

A Containerized Service-Based Integration Framework for Heterogeneous-Geospatial-Analysis Models

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Research Background
1.2. Issues and Challenges
1.2.1. Characteristics of Geospatial-Analysis Models
1.2.2. Advances of Geospatial-Analysis Models
1.2.3. Challenges of Integrating Geospatial-Analysis Models
1.3. Contributions
- (1)
- The model encapsulation component designs the model-servicized structure for the characteristics of model structural heterogeneity. With this model-servicized structure, diverse types of geospatial-analysis models can be effectively described and integrated based on standardized constraints. This approach ultimately enhances the interoperability and reusability of models across different systems and platforms.
- (2)
- The model orchestration component designs a prioritization-based orchestration method for the characteristics of model-dependency heterogeneity. The approach prioritizes and optimizes resource discovery based on model relationships, service performance, and runtime feedback. This enables optimal combination and capability integration of large-scale heterogeneous-geospatial-analysis models.
- (3)
- The model publication component designs a heuristic scheduling method for the characteristics of the execution-mode heterogeneity. This method utilizes containerization technology to isolate the execution of different geospatial-analysis models, thereby mitigating the effects of heterogeneous runtime environments and accommodating diverse execution modes. Additionally, it establishes optimal mapping between models and underlying computational resources, enhancing the adaptability of models to cloud environments, while improving their stability and service performance.
