
Spatial Concept Query Based on Lattice-Tree


Abstract
1. Introduction
- (1)
- We define spatial textual concept (STC) to formalize a set of similar spatial objects and develop a hybrid index structure, a lattice-tree, to index the STCs in spatial textual big data. By embedding concept lattice structures into R-tree nodes, it can not only supply a tree-like spatial location index but also present the many-to-many relationships between spatial objects and textual features.
- (2)
- Based on STC, we also develop a top-k spatial concept query (TkSCQ) algorithm to retrieve the set of similar spatial objects from spatial textual big data. The TkSCQ algorithm transforms the user’s query request into an STC and retrieves the similar spatial objects by lattice-tree.
- (3)
- We conduct a series of performance experiments and comparative experiments with two baseline algorithms. The results demonstrate the applicability of STC to spatial textual big data and the efficiency of the proposed lattice-tree and TkSCQ.
2. Related Work
3. Methodology
3.1. Principles
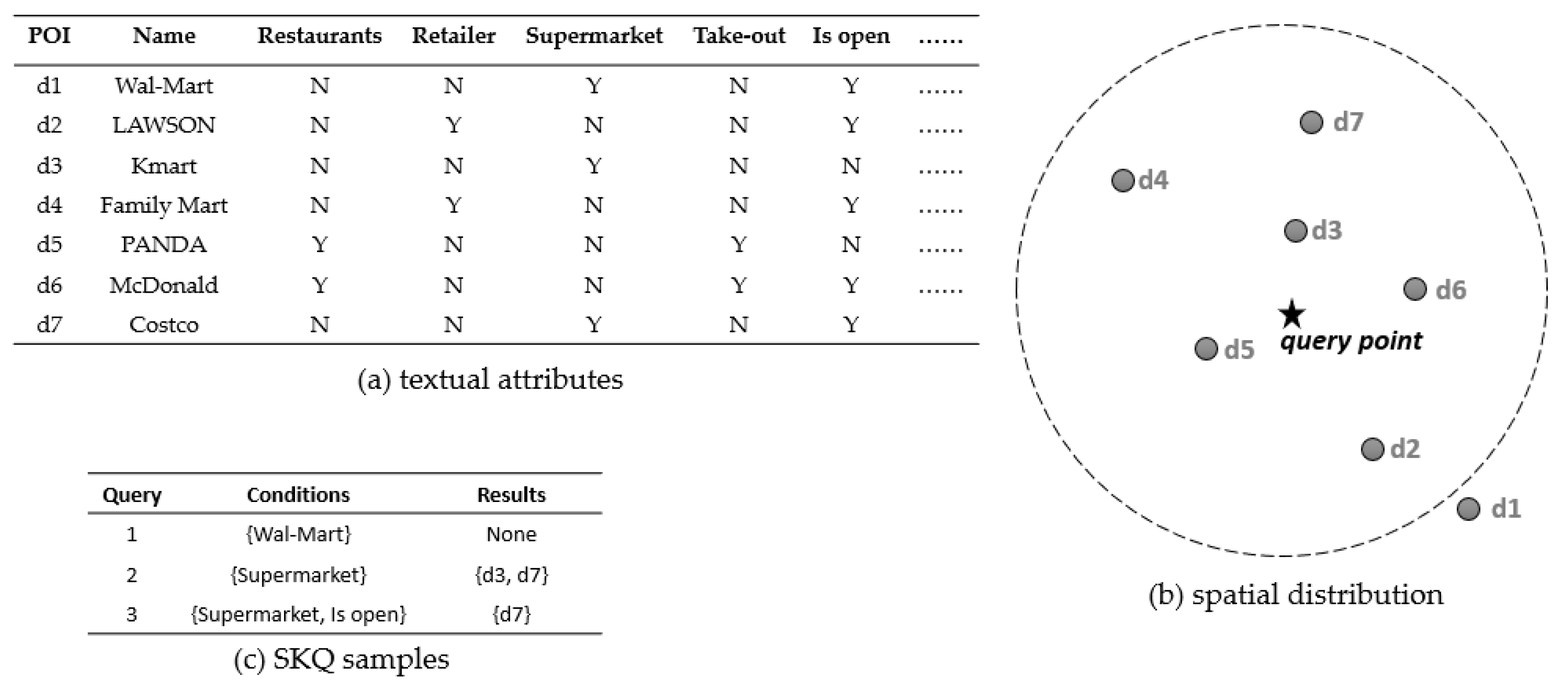
3.2. STC Formulations
- is the considered spatial region,
- , is a set of spatial objects contained in ,
- represents the common features of the spatial object of .
- represents the pairs indicating that the spatial object in has the feature in .
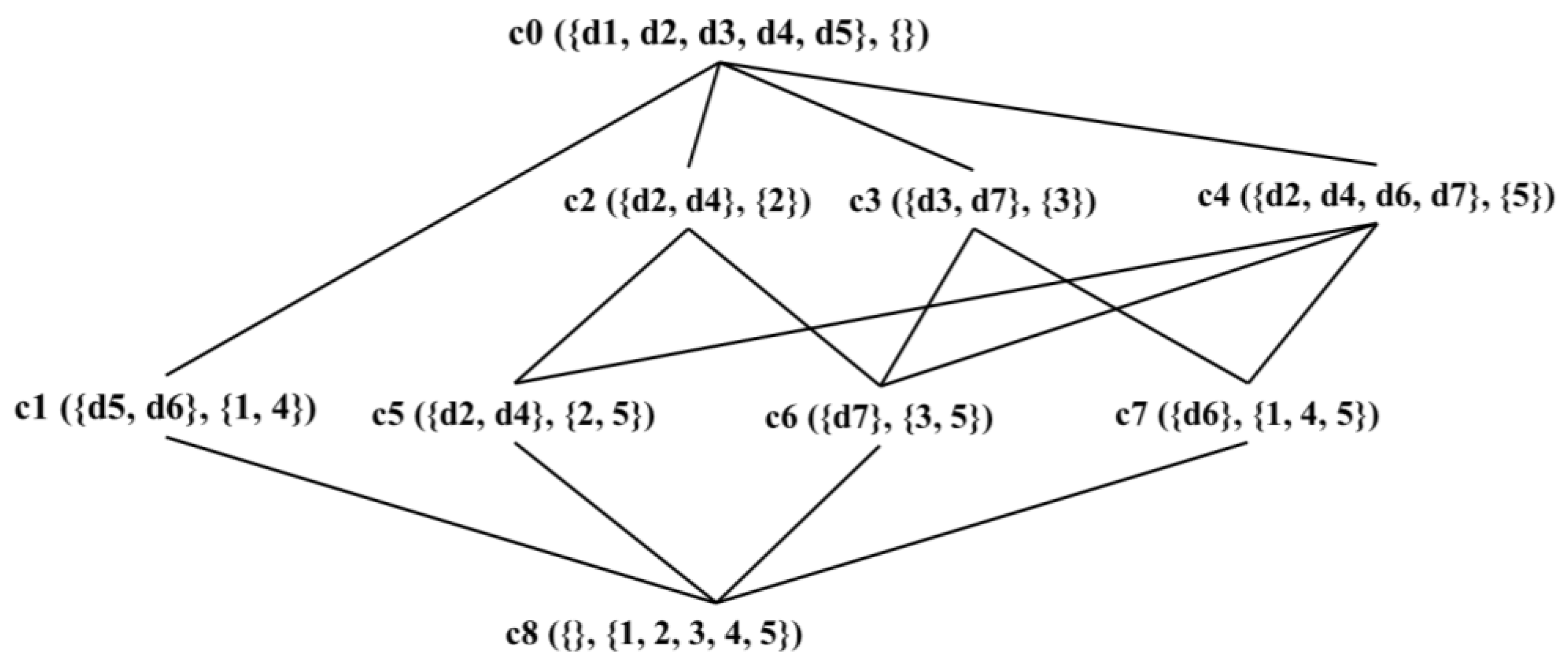
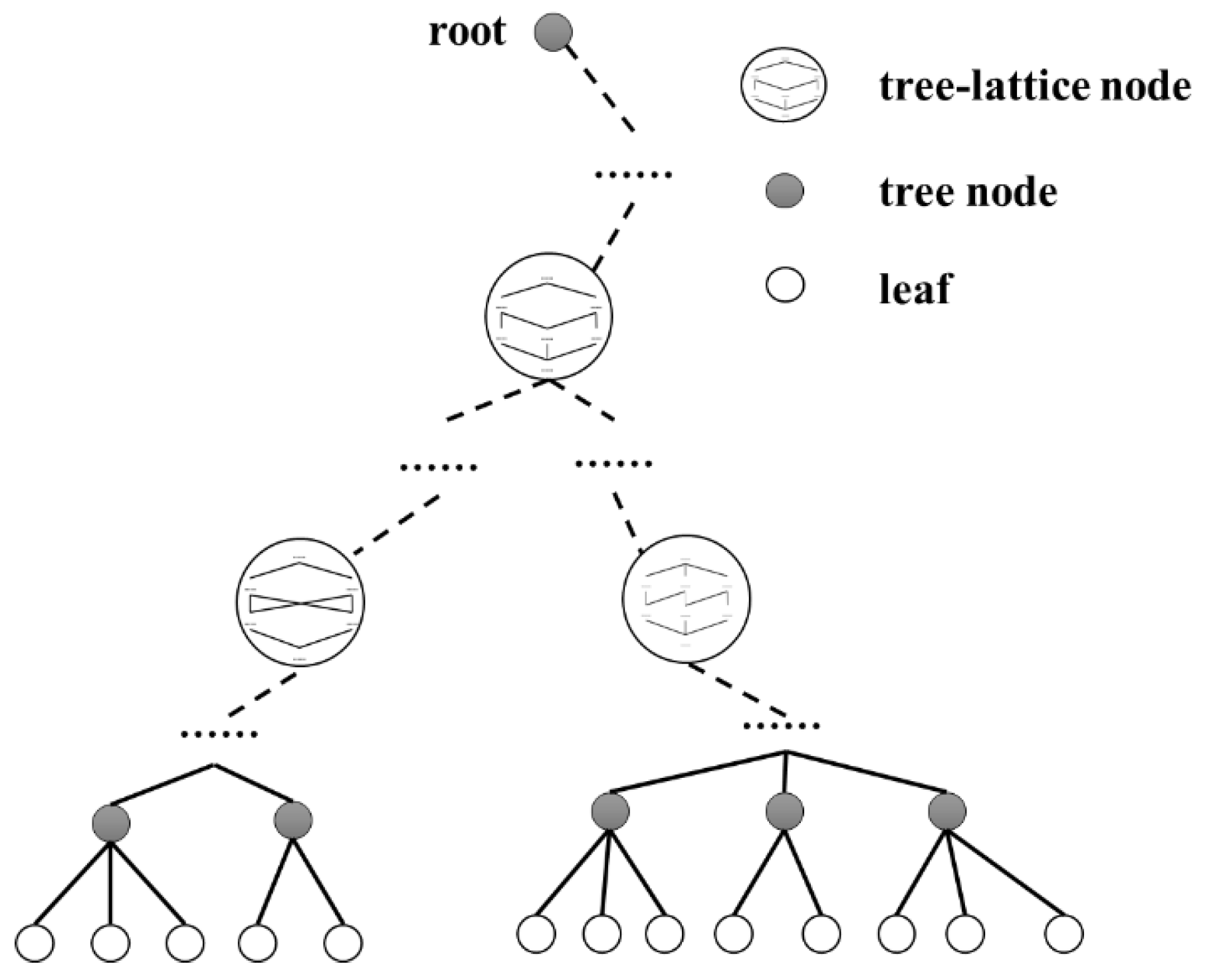
3.3. Lattice-Tree
| Algorithm 1: The initialization of lattice-tree |
| Input: , , ; Output: ; 1: for each : //create tree structure 2: insert into ; 3: if : 4: generate a new tree node and update ; 5: end for; 6: for each : //create concept lattice structure 7: if : 8: generate the STC set of → ; 9: 10: 11: end for 12: return |
