
Crowd Anomaly Detection via Spatial Constraints and Meaningful Perturbation


Abstract
:1. Introduction
2. Literature Review
2.1. Crowd Anomaly Detection
2.2. Crowd Anomaly Localization
3. Materials and Methods
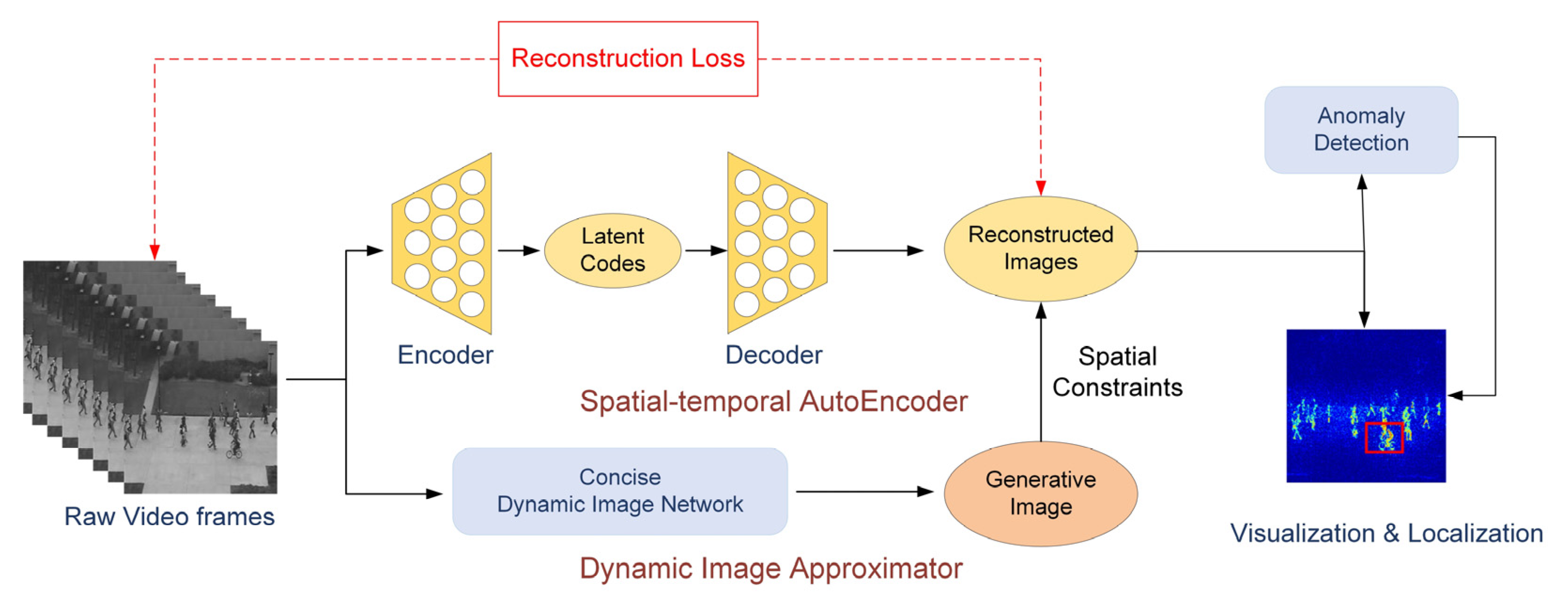
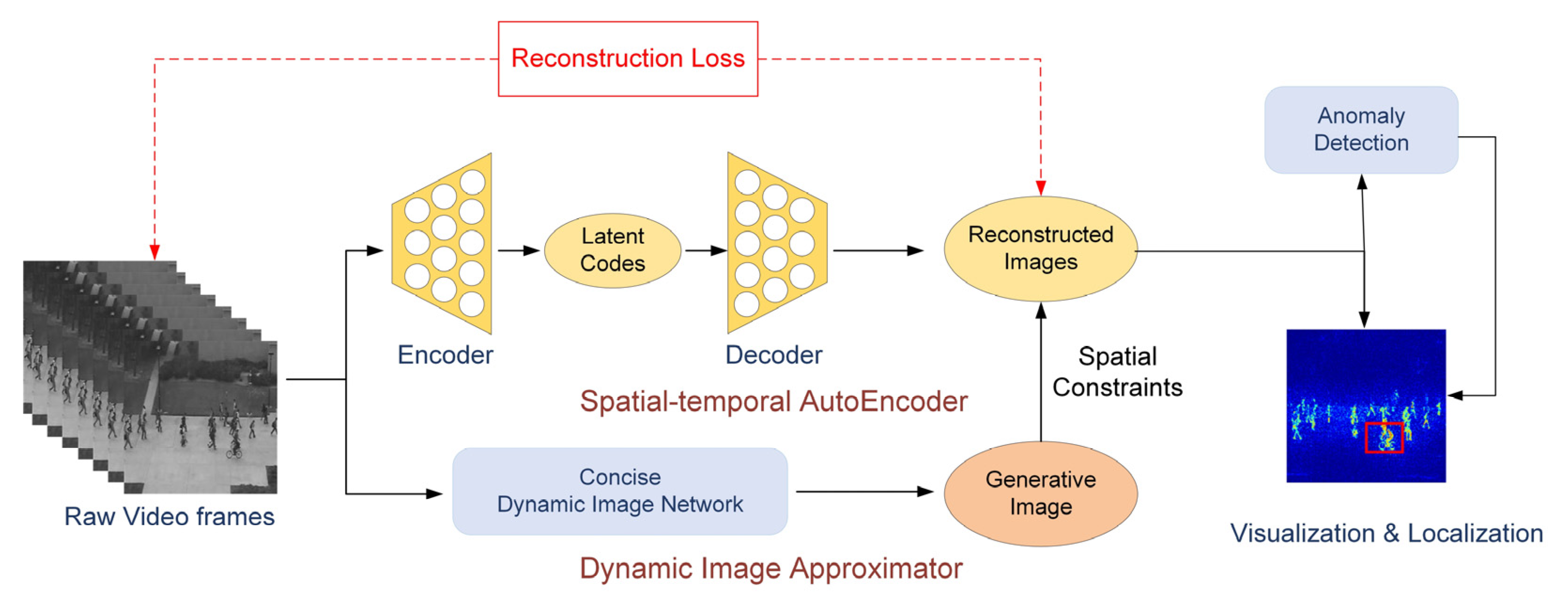
3.1. Overview
3.2. Problem Statements
3.3. Spatiotemporal Autoencoder with Dynamic Map Approximation
3.3.1. Basic Concepts
3.3.2. Spatiotemporal Autoencoder
3.3.3. Dynamic Image Approximator
3.4. Anomaly Detection
| Algorithm 1. Crowd Anomaly Detection Algorithm |
| is a batch of raw video frames in time t Output: Anomaly video frames 1: Resize to 224 × 224 pixels in Input block 2: for each video frame in do 3: Forward propagate video frame through Spatial Encoder block 4: Select the feature maps SF from layer C2 of Spatial Encoder block 5: Forward propagate SF through Temporal Encoder block 6: if generated SFs = 16 Generate Dynamic image through Approximator block Compute identity matrix from Dynamic image (Equation (9)) Initialize Dynamic image end if 7: Forward propagate SF through Temporal Encoder block 8: Select the feature maps TF from layer CL3 of the Temporal Encoder block 9: Forward propagate TF through Decoder block 10: Select the reconstructed frame RF from layer DC2 of Encoder block 11: end for 12: for RF index = 1 to 16, do 13: Computing regularity score for each RF (Equations (10)–(14)) if regularity score < threshold Output RF end if 14: end for |
3.5. Anomaly Visualization and Localization
4. Experiment and Results
4.1. Dataset
4.2. Implementation Details
4.3. Results and Analysis
4.3.1. Accuracy Evaluation
4.3.2. Time–Cost Evaluation
4.3.3. Qualitative Analysis
4.3.4. Visual Explanations by Meaningful Perturbation
4.3.5. Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, Y.; Qin, M.; Wang, X.; Zhang, C. Regional Crowd Status Analysis based on GeoVideo and Multimedia Data Collaboration. In Proceedings of the 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 18–20 June 2021; pp. 1278–1282. [Google Scholar]
- Pidhorskyi, S.; Almohsen, R.; Doretto, G. Generative probabilistic novelty detection with adversarial autoencoders. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; Volume 31, pp. 6822–6833. [Google Scholar]
- Fan, S.; Meng, F. Video prediction and anomaly detection algorithm based on dual discriminator. In Proceedings of the 2020 5th International Conference on Computational Intelligence and Applications (ICCIA), Beijing, China, 19–21 June 2020; pp. 123–127. [Google Scholar]
