
Road Network Intelligent Selection Method Based on Heterogeneous Graph Attention Neural Network
 ,
,
Abstract
1. Introduction
2. Related Work
- Not exploring the importance of each feature of graph neural networks in the road network selection task;
- Performance Gaps in Intermediate-Grade Roads: Homogeneous graph selection algorithms exhibit poor performance, particularly concerning intermediate-grade roads. Additionally, there is a need to enhance the overall connectivity of the selected road network;
- Lack of Comparison in Transductive and Inductive Tasks: Previous studies have not adequately compared the selection performance of the model in both transductive and inductive tasks. Transductive tasks involve training a model using road data with a small number of known labels to infer the majority of the remaining labels. Inductive tasks, on the other hand, entail training a model using road data with numerous known labels to predict labels for nodes on a new road dataset. Such comparisons are essential for a comprehensive evaluation of the selection model, especially when considering road au-to-selection tasks in different spatial domains.
3. Methods
3.1. Measurement of Road Feature Importance Based on Feature Masking Method
3.2. Construction of HAN Model for Road Network Selection
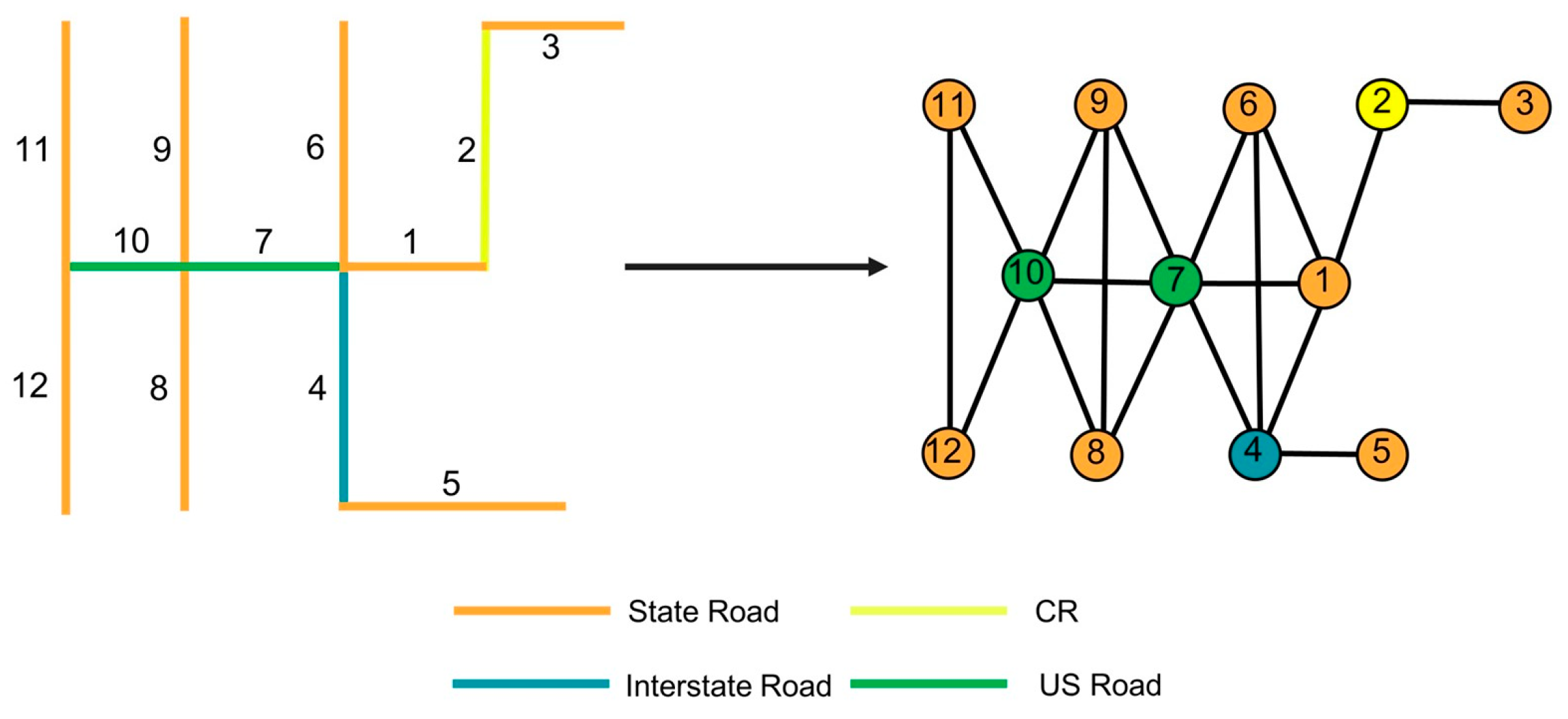
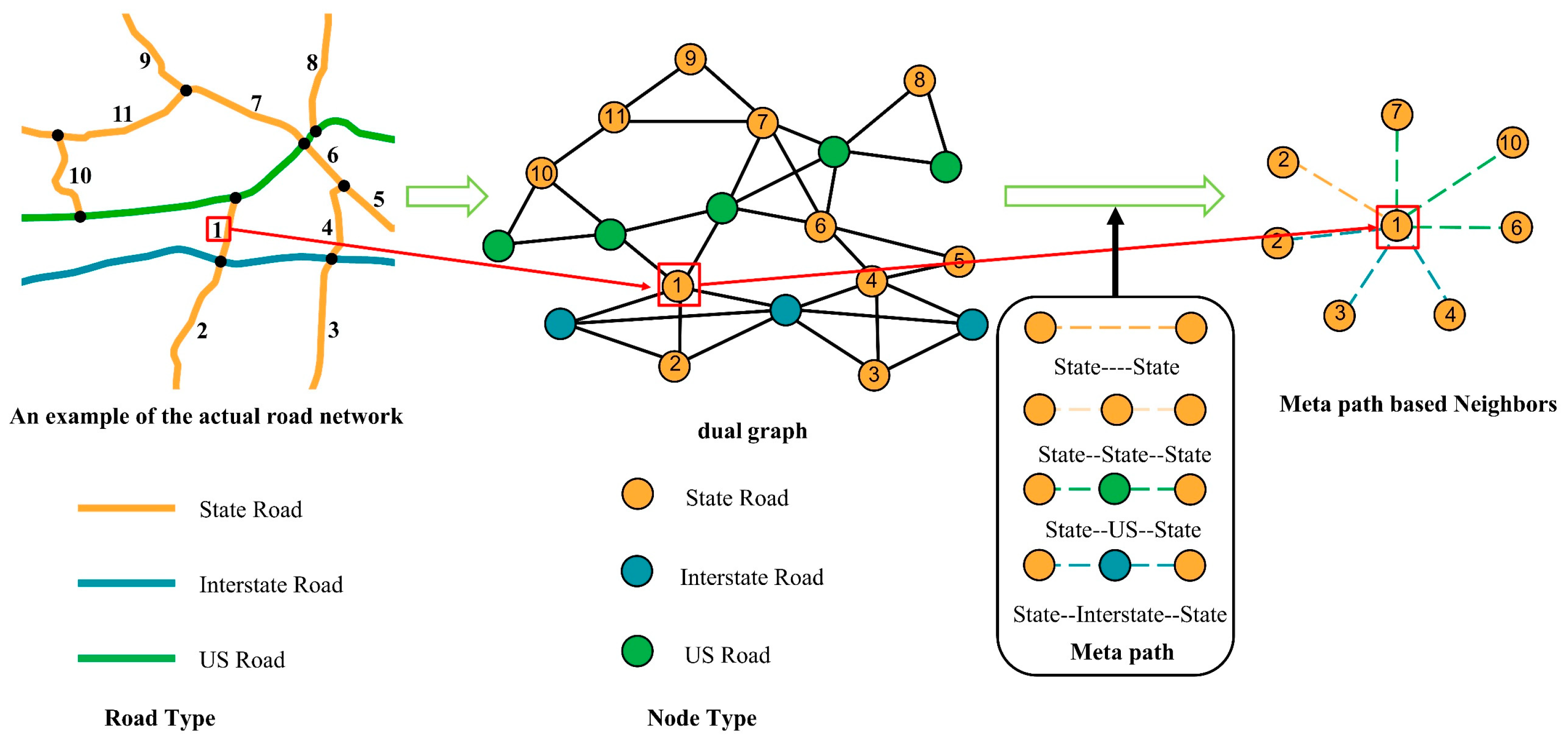
3.2.1. Meta-Path Design Method Based on Road Correlation
- State Road: Highways constructed and maintained by state governments, facilitating connections between cities and regions within a state.
- US Road: Before the construction of the Highway System, US Roads served as the primary highway network. Nowadays, they continue to play a crucial role as major transportation corridors within states and between regions.
- Interstate Road: The primary objective of an Interstate Road is to enhance the safety and efficiency of automotive travel. Generally, Interstate Roads permit the fastest speeds compared with any other roadways in the vicinity.
- CR: County roads constructed and maintained by local governments serve as vital conduits linking cities and regions within a county.
