
Integrating NoSQL, Hilbert Curve, and R*-Tree to Efficiently Manage Mobile LiDAR Point Cloud Data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
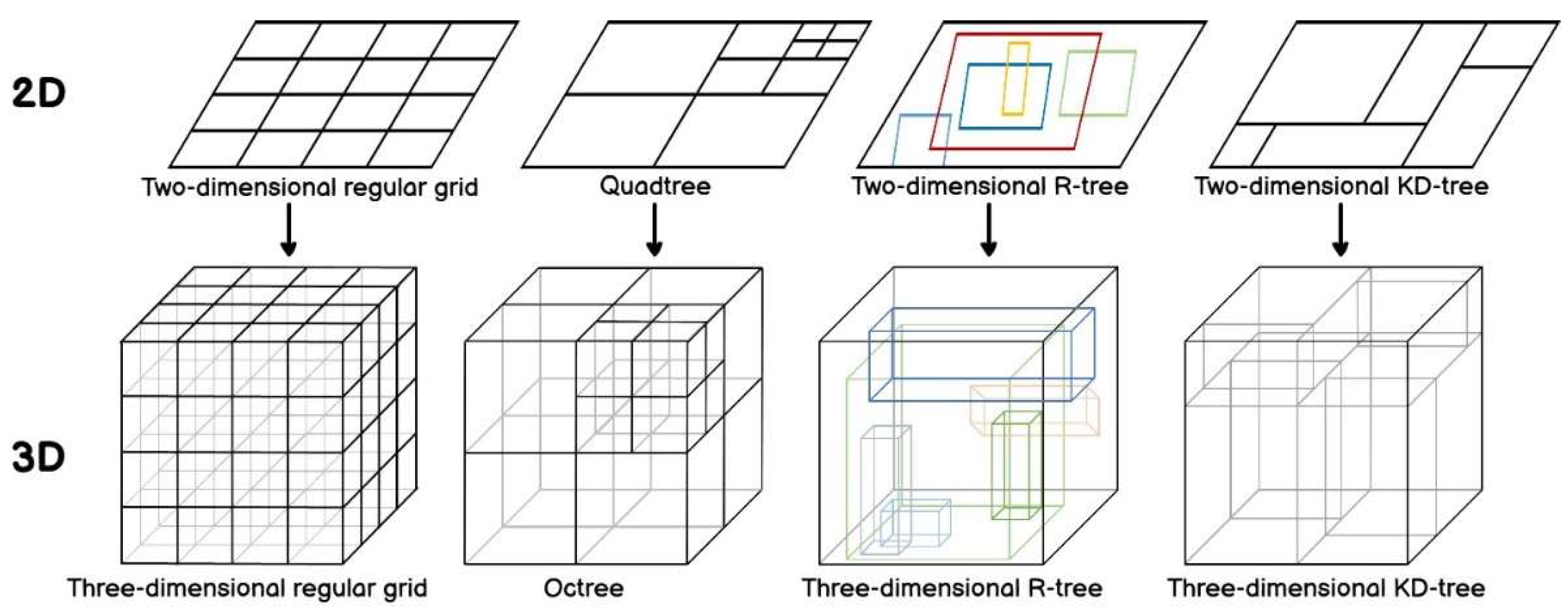
2.1. Indexes for Point Cloud Data
2.2. Storage Management System for Point Cloud Data
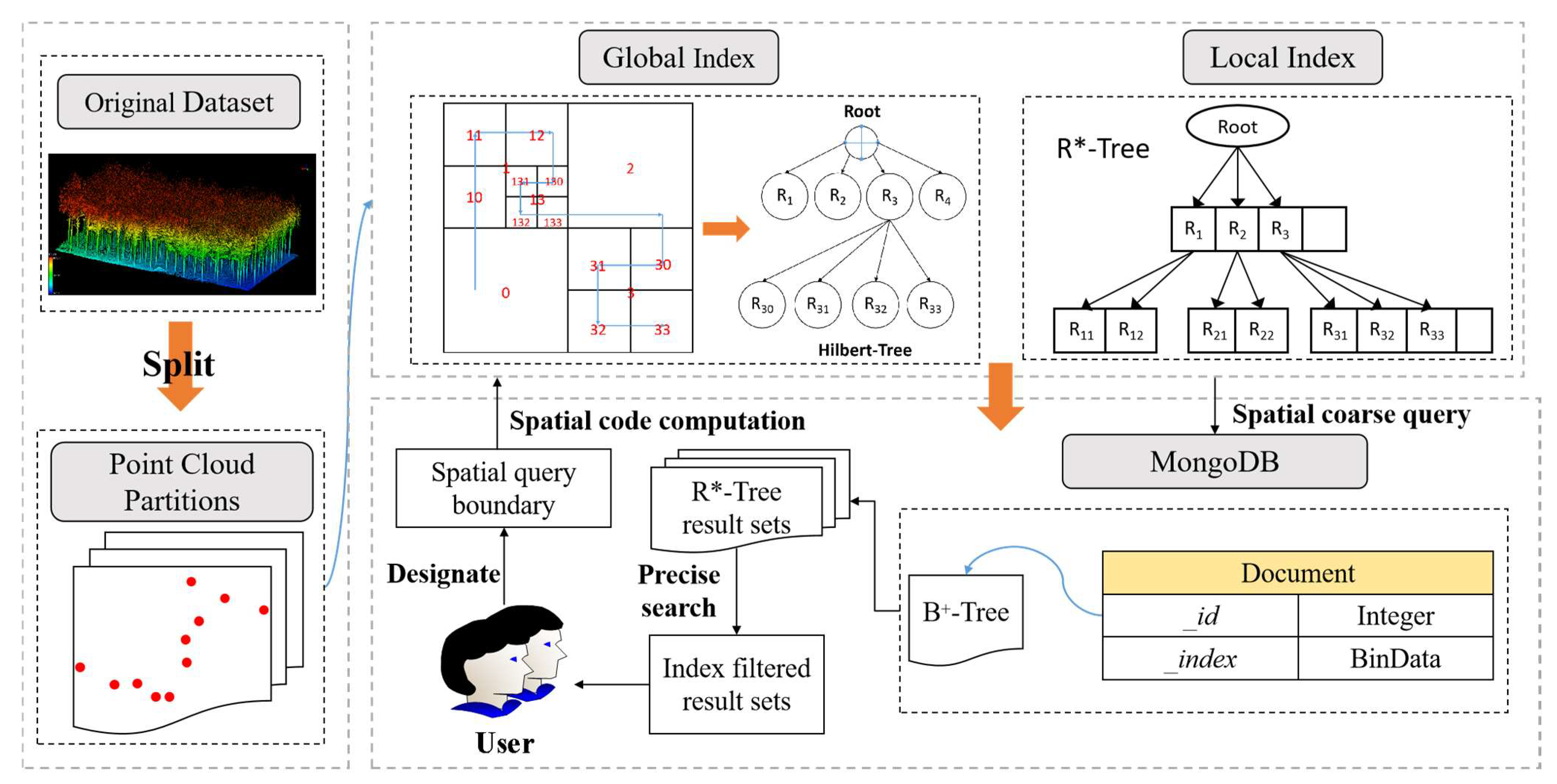
3. Methodology
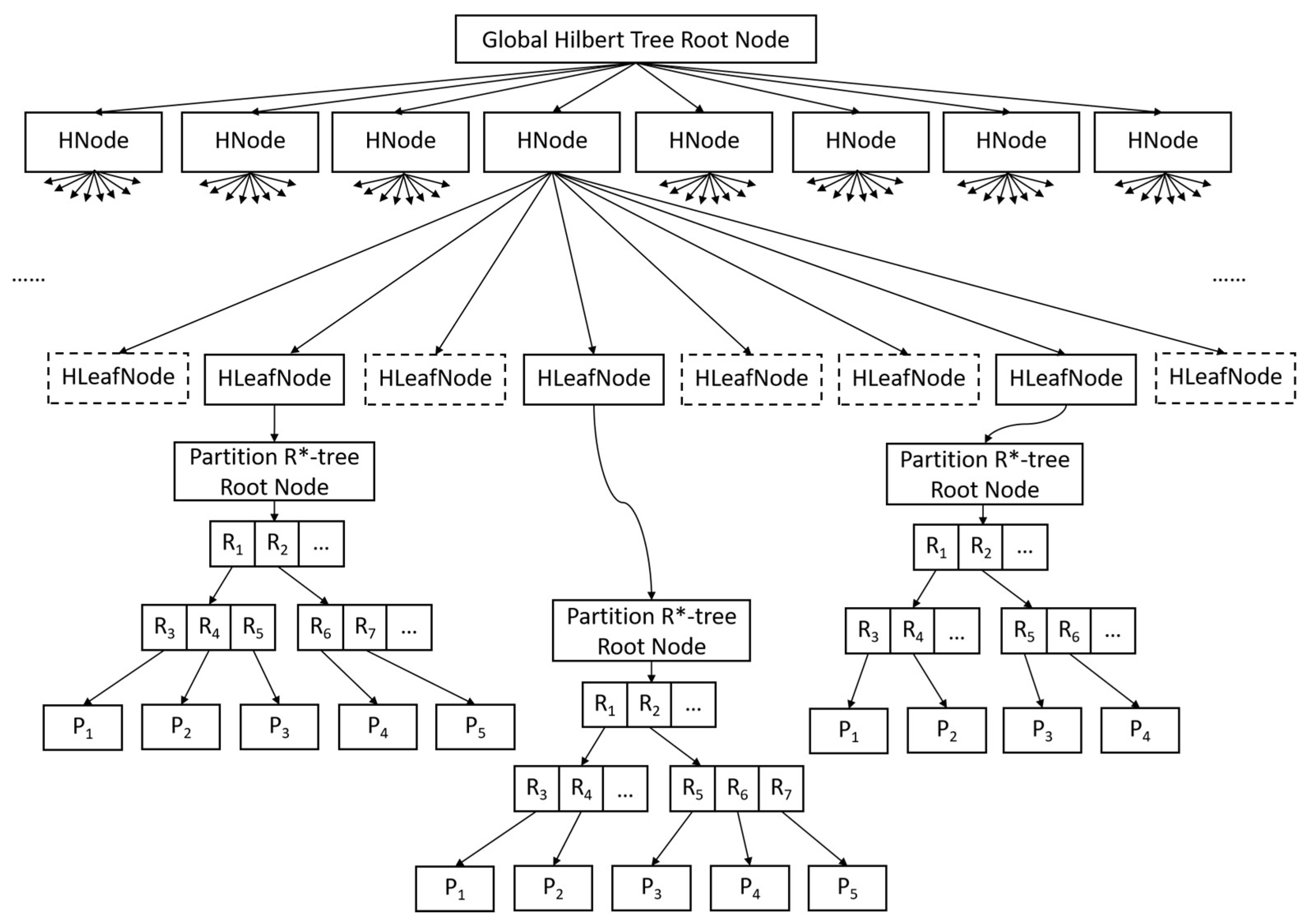
3.1. The Architecture of the Hierarchical Index
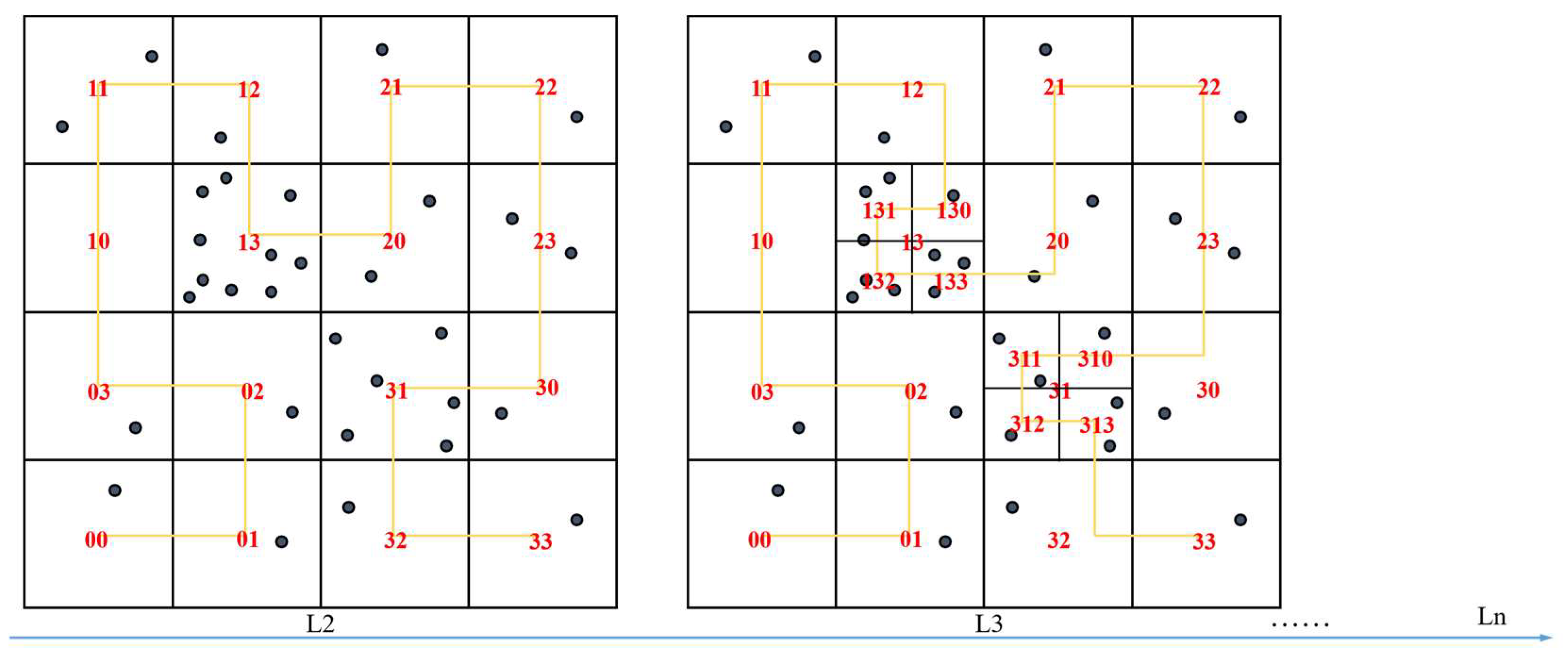
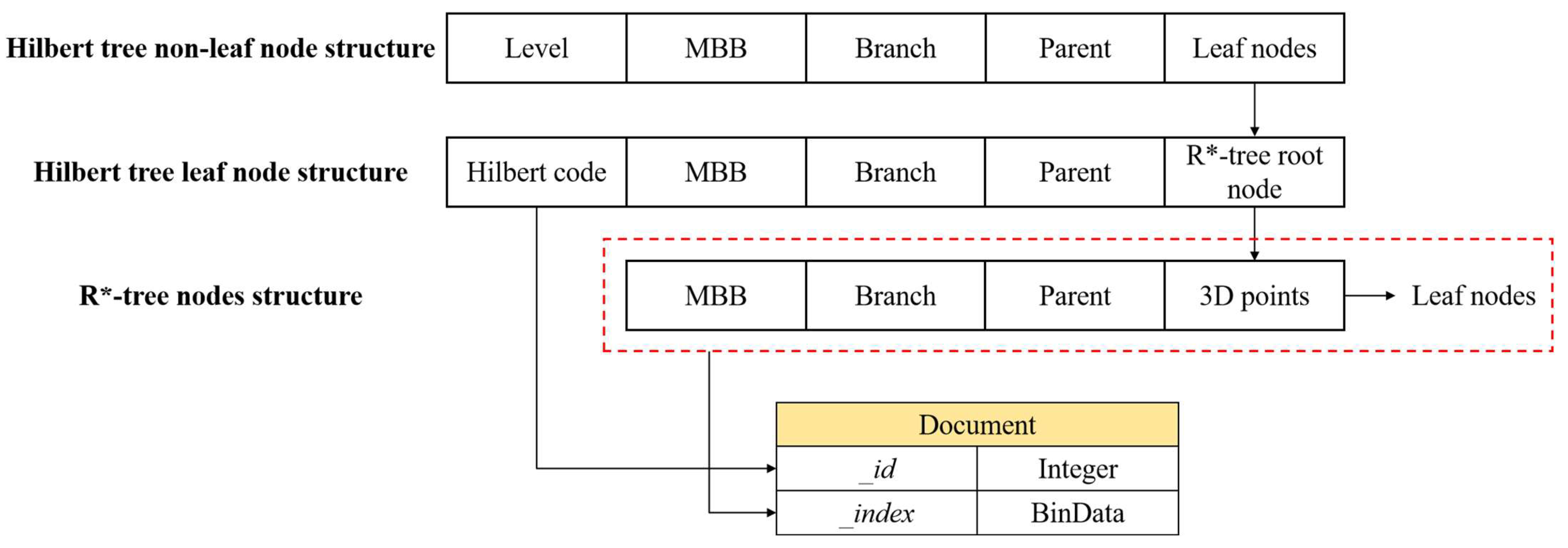
3.1.1. Global Index for High Data Locality
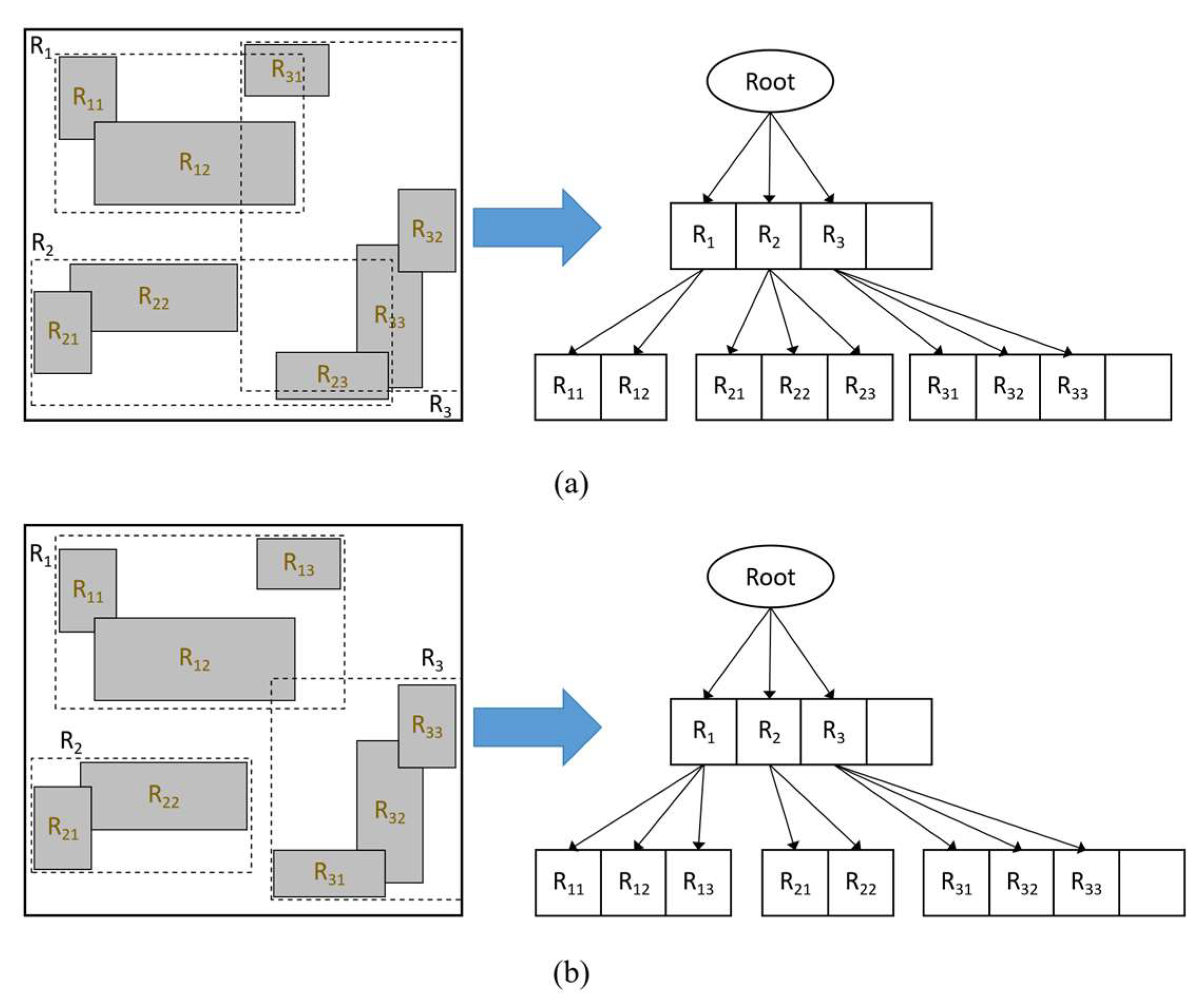
3.1.2. Local Index of Point Clouds Based on R*-Tree
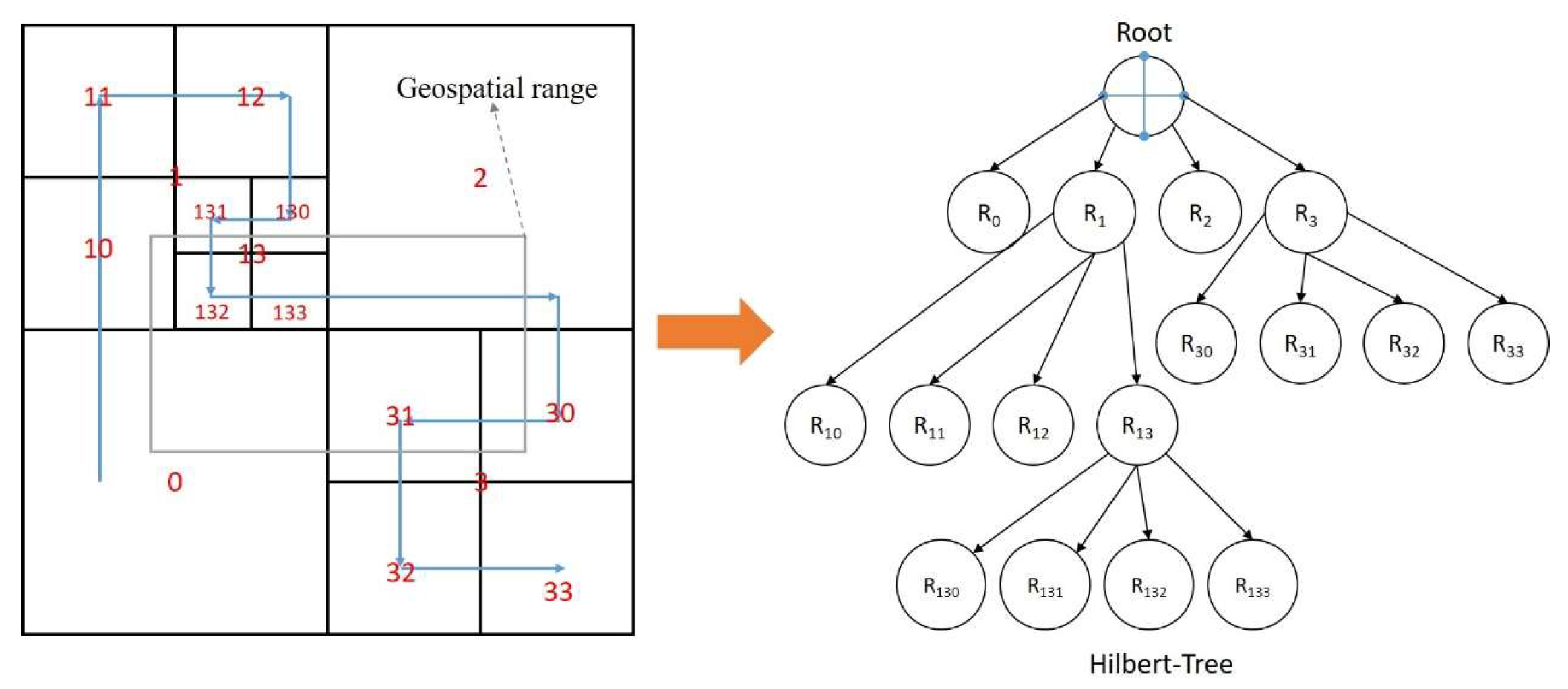
3.2. Construction of Hierarchical Index Tree
