Contextual Building Selection Based on a Genetic Algorithm in Map Generalization



Abstract
1. Introduction
2. Related Work
3. Cartographic Selection from a GA Perspective
3.1. GA Summary
- Encoding: transforming solutions of a problem into gene representations.
- Initialization: generating a set of chromosomes that represent optional solutions to the problem.
- Selection: selecting individuals from the current population as parents for reproduction, based on their fitness values.
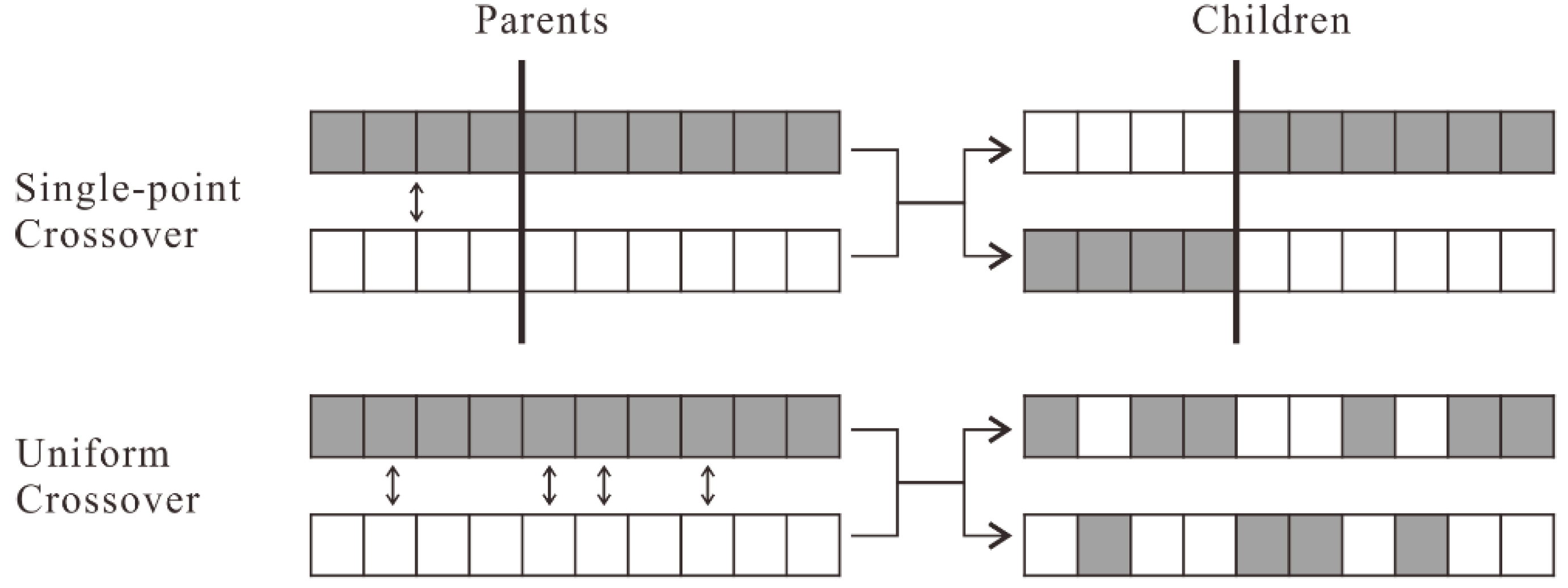
- Crossover: producing children by recombining the genes of two parents.
