
Flood Susceptibility Mapping Using GIS-Based Frequency Ratio and Shannon’s Entropy Index Bivariate Statistical Models: A Case Study of Chandrapur District, India
 , , , and
, , , and
Abstract
:1. Introduction
2. Study Area
3. Materials and Methods
3.1. Data Used and Their Sources
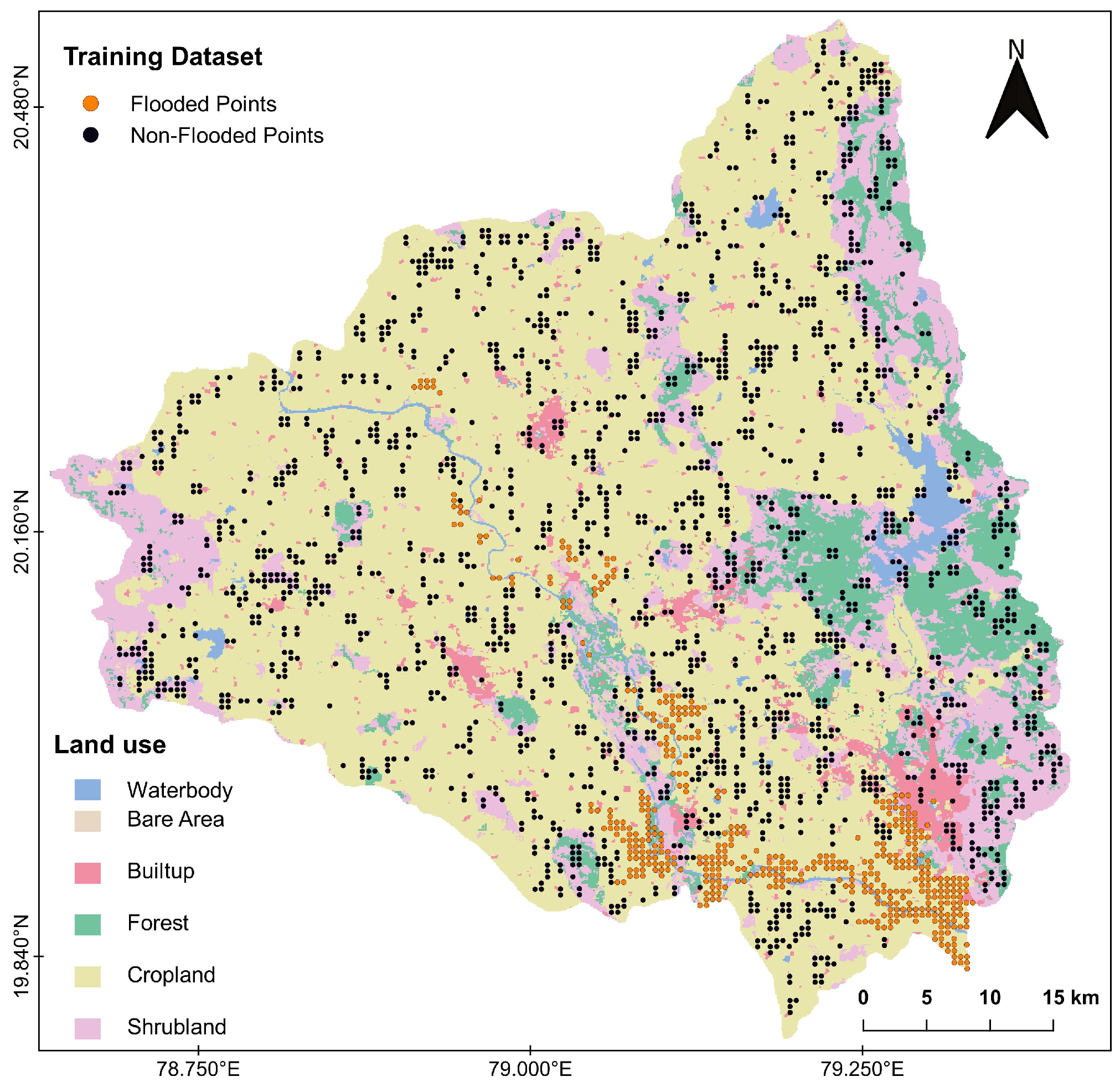
3.2. Flood Inventory Mapping
3.3. Multi-Collinearity Analysis, Prediction Ability Assessment, and Selection of Factors
3.4. Flood-Contributing Factors
- Elevation (m): The height of a geographical feature above mean sea level is termed elevation. Elevation is a key parameter in the determination of flood-susceptible areas, and it also influences the climate of a region. Downstream low-elevation areas are generally more susceptible to flooding. The elevation data were categorized into five classes: (1) 80–110 m, (2) 110–115 m, (3) 115–120 m, (4) 120–125 m, and (5) 125–279 m. The north-eastern and western parts of the study area have elevations more than 220 m. The historical flood data analysis showed that the elevation range of 94–137 m covers almost 70% of the study area and contains the majority of past flood-inundated areas.
