
Functional Data Visualization and Outlier Detection on the Anomaly of El Niño Southern Oscillation


Abstract
:1. Introduction
2. Materials and Methods
2.1. Functional Data Smoothing
2.2. Summary Statistics of Functional Data
2.3. Functional Principal Component Analysis (FPCA)
- Let be the functional observations obtained by smoothing the discrete observations
- Let be the centred functional observations where is the mean function. A FPCA is then applied to , creating a small set of functions, called harmonics, that reveal the most important variations in the data.
- The first principal component describes a weight function for the that exists over the same range and accounts for the maximum variation. The first principal component yields the maximum variation in the functional principal component scoressubject to the normalization constraint
- The next principal components are obtained by maximizing the variance of the corresponding scoresunder the constraints
2.4. Visualization and Outlier Detection Using a Functional Concept
2.4.1. Rainbow Plot
2.4.2. Functional Bagplot
2.4.3. Functional High-Density Region (HDR) Boxplot
3. Results and Discussion
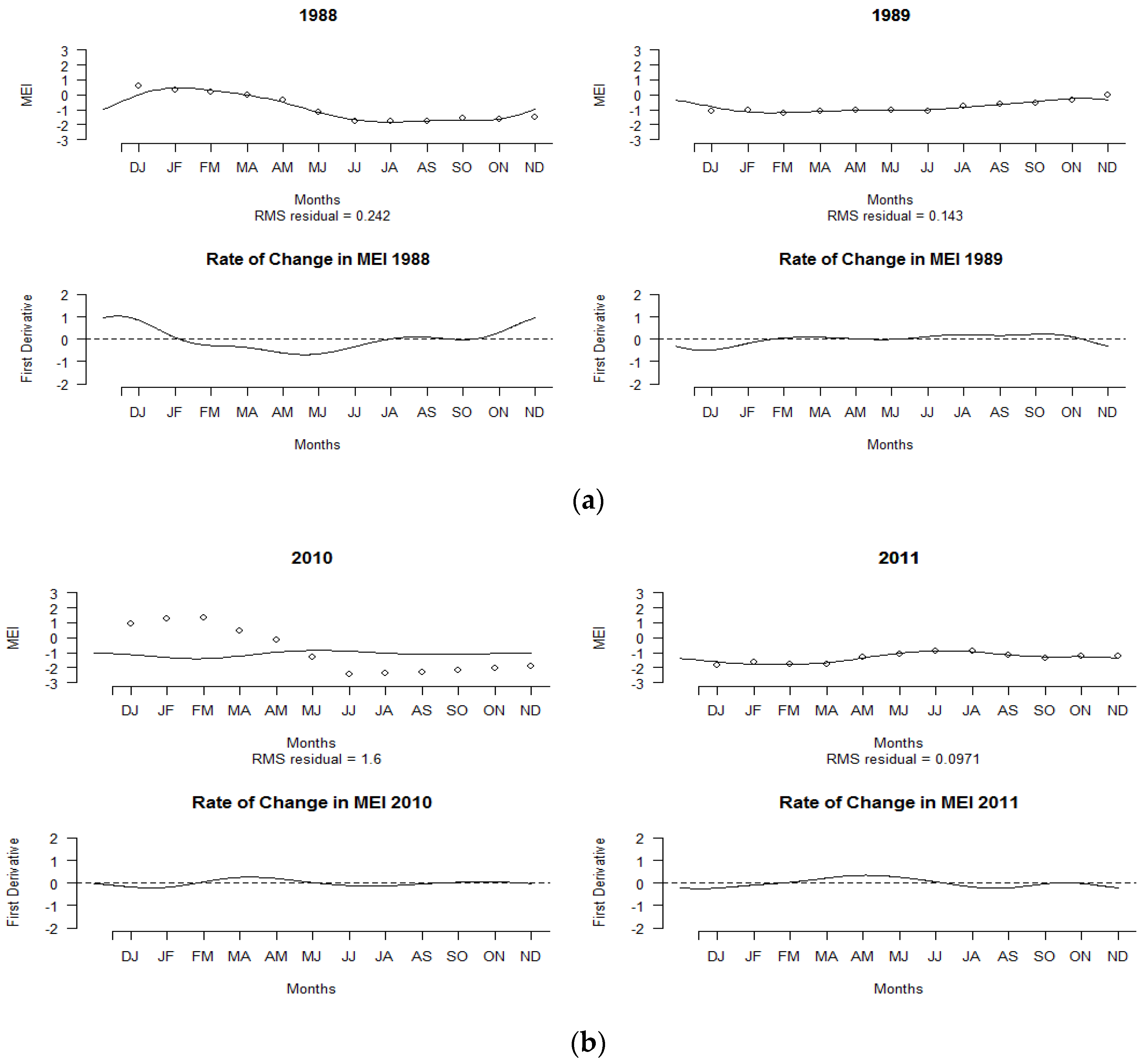
3.1. Reconstructing Multivariate El Niño Southern Oscillation Index Using a Basis Function
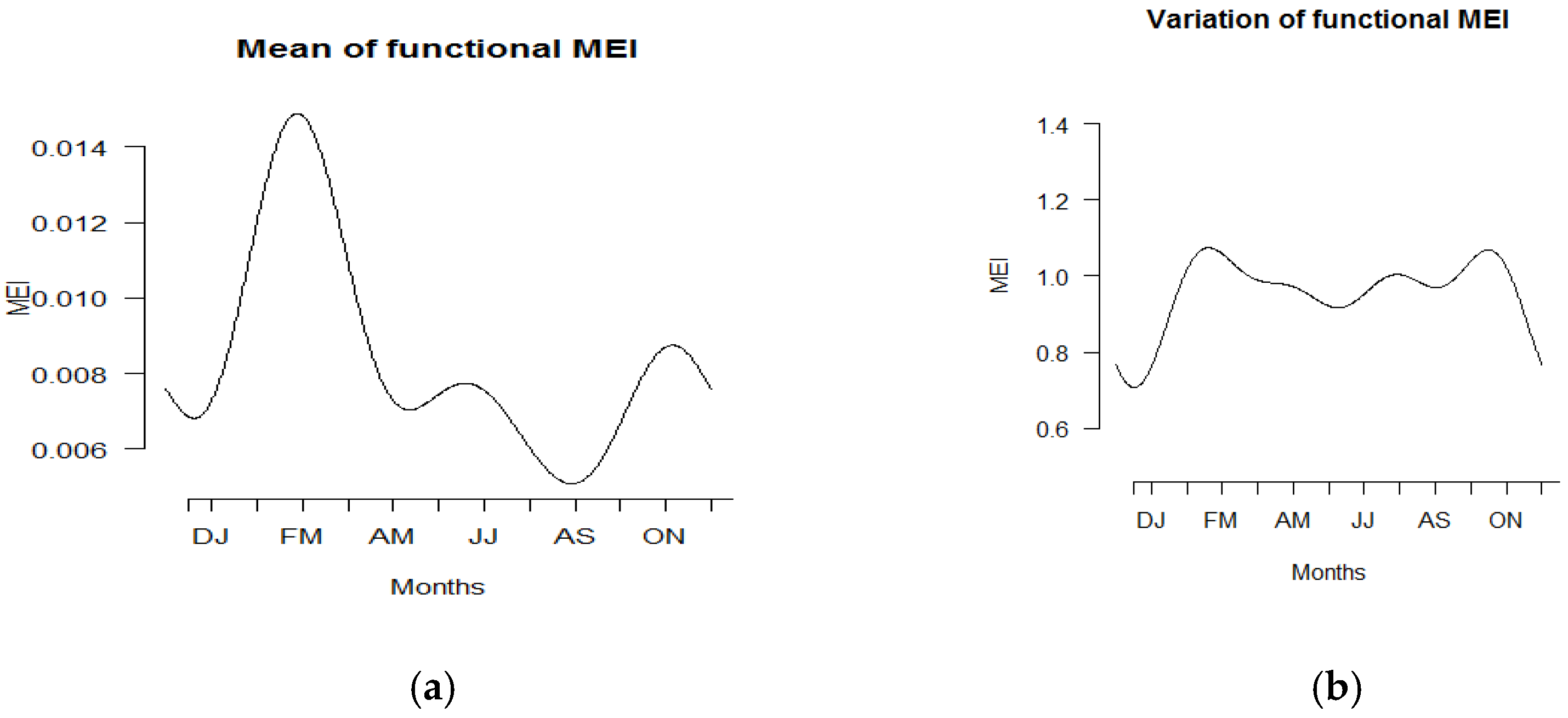
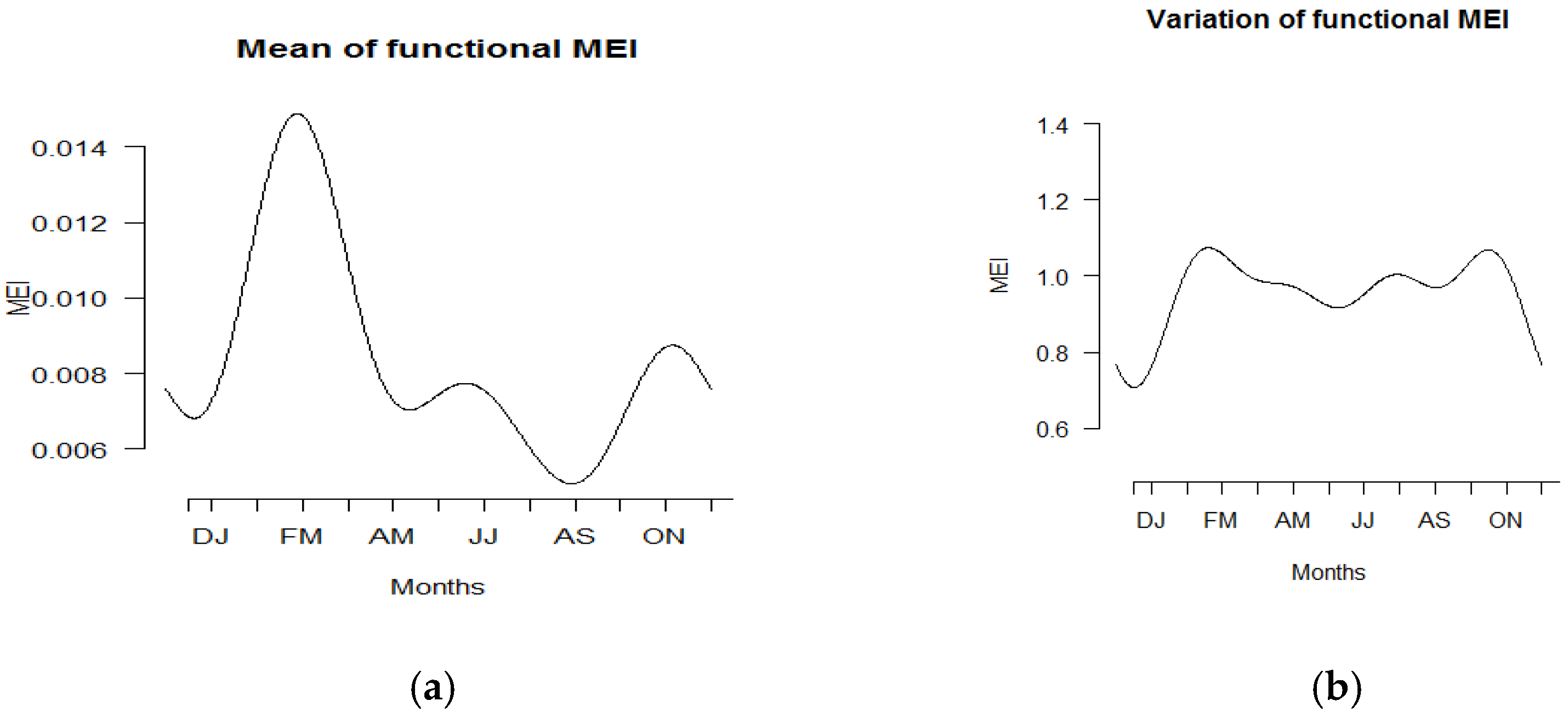
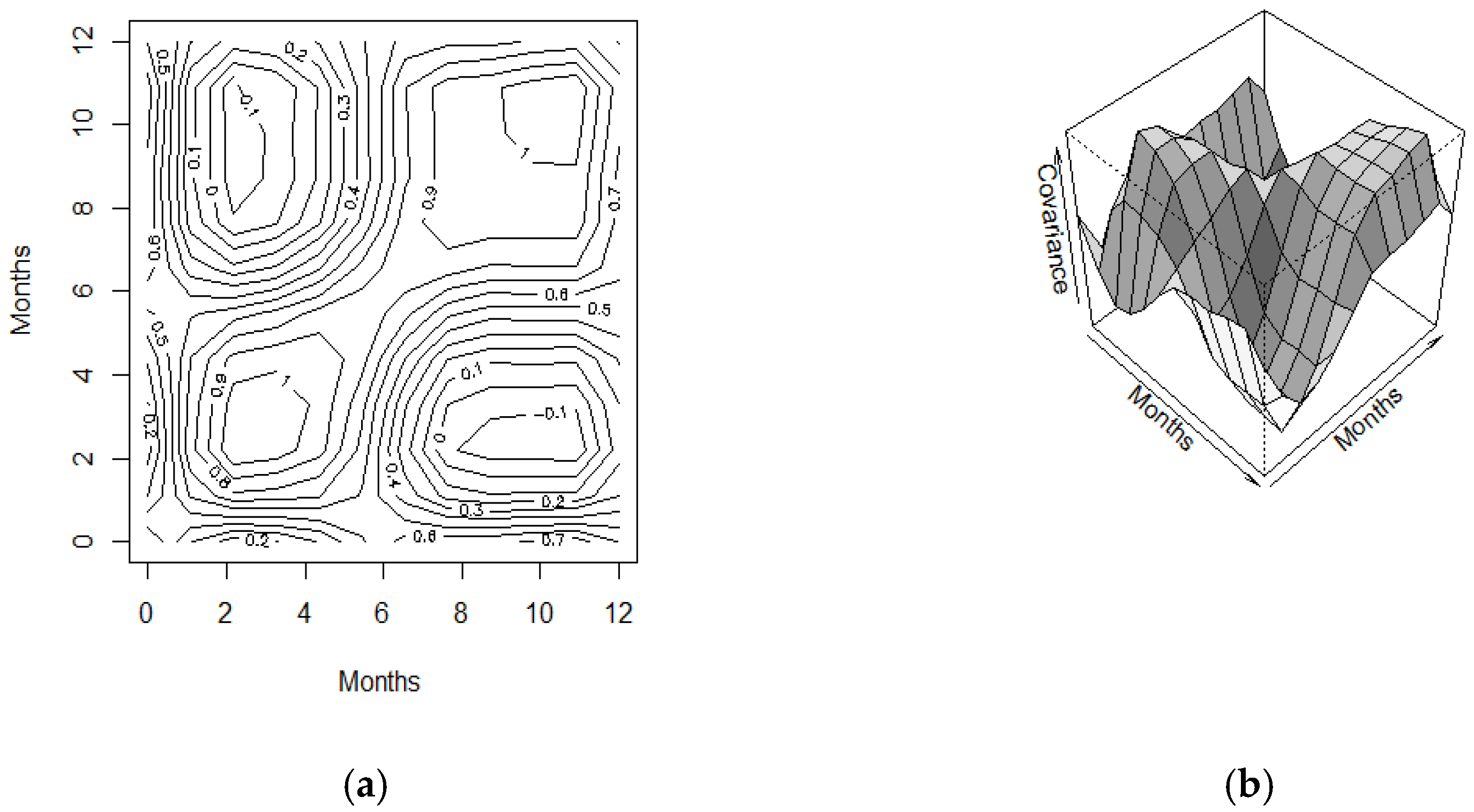
