

A Method for Constructing an Urban Waterlogging Emergency Knowledge Graph Based on Spatiotemporal Processes



Abstract
1. Introduction
2. Related Works
2.1. Geographic Knowledge Graph and Construction Methods
2.1.1. Geographic Knowledge Graph
2.1.2. Construction Methods for Geographic Knowledge Graph
2.2. Representation of Geographic Spatiotemporal Process Knowledge
2.3. Structured Representation of Urban Waterlogging Knowledge
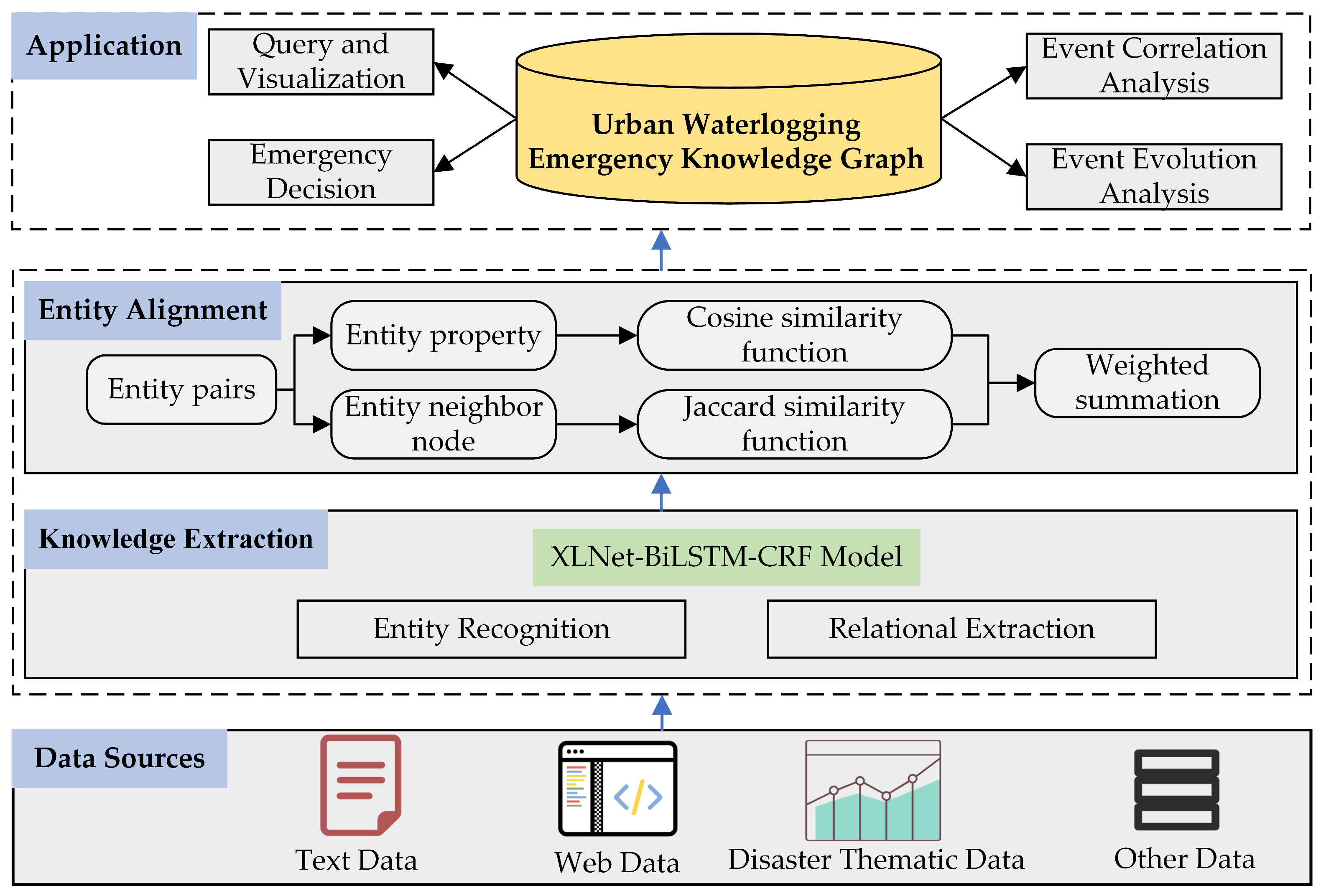
3. Methodology
3.1. Overall Framework
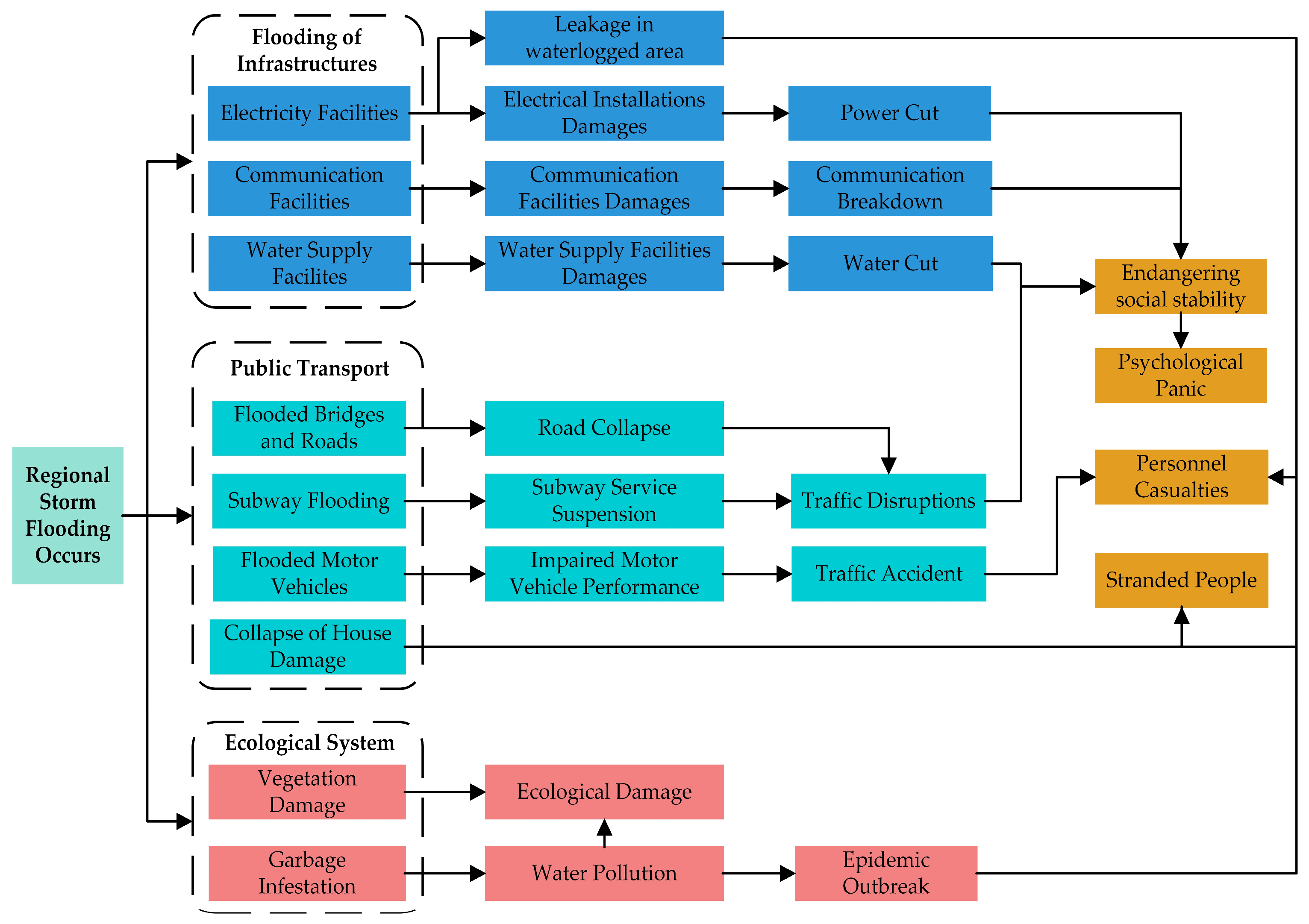
3.2. Timeline-Based Representation of Urban Waterlogging Emergency Response Process
