

A Fault Diagnosis Method under Data Imbalance Based on Generative Adversarial Network and Long Short-Term Memory Algorithms for Aircraft Hydraulic System


Abstract
:1. Introduction
2. Model Design of Fault Diagnosis
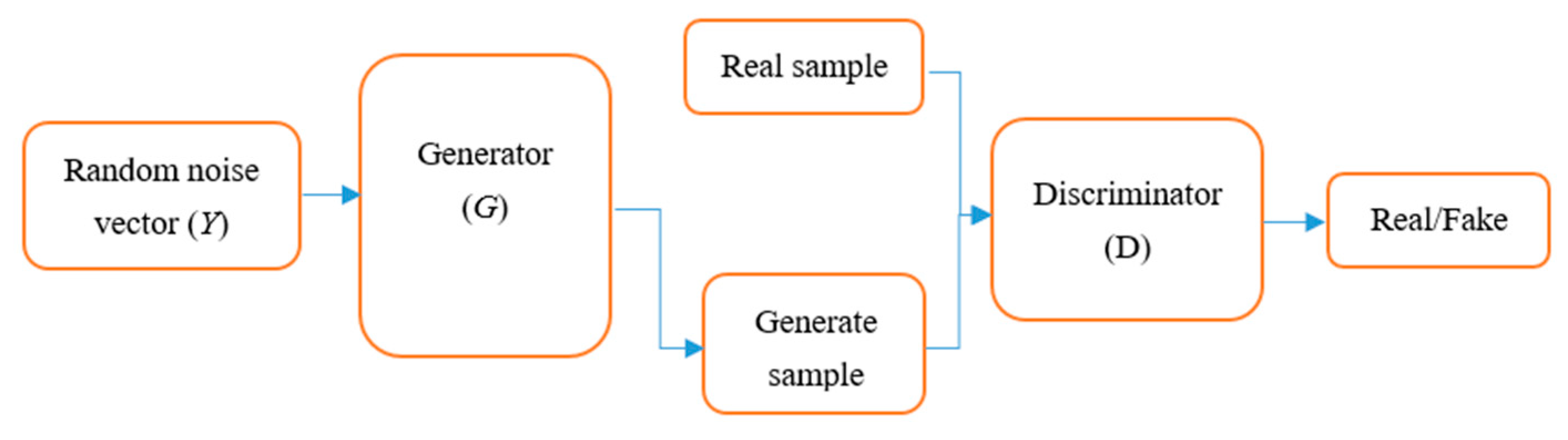
2.1. GAN Algorithm
2.2. Fault Detection Method Proposed in This Paper
2.3. Design of Generator and Discriminator in the GAN Model
2.4. Model Description and Evaluation of ACWGAN-gp
3. Data Acquisition and Generation of the Aircraft Hydraulic System
3.1. Acquisition of Normal and Fault Data of Aircraft Hydraulic System
3.2. Generation of the Aircraft Hydraulic System Fault Sample
4. Comparative Analysis of Fault Detection Methods under Imbalanced Data
4.1. The GAN-LSTM Fault Diagnosis Method
4.2. Comparison of GAN-LSTM with Other Different Fault Diagnosis Methods
4.3. The Quality Comparison of Different GAN Methods
4.4. Anti-Noise Performance Analysis of the GAN-LSTM
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cui, J.; Lin, Z.; Chen, X.; Lv, R.; Qi, Y.; Jiang, L. Research on health assessment of the aircraft hydraulic system. Control. Eng. China 2014, 21, 446–449. [Google Scholar]
- Yu, C.; Wang, X.; Wang, B.; Meng, X. A mechanical damage detection method of aircraft hydraulic pipeline based on acoustic emission technology. J. Air Force Eng. Univ. (Nat. Sci. Ed.) 2022, 23, 7–11. [Google Scholar]
- Xu, L.; Li, X.; Yang, S. Analysis and improvement measures of hydraulic system oil leakage. Hydraul. Pneum. Seals 2022, 42, 92–96. [Google Scholar]
- Su, X. Failure analysis of a certain airplane hydraulic system pressure changing with engine speed. Hydraul. Pneum. Seals 2021, 41, 88–91. [Google Scholar]
- Cui, J.; Fu, K.; Chen, X.; Qi, Y.; Jiang, L. Multiple attribute maintenance decision making of aircraft based on grey-fuzziness and analytical hierarchy process. Acta Aeronaut. Astronaut. Sin. 2014, 35, 478–486. [Google Scholar]
- He, L.; Liang, L.; Ma, C. Multiple failure simulation and health evaluation of aircraft landing gear hydraulic retraction/extension system. J. Northwest Polytech. Univ. 2016, 36, 990–995. [Google Scholar]
- Wang, L.; Liu, Q.; Huo, J.; Jiang, X.; Hu, J.; Tang, J. Identification of leakage degree of hydraulic pipeline based on probabilistic neural network. Mach. Tool Hydraul. 2020, 48, 159–164. [Google Scholar]
- Ma, J.; Duan, F.; Wang, H. Reliability Research of Certain Aircraft Hydraulic System Based on GO Methodology. J. Dalian Univ. Technol. 2019, 59, 492–500. [Google Scholar]