- Step 1: Obtain the initial partitioning results, take each independent partition as a child node of the Hilbert tree, and the smallest bounding box containing all child nodes is the root node;
- Step 2: Count the number of points (ptNum) contained in each child node; if ptNum > N, divide the space into eight child nodes uniformly and assign the 3D point objects to the corresponding child nodes. If ptNum ≤ N is satisfied, the division stops and goes directly to step 3; otherwise, the recursive division needs to be continued;
- Step 3: Construct the initialized three-dimensional R*-tree for leaf nodes of the Hilbert tree that satisfy the threshold condition if ptNum ≠ 0 in the current node, and insert the three-dimensional point objects into the three-dimensional R*-tree one by one; otherwise, remove the current node from the index tree and reconstruct the parent node;
- Step 4: Perform the insertion operation of the 3D R*-tree; if the inserted node contains the number of child nodes (chNum) < fmin after insertion, then this reorganizes the node objects within the node; otherwise, continue to step 5;
- Step 5: Divide an overflow situation after the insertion of the node containing chNum > fmax into two cases. If the node is in the layer of the first overflow, then perform the re-insertion operation; otherwise, perform the node split operation. If chNum < fmax, then this three-dimensional point object is used to complete the insertion and continue on to step 6;
- Step 6: Check whether 3D point objects have not been inserted; if so, repeat step 4 and step 5 until all 3D point objects are inserted into the tree structure and the algorithm ends.
