
Visual Attention and Recognition Differences Based on Expertise in a Map Reading and Memorability Study



Abstract
:1. Introduction and Background
- Which map landmarks are easily remembered? (memorability)
- How are task difficulty and recognition (or cued recall) performance associated? (task difficulty)
- How do experts and novices differ in terms of recognition performance? (expertise)
Our Contributions
2. Methodology
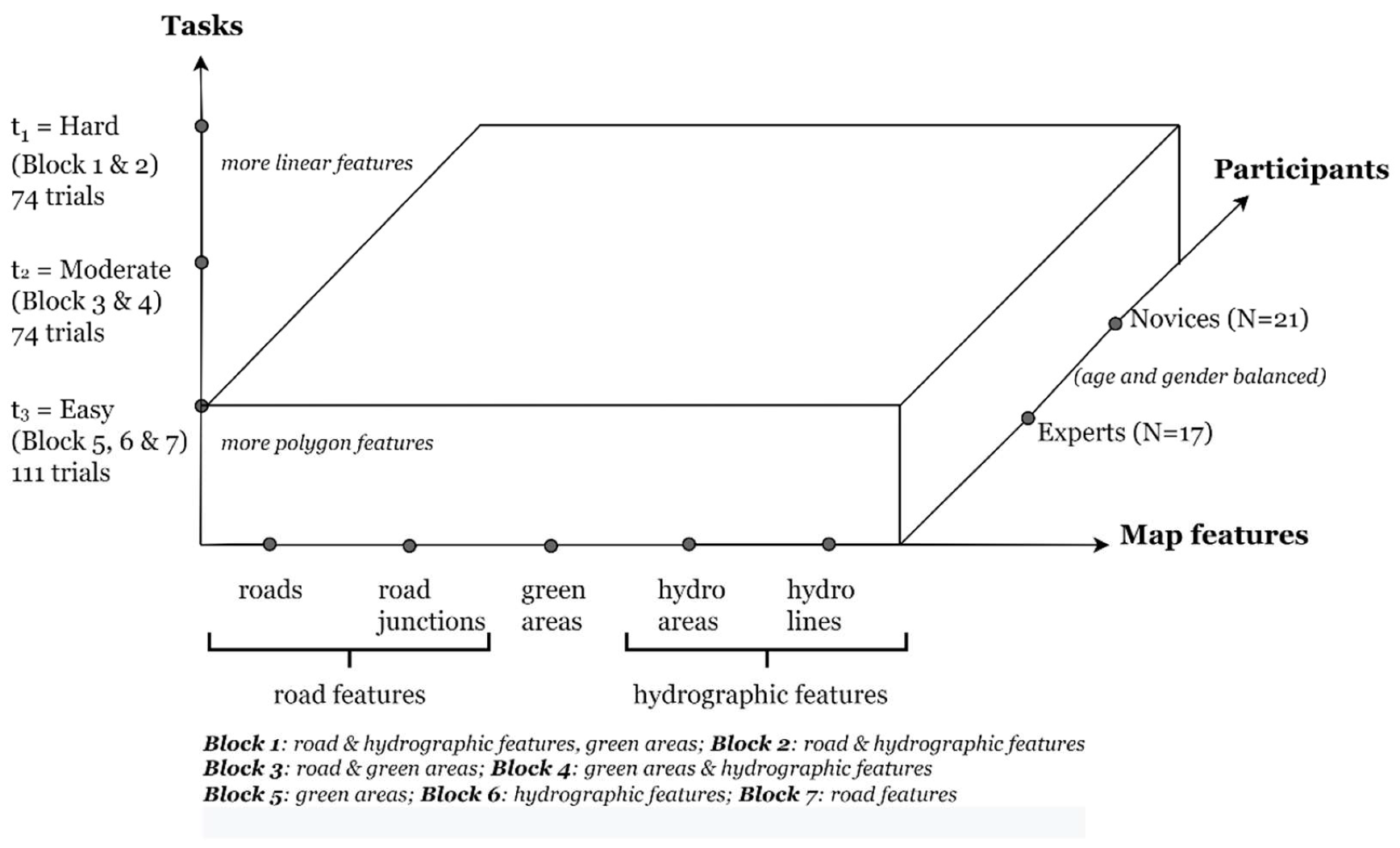
2.1. Experiment Design
- H1: Expertise x task difficulty: Experts might spend more time and have longer fixation durations for task-relevant features than novices do due to their ability to identify what is task-relevant, as well as possibly higher motivation to complete the given tasks.
- H2: Task difficulty x expertise: Task difficulty might moderate the effects observed in H1 due to increased cognitive load, especially for non-expert users.
- H3: Map feature type x expertise (1): Map features that are complex (e.g., road junctions) and large in size albeit simple (e.g., green areas and hydrographic areas) might draw more attention, and consequently be more memorable than moderately complex features due to a known coupling between attention and memorability. We expect this effect to be more pronounced for expert users as they might be more driven (reasoning similar to H1).
- H4: Map feature type x expertise (2): Attention and memory differences between experts and novices might be more pronounced in polygon map features since previous work has shown that linear features are easier to learn and remember irrespective of expertise.
2.2. Apparatus
2.3. Participants
2.4. Stimuli and Tasks
- Block 2: roads + road junctions + water bodies + rivers = 40 landmarks,
- Block 3: roads + road junctions + green areas = 30 landmarks,
- Block 4: green areas + water bodies + rivers = 30 landmarks,
- Block 5: green areas = 10 landmarks,
- Block 6: water bodies + rivers = 20 landmarks, and
- Block 7: road + road junctions = 20 landmarks.
