3.1. Network Overview
Similar to most late-fusion methods, the proposed method constructs a discriminative difference feature map in the highest layer, which means the extracted features pair from CNN backbone are enhanced by the hybrid transformer first. Then, the produced difference feature maps are forwarded into the decoder to restore context change representation with initial size. Significantly different from the general CD pipeline, which treats fused features of bitemporal images from the highest layer as change semantic representations, here, we introduced transformer structure into the feature fusion stage to obtain pixel-level discriminative features with the compact tokens pair.
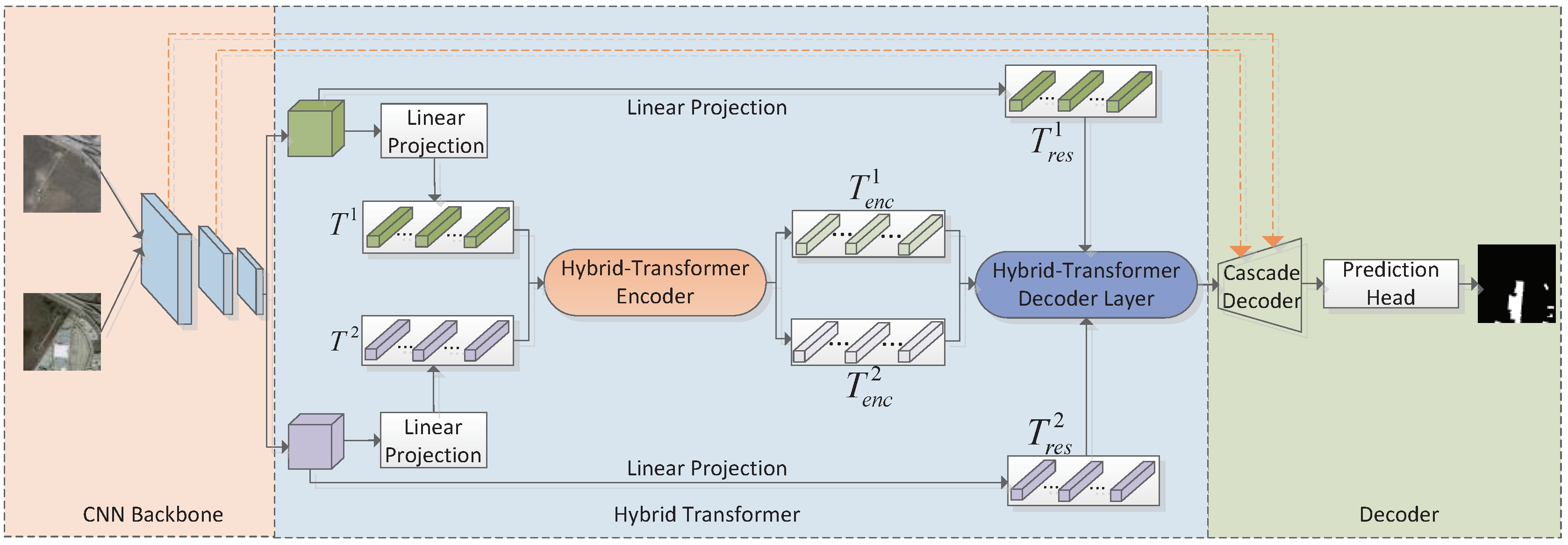
The overall network flow is shown in
Figure 3. A hybrid transformer module is incorporated into the general CNN-based pipeline to leverage an elaborate bitemporal feature pair extracted by the Siamese backbone expressed as
, and global context enhanced by the transformer, thus generating an encoded token pair denoted as
, where
P represents the embed patch number, while the
D represents the predefined parameter of token hidden dimensions to be projected.
