
The Missing Millions in Maps: Exploring Causes of Uncertainties in Global Gridded Population Datasets




Abstract
:
1. Introduction
- What is the relatedness of GHS-POP and local population data at the lowest available administrative level?
- What is the relationship between the spatial pattern of over-and underestimated areas and the types of land use?
- What are the implications for the use of presently available population data in urban growth models?
2. Gridded Population Models—Their Strengths and Limitations
3. Materials and Methods
3.1. Accuracy Assessment Approach
3.2. Selection of Case Studies
3.3. Comparison of Case Studies: Spatial Patterns of Uncertainties
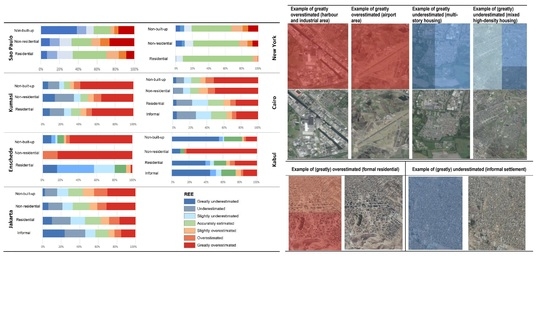
4. Results
4.1. Overall Error Estimation per Case Study
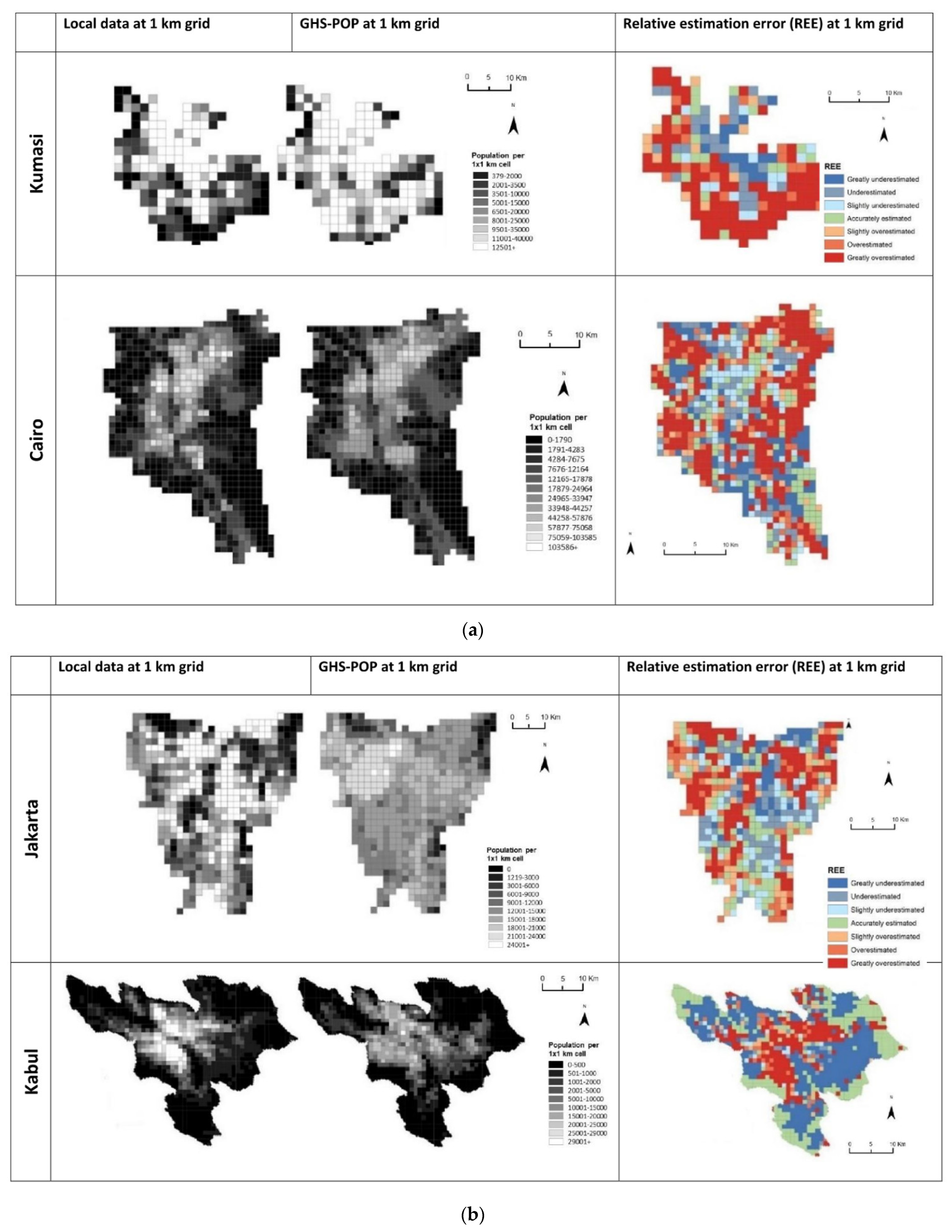
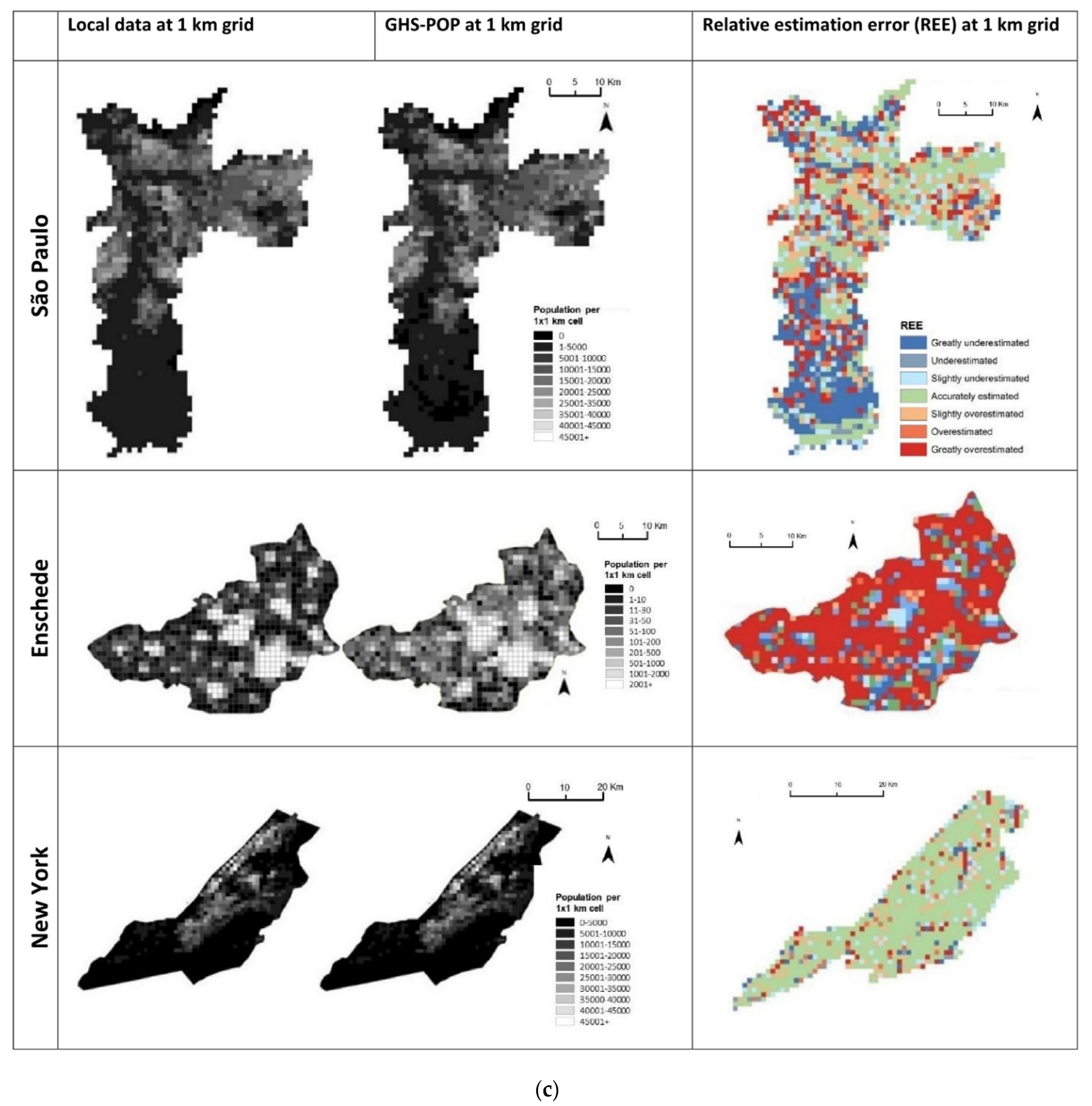
4.2. Spatial Patterns of Errors
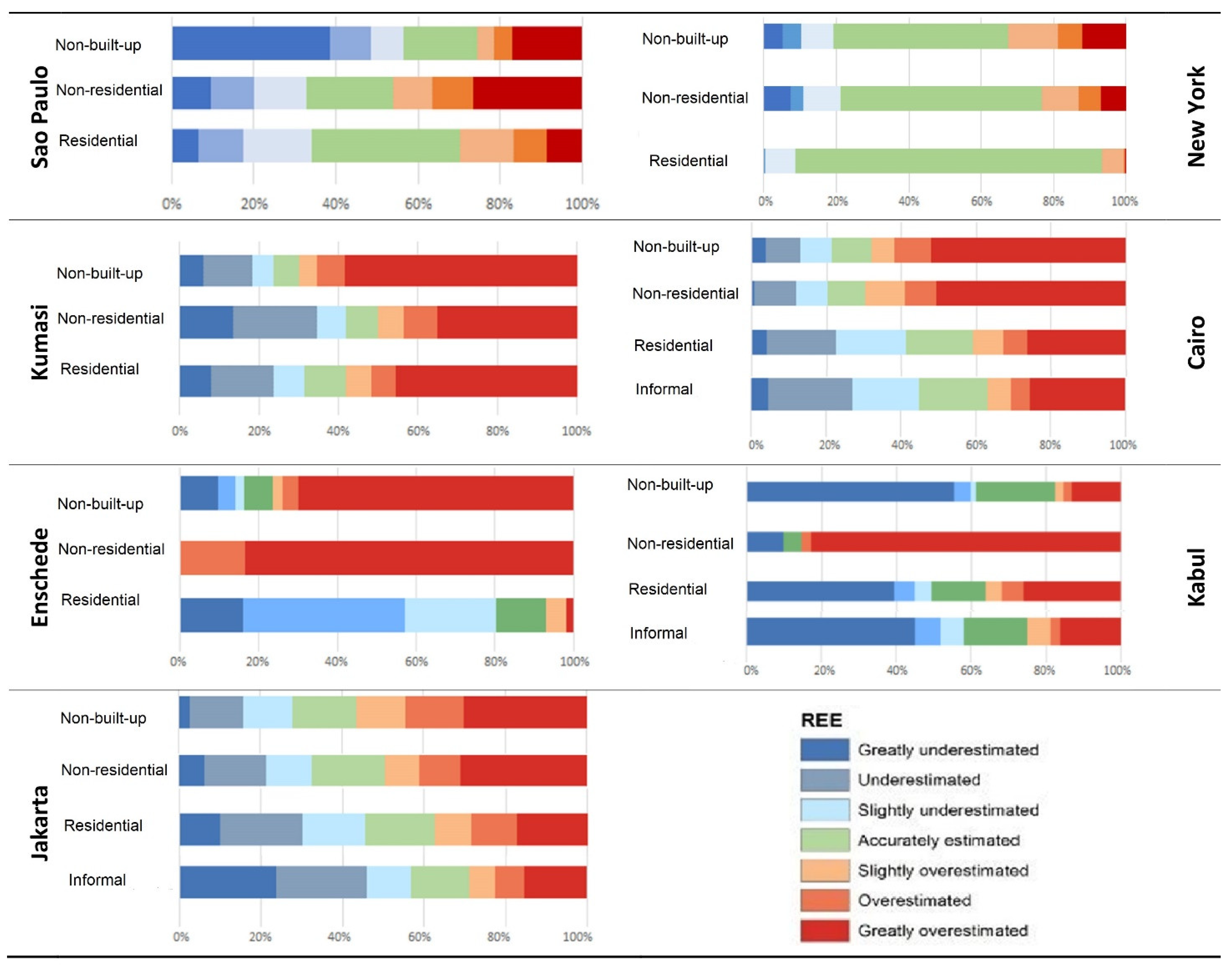
4.3. Land Use and Population Distribution Relationships
5. Discussion
5.1. What Are the Common Issues across All Case Studies?
5.2. What Are the Recommendations for Built-Up Modellers When Using the Data?
5.3. What Are the Recommendations for Population Modellers to Improve Their Models?
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Dataset name | Population Concept | Methods | Resolution | Source | Years | Coverage | Ancillary Data | Distribution Policy |
