
Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application


Abstract
1. Introduction
1.1. Air Traffic Control Safety
1.2. Spoken Instruction Understanding
- (a)
- ASR: translates the ATCO’s instruction from speech signal into text representation (human- or computer-readable). The ASR technique concerns the acoustic model, language model, or other contextual information.
- (b)
- LU: also known as text instruction understanding, with the goal to extract ATC-related elements from the text instruction since the ATC system cannot process the text directly, i.e., from text to an ATC-related structured data. The ATC elements are further applied to improve the operational safety of air traffic. In general, the LU task can be divided into three parts: role recognition, intent detection, and slot filling (ATC-related element extraction, such as aircraft identity, altitude, etc.).
1.3. Research Design
- (1)
- Purpose: presents the significance of the SIU task to clarify why we study it (Section 1.1).
- (2)
- Problem: presents the SIU system architecture (Section 1.2) and the difficulties we need to address to achieve the ASR task (Section 2).
- (3)
- (4)
- Application: introduces the potential application and benefits of applying the SIU task to real industrial systems (Section 4).
- Firstly, as mentioned before, thanks to a large amount of available industrial data storage and the development of deep learning techniques, the performance of concerned techniques of the SIU task are greatly improved in recent years. Therefore, this research mainly focuses on improving the deep learning-based approaches to achieve the SIU task.
- As is well known, the deep learning-based model is a kind of data-driven approach, which achieves the desired tasks (specifically, the pattern recognition tasks) by fitting the complicated distribution between the input and the output data. That is to say, the training data is essential to the deep learning model, whose performance highly depends on the quality of the training samples.
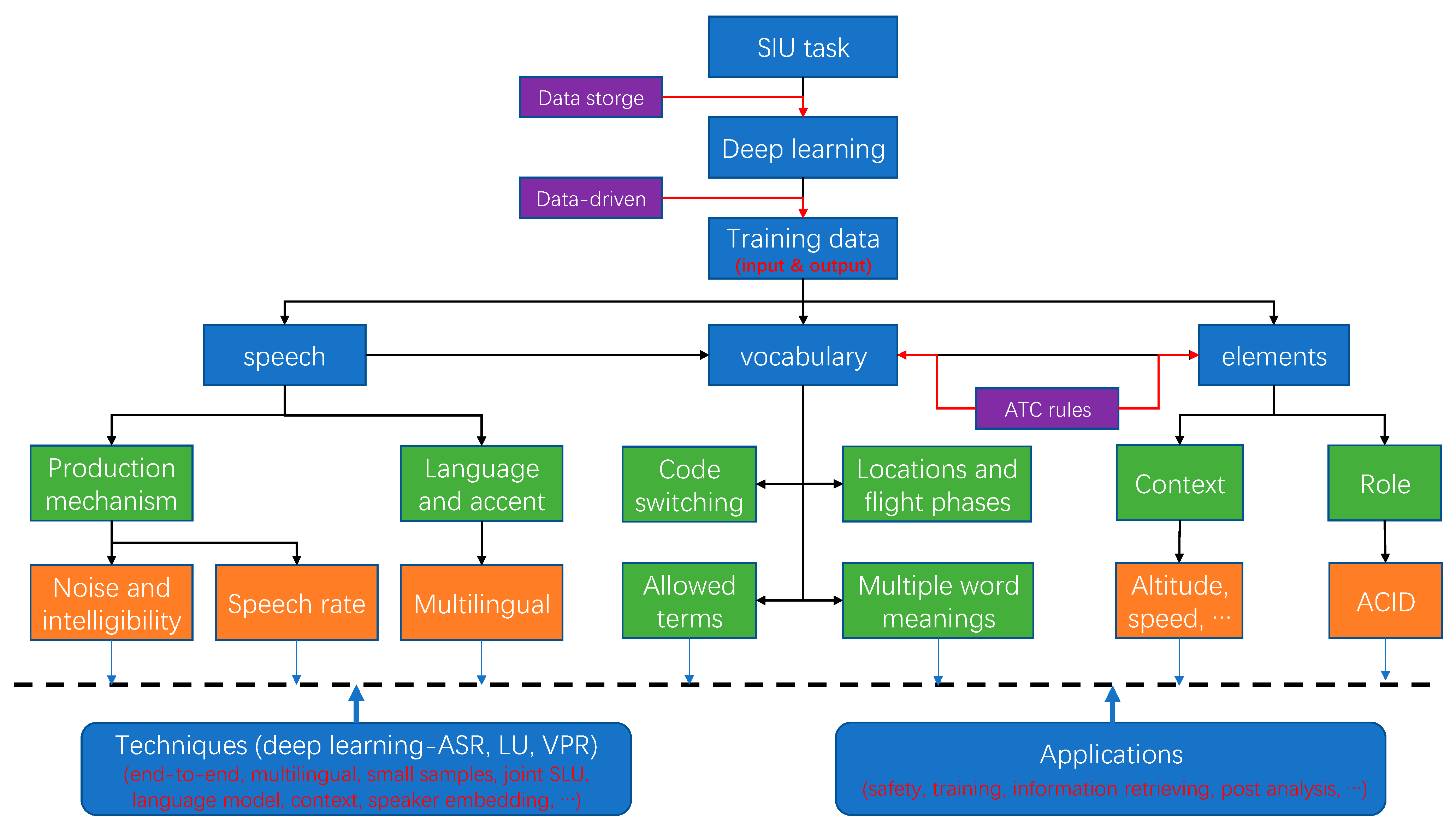
- Following the last description, the analysis of the task specificities of the SIU task in the ATC domain will focus on the input and output of the SIU techniques, i.e., ASR, LU, and VPR. In general, the input and output of the SIU model consist of the ATC speech, vocabulary, and ATC-related elements, as can be found in Figure 1.
