

Wetland Classification, Attribute Accuracy, and Scale



Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area and Data Sources
2.2. Wetlands Classification Systems
2.3. Confusion Matrices and Evaluation Metrics
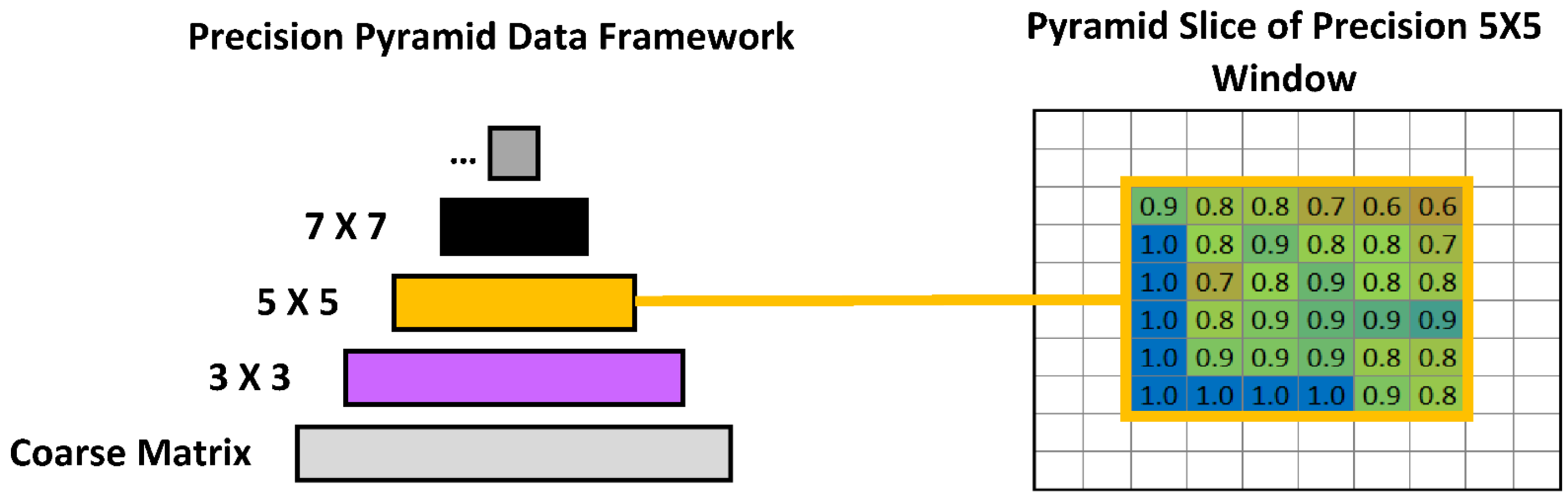
2.4. Pyramid Data Framework
3. Results
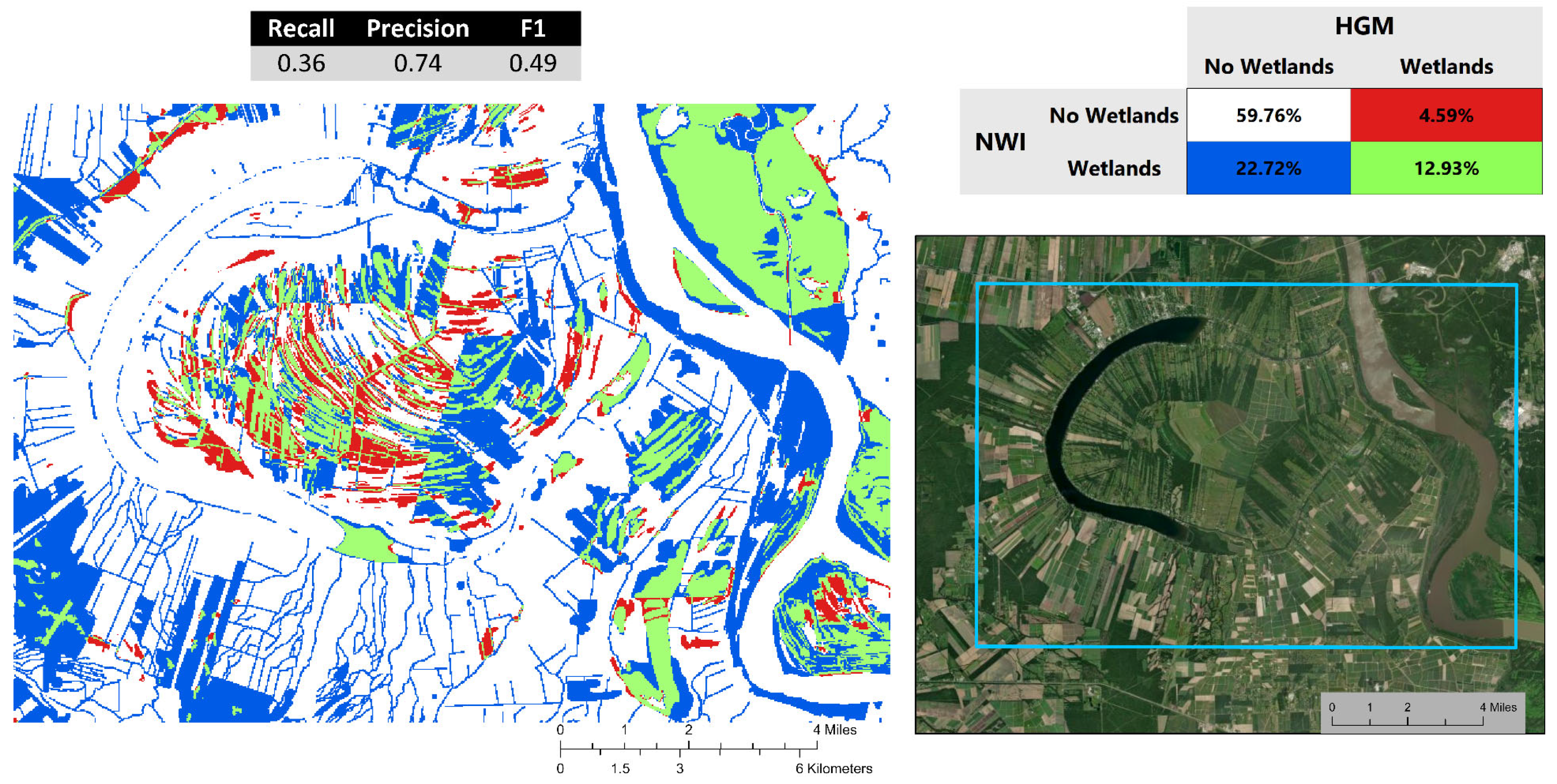
3.1. Coarse Matrix—Wetlands Presence or Absence
3.2. Fine Matrix—Wetland Type
3.3. Multiscale Analysis
3.3.1. Recall
3.3.2. Precision
3.3.3. F1
3.3.4. Consolidating and Comparing Metrics in the Pyramid Framework
4. Discussion
4.1. Evaluating Differences between Independently Compiled Data Classification Systems
4.2. Advantages of Confusion Matrix Analysis to Highlight Classification Inconsistency
4.3. Benefits of the Pyramid Framework in Analyzing Confusion Matrix Metrics
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Couclelis, H. The Certainty of Uncertainty: GIS and the Limits of Geographic Knowledge. Trans. GIS 2003, 7, 165–175. [Google Scholar] [CrossRef]
- Hope, S.; Hunter, G.J. Testing the effects of positional uncertainty on spatial decision-making. Int. J. Geogr. Inf. Sci. 2007, 21, 645–665. [Google Scholar] [CrossRef]
- MacEachren, A.M. Visualizing Uncertain Information. Cartogr. Perspect. 1992, 13, 10–19. [Google Scholar] [CrossRef]
- Mason, J.S.; Klippel, A.; Bleisch, S.; Slingsby, A.; Deitrick, S. Special issue introduction: Approaching spatial uncertainty visualization to support reasoning and decision making. Spat. Cogn. Comput. 2016, 16, 97–105. [Google Scholar] [CrossRef][Green Version]
- International Union of Conservation of Nature (IUCN). Contributing to the Kunming-Montreal Global Biodiversity Framework: Nature 2030, IUCN Resolutions and Conservation Tools; IUCN International Policy Centre: Gland, Switzerland, 2023; Available online: https://www.iucn.org/sites/default/files/2023-10/information-note-iucn-and-the-gbf.pdf (accessed on 14 March 2024).