- Topographic slope (degree): The slope of a region is the difference between elevations of two points of the region divided by the distance between those two points. Surface runoff and infiltration rates are directly affected by the slope of a region. The slope of the study region was categorized into five classes: (1) 0–1°, (2) 1–2°, (3) 2–3°, (4) 3–4°, and (5) 4–10°. The slope range 0–3° covers nearly 80% of the study area and contains the majority of historical flood events.
- Flow accumulation: Flow accumulation is an indirect method for the determination of drainage areas. In other words, it is an estimation of cells which drain into a given area or cell, and hence acts as a key determinant in flood genesis. Flow accumulation data were categorized into five classes: (1) 0–1 k, (2) 1–5 k, (3) 5–10 k, (4) 10–20 k, and (5) 20–5700 k. The flow accumulation class 0–1 k covers almost half of the study area.
- Drainage density (km/km2): The proportion of the overall length of all the streams and rivers in a drainage basin and the overall area of the drainage basin is termed as drainage density. In other words, it tells us about the capacity of stream networks or rivers to drain out water from the basin or sub-basin. Drainage density was divided into five classes: (1) 0–30 km/km2, (2) 30–60 km/km2, (3) 60–90 km/ km2, (4) 90–120 km/km2, and (5) 120–330 km/km2. The drainage density in the range 0–80 km/km2 covers nearly 80% of the total study area. The drainage density in the range 0–80 km/km2 and 150–240 km/km2 together cover the majority of historically flooded areas.
- Topographic wetness index (TWI): The TWI is the estimation of the propensity of a region to accrue water. The spatial scale effects on hydrological processes have been studied using the TWI. In other words, it tells us how likely an area is to be wet. The TWI was calculated using the local slope angle and the local ascending area that flows through a certain point per unit contour length. The regions with higher TWI values are expected to be moist in comparison with regions having lesser TWI scores. The TWI was calculated using Equation (1) [25].where is the local ascending area (m2/m) that flows through a certain point per unit contour length, and θ is the local slope angle in degrees. The TWI data were categorized into five classes: (1) 0–7, (2) 7–8, (3) 8–9, (4) 9–10, and (5) 10–14. The TWI range of 6–10 covers about 81% of the study area and the majority of the historical flooded area.
- Rainfall (mm): Rainfall is one of the crucial factors in flooding. The extends of a flood is directly connected to the intensity and duration of rainfall. The rainfall data of the study area from the years 1980 to 2013 were obtained from the Water Resources Department of the Government of Maharashtra [18]. The hourly rainfall data were analyzed using the I-D-F (Intensity–Duration–Frequency) curve method and rainfall depth for the 25-year return period was used for FSM in mm. The rainfall data are categorized into five different classes: (1) 0–90 mm, (2) 90–122 mm, (3) 122–140 mm, (4) 140–160 mm, and (5) 160–200 mm. The rainfall distribution varies from more than 150 mm in the eastern parts to less than 52 mm in the western parts of the study area.
- Land use: Natural as well as human-actuated covering of the earth’s surface represents the land use of an area [7]. Flood frequency is affected by runoff and sediment transport, both of which are influenced by the land use of a region. Land use has an important role in runoff speed, infiltration, and evapotranspiration. By having a direct or indirect influence on many hydrological processes, land use acts as a vital factor for the flood susceptibility study of a region. Land use data were prepared using the Global Land Cover 1992–2019 database at 300 m resolution, available at the European Space Agency Climate Change Initiative website [19]. Land use has been categorized into six classes: (1) waterbody, (2) bare area, (3) built-up region, (4) forest, (5) cropland, and (6) shrubland. The majority of the land use is cropland and it covers 68.84% of the total area, while bare area, which covers only 0.45% of the area of the district, was the least contributing land use class. Water bodies encompass 2.29% of the study area, while built-up regions cover 3.77% of the area. Forest land covers 8.89%, while 15.75% of the area is covered by shrubland.
3.5. Flood Susceptibility Mapping
3.5.1. Frequency Ratio (FR) Model
- Frequency ratio (FR): The flood incidence and area ratio for each class of contributing factor was first estimated, and thereafter, the FR value of each class was determined. The FR values for each class of a particular flood-contributing factor were computed using Equation (2).where FRij denotes the frequency ratio of class i of factor j; is the flood pixels in class i of factor j; is the total area pixels in class i of factor j; m represents the total classes in the particular flood-contributing factor.The FR scores for each class of flood-contributing factor can also be calculated by dividing the % of the flooded area enclosed by a particular class of respective factor by the % of the overall study area enclosed by that class.where FRij denotes the frequency ratio of class i of factor j.