Specifically, regarding each temporal feature, a hybrid-transformer encoder (H-TE) is employed for building coarse-grained and fine-grained patch embeddings. The generated semantic tokens pair together with corresponding residual patch embeddings are forwarded into the hybrid-transformer decoder (H-DE) layer to leverage dependencies between encoded semantic tokens and original pixel-level features, the generated difference tokens are subsequently restored into a feature-dimensional tensor represented as by performing permutation and reshaping operations, where D is the predefined number of hidden channels. As the absolute difference is first taken from the encoded token pair and then decoded (early difference), or the token pair is decoded first and then made (late difference), the produced features contain abundant semantic change information. Subsequently, the fused features accompanied by skip-connections from CNN backbone are upsampled to restore original resolution by the proposed cascade feature decoder. The prediction head composed of a convolution is employed for generating a predicted change probability map .
Significantly, the hybrid ResNet [
7], rather than a pure transformer extractor, is employed for leveraging CNN-transformer strength. The Siamese H-TE is constructed by a multiple hybrid encoder transformer block (
M) while the H-TD is composed of
N hybrid decoder transformer blocks, thus stabilizing appropriate computation efficiency.
3.2. Hybrid-Transformer Encoder
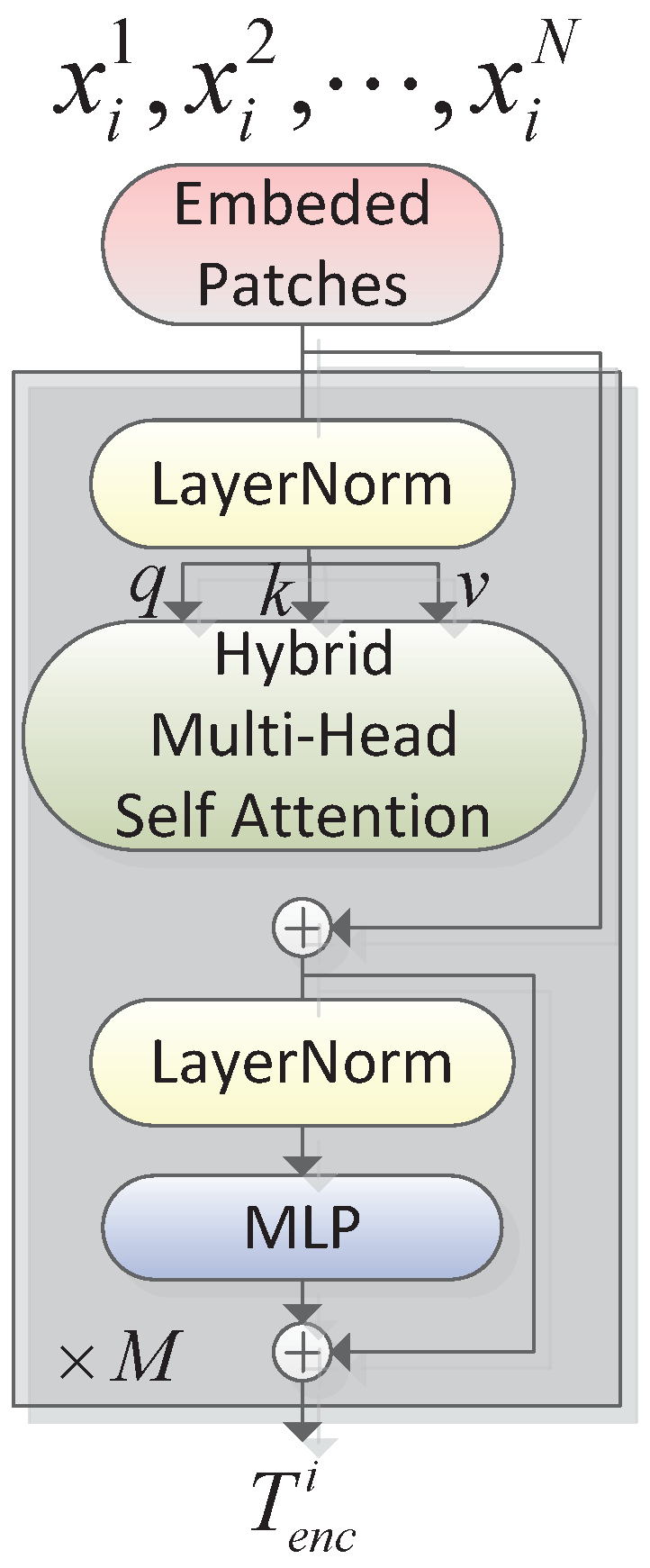
As the major component of ViT, the transformer encoder module is used to extract image features. Specifically, the original two-dimensional image is converted into a one-dimensional embedding sequence, that is, the input
is divided into block sequences of size
, and the sequence length is
. At the same time, position embedding is added to encode the position information of tokens, avoiding the model, to learn absolute position information with the semantics of image patches. As can be seen from
Figure 4, the transformer encoder contains a multi-head attention (MHA), two normalization layers (Norm) and a multi-layer perceptron layer (MLP), performing with the scaled dot product attention, as shown in
Figure 5. The query, key, and value are produced by
convolution, where key and value are paired. According to self-attention, the inner product is calculated by matching
k key vectors (
) with query vector (
), which is then normalized by
. For multi-head attention MHA (
Figure 6),
h attention heads act on the input sequence, respectively, and in practice, the image sequence patches are divided into
h subsequences with the size of
, and the outputs from
h different attention heads are concatenated together. Finally, a linear transformation is performed to obtain the ultimate output, which is expressed as
where,
For each MSA, a feedforward network (FFN) is followed for nonlinear mapping.
Given the high-level feature represented by CNN, the tokenization operation is firstly performed to obtain two-dimensional patch sequences denoted as , where the patch size is , and means the length of patches.
