
A Distributed Hybrid Indexing for Continuous KNN Query Processing over Moving Objects



Abstract
:1. Introduction
- We propose a novel indexing approach, namely the Velocity SpatioTemporal indexing approach (VeST), for continuous querying, mainly Continuous K-nearest Neighbor (CKNN) and continuous range queries.
- We design a compact multilayer index structure on a distributed setting and propose a CKNN search algorithm for accurate results using a candidate cell identification process.
- We provide a comprehensive vision of our indexing model and the adopted querying technique.
- We conducted a comprehensive set of experiments, compared our results with existing approaches, and employed different distribution techniques.
2. Literature Review
3. Preliminaries
4. Proposed Methodology
5. Velocity Spatiotemporal Indexing Model
5.1. Vest Architecture
5.2. Velocity-Based Partitioning Phase
5.3. Index Building Phases
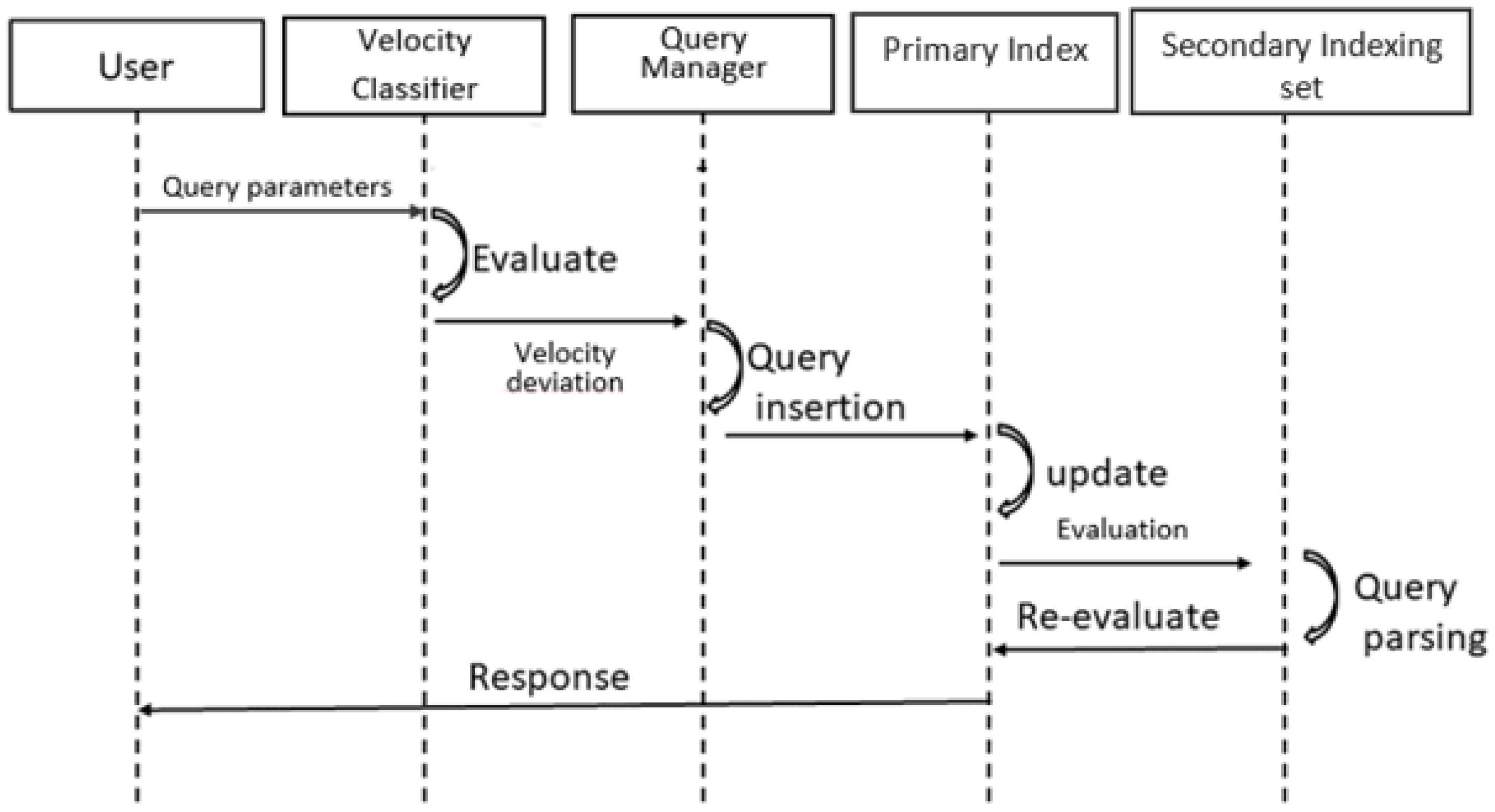
5.4. Distributed Query Processing
6. Experimental Settings and Results
6.1. Simulation Environment
6.2. Exploratory Data Analysis
6.3. Experimental Results
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LBS | Location-Based Services |
| GPS | Global Positioning System |
| MO | Moving Objects |
| KNN | K-nearest Neighbors |
| CKNN | Continuous KNN |
| IoT | Internet of Things (IoT) |
| GIS | Geographic Information System |
| BGI | Block Grid Index |
| DSI | Dynamic Stripe Index |
| DKNN | DSI-based K-NN |
| CNN | Convolutional Neural Network |
| SEA | Shared Execution Algorithm |
| RE | Random Estimation |
References
- Afanador, J.J.C.; Rivero, A.J.L.; Gallego, J.Á.R. Analysis of geolocation accuracy by GPS: Dedicated support signal integration and collaborative network in location-based services. In Proceedings of the 2020 15th Iberian Conference on Information Systems and Technologies (CISTI), Seville, Spain, 24–27 June 2020; pp. 1–8. [Google Scholar]
- Basiri, A.; Moore, T.; Hill, C.; Bhatia, P. Challenges of location-based services market analysis: Current market description. In Progress in Location-Based Services 2014; Springer: Berlin/Heidelberg, Germany, 2015; pp. 273–282. [Google Scholar]
- Khan, P.W.; Byun, Y.C. Smart contract centric inference engine for intelligent electric vehicle transportation system. Sensors 2020, 20, 4252. [Google Scholar] [CrossRef] [PubMed]
- Arroyo Ohori, K.; Diakité, A.; Krijnen, T.; Ledoux, H.; Stoter, J. Processing BIM and GIS models in practice: Experiences and recommendations from a GeoBIM project in the Netherlands. Isprs Int. J.-Geo-Inf. 2018, 7, 311. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.S.; Sun, C.G.; Cho, H.I. Geospatial big data-based geostatistical zonation of seismic site effects in Seoul metropolitan area. Isprs Int. J.-Geo-Inf. 2017, 6, 174. [Google Scholar] [CrossRef] [Green Version]
