A New Architecture of Densely Connected Convolutional Networks for Pan-Sharpening



Abstract
:
1. Introduction
2. Related Work
2.1. CNN-Based Pan-Sharpening
2.2. Densely Connected Convolutional Network
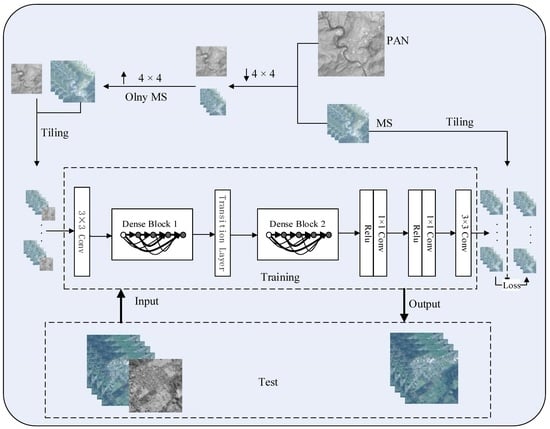
3. Methodology
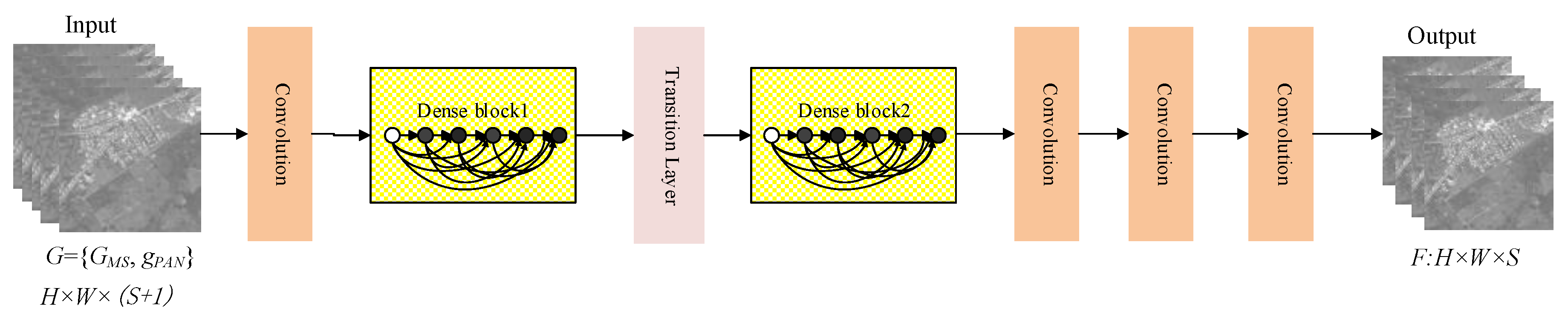
3.1. Improved Dense Block
3.2. The Architecture of DCCNP
| Algorithm 1 Pan-sharpening by the DCCNP algorithm |
| Input: The high-resolution PAN image and low-resolution MS images with S bands. Step 1: Given the training set: original PAN image and MS images with S bands. The low-resolution PAN image and MS images are obtained by spatial blurring and downsampling of the original PAN image and MS images with S bands. Step 2: The is interpolated to obtain an enlarged low-resolution MS images , so that the size of each band image is consistent with the size of the PAN image and is then spliced into the band low-resolution images . Step 3: A slider with a step size of l and a window size of extracts low-resolution image patches () and high-resolution image patches from G and , respectively. Thus, we obtain the consistent training set for pixel positions of N. Step 4: Taking as the input data of the first layer of the convolutional neural network, the expected high-resolution image patches are obtained according to the initial weight and forward propagation algorithm. Step 5: Using and , the optimal parameters in the DCCNP architecture were obtained by fine tuning the network according to Formula (2). Step 6: Input the original PAN image and MS images ; repeat Steps 1 and 2; obtain -dimensional images G as the input data of the network; load the model; and obtain the desired high-resolution images F. Output: The Pan-sharpened MS images F. |
4. Experiment
4.1. Experimental Settings
4.2. Simulation Experimental Results and Analysis
4.2.1. Detailed Experimental Implementation
4.2.2. Experiment Using IKONOS Data
4.2.3. Experiment Using QuickBird Data
4.2.4. Comparison of Execution Time
4.3. Real Experimental Results and Analysis
4.4. Discussion of the BN Layer
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sun, L.; Ma, C.; Chen, Y.; Shim, H.J.; Wu, Z.; Jeon, B. Adjacent superpixel-based multiscale spatial-spectral kernel for hyperspectral classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 312, 1905–1919. [Google Scholar] [CrossRef]
- Wu, Z.; Zhu, W.; Chanussot, J.; Xu, Y.; Osher, S. Hyperspectral anomaly detection via global and local joint modeling of background. IEEE Trans. Signal Process. 2019, 67, 3858–3869. [Google Scholar] [CrossRef]
- Sun, L.; Ge, W.; Chen, Y.; Zhang, J.; Jeon, B. Hyperspectral unmixing employing l1-l2 sparsity and total variation regularization. Inter. J. Remote Sens. 2018, 39, 6037–6060. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Chanussot, J.; Wei, Z. Nonlocal patch tensor sparse representation for hyperspectral image super-resolution. IEEE Trans. Image Process. 2019, 28, 3034–3047. [Google Scholar] [CrossRef] [PubMed]
- Loncan, L.; De Almeida, L.B.; Bioucas-Dias, J.M.; Briottet, X.; Chanussot, J.; Dobigeon, N.; Fabre, S.; Liao, W.; Licciardi, G.A.; Simões, M.; et al. Hyperspectral Pansharpening: A Review. IEEE Trans. Geosci. Remote Sens. Mag. 2015, 3, 27–46. [Google Scholar] [CrossRef] [Green Version]