- Wang, T.; Qiao, M.; Lin, Z.; Li, C.; Snoussi, H.; Liu, Z.; Choi, C. Generative Neural Networks for Anomaly Detection in Crowded Scenes. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1390–1399. [Google Scholar] [CrossRef]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; Hengel, A.V.D. Memorizing Normality to Detect Anomaly: Memory-Augmented Deep Autoencoder for Unsupervised Anomaly Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1705–1714. [Google Scholar]
- Vu, H.; Nguyen, T.D.; Travers, A.; Venkatesh, S.; Phung, D. Energy-Based Localized Anomaly Detection in Video Surveillance. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Cham, Germany, 2017; pp. 641–653. [Google Scholar]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future Frame Prediction for Anomaly Detection—A New Baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6536–6545. [Google Scholar]
- Babaeizadeh, M.; Finn, C.; Erhan, D.; Campbell, R.H.; Levine, S. Stochastic variational video prediction. arXiv 2017, arXiv:1710.11252. [Google Scholar]
- Castrejon, L.; Ballas, N.; Courville, A. Improved conditional VRNNs for video prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7608–7617. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NeurIPS 2014), Montréal, QC, Canada, 8–13 December 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Gowsikhaa, D.; Abirami, S.; Baskaran, R. Automated human behavior analysis from surveillance videos: A survey. Artif. Intell. Rev. 2014, 42, 747–765. [Google Scholar] [CrossRef]
- Ojha, S.; Sakhare, S. Image processing techniques for object tracking in video surveillance—A survey. In Proceedings of the 2015 International Conference on Pervasive Computing (ICPC), Pune, India, 8–10 January 2015; pp. 1–6. [Google Scholar]
- Kiran, B.R.; Thomas, D.M.; Parakkal, R. An overview of deep learning based methods for unsupervised and semi-supervised anomaly detection in videos. J. Imaging 2018, 4, 36. [Google Scholar] [CrossRef] [Green Version]
- Cong, Y.; Yuan, J.; Liu, J. Sparse reconstruction cost for abnormal event detection. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3449–3456. [Google Scholar]
- Liu, C.; Ghosal, S.; Jiang, Z.; Sarkar, S. An Unsupervised Spatiotemporal Graphical Modeling Approach to Anomaly Detection in Distributed CPS. In Proceedings of the 2016 ACM/IEEE 7th International Conference on Cyber-Physical Systems (ICCPS), Vienna, Austria, 11–14 April 2016; pp. 1–10. [Google Scholar]
- Zhou, S.; Shen, W.; Zeng, D.; Fang, M.; Wei, Y.; Zhang, Z. Spatial-temporal convolutional neural networks for anomaly detection and localization in crowded scenes. Signal Process. Image Commun. 2016, 47, 358–368. [Google Scholar] [CrossRef]
- Cong, Y.; Yuan, J.; Tang, Y. Video Anomaly Search in Crowded Scenes via Spatial-temporal Motion Context. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1590–1599. [Google Scholar] [CrossRef]