- Theodoropoulos, P.; Spandonidis, C.C.; Giannopoulos, F.; Fassois, S. A Deep Learning-Based Fault Detection Model for Optimization of Shipping Operations and Enhancement of Maritime Safety. Sensors 2021, 21, 5658. [Google Scholar] [CrossRef]
- Encalada-Dávila, Á.; Puruncajas, B.; Tutivén, C.; Vidal, Y. Wind turbine main bearing fault prognosis based solely on scada data. Sensors 2021, 21, 2228. [Google Scholar] [CrossRef]
- Kilic, U.; Unal, G. Sensor fault detection and reconstruction system for commercial aircraft. Aeronaut. J. 2022, 126, 889–905. [Google Scholar] [CrossRef]
- Kiyak, E. Sensor faults diagnosis in aircraft lateral flight control using model based approaches. J. Aeronaut. Space Technol. 2015, 8, 1–8. [Google Scholar] [CrossRef]
- Ermeydan, A.; Kiyak, E. Fault tolerant control against actuator faults based on enhanced PID controller for a quadrotor. Aircr. Eng. Aerosp. Technol. 2017, 89, 468–476. [Google Scholar] [CrossRef]
- Yazar, I.; Caliskan, F.; Kiyak, E. Multiple fault-based FDI and reconfiguration for aircraft engine sensors. Aircr. Eng. Aerosp. Technol. 2017, 89, 397–405. [Google Scholar] [CrossRef]
- Hu, Z.; Jiang, P. An imbalance modified deep neural network with dynamical incremental learning for chemical fault diagnosis. IEEE Trans Ind. Electron. 2019, 66, 540–550. [Google Scholar] [CrossRef]
- Mathew, J.; Pang, C.K.; Luo, M.; Hoe, W.; Leong, W. Classification of imbalanced data by oversampling in kernel space of support vector machines. IEEE Trans Neural. Netw. Learn Syst. 2018, 29, 4065–4076. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lu, N.; Xing, S. Deep normalized convolutional neural network for imbalanced fault classification of machinery and its understanding via visualization. Mech. Syst. Signal Process 2018, 110, 349–367. [Google Scholar] [CrossRef]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.; Wang, Z.; Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Isola, P.; Zhu, Y.J.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1558–1566. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Star-gan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Cao, S.; Wen, L.; Li, X.; Gao, L. Application of generative adversarial networks for intelligent fault diagnosis. In Proceedings of the 2018 IEEE 14th International Conference on Automation Science and Engineering (CASE), IEEE, Munich, Germany, 20–24 August 2018; pp. 711–715. [Google Scholar]