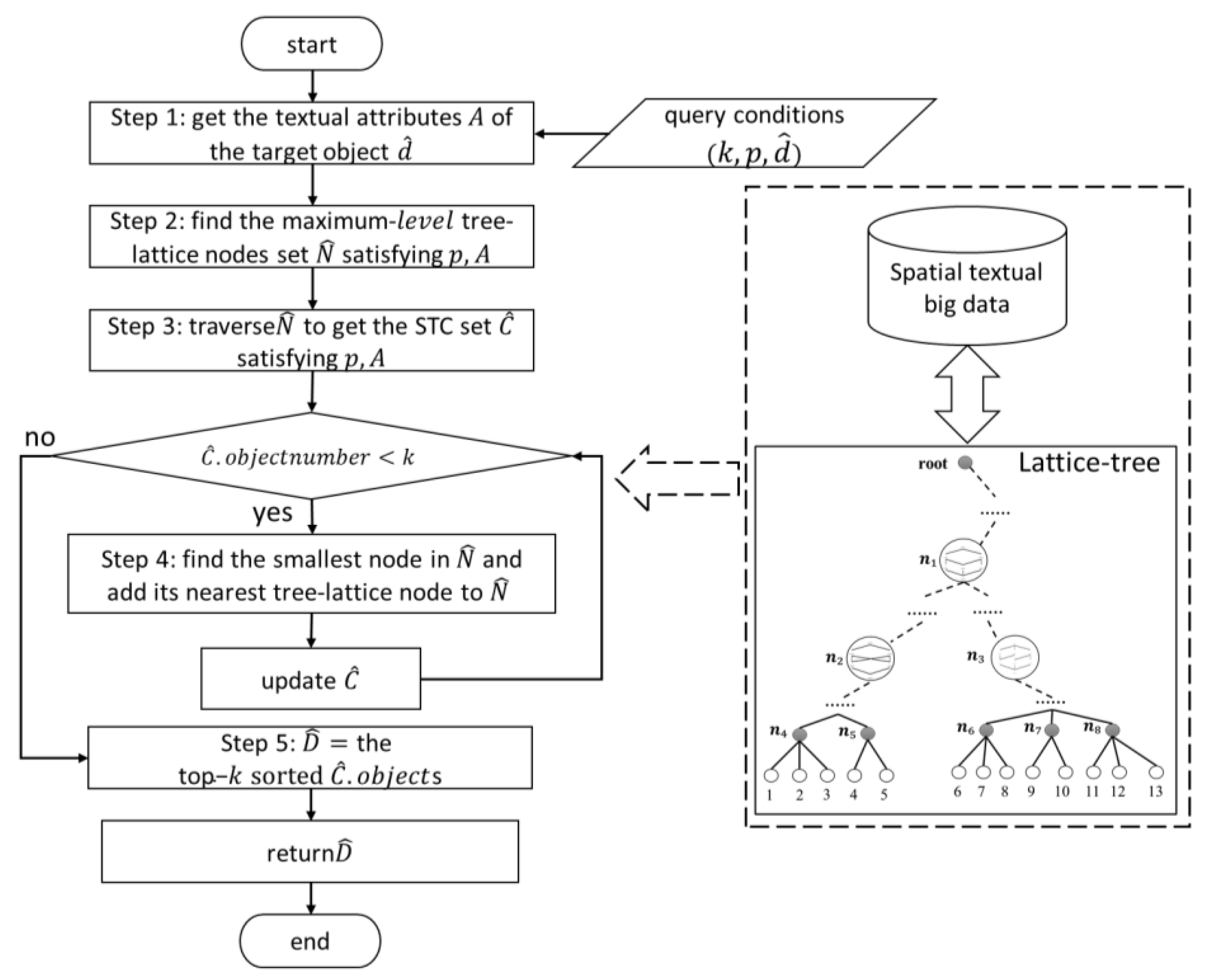
3.4. Top-k Spatial Concept Query
| Algorithm 2: TkSCQ |
| Input:; Output: the set of sorted spatial objects ; 1: traverse to retrieve the spatial object and let ; //Step 1 2: //Step 2 3: while : 4: if and , : 5: 6: if : 7: and delete from 8: end while 9: for each : //Step 3 10: if , 11: ; 12: end for 13: while : //Step 4 14: = min (); 15: = the nearest tree-lattice node of ; 16: insert into ; 17: update ; 18: end while 19: //Step 5 20: 21: return |
4. Experiment
4.1. Data and Preprocessing
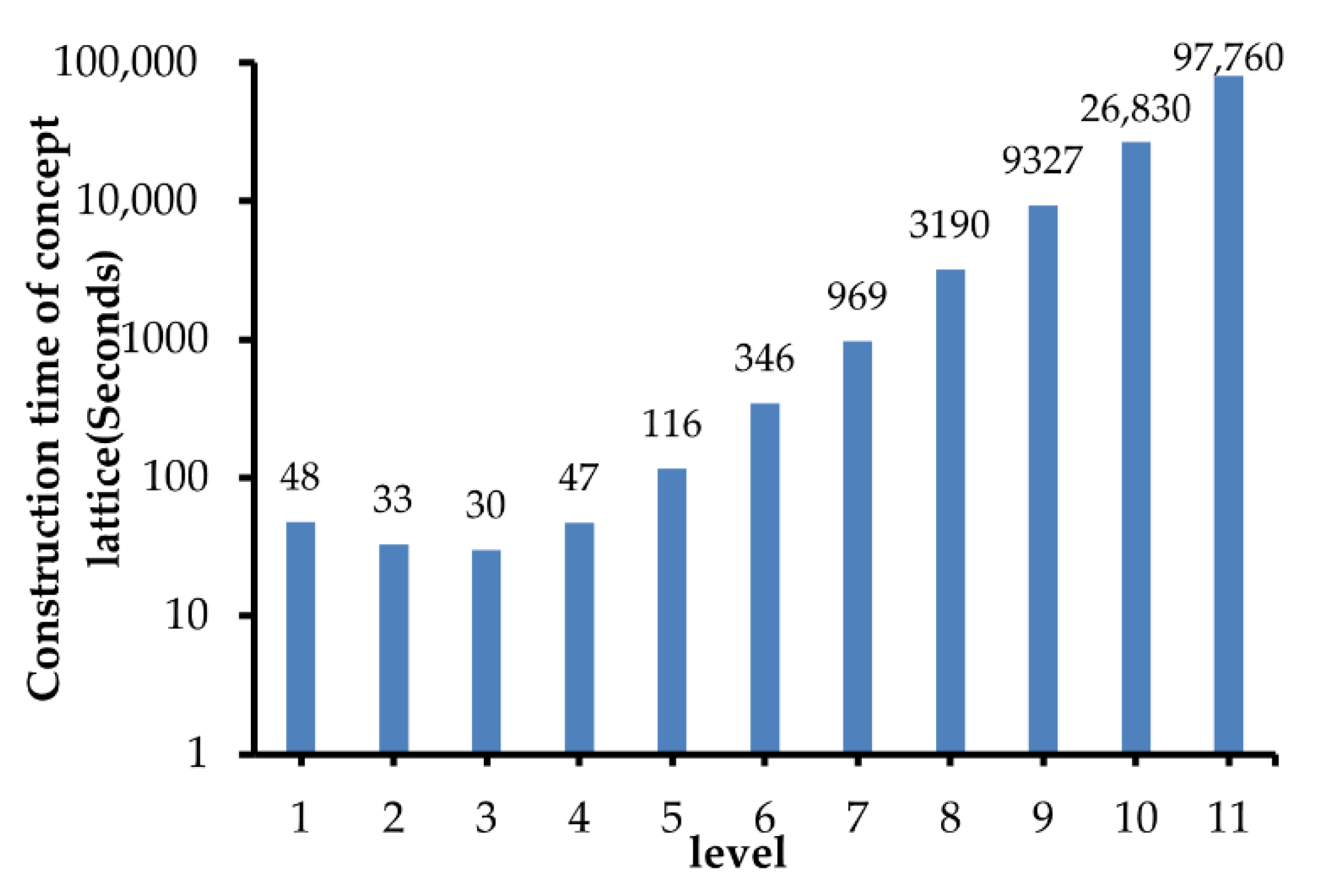
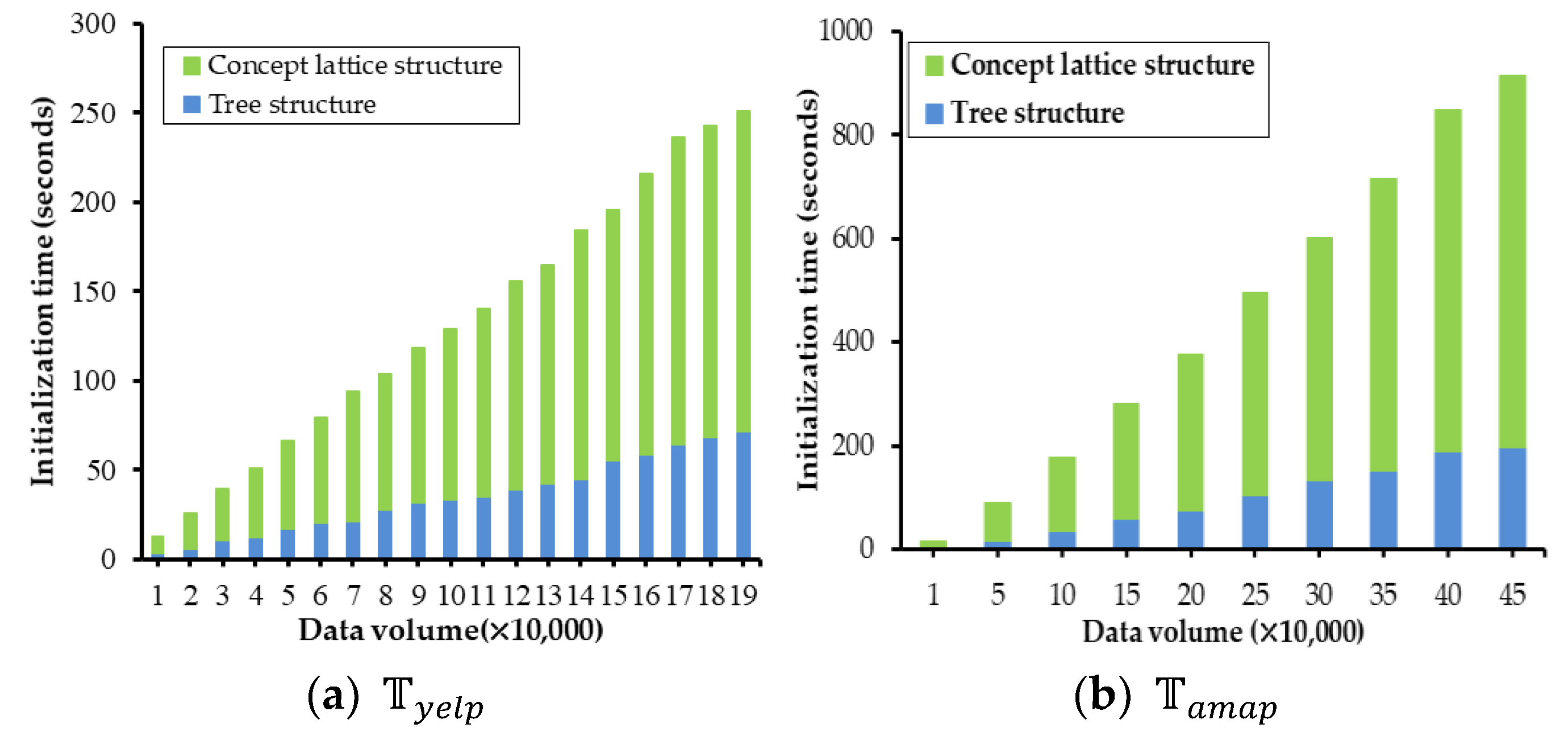
4.2. The Initialization of Lattice-Tree
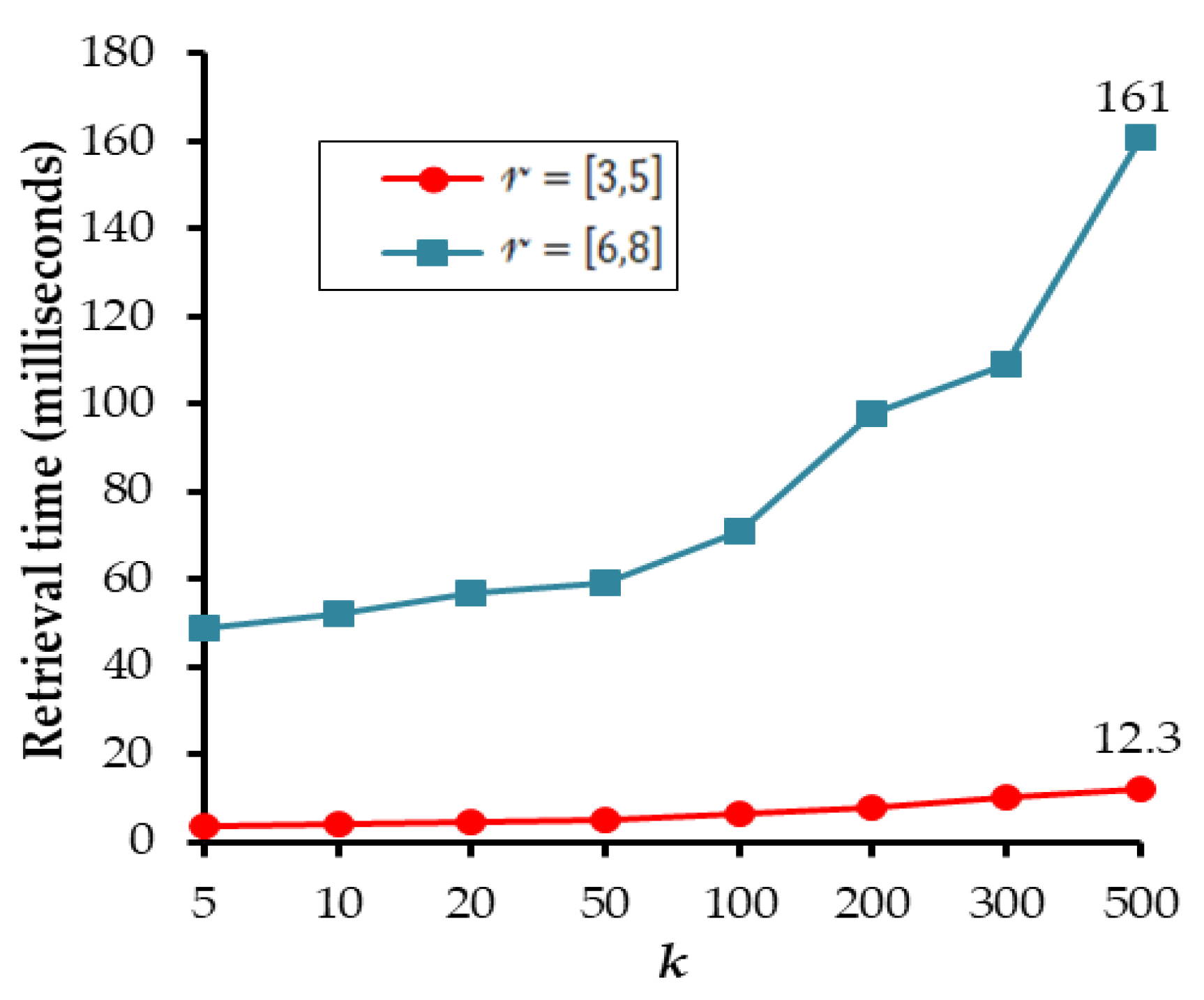
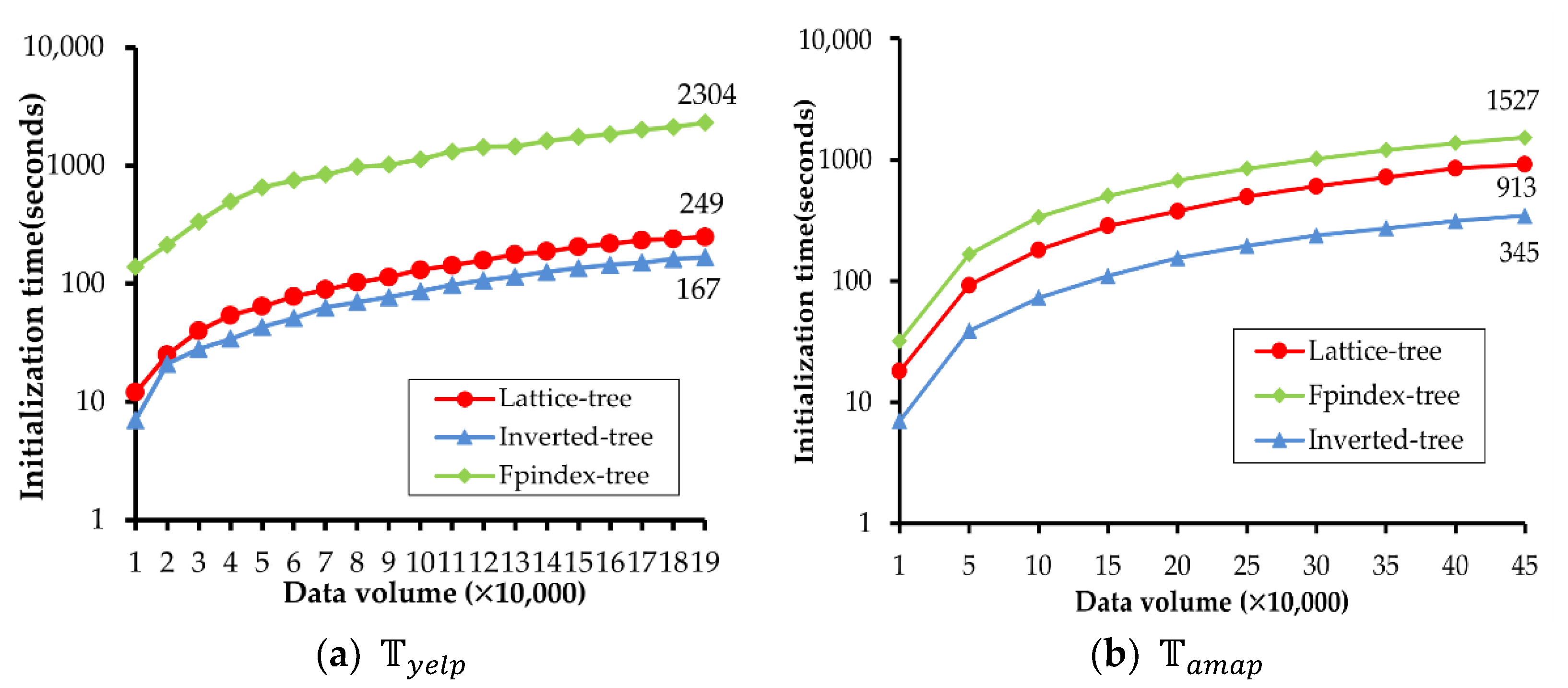
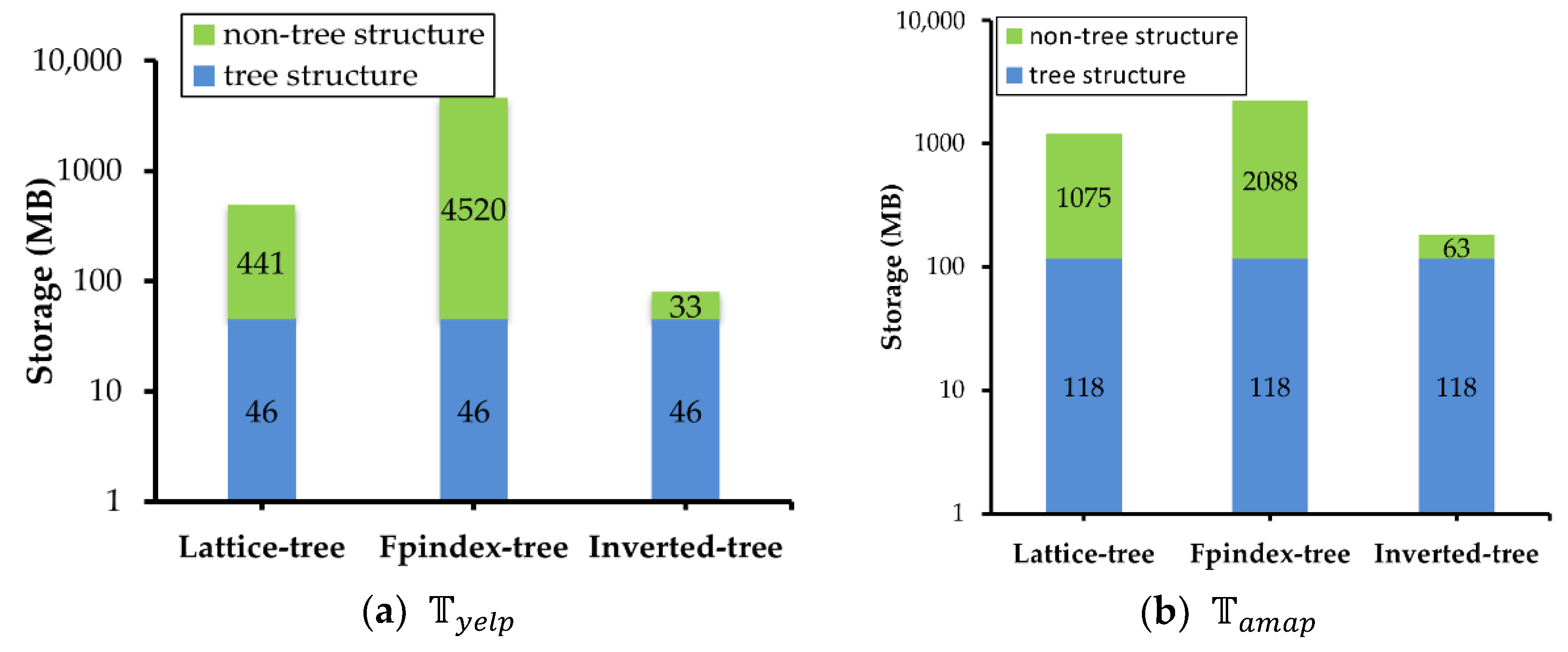
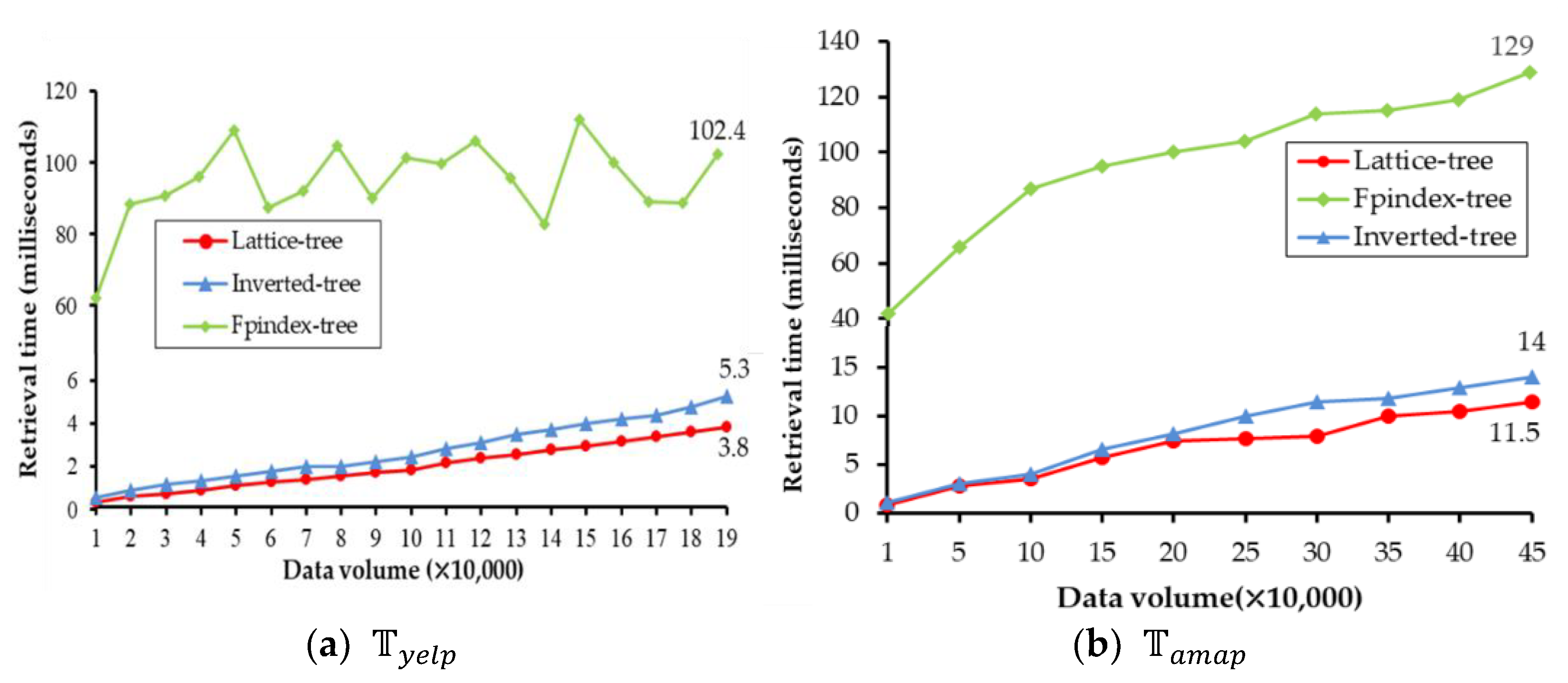
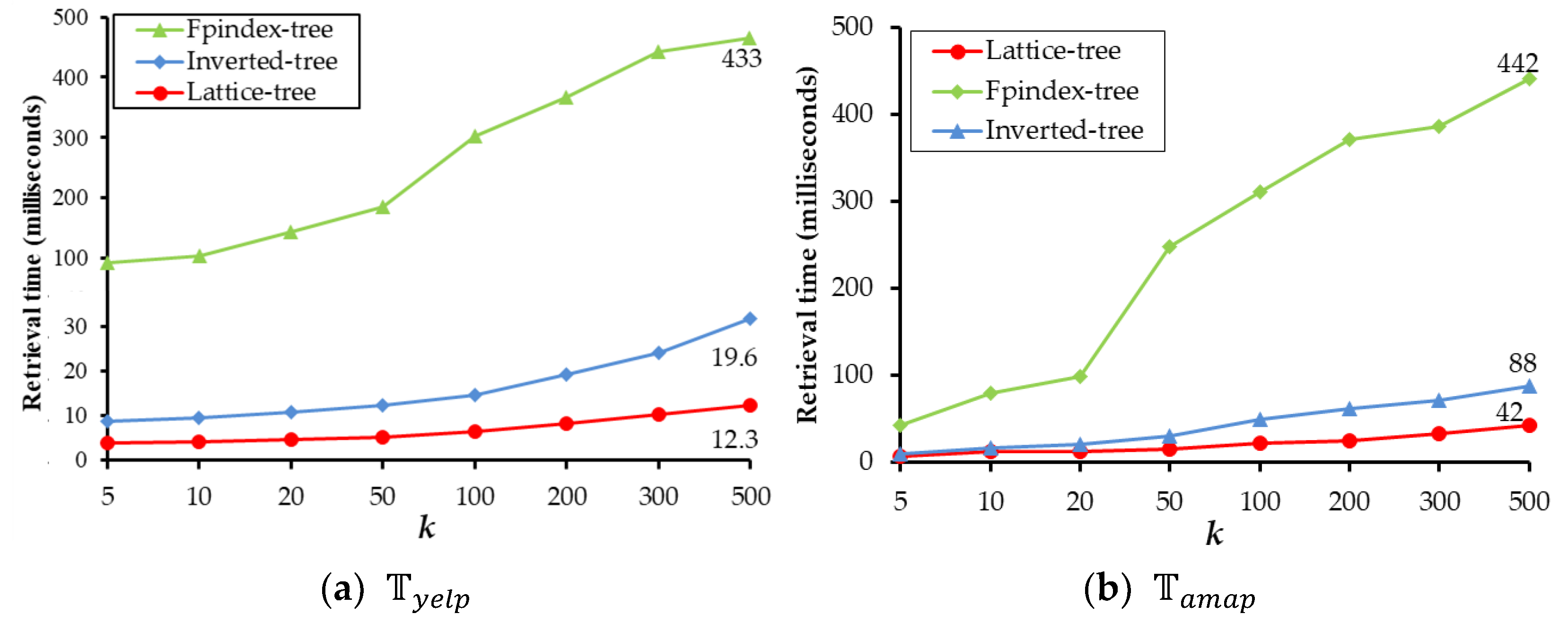
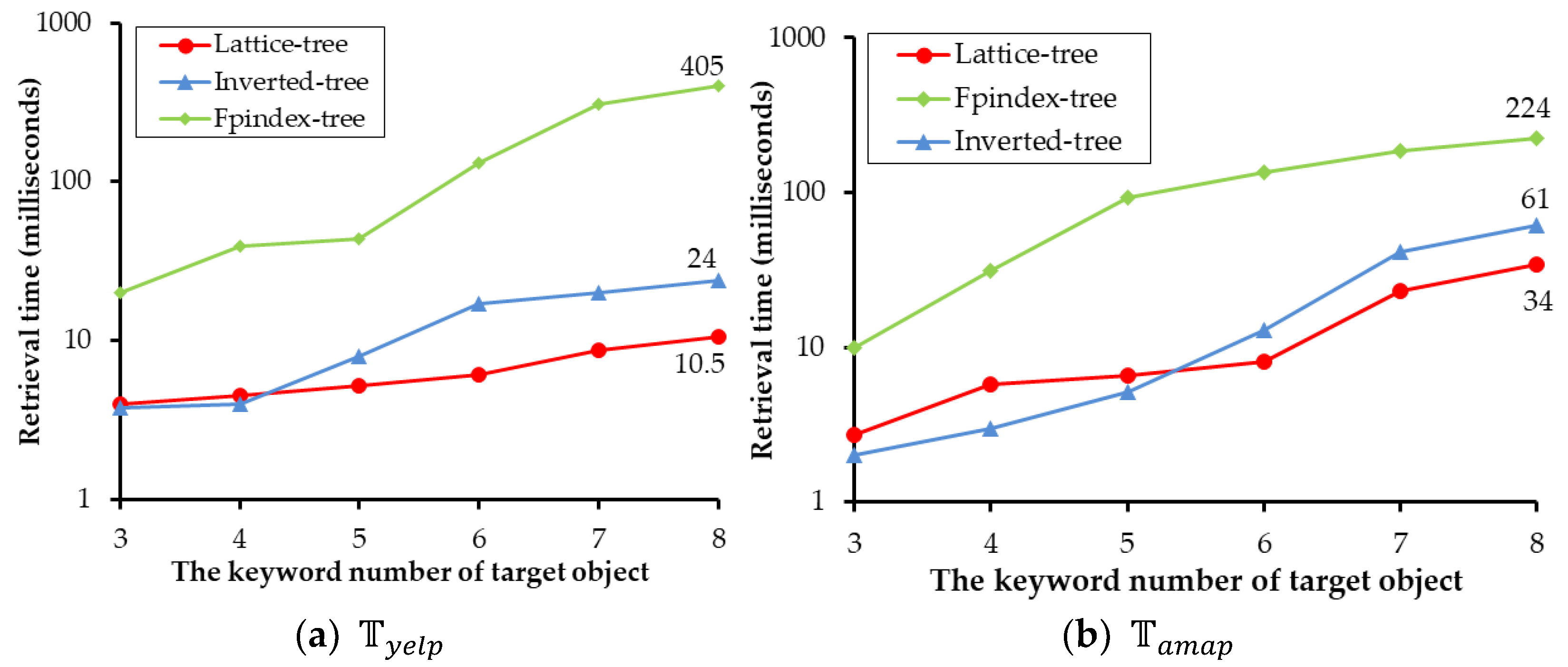
4.3. Evaluation and Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cong, G.; Jensen, C.S.; Wu, D. Efficient retrieval of the top-k most relevant spatial web objects. Proc. VLDB Endow. 2009, 2, 337–348. [Google Scholar] [CrossRef]
- Li, Z.; Lee, K.C.K.; Zheng, B.; Lee, W.C.; Lee, D.L.; Wang, X. IR-Tree: An Efficient Index for Geographic Document Search. IEEE Trans. Knowl. Data Eng. 2011, 23, 585–599. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, Y.; Zhang, W.; Lin, X. Inverted Linear Quadtree: Efficient Top k Spatial Keyword Search. IEEE Trans. Knowl. Data Eng. 2016, 28, 1706–1721. [Google Scholar] [CrossRef]
- Hong, H.J.; Chiu, G.M.; Tsai, W.Y. A single quadtree-based algorithm for top-k spatial keyword query. Pervasive Mob. Comput. 2017, 42, 93–107. [Google Scholar] [CrossRef]