3.3. Point Cloud Storage and Query
3.3.1. Structural Design of MongoDB
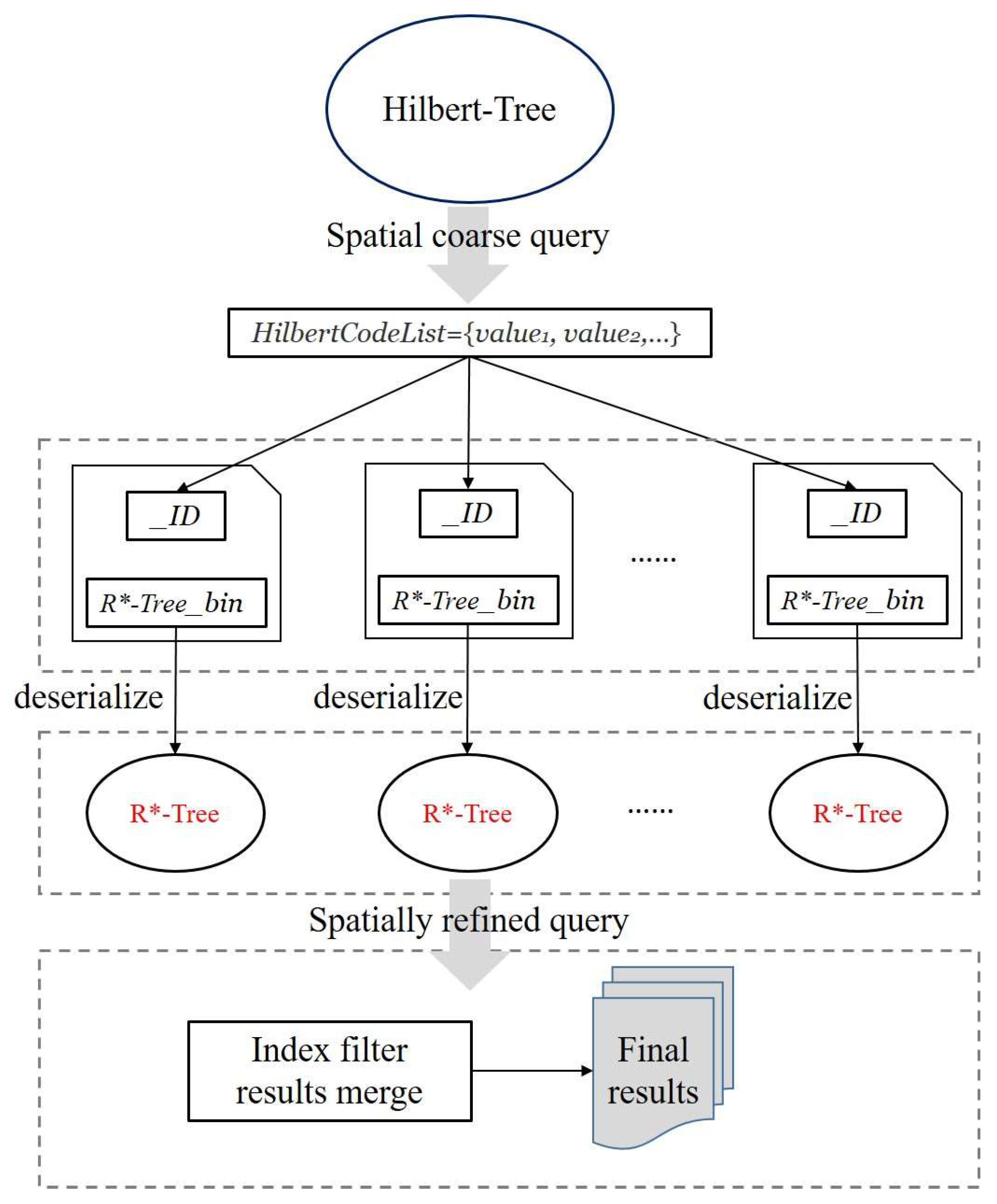
3.3.2. Point Cloud Spatial Query
- Step 1: Obtain the given query boundary information;
- Step 2: Compute a Hilbert grid code set from the Hilbert tree based on the given spatial query boundary to implement a spatial coarse query to clip the query null;
- Step 3: Traverse each Hilbert code in the grid code set to obtain information about the corresponding R*-tree node represented as a binary block in MongoDB;
- Step 4: Deserialize the R*-tree node information represented as binary blocks into memory, retrieve leaf nodes from R*-tree that satisfy the query conditions according to the given spatial query boundaries, and obtain point cloud data from leaf nodes that satisfy the conditions;
- Step 5: Merge and return all R*-tree filtering results and finish the query.