3.3. An Ontology Construction Method Based on Spatiotemporal Process
3.3.1. Proposed Conceptual Model
3.3.2. Ontology Construction for Urban Waterlogging Emergency
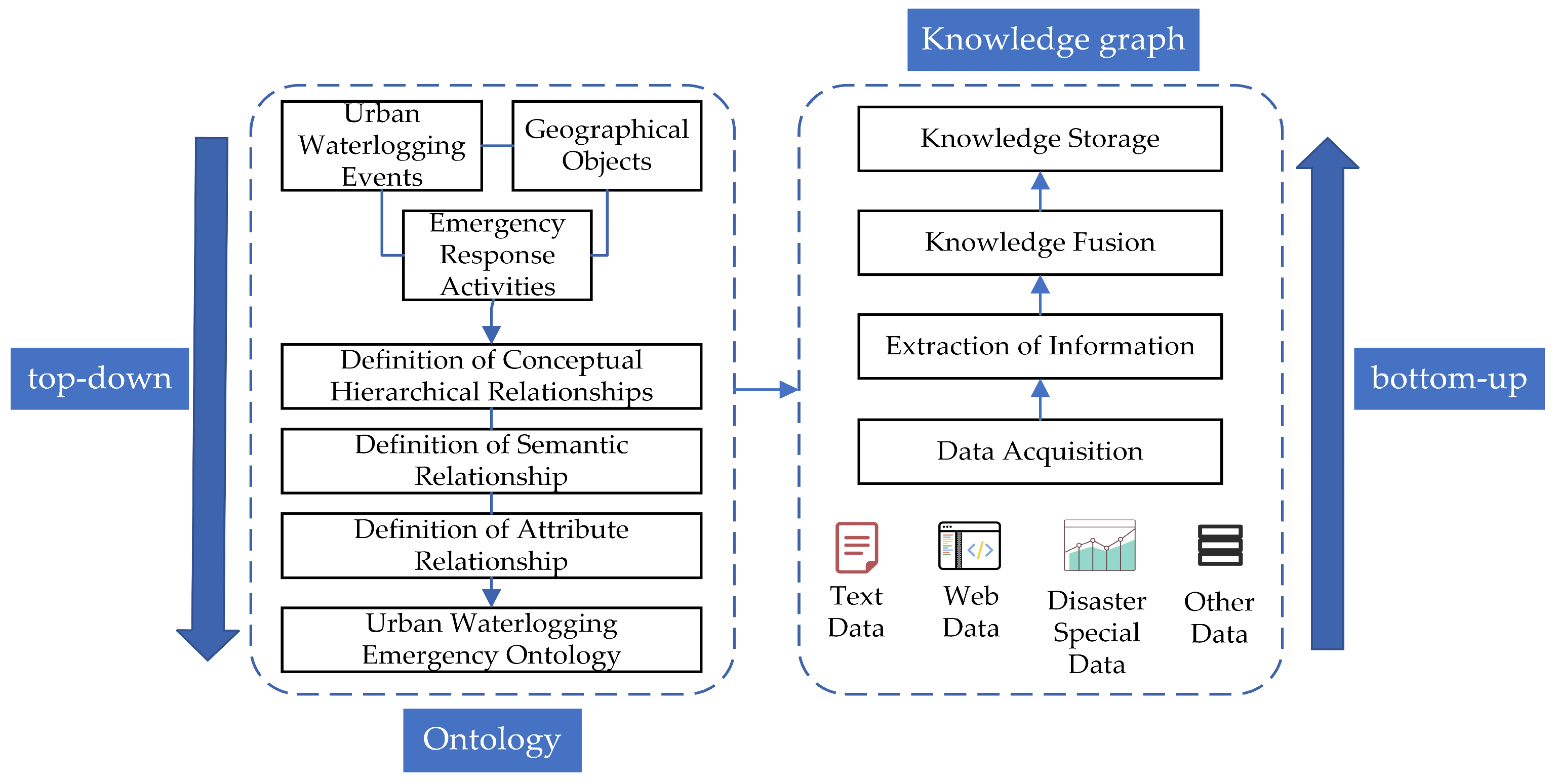
3.4. Urban Waterlogging Emergency Knowledge Graph Construction Method
3.4.1. Construction Process
3.4.2. Entity and Relation Extraction
- Forward LSTM: Starting from the starting position of the input sequence, it gradually reads each word vector () and generates a forward hidden state vector ().
- Backward LSTM: Starting from the end position of the input sequence, it reverse-reads each word vector () and generates a backward hidden state vector ().