1.4. Paper Organization
2. Design of the Framework
3. Design of the Component
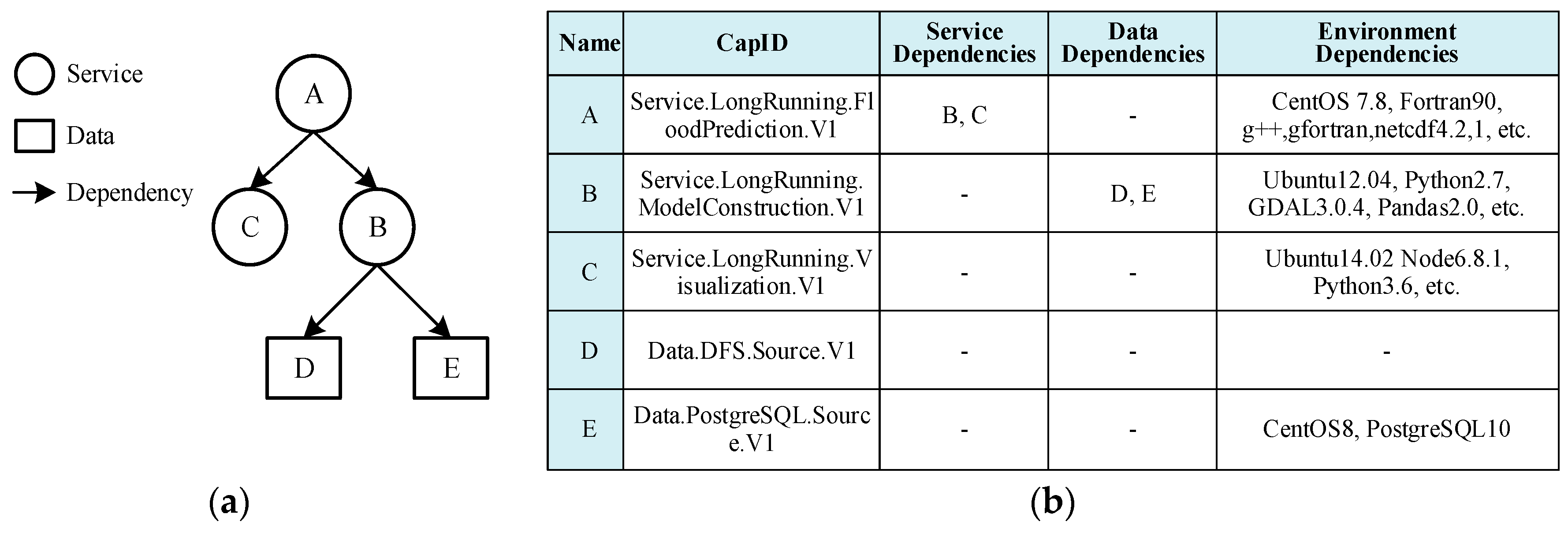
3.1. Servicized Encapsulation of Geospatial-Analysis Models
3.1.1. Servicized Declaration of Geospatial-Analysis Models
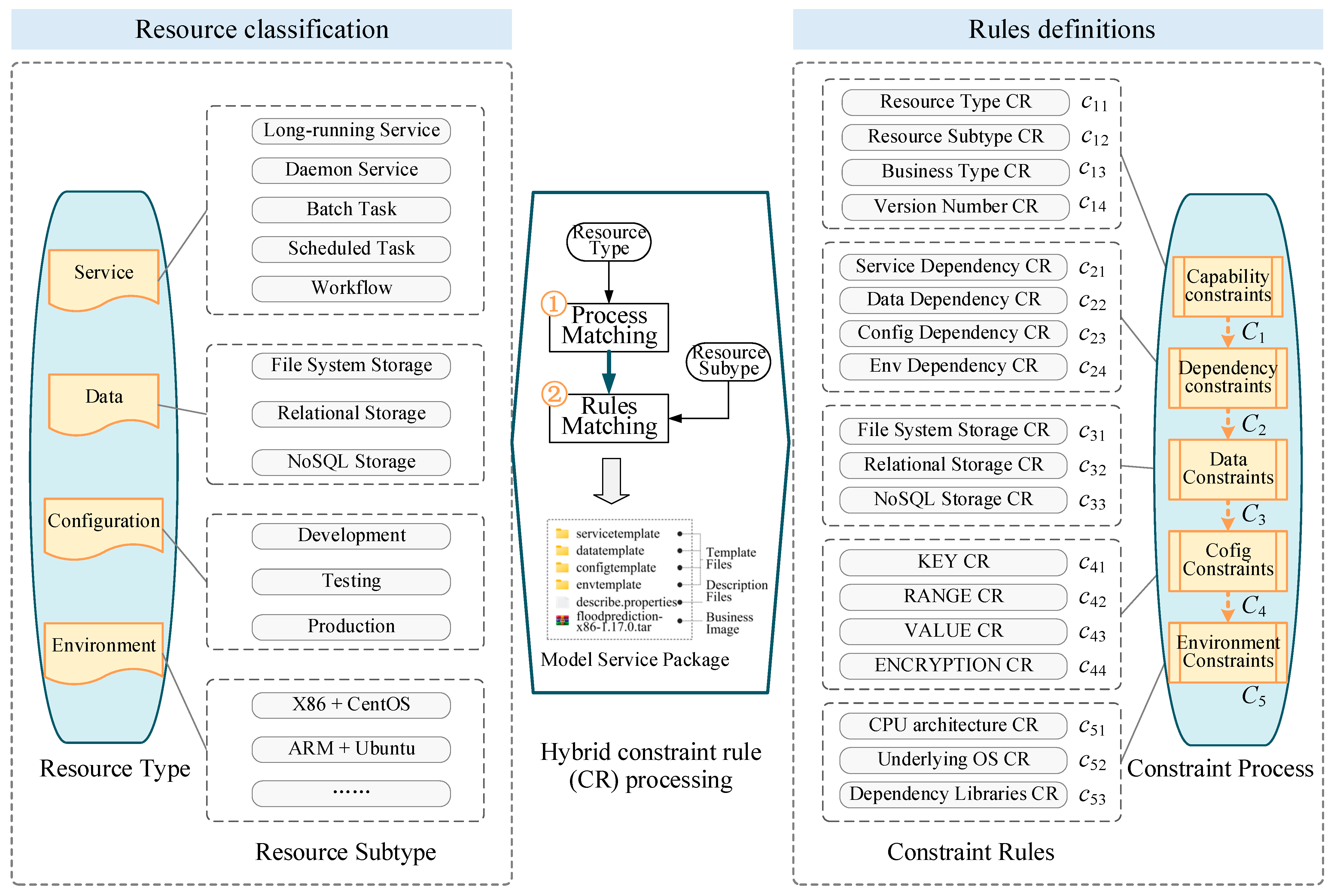
3.1.2. Standardized Constraints of Model Services
3.2. Prioritization-Based Orchestration of Geospatial-Analysis Models
3.2.1. Priority Selection of Dependent Resources
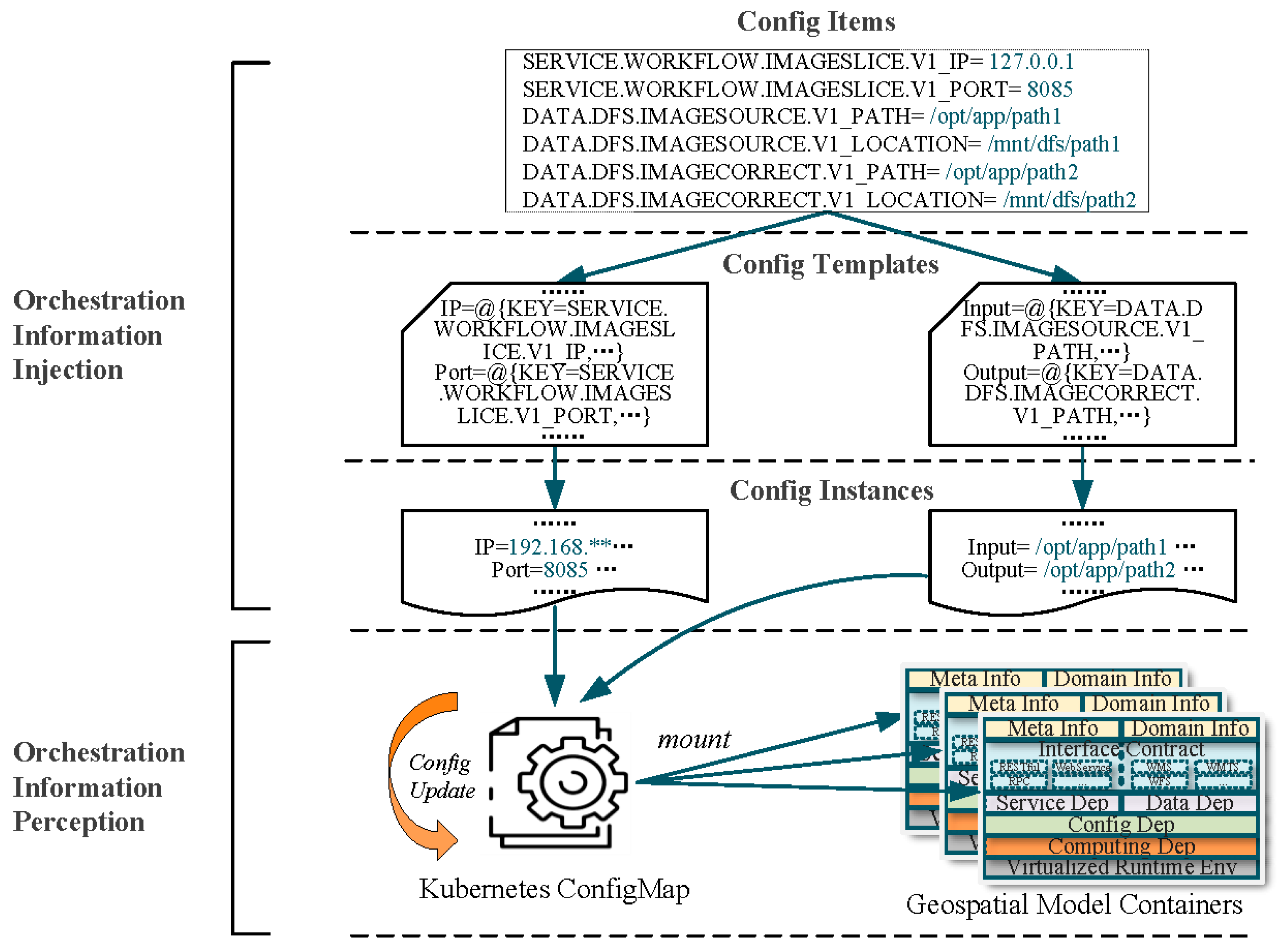
3.2.2. Implementation of Dependency Orchestration
3.3. Adaptive Publication of Geospatial-Analysis Models
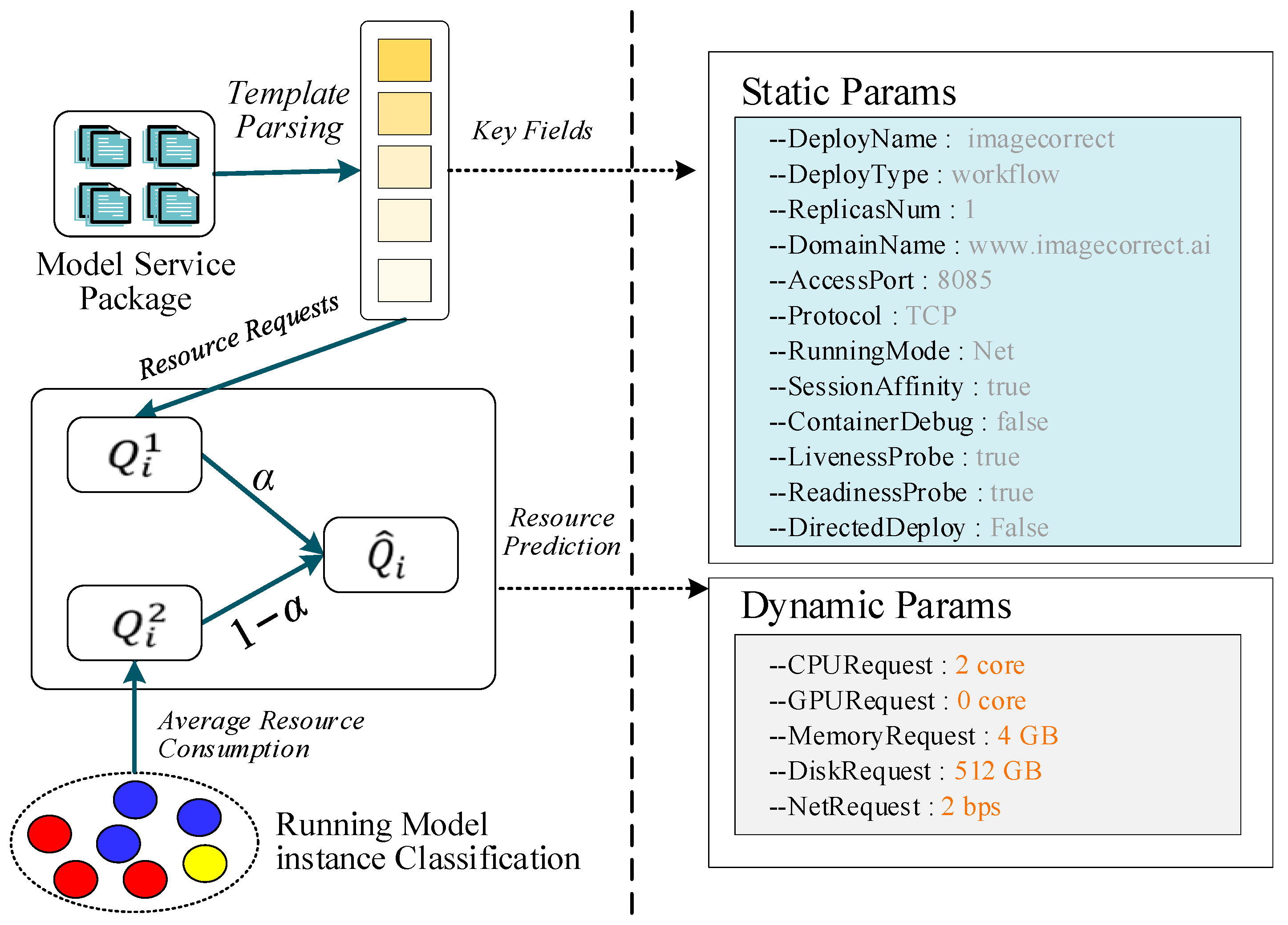
3.3.1. Model-Feature Parameterization
3.3.2. Heuristic Model Scheduling Policies
4. Design of the System
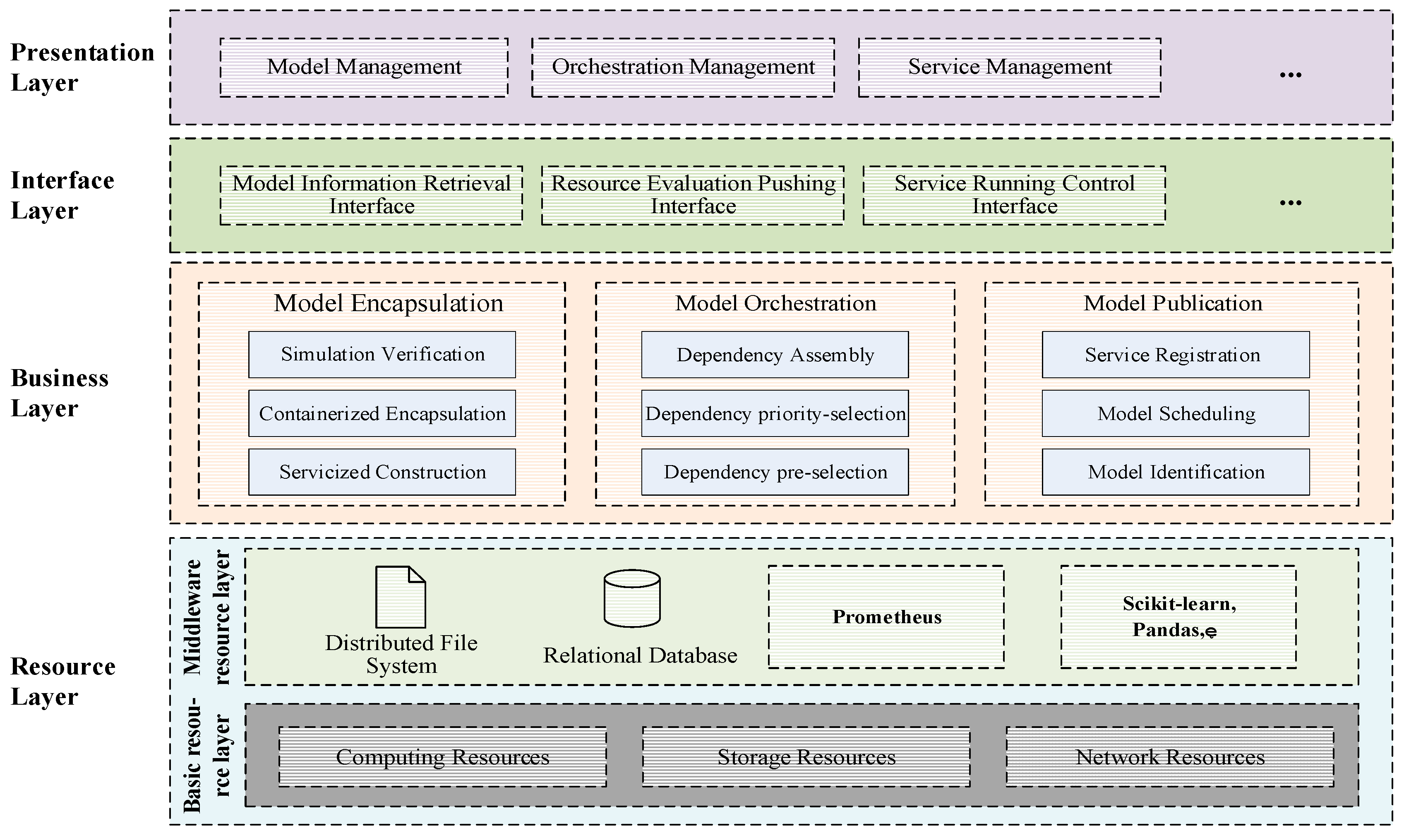
4.1. System Architecture and Its Component Relationships
4.2. System Implementation and Function Introduction
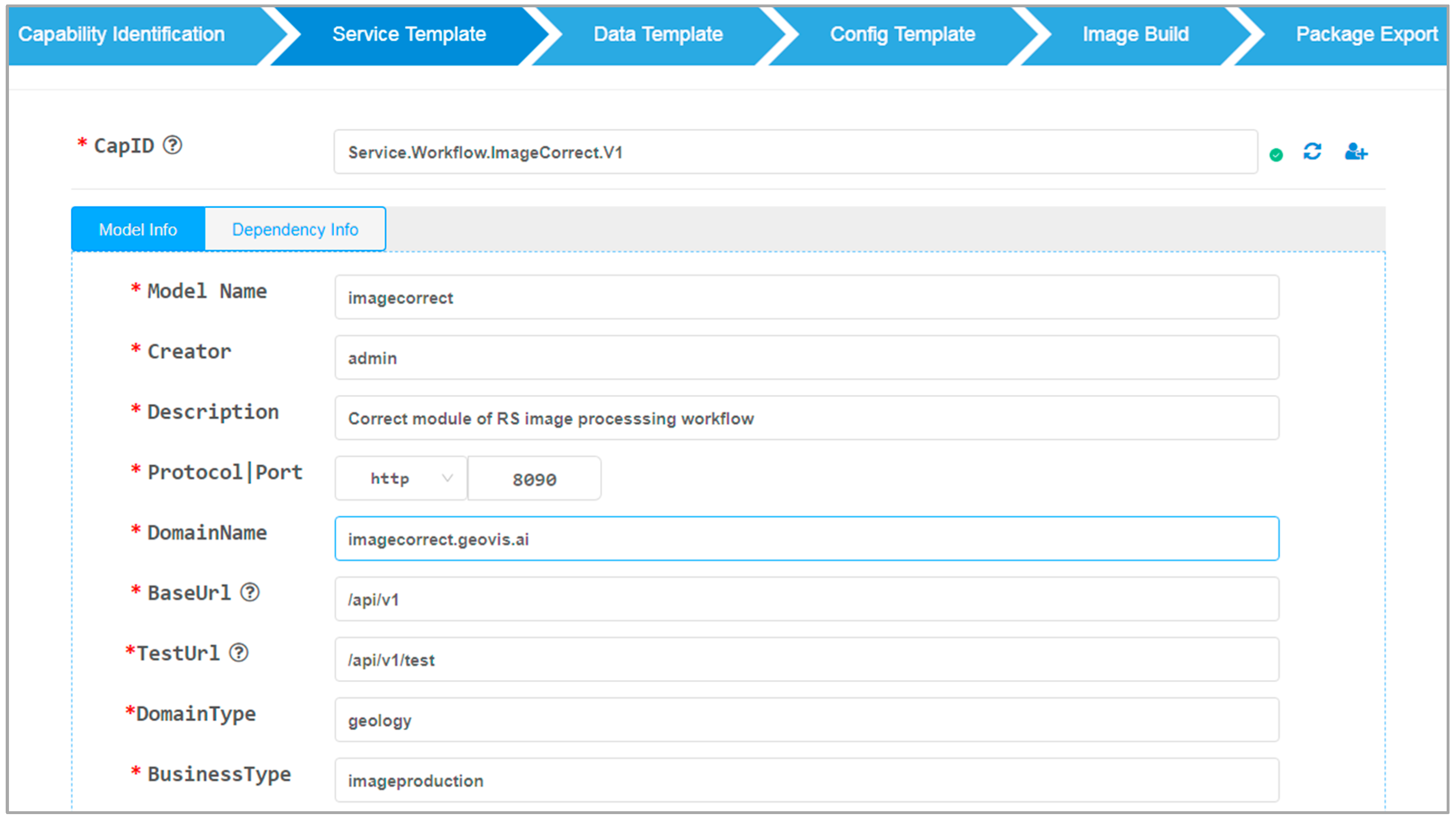
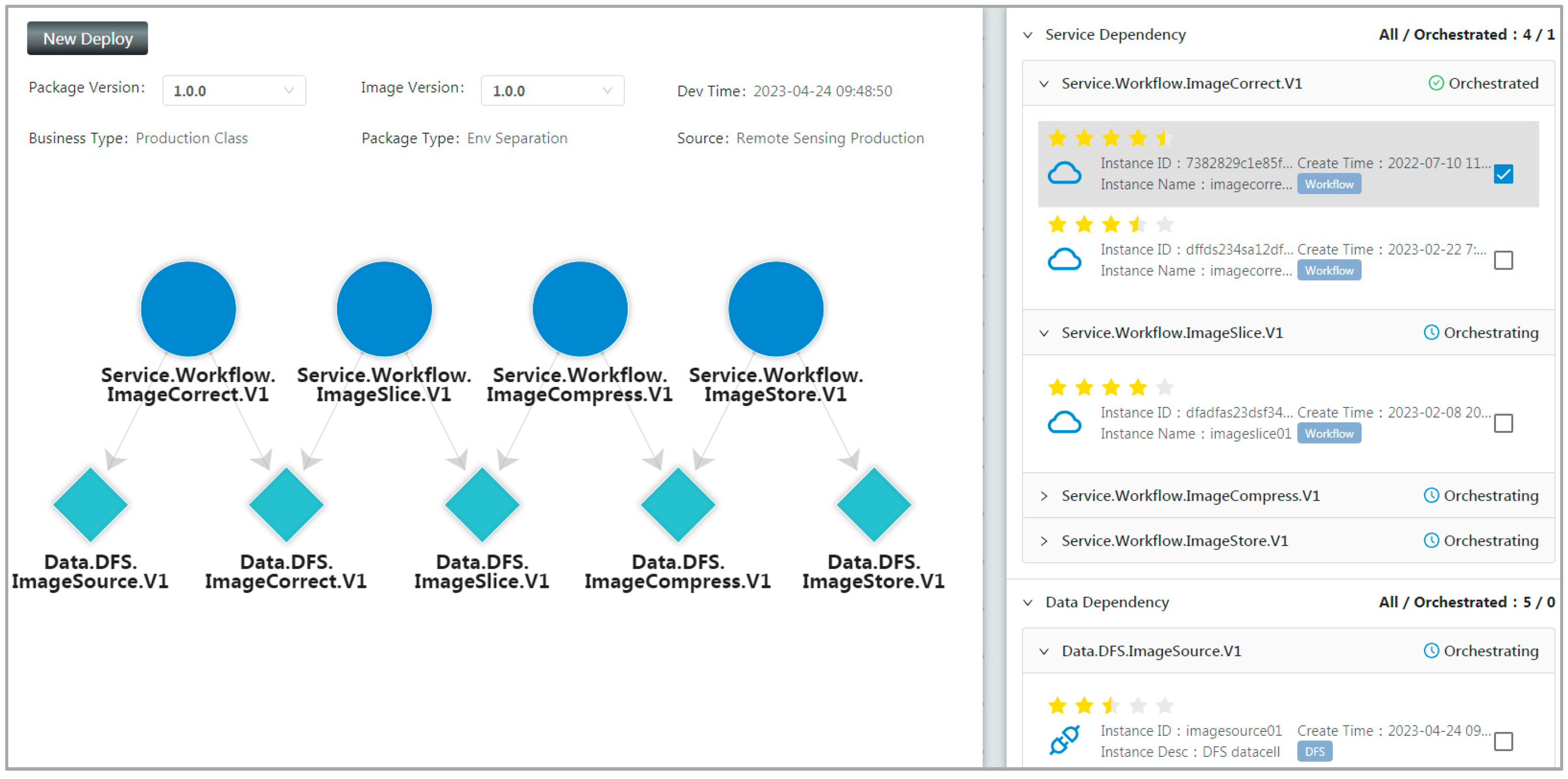
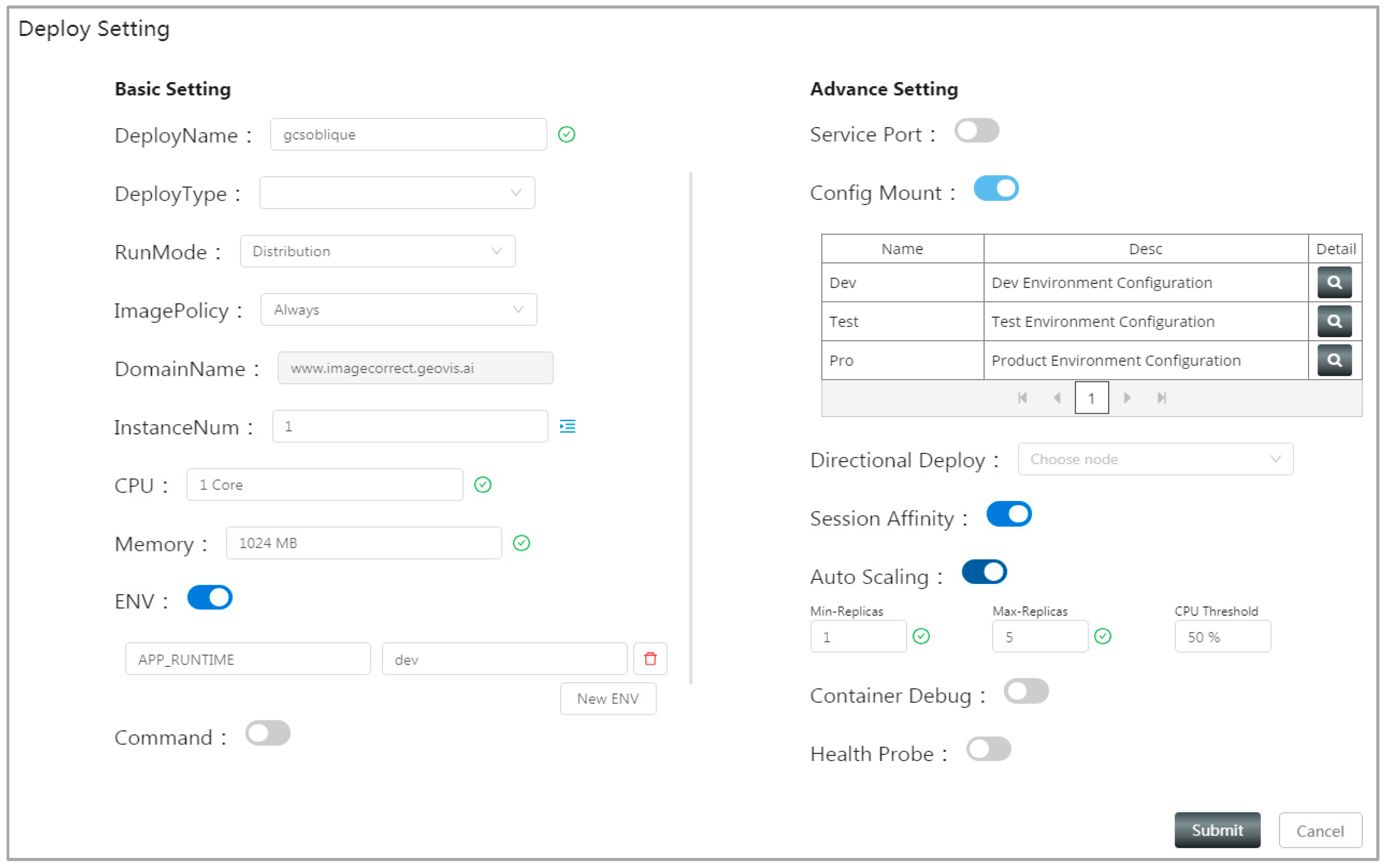
5. Case Studies
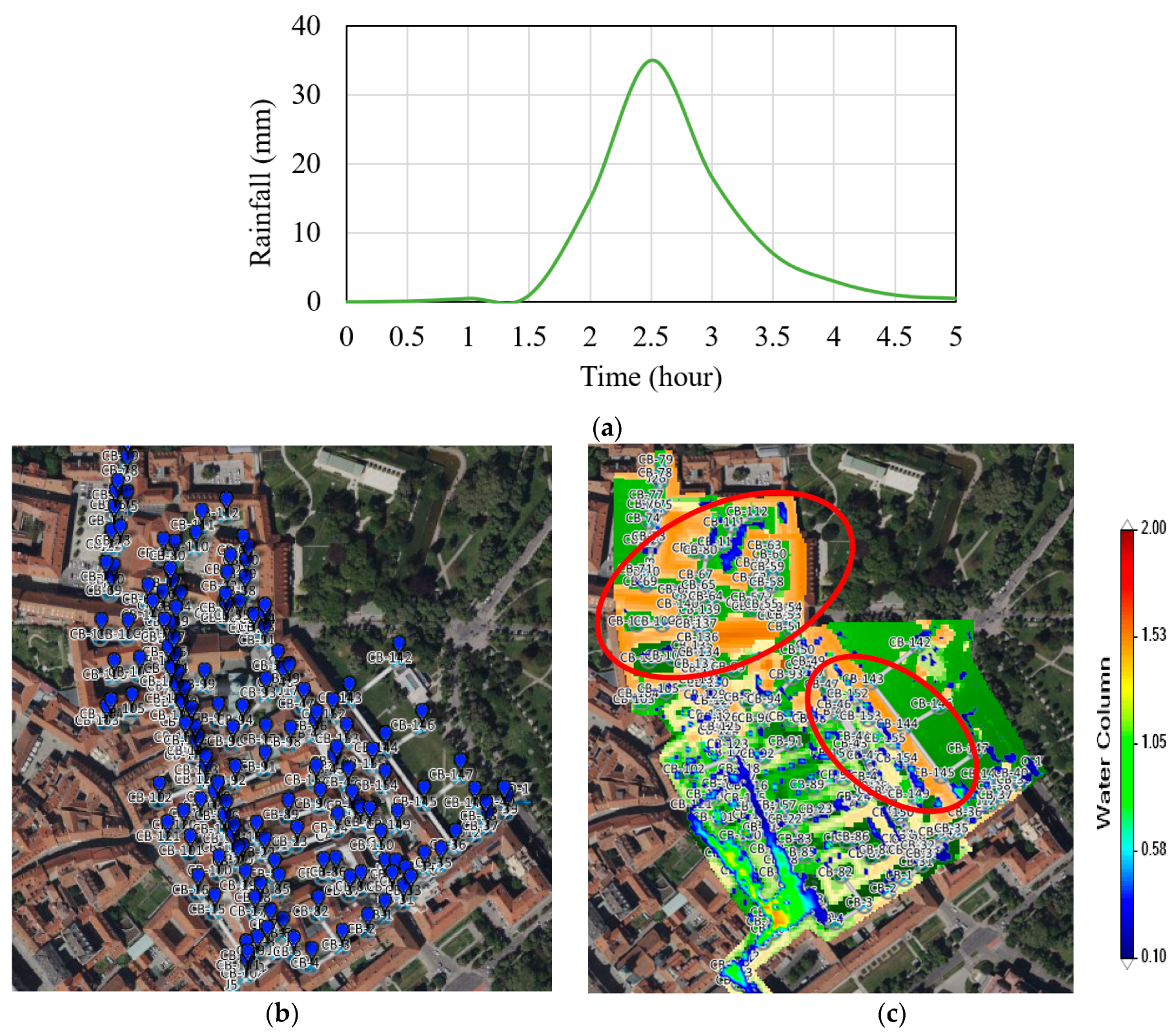
5.1. Geospatial-Analysis Models for Flood-Disaster Prediction
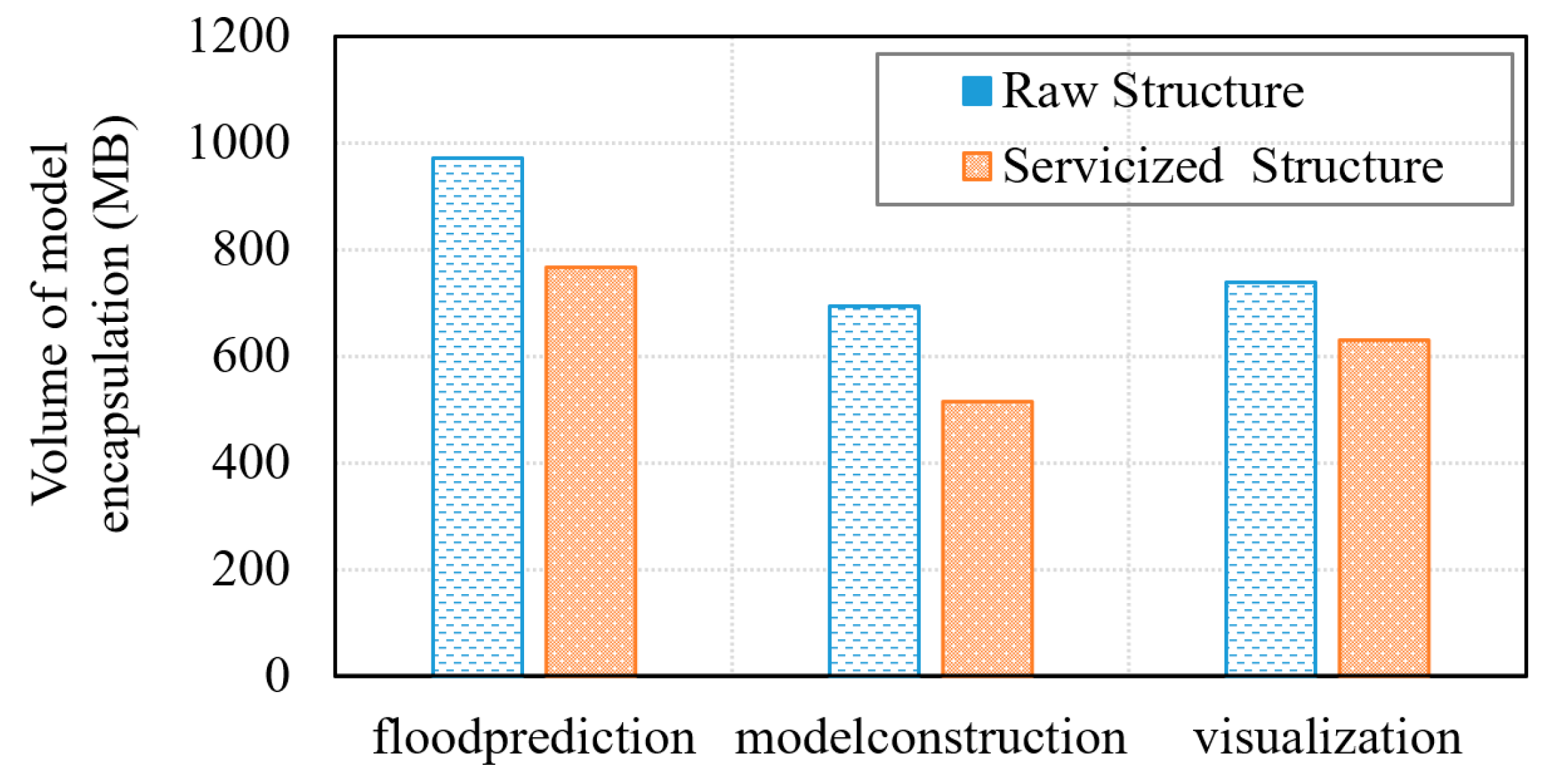
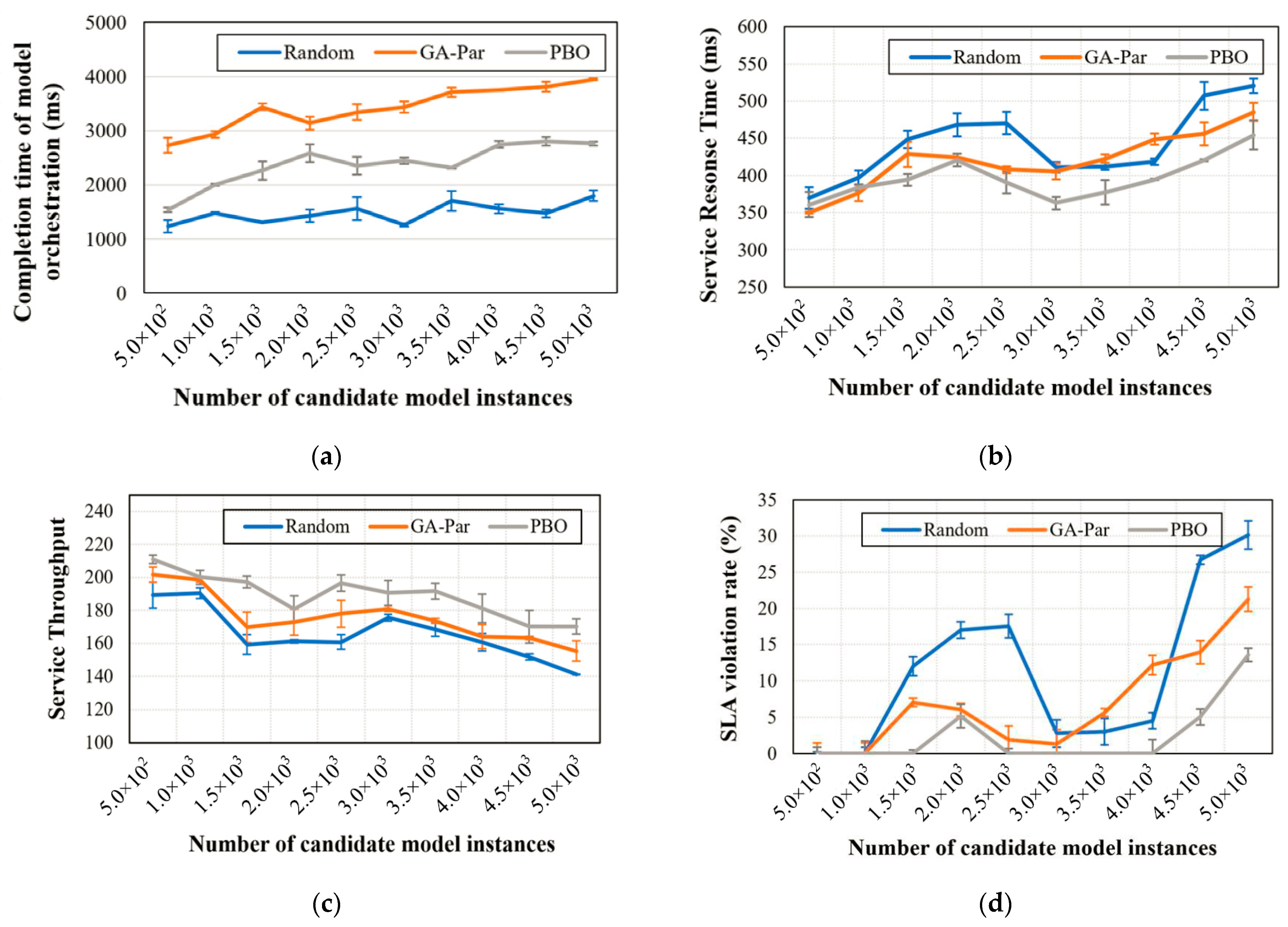
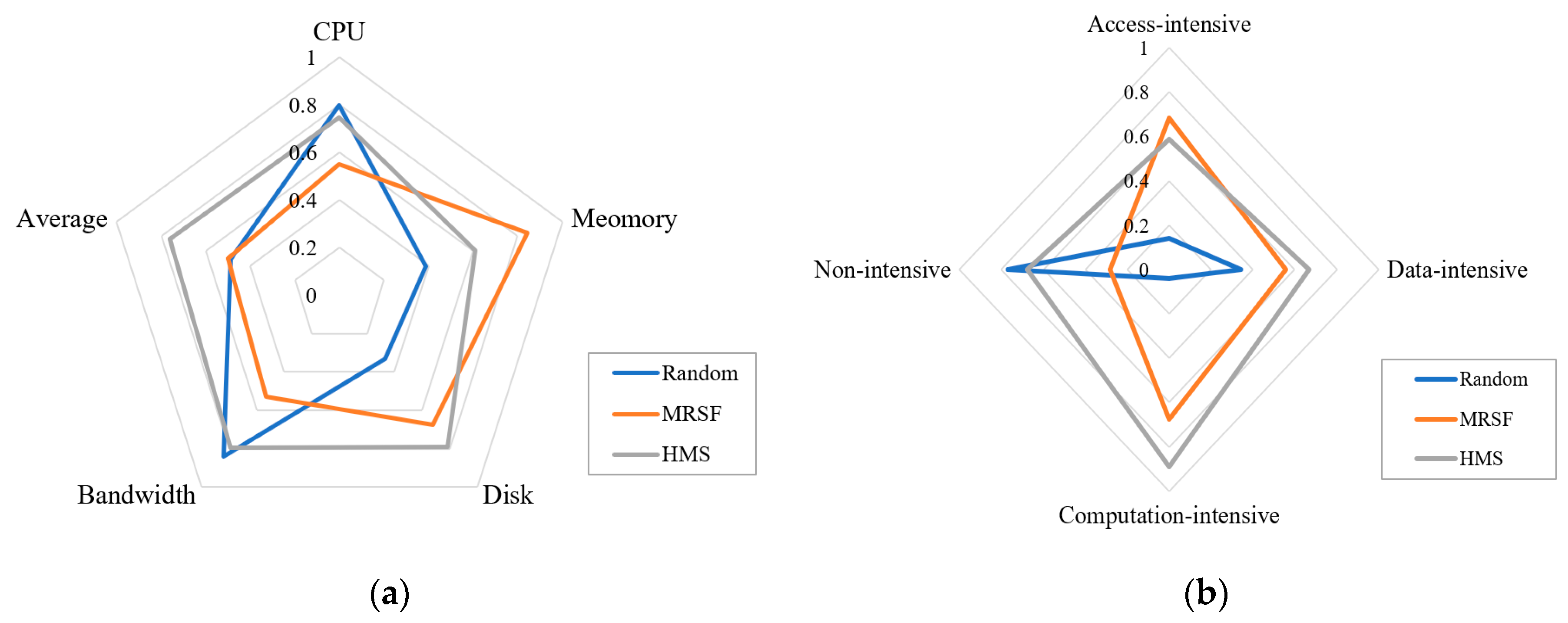
5.2. Integration Verification of Heterogeneous Geospatial-Analysis Models
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yue, S.; Wen, Y.; Chen, M.; Lu, G.; Hu, D.; Zhang, F. A data description model for reusing, sharing and integrating geo-analysis models. Environ. Earth Sci. 2015, 74, 7081–7099. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, M.; Ames, D.P.; Shen, C.R.; Yue, S.S.; Wen, Y.N.; Lü, G.N. Design and development of a service-oriented wrapper system for sharing and reusing distributed geoanalysis models on the web. Environ. Model. Softw. 2019, 111, 498–509. [Google Scholar] [CrossRef]