- Vaid, S.; Jones, C.B.; Joho, H.; Sanderson, M. Spatio-textual indexing for geographical search on the web. Int. Symp. Spat. Temporal Databases 2005, 3633, 218–235. [Google Scholar]
- Luo, S.; Luo, Y.; Zhou, S.; Cong, G.; Guan, J. DISKs: A system for distributed spatial group keyword search on road networks. Proc. VLDB Endow. 2012, 5, 1966–1969. [Google Scholar] [CrossRef]
- Gao, Y.; Zhao, J.; Zheng, B.; Chen, G. Efficient Collective Spatial Keyword Query Processing on Road Networks. IEEE Trans. Intell. Transp. Syst. 2016, 17, 469–480. [Google Scholar] [CrossRef]
- Su, S.; Zhao, S.; Cheng, X.; Bi, R.; Cao, X.; Wang, J. Group-based collective keyword querying in road networks. Inf. Processing Lett. 2017, 118, 83–90. [Google Scholar] [CrossRef][Green Version]
- Regalado, A.; Goncalves, M.; Abad-Mota, S. Evaluating Skyline Queries on Spatial Web Objects. Database Expert Syst. Appl. 2012, 7447, 416–423. [Google Scholar]
- Li, J.; Wang, H.; Li, J.; Gao, H. Skyline for geo-textual data. GeoInformatica 2016, 20, 453–469. [Google Scholar] [CrossRef]
- Shi, J.; Wu, D.; Mamoulis, N. Textually relevant spatial skylines. IEEE Trans. Knowl. Data Eng. 2016, 28, 224–237. [Google Scholar] [CrossRef]
- Chen, G.; Zhao, J.; Gao, Y.; Chen, L.; Chen, R. Time-Aware Boolean Spatial Keyword Queries. IEEE Trans. Knowl. Data Eng. 2017, 29, 2601–2614. [Google Scholar] [CrossRef]
- Mehta, P.; Skoutas, D.; Voisard, A. Spatio-temporal keyword queries for moving objects. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems. Association for Computing Machinery, New York, NY, USA, 1–4 November 2015; Volume 55. [Google Scholar]