| Gridded Population of the World v4 | Night-time | Areal weighted | 1 km | Columbia University— Center for International Earth Science Information Network (CIESIN) https://sedac.ciesin.columbia.edu/data/collection/gpw-v4 (accessed on 15 June 2022) | 2000, 2005, 2010, 2015, 2020 | Global | ☑*7,8 | Open access |
| Global Human Settlement Population (GHS-POP) | Night-time | Binary dasymetric model (using GHSL built-up and census population) | 250 m 1 km | European Commission Joint Research Centre (JRC) and CIESIN—Columbia University https://ghsl.jrc.ec.europa.eu/ghs_pop.php (accessed on 15 June 2022) | 1975, 1990, 2000, 2015 | Global | ☑*2 | Open access |
| Global Rural Urban Mapping Project (GRUMP) | Night-time | Binary dasymetric model (using DMSP-OLS night-time lights and census population data) | 1 km | CIESIN; International Food Policy Research Institute (IFPRI), The World Bank, Centro International de Agricultural Tropical (CIAT) https://sedac.ciesin.columbia.edu/data/collection/grump-v1 (accessed on 15 June 2022) | 1990, 1995, 2000 | Global | ☑*4,7,8,9 | Open access |
| History Database of the Global Environment (HYDE) Population Grids, version 3.1 | Night-time | Spatially explicit dasymetric model (using historical population, cropland and pasture statistics, satellite information and specific allocation algorithm) | 10 km | Netherlands Environmental Assessment Agency (PBL) https://themasites.pbl.nl/tridion/en/themasites/hyde/download/index-2.html (accessed on 15 June 2022) | 10,000 BC to 2015 | Global | ☑*1 | Open access |