- Mutation: randomly selecting genes in an individual and replacing them by their allele to ensure diversity.
- Termination criterion: stopping the algorithm when the algorithm converges or when the number of iterations reaches a pre-specified value.
- Definition and expression of the solution to the problem, namely how to design the genes of an individual in the GA.
- Choice of appropriate genetic operators, such as selection, crossover, mutation, etc., to evolve the population of solutions.
- Definition of a fitness function to evaluate the quality of the solution with respect to a practical problem.
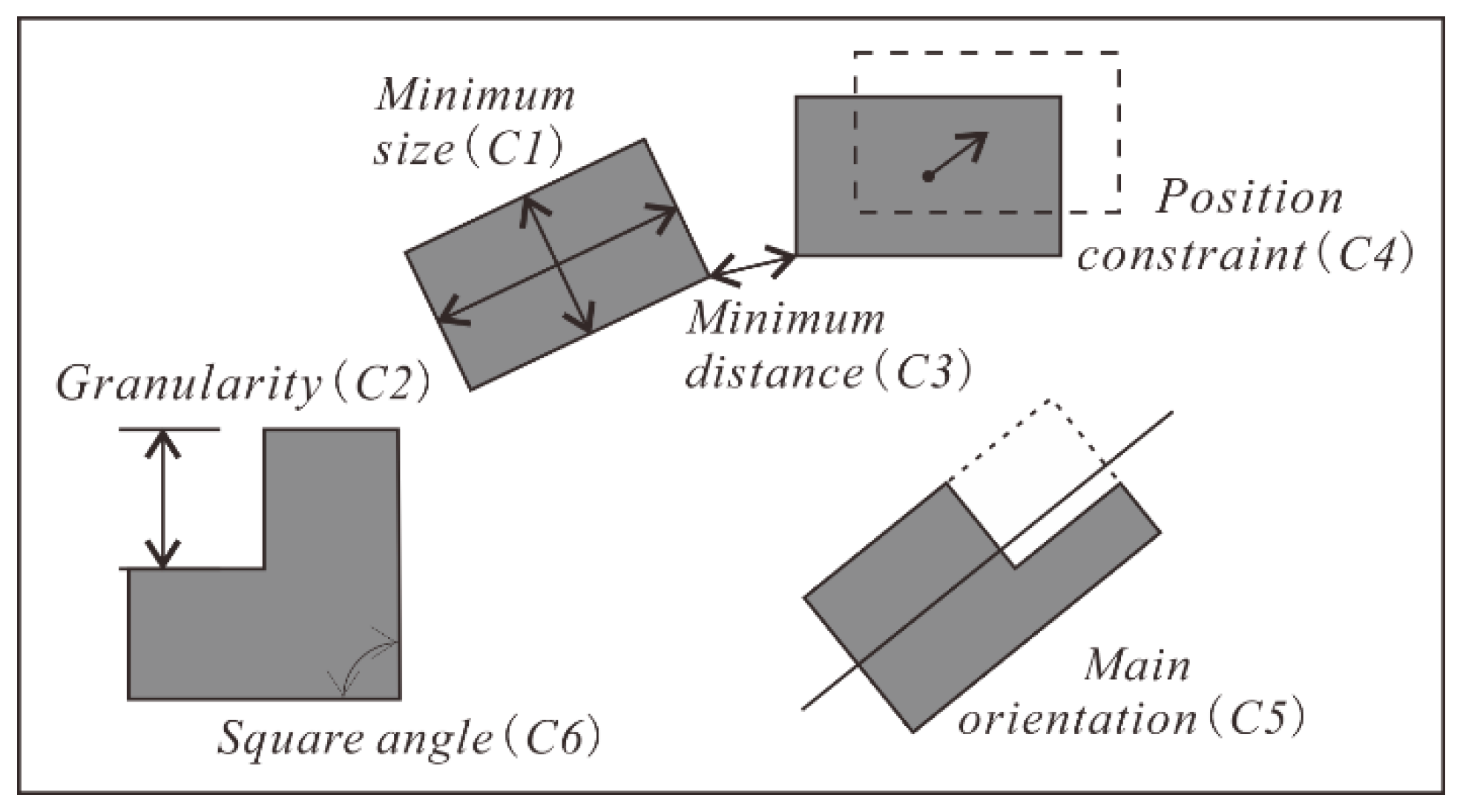