3.2. Summary Statistics of Functional Data
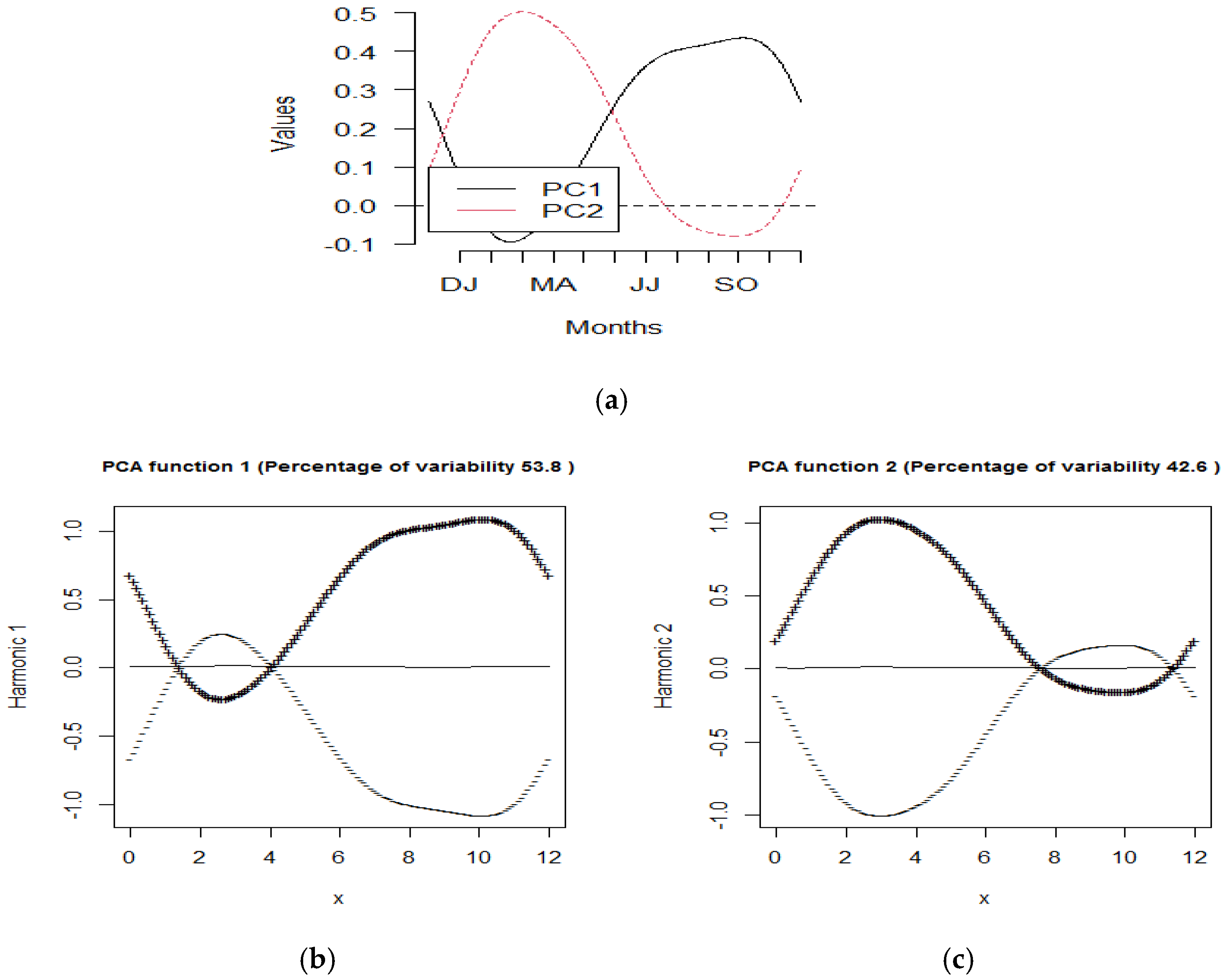
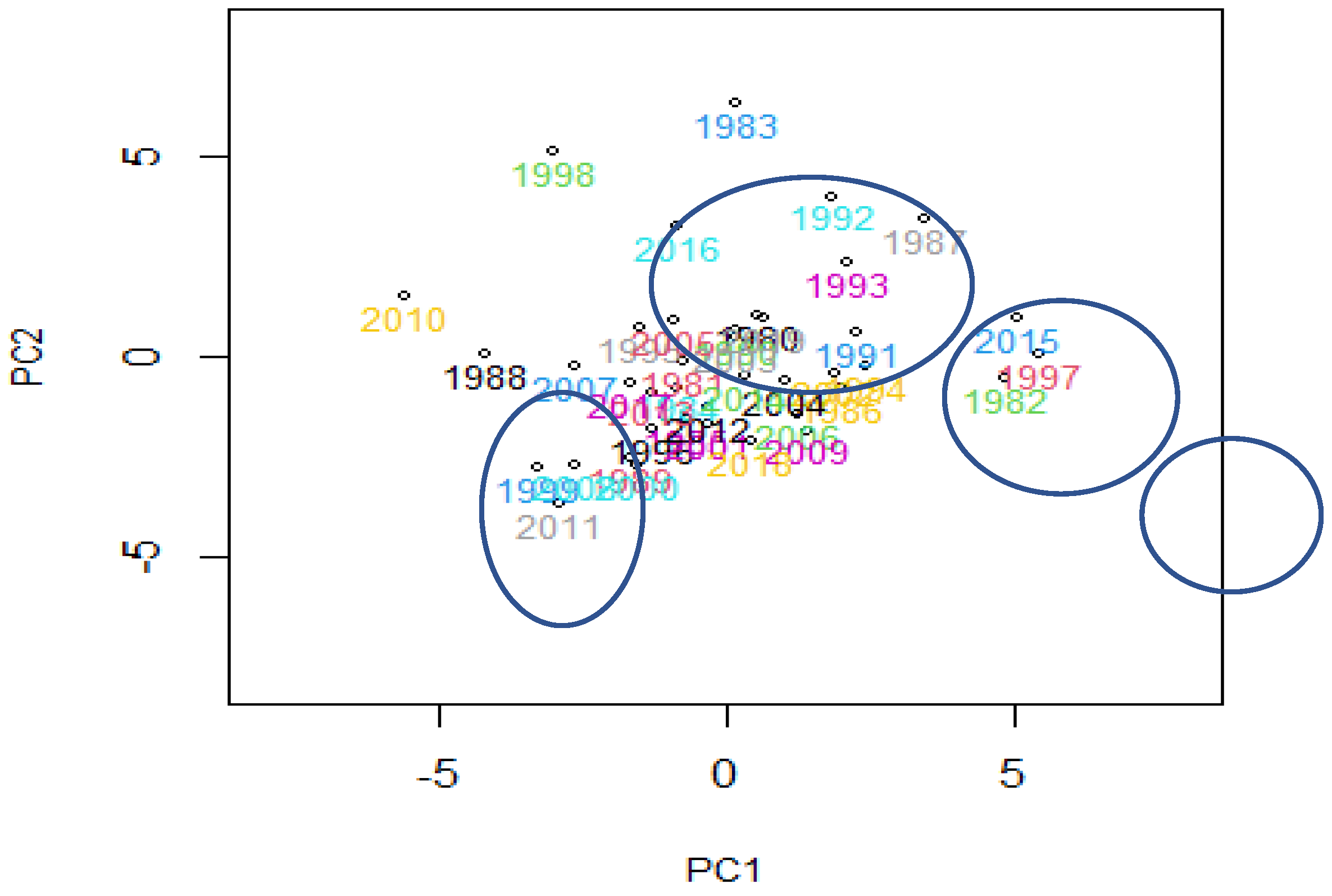
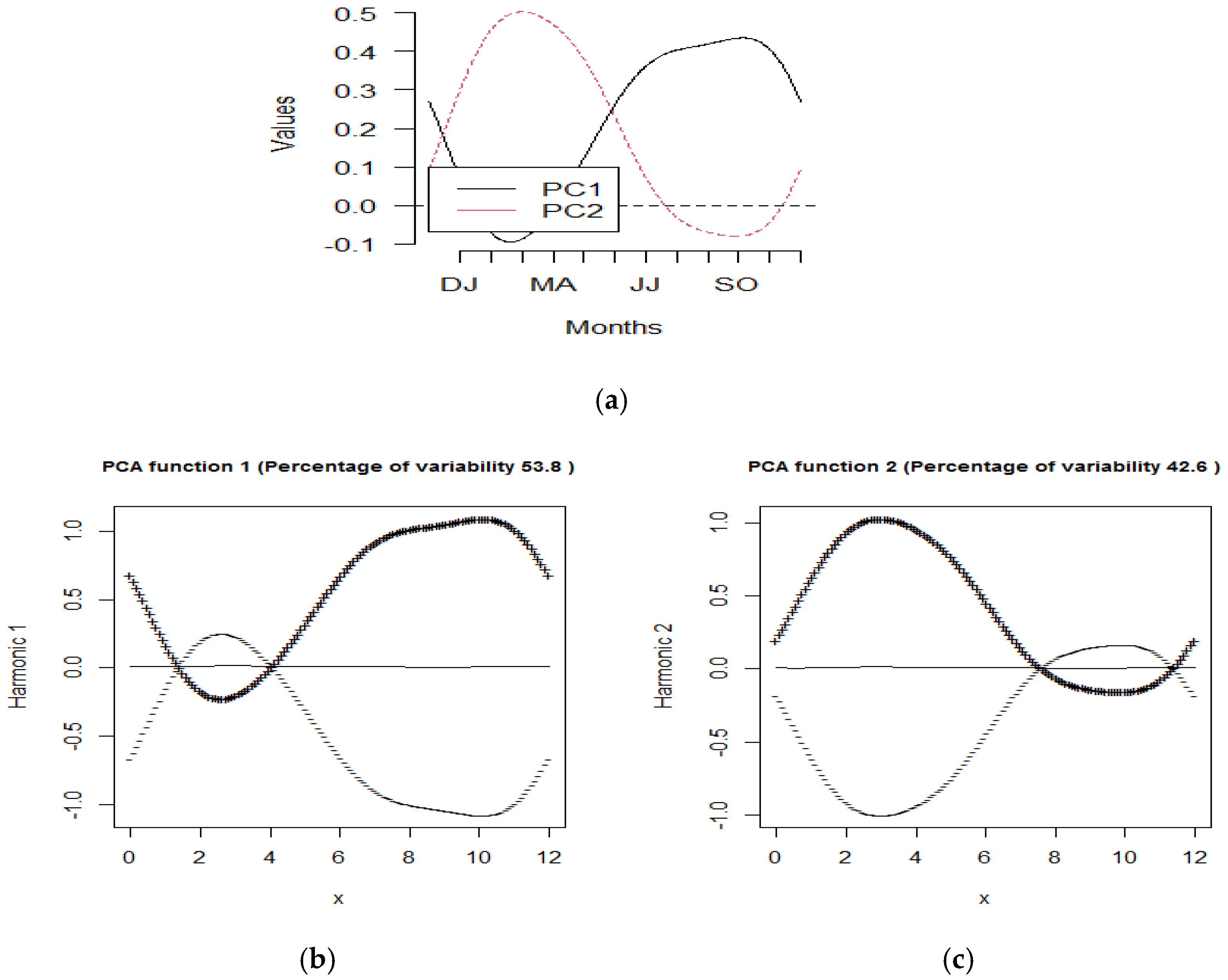
3.3. Results of FPCA
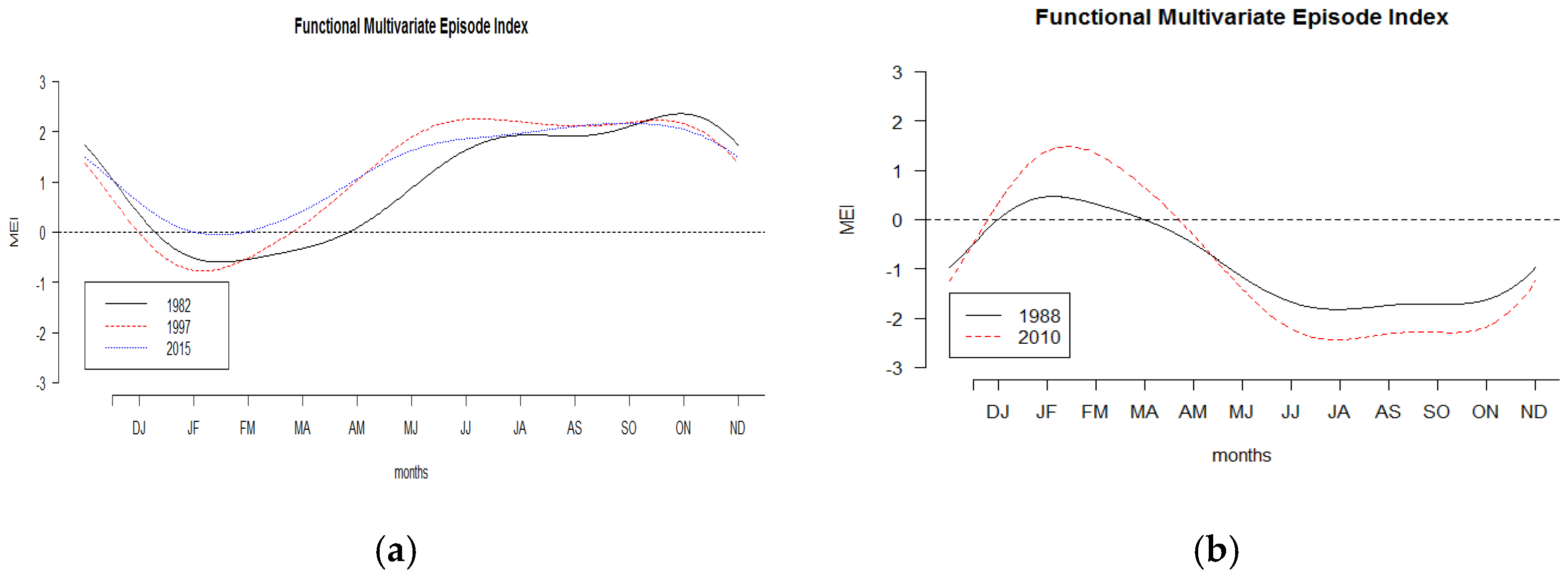
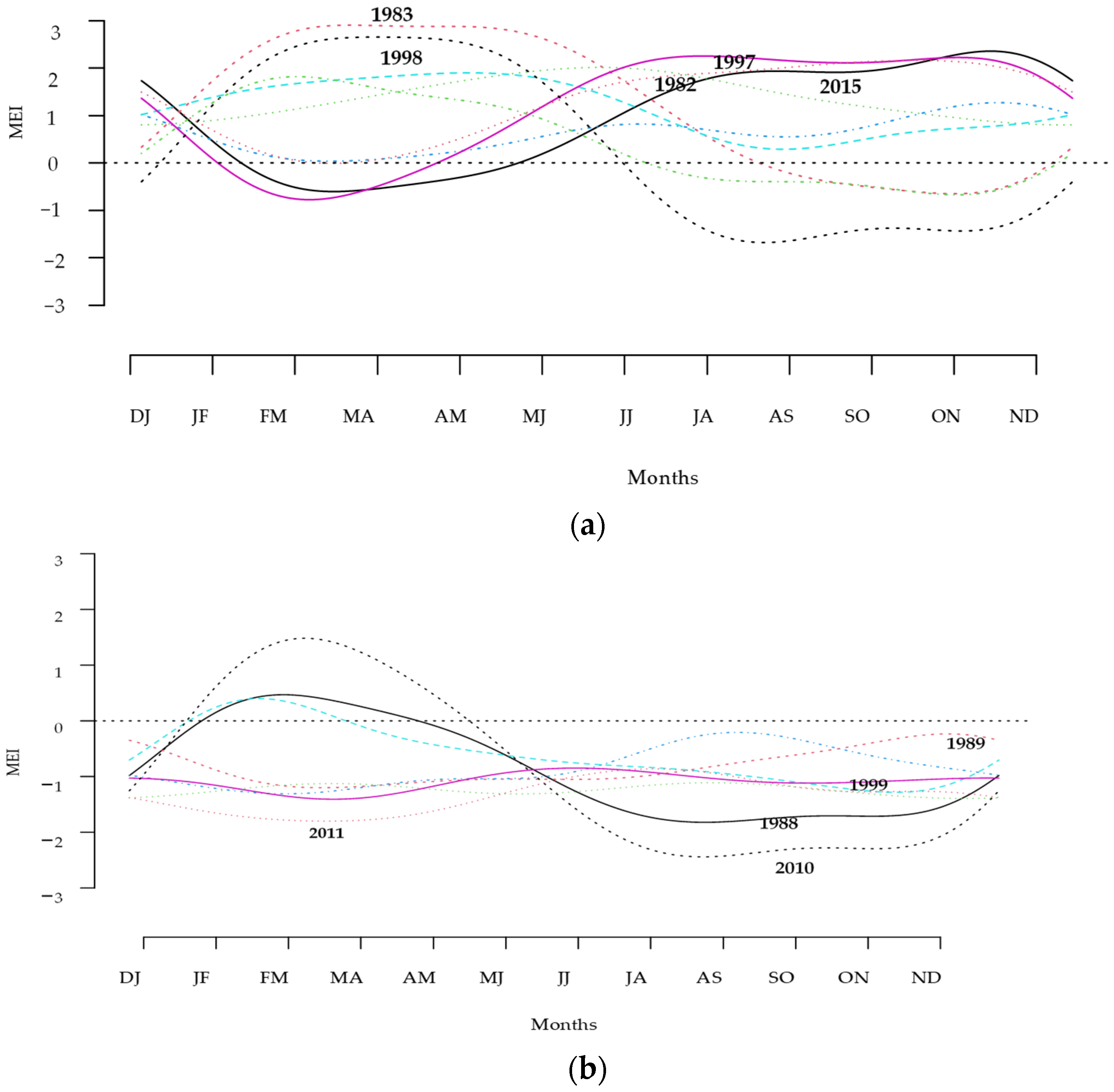
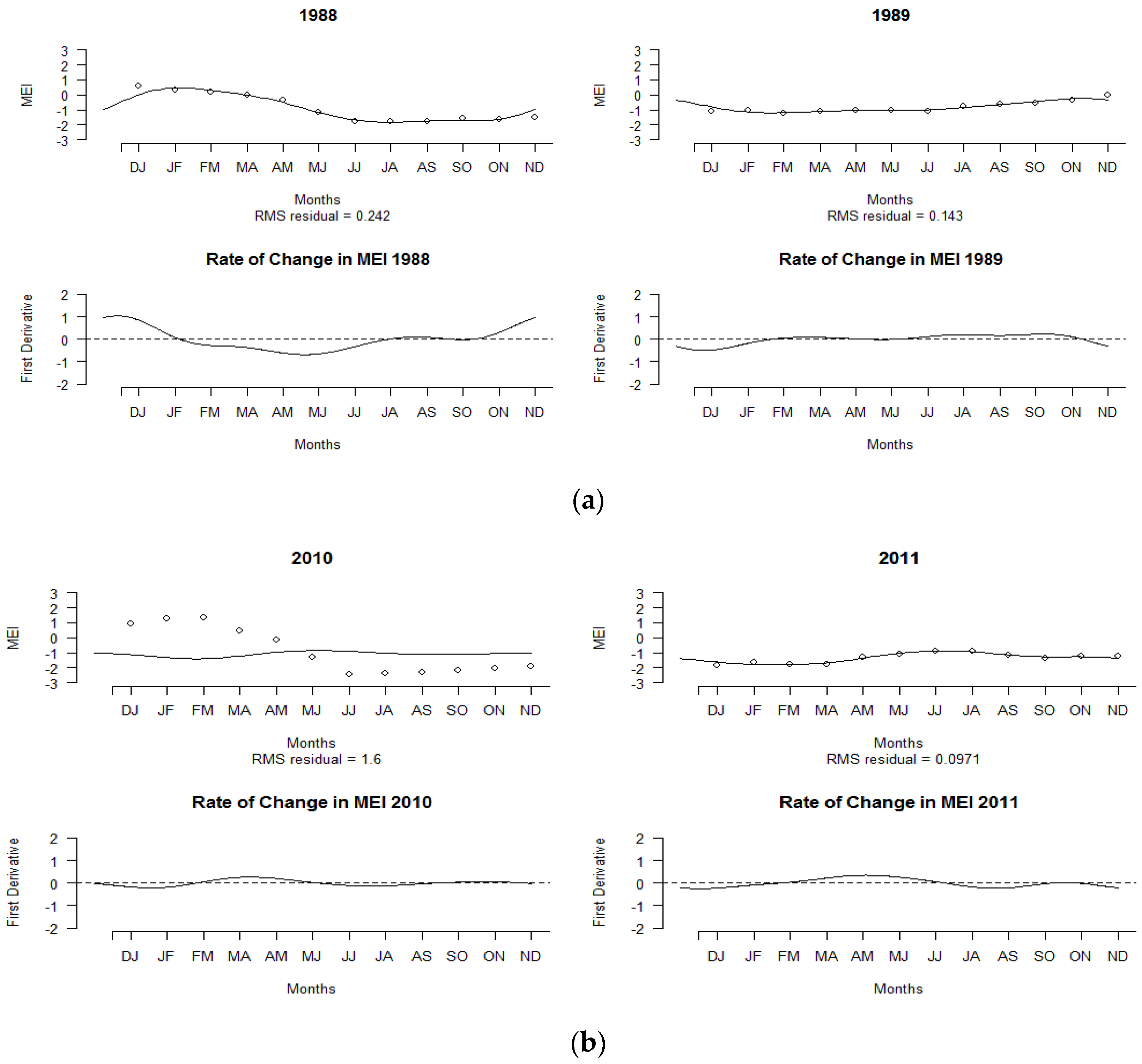
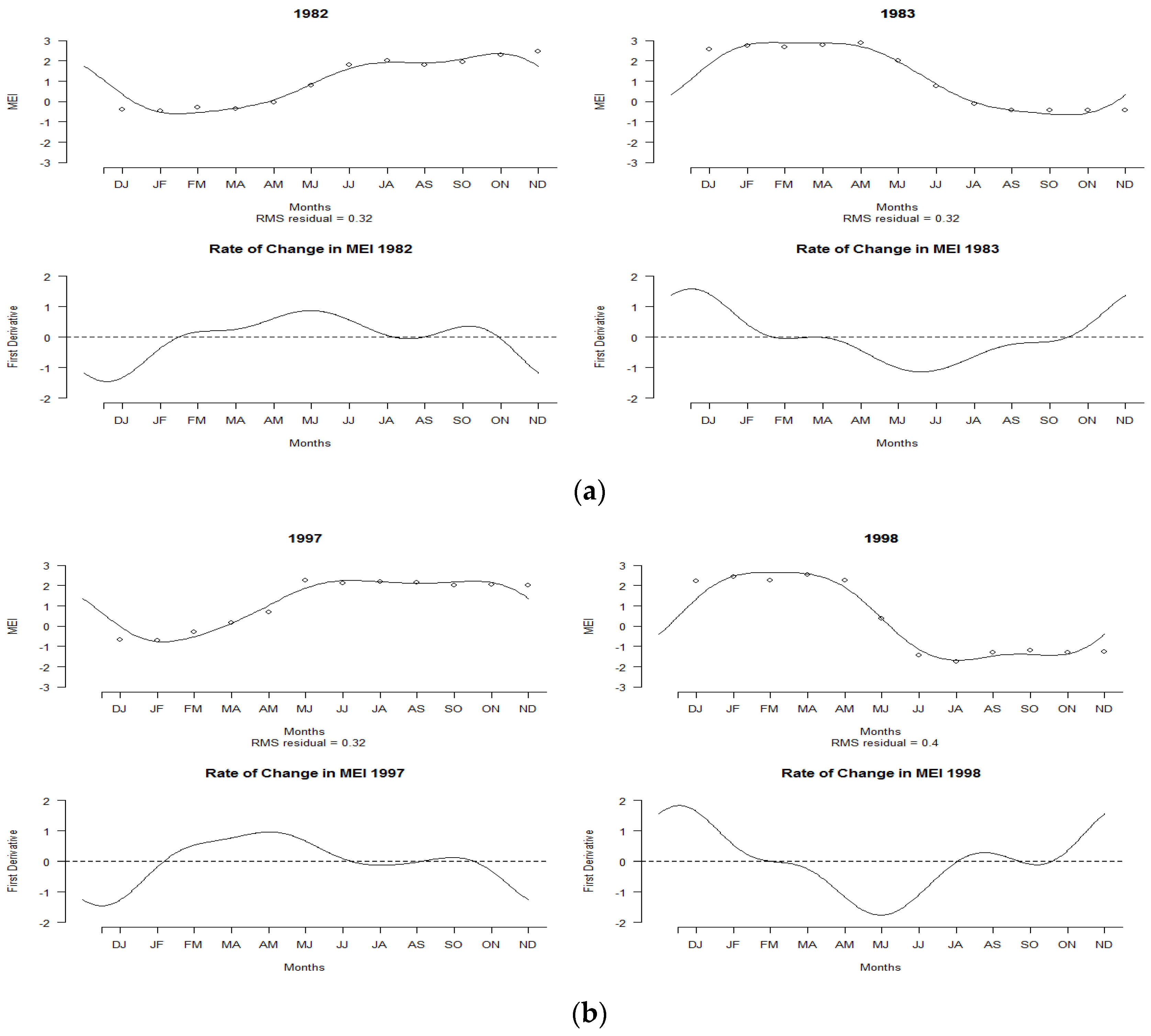