| LandScan Global Population database | Ambient | Multi-variable dasymetric model (using spatial data and imagery for the population allocation to each country and region) | 1 km | Oak Ridge National Laboratory (ORNL) https://landscan.ornl.gov/ (accessed on 15 June 2022) | 2000–2017 (annual release) | Global (100 m is available for 23 countries) | ☑*1–9 | Paid/ free for research purpose |
| High Resolution Settlement Layer (HRSL) | Night-time | Binary dasymetric | 30 m | Facebook, CIESIN, and the World Bank https://ciesin.columbia.edu/data/hrsl/ (accessed on 15 June 2022) | 2015–2019 | 140 countries | ☑*1,2,3,5,7,8 | Open access |
| World Population Estimate (WPE) | Night-time | Dasymetric redistribution (Smart) | 150 m 250 m | Environmental System Research Institute (ESRI) https://sites.google.com/ciesin.columbia.edu/popgrid/find-data/esri (accessed on 15 June 2022) | 2013, 2015 and 2016 (150 m) | Global | ☑*1,3,8,9 | Paid |
| WorldPop | Night-time | Random forest Dasymetric | 100 m | WorldPop, University of Southampton https://www.worldpop.org/ (accessed on 15 June 2022) | 2000–2020 | Global and country specific years | ☑*1–9 | Open access |
| LandScan HD | Ambient | 100 m | Oak Ridge National Laboratory https://landscan.ornl.gov/ (accessed on 15 June 2022) | Not specific (varying) | 23 countries | ☑*1–9 | Paid/ free for research purpose | |
| *1 Land cover/use, *2 built-up, *3 roads, *4 night-time lights, *5 infrastructure, *6 environmental/topographic data, *7 protected areas, *8 waterbodies, *9 cities or urban areas. | ||||||||