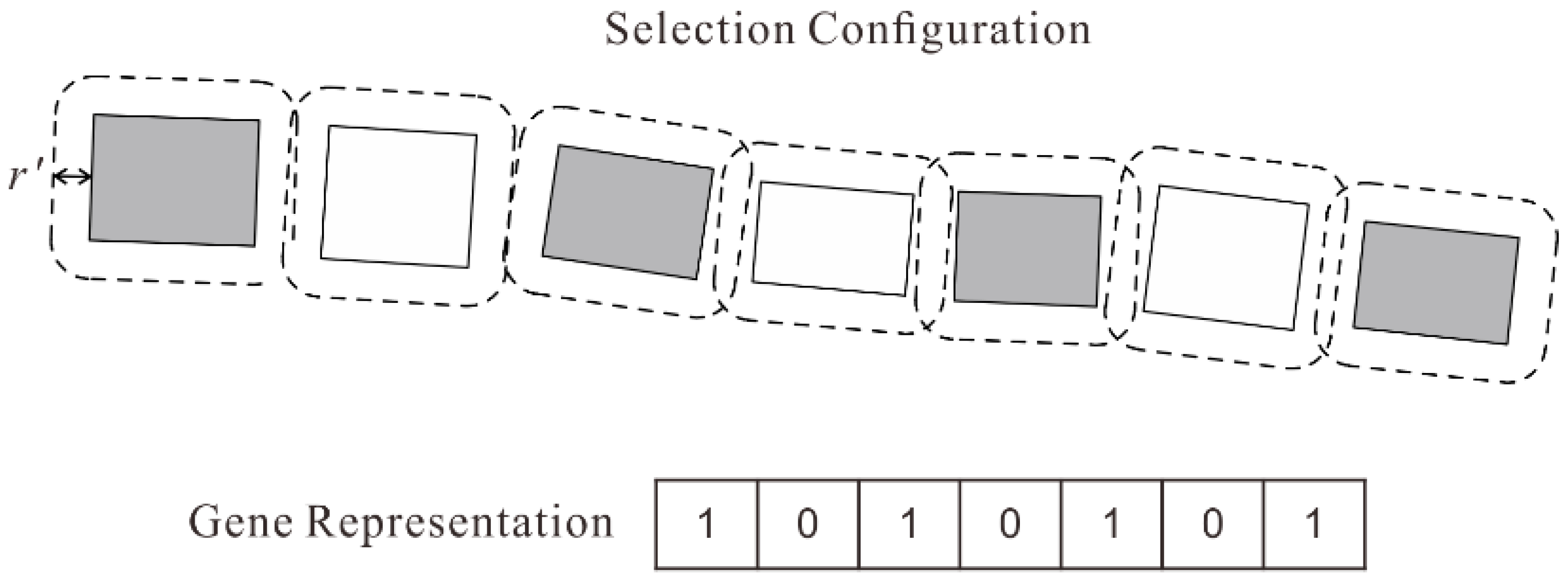
3.2. Selection Constraints
3.3. An Improved GA
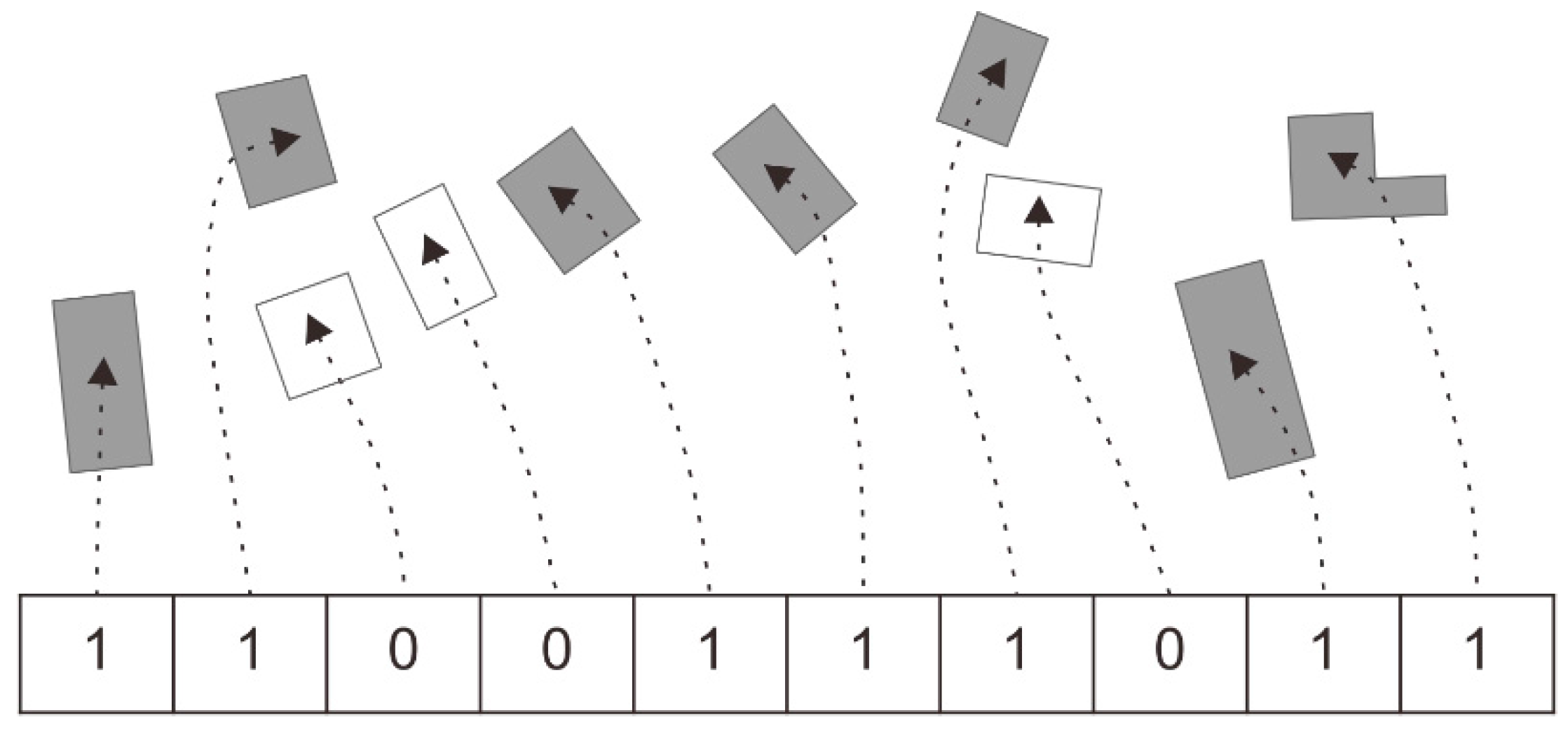
3.3.1. Encoding
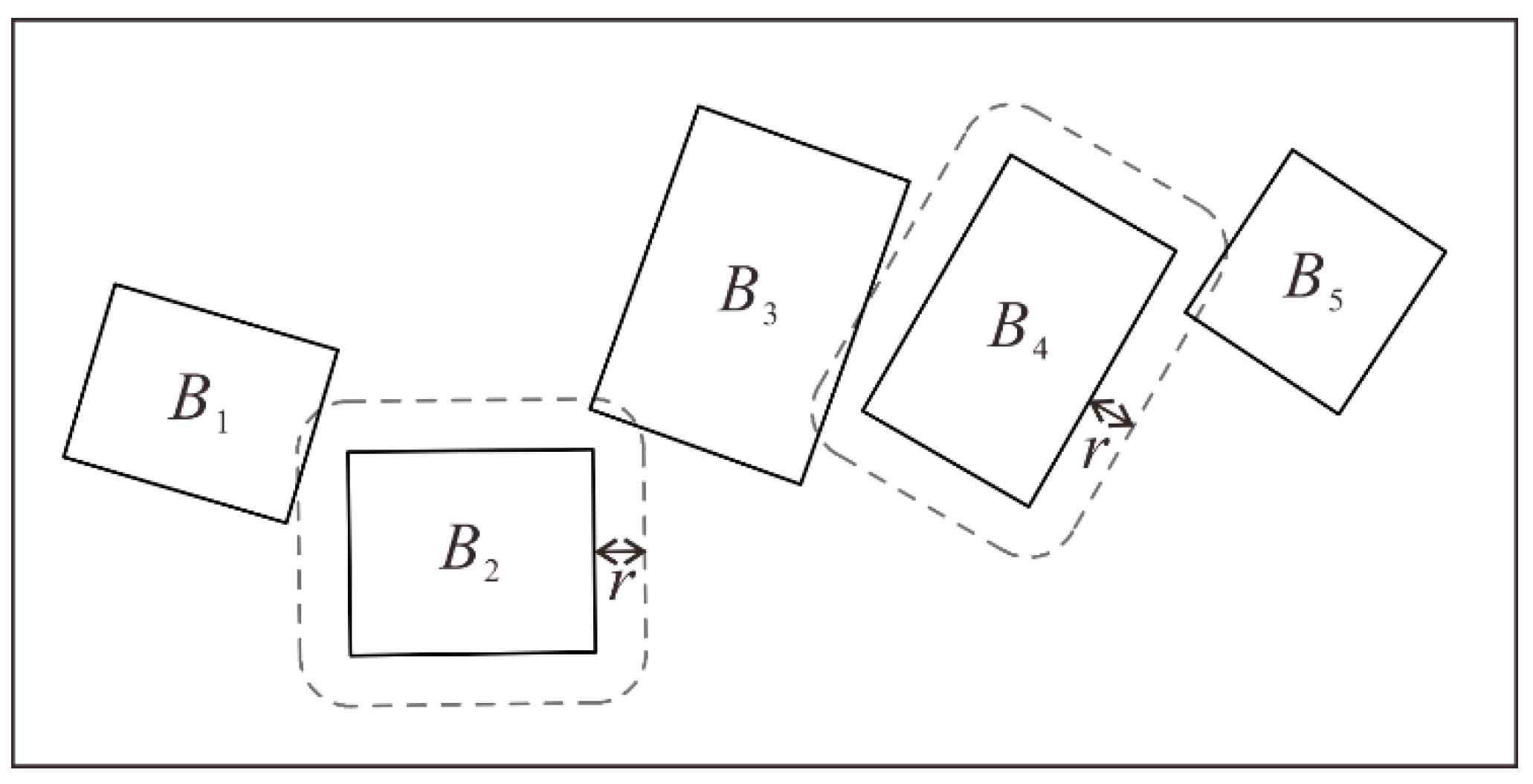
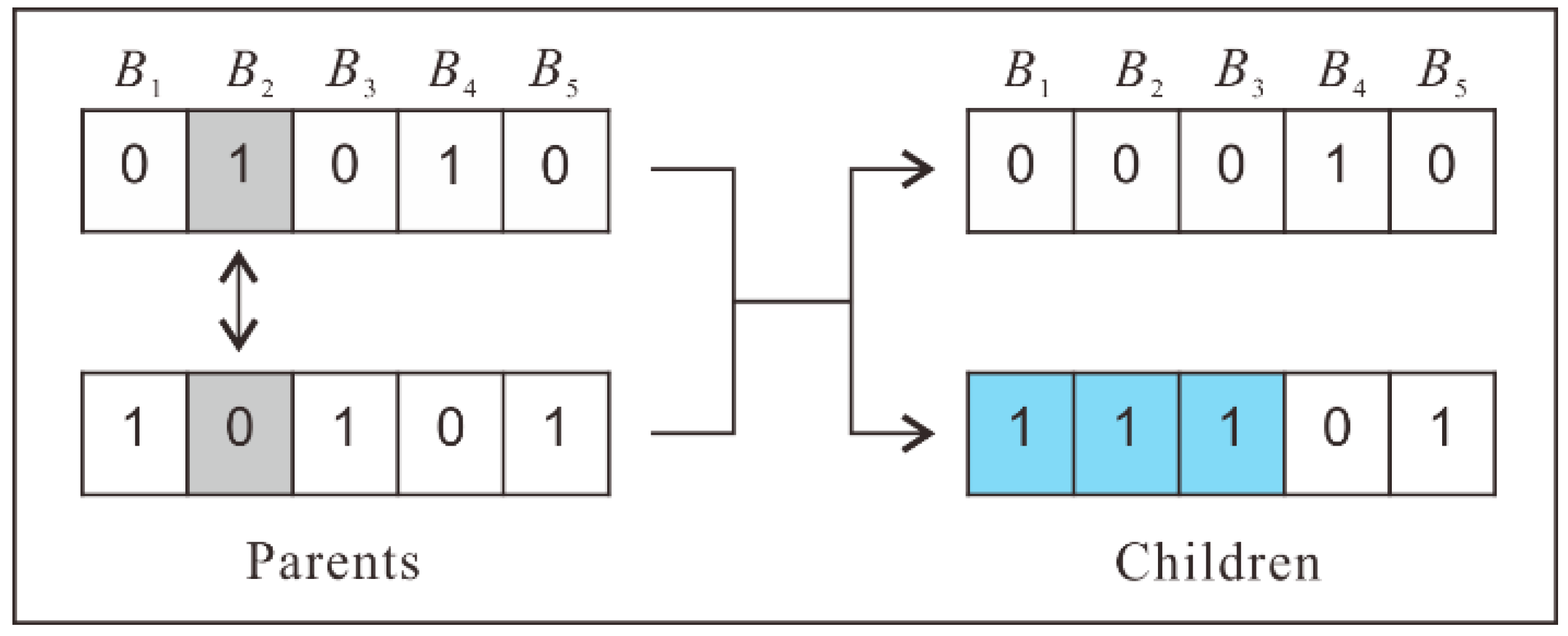
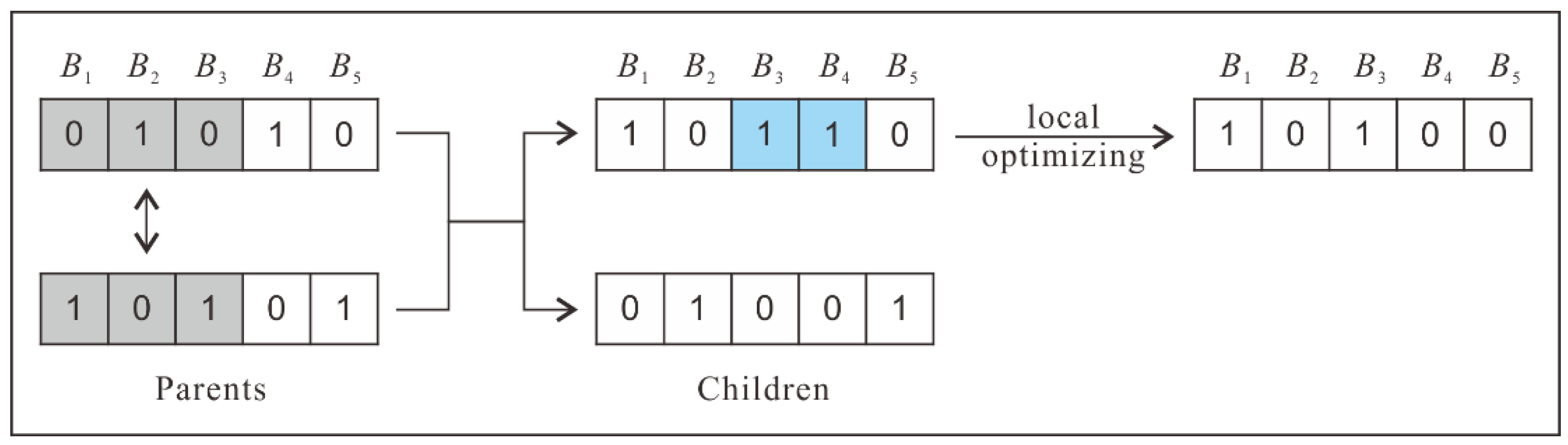
3.3.2. Crossover and Mutation by Considering Conflicting Blocks
3.3.3. Objective Function and Fitness Function
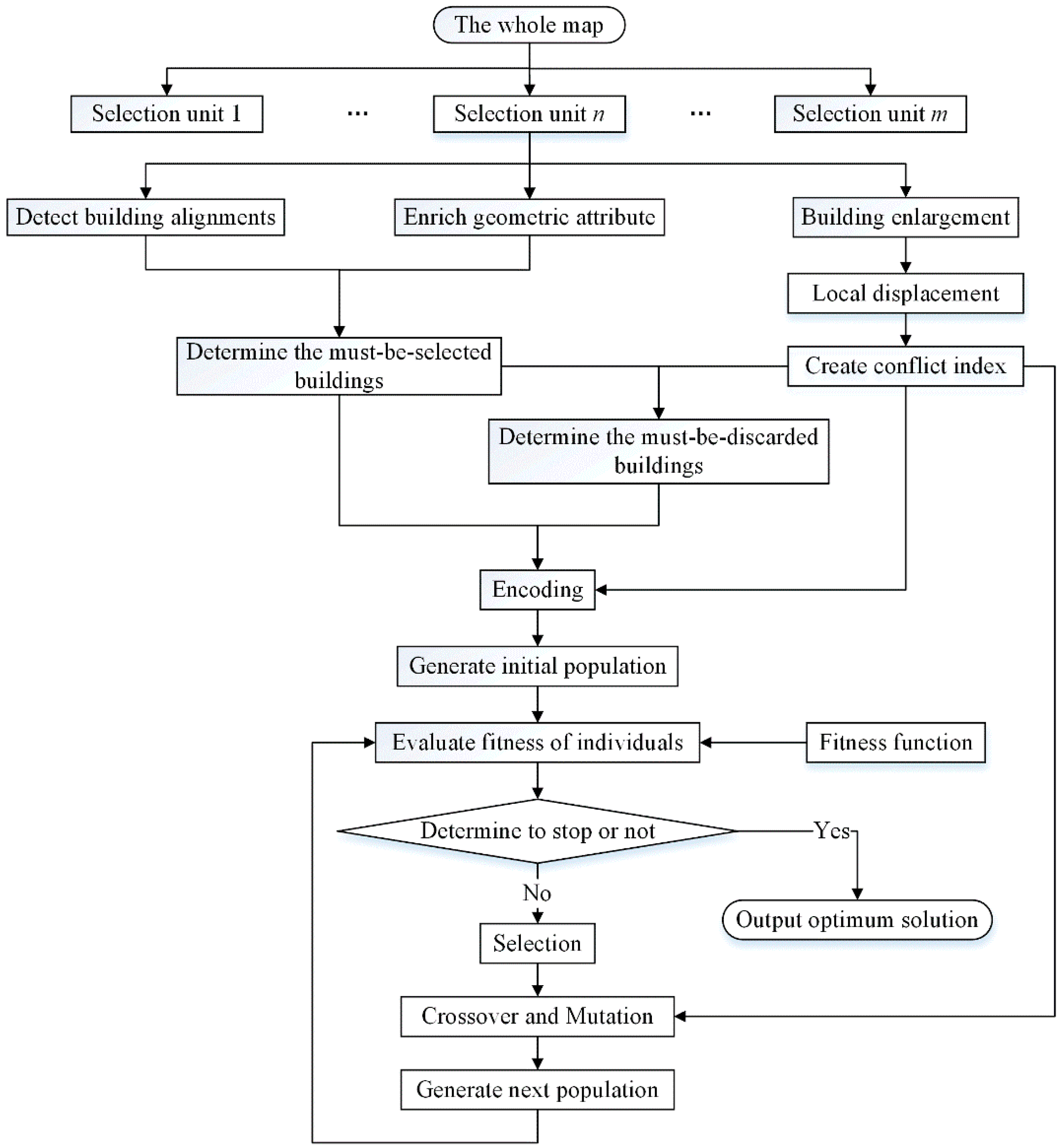
4. Implementation of the Proposed Method
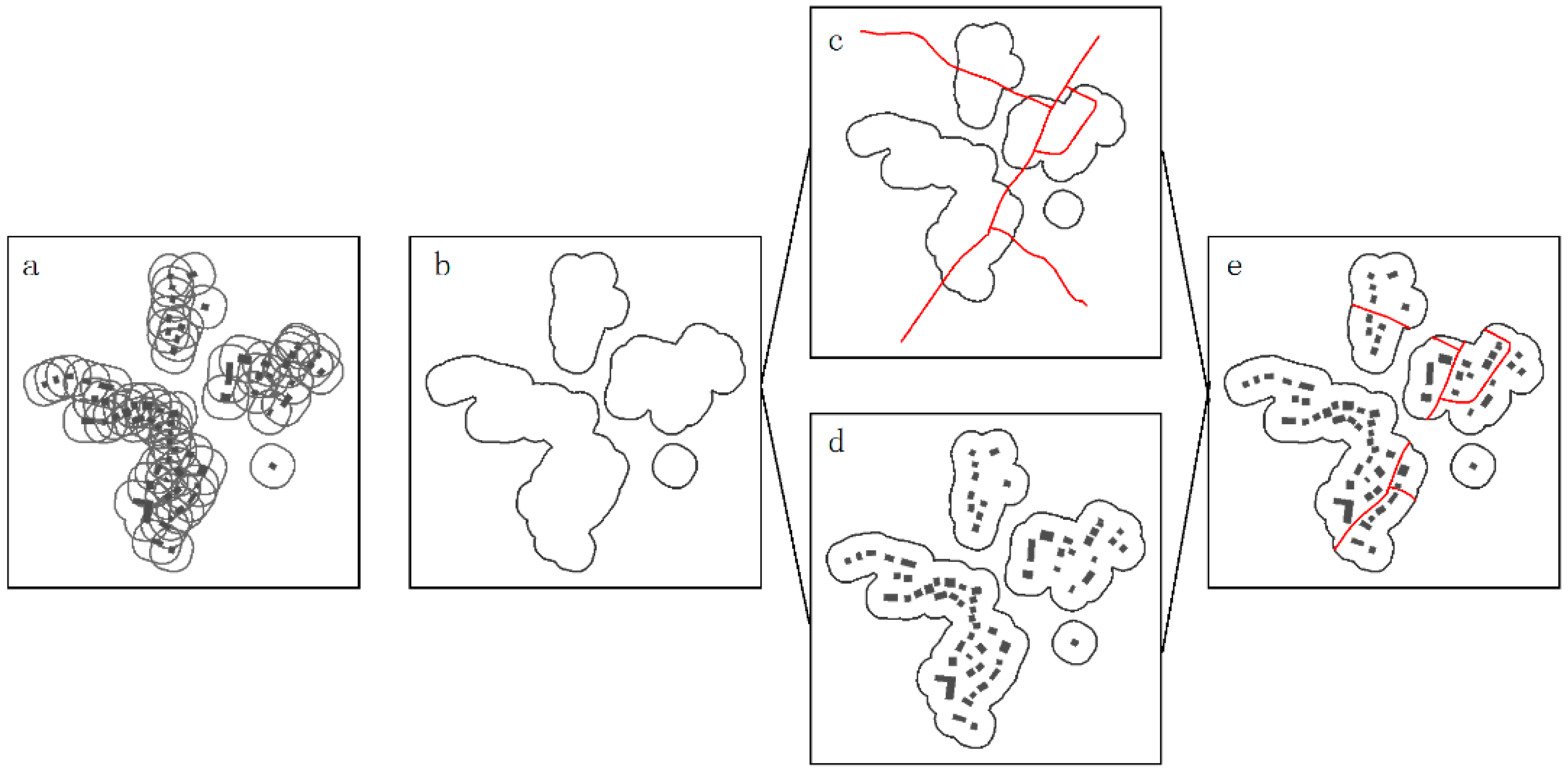
4.1. Extraction of Selection Units
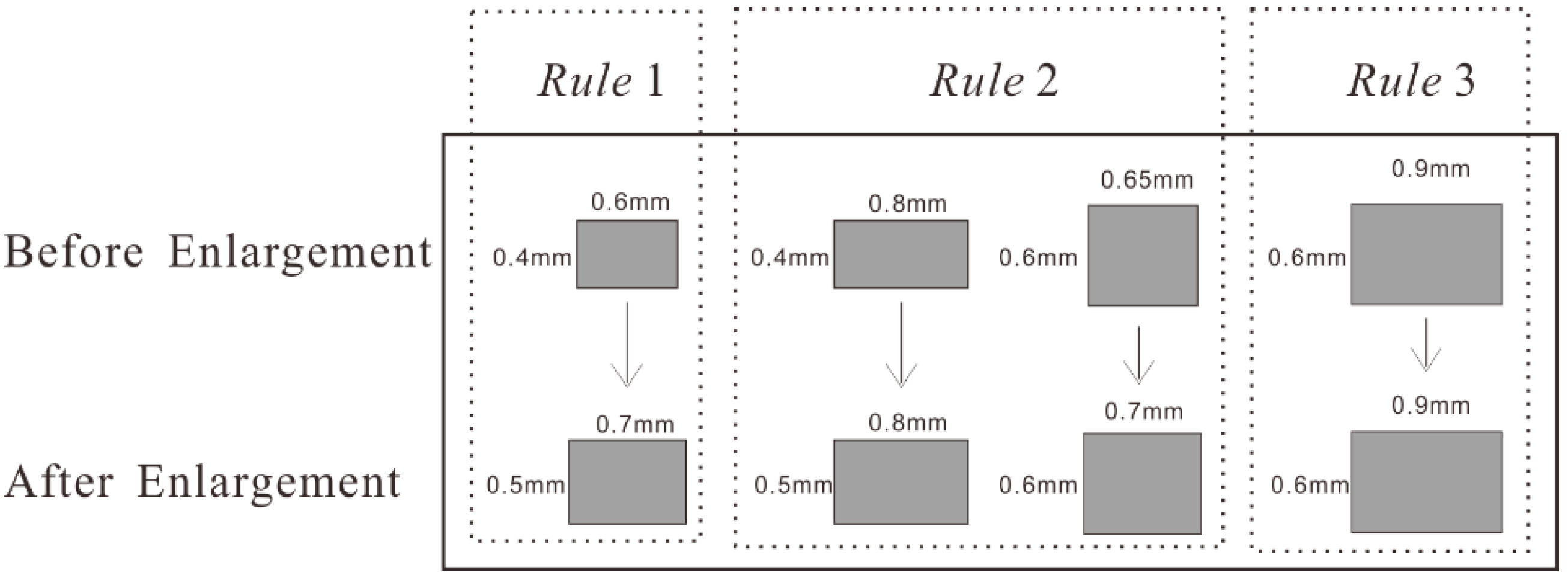
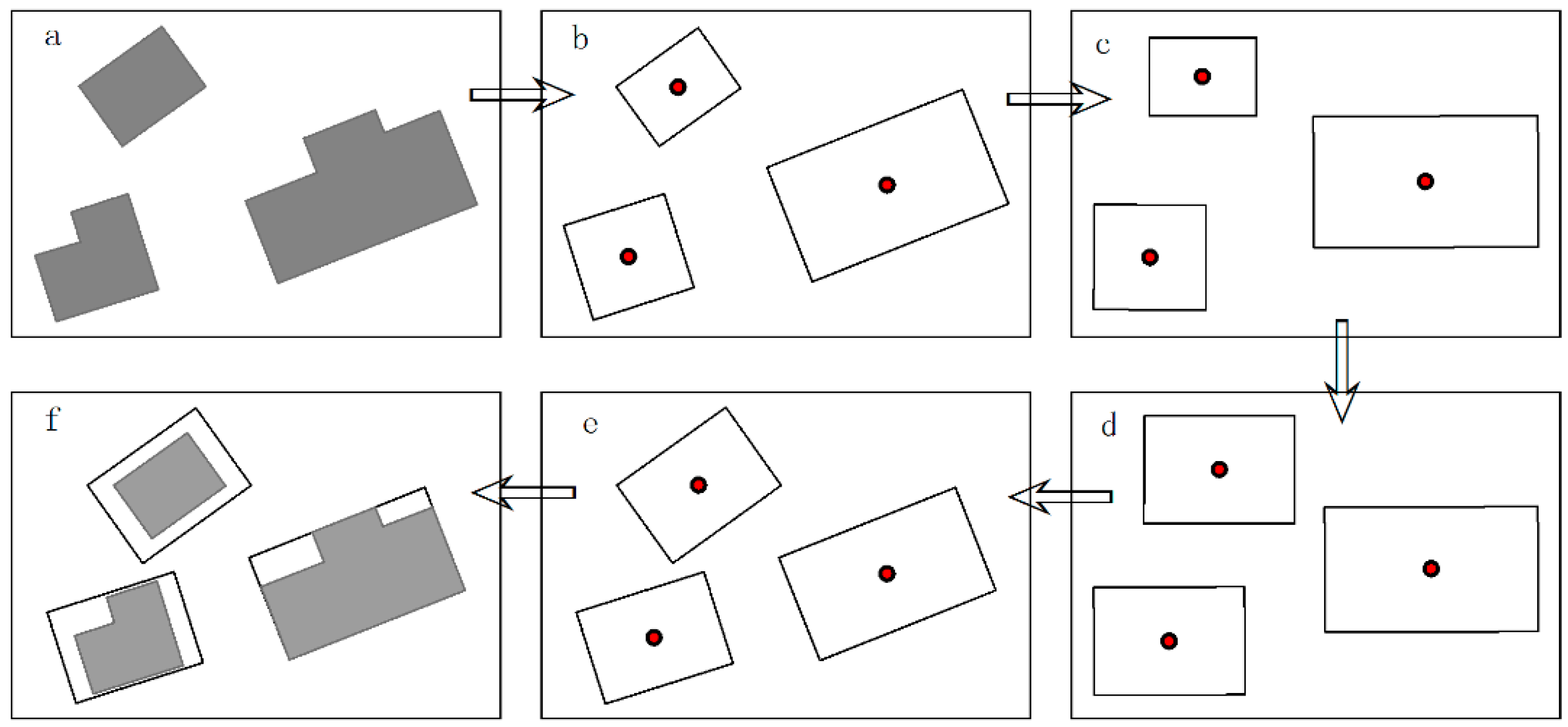
4.2. Building Enlargement
- Rule 1.
