
Visibility-Based R-Tree Spatial Index for Consistent Visualization in Indoor and Outdoor Scenes
 , ,
, ,
Abstract
:1. Introduction
2. Related Works
2.1. Improved Visualization with Data Processing
2.2. Improved Visualization Using Spatial Index Technology
2.3. Predictive Visibility-Based Visualization Enhancement
3. Methodology
3.1. Context
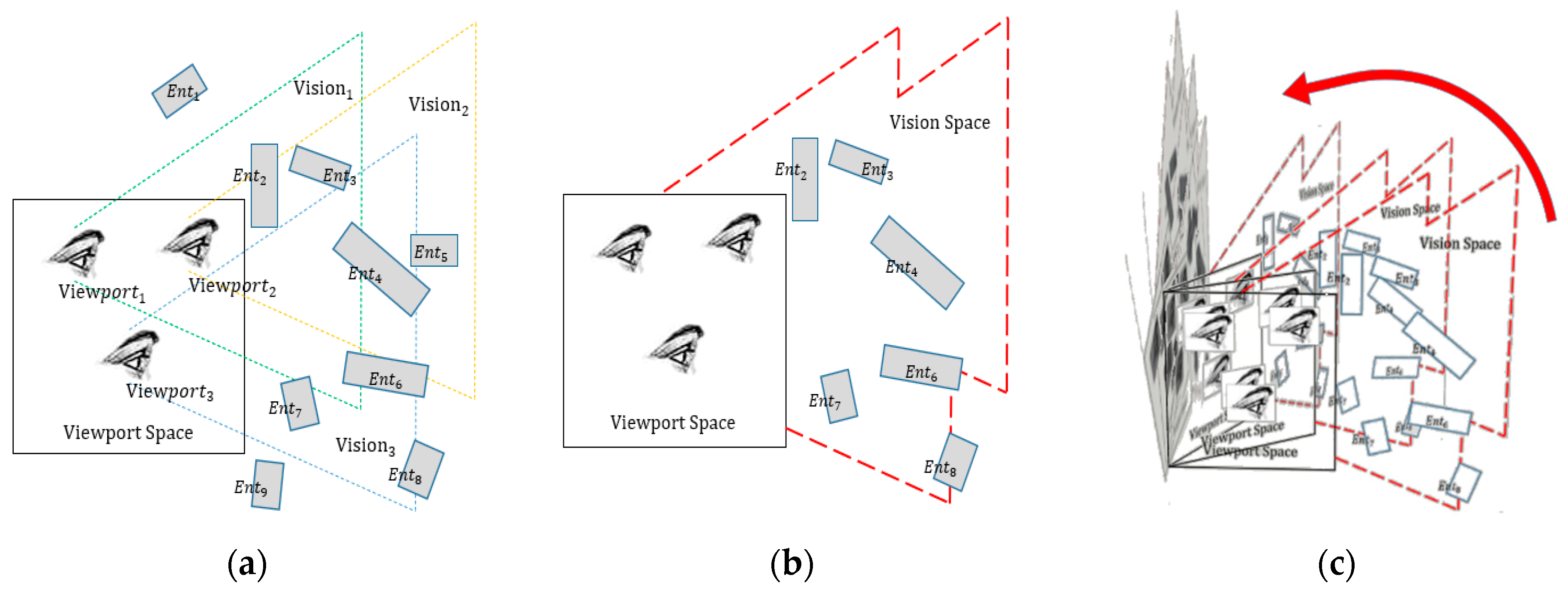
3.2. Connotation and Mathematical Representation of VESI
3.3. The Construction Procedure of VESI
3.3.1. Viewpoint Space Subdivision
- Outdoor space is defined as a region with a certain distance from the building where observers have access to an empty area with a relatively wide field of view and are often able to see the outer surface of buildings at a distance.