- Zhao, C.; Gao, X.; Emery, W.J.; Wang, Y.; Li, J. An integrated spatio-spectral temporal sparse representation method for fusing remote-sensing images with different resolutions. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3358–3370. [Google Scholar] [CrossRef]
- Scarpa, G.; Vitale, S.; Cozzolino, D. Target-adaptive CNN-based pansharpening. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5443–5457. [Google Scholar] [CrossRef] [Green Version]
- Lolli, S.; Alparone, L.; Garzelli, A.; Vivone, G. Benefits of haze removal for modulation-based pansharpening. In Proceedings of the Image and Signal Processing for Remote Sensing, Warsaw, Poland, 4–6 Octobor 2017. [Google Scholar]
- Gaetano, R.; Masi, G.; Poggi, G.; Verdoliva, L.; Scarpa, G. Marker-controlled watershed-based segmentation of multiresolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2987–3004. [Google Scholar] [CrossRef]
- Ayhan, E.; Atay, G. Spectral and spatial quality analysis in pan sharpening process. J. Indian Soc. Remote Sens. 2011, 40, 379–388. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, J.; Cao, D. Fusion of multispectral and panchromatic satellite images based on ihs and curvelet transformations. In Proceedings of the 2007 International Conference on Wavelet Analysis and Pattern Recognition, Beijng, China, 2–4 November 2007. [Google Scholar]
- Zhu, X.; Bao, W. Comparison of remote sensing image fusion strategies adopted in HSV and IHS. Int. J. Remote Sens. 2017, 46, 377–385. [Google Scholar] [CrossRef]
- Pohl, C.; Van Genderen, J. Review article multisensor image fusion in remote sensing: Concepts, methods and applications. J. Indian Soc. Remote Sens. 1998, 19, 823–854. [Google Scholar] [CrossRef] [Green Version]
- Choi, J.; Yu, K.; Kim, Y. A new adaptive component-substitution-based satellite image fusion by using partial replacement. IEEE Trans. Geosci. Remote Sens. 2011, 49, 295–309. [Google Scholar] [CrossRef]
- Laporterie, F.; Flouzat, G. The morphological pyramid concept as a tool for multi-resolution data fusion in remote sensing. Integr. Comput. Aided Eng. 2003, 10, 63–79. [Google Scholar] [CrossRef]
- Amro, I.; Mateos, J. Multispectral image pansharpening based on the contourlet transform. Inf. Opt. Photonics 2010, 206, 247–261. [Google Scholar]
- Panchal, S.; Thakker, R. Contourlet transform with sparse representation-based integrated approach for image pansharpening. IETE J. Res. 2017, 56, 1–11. [Google Scholar] [CrossRef]
- Yang, Y.; Que, Y.; Huang, S.; Lin, P. Multimodal sensor medical image fusion based on type-2 fuzzy logic in NSCT domain. IEEE Sens. J. 2016, 1–10. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, Y.; Zhang, K. Remote sensing image fusion method based on PCA and curvelet transform. J. Indian Soc. Remote Sens. 2018, 46, 687–695. [Google Scholar] [CrossRef]
- Moghadam, F.; Shahdoosti, H. A new multifocus image fusion method using contourlet transform. arXiv 2017, arXiv:1709.09528. [Google Scholar]