- If the graphic length and graphic width of a building are less than 0.7 mm and 0.5 mm, respectively, then replace the building with a predefined symbol of the appropriate size and orientation.
- Rule 2.
- If the graphic length of a building is larger than 0.7 mm, but its graphic width is less than 0.5 mm, then expand its symbol width to 0.5 mm. Similarly, if the graphic width of a building is larger than 0.5 mm, but its graphic length is less than 0.7 mm, then expand its symbol length to 0.7 mm.
- Rule 3.
- If the graphic length and graphic width of a building are larger than 0.7 mm and 0.5 mm, respectively, then represent them with their original outline.
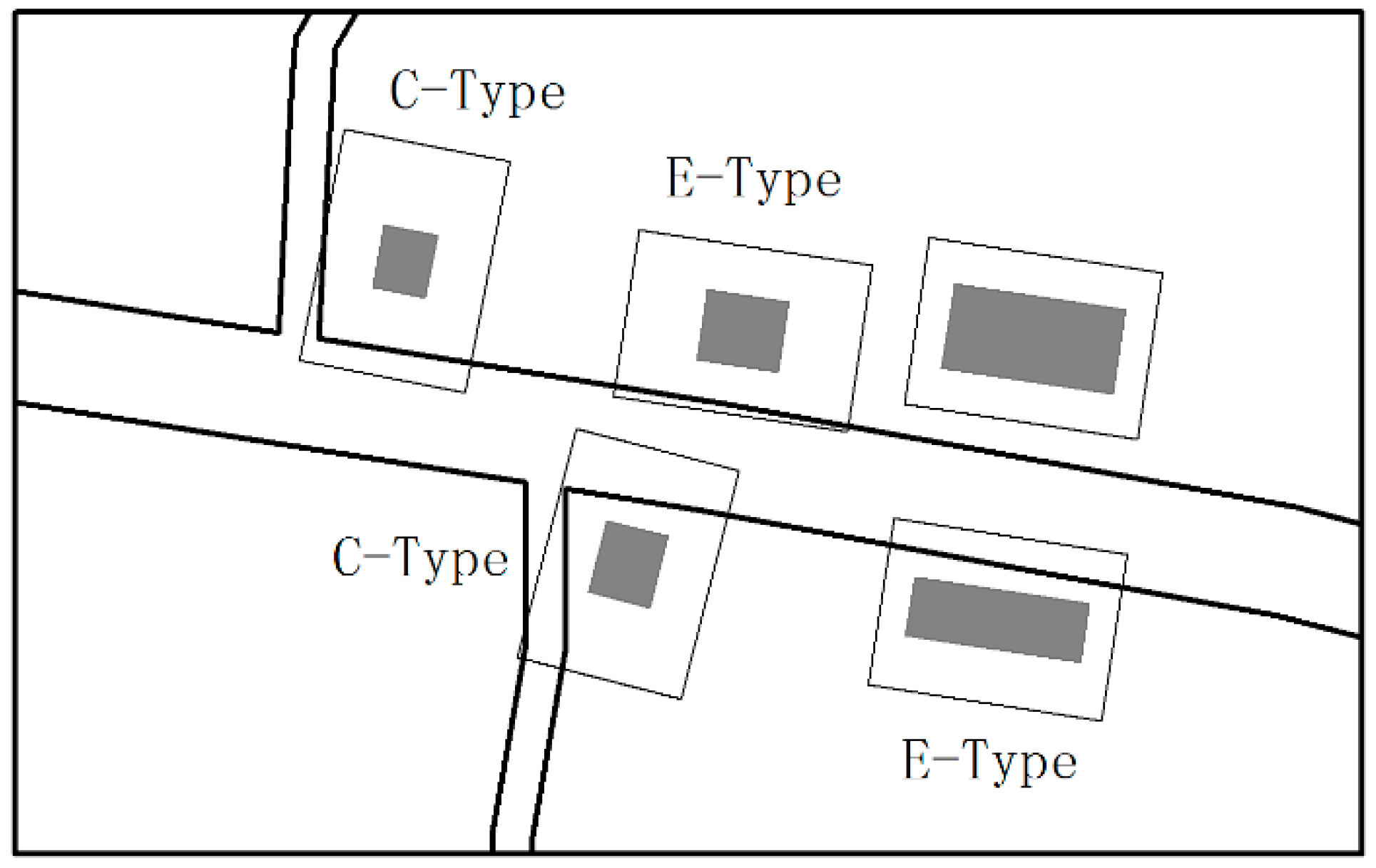
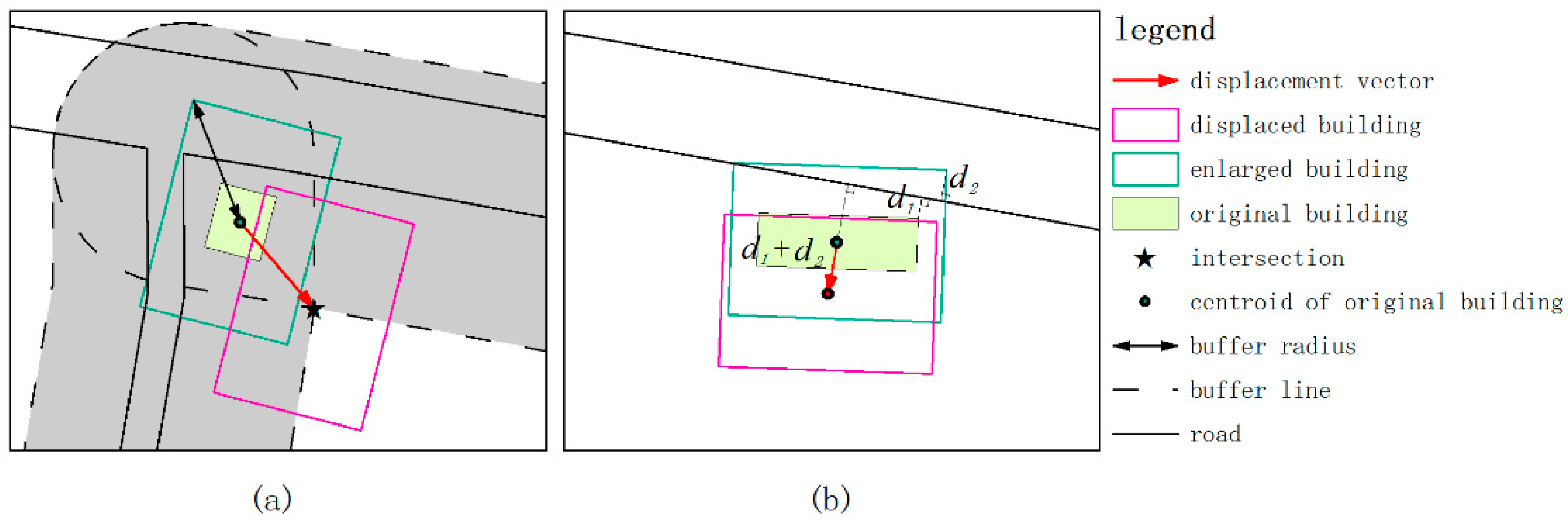
4.3. Local Displacement
- A C-type building is one that is located at a road corner and overlaps at least one of the roads.
- An E-type building is one that is located on one side of the road and only overlaps one of the roads.