- Nepomnyachiy, S.; Gelley, B.; Jiang, W.; Minkus, T. What, where, and when: Keyword search with spatio-temporal ranges. In Proceedings of the 8th Workshop on Geographic Information Retrieval, Dallas, TX, USA, 1–8 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; Volume 2. [Google Scholar]
- Zhang, D.; Tan, K.L.; Tung, A.K.H. Scalable top-k spatial keyword search. In Proceedings of the 16th International Conference on Extending Database Technology, Genoa, Italy, 18–22 March 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 359–370. [Google Scholar]
- Christoforaki, M.; He, J.; Dimopoulos, C.; Markowetz, A.; Suel, T. Text vs. space: Efficient geo-search query processing. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 423–432. [Google Scholar]
- Felipe, I.D.; Hristidis, V.; Rishe, N. Keyword Search on Spatial Databases. In Proceedings of the 2008 IEEE 24th International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008; pp. 656–665. [Google Scholar]
- Zhang, D.; Chee, Y.M.; Mondal, A.; Tung, A.K.H.; Kitsuregawa, M. Keyword Search in Spatial Databases: Towards Searching by Document. In Proceedings of the 2009 IEEE 25th International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; pp. 688–699. [Google Scholar]
- Wu, D.; Yiu, M.L.; Cong, G.; Jensen, C.S. Joint Top-K Spatial Keyword Query Processing. IEEE Trans. Knowl. Data Eng. 2012, 24, 1889–1903. [Google Scholar] [CrossRef]
- Xu, J.; Sun, J.; Zhou, R.; Liu, C.; Yin, L. CISK: An interactive framework for conceptual inference based spatial keyword query. Neurocomputing 2021, 428, 368–375. [Google Scholar] [CrossRef]
- Wille, R. Restructuring lattice theory: An approach based on hierarchies of concepts. In NATO Advanced Study Institutes Series; Rival, I., Ed.; Series C—Mathematical and Physical Sciences; Springer: Dordrecht, The Netherlands, 1982; Volume 83, pp. 445–470. [Google Scholar]
