
Similarity Search on Semantic Trajectories Using Text Processing


Abstract
:1. Introduction
- The proposition of a new approach to represent trajectory data based on text.
- The development of a search engine for querying semantic trajectories taking into account not only the POIs name and categories, but also the semantic trajectory aspects.
- The specification of a new ranking algorithm that enables searching for trajectory similarity.
- The implementation of a simple and efficient approach—execution time and storage requirements—to perform queries on semantic trajectories, when compared to the SPARQL-based approach.
2. Related Work
3. SETHE: A Semantic Trajectory Retrieval Approach
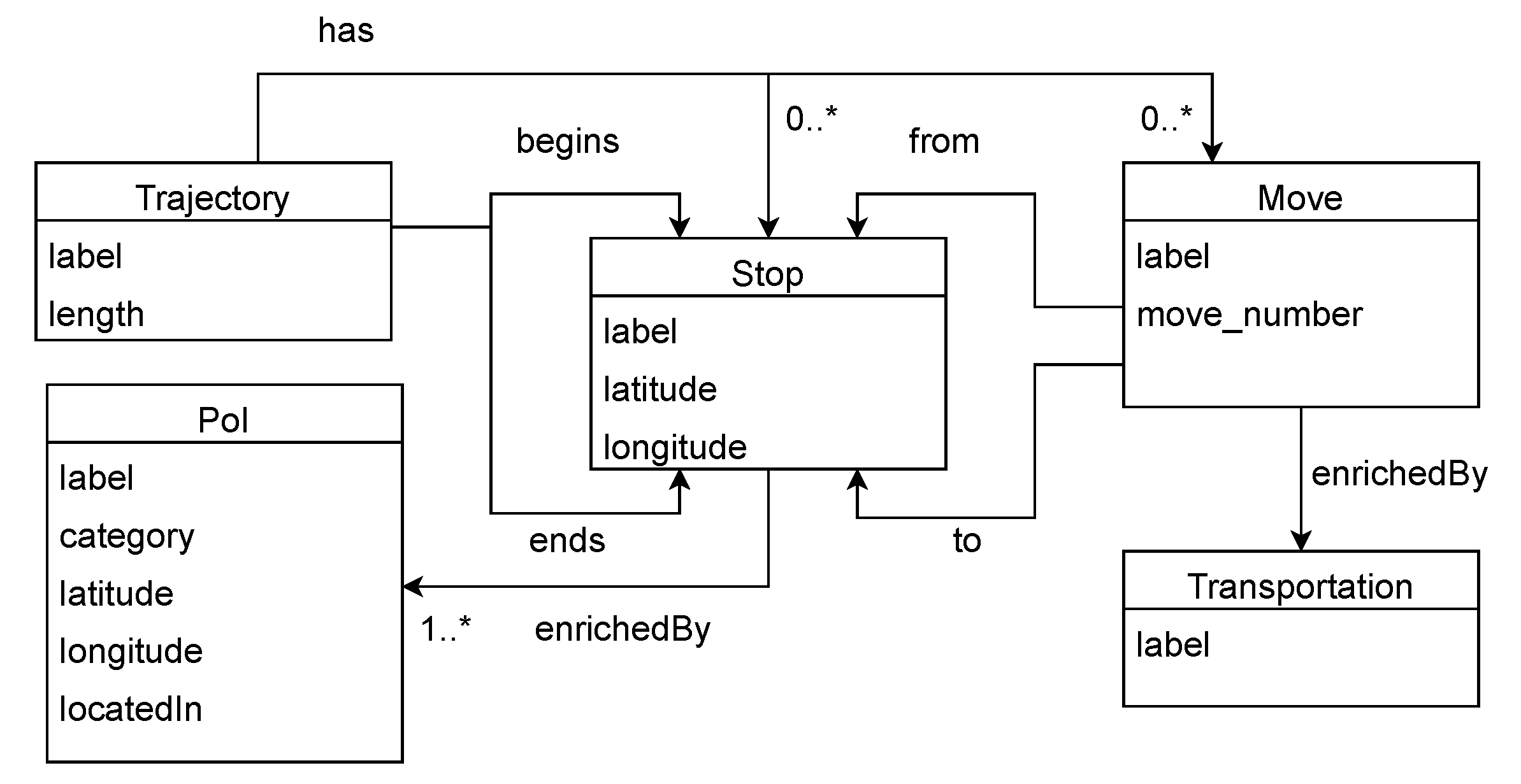
3.1. Basic Concepts
3.2. Query Processing
3.2.1. Query Building
- Erepresents the POI sequence of a nonempty set of tuples, , . Eachis a sequence ofmregular expressions, with one for each POI.