- Yuan, Y.; Wang, D.; Wang, Q. Anomaly Detection in Traffic Scenes via Spatial-Aware Motion Reconstruction. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1198–1209. [Google Scholar] [CrossRef] [Green Version]
- Chu, W.; Xue, H.; Yao, C.; Cai, D. Sparse Coding Guided Spatiotemporal Feature Learning for Abnormal Event Detection in Large Videos. IEEE Trans. Multimedia 2019, 21, 246–255. [Google Scholar] [CrossRef]
- Zhou, J.T.; Du, J.; Zhu, H.; Peng, X.; Liu, Y.; Goh, R.S.M. AnomalyNet: An Anomaly Detection Network for Video Surveillance. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2537–2550. [Google Scholar] [CrossRef]
- Yuan, Y.; Feng, Y.; Lu, X. Statistical Hypothesis Detector for Abnormal Event Detection in Crowded Scenes. IEEE Trans. Cybern. 2017, 47, 3597–3608. [Google Scholar] [CrossRef]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning Temporal Regularity in Video Sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 733–742. [Google Scholar]
- Tudor Ionescu, R.; Smeureanu, S.; Alexe, B.; Popescu, M. Unmasking the Abnormal Events in Video. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2914–2922. [Google Scholar]
- Xu, D.; Yan, Y.; Ricci, E.; Sebe, N. Detecting anomalous events in videos by learning deep representations of appearance and motion. Comput. Vis. Image Underst. 2017, 156, 117–127. [Google Scholar] [CrossRef]
- Luo, W.; Liu, W.; Gao, S. Remembering history with convolutional LSTM for anomaly detection. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 439–444. [Google Scholar]
- Wang, L.; Zhou, F.; Li, Z.; Zuo, W.; Tan, H. Abnormal Event Detection in Videos Using Hybrid Spatial-temporal Autoencoder. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2276–2280. [Google Scholar]
- Peipei, Z.; Qinghai, D.; Haibo, L.; Xinglin, H. Anomaly detection and location in crowded surveillance videos. Acta Opt. Sin. 2018, 38, 97–105. [Google Scholar]
- Li, X.; Chen, M.; Wang, Q. Quantifying and Detecting Collective Motion in Crowd Scenes. IEEE Trans. Image Process. 2020, 29, 5571–5583. [Google Scholar] [CrossRef] [PubMed]
- Lyu, Y.; Han, Z.; Zhong, J.; Li, C.; Liu, Z. A Generic Anomaly Detection of Catenary Support Components Based on Generative Adversarial Networks. IEEE Trans. Instrum. Meas. 2019, 69, 2439–2448. [Google Scholar] [CrossRef]
- Wang, C.; Yao, Y.; Yao, H. Video anomaly detection method based on future frame prediction and attention mechanism. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Online. 27–30 January 2021; pp. 405–407. [Google Scholar]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Moayed, Z.; Klette, R. Deep-anomaly: Fully convolutional neural network for fast anomaly detection in crowded scenes. Comput. Vis. Image Underst. 2018, 172, 88–97. [Google Scholar] [CrossRef] [Green Version]