- Kainz, W.; Egenhofer, M.J.; Greasley, I. Modelling spatial relations and operations with partially ordered sets. Int. J. Geogr. Inf. Syst. 1993, 7, 215–229. [Google Scholar] [CrossRef]
- Bian, F.; Li, J.; Zhang, W.; Hu, R.; Wang, J.; Li, L.; Wu, W.; Liu, W.; Wang, H.; Zhang, H.; et al. A Research about Spatial Association Rule Mining Based on Concept Lattice. In Proceedings of the 2007 International Conference on Wireless Communications, Networking and Mobile Computing, Shanghai, China, 21–25 September 2007; pp. 5979–5982. [Google Scholar]
- Tripathy, A.; Mishra, L.; Patra, P.K. A multi dimensional design framework for querying spatial data using concept lattice. In Proceedings of the 2010 IEEE 2nd International Advance Computing Conference, Patiala, India, 19–20 February 2010; pp. 394–399. [Google Scholar]
- Han, J.; Pei, J.; Yin, Y. Mining Frequent Patterns without Candidate Generation. ACM SIGMOD Record 2000, 29, 1–12. [Google Scholar] [CrossRef]
- Cao, X.; Cong, G.; Jensen, C.S. Retrieving top-k prestige-based relevant spatial web objects. Proc. VLDB Endow. 2010, 3, 373–384. [Google Scholar] [CrossRef]
- Zhang, P.; Lin, H.; Yao, B.; Lu, D. Level-aware collective spatial keyword queries. Inf. Sci. 2017, 378, 194–214. [Google Scholar] [CrossRef]
- Fang, Y.; Cheng, R.; Cong, G.; Mamoulis, N.; Li, Y. On Spatial Pattern Matching. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering, Paris, France, 16–19 April 2018; pp. 293–304. [Google Scholar]
- Ahuja, R.; Armenatzoglou, N.; Papadias, D.; Fakas, G.J. Geo-Social Keyword Search. Adv. Spat. Temporal Databases. SSTD 2015, 9239, 431–450. [Google Scholar]