- Ais another representation of the POI sequence represented by a set of tuples, b〉, …,, whereis the number of optional aspects. Eachis a sequence ofmregular expressions, with one for each POI.
- is a set of weights, where each weight is associated with an optional aspect, and. If, then.
- denotes a set of distance functions. A distance function exists for each optional aspect. If, then.
- is the threshold set that each distance function may achieve. There is a threshold for each function, and if,.
- Using the regex function to obtain the trajectories that pass through the POIs with the names and categories of the expressions.
- Extracting the sub-sequences of T trajectory, in which both the name and category of the POIs match E regular expressions.
- Using distance functions and aspect weights to calculate the query coefficient similarity with the sub-sequences.
- Ranking the result according to the coefficient in descending order.
3.2.2. Discovering Sub-Sequences
| Algorithm 1 Extract Sub-sequence from ST |
|
| Algorithm 2 Insert a Node in the Tree |
|
| Algorithm 3 Remove Incomplete Sub-sequence from the Tree |
|
| =( | shop | museum | church | museum | tower | ) |
| Algorithm 4 Extract Sub-sequence from Tree Algorithm |
|
3.2.3. Transforming a Sub-Sequence into a Vector
4. Running Example
- . As we define the first point as the Leaning Tower of Pisa, we do not need to specify the category of the first point.
- .
- .
- .
- .
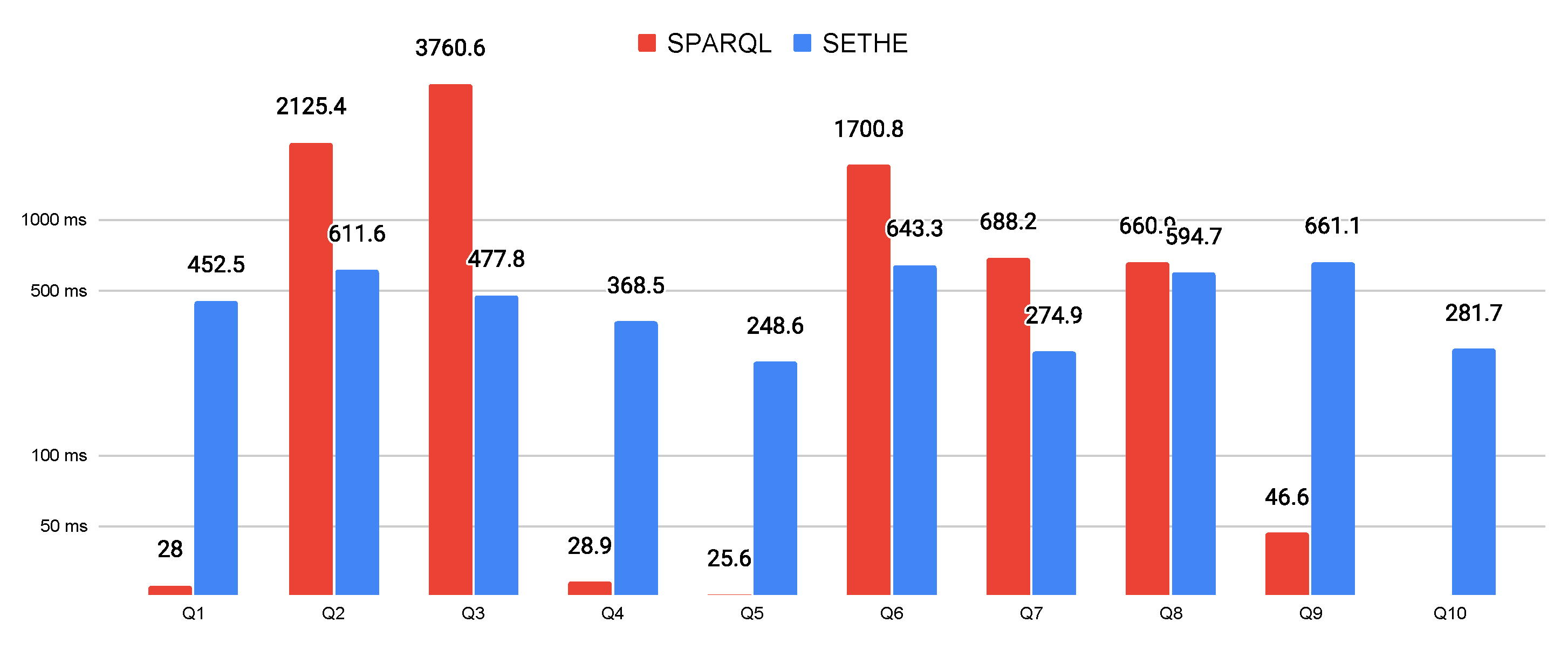
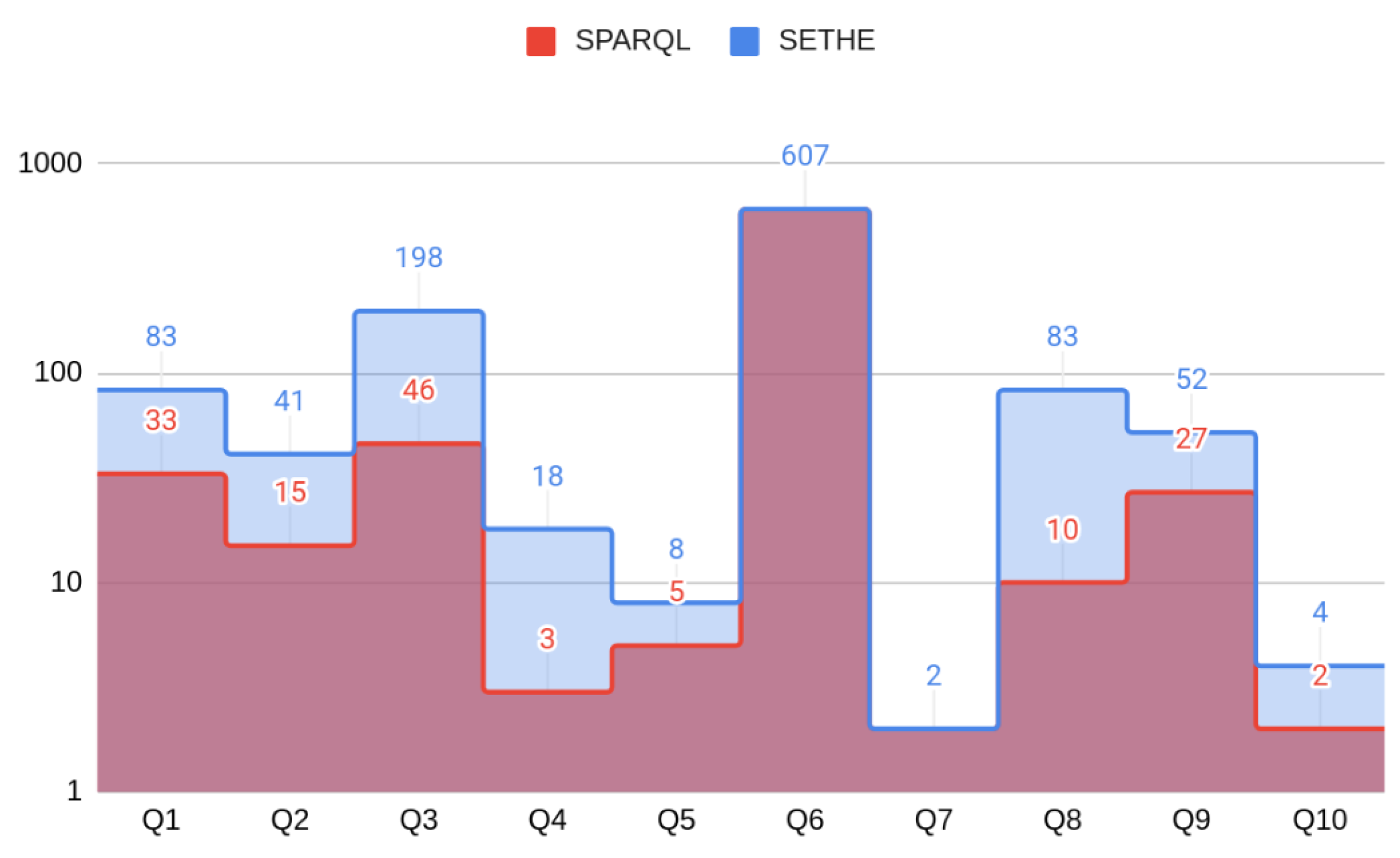
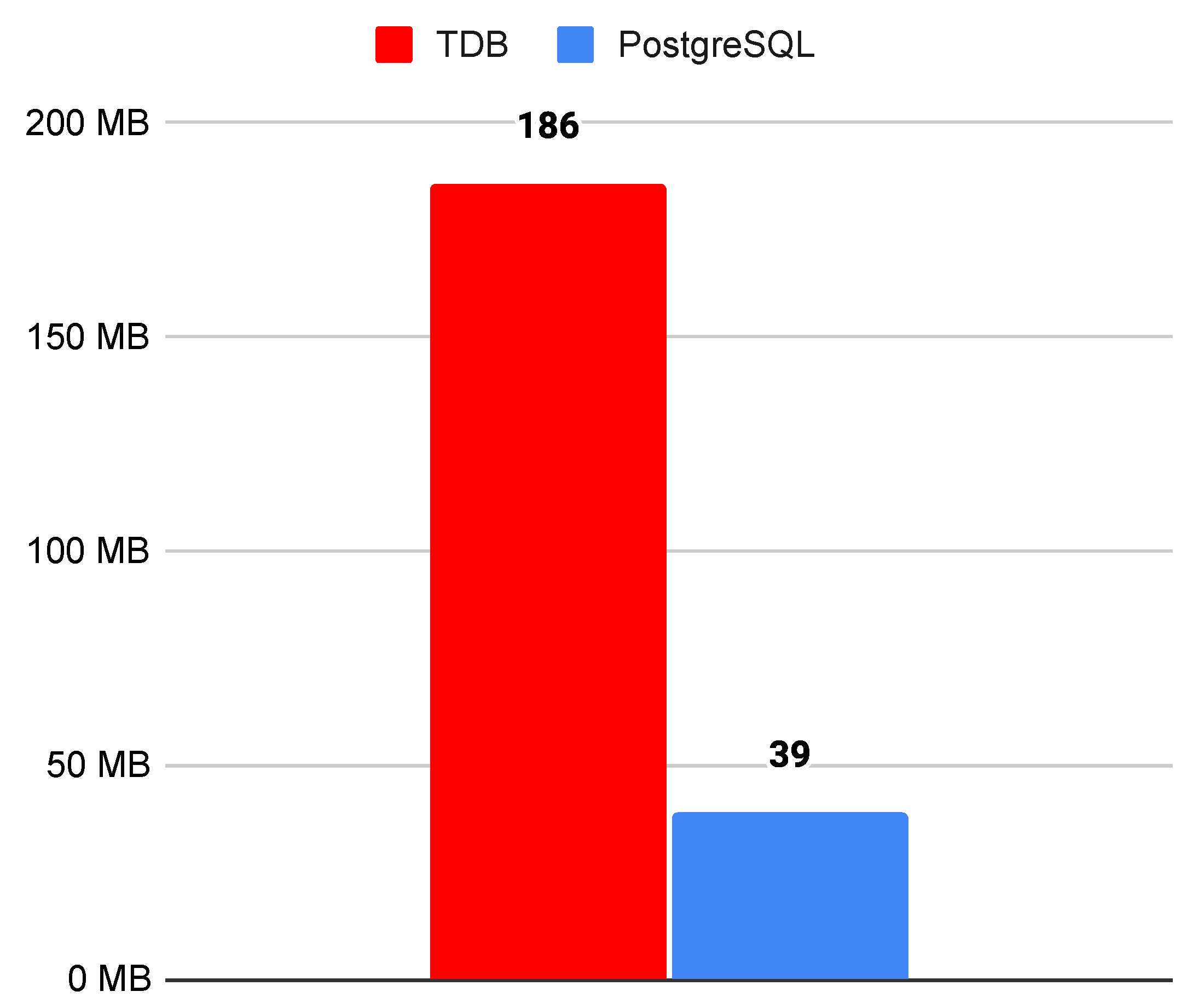
5. Experiments and Results
5.1. Dataset
5.2. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kong, X.; Li, M.; Ma, K.; Tian, K.; Wang, M.; Ning, Z.; Xia, F. Big trajectory data: A survey of applications and services. IEEE Access 2018, 6, 58295–58306. [Google Scholar] [CrossRef]