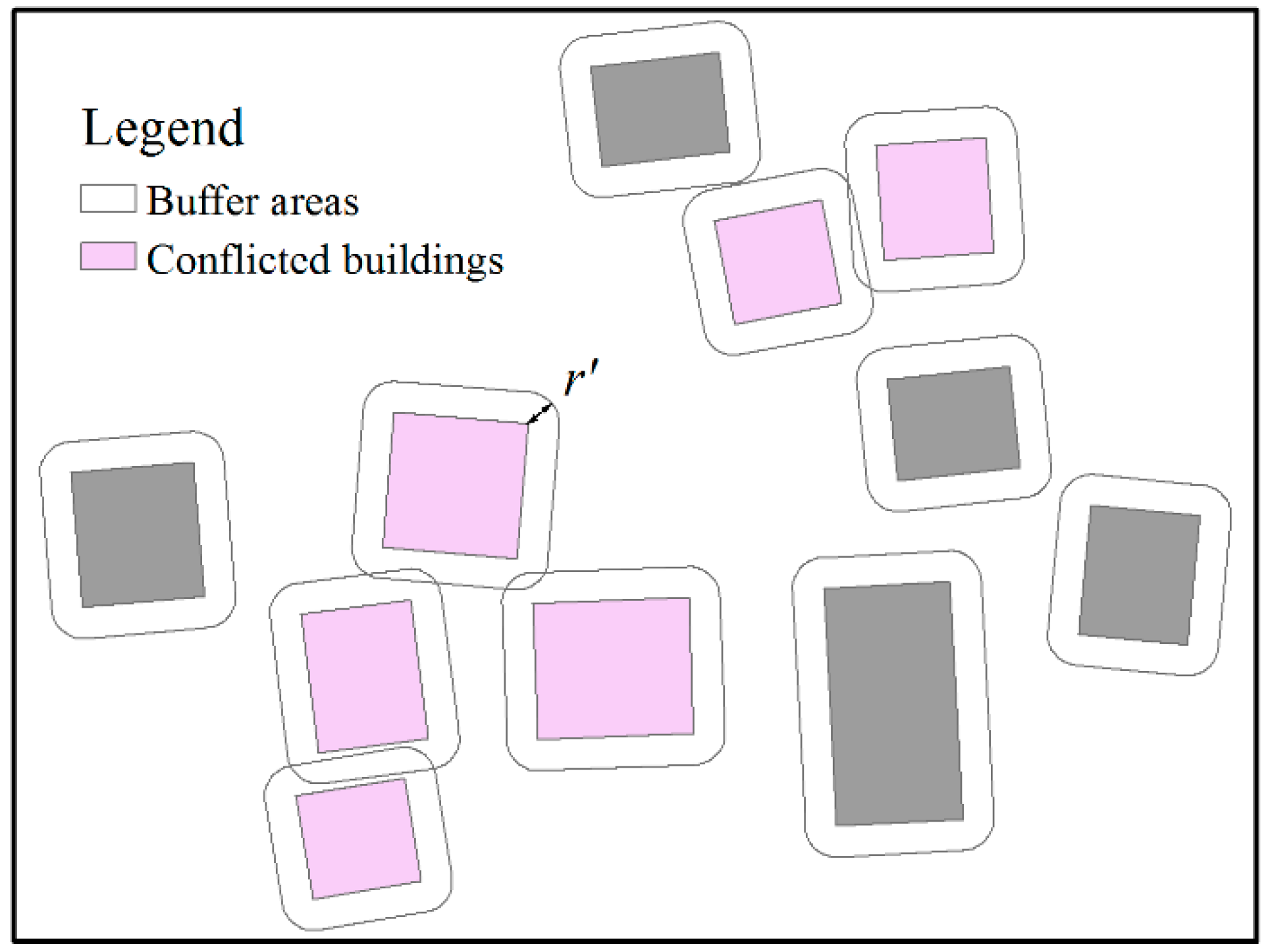
4.4. Conflict Detection among Buildings
4.5. Enrichment of Geometric Attributes
- (1)
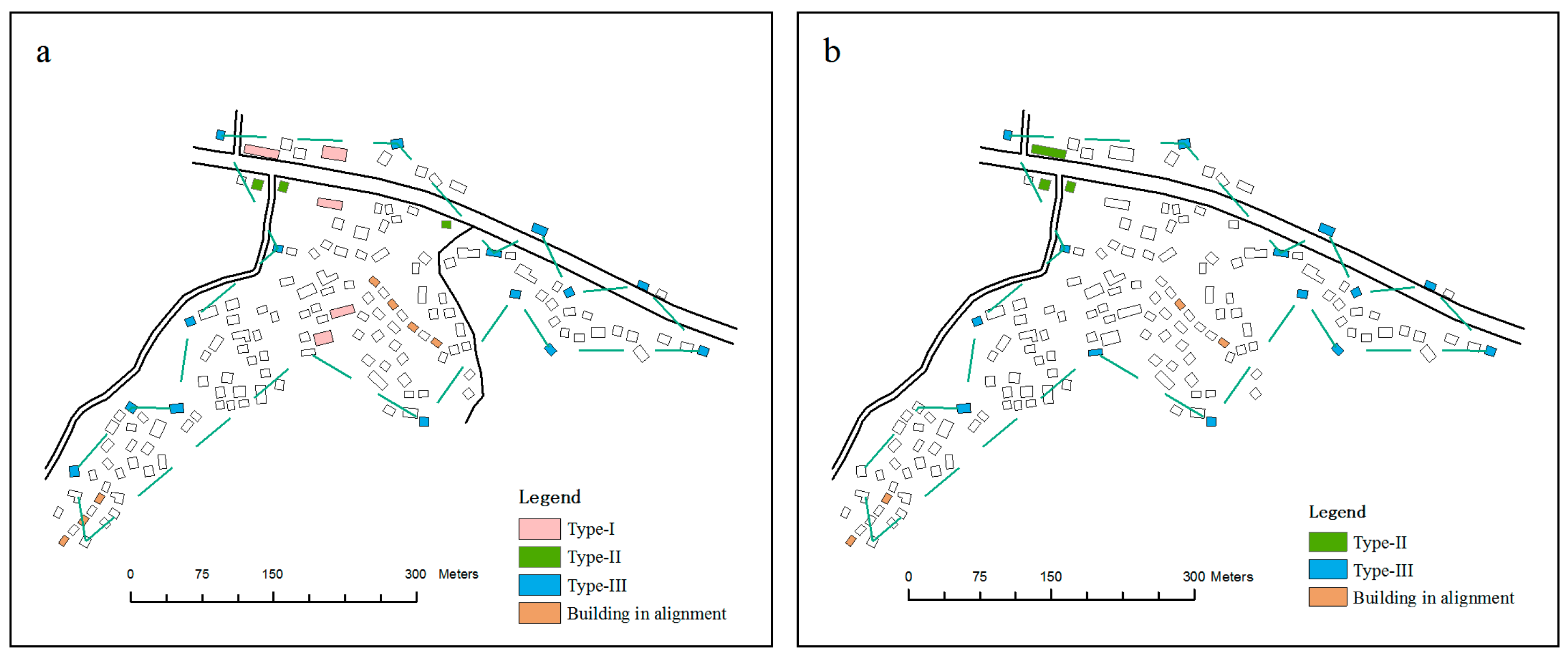
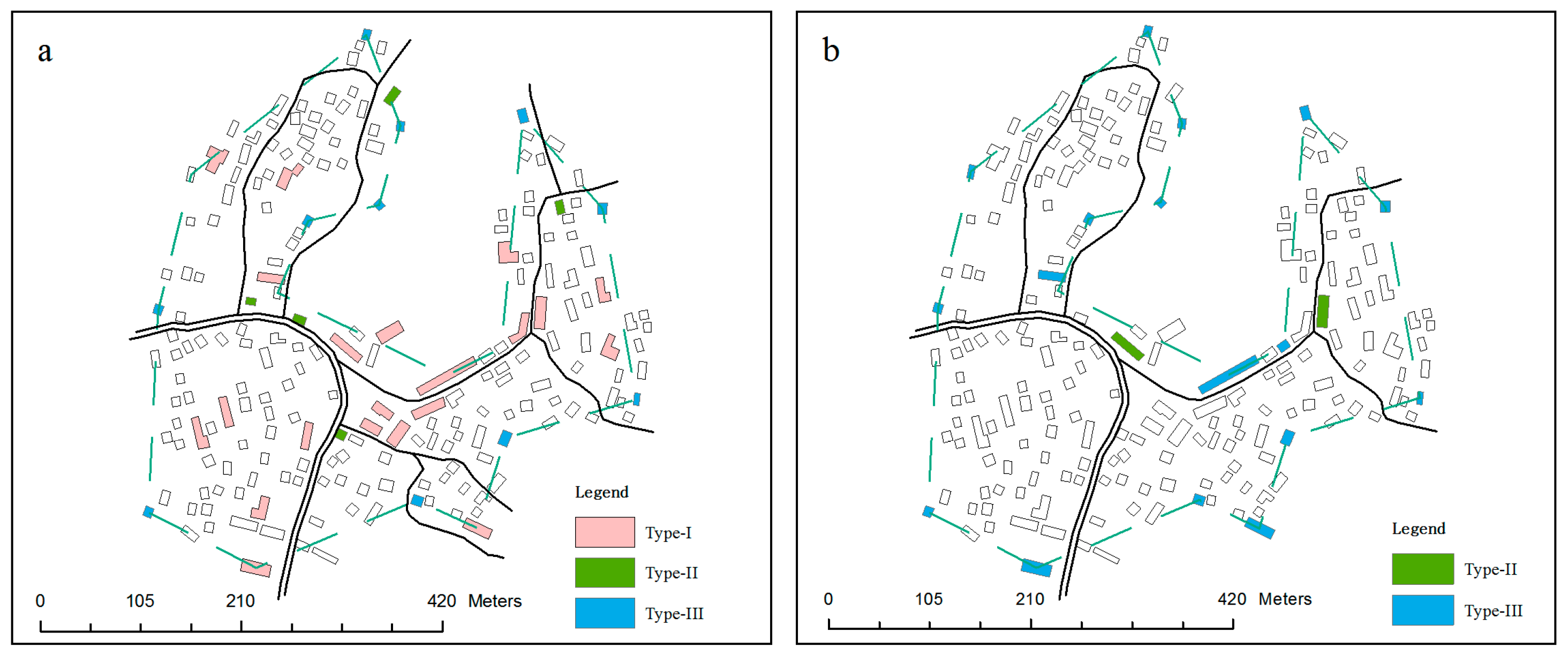
- A type I building is determined by simple area calculation and comparison to the minimum size threshold. According to the National Administration of Surveying [43], buildings with an area of more than 0.35 mm2 are considered to be of this type.
- (2)
- A type II building is identified on the basis of detecting the proximity relationship among buildings and roads. Before performing the GA on a selection unit, a proximity graph is constructed using the method proposed by Liu et al. [51]. It is then possible to obtain information as to whether a building is adjacent to a road and how close it is. Utilizing the information, a building that is adjacent to two or more roads and whose proximity distance to each road is less than a certain threshold (e.g., 15 m) can be defined as a type II building.
- (3)
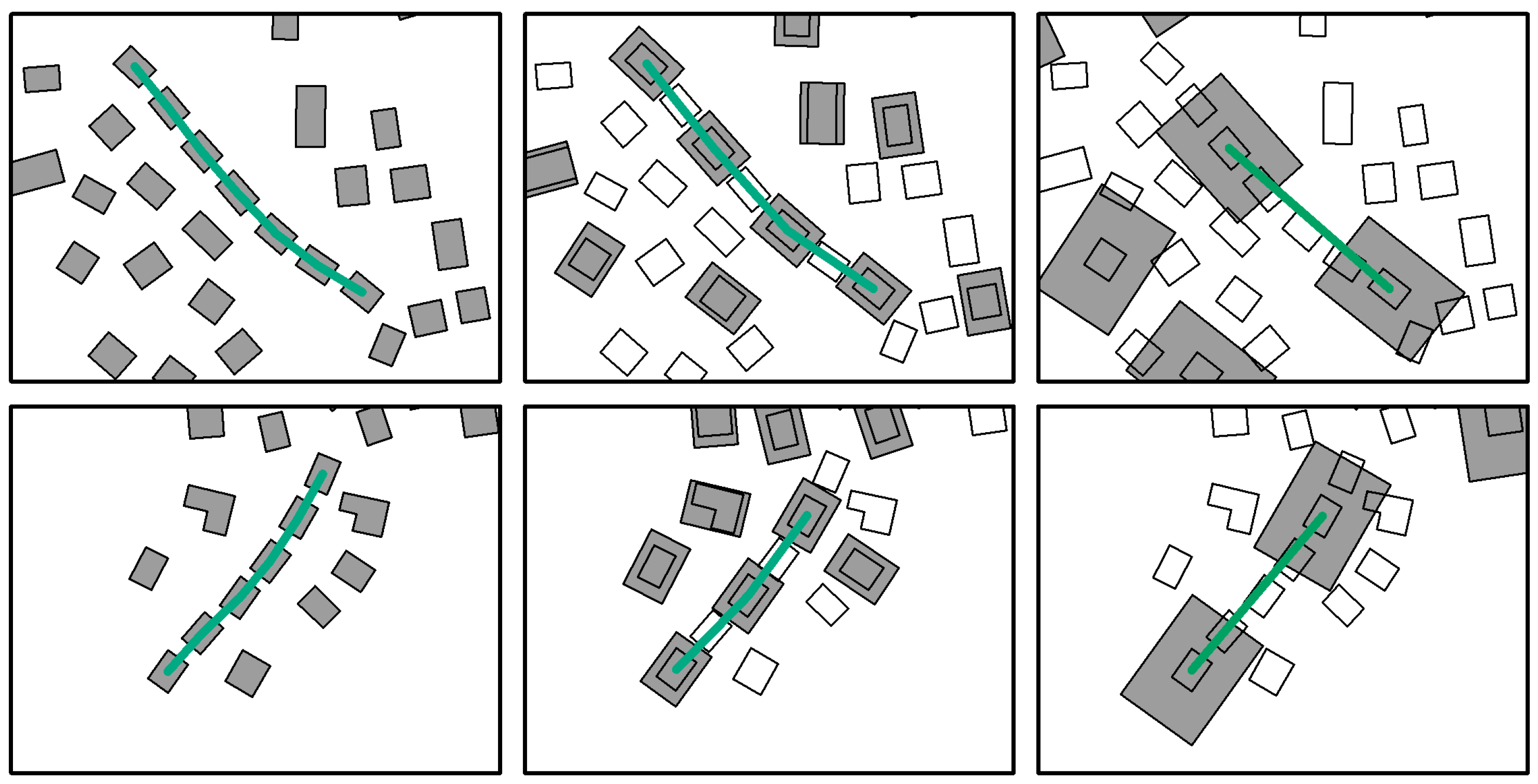
- To identify a type III building, the boundary of a settlement should be defined first. A boundary deriving method proposed by Yan and Weibel [17] is adopted after converting the building group to a point cluster. The buildings that overlap the generated boundary are called the boundary buildings. A type III building can be derived from these boundary buildings by performing a line reduction algorithm on the boundary line. The Douglas–Peucker algorithm [52] is preferred because it keeps all the key points that make up the basic shape of a line and removes the other points. The simplified tolerance in the algorithm is set to 25 m by experiment. The buildings corresponding to the points retained on the simplified line will be type III buildings.