2.5. Procedure
2.6. Creating AOIs for Map Landmarks
2.7. AOI-Based Fixation Analysis of Map Landmarks
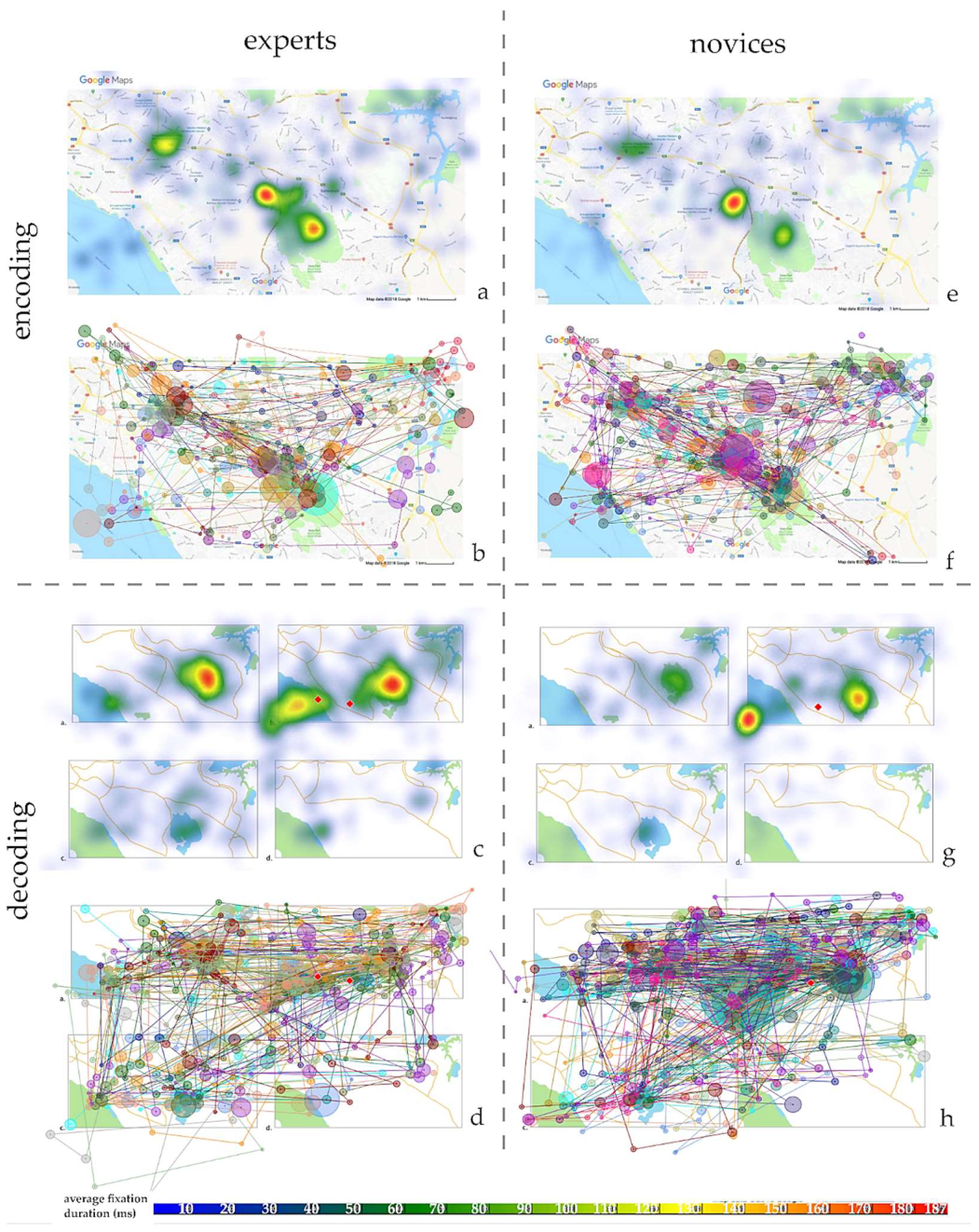
2.7.1. Encoding Stage
2.7.2. The Encoding vs. Decoding Stage
3. Results
3.1. Encoding Stage
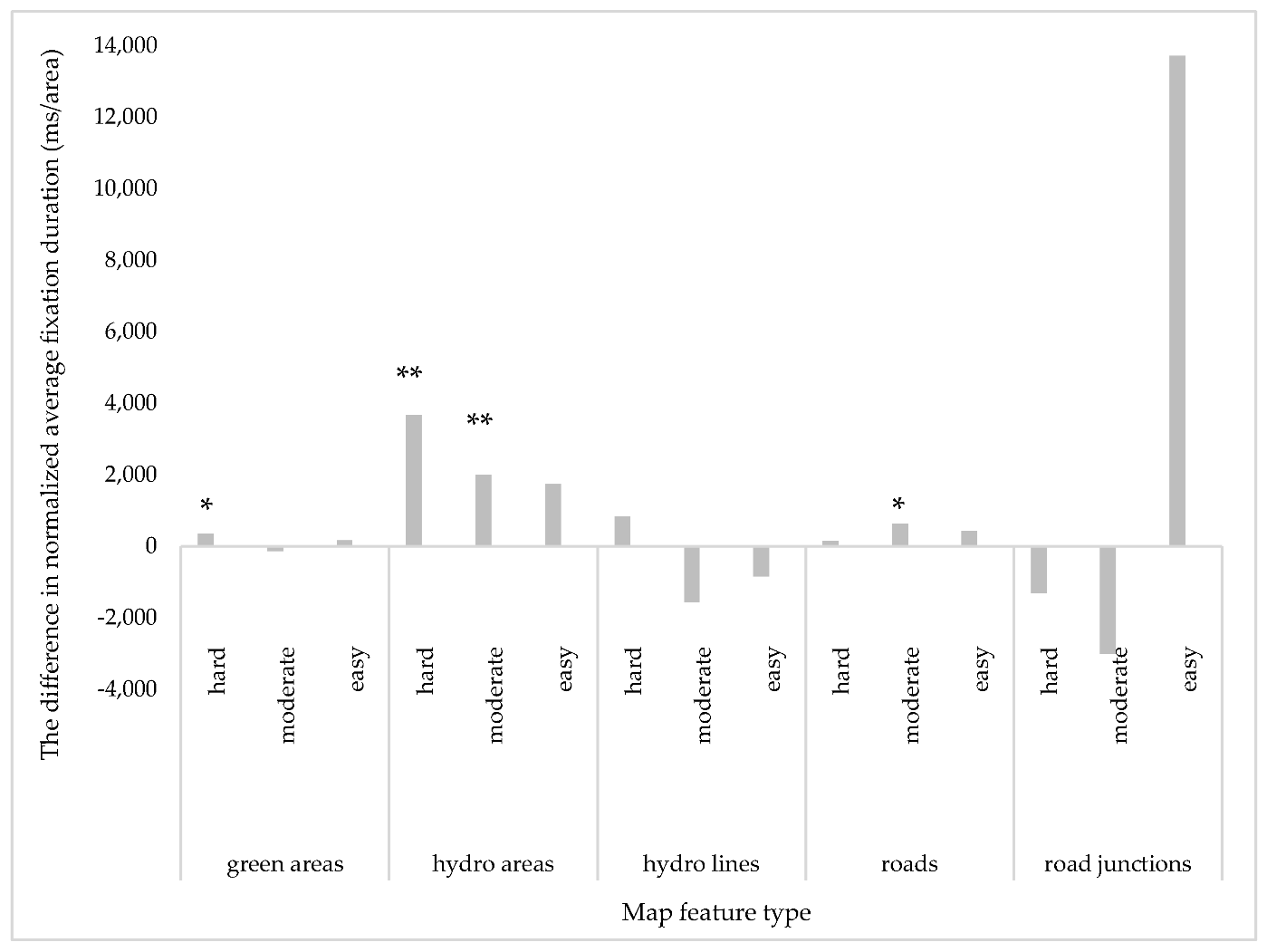
- Map feature type: Road junctions received longer fixation durations than the rest of the map features (p < 0.001 ***) followed by hydrographic areas (p < 0.001 ***) (Figure 6).
- Task difficulty: Moderate tasks received longer fixation durations than easy and moderate tasks (p < 0.001 ***).
- Map feature type × Expertise: Hydrographic areas (p < 0.001 ***) and roads (p < 0.05 *) received longer fixation durations from experts.
- Map feature type × Task difficulty: Irrespective of task type/difficulty, road junctions received longer fixations than the rest of the map features (p < 0.001 ***). For moderate tasks, hydrographic areas received longer fixation durations than other map feature types (hydro areas-green areas: p < 0.001 ***; hydro areas-hydro lines: p < 0.05 *; hydro areas-roads: p < 0.001 ***) except for road junctions (hydro areas-road junctions: p < 0.05 *).
- Expertise × Map feature type x Task difficulty: Experts had a significantly longer fixation duration (i) for green areas at hard tasks (p < 0.05 *), (ii) for hydrographic areas at moderate (p < 0.01 **) and hard tasks (p < 0.01 **), and (iii) for roads at moderate tasks (p < 0.05 *) (Figure 7).
