

SGIR-Tree: Integrating R-Tree Spatial Indexing as Subgraphs in Graph Database Management Systems

Abstract
:1. Introduction
- We propose a new index structure named SGIR-Tree, which integrates spatial index components as a subgraph based on representative spatial index R-Tree. This integration minimizes the I/O overhead and improves index management, thereby providing a more efficient and scalable solution for spatial indexing within GDBMS environments.
- We enhance query processing capabilities by seamlessly integrating spatial and graph queries. This integration facilitates more efficient handling of complex queries that require both spatial search and graph traversal.
- We implement and test the SGIR-Tree in a widely used GDBMS, Neo4j, demonstrating its effectiveness with various spatial data types and queries such as spatial join, KNN, and spatial range. The experiments conducted show that the SGIR-Tree outperforms both disconnected spatial indices stored within the GDBMS and externally stored spatial indices for spatial graph queries.
2. Related Work
2.1. Type of Spatial Index
2.2. Spatial Index in GDBMS
2.2.1. RDF
2.2.2. LPG
2.3. Summary
3. Methodology
3.1. Preliminaries
- 1.
- N: a set of nodes;
- 2.
- E: a set of edges;
- 3.
- : a function assigning labels to nodes;
- 4.
- : a function assigning labels to edges;
- 5.
- ϕ: a function mapping each node to a set of properties;
- 6.
- χ: a function mapping each edge to a set of properties.
- 1.
- At least one node has a geometry property: , where is a well-known text representation of a geometric object.
- 2.
- The set of nodes N is partitioned into spatial nodes and non-spatial nodes :where and .
- 3.
- The set of node labels is partitioned into spatial labels and non-spatial labels such that and .
- 4.
- For any label , the label-specific node set is defined as .
3.2. Index Structure
- 1.
- is the set of SGIR-Tree nodes;
- 2.
- is the set of SGIR-Tree edges;
- 3.
- is the SGIR-Tree node labeling function, where is the common label for all nodes of this SGIR-Tree (e.g., ‘RestaurantRTree’);
- 4.
- is the SGIR-Tree edge labeling function;
- 5.
- is the SGIR-Tree node MBR function, where represents of MBR;
- 6.
- is the SGIR-Tree edge MBR function, where represents of MBR;
- 7.
- is a function that maps leaf nodes to sets of spatial nodes, where is the label-specific set of spatial nodes for label l.
- There exists exactly one layer node such that .
- For the layer node , we have the following:
- −
- such that with
- For each leaf node (a node with no outgoing RTREE_CHILD edges), we have the following:
- −
- is the set of spatial nodes connected to n;
- −
- such that and .
3.3. Initialization and Maintenance
3.3.1. Initialization
| Algorithm 1 UpdateMBR Function |
|
3.3.2. Maintenance
- Choose leaf: Select the appropriate leaf node to insert the new spatial node.
- Add node: Add the new spatial node to the selected leaf node and create an edge between them.
- Adjust tree: Update the MBR from the leaf node up to the root. During this process, the UpdateMBR function is used to update the MBR information in the nodes and edges simultaneously.
- Split nodes if needed: If the node exceeds its capacity, perform a split considering the index graph structure to achieve the optimal division.
- Find leaf: Locate the leaf node containing the spatial node to be deleted.
- Remove reference: Delete the edge (RTREE_REFERENCE) between the leaf node and the spatial node, effectively removing the spatial node from the index structure.
- Condense tree: If the node’s capacity falls below the minimum threshold, perform reinsertion or merging to efficiently restructure the graph with minimal changes.
- Adjust tree: Update the MBR from the leaf node up to the root. The UpdateMBR function is used to update the MBR information in both nodes and edges simultaneously.
3.4. Spatial Query Processing
- condition:
- The specific spatial query conditions are determined by the parameters P and the type t, and are explained in detail for each spatial query type in the following subsections.
- condition: All mappings f from to must satisfy the following:
- Spatial node: where , must satisfy the spatial predicate .
- Node label: .
- Edge label: .
- Node property: .
- Edge property: .
where m is a node different from n.
