
Extracting Human Activity Areas from Large-Scale Spatial Data with Varying Densities




Abstract
:1. Introduction
- A new clustering model for high-density data with adaptive parameters is proposed. Compared with existing methods, our method can reduce the uncertainty introduced by human subjective factors.
- We designed a method to divide the low-density data according to the spatial features of high-density clusters, which can judge the noise more reasonably.
- A re-segmented model was built that can automatically judge the re-segmentation effect according to the clustering characteristics. Compared with existing methods, it can better address the varying density problem of large-scale spatial data.
- A new strategy was developed to recover noise data during re-segmentation, which can avoid unnecessary noise compared with existing hierarchical clustering algorithms.
2. Related Works
3. Methodology
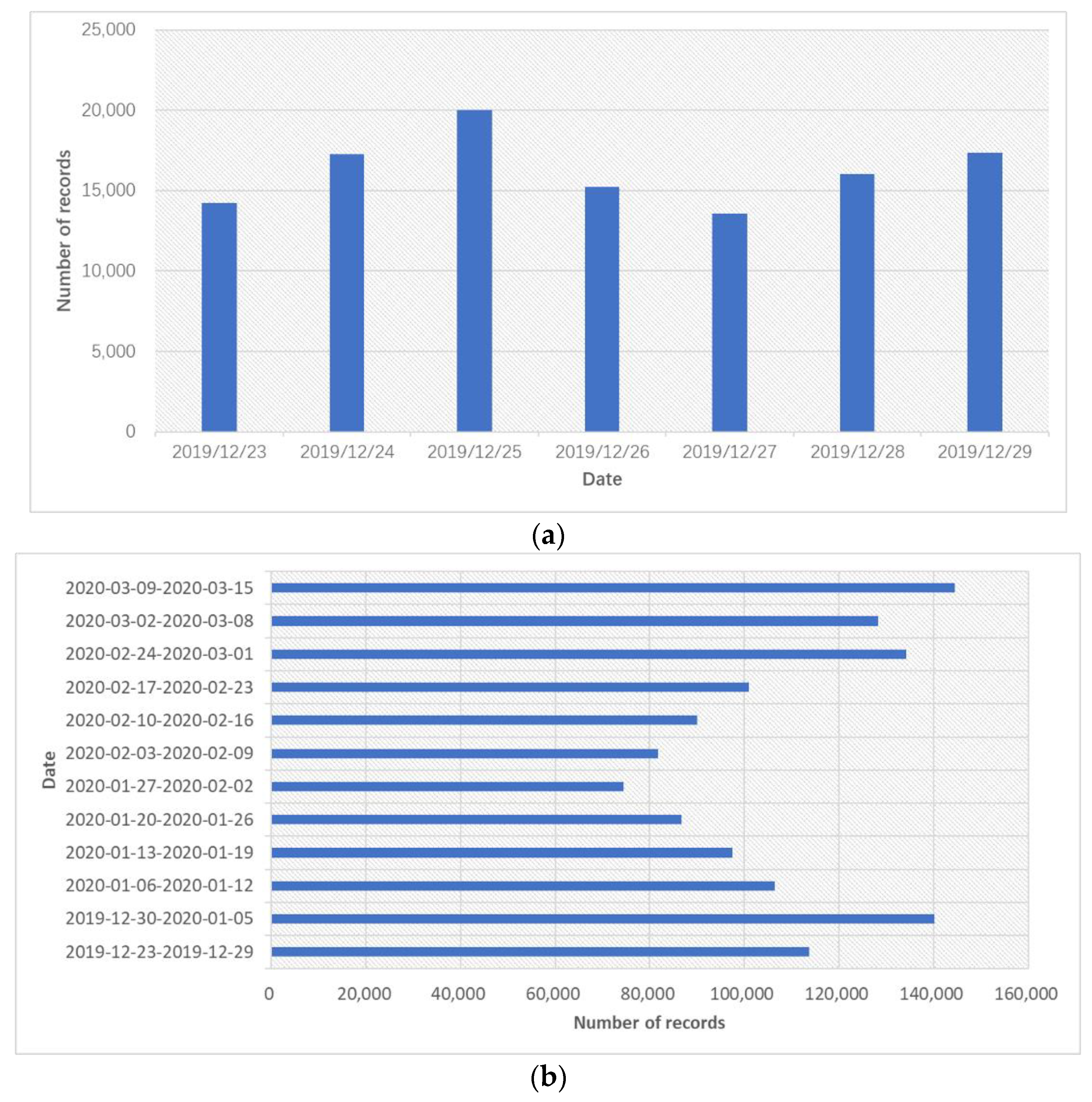
3.1. Data Description
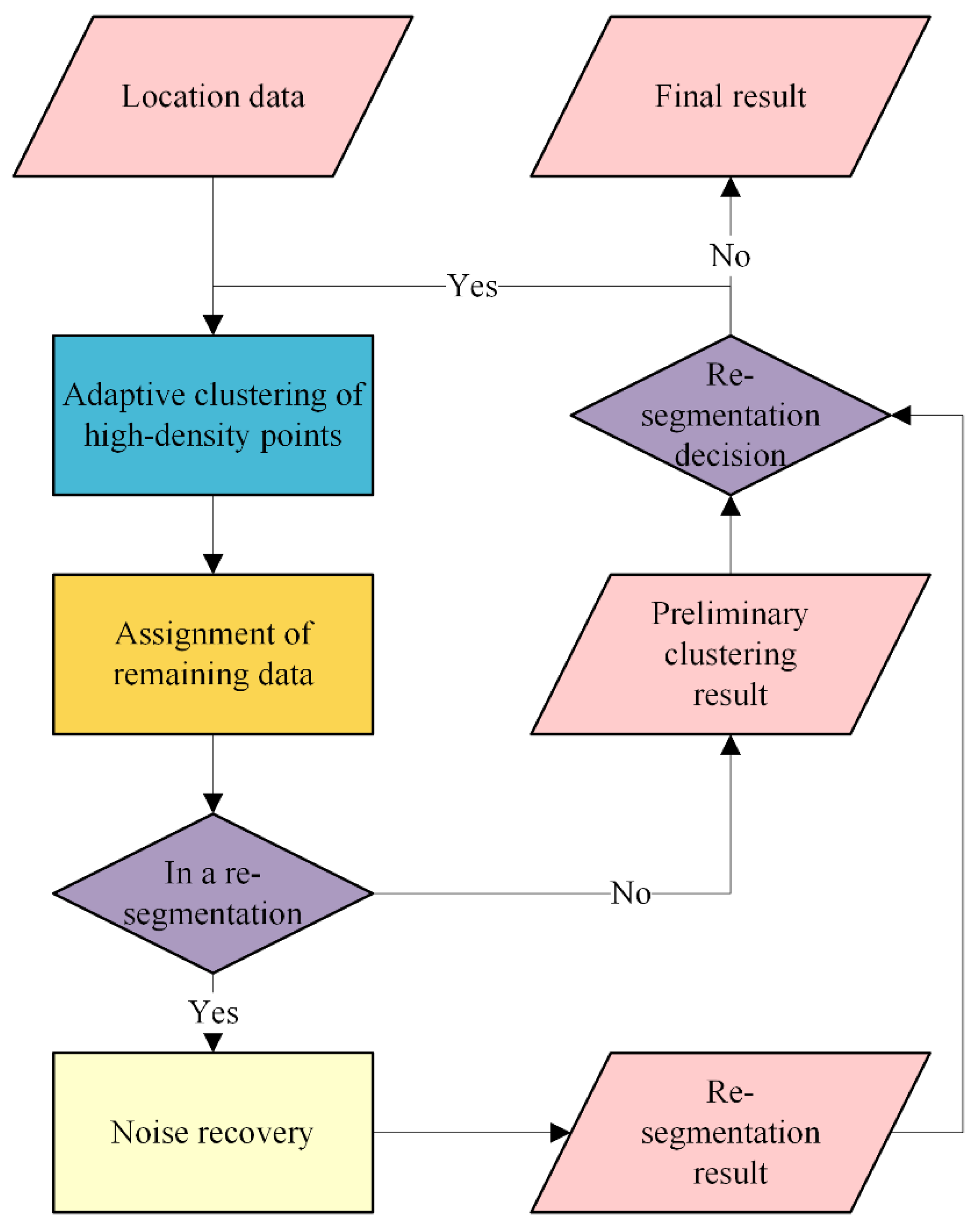
3.2. Extracting Human Activity Areas from Large-Scale Spatial Data with Varying Densities
- (1)
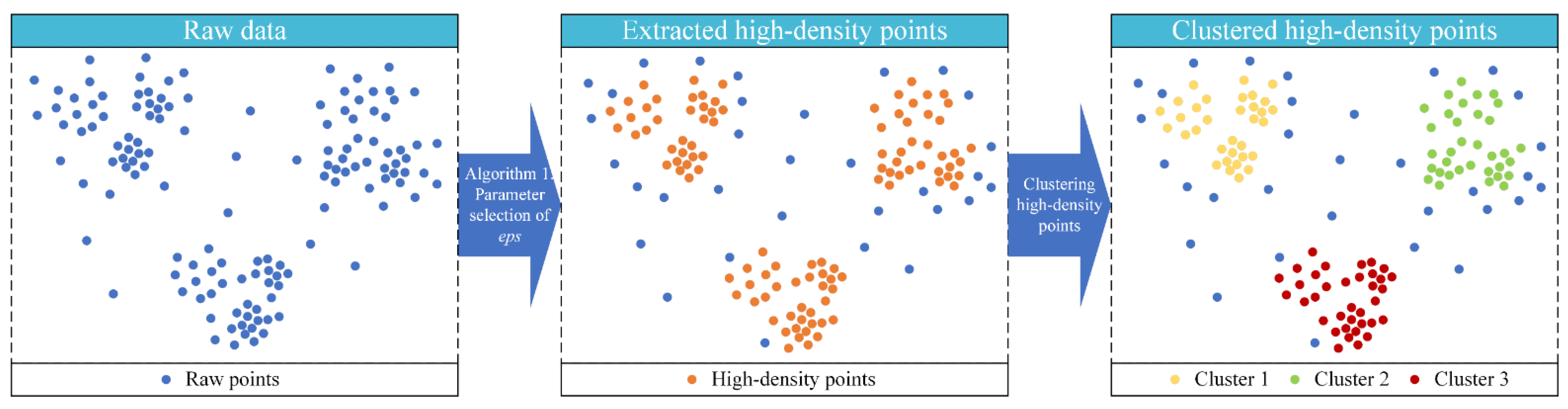
- Adaptive clustering of high-density points. A distance parameter adaptive method is proposed to calculate the density of the points in the location data. The high-density points are then extracted as core points. The distance parameter is used to divide the core points into different clusters.