3.2. The Encoding vs. Decoding Stage
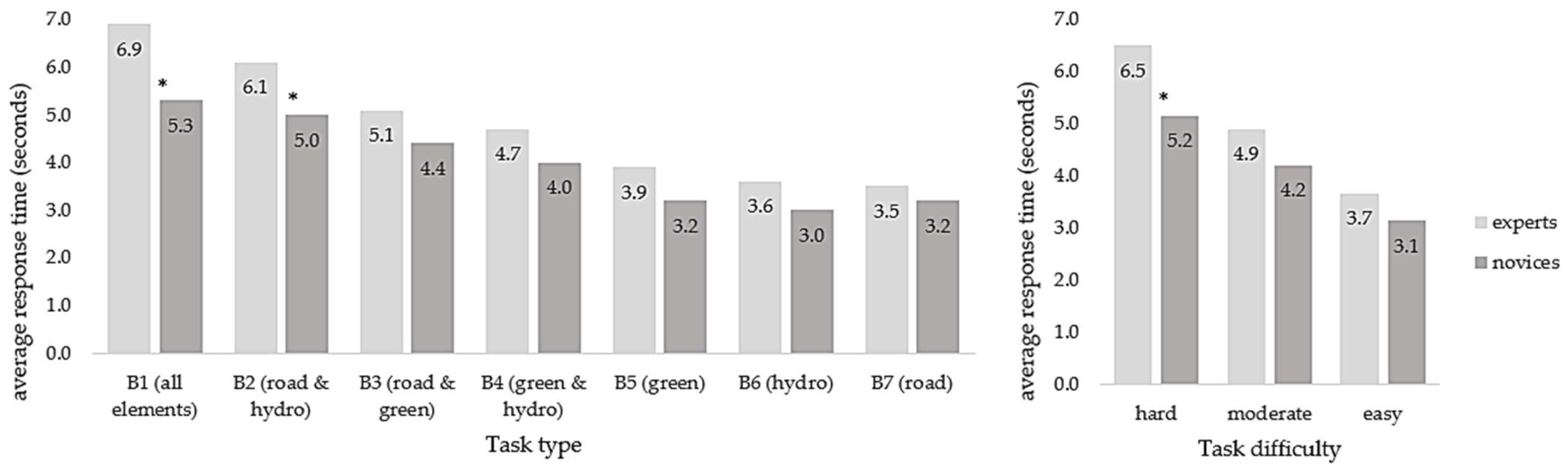
3.3. Participants’ Response Accuracy and Response Time
3.4. Self-Reported Task Difficulty Rating
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. The Post-Test Questionnaire

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| % | Q1: Please Choose the Highest Level of Education You Have Completed | Q2: How Often Do You Use Google Maps? | Q3: On a Scale of 1-5, with 5 Being “Strongly Agree” and & Being “Strongly Disagree” Please Answer: Do You Think Google Maps is Easy to Use? | Q4: What Do You Think about the Experiment? | ||||
|---|---|---|---|---|---|---|---|---|
| N | N | N | N | |||||
| Experts (N = 17) | PhD | 1 | everyday | 10 | 5 | 13 | Positive | 11 |
| MSc | 16 | once/twice a week | 6 | 4 | 4 | Neutral | 2 | |
| once a month | 1 | 3≤ | 0 | Negative | 4 | |||
| Novices (N = 21) | MSc | 11 | everyday | 8 | 5 | 8 | Positive | 5 |
| BSc | 8 | once/twice a week | 11 | 4 | 11 | Neutral | 10 | |
| High School | 2 | once a month | 2 | 3 | 1 | Negative | 6 | |
Appendix B. Larger Versions of Maps in Figure


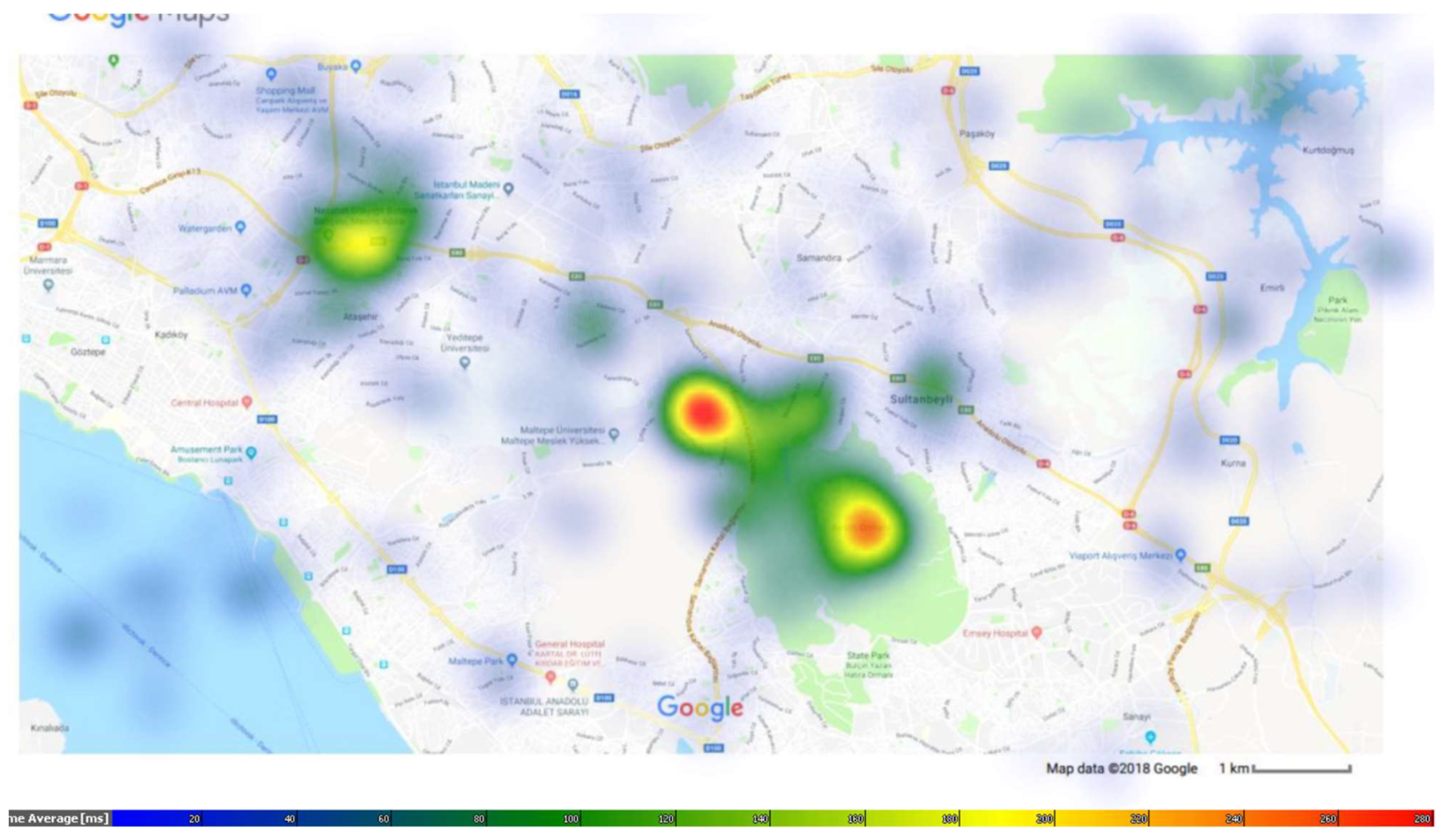