- Liu, J.; Zhang, J.; Du, Y. A fusion method of multi-spectral image and panchromatic image based on NSCT transform and adaptive Gamma correction. In Proceedings of the 3rd International Conference on Information Systems Engineering (ICISE), Shanghai, China, 4–6 May 2018. [Google Scholar]
- Lim, W.Q. The discrete shearlet transform: A new directional transform and compactly supported shearlet frames. IEEE Trans. Image Process. 2010, 19, 1166–1180. [Google Scholar]
- Sheng, D.; Wu, Y. Method of remote sensing image enhancement in NSST domain based on multi-stages particle swarm optimization. In Proceedings of the 2nd International Conference on Multimedia and Image Processing (ICMIP), Wuhan, China, 17–19 March 2017. [Google Scholar]
- Song, Y.; Yang, G.; Xie, H.; Zhang, D.; Sun, X. Residual domain dictionary learning for compressed sensing video recovery. Multimed. Tools Appl. 2017, 76, 10083–10096. [Google Scholar] [CrossRef]
- Li, S.; Yang, B. A new pan-sharpening method using a compressed sensing technique. IEEE Trans. Geosci. Remote Sens. 2011, 49, 738–746. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, H.; Shen, H.; Zhang, L. A practical compressed sensing-based pan-sharpening method. IEEE Trans. Geosci. Remote Sens. 2012, 9, 629–633. [Google Scholar] [CrossRef]
- Li, S.; Yin, H.; Fang, L. Remote sensing image fusion via sparse representations over learned dictionaries. IEEE Trans. Image Process. 2013, 51, 4779–4789. [Google Scholar] [CrossRef]
- Guo, M.; Zhang, H.; Li, J.; Zhang, L.; Shen, H. An online coupled dictionary learning approach for remote sensing image fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1284–1294. [Google Scholar] [CrossRef]
- Zhu, X.; Bamler, R. A sparse image fusion algorithm with application to pan-sharpening. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2827–2836. [Google Scholar] [CrossRef]
- Long, M.; Yan, Z. Detecting Iris liveness with batch normalized convolutional neural network. Comput. Mater. Contin. 2019, 58, 493–504. [Google Scholar] [CrossRef]
- Zeng, D.; Dai, Y.; Li, F.; Sherratt, R.; Wang, J. Adversarial learning for distant dupervised relation extraction. Comput. Mater. Contin. 2018, 55, 121–136. [Google Scholar]
- Zhou, S.; Ke, M.; Luo, P. Multi-camera transfer GAN for person re-dentification. J. Vis. Commun. Image Remote 2019, 59, 393–400. [Google Scholar] [CrossRef]
- Huang, W.; Xiao, L.; Wei, Z.; Liu, H.; Tang, S. A new pan-sharpening method with deep neural networks. IEEE Geosc. Remote Sens. Lett. 2015, 12, 1037–1041. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef] [Green Version]
- Meng, R.; Rice, S.G.; Wang, J.; Sun, X. A fusion steganographic algorithm based on faster R-CNN. Comput. Mater. Contin. 2018, 55, 1–16. [Google Scholar]
- Rao, Y.; He, L.; Zhu, J. A residual convolutional neural network for pan-shaprening. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017. [Google Scholar]
- Yuan, Q.; Wei, Y.; Meng, X.; Shen, H.; Zhang, L. A multiscale and multidepth convolutional neural network for remote sensing imagery Pan-sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 978–989. [Google Scholar] [CrossRef] [Green Version]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of deep-learning approaches for remote sensing observation enhancement. Sensors 2019, 29, 3929. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Jiang, Y.; Luo, Y.; Ji, L.; Wang, X.; Zhang, T. An advanced deep residual dense network (DRDN) approach for image super-resolution. Int. J. Comput. Int. Syst. 2019, 12, 1592–1601. [Google Scholar]