- In–outdoor space represents the transitional zone between the interior and exterior spaces. The creation of in–outdoor space is achieved by strategically establishing the distances before and after entering a building. Within these spaces, observers are afforded the opportunity to simultaneously perceive both the interior objects through windows and doors, as well as the exterior surfaces of neighboring buildings.
- Interior spaces are located at a certain distance after observers completely enter a building, where they can only observe indoor objects that are more densely distributed than those found in outdoor spaces.
3.3.2. Potential Visible Set Detection
3.3.3. R-Tree-Based Spatial Indexing
3.3.4. Data Scheduling Using VESI
4. Empirical Exploration and Methodical Analysis
4.1. The Process of Creating a VESI
4.2. The Creation Efficiency of VESI
4.3. The Visual Effects Analysis of VESI
4.3.1. Analysis of Roaming Fluency and Visualization Effects
4.3.2. Visual Stability Analysis under Regional Changes
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kalogianni, E.; van Oosterom, P.; Dimopoulou, E.; Lemmen, C. 3D Land Administration: A Review and a Future Vision in the Context of the Spatial Development Lifecycle. ISPRS Int. J. Geo-Inf. 2020, 9, 107. [Google Scholar] [CrossRef]
- Qi, C.; Zhou, H.; Yuan, L.; Li, P.; Qi, Y. Application of BIM+ GIS Technology in Smart City 3D Design System. In Proceedings of the International Conference on Cyber Security Intelligence and Analytics, Shanghai, China, 30–31 March 2023; Springer: Cham, Switzerland, 2023; pp. 37–45. [Google Scholar]
- Zhan, W.; Chen, Y.; Chen, J. 3D Tiles-Based High-Efficiency Visualization Method for Complex BIM Models on the Web. ISPRS Int. J. Geo-Inf. 2021, 10, 476. [Google Scholar] [CrossRef]
- Huo, Y.; Yang, A.; Jia, Q.; Chen, Y.; He, B.; Li, J. Efficient Visualization of Large-Scale Oblique Photogrammetry Models in Unreal Engine. ISPRS Int. J. Geo-Inf. 2021, 10, 643. [Google Scholar] [CrossRef]
- Chen, Y.; Shooraj, E.; Rajabifard, A.; Sabri, S. From IFC to 3D Tiles: An Integrated Open-Source Solution for Visualising BIMs on Cesium. ISPRS Int. J. Geo-Inf. 2018, 7, 393. [Google Scholar] [CrossRef]
- Clark, J.H. Hierarchical Geometric Models for Visible Surface Algorithms. Commun. ACM 1976, 19, 547–554. [Google Scholar] [CrossRef]
- El-Mekawy, M.; Östman, A.; Shahzad, K. Towards interoperating CityGML and IFC building models: A unified model based approach. In Advances in 3D Geo-Information Sciences; Springer: Berlin/Heidelberg, Germany, 2010; pp. 73–93. [Google Scholar]
- Gröger, G.; Plümer, L. CityGML—Interoperable semantic 3D city models. ISPRS J. Photogramm. Remote Sens. 2012, 71, 12–33. [Google Scholar] [CrossRef]
- Zhu, Q.; Hu, M.Y. Semantics-based 3D dynamic hierarchical house property model. Int. J. Geogr. Inf. Sci. 2010, 24, 165–188. [Google Scholar] [CrossRef]
- Biljecki, F.; Ledoux, H.; Stoter, J. An improved LOD specification for 3D building models. Comput. Environ. Urban Syst. 2016, 59, 25–37. [Google Scholar] [CrossRef]
- Löwner, M.O.; Gröger, G.; Benner, J.; Biljecki, F.; Nagel, C. Proposal for a new LOD and multi-representation concept for CityGML. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. 2016, 4, 3–12. [Google Scholar] [CrossRef]