- Usery, E.L.; Finn, M.P.; Cox, J.D.; Beard, T.; Ruhl, S.; Bearden, M. Projecting Global Datasets to Achieve Equal Areas. Cartogr. Geogr. Inf. Sci. 2003, 30, 69–79. [Google Scholar] [CrossRef]
- Tobler, W.R. A Transformational View of Cartography. Am. Cartogr. 1979, 6, 101–106. [Google Scholar] [CrossRef][Green Version]
- Visvalingham, M.; Whyatt, J.D. Line Generalization by Repeated Elimination of Points. Cartogr. J. 1993, 30, 46–51. [Google Scholar] [CrossRef]
- Kronenfeld, B.J.; Stanislawski, L.V.; Buttenfield, B.P.; Brockmeyer, T. Simplification of Polylines by Segment Collapse: Minimizing Areal Displacement While Preserving Area. Int. J. Cartogr. 2019, 6, 22–46. [Google Scholar] [CrossRef]
- Radtke, P.J.; Burkhardt, H.E. A Comparison of Methods for Edge Bias Compensation. Can. J. For. Res. 2011, 28, 942–945. [Google Scholar] [CrossRef]
- Jenks, G.F. Optimal Data Classification for Choropleth Maps; Occasional Paper #2; Department of Geography, University of Kansas: Lawrence, KS, USA, 1977. [Google Scholar]
- Slocum, T.A.; McMaster, R.B.; Kessler, F.C.; Howard, H.H. Thematic Cartography and Geovisualization, 4th ed.; CRC Press: Boca Raton, FL, USA, 2022. [Google Scholar] [CrossRef]
- Millennium Ecosystem Assessment. Ecosystems and Human Well-Being: Wetlands and Water; World Resources Institute: Washington, DC, USA, 2005; Available online: https://www.unep.org/resources/report/ecosystems-and-human-well-being-wetlands-and-water-synthesis (accessed on 14 March 2024).
- Smith, R.D.; Ammann, A.; Bartoldus, C.; Brinson, M.M. An Approach for Assessing Wetland Functions Using Hydrogeomorphic Classification, Reference Wetlands, and Functional Indices; Technical Report WRP-DE-9; U.S Army Corps of Engineers, Wetlands Research Program: Washington, DC, USA, 1995; Available online: https://www.semanticscholar.org/paper/An-approach-for-assessing-wetland-functions-using-%3B-Smith-Ammann/63aae965cd55159cf32861d1d4bbda0e45e0449f (accessed on 14 March 2024).
- McCauley, L.A.; Jenkins, D.G.; Quintana-Ascencio, P.F. Isolated Wetland Loss and Degradation Over Two Decades in an Increasingly Urbanized Landscape. Wetlands 2013, 33, 117–127. [Google Scholar] [CrossRef]
- Tiner, R.W. Assessing cumulative loss of wetland functions in the Nanticoke River watershed using enhanced National Wetlands Inventory data. Wetlands 2005, 25, 405–419. [Google Scholar] [CrossRef]
- Dahl, T.E. Wetlands Losses in the United States 1780’s to 1980’s; U.S. Department of the Interior, Fish and Wildlife Service: Washington, DC, USA, 1990. Available online: https://www.fws.gov/media/wetland-losses-united-states-1780s-1980s (accessed on 14 March 2024).
- Coastal Protection and Restoration Authority of Louisiana. Louisiana’s Comprehensive Master Plan for a Sustainable Coast; Coastal Protection and Restoration Authority of Louisiana: Baton Rouge, LA, USA, 2017. Available online: http://coastal.la.gov/wp-content/uploads/2017/04/2017-Coastal-Master-Plan_Web-Single-Page_CFinal-with-Effective-Date-06092017.pdf (accessed on 14 March 2024).
- Laws, F. Swampbuster Rules Set Off 18-Year Court Battle; Delta Farm Press: Boone, IA, USA, 2020; Available online: https://www.farmprogress.com/farm-life/swampbuster-rules-set-off-18-year-court-battle (accessed on 14 March 2024).
- Dvorett, D.; Bidwell, J.; Davis, C.; DuBois, C. Developing a Hydrogeomorphic Wetland Inventory: Reclassifying National Wetlands Inventory Polygons in Geographic Information Systems. Wetlands 2012, 32, 83–93. [Google Scholar] [CrossRef]
- FGDC (Federal Geographic Data Committee). Classification of Wetlands and Deepwater Habitats of the United States (FGDC-STD-004-2013), 2nd ed.; Wetlands Subcommittee, Federal Geographic Data Committee and U.S. Fish and Wildlife Service: Reston, VA, USA, 2013. Available online: https://www.fws.gov/sites/default/files/documents/Classification-of-Wetlands-and-Deepwater-Habitats-of-the-United-States-2013.pdf (accessed on 14 March 2024).
