1. Introduction
Preserving our cultural heritage for future generations and making it available to both historians and a wider public is an important task. In this context, a key strategy is the digitization of collections of historical objects in the form of searchable databases with standardized annotations and, potentially, images, which is also a prerequisite for fast and easy access to the related knowledge by both expert and non-expert users. It was the goal of the EU H2020 project SILKNOW (
http://silknow.eu/, visited on 30 November 2021) to take one step in this direction for the preservation of European cultural heritage related to silk. Silk has played an important role in many different areas for hundreds of years and still does so in the present. For instance, it has triggered technical developments such as the Jacquard loom, which introduced the concept of punched cards for storing information. It also has an economic impact through the textile and creative industries and a functional aspect as a component of clothes and furniture, and it is also relevant from a cultural and symbolic perspective through forming individuality and identity [
1]. To make silk-related knowledge from the past accessible for future generations, a knowledge graph related to silk fabrics was built by harvesting existing online collections and converting the meta-information into a standardized format [
1]. The present paper is motivated by the requirement to provide easy access to this knowledge graph and presents a new deep learning-based method for image retrieval that can be used to search for records in a database on the basis of images.
For image retrieval, a feature vector (
descriptor) is pre-computed for every image available in the database. As soon as a user provides a
query image, a corresponding
query descriptor is derived, which serves as an index to the database: the images that are most similar to the query image are identified by finding the most similar descriptors of database images, typically using the Euclidean distance as a similarity measure. To speed up the search for nearest neighbors, the descriptors of the images from the database are stored in a spatial index, typically a kd-tree [
2]. Several approaches for image retrieval have focused on hand-crafted image descriptors; e.g., encoding visual properties of images [
3,
4] or exploiting text associated with images [
5]. More recent approaches utilize methods based on
convolutional neural networks (CNNs) [
6,
7] to learn descriptors that reflect the similarity of image pairs. The training process of such a CNN usually requires training samples consisting of pairs of images with a known similarity status; i.e., it has to be known whether the two images of a training pair are
similar or
dissimilar [
8]. In the training process, the network learns to generate descriptors with small Euclidean distances for similar image pairs and descriptors with large Euclidean distances for dissimilar ones.
In this context, a major problem is the generation of training samples. Often, they are generated by manual labeling [
9,
10], but this is a tedious and time-consuming task; in the context of image retrieval for searching in a database of works of art, it also has the disadvantage that, in particular if based on purely visual aspects, it is highly subjective. To solve this problem, it is desirable to generate the training samples automatically by defining similarity based on additional information that is assigned to images; e.g., class labels describing the type of the depicted object [
11,
12,
13,
14] or descriptive texts [
15,
16]. This strategy for generating training data was also applied for image retrieval in the context of digital collections of works of art [
17,
18,
19]. It allows the generation of samples consisting of pairs of images with a known similarity status from existing datasets containing images with annotations. In most of the cited approaches, the similarity of images is considered to be a binary concept: a pair of images is either similar or not [
11,
17].
However, in the context of image retrieval in databases of works of art, a gradual concept of similarity [
13,
14] might be more intuitive than a binary one. One option to define such a non-binary concept of similarity can be obtained by measuring the level of similarity of an image pair by the level of agreement of the semantic annotations for multiple variables—a concept we referred to as
semantic similarity in [
20,
21]. In these works, we also considered the problem of
missing information: if harvested automatically from online collections of museums, many records in a database containing information about cultural heritage objects will not contain annotations for all variables considered to be relevant for defining similarity.
In this paper, we present a CNN-based method for image retrieval that can be applied to any database containing images with semantic annotations. Based on our previous work [
21], training samples are determined automatically from the database, leading to a gradual concept of semantic similarity, which also can be combined with visual ones. This is expected to lead to retrieval results that are particularly meaningful for persons wanting to learn something about the properties of the query images by analyzing the annotations of the retrieved images, and it also allows a quantitative evaluation based on a k-nearest neighbor (kNN) classification. Our method also allows for samples with incomplete annotations to be considered in training. Compared to our previous work, we modify the training loss for learning similarity slightly and, more importantly, add an additional
auxiliary classification loss for every training sample, which we expect to support the clustering in the descriptor space by forcing the descriptors to have a better intra-class connectivity.
The scientific contributions of this paper can be formulated as follows:
The remainder of this paper starts with an overview about the related work (
Section 2). Our new method for image retrieval is presented in
Section 3.
Section 4 describes the datasets used for the evaluation of this method, whereas
Section 5 presents a comprehensive set of experiments based on these datasets. Finally,
Section 6 summarizes our main findings and makes suggestions for future work.
2. Related Work
Early work on image retrieval relied on hand-crafted features. In content-based image retrieval (CBIR), the descriptors exclusively reflect the visual content of an image in form of color histogram features, shape features and texture features [
3,
4]. As such, these features focus on the visual appearance of images, and the retrieval results are often not representative on a conceptual level, which is referred to as the
semantic gap [
26]. In order to provide semantically meaningful retrieval results and thus to overcome this semantic gap, additional semantic features derived from textual annotations of images have been investigated in the context of semantic-based image retrieval (SBIR). For instance, ref. [
27] derived text features from image captions among others that can be integrated in image retrieval [
5]. However, none of these early works learn the descriptors from training data, which is considered to be the strength of methods based on deep learning.