- Jiang, J.; Lu, H.; Yang, B.; Cui, B. Finding top-k local users in geo-tagged social media data. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 267–278. [Google Scholar]
- Wu, D.; Li, Y.; Choi, B.; Xu, J. Social-Aware Top-k Spatial Keyword Search. In Proceedings of the 2014 IEEE 15th International Conference on Mobile Data Management, Brisbane, QLD, Australia, 14–18 July 2014; pp. 235–244. [Google Scholar]
- Shekhar, S.; Gunturi, V.; Evans, M.R.; Yang, K.S. Spatial big-data challenges intersecting mobility and cloud computing. In Proceedings of the Eleventh ACM International Workshop on Data Engineering for Wireless and Mobile Access, Scottsdale, AZ, USA, 1–6 May 2012; Association for Computing Machinery: New York, NY, USA, 2012. [Google Scholar]
- Zhao, L.; Chen, L.; Ranjan, R.; Choo, K.K.R.; He, J. Geographical information system parallelization for spatial big data processing: A review. Clust. Comput. 2016, 19, 139–152. [Google Scholar] [CrossRef]
- Göbel, R.; Henrich, A.; Niemann, R.; Blank, D. A hybrid index structure for geo-textual searches. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 1625–1628. [Google Scholar]
- Wu, D.; Cong, G.; Jensen, C.S. A framework for efficient spatial web object retrieval. VLDB J. 2012, 21, 797–822. [Google Scholar] [CrossRef]
- Khodaei, A.; Shahabi, C.; Li, C. Hybrid Indexing and Seamless Ranking of Spatial and Textual Features of Web Documents. Database Expert Syst. Appl. 2010, 6261, 450–466. [Google Scholar]
- Chen, Y.Y.; Suel, T.; Markowetz, A. Efficient query processing in geographic web search engines. In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27–29 June 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 277–288. [Google Scholar]