Then, the serialized patches are embedded into latent high-dimensional space (
D) using learnable linear projections. Specifically, we take a convolution with a
kernel size and the stride of
P. To learn patch position information, we added trainable position embedding as follows:
where
is the projection weight of patch embeddings, and
encodes the space–time dimensional absolute positions of tokens.
The linearly projected tokens pair is fed into the Siamese encoder containing multiple hybrid transformer encoder blocks for producing richer semantic context among per-temporal image. For each hybrid transformer encoder block, the forwarded input is normalized by the pre-norm residual unit (PreNorm) [
8] at first. Then, the output sequences are projected into query (
Q), key (
K), and value (
V). Next, an improved hybrid multi-head self-attention (H-MSA) operation is adopted to parallelly compute hybrid self-attention (
Figure 7). Different from the swin [
25] that splits broader
into multiple small regions, we follow the SRA layer in PVT [
24] to adopt a hybrid spatial–reduction attention strategy, to mitigate the computational cost and capture multi-granularity semantic information in the meantime. The comparisons between different self-attention manners are depicted in
Figure 8. Instead of applying self-attention globally on final downsampled feature maps or local self-attention on large-scale feature maps within divided small regions, our hybrid self-attention employs token aggregation among multiple key–value pairs, where each key–value pair is generated by downsampling to different sizes. Specifically, at each block
b, the
K and
V from different heads are represented as
where
,
, and
are learnable linear projection weights for the previous output
in the
i-th head. The
perform a multi-scale token aggregation operation with the downsampling rate of
in the
i-th head. Here, a convolution layer with kernel size
and stride of
is implemented. In actuality, various
within one layer among multiple heads brings multi-scale self-attention computed by
K and
V.
is the local augment stage of
, implemented by a depthwise convolution for
V. Compared with the SRA module in PVT, the transformer encoder learns complementary fine-grained and coarse spatiotemporal spectrum information. The
i-th attention head is calculated by
where
represents projected channel dimension and
is the softmax function. The multi-head self-attention (
MSA) then perform a concatenation operation to fuse representation information from different dimension spaces. Specifically,
where
is the linear projection weight matrix while
h denotes the head number. The
is the feedforward layer to reproject tokens normalized by layer norm (
); here, we give an improved detail-enhancement (
DE) feedforward layer to complement local representations specified for details. As in
Figure 9, compared with traditional
and
, we add a DE layer between two fully connected layers, thus preserving fine-grained local details, where
and
are depthwise separable convolution and nonlinear activation functions. The formula is
where
and
are learnable weight parameters of
.
