
An Automatic Matcher and Linker for Transportation Datasets

Abstract
:1. Introduction
1.1. Schema Matching
1.2. Data Interlinking
2. State of the Art
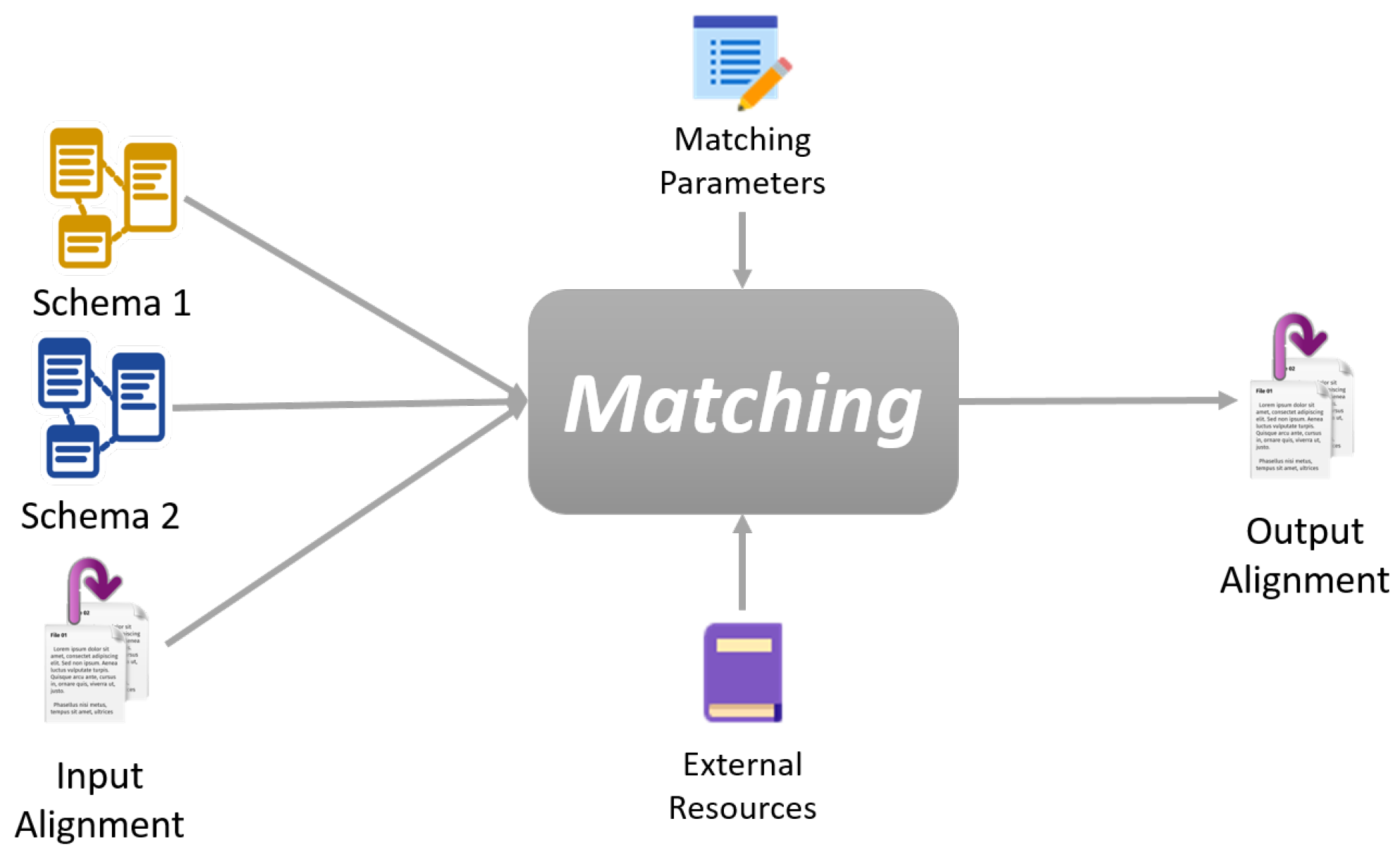
2.1. Automatic Schema Matching
- id is a unique identifier of the given mapping element
- e and e’ are the entities of the first schema/ontology, respectively