It was already shown in [
28] that representations derived by a CNN pre-trained for a completely different task, e.g., classification, can be used to achieve more meaningful image retrieval results than classical methods specifically designed for image retrieval. Many deep learning approaches designed for image retrieval apply Siamese CNNs consisting of two branches with shared weights [
29]. When training a Siamese network, the contrastive loss [
8] is often applied. It forces the network to produce similar descriptors for image pairs considered to be similar and to produce dissimilar descriptors for image pairs considered to be dissimilar. As the Euclidean distance is used to measure the similarity of descriptors in this loss, it can also be used for image retrieval, e.g., [
10]. Whereas training with a contrastive loss requires pairs of images that are either similar or dissimilar, the triplet loss [
9] requires image triplets, each consisting of an anchor image, a positive sample—i.e., an image defined to be similar to the anchor—and a negative sample that is dissimilar to the anchor. This loss forces the descriptor of the positive sample to be more similar to the descriptor of the anchor in terms of the Euclidean distance than the descriptor of the negative sample by at least a predefined margin. Both training procedures require training samples with known binary similarity status, which are often generated by manual labeling; e.g., [
9,
10].
2.1. Exploiting Semantic Annotations
An alternative to manual labeling is to exploit semantic annotations assigned to the images to define similarity. A straightforward way to do this while maintaining a binary similarity concept is to consider class labels of one semantic variable only: if two images have the same class label, they are considered to be similar; otherwise, they are dissimilar. An example for such an approach is [
11], where the resultant pairs with a known binary similarity status are used in a training procedure involving the triplet loss. Although this strategy solves the problem of manual labeling if a database with annotated images is available, the similarity status of an image pair is still defined in a binary way, which does not take into account the fact that some images may be considered more similar to each other than others and does not allow a method to be trained to retrieve images that are similar to the query image with respect to multiple semantic variables.
If multiple annotations per image are considered, different degrees of similarity of two images can be defined [
12,
13,
14]. In [
12], different levels of semantic similarity are defined on the basis of the number of identical labels assigned to two images. Training is based on a triplet loss, using the different degrees of similarity to weight the importance of a triplet in training while maintaining a constant margin hyperparameter. Thus, the minimal distance that is enforced between the distances of the descriptors of the positive and the negative samples from the anchor descriptor is identical for all triplets, independently of their degree of similarity.
In [
13], training requires the descriptor distances to reflect different degrees of similarity. Using the contrastive loss, descriptors of images whose annotations agree completely are forced to have a distance shorter than a pre-defined positive margin, whereas the margin defining the minimal descriptor distance between images with partly or completely different annotations is weighted by the degree of similarity; the margin is a hyperparameter to be chosen. A gradual definition of semantic similarity based on the cosine distance between two label vectors is proposed in [
14]. The authors formulate a loss based on pairs of images that forces the image descriptor similarity to match the gradual semantic similarity during training without the need to tune a margin hyperparameter.
All of the cited papers using multiple annotations [
12,
13,
14] aim to learn binary hash codes as image descriptors instead of real-valued feature vectors. The labels used in these papers describe different aspects of the depicted scene, e.g., different object types, whereas in our work, they are related to more abstract semantic properties of the depicted object, e.g., the place and time of origin of the depicted object. Furthermore, even though they allow for a different number of labels assigned to an image, the cited papers do not consider missing annotations in theirs definitions of similarity. We explicitly deal with missing annotations in triplet-based learning, using them to define a degree of uncertainty of the similarity status that has an impact on the margin of the triplet loss.
2.2. Auxiliary Losses
The usability of feature vectors learned in the context of image classification to serve as descriptors for image retrieval has already been investigated [
28,
30,
31,
32]. Even leveraging the softmax layer activations for image retrieval seems to be possible [
33]. In [
34], classification is used to restrict the search space for image retrieval to the images belonging to the same category as the search image. To further improve the clustering of image descriptors with respect to the similarity of the represented images, descriptor learning can be realized by combining the pairwise or triplet losses with an additional
auxiliary classification loss.
In [
22], descriptor learning based on the contrastive loss is combined with a classification loss. A single variable only is considered both for defining the similarity of images in a binary way and for classification. Similar approaches relying on a single variable are shown in [
23,
24], but in these papers, the triplet loss is used in combination with a classification loss. This is also the case in [
35], where two additional auxiliary loss functions are proposed: a
spherical loss, designed to support the learning of inter-class separability, and a
center loss, expected to support the intra-class connectivity. All of these works exploit the class labels of one variable only to define similarity, which leads to a binary similarity status of images and thus does not allow different degrees of similarity to be learned. In [
36], descriptor learning is also combined with a classification loss, where several semantic variables are used to perform multi-task learning. The goal of descriptor learning is to force the high-level image descriptors that are produced by the last layer of the feature extractor to be invariant to the characteristics of the dataset an image belongs to; in [
36], two different descriptors are considered. For that purpose, the descriptors produced by two multi-task network architectures, one per dataset, are presented to a triplet loss, forcing the descriptors belonging to different datasets to be more similar than a descriptor pair belonging to images from the same dataset. Although [
36] exploits the class labels of several variables to learn descriptors by means of multi-task learning, the concept of similarity is still defined in a binary way.