- Upadhyay, P.; Pandey, M.K.; Kohli, N. Periodic pattern mining from spatio-temporal database using novel global pollination artificial fish swarm optimizer-based clustering and modified FP tree. Soft Comput. 2021, 25, 4327–4344. [Google Scholar] [CrossRef]
- Zhang, J.; Kong, X.; Philip, S.Y. Predicting Social Links for New Users across Aligned Heterogeneous Social Networks. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 1289–1294. [Google Scholar]
- Hristova, D.; Noulas, A.; Brown, C.; Musolesi, M.; Mascolo, C. A multilayer approach to multiplexity and link prediction in online geo-social networks. EPJ Data Sci. 2016, 5, 24. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Xu, J.; Zhou, R.; Liu, C.; Fang, J.; Zhao, L. S2R-tree: A pivot-based indexing structure for semantic-aware spatial keyword search. Geoinformatica 2020, 24, 3–25. [Google Scholar] [CrossRef]
- Carpineto, C.; Romano, G. A Lattice Conceptual Clustering System and Its Application to Browsing Retrieval. Mach. Learn. 1996, 24, 95–122. [Google Scholar] [CrossRef]
- Nguyen, P.H.P.; Corbett, D. A basic mathematical framework for conceptual graphs. IEEE Trans. Knowl. Data Eng. 2006, 18, 261–271. [Google Scholar] [CrossRef]
- Tu, X.; Wang, Y.; Zhang, M.; Wu, J. Using Formal Concept Analysis to Identify Negative Correlations in Gene Expression Data. IEEE/ACM Trans. Comput. Biol. Bioinform. 2016, 13, 380–391. [Google Scholar] [CrossRef]
- Zou, C.; Zhang, D.; Wan, J.; Hassan, M.M.; Lloret, J. Using Concept Lattice for Personalized Recommendation System Design. IEEE Syst. J. 2017, 11, 305–314. [Google Scholar] [CrossRef]
- Sampath, S.; Sprenkle, S.; Gibson, E.; Pollock, L.; Greenwald, A.S. Applying Concept Analysis to User-Session-Based Testing of Web Applications. IEEE Trans. Softw. Eng. 2007, 33, 643–658. [Google Scholar] [CrossRef]