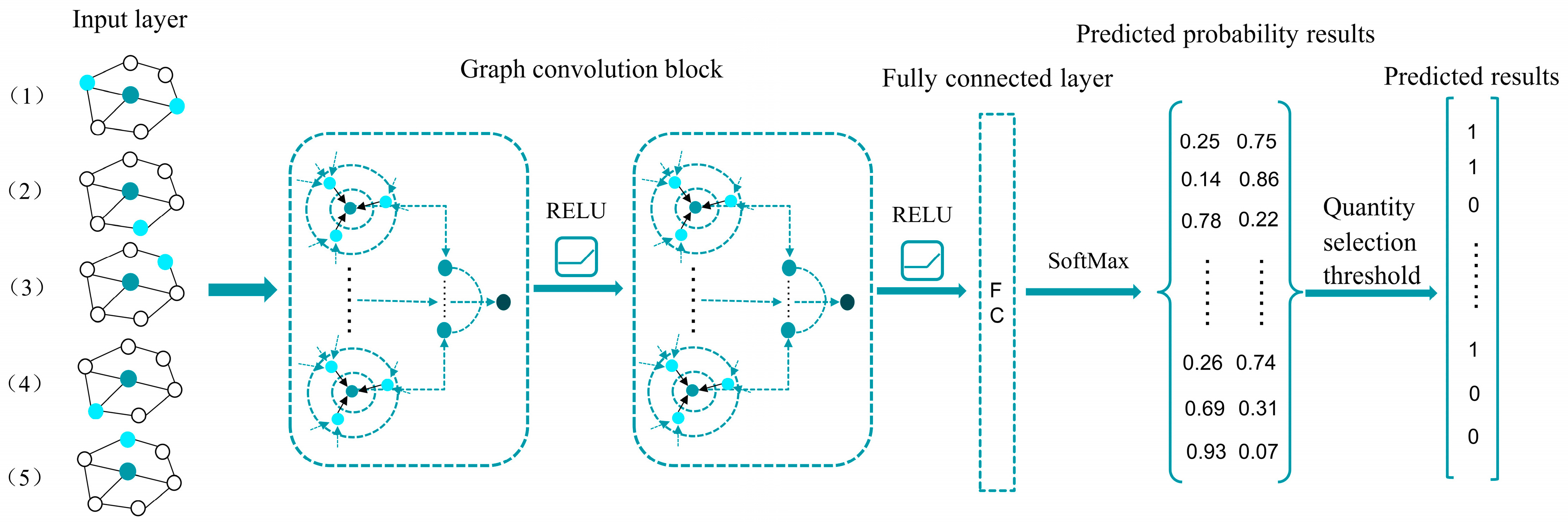
3.2.2. Heterogeneous Graph Attention Network Embedding Road Features
3.3. The Framework of the HAN Model
3.4. Evaluation Metrics for the HAN Model
3.4.1. Evaluation Metrics for Quantity Assessment of the HAN Model
3.4.2. Road Network Density
3.4.3. Metrics Related to Isolated Road
4. Experimental Process and Results
4.1. Experimental Data and Data Preprocessing
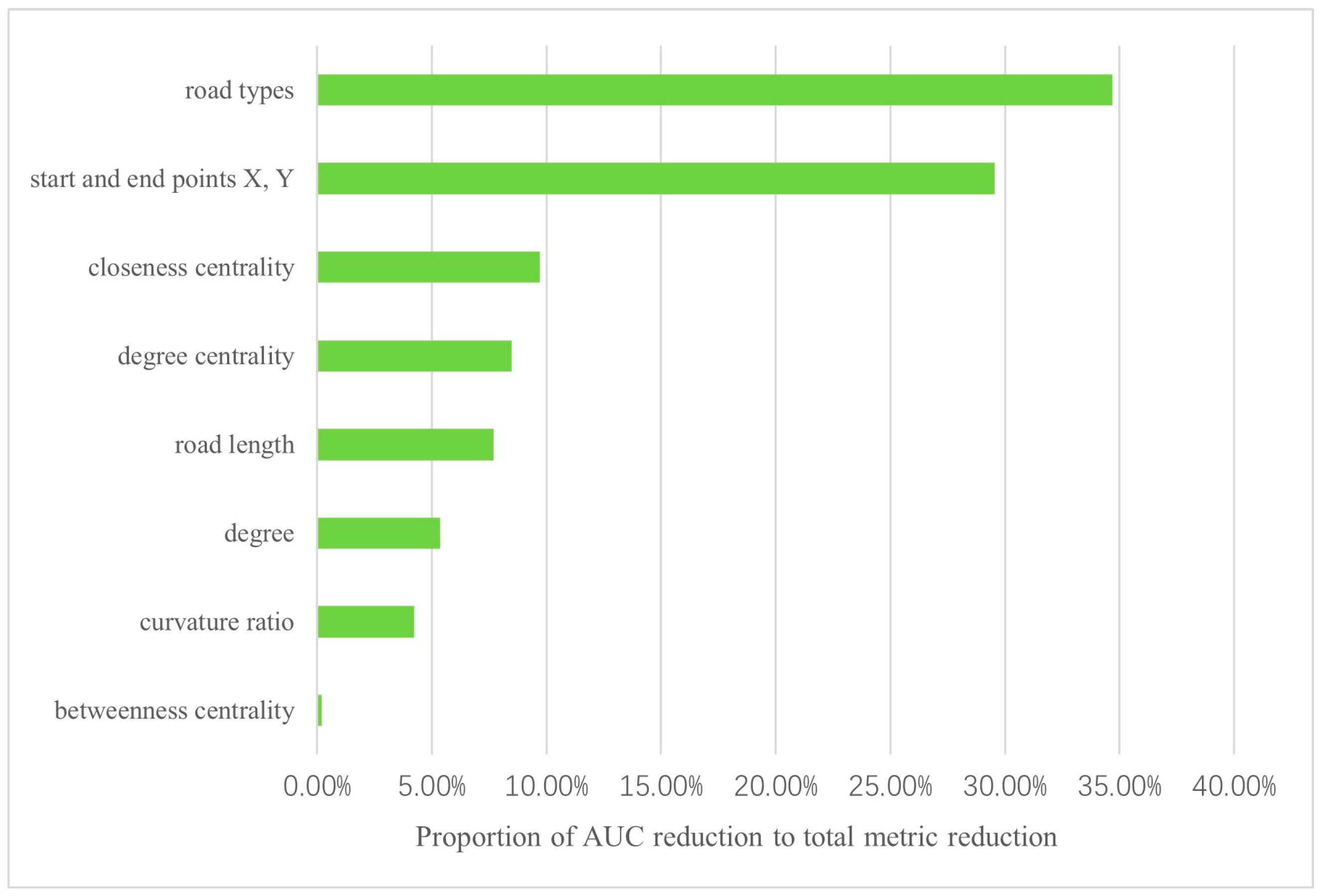
4.2. Results of Road Feature Importance Measurement
4.3. Analysis of the Results of the Transductive and Inductive Road Network Selection Task
4.3.1. Analysis of the Road Selection Results in the Transductive Task
4.3.2. Analysis of the Road Selection Results in the Inductive Task
4.3.3. Analysis of Ablation Study Results
4.4. Exploring Selection Performance at Various Scales and in Various Locations
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, Z.; Liu, W.; Xu, Z.; Ti, P.; Gao, P.; Yan, C.; Lin, Y.; Li, R.; Liu, C. Cartographic Representation of Spatio-Temporal Data: Fundamental Issues and Research Progress. Acta Geod. Cartogr. Sin. 2021, 50, 1033. [Google Scholar]
- Wang, J.; Wu, F.; Yan, H. Cartography: Its Past, Present and Future. Acta Geod. Et Cartogr. Sin. 2022, 51, 829. [Google Scholar]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat. Deep Learning and Process Understanding for Data-Driven Earth System Science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Kronenfeld, B.J.; Buttenfield, B.P.; Stanislawski, L.V. Map Generalization for the Future: Editorial Comments on the Special Issue. ISPRS Int. J. Geo-Inf. 2020, 9, 468. [Google Scholar] [CrossRef]
- Li, Z.; Lan, T.; Ti, P.; Xu, Z. Advances in Cartography from the Perspective of Maslow’s Hierarchy of Needs. Acta Geod. Cartogr. Sin. 2022, 51, 1536. [Google Scholar]
- Sun, Y.; Han, J. Mining Heterogeneous Information Networks: A Structural Analysis Approach. SIGKDD Explor. Newsl. 2013, 14, 20–28. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, C.T.; Zhou, M.; Xie, S.; Chang, Y.; Yu, P.S. Heer: Heterogeneous Graph Embedding for Emerging Relation Detection from News. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016. [Google Scholar]
- Dong, Y.; Chawla, N.V.; Swami, A. Metapath2vec: Scalable Representation Learning for Heterogeneous Networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 135–144. [Google Scholar]
- Sankar, A.; Zhang, X.; Chang, K.C.C. Meta-Gnn: Metagraph Neural Network for Semi-Supervised Learning in Attributed Heterogeneous Information Networks. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Vancouver, BC, Canada, 27–30 August 2019. [Google Scholar]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous Graph Attention Network. In Proceedings of the World Wide Web Conference 2019, Online, 13–17 May 2019. [Google Scholar]