References
- United Nations. Demographic and Social Statistics. Available online: https://unstats.un.org/unsd/demographic-social/census/document-resources/ (accessed on 14 December 2020).
- Boo, G.; Darin, E.; Leasure, D.R.; Dooley, C.A.; Chamberlain, H.R.; Lázár, A.N.; Tschirhart, K.; Sinai, C.; Hoff, N.A.; Fuller, T.; et al. High-resolution population estimation using household survey data and building footprints. Nat. Commun. 2022, 13, 1330. [Google Scholar] [CrossRef] [PubMed]
- Weber, E.M.; Seaman, V.Y.; Stewart, R.N.; Bird, T.J.; Tatem, A.J.; McKee, J.J.; Bhaduri, B.L.; Moehl, J.J.; Reith, A.E. Census-independent population mapping in northern Nigeria. Remote Sens. Environ. 2018, 204, 786–798. [Google Scholar] [CrossRef] [PubMed]
- Leyk, S.; Uhl, J.H.; Balk, D.; Jones, B. Assessing the accuracy of multi-temporal built-up land layers across rural-urban trajectories in the United States. Remote Sens. Environ. 2018, 204, 898–917. [Google Scholar] [CrossRef] [PubMed]
- Kavvada, A.; Metternicht, G.; Kerblat, F.; Mudau, N.; Haldorson, M.; Laldaparsad, S.; Friedl, L.; Held, A.; Chuvieco, E. Towards delivering on the sustainable development goals using earth observations. Remote Sens. Environ. 2020, 247, 111930. [Google Scholar] [CrossRef]
- United Nations Statistics Division. The Sustainable Development Goals Report. 2018. Available online: https://unstats.un.org/sdgs/report/2018/overview/ (accessed on 9 December 2019).