- Xu, P.; Du, R.; Zhang, Z. Predicting pipeline leakage in petrochemical system through GAN and LSTM. Knowl. -Based Syst. 2019, 175, 50–61. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, R.; Pan, R.; Pan, H. Imbalanced fault diagnosis of rolling bearing using enhanced generative adversarial networks. IEEE Access 2020, 8, 185950–185963. [Google Scholar] [CrossRef]
- Zhou, F.; Yang, S.; Fujita, H.; Chen, D.; Wen, C. Deep learning fault diagnosis method based on global optimization GAN for unbalanced data. Knowl. -Based Syst. 2020, 187, 104837. [Google Scholar] [CrossRef]
- Dixit, S.; Verma, N.K.; Ghosh, A.K. Intelligent fault diagnosis of rotary machines: Conditional auxiliary classifier GAN coupled with meta learning using limited data. IEEE Trans. Instrum. Meas. 2021, 70, 3517811. [Google Scholar] [CrossRef]
- Afrasiabi, S.; Afrasiabi, M.; Parang, B.; Mohammadi, M.; Arefi, M.M.; Rastegar, M. Wind turbine fault diagnosis with generative-temporal convolutional neural network. In Proceedings of the 2019 IEEE International Conference on Environment and Electrical Engineering and 2019 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), IEEE, Genova, Italy, 11–14 June 2019; pp. 1–5. [Google Scholar]
- Wang, Z.; Wang, J.; Wang, Y. An intelligent diagnosis scheme based on generative adversarial learning deep neural networks and its application to planetary gearbox fault pattern recognition. Neurocomputing 2018, 310, 213–222. [Google Scholar] [CrossRef]
- Zhong, C.; Yan, K.; Dai, Y.; Jin, N.; Lou, B. Energy efficiency solutions for buildings: Automated fault diagnosis of air handling units using generative adversarial networks. Energies 2019, 12, 527. [Google Scholar] [CrossRef]
- Liu, S.; Chen, J.; Qu, C.; Hou, R.; Lv, H.; Pan, T. LOSGAN: Latent optimized stable GAN for intelligent fault diagnosis with limited data in rotating machinery. Meas. Sci. Technol. 2021, 32, 045101. [Google Scholar] [CrossRef]
- Huang, N.; Chen, Q.; Cai, G.; Xu, D.; Zhang, L.; Zhao, W. Fault diagnosis of bearing in wind turbine gearbox under actual operating conditions driven by limited data with noise labels. IEEE Trans. Instrum. Meas. 2020, 70, 3502510. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Proc. Adv. Neural. Inf. Process Syst. (NIPS 2014) 2014, 27, 2672–2680. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier GANs. arXiv 2016. Available online: http://arxiv.org/abs/1610.09585 (accessed on 10 November 2022).
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. arXiv 2017. Available online: https://arxiv.org/abs/1701.07875 (accessed on 10 November 2022).
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. arXiv 2017. Available online: http://arxiv.org/abs/1701.04862 (accessed on 10 November 2022).
