
Spatial-Temporal Diffusion Convolutional Network: A Novel Framework for Taxi Demand Forecasting


Abstract
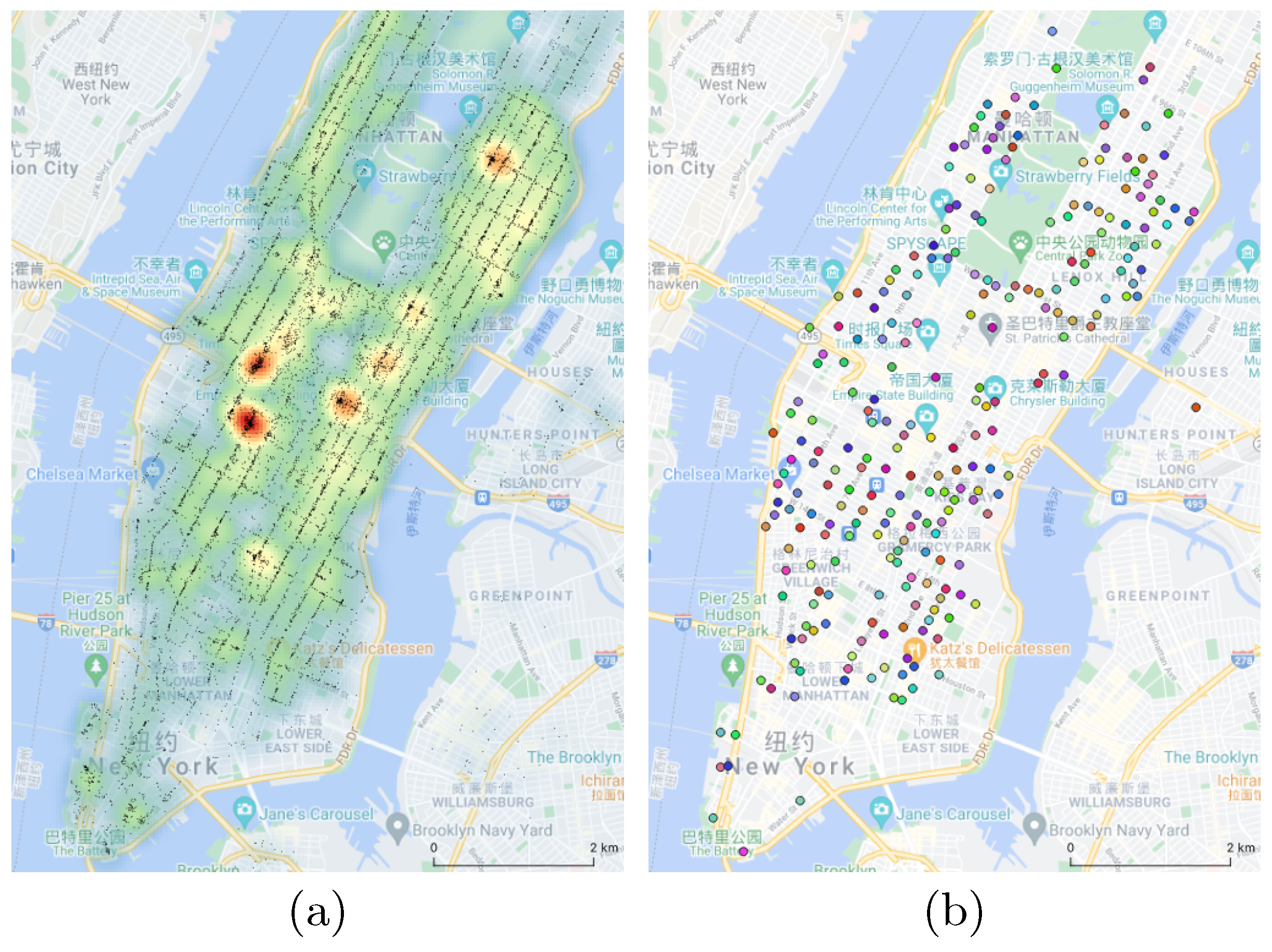
:1. Introduction
- We design a two-phase graph diffusion convolutional network, which can effectively address the limitations of graph convolutional neural networks. During the diffusion process of the convolution, we use two types of adjacency matrices and introduce the attention mechanism to capture the dynamic spatial dependencies adaptively;
- Hybrid Dilated Causal Convolution is used to capture the temporal dependencies, which can tackle the grid effect problem of conventional dilated convolution. We use a gating mechanism to efficiently control the information flow of nodes and further consider the periodicity of taxi demand data;
- We evaluated our approach on two large-scale real-world datasets. The experimental results demonstrate that ST-DCN outperforms seven existing state-of-the-art baseline methods.