- Engstrom, R.; Newhouse, D.; Soundararajan, V. Estimating Small Area Population Density Using Survey Data and Satellite Imagery: An Application to Sri Lanka; World Bank: Washington, DC, USA, 2019. [Google Scholar]
- Lloyd, C.T.; Chamberlain, H.; Kerr, D.; Yetman, G.; Pistolesi, L.; Stevens, F.R.; Gaughan, A.E.; Nieves, J.J.; Hornby, G.; MacManus, K.; et al. Global spatio-temporally harmonised datasets for producing high-resolution gridded population distribution datasets. Big Earth Data 2019, 3, 108–139. [Google Scholar] [CrossRef] [Green Version]
- Qiu, G.; Bao, Y.; Yang, X.; Wang, C.; Ye, T.; Stein, A.; Jia, P. Local Population Mapping Using a Random Forest Model Based on Remote and Social Sensing Data: A Case Study in Zhengzhou, China. Remote Sens. 2020, 12, 1618. [Google Scholar] [CrossRef]
- Thomson, D.R.; Stevens, F.R.; Ruktanonchai, N.W.; Tatem, A.J.; Castro, M.C. GridSample: An R package to generate household survey primary sampling units (PSUs) from gridded population data. Int. J. Health Geogr. 2017, 16, 25. [Google Scholar] [CrossRef] [Green Version]
- Thomson, D.R.; Rhoda, D.A.; Tatem, A.J.; Castro, M.C. Gridded population survey sampling: A systematic scoping review of the field and strategic research agenda. Int. J. Health Geogr. 2020, 19, 34. [Google Scholar] [CrossRef]
- Schiavina, M.; Freire, S.; MacManus, K. GHS Population Grid Multitemporal (1975, 1990, 2000, 2015) R2019A; European Commission, Joint Research Centre (JRC), Eds.; European Commission: Brussels, Belgium, 2019. [Google Scholar]
- Badmos, O.S.; Rienow, A.; Callo-Concha, D.; Greve, K.; Jürgens, C. Simulating slum growth in Lagos: An integration of rule based and empirical based model. Comput. Environ. Urban Syst. 2019, 77, 101369. [Google Scholar] [CrossRef]
- Pérez-Molina, E.; Sliuzas, R.; Flacke, J.; Jetten, V. Developing a cellular automata model of urban growth to inform spatial policy for flood mitigation: A case study in Kampala, Uganda. Comput. Environ. Urban Syst. 2017, 65, 53–65. [Google Scholar] [CrossRef]
- Nduwayezu, G.; Sliuzas, R.; Kuffer, M. Modeling urban growth in Kigali city Rwanda. Rwanda J. 2016, 1, 82–87. [Google Scholar] [CrossRef] [Green Version]
- Wardrop, N.A.; Jochem, W.C.; Bird, T.J.; Chamberlain, H.R.; Clarke, D.; Kerr, D.; Bengtsson, L.; Juran, S.; Seaman, V.; Tatem, A.J. Spatially disaggregated population estimates in the absence of national population and housing census data. Proc. Natl. Acad. Sci. USA 2018, 115, 3529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carr-Hill, R. Missing millions and measuring development progress. World Dev. 2013, 46, 30–44. [Google Scholar] [CrossRef]
- Roy, D.; Lees, M.H.; Pfeffer, K.; Sloot, P. Modelling the impact of household life cycle on slums in Bangalore. Comput. Environ. Urban Syst. 2017, 64, 275–287. [Google Scholar] [CrossRef]
- Openshaw, S. The Modifiable Areal Unit Problem; Geobooks: Norwich, UK, 1984. [Google Scholar]
- Balk, D.L.; Deichmann, U.; Yetman, G.; Pozzi, F.; Hay, S.I.; Nelson, A. Determining Global Population Distribution: Methods, Applications and Data. In Advances in Parasitology; Hay, S.I., Graham, A., Rogers, D.J., Eds.; Academic Press: Cambridge, MA, USA, 2006; Volume 62, pp. 119–156. [Google Scholar]
- Doxsey-Whitfield, E.; MacManus, K.; Adamo, S.B.; Pistolesi, L.; Squires, J.; Borkovska, O.; Baptista, S.R. Taking Advantage of the Improved Availability of Census Data: A First Look at the Gridded Population of the World, Version 4. Pap. Appl. Geogr. 2015, 1, 226–234. [Google Scholar] [CrossRef]
- Freire, S.; Macmanus, K.; Pesaresi, M.; Doxsey-Whitfield, E.; Mills, J. Development of New Open and Free Multi-Temporal Global Population Grids at 250 m Resolution; Geospatial Data in a Changing World; Association of Geographic Information Laboratories in Europe (AGILE) (Organiser); AGILE: Helsinki, Finland, 2016. [Google Scholar]
- Chen, R.; Yan, H.; Liu, F.; Du, W.; Yang, Y. Multiple Global Population Datasets: Differences and Spatial Distribution Characteristics. ISPRS Int. J. Geo-Inf. 2020, 9, 637. [Google Scholar] [CrossRef]
- McEvedy, C.; Jones, R. Atlas of World Population History; Pengium Books Ltd.: New York, NY, USA; Allen Lane: New York, NY, USA, 1979. [Google Scholar]