- Yun, S.; Jeong, M.; Kim, R.; Kang, J.; Kim, H.J. Graph Transformer Networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Zhou, S.; Bu, J.; Wang, X.; Chen, J.; Hu, B.; Chen, D.; Wang, C. Hahe: Hierarchical Attentive Heterogeneous Information Network Embedding. arXiv 2019, arXiv:1902.01475. [Google Scholar]
- Jia, X.; Dong, Y.; Zhu, F.; Qian, J. Research Progress of Heterogeneous Graph Convolutional Networks. Comput. Eng. Appl. 2021, 57, 36–49. [Google Scholar]
- Yun, S.; Jeong, M.; Yoo, S.; Lee, S.; Yi, S.S.; Kim, R.; Kang, J.; Kim, H.J. Graph Transformer Networks: Learning Meta-Path Graphs to Improve Gnns. Neural Netw. 2022, 153, 104–119. [Google Scholar] [CrossRef]
- Bing, R.; Yuan, G.; Zhu, M.; Meng, F.; Ma, H.; Qiao, S. Heterogeneous Graph Neural Networks Analysis: A Survey of Techniques, Evaluations and Applications. Artif. Intell. Rev. 2023, 56, 8003–8042. [Google Scholar] [CrossRef]
- Wu, F.; Gong, X.; Du, J. Overview of the Research Progress in Automated Map Generalization. Acta Geod. Cartogr. Sin. 2017, 46, 1645–1664. [Google Scholar]
- Jiang, B.; Claramunt, C. A Structural Approach to the Model Generalization of an Urban Street Network*. GeoInformatica 2004, 8, 157–171. [Google Scholar] [CrossRef]
- Touya, G. A Road Network Selection Process Based on Data Enrichment and Structure Detection. Trans. GIS 2010, 14, 595–614. [Google Scholar] [CrossRef]
- Weiss, R.; Weibel, R. Road Network Selection for Small-Scale Maps Using an Improved Centrality-Based Algorithm. J. Spat. Inf. Sci. 2014, 9, 71–99. [Google Scholar] [CrossRef]
- Shoman, W.; Gülgen, F. Centrality-Based Hierarchy for Street Network Generalization in Multi-Resolution Maps. Geocarto Int. 2016, 32, 1352–1366. [Google Scholar] [CrossRef]
- Gülgen, F.; Gökgöz, T. A Block-Based Selection Method for Road Network Generalization. Int. J. Digit. Earth 2011, 4, 133–153. [Google Scholar] [CrossRef]
- Thomson, R.C. The Stroke’ Concept in Geographic Network Generalization and Analysis. In Progress in Spatial Data Handling: 12th International Symposium on Spatial Data Handling; Riedl, A., Kainz, W., Elmes, G.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 681–697. [Google Scholar]
- Zhou, Q.; Li, Z. A Comparative Study of Various Strategies to Concatenate Road Segments into Strokes for Map Generalization. Int. J. Geogr. Inf. Sci. 2012, 26, 691–715. [Google Scholar] [CrossRef]
- Chen, J.; Hu, Y.; Li, Z.; Zhao, R.; Meng, L. Selective Omission of Road Features Based on Mesh Density for Automatic Map Generalization. Int. J. Geogr. Inf. Sci. 2009, 23, 1013–1032. [Google Scholar] [CrossRef]
- Zhou, Q.; Li, Z. Empirical Determination of Geometric Parameters for Selective Omission in a Road Network. Int. J. Geogr. Inf. Sci. 2015, 30, 263–299. [Google Scholar] [CrossRef]
- Liu, Y.; Li, W. A New Algorithms of Stroke Generation Considering Geometric and Structural Properties of Road Network. ISPRS Int. J. Geo-Inf. 2019, 8, 304. [Google Scholar] [CrossRef]