4. Performance Evaluation
4.1. Data Description and Experimental Platform
4.2. Performance Analysis
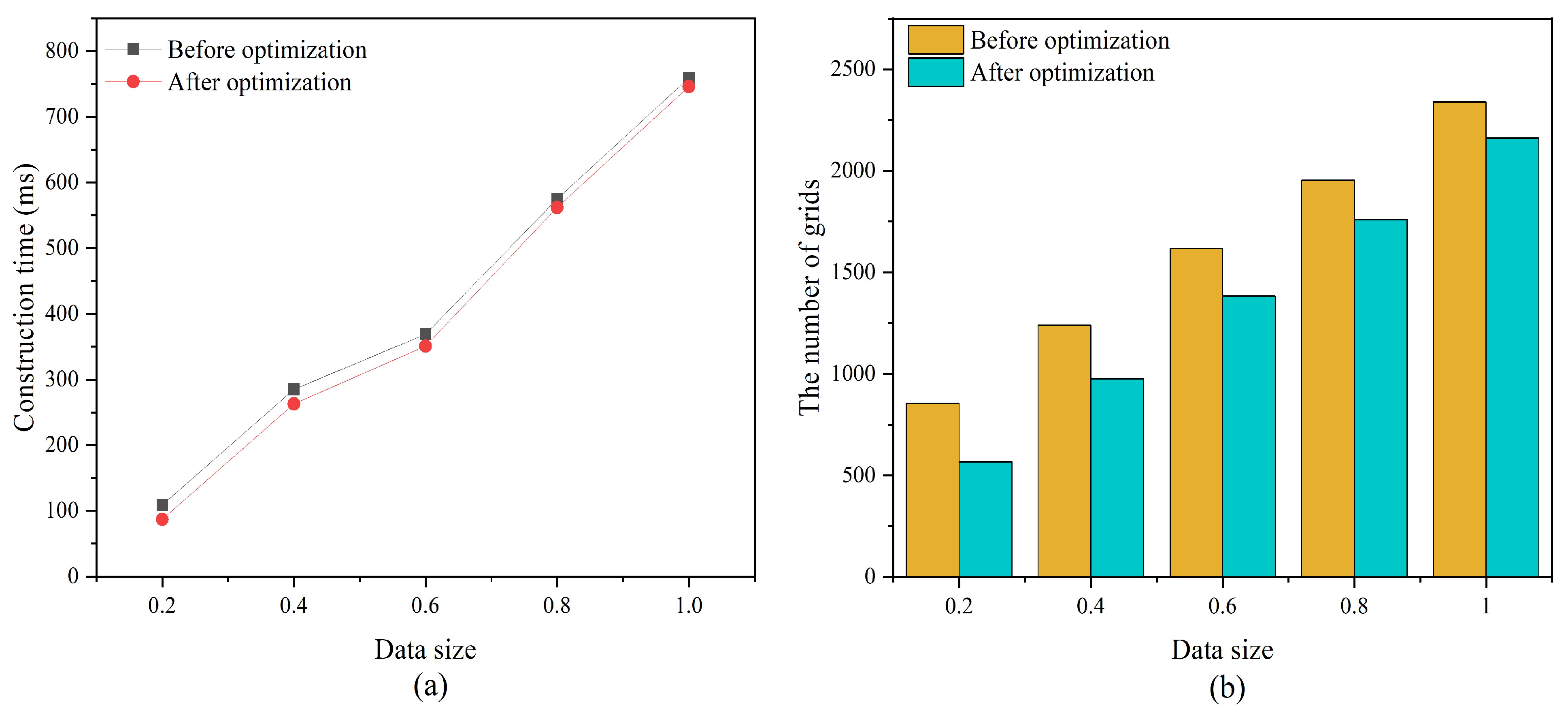
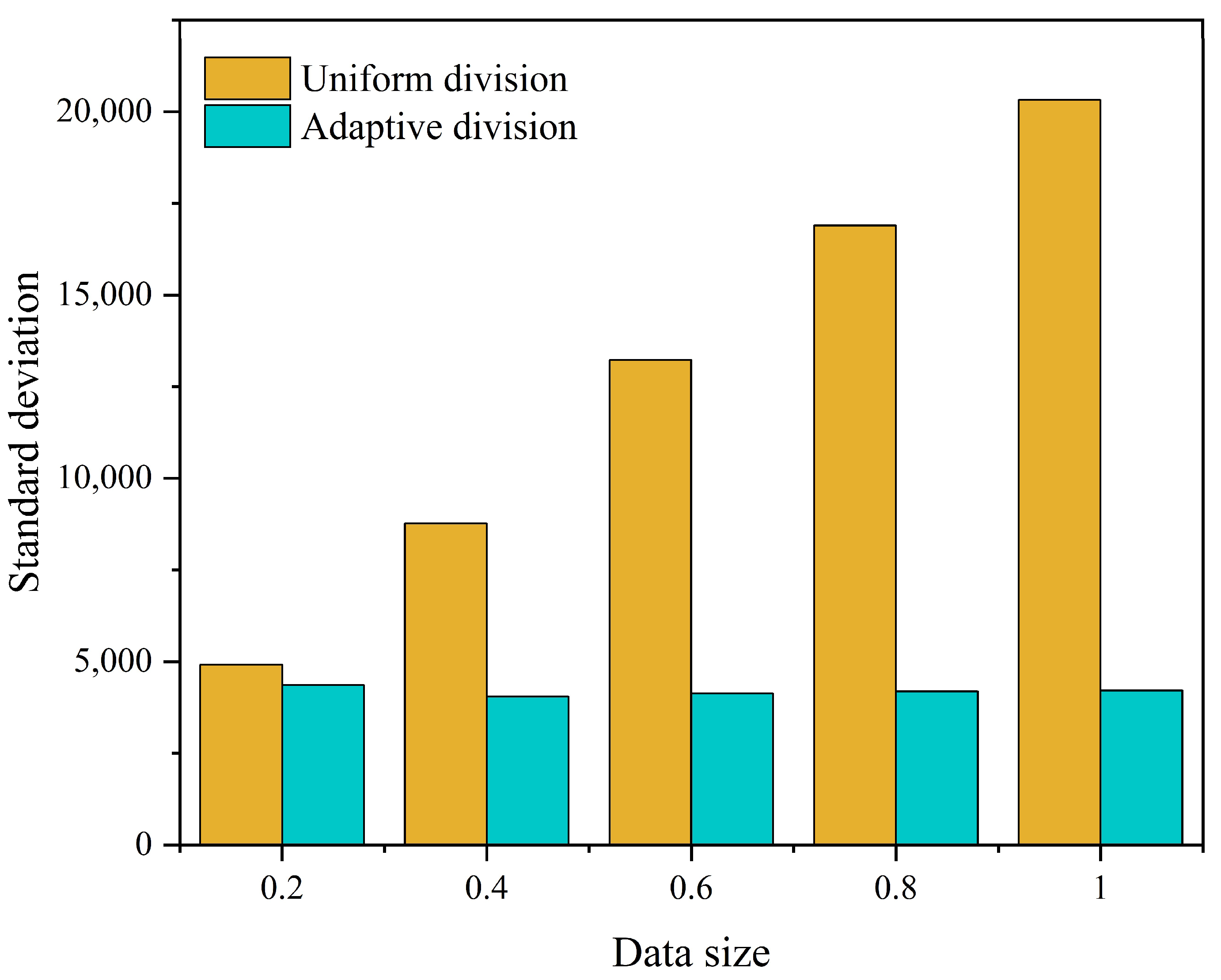
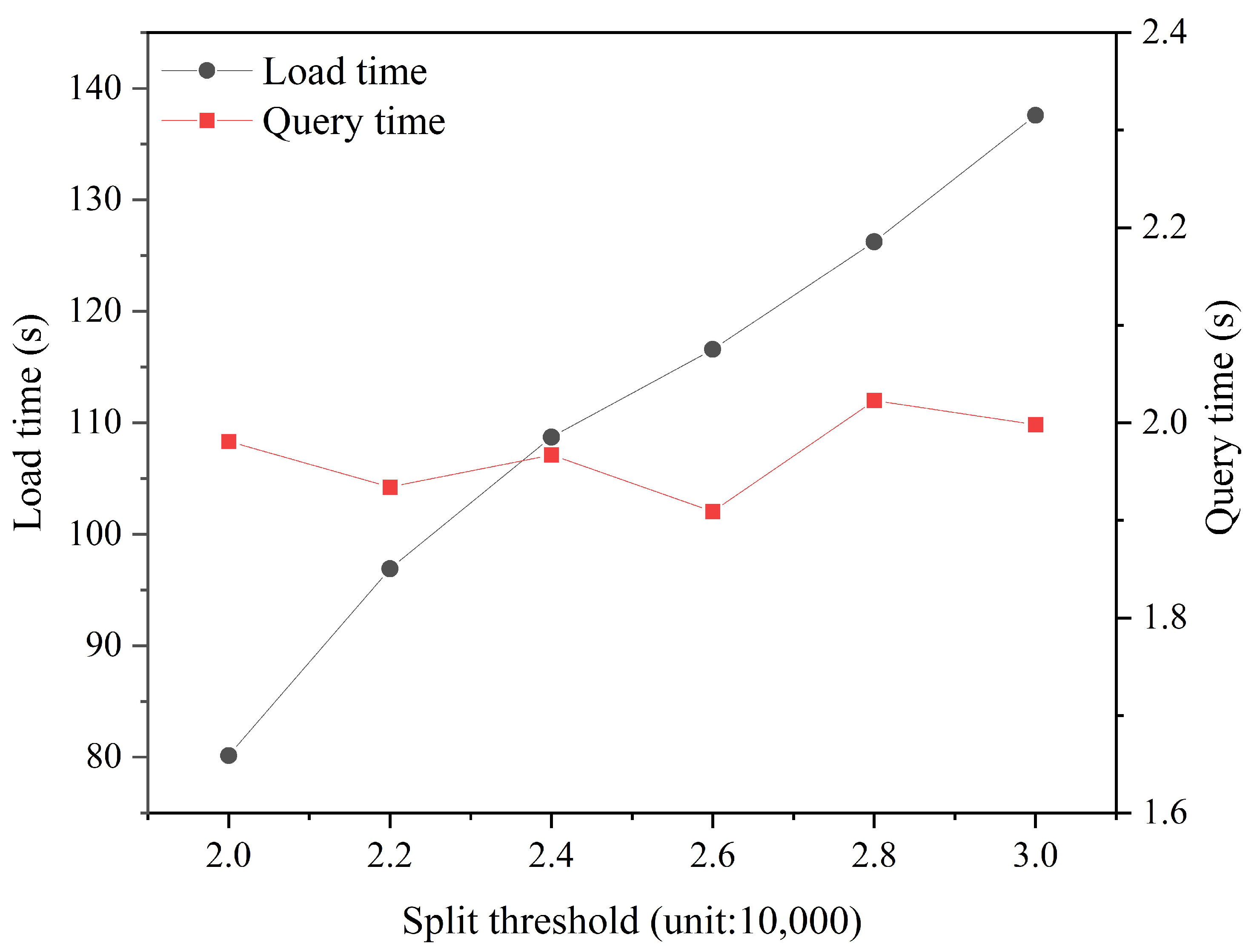
4.2.1. Validation of the Effectiveness of the Hilbert Tree Optimization
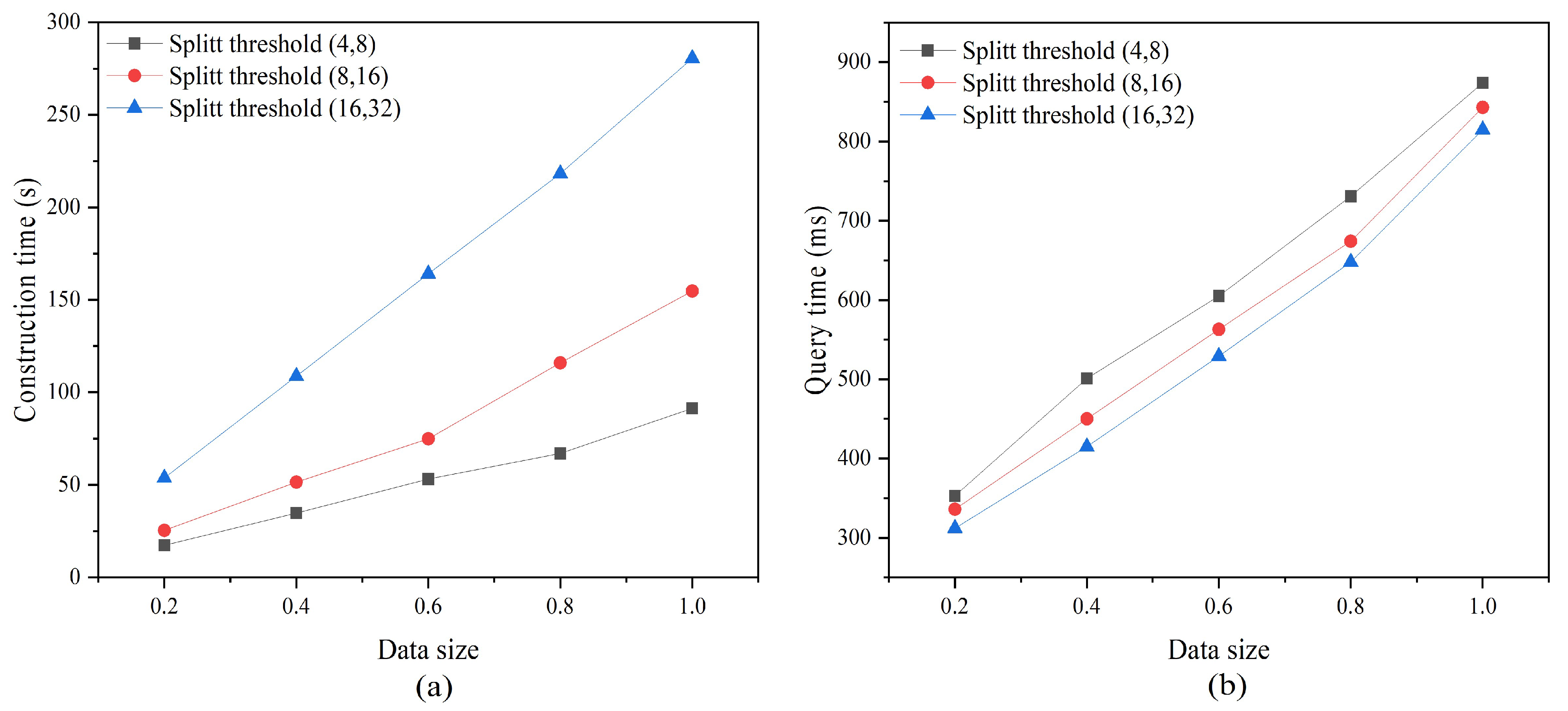
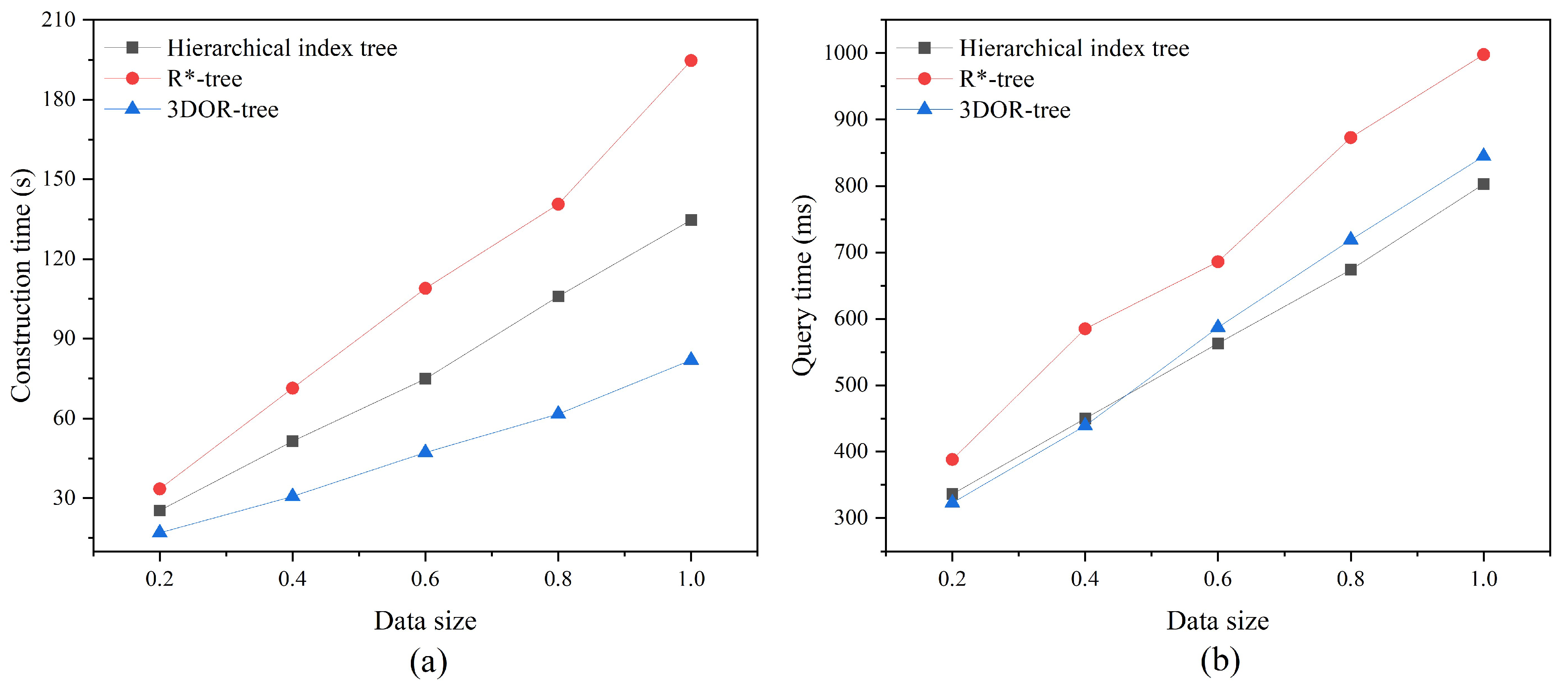
4.2.2. Index Performance Evaluation
4.2.3. Point Cloud Query Efficiency
5. Conclusions and Discussion
- Larger point cloud datasets will be selected for performance testing, while the coding accuracy of Hilbert curves will be extended beyond 64 bits to cover larger spatial regions and improve coordinate accuracy;
- Additional types of point cloud data will be selected for testing, such as airborne LiDAR data and fixed LiDAR data, to discuss the wide applicability of the method;
- The method in this study provides a limited variety of point cloud queries and only considers range queries that are widely used in practical engineering. Therefore, we will provide additional point cloud query algorithms, such as kNN query, to perform similar queries in the future;
- The methodology proposed in this paper will be used in real point cloud data application scenarios, while a more comprehensive methodology comparison will be carried out to compare the performance of the proposed method with that of other database management systems, e.g., Cassandra and PostgreSQL, to refine the methodology of this paper and apply it in a clustered environment;
- Cloud computing and virtualization technologies provide on-demand, scalable computing resources that have been widely used to support a variety of geospatial studies. Thus, the feasibility of the proposed approach will be explored in other cloud computing environments.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, C.; Hu, F.; Sha, D.; Han, X. Efficient LiDAR point cloud data managing and processing in a hadoop-based distributed framework. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 121–124. [Google Scholar] [CrossRef]
- Che, E.; Jung, J.; Olsen, M.J. Object Recognition, Segmentation, and Classification of Mobile Laser Scanning Point Clouds: A State of the Art Review. Sensors 2019, 19, 810. [Google Scholar] [CrossRef] [PubMed]
- Poux, F. The Smart Point Cloud: Structuring 3D Intelligent Point Data. Ph.D. Thesis, Université de Liège, Liège, Belgium, 2019. [Google Scholar]
- Yang, B.; Haala, N.; Dong, Z. Progress and Perspectives of Point Cloud Intelligence. Geo-Spat. Inf. Sci. 2023, 26, 189–205. [Google Scholar] [CrossRef]
- Vo, A.V.; Hewage, C.N.L.; Russo, G.; Chauhan, N.; Laefer, D.F.; Bertolotto, M.; Le-Khac, N.-A.; Oftendinger, U. Efficient LiDAR Point Cloud Data Encoding for Scalable Data Management within the Hadoop Eco-System. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5644–5653. [Google Scholar]
- Vo, A.V.; Laefer, D.F.; Trifkovic, M.; Hewage, C.N.L.; Bertolotto, M.; Le-Khac, N.A.; Ofterdinger, U. A highly scalable data management system for point cloud and full waveform lidar data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B4-2020, 507–512. [Google Scholar] [CrossRef]