- Fileto, R.; Raffaetà, A.; Roncato, A.; Sacenti, J.A.; May, C.; Klein, D. A semantic model for movement data warehouses. In Proceedings of the 17th International Workshop on Data Warehousing and OLAP, Shanghai, China, 3–7 November 2014; pp. 47–56. [Google Scholar]
- Nardini, F.M.; Orlando, S.; Perego, R.; Raffaetà, A.; Renso, C.; Silvestri, C. Analysing trajectories of mobile users: From data warehouses to recommender systems. In A Comprehensive Guide through the Italian Database Research over the Last 25 Years; Springer: Berlin/Heidelberg, Germany, 2018; pp. 407–421. [Google Scholar]
- Wagner, R.; Macedo, J.A.F.d.; Raffaetà, A.; Renso, C.; Roncato, A.; Trasarti, R. Mob-warehouse: A semantic approach for mobility analysis with a trajectory data warehouse. In Proceedings of the International Conference on Conceptual Modeling, Hong Kong, China, 11–13 November 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 127–136. [Google Scholar]
- Alsahfi, T.; Almotairi, M.; Elmasri, R. A survey on trajectory data warehouse. Spat. Inf. Res. 2020, 28, 53–66. [Google Scholar] [CrossRef] [Green Version]
- Emmanouilidis, C.; Koutsiamanis, R.A.; Tasidou, A. Mobile guides: Taxonomy of architectures, context awareness, technologies and applications. J. Netw. Comput. Appl. 2013, 36, 103–125. [Google Scholar] [CrossRef]
- Fileto, R.; May, C.; Renso, C.; Pelekis, N.; Klein, D.; Theodoridis, Y. The Baquara2 Knowledge-Based Framework for Semantic Enrichment and Analysis of Movement Data. Data Knowl. Eng. 2015, 98, 104–122. [Google Scholar] [CrossRef]
- Qin, Y.; Sheng, Q.Z.; Falkner, N.J.; Dustdar, S.; Wang, H.; Vasilakos, A.V. When things matter: A survey on data-centric internet of things. J. Netw. Comput. Appl. 2016, 64, 137–153. [Google Scholar] [CrossRef] [Green Version]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef] [Green Version]