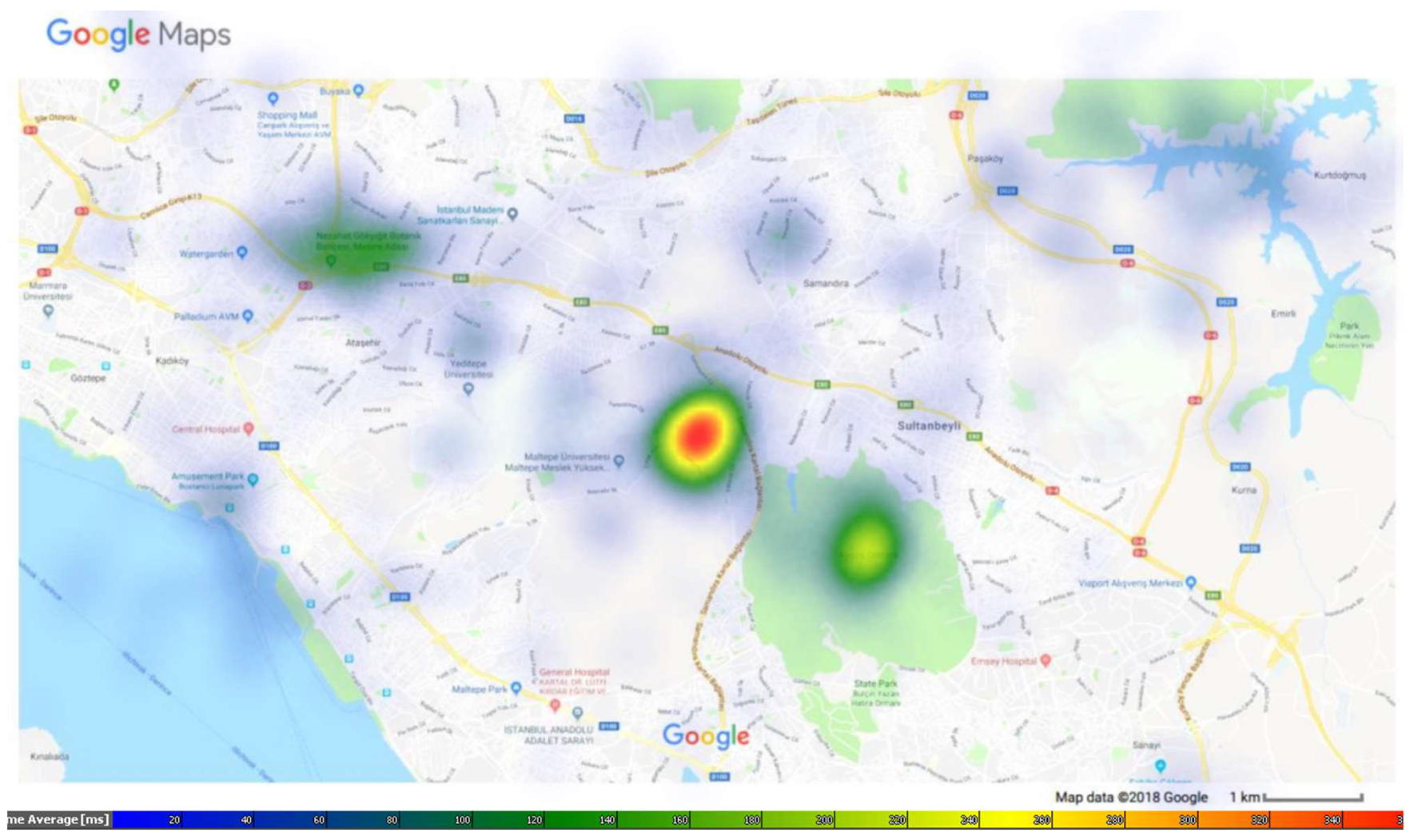
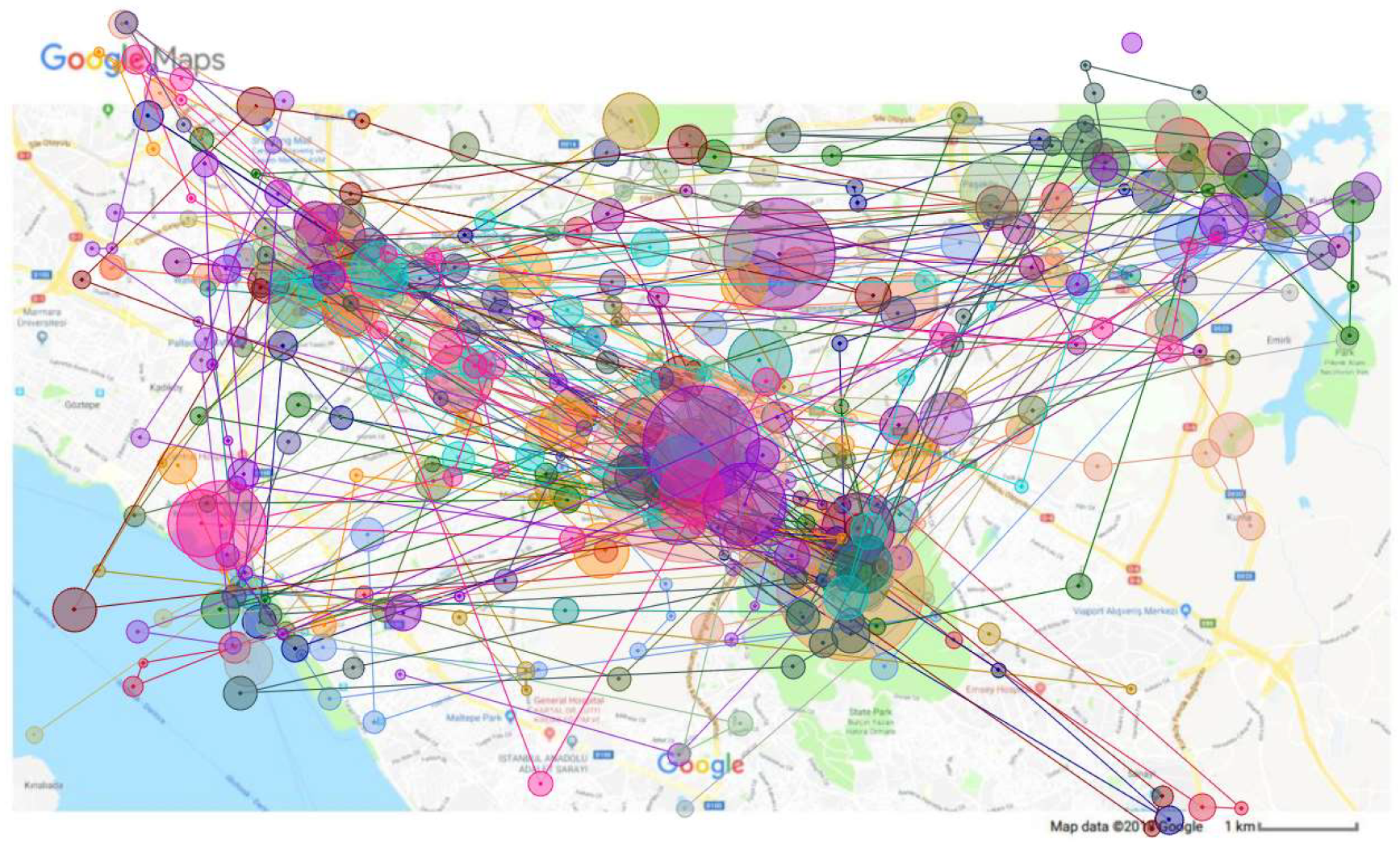
Appendix C. The Description of the Dataset
- Raw_ET_data: The collected eye tracking data in txt format, and can be linked with the map stimuli using the SYNC number in lines with, e.g., # Message: SYNC 103.
- AOIs: The coordinates of AOIs are shared as csv file format.
- Map stimuli: The snapshots of 2D static Google navigational maps were taken at zoom level 15 and approx. 1:40 k scale. The total number of map stimuli used in the experiment is 37 and can be found under Map_stimuli folder in png format. Below are some examples (see Table A2 for the resolution of the stimuli) (Figure A7):

- 4.
- The outputs of the scripts can be found in Final Fixations and AOIs_all_results folders as single. csv files organized per stimulus, map feature type, participant and task type. The explanation of columns are as follows:
- Column 1: Gaze position X (left eye),
- Column 1: Gaze position Y (left eye),
- Column 1: Trial duration,
- Column 1: Duration start,
- Column 1: Duration end, and
- Column 1: The number of points clustered in the same fixation.