- Relative frequency (RF): The relationship between historical flood locations and predictor classes was investigated using relative frequency values. The normalization of previous frequency ratio values as expressed in Equation (4) [10] gives the values of relative frequency.where RFij represents relative frequency value for class i of factor j; FRij stands for the frequency ratio for class i of factor j; represents the FR total values of all classes of factor j.
- Prediction rate (PR): The interrelationships among the flood-contributing factors were acknowledged through the calculation of prediction rate values. PR values were estimated using Equation (5) [10].where PRj stands for the prediction rate value of factor j; MaxRFj denotes the uppermost value of RF among all class of factor j; MinRFj represents the smallest value of RF out of all classes of factor j; Min(MaxRFj − MinRFj) is the minimum value from all values of (MaxRFj − MinRFj) among all factors.
elevation: 0.156, drainage density: 0.139, waterbody: 0.030,
bare area: 0.030, built-up: 0.030, forest: 0.030,
cropland: 0.030, shrubland: 0.030}
- ○
- FRweightsi represents the normalized weight for ith variable;
- ○
- denotes the sum across the specified land use attribute.
3.5.2. Shannon Entropy Index (SEI) Model
- Probability Density (Pdij): Probability density (Pdij) was calculated using frequency ratio (FR) values of each class of a particular flood-contributing factor. As expressed in Equation (8), FR values of each class of a particular factor are divided by the sum of FR values of all classes of that factor to obtain the PDij values of each class [8,10]. The probability density (Pdij) values of the SEI model correspond to the relative frequency (RF) values of the FR model.where Pdij is the probability density of class i of factor j; FRij is the frequency ratio value of class i of factor j; mj denotes the total classes in factor j.
- Entropy Values (Hj and Hj max): The entropy measurement of each class of a particular factor was carried out using Equations (9) and (10) [7,8].where Hj and Hjmax are the entropy values of factor j; Pdij is the probability density of class i of factor j; mj is the overall classes of a particular flood-contributing factor.
- Weights of factors (Wj): The weight values attributed to each flood-contributing factor were determined using Equation (12) [8].where Wj is the weight value estimated for factor j; Icj is the information coefficient for factor j, and Pj = ; FRij is the frequency ratio value of class i of factor j, and mj is the overall classes in factor j.Wj = Icj × Pj
elevation: 0.333, drainage density: 0.151, waterbody: 0.022,
bare area: 0.022, built-up: 0.022, forest: 0.022,
cropland: 0.022, shrubland: 0.022}
3.6. Performance Evaluation and Validation
3.6.1. Calculation of Statistical Indicators
- Sensitivity: This provides information about the model-computed total number of flood pixels that are accurately categorized as a flood event, and it was calculated as expressed in Equation (15).where TP (true positive) and FN (false negative) are pixels in this study.
- Specificity: This provides information about the model-computed total number of non-flood pixels that are accurately categorized as a non-flood event and was estimated using Equation (16).where TN (true negative) and FP (false positive) are pixels in this study.
- Accuracy: This provides information on accurately categorized flood pixels and non-flood pixels and was computed using Equation (17).where TP (true positive) and TN (true negative) represent pixels that are accurately defined as flooded and non–flooded pixels, and FP (false positive) and FN (false negative) denote the pixels which are inaccurately categorized as flooded and non-flooded.
- Positive prediction value (PPV): This is the likelihood that a flood pixel predicted by the model is an actual flood pixel and was estimated using Equation (18).
- Negative prediction value (NPV): This is the likelihood that a non-flood pixel predicted by the model is an actual non-flood pixel and was calculated using Equation (19).