- Parent, C.; Spaccapietra, S.; Renso, C.; Andrienko, G.; Andrienko, N.; Bogorny, V.; Damiani, M.L.; Gkoulalas-Divanis, A.; Macedo, J.; Pelekis, N.; et al. Semantic trajectories modeling and analysis. ACM Comput. Surv. CSUR 2013, 45, 42. [Google Scholar] [CrossRef]
- Almeida, D.R.d.; Baptista, C.d.S.; Andrade, F.G.d.; Soares, A. A Survey on Big Data for Trajectory Analytics. ISPRS Int. J. Geo-Inf. 2020, 9, 88. [Google Scholar] [CrossRef] [Green Version]
- Petry, L.M.; Ferrero, C.A.; Alvares, L.O.; Renso, C.; Bogorny, V. Towards semantic-aware multiple-aspect trajectory similarity measuring. Trans. GIS 2019, 23, 960–975. [Google Scholar] [CrossRef] [Green Version]
- Mello, R.d.S.; Bogorny, V.; Alvares, L.O.; Santana, L.H.Z.; Ferrero, C.A.; Frozza, A.A.; Schreiner, G.A.; Renso, C. MASTER: A multiple aspect view on trajectories. Trans. GIS 2019, 23, 805–822. [Google Scholar] [CrossRef] [Green Version]
- Noël, D.; Villanova-Oliver, M.; Gensel, J.; Le Quéau, P. Modeling semantic trajectories including multiple viewpoints and explanatory factors: Application to life trajectories. In Proceedings of the 1st International ACM SIGSPATIAL Workshop on Smart Cities and Urban Analytics, Bellevue, WA, USA, 3–6 November 2015; pp. 107–113. [Google Scholar]
- Izquierdo, Y.T.; Monteagudo Garcia, G.; Casanova, M.A.; Paes Leme, L.A.P.; Sardianos, C.; Tserpes, K.; Varlamis, I.; Ruback Rodrigues, L.C. Stop-and-move sequence expressions over semantic trajectories. Int. J. Geogr. Inf. Sci. 2021, 35, 793–818. [Google Scholar] [CrossRef]
- Brilhante, I.; Macedo, J.A.; Nardini, F.M.; Perego, R.; Renso, C. Tripbuilder: A tool for recommending sightseeing tours. In Proceedings of the European Conference on Information Retrieval, Amsterdam, The Netherlands, 13–16 April 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 771–774. [Google Scholar]