- Tang, L.; Li, L.; Ying, S.; Lei, Y. A full level-of-detail specification for 3D building models combining indoor and outdoor scenes. ISPRS Int. J. Geo-Inf. 2018, 7, 419. [Google Scholar] [CrossRef]
- Chen, Z.; Pouliot, J.; Hubert, F. A First Attempt to Define Level of Details Based on Decision-Making Tasks: Application to Underground Utility Network. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2021, 46, 137–144. [Google Scholar] [CrossRef]
- Tang, L.; Ying, S.; Li, L.; Biljecki, F.; Zhu, H.; Zhu, Y.; Yang, F.; Su, F. An application-driven LOD modeling paradigm for 3D building models. ISPRS J. Photogramm. Remote Sens. 2020, 161, 194–207. [Google Scholar] [CrossRef]
- Zhu, Q.; Gong, J.; Zhang, Y. An efficient 3D R-tree spatial index method for virtual geographic environments. ISPRS J. Photogramm. Remote Sens. 2007, 62, 217–224. [Google Scholar] [CrossRef]
- Zhang, L.Q.; Guo, Z.F.; Kang, Z.Z.; Zhang, L.X.; Zhang, X.M.; Yang, L. Web-based visualization of spatial objects in 3DGIS. Sci. China Ser. F-Inf. Sci. 2009, 52, 1588–1597. [Google Scholar] [CrossRef]
- Yang, J.; Huang, X. A hybrid spatial index for massive point cloud data management and visualization. Trans. GIS 2014, 18, 97–108. [Google Scholar] [CrossRef]
- Ke, S.; Gong, J.; Li, S.; Zhu, Q.; Liu, X.; Zhang, Y. A hybrid spatio-temporal data indexing method for trajectory databases. Sensors 2014, 14, 12990–13005. [Google Scholar] [CrossRef]
- Han, J.; Na, C.-W.; Lee, D.; Lee, D.-H.; On, B.-W.; Lee, R.; Park, M.-W.; Lee, S.-H. An Unified Spatial Index and Visualization Method for the Trajectory and Grid Queries in Internet of Things. J. Korea Soc. Comput. Inf. 2019, 24, 83–95. [Google Scholar]
- Yu, Y.; Zhu, H.; Yang, L.; Wang, C. Spatial indexing for effective visualization of vector-based electronic nautical chart. In Proceedings of the 2016 International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration, Wuhan, China, 3–4 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 323–326. [Google Scholar]
- Liu, Z.; Chen, L.; Yang, A.; Ma, M.; Cao, J. Hiindex: An efficient spatial index for rapid visualization of large-scale geographic vector data. ISPRS Int. J. Geo-Inf. 2021, 10, 647. [Google Scholar] [CrossRef]
- Wu, H.; Zhu, Q.; Guo, Y.; Zheng, W.; Zhang, L.; Wang, Q.; Zhou, R.; Ding, Y.; Wang, W.; Pirasteh, S.; et al. Multi-level voxel representations for digital twin models of tunnel geological environment. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102887. [Google Scholar] [CrossRef]
- Andújar, C.; Saona-Vázquez, C.; Navazo, I.; Brunet, P. Integrating Occlusion Culling and Levels of Detail through Hardly-Visible Sets. In Computer Graphics Forum; Blackwell Publishers Ltd.: Oxford, UK; Boston, MA, USA, 2000; Volume 19, pp. 499–506. [Google Scholar]
- Cohen-Or, D.; Fibich, G.; Halperin, D.; Zadicario, E. Conservative visibility and strong occlusion for viewspace partitioning of densely occluded scenes. In Computer Graphics Forum; Blackwell Publishers Ltd.: Oxford, UK; Boston, MA, USA, 1998; Volume 17, pp. 243–253. [Google Scholar]