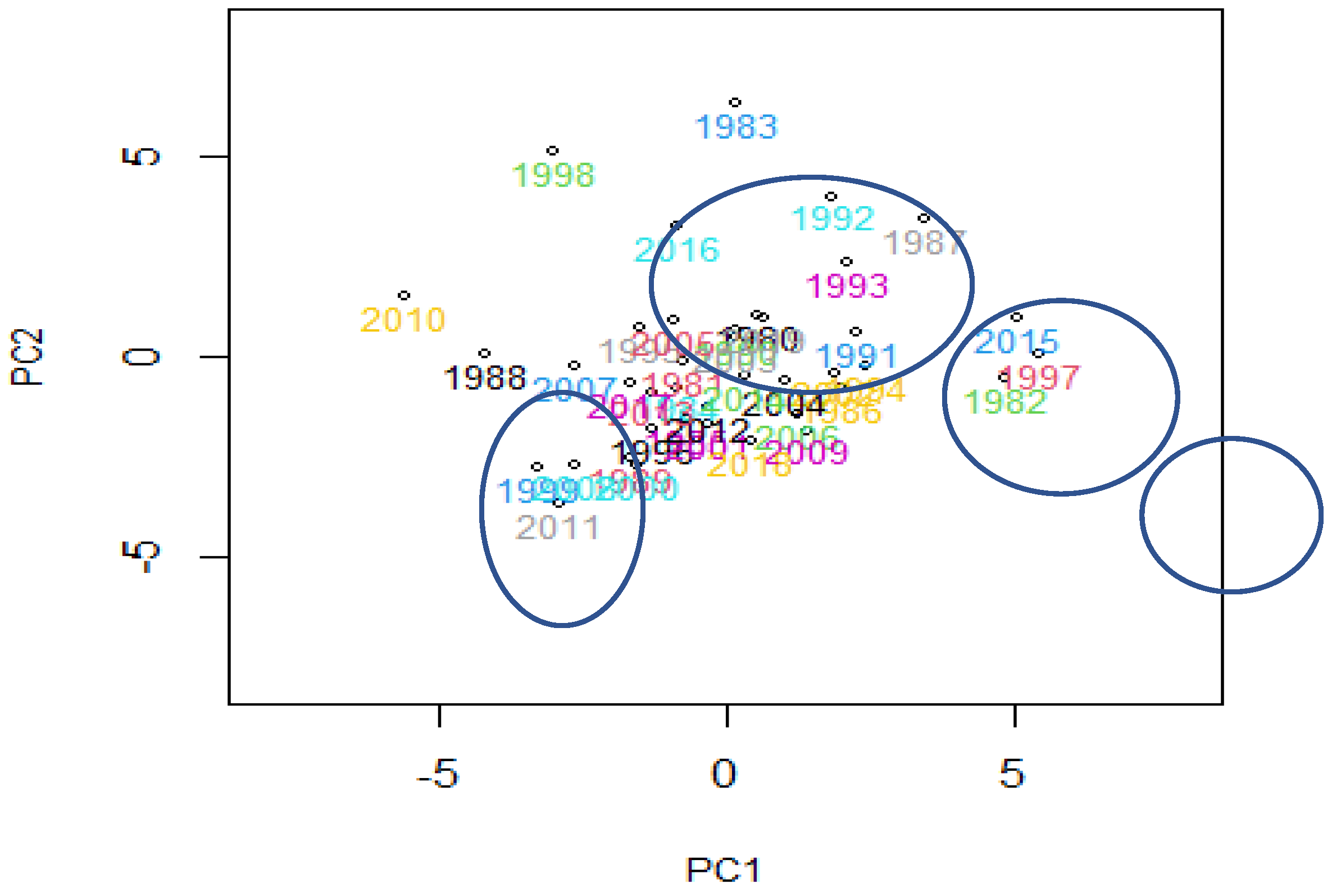
3.4. Functional Outliers
4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- L’Heureux, M. What Is the El Niño–Southern Oscillation (ENSO) in a Nutshell? Available online: https://www.climate.gov/news-features/blogs/enso/whatni%C3%B1o%E2%80%93southern-oscillation-enso-nutshell (accessed on 28 June 2021).