- n is a confidence measure holding the correspondence between the entities e and e’
- R is a relation (e.g., equivalence, more general, disjointedness, overlapping) holding between the entities e and e’
2.2. Data Interlinking
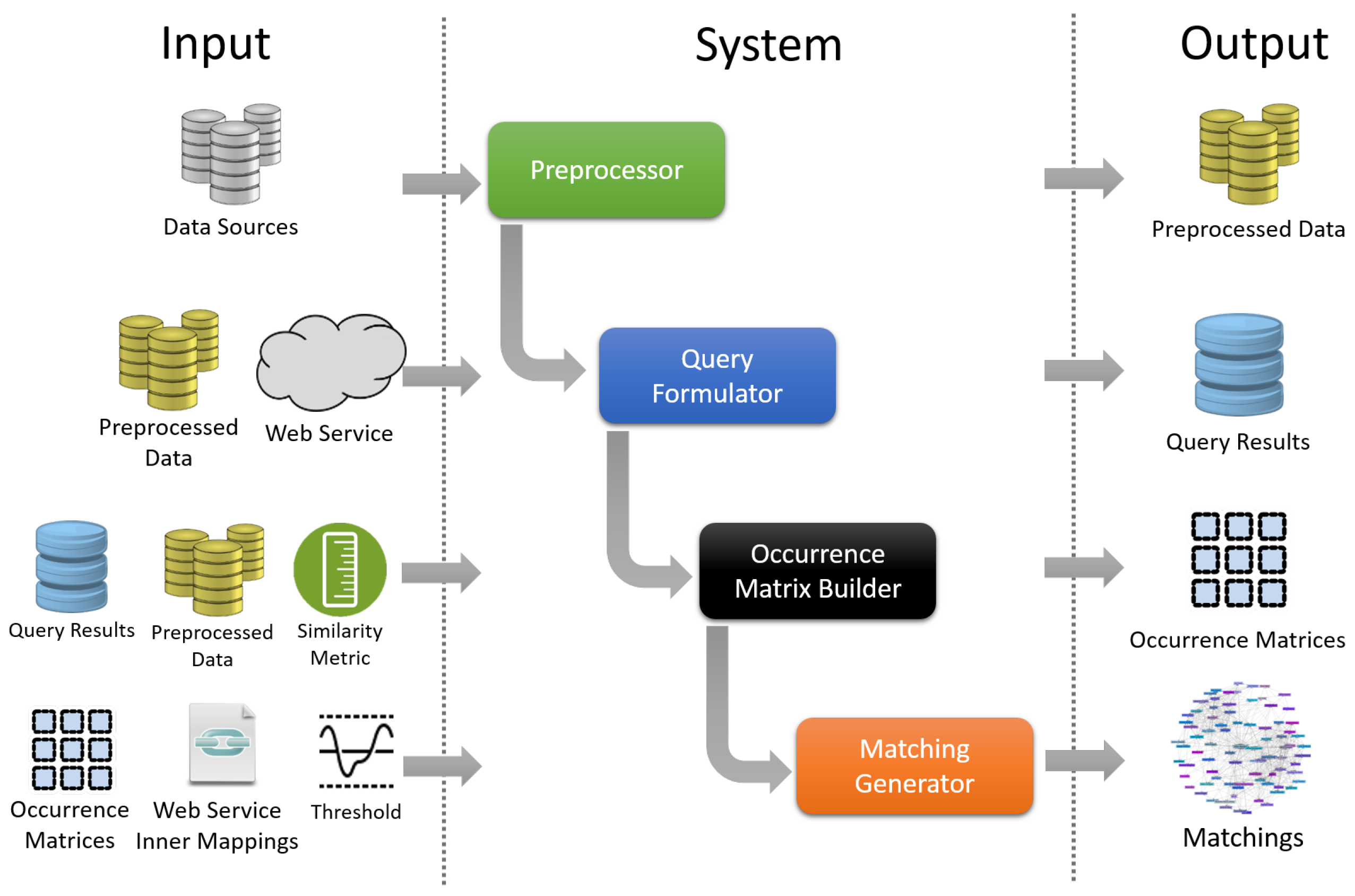
3. An Automatic Matcher for Transportation Datasets
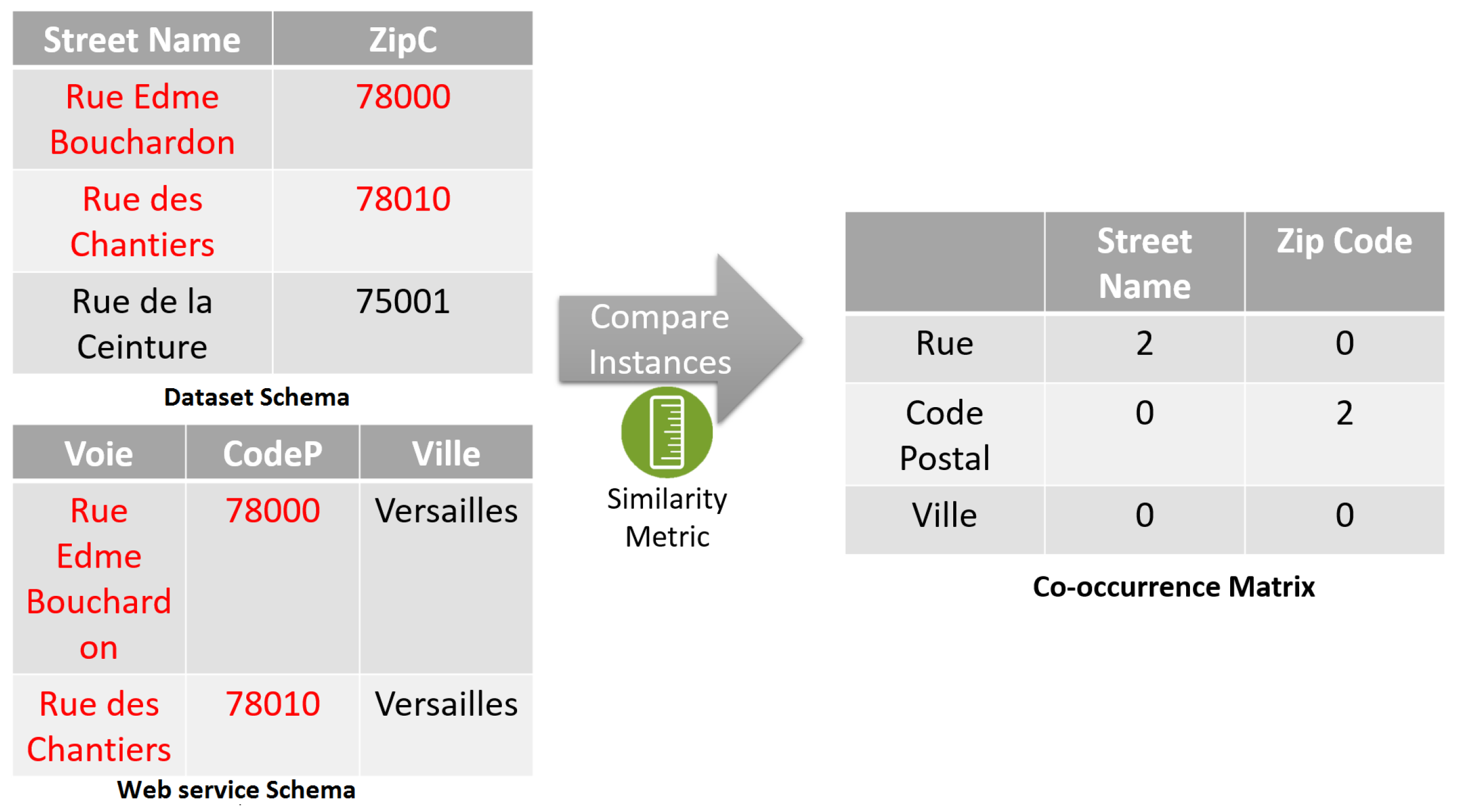