3.4.1. KNN
3.4.2. Spatial Join
3.4.3. Spatial Range
4. Experiments
4.1. Data
4.2. Experimental Settings
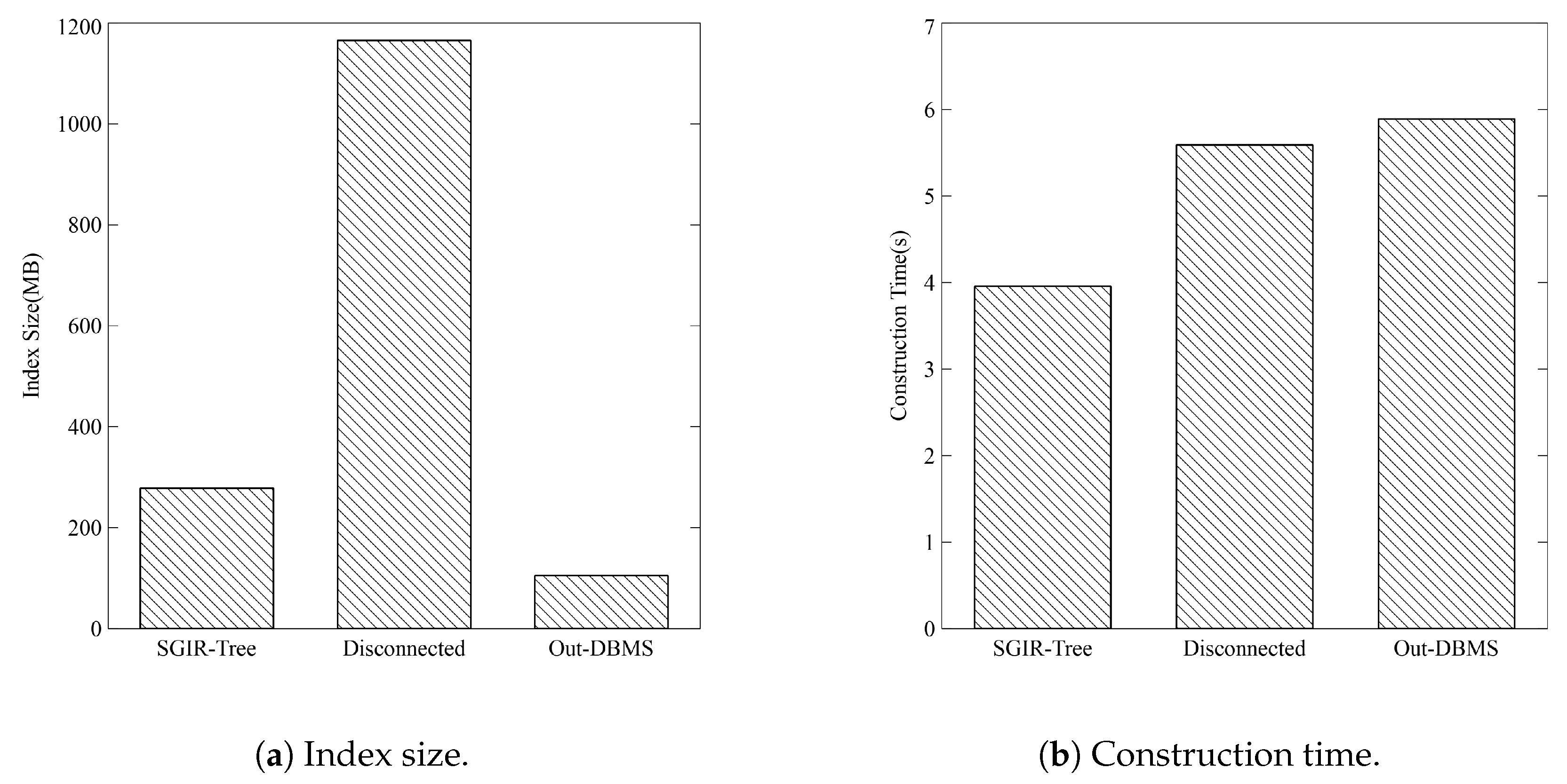
4.3. Index Overhead Results
4.4. Query Overhead Results
4.4.1. Query Overhead in SGIR-Tree
4.4.2. Comparison to Disconnected and Out-DBMS Spatial Index
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yeung, A.K.W.; Hall, G.B. Spatial Database Systems: Design, Implementation and Project Management; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Sun, L.; Jin, B. Improving NoSQL Spatial-Query Processing with Server-Side In-Memory R*-Tree Indexes for Spatial Vector Data. Sustainability 2023, 15, 2442. [Google Scholar] [CrossRef]
- Park, S.; Cheng, T. Framework for Constructing Multimodal Transport Networks and Routing Using a Graph Database: A Case Study in London. Trans. GIS 2023, 27, 1391–1417. [Google Scholar] [CrossRef]
- Xiao, F.; Guo, W.; Liu, W.; Zeng, J. A Spatio-temporal Big Data Decision Support System of Real Estate. In Proceedings of the 2021 International Conference on Information Technology and Biomedical Engineering (ICITBE), Nanchang, China, 24–26 December 2021; pp. 30–34. [Google Scholar] [CrossRef]
- Stadler, C.; Lehmann, J.; Höffner, K.; Auer, S. LinkedGeoData: A Core for a Web of Spatial Open Data. Semant. Web 2012, 3, 333–354. [Google Scholar] [CrossRef]
- Qiao, Y.; Luo, X.; Li, C.; Tian, H.; Ma, J. Heterogeneous Graph-Based Joint Representation Learning for Users and POIs in Location-Based Social Network. Inf. Process. Manag. 2020, 57, 102151. [Google Scholar] [CrossRef]
- Yue, P.; Tan, Z. 1.06 GIS Databases and NoSQL Databases. In Comprehensive Geographic Information Systems; Huang, B., Ed.; Elsevier: Oxford, UK, 2018; pp. 50–79. [Google Scholar] [CrossRef]
- Sun, Y.; Sarwat, M. Riso-Tree: An Efficient and Scalable Index for Spatial Entities in Graph Database Management Systems. ACM Trans. Spat. Algorithms Syst. 2021, 7, 1–39. [Google Scholar] [CrossRef]
- Li, W.; Wang, S.; Wu, S.; Gu, Z.; Tian, Y. Performance benchmark on semantic web repositories for spatially explicit knowledge graph applications. Comput. Environ. Urban Syst. 2022, 98, 101884. [Google Scholar] [CrossRef]
- Bertella, P.G.K.; Lopes, Y.K.; de Oliveira, R.A.P.; Carniel, A.C. A Systematic Review of Spatial Approximations in Spatial Database Systems. J. Inf. Data Manag. 2022, 13, 2519. [Google Scholar] [CrossRef]
- Sun, Y.; Sarwat, M. A Spatially-Pruned Vertex Expansion Operator in the Neo4j Graph Database System. GeoInformatica 2019, 23, 397–423. [Google Scholar] [CrossRef]
- Guttman, A. R-Trees: A Dynamic Index Structure for Spatial Searching. In Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data-SIGMOD ’84, Boston, MA, USA, 18–21 June 1984; p. 47. [Google Scholar] [CrossRef]