We could identify exactly one work that allows for a fine-grained definition of similarity and additionally utilizes a classification loss to support descriptor learning. In [
37], a fine-grained definition of similarity by exploiting the semantic relatedness of class labels according to their relative distance in a WordNet ontology [
38] is proposed. Descriptor training, which can be optionally combined with the training of a classifier, is realized by learning a mapping from images to embeddings that are enforced to match pre-calculated class embeddings, where the class embeddings can iteratively be derived from a similarity measure for images considering semantic aspects. To the best of our knowledge, there is no work that learns different degrees of descriptor similarity in combination with a classification loss in an end-to-end manner. In particular, we could not find any work that exploits the classes of several semantic variables to both define a fine-grained concept of semantic similarity and to learn to predict the variables in order to support descriptor learning.
2.3. Image Retrieval for Cultural Heritage
All works cited so far address descriptor learning for image retrieval, but in the context of applications that do not involve the preservation of cultural heritage. Many works investigating machine learning methods in the field of heritage preservation focus on the image-based classification of depicted artworks with respect to one [
39,
40,
41] or multiple variables [
42,
43,
44]. Nevertheless, image retrieval is becoming an increasingly important task in that field as well [
45].
The first approaches exploit graph-based representations of images in order to search for similar objects in a database [
46]. More recent approaches for image retrieval in the context of cultural heritage rely on high-level image features learned by a CNN; e.g., [
17,
47]. In [
47], an unsupervised approach for image retrieval based on extracting image features with a pre-trained CNN is proposed. After transforming these features to more compact descriptors by means of a principal component analysis, image retrieval is performed by searching the nearest neighbors in the descriptor space based on Euclidean distances. In contrast, the authors of [
17] propose to train a CNN to generate image features suitable for retrieval by minimizing a triplet loss. For that purpose, they generate training data exploiting the class labels of five semantic variables to define the similarity of images in a binary way; two images are assumed to be similar in cases with more than two identical class labels.
Instead of aiming to retrieve the images that are most similar to a query image,
cross-modal retrieval aims at finding the images most closely related to a provided query text or at finding the best descriptive texts for a query image. Cross-modal image retrieval plays an important role in the context of querying art collections, e.g., [
18,
19], where it is a challenging task to match images and texts in cultural heritage related collections [
48]. In [
18], descriptors are learned by minimizing a variant of the triplet loss, where image descriptors and text descriptors are forced to be similar with respect to their dot product. The approach in [
19] also addresses cross-modal retrieval using strategies that are similar to the ones used in our work. The authors obtain image descriptors for retrieval on the basis of a CNN (ContextNet) pre-trained for the multi-task classification of four semantic variables. In order to learn semantically meaningful image representations, the training of ContextNet combines classification with the mapping of image descriptors to node2vec representations [
49] that describe the context of the depicted object with respect to a knowledge graph containing works of art. Nevertheless, the authors do not investigate image-to-image retrieval but evaluate the potential of the image descriptors learned using their method for cross-modal image retrieval.
Although there are works addressing image retrieval in the context of cultural heritage applications, none of them except for our own previous work [
21] exploits multiple semantic variables to define different degrees of similarity for training. Furthermore, no work could be found that combines descriptor learning with an auxiliary classification loss to support the clustering in feature space. The approach in [
19] is most similar to ours, but on the one hand, image classification and descriptor learning are realized in two steps in that paper, and on the other hand, this approach addresses multi-modal retrieval instead of image-to-image retrieval. Finally, we could not find any work on image retrieval in the field of cultural heritage that focuses on images of silk fabrics; all works cited so far utilize datasets of images showing paintings.
2.4. Discussion
Even though there are quite a few works addressing image retrieval for images showing fabrics, most of them address the retrieval of processed fabrics such as clothes [
36,
50,
51,
52] instead of plain fabrics. A few works also investigate image retrieval for plain fabrics, but they define the similarity status of training pairs exclusively on the basis of the class labels of a single variable [
53], or they train the network for fabric classification only and use the high-level features for image retrieval [
54]. To the best of our knowledge, ours is the only work addressing fabric image retrieval in the context of cultural heritage except for our previous work [
21].
Whereas there are existing methods focusing on learning different degrees of similarity [
13,
14] as well as methods dealing with image retrieval in the context of cultural heritage [
17,
19], there does not seem to be any work investigating a fine-grained similarity concept on the basis of multiple variables under consideration of missing annotations except for our previous work [
21]. Furthermore, to the best of our knowledge, there is no work that combines such a similarity concept with an auxiliary classification loss to predict the variables used to define similarity. In [
22,
23,
24,
36], descriptor learning is combined with an auxiliary loss, but these approaches are all based on a single variable either for the auxiliary classification or for the similarity concept, or for both.
The most similar works to the approach presented in this paper are [
19] and our own previous work [
21]. Even though [
19] learns to predict multiple variables describing the properties of cultural heritage, training the classifier can be seen as a preprocessing step from the perspective of the subsequently trained descriptors for cross-modal retrieval. In this paper, we adopt a variant of the visual and semantic similarity defined in [
21] that allows for different degrees of similarity while explicitly considering missing semantic annotations. In contrast to [
21], we introduce an additional auxiliary classification loss in order to improve the clustering behavior in the descriptor space with respect to the semantic properties of the silk objects depicted in the related images. For that purpose, we exploit a variant of a multi-task classification loss that is also able to deal with missing annotations [
55].