- (2)
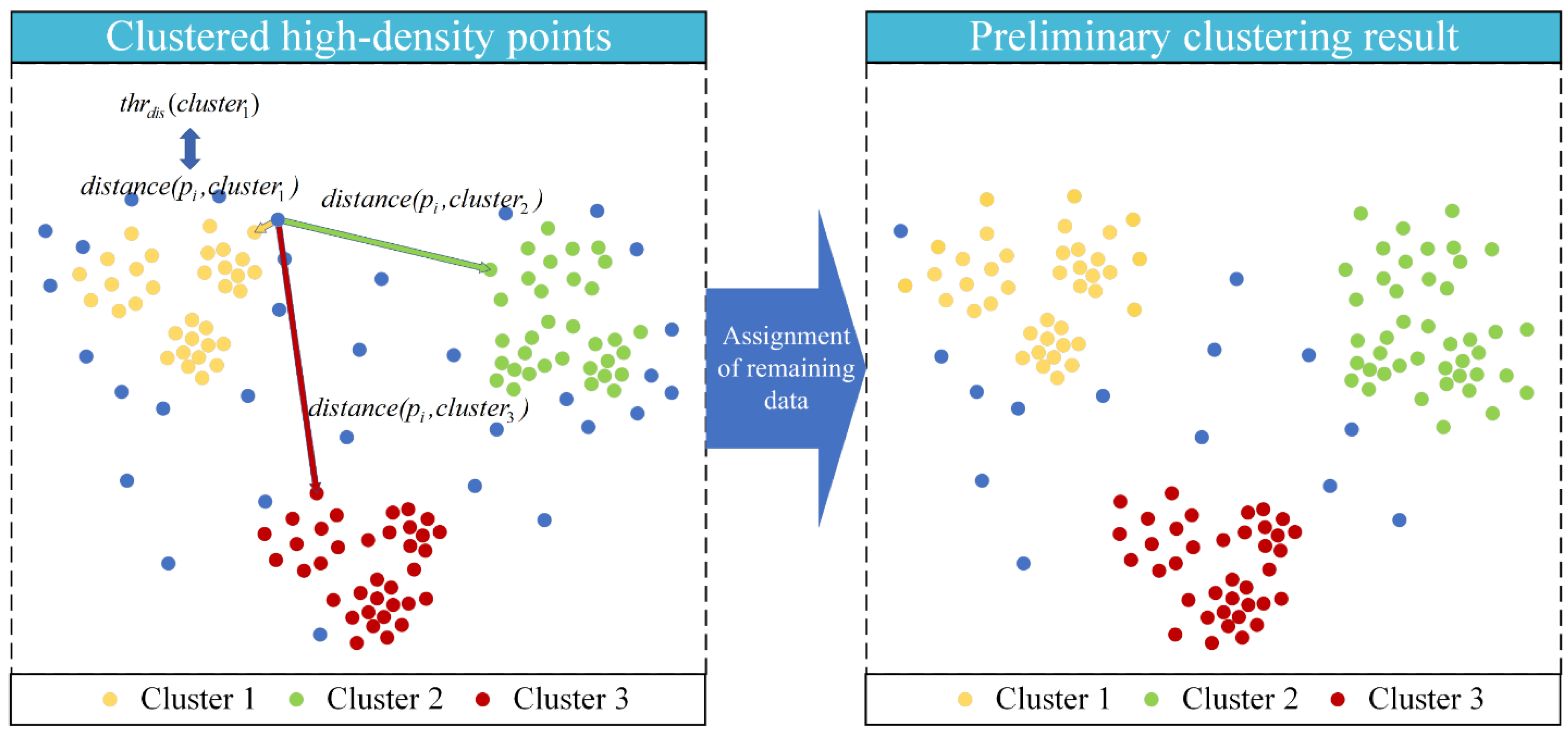
- Assignment of remaining data. The spatial features of the core point clusters are extracted, which can describe the tightness of the core points in each cluster. Then, the features are combined into a distance threshold. For a remaining point, the nearest core point cluster is found, and the distance between them is compared with the distance threshold for point assignment.
- (3)
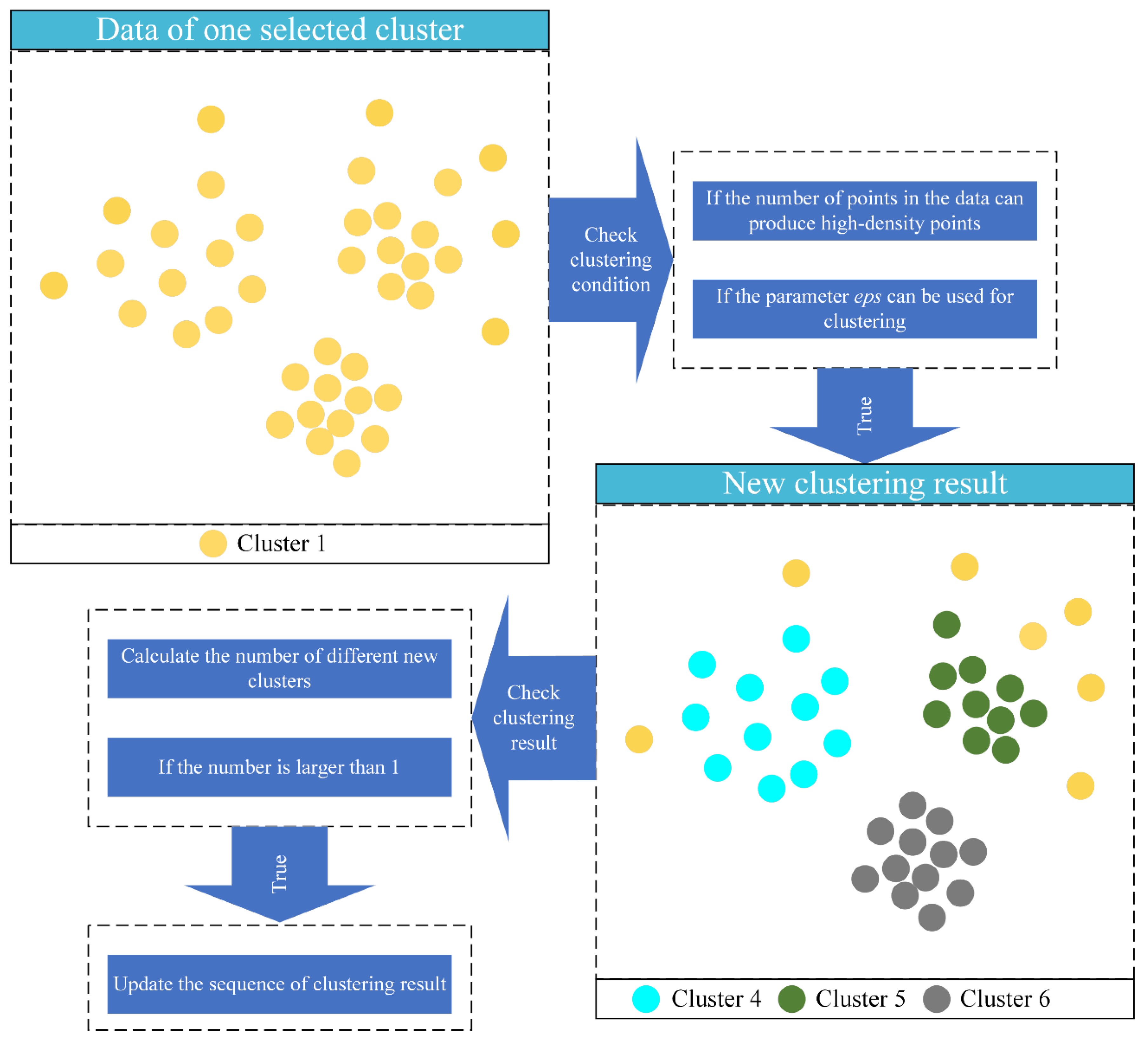
- Re-segmentation decision. The preliminary clustering result obtained from the above two steps is used for the re-segmentation decision. Specifically, the number of points in a cluster is firstly used to decide if this cluster can be re-segmented. Then, the points are clustered again, and the distance parameter, the number of new clusters, and the noise points are used to decide if the re-segmentation is suitable.