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of Wasserstein GANs. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Li, Y.; Wang, X. Fault diagnosis of aircraft hydraulic system. Comput. Eng. Appl. 2019, 55, 232–236. [Google Scholar]
- Hu, X.; Ma, C.; He, L.; Liang, L. Modeling and fault simulation of the landing gear extension and retraction system. Comput. Eng. Sci. 2016, 38, 1286–1293. [Google Scholar]
- Xia, Z.; Song, Y.; Ma, J.; Zhou, L.; Dong, Z. Research on the Pearson correlation coefficient evaluation method of analog signal in the process of unit peak load regulation. In Proceedings of the 2017 13th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Yangzhou, China, 20–22 October 2017; pp. 522–527. [Google Scholar]
- Chanwimalueang, T.; Mandic, D.P. Cosine similarity entropy: Self-correlation-based complexity analysis of dynamical systems. Entropy 2017, 19, 652. [Google Scholar] [CrossRef]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef] [PubMed]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Davis, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Jalayer, M.; Orsenigo, C.; Vercellis, C. Fault detection and diagnosis for rotating machinery: A model based on convolutional LSTM, Fast Fourier and continuous wavelet transforms. Comput. Ind. 2021, 125, 103378. [Google Scholar] [CrossRef]
- Xiang, L.; Wang, P.; Yang, X.; Hu, A.; Su, H. Fault detection of wind turbine based on SCADA data analysis using CNN and LSTM with attention mechanism. Measurement 2021, 175, 109094. [Google Scholar] [CrossRef]
- Han, Y.; Qi, W.; Ding, N.; Geng, Z. Short-time wavelet entropy integrating improved LSTM for fault diagnosis of modular multilevel converter. IEEE Trans. Cybern. 2021, 52, 7504–7512. [Google Scholar] [CrossRef]
- Su, S.; Qu, J.; Cao, Y.; Li, R.; Wang, G. Adversarial training lattice lstm for named entity recognition of rail fault texts. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21201–21215. [Google Scholar] [CrossRef]
- Yan, K.; Zhong, C.; Ji, Z.; Huang, J. Semi-supervised learning for early detection and diagnosis of various air handling unit faults. Energy Build. 2018, 181, 75–83. [Google Scholar] [CrossRef]
- Vlachas, P.R.; Byeon, W.; Wan, Z.Y.; Sapsis, T.P.; Koumoutsakos, P. Data-driven forecasting of high-dimensional chaotic systems with long short-term memory networks. Proc. R. Soc. A Math Phys. Eng. Sci. 2018, 474, 20170844. [Google Scholar] [CrossRef]
- Jin, C.; Shi, F.; Xiang, D.; Jiang, X.; Zhang, B.; Wang, X.; Zhu, W.; Gao, E.; Chen, X. 3D fast automatic segmentation of kidney based on modified AAM and random forest. IEEE Trans Med. Imag. 2016, 35, 1395–1407. [Google Scholar] [CrossRef]
- Sulistyo, S.B.; Wu, D.; Woo, W.L.; Dlay, D.D.; Gao, B. Computational deep intelligence vision sensing for nutrient content estimation in agricultural automation. IEEE Trans Autom. Sci. Eng. 2018, 15, 1243–1257. [Google Scholar] [CrossRef]
- Kim, T.Y.; Cho, S.B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Element Names | Meaning | Parameter Value |
|---|---|---|---|
| 1 | Booster tank | Provides hydraulic oil | Preset pressure: 50 psi |
| 2 | Engine-driven pump 1 | Provides power for aircraft hydraulics | Rpm: 5000 rec/min |
| 3 | Electrical-motor-driven pump 1 | Auxiliary EDP1 oil supply | Rpm: 5000 rec/min |
| 4 | Throttle valve | Controls hydraulic flow | / |
| 5 | One-way valve | Prevents hydraulic oil backflow | / |
| 6 | Hydraulic oil filter | Prevents impurities in hydraulic filtration | / |
| 7 | Relief pressure control valve | Reduces the pressure, prevents too high pressure | Open: 3400 psi Close: 3200 psi |