3. Methodology
The main objective of the proposed method is image retrieval based on descriptors that can serve as an index to a database. The result consists of the set of
k images in a database with the most similar descriptors to the descriptor of a query image. Our approach for learning descriptors requires a set of images with known annotations for an arbitrary set of variables. These annotations may be incomplete; i.e., annotations for some variables may be missing for some or even all samples. Our method is based on a CNN that takes an RGB image as an input and generates the required descriptor. In the training process, it learns to generate descriptors whose Euclidean distances implicitly provide information about the degree of similarity of the input images. In this context, our focus is on semantic similarity, which measures the similarity of two images by the degree of agreement of the semantic properties of these images. As shown in [
21], visual similarity aspects can improve the learning of semantic similarity with a strongly varying frequency of the individual properties, so a combination of semantic and visual concepts of similarity are also considered here, but in a slightly modified form compared to [
21]. The training data are derived automatically from available data.
The key idea of this paper is to combine descriptor learning with multi-task learning for predicting the semantic properties used to define semantic similarity. A joint representation that is used both for generating the descriptors and for predicting the class labels of multiple semantic variables is learned end-to-end by minimizing a loss related to the similarity of pairs or triplets of images together with a multi-task classification loss. Adding the classification loss to descriptor learning is assumed to lead to descriptors whose Euclidean distances reflect the degree of semantic similarity of the corresponding image pairs in a better way. This combination is expected to lead to better clusters corresponding to images with similar semantic properties, because this will be favored by both types of tasks in training. Consequently, it is also assumed to lead to a better representation of underrepresented classes, because the CNN learns that certain patterns are related to such a class.
The remainder of this section starts with a detailed description of the CNN architecture in
Section 3.1. In
Section 3.2, the training procedure as well as the loss function proposed to train the CNN is introduced. To make this paper self-contained,
Section 3.2.1 briefly presents the similarity concepts introduced in [
21] as well as a detailed description of the integration of the similarity concepts in the image retrieval training objective. The auxiliary image classification loss is described in
Section 3.2.2. Finally, details on the way in which training batches are generated can be found in
Section 3.3.
3.1. Network Architecture
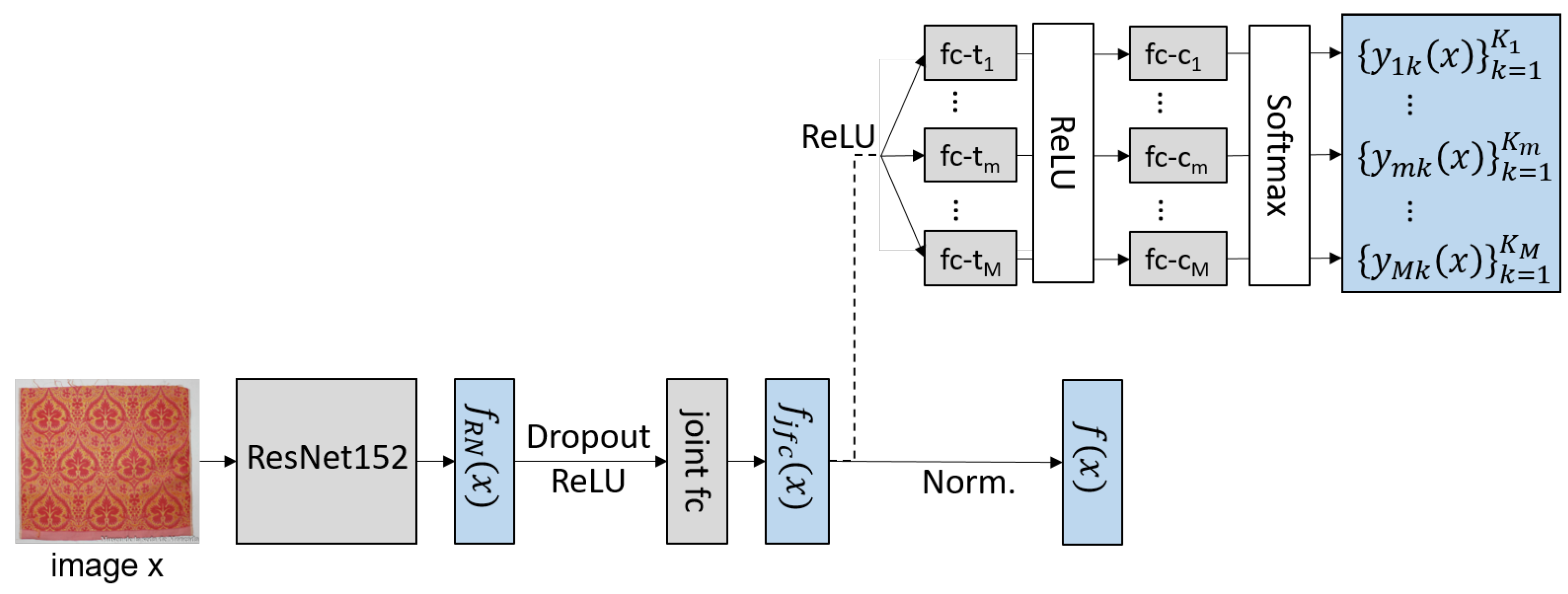
The main objective of the CNN is to map an input image
x to an image descriptor
to be used for image retrieval. For that purpose, the network architecture presented in
Figure 1 is proposed. It consists of three main parts: a feature extraction part delivering features
, an image retrieval head delivering the actual descriptor
and a classification head delivering normalized class scores
that can be interpreted as posterior probabilities
for the
kth class of the
mth semantic variable. The classification head exists only during training to allow for an auxiliary classification loss that is supposed to support descriptor learning.