From above, our hybrid transformer block is capable of capturing objects of different scales. By controlling the downsampling rate r, we can achieve the available performance at the cost of efficient computational costs. Specifically, the larger r is, the more short tokens () are merged, thus producing richer semantic tokens for large regions in a lightweight manner. On the contrary, the smaller r preserves more local details for small objects. The integration of multiple r within one attention block learns multi-granularity features. In our work, we construct Siamese H-TE with different numbers of hybrid transformer blocks, generating encoded semantic tokens among bitemporal images.
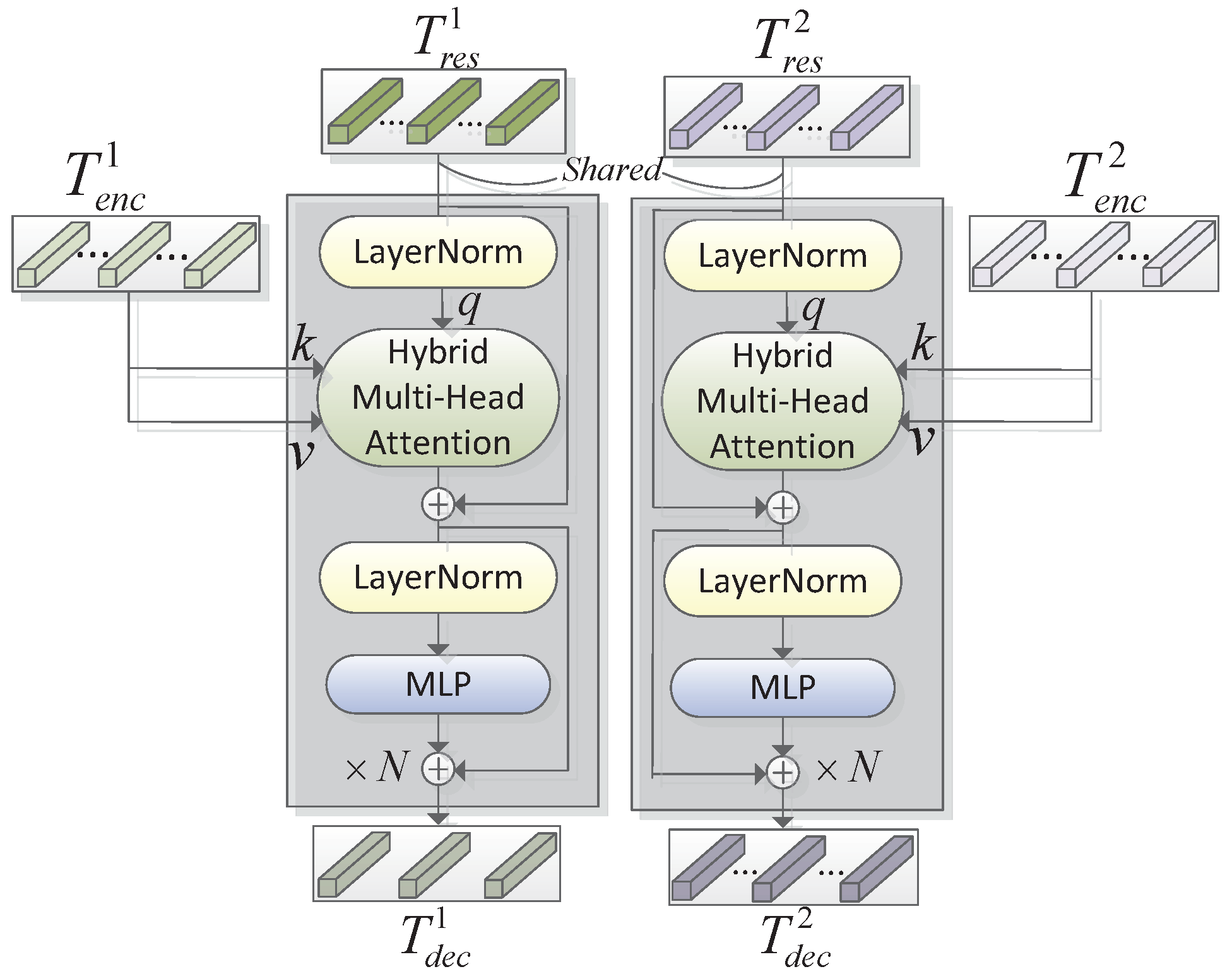
3.3. Hybrid-Transformer Decoder
In this section, we introduce the improved hybrid-transformer decoder. The MLP, LayerNorm, and self-attention operation here are identical to the hybrid-transformer encoder, except the MHA is replaced by MA.