- Ustugova, S.; Parygin, D.; Sadovnikova, N.; Yadav, V.; Prikhodkova, I. Geoanalytical system for support of urban processes management tasks. In Proceedings of the Creativity in Intelligent Technologies and Data Science: Second Conference, CIT&DS 2017, Volgograd, Russia, 12–14 September 2017; pp. 430–440. [Google Scholar]
- Wang, J.; Chen, M.; Lü, G.; Yue, S.; Chen, K.; Wen, Y. A study on data processing services for the operation of geo-analysis models in the open web environment. Earth Space Sci. 2018, 5, 844–862. [Google Scholar] [CrossRef]
- Zhang, B.C.; Chen, M.; Ma, Z.Y.; Zhang, Z.; Yue, S.S.; Xiao, D.W.; Zhu, Z.Y.; Wen, Y.N.; Lü, G.N. An online participatory system for SWMM-based flood modeling and simulation. Environ. Sci. Pollut. Res. 2022, 29, 7322–7343. [Google Scholar] [CrossRef] [PubMed]
- Lin, Q.; Lin, B.; Zhang, D.; Wu, J. Web-based prototype system for flood simulation and forecasting based on the HEC-HMS model. Environ. Model. Softw. 2022, 158, 105541. [Google Scholar] [CrossRef]
- Fang, Z.; Yue, P.; Zhang, M.D.; Xie, J.B.; Wu, D.J.; Jiang, L.C. A service-oriented collaborative approach to disaster decision support by integrating geospatial resources and task chain. Int. J. Appl. Earth Obs. Geoinf. 2023, 117, 103217–103230. [Google Scholar] [CrossRef]
- Bhandari, P.; Anastasopoulos, A.; Pfoser, D. Are large language models geospatially knowledgeable? In Proceedings of the 31st ACM International Conference on Advances in Geographic Information Systems, Hamburg, Germany, 13–16 November 2023; pp. 1–4. [Google Scholar]