- Bentley, J.L. Multidimensional Binary Search Trees Used for Associative Searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Sellis, T.K.; Roussopoulos, N.; Faloutsos, C. The R+-Tree: A Dynamic Index for Multi-Dimensional Objects. In Proceedings of the 13th International Conference on Very Large Data Bases, San Francisco, CA, USA, 1–4 September 1987; VLDB’87. pp. 507–518. [Google Scholar]
- Beckmann, N.; Kriegel, H.P.; Schneider, R.; Seeger, B. The R*-Tree: An Efficient and Robust Access Method for Points and Rectangles. In Proceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, 23–26 May 1990; SIGMOD’90. pp. 322–331. [Google Scholar] [CrossRef]
- Robinson, J.T. The K-D-B-tree: A Search Structure for Large Multidimensional Dynamic Indexes. In Proceedings of the 1981 ACM SIGMOD International Conference on Management of Data, Ann Arbor, MI, USA, 29 April–1 May 1981; SIGMOD’81. pp. 10–18. [Google Scholar] [CrossRef]
- Procopiuc, O.; Agarwal, P.K.; Arge, L.; Vitter, J.S. Bkd-Tree: A Dynamic Scalable kd-Tree. In Advances in Spatial and Temporal Databases, Proceedings of the 8th International Symposium, SSTD 2003, Santorini Island, Greece, 24–27 July 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 46–65. [Google Scholar] [CrossRef]
- Finkel, R.A.; Bentley, J.L. Quad Trees a Data Structure for Retrieval on Composite Keys. Acta Inform. 1974, 4, 1–9. [Google Scholar] [CrossRef]
- Amiri, A.M.; Samavati, F.; Peterson, P. Categorization and Conversions for Indexing Methods of Discrete Global Grid Systems. ISPRS Int. J. Geo-Inf. 2015, 4, 320–336. [Google Scholar] [CrossRef]
- Zhu, J.; Chong, H.Y.; Zhao, H.; Wu, J.; Tan, Y.; Xu, H. The Application of Graph in BIM/GIS Integration. Buildings 2022, 12, 2162. [Google Scholar] [CrossRef]
- Brodt, A.; Nicklas, D.; Mitschang, B. Deep Integration of Spatial Query Processing into Native RDF Triple Stores. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; GIS’10. pp. 33–42. [Google Scholar] [CrossRef]
- Wang, D.; Zou, L.; Feng, Y.; Shen, X.; Tian, J.; Zhao, D. S-Store: An Engine for Large RDF Graph Integrating Spatial Information. In Database Systems for Advanced Applications, Proceedings of the 18th International Conference, DASFAA 2013, Wuhan, China, 22–25 April 2013; Meng, W., Feng, L., Bressan, S., Winiwarter, W., Song, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 31–47. [Google Scholar] [CrossRef]
- Liagouris, J.; Mamoulis, N.; Bouros, P.; Terrovitis, M. An Effective Encoding Scheme for Spatial RDF Data. Proc. VLDB Endow. 2014, 7, 1271–1282. [Google Scholar] [CrossRef]
- Theocharidis, K.; Liagouris, J.; Mamoulis, N.; Bouros, P.; Terrovitis, M. SRX: Efficient Management of Spatial RDF Data. VLDB J. 2019, 28, 703–733. [Google Scholar] [CrossRef]