3.6.2. Model Validation Using the AUC-ROC Curve Method
4. Results
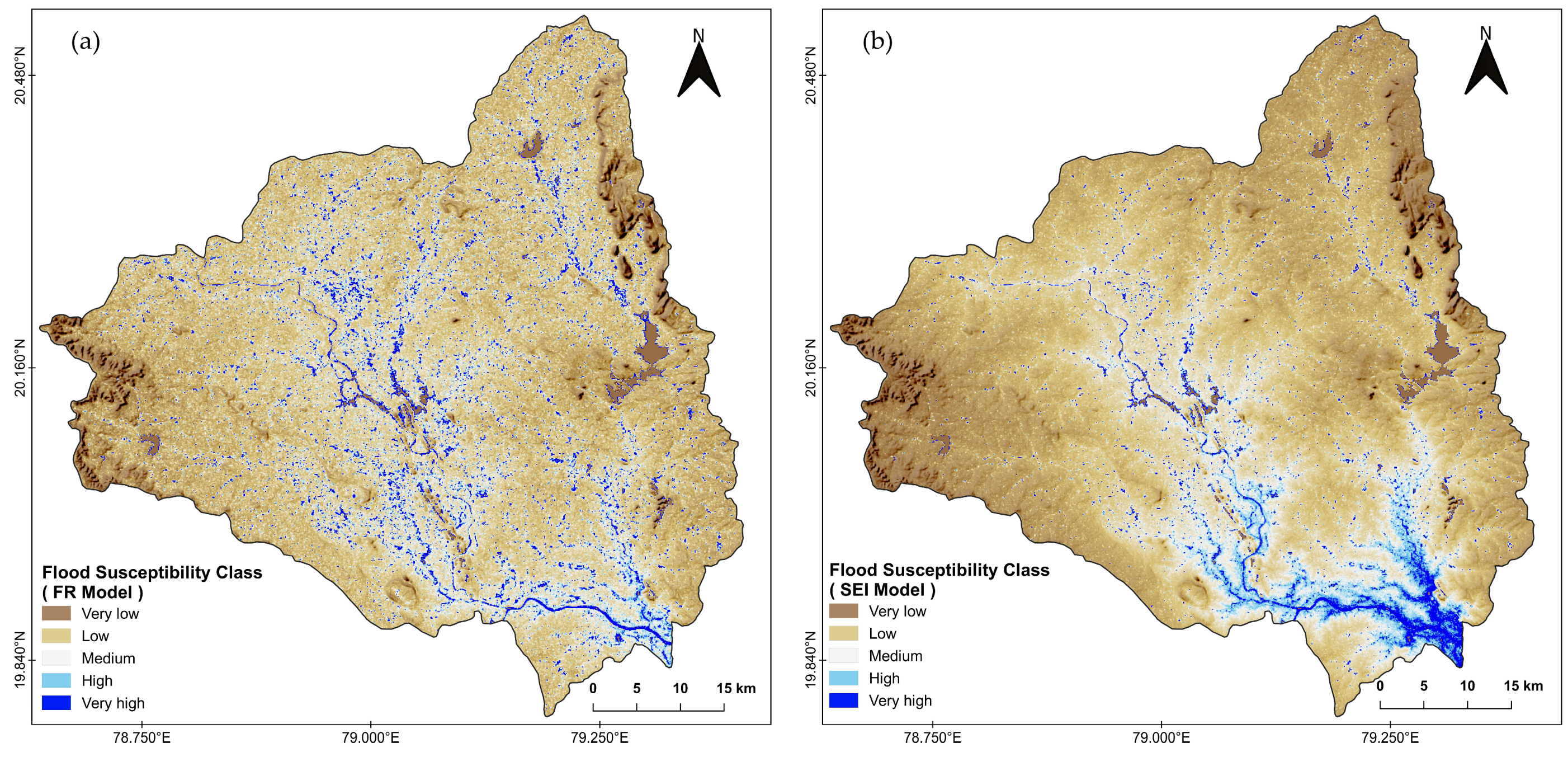
4.1. Frequency Ratio (FR) Model Outcomes
4.2. Shannon Entropy Index (SEI) Model Outcomes
4.3. Performance Evaluation of Models
5. Discussion
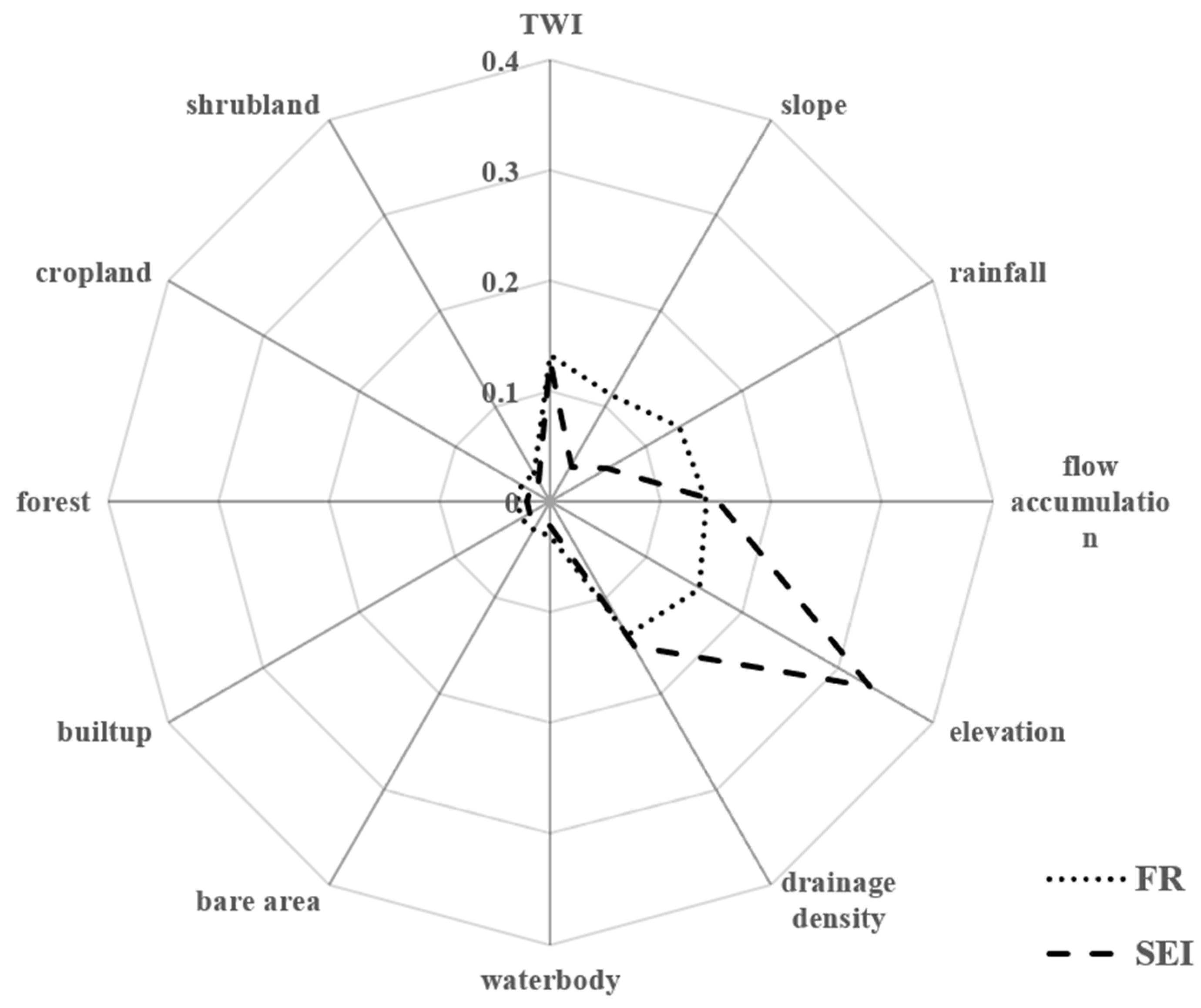
5.1. Analysis of Model Parameters and Their Association with Flood Factors
5.2. Comparing the Model Performance and Weights
5.3. Limitations of the Models and the Contribution of the Study
5.4. Study Limitations and Future Prospects
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Economic Forum Global Risks Report 2022. Available online: https://www.weforum.org/publications/global-risks-report-2022/ (accessed on 26 July 2024).
- Gourley, J.J.; Hong, Y.; Flamig, Z.L.; Arthur, A.; Clark, R.; Calianno, M.; Ruin, I.; Ortel, T.; Wieczorek, M.E.; Kirstetter, P.-E.; et al. A Unified Flash Flood Database across the United States. Bull. Am. Meteorol. Soc. 2013, 94, 799–805. [Google Scholar] [CrossRef]
- Mrozik, K.D. Problems of Local Flooding in Functional Urban Areas in Poland. Water 2022, 14, 2453. [Google Scholar] [CrossRef]
- UNDRR Sendai Framework for Disaster Risk Reduction 2015–2030|UNDRR. Available online: http://www.undrr.org/publication/sendai-framework-disaster-risk-reduction-2015-2030 (accessed on 26 July 2024).