2. Preliminary
3. Methodology
3.1. Spatial Dependency Modeling
3.2. Temporal Dependence Modeling
- The dilation rate of a stacked dilated convolution should not have a common factor greater than 1. For example, [2, 4, 6] would not be a suitable three-layer convolution as it still has gridding effects;
- The dilation rate is designed as a jagged structure, e.g., a cyclic structure like [1, 2, 5, 1, 2, 5];
- The dilation rate needs to satisfy the equation:
3.3. Extra Components
4. Experiments
4.1. Experimental Settings
- NYC Taxi (https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page (accessed on 5 May 2021)): This dataset includes 91 days of 35 million taxi trip records of NYC in yellow taxis from 1 April 2016 to 30 June 2016.
- Didi Taxi (https://outreach.didichuxing.com/research/opendata/en/ (accessed on 7 July 2021)): The dataset contains taxi requests from 1 November 2016 to 30 November 2016 for the city of Chengdu with more than 7 million taxi trip records.
4.2. Baselines
- LSTM [34]: Long Short-Term Memory Network, a special RNN model for time series prediction;
- DCRNN [8]: Diffusion Convolutional Recurrent Neural Network, which combines diffusion graph convolutional networks with GRU in an encoder-decoder manner;
- STGCN [35]: A Spatial-Temporal Graph Convolutional Network uses ChebNet graph convolution and 1D convolutional networks to capture spatial dependencies and temporal correlations, respectively;
- GWNet [11]: A Spatial-Temporal Graph Convolutional Network integrates adaptive adjacency matrix into diffusion graph convolutions with 1D dilated casual convolutions;
- ASTGCN [9]: Attention Based Spatial-Temporal Graph Convolutional Networks, which introduces spatial attention and temporal attention mechanisms to model spatial and temporal dynamics, respectively. For fairness, we only take its recent components;
- MTGNN [36]: A Graph Neural Network designed for multivariate time series forecasting by adding a graph learning layer to capture the hidden relationships among time series data;
- CCRNN [22]: A Coupled Layer-wise Graph Convolution designed for transportation demand prediction.
4.3. Performance Comparison
4.4. Component Analysis
- Basic: This model does not equip with hybrid dilated convolution, two-phase graph diffusion convolution, and temporal periodicity;
- +HDC: This model uses hybrid dilated convolution to overcome the gridding effect;
- Two-phase: This model uses two-phase graph diffusion convolution to address two limitations of graph convolution, but it does not employ hybrid dilated convolution;
- One T-block (1 day): This model considers the daily period in one T-block (only yesterday is included);
- Multi T-block (1 day): This model considers the daily period in multi T-blocks (only yesterday is included);
- One T-block (7 day): This model considers the daily and weekly period in one T-block;
- ST-DCN (multi T-block (7 day)): This model considers the daily and weekly period in multi T-blocks. It is the complete version of our proposed approach ST-DCN.