- (4)
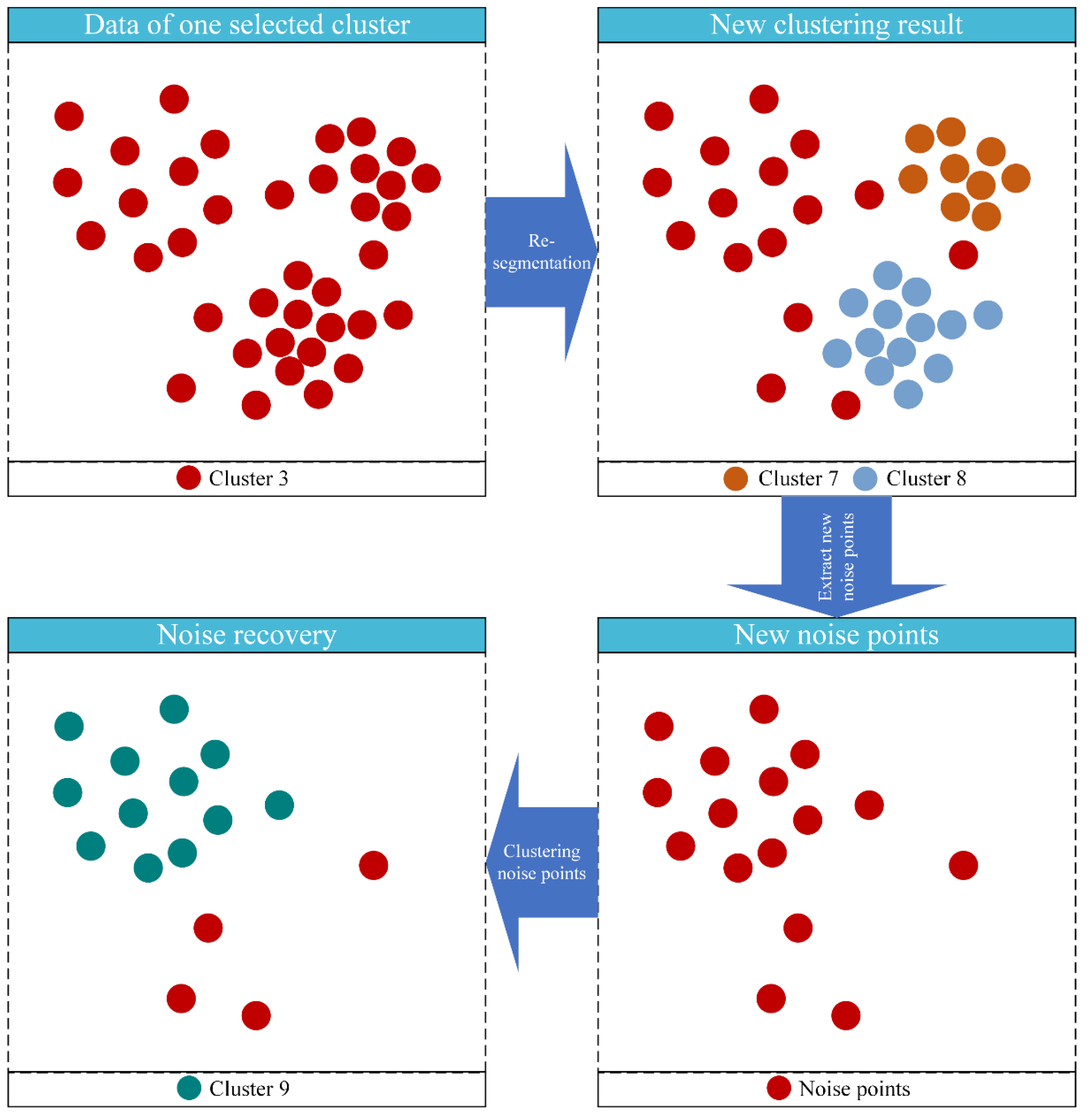
- Noise recovery. In the re-segmentation step, the points in clusters may be considered noise, and as a result, too many noise points may be produced. Therefore, for each re-segmentation, the new noise points are re-clustered according to the old distance parameter, which has assigned them into a cluster, and the new distance parameter extracted from the noise points.
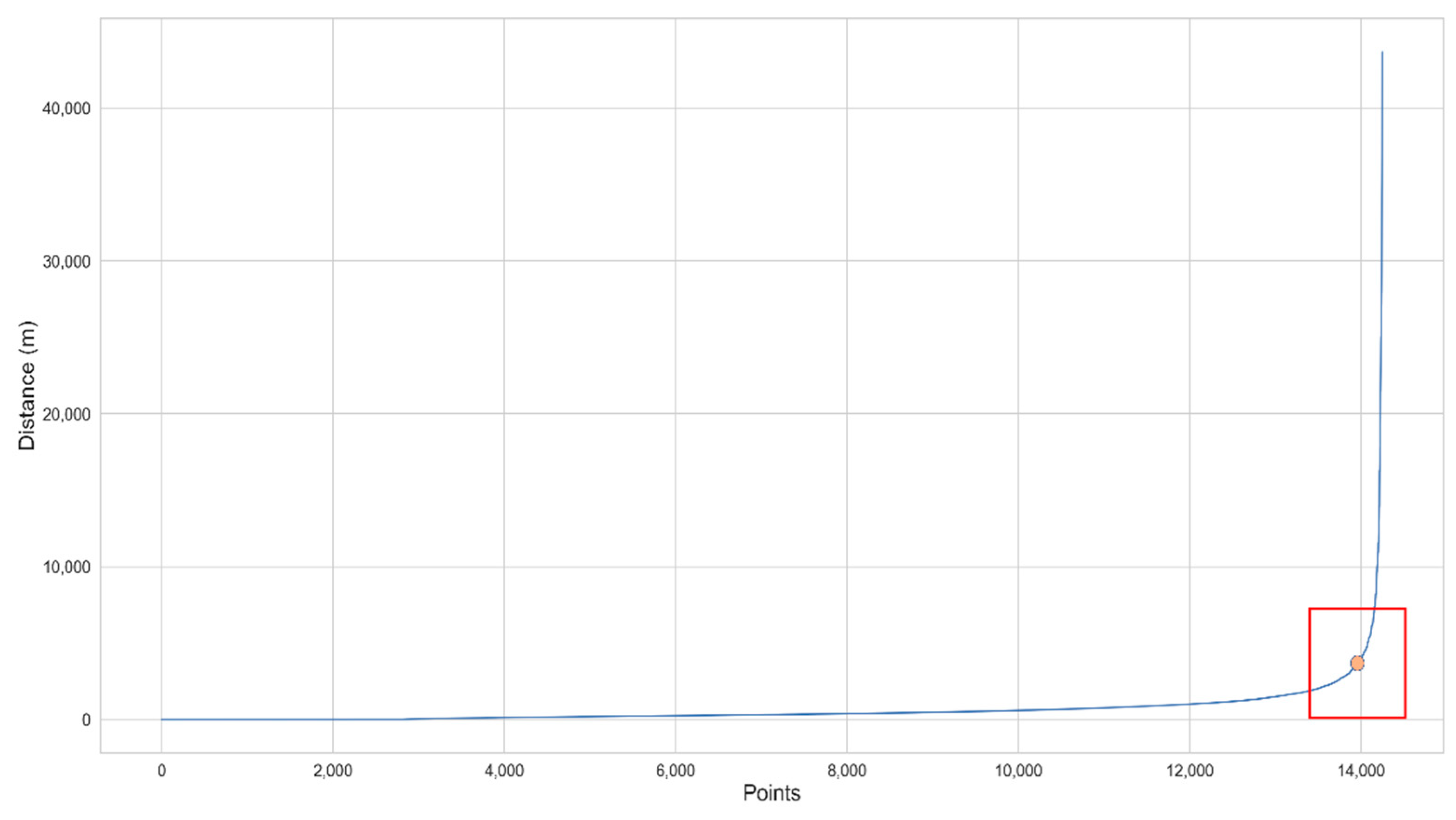
3.2.1. Adaptive Clustering of High-Density Points
| Algorithm 1: Parameter selection of |
| Input: All the points for clustering |
| Output: |
|
3.2.2. Assignment of Remaining Data
| Algorithm 2: Assignment of remaining data |
| Input: Clustering result of high-density points |
| Output: Preliminary clustering result recorded in updated |
|
3.2.3. Re-Segmentation Decision
| Algorithm 3: Re-segmentation once |
| Input: Preliminary clustering result , parameter |
| Output: Re-segmentation result recorded in updated |
|
3.2.4. Noise Recovery
| Algorithm 4: Noise recovery |
| Input: Clustering result , parameters and |
| Output: Clustering result of noise data |
|
3.3. Clustering Algorithms for Comparison
- DPC: This algorithm introduces the idea that cluster centers have higher densities than the points around them and the distances between centers are large. Therefore, the algorithm clusters data by extracting points, meeting the idea, as cluster centers, and then assigning other points to the centers. It has two parameters that need to be selected manually, including and . A point with a density larger than is considered a high-density point and high-density points with distances between them larger than are cluster centers. This algorithm also provides a method to set the parameters according to the distribution graphs of density and distance. Therefore, we set the parameters according to the method in the paper for each dataset, and mainly the and were set to 7000 and 50.
- DBSCAN: Core points are defined in this algorithm according to the number of points in the neighborhoods. As shown in Table 2 a core point has at least points with the distance between them smaller than . For each core point, find all other points in its neighborhoods and assign them to the same cluster. When a cluster has new core points, repeat the previous step. The parameter is set to twice the dimensions of the data, which is 4 in this research, according to the suggestion of the algorithm. Another parameter, , was set to different values: 200, 400, 800, and 1600.
- HDBSCAN: The data are first transformed into a new distance form based on the core distance to reduce the influence of noise. A minimum spanning tree is built to describe the data and transform the data into a cluster hierarchy by creating clusters for the edges in the spanning tree. The clusters with sizes smaller than are considered noises and then the cluster hierarchy tree can be condensed. At last, clusters can be extracted based on an index that measures the stabilities of clusters. The parameter, , were set to different values in this research, including 4, 8, 16, and 32.