- Benz, S.A.; Weibel, R. Road Network Selection for Medium Scales Using an Extended Stroke-Mesh Combination Algorithm. Cartogr. Geogr. Inf. Sci. 2014, 41, 323–339. [Google Scholar] [CrossRef]
- Xu, Z.; Wang, Z.; Yan, H.; Wu, F.; Duan, X.; Sun, L. A Method for Automatic Road Selection Combined with Poi Data. J. Geo-Inf. Sci. 2018, 20, 159–166. [Google Scholar]
- Deng, M.; Chen, X.; Tang, J.; Liu, H.; He, J. A Method for Road Network Selection Considering the Traffic Flowsemantic Information. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 1438–1447. [Google Scholar]
- Yu, W.; Zhang, Y.; Ai, T.; Guan, Q.; Chen, Z.; Li, H. Road Network Generalization Considering Traffic Flow Patterns. Int. J. Geogr. Inf. Sci. 2020, 34, 119–149. [Google Scholar] [CrossRef]
- Lyu, Z.; Sun, Q.; Ma, J.; Xu, Q.; Li, Y.; Zhang, F. Road Network Generalization Method Constrained by Residential Areas. ISPRS Int. J. Geo-Inf. 2022, 11, 159. [Google Scholar] [CrossRef]
- Liu, K.; Ma, J.S. Research on Intelligent Selection Ofroad Network Automatic Generalization Based on Kernel-Based Machine Learning; Nanjing University: Nanjing, China, 2017. [Google Scholar]
- Liu, K.; Li, J.; Shen, J.; Ma, J. Selection of Road Network Using Bp Neural Networkand Topological Parameters. J. Geomat. Sci. Technol. 2016, 33, 325–330. [Google Scholar]
- Liu, P.; Yuan, L.H.; Zhang, K.; Shen, J.; Ma, J.S. Intelligent Selection of Osm Road Network Based on Rbf Neural Network. Geomat. World 2019, 26, 8–13. [Google Scholar]
- Karsznia, I.; Wereszczyńska, K.; Weibel, R. Make It Simple: Effective Road Selection for Small-Scale Map Design Using Decision-Tree-Based Models. ISPRS Int. J. Geo-Inf. 2022, 11, 457. [Google Scholar] [CrossRef]
- Guo, X.; Qian, H.; Wang, X.; Liu, J.; Ren, Y.; Zhao, Y.; Chen, G. Ontology Knowledge Reasonin Method for Multi-Source Intelligent Road Selection. Acta Geod. Cartogr. Sin. 2022, 51, 279–289. [Google Scholar]
- Karsznia, I.; Adolf, A.; Leyk, S.; Weibel, R. Using Machine Learning and Data Enrichment in the Selection of Roads for Small-Scale Maps. Cartogr. Geogr. Inf. Sci. 2023, 51, 60–78. [Google Scholar] [CrossRef]
- Wang, J.; Cui, T.; Wang, G. Application of Graph Theory in Automatic Selection of Road Network. J. Geomat. Sci. Technol. 1985, 2, 79–86. [Google Scholar]
- Liu, G.; Li, Y.; Yang, J.; Zhang, X. Auto-Selection Method of Road Networks Based on Evaluation of Node Importance for Dual Graph. Acta Geod. Cartogr. Sin. 2014, 43, 97–104. [Google Scholar]
- Cao, W.; Zhang, H.; He, J.; Lan, T. Road Selection Considering Structural and Geometric Properties. Geomat. Inf. Sci. Wuhan Univ. 2017, 42, 520–524. [Google Scholar]