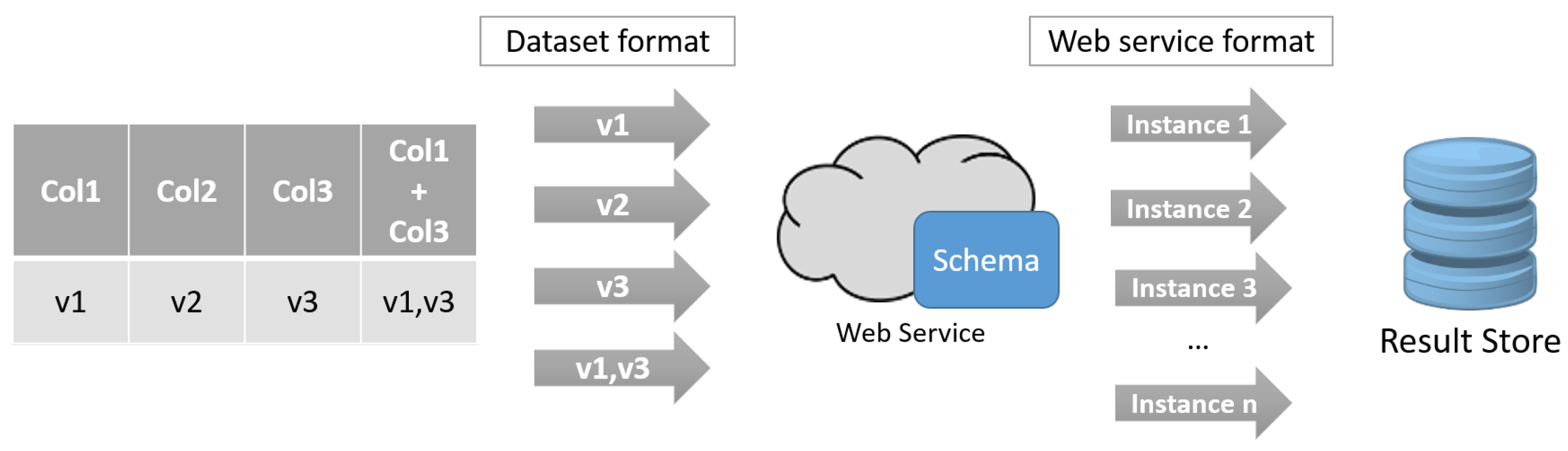
3.1. Web Service-Based Query Formulation
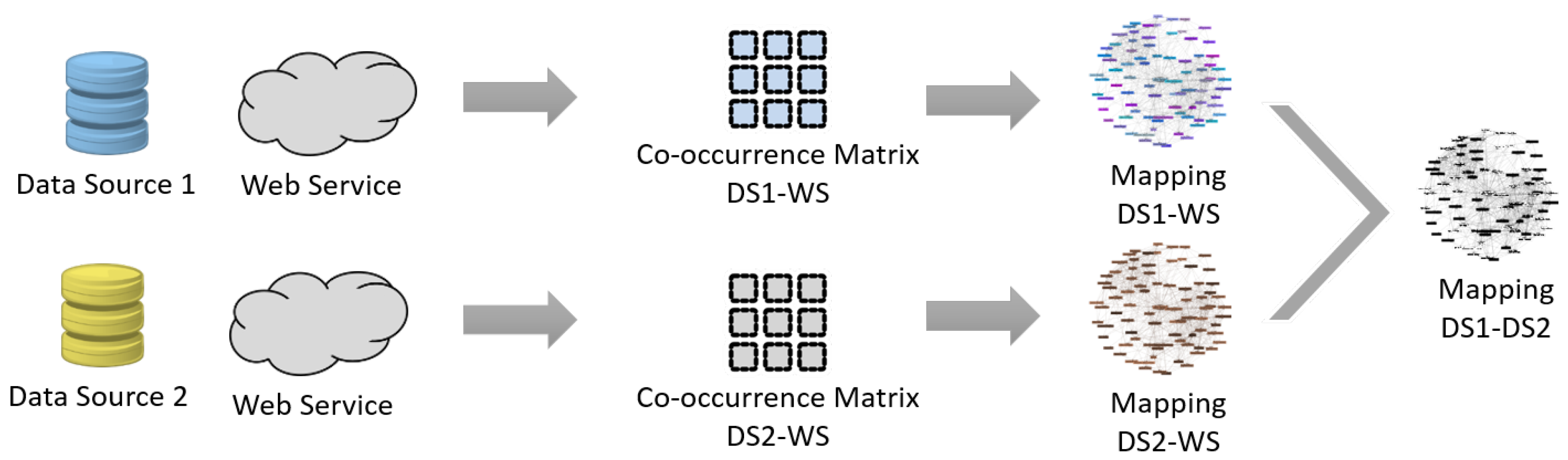
3.2. Co-Occurrence Matrix Construction
3.3. Matching Rules Generation
4. Discovering Semantic Connections between Transportation Datasets
- The definition phase, where users define the connection patterns, the required functions and linking rules.
