| 8: Calculate sim according to Equation (7) |
| Algorithm 4: User behavioral preference calculation based on the CF algorithm. |
| Input: the target user , the target POI , all check-in records |
| Output: user behavioral preference probability pscore(, ) |
| 1: fordo |
| 2: |
| 3: for each do |
| 4: Initialize latent vector by embedding model |
| 5: end for |
| 6: Calculate by aggregating |
| 7: |
| 8: |
| 9: end for |
| 10: Calculate according to Equation (8) |
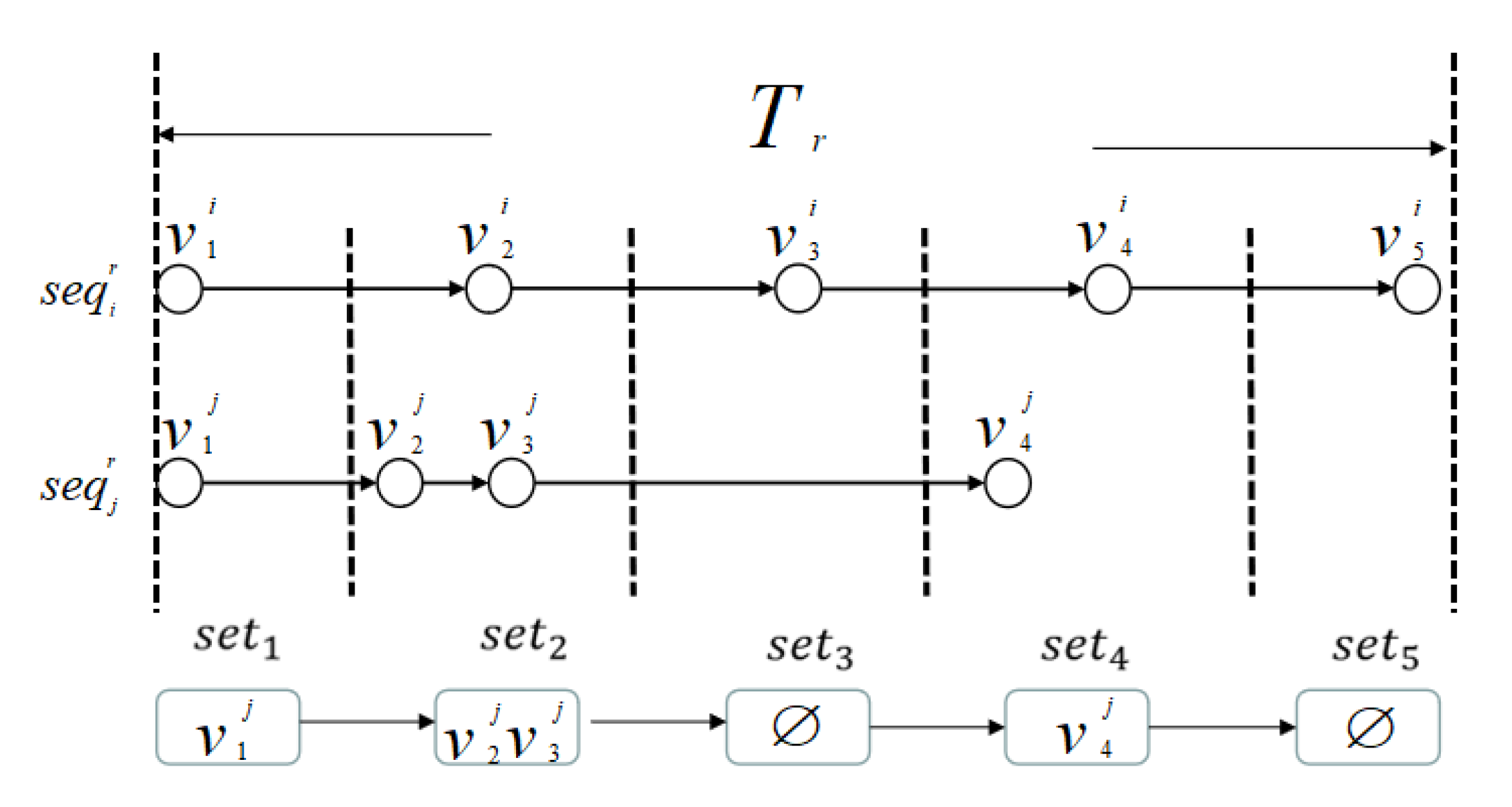
4.2. Construct Virtual Common Access Sequence
4.3. New User Similarity Calculation
4.3.1. POI Recommendation Based on CF
4.3.2. POI Recommendation Based on KDE
5. Results
5.1. Datasets
5.2. Evaluation Metrics
5.3. Comparative Method
5.4. Results Analysis
5.4.1. Performance Comparison
5.4.2. Effect of Parameter
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, X.; Yang, Y.; Xu, Y.; Yang, F.; Huang, Q.; Wang, H. Real-time POI recommendation via modeling long- and short-term user preferences. Neurocomputing 2022, 467, 454–464. [Google Scholar] [CrossRef]
- Cheng, C.; Yang, H.; King, I.; Lyu, M.R. Fused matrix factorization with geographical and social influence in location-based social networks. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; Association for the Advancement of Artificial Intelligence: Menlo Park, CA, USA, 2012; Volume 26, p. 1. [Google Scholar]
- Salakhutdinov, R.; Mnih, A. Probabilistic Matrix Factorization. In Advances in Neural Information Processing Systems 20, Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; Neural Information Processing Systems Foundation: La Jolla, CA, USA, 2007; pp. 1257–1264. [Google Scholar]
- Yuan, Q.; Cong, G.; Sun, A. Graph-based point-of-interest recommendation with geographical and temporal influences. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, CIKM 2014, Shanghai, China, 3–7 November 2014; ACM, Inc.: Tipp City, OH, USA, 2014; pp. 659–668. [Google Scholar]
- Jiao, X.; Xiao, Y.; Zheng, W.; Wang, H.; Hsu, C. A novel next new point-of-interest recommendation system based on simulated user travel decision-making process. Future Gener. Comput. Syst. 2019, 100, 982–993. [Google Scholar] [CrossRef]
- Rahmani, H.A.; Aliannejadi, M.; Zadeh, R.M.; Baratchi, M.; Afsharchi, M.; Crestani, F. Category-aware location embedding for point-of-interest recommendation. In Proceedings of the 2019 ACM SIGIR International Conference on Theory of Information Retrieval, ICTIR 2019, Santa Clara, CA, USA, 2–5 October 2019; ACM, Inc.: Tipp City, OH, USA, 2019; pp. 173–176. [Google Scholar]
- He, J.; Li, X.; Liao, L. Category-aware next point-of-interest recommendation via listwise bayesian personalized ranking. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, 19–25 August 2017; ACM Digital Library: New York, NY, USA, 2017; Volume 17, pp. 1837–1843. [Google Scholar]
- Lyu, Y.; Chow, C.; Wang, R.; Lee, V.C.S. iMCRec: A multi-criteria framework for personalized point-of-interest recommendations. Inf. Sci. 2019, 483, 294–312. [Google Scholar] [CrossRef]