- Güting, R.H.; Schneider, M. Moving Objects Databases; Elsevier: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Yan, Z.; Chakraborty, D.; Parent, C.; Spaccapietra, S.; Aberer, K. SeMiTri: A framework for semantic annotation of heterogeneous trajectories. In Proceedings of the 14th International Conference on Extending Database Technology, Uppsala, Sweden, 21–24 March 2011; ACM: New York, NY, USA, 2011; pp. 259–270. [Google Scholar]
- Spaccapietra, S.; Parent, C.; Damiani, M.L.; de Macedo, J.A.; Porto, F.; Vangenot, C. A conceptual view on trajectories. Data Knowl. Eng. 2008, 65, 126–146. [Google Scholar] [CrossRef] [Green Version]
- Bogorny, V.; Renso, C.; de Aquino, A.R.; de Lucca Siqueira, F.; Alvares, L.O. Constant—A Conceptual Data Model for Semantic Trajectories of Moving Objects. Trans. GIS 2014, 18, 66–88. [Google Scholar] [CrossRef]
- Nikitopoulos, P.; Vlachou, A.; Doulkeridis, C.; Vouros, G.A. DiStRDF: Distributed Spatio-temporal RDF Queries on Spark. In Proceedings of the EDBT/ICDT Workshops, Vienna, Austria, 26 March 2018; pp. 125–132. [Google Scholar]
- Dividino, R.; Soares, A.; Matwin, S.; Isenor, A.W.; Webb, S.; Brousseau, M. Semantic Integration of Real-Time Heterogeneous Data Streams for Ocean-Related Decision Making. In Proceedings of the Big Data and Artificial Intelligence for Military Decision Making, Bordeaux, France, 30 May–1 June 2018. [Google Scholar] [CrossRef]
- Alvares, L.O.; Bogorny, V.; Kuijpers, B.; de Macedo, J.A.F.; Moelans, B.; Vaisman, A. A model for enriching trajectories with semantic geographical information. In Proceedings of the 15th Annual ACM International Symposium on Advances in Geographic Information Systems, Seattle, WA, USA, 7–9 November 2007; pp. 1–8. [Google Scholar]