- Kaya, C.M.; Derin, L. Parameters and Methods Used in Flood Susceptibility Mapping: A Review. J. Water Clim. Chang. 2023, 14, 1935–1960. [Google Scholar] [CrossRef]
- Rahmati, O.; Pourghasemi, H.R.; Zeinivand, H. Flood Susceptibility Mapping Using Frequency Ratio and Weights-of-Evidence Models in the Golastan Province, Iran. Geocarto Int. 2016, 31, 42–70. [Google Scholar] [CrossRef]
- Arora, A.; Pandey, M.; Siddiqui, M.A.; Hong, H.; Mishra, V.N. Spatial Flood Susceptibility Prediction in Middle Ganga Plain: Comparison of Frequency Ratio and Shannon’s Entropy Models. Geocarto Int. 2021, 36, 2085–2116. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H.; Costache, R.; Tang, X. Flood Susceptibility Mapping by Integrating Frequency Ratio and Index of Entropy with Multilayer Perceptron and Classification and Regression Tree. J. Environ. Manag. 2021, 289, 112449. [Google Scholar] [CrossRef] [PubMed]
- Saha, S.; Sarkar, D.; Mondal, P. Efficiency Exploration of Frequency Ratio, Entropy and Weights of Evidence-Information Value Models in Flood Vulnerabilityassessment: A Study of Raiganj Subdivision, Eastern India. Stoch. Environ. Res. Risk Assess. 2022, 36, 1721–1742. [Google Scholar] [CrossRef]
- Sarkar, D.; Saha, S.; Mondal, P. GIS-Based Frequency Ratio and Shannon’s Entropy Techniques for Flood Vulnerability Assessment in Patna District, Central Bihar, India. Int. J. Environ. Sci. Technol. 2022, 19, 8911–8932. [Google Scholar] [CrossRef]
- Pawar, U.; Suppawimut, W.; Muttil, N.; Rathnayake, U. A GIS-Based Comparative Analysis of Frequency Ratio and Statistical Index Models for Flood Susceptibility Mapping in the Upper Krishna Basin, India. Water 2022, 14, 3771. [Google Scholar] [CrossRef]
- Roopnarine, C.; Ramlal, B.; Roopnarine, R. A Comparative Analysis of Weighting Methods in Geospatial Flood Risk Assessment: A Trinidad Case Study. Land 2022, 11, 1649. [Google Scholar] [CrossRef]
- Megahed, H.A.; Abdo, A.M.; AbdelRahman, M.A.E.; Scopa, A.; Hegazy, M.N. Frequency Ratio Model as Tools for Flood Susceptibility Mapping in Urbanized Areas: A Case Study from Egypt. Appl. Sci. 2023, 13, 9445. [Google Scholar] [CrossRef]
- District Administration Chandrapur Demography|District Chandrapur, Government of Maharashtra|India. Available online: https://chanda.nic.in/en/demography/ (accessed on 29 July 2024).
- The Times of India. 350 Rescued as Flood Situation Turns Grim in Chandrapur. Times India, 11 August 2022.
- Rase, D.M.; Narayanan, P.S.; Mohan, K.N. Impact of Extreme Weather Events in Relation to Floods over Maharashtra in Recent Years. Available online: https://imetsociety.org/wp-content/pdf/vayumandal/2017432/2017432_7.pdf (accessed on 20 August 2024).
- EORC JAXA Dataset|ALOS@EORC. Available online: https://www.eorc.jaxa.jp/ALOS/index_e.htm (accessed on 31 July 2024).
- Hydrology Project, Government of Maharashtra Rainfall Data. Available online: https://mahahp.gov.in/DisplayRainfall.aspx?data=Rainfall (accessed on 31 July 2024).
- ESA Global Land Cover 1992–2019. Available online: https://supply-chain-data-hub-nmcdc.hub.arcgis.com/apps/NMCDC::global-land-cover-1992-2019-1/about (accessed on 31 July 2024).
- NRSC Bhuvan|ISRO’s Geoportal|Gateway to Indian Earth Observation|Disaster Services. Available online: https://bhuvan-app1.nrsc.gov.in/disaster/disaster.php?id=flood_hz# (accessed on 31 July 2024).