- Zhao, S.; Zhao, T.; King, I.; Lyu, M.R. Geo-teaser: Geo-temporal sequential embedding rank for point-of-interest recommendation. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; ACM, Inc.: Tipp City, OH, USA, 2017; pp. 153–162. [Google Scholar]
- Ye, M.; Yin, P.; Lee, W.; Lee, D.L. Exploiting geographical influence for collaborative point-of-interest recommendation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2011, Beijing, China, 25–29 July 2011; ACM, Inc.: Tipp City, OH, USA, 2011; pp. 325–334. [Google Scholar]
- Chen, J.; Zhang, W.; Zhang, P.; Ying, P.; Niu, K.; Zou, M. Exploiting Spatial and Temporal for Point of Interest Recommendation. Complexity 2018, 2018, 6928605:1–6928605:16. [Google Scholar] [CrossRef] [Green Version]
- Gao, H.; Tang, J.; Hu, X.; Liu, H. Exploring temporal effects for location recommendation on location-based social networks. In Proceedings of the Seventh ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; ACM, Inc.: Tipp City, OH, USA, 2013; pp. 93–100. [Google Scholar]
- Hosseini, S.; Li, L.T. Point-of-interest recommendation using temporal orientations of users and locations. In Proceedings of the Database Systems for Advanced Applications—21st International Conference, DASFAA 2016, Dallas, TX, USA, 16–19 April 2016; Proceedings, Part I. Springer: Berlin, Germany, 2016; Volume 9642, pp. 330–347. [Google Scholar]
- Gao, R.; Li, J.; Li, X.; Song, C.; Chang, J.; Liu, D.; Wang, C. STSCR: Exploring spatial-temporal sequential influence and social information for location recommendation. Neurocomputing 2018, 319, 118–133. [Google Scholar] [CrossRef]
- Gan, M.; Gao, L. Discovering memory-based preferences for POI recommendation in location-based social networks. ISPRS Int. J. Geo-Inf. 2019, 8, 279. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Gan, M.; Sun, X. Incorporating memory-based preferences and point-of-Interest stickiness into recommendations in location-based social networks. ISPRS Int. J. Geo-Inf. 2021, 10, 36. [Google Scholar] [CrossRef]
- Bao, J.; Zheng, Y.; Mokbel, M.F. Location-based and preference-aware recommendation using sparse geo-social networking data. In Proceedings of the SIGSPATIAL 2012 International Conference on Advances in Geographic Information Systems (Formerly Known as GIS), Redondo Beach, CA, USA, 7–9 November 2012; ACM, Inc.: Tipp City, OH, USA, 2012; pp. 199–208. [Google Scholar]
- Liu, X.; Liu, Y.; Aberer, K.; Miao, C. Personalized point-of-interest recommendation by mining users’ preference transition. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; ACM, Inc.: Tipp City, OH, USA, 2013; pp. 733–738. [Google Scholar]
- Zhou, D.; Rahimi, S.M.; Wang, X. Similarity-based probabilistic category-based location recommendation utilizing temporal and geographical influence. Int. J. Data Sci. Anal. 2016, 1, 111–121. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Zheng, W.; Xiao, Y.; Zhu, K.; Huang, W. Exploring temporal and spatial features for next POI recommendation in LBSNs. IEEE Access 2021, 9, 35997–36007. [Google Scholar] [CrossRef]