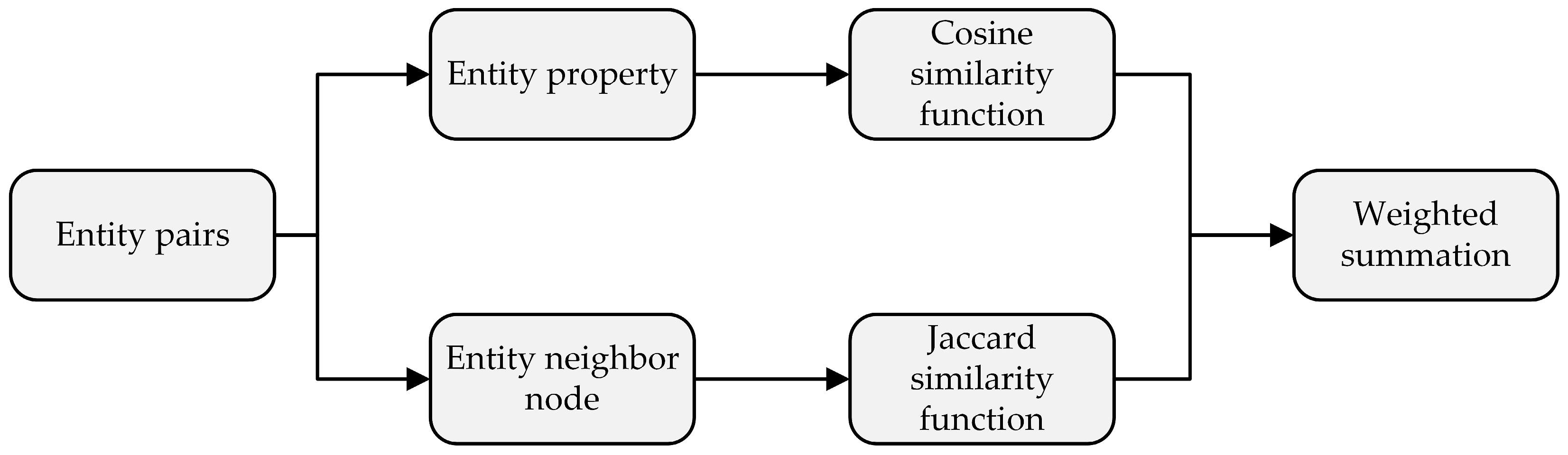
3.4.3. Knowledge Fusion
3.4.4. Knowledge Storage Based on Neo4j Graph Database
4. Experiment and Result Analysis
4.1. Experimental Data Acquisition and Processing
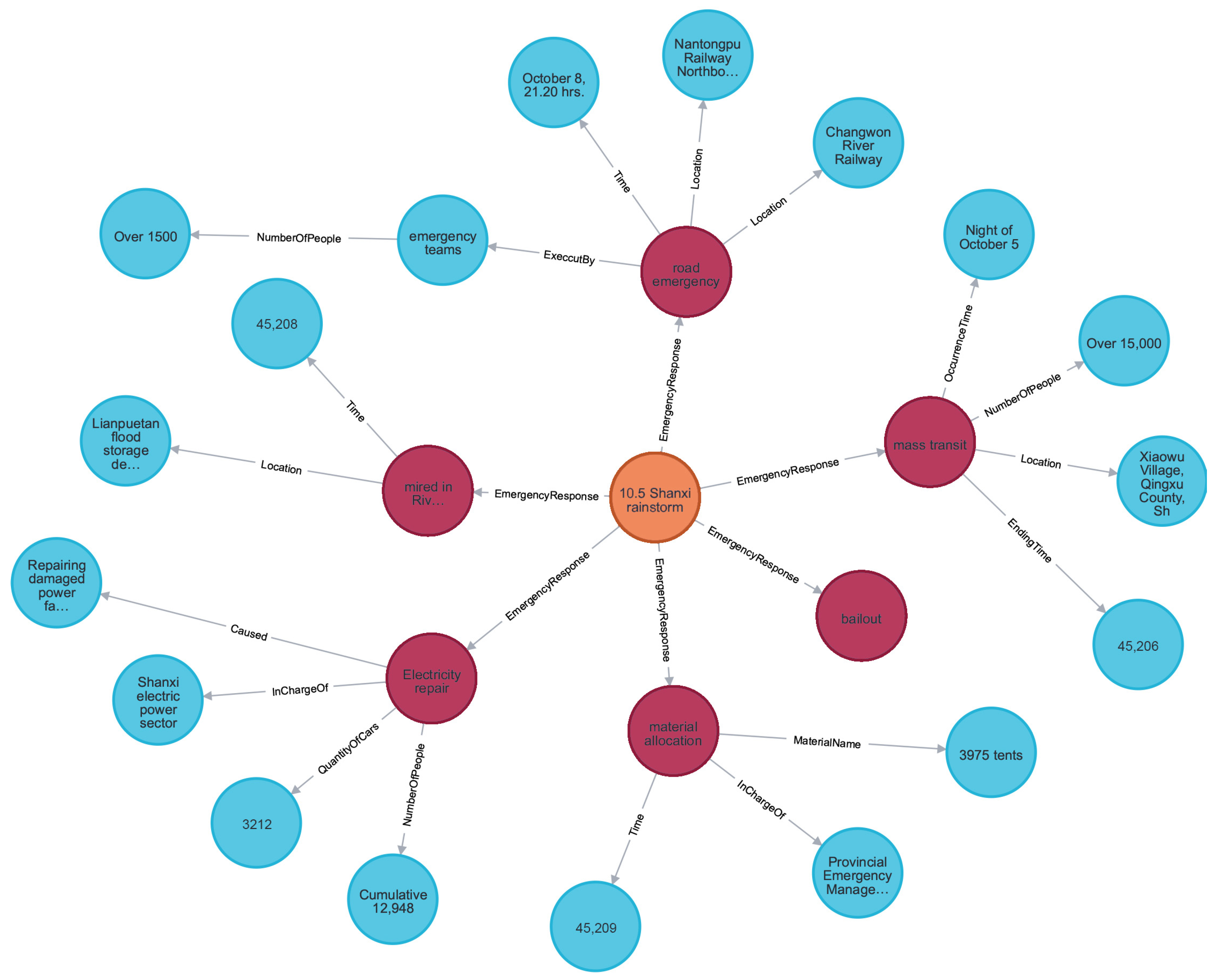
4.2. Knowledge Graph Generation for Urban Waterlogging Emergency
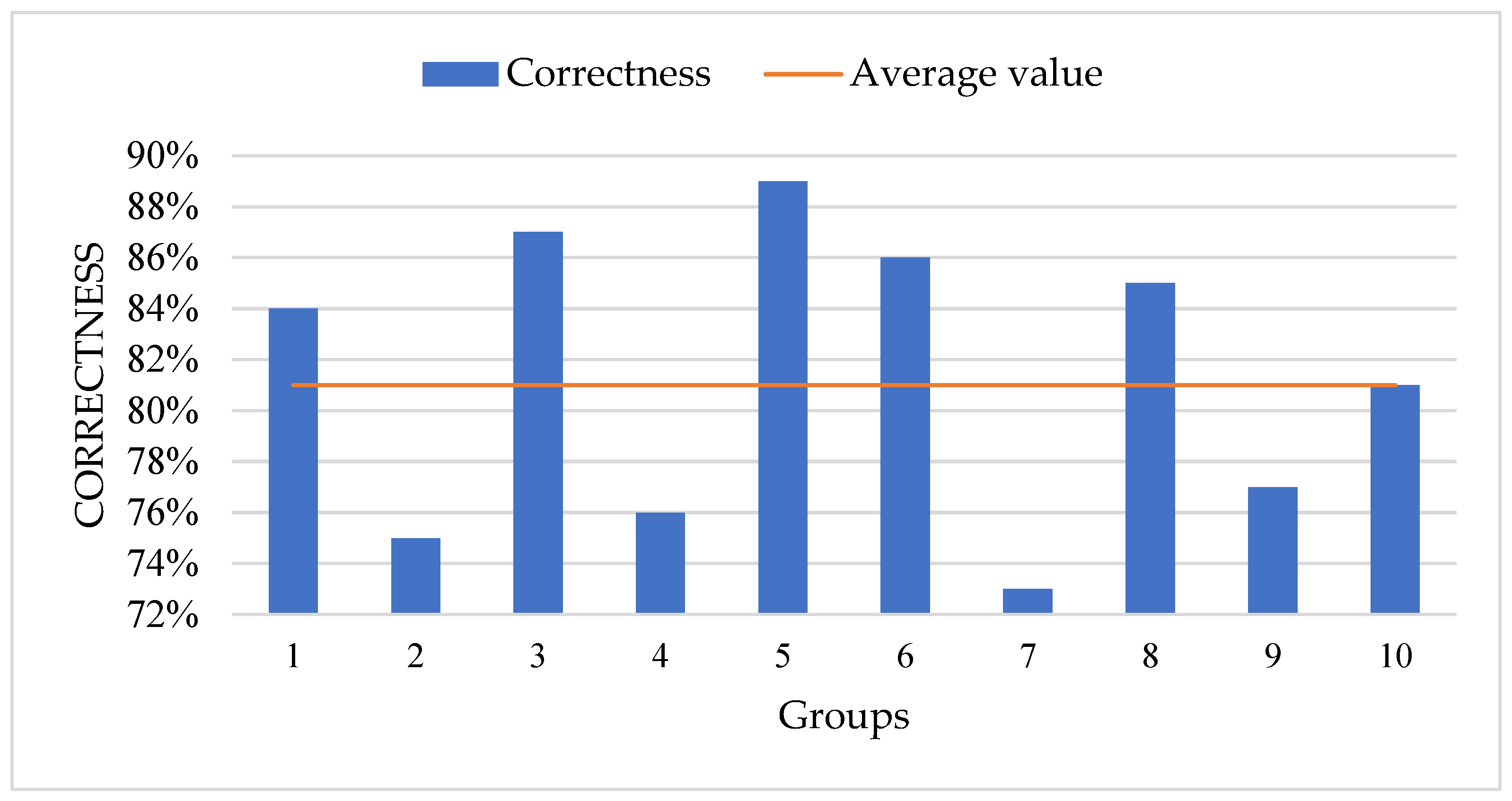
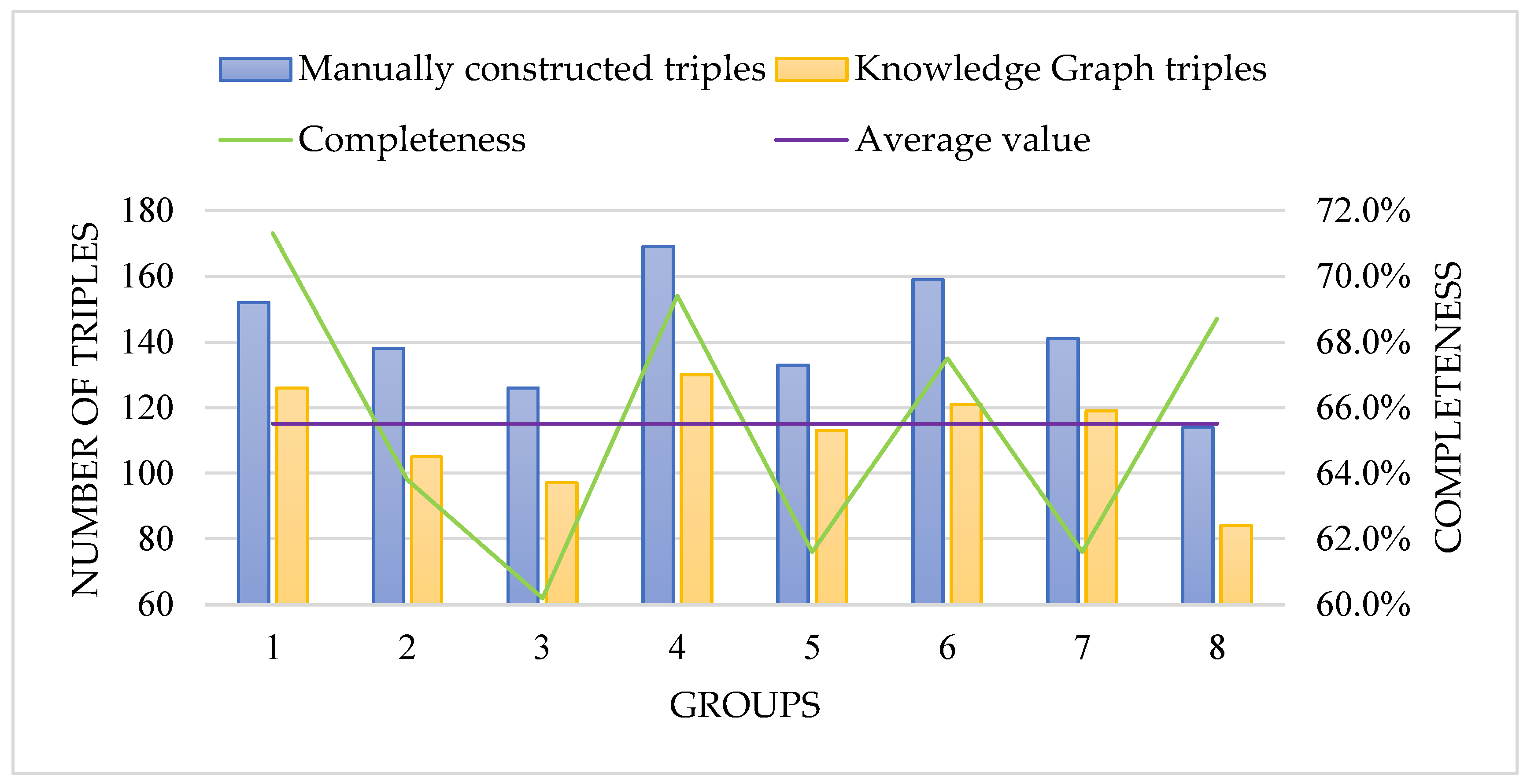
4.3. Quality Assessment of Urban Waterlogging Emergency Knowledge Graph
4.4. Application of Knowledge Graph for Urban Waterlogging Emergency
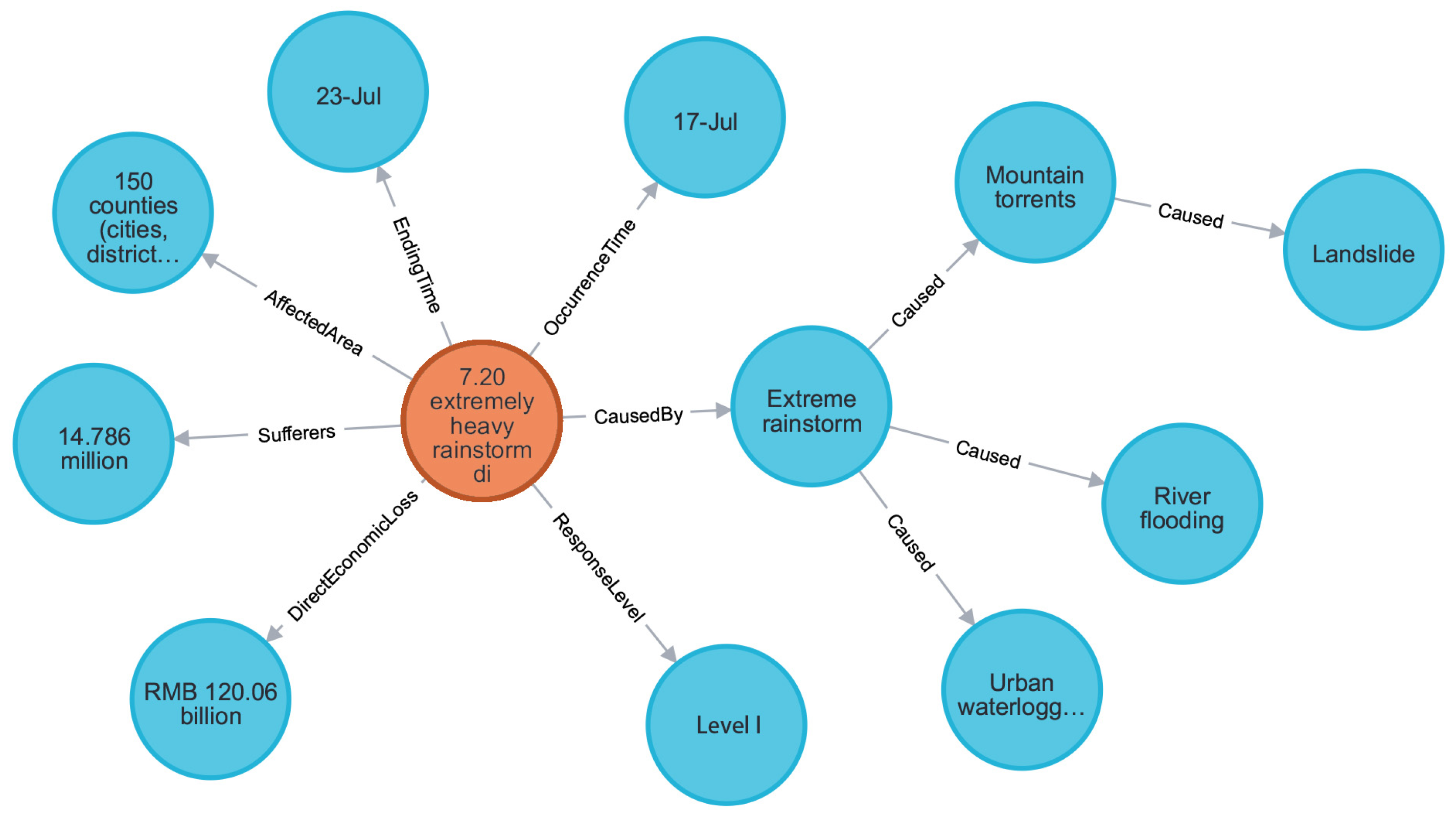
4.4.1. Query and Visualization
| MATCH (c:City {name:” city name “})-[:HAS_FLOODING_EVENT]->(e:Event) RETURN e |
| MATCH (n:Location) WHERE geo.distance(n.location, point({x: 34.804909, y: 113.300109})) < 10,000 RETURN n.name, n.location, geo.distance(n.location, point({x: 34.804909, y: 113.300109})) AS distance ORDER BY distance |
| MATCH (n:Location) WHERE geo.withinPolygon(n.location, [[34.17, 112.42], [34.17, 114.14], [34.45, 114.14], [34.45, 112.42], [34.17, 112.42]]) RETURN n.name, n.location |
4.4.2. Analysis of Urban Waterlogging Emergency Events
| MATCH (n:Event)-[r:RELATED_TO]->(m:ResponsePlan) WHERE n.name = “October 2021 Shanxi rainstorms “ AND r.relation_type = “emergency_response” RETURN n,r,m |
| MATCH (n: WaterloggingEvent) WHERE n. occurrence time >= date(“2022-01-01”) AND n. occurrence time < date(“2022-12-31”) RETURN n. event name, n. occurrence time, n. duration, n. occurrence area, n. response level |
5. Discussion
6. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, Q.; Wu, Z.; Zhang, H.; Dalla Fontana, G.; Tarolli, P. Identifying dominant factors of waterlogging events in metropolitan coastal cities: The case study of Guangzhou, China. J. Environ. Manag. 2020, 271, 110951. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Zhu, J.; Pirasteh, S.; Zhu, Q.; Guo, Y.; Luo, L.; Dehbi, Y. A 3D virtual geographic environment for flood representation towards risk communication. Int. J. Appl. Earth Obs. Geoinf. 2024, 128, 103757. [Google Scholar] [CrossRef]
- Li, W.; Zhu, J.; Pirasteh, S.; Zhu, Q.; Fu, L.; Wu, J.; Hu, Y.; Dehbi, Y. Investigations of disaster information representation from a geospatial perspective: Progress, challenges and recommendations. Trans. GIS 2022, 26, 1376–1398. [Google Scholar] [CrossRef]
- Li, S.; Dragicevic, S.; Castro, F.A.; Sester, M.; Winter, S.; Coltekin, A.; Pettit, C.; Jiang, B.; Haworth, J.; Stein, A. Geospatial big data handling theory and methods: A review and research challenges. ISPRS J. Photogramm. Remote Sens. 2016, 115, 119–133. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, X.; Ye, P.; Du, M.; Lu, Y.; Xue, H. Geographic knowledge graph (GeoKG): A formalized geographic knowledge representation. ISPRS Int. J. Geo-Inf. 2019, 8, 184. [Google Scholar] [CrossRef]
- Du, J.; Wang, S.; Ye, X.; Sinton, D.S.; Kemp, K. GIS-KG: Building a large-scale hierarchical knowledge graph for geographic information science. Int. J. Geogr. Inf. Sci. 2022, 36, 873–897. [Google Scholar] [CrossRef]
- Jiang, B.; Tan, L.; Ren, Y.; Li, F. Intelligent interaction with virtual geographical environments based on geographic knowledge graph. ISPRS Int. J. Geo-Inf. 2019, 8, 428. [Google Scholar] [CrossRef]
- Mai, G.; Janowicz, K.; Cai, L.; Zhu, R.; Regalia, B.; Yan, B.; Shi, M.; Lao, N. SE-KGE: A location-aware knowledge graph embedding model for geographic question answering and spatial semantic lifting. Trans. GIS 2020, 24, 623–655. [Google Scholar] [CrossRef]