The feature extraction part is a ResNet152 [
56] backbone without the classification layer. It takes an RGB input image
x of the size 224 by 224 pixels and calculates a 2048-dimensional feature vector
, where
denotes a vector containing all weights and biases of the ResNet152. The ResNet output
is the argument of a ReLU (rectified linear unit [
57]) nonlinearity and afterwards, a dropout [
58] with a probability
is applied. This is followed by
fully connected layers (
joint fc in
Figure 1) consisting of
nodes each. They are at the core of our method because the resulting feature vectors
are the input to both the image retrieval and classification heads. Thus, the weights
of the
joint fc layers are both influenced by the auxiliary multi-task classification loss as well as by the losses used for descriptor learning. Accordingly, it is assumed that the learned image representation
is more meaningful with regard to the semantic annotations of the input image.
The image retrieval head consists of a simple normalization of the feature vector to unit length and does not require any further network weights. In the remainder of the paper, we use the shorthand to denote the weights that have an influence on the descriptor. The result of normalization is the image descriptor to be used for image retrieval.
The image classification head takes the unnormalized vector
. After being processed by a ReLU activation, it is presented to
M separate branches, each corresponding to one classification task to be learned; i.e., to the prediction of one of the
M variables. Each branch is connected to the
joint fc layer and consists of
task-specific fully connected layers
-
of
nodes, each with a ReLU. Finally, each branch has a classification layer
-
with
nodes, where
is the number of classes to be distinguished for the
mth variable, delivering unnormalized class scores
. The weights
denote all weights in the classification head, where
denotes the weights in the layers
-
and
are the weights of the layers
-
. All
M classification layers have a softmax activation [
59] delivering the normalized class scores
which can be interpreted as posterior probabilities
; i.e., the network’s beliefs that the input image
x belongs to class
k for variable
m.
3.2. Network Training
The training of the CNN depicted in
Figure 1 is achieved by minimizing a loss function
. The proposed CNN has two sets of parameters from the perspective of training: the weights
of the ResNet152 and the remaining weights
of the additional layers. The weights
are initialized by pre-trained weights obtained on the ILSVRC-2012-CLS dataset [
60], whereas the weights
of the additional layers of the CNN are initialized randomly using variance scaling [
61]. As it is expected that silk fabrics or other objects in the context of cultural heritage belong to another domain than objects depicted in the ImageNet dataset, the last residual blocks consisting of
layers are potentially fine-tuned [
62]. Denoting the parameters of the frozen ResNet layers by
and those of the fine-tuned ResNet layers by
, the parameters to be determined in training are
. Note that the entire parameter vector becomes
.
Training is based on a set of training samples
that consist of images with semantic annotations for at least one of the
M variables. In addition, the information that two or more images show the same object can be considered in training if available; for instance, the images can be exported from a database containing records about objects that are associated with multiple images [
21]. Training is based on stochastic gradient descent mini-batch with adaptive moments [
63]. In each training iteration, only a mini-batch
consisting of
training samples is considered, and only the loss
achieved for the current mini-batch is used to update the parameters
. We use early stopping; i.e., the training procedure is terminated when the validation loss is saturated.
As the key idea of this paper is to support descriptor learning by simultaneously learning an auxiliary multi-task classifier in order to improve the clustering of the descriptors, the loss
consists of an image retrieval loss
, a classification loss
and a regularization loss
:
The image retrieval loss
incorporates several similarity concepts to learn the trainable network weights
based on a set of training samples
such that the Euclidean distances of the descriptors
(cf.
Figure 1) correspond to the degree of similarity of
; this is described in detail in
Section 3.2.1. The image classification loss
realizes a mathematical dependency of the weights
on the network’s ability to predict the correct class labels for all images
. Thus, it can be seen as an auxiliary loss term for descriptor learning that supports the clustering of the descriptors with respect to the semantic properties of the depicted objects; details on that loss are presented in
Section 3.2.2. The weights
and
in Equation (
2) control the impact of the image retrieval and classification losses, respectively, on the total loss. Finally,
denotes a weight decay term that is defined as [
59]:
Adding weight decay to a loss function aims to avoid overfitting by penalizing large values of . The parameter controls the influence of the regularization term on the loss , as another hyperparameter to be tuned.
3.2.1. Image Retrieval Training Objective
The image retrieval loss should train the network by adapting the learnable parameters
to produce descriptors such that for any pair of images
, the Euclidean distance
of the corresponding descriptors
and
reflects the degree of similarity of the two images, where
where
n is an index of a pair
that will be defined differently for different loss functions. We propose a loss function that consists of three similarity loss terms:
Each of the three terms in Equation (
5) corresponds to a specific concept of similarity and requires a specific type of training samples generated from the images of the mini-batch
. The loss term
, requiring a set
of
triplets of training images from
, integrates
semantic similarity into network training. The second term,
, considers
color similarity. It requires a set
of
pairs of training images from
. Finally,
realizes the learning of
self-similarity and requires a set
of
pairs of images of the same object extracted from
. The impact of the individual loss terms on
is controlled by the weights
,
, and
. The subsequent paragraphs contain a detailed description of all three similarity concepts as well as their integration into losses in the order in which they occur in Equation (
5). The way in which the set
of triplets and the sets
and
of image pairs are determined given a mini-batch
is described in detail in
Section 3.3.