- Hor, A.; Jadidi, A.; Sohn, G. BIM-GIS integrated geospatial information model using semantic web and RDF graphs. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci 2016, 3, 73–79. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Xiong, L.; Sunderam, V.; Liu, J.; Luo, J. Speed partitioning for indexing moving objects. In Proceedings of the International Symposium on Spatial and Temporal Databases, Online, 23–25 August 2021; Springer: Berlin/Heidelberg, Germany, 2015; pp. 216–234. [Google Scholar]
- Wu, C.; Zhu, Q.; Zhang, Y.; Du, Z.; Ye, X.; Qin, H.; Zhou, Y. A NOSQL–SQL hybrid organization and management approach for real-time geospatial data: A case study of public security video surveillance. Isprs Int. J.-Geo-Inf. 2017, 6, 21. [Google Scholar] [CrossRef] [Green Version]
- de Oliveira, T.H.M.; Painho, M. Open Geospatial Data Contribution Towards Sentiment Analysis Within the Human Dimension of Smart Cities. In Open Source Geospatial Science for Urban Studies; Springer: Berlin/Heidelberg, Germany, 2021; pp. 75–95. [Google Scholar]
- Dou, S.; Zhang, H.; Zhao, Y.; Wang, A.; Xiong, Y.; Zuo, J. Research on construction of spatio-temporal data visualization platform for gis and bim fusion. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2020, 42, 555–563. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Z.; Liu, H.; Liu, Y.; Zhang, D.; Yi, F.; Zhu, N.; Xiong, H. Spatio-temporal dual graph attention network for query-poi matching. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 629–638. [Google Scholar]
- Zhu, H.; Yang, X.; Wang, B.; Lee, W.C.; Yin, J.; Xu, J. Processing Continuous k Nearest Neighbor Queries in Obstructed Space with Voronoi Diagrams. Acm Trans. Spat. Algorithms Syst. (TSAS) 2020, 7, 1–27. [Google Scholar] [CrossRef]
- Cho, H.J. A Batch Processing Algorithm for Moving K-nearest Neighbor Queries in Dynamic Spatial Networks. J. Korea Soc. Comput. Inf. 2021, 26, 63–74. [Google Scholar]
- Song, L.; Fei, K. Research on K Nearest Neighbor Skyline Query in Time Dependent Road Network. J. Phys. Conf. Ser. 2021, 1848, 012140. [Google Scholar] [CrossRef]
- Yang, R.; Niu, B. Continuous k Nearest Neighbor Queries over Large-Scale Spatial–Textual Data Streams. Isprs Int. J.-Geo-Inf. 2020, 9, 694. [Google Scholar] [CrossRef]
- Jiang, W.; Li, G.; An, J.; Sun, Y.; Chen, H.; Li, X. Research on Indexing and KNN Query of Moving Objects in Road Network Environment. In Proceedings of the International Conference in Communications, Signal Processing, and Systems, Changbaishan, China, 4–5 July 2020; pp. 1944–1950. [Google Scholar]
- Zhang, F.; Zheng, Y.; Xu, D.; Du, Z.; Wang, Y.; Liu, R.; Ye, X. Real-time spatial queries for moving objects using storm topology. Isprs Int. J.-Geo-Inf. 2016, 5, 178. [Google Scholar] [CrossRef]