- Zheng, K.; Xie, M.H.; Zhang, J.B.; Xie, J.; Xia, S.H. A knowledge representation model based on the geographic spatiotemporal process. Int. J. Geogr. Inf. Sci. 2022, 36, 674–691. [Google Scholar] [CrossRef]
- Zhou, C.; Wang, H.; Wang, C.; Hou, Z.; Zheng, Z.; Shen, S.; Cheng, Q.; Feng, Z.; Wang, X.; Lv, H. Geoscience knowledge graph in the big data era. Sci. China Earth Sci. 2021, 64, 1105–1114. [Google Scholar] [CrossRef]
- Sun, S.; Dustdar, S.; Ranjan, R.; Morgan, G.; Dong, Y.; Wang, L. Remote sensing image interpretation with semantic graph-based methods: A survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4544–4558. [Google Scholar] [CrossRef]
- Wu, X.; Gao, J.; Bilal, M.; Dai, F.; Xu, X.; Qi, L.; Dou, W. Federated learning-based private medical knowledge graph for epidemic surveillance in internet of things. Expert Syst. 2023, e13372. [Google Scholar] [CrossRef]
- Cao, Q.; Jiang, R.; Yang, C.; Fan, Z.; Song, X.; Shibasaki, R. Mepognn: Metapopulation epidemic forecasting with graph neural networks. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Grenoble, France, 19–23 September 2022; pp. 453–468. [Google Scholar]
- Li, W.; Wang, S.; Chen, X.; Tian, Y.; Gu, Z.; Lopez-Carr, A.; Schroeder, A.; Currier, K.; Schildhauer, M.; Zhu, R. Geographvis: A knowledge graph and geovisualization empowered cyberinfrastructure to support disaster response and humanitarian aid. ISPRS Int. J. Geo-Inf. 2023, 12, 112. [Google Scholar] [CrossRef]
- Liu, J.; Li, T.; Ji, S.; Xie, P.; Du, S.; Teng, F.; Zhang, J. Urban flow pattern mining based on multi-source heterogeneous data fusion and knowledge graph embedding. IEEE Trans. Knowl. Data Eng. 2021, 35, 2133–2146. [Google Scholar] [CrossRef]
- Qun, Y.; Linfu, X.; Yongsheng, L.; Rui, W.; Bo, W.; Ke, D.; Jianbang, W. Mineral prospectivity mapping integrated with geological map Knowledge graph and geochemical data: A Case Study of gold deposits at Raofeng area, Shaanxi Province. Ore Geol. Rev. 2023, 105651. [Google Scholar]
- Ma, C.; Kale, A.S.; Zhang, J.; Ma, X. A knowledge graph and service for regional geologic time standards. Geosci. Front. 2023, 14, 101453. [Google Scholar] [CrossRef]
- Li, W.; Zhu, J.; Zhang, Y.; Fu, L.; Gong, Y.; Hu, Y.; Cao, Y. An on-demand construction method of disaster scenes for multilevel users. Nat. Hazards 2020, 101, 409–428. [Google Scholar] [CrossRef]
- Rondón Díaz, J.D.; Vilches-Blázquez, L.M. Characterizing water quality datasets through multi-dimensional knowledge graphs: A case study of the Bogota river basin. J. Hydroinform. 2022, 24, 295–314. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, J.; Zhu, Q.; Xie, Y.; Li, W.; Fu, L.; Zhang, J.; Tan, J. The construction of personalized virtual landslide disaster environments based on knowledge graphs and deep neural networks. Int. J. Digit. Earth 2020, 13, 1637–1655. [Google Scholar] [CrossRef]
- Yu, L.; Qiu, P.; Gao, J.; Lu, F. A knowledge-based filtering method for open relations among geo-entities. ISPRS Int. J. Geo-Inf. 2019, 8, 59. [Google Scholar] [CrossRef]
- Qiu, P.; Gao, J.; Yu, L.; Lu, F. Knowledge embedding with geospatial distance restriction for geographic knowledge graph completion. ISPRS Int. J. Geo-Inf. 2019, 8, 254. [Google Scholar] [CrossRef]
- Qiu, P.; Yu, L.; Gao, J.; Lu, F. Detecting geo-relation phrases from web texts for triplet extraction of geographic knowledge: A context-enhanced method. Big Earth Data 2019, 3, 297–314. [Google Scholar] [CrossRef]
- Nguyen, H.L.; Vu, D.T.; Jung, J.J. Knowledge graph fusion for smart systems: A survey. Inf. Fusion 2020, 61, 56–70. [Google Scholar] [CrossRef]