Semantic Similarity Loss
The goal of the semantic similarity loss is to learn the CNN parameters such that the resulting descriptors reflect the semantic similarity of the respective images. For that purpose, a concept of semantic similarity exploiting the class labels of
M semantic variables is required. The degree of equivalence of the class labels of
M variables assigned to an image pair
can be measured by means of the semantic similarity defined in [
21]:
In Equation (
6),
with
denotes whether the class label of the
mth variable is known for the image with index
q (
) or not (
). The actual comparison of the
class labels of the
mth variable in Equation (
6) is realized by the function
where
is a vector indicating the class label for the
mth variable that is assigned to
, with
. If the
kth class of the
mth variable is assigned to the image
, the indicator
is 1; otherwise,
. Thus, the Kronecker delta function
returns 1 in case the
kth class label is assigned to both
and
, and it returns 0 in all other cases. This formalization of
implies that the label for the
mth variable may be unknown either for
or for
or for both of them. If annotations for all variables are known, all values of
will be 1, and
will correspond to the percentage of identical annotations for the two images. Consequently, the uncertainty about the equivalence of the class labels of the
M variables depends on the percentage of variables for which either
or
has no annotation, which can be expressed as
The goal of the semantic similarity loss is to learn the CNN parameters
such that the semantic similarity
of the image pair
defined in Equation (
6) corresponds to the descriptor similarity
in Equation (
4). For that purpose, the triplet loss [
25] was adapted in [
21], resulting in the semantic similarity loss
The loss function in Equation (
9) requires triplets
with
, each consisting of an anchor sample
, a positive sample
and a negative sample
, where
is a sample that is more similar to the anchor sample than
. This loss forces
to have a Euclidean distance from
that is smaller than the distance of
from
by at least a margin of
:
In Equation (
10),
represents the uncertainty of the similarity status of the pair
according to Equation (
8). Thus, the term
can be interpreted as the maximal positive semantic similarity of
(i.e., assuming all missing annotations were identical), and the margin becomes the difference between the similarity
of the anchor and the positive sample and the maximum positive similarity of the anchor and the negative sample. Accordingly,
can be interpreted as the guaranteed difference in semantic similarity between the image pairs
and
. The constraint
expressed in Equation (
10) is considered in the definition of the set of triplets considered in this loss: only triplets of images fulfilling that constraint are eligible for contributing to this loss (cf.
Section 3.3).
Color Similarity Loss
The goal of the color similarity loss is to learn the CNN parameters such that the resulting descriptors are similar for images with a similar color distribution and dissimilar for images with a different color distribution. The agreement between the color distributions of two images
and
, denoted as color similarity, can be calculated by means of the normalized cross correlation coefficient
of color feature vectors
and
[
21]:
where
is the
element of
with
,
is the number of elements of a feature vector, and
is the mean over all
. The color feature vector
of an image
describes the color distribution of that image in the
HSV (
H: hue,
S: saturation,
V: value) color space. To derive this feature vector, the hue
H and saturation
S values of every pixel of the image
resized to 224 × 224 pixels are considered to be polar coordinates. They can be converted to Cartesian coordinates
so that all values of
and
are in the range
. We define a discrete grid consisting of
raster cells (we use
r = 5) and count the number of points
in each raster cell
. Finally, we concatenate the corresponding rows to form the vector
. Thus,
is the number of points in the raster cell
, where
; this implies
.
The correlation coefficient expresses the linear dependency between the two color feature vectors and . In case of identical color distributions of in HSV color space, the color descriptors are identical and thus becomes 1, indicating 100% color similarity. The lower the correlation coefficient, the lower the degree of similarity is supposed to be.
The color similarity loss aims to learn descriptors
whose Euclidean distance corresponds to the color similarity
of the image pair
defined in Equation (
11). This can be achieved by minimizing the following loss function [
21]
This loss function requires pairs
of images from the mini-batch, with
;
is the number of pairs of images from
. Essentially, it forces the descriptor distance
to be small for pairs of images with a large color similarity and to be large for image pairs of low similarity. If
, indicating 100% color similarity of
and
, the descriptor distance is forced to be zero; in the other extreme case of maximum dissimilarity—i.e.,
—it should be
—i.e., the maximum possible descriptor distance given the fact that the descriptors are normalized to unit length (cf.
Section 3.1).
Self-Similarity Loss
The goal of the self-similarity loss is to learn that the descriptors of images showing the same object are similar and thus to learn descriptors that are invariant to geometrical and radiometric transformations to some degree. Self-similarity means that an image
is defined to be similar to an image
that depicts the same object. This is the only similarity concept in our method that is not gradual. The corresponding loss requires the descriptor distances of all pairs
to be zero [
21]:
This loss function requires pairs of images where is an image of the mini-batch, with . As there will be one such pair for every image , we have . There are two options for the origin of given an image .
If the dataset contains images showing the same object,
is selected to be one of these objects. This corresponds to rule 1 of the rule-based similarity proposed in [
21]; note that the related rule-based loss of [
21] is not considered in this paper.
If the dataset contains no such images or if it is not known whether it contains such images, the image
is generated synthetically from
, and in this case, the loss in Equation (
14) could be seen as a variant of data augmentation; this is the only case considered in the self similarity loss of [
21].