4. Results
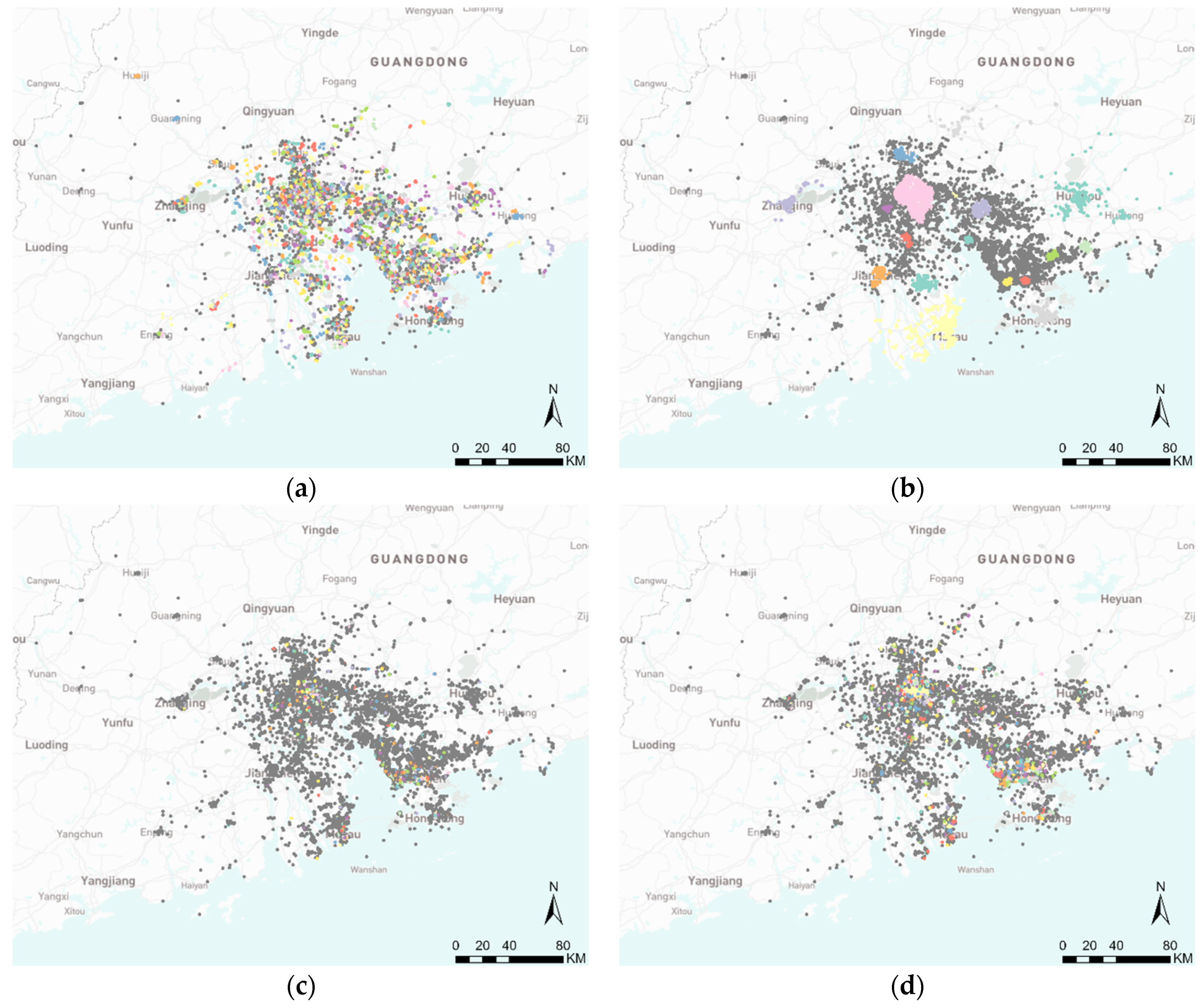
4.1. Performance Comparison Using the First-Day Data of the GBA Dataset as an Example
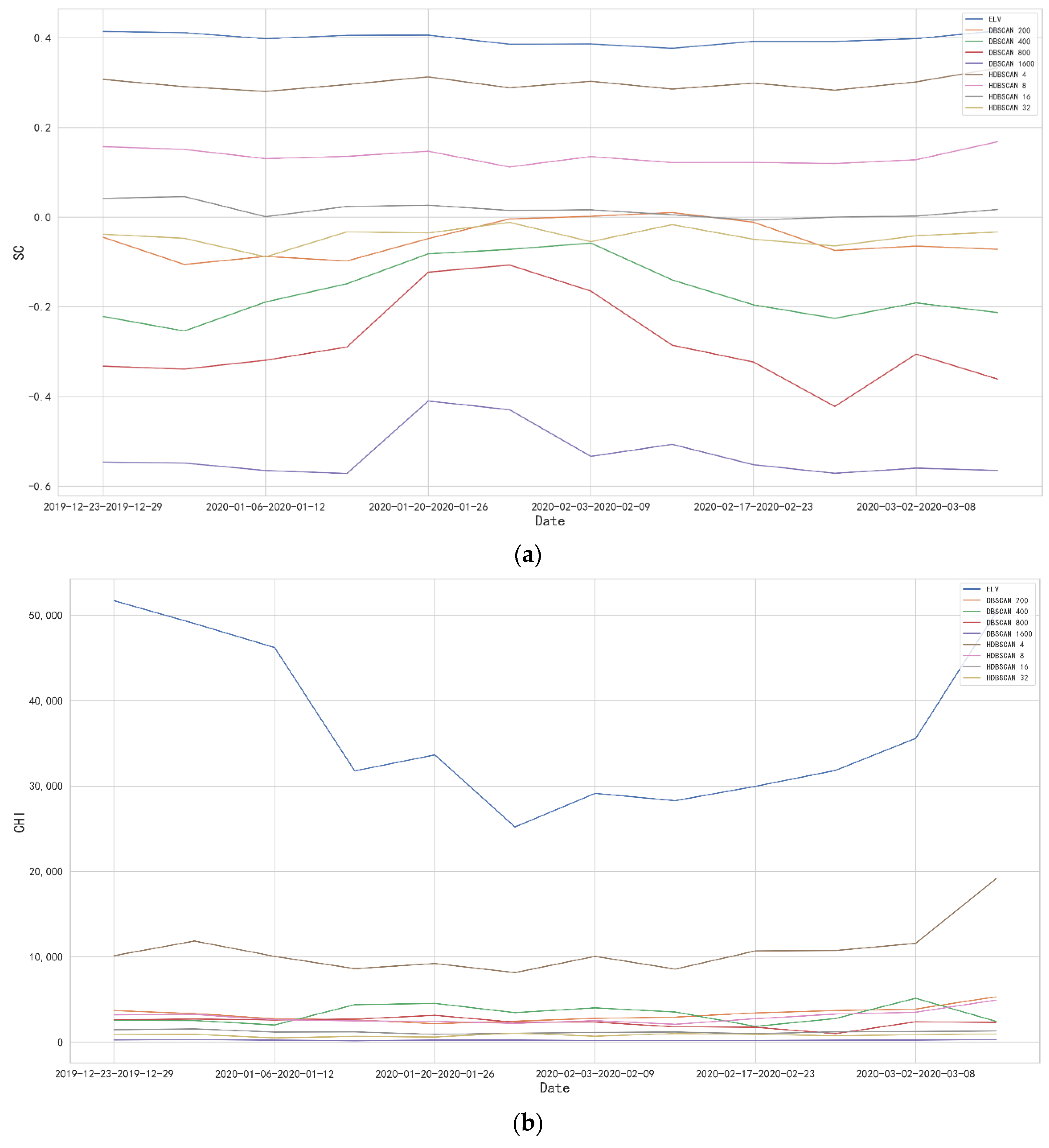
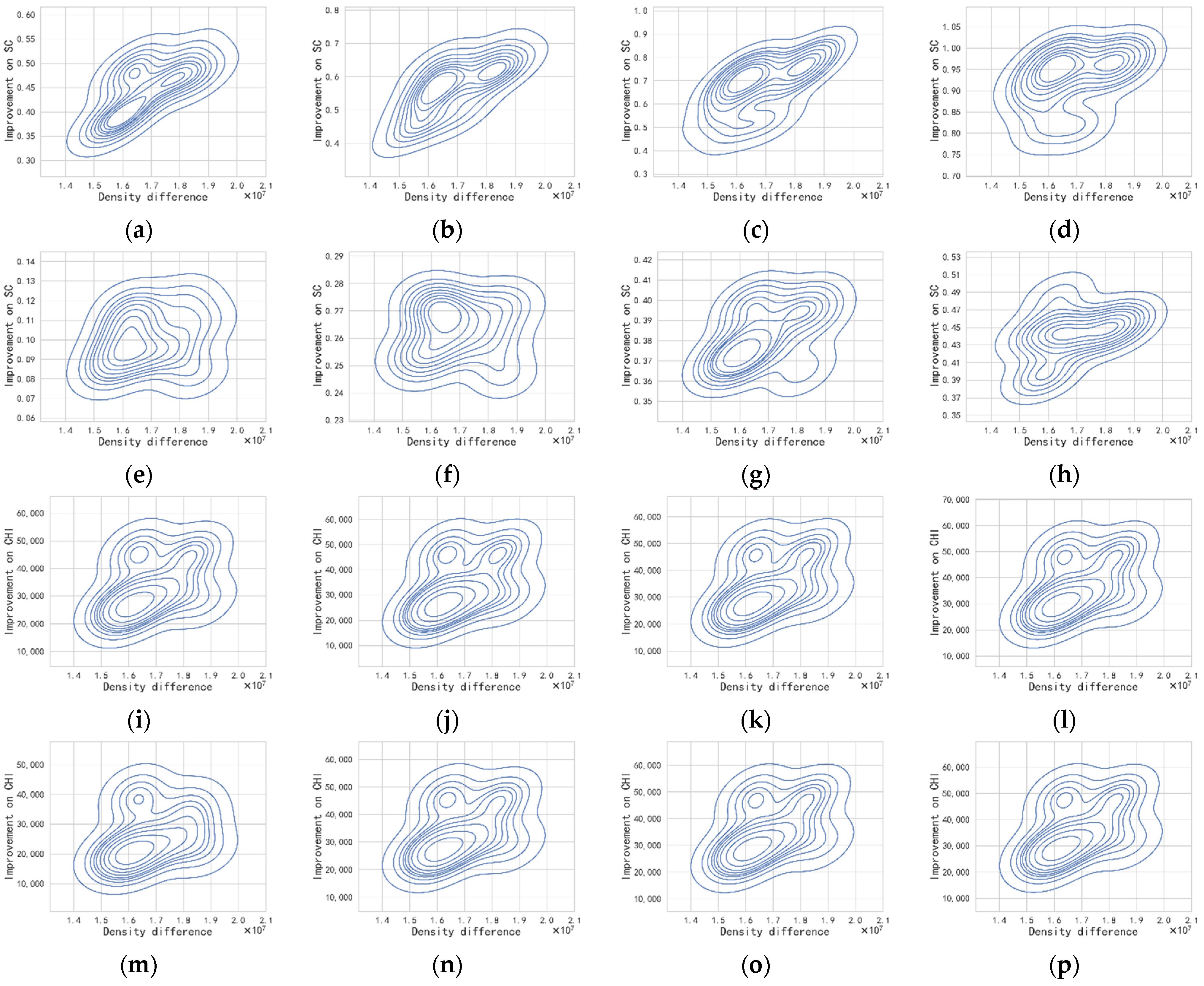
4.2. Performance Evaluation Using the Whole Datasets Based on Two Indicators
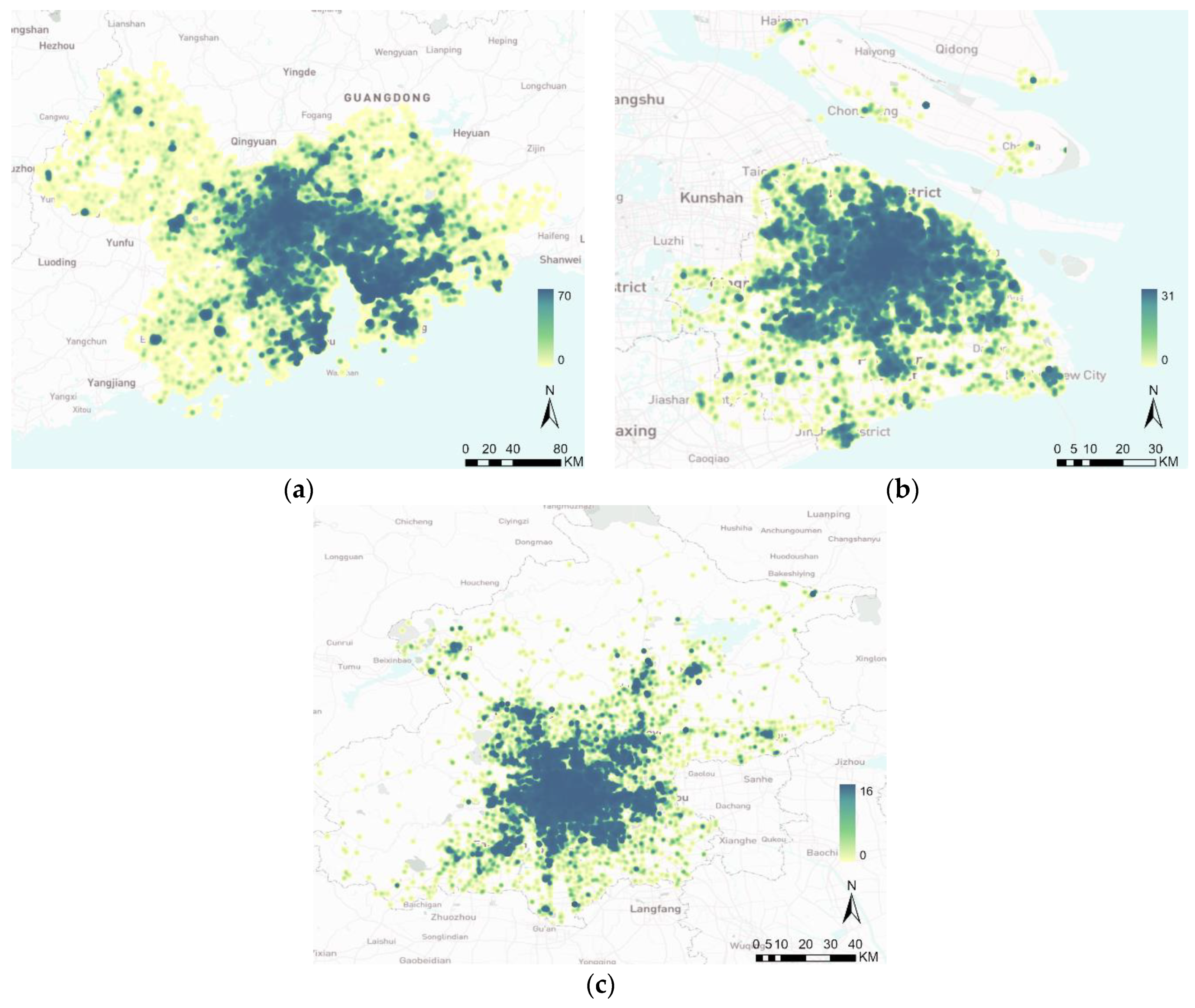
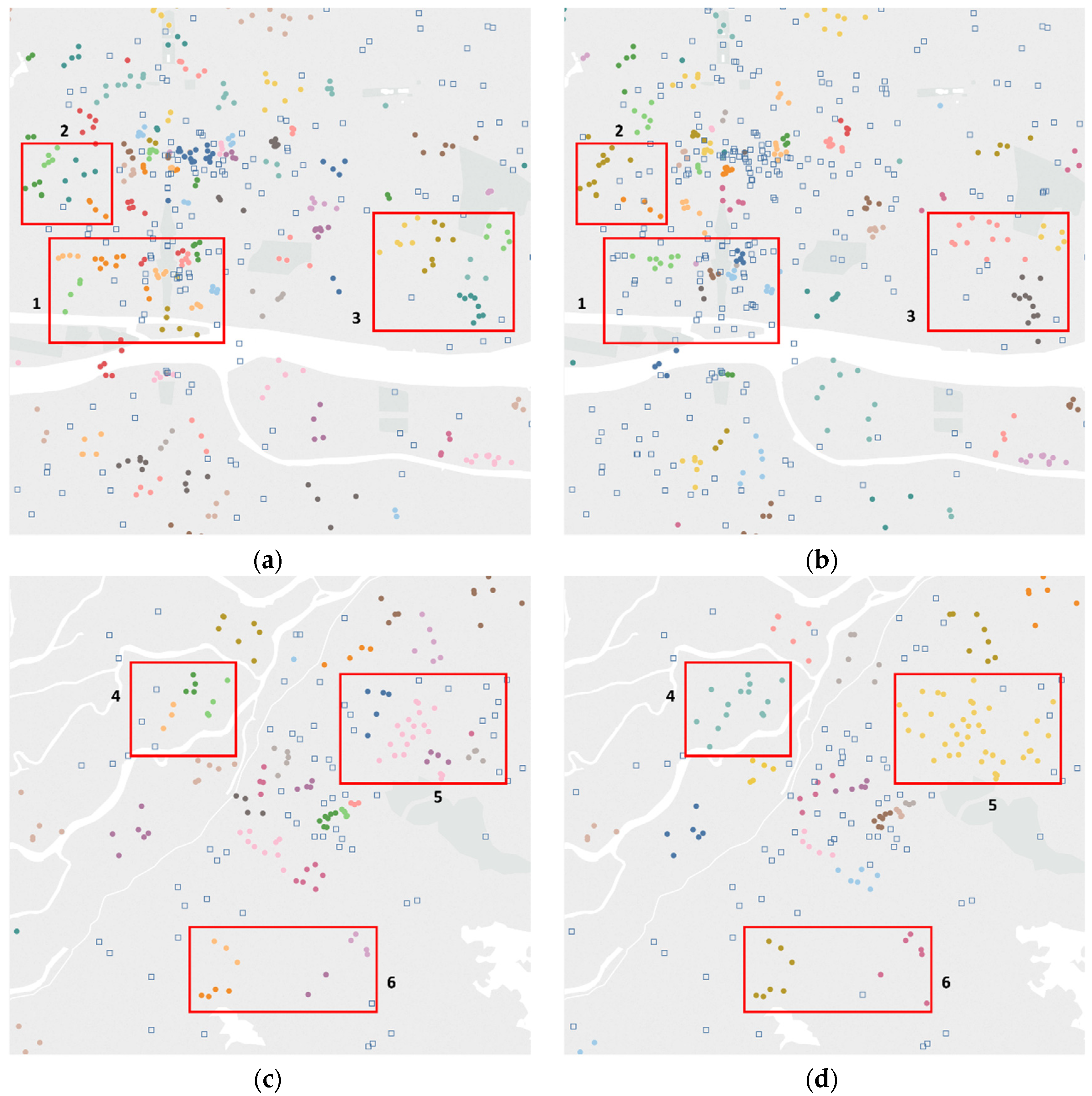
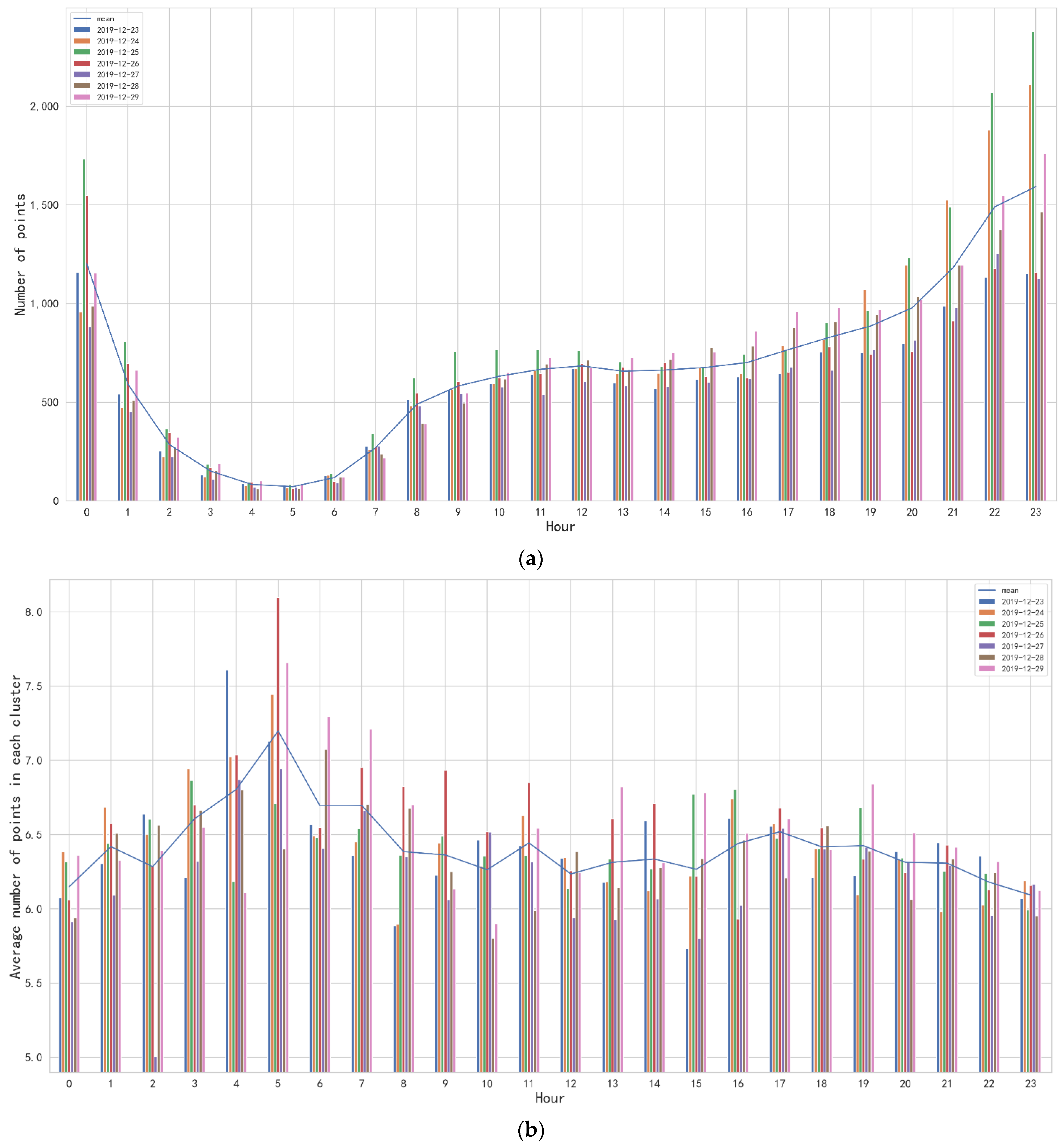
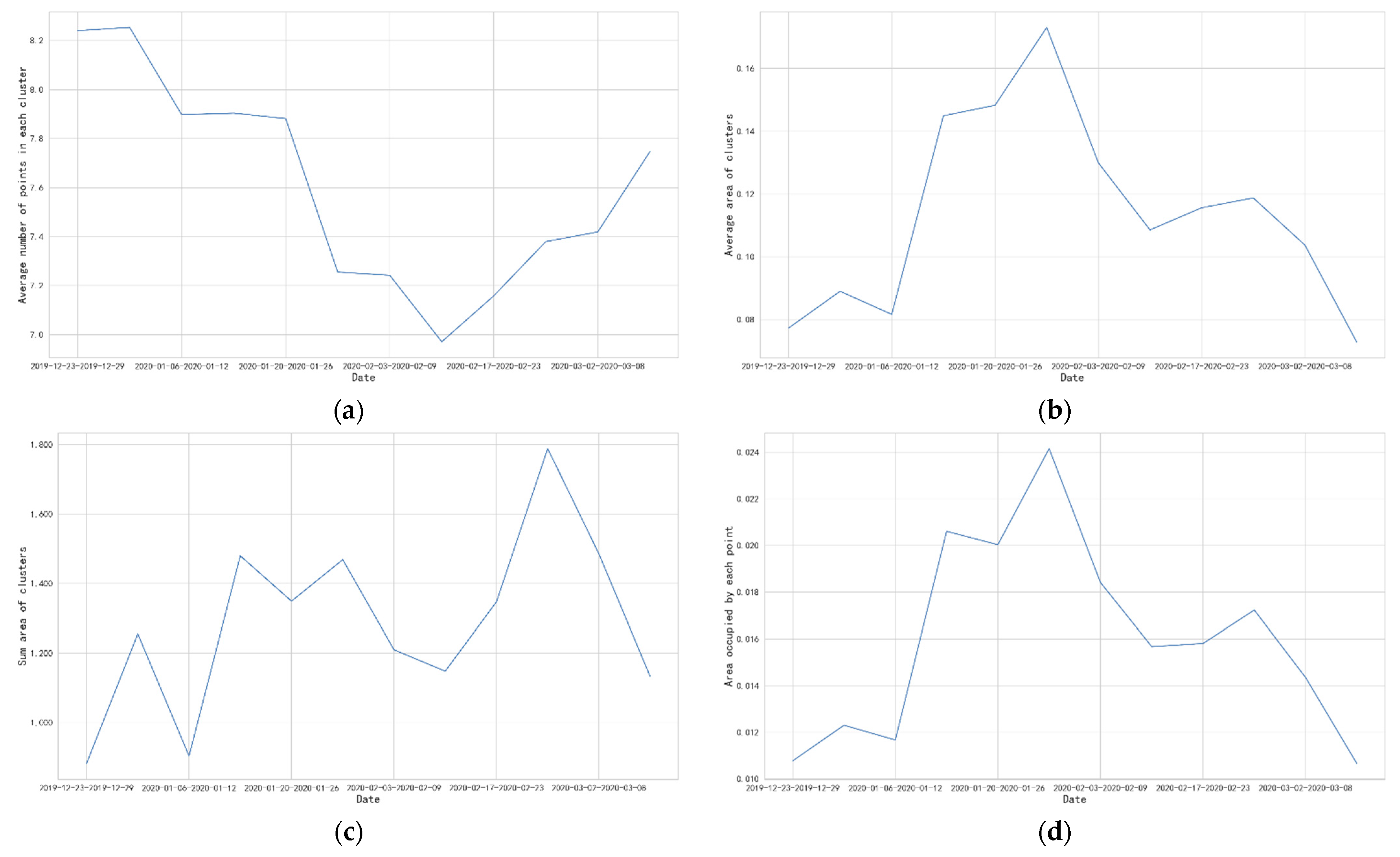
4.3. Clustering Result Analysis
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shekhar, S.; Gunturi, V.; Evans, M.R.; Yang, K. Spatial big-data challenges intersecting mobility and cloud computing. In Proceedings of the Eleventh ACM International Workshop on Data Engineering for Wireless and Mobile Access, Scottsdale, AZ, USA, 20 May 2012; pp. 1–6. [Google Scholar]
- Leszczynski, A.; Crampton, J. Introduction: Spatial big data and everyday life. Big Data Soc. 2016, 3, 2053951716661366. [Google Scholar] [CrossRef] [Green Version]
- Khan, S.; Kannapiran, T. Indexing issues in spatial big data management. In Proceedings of the International Conference on Advances in Engineering Science Management & Technology (ICAESMT)-2019, Uttaranchal University, Dehradun, India, 14 March 2019. [Google Scholar]
- Huang, Q. Mining online footprints to predict user’s next location. Int. J. Geogr. Inf. Sci. 2017, 31, 523–541. [Google Scholar] [CrossRef]
- Chen, P.; Shi, W.; Zhou, X.; Liu, Z.; Fu, X. STLP-GSM: A method to predict future locations of individuals based on geotagged social media data. Int. J. Geogr. Inf. Sci. 2019, 33, 2337–2362. [Google Scholar] [CrossRef]
- Ye, M.; Yin, P.; Lee, W.-C. Location recommendation for location-based social networks. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 458–461. [Google Scholar]
- Lim, K.H.; Chan, J.; Karunasekera, S.; Leckie, C. Tour recommendation and trip planning using location-based social media: A survey. Knowl. Inf. Syst. 2019, 60, 1247–1275. [Google Scholar] [CrossRef]
- Lian, D.; Zheng, K.; Ge, Y.; Cao, L.; Chen, E.; Xie, X. GeoMF++ scalable location recommendation via joint geographical modeling and matrix factorization. ACM Trans. Inf. Syst. 2018, 36, 33. [Google Scholar] [CrossRef]
- Jeung, H.; Yiu, M.L.; Jensen, C.S.; Chow, C.C.-Y.; Mokbel, M.M.F. Trajectory Pattern Mining. In Computing with Spatial Trajectories; Springer: Berlin/Heidelberg, Germany, 2011; pp. 143–177. [Google Scholar] [CrossRef]
- Cesario, E.; Comito, C.; Talia, D. A Comprehensive Validation Methodology for Trajectory Pattern Mining of GPS Data. In Proceedings of the 2016 IEEE 14th Intl Conf on Dependable, Autonomic and Secure Computing, 14th Intl Conf on Pervasive Intelligence and Computing, 2nd Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Auckland, New Zealand, 13 October 2016; pp. 819–826. [Google Scholar] [CrossRef]