- Guttman, A. R-trees: A dynamic index structure for spatial searching. In Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data, Boston, MA, USA, 18–21 June 1984; Association for Computing Machinery: New York, NY, USA, 1984; pp. 47–57. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| STC | Extent | Intent * |
|---|---|---|
| c0 | d2, d3, d4, d5, d6, d7 | |
| c1 | d5, d6 | 1, 4 |
| c2 | d2, d4 | 2 |
| c3 | d3, d7 | 3 |
| c4 | d2, d4, d6, d7 | 5 |
| c5 | d2, d4 | 2, 5 |
| c6 | d7 | 3, 5 |
| c7 | d6 | 1, 4, 5 |
| c8 | 1, 2, 3, 4, 5 |
| Description | ||
|---|---|---|
| Data volume | 100 Mb | 192 Mb |
| Index volume | 487 Mb | 1193 Mb |
| The number of objects | 192,690 | 483,990 |
| The number of features | 45 | 30 |
| Total of level | 12 | 14 |
| The number of leaf nodes | 192,690 | 483,990 |
| The number of non-leaf nodes | 99,069 | 248,350 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, A.; Zhang, Z.; Ma, X.; Zhang, Z.; Xu, T. Spatial Concept Query Based on Lattice-Tree. ISPRS Int. J. Geo-Inf. 2022, 11, 312. https://doi.org/10.3390/ijgi11050312
Xu A, Zhang Z, Ma X, Zhang Z, Xu T. Spatial Concept Query Based on Lattice-Tree. ISPRS International Journal of Geo-Information. 2022; 11(5):312. https://doi.org/10.3390/ijgi11050312
Chicago/Turabian StyleXu, Aopeng, Zhiyuan Zhang, Xiaqing Ma, Zixiang Zhang, and Tao Xu. 2022. "Spatial Concept Query Based on Lattice-Tree" ISPRS International Journal of Geo-Information 11, no. 5: 312. https://doi.org/10.3390/ijgi11050312
APA StyleXu, A., Zhang, Z., Ma, X., Zhang, Z., & Xu, T. (2022). Spatial Concept Query Based on Lattice-Tree. ISPRS International Journal of Geo-Information, 11(5), 312. https://doi.org/10.3390/ijgi11050312