- 5.
- Calculate_AOIs_areas: includes the areas of AOIs (square pixel) separately for each stimulus and map feature type, and aggregated in a single file named “all_AOI_areas.csv”.
| Stimulus ID | Width | Height | Stimulus ID | Width | Height | Stimulus ID | Width | Height | Stimulus ID | Width | Height |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 101 | 1148 | 660 | 131 | 1356 | 773 | 153 | 1199 | 587 | 173 | 1338 | 759 |
| 103 | 1148 | 660 | 133 | 1360 | 752 | 155 | 1418 | 834 | 175 | 1218 | 692 |
| 105 | 1721 | 877 | 135 | 1353 | 787 | 157 | 1336 | 756 | 177 | 1246 | 733 |
| 107 | 1210 | 613 | 137 | 1354 | 792 | 159 | 1419 | 834 | 179 | 1124 | 669 |
| 117 | 1279 | 660 | 139 | 1354 | 787 | 161 | 1198 | 591 | 181 | 1336 | 803 |
| 119 | 1356 | 785 | 141 | 1326 | 750 | 163 | 1196 | 588 | 187 | 1207 | 591 |
| 121 | 1357 | 778 | 145 | 1248 | 735 | 165 | 1338 | 758 | 189 | 1211 | 596 |
| 123 | 1360 | 776 | 147 | 1336 | 805 | 167 | 1342 | 755 | 191 | 1129 | 717 |
| 127 | 1292 | 708 | 149 | 1337 | 756 | 169 | 1222 | 720 | |||
| 129 | 1281 | 698 | 151 | 1340 | 809 | 171 | 1245 | 731 |
References
- Bertin, J. Semiology of Graphics; Berg, W.J., Translator; Translated from Sémiologie Graphique; Gauthier-Villars: Paris, France, 1967. [Google Scholar]
- Skopeliti, A.; Stamou, L. Online Map Services: Contemporary Cartography or a New Cartographic Culture? ISPRS Int. J. Geo-Inf. 2019, 8, 215. [Google Scholar] [CrossRef] [Green Version]
- Gilhooly, K.J.; Wood, M.; Kinnear, P.R.; Green, C. Skill in Map Reading and Memory for Maps. Q. J. Exp. Psychol. Sect. A 1988, 40, 87–107. [Google Scholar] [CrossRef]
- Çöltekin, A.; Christophe, S.; Robinson, A.; Demšar, U. Designing Geovisual Analytics Environments and Displays with Humans in Mind. ISPRS Int. J. Geo-Inf. 2019, 8, 572. [Google Scholar] [CrossRef] [Green Version]
- Keskin, M.; Ooms, K.; Dogru, A.O.; De Maeyer, P. Exploring the Cognitive Load of Expert and Novice Map Users Using EEG and Eye Tracking. ISPRS Int. J. Geo-Inf. 2020, 9, 429. [Google Scholar] [CrossRef]
- Krassanakis, V.; Cybulski, P. Eye Tracking Research in Cartography: Looking into the Future. ISPRS Int. J. Geo-Inf. 2021, 10, 411. [Google Scholar] [CrossRef]
- Kuchinke, L.; Dickmann, F.; Edler, D.; Bordewieck, M.; Bestgen, A.-K. The Processing and Integration of Map Elements during a Recognition Memory Task Is Mirrored in Eye-Movement Patterns. J. Environ. Psychol. 2016, 47, 213–222. [Google Scholar] [CrossRef]
- Rust, N.C.; Mehrpour, V. Understanding Image Memorability. Trends Cogn. Sci. 2020, 24, 557–568. [Google Scholar] [CrossRef] [PubMed]
- Bainbridge, W.A. Memorability: How What We See Influences What We Remember. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 2019; Volume 70, pp. 1–27. [Google Scholar]
- Bainbridge, W.A.; Hall, E.H.; Baker, C.I. Drawings of Real-World Scenes during Free Recall Reveal Detailed Object and Spatial Information in Memory. Nat. Commun. 2019, 10, 5. [Google Scholar] [CrossRef] [Green Version]
- Lenneberg, E.H. Color Naming, Color Recognition, Color Discrimination: A Re-Appraisal. Percept. Mot. Skills 1961, 12, 375–382. [Google Scholar] [CrossRef]
- Borkin, M.A.; Vo, A.A.; Bylinskii, Z.; Isola, P.; Sunkavalli, S.; Oliva, A.; Pfister, H. What Makes a Visualization Memorable? IEEE Trans. Vis. Comput. Graph. 2013, 19, 2306–2315. [Google Scholar] [CrossRef]
- Oliva, A. Gist of the Scene. In Neurobiology of Attention; Elsevier: Amsterdam, The Netherlands, 2005; pp. 251–256. [Google Scholar]
- Denis, M.; Mores, C.; Gras, D.; Gyselinck, V.; Daniel, M.-P. Is Memory for Routes Enhanced by an Environment’s Richness in Visual Landmarks? Spat. Cogn. Comput. 2014, 14, 284–305. [Google Scholar] [CrossRef]
- Edler, D.; Bestgen, A.-K.; Kuchinke, L.; Dickmann, F. Grids in Topographic Maps Reduce Distortions in the Recall of Learned Object Locations. PLoS ONE 2014, 9, e98148. [Google Scholar] [CrossRef] [Green Version]
- Keskin, M.; Ooms, K.; Dogru, A.O.; De Maeyer, P. Digital Sketch Maps and Eye Tracking Statistics as Instruments to Obtain Insights into Spatial Cognition. J. Eye Mov. Res. 2018, 11. [Google Scholar] [CrossRef]
- Ooms, K.; De Maeyer, P.; Fack, V. Listen to the Map User: Cognition, Memory, and Expertise. Cartogr. J. 2015, 52, 3–19. [Google Scholar] [CrossRef] [Green Version]
- Bestgen, A.-K.; Edler, D.; Kuchinke, L.; Dickmann, F. Analyzing the Effects of VGI-Based Landmarks on Spatial Memory and Navigation Performance. KI-Künstl. Intell. 2017, 31, 179–183. [Google Scholar] [CrossRef]
- Dickmann, F.; Edler, D.; Bestgen, A.-K.; Kuchinke, L. Exploiting Illusory Grid Lines for Object-Location Memory Performance in Urban Topographic Maps. Cartogr. J. 2017, 54, 242–253. [Google Scholar] [CrossRef]
- Miyake, A.; Shah, P. Models of Working Memory: Mechanisms of Active Maintenance and Executive Control, 1st ed.; Miyake, A., Shah, P., Eds.; Cambridge University Press: Cambridge, UK, 1999; ISBN 978-0-521-58721-1. [Google Scholar]
- Chai, W.J.; Abd Hamid, A.I.; Abdullah, J.M. Working Memory From the Psychological and Neurosciences Perspectives: A Review. Front. Psychol. 2018, 9, 401. [Google Scholar] [CrossRef] [Green Version]