- Ye, T.; Zhao, N.; Yang, X.; Ouyang, Z.; Liu, X.; Chen, Q.; Hu, K.; Yue, W.; Qi, J.; Li, Z.; et al. Improved population mapping for China using remotely sensed and points-of-interest data within a random forests model. Sci. Total Environ. 2019, 658, 936–946. [Google Scholar] [CrossRef]
- Stevens, F.R.; Gaughan, A.E.; Nieves, J.J.; King, A.; Sorichetta, A.; Linard, C.; Tatem, A.J. Comparisons of two global built area land cover datasets in methods to disaggregate human population in eleven countries from the global South. Int. J. Digit. Earth 2020, 13, 78–100. [Google Scholar] [CrossRef]
- Kit, O.; Lüdeke, M.; Reckien, D. Defining the bull’s eye: Satellite imagery-assisted slum population assessment in Hyderabad, India. Urban Geogr. 2013, 34, 413–424. [Google Scholar] [CrossRef]
- Schwarz, N.; Flacke, J.; Sliuzas, R.V. Modelling the impacts of urban upgrading on population dynamics. Environ. Model. Softw. 2016, 78, 150–162. [Google Scholar] [CrossRef]
- Wu, C.; Murray, A.T. Population Estimation Using Landsat Enhanced Thematic Mapper Imagery. Geogr. Anal. 2007, 39, 26–43. [Google Scholar] [CrossRef]
- Roni, R.; Jia, P. An Optimal Population Modeling Approach Using Geographically Weighted Regression Based on High-Resolution Remote Sensing Data: A Case Study in Dhaka City, Bangladesh. Remote Sens. 2020, 12, 1184. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Gaughan, A.E.; Stevens, F.R.; Huang, Z.; Nieves, J.J.; Sorichetta, A.; Lai, S.; Ye, X.; Linard, C.; Hornby, G.M.; Hay, S.I.; et al. Spatiotemporal patterns of population in mainland China, 1990 to 2010. Sci. Data 2016, 3, 160005. [Google Scholar] [CrossRef] [PubMed]
- Leyk, S.; Gaughan, A.E.; Adamo, S.B.; de Sherbinin, A.; Balk, D.; Freire, S.; Rose, A.; Stevens, F.R.; Blankespoor, B.; Frye, C.; et al. The spatial allocation of population: A review of large-scale gridded population data products and their fitness for use. Earth Syst. Sci. Data 2019, 11, 1385–1409. [Google Scholar] [CrossRef] [Green Version]
- Thomson, D.R.; Gaughan, A.E.; Stevens, F.R.; Yetman, G.; Elias, P.; Chen, R. Evaluating the Accuracy of Gridded Population Estimates in Slums: A Case Study in Nigeria and Kenya. Urban Sci. 2021, 5, 48. [Google Scholar] [CrossRef]
- Kuffer, M.; Persello, C.; Pfeffer, K.; Sliuzas, R.; Rao, V. Do we underestimate the global slum population? In Proceedings of the 2019 Joint Urban Remote Sensing Event (JURSE), Vannes, France, 22–24 May 2019; pp. 1–4. [Google Scholar]
- Sliuzas, R.; Kuffer, M.; Kemper, T. Assessing the quality of Global Human Settlement Layer products for Kampala, Uganda. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, United Arab Emirates, 6–8 March 2017; pp. 1–4. [Google Scholar]
- Aubrecht, C.; Gunasekera, R.; Ungar, J.; Ishizawa, O. Consistent yet adaptive global geospatial identification of urban–rural patterns: The iURBAN model. Remote Sens. Environ. 2016, 187, 230–240. [Google Scholar] [CrossRef] [Green Version]
- Gunasekera, R.; Ishizawa, O.; Aubrecht, C.; Blankespoor, B.; Murray, S.; Pomonis, A.; Daniell, J. Developing an adaptive global exposure model to support the generation of country disaster risk profiles. Earth-Sci. Rev. 2015, 150, 594–608. [Google Scholar] [CrossRef] [Green Version]
- Calka, B.; Bielecka, E. GHS-POP Accuracy Assessment: Poland and Portugal Case Study. Remote Sens. 2020, 12, 1105. [Google Scholar] [CrossRef] [Green Version]
- Azar, D.; Engstrom, R.; Graesser, J.; Comenetz, J. Generation of fine-scale population layers using multi-resolution satellite imagery and geospatial data. Remote Sens. Environ. 2013, 130, 219–232. [Google Scholar] [CrossRef]
- Freire, S.; Schiavina, M.; Florczyk, A.J.; MacManus, K.; Pesaresi, M.; Corbane, C.; Borkovska, O.; Mills, J.; Pistolesi, L.; Squires, J.; et al. Enhanced data and methods for improving open and free global population grids: Putting ‘leaving no one behind’ into practice. Int. J. Digit. Earth 2020, 13, 61–77. [Google Scholar] [CrossRef] [Green Version]
- Uhl, J.H.; Zoraghein, H.; Leyk, S.; Balk, D.; Corbane, C.; Syrris, V.; Florczyk, A.J. Exposing the urban continuum: Implications and cross-comparison from an interdisciplinary perspective. Int. J. Digit. Earth 2020, 13, 22–44. [Google Scholar] [CrossRef] [PubMed]