- Shi, J.; Wu, D.; Mamoulis, N. Top-k Relevant Semantic Place Retrieval on Spatial RDF Data. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; SIGMOD’16. pp. 1977–1990. [Google Scholar] [CrossRef]
- Cai, Z.; Kalamatianos, G.; Fakas, G.J.; Mamoulis, N.; Papadias, D. Diversified Spatial Keyword Search on RDF Data. VLDB J. 2020, 29, 1171–1189. [Google Scholar] [CrossRef]
- Virtuoso Documentation. Available online: https://docs.openlinksw.com/virtuoso/sqlrefgeospatial/ (accessed on 24 September 2024).
- Osman, T. GeoSPARQL-Jena: Implementation and Benchmarking of a GeoSPARQL Graphstore. Eur. Conf. Knowl. Manag. 2022, 23, 885–894. [Google Scholar] [CrossRef]
- Jin, X.; Shin, S.; Jo, E.; Lee, K.H. Collective Keyword Query on a Spatial Knowledge Base. IEEE Trans. Knowl. Data Eng. 2019, 31, 2051–2062. [Google Scholar] [CrossRef]
- Wu, D.; Hou, C.; Xiao, E.; Jensen, C.S. Semantic Region Retrieval from Spatial RDF Data. In Proceedings of the Database Systems for Advanced Applications; Nah, Y., Cui, B., Lee, S.W., Yu, J.X., Moon, Y.S., Whang, S.E., Eds.; Springer: Cham, Switzerland, 2020; pp. 415–431. [Google Scholar] [CrossRef]
- Wang, C.J.; Ku, W.S.; Chen, H. Geo-Store: A spatially-augmented SPARQL query evaluation system. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; SIGSPATIAL’12. pp. 562–565. [Google Scholar] [CrossRef]
- Lee, K.; Liu, L.; Ganti, R.K.; Srivatsa, M.; Zhang, Q.; Zhou, Y.; Wang, Q. Lightweight Indexing and Querying Services for Big Spatial Data. IEEE Trans. Serv. Comput. 2016, 12, 343–355. [Google Scholar] [CrossRef]
- Leeka, J.; Bedathur, S.; Bera, D.; Lakshminarasimhan, S. STREAK: An Efficient Engine for Processing Top-k SPARQL Queries with Spatial Filters. arXiv 2017, arXiv:1710.07411. [Google Scholar]
- RDF4j Github Repository. Available online: https://github.com/eclipse-rdf4j/rdf4j/issues/1160 (accessed on 24 September 2024).
- Stardog Documentation Release-Note. Available online: https://docs.stardog.com/release-notes/stardog-platform (accessed on 24 September 2024).
- GraphDB 7.0 Documnetation. Available online: https://graphdb.ontotext.com/documentation/7.0/enterprise/geo-spatial-extensions.html?highlight=spatial%20index# (accessed on 24 September 2024).
- Hadjieleftheriou, M.; Hoel, E.; Tsotras, V.J. SaIL: A Spatial Index Library for Efficient Application Integration. GeoInformatica 2005, 9, 367–389. [Google Scholar] [CrossRef]
- Huang, W.; Raza, S.A.; Mirzov, O.; Harrie, L. Assessment and Benchmarking of Spatially Enabled RDF Stores for the Next Generation of Spatial Data Infrastructure. ISPRS Int. J. Geo-Inf. 2019, 8, 310. [Google Scholar] [CrossRef]
- Neo4j Spatial Plugin Github Repository. Available online: https://github.com/neo4j-contrib/spatial (accessed on 24 September 2024).