Compared to [
21], the set of transformations potentially applied to
in the second case has been expanded. It includes the following geometrical transformations: a rotation of 90
, horizontal and vertical flips, cropping by a random percentage
and small random rotations
. The set of potential radiometric transformations consists of a change of the hue
by adding a random value delta
and an adaptation of the saturation
S by multiplying it by a random factor
. Finally, a random zero mean Gaussian noise with a standard deviation
can be added to generate the image
.
As described above, we have expanded the concept of self-similarity in [
21] by prioritizing images
extracted from the dataset over a synthetic generation of
for the definition of an image pair
.
3.2.2. Auxiliary Multi-Task Learning Training Objective
An auxiliary multi-task classification is supposed to support descriptor learning to generate clusters of image descriptors that better correspond to images of objects with similar semantic properties. As this loss affects the weights of the joint fc layers, it is expected to support the CNN in generating descriptors that represent variable-specific characteristics in the images in a better way.
In [
55], a multi-task classification loss for training a CNN to predict multiple variables related to images
of silk fabrics was proposed:
It is an extension of the softmax-cross entropy for multi-task learning with missing annotations for
M variables. In Equation (
15),
denotes the softmax output for class
k of variable
m,
is the corresponding number of classes and
is an indicator variable with
if
k is the true class label of variable
m for image
and
otherwise. The second sum is only taken over variables
, where
is defined to be the subset of variables for which an annotation is available. In order to mitigate problems with underrepresented classes, we extend the loss in Equation (
15) by a variant of the focal loss [
64]. Whereas the variant presented [
65] focuses on hard training examples in multi-class classification problems, we use a combination of the multi-class focal loss in [
65] and the multi-task-loss in Equation (
15), leading to the multi-task multi-class focal loss:
In Equation (
16),
is the number of available annotations for all
M variables; i.e.,
. The focusing parameter
controls the influence of the focal weight
on the loss
. As the focal weight becomes 1 for
and the focal weight becomes 0 for
, the loss
depends more strongly on
with small softmax scores
. Thus, the network weights
are influenced more strongly by hard training examples indicated by small
for
when minimizing
. Assuming class imbalances for the class distributions of at least one of the
M variables, the focal loss in Equation (
16) is supposed to improve the classification performance of underrepresented classes as the class scores of such classes are generally low, thus also supporting the CNN to produce descriptors which are more likely to help in retrieving images with similar semantic properties for query images corresponding to underrepresented classes for some variables.
3.3. Batch Generation
This section gives an overview of how a mini-batch of images with related class labels as well as potential information indicating images that depict the same object is processed in order to generate the datasets required by the individual loss terms. In general, the auxiliary classification loss requires a set of independent images, whereas the loss terms in the image retrieval loss need sets of pairs or triplets of images in order to learn similarity; i.e., to produce descriptors whose pairwise Euclidean distance reflect similarity. These sets are generated as follows:
Due the normalization of all loss terms by the number of terms of the sum in the individual loss functions, the total loss is not biased towards loss terms with a larger number of summands.
6. Conclusions and Outlook
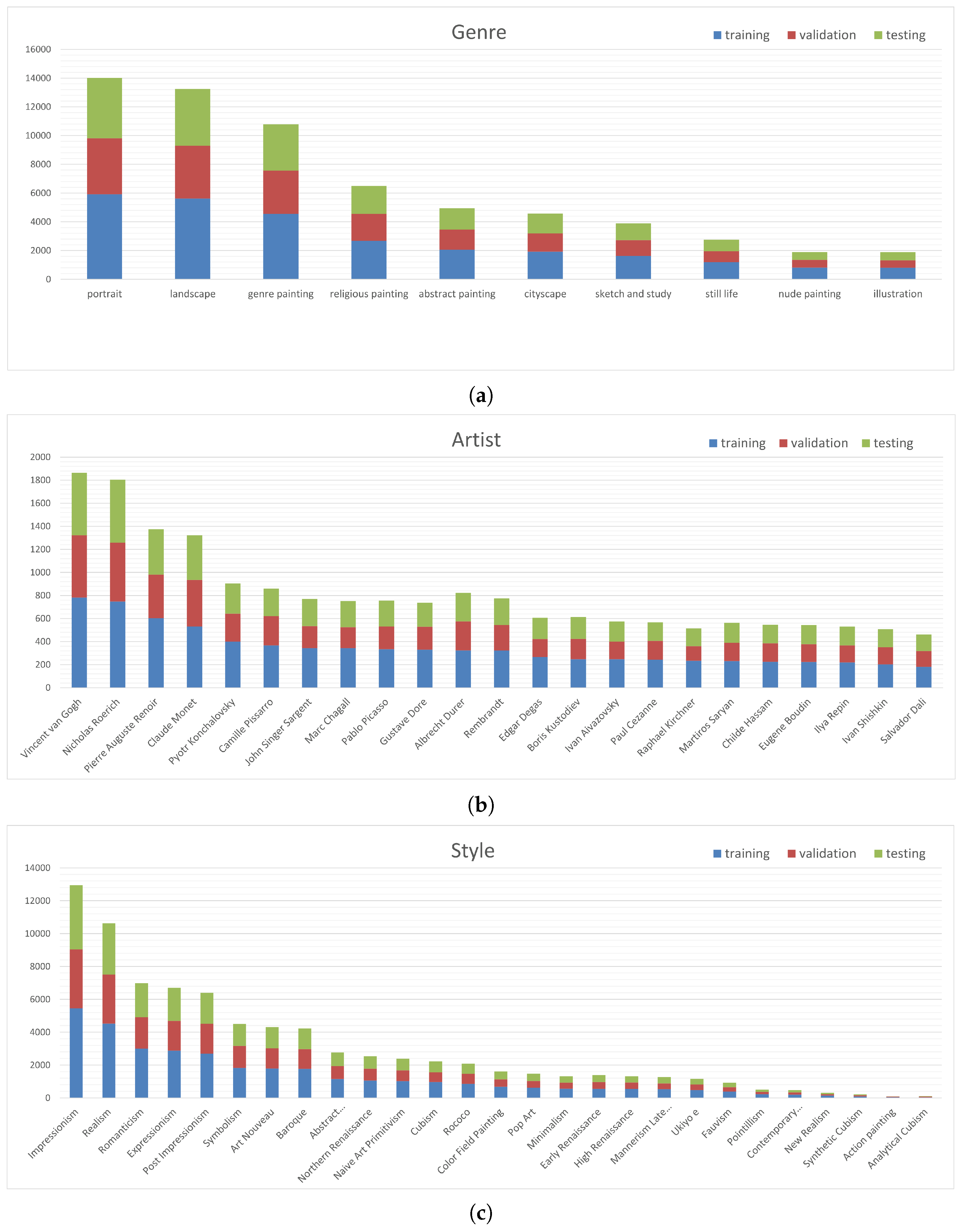
We have presented an approach for CNN-based descriptor learning in order to derive suitable image descriptors for silk image retrieval in the context of preserving European silk heritage. The training of the CNN considers both visual similarity concepts as well as semantic similarity concepts, where training data can be generated automatically by exploiting annotations related to the images in a digital collection. In this context, the annotations assigned to an image do not have to be complete to allow the image to contribute to training, which is of special interest given a real-world dataset. Besides similarity concepts that allow for the generation of training data without manual labeling, we proposed the integration of an auxiliary multi-task classification loss with the goal of supporting the