- Vo, A.-V.; Konda, N.; Chauhan, N.; Aljumaily, H.; Laefer, D.F. Lessons Learned with Laser Scanning Point Cloud Management in Hadoop HBase. In Proceedings of the Advanced Computing Strategies for Engineering; Smith, I.F.C., Domer, B., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 231–253. [Google Scholar]
- Béjar-Martos, J.A.; Rueda-Ruiz, A.J.; Ogayar-Anguita, C.J.; Segura-Sánchez, R.J.; López-Ruiz, A. Strategies for the Storage of Large LiDAR Datasets—A Performance Comparison. Remote Sens. 2022, 14, 2623. [Google Scholar] [CrossRef]
- Ogayar-Anguita, C.J.; López-Ruiz, A.; Rueda-Ruiz, A.J.; Segura-Sánchez, R.J. Nested Spatial Data Structures for Optimal Indexing of LiDAR Data. ISPRS J. Photogramm. Remote Sens. 2023, 195, 287–297. [Google Scholar] [CrossRef]
- Schütz, M.; Ohrhallinger, S.; Wimmer, M. Fast Out-of-Core Octree Generation for Massive Point Clouds. Comput. Graph. Forum 2020, 39, 155–167. [Google Scholar] [CrossRef]
- Wang, W.; Hu, Q. The Method of Cloudizing Storing Unstructured LiDAR Point Cloud Data by MongoDB. In Proceedings of the 2014 22nd International Conference on Geoinformatics, Kaohsiung, Taiwan, 25–27 June 2014; pp. 1–5. [Google Scholar]
- Hu, F.; Yang, C.; Jiang, Y.; Li, Y.; Song, W.; Duffy, D.Q.; Schnase, J.L.; Lee, T. A Hierarchical Indexing Strategy for Optimizing Apache Spark with HDFS to Efficiently Query Big Geospatial Raster Data. Int. J. Digit. Earth 2020, 13, 410–428. [Google Scholar] [CrossRef]
- Hanusniak, V.; Svalec, M.; Branicky, J.; Takac, L.; Zabovsky, M. Exploitation of Hadoop Framework for Point Cloud Geographic Data Storage System. In Proceedings of the 2015 Fifth International Conference on Digital Information Processing and Communications (ICDIPC), Sierre, Switzerland, 7–9 October 2015; pp. 197–200. [Google Scholar]
- Li, Z.; Yang, C.; Liu, K.; Hu, F.; Jin, B. Automatic Scaling Hadoop in the Cloud for Efficient Process of Big Geospatial Data. ISPRS Int. J. Geo-Inf. 2016, 5, 173. [Google Scholar] [CrossRef]
- Li, Z.; Hodgson, M.E.; Li, W. A General-Purpose Framework for Parallel Processing of Large-Scale LiDAR Data. Int. J. Digit. Earth 2018, 11, 26–47. [Google Scholar] [CrossRef]
- Boehm, J.; Liu, K. NOSQL For Storage and Retrieval of Large LiDAR Data Collections. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 577–582. [Google Scholar] [CrossRef]
- Rueda-Ruiz, A.J.; Ogáyar-Anguita, C.J.; Segura-Sánchez, R.J.; Béjar-Martos, J.A.; Delgado-Garcia, J. SPSLiDAR: Towards a Multi-Purpose Repository for Large Scale LiDAR Datasets. Int. J. Geogr. Inf. Sci. 2022, 36, 992–1011. [Google Scholar] [CrossRef]
- Lokugam Hewage, C.N.; Laefer, D.F.; Vo, A.-V.; Le-Khac, N.-A.; Bertolotto, M. Scalability and Performance of LiDAR Point Cloud Data Management Systems: A State-of-the-Art Review. Remote Sens. 2022, 14, 5277. [Google Scholar] [CrossRef]
- Lu, B.; Wang, Q.; Li, A. Massive Point Cloud Space Management Method Based on Octree-like Encoding. Arab. J. Sci. Eng. 2019, 44, 9397–9411. [Google Scholar] [CrossRef]