| 8 | Hydraulic accumulator | Reduces the pulse of pressure and assists energy supply | Preset pressure: 1800 psi |
| 9 | Two-position three-way directional control valve | Control PTU | / |
| 10 | Three-position four-way directional control valve | Control actuator | / |
| 11 | Actuator | The mechanical part of the aircraft hydraulic system | / |
| 12 | EMP2 | Auxiliary EDP2 oil supply | Rpm: 5000 rec/min |
| 13 | EDP2 | Provides power for aircraft hydraulics | Rpm: 5000 rec/min |
| 14 | RAT | Provides an emergency power source for the aircraft hydraulic system | Rpm: 4000 rev/min |
| 15 | EMP3 | Auxiliary oil supply | Rpm: 5000 rec/min |
| 16 | Hydraulic oil | Used to set the types and parameters of hydraulic oil | Density: 1003 g/L |
| Component Number | Type of Inserted Fault | Fault Mode Parameters | Normal Status | Moderate Fault | Severe Fault |
|---|---|---|---|---|---|
| 2 | Pump leak | Equivalent aperture/mm | 0.1–0.5 | 0.5–1.0 | 1.5–2 |
| 11 | Actuator leakage | Leak coefficient | 0–0.01 | 0.05–0.09 | 0.1–0.15 |
| 16 | Hydraulic oil pollution | Gas content/% | 0.1–0.3 | 5–10 | 15–20 |
| Classification of Sample Sets | Sample Length | Training Set | Test Set | Class Classifier |
|---|---|---|---|---|
| Normal status | 2000 | 1000 | 200 | 0 |
| Actuator leak (mild) | 2000 | 100 | 200 | 1 |
| Actuator leak (severe) | 2000 | 100 | 200 | 2 |
| Hydraulic oil pollution (mild) | 2000 | 100 | 200 | 3 |
| Hydraulic oil pollution (severe) | 2000 | 100 | 200 | 4 |
| Pump leak (mild) | 2000 | 100 | 200 | 5 |
| Pump leak (severe) | 2000 | 100 | 200 | 6 |
| Sample Class | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| PCC | 0.725 | 0.738 | 0.652 | 0.803 | 0.665 | 0.692 | 0.745 |
| CS | 0.822 | 0.835 | 0.804 | 0.824 | 0.872 | 0.832 | 0.855 |
| Parameter | Number |
|---|---|
| Epoch | 100 |
| Lr | 0.0001 |
| Batch size | 800 |
| Optimizer | Adam |
| Activation | ReLu |
| Sample Class | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| Training set | 500 | 5 | 5 | 5 | 5 | 5 | 5 |
| Test set | 200 | 200 | 200 | 200 | 200 | 200 | 200 |
| Generated Data | 0 | 5 | 15 | 35 | 75 | 95 | 195 | 295 | 395 | 495 |
|---|---|---|---|---|---|---|---|---|---|---|
| Training set | 5 | 10 | 20 | 40 | 80 | 100 | 200 | 300 | 400 | 500 |
| BR | 0.01 | 0.02 | 0.04 | 0.08 | 0.16 | 0.2 | 0.4 | 0.6 | 0.8 | 1 |
| Sample Set | GAN | Conditional-GAN | ACWGAN-GP |
|---|---|---|---|
| Normal sample | 0.2833 | 0.2423 | 0.1327 |
| Fault sample | 0.6967 | 0.4933 | 0.3023 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, K.; Zhao, D. A Fault Diagnosis Method under Data Imbalance Based on Generative Adversarial Network and Long Short-Term Memory Algorithms for Aircraft Hydraulic System. Aerospace 2023, 10, 164. https://doi.org/10.3390/aerospace10020164
Shen K, Zhao D. A Fault Diagnosis Method under Data Imbalance Based on Generative Adversarial Network and Long Short-Term Memory Algorithms for Aircraft Hydraulic System. Aerospace. 2023; 10(2):164. https://doi.org/10.3390/aerospace10020164
Chicago/Turabian StyleShen, Kenan, and Dongbiao Zhao. 2023. "A Fault Diagnosis Method under Data Imbalance Based on Generative Adversarial Network and Long Short-Term Memory Algorithms for Aircraft Hydraulic System" Aerospace 10, no. 2: 164. https://doi.org/10.3390/aerospace10020164
APA StyleShen, K., & Zhao, D. (2023). A Fault Diagnosis Method under Data Imbalance Based on Generative Adversarial Network and Long Short-Term Memory Algorithms for Aircraft Hydraulic System. Aerospace, 10(2), 164. https://doi.org/10.3390/aerospace10020164