- Yan, S.; Smith, J.S.; Lu, W.; Zhang, B. Abnormal Event Detection from Videos Using a Two-Stream Recurrent Variational Autoencoder. IEEE Trans. Cogn. Dev. Syst. 2020, 12, 30–42. [Google Scholar] [CrossRef]
- Prawiro, H.; Peng, J.W.; Pan, T.Y.; Hu, M.C. Abnormal Event Detection in Surveillance Videos Using Two-Stream Decoder. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Nawaratne, R.; Alahakoon, D.; De Silva, D.; Yu, X. Spatiotemporal Anomaly Detection Using Deep Learning for Real-Time Video Surveillance. IEEE Trans. Ind. Inform. 2020, 16, 393–402. [Google Scholar] [CrossRef]
- Tariq, S.; Farooq, H.; Jaleel, A.; Wasif, S.M. Anomaly Detection with Particle Filtering for Online Video Surveillance. IEEE Access 2021, 9, 19457–19468. [Google Scholar]
- Zhu, Y.; Newsam, S. Motion-aware feature for improved video anomaly detection. arXiv 2019, arXiv:1907.10211. [Google Scholar]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Klette, R. Deep-Cascade: Cascading 3D Deep Neural Networks for Fast Anomaly Detection and Localization in Crowded Scenes. IEEE Trans. Image Process. 2017, 26, 1992–2004. [Google Scholar] [CrossRef]
- Lv, H.; Zhou, C.; Cui, Z.; Xu, C.; Li, Y.; Yang, J. Localizing Anomalies from Weakly-Labeled Videos. IEEE Trans. Image Process. 2021, 30, 4505–4515. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, A.; Sajan, K.S.; Srivastava, A.; Wu, Y. Anomaly Detection, Localization and Classification Using Drifting Synchrophasor Data Streams. IEEE Trans. Smart Grid. 2021, 12, 3570–3580. [Google Scholar] [CrossRef]
- Ganokratanaa, T.; Aramvith, S.; Sebe, N. Unsupervised Anomaly Detection and Localization Based on Deep Spatiotemporal Translation Network. IEEE Access 2020, 8, 50312–50329. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient Deep CNN-Based Fire Detection and Local-ization in Video Surveillance Applications. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1419–1434. [Google Scholar] [CrossRef]
- Coyle, D.; Weller, A. “Explaining” machine learning reveals policy challenges. Science 2020, 368, 1433–1434. [Google Scholar] [CrossRef]
- Hou, B.J.; Zhou, Z.H. Learning with Interpretable Structure from Gated RNN. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2267–2279. [Google Scholar] [CrossRef] [Green Version]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Jiang, P.T.; Zhang, C.B.; Hou, Q.; Cheng, M.M.; Wei, Y. LayerCAM: Exploring Hierarchical Class Activation Maps for Localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Ding, S.; Mardziel, P.; Hu, X. Score-CAM: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 24–25. [Google Scholar]