- Barrouillet, P.; Bernardin, S.; Camos, V. Time Constraints and Resource Sharing in Adults’ Working Memory Spans. J. Exp. Psychol. Gen. 2004, 133, 83–100. [Google Scholar] [CrossRef] [Green Version]
- Barrouillet, P.; Gavens, N.; Vergauwe, E.; Gaillard, V.; Camos, V. Working Memory Span Development: A Time-Based Resource-Sharing Model Account. Dev. Psychol. 2009, 45, 477–490. [Google Scholar] [CrossRef] [Green Version]
- Barrouillet, P.; Camos, V. The Time-Based Resource-Sharing Model of Working Memory. In The Cognitive Neuroscience of Working Memory; Osaka, N., Logie, R.H., D’Esposito, M., Eds.; Oxford University Press: Oxford, UK, 2007; pp. 59–80. ISBN 978-0-19-857039-4. [Google Scholar]
- Lokka, I.E.; Çöltekin, A.; Wiener, J.; Fabrikant, S.I.; Röcke, C.; Çöltekin, A.; Wiener, J.; Fabrikant, S.I.; Röcke, C. Virtual Environments as Memory Training Devices in Navigational Tasks for Older Adults. Sci. Rep. 2018, 8, 10809. [Google Scholar] [CrossRef]
- Lokka, I.E.; Çöltekin, A. Toward Optimizing the Design of Virtual Environments for Route Learning: Empirically Assessing the Effects of Changing Levels of Realism on Memory. Int. J. Digit. Earth 2019, 12, 137–155. [Google Scholar] [CrossRef]
- Lokka, I.E.; Çöltekin, A. Perspective Switch and Spatial Knowledge Acquisition: Effects of Age, Mental Rotation Ability and Visuospatial Memory Capacity on Route Learning in Virtual Environments with Different Levels of Realism. Cartogr. Geogr. Inf. Sci. 2020, 47, 14–27. [Google Scholar] [CrossRef]
- Aravind, G.; Lamontagne, A. Dual Tasking Negatively Impacts Obstacle Avoidance Abilities in Post-Stroke Individuals with Visuospatial Neglect: Task Complexity Matters! Restor. Neurol. Neurosci. 2017, 35, 423–436. [Google Scholar] [CrossRef] [PubMed]
- Castro-Alonso, J.C.; Ayres, P.; Sweller, J. Instructional Visualizations, Cognitive Load Theory, and Visuospatial Processing. In Visuospatial Processing for Education in Health and Natural Sciences; Springer: Berlin/Heidelberg, Germany, 2019; pp. 111–143. [Google Scholar]
- Haji, F.A.; Rojas, D.; Childs, R.; de Ribaupierre, S.; Dubrowski, A. Measuring Cognitive Load: Performance, Mental Effort and Simulation Task Complexity. Med. Educ. 2015, 49, 815–827. [Google Scholar] [CrossRef] [PubMed]
- Gobet, F. The Future of Expertise: The Need for a Multidisciplinary Approach. J. Expert. 2018, 1, 107–113. [Google Scholar]
- Brams, S.; Ziv, G.; Levin, O.; Spitz, J.; Wagemans, J.; Williams, A.M.; Helsen, W.F. The Relationship between Gaze Behavior, Expertise, and Performance: A Systematic Review. Psychol. Bull. 2019, 145, 980–1027. [Google Scholar] [CrossRef]
- Ericsson, K.A.; Kintsch, W. Long-Term Working Memory. Psychol. Rev. 1995, 102, 211. [Google Scholar] [CrossRef]
- Haider, H.; Frensch, P.A. Eye Movement during Skill Acquisition: More Evidence for the Information-Reduction Hypothesis. J. Exp. Psychol. Learn. Mem. Cogn. 1999, 25, 172. [Google Scholar] [CrossRef]
- Kundel, H.L.; Nodine, C.F.; Conant, E.F.; Weinstein, S.P. Holistic Component of Image Perception in Mammogram Interpretation: Gaze-Tracking Study. Radiol.-Radiol. Soc. N. Am. 2007, 242, 396–402. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Cave, K.R.; Franzel, S.L. Guided Search: An Alternative to the Feature Integration Model for Visual Search. J. Exp. Psychol. Hum. Percept. Perform. 1989, 15, 419. [Google Scholar] [CrossRef]
- Gegenfurtner, A.; Lehtinen, E.; Säljö, R. Expertise Differences in the Comprehension of Visualizations: A Meta-Analysis of Eye-Tracking Research in Professional Domains. Educ. Psychol. Rev. 2011, 23, 523–552. [Google Scholar] [CrossRef]
- Kimerling, A.J.; Muehrcke, J.O.; Buckley, A.R.; Muehrcke, P.C. Map Use: Reading and Analysis; Esri Press: Redlands, CA, USA, 2010. [Google Scholar]
- MacEachren, A.M. How Maps Work: Representation, Visualization, and Design; Guilford Press: New York, NY, USA, 2004; ISBN 978-1-57230-040-8. [Google Scholar]
- Thorndyke, P.W.; Stasz, C. Individual Differences in Procedures for Knowledge Acquisition from Maps. Cognit. Psychol. 1980, 12, 137–175. [Google Scholar] [CrossRef]
- Kulhavy, R.W.; Stock, W.A. How Cognitive Maps Are Learned and Remembered. Ann. Assoc. Am. Geogr. 1996, 86, 123–145. [Google Scholar] [CrossRef]
- Çöltekin, A.; Fabrikant, S.I.; Lacayo, M. Exploring the Efficiency of Users’ Visual Analytics Strategies Based on Sequence Analysis of Eye Movement Recordings. Int. J. Geogr. Inf. Sci. 2010, 24, 1559–1575. [Google Scholar] [CrossRef]
- Li, W.-C.; Chiu, F.-C.; Kuo, Y.; Wu, K.-J. The Investigation of Visual Attention and Workload by Experts and Novices in the Cockpit. In Proceedings of the International Conference on Engineering Psychology and Cognitive Ergonomics, Las Vegas, NV, USA, 21–26 July 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 167–176. [Google Scholar]
- Ooms, K.; De Maeyer, P.; Fack, V. Study of the Attentive Behavior of Novice and Expert Map Users Using Eye Tracking. Cartogr. Geogr. Inf. Sci. 2014, 41, 37–54. [Google Scholar] [CrossRef] [Green Version]
- Dong, W.; Zheng, L.; Liu, B.; Meng, L. Using Eye Tracking to Explore Differences in Map-Based Spatial Ability between Geographers and Non-Geographers. ISPRS Int. J. Geo-Inf. 2018, 7, 337. [Google Scholar] [CrossRef] [Green Version]