- Wang, H.; Fang, Z.; Zhang, L.; Pan, J.Z.; Ruan, T. Effective online knowledge graph fusion. In Proceedings of the International Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015; pp. 286–302. [Google Scholar]
- Huang, Z.; Qiu, P.; Yu, L.; Lu, F. MSEN-GRP: A Geographic Relations Prediction Model Based on Multi-Layer Similarity Enhanced Networks for Geographic Relations Completion. ISPRS Int. J. Geo-Inf. 2022, 11, 493. [Google Scholar] [CrossRef]
- Wang, J.; Hu, Y.; Joseph, K. NeuroTPR: A neuro-net toponym recognition model for extracting locations from social media messages. Trans. GIS 2020, 24, 719–735. [Google Scholar] [CrossRef]
- Ding, L.; Xiao, G.; Pano, A.; Fumagalli, M.; Chen, D.; Feng, Y.; Calvanese, D.; Fan, H.; Meng, L. Integrating 3D city data through knowledge graphs. Geo-Spat. Inf. Sci. 2024, 27, 1–20. [Google Scholar] [CrossRef]
- Ding, L.; Xiao, G.; Pano, A.; Stadler, C.; Calvanese, D. Towards the next generation of the LinkedGeoData project using virtual knowledge graphs. J. Web Semant. 2021, 71, 100662. [Google Scholar] [CrossRef]
- Zou, Y.; Huang, Y.; Wang, Y.; Zhou, F.; Xia, Y.; Shen, Z. The construction of urban rainstorm disaster event knowledge graph considering evolutionary processes. Water 2024, 16, 942. [Google Scholar] [CrossRef]
- Berragan, C.; Singleton, A.; Calafiore, A.; Morley, J. Transformer based named entity recognition for place name extraction from unstructured text. Int. J. Geogr. Inf. Sci. 2023, 37, 747–766. [Google Scholar] [CrossRef]
- Li, W.; Sun, K.; Wang, S.; Zhu, Y.; Dai, X.; Hu, L. DePNR: A DeBERTa-based deep learning model with complete position embedding for place name recognition from geographical literature. Trans. GIS 2024, 28, 993–1020. [Google Scholar] [CrossRef]
- Trisedya, B.D.; Qi, J.; Zhang, R. Entity alignment between knowledge graphs using attribute embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 297–304. [Google Scholar]
- Yu, L.; Qiu, P.; Liu, X.; Lu, F.; Wan, B. A holistic approach to aligning geospatial data with multidimensional similarity measuring. Int. J. Digit. Earth 2018, 11, 845–862. [Google Scholar] [CrossRef]
- Worboys, M.F. A generic model for planar geographical objects. Int. J. Geogr. Inf. Syst. 1992, 6, 353–372. [Google Scholar] [CrossRef]
- Yi, J.; Du, Y.; Liang, F.; Zhou, C.; Wu, D.; Mo, Y. A representation framework for studying spatiotemporal changes and interactions of dynamic geographic phenomena. Int. J. Geogr. Inf. Sci. 2014, 28, 1010–1027. [Google Scholar] [CrossRef]
- Xue, C.; Wu, C.; Liu, J.; Su, F. A novel process-oriented graph Storage for dynamic geographic phenomena. ISPRS Int. J. Geo-Inf. 2019, 8, 100. [Google Scholar] [CrossRef]
- Zheng, L.; Zhou, L.; Zhao, X.; Liao, L.; Liu, W. The spatio-temporal data modeling and application based on graph database. In Proceedings of the 2017 4th International Conference on Information Science and Control Engineering (ICISCE), Changsha, China, 21–23 July 2017; pp. 741–746. [Google Scholar]
- Yu, B.; Zhang, C.; Sun, J.; Zhang, Y. Massive GIS spatio-temporal data storage method in cloud environment. In Proceedings of the 2018 2nd International Conference on Computer Science and Artificial Intelligence, Chengdu, China, 25–26 March 2018; pp. 105–109. [Google Scholar]
- Gruber, T.R. Toward principles for the design of ontologies used for knowledge sharing? Int. J. Hum.-Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Alirezaie, M.; Kiselev, A.; Längkvist, M.; Klügl, F.; Loutfi, A. An ontology-based reasoning framework for querying satellite images for disaster monitoring. Sensors 2017, 17, 2545. [Google Scholar] [CrossRef]