- The generation phase, where the definitions are taken and applied to the datasets. The rule is applied to the entities, and when valid, a connection will be created and stored in a repository.
- Input data sources and representing the datasets to be linked
- O is the custom-defined connection pattern
- R is the linkage rule that defines when a connection must be generated
- F is a set of functions required for the linking task
- L is a set of pre-defined libraries implementing the dependencies of F
4.1. Specifying Custom Functions and External Libraries
4.2. Defining a Linking Rule
4.3. Configuring a Connection Pattern
4.4. Connection Discovery Algorithm
| Algorithm 1: Connection discovery algorithm. |
 |
5. Evaluation
5.1. Automatic Schema Matching
5.2. Link Discovery
- Timetable connection that has specific departure and arrival times. This type of connection will be referred to as a scheduled connection. It has the following properties: departure-time, arrival-time, departure-stop and arrival-stop.
- Other connections that have no schedule information and for which availability is not restricted by timing constraints. We will refer to these connections as unscheduled connections. They have the following properties: departure-stop, arrival-stop and distance.
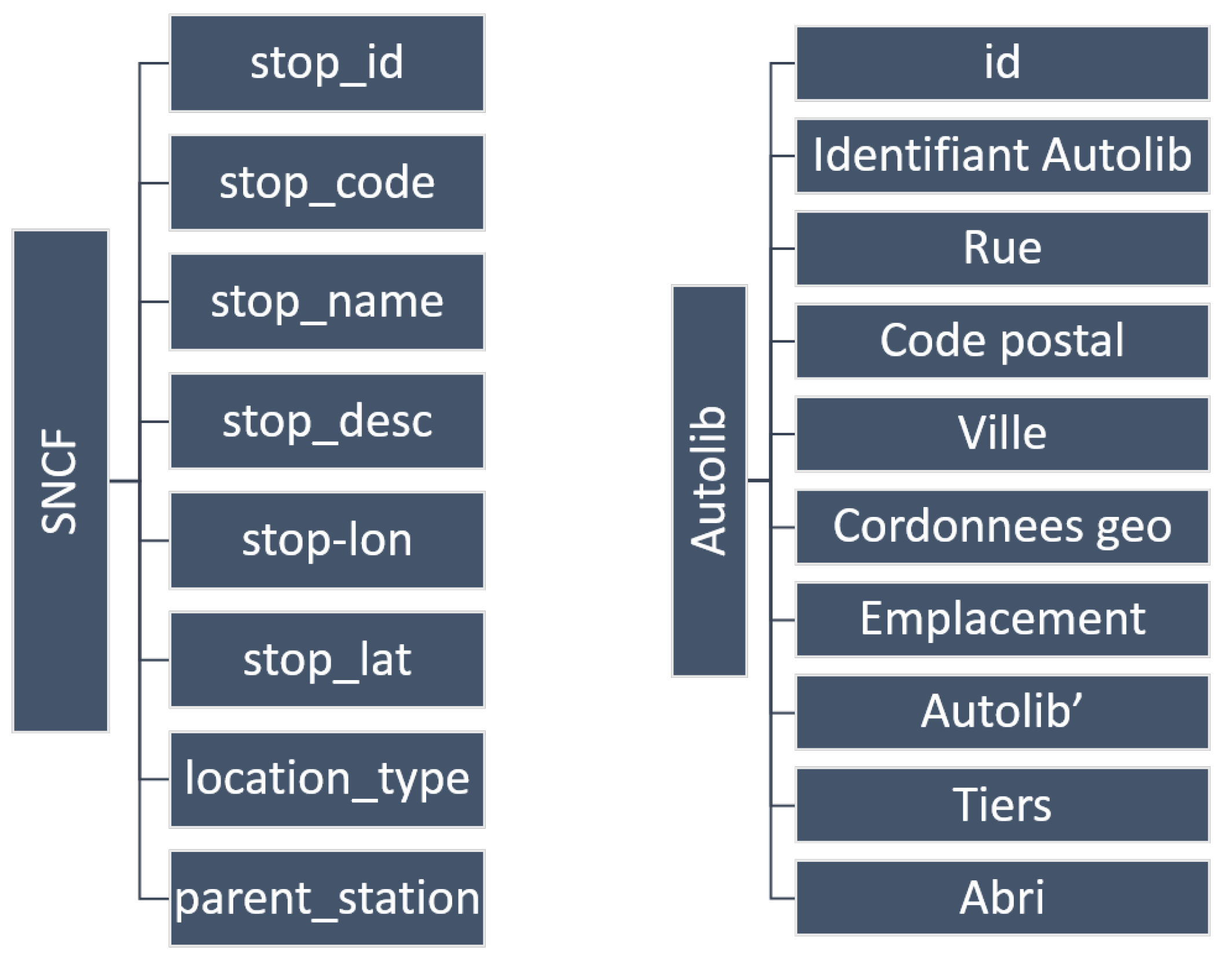
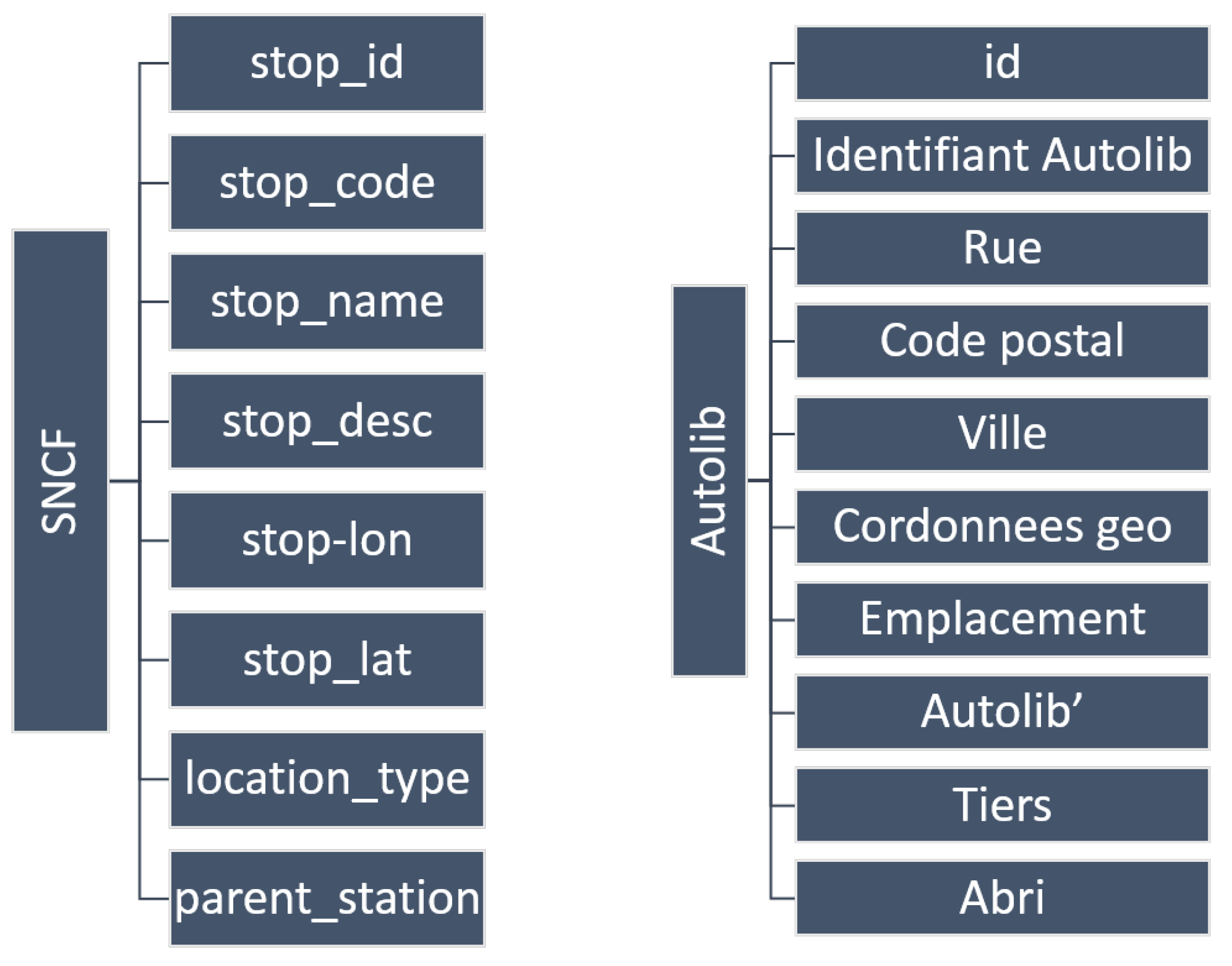
5.2.1. Data Preparation
5.2.2. Discovering New Connections
- Defining custom functions: Our system is flexible as it allows users to create any custom function to be used in the linking task. Users can use external dependencies, as well. In our example, we define the functions getWalkingDistance, getWalkingTime, getDrivingDistance and getDrivingTime. In a real scenario, we get this information from a web service, such as Google’s distance matrix API (https://developers.google.com/maps/documentation/distance-matrix/), However, due to the query limit, we have chosen to implement them by local functions based on mathematical calculations (http://www.movable-type.co.uk/scripts/latlong.html).
- Define the linking rules: Recall that the linking rule describes the condition that triggers the creation of a connection. Two rules are required, one for Autolib-Autolib and the other for Autolib-SNCF. For the first one, the condition of the defined rule is the following: “If a driving path exists within 200 km (the time before the battery is totally discharged), create a connection”. For Autolib-SNCF connections, the rule is: “If a walking path exists from one stop to another within one kilometer, create a connection”. Rules are written in XML format, and the functions that calculate the walking distance and time are referenced from the custom functions file. We note that the parameters “200 km” and “1 km” are given by the user who is responsible for the configuration. We set these parameters as the maximum feasible scope for a person to ride the car or walk from one station to another. Figure 9 shows an example of how a rule can be defined.