- Van Huijstee, J.; Van Bemmel, B.; Bouwman, A.; Van Rijn, F. Towards an Urban Preview: Modelling Future Urban Growth with 2UP; PBL Netherlands Environmental Assessment Agency: The Hague, The Netherlands, 2018. [Google Scholar]
- Aguilar, R.; Kuffer, M. Cloud Computation Using High-Resolution Images for Improving the SDG Indicator on Open Spaces. Remote Sens. 2020, 12, 1144. [Google Scholar] [CrossRef] [Green Version]
- Pesaresi, M.; Corbane, C.; Ren, C.; Edward, N. Generalized Vertical Components of built-up areas from global Digital Elevation Models by multi-scale linear regression modelling. PLoS ONE 2021, 16, e0244478. [Google Scholar] [CrossRef]
- Li, M.; Koks, E.; Taubenböck, H.; van Vliet, J. Continental-scale mapping and analysis of 3D building structure. Remote Sens. Environ. 2020, 245, 111859. [Google Scholar] [CrossRef]
- Schiavina, M.; Freire, S.; MacManus, K. GHS-POP R2022A-GHS Population Grid Multitemporal (1975–2030); European Commission, Joint Research Centre (JRC), Eds.; European Commission: Brussels, Belgium, 2022. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name. | Population Data/ Dependency | Strengths | Weaknesses |
|---|---|---|---|
| GPWv4 | Census between 2005 and 2014 |
|
|
| GHS-POP | GPWv4 |
|
|
| GRUMP | GPWv3 |
|
|
| HYDE |
|
| |
| LandScan | Subnational census and administrative data |
|
|
| HRSL | GPWv4 |
|
|
| WPE | Processed country-official data (138 countries) |
|
|
| WorldPOP | GPWv4 |
|
|
| LandScan HD |
|
|
| Causes of Errors | Probable Causes | Recommendations | Key References |
|---|---|---|---|
| Spatial heterogeneity affects population counts | Uniform distribution assumption | Complex spatialization models are likely to perform better in complex urban distribution settings | [9,25,34] |
| Quality of census data | Gaps, and low spatial and temporal granularities | Combine or replace with bottom-up models | [32,33,34,41] |
| Quality of ancillary data | Poor ancillary data quality (errors propagate into the model) | Inspect ancillary data before using as an input Check data redundancy and covariates contribution | [7,16] |
| Scale effect and temporal mismatch | Data inconsistencies at spatial and temporal scale | When available, use high-resolution RS input When not, be conscious on probable uncertainties and allocate time for data corrections | [8] |
| Differences in regional and local characteristics | Top-down modelling approaches are less sensitive to regional characteristics Lack of reliable ancillary data with high resolution in the global level | Experiment with different ancillary datasets regarding environmental and morphological variables to better characterize the local specificities increasing the model sensitivity | [7,32] |
| Error Metrics | Equations | Comments |
|---|---|---|
| Root mean square error (RMSE) | Where ypred is the predicted/estimated value and yref the local reference value, (ypred − yref)2 = differences, squared and n is number of observations | |
| Mean absolute percentage error (MAPE) | ||
| Relative estimation error (REE) | Where AEE is the absolute estimation error (ypred − yref) | |
| Coefficient of determination (R2) | Where RSS is total sum of square residuals and TSS total sum of squares |
| Value Range | Category | Abbreviation |
|---|---|---|
| −100 to 50 | Greatly underestimated | GU |
| −50 to 25 | Underestimated | U |
| −25 to 10 | Slightly underestimated | SU |
| −10 to 10 | Accurately estimated | AE |
| 10 to 25 | Slightly overestimated | SO |
| 25 to 50 | Overestimated | O |
| 50 to 100+ | Greatly overestimated | GO |
| Region | Country | City | Year of Local Population Data | Year GHS-POP | Land Use map | Informal Layer (Y/N) |
|---|---|---|---|---|---|---|
| East Asia and Pacific | Indonesia | Jakarta | 2019 | 2015 | 2017 | Y |
| Europe | Netherlands | Enschede and Twente region | 2015 | 2015 | 2012 | N |
| Latin America and Caribbean | Brazil | São Paulo | 2010 | 2015 | 2014/20 | Y |
| The Middle East and North Africa | Egypt | Cairo | 1996 | 2000 | 2000 | Y |
| North America | USA | New York | 2010 | 2015 | 2020 | N |
| South Asia | Kabul | Afghanistan | 2015 | 2015 | 2015 | Y |