- Ma, C.; Sun, Q.; Chen, H.; Xu, Q.; Wen, B. Application of Weighted Pagerank Algorithm in Road Network Auto-Selection. Geomat. Inf. Sci. Wuhan Univ. 2018, 43, 1159–1165. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Velikovi, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Courtial, A.; Touya, G.; Zhang, X. Can Graph Convolution Networks Learn Spatial Relations? Abstract of ICA. In Proceedings of the 30th International Cartographic Conference, Florence, Italy, 14–18 December 2021; Volume 3, pp. 1–2. [Google Scholar]
- Zhang, K.; Zheng, J.; Shen, J.; Ma, J. Application of the Graph Convolution Network in the Selection of Road Network. Sci. Surv. Mapp. 2021, 46, 165–170+177. [Google Scholar]
- Zheng, J.; Gao, Z.; Ma, J.; Shen, J.; Zhang, K. Zhang. Deep Graph Convolutional Networks for Accurate Automatic Road Network Selection. ISPRS Int. J. Geo-Inf. 2021, 10, 768. [Google Scholar] [CrossRef]
- Ma, C.; Xiong, S.; Jiang, D. Application of the Graph Convolution Network in the Road Network Auto-Selection. Sci. Surv. Mapp. 2022, 47, 200–205+215. [Google Scholar]
- Zhu, Y.; Yang, M.; Yan, X. A Road Network Selection Method Using Graph Convolutional Network. Beijing Surv. Mapp. 2022, 36, 1455–1459. [Google Scholar]
- Guo, X.; Liu, J.; Wu, F.; Qian, H. A Method for Intelligent Road Network Selection Based on Graph Neural Network. ISPRS Int. J. Geo-Inf. 2023, 12, 336. [Google Scholar] [CrossRef]
- Wang, D.; Qian, H. Graph Neural Network Method for the Intelligent Selection of River System. Geocarto Int. 2023, 38, 2252762. [Google Scholar] [CrossRef]
- Yu, H.; Ai, T.; Yang, M.; Li, J.; Wang, L.; Gao, A.; Xiao, T.; Zhou, Z. Integrating Domain Knowledge and Graph Convolutional Neural Networks to Support River Network Selection. Trans. GIS 2023, 27, 1898–1927. [Google Scholar] [CrossRef]
- He, H.; Qian, H.; Liu, H.; Wang, X.; Hu, H. Road Network Selection Based on Road Hierarchical Structure Control. Acta Geod. Cartogr. Sin. 2015, 44, 453–461+470. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Types | Feature Indicators | Detailed Explanation |
|---|---|---|
| Semantic feature | road type | Road type is a system that classifies roads according to characteristics such as traffic flow, scale, and function. |
| Geometric features | road length | The length of roads in projected coordinates. |
| number of road vertices | The number of vertices in each road polyline. | |
| road aspect ratio | The ratio of the length of the road’s horizontal coordinates to its vertical coordinates. | |
| mesh density | The maximum ratio of the perimeter to the area of the left and right polygons associated with each road (if there are no left and right polygons, the value is set to 0). | |
| curvature ratio | The ratio of the road length to the straight-line length between the start and end coordinates of the road. | |
| start and end points (X, Y) | Start and end point coordinates (four values in total). | |
| Topological features | degree | The degree of each road is equal to the number of intersections it has with other roads. |