- Qi, Y.; Jiang, H.; Li, S.; Cao, J. ConvLSTM coupled economics indicators quantitative trading decision model. Symmetry 2022, 14, 1896. [Google Scholar] [CrossRef]
- Islam, T.; Rahman, M.R.; Khan, A.; Moni, M.A. Integration of Mendelian randomisation and systems biology models to identify novel blood-based biomarkers for stroke. J. Biomed. Inform. 2023, 141, 104345–104381. [Google Scholar] [CrossRef]
- Torres, W.; Van den Brand, M.G.J.; Serebrenik, A. A systematic literature review of cross-domain model consistency checking by model management tools. Softw. Syst. Model. 2021, 20, 897–916. [Google Scholar] [CrossRef]
- Li, M.; Stefanakis, E. Geospatial operations of discrete global grid systems—A comparison with traditional GIS. J. Geovisualization Spat. Anal. 2020, 4, 1–21. [Google Scholar] [CrossRef]
- Abdulrahman, I.; Radman, G. Power system spatial analysis and visualization using geographic information system (GIS). Spat. Inf. Res. 2020, 28, 101–112. [Google Scholar] [CrossRef]
- Kraak, M.J.; Ormeling, F. Cartography: Visualization of Geospatial Data; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Pu, H.; Wan, X.J.; Song, T.R.; Schonfeld, P.; Li, W.; Hu, J.P. A geographic information model for 3-D environmental suitability analysis in railway alignment optimization. Integr. Comput. Aided Eng. 2023, 30, 67–88. [Google Scholar] [CrossRef]
- Jena, R.; Pradhan, B.; Naik, S.P.; Alamri, A.M. Earthquake risk assessment in NE India using deep learning and geospatial analysis. Geosci. Front. 2021, 12, 101110–101125. [Google Scholar] [CrossRef]
- Manna, P.; Bonfante, A.; Colandrea, M. A geospatial decision support system to assist olive growing at the landscape scale. Comput. Electron. Agric. 2020, 168, 105143–105153. [Google Scholar] [CrossRef]