- Fan, P.; Li, G.; Yuan, L.; Li, Y. Vague continuous K-nearest neighbor queries over moving objects with uncertain velocity in road networks. Inf. Syst. 2012, 37, 13–32. [Google Scholar] [CrossRef]
- Mahmood, A.R.; Punni, S.; Aref, W.G. Spatio-temporal access methods: A survey (2010–2017). GeoInformatica 2019, 23, 1–36. [Google Scholar] [CrossRef]
- Tao, Y.; Papadias, D.; Shen, Q. Continuous nearest neighbor search. In Proceedings of the VLDB’02: Proceedings of the 28th International Conference on very Large Databases, Hong Kong, China, 20–23 August 2002; pp. 287–298. [Google Scholar]
- Yang, M.; Ma, K.; Yu, X. An efficient index structure for distributed K-nearest neighbours query processing. Soft Comput. 2020, 24, 5539–5550. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, Y.; Yu, X.; Pu, K.Q. Scalable distributed processing of K nearest neighbor queries over moving objects. IEEE Trans. Knowl. Data Eng. 2014, 27, 1383–1396. [Google Scholar] [CrossRef]
- Sibolla, B.H.; Coetzee, S.; Van Zyl, T.L. A framework for visual analytics of spatio-temporal sensor observations from data streams. Isprs Int. J.-Geo-Inf. 2018, 7, 475. [Google Scholar] [CrossRef] [Green Version]
- Xiong, X.; Mokbel, M.F.; Aref, W.G. Sea-cnn: Scalable processing of continuous K-nearest neighbor queries in spatio-temporal databases. In Proceedings of the 21st International Conference on Data Engineering (ICDE’05), Tokyo, Japan, 5–8 April 2005; pp. 643–654. [Google Scholar]
- Hua, M.; Lau, M.K.; Pei, J.; Wu, K. Continuous K-means monitoring with low reporting cost in sensor networks. IEEE Trans. Knowl. Data Eng. 2009, 21, 1679–1691. [Google Scholar]
- Yu, Z.; Jiao, K. Incremental Processing of Continuous K Nearest Neighbor Queries Over Moving Objects. In Proceedings of the 2017 International Conference on Computer Systems, Electronics and Control (ICCSEC), Dalian, China, 25–27 December 2017; pp. 1–4. [Google Scholar]
- Servigne, S.; Noël, G. Real time and spatiotemporal data indexing for sensor based databases. In Geospatial Information Technology for Emergency Response; CRC Press: Boca Raton, FL, USA, 2008; pp. 123–142. [Google Scholar]
- Bareche, I.; Xia, Y. Selective Velocity Distributed Indexing for Continuously Moving Objects Model. In Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, Melbourne, VIC, Australia, 9–11 December 2019; pp. 339–348. [Google Scholar]
- Jayachandran, P.; Tunga, K.; Kamat, N.; Nandi, A. Combining user interaction, speculative query execution and sampling in the DICE system. Proc. VLDB Endow. 2014, 7, 1697–1700. [Google Scholar] [CrossRef] [Green Version]
- Suel, T.; Mathur, C.; Wu, J.W.; Zhang, J.; Delis, A.; Kharrazi, M.; Long, X.; Shanmugasundaram, K. ODISSEA: A Peer-to-Peer Architecture for Scalable Web Search and Information Retrieval. In Proceedings of the International Workshop on the Web and Databases (WebDB), San Diego, CA, USA, 12–13 June 2003; Volume 3, pp. 67–72. [Google Scholar]