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Zheng, Y.; Qi, D. Deep spatio-temporal residual networks for citywide crowd flows prediction. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 1655–1661. [Google Scholar]
- Sun, J.; Zhang, J.; Li, Q.; Yi, X.; Liang, Y.; Zheng, Y. Predicting Citywide Crowd Flows in Irregular Regions Using Multi-View Graph Convolutional Networks. IEEE Trans. Knowl. Data Eng. 2020, 14. [Google Scholar] [CrossRef]
- Yao, H.; Wu, F.; Ke, J.; Tang, X.; Jia, Y.; Lu, S.; Gong, P.; Li, Z.; Ye, J.; Chuxing, D. Deep multi-view spatial-temporal network for taxi demand prediction. arXiv 2018, arXiv:1802.08714. [Google Scholar]
- Geng, X.; Li, Y.; Wang, L.; Zhang, L.; Yang, Q.; Ye, J.; Liu, Y. Spatiotemporal multi-graph convolution network for ride-hailing demand forecasting. In Proceedings of the AAAI, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3656–3663. [Google Scholar]
- Bai, L.; Yao, L.; Kanhere, S.S.; Wang, X.; Sheng, Q.Z. STG2seq: Spatial-temporal graph to sequence model for multi-step passenger demand forecasting. IJCAI 2019, 1981–1987. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Qiu, Z.; Li, G.; Wang, Q.; Ouyang, W.; Lin, L. Contextualized Spatialoral Network for Taxi Origin-Destination Demand Prediction. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3875–3887. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wo, T.; Yin, H.; Xu, J.; Chen, H.; Zheng, K. Origin-destination matrix prediction via graph convolution: A new perspective of passenger demand modeling. In Proceedings of the 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1227–1235. [Google Scholar] [CrossRef]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv 2018, arXiv:1707.01926. [Google Scholar]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In Proceedings of the AAAI, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 922–929. [Google Scholar]
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-gcn: A temporal graph convolutional network for traffic prediction. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3848–3858. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph wavenet for deep spatial-temporal graph modeling. IJCAI 2019, 1907–1913. [Google Scholar] [CrossRef] [Green Version]
- Shi, X.; Qi, H.; Shen, Y.; Wu, G.; Yin, B. A spatial-temporal attention approach for traffic prediction. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4909–4918. [Google Scholar] [CrossRef]
- Yao, H.; Tang, X.; Wei, H.; Zheng, G.; Li, Z. Revisiting spatial-temporal similarity: A deep learning framework for traffic prediction. In Proceedings of the AAAI, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5668–5675. [Google Scholar]
- Song, C.; Lin, Y.; Guo, S.; Wan, H. Spatial-temporal synchronous graph convolutional networks: A new framework for spatial-temporal network data forecasting. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020; pp. 914–921. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, C.; Xu, Y.; Xia, L.; Dai, P.; Bo, L.; Zhang, J.; Zheng, Y. Traffic Flow Forecasting with Spatial-Temporal Graph Diffusion Network. In Proceedings of the AAAI, Virtual, 2–9 February 2021; Volume 35, pp. 15008–15015. [Google Scholar]
- Li, M.; Zhu, Z. Spatial-Temporal Fusion Graph Neural Networks for Traffic Flow Forecasting. In Proceedings of the AAAI, Virtual, 2–9 February 2021; Volume 35, pp. 4189–4196. [Google Scholar]
- Lin, L.; He, Z.; Peeta, S. Predicting station-level hourly demand in a large-scale bike-sharing network: A graph convolutional neural network approach. Transp. Res. Part C Emerg. Technol. 2018, 97, 258–276. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Zhu, F.; Lv, Y.; Ye, P.; Wang, F.Y. MLRNN: Taxi Demand Prediction Based on Multi-Level Deep Learning and Regional Heterogeneity Analysis. IEEE Trans. Intell. Transp. Syst. 2021, 1–11. [Google Scholar] [CrossRef]
- Kaltenbrunner, A.; Meza, R.; Grivolla, J.; Codina, J.; Banchs, R. Urban cycles and mobility patterns: Exploring and predicting trends in a bicycle-based public transport system. Pervasive Mob. Comput. 2010, 6, 455–466. [Google Scholar] [CrossRef]
- Moreira-Matias, L.; Gama, J.; Ferreira, M.; Mendes-Moreira, J.; Damas, L. Predicting taxi–passenger demand using streaming data. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1393–1402. [Google Scholar] [CrossRef] [Green Version]