- Chang, B.; Park, Y.; Kim, S.; Kang, J. DeepPIM: A deep neural point-of-interest imputation model. Inf. Sci. 2018, 465, 61–71. [Google Scholar] [CrossRef]
- Gusfield, D. Algorithms on Strings, Trees and Sequences: Computer Science and Computational Biology; Cambridge University Press: New York, NY, USA, 1997. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| POI Name | Cappella Dal Pozzo | Museo Delle Sinopie | Teatro Sant’Andrea |
|---|---|---|---|
| Category | Chapel | Museum | Theater |
| Transport means | Walk | Bus | Taxi |
| Temperature | 22 C | 21 C | 23 C |
| word2vec Funtion | Equals Function | Euclidean Function |
|---|---|---|
| word2vec(taxi, bus) = 0.74 | equals(rain, fog) = 0 | Euclidean(4.0, 5.0) = 1.0 |
| word2vec(bus, walk) = 0.67 | equals(clear, clear) = 1 | Euclidean(5.0, 1.0) = 4.0 |
| Expression | Explanation | Query Example | Result Example |
|---|---|---|---|
| ⌃ | begins with | (⌃museum; .*) | museum, chapel, tower |
| $ | ends with | (.*; museum$) | chapel, tower, museum |
| | | “or” operator | ( (museum|chapel); tower) | chapel, square, tower |
| .* | any text | (.*; chapel$) | square, tower, chapel |
| (exp)* | the expression may be repeated zero or more times | ((tower)*; museum) | tower, tower, museum |
| (?-) | The value ahead is repeated in the previous positions until the last expression of the trajectory begins | (?-) (Taxi; (?-) Bus) | (?-) Taxi, Bus, Bus, Bus |
| ∼ | proximity aspect | (museum; tower) ( .*; ∼) | museum, tower, square |
| Subway | 4 | Walk | 5 | Walk | 3 | |
| score | 0 | 0.24 | 0 | 0.3 | 0.7 | 0.24 |
| Subway | 4 | Subway | 4 | Walk | 3 | |
| score | 0 | 0.24 | 0 | 0.24 | 0.7 | 0.24 |
| Bus | 4 | Walk | 5 | Walk | 3 | |
| score | 0 | 0.24 | 0 | 0.3 | 0.7 | 0.24 |
| Bus | 4 | Subway | 4 | Walk | 3 | |
| score | 0 | 0.24 | 0 | 0.24 | 0.7 | 0.24 |
| Walk | 5 | Walk | 3 | Subway | 3 | |
| score | 0 | 0.3 | 0 | 0.18 | 0 | 0.24 |