- Çöltekin, A.; Brychtová, A.; Griffin, A.L.; Robinson, A.C.; Imhof, M.; Pettit, C. Perceptual Complexity of Soil-Landscape Maps: A User Evaluation of Color Organization in Legend Designs Using Eye Tracking. Int. J. Digit. Earth 2017, 10, 560–581. [Google Scholar] [CrossRef]
- Beatty, W.W.; Bruellman, J.A. Absence of Gender Differences in Memory for Map Learning. Bull. Psychon. Soc. 1987, 25, 238–239. [Google Scholar] [CrossRef] [Green Version]
- Keskin, M. Exploring the Cognitive Processes of Map Users Employing Eye Tracking and EEG. Ph.D. Thesis, Ghent University, Ghent, Belgium, 2020. [Google Scholar]
- Kummerer, M.; Wallis, T.S.A.; Bethge, M. Saliency Benchmarking Made Easy: Separating Models, Maps and Metrics. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 798–814. [Google Scholar]
- Tliba, M.; Kerkouri, M.A.; Ghariba, B.; Chetouani, A.; Çöltekin, A.; Shehata, M.S.; Bruno, A. SATSal: A Multi-Level Self-Attention Based Architecture for Visual Saliency Prediction. IEEE Access 2022, 10, 20701–20713. [Google Scholar] [CrossRef]
- Keskin, M.; Ooms, K.; Dogru, A.O.; De Maeyer, P. EEG & Eye Tracking User Experiments for Spatial Memory Task on Maps. ISPRS Int. J. Geo-Inf. 2019, 8, 546. [Google Scholar]
- Krassanakis, V.; Filippakopoulou, V.; Nakos, B. EyeMMV Toolbox: An Eye Movement Post-Analysis Tool Based on a Two-Step Spatial Dispersion Threshold for Fixation Identification. J. Eye Mov. Res. 2014, 7, 1–10. [Google Scholar] [CrossRef]
- Krassanakis, V.; Misthos, L.-M.; Menegaki, M. LandRate Toolbox: An Adaptable Tool for Eye Movement Analysis and Landscape Rating. In Proceedings of the Eye Tracking for Spatial Research. In Proceedings of the 3rd International Workshop; ETH Zurich, Zürich, Switzerland, 14 January 2018. [Google Scholar]
- Perrin, A.-F.; Krassanakis, V.; Zhang, L.; Ricordel, V.; Perreira Da Silva, M.; Le Meur, O. EyeTrackUAV2: A Large-Scale Binocular Eye-Tracking Dataset for UAV Videos. Drones 2020, 4, 2. [Google Scholar] [CrossRef]
- Krassanakis, V.; Da Silva, M.P.; Ricordel, V. Monitoring Human Visual Behavior during the Observation of Unmanned Aerial Vehicles (UAVs) Videos. Drones 2018, 2, 36. [Google Scholar] [CrossRef] [Green Version]
- Ooms, K.; Krassanakis, V. Measuring the Spatial Noise of a Low-Cost Eye Tracker to Enhance Fixation Detection. J. Imaging 2018, 4, 96. [Google Scholar] [CrossRef] [Green Version]
- Popelka, S. Optimal Eye Fixation Detection Settings for Cartographic Purposes. In Proceedings of the 14th International Multidisciplinary Scientific GeoConference SGEM, Albena, Bulgaria, 17–26 June 2014; pp. 705–712. [Google Scholar]
- Manor, B.R.; Gordon, E. Defining the Temporal Threshold for Ocular Fixation in Free-Viewing Visuocognitive Tasks. J. Neurosci. Methods 2003, 128, 85–93. [Google Scholar] [CrossRef]
- Kiefer, P.; Giannopoulos, I.; Raubal, M. Where Am I? Investigating Map Matching During Self-Localization With Mobile Eye Tracking in an Urban Environment. Trans. GIS 2014, 18, 660–686. [Google Scholar] [CrossRef]
- Yarbus, A.L. Eye Movements during Perception of Complex Objects. In Eye Movements and Vision; Springer: Berlin/Heidelberg, Germany, 1967; pp. 171–211. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A Model of Saliency-Based Visual Attention for Rapid Scene Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Edler, D.; Keil, J.; Kuchinke, L.; Dickmann, F. Correcting distortion errors in memory of object locations: The example of grid line spacing in topographic maps. Int. J. Cartogr. 2019, 5, 92–109. [Google Scholar] [CrossRef]
- Röser, F.; Hamburger, K.; Krumnack, A.; Knauff, M. The Structural Salience of Landmarks: Results from an on-Line Study and a Virtual Environment Experiment. J. Spat. Sci. 2012, 57, 37–50. [Google Scholar] [CrossRef]
- Wolfe, J.M. Visual Attention. In Seeing; Elsevier: Amsterdam, The Netherlands, 2000; pp. 335–386. [Google Scholar]
- Ooms, K. Maps, How Do Users See Them?: An in Depth Investigation of the Map Users’ Cognitive Processes. Doctoral Dissertation, Ghent University, Ghent, Belgium, 2012. [Google Scholar]
- Lochhead, I.; Hedley, N.; Çöltekin, A.; Fisher, B. The Immersive Mental Rotations Test: Evaluating Spatial Ability in Virtual Reality. Front. Virtual Real. 2022, 3, 820237. [Google Scholar] [CrossRef]
- Uttal, D.H.; Meadow, N.G.; Tipton, E.; Hand, L.L.; Alden, A.R.; Warren, C.; Newcombe, N.S. The Malleability of Spatial Skills: A Meta-Analysis of Training Studies. Psychol. Bull. 2013, 139, 352. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krejtz, K.; Duchowski, A.; Krejtz, I.; Szarkowska, A.; Kopacz, A. Discerning Ambient/Focal Attention with Coefficient K. ACM Trans. Appl. Percept. TAP 2016, 13, 1–20. [Google Scholar] [CrossRef]
- Krejtz, K.; Coltekin, A.; Duchowski, A.; Niedzielska, A. Using Coefficient K to Distinguish Ambient/Focal Visual Attention during Map Viewing. J. Eye Mov. Res. 2017, 10, 3. [Google Scholar] [CrossRef] [PubMed]
- Cheng, S.; Wang, J.; Shen, X.; Chen, Y.; Dey, A. Collaborative Eye Tracking Based Code Review through Real-Time Shared Gaze Visualization. Front. Comput. Sci. 2022, 16, 1–11. [Google Scholar] [CrossRef]
- Krassanakis, V. Aggregated Gaze Data Visualization Using Contiguous Irregular Cartograms. Digital 2021, 1, 130–144. [Google Scholar] [CrossRef]