- Juneng, L.; Tangang, F.T. Evolution of ENSO-related rainfall anomalies in Southeast Asia region and its relationship with atmosphere-ocean variations in Indo-Pacific sector. Clim. Dyn. 2005, 25, 337–350. [Google Scholar] [CrossRef]
- Susilo, G.E.; Yamamoto, K.; Imai, T.; Ishii, Y.; Fukami, H.; Sekine, M. The effect of ENSO on rainfall characteristics in the tropical peatland areas of Central Kalimantan, Indonesia. Hydrol. Sci. J. 2013, 58, 539–548. [Google Scholar] [CrossRef] [Green Version]
- Stanley Raj, A.; Chendhoor, B. Impact of Climate Extremes of El Nina and La Nina in Patterns of Seasonal Rainfall over Coastal Karnataka, India. In India: Climate Change Impacts, Mitigation and Adaptation in Developing Countries; Springer Climate; Islam, M.N., van Amstel, A., Eds.; Springer: Cham, Switzerland, 2021; pp. 227–242. [Google Scholar] [CrossRef]
- Abtew, W.; Trimble, P. El Niño–Southern Oscillation Link to South Florida Hydrology and Water Management Applications. Water. Resour. Manage. 2010, 24, 4255–4271. [Google Scholar] [CrossRef]
- Bayer, A.M.; Danysh, H.E.; Garvich, M.; Gonzálvez, G.; Checkley, W.; Alvarez, M.; Gilman, R.H. The 1997–1998 El Niño as an unforgettable phenomenon in northern Peru: A qualitative study. Disasters 2014, 38, 351–374. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahn, J.H.; Kim, H.S. Nonlinear modelling of El Nino Southern Oscillation Index. J. Hydrol. Eng. 2005, 10, 8–15. [Google Scholar] [CrossRef]
- Brockwell, P.; Davis, A. Time Series: Theory and Methods; Springer: New York, NY, USA, 1987. [Google Scholar]
- Box, G.; Jenkins, G. Time Series Analysis; Holden Day: New York, NY, USA, 1996. [Google Scholar]
- Bosq, D. Non-parametric statistics for stochastic processes, estimation and prediction. In Lecture Notes in Statistics; Springer: New York, NY, USA, 1996; Volume 110. [Google Scholar]
- Collomb, G. From non-parametric regression to non-parametric prediction: Survey on the mean square error and original results on the predictogram. In Lecture Notes in Statistics; Springer: Berlin, Heidelberg; New York, NY, USA, 1983; Volume 16, pp. 182–204. [Google Scholar]
- Gyorfi, L.; Hardle, W.; Sarda, P.; Vieu, P. Non-Parametric Curve Estimation from Time Series; Springer: New York, NY, USA, 1989. [Google Scholar]
- Ham, Y.-G.; Kim, J.-H.; Luo, J.-J. Deep learning for multi-year ENSO forecasts. Nature 2019, 573, 568–572. [Google Scholar] [CrossRef] [PubMed]
- He, D.; Lin, P.; Liu, H.; Ding, L.; Jiang, J. DLENSO: A Deep Learning ENSO Forecasting Model. In Trends in Artificial Intelligence, Lecture Notes in Computer Science; Nayak, A., Sharma, A., Eds.; Springer: Cham, Switzerland, 2019; Volume 11671. [Google Scholar] [CrossRef]
- Huang, A.; Vega-Westhoff, B.; Sriver, R.L. Analyzing El Niño-Southern Oscillation predictability using long-short-term-memory models. Earth Space Sci. 2019, 6, 212–221. [Google Scholar] [CrossRef]
- Pal, M.; Maity, R.; Ratnam, J.V.; Nonaka, M.; Behera, S.K. Long-lead prediction of ENSO Modoki Index using Machine Learning Algorithms. Sci. Rep. 2020, 10, 365. [Google Scholar] [CrossRef]
- Katz, R.W. Sir Gilbert Walker and a connection between El Nino and statistics. Stat. Sci. 2002, 17, 97–112. [Google Scholar] [CrossRef]
- Fedorov, A.V.; Harper, S.L.; Philander, S.G.; Winter, B.; Witternberg, A. How predictable is El Nino. Bull. Am. Meteorol. Soc. 2003, 84, 911–919. [Google Scholar] [CrossRef] [Green Version]
- Gallo, I.C.; Akhavan-Tabatabaei, R.; Sa’nchez-Silva, M.; Bastidas-Arteaga, E. A Markov regime-switching framework to forecast El Nino Southern Oscillation patterns. Nat. Hazards 2015, 81, 829–843. [Google Scholar] [CrossRef] [Green Version]
- Hanley, D.; Bourassa, M.; O’Brien, J.; Smith, S.; Spade, E. A quantitative evaluation of ENSO indices. J. Clim. 2003, 16, 1249–1258. [Google Scholar] [CrossRef]
- Mazzarella, A.; Giuliacci, A.; Scafetta, N. Quantifying the Multivariate ENSO Index (MEI) coupling to CO2 concentration and to the length of day variations. Theor. Appl. Climatol. 2013, 111, 601–607. [Google Scholar] [CrossRef] [Green Version]
- Mazzarella, A.; Giuliacci, A.; Liritzis, I. On the 60-month cycle of multivariate ENSO index. Theor. Appl. Climatol. 2010, 100, 23–27. [Google Scholar] [CrossRef]
- Alaya, M.A.B.; Ternynck, C.; Dabo-Niang, S.; Chebana, F.; Ouarda, T.B.M.J. Change point detection of flood events using a functional data framework. Adv. Water Resour. 2020, 137, 103522. [Google Scholar] [CrossRef]
- Bonner, S.J.; Newlands, N.K.; Heckman, N.E. Modelling regional impacts of climate teleconnections using functional data analysis. Environ. Ecol. Stat. 2014, 21, 1–26. [Google Scholar] [CrossRef]
- Chebana, F.; Dabo-Niang, S.; Ouarda, T.B.M.J. Exploratory functional flood frequency analysis and outlier detection. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef] [Green Version]
- Hael, M.A. Modeling of rainfall variability using functional principal component method: A case study of Taiz region, Yemen. Model. Earth Syst. Environ. 2020. [Google Scholar] [CrossRef]