- Mind’je, R.; Li, L.; Kayumba, P.M.; Mindje, M.; Ali, S.; Umugwaneza, A. Integrated geospatial analysis and hydrological modeling for peak flow and volume simulation in Rwanda. Water 2021, 13, 2926. [Google Scholar] [CrossRef]
- Stoimenov, L.; Stanimirovi, A.; Djordjevi-Kajan, S. Realization of component-based GIS application framework. In Proceedings of the 7th AGILE Conference on Geographic Information Science, Heraklion, Greece, 29 April–1 May 2004; pp. 113–120. [Google Scholar]
- Liu, S.H.; Liu, L.P.; Yu, H.L. XML based GIS application model definition and description language GBMDL. China Manag. Inform. 2009, 12, 93–98. [Google Scholar]
- Zhou, L.L.; Wang, R.J.; Cui, C.Y.; Xie, C.J. GIS application model based on cloud computing. In Proceedings of the Network Computing and Information Security: Second International Conference, NCIS 2012, Shanghai, China, 7–9 December 2012; pp. 130–136. [Google Scholar]
- Ou, S.J. Research and Application of Geographic Information System Development Based on Component Architecture. Ph.D. Thesis, Jilin University, Jilin, China, 2003. [Google Scholar]
- Jia, J. Research on key technologies of geographic information system development. Constr. Des. Project 2022, 9, 142–144. [Google Scholar]
- Dontsov, A.A.; Sutorikhin, I.A. Development of a geographic information system for data collection and analysis based on microservice architecture. CEUR Workshop Proc. 2021, 3006, 280–287. [Google Scholar]
- Zhang, X.L.; Ren, Z.G.; Cao, Y.B. Research on seamless integration of spatial analysis model and GIS. Geospat. Inf. 2014, 12, 156–158+12. [Google Scholar]