- Dong, C.; Loy, C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of satellite images of different spatial resolution: Assessing the quality of resulting images. Photogramm. Eng. Remote Sens. 1997, 63, 691–699. [Google Scholar]
- Zeng, D.; Dai, Y.; Li, F.; Wang, J.; Sangaiah, A.K. Aspect based sentiment analysis by a linguistically regularized CNN with gated mechanism. J. Intell. Fuzzy Syst. 2019, 36, 3971–3980. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Luo, Y.; Qin, J.; Xiang, X.; Tan, Y.; Liu, Q.; Xiang, L. Coverless real-time image information hiding based on image block matching and dense convolutional network. J. Real-Time Image Process. 2020, 17, 125–135. [Google Scholar] [CrossRef]
- Rahmani, S.; Strait, M.; Merkurjev, D.; Moeller, M.; Wittman, T. An Adaptive IHS Pan-Sharpening Method. IEEE Geosci. Remote Sci. 2010, 7, 746–750. [Google Scholar] [CrossRef] [Green Version]
- Nunez, J.; Otazu, X.; Fors, O.; Prades, A.; Pala, V.; Arbiol, R. Multiresolution-based image fusion with additive wavelet decomposition. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1204–1211. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. Available online: https://arxiv.org/pdf/1412.6980.pdf (accessed on 2 April 2020).
- Zhou, J.; Civco, D.L.; Silander, J.A. A wavelet transform method to merge Landsat TM and SPOT panchromatic data. Int. J. Remote Sens. 1998, 19, 743–757. [Google Scholar] [CrossRef]
- Liu, Z.; Blasch, E.; Xue, Z.; Zhao, J.; Laganiere, R.; Wu, W. Objective assessment of multiresolution image fusion algorithms for context enhancement in night vision: A comparative study. IEEE Trans. Pattern Anal. 2012, 34, 94–109. [Google Scholar] [CrossRef] [PubMed]
- Wald, L. Data Fusion: Definitions and Architectures-Fusion of Images of Different Spatial Resolutions; Presses desMines: Paris, France, 2002; pp. 135–141. [Google Scholar]
- Yuhas, R.H.; Goetz, A.F.H.; Boardman, J.W. Discrimination among semi-arid landscape endmembers usingthe Spectral AngleMapper (SAM) algorithm. In Proceedings of the Summaries of the Third Annual JPL Airborne GeoscienceWorkshop, AVIRIS Workshop, Pasadena, CA, USA, 1–5 June 1992. [Google Scholar]
- Alparone, L.; Baronti, S.; Garzelli, A.; Nencini, F. A global quality measurement of Pan-sharpened multispectral imagery. IEEE Geosci. Remote Sens. Lett. 2004, 1, 313–317. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A. A universal image quality index. IEEE Signal Process. Lett. 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Alparone, L.; Aiazzi, B.; Baronti, S.; Garzelli, A.; Nencini, F.; Selva, M. Multispectral and panchromatic data fusion assessment without reference. Photogram Eng. Remote Sens. 2008, 74, 1204–1211. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Liu, J.; Ye, S.; Sun, L.; Wei, Z. Optimization of minimum volume constrained hyperspectral image unmixing on CPU-GPU heterogeneous platform. J. Real-Time Image Process. 2018, 15, 265–277. [Google Scholar] [CrossRef]