- EPA (U.S. Environmental Protection Agency). Methods for Evaluating Wetland Condition: Wetlands Classification; EPA-822-R-02-017; EPA Office of Water: Washington, DC, USA, 2002. Available online: https://www.epa.gov/sites/default/files/documents/wetlands_7classification.pdf (accessed on 14 March 2024).
- Brinson, M.M. A Hydrogeomorphic Classification for Wetlands; Technical Report WRP-DE-4; U.S. Army Engineer Waterways Experiment Station, Wetlands Research Program: Vicksburg, MS, USA, 1993; Available online: https://wetlands.el.erdc.dren.mil/pdfs/wrpde4.pdf (accessed on 14 March 2024).
- FS077-99; SDTS, (Spatial Data Transfer Standard). U.S. Geological Survey: Washington, DC, USA, 1999. [CrossRef]
- Smith, R.D.; Noble, C.V.; Berkowitz, J.F. Hydrogeomorphic (HGM) Approach to Assessing Wetland Functions: Guidelines for Developing Guidebooks (Version 2); Report # ERDC/EL TR-13-11; U.S. Army Engineer Research and Development Center Wetlands Regulatory Assistance Program: Vicksburg, MS, USA, 2013; Available online: https://www.semanticscholar.org/paper/Hydrogeomorphic-HGM-Approach-to-Assessing-Wetland-Smith-Noble/719ffd937c00bb8ae9c526f8a9a4abc60dad63de (accessed on 14 March 2024).
- ISO (International Organization for Standardization). Report 19115-1:2014/Amd 2:2020 Geographic Information–Metadata; International Organization for Standardization: Geneva, Switzerland, 2020; Available online: https://www.iso.org/standard/80275.html (accessed on 14 March 2024).
- FGDC (Federal Geographic Data Committee). Content Standard for Digital Geospatial Metadata (FGDC-STD-001-1998); Federal Geographic Data Committee: Washington, DC, USA, 1998. Available online: https://www.fgdc.gov/standards/projects/metadata/base-metadata/v2_0698.pdf (accessed on 14 March 2024).
- Tobler, W.R.T. Measuring Spatial Resolution. In Proceedings of the International Workshop on Land Use and Remote Sensing, Beijing, China, 25–28 January 1987; Available online: https://www.researchgate.net/publication/291877360_Measuring_spatial_resolution (accessed on 14 March 2024).
- Cedfeldt, P.T.; Watzin, M.C.; Richardson, B.D. Using GIS to Identify Functionally Significant Wetlands in the Northeastern United States. Environ. Manag. 2000, 26, 13–24. [Google Scholar] [CrossRef] [PubMed]
- Adamus, P.; Christy, J.; Jones, A.; McCune, M.; Bauer, J. A Geodatabase and Digital Characterization of Wetlands Mapped in the Willamette Valley with Particular Reference to Prediction of Their Hydrogeomorphic (HGM) Class; U.S. Environmental Protection Agency Region: Portland, OR, USA, 2010; Volume 10. [Google Scholar] [CrossRef]
- Van Deventer, H.; Nel, J.; Mbona, N.; Job, N.; Ewart-Smith, J.; Snaddon, K.; Maherry, A. Desktop classification of inland wetlands for systematic conservation planning in data-scarce countries: Mapping wetland ecosystem types, disturbance indices and threatened species associations at country-wide scale. Aquat. Conserv. Mar. Freshw. Ecosyst. 2016, 26, 57–75. [Google Scholar] [CrossRef]
- Rivers-Moore, N.A.; Kotze, D.C.; Job, N.; Mohanlal, S. Prediction of Wetland Hydrogeomorphic Type Using Morphometrics and Landscape Characteristics. Front. Environ. Sci. 2020, 8, 58. [Google Scholar] [CrossRef]
- Tiner, R.W. Keys to Landscape Position and Landform Descriptors for U.S. Wetlands; U.S. Fish and Wildlife Service, National Wetlands Inventory Program, Northeast Region: Hadley, MA, USA, 1997. [Google Scholar]