- Giupponi, C.; Mojtahed, V.; Gain, A.K.; Biscaro, C.; Balbi, S. Integrated risk assessment of water-related disasters. In Hydro-Meteorological Hazards, Risks and Disasters; Elsevier: Amsterdam, The Netherlands, 2015; pp. 163–200. [Google Scholar]
- Jung, H.; Chung, K. Ontology-driven slope modeling for disaster management service. Clust. Comput. 2015, 18, 677–692. [Google Scholar] [CrossRef]
- De Wrachien, D.; Garrido, J.; Mambretti, S.; Requena, I. Ontology for flood management: A proposal. WIT Trans. Ecol. Environ. 2012, 159, 3–13. [Google Scholar]
- Wu, Z.; Shen, Y.; Wang, H.; Wu, M. An ontology-based framework for heterogeneous data management and its application for urban flood disasters. Earth Sci. Inform. 2020, 13, 377–390. [Google Scholar] [CrossRef]
- Parsons, S.; Atkinson, P.M.; Simperl, E.; Weal, M. Thematically analysing social network content during disasters through the lens of the disaster management lifecycle. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1221–1226. [Google Scholar]
- Matsuo, I.; Kuribayashi, T.; Kamura, K. Disaster Reduction Measures Against Inundation in Underground Area and Development of Disaster Prevention Action Plan Using TimeLine. J. Disaster Res. 2016, 11, 322–333. [Google Scholar] [CrossRef]
- Satomura, S.; Sutou, J.; Itou, K.; Hiraide, R.; Kandatsu, T.; Mizokami, H.; Kobayashi, H.; Kawashima, H.; Shirakawa, N.; Ito, T. Social Experiment for My-Timeline Development to Improve Residents’awareness of Flood Disaster Prevention. J. JSCE 2020, 8, 261–273. [Google Scholar] [CrossRef] [PubMed]
- Leijie, F.; Yv, B.; Zhenyuan, Z. Constructing a vertical knowledge graph for non-traditional machining industry. In Proceedings of the 2018 IEEE 15th International Conference on Networking, Sensing and Control (ICNSC), Zhuhai, China, 27–29 March 2018; pp. 1–5. [Google Scholar]
- Grüninger, M. Verification of the OWL-time ontology. In Proceedings of the International Semantic Web Conference, Bonn, Germany, 23–27 October 2011; pp. 225–240. [Google Scholar]
- Sun, J.; Liu, Y.; Cui, J.; He, H. Deep learning-based methods for natural hazard named entity recognition. Sci. Rep. 2022, 12, 4598. [Google Scholar] [CrossRef] [PubMed]
- Huaman, E.; Fensel, D. Knowledge graph curation: A practical framework. In Proceedings of the 10th International Joint Conference on Knowledge Graphs, Online, 6–8 December 2021; pp. 166–171. [Google Scholar]
- Chen, H.; Cao, G.; Chen, J.; Ding, J. A practical framework for evaluating the quality of knowledge graph. In Proceedings of the Knowledge Graph and Semantic Computing: Knowledge Computing and Language Understanding: 4th China Conference, CCKS 2019, Hangzhou, China, 24–27 August 2019; Revised Selected Papers 4, 2019. pp. 111–122. [Google Scholar]
- Xue, B.; Zou, L. Knowledge graph quality management: A comprehensive survey. IEEE Trans. Knowl. Data Eng. 2022, 35, 4969–4988. [Google Scholar] [CrossRef]
- Paulheim, H. Knowledge graph refinement: A survey of approaches and evaluation methods. Semant. Web 2017, 8, 489–508. [Google Scholar] [CrossRef]



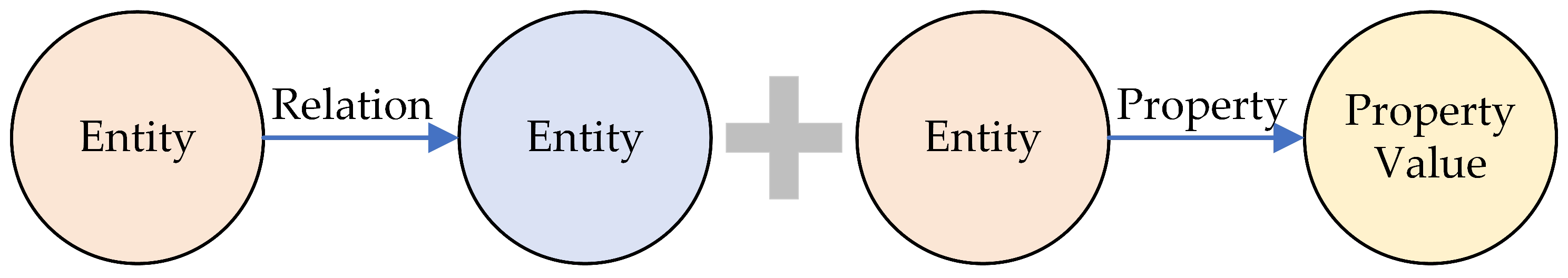



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Property | Description |
|---|---|---|
| Time property | Start time | Event start time |
| End time | Event end time | |
| Spatial property | Location (latitude and longitude) | The latitude and longitude coordinates of the disaster event |
| Location (administrative division) | Indicates the administrative division where the waterlogging event occurred | |
| Morphological properties | Scope of disaster | Refers to the extent of the area involved in an urban waterlogging event, usually expressed in km2 |