- Kim, T.; Lee, J.; Kim, K.-S.; Matono, A.; Li, K.-J. Utilizing Extended Geocodes for Handling Massive Three-Dimensional Point Cloud Data. World Wide Web 2021, 24, 1321–1344. [Google Scholar] [CrossRef]
- Wang, J.; Shan, J. Space-Filling Curve Based Point Clouds Index. In Proceedings of the 8th International Conference on GeoComputation, Kraków, Poland, 23–25 June 2008. [Google Scholar]
- Guan, X.; Van Oosterom, P.; Cheng, B. A Parallel N-Dimensional Space-Filling Curve Library and Its Application in Massive Point Cloud Management. ISPRS Int. J. Geo-Inf. 2018, 7, 327. [Google Scholar] [CrossRef]
- Chen, J.; Yu, L.; Wang, W. Hilbert Space Filling Curve Based Scan-Order for Point Cloud Attribute Compression. IEEE Trans. Image Process. 2022, 31, 4609–4621. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Zhu, X.; Chen, G.; Yu, B. Efficient Point Cloud Analysis Using Hilbert Curve. In Proceedings of the Computer Vision—ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 730–747. [Google Scholar]
- Elseberg, J.; Borrmann, D.; Nüchter, A. One Billion Points in the Cloud—An Octree for Efficient Processing of 3D Laser Scans. ISPRS J. Photogramm. Remote Sens. 2013, 76, 76–88. [Google Scholar] [CrossRef]
- Tian, S.; Li, X.; Zeng, J.; Wei, Z. The Organization of Point Cloud Data Based on the Compact Octree Model. J. Phys. Conf. Ser. 2019, 1302, 022047. [Google Scholar] [CrossRef]
- Huang, H. Construction of Multi-Resolution Spatial Data Organization for Ultralarge-Scale 3D Laser Point Cloud. Sens. Mater. 2023, 35, 87. [Google Scholar] [CrossRef]
- Zhang, R.; Li, G.; Wang, L.; Li, M.; Zhou, Y. A New Method of Hybrid Index for Mobile LiDAR Point Cloud Data. Geomat. Inf. Sci. Wuhan Univ. 2018, 43, 993–999. [Google Scholar]
- Wang, Y.; Lv, H.; Ma, Y. Geological Tetrahedral Model-Oriented Hybrid Spatial Indexing Structure Based on Octree and 3D R*-tree. Arab. J. Geosci. 2020, 13, 728. [Google Scholar] [CrossRef]
- Zhu, Q.; Gong, J.; Zhang, Y. An Efficient 3D R-Tree Spatial Index Method for Virtual Geographic Environments. ISPRS J. Photogramm. Remote Sens. 2007, 62, 217–224. [Google Scholar] [CrossRef]
- Gong, J.; Zhu, Q.; Zhong, R.; Zhang, Y.; Xie, X. An Efficient Point Cloud Management Method Based on a 3D R-Tree. Photogramm. Eng. Remote Sens. 2012, 78, 373–381. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, L.; Liao, L.; Pan, H. Integrated laser point cloud data storage structure based on octree and 3D R*-tree. J. Geo-Inf. Sci. 2017, 19, 587–594. [Google Scholar]
- Yu, A.; Mei, W. Efficient Management Method for Massive Point Cloud Data of Metro Tunnel Based on R-tree and Grid. Geomat. Inf. Sci. Wuhan Univ. 2019, 44, 1553–1559. [Google Scholar]
- Deibe, D.; Amor, M.; Doallo, R. Big Data Storage Technologies: A Case Study for Web-Based LiDAR Visualization. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 3831–3840. [Google Scholar]
- Pajić, V.; Govedarica, M.; Amović, M. Model of Point Cloud Data Management System in Big Data Paradigm. ISPRS Int. J. Geo-Inf. 2018, 7, 265. [Google Scholar] [CrossRef]
- Deibe, D.; Amor, M.; Doallo, R. Big Data Geospatial Processing for Massive Aerial LiDAR Datasets. Remote Sens. 2020, 12, 719. [Google Scholar] [CrossRef]