- Xu, Z.H. GIS functional component library and functional integration. Geomat. Inf. Sci. Wuhan Univ. 2001, 4, 303–309. [Google Scholar]
- Lv, D.; Ying, X.X.; Gao, X.B.; Tao, W.D.; Cui, Y.J.; Hua, T.T. A WebGIS platform design and implementation based on open source GIS middleware. In Proceedings of the 24th International Conference on Geoinformatics, Galway, Ireland, 14–20 August 2016; pp. 1–5. [Google Scholar]
- Wang, S.H.; Zhong, Y.; Wang, E.Q. An integrated GIS platform architecture for spatiotemporal big data. Future Gener. Comput. Syst. 2019, 94, 160–172. [Google Scholar] [CrossRef]
- Wen, Y.N.; Chen, M.; Lu, G.N.; Lin, H.; He, L.; Yue, S.S. Prototyping an open environment for sharing geospatial analysis models on cloud computing platform. Int. J. Digit. Earth 2013, 6, 356–382. [Google Scholar] [CrossRef]
- Qiao, X.H.; Li, Z.Y.; Zhang, F.Y.; Ames, D.P.; Chen, M.; Nelson, E.J.; Khattar, R. A container-based approach for sharing environmental models as web services. Int. J. Digit. Earth 2021, 14, 1067–1086. [Google Scholar] [CrossRef]
- Jiang, B. Geospatial analysis requires a different way of thinking: The problem of spatial heterogeneity. GeoJournal 2015, 80, 1–13. [Google Scholar] [CrossRef]
- Jat, M.K.; Choudhary, M.; Saxena, A. Application of geo-spatial techniques and cellular automata for modelling urban growth of a heterogeneous urban fringe. Egypt. J. Remote Sens. Space Sci. 2017, 20, 223–241. [Google Scholar] [CrossRef]
- Patanè, G.; Spagnuolo, M. Heterogeneous Spatial Data: Fusion, Modeling, and Analysis for GIS Applications; Springer Nature: Berlin, Germany, 2022. [Google Scholar]
- Hu, N.; Meng, X.; Liu, H. Exploring geospatial data visualization based on python. In Proceedings of the 2022 2nd International Conference on Control and Intelligent Robotics, Nanjing, China, 24–26 June 2022; pp. 858–862. [Google Scholar]