| Depth of waterlogging | Refers to the depth to which waterlogged ground is submerged during an urban waterlogging event, usually expressed in cm | |
| Waterlogging flow rate | Refers to the velocity of waterlogged water flow during an urban waterlogging event, usually expressed in units of m/s | |
| Disaster Property | Intensity of disaster | Refers to the severity of urban waterlogging events, which are generally categorized as light, medium, or heavy |
| Damage to buildings | Refers to the extent of damage to buildings during urban waterlogging events, e.g., number of collapsed houses, number of severely damaged houses, etc. | |
| Damage to the transportation system | Documentation of damage to the transportation system caused by urban waterlogging events | |
| Casualties | Describes the human casualties of a disaster event, including the number of people killed, injured, and missing | |
| Economic loss | This attribute describes the economic damage caused by the disaster event | |
| Other losses | Described other losses that may be caused by urban waterlogging events, such as the area of crops affected, the number of livestock affected, etc. |
| Category | Property | Description |
|---|---|---|
| Pre-, During, and Post-disaster | Mission name | Refers to the name of a specific mission developed in response to urban waterlogging, e.g., “Drainage Pumping Station Activation Mission”, “Leakage Plugging Mission”, etc. |
| Type of mission | Refers to the categorization of urban waterlogging emergency response missions, e.g., drainage missions, rescue missions, flood control missions, etc. | |
| Mission level | Attributes that describe the urgency and importance of the urban waterlogging emergency response mission | |
| Name of emergency response organization | Indicates the name of the agency that performs the emergency response mission, e.g., a city’s Emergency Management Agency, or a county’s Flood Control Office | |
| emergency worker | Records information on personnel involved in emergency response | |
| Description of emergency action | Refers to the description of specific actions taken by emergency response agencies and personnel in response to an urban waterlogging event, such as evacuation of people and deployment of materials |
| Relationship Class | Relationship Name | Relationship Description |
|---|---|---|
| Implementation relationship | In Charge Of | A in charge of B |
| Executed By | A executed by B | |
| Has Participant | A has participant B | |
| Containment relationship | Is Part Of | A is part of B |
| Has Component | A has component B | |
| logical relationship | Caused | A caused B to respond |
| Caused By | A’s response is caused by B | |
| Follow | A follows the onset of B |
| Entity 1 | Entity 2 | After Fusion |
|---|---|---|
| Urban drainage system | Urban wastewater treatment systems | Urban wastewater treatment systems -> Urban drainage system |
| Sewer | Drainage pipe | Sewer -> Drainage pipe |
| Drainage pumping station | Drainage engine room | Drainage pumping station -> Drainage engine room |
| Rainwater well | Drainage well | Rainwater well -> Drainage well |
| Data Type | Data Source | Data Description | |
|---|---|---|---|
| Structured data | Disaster thematic data | National Earth System Science Data Center | Contains basic geographic, sociodemographic, and flood prediction and forecasting data of the affected area in its thematic data |
| Unstructured data | Search engine | Wikipedia | Using waterlogging disaster events as key words to search, including basic information |