- Chen, J.; Li, S.E.; Tomizuka, M. Interpretable End-to-End Urban Autonomous Driving with Latent Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2021, 1–11. [Google Scholar] [CrossRef]
- Lipton, Z.C. The mythos of model interpretability. Commun. ACM 2016, 61, 36–43. [Google Scholar] [CrossRef]
- Bau, D.; Zhou, B.; Khosla, A.; Oliva, A.; Torralba, A. Network dissection: Quantifying Interpretability of deep visual representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6541–6549. [Google Scholar]
- Fan, M.; Wei, W.; Xie, X.; Liu, Y.; Guan, X.; Liu, T. Can We Trust Your Explanations? Sanity Checks for Interpreters in Android Malware Analysis. IEEE Trans. Inf. Forensic Secur. 2021, 16, 838–853. [Google Scholar] [CrossRef]
- Bilen, H.; Fernando, B.; Gavves, E.; Vedaldi, A. Action Recognition with Dynamic Image Network. IEEE Trans. Pattern Anal. 2018, 40, 2799–2813. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fong, R.C.; Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3429–3437. [Google Scholar]
- Dabkowski, P.; Gal, Y. Real time image saliency for black box classifiers. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Wagner, J.; Kohler, J.M.; Gindele, T.; Hetzel, L.; Wiedemer, J.T.; Behnke, S. Interpretable and fine-grained visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9097–9107. [Google Scholar]
- Rao, Z.; He, M.; Zhu, Z. Input-Perturbation-Sensitivity for Performance Analysis of CNNS on Image Recognition. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2496–2500. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 fps in matlab. In Proceedings of the IEEE international Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Adam, A.; Rivlin, E.; Shimshoni, I.; Reinitz, D. Robust Real-Time Unusual Event Detection using Multiple Fixed-Location Monitors. IEEE Trans. Pattern Anal. 2008, 30, 555–560. [Google Scholar] [CrossRef] [PubMed]
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1975–1981. [Google Scholar]
- Singh, D.; Mohan, C.K. Deep Spatio-Temporal Representation for Detection of Road Accidents Using Stacked Autoencoder. IEEE Trans. Intell. Transp. 2019, 20, 879–887. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Type | AUC/EER (%) | ||||
|---|---|---|---|---|---|---|
| Avenue | Ped1 | Ped2 | Entrance | Exit | ||
| HOFME [17] | Offline | - | 72.7/33.1 | 87.5/20.0 | 81.6/22.8 | 84.9/17.8 |
| Conv-AE [16] | Offline | 74.2/27.3 | 79.2/28.9 | 81.7/22.4 | 85.3/25.1 | 84.7/12.5 |
| ConvLSTM-AE [19] | Offline | 74.5/- | 75.5/- | 75.5/- | 88.1/- | 80.2/- |
| R-ConvAE [25] | Offline | 76.8/26.5 | 74.5/27.5 | 83.4/20.3 | 85.3/23.4 | 86.7/17.9 |
| ConvLSTM [31] | Offline | 77.3/25.7 | 89.9/27.5 | 83.6/19.4 | 84.7/24.3 | 88.4/13.3 |