- Powers, D.M.W. Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness and Correlation. arXiv 2010, arXiv:2010.16061. [Google Scholar] [CrossRef]
- Hand, D.; Christen, P. A note on using the F-measure for evaluating record linkage algorithms. Stat. Comput. 2018, 28, 539–547. [Google Scholar] [CrossRef]
- Fisher, P.F. Models of uncertainty in spatial data. In Geographical Information Systems: Principles, Techniques, Management and Applications, 2nd ed.; Longley, P.A., Goodchild, M.F., Maguire, D.J., Rhind, D.W., Eds.; Wiley: London, UK, 2005; pp. 191–205. [Google Scholar]
- Comber, A.J.; Fisher, P.F.; Harvey, F.; Gahegan, M.; Wadsworth, R. Using Metadata to Link Uncertainty and Data Quality Assessments. In Progress in Spatial Data Handling; Riedl, A., Kainz, W., Elmes, G.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 279–292. [Google Scholar] [CrossRef]
- National Standards and Support Team. Technical Procedures for Conducting Status and Trends of the Nation’s Wetlands; Version 2; U.S. Fish and Wildlife Service: Washington, DC, USA, 2017. Available online: https://www.govinfo.gov/content/pkg/GOVPUB-I49-PURL-gpo145058/pdf/GOVPUB-I49-PURL-gpo145058.pdf (accessed on 18 March 2024).
- NRCS (U.S. Natural Resources Conservation Service). Field Indicators of Hydric Soils in the United States; A Guide for Identifying and Delineating Hydric Soils; Version 8.2; U.S. Department of Agriculture, in cooperation with the National Technical Committee for Hydric Soils: Washington, DC, USA, 2018. Available online: https://www.nrcs.usda.gov/resources/guides-and-instructions/field-indicators-of-hydric-soils (accessed on 18 March 2024).
- Carlson, K. Wetland Classification Accuracy and Scale: Visualizing Uncertainty Metrics Across Multiple Resolutions. Master’s Thesis, Department of Geography, University of Colorado–Boulder, Boulder, CO, USA, 2021. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Layer | Source | Resolution | Years Collected |
|---|---|---|---|
| Land Cover | NLCD-USGS | 30 m | 2016 |
| Wetlands | NWI-FWS | 1:65,000 | 1970s, 1980s, 2010s |
| Elevation | USGS | 30 m | 2016 |
| Hydric Soils | SSURGO-NRCS | 1:20,000 | 2000s–2019 |
| Hydrography | NHD-USGS | 1:24,000 | 2000s–2010 |
| Recall | Precision | F1 | ||||||
|---|---|---|---|---|---|---|---|---|
| Layer | Window Size | # of Windows | Std Dev | Mean | Std Dev | Mean | Std Dev | Mean |
| 5 | 7 | 37,636 | 0.32 | 0.64 | 0.30 | 0.66 | 0.24 | 0.54 |
| 10 | 17 | 33,856 | 0.28 | 0.58 | 0.27 | 0.59 | 0.20 | 0.50 |
| 15 | 27 | 30,276 | 0.23 | 0.58 | 0.27 | 0.57 | 0.17 | 0.51 |
| 20 | 37 | 26,896 | 0.19 | 0.59 | 0.19 | 0.56 | 0.14 | 0.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carlson, K.; Buttenfield, B.P.; Qiang, Y. Wetland Classification, Attribute Accuracy, and Scale. ISPRS Int. J. Geo-Inf. 2024, 13, 103. https://doi.org/10.3390/ijgi13030103
Carlson K, Buttenfield BP, Qiang Y. Wetland Classification, Attribute Accuracy, and Scale. ISPRS International Journal of Geo-Information. 2024; 13(3):103. https://doi.org/10.3390/ijgi13030103
Chicago/Turabian StyleCarlson, Kate, Barbara P. Buttenfield, and Yi Qiang. 2024. "Wetland Classification, Attribute Accuracy, and Scale" ISPRS International Journal of Geo-Information 13, no. 3: 103. https://doi.org/10.3390/ijgi13030103
APA StyleCarlson, K., Buttenfield, B. P., & Qiang, Y. (2024). Wetland Classification, Attribute Accuracy, and Scale. ISPRS International Journal of Geo-Information, 13(3), 103. https://doi.org/10.3390/ijgi13030103