| Walk | 5 | Bus | 3 | Subway | 3 | |
| score | 0 | 0.3 | 0.7 | 0.18 | 0 | 0.24 |
| Taxi | 5 | Bus | 3 | Subway | 4 | |
| score | 0.7 | 0.3 | 0.7 | 0.18 | 0 | 0.3 |
| Taxi | 5 | Bus | 3 | Walk | 3 | |
| score | 0.7 | 0.3 | 0.7 | 0.18 | 0.7 | 0.24 |
| Taxi | 5 | Bus | 3 | Walk | 3 | |
| score | 0.7 | 0.3 | 0.7 | 0.18 | 0.7 | 0.24 |
| IdTraj | Value |
|---|---|
| TF10018 | Statua_equestre_di_Cosimo_I_de_Medici, Loggia_della_Signoria, Castello_dAltafronte, Torre_della_Pagliazza, Palazzo_Bartolini-Torrigiani |
| TF10019 | Palazzo_dei_Vescovi_a_San_Miniato_al_Monte, Basilica_di_San_Miniato_al_Monte |
| TF10027 | Palazzo_Roffia, Porta_della_Mandorla, Campanile_di_Giotto, Battistero_di_San_Giovanni_(Firenze), Porta_della_Mandorla, Campanile_di_Giotto, Torre_dei_Caponsacchi, Palazzo_dei_Vescovi_a_San_Miniato_al_Monte, Basilica_di_Santa_Croce, Torre_dei_Caponsacchi |
| IdTraj | Value |
|---|---|
| TF10018 | scultureafirenze, loggedifirenze, castellidifirenze, torridifirenze, palazzidifirenze |
| TF10019 | palazzidifirenze, basilichedifirenze |
| TF10027 | palazzidifirenze, cattedralidellaprovinciadifirenze, campanili,
battisteridellatoscana, cattedralidellaprovinciadifirenze, campanili, torridifirenze, palazzidifirenze, basilichedifirenze, torridifirenze |
| IdTraj | Value |
|---|---|
| TF10018 | N/A, Subway, Taxi, Subway, Bus, Subway |
| TF10019 | N/A, Subway |
| TF10027 | N/A, Walk, Bus, Subway, Subway, Bus, Taxi, Taxi, Taxi, Taxi |
| Qid | Free Text Query |
|---|---|
| Q1 | Trajectories that stop at a museum and then at a chapel. |
| Q2 | Trajectories that stop at a tower, then stop at a chapel or church, then stop at a chapel or church again, and then at a museum. |
| Q3 | Trajectories that stop at least once in a tower, and then at a museum. |
| Q4 | Trajectories that stop at the Lion Tower and then at the Leaning Tower, or stop at the Leaning Tower and then at the Lion Tower. |