- Defining the connection pattern: We define the output generated by the system at each valid rule. We have chosen the following properties to be represented in a connection pattern: source-id, target-id, walking/driving distance and walking/driving time. This pattern is the same for both tasks, and an example is shown in Figure 10.
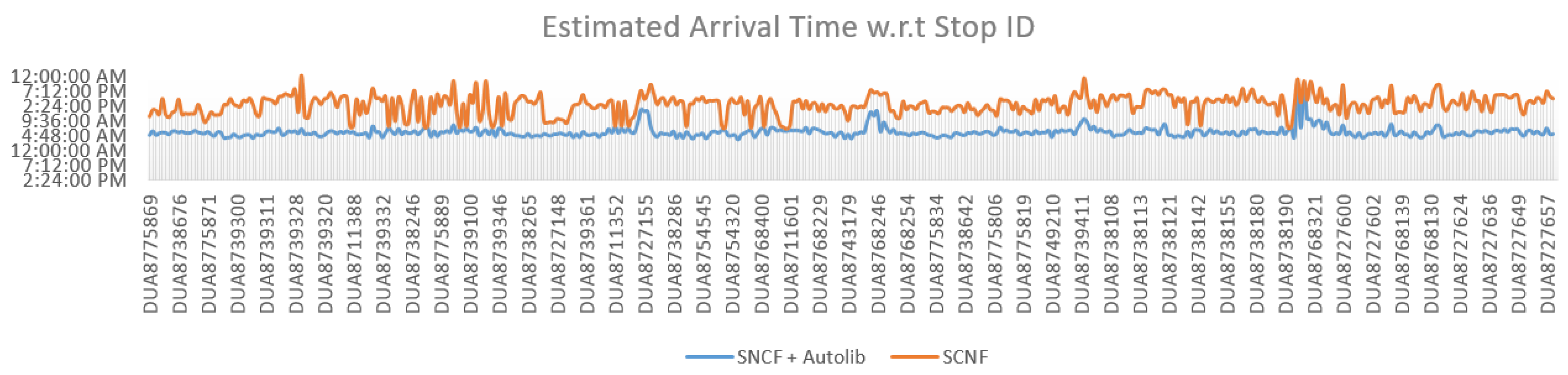
5.2.3. Calculating Routes Using Discovered Connections
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Gurstein, M.B. Open data: Empowering the empowered or effective data use for everyone? First Monday 2011. [Google Scholar] [CrossRef]
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked data-the story so far. Int. J. Semant. Web Inf. Syst. 2009, 5, 1–22. [Google Scholar] [CrossRef]
- Plu, J.; Scharffe, F. Publishing and linking transport data on the web: Extended version. In Proceedings of the First International Workshop on Open Data, Nantes, France, 25 May 2012; pp. 62–69.
- Consoli, S.; Mongiovì, M.; Recupero, D.R.; Peroni, S.; Gangemi, A.; Nuzzolese, A.G.; Presutti, V. Producing linked data for smart cities: The case of Catania. Big Data Res. 2016. [Google Scholar] [CrossRef]
- Euzenat, J. An API for ontology alignment. In The Semantic Web–ISWC 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 698–712. [Google Scholar]
- Euzenat, J.; Shvaiko, P. Ontology Matching; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Shvaiko, P.; Euzenat, J. A survey of schema-based matching approaches. In Journal on Data Semantics IV; Springer: Berlin/Heidelberg, Germany, 2005; pp. 146–171. [Google Scholar]
- Segev, A.; Kantola, J.; Jung, C.; Lee, J. Analyzing multilingual knowledge innovation in patents. Expert Syst. Appl. 2013, 40, 7010–7023. [Google Scholar] [CrossRef]
- Rahm, E.; Bernstein, P.A. A survey of approaches to automatic schema matching. VLDB J. 2001, 10, 334–350. [Google Scholar] [CrossRef]
- Kalfoglou, Y.; Schorlemmer, M. Ontology mapping: The state of the art. Knowl. Eng. Rev. 2003, 18, 1–31. [Google Scholar] [CrossRef]
- Wache, H.; Voegele, T.; Visser, U.; Stuckenschmidt, H.; Schuster, G.; Neumann, H.; Hübner, S. Ontology-based integration of information-a survey of existing approaches. In IJCAI-01 Workshop: Ontologies and Information Sharing; Citeseer: Princeton, NJ, USA, 2001; pp. 108–117. [Google Scholar]
- Bernstein, P.A.; Madhavan, J.; Rahm, E. Generic schema matching, ten years later. Proc. VLDB Endow. 2011, 4, 695–701. [Google Scholar]
- Shvaiko, P.; Euzenat, J. Ontology matching: State of the art and future challenges. IEEE Trans. Knowl. Data Eng. 2013, 25, 158–176. [Google Scholar] [CrossRef] [Green Version]
- Daskalaki, E.; Flouris, G.; Fundulaki, I.; Saveta, T. Instance matching benchmarks in the era of Linked Data. Web Semant. Sci. Serv. Agents World Wide Web 2016, 39, 1–14. [Google Scholar] [CrossRef]
- Zaiss, K.; Conrad, S.; Vater, S. A benchmark for testing instance-based ontology matching methods. In Proceedings of the 17th International Conference Knowledge Engineering and Knowledge Management, Lisbon, Portugal, 11–15 October 2010.