clustering of the learned descriptors with respect to the characteristics of the depicted objects. Comprehensive experiments allow for an analysis of the impact of the individual loss components on the descriptors’ ability to reflect the similarity of a query image and the retrieved images in terms of the semantic annotations. In the experiments, k-NN-classification was conducted to allow for a quantitative evaluation without the need for a reference defining the optimal retrieval results for a set of test images or a known similarity status for each pair of images. The evaluation based on a dataset consisting of images of silk fabrics shows that utilizing the auxiliary classification loss during training indeed improves the performance by up to 3.3% in terms of the variable-specific overall accuracy and by up to 8.4% in terms of variable-specific F1 scores. It was observed that the largest improvements were achieved for variables with imbalanced class distributions. Further experiments on the WikiArt dataset showed the transferability of our approach to other digital collections, even though it was developed in the context of querying silk databases.
Future work could either focus on variations of the
dataset to further investigate the transferability of the proposed method or to give hints for required modifications of the approach. As the presented descriptor learning approach relies on images with annotations indicating the classes of at least one semantic variable, it could theoretically be applied to any dataset or digital collection consisting of image and class labels of one or several variables. Thus, it would be interesting to analyze its behavior on other cultural heritage datasets, e.g.,
Art500k [
17] or
OmniArt [
43], both consisting of images of artworks from different centuries, on other datasets related to fabrics, e.g.,
DeepFashion [
67], consisting of images depicting clothes, and finally, on datasets showing images from a completely different domain, e.g.,
CelebA [
68], consisting of face images with different face attributes. As far as the WikiArt data are concerned, additional hyperparameter tuning might improve the results beyond what could be shown in this paper.
From a methodological point of view, it would be interesting to investigate further
auxiliary losses in order to improve the clustering behavior. This could include losses that directly address the clustering in descriptor space, such as the spherical loss or the center loss presented in [
35]. Alternatively, a variation of the proposed self-similarity loss—e.g., the representation learning approach in [
69]—could be investigated, which forces the descriptors to be invariant to different appearances of an object in an image. In contrast to the self-similarity loss presented in this paper, which directly forces the descriptors of two images of the same object to be similar, ref. [
69] allows the network to learn a mapping between the descriptors. A further possibility would be to introduce not only further restrictions on the descriptors by formulating constraints in a loss function but to exploit further information about the depicted objects by considering descriptive texts assigned to images. Possible datasets to develop and test such approaches could either be generated from the SILKNOW knowledge graph [
1], like the dataset in the present work, or other multi-modal datasets with both annotations for multiple semantic variables as well as descriptive texts; e.g.,
SemArt [
70].
Furthermore, an evaluation with another focus of the results of the presented image retrieval method would be interesting. Such an evaluation could aim to obtain an impression of how visually similar the retrieved images are, which probably requires interactive assessment by domain experts. Another conceivable goal of a further evaluation could be to analyze the impact of the similarity losses on the image classification. Instead of handling the classification loss as an auxiliary loss, one or several similarity losses could be analyzed with respect to their ability to improve image classification, where the similarity losses would than function as auxiliary losses for image classification. A strong motivation for such experiments is our observation that the combination of descriptor learning and image classification during training improves the ability of the learned descriptors to represent semantic properties, primarily those of variables with many classes and imbalanced class structures at test time. In this context, it would be interesting to compare the utilization of auxiliary similarity losses with other strategies that aim to tackle class imbalance problems in image classification.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}