- Sun, K.; Zhu, Y.Q.; Pan, P.; Hong, Z.W.; Wang, D.X.; Li, W.R.; Song, J. Geospatial data ontology: The semantic foundation of geospatial data integration and sharing. Big Earth Data 2019, 3, 269–296. [Google Scholar] [CrossRef]
- Mena, M.; Corral, A.; Iribarne, L.; Criado, J. A progressive web application based on microservices combining geospatial data and the internet of things. IEEE Access 2019, 7, 104577–104590. [Google Scholar] [CrossRef]
- Anthopoulos, L.; Janssen, M.; Weerakkody, V. A Unified Smart City Model (USCM) for smart city conceptualization and benchmarking. Int. J. Electron. Gov. Res. 2016, 12, 247–264. [Google Scholar] [CrossRef]
- Wen, Y.N.; Chen, M.; Yue, S.S.; Zheng, P.B.; Peng, G.Q.; Lu, G.N. A model-service deployment strategy for collaboratively sharing geo-analysis models in an open web environment. Int. J. Digit. Earth 2017, 10, 405–425. [Google Scholar] [CrossRef]
- Fricke, A.; Asche, H. Geospatial database for the generation of multidimensional virtual city models dedicated to urban analysis and decision-making. In Proceedings of the Computational Science and Its Applications—ICCSA 2019: 19th International Conference, Saint Petersburg, Russia, 1–4 July 2019; pp. 711–726. [Google Scholar]
- Wan, W.; Du, X.Q.; Zhao, X.W.; Yang, Z.K. A cloud-enabled collaborative hub for analysis of geospatial big data. In Proceedings of the 2021 IEEE 6th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), Chengdu, China, 24–26 April 2021; pp. 1–5. [Google Scholar]