- Gökstorp, S.G.E.; Breckon, T.P. Temporal and Non-Temporal Contextual Saliency Analysis for Generalized Wide-Area Search within Unmanned Aerial Vehicle (UAV) Video. Vis. Comput. 2022, 38, 2033–2040. [Google Scholar] [CrossRef]
- Cybulski, P.; Krassanakis, V. The Effect of Map Label Language on the Visual Search of Cartographic Point Symbols. Cartogr. Geogr. Inf. Sci. 2022, 49, 189–204. [Google Scholar] [CrossRef]
- Tzelepis, N.; Kaliakouda, A.; Krassanakis, V.; Misthos, L.-M.; Nakos, B. Evaluating the Perceived Visual Complexity of Multidirectional Hill-Shading. Geod. Cartogr. 2020, 69, 161–172. [Google Scholar]
- Krassanakis, V. Exploring the Map Reading Process with Eye Movement Analysis. In Proceedings of the Proceedings of the International Workshop on Eye Tracking for Spatial Research, Scarborough, UK, 2 September 2013; pp. 2–5. [Google Scholar]
- Kiefer, P.; Giannopoulos, I.; Raubal, M.; Duchowski, A. Eye Tracking for Spatial Research: Cognition, Computation, Challenges. Spat. Cogn. Comput. 2017, 17, 1–19. [Google Scholar] [CrossRef]



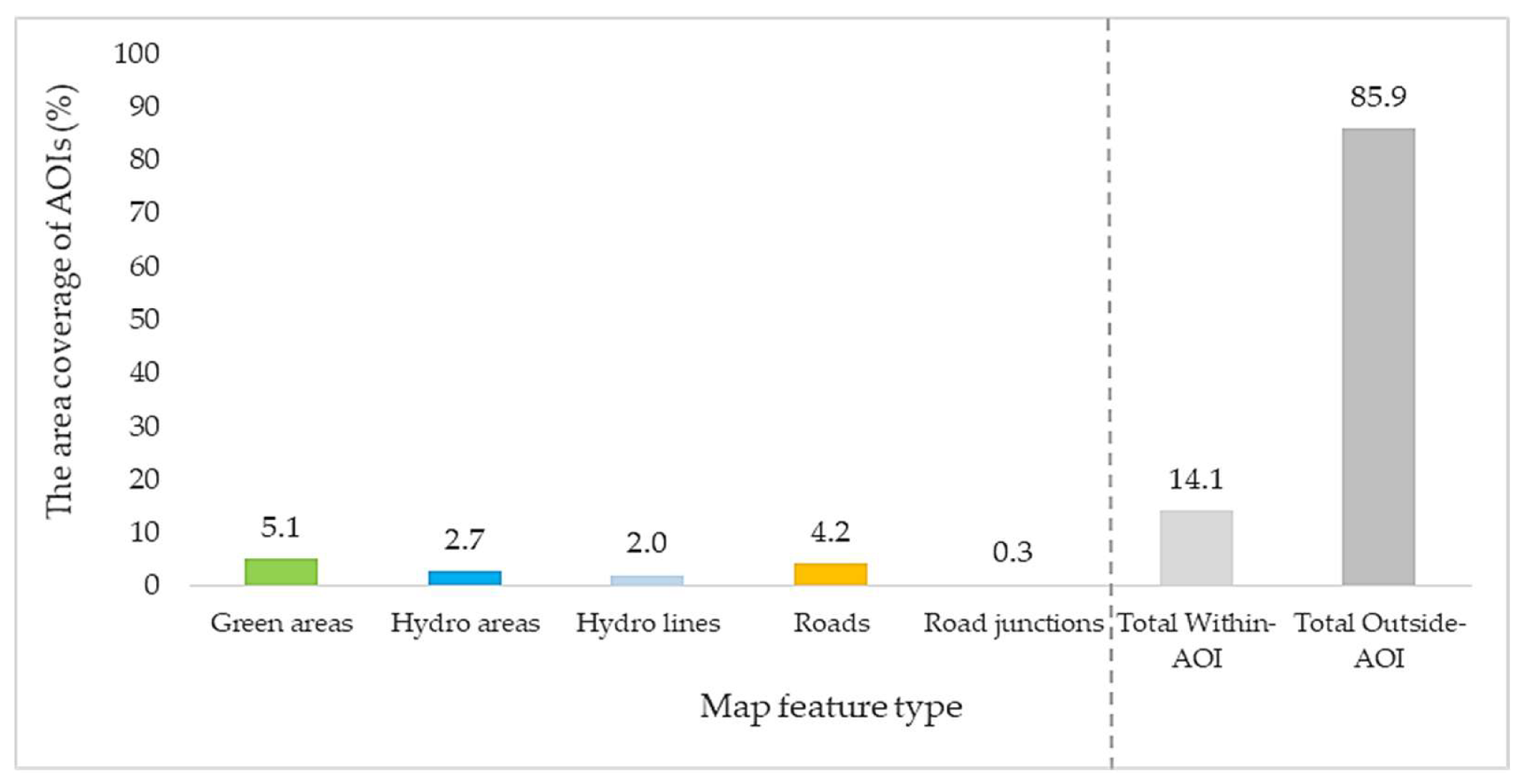

| Map Feature Type | Areas (Square Pixel) | Inverse Weights |
|---|---|---|
| Green areas | 1,786,107.4 | 17.0 |
| Hydro areas | 939,475.4 | 32.3 |
| Hydro lines | 691,480.1 | 43.9 |
| Roads | 1,481,814.3 | 20.5 |
| Road junctions | 93,290.0 | 325.3 |
| Total Within-AOI | 4,992,167.3 | 6.1 |
| Total Outside-AOI | 30,350,484.7 | 1.0 |
| Main Effects | Repeated Measures ANOVA | Significance * |
|---|---|---|
| Overall Within- vs. outside-AOI (n = 38) | F = 125.468, p < 0.001, power = 1.000 | *** |
| Expert (n = 17) vs. novice (n = 21) | F = 7.610, p < 0.01, power = 1.000 | ** |
| Map feature type (5×) (n = 38) | F = 23.742, p < 0.001, power = 1.000 | *** |
| Task difficulty (3×) (n = 38) | F = 55.225, p < 0.01, power = 1.000 | *** |
| Interactions | Repeated Measures ANOVA | Significance * |
|---|---|---|
| Expertise × AOI type | F = 0.010, p = 0.919, power = 0.051 | Not significant |
| Map feature type × AOI type | F = 24.292, p < 0.001, power = 1.000 | *** |
| Task difficulty × AOI type | F = 11.278, p < 0.001, power = 0.993 | *** |
| Map feature type × Expertise | F = 3.409, p < 0.01, power = 0.856 | ** |
| Expertise × Task difficulty | F = 1.780, p = 0.169, power = 0.375 | Not significant |
| Map feature type × Task difficulty | F = 4.625, p < 0.001, power = 0.998 | *** |
| Expertise × Map feature type × AOI type | F = 3.743, p < 0.01, power = 0.891 | ** |
| Expertise × Task difficulty × AOI type | F = 0.241, p = 0.786, power = 0.088 | Not significant |
| Map feature type × Task difficulty × AOI type | F = 5.154, p < 0.001, power = 0.999 | *** |
| Expertise × Map feature type × Task difficulty | F = 1.099, p = 0.360, power = 0.522 | Not significant |
| Expertise × Map feature type × Task difficulty × AOI type | F = 1.288, p = 0.245, power = 0.603 | Not significant |
| Task Type | Average Success Rate for Experts (%) | Average Success Rate for Novices (%) | Total Average Success Rate (%) | Total Average Success Rate (%) | Task Difficulty |
|---|---|---|---|---|---|
| B1 (all elements) | 91.5 | 90.9 | 90.8 | 88.8 | HARD |
| B2 (road and hydro) | 87.3 | 85.6 | 86.8 | ||
| B3 (road and green) | 92.1 | 90.4 | 91.3 | 91.4 | MODERATE |
| B4 (green and hydro) | 92.7 | 90.6 | 91.5 | ||
| B5 (green) | 93.5 | 93.0 | 93.3 | 94.9 | EASY |
| B6 (hydro) | 97.3 | 97.4 | 97.3 | ||
| B7 (road) | 94.5 | 93.9 | 94.2 |
| Task Type | Personal Ranking (Column 1–7: Level of Difficulty in Increasing Order) | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| B1 (all elements) | 29 | 0 | 5 | 0 | 0 | 19 | 48 | |
| B2 (road and hydro) | 0 | 14 | 14 | 14 | 19 | 33 | 5 | |
| B3 (road and green) | 0 | 14 | 19 | 29 | 33 | 5 | 0 | |
| B4 (green and hydro) | 0 | 0 | 24 | 38 | 14 | 19 | 5 | |
| B5 (green) | 24 | 29 | 5 | 5 | 5 | 10 | 24 | |
| B6 (hydro) | 29 | 29 | 14 | 0 | 14 | 10 | 5 | |
| B7 (road) | 19 | 14 | 19 | 14 | 14 | 5 | 14 | experts |
| B1 (all elements) | 0 | 6 | 6 | 0 | 6 | 6 | 75 | |
| B2 (road and hydro) | 13 | 0 | 6 | 13 | 19 | 50 | 0 | |
| B3 (road and green) | 6 | 6 | 6 | 41 | 35 | 6 | 0 | |
| B4 (green and hydro) | 7 | 7 | 0 | 27 | 33 | 20 | 7 | |
| B5 (green) | 19 | 19 | 38 | 6 | 0 | 13 | 6 | |
| B6 (hydro) | 31 | 38 | 19 | 6 | 0 | 0 | 6 | |
| B7 (road) | 25 | 25 | 25 | 6 | 6 | 6 | 6 | novices |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Keskin, M.; Krassanakis, V.; Çöltekin, A. Visual Attention and Recognition Differences Based on Expertise in a Map Reading and Memorability Study. ISPRS Int. J. Geo-Inf. 2023, 12, 21. https://doi.org/10.3390/ijgi12010021
Keskin M, Krassanakis V, Çöltekin A. Visual Attention and Recognition Differences Based on Expertise in a Map Reading and Memorability Study. ISPRS International Journal of Geo-Information. 2023; 12(1):21. https://doi.org/10.3390/ijgi12010021
Chicago/Turabian StyleKeskin, Merve, Vassilios Krassanakis, and Arzu Çöltekin. 2023. "Visual Attention and Recognition Differences Based on Expertise in a Map Reading and Memorability Study" ISPRS International Journal of Geo-Information 12, no. 1: 21. https://doi.org/10.3390/ijgi12010021