| Disaster public announcement | National Disaster Reduction Official Website (NDRCC) | With a high degree of authority and credibility, it can quickly release disaster-related information, including the time, place, and scope of impact of the disaster | |
| News media | CCTV | Disaster-related information is provided through news reports and special programs | |
| Huanqiu net | Not only provides coverage of news events but also provides in-depth analysis and commentary | ||
| Original Text | Extraction Result | ||
|---|---|---|---|
| A historically rare rainstorm occurred in Zhengzhou, Henan Province, China, on 20 July 2021. The rain lasted for 24 h, flooding subway lines and bringing traffic to a standstill. Citizens were trapped in subway cars and flooded homes. The local government launched an emergency plan, and emergency rescue teams and volunteers rushed to the scene to carry out rescue work. In dozens of hours of struggle, rescue workers moved scores of stranded citizens and took steps to unblock drainage systems. The storm has killed at least 300 people, left more than 50 missing and caused direct economic losses of more than 10 billion yuan. | Entity | Relation/property | Entity/property value |
| Urban waterlogging | Start time | 20 July 2021 | |
| Urban waterlogging | Location | Zhengzhou, Henan Province, China | |
| Urban waterlogging | Duration | Lasted for 24 h | |
| Urban waterlogging | Caused | Flooding subway lines | |
| Urban waterlogging | Caused | Traffic to a standstill | |
| Urban waterlogging | Caused | Citizens are trapped | |
| Local government | Launched | An emergency plan | |
| Emergency rescue teams | Carry out | Rescue work | |
| Emergency rescue teams | Moved | Scores of stranded citizens | |
| Emergency rescue teams | Unblock | Drainage systems | |
| Urban waterlogging | Casualties | At least 300 people | |
| Urban waterlogging | Economic loss | More than 10 billion yuan | |
| Node or Relationship Type | Number of Nodes or Relationships | Number of Errors | Correctness |
|---|---|---|---|
| Event nodes | 58 | 5 | 91.4% |
| Emergency response nodes | 117 | 26 | 77.8% |
| Geographic object nodes | 74 | 21 | 71.6% |
| Time attribute nodes | 36 | 5 | 86.1% |
| Spatial attribute nodes | 15 | 2 | 86.7% |
| Composition | 972 | 179 | 81.6% |
| Association | 377 | 52 | 86.2% |
| Generalization | 166 | 45 | 72.9% |
| Aggregation | 123 | 27 | 78.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, W.; Shen, J.; Su, Q.; Liu, S.; Pirasteh, S.; Ishii, K. A Method for Constructing an Urban Waterlogging Emergency Knowledge Graph Based on Spatiotemporal Processes. ISPRS Int. J. Geo-Inf. 2024, 13, 349. https://doi.org/10.3390/ijgi13100349
Mao W, Shen J, Su Q, Liu S, Pirasteh S, Ishii K. A Method for Constructing an Urban Waterlogging Emergency Knowledge Graph Based on Spatiotemporal Processes. ISPRS International Journal of Geo-Information. 2024; 13(10):349. https://doi.org/10.3390/ijgi13100349
Chicago/Turabian StyleMao, Wei, Jie Shen, Qian Su, Sihu Liu, Saied Pirasteh, and Kunihiro Ishii. 2024. "A Method for Constructing an Urban Waterlogging Emergency Knowledge Graph Based on Spatiotemporal Processes" ISPRS International Journal of Geo-Information 13, no. 10: 349. https://doi.org/10.3390/ijgi13100349
APA StyleMao, W., Shen, J., Su, Q., Liu, S., Pirasteh, S., & Ishii, K. (2024). A Method for Constructing an Urban Waterlogging Emergency Knowledge Graph Based on Spatiotemporal Processes. ISPRS International Journal of Geo-Information, 13(10), 349. https://doi.org/10.3390/ijgi13100349