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood Susceptibility Mapping Using a Novel Ensemble Weights-of-Evidence and Support Vector Machine Models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Darabi, H.; Choubin, B.; Rahmati, O.; Torabi Haghighi, A.; Pradhan, B.; Kløve, B. Urban Flood Risk Mapping Using the GARP and QUEST Models: A Comparative Study of Machine Learning Techniques. J. Hydrol. 2019, 569, 142–154. [Google Scholar] [CrossRef]
- Norallahi, M.; Seyed Kaboli, H. Urban Flood Hazard Mapping Using Machine Learning Models: GARP, RF, MaxEnt and NB. Nat. Hazards 2021, 106, 119–137. [Google Scholar] [CrossRef]
- Bui, D.T.; Ngo, P.-T.T.; Pham, T.D.; Jaafari, A.; Minh, N.Q.; Hoa, P.V.; Samui, P. A Novel Hybrid Approach Based on a Swarm Intelligence Optimized Extreme Learning Machine for Flash Flood Susceptibility Mapping. CATENA 2019, 179, 184–196. [Google Scholar] [CrossRef]
- Sørensen, R.; Zinko, U.; Seibert, J. On the Calculation of the Topographic Wetness Index: Evaluation of Different Methods Based on Field Observations. Hydrol. Earth Syst. Sci. 2006, 10, 101–112. [Google Scholar] [CrossRef]
- Shafapour Tehrany, M.; Shabani, F.; Neamah Jebur, M.; Hong, H.; Chen, W.; Xie, X. GIS-Based Spatial Prediction of Flood Prone Areas Using Standalone Frequency Ratio, Logistic Regression, Weight of Evidence and Their Ensemble Techniques. Geomat. Nat. Hazards Risk 2017, 8, 1538–1561. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flood-Contributing Factors | Subclass | Total Pixel | Total Area (km2) | % of Total Area (X) | Flood Pixel | Flood Area (km2) | % of Flood Area (Y) | FR Model Parameters | SEI Model Parameters | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FR (Y/X) | Relative Frequency (RF) | Prediction Rate (PR) | Pdij | Hj | Hj max | Icj | Pj | Wj | ||||||||
| Elevation (m) | 80–110 | 168 | 1.68 | 6.78 | 168 | 1.68 | 29.07 | 4.29 | 0.32 | 1.41 | 0.32 | 1.94 | 2.32 | 0.17 | 2.65 | 0.44 |
| 110–115 | 193 | 1.93 | 7.79 | 187 | 1.87 | 32.35 | 4.15 | 0.31 | 0.31 | |||||||
| 115–120 | 188 | 1.88 | 7.59 | 145 | 1.45 | 25.09 | 3.31 | 0.25 | 0.25 | |||||||
| 120–125 | 143 | 1.43 | 5.77 | 47 | 0.47 | 8.13 | 1.41 | 0.11 | 0.11 | |||||||
| 125–279 | 1786 | 17.86 | 72.07 | 31 | 0.31 | 5.36 | 0.07 | 0.01 | 0.01 | |||||||
| Slope (degree) | 0–1 | 51 | 0.51 | 2.06 | 27 | 0.27 | 4.67 | 2.27 | 0.35 | 1.00 | 0.35 | 2.22 | 2.32 | 0.04 | 1.29 | 0.05 |
| 1–2 | 1169 | 11.69 | 47.18 | 222 | 2.22 | 38.41 | 0.81 | 0.13 | 0.13 | |||||||
| 2–3 | 1048 | 10.48 | 42.29 | 275 | 2.75 | 47.58 | 1.12 | 0.17 | 0.17 | |||||||
| 3–4 | 150 | 1.5 | 6.05 | 38 | 0.38 | 6.57 | 1.09 | 0.17 | 0.17 | |||||||
| 4–10 | 60 | 0.6 | 2.42 | 16 | 0.16 | 2.77 | 1.14 | 0.18 | 0.18 | |||||||
| Flow accumulation | 0–1 k | 2044 | 20.44 | 82.49 | 332 | 3.32 | 57.44 | 0.70 | 0.07 | 1.27 | 0.07 | 2.10 | 2.32 | 0.10 | 2.13 | 0.20 |
| 1 k–5 k | 143 | 1.43 | 5.77 | 45 | 0.45 | 7.79 | 1.35 | 0.13 | 0.13 | |||||||
| 5 k–10 k | 90 | 0.9 | 3.63 | 34 | 0.34 | 5.88 | 1.62 | 0.15 | 0.15 | |||||||
| 10 k–20 k | 77 | 0.77 | 3.11 | 58 | 0.58 | 10.03 | 3.23 | 0.30 | 0.30 | |||||||
| 20 k –5700 k | 124 | 1.24 | 5.00 | 109 | 1.09 | 18.86 | 3.77 | 0.35 | 0.35 | |||||||
| Drainage density (km/km2) | 0–30 | 1816 | 18.16 | 73.28 | 147 | 1.47 | 25.43 | 0.35 | 0.04 | 1.26 | 0.04 | 2.09 | 2.32 | 0.10 | 1.96 | 0.20 |
| 30–60 | 342 | 3.42 | 13.80 | 237 | 2.37 | 41.00 | 2.97 | 0.30 | 0.30 | |||||||
| 60–90 | 56 | 0.56 | 2.26 | 20 | 0.2 | 3.46 | 1.53 | 0.16 | 0.16 | |||||||
| 90–120 | 64 | 0.64 | 2.58 | 27 | 0.27 | 4.67 | 1.81 | 0.18 | 0.18 | |||||||