In order to capture strong discriminate semantic information, the hybrid-transformer decoder (H-TD) layer containing two H-TD structures is proposed for projecting encoded tokens back to pixel-space, thus producing refined change features. Specifically, the projected tokens pair
from original features pair
together with context-encoded tokens pair
are forwarded into the H-TD layer to exploit separate relations between each pixel per features and corresponding encoded token
(
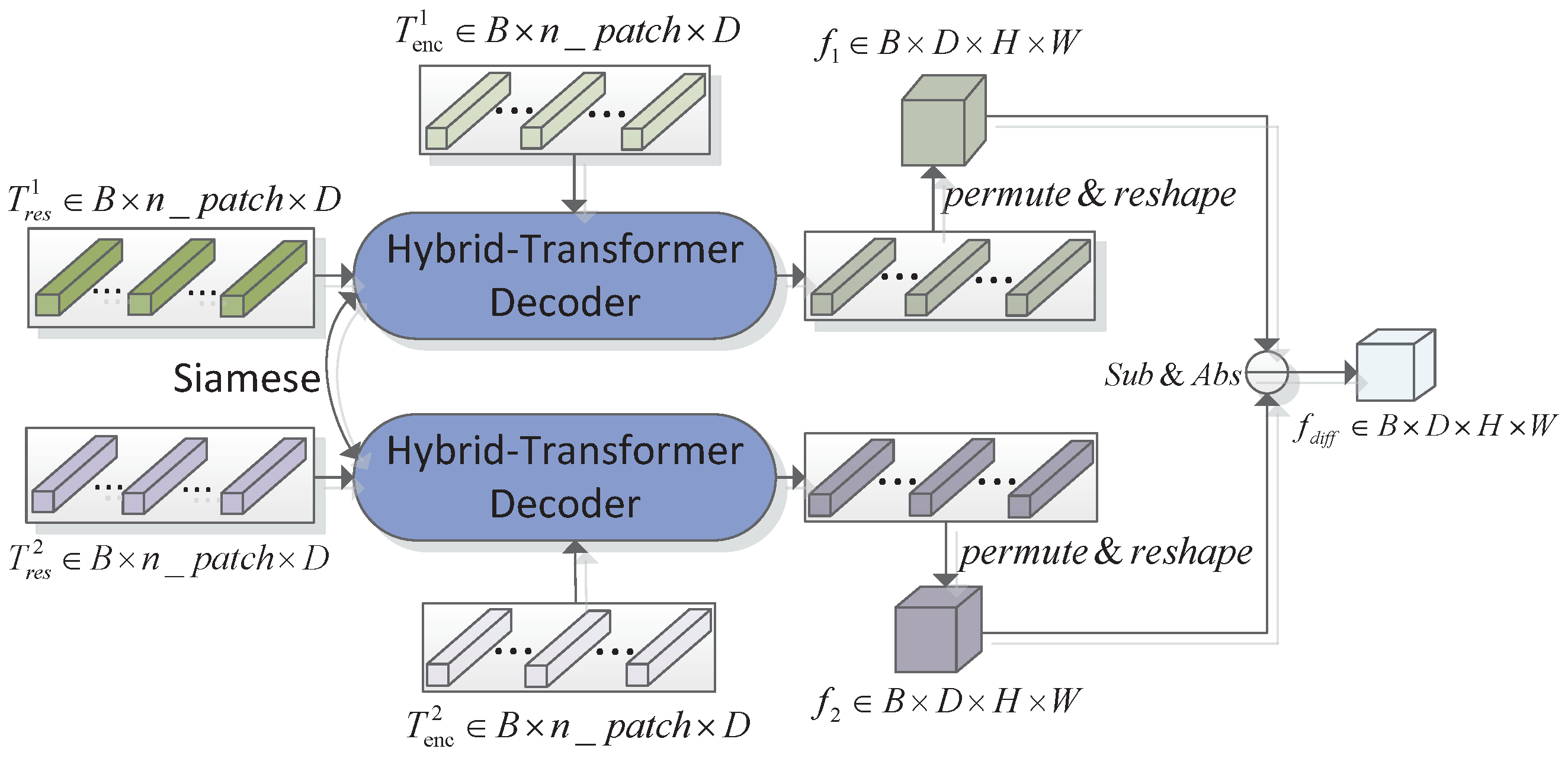
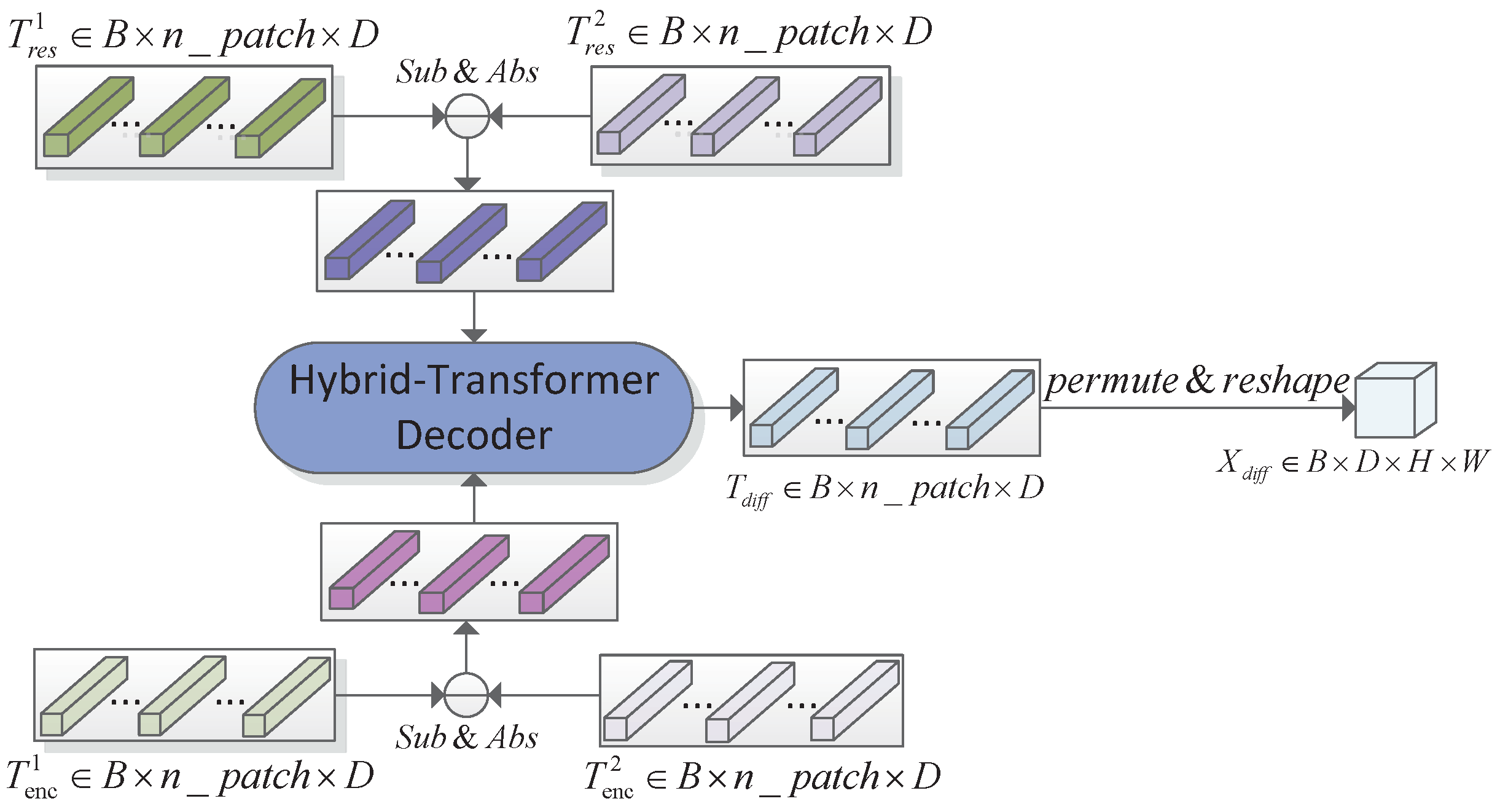
Figure 10), or change relations between each pixel of difference features and encoded difference token (
Figure 11).
Given feature tokens pair and rich context tokens pair , the first decoder structure adopts the Siamese hybrid-transformer decoder to obtain decoded representations for each temporal image, which then perform reshape and permute operations to restore into the final pixel-level features pair . Finally, the change discrimination feature maps are generated by performing absolute difference between and . Different from the first late-difference () manner, the second early-difference () structure performs the difference operations in a earlier stage. In practice, the residual tokens pair and encoded tokens pair subtract, respectively, the outputs that are efficiently exploited with the H-TD. By difference