- Dai, B.T.; Koudas, N.; Srivastava, D.; Tung, A.K.; Venkatasubramanian, S. Validating multi-column schema matchings by type. In Proceedings of the 2008 IEEE 24th International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008.
- Warren, R.H.; Tompa, F.W. Multi-column substring matching for database schema translation. In Proceedings of the 32nd International Conference on Very Large Data Bases, Seoul, Korea, 12–15 September 2006.
- Bohannon, P.; Elnahrawy, E.; Fan, W.; Flaster, M. Putting context into schema matching. In Proceedings of the 32nd International Conference on Very Large Data Bases, Seoul, Korea, 12–15 September 2006.
- Partyka, J.; Parveen, P.; Khan, L.; Thuraisingham, B.; Shekhar, S. Enhanced geographically typed semantic schema matching. Web Semant. Sci. Serv. Agents World Wide Web 2011, 9, 52–70. [Google Scholar] [CrossRef]
- Li, W.S.; Clifton, C. SEMINT: A tool for identifying attribute correspondences in heterogeneous databases using neural networks. Data Knowl. Eng. 2000, 33, 49–84. [Google Scholar] [CrossRef]
- Embley, D.W.; Xu, L.; Ding, Y. Automatic direct and indirect schema mapping: Experiences and lessons learned. ACM SIGMOD Rec. 2004, 33, 14–19. [Google Scholar] [CrossRef]
- Brauner, D.F.; Intrator, C.; Freitas, J.C.; Casanova, M.A. An instance-based approach for matching export schemas of geographical database web services. In Proceedings of the IX Brazilian Symposium on Geoinformatics, São Paulo, Brazil, 25–28 November 2007.
- Feliachia, A.; Abadieb, N.; Hamdic, F. Matching and Visualizing Thematic Linked Data: An Approach Based on Geographic Reference Data; IOS Press: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Al-Salman, R.; Dylla, F.; Fogliaroni, P. Matching geo-spatial information by qualitative spatial relations. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Crowdsourced and Volunteered Geographic Information, Redondo Beach, CA, USA, 7–9 November 2012.
- Smid, M.; Kremen, P. OnGIS: Semantic Query Broker for Heterogeneous Geospatial Data Sources. Open J. Semant. Web (OJSW) 2016, 3, 32–50. [Google Scholar]
- Lüscher, P.; Burghardt, D.; Weibel, R. Matching road data of scales with an order of magnitude difference. In Proceedings of the XXIII International Cartographic Conference, Moscow, Russia, 4–10 August 2007.
- Yi, S.; Huang, B.; Wang, C. Pattern matching for heterogeneous geodata sources using attributed relational graph and probabilistic relaxation. Photogramm. Eng. Remote Sens. 2007, 73, 663–670. [Google Scholar] [CrossRef]
- Li, J.; Wang, Z.; Zhang, X.; Tang, J. Large scale instance matching via multiple indexes and candidate selection. Knowl.-Based Syst. 2013, 50, 112–120. [Google Scholar] [CrossRef]
- Jain, P.; Hitzler, P.; Sheth, A.P.; Verma, K.; Yeh, P.Z. Ontology alignment for linked open data. In The Semantic Web–ISWC 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 402–417. [Google Scholar]
- Ferrara, A.; Nikolov, A.; Noessner, J.; Scharffe, F. Evaluation of instance matching tools: The experience of OAEI. Web Semant. Sci. Serv. Agents World Wide Web 2013, 21, 49–60. [Google Scholar] [CrossRef]
- Isele, R.; Bizer, C. Active learning of expressive linkage rules using genetic programming. Web Semant. Sci. Serv. Agents World Wide Web 2013, 23, 2–15. [Google Scholar] [CrossRef]
- Scharffe, F.; Euzenat, J. MeLinDa: An interlinking framework for the web of data. Artif. Intell. 2011. [Google Scholar]
- Le Grange, J.J.; Lehmann, J.; Athanasiou, S.; Garcia-Rojas, A.; Giannopoulos, G.; Hladky, D.; Isele, R.; Ngomo, A.C.N.; Sherif, M.A.; Stadler, C.; et al. The GeoKnow Generator: Managing Geospatial Data in the Linked Data Web. In Proceedings of the Linking Geospatial Data, London, UK, 5–6 March 2014.
- Scharffe, F.; Atemezing, G.; Troncy, R.; Gandon, F.; Villata, S.; Bucher, B.; Hamdi, F.; Bihanic, L.; Képéklian, G.; Cotton, F.; et al. Enabling linked data publication with the Datalift platform. In Proceedings of the AAAI Workshop on Semantic Cities, Toronto, ON, Canada, 22–23 July 2012.
- Hamdi, F.; Abadie, N.; Bucher, B.; Feliachi, A. Geomrdf: A geodata converter with a fine-grained structured representation of geometry in the web. Int. Workshop Geospat. Linked Data arXiv 2015. [Google Scholar]
- Volz, J.; Bizer, C.; Gaedke, M.; Kobilarov, G. Silk-A Link Discovery Framework for the Web of Data. Linked Data Web 2009. [Google Scholar] [CrossRef]
- Ngomo, A.C.N.; Auer, S. Limes-a time-efficient approach for large-scale link discovery on the web of data. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011.
- Raimond, Y.; Sutton, C.; Sandler, M.B. Automatic interlinking of music datasets on the Semantic Web. In Proceedings of the Linked Data on the Web (LDOW 2008), Beijing, China, 22 April 2008.