| degree centrality | The degree of each road is divided by the total number of roads minus one. | |
| eigenvector centrality | The eigenvector corresponding to the largest eigenvalue of the adjacency matrix represents the centrality of the eigenvector for each node. | |
| betweenness centrality | The ratio of the number of times the shortest paths between all other pairs of nodes pass through a particular node to the total number of shortest paths in a graph. | |
| closeness centrality | The total number of nodes minus one divided by the total number of shortest paths from that node to other nodes. |
| Meta-Path | Indices of Neighboring Nodes to Be Aggregated |
|---|---|
| State-State | 6 |
| State-State-State | none |
| State-US-State | 6, 8, 9 |
| State-Interstate-State | 5, 6 |
| State-CR-State | 3 |
| Road Types | Positive Training Samples | Negative Training Samples | Positive Validation Samples | Negative Validation Samples | Total |
|---|---|---|---|---|---|
| State | 4840 | 4151 | 1221 | 1042 | 11,254 |
| US | 4205 | 266 | 1030 | 63 | 5564 |
| Inter | 1861 | 64 | 471 | 15 | 2411 |
| CR | 14 | 18 | 7 | 4 | 43 |
| Road Types | Positive Training Samples | Negative Training Samples | Positive Validation Samples | Negative Validation Samples | Positive Testing Samples | Negative Testing Samples | Total |
|---|---|---|---|---|---|---|---|
| State | 1205 | 1037 | 607 | 518 | 4249 | 3638 | 11,254 |
| US | 1061 | 64 | 517 | 34 | 3657 | 231 | 5564 |
| Inter | 462 | 20 | 241 | 9 | 1629 | 50 | 2411 |
| CR | 1 | 3 | 1 | 2 | 19 | 17 | 43 |
| Road Types | Positive Training Samples | Negative Training Samples | Positive Validation Samples | Negative Validation Samples | Positive Testing Samples | Negative Testing Samples | Total |
|---|---|---|---|---|---|---|---|
| State | 4869 | 4162 | 1192 | 1031 | 495 | 702 | 12,451 |
| US | 4165 | 255 | 1070 | 74 | 1095 | 133 | 6792 |
| Inter | 1864 | 63 | 468 | 16 | 268 | 46 | 2725 |
| CR | 21 | 18 | 0 | 4 | 0 | 1 | 44 |
| Road Types | Road Length | Mesh Density | Number of Road Vertices | Road Aspect Ratio | Curvature Ratio |
| 0.6108 | 0.7902 | 0.8414 | 0.8417 | 0.8413 | 0.8131 |
| Betweenness Centrality | Eigenvector Centrality | Closeness Centrality | Start and End Points X, Y | Degree | Degree Centrality |
| 0.8399 | 0.8414 | 0.7767 | 0.6449 | 0.8056 | 0.7850 |
| Road Type | State Road | US Road | Interstate Road | CR |
|---|---|---|---|---|
| ACC | 0.6681 | 0.9424 | 0.9691 | 0.7273 |
| Evaluation Metrics | Model | All | State | US | Interstate |
|---|---|---|---|---|---|
| ACC | HAN | 0.7535 | 0.6416 | 0.9051 | 0.9363 |
| GAT | 0.7385 | 0.6163 | 0.8976 | 0.9517 | |
| FastGTN | 0.7433 | 0.6254 | 0.8968 | 0.9488 | |
| MLP | 0.7316 | 0.6120 | 0.8876 | 0.9398 | |
| f1 score for positive samples | HAN | 0.8257 | 0.6664 | 0.9495 | 0.9671 |
| GAT | 0.8152 | 0.6440 | 0.9455 | 0.9751 | |
| FastGTN | 0.8156 | 0.6521 | 0.9451 | 0.9735 | |