| 120–400 | 200 | 2 | 8.07 | 147 | 1.47 | 25.43 | 3.15 | 0.32 | 0.32 | |||||||
| TWI | 0–7 | 134 | 1.34 | 5.41 | 27 | 0.27 | 4.67 | 0.86 | 0.10 | 1.20 | 0.10 | 2.08 | 2.32 | 0.10 | 1.70 | 0.17 |
| 7–8 | 1702 | 17.02 | 68.68 | 393 | 3.93 | 67.99 | 0.99 | 0.12 | 0.12 | |||||||
| 8–9 | 579 | 5.79 | 23.37 | 116 | 1.16 | 20.07 | 0.86 | 0.10 | 0.10 | |||||||
| 9–10 | 36 | 0.36 | 1.45 | 22 | 0.22 | 3.81 | 2.62 | 0.31 | 0.31 | |||||||
| 10–18 | 27 | 0.27 | 1.09 | 20 | 0.2 | 3.46 | 3.18 | 0.37 | 0.37 | |||||||
| Rainfall (mm) | 0–90 | 528 | 5.28 | 21.31 | 45 | 0.45 | 7.79 | 0.37 | 0.07 | 1.22 | 0.07 | 2.13 | 2.32 | 0.08 | 1.02 | 0.08 |
| 90–122 | 393 | 3.93 | 15.86 | 163 | 1.63 | 28.20 | 1.78 | 0.35 | 0.35 | |||||||
| 122–140 | 447 | 4.47 | 18.04 | 143 | 1.43 | 24.74 | 1.37 | 0.27 | 0.27 | |||||||
| 140–160 | 786 | 7.86 | 31.72 | 182 | 1.82 | 31.49 | 0.99 | 0.19 | 0.19 | |||||||
| 160–200 | 324 | 3.24 | 13.08 | 45 | 0.45 | 7.79 | 0.60 | 0.12 | 0.12 | |||||||
| Land use | Waterbody | 4 | 0.04 | 0.16 | 0 | 0 | 0.00 | 0.00 | 0.00 | 1.65 | 0.00 | 2.04 | 2.58 | 0.21 | 0.87 | 0.18 |
| Barren land | 9 | 0.09 | 0.36 | 2 | 0.02 | 0.35 | 0.95 | 0.18 | 0.18 | |||||||
| Built-up area | 99 | 0.99 | 4.00 | 45 | 0.45 | 7.79 | 1.95 | 0.37 | 0.37 | |||||||
| Forest land | 319 | 3.19 | 12.87 | 88 | 0.88 | 15.22 | 1.18 | 0.23 | 0.23 | |||||||
| Cropland | 1801 | 18.01 | 72.68 | 437 | 4.37 | 75.61 | 1.04 | 0.20 | 0.20 | |||||||
| Shrubland | 246 | 2.46 | 9.93 | 6 | 0.06 | 1.04 | 0.10 | 0.02 | 0.02 | |||||||
| Parameters | FR Model | SEI Model | ||
|---|---|---|---|---|
| Training Dataset | Testing Dataset | Training Dataset | Testing Dataset | |
| True positive (pixels) | 162 | 90 | 341 | 184 |
| True negative (pixels) | 1330 | 563 | 1261 | 547 |
| False positive (pixels) | 2 | 5 | 71 | 21 |
| False negative (pixels) | 212 | 114 | 33 | 20 |
| Sensitivity | 0.433 | 0.441 | 0.912 | 0.901 |
| Specificity | 0.998 | 0.991 | 0.946 | 0.963 |
| PPV | 0.987 | 0.947 | 0.827 | 0.897 |
| NPV | 0.862 | 0.831 | 0.974 | 0.964 |
| Accuracy | 0.874 | 0.845 | 0.939 | 0.946 |
| AUC | 0.971 | 0.966 | 0.982 | 0.978 |
| Overall Correlation (R) | 0.606 | 0.580 | 0.830 | 0.864 |
| Overall Standard Deviation Ratio (σ) | 0.712 | 0.745 | 1.034 | 1.002 |
| Overall Root Mean Square Error (RMSE) | 0.354 | 0.393 | 0.247 | 0.230 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, A.; Poonia, M.; Rai, A.; Biniwale, R.B.; Tügel, F.; Holzbecher, E.; Hinkelmann, R. Flood Susceptibility Mapping Using GIS-Based Frequency Ratio and Shannon’s Entropy Index Bivariate Statistical Models: A Case Study of Chandrapur District, India. ISPRS Int. J. Geo-Inf. 2024, 13, 297. https://doi.org/10.3390/ijgi13080297
Sharma A, Poonia M, Rai A, Biniwale RB, Tügel F, Holzbecher E, Hinkelmann R. Flood Susceptibility Mapping Using GIS-Based Frequency Ratio and Shannon’s Entropy Index Bivariate Statistical Models: A Case Study of Chandrapur District, India. ISPRS International Journal of Geo-Information. 2024; 13(8):297. https://doi.org/10.3390/ijgi13080297
Chicago/Turabian StyleSharma, Asheesh, Mandeep Poonia, Ankush Rai, Rajesh B. Biniwale, Franziska Tügel, Ekkehard Holzbecher, and Reinhard Hinkelmann. 2024. "Flood Susceptibility Mapping Using GIS-Based Frequency Ratio and Shannon’s Entropy Index Bivariate Statistical Models: A Case Study of Chandrapur District, India" ISPRS International Journal of Geo-Information 13, no. 8: 297. https://doi.org/10.3390/ijgi13080297