- Masehian, E.; Amin-Naseri, M.R. A voronoi diagram-visibility graph-potential field compound algorithm for robot path planning. J. Robot. Syst. 2004, 21, 275–300. [Google Scholar] [CrossRef]
- Roden, T.; Parberry, I. Portholes and planes: Faster dynamic evaluation of potentially visible sets. Comput. Entertain. 2005, 3, 3. [Google Scholar] [CrossRef]
- Li, B.; Wang, C.; Li, L. Efficient occlusion culling with occupancy proportion. In Proceedings of the 2008 International Conference on Computer Science and Software Engineering, Wuhan, China, 12–14 December 2008; pp. 1058–1061. [Google Scholar]
- Bittner, J.; Mattausch, O.; Wonka, P.; Havran, V.; Wimmer, M. Adaptive global visibility sampling. ACM Trans. Graph. 2009, 28, 1–10. [Google Scholar] [CrossRef]
- Wang, W.; Lv, Z.; Li, X.; Xu, W.; Zhang, B.; Zhu, Y.; Yan, Y. Spatial query based virtual reality GIS analysis platform. Neurocomputing 2018, 274, 88–98. [Google Scholar] [CrossRef]
- Kim, J.; Lee, S. Potentially Visible Hidden-Volume Rendering for Multi-View Warping. ACM Trans. Graph. 2023, 42, 1–11. [Google Scholar] [CrossRef]
- Voglreiter, P.; Kerbl, B.; Weinrauch, A.; Mueller, J.H.; Neff, T.; Steinberger, M.; Schmalstieg, D. Trim Regions for Online Computation of From-Region Potentially Visible Sets. ACM Trans. Graph. 2023, 42, 1–15. [Google Scholar] [CrossRef]
- Hladky, J.; Seidel, H.P.; Steinberger, M. The camera offset space: Real-time potentially visible set computations for streaming rendering. ACM Trans. Graph. 2019, 38, 1–14. [Google Scholar] [CrossRef]
- Kobrtek, J.; Milet, T.; Herout, A. Silhouette extraction for shadow volumes using potentially visible sets. J. WSCG 2018, 26, 9–16. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indoor Structure | Reorganization Setting | Post-Reorganization | ||||
|---|---|---|---|---|---|---|
| Total Tri(s) | Threshold | Objects | Tri(s) Ave. | Tri(s) Min. | Tri(s) Max. | |
| Building 1 | 1,956,156 | 3000 | 1409 | 1388 | 18 | 2680 |
| Building 2 | 25,274 | 1000 | 37 | 683 | 24 | 912 |
| Building 3 | 10,148 | 1000 | 18 | 558 | 24 | 631 |
| Viewpoint Space | Voxel Size | VS Voxel Num. | Visible Objects Per Voxel | ||
|---|---|---|---|---|---|
| Ave. | Min. | Max. | |||
| Outdoor | 8 × 4 × 3 | 1262 | 5 | 2 | 16 |
| building 1 | 2 × 2 × 1 | 4408 | 25 | 6 | 52 |
| building 2 | 2 × 2 × 1 | 204 | 10 | 7 | 22 |
| building 3 | 2 × 2 × 1 | 126 | 9 | 7 | 18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Kuai, X.; He, B.; Zhao, Z.; Lin, H.; Zhu, W.; Liu, Y.; Guo, R. Visibility-Based R-Tree Spatial Index for Consistent Visualization in Indoor and Outdoor Scenes. ISPRS Int. J. Geo-Inf. 2023, 12, 498. https://doi.org/10.3390/ijgi12120498
Li C, Kuai X, He B, Zhao Z, Lin H, Zhu W, Liu Y, Guo R. Visibility-Based R-Tree Spatial Index for Consistent Visualization in Indoor and Outdoor Scenes. ISPRS International Journal of Geo-Information. 2023; 12(12):498. https://doi.org/10.3390/ijgi12120498
Chicago/Turabian StyleLi, Chengpeng, Xi Kuai, Biao He, Zhigang Zhao, Haojia Lin, Wei Zhu, Yu Liu, and Renzhong Guo. 2023. "Visibility-Based R-Tree Spatial Index for Consistent Visualization in Indoor and Outdoor Scenes" ISPRS International Journal of Geo-Information 12, no. 12: 498. https://doi.org/10.3390/ijgi12120498