- Yao, D.; Zhang, C.; Huang, J.; Bi, J. Serm: A recurrent model for next location prediction in semantic trajectories. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 2411–2414. [Google Scholar]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the next location: A recurrent model with spatial and temporal contexts. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Chainey, S.; Tompson, L.; Uhlig, S. The utility of hotspot mapping for predicting spatial patterns of crime. Secur. J. 2008, 21, 4–28. [Google Scholar] [CrossRef]
- Chainey, S.P. Examining the influence of cell size and bandwidth size on kernel density estimation crime hotspot maps for predicting spatial patterns of crime. Bull. Geogr. Soc. Liege 2013, 60, 7–19. [Google Scholar]
- Yang, X.; Zhao, Z.; Lu, S. Exploring spatial-temporal patterns of urban human mobility hotspots. Sustainability 2016, 8, 674. [Google Scholar] [CrossRef] [Green Version]
- Lawson, A.B. Hotspot detection and clustering: Ways and means. Environ. Ecol. Stat. 2010, 17, 231–245. [Google Scholar] [CrossRef]
- Xia, Z.; Li, H.; Chen, Y.; Liao, W. Identify and delimitate urban hotspot areas using a network-based spatiotemporal field clustering method. ISPRS Int. J. Geo-Inf. 2019, 8, 344. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Shi, W.; Zhang, H. A Two-Phase Clustering Approach for Urban Hotspot Detection with Spatiotemporal and Network Constraints. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3695–3705. [Google Scholar] [CrossRef]
- Ashbrook, D.; Starner, T. Using GPS to learn significant locations and predict movement across multiple users. Pers. Ubiquitous Comput. 2003, 7, 275–286. [Google Scholar] [CrossRef]
- Chen, Q.; Yi, H.; Hu, Y.; Xu, X.; Li, X. A New Method of Selecting K-means Initial Cluster Centers Based on Hotspot Analysis. In Proceedings of the 2018 26th International Conference on Geoinformatics, Kunming, China, 28–30 June 2018; pp. 1–6. [Google Scholar]
- Rosenberg, A.; Hirschberg, J. V-measure: A conditional entropy-based external cluster evaluation measure. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 410–420. [Google Scholar]
- Sinaga, K.P.; Yang, M.-S. Unsupervised K-means clustering algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Tang, J.; Liu, F.; Wang, Y.; Wang, H. Uncovering urban human mobility from large scale taxi GPS data. Phys. Stat. Mech. Appl. 2015, 438, 140–153. [Google Scholar] [CrossRef]
- Mohammed, A.F.; Baiee, W.R. The GIS based Criminal Hotspot Analysis using DBSCAN Technique. In Materials Science and Engineering, Proceedings of the IOP Conference Series, Thi-Qar, Iraq, 15–16 July 2020; IOP Publishing: Bristol, UK, 2020; Volume 928, p. 32081. [Google Scholar]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Huang, Q.; Gao, S. Exploring the uncertainty of activity zone detection using digital footprints with multi-scaled DBSCAN. Int. J. Geogr. Inf. Sci. 2019, 33, 1196–1223. [Google Scholar] [CrossRef]