| Sub-Saharan Africa | Ghana | Kumasi | 2010 | 2015 | 2016 | Y |
| Sao Paulo | Kumasi | Enschede | Jakarta | New York | Kabul | Cairo | |
|---|---|---|---|---|---|---|---|
| MAPE (%) | 10.7% | 98.3% | −11.3% | 74.4% | 6.1% | −1793.7% | 298.0% |
| RMSE | 3020.6 | 8059.9 | 568.3 | 9814.9 | 896.0 | 5469.8 | 11881.9 |
| R2 | 0.86 | 0.33 | 0.74 | 0.26 | 0.98 | 0.60 | 0.71 |
| Interpretation | Strong fit of model Low error: underestimation | Weak fit of model: High error: underestimation | Strong fit of model Low error: overestimation | Weak fit of model High error: underestimation | Strong fit of model Low error: underestimation | Moderate fit of model High error: overestimation | Strong fit of model High error: underestimation |
| City | Overall Conclusion | Reasons for Errors | Overall Recommendations | Correct Estimation for Residential Areas |
|---|---|---|---|---|
| São Paulo | GHS-POP shows an overall good prediction |
| Use of a land-use layer that allows for improved estimation of non-residential built-up areas and high-density areas (including build heights) | Correct area: 26.73% |
| Kumasi | GHS-POP shows an overall poor fit with the local population data |
| Use of a land-use layer that allows for improved estimation of non-residential built-up areas and data on built-up densities and slum layer | Correct area: 8.9% |
| Enschede | Overall the GHS-POP data capture the population distribution well |
| The inclusion of basic land use/cover (e.g., provided by the Urban Atlas) could mitigate the wrong allocation of population For multi-storey housing areas, building height information would be beneficial | Correct area: 12.0% |
| Jarkarta | GHS-POP has serious allocation errors and fails to accurately characterize the spatial patterns of population distribution |
| The poor performance of GHS-POP can be attributed to the coarse resolution of the input population data used for Jakarta Built-up densities vary starkly in Jakarta between different land-use types, meaning the inclusion of land-use data that also differentiate between formal and informal would be beneficial | Correct area: 16.2% |
| New York | The GHS-POP layer provides a good depiction of the population distribution |
| The inclusion of basic land use/cover could mitigate the incorrect allocation of population For multi-storey housing areas, building height information would be beneficial | Correct area: 68.2% |
| Cairo | GHS-POP failed to accurately characterize the spatial patterns of population distribution |
| The GHS-POP performs relatively well in desert areas Information on high-density and informal areas would be important to improve the GHS-POP layer | Correct area: 13.4% |
| Kabul | GHS-POP failed to accurately characterize the spatial patterns of population distribution |
| The GHSL layer would require improvements to better account for built-up and non-built-up areas Use of a land-use layer could improve the estimation of non-residential built-up areas and high-density informal areas | Correct area: 27.8% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuffer, M.; Owusu, M.; Oliveira, L.; Sliuzas, R.; van Rijn, F. The Missing Millions in Maps: Exploring Causes of Uncertainties in Global Gridded Population Datasets. ISPRS Int. J. Geo-Inf. 2022, 11, 403. https://doi.org/10.3390/ijgi11070403
Kuffer M, Owusu M, Oliveira L, Sliuzas R, van Rijn F. The Missing Millions in Maps: Exploring Causes of Uncertainties in Global Gridded Population Datasets. ISPRS International Journal of Geo-Information. 2022; 11(7):403. https://doi.org/10.3390/ijgi11070403
Chicago/Turabian StyleKuffer, Monika, Maxwell Owusu, Lorraine Oliveira, Richard Sliuzas, and Frank van Rijn. 2022. "The Missing Millions in Maps: Exploring Causes of Uncertainties in Global Gridded Population Datasets" ISPRS International Journal of Geo-Information 11, no. 7: 403. https://doi.org/10.3390/ijgi11070403
APA StyleKuffer, M., Owusu, M., Oliveira, L., Sliuzas, R., & van Rijn, F. (2022). The Missing Millions in Maps: Exploring Causes of Uncertainties in Global Gridded Population Datasets. ISPRS International Journal of Geo-Information, 11(7), 403. https://doi.org/10.3390/ijgi11070403