- Williams, B.M.; Hoel, L.A. Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: Theoretical basis and empirical results. J. Transp. Eng. 2003, 129, 664–672. [Google Scholar] [CrossRef] [Green Version]
- Ye, J.; Sun, L.; Du, B.; Fu, Y.; Xiong, H. Coupled Layer-wise Graph Convolution for Transportation Demand Prediction. In Proceedings of the AAAI, Virtual, 2–9 February 2021; Volume 35, pp. 4617–4625. [Google Scholar]
- Du, B.; Hu, X.; Sun, L.; Liu, J.; Qiao, Y.; Lv, W. Traffic demand prediction based on dynamic transition convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1237–1247. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NE, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Alon, U.; Yahav, E. On the Bottleneck of Graph Neural Networks and its Practical Implications. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Oono, K.; Suzuki, T. Graph Neural Networks Exponentially Lose Expressive Power for Node Classification. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Li, Q.; Han, Z.; Wu, X.M. Deeper insights into graph convolutional networks for semi-supervised learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Orhan, E.; Pitkow, X. Skip Connections Eliminate Singularities. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. arXiv 2017, arXiv:1709.04875. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the Dots: Multivariate Time Series Forecasting with Graph Neural Networks. arXiv 2020, arXiv:2005.11650, 753–763. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | p = 3 | p = 6 | p = 12 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | PCC | MAE | RMSE | PCC | MAE | RMSE | PCC | |
| LSTM | 22.2593 | 35.3812 | 0.0396 | 22.2777 | 35.3053 | 0.0846 | 22.3101 | 35.3657 | 0.0744 |
| DCRNN | 5.2734 | 8.7323 | 0.9691 | 5.3217 | 8.9063 | 0.9679 | 5.4931 | 9.1450 | 0.9665 |
| ASTGCN | 5.4692 | 9.4815 | 0.9650 | 5.3771 | 9.4569 | 0.9638 | 5.6197 | 9.9337 | 0.9608 |
| MTGNN | 5.4587 | 9.2379 | 0.9654 | 6.1552 | 10.4912 | 0.9554 | 7.3898 | 12.7436 | 0.9344 |
| STGCN | 6.2332 | 10.5332 | 0.9547 | 6.4520 | 10.8703 | 0.9517 | 6.6751 | 11.2684 | 0.9485 |
| GWNet | 5.2345 | 8.7947 | 0.9717 | 5.1035 | 8.8489 | 0.9690 | 5.3518 | 9.2376 | 0.9674 |
| CCRNN | 4.8576 | 8.2347 | 0.9754 | 5.2650 | 9.1107 | 0.9699 | 5.4746 | 9.5675 | 0.9672 |
| ST-DCN | 0.9747 | ||||||||
| Models | p = 3 | p = 6 | p = 12 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | PCC | MAE | RMSE | PCC | MAE | RMSE | PCC | |
| LSTM | 186.5467 | 316.6753 | 0.0491 | 186.3385 | 316.9454 | 0.0271 | 185.8830 | 315.5982 | 0.0944 |
| DCRNN | 13.1659 | 25.6185 | 0.9967 | 13.3274 | 25.9840 | 0.9967 | 13.7034 | 25.9839 | 0.9966 |
| ASTGCN | 17.0968 | 34.7806 | 0.9940 | 17.2186 | 34.7206 | 0.9940 | 18.2122 | 37.4844 | 0.9930 |
| MTGNN | 14.2991 | 27.8156 | 0.9963 | 15.0434 | 30.1220 | 0.9956 | 16.2260 | 32.4549 | 0.9948 |
| STGCN | 16.5549 | 34.1537 | 0.9944 | 17.7299 | 37.1672 | 0.9932 | 19.9882 | 41.4199 | 0.9917 |
| GWNet | 12.0914 | 24.5351 | 0.9970 | 13.7161 | 27.4267 | 0.9963 | 14.1064 | 29.5471 | 0.9957 |
| CCRNN | 14.6755 | 28.3034 | 0.9962 | 15.2797 | 31.2508 | 0.9955 | 19.3367 | 40.3984 | 0.9933 |
| ST-DCN | |||||||||
| Models | MAE | RMSE | PCC |
|---|---|---|---|
| basic | 5.4035 | 9.2762 | 0.9664 |
| +HDC | 5.3371 | 9.2543 | 0.9655 |
| two-phase | 5.3327 | 9.1792 | 0.9671 |
| one T-block (1 day) | 5.2181 | 9.0306 | 0.9679 |
| multi T-block (1 day) | 5.1653 | 8.8413 | 0.9685 |
| one T-block (7 day) | 5.0545 | 8.8018 | 0.9698 |
| ST-DCN (multi T-block (7 day)) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, A.; Shangguan, B.; Yang, C.; Gao, F.; Fang, Z.; Yu, D. Spatial-Temporal Diffusion Convolutional Network: A Novel Framework for Taxi Demand Forecasting. ISPRS Int. J. Geo-Inf. 2022, 11, 193. https://doi.org/10.3390/ijgi11030193
Luo A, Shangguan B, Yang C, Gao F, Fang Z, Yu D. Spatial-Temporal Diffusion Convolutional Network: A Novel Framework for Taxi Demand Forecasting. ISPRS International Journal of Geo-Information. 2022; 11(3):193. https://doi.org/10.3390/ijgi11030193
Chicago/Turabian StyleLuo, Aling, Boyi Shangguan, Can Yang, Fan Gao, Zhe Fang, and Dayu Yu. 2022. "Spatial-Temporal Diffusion Convolutional Network: A Novel Framework for Taxi Demand Forecasting" ISPRS International Journal of Geo-Information 11, no. 3: 193. https://doi.org/10.3390/ijgi11030193