- JanusGraph Github Repository. Available online: https://github.com/JanusGraph/janusgraph/issues/3015 (accessed on 24 September 2024).
- JanusGraph Github Repository. Available online: https://github.com/JanusGraph/janusgraph/commits/master/janusgraph-lucene/src/main/java/org/janusgraph/diskstorage/lucene/LuceneIndex.java?after=4a576f67ff0e53b699ed078dad964d448bc94b10+34 (accessed on 24 September 2024).
- NebulaGraph Documentation. Available online: https://www.nebula-graph.io/posts/explore-geospatial-data-with-nebulagraph (accessed on 24 September 2024).
- TigerGraph Blog. Available online: https://medium.com/tigergraph/leveraging-geospatial-data-with-a-native-parallel-graph-database-d2c92e24d675 (accessed on 24 September 2024).
- Kamel, I.; Faloutsos, C. Hilbert R-tree: An Improved R-tree Using Fractals. In Proceedings of the 20th International Conference on Very Large Data Bases, San Francisco, CA, USA, 12–15 September 1994; VLDB’94. pp. 500–509. [Google Scholar]
- Roumelis, G.; Vassilakopoulos, M.; Loukopoulos, T.; Corral, A.; Manolopoulos, Y. The xBR+-Tree: An Efficient Access Method for Points. In Proceedings of the Database and Expert Systems Applications, Valencia, Spain, 31 August 2015; Chen, Q., Hameurlain, A., Toumani, F., Wagner, R., Decker, H., Eds.; Springer: Cham, Switzerland, 2015; pp. 43–58. [Google Scholar] [CrossRef]
- Gu, T.; Feng, K.; Cong, G.; Long, C.; Wang, Z.; Wang, S. The RLR-Tree: A Reinforcement Learning Based R-Tree for Spatial Data. Proc. ACM Manag. Data 2023, 1, 63:1–63:26. [Google Scholar] [CrossRef]
- Lee, T.; Moon, B.; Lee, S. Bulk Insertion for R-Tree by Seeded Clustering. In Database and Expert Systems Applications, Proceedings of the 14th International Conference, DEXA 2003, Prague, Czech Republic, 1–5 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 129–138. [Google Scholar] [CrossRef]
- Cheung, K.L.; Fu, A.W.C. Enhanced Nearest Neighbour Search on the R-tree. ACM SIGMOD Rec. 1998, 27, 16–21. [Google Scholar] [CrossRef]
- Brinkhoff, T.; Kriegel, H.P.; Seeger, B. Efficient Processing of Spatial Joins Using R-trees. ACM SIGMOD Rec. 1993, 22, 237–246. [Google Scholar] [CrossRef]
- Dsouza, A.; Tempelmeier, N.; Gottschalk, S.; Yu, R.; Demidova, E. WorldKG: World-Scale Completion of Geographic Information. In Volunteered Geographic Information: Interpretation, Visualization and Social Context; Burghardt, D., Demidova, E., Keim, D.A., Eds.; Springer Nature: Cham, Switzerland, 2023; pp. 3–19. [Google Scholar] [CrossRef]
- Yang, J.; Jang, H.; Yu, K. Geographic Knowledge Base Question Answering over OpenStreetMap. ISPRS Int. J. Geo-Inf. 2024, 13, 10. [Google Scholar] [CrossRef]
- Hoffart, J.; Suchanek, F.M.; Berberich, K.; Weikum, G. YAGO2: A Spatially and Temporally Enhanced Knowledge Base from Wikipedia. Artif. Intell. 2013, 194, 28–61. [Google Scholar] [CrossRef]
- Karalis, N.; Mandilaras, G.; Koubarakis, M. Extending the YAGO2 Knowledge Graph with Precise Geospatial Knowledge. In The Semantic Web–ISWC 2019, Proceedings of the 18th International Semantic Web Conference, Auckland, New Zealand, 26–30 October 2019; Ghidini, C., Hartig, O., Maleshkova, M., Svátek, V., Cruz, I., Hogan, A., Song, J., Lefrançois, M., Gandon, F., Eds.; Springer: Cham, Switzerland, 2019; pp. 181–197. [Google Scholar] [CrossRef]