| Q5 | Trajectories that begin at a museum and then end at a chapel. |
| Q6 | Trajectories that stop at a museum and, later on, end at a chapel or a church optionally. |
| Q7 | Trajectories that begin at a chapel, stop at zero or more chapels, and end at a chapel. |
| Q8 | Trajectories that stop at a museum and then take a bus to a chapel. |
| Q9 | Trajectories that begin at a chapel or a church, always move by bus between stops, and end at the Leaning Tower. |
| Q10 | Trajectories that begin at a tower, then walk to take a bus to a church, and then, using any transportation means, end at a palace. |
| Qid | SETHE Query |
|---|---|
| Q1 | ∼〉 |
| Q2 | ; ∼; ; ∼〉 |
| Q3 | ∼〉 |
| Q4 | |
| { ∼ | |
| ∼ | |
| Q5 | ∼〉 |
| Q6 | |
| Q7 | ⌃ |
| Q8 | |
| Q9 | ⌃ |
| Q10 | ⌃ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ribeiro de Almeida, D.; de Souza Baptista, C.; de Andrade, F.G. Similarity Search on Semantic Trajectories Using Text Processing. ISPRS Int. J. Geo-Inf. 2022, 11, 412. https://doi.org/10.3390/ijgi11070412
Ribeiro de Almeida D, de Souza Baptista C, de Andrade FG. Similarity Search on Semantic Trajectories Using Text Processing. ISPRS International Journal of Geo-Information. 2022; 11(7):412. https://doi.org/10.3390/ijgi11070412
Chicago/Turabian StyleRibeiro de Almeida, Damião, Cláudio de Souza Baptista, and Fabio Gomes de Andrade. 2022. "Similarity Search on Semantic Trajectories Using Text Processing" ISPRS International Journal of Geo-Information 11, no. 7: 412. https://doi.org/10.3390/ijgi11070412
APA StyleRibeiro de Almeida, D., de Souza Baptista, C., & de Andrade, F. G. (2022). Similarity Search on Semantic Trajectories Using Text Processing. ISPRS International Journal of Geo-Information, 11(7), 412. https://doi.org/10.3390/ijgi11070412