- Wu, Z.; Shi, L.; Li, J.; Wang, Q.; Sun, L.; Wei, Z.; Plaza, J.; Plaza, A. GPU Parallel Implementation of Spatially Adaptive Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1131–1143. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhao, M.; Hu, C.; He, L.; Bai, H.; Wang, J. A parallel FP-growth algorithm on World Ocean Atlas data with multi-core CPU. J. Supercomput. 2019, 75, 732–745. [Google Scholar] [CrossRef]
- Tu, Y.; Lin, Y.; Wang, J.; Kim, J.U. Semi-supervised learning with Generative Adversarial Networks on digital signal modulation classification. Comput. Mater. Contin. 2018, 55, 243–254. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensors | Training | Validation | Test |
|---|---|---|---|
| IKONOS | Input: 19,249 | Input: | Input: |
| Output: 19,249 | Output: | Output: | |
| QuickBird | Input: 19,249 | Input: | Input: |
| Output: 19,249 | Output: | Output: |
| AIHS | ATWT | PNN | MSDCNN | DCCNP | |
|---|---|---|---|---|---|
| 0.7924 | 0.8819 | 0.9491 | 0.9522 | 0.9616 | |
| 0.0061 | 0.0037 | 0.0016 | 0.0015 | 0.0012 | |
| ERGAS | 3.1983 | 2.4858 | 1.6384 | 1.5794 | 1.4223 |
| SAM | 0.0653 | 0.0520 | 0.0322 | 0.0316 | 0.0289 |
| 0.7627 | 0.8211 | 0.9323 | 0.9362 | 0.9480 |
| AIHS | ATWT | PNN | MSDCNN | DCCNP | |
|---|---|---|---|---|---|
| 0.8184 | 0.8412 | 0.9454 | 0.9479 | 0.9754 | |
| 0.0079 | 0.0070 | 0.0020 | 0.0019 | 0.0009 | |
| ERGAS | 4.5807 | 4.3198 | 2.4660 | 2.3835 | 1.6355 |
| SAM | 0.0984 | 0.0914 | 0.0483 | 0.0475 | 0.0386 |
| 0.8128 | 0.8223 | 0.9566 | 0.9584 | 0.9790 |
| AIHS | ATWT | PNN | MSDCNN | DCCNP | |
|---|---|---|---|---|---|
| 0.0966 | 0.0923 | 0.0507 | 0.0543 | 0.0472 | |
| 0.0793 | 0.0833 | 0.0987 | 0.0891 | 0.0784 | |
| 0.8354 | 0.8321 | 0.8592 | 0.8614 | 0.8792 |
| ERGAS | SAM | ||||
|---|---|---|---|---|---|
| 0.9616 | 0.0012 | 1.4223 | 0.0289 | 0.9480 | |
| 0.9501 | 0.0015 | 1.5246 | 0.0308 | 0.9364 | |
| 0.9585 | 0.0014 | 1.4763 | 0.0257 | 0.9387 |
| ERGAS | SAM | ||||
|---|---|---|---|---|---|
| 0.9754 | 0.0009 | 1.6355 | 0.0386 | 0.9790 | |
| 0.9547 | 0.0018 | 1.5246 | 0.0425 | 0.9578 | |
| 0.9684 | 0.0012 | 1.4763 | 0.0317 | 0.9687 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Feng, J.; Wang, H.; Sun, L. A New Architecture of Densely Connected Convolutional Networks for Pan-Sharpening. ISPRS Int. J. Geo-Inf. 2020, 9, 242. https://doi.org/10.3390/ijgi9040242
Huang W, Feng J, Wang H, Sun L. A New Architecture of Densely Connected Convolutional Networks for Pan-Sharpening. ISPRS International Journal of Geo-Information. 2020; 9(4):242. https://doi.org/10.3390/ijgi9040242
Chicago/Turabian StyleHuang, Wei, Jingjing Feng, Hua Wang, and Le Sun. 2020. "A New Architecture of Densely Connected Convolutional Networks for Pan-Sharpening" ISPRS International Journal of Geo-Information 9, no. 4: 242. https://doi.org/10.3390/ijgi9040242
APA StyleHuang, W., Feng, J., Wang, H., & Sun, L. (2020). A New Architecture of Densely Connected Convolutional Networks for Pan-Sharpening. ISPRS International Journal of Geo-Information, 9(4), 242. https://doi.org/10.3390/ijgi9040242