| MLP | 0.8104 | 0.6395 | 0.9402 | 0.9710 | |
| Isolated roads (number|total length) | HAN | 40|343.01 km | 26|278.57 km | 4|9.80 km | 10|54.64 km |
| GAT | 198|1757.45 km | 61|712.64 km | 130|998.95 km | 7|45.87 km | |
| FastGTN | 281|1342.01 km | 243|990.96 km | 38|351.06 km | 0|0 km | |
| MLP | 245|942.37 km | 104|362.05 km | 80|338.94 km | 61|241.37 km | |
| Road network density (km/km2) | Expert Selection | 0.13513 | 0.06675 | 0.04855 | 0.01961 |
| HAN | 0.14212 | 0.07309 | 0.04912 | 0.01938 | |
| GAT | 0.14591 | 0.07721 | 0.04845 | 0.01973 | |
| FastGTN | 0.13784 | 0.0682 | 0.04934 | 0.01971 | |
| MLP | 0.13661 | 0.0692 | 0.04746 | 0.01939 |
| Evaluation Metrics | Model | All | State | US | Interstate |
|---|---|---|---|---|---|
| ACC | HAN | 0.7021 | 0.5589 | 0.8306 | 0.7452 |
| GAT | 0.7011 | 0.5522 | 0.8225 | 0.7962 | |
| FastGTN | 0.6904 | 0.5322 | 0.8339 | 0.7325 | |
| MLP | 0.6608 | 0.5038 | 0.7964 | 0.7093 | |
| F1 score for positive samples. | HAN | 0.7804 | 0.4667 | 0.9050 | 0.8507 |
| GAT | 0.7799 | 0.4586 | 0.9004 | 0.8806 | |
| FastGTN | 0.7710 | 0.4343 | 0.9068 | 0.8582 | |
| MLP | 0.7519 | 0.4000 | 0.8932 | 0.8545 | |
| Isolated roads (number|total length) | HAN | 18|77.62 km | 3|11.91 km | 15|65.72 km | 0|0 km |
| GAT | 89|695.19 km | 40|320.10 km | 48|374.08 km | 1|1.02 km | |
| FastGTN | 37|443.38 km | 10|189.37 km | 27|254.02 km | 0|0 km | |
| MLP | 72|242.31 km | 2|2.36 km | 52|191.15 km | 18|48.80 km | |
| Road network density (km/km2) | Expert Selection | 0.10662 | 0.03395 | 0.06002 | 0.01266 |
| HAN | 0.11179 | 0.03924 | 0.06015 | 0.01361 | |
| GAT | 0.11228 | 0.03991 | 0.05938 | 0.01299 | |
| FastGTN | 0.11916 | 0.04468 | 0.06118 | 0.01330 | |
| MLP | 0.09833 | 0.03250 | 0.05368 | 0.01215 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, H.; Zhang, J.; Li, H.; Wang, G.; Guo, J.; Wang, J. Road Network Intelligent Selection Method Based on Heterogeneous Graph Attention Neural Network. ISPRS Int. J. Geo-Inf. 2024, 13, 300. https://doi.org/10.3390/ijgi13090300
Zheng H, Zhang J, Li H, Wang G, Guo J, Wang J. Road Network Intelligent Selection Method Based on Heterogeneous Graph Attention Neural Network. ISPRS International Journal of Geo-Information. 2024; 13(9):300. https://doi.org/10.3390/ijgi13090300
Chicago/Turabian StyleZheng, Haohua, Jianchen Zhang, Heying Li, Guangxia Wang, Jianzhong Guo, and Jiayao Wang. 2024. "Road Network Intelligent Selection Method Based on Heterogeneous Graph Attention Neural Network" ISPRS International Journal of Geo-Information 13, no. 9: 300. https://doi.org/10.3390/ijgi13090300
APA StyleZheng, H., Zhang, J., Li, H., Wang, G., Guo, J., & Wang, J. (2024). Road Network Intelligent Selection Method Based on Heterogeneous Graph Attention Neural Network. ISPRS International Journal of Geo-Information, 13(9), 300. https://doi.org/10.3390/ijgi13090300