- Hassanzadeh, O.; Lim, L.; Kementsietsidis, A.; Wang, M. A declarative framework for semantic link discovery over relational data. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009.
- Jaffri, A.; Glaser, H.; Millard, I. Managing URI synonymity to enable consistent reference on the Semantic Web. In Proceedings of the IRSW2008—Identity and Reference on the Semantic Web, Tenerife, Spain, 2 June 2008.
- Scharffe, F.; Liu, Y.; Zhou, C. Rdf-ai: An architecture for rdf datasets matching, fusion and interlink. In Proceedings of the IJCAI 2009 Workshop on Identity, Reference, and Knowledge Representation (IR-KR), Pasadena, CA, USA, 11 July 2009.
- Arnold, P.; Rahm, E. Enriching ontology mappings with semantic relations. Data Knowl. Eng. 2014, 93, 1–18. [Google Scholar] [CrossRef]
- Athanasiou, S.; Hladky, D.; Giannopoulos, G.; Garcia Rojas, A.; Lehmann, J. GeoKnow: Making the web an exploratory place for geospatial knowledge. ERCIM News 2014, 96, 12–13. [Google Scholar]
- Stadler, C.; Lehmann, J.; Höffner, K.; Auer, S. Linkedgeodata: A core for a web of spatial open data. Semant. Web 2012, 3, 333–354. [Google Scholar]
- Batet, M.; Harispe, S.; Ranwez, S.; Sánchez, D.; Ranwez, V. An information theoretic approach to improve semantic similarity assessments across multiple ontologies. Inf. Sci. 2014, 283, 197–210. [Google Scholar] [CrossRef]
- Cheatham, M.; Hitzler, P. String similarity metrics for ontology alignment. In Proceedings of the 12th International Semantic Web Conference, Sydney, Australia, 21–25 October 2013.
- Lesot, M.J.; Rifqi, M.; Benhadda, H. Similarity measures for binary and numerical data: A survey. Int. J. Knowl. Eng. Soft Data Paradig. 2008, 1, 63–84. [Google Scholar] [CrossRef]
- Dibbelt, J.; Pajor, T.; Strasser, B.; Wagner, D. Intriguingly simple and fast transit routing. In Experimental Algorithms; Springer: Berlin/Heidelberg, Germany, 2013; pp. 43–54. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Techniques | Output | Domain | |
|---|---|---|---|
| RKB-CRS [40] | String | owl:sameAs | Publications |
| GNAT [38] | String, similarity-propagation | owl:sameAs | Music |
| ODD-Linker [39] | String | link set | Independent |
| RDF-AI [41] | String, WordNet | alignment format | Independent |
| Silk [36] | String, numerical, date | owl:sameAs, user-specified | Independent |
| LIMES [37] | String, geographical, numerical, date | owl:sameAs, user-specified | Independent |
| Link++ | User-defined | User-defined | Independent |
| Formatted_Address | Lat | Lng | |
|---|---|---|---|
| stop_id | 0 | 35.750 | 39.625 |
| stop_code | 0 | 0 | 0 |
| stop_name | 11.875 | 0 | 0 |
| stop_desc | 1.375 | 0 | 0 |
| stop_lat | 0 | 296.875 | 5.375 |
| stop_lon | 0 | 0.625 | 14.375 |
| location_type | 0 | 0 | 0 |
| parent_station | 0 | 0 | 0 |
| Formatted_Address | Lat | Lng | |
|---|---|---|---|
| ID | 0 | 12.364 | 0.364 |
| Identifiant Autolib’ | 18.818 | 0 | 0 |
| Rue | 2.545 | 0 | 0 |
| Code postal | 0 | 0 | 0 |
| Ville | 27.636 | 0 | 0 |
| Coordonnees geo_0 | 0 | 5876.818 | 523.909 |
| Coordonnees geo_1 | 0 | 545.636 | 916.636 |
| Emplacement | 0 | 0 | 0 |
| Autolib’ | 1397 | 0 | 0 |
| Tiers | 0 | 0 | 0 |
| Abri | 0 | 0 | 0 |
| Precision | Recall | F-Measure | |
|---|---|---|---|
| SNCF 1 | 1 | 0.8 | 0.88 |
| Autolib 2 | 1 | 0.42 | 0.59 |
| Hospitals 3 | 1 | 0.8 | 0.88 |
| POI 4 | 1 | 1 | 1 |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Masri, A.; Zeitouni, K.; Kedad, Z.; Leroy, B. An Automatic Matcher and Linker for Transportation Datasets. ISPRS Int. J. Geo-Inf. 2017, 6, 29. https://doi.org/10.3390/ijgi6010029
Masri A, Zeitouni K, Kedad Z, Leroy B. An Automatic Matcher and Linker for Transportation Datasets. ISPRS International Journal of Geo-Information. 2017; 6(1):29. https://doi.org/10.3390/ijgi6010029
Chicago/Turabian StyleMasri, Ali, Karine Zeitouni, Zoubida Kedad, and Bertrand Leroy. 2017. "An Automatic Matcher and Linker for Transportation Datasets" ISPRS International Journal of Geo-Information 6, no. 1: 29. https://doi.org/10.3390/ijgi6010029
APA StyleMasri, A., Zeitouni, K., Kedad, Z., & Leroy, B. (2017). An Automatic Matcher and Linker for Transportation Datasets. ISPRS International Journal of Geo-Information, 6(1), 29. https://doi.org/10.3390/ijgi6010029