- Bast, H.; Brosi, P.; Kalmbach, J.; Lehmann, A. An Efficient RDF Converter and SPARQL Endpoint for the Complete OpenStreetMap Data. In Proceedings of the 29th International Conference on Advances in Geographic Information Systems, Beijing, China, 2–5 November 2021; SIGSPATIAL’21. pp. 536–539. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Partitioning Type | Index | Paper or Store | In-DBMS |
|---|---|---|---|
| Data driven | R-Tree | Brodt et al. (2010) [21] | |
| Wang et al. (2013) [22] | ✓ | ||
| Liagouris et al. (2014) [23] and Theocharidis et al. (2019) [24] | |||
| Shi et al. (2016) [25] | |||
| Cai et al. (2020) [26] | |||
| Virtuoso (2010) * [27] | ✓ | ||
| GeoSPARQL-Jena (2018) * [28] | |||
| R*-Tree | Jin et al. (2018) [29] | ||
| Wu et al. (2020) [30] | |||
| Space-Driven | Hilbert curve | Wange et al. (2012) [31] | ✓ |
| Geohash | Lee et al. (2016) [32] | ✓ | |
| Quad-Tree | Leeka et al. (2017) [33] | ✓ | |
| Quad (Geohash)-Prefix-Tree (Lucene) | RDF4j (2018) * [34] | ||
| Stardog (2016) * [35] | |||
| GraphDB (2016) * [36] |
| Partitioning Type | Index | Paper or GDBMS | In-DBMS |
|---|---|---|---|
| Data-driven | R-Tree | Neo4j (2010) * [39] | ✓ |
| Augmented R-Tree | Sun et al. (2021) [8] | ✓ | |
| BKD-Tree (ElasticSearch) | JanusGraph (2022) * [40] | ||
| Space-Driven | Quad (Geohash)-Prefix-Tree (Lucene) | JanusGraph (2017) * [41] | |
| Hilbert Curve (Google S2) | NebulaGraph (2021) * [42] | ✓ | |
| Uniform Grid | TigerGraph (2019) * [43] | ✓ | |
| Uniform Grid | Sun et al. (2019) [11] | ✓ |
| Notation | Description |
|---|---|
| N | The set of nodes |
| E | The set of edges |
| Mapping function for node labels | |
| Mapping function for edge labels | |
| Mapping function for node properties | |
| Mapping function for edge properties | |
| Set of node labels | |
| Set of edge labels | |
| The set of spatial nodes | |
| The set of non-spatial nodes | |
| A labeled property graph | |
| A geospatial graph | |
| SGIR-Tree for spatial label l | |
| Set of SGIR-Tree nodes | |
| Set of SGIR-Tree edges | |
| SGIR-Tree node labeling function | |
| SGIR-Tree edge labeling function | |
| SGIR-Tree node MBR function | |
| SGIR-Tree edge MBR function | |
| Function mapping leaf nodes to sets of spatial nodes | |
| MBR function | |
| Four real values representing an MBR |
| Category | Node Type | Node Count | Relationship Count |
|---|---|---|---|
| spatial nodes | Building | 1,082,417 | - |
| Highway | 517,444 | - | |
| LandUse | 17,379 | - | |
| Natural | 51,602 | - | |
| Place | 582 | - | |
| Shop | 21,460 | - | |
| non-spatial nodes | Brand | 331 | 1067 (to Building) |
| Color | 1531 | 2300 (to Building) | |
| Crossing | 31 | 174,757 (to Highway) | |
| Total | - | 1,692,777 | 178,124 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Hong, S.; Jeong, S.; Park, S.; Yu, K. SGIR-Tree: Integrating R-Tree Spatial Indexing as Subgraphs in Graph Database Management Systems. ISPRS Int. J. Geo-Inf. 2024, 13, 346. https://doi.org/10.3390/ijgi13100346
Kim J, Hong S, Jeong S, Park S, Yu K. SGIR-Tree: Integrating R-Tree Spatial Indexing as Subgraphs in Graph Database Management Systems. ISPRS International Journal of Geo-Information. 2024; 13(10):346. https://doi.org/10.3390/ijgi13100346
Chicago/Turabian StyleKim, Juyoung, Seoyoung Hong, Seungchan Jeong, Seula Park, and Kiyun Yu. 2024. "SGIR-Tree: Integrating R-Tree Spatial Indexing as Subgraphs in Graph Database Management Systems" ISPRS International Journal of Geo-Information 13, no. 10: 346. https://doi.org/10.3390/ijgi13100346