- Campello, R.J.G.B.; Moulavi, D.; Sander, J. Density-based clustering based on hierarchical density estimates. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Gold Coast, Australia, 14–17 April 2013; pp. 160–172. [Google Scholar]
- Jarv, P.; Tammet, T.; Tall, M. Hierarchical regions of interest. In Proceedings of the 2018 19th IEEE International Conference on Mobile Data Management (MDM), Aalborg, Denmark, 25–28 June 2018; pp. 86–95. [Google Scholar] [CrossRef]
- Korakakis, M.; Spyrou, E.; Mylonas, P.; Perantonis, S.J. Exploiting social media information toward a context-aware recommendation system. Soc. Netw. Anal. Min. 2017, 7, 42. [Google Scholar] [CrossRef]
- Singh, P.; Bose, S.S. Ambiguous D-means fusion clustering algorithm based on ambiguous set theory: Special application in clustering of CT scan images of COVID-19. Knowl.-Based Syst. 2021, 231, 107432. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhao, K.; Xia, K.; Xue, J.; Zhou, L.; Ding, Y.; Qian, P. A novel distributed multitask fuzzy clustering algorithm for automatic MR brain image segmentation. J. Med. Syst. 2019, 43, 118. [Google Scholar] [CrossRef]
- Liu, Y.; Kang, C.; Gao, S.; Xiao, Y.; Tian, Y. Understanding intra-urban trip patterns from taxi trajectory data. J. Geogr. Syst. 2012, 14, 463–483. [Google Scholar] [CrossRef]
- Yao, Z.; Zhong, Y.; Liao, Q.; Wu, J.; Liu, H.; Yang, F. Understanding human activity and urban mobility patterns from massive cellphone data: Platform design and applications. IEEE Intell. Transp. Syst. Mag. 2020, 13, 206–219. [Google Scholar] [CrossRef]
- Jiang, S.; Ferreira, J.; Gonzalez, M.C. Activity-based human mobility patterns inferred from mobile phone data: A case study of Singapore. IEEE Trans. Big Data 2017, 3, 208–219. [Google Scholar] [CrossRef] [Green Version]
- Zhong, C.; Batty, M.; Manley, E.; Wang, J.; Wang, Z.; Chen, F.; Schmitt, G. Variability in regularity: Mining temporal mobility patterns in London, Singapore and Beijing using smart-card data. PLoS ONE 2016, 11, e0149222. [Google Scholar]
- Yang, F.; Ding, F.; Qu, X.; Ran, B. Estimating urban shared-bike trips with location-based social networking data. Sustainability 2019, 11, 3220. [Google Scholar] [CrossRef] [Green Version]
- Qiao, S.; Han, N.; Huang, J.; Yue, K.; Mao, R.; Shu, H.; He, Q.; Wu, X. A Dynamic Convolutional Neural Network Based Shared-Bike Demand Forecasting Model. ACM Trans. Intell. Syst. Technol. 2021, 12, 70. [Google Scholar] [CrossRef]
- Cai, L.; Jiang, F.; Zhou, W.; Li, K. Design and application of an attractiveness index for urban hotspots based on GPS trajectory data. IEEE Access 2018, 6, 55976–55985. [Google Scholar] [CrossRef]
- Kang, C.; Qin, K. Understanding operation behaviors of taxicabs in cities by matrix factorization. Comput. Environ. Urban Syst. 2016, 60, 79–88. [Google Scholar] [CrossRef]
- Zhao, S.; Zhao, P.; Cui, Y. A network centrality measure framework for analyzing urban traffic flow: A case study of Wuhan, China. Phys. Stat. Mech. Appl. 2017, 478, 143–157. [Google Scholar] [CrossRef]