- Xu, X.; Xiong, L.; Sunderam, V.; Liu, J.; Luo, J. VPIndexer Dataset. 2022. Available online: http://www.mathcs.emory.edu/~lxiong/aims/spindex/VPIndexer/data/sz/ (accessed on 20 November 2020).
- Sinno, Z.; Bovik, A.C. Spatio-temporal measures of naturalness. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1750–1754. [Google Scholar]
- Mouratidis, K.; Yiu, M.L.; Papadias, D.; Mamoulis, N. Continuous nearest neighbor monitoring in road networks. In Proceedings of the VLDB 2006: Proceedings of the 32nd International Conference on very Large Data Bases, Seoul, Korea, 12–15 September 2006; pp. 43–54. [Google Scholar]
- Huang, Y.K.; Chen, Z.W.; Lee, C. Continuous K-nearest neighbor query over moving objects in road networks. In Advances in Data and Web Management; Springer: Berlin/Heidelberg, Germany, 2009; pp. 27–38. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definitions |
|---|---|
| N | Number (Count) of moving objects in the space |
| MO | Moving object |
| obj_id | A moving object identifier |
| x_loc | Longitude position of an object |
| y_loc | Latitude position of an object |
| x_vel | Velocity according to X axis |
| y_vel | Velocity according to Y axis |
| t | Time |
| Component | Description | |
|---|---|---|
| 1 | Processing Unit | Intel Core i5-8500 @ 3.00 GHz |
| 2 | RAM | 16 GB |
| 3 | Operating System | Window 10 |
| 4 | Integrated Development Environment | Jupyter notebook |
| 5 | Programming Language | Python |
| 6 | Python | v 3.6 |
| 7 | Mathematical Functions Module | math V 3.9.1 |
| 8 | Array Library | NumPy v 1.17.5 |
| 9 | Data Analysis Library | pandas V 0.25.3 |
| 10 | Plots Library | plotly V 4.4.1 |
| object_ID | X_loc | Y_loc | X_Vel | Y_Vel | Time | |
|---|---|---|---|---|---|---|
| Mean | / | 5631.91 | 3718.73 | 0.06 | −0.04 | / |
| STD | / | 2326.78 | 2377.48 | 4.85 | 4.040 | / |
| Min | 0 | 0 | 2.23 | −33.2 | −32.97 | 0 |
| Max | 10,928 | 9991.1 | 9999.73 | 33.25 | 33.19 | 7199 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bareche, I.; Xia, Y. A Distributed Hybrid Indexing for Continuous KNN Query Processing over Moving Objects. ISPRS Int. J. Geo-Inf. 2022, 11, 264. https://doi.org/10.3390/ijgi11040264
Bareche I, Xia Y. A Distributed Hybrid Indexing for Continuous KNN Query Processing over Moving Objects. ISPRS International Journal of Geo-Information. 2022; 11(4):264. https://doi.org/10.3390/ijgi11040264
Chicago/Turabian StyleBareche, Imene, and Ying Xia. 2022. "A Distributed Hybrid Indexing for Continuous KNN Query Processing over Moving Objects" ISPRS International Journal of Geo-Information 11, no. 4: 264. https://doi.org/10.3390/ijgi11040264