| ISTL [34] | Online | 76.8/29.2 | 75.2/29.8 | 91.1/8.9 | - | - |
| Rethman et al. [35] | Online | - | -/29.0 | -/29.5 | - | - |
| TSR-ConvVAE [32] | Offline | 79.6/27.5 | 75.0/32.4 | 91.0/15.5 | 85.1/19.8 | 91.7/16.9 |
| Ours (No SC) | Online | 78.5/25.5 | 80.3/26.9 | 87.1/17.4 | 87.9/20.7 | 89.8/14.3 |
| Ours | Online | 81.3/24.9 | 83.6/24.8 | 90.8/14.3 | 89.4/17.5 | 92.1/15.4 |
| Method | Correct Detection/False Alarm (* Indicates Numbers of Abnormal Events) | ||||
|---|---|---|---|---|---|
| Avenue (47 *) | Ped1 (40 *) | Ped2 (12 *) | Entrance (66 *) | Exit (19 *) | |
| ConvAE [16] | 45/4 | 38/6 | 12/1 | 61/15 | 17/5 |
| ConvLSTM [19] | 44/6 | - | - | 61/9 | 18/10 |
| TSR-ConvVAE [32] | 34/6 | 38/5 | 12/0 | 56/7 | 18/4 |
| Ours (No SC) | 45/5 | 38/7 | 12/0 | 59/7 | 18/7 |
| Ours | 46/5 | 39/7 | 12/0 | 59/6 | 18/6 |
| Method | Avenue | Ped1 | Ped2 | Entrance | Exit |
|---|---|---|---|---|---|
| ConvAE [16] | 244 | 198 | 62 | 320 | 140 |
| R-ConvAE [25] | 312 | 276 | 73 | 766 | 452 |
| ConvLSTM [31] | 180 | 134 | 42 | 284 | 126 |
| Ours (No SC) | 168 | 100 | 30 | 234 | 98 |
| Ours | 176 | 112 | 34 | 245 | 106 |
| Method | Avenue | Ped1 | Ped2 | Entrance | Exit |
|---|---|---|---|---|---|
| ConvLSTM-AE [19] | 23.2 | 25.7 | 24.1 | 20.4 | 22.4 |
| ConvLSTM [31] | 33.4 | 35.2 | 36.5 | 26.7 | 31.7 |
| ConvAE [33] | 21.9 | 24.2 | 27.5 | 18.5 | 19.8 |
| FramePred [59] | 22.4 | 25.0 | 25.0 | 19.5 | 20.1 |
| Nawaratne et al. [34] | 27.1 | 26.9 | 27.8 | - | - |
| Rethman et al. [35] | - | ~37.0 | ~40.0 | - | - |
| Ours (No SC) | 67.3 | 69.4 | 69.8 | 56.2 | 64.3 |
| Ours | 62.5 | 63.1 | 63.4 | 52.9 | 60.8 |
| Method | Avenue | Ped2 | Entrance | Exit |
|---|---|---|---|---|
| Precision | 0.886 | 0.872 | 0.838 | 0.847 |
| Recall | 0.983 | 0.976 | 0.971 | 0.989 |
| Time (m per frame) | 0.0042 | 0.0045 | 0.0057 | 0.0059 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, J.; Wang, D.; Zhang, L. Crowd Anomaly Detection via Spatial Constraints and Meaningful Perturbation. ISPRS Int. J. Geo-Inf. 2022, 11, 205. https://doi.org/10.3390/ijgi11030205
Feng J, Wang D, Zhang L. Crowd Anomaly Detection via Spatial Constraints and Meaningful Perturbation. ISPRS International Journal of Geo-Information. 2022; 11(3):205. https://doi.org/10.3390/ijgi11030205
Chicago/Turabian StyleFeng, Jiangfan, Dini Wang, and Li Zhang. 2022. "Crowd Anomaly Detection via Spatial Constraints and Meaningful Perturbation" ISPRS International Journal of Geo-Information 11, no. 3: 205. https://doi.org/10.3390/ijgi11030205
APA StyleFeng, J., Wang, D., & Zhang, L. (2022). Crowd Anomaly Detection via Spatial Constraints and Meaningful Perturbation. ISPRS International Journal of Geo-Information, 11(3), 205. https://doi.org/10.3390/ijgi11030205