relations modeling directly, the produced token sequence represents a pixel-level semantic change discrimination. The permutation and reshape operations are also accomplished to obtain high-level change features.
Significantly, our H-TD consists of
N blocks of the hybrid transformer decoder block, each of which constructs improved hybrid multi-head attention (H-MA) and DE feedforward layers. Rather than build self-attention within encoded tokens, the MA strongly builds mutual attention between encoded tokens and the original unprocessed ones. In addition, both ED and LD capture multi-scale representations thanks to the multiple values of
, thus capturing small-change objects surrounded by large background regions. The specific structure of the hybrid transformer decoder block is illustrated in
Figure 12; the only difference from the H-TD block is that the queries in MA are derived from
or
rather than the pure tokens
. The formulations are defined as
to obtain decoded tokens, formulated as
The decoded difference tokens set is finally unfolded into three-dimensional features .
3.4. Cascaded Feature Decoder
Concurrent vision works demonstrate the efficiency of multi-scale feature fusion in encoded low-level and high-level layers; skip-connections in decoder stages powerfully mitigate the missing details caused by global upsampling processes. Here, we propose a cascaded feature decoder (CFD) to aggregate semantic features varying multiple scales in a dense manner. As in
Figure 13, the feature maps enhanced by our hybrid transformer are upsampled to the common scale from the highest layer of CNN backbone, and the output together with previous skip-connection acts as the input of the next decoder block. The features in the
n-th decoder stage can be formulated as
where
and
are
convolution and upsampling operations, respectively. In our work, four decoder blocks are employed for generating decoded features, where each block contains upsampling with bilinear interpolation, concatenation, and two convolutions with kernel size of
. For multiple decoder stages, the decoded channel numbers are
.
Until now, we have obtained upsampled feature maps , where the spatial size is identical to the input image. To obtain change probability maps , a prediction head composed of a light convolution and a softmax function are utilized to map dense prediction result, where the convolution kernel size is and padding is 1. The pixel-wise probability map among each channel of P represents the changed and unchanged probability corresponding to this pixel, where the higher value will be determined. In the inference stage, a pixel-wise operation is adopted for producing a visual prediction map.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}