4.6. Selection Based on the GA
4.6.1. Initialization
- (1)
- Mark all genes as ‘free’;
- (2)
- Assign the gene values corresponding with the must-be-selected buildings as 1 s and mark these genes as ‘fixed’;
- (3)
- Assign the gene values corresponding with the must-be-discarded buildings as 0 s and mark these genes as ‘fixed’;
- (4)
- Repeat the following steps until the number of genes assigned as 1 s reaches the target selection number or all the genes are marked as ‘fixed’;
- (4.1)
- Randomly select a ‘free’ building B and assign its gene as 1, then mark the gene as ‘fixed’;
- (4.2)
- Identify ‘free’ buildings from CB(B), assign the corresponding genes as 0 s and mark these genes as ‘fixed’;
4.6.2. Selection, Crossover, and Mutation
4.6.3. Iteration and the Elite Retention Strategy
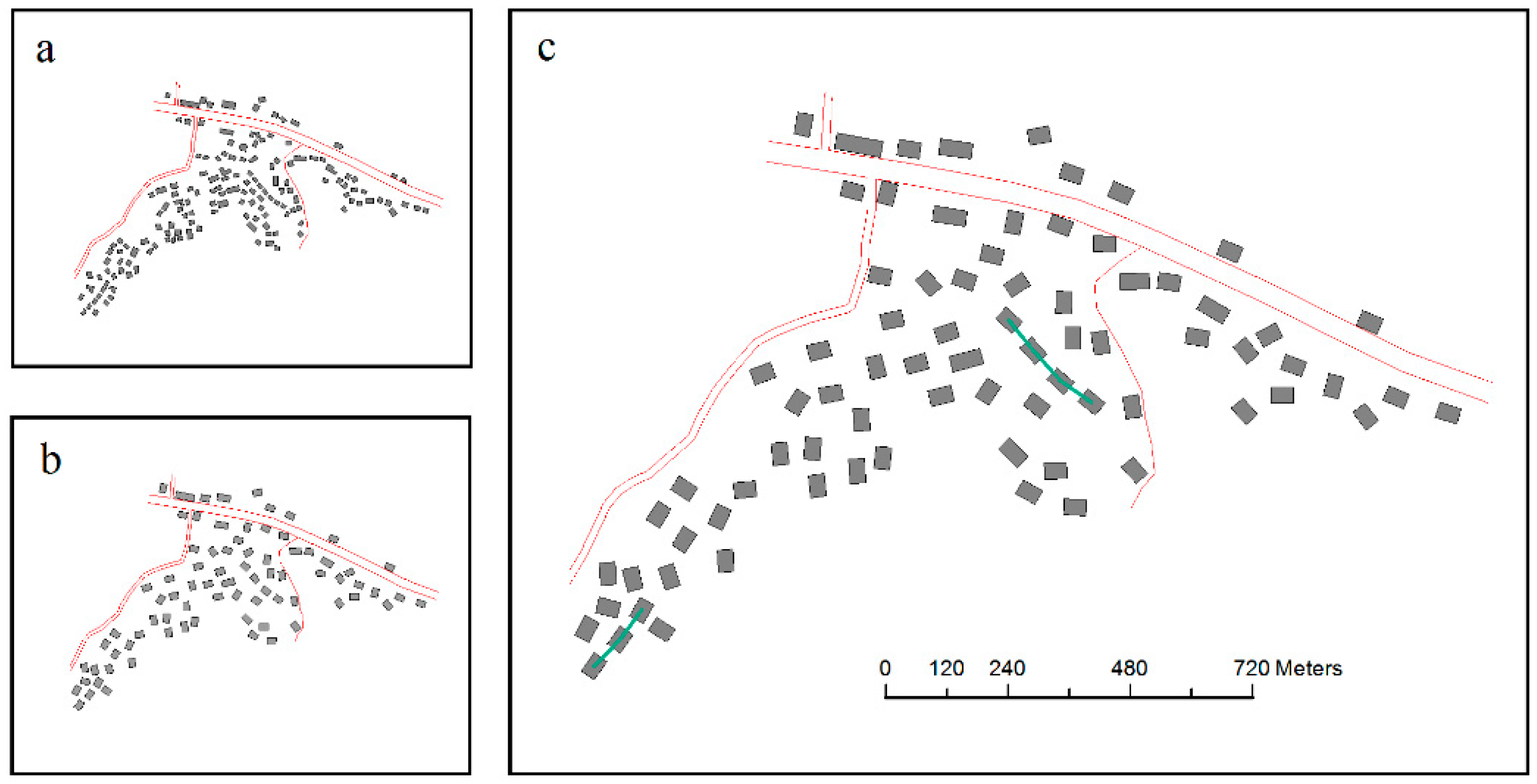
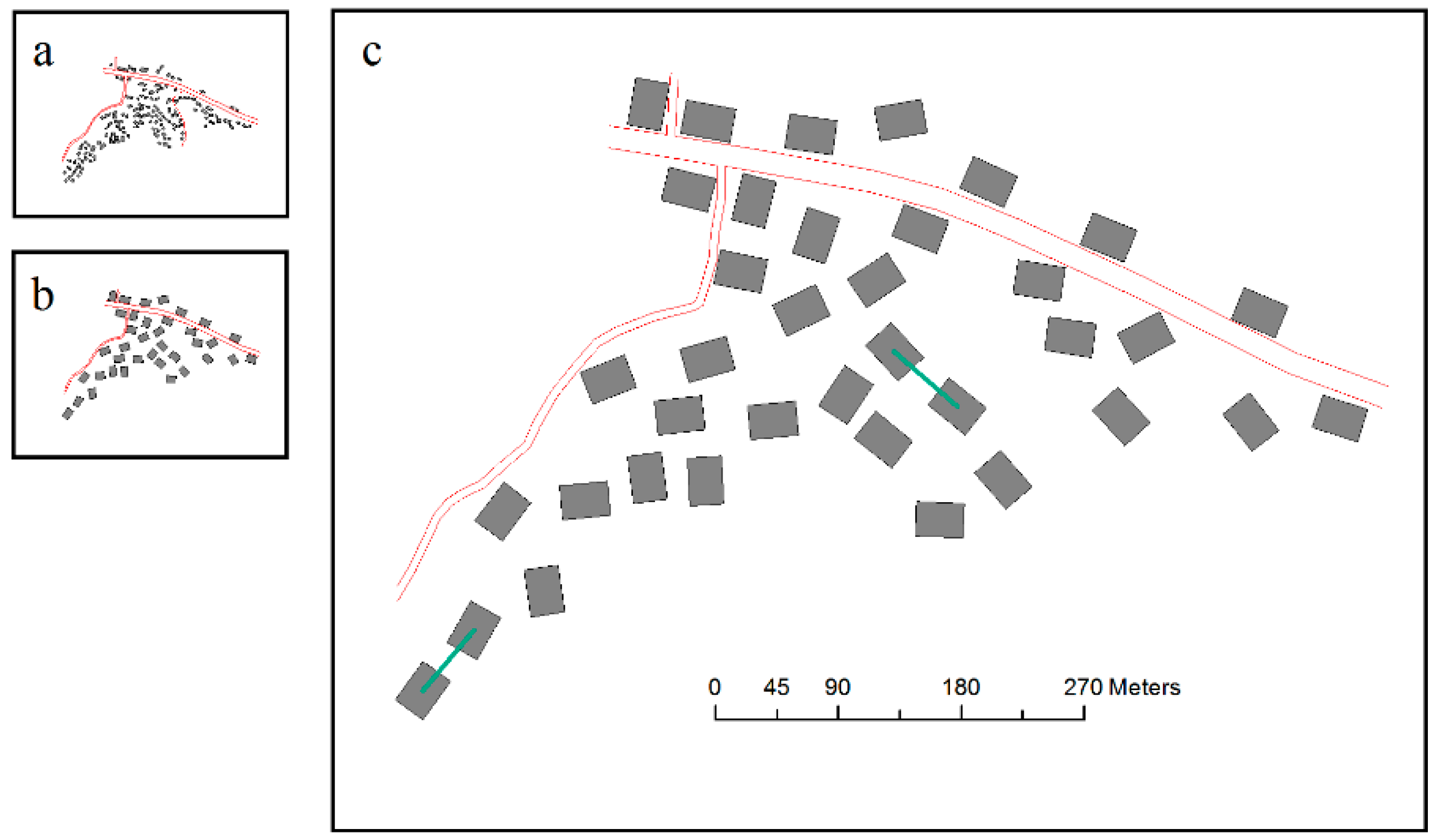
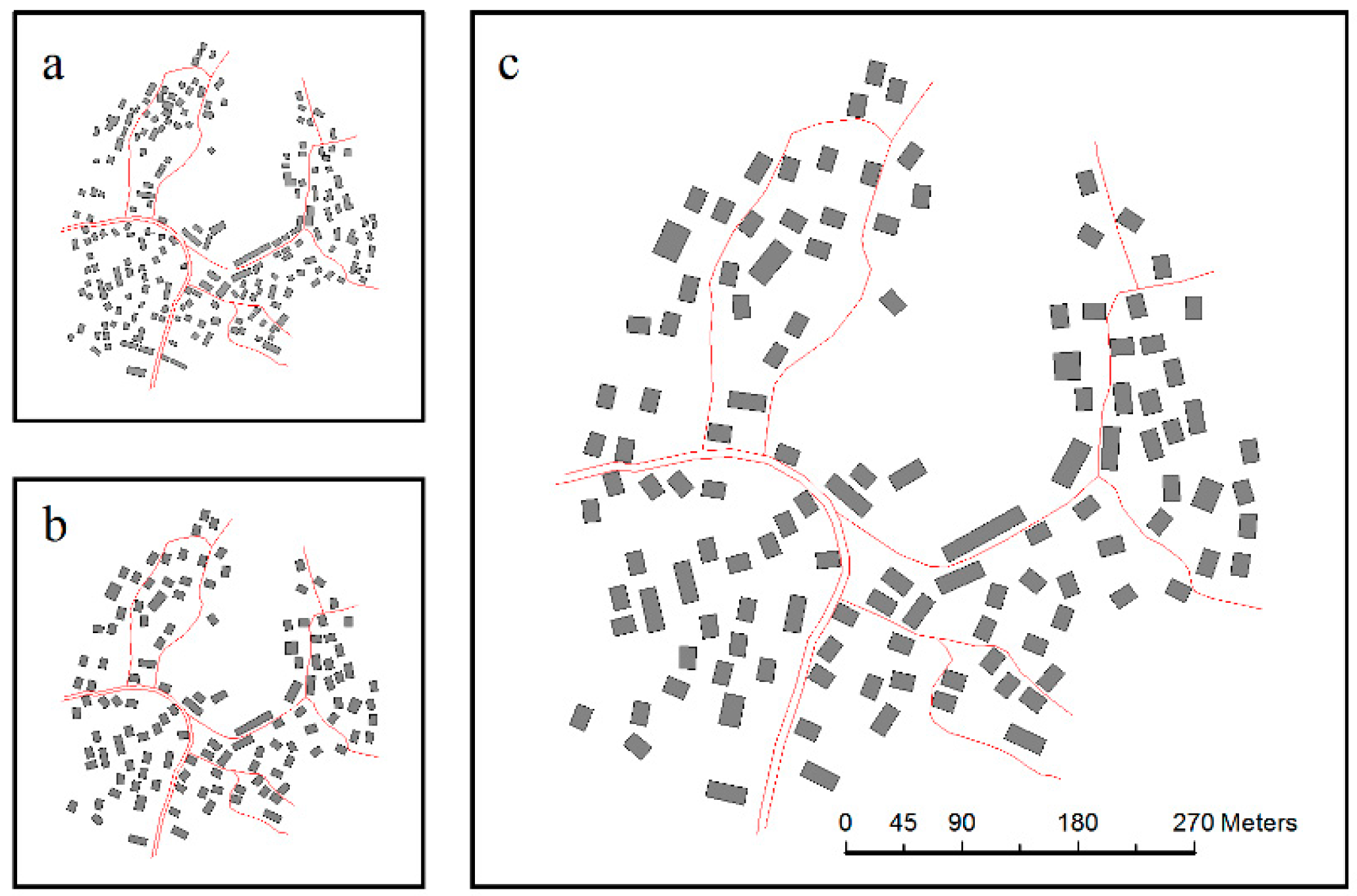
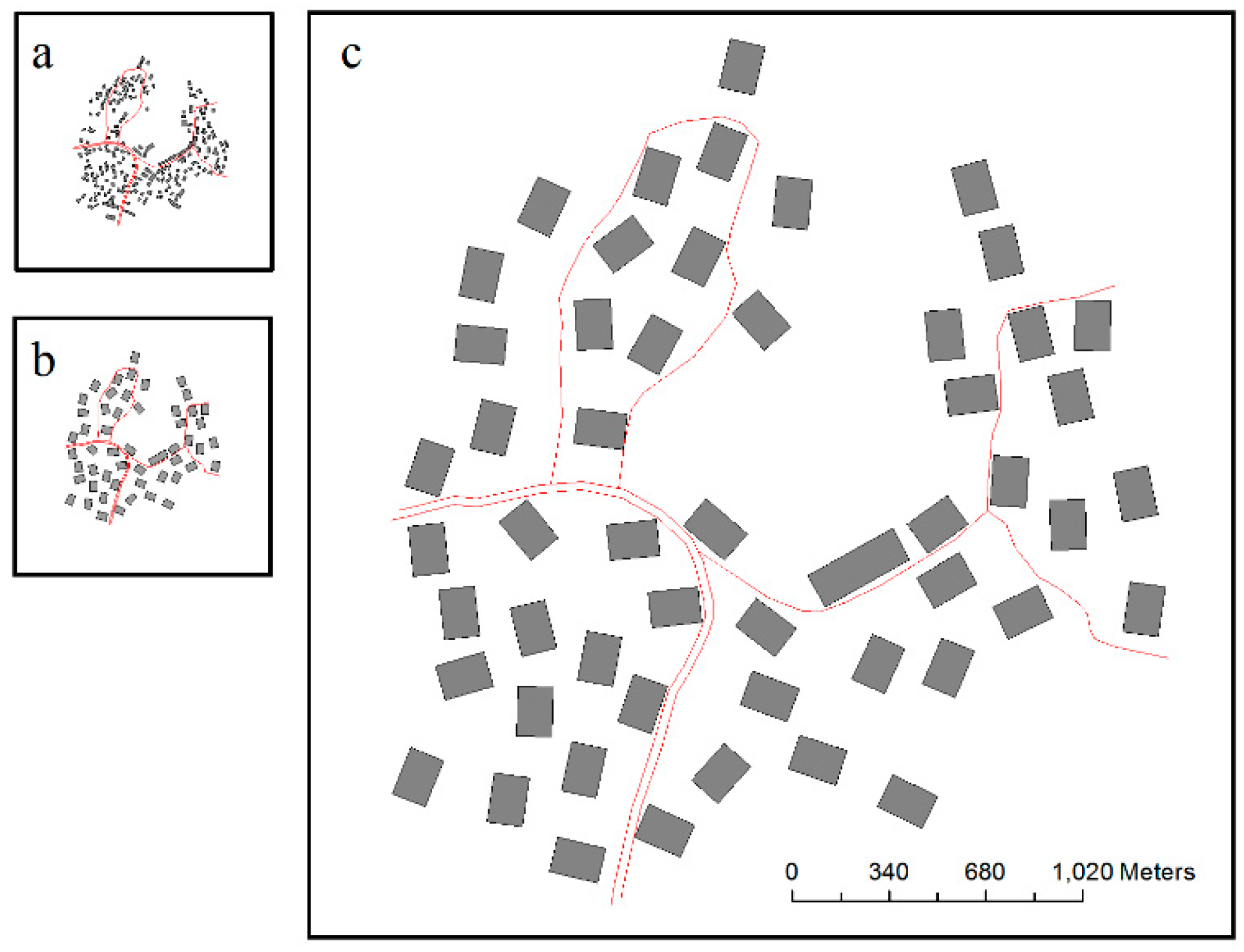
5. Results and Analysis
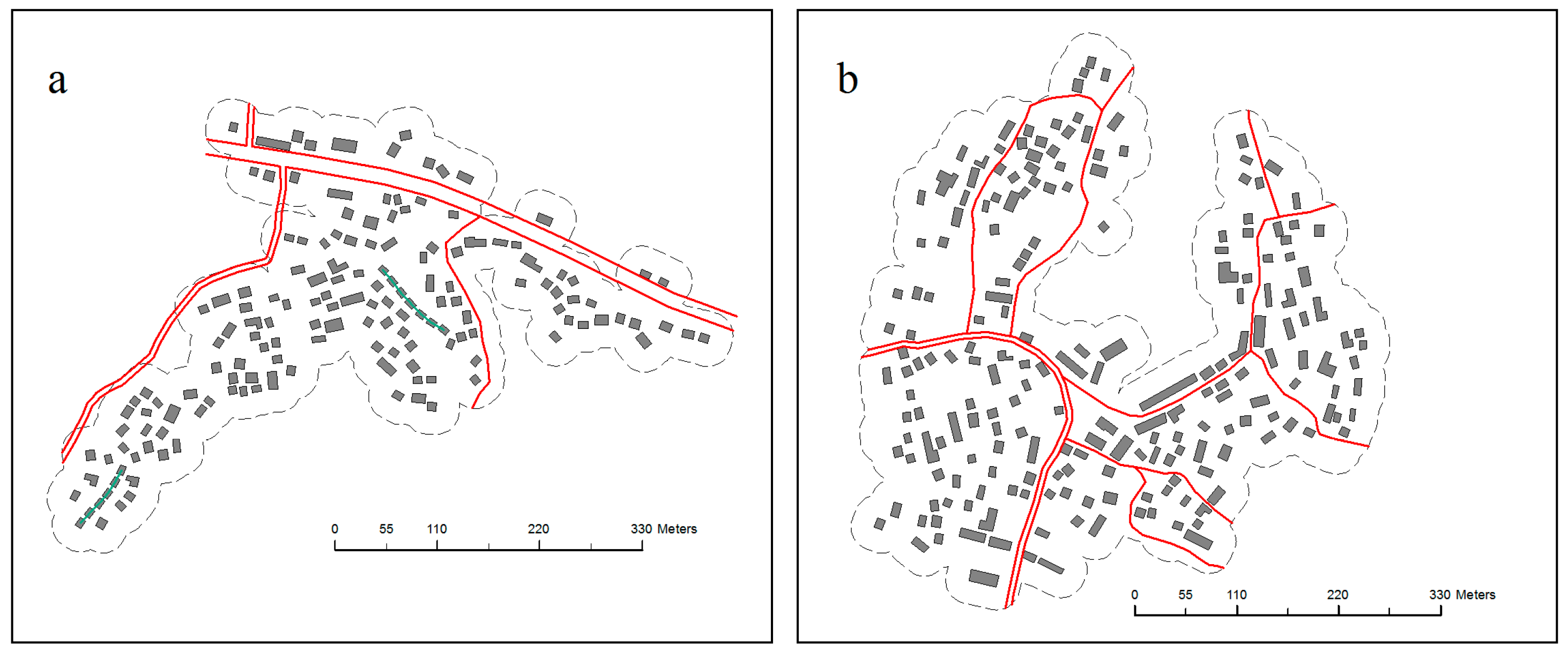
5.1. Experimental Results
5.2. Analysis
5.2.1. Local Constraints
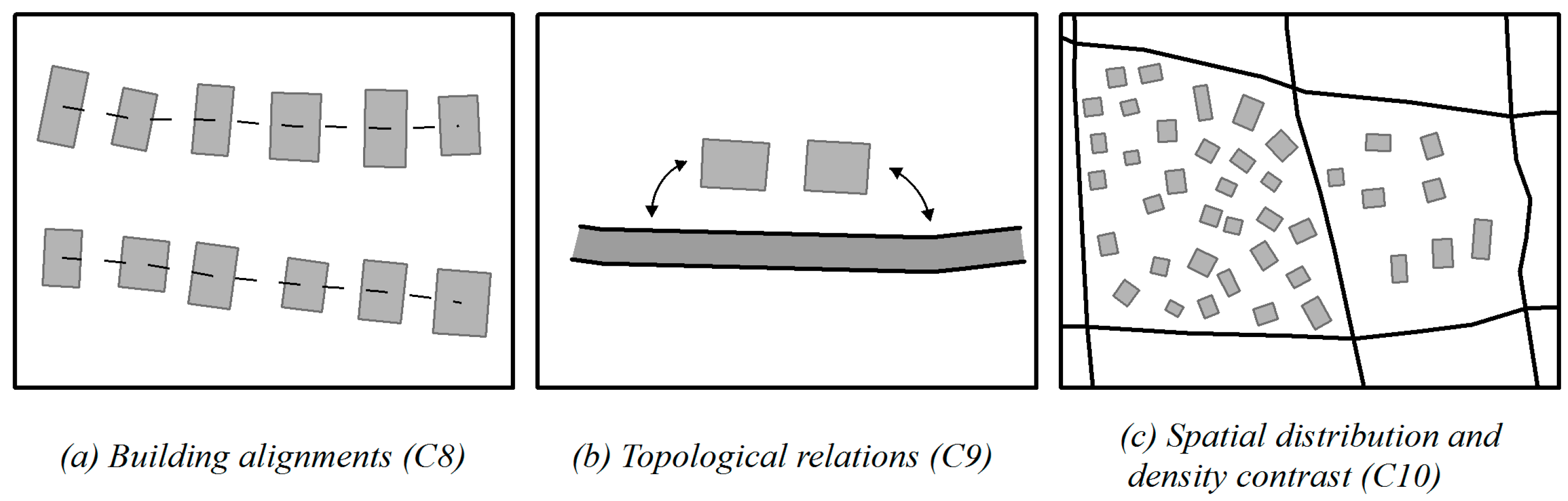
5.2.2. Contextual Constraint of Spatial Relationships and Patterns
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- McMaster, R.B.; Shea, K.S. Generalization in digital cartography. In Spatial Data Handling; Association of American Geographers: Washington, DC, USA, 1992; pp. 6.1–6.18. [Google Scholar]
- Ruas, A.; Plazanet, C. Strategies for automated generalization. In Proceedings of the 7th International Symposium on Spatial Data Handling, Delft, The Netherlands, 12–16 August 1996. [Google Scholar]
- Brassel, K.E.; Weibel, R. A review and conceptual framework of automated map generalization. Int. J. Geogr. Inf. Syst. 1988, 2, 229–244. [Google Scholar] [CrossRef]
- Mackaness, W.A. An algorithm for conflict identification and feature displacement in automated map generalization. Cartogr. Geogr. Inf. Syst. 1994, 21, 219–232. [Google Scholar] [CrossRef]
- Ruas, A. A method for building displacement in automated map generalisation. Int. J. Geogr. Inf. Syst. 1998, 12, 789–803. [Google Scholar] [CrossRef]
- Lonergan, M.; Jones, C.B. An iterative displacement method for conflict resolution in map generalization. Algorithmica 2001, 30, 287–301. [Google Scholar] [CrossRef]
- Harrie, L.; Sarjakoski, T. Simultaneous graphic generalization of vector data sets. GeoInformatica 2002, 6, 233–261. [Google Scholar] [CrossRef]
- Bader, M.; Barrault, M.; Weibel, R. Building displacement over a ductile truss. Int. J. Geogr. Inf. Sci. 2005, 19, 915–936. [Google Scholar] [CrossRef]
- Ai, T.; Zhang, X.; Zhou, Q.; Yang, M. A vector field model to handle the displacement of multiple conflicts in building generalization. Int. J. Geogr. Inf. Sci. 2015, 29, 1310–1331. [Google Scholar] [CrossRef]
- Ai, T.; Zhang, X. The aggregation of urban building clusters based on the skeleton partitioning of gap space. In The European Information Society; Fabrikant, S., Wachowicz, M., Eds.; Springer: Aalborg, Denmark, 2007; pp. 153–170. [Google Scholar]
- Regnauld, N. Contextual building typification in automated map generalization. Algorithmica 2001, 30, 312–333. [Google Scholar] [CrossRef]
- Yan, H.; Weibel, R.; Yang, B. A multi-parameter approach to automated building grouping and generalization. Geoinformatica 2008, 12, 73–89. [Google Scholar] [CrossRef]
- Kadmon, N. Automated selection of settlements in map generalisation. Cartogr. J. 1972, 9, 93–98. [Google Scholar] [CrossRef]
- Langran, G.E.; Poiker, T.K. Integration of name selection and name placement. In Proceedings of the 2nd International Symposium on Spatial Data Handling, Seattle, WA, USA, 5–10 July 1986; International Geographical Union and International Cartographic Association: Seattle, WA, USA, 1986; pp. 50–64. [Google Scholar]
- Ai, T.; Liu, Y. Analysis and simplification of point cluster based on delaunay triangulation model. In Advances in Spatial Analysis and Decision Making; Li, Z., Zhou, Q., Kainz, W., Eds.; Taylor & Francis: London, UK, 2003; pp. 9–18. [Google Scholar]
- Qian, H.; Meng, L. Polarization transformation as an algorithm for automatic generalization and quality assessment. In Proceedings of the SPIE 6751, Geoinformatics 2007: Cartographic Theory and Models, Nanjing, China, 25–27 May 2007; Li, M., Wang, J., Eds.; The International Society for Optical Engineering: Nanjing, China, 2007; Volume 67510Y. [Google Scholar]