- Yao, X.; Mokbel, M.F.; Alarabi, L.; Eldawy, A.; Yang, J.; Yun, W.; Li, L.; Ye, S.; Zhu, D. Spatial Coding-Based Approach for Partitioning Big Spatial Data in Hadoop. Comput. Geosci. 2017, 106, 60–67. [Google Scholar] [CrossRef]
- Di Stefano, F.; Chiappini, S.; Gorreja, A.; Balestra, M.; Pierdicca, R. Mobile 3D Scan LiDAR: A Literature Review. Geomat. Nat. Hazards Risk 2021, 12, 2387–2429. [Google Scholar] [CrossRef]
- Yiğit, A.Y.; Gamze Hamal, S.N.; Ulvi, A.; Yakar, M. Comparative Analysis of Mobile Laser Scanning and Terrestrial Laser Scanning for the Indoor Mapping. Build. Res. Inf. 2024, 52, 402–417. [Google Scholar] [CrossRef]
- Cao, B.; Feng, H.; Liang, J.; Li, X. Hilbert Curve and Cassandra Based Indexing and Storing Approach for Large-Scale Spatiotemporal Data. Geomat. Inf. Sci. Wuhan Univ. 2021, 46, 620–629. [Google Scholar]
- Eldawy, A.; Alarabi, L.; Mokbel, M.F. Spatial Partitioning Techniques in SpatialHadoop. Proc. VLDB Endow. 2015, 8, 1602–1605. [Google Scholar] [CrossRef]
- Kang, Y.; Gui, Z.; Ding, J.; Wu, J.; Wu, H. Parallel Ripley’s K function based on Hilbert spatial partitioning and Geohash indexing. J. Geo-Inf. Sci. 2022, 24, 74–86. [Google Scholar]
- Yao, X.; Yang, J.; Li, L.; Ye, S.; Yun, W.; Zhu, D. Parallel Algorithm for Partitioning Massive Spatial Vector Data in Cloud Environment. Geomat. Inf. Sci. Wuhan Univ. 2018, 43, 1092–1097. [Google Scholar]
- Moten, D. Hilbert-Curve. Available online: https://github.com/davidmoten/hilbert-curve (accessed on 23 February 2017).
- Wang, H.; Belhassena, A. Parallel Trajectory Search Based on Distributed Index. Inf. Sci. 2017, 388–389, 62–83. [Google Scholar] [CrossRef]
- Beckmann, N.; Kriegel, H.-P.; Schneider, R.; Seeger, B. The R*-tree: An Efficient and Robust Access Method for Points and Rectangles. In Proceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, 23–25 May 1990; pp. 322–331. [Google Scholar]
- Moten, D. Rtree. Available online: https://github.com/davidmoten/rtree (accessed on 1 September 2014).
- van Oosterom, P.; Martinez-Rubi, O.; Ivanova, M.; Horhammer, M.; Geringer, D.; Ravada, S.; Tijssen, T.; Kodde, M.; Gonçalves, R. Massive Point Cloud Data Management: Design, Implementation and Execution of a Point Cloud Benchmark. Comput. Graph. 2015, 49, 92–125. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Zuo, X.; Zhao, K.; Li, Y. Integrating NoSQL, Hilbert Curve, and R*-Tree to Efficiently Manage Mobile LiDAR Point Cloud Data. ISPRS Int. J. Geo-Inf. 2024, 13, 253. https://doi.org/10.3390/ijgi13070253
Yang Y, Zuo X, Zhao K, Li Y. Integrating NoSQL, Hilbert Curve, and R*-Tree to Efficiently Manage Mobile LiDAR Point Cloud Data. ISPRS International Journal of Geo-Information. 2024; 13(7):253. https://doi.org/10.3390/ijgi13070253
Chicago/Turabian StyleYang, Yuqi, Xiaoqing Zuo, Kang Zhao, and Yongfa Li. 2024. "Integrating NoSQL, Hilbert Curve, and R*-Tree to Efficiently Manage Mobile LiDAR Point Cloud Data" ISPRS International Journal of Geo-Information 13, no. 7: 253. https://doi.org/10.3390/ijgi13070253