- Lv, Q.; Qiao, Y.; Ansari, N.; Liu, J.; Yang, J. Big Data Driven Hidden Markov Model Based Individual Mobility Prediction at Points of Interest. IEEE Trans. Veh. Technol. 2017, 66, 5204–5216. [Google Scholar] [CrossRef]
- Shen, P.; Ouyang, L.; Wang, C.; Shi, Y.; Su, Y. Cluster and characteristic analysis of Shanghai metro stations based on metro card and land-use data. Geo-Spat. Inf. Sci. 2020, 23, 352–361. [Google Scholar] [CrossRef]
- Chen, C.-F.; Huang, C.-Y. Investigating the effects of a shared bike for tourism use on the tourist experience and its consequences. Curr. Issues Tour. 2021, 24, 134–148. [Google Scholar] [CrossRef]
- Sun, X.; Huang, Z.; Peng, X.; Chen, Y.; Liu, Y. Building a model-based personalised recommendation approach for tourist attractions from geotagged social media data. Int. J. Digit. Earth 2019, 12, 661–678. [Google Scholar] [CrossRef]
- Cai, J.; Wei, H.; Yang, H.; Zhao, X. A novel clustering algorithm based on DPC and PSO. IEEE Access 2020, 8, 88200–88214. [Google Scholar] [CrossRef]
- Lin, K.; Chen, H.; Xu, C.-Y.; Yan, P.; Lan, T.; Liu, Z.; Dong, C. Assessment of flash flood risk based on improved analytic hierarchy process method and integrated maximum likelihood clustering algorithm. J. Hydrol. 2020, 584, 124696. [Google Scholar] [CrossRef]
- Lei, Y.; Zhou, Y.; Shi, J. Overlapping communities detection of social network based on hybrid C-means clustering algorithm. Sustain. Cities Soc. 2019, 47, 101436. [Google Scholar] [CrossRef]
- Oskouei, A.G.; Hashemzadeh, M.; Asheghi, B.; Balafar, M.A. CGFFCM: Cluster-weight and Group-local Feature-weight learning in Fuzzy C-Means clustering algorithm for color image segmentation. Appl. Soft Comput. 2021, 113, 108005. [Google Scholar] [CrossRef]
- Benabdellah, A.C.; Benghabrit, A.; Bouhaddou, I. A survey of clustering algorithms for an industrial context. Procedia Comput. Sci. 2019, 148, 291–302. [Google Scholar] [CrossRef]
- Ahmad, A.; Khan, S.S. Survey of state-of-the-art mixed data clustering algorithms. IEEE Access 2019, 7, 31883–31902. [Google Scholar] [CrossRef]
- Aggarwal, C.C. A survey of stream clustering algorithms. In Data Clustering; Chapman and Hall/CRC: London, UK, 2018; pp. 231–258. [Google Scholar]
- Tabarej, M.S.; Minz, S. Rough-set based hotspot detection in spatial data. In Proceedings of the International Conference on Advances in Computing and Data Sciences, Ghaziabad, India, 12–13 April 2019; pp. 356–368. [Google Scholar]
- Hu, Y.; Huang, H.; Chen, A.; Mao, X.-L. Weibo-COV: A Large-Scale COVID-19 Social Media Dataset from Weibo. In Proceedings of the 1st Workshop on NLP for COVID-19 (Part 2) at EMNLP 2020, Online, 20 November 2020; Association for Computational Linguistics: Cambridge, MA, USA, 2020. [Google Scholar]
- Esri Inc. ArcGIS Pro; Esri Inc.: Redlands, CA, USA; Available online: https://www.esri.com/en-us/arcgis/products/arcgis-pro/overview (accessed on 1 June 2020).