- Wang, H.; Shen, H.; Ouyang, W.; Cheng, X. Exploiting POI-specific geographical influence for Point-of-interest recommendation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018; ACM, Inc.: Tipp City, OH, USA, 2018; pp. 3877–3883. [Google Scholar]
- Rahmani, H.A.; Aliannejadi, M.; Ahmadian, S.; Baratchi, M.; Afsharchi, M.; Crestani, F. LGLMF: Local geographical based logistic matrix factorization model for POI recommendation. In Proceedings of the Information Retrieval Technology: 15th Asia Information Retrieval Societies Conference, AIRS 2019, Hong Kong, China, 7–9 November 2019; Proceedings. Springer: Berlin, Germany, 2020; Volume 12004, pp. 66–78. [Google Scholar]
- Li, X.; Cong, G.; Li, X.; Pham, T.N.; Krishnaswamy, S. Rank-geofm: A ranking based geographical factorization method for point of interest recommendation. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; ACM, Inc.: Tipp City, OH, USA, 2015; pp. 433–442. [Google Scholar]
- Liu, B.; Fu, Y.; Yao, Z.; Xiong, H. Learning geographical preferences for point-of-interest recommendation. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 2013, Chicago, IL, USA, 11–14 August 2013; ACM, Inc.: Tipp City, OH, USA, 2013; pp. 1043–1051. [Google Scholar]
- Yin, H.; Wang, W.; Wang, H.; Chen, L.; Zhou, X. Spatial-aware hierarchical collaborative deep learning for POI recommendation. IEEE Trans. Knowl. Data Eng. 2017, 29, 2537–2551. [Google Scholar] [CrossRef]
- Yu, D.; Wanyan, W.; Wang, D. Leveraging contextual influence and user preferences for point-of-interest recommendation. Multimed. Tools Appl. 2021, 80, 1487–1501. [Google Scholar] [CrossRef]
- Yang, D.; Zhang, D.; Zheng, V.W.; Yu, Z. Modeling user activity preference by leveraging user spatial temporal characteristics in LBSNs. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 129–142. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DATASETS | New York | Tokyo |
|---|---|---|
| Users | 825 | 2214 |
| Venus | 1086 | 2877 |
| Check-ins | 40,197 | 329,744 |
| Sparsity | 0.9552 | 0.9483 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Liu, Y.; Zhou, X.; Wang, X.; Leng, Z. A Point-of-Interest Recommendation Method Exploiting Sequential, Category and Geographical Influence. ISPRS Int. J. Geo-Inf. 2022, 11, 80. https://doi.org/10.3390/ijgi11020080
Wang X, Liu Y, Zhou X, Wang X, Leng Z. A Point-of-Interest Recommendation Method Exploiting Sequential, Category and Geographical Influence. ISPRS International Journal of Geo-Information. 2022; 11(2):80. https://doi.org/10.3390/ijgi11020080
Chicago/Turabian StyleWang, Xican, Yanheng Liu, Xu Zhou, Xueying Wang, and Zhaoqi Leng. 2022. "A Point-of-Interest Recommendation Method Exploiting Sequential, Category and Geographical Influence" ISPRS International Journal of Geo-Information 11, no. 2: 80. https://doi.org/10.3390/ijgi11020080