- Yan, H.; Weibel, R. An algorithm for point cluster generalization based on the voronoi diagram. Comput. Geosci. 2008, 34, 939–954. [Google Scholar] [CrossRef]
- Peters, S. Quadtree-and octree-based approach for point data selection in 2D or 3D. Ann. GIS 2013, 19, 37–44. [Google Scholar] [CrossRef]
- Yan, H.; Li, J. An approach to simplifying point features on maps using the multiplicative weighted voronoi diagram. J. Spat. Sci. 2013, 58, 291–304. [Google Scholar] [CrossRef]
- Bjørke, J.T. Framework for entropy-based map evaluation. Cartogr. Geogr. Inf. Syst. 1996, 23, 78–95. [Google Scholar] [CrossRef]
- Ruas, A. Modèle de Généralisation de Données Géographiques à Base de Contraintes et D’autonomie. Ph.D. Thesis, Université de Marne la Vallée, Marne La Vallée, France, 1999. [Google Scholar]
- Burghardt, D.; Cecconi, A. Mesh simplification for building typification. Int. J. Geogr. Inf. Sci. 2007, 21, 283–298. [Google Scholar] [CrossRef]
- Gong, X.; Wu, F. A typification method for linear pattern in urban building generalisation. Geocarto Int. 2016, 1–19. [Google Scholar] [CrossRef]
- Sester, M. Optimization approaches for generalization and data abstraction. Int. J. Geogr. Inf. Sci. 2005, 19, 871–897. [Google Scholar] [CrossRef]
- Li, Z.; Yan, H.; Ai, T.; Chen, J. Automated building generalization based on urban morphology and gestalt theory. Int. J. Geogr. Inf. Sci. 2004, 18, 513–534. [Google Scholar] [CrossRef]
- Steiniger, S.; Taillandier, P.; Weibel, R. Utilising urban context recognition and machine learning to improve the generalisation of buildings. Int. J. Geogr. Inf. Sci. 2010, 24, 253–282. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization, and Machine Learning; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1989. [Google Scholar]
- Wilson, I.D.; Ware, J.M.; Ware, J.A. A genetic algorithm approach to cartographic map generalisation. Comput. Ind. 2003, 52, 291–304. [Google Scholar] [CrossRef]
- Ware, J.M.; Wilson, I.D.; Ware, J.A. A knowledge based genetic algorithm approach to automating cartographic generalisation. Knowl. Based Syst. 2003, 16, 295–303. [Google Scholar] [CrossRef]
- Sun, Y.; Guo, Q.; Liu, Y.; Ma, X.; Weng, J. An immune genetic algorithm to buildings displacement in cartographic generalization. Trans. GIS 2016, 20, 585–612. [Google Scholar] [CrossRef]
- Van Dijk, S.; Thierens, D.; De Berg, M. Using genetic algorithms for solving hard problems in GIS. GeoInformatica 2002, 6, 381–413. [Google Scholar] [CrossRef]
- Wu, F.; Deng, H.-Y. Using genetic algorithms for solving problems in automated line simplification. Acta Geodaetica Cartogr. Sin. 2003, 4, 013. [Google Scholar]
- Lamy, S.; Ruas, A.; Demazeau, Y.; Jackson, M.; Mackaness, W.; Weibel, R. The application of agents in automated map generalisation. In Proceedings of the 19th ICA Meeting, Ottawa, ON, Canada, 14–21 August 1999; Volume 14, pp. 1–8. [Google Scholar]
- Duchêne, C.; Ruas, A.; Cambier, C. The cartacom model: Transforming cartographic features into communicating agents for cartographic generalisation. Int. J. Geogr. Inf. Sci. 2012, 26, 1533–1562. [Google Scholar] [CrossRef]
- Jones, C.B.; Bundy, G.L.; Ware, M.J. Map generalization with a triangulated data structure. Cartogr. Geogr. Inform. 1995, 22, 317–331. [Google Scholar]
- Topfer, F.; Pillewizer, W. The principles of selection. Cartogr. J. 1966, 3, 10–16. [Google Scholar] [CrossRef]
- Christophe, S.; Ruas, A. Detecting building alignments for generalisation purposes. In Advances in Spatial Data Handling; Richardson, D.E., Oosterom, P.V., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 419–432. [Google Scholar]
- Regnauld, N. Recognition of building clusters for generalization. In Proceedings of the 7th International Symposium on Spatial Data Handling, Delft, The Netherlands, 12–16 August 1996; Kraak, M.-J.M.M., Ed.; Taylor & Francis: London, UK, 1996; Volume 1, pp. 185–198. [Google Scholar]
- Anders, K.-H.; Sester, M. Parameter-free cluster detection in spatial databases and its application to typification. Int. Arch. Photogramm. Remote Sens. 2000, 33, 75–83. [Google Scholar]
- Basaraner, M.; Selcuk, M. A structure recognition technique in contextual generalisation of buildings and built-up areas. Cartogr. J. 2008, 45, 274–285. [Google Scholar] [CrossRef]