- Suhaila, J.; Yusop, Z. Spatial and temporal variability of rainfall data using functional data analysis. Theor. Appl. Climatol. 2017, 129, 229–242. [Google Scholar] [CrossRef]
- Suhaila, J.; Jemain, A.A.; Hamdan, M.F.; Zin, W.W.Z. Comparing rainfall patterns between regions in Peninsular Malaysia via functional data analysis techniques. J. Hydrol. 2011, 411, 197–206. [Google Scholar] [CrossRef]
- Wang, J.L.; Chiou, J.M.; Muller, H.G. Review of functional data analysis. Annu. Rev. Stat. 2015, 3, 257–295. [Google Scholar] [CrossRef] [Green Version]
- Ullah, S.; Finch, C.F. Applications of functional data analysis: A systematic review. BMC Med. Res. Methodol. 2013, 13, 43. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wolter, K.; Timlin, M.S. Monitoring ENSO in COADS with a seasonally adjusted principal component index. In Proceedings of the 17th Climate Diagnostics Workshop, Norman, OK, USA, 18–23 October 1992; Volume 52, pp. 52–57. [Google Scholar]
- Wolter, K.; Timlin, M.S. El Niño/Southern Oscillation behaviour since 1871 as diagnosed in an extended multivariate ENSO index (MEI.ext). Int. J. Climatol. 2011, 31, 1074–1087. [Google Scholar] [CrossRef]
- Ramsay, J.O.; Silverman, B. Functional Data Analysis; Springer: New York, NY, USA, 2005. [Google Scholar]
- Levitin, D.J.; Nuzzo, R.L.; Vines, B.W.; Ramsay, J.O. Introduction to functional data analysis. Can. Psychol. 2007, 48, 135–155. [Google Scholar] [CrossRef] [Green Version]
- Fraiman, R.; Muniz, G. Trimmed means for functional data. Test 2001, 10, 419–440. [Google Scholar] [CrossRef]
- Febrero, M.; Galeano, P.; Gonzalez-Manteiga, W. Outlier detection in functional data by depth measures, with application to identify abnormal NOx levels. Environmetrics 2008, 19, 331–345. [Google Scholar] [CrossRef]
- Shang, H.L. A survey of functional principal component analysis. AStA Adv. Stat. Anal. 2014, 98, 121–142. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.J.; Shang, H.L. Rainbow Plots, Bagplots, and Boxplots for Functional Data. J. Comput. Graph. Stat. 2010, 19, 29–45. [Google Scholar] [CrossRef] [Green Version]
- Tukey, J.W. Mathematics and the picturing of data. In Proceedings of the International Congress of Mathematicians 1974 Vancouver, 21–29 August 1974; Canadian Mathematical Society Ottawa: Ottawa, CA, Canada, 1975; Volume 2, pp. 523–531. [Google Scholar]
- Rousseeuw, P.J.; Ruts, I.; Tukey, J.W. The bagplot: A bivariate boxplot. Am. Stat. 1999, 53, 382–387. [Google Scholar]
- Hyndman, R.J. Computing and Graphing Highest Density Regions. Am. Stat. 1996, 50, 120–126. [Google Scholar]
- Lindsey, R. La Niña Continuing in the New Year. Available online: https://www.climate.gov/news-features/event-tracker/2010-la-ni%C3%B1a-continuing-new-year (accessed on 28 June 2021).
- What Is El Niño? Available online: https://www.pmel.noaa.gov/elnino/what-is-el-nino (accessed on 28 June 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YEAR | FPC1 | FPC2 |
|---|---|---|
| 1980 | 0.5634 | 1.0129 |
| 1981 | −0.7354 | −0.1321 |
| 1982 | 4.8422 | −0.5380 |
| 1983 | 0.1909 | 6.2850 |
| 1984 | −0.8539 | −0.7648 |
| 1985 | −0.6886 | −1.5971 |
| 1986 | 1.9950 | −0.8023 |
| 1987 | 3.4397 | 3.4135 |
| 1988 | −4.1807 | 0.0654 |
| 1989 | −1.6430 | −2.5272 |
| 1990 | 0.1904 | 0.6399 |
| 1991 | 2.2735 | 0.6008 |
| 1992 | 1.8214 | 3.9927 |
| 1993 | 2.0924 | 2.3116 |
| 1994 | 2.4518 | −0.2431 |
| 1995 | −1.4697 | 0.6950 |
| 1996 | −1.2976 | −1.8288 |
| 1997 | 5.4765 | 0.0473 |
| 1998 | −3.0029 | 5.0775 |
| 1999 | −3.2550 | −2.7936 |
| 2000 | −1.5200 | −2.7340 |
| 2001 | −0.3334 | −1.6938 |
| 2002 | 1.8934 | −0.4078 |
| 2003 | 0.1893 | 0.4581 |
| 2004 | 1.0644 | −0.5939 |
| 2005 | −0.8842 | 0.8795 |
| 2006 | 1.2594 | −1.4574 |
| 2007 | −2.6395 | −0.2433 |
| 2008 | −2.5981 | −2.7190 |
| 2009 | 1.4150 | −1.8415 |
| 2010 | −5.5991 | 1.4806 |
| 2011 | −2.8756 | −3.6729 |
| 2012 | −0.3109 | −1.2757 |
| 2013 | −1.2971 | −0.8870 |
| 2014 | 0.3250 | −0.5038 |
| 2015 | 5.0918 | 0.9263 |
| 2016 | −0.8640 | 3.2373 |
| 2017 | −1.6409 | −0.6941 |
| 2018 | 0.4335 | −2.1305 |
| 2019 | 0.6808 | 0.9584 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suhaila, J. Functional Data Visualization and Outlier Detection on the Anomaly of El Niño Southern Oscillation. Climate 2021, 9, 118. https://doi.org/10.3390/cli9070118
Suhaila J. Functional Data Visualization and Outlier Detection on the Anomaly of El Niño Southern Oscillation. Climate. 2021; 9(7):118. https://doi.org/10.3390/cli9070118
Chicago/Turabian StyleSuhaila, Jamaludin. 2021. "Functional Data Visualization and Outlier Detection on the Anomaly of El Niño Southern Oscillation" Climate 9, no. 7: 118. https://doi.org/10.3390/cli9070118
APA StyleSuhaila, J. (2021). Functional Data Visualization and Outlier Detection on the Anomaly of El Niño Southern Oscillation. Climate, 9(7), 118. https://doi.org/10.3390/cli9070118