- Batt, S.; Grealis, T.; Harmon, O.; Tomolonis, P. Learning Tableau: A data visualization tool. J. Econ. Educ. 2020, 51, 317–328. [Google Scholar] [CrossRef]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 56–61. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Astels, S. hdbscan: Hierarchical density based clustering. J. Open Source Softw. 2017, 2, 205. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M.L. Seaborn: Statistical data visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Strehl, A.; Ghosh, J. Cluster ensembles—A knowledge reuse framework for combining multiple partitions. J. Mach. Learn. Res. 2002, 3, 583–617. [Google Scholar]
- Steinley, D. Properties of the hubert-arable adjusted rand index. Psychol. Methods 2004, 9, 386. [Google Scholar] [CrossRef]
- Yu, H.; Liu, P.; Chen, J.; Wang, H. Comparative analysis of the spatial analysis methods for hotspot identification. Accid. Anal. Prev. 2014, 66, 80–88. [Google Scholar] [CrossRef]
- Shen, X.; Shi, W.; Chen, P.; Liu, Z.; Wang, L. Novel model for predicting individuals’ movements in dynamic regions of interest. GIScience Remote Sens. 2022, 59, 250–271. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GBA Dataset | Shanghai Dataset | Beijing Dataset | |
|---|---|---|---|
| Time span | 2019-12-23 to 2020-03-15 | 2020-7-6 to 2020-7-12 | 2019-12-23 to 2019-12-29 |
| Space span | 56,097 km2 | 6340 km2 | 16,410 km2 |
| Number of cities | 11 | 1 | 1 |
| Total records | 1,299,106 | 79,655 | 105,254 |
| Algorithm | Parameter | Description | Value |
|---|---|---|---|
| DPC | distance threshold used to extract cluster centers | 7000 | |
| density threshold used to extract cluster centers | 50 | ||
| DBSCAN | min number of points in neighborhoods of core points | 4 | |
| distance to define the size of neighborhoods | 200, 400, 800, and 1600 | ||
| HDBSCAN | minimum cluster size | 4, 8, 16, and 32 |
| Methods | Number of Clusters | Average Number of Points in Each Cluster | Clustered Points | Noise Points | ||
|---|---|---|---|---|---|---|
| Number | Ratio | Number | Ratio | |||
| ELV | 1660 | 6.78 | 11,252 | 78.97% | 2996 | 21.03% |
| DPC | 18 | 434.78 | 7826 | 54.93% | 6422 | 45.07% |
| DBSCAN 200 | 586 | 9.60 | 5624 | 39.47% | 8624 | 60.53% |
| DBSCAN 400 | 599 | 15.09 | 9041 | 63.45% | 5207 | 36.55% |
| DBSCAN 800 | 422 | 28.11 | 11,863 | 83.26% | 2385 | 16.74% |
| DBSCAN 1600 | 211 | 63.53 | 13,405 | 94.08% | 843 | 5.92% |
| HDBSCAN 4 | 952 | 10.52 | 10,013 | 70.28% | 4235 | 29.72% |
| HDBSCAN 8 | 405 | 21.34 | 8642 | 60.65% | 5606 | 39.35% |
| HDBSCAN 16 | 172 | 45.46 | 7819 | 54.88% | 6429 | 45.12% |
| HDBSCAN 32 | 68 | 107.88 | 7336 | 51.49% | 6912 | 48.51% |
| Silhouette Coefficient (SC) | ELV | DCP | DBSCAN | HDBSCAN | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 200 | 400 | 800 | 1600 | 4 | 8 | 16 | 32 | ||||
| GBA dataset | 2019/12/23 | 0.3 | −0.01 | −0.27 | −0.12 | −0.07 | −0.07 | 0.18 | 0.04 | −0.06 | −0.1 |
| 2019/12/24 | 0.29 | −0.04 | −0.22 | −0.11 | −0.1 | −0.09 | 0.16 | 0.04 | −0.05 | −0.12 | |
| 2019/12/25 | 0.31 | −0.03 | −0.19 | −0.1 | −0.14 | −0.07 | 0.18 | 0.04 | −0.05 | −0.09 | |
| 2019/12/26 | 0.29 | −0.04 | −0.24 | −0.12 | −0.08 | −0.07 | 0.18 | 0.04 | −0.06 | −0.12 | |
| 2019/12/27 | 0.31 | −0.05 | −0.29 | −0.13 | −0.07 | −0.06 | 0.19 | 0.03 | −0.07 | −0.1 | |
| 2019/12/28 | 0.31 | −0.06 | −0.2 | −0.05 | −0.12 | −0.09 | 0.2 | 0.05 | −0.05 | −0.08 | |
| 2019/12/29 | 0.33 | −0.02 | −0.16 | −0.06 | −0.12 | −0.11 | 0.19 | 0.09 | −0.03 | −0.08 | |
| First week | 0.41 | \ | −0.04 | −0.22 | −0.33 | −0.55 | 0.31 | 0.16 | 0.04 | −0.03 | |
| Average value of all weeks | 0.4 | \ | −0.06 | −0.18 | −0.3 | −0.54 | 0.3 | 0.14 | 0.02 | −0.04 | |
| Whole dataset | 0.42 | \ | −0.34 | −0.53 | −0.66 | −0.63 | 0.36 | 0.29 | 0.19 | 0.09 | |
| Shanghai dataset | 0.59 | \ | −0.01 | −0.33 | −0.21 | 0.19 | 0.51 | 0.35 | 0.19 | 0.06 | |
| Beijing dataset | 0.55 | \ | −0.24 | −0.32 | −0.14 | 0.03 | 0.48 | 0.33 | 0.18 | 0.06 | |
| Calinski–Harabasz Index (CHI) | ELV | DCP | DBSCAN | HDBSCAN | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 200 | 400 | 800 | 1600 | 4 | 8 | 16 | 32 | ||||
| GBA dataset | 2019/12/23 | 4728 | 229 | 218 | 433 | 715 | 1238 | 1172 | 462 | 293 | 182 |
| 2019/12/24 | 4259 | 160 | 363 | 692 | 891 | 1658 | 1319 | 640 | 323 | 221 | |
| 2019/12/25 | 5894 | 246 | 451 | 995 | 1055 | 1467 | 1309 | 500 | 373 | 261 | |
| 2019/12/26 | 5635 | 199 | 282 | 592 | 813 | 1202 | 1217 | 518 | 282 | 146 | |
| 2019/12/27 | 5236 | 148 | 180 | 452 | 703 | 1110 | 1376 | 507 | 212 | 194 | |
| 2019/12/28 | 5029 | 158 | 413 | 999 | 789 | 1146 | 1248 | 494 | 251 | 288 | |
| 2019/12/29 | 5166 | 203 | 644 | 897 | 731 | 1157 | 1303 | 728 | 367 | 255 | |
| First week | 51,689 | \ | 3713 | 2563 | 2636 | 267 | 10,127 | 3394 | 1484 | 931 | |
| Average value of all weeks | 38,210 | \ | 3406 | 3212 | 2297 | 247 | 11,167 | 3085 | 1242 | 832 | |
| Whole dataset | 354,652 | \ | 936 | 430 | 82 | 70 | 100,043 | 22,395 | 5553 | 2151 | |
| Shanghai dataset | 47,865 | \ | 917 | 535 | 436 | 484 | 26,206 | 6220 | 2229 | 916 | |
| Beijing dataset | 19,526 | \ | 312 | 455 | 579 | 457 | 11,817 | 5274 | 1707 | 839 | |
| Strengths | Weaknesses | |
|---|---|---|
| ELV | No manual parameter setting; Considering features of individual clusters; Fine-grained clusters generated by re-segmentation; Reduced noise points benefitting from noise recovery; Good performance on varying density spatial data | Low universality due to the special design for large-scale spatial data; Relatively slow processing efficiency; |
| DPC | Clear parameter selection method; Efficient high-density region extraction; | Manual parameter setting; Much slow processing efficiency on large-scale data; Neglect of low-density areas; |
| DBSCAN | High universality; High processing efficiency even on large-scale data; Efficient high-density region extraction with low noise ratio using large ; Fine-grained clusters generated using small ; | Manual parameter setting; Too many points divided into several clusters using large ; Too much noise points generated using small ; |
| HDBSCAN | High processing efficiency even on large-scale data; Only one parameter defining the min points in a cluster; Relatively good performance on varying density spatial data; | Manual parameter setting; Lots of noise points in high-density areas; Too many points divided into several clusters into low-density areas. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, X.; Shi, W.; Liu, Z.; Zhang, A.; Wang, L.; Zeng, F. Extracting Human Activity Areas from Large-Scale Spatial Data with Varying Densities. ISPRS Int. J. Geo-Inf. 2022, 11, 397. https://doi.org/10.3390/ijgi11070397
Shen X, Shi W, Liu Z, Zhang A, Wang L, Zeng F. Extracting Human Activity Areas from Large-Scale Spatial Data with Varying Densities. ISPRS International Journal of Geo-Information. 2022; 11(7):397. https://doi.org/10.3390/ijgi11070397
Chicago/Turabian StyleShen, Xiaoqi, Wenzhong Shi, Zhewei Liu, Anshu Zhang, Lukang Wang, and Fanxin Zeng. 2022. "Extracting Human Activity Areas from Large-Scale Spatial Data with Varying Densities" ISPRS International Journal of Geo-Information 11, no. 7: 397. https://doi.org/10.3390/ijgi11070397
APA StyleShen, X., Shi, W., Liu, Z., Zhang, A., Wang, L., & Zeng, F. (2022). Extracting Human Activity Areas from Large-Scale Spatial Data with Varying Densities. ISPRS International Journal of Geo-Information, 11(7), 397. https://doi.org/10.3390/ijgi11070397