- Zhang, X.; Ai, T.; Stoter, J.; Kraak, M.-J.; Molenaar, M. Building pattern recognition in topographic data: Examples on collinear and curvilinear alignments. Geoinformatica 2013, 17, 1–33. [Google Scholar] [CrossRef]
- National Administration of Surveying, Mapping and Geoinformation of China. Cartographic Symbols for National Fundamental Scale Map-Part3: Specifications for Cartographic Symbols 1:25,000, 1:50,000 & 1:100,000 Topographic Maps; China Zhijian Publishing House: Beijing, China, 2006.
- Swiss Society of Cartography. Topographic Maps: Map Graphics and Generalization; Federal Office of Topography: Berne, Switzerland, 2005.
- National Administration of Surveying, Mapping and Geoinformation of China. Compilation Specification for National Fundamental Scale Maps-Part1: Complilation Specifications for 1:25,000, 1:50,000 & 1:100,000 Topographic Maps; China Zhijian Publishing House: Beijing, China, 2008.
- Regnauld, N. Preserving density contrasts during cartographic generalization. In GIS and Geocomputation; Peter, M., David, M., Eds.; Taylor & Francis: London, UK, 2000; pp. 175–186. [Google Scholar]
- Cheng, R.; Gen, M.; Oren, S.S. An adaptive hyperplane approach for multiple objective optimization problems with complex constraints. In Proceedings of the 2nd Annual Conference on Genetic and Evolutionary Computation, Las Vegas, NV, USA, 10–12 July 2000; Whitley, L.D., Goldberg, D.E., Cantú-Paz, E., Spector, L., Parmee, I.C., Eds.; Morgan Kaufmann Publishers Inc.: Las Vegas, NV, USA, 2000; pp. 299–306. [Google Scholar]
- Boffet, A. Méthode de Création D’Informations Multi-Niveaux Pour la Généralisation Cartographique de L’urbain. Ph.D. Thesis, Université de Marne la Vallée, Marne La Vallée, France, 2001. [Google Scholar]
- Bader, M. Energy Minimization Methods for Feature Displacement in Map Generalization. Ph.D. Thesis, University of Zurich, Zurich, Switzerland, 2001. [Google Scholar]
- Nickerson, B.G. Automated cartographic generalization for linear features. Int. J. Geogr. Inf. Geovis. 1988, 25, 15–66. [Google Scholar] [CrossRef]
- Liu, Y.; Guo, Q.; Sun, Y.; Ma, X. A combined approach to cartographic displacement for buildings based on skeleton and improved elastic beam algorithm. PLoS ONE 2014, 9, e113953. [Google Scholar] [CrossRef] [PubMed]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Int. J. Geogr. Inf. Geovis. 1973, 10, 112–122. [Google Scholar] [CrossRef]
- Jong, K.A.D. An Analysis of the Behavior of a Class of Genetic Adaptive Systems. Ph.D. Thesis, University of Michigan, Ann Arbor, MI, USA, 1975. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Selection Unit | Scale | Initial Conflicts | Final Conflicts | Estimated Building Number | Resultant Building Number | Execution Time (s) |
|---|---|---|---|---|---|---|
| A | 1:25,000 | 170 | 0 | 99 | 79 | 66 |
| 1:50,000 | 642 | 0 | 70 | 37 | 136 | |
| B | 1:25,000 | 132 | 0 | 129 | 125 | 108 |
| 1:50,000 | 637 | 0 | 91 | 53 | 193 |
| Selection Unit | Unit A | Unit B | ||
|---|---|---|---|---|
| Scale | 1:25,000 | 1:50,000 | 1:25,000 | 1:50,000 |
| Ratio of changes (%) | 3.38 | 11.24 | 1.85 | 9.99 |
| Selection Unit | Unit A | Unit B | ||||
|---|---|---|---|---|---|---|
| Scale | 1:10,000 | 1:25,000 | 1:50,000 | 1:10,000 | 1:25,000 | 1:50,000 |
| Building density | 0.112 | 0.122 | 0.206 | 0.126 | 0.149 | 0.212 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Guo, Q.; Liu, Y.; Sun, Y.; Wei, Z. Contextual Building Selection Based on a Genetic Algorithm in Map Generalization. ISPRS Int. J. Geo-Inf. 2017, 6, 271. https://doi.org/10.3390/ijgi6090271
Wang L, Guo Q, Liu Y, Sun Y, Wei Z. Contextual Building Selection Based on a Genetic Algorithm in Map Generalization. ISPRS International Journal of Geo-Information. 2017; 6(9):271. https://doi.org/10.3390/ijgi6090271
Chicago/Turabian StyleWang, Lin, Qingsheng Guo, Yuangang Liu, Yageng Sun, and Zhiwei Wei. 2017. "Contextual Building Selection Based on a Genetic Algorithm in Map Generalization" ISPRS International Journal of Geo-Information 6, no. 9: 271. https://doi.org/10.3390/ijgi6090271
APA StyleWang, L., Guo, Q., Liu, Y., Sun, Y., & Wei, Z. (2017). Contextual Building Selection Based on a Genetic Algorithm in Map Generalization. ISPRS International Journal of Geo-Information, 6(9), 271. https://doi.org/10.3390/ijgi6090271