- Scheider, S.; Nyamsuren, E.; Kruiger, H.; Xu, H.Q. Geo-analytical question-answering with GIS. Int. J. Digit. Earth 2021, 14, 1–14. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Papathanasiou, J.; Ploskas, N.; Papathanasiou, J.; Ploskas, N.T. Multiple Criteria Decision Aid: Methods, Examples and Python Implementations; Springer: London, UK, 2018; Volume 136, pp. 1–30. [Google Scholar]
- Burns, B.; Grant, B.; Oppenheimer, D.; Brewer, E.; Wilkes, J. Borg, Omega, and Kubernetes. Commun. ACM 2016, 59, 50–57. [Google Scholar] [CrossRef]
- Wen, Z.Y.; Lin, T.; Yang, R.Y.; Ji, S.L.; Ranjan, R.; Romanovsky, A.; Lin, C.T.; Xu, J. GA-Par: Dependable microservice orchestration framework for geo-distributed clouds. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 129–143. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, L.; Wang, Y.; Kong, Y.; Hu, Y.; Huang, K. A Containerized Service-Based Integration Framework for Heterogeneous-Geospatial-Analysis Models. ISPRS Int. J. Geo-Inf. 2024, 13, 28. https://doi.org/10.3390/ijgi13010028
Zhu L, Wang Y, Kong Y, Hu Y, Huang K. A Containerized Service-Based Integration Framework for Heterogeneous-Geospatial-Analysis Models. ISPRS International Journal of Geo-Information. 2024; 13(1):28. https://doi.org/10.3390/ijgi13010028
Chicago/Turabian StyleZhu, Lilu, Yang Wang, Yunbo Kong, Yanfeng Hu, and Kai Huang. 2024. "A Containerized Service-Based Integration Framework for Heterogeneous-Geospatial-Analysis Models" ISPRS International Journal of Geo-Information 13, no. 1: 28. https://doi.org/10.3390/ijgi13010028
APA StyleZhu, L., Wang, Y., Kong, Y., Hu, Y., & Huang, K. (2024). A Containerized Service-Based Integration Framework for Heterogeneous-Geospatial-Analysis Models. ISPRS International Journal of Geo-Information, 13(1), 28. https://doi.org/10.3390/ijgi13010028