- In succession, based on the production mechanism of the ATC speech and ATC rules, a systematic analysis for the task specificities is achieved from various perspectives.
1.4. Document Structure
2. Challenges
2.1. Data Collection and Annotation
2.2. Volatile Background Noise and Inferior Intelligibility
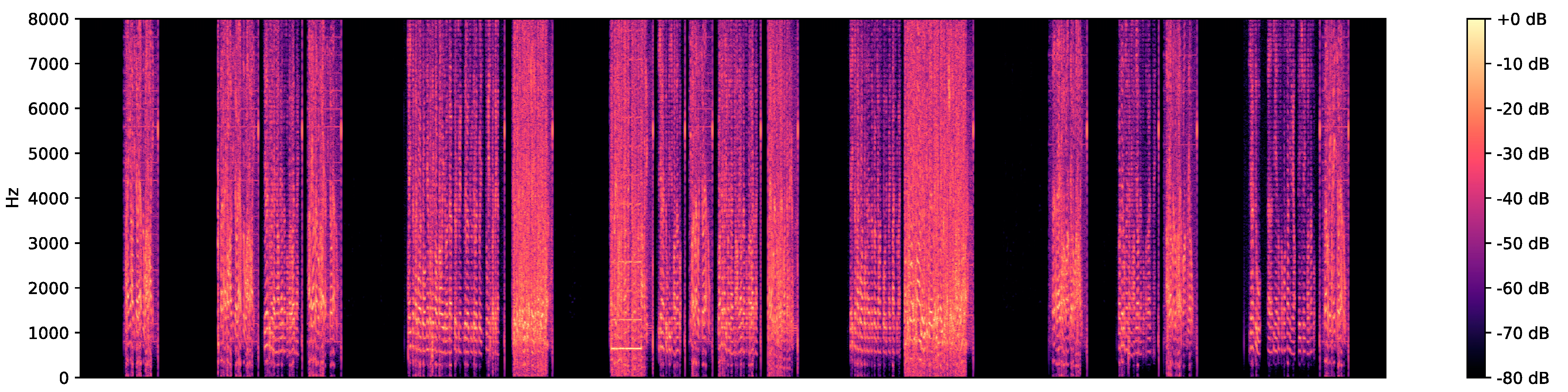
- Due to the resource limitation of the radio transmission, an ATCO usually communicates with several pilots in the same communication frequency. Therefore, the equipment and radio transmission conditions change as the speaker changes [27], which further results in volatile background noise in the same frequency, as shown in Figure 3. It is clear that the feature intensities distribute in different frequency ranges due to the different noise models (communication equipment or conditions).
- In general, the speech signal of ATC communication is recorded in a very low sample rate (8000 Hz), which degenerates the intelligibility of the speech.
- Since the spoken instruction is transmitted by radio communication, the robustness of the communication is always a fatal obstacle to receive high-quality speech for both ATCOs and pilots in the ATC domain.
- In general, the speech rate of ATC speech is higher than that in daily life due to the time constraints of the traffic situation. This fact severely damages the quality and intelligibility of the ATC speech. For example, speaking “two two” in a fast speech rate may probably cause an overlapped speech segment, and the ASR system can only output one “two” (incorrect results).
2.3. Unstable Speech Rate
- Traffic situation: the ATCO unconsciously speeds up his speech when facing a busy sector or peaking hours.
- Language: the ATCOs usually speak their native language at a higher speech rate than that of other languages. For example, ATCOs in China speak Chinese at a higher speech rate than English.
- Emotion: The speech rate is also impacted by the ATCO’s emotion and presents an irregular and unstable state.
2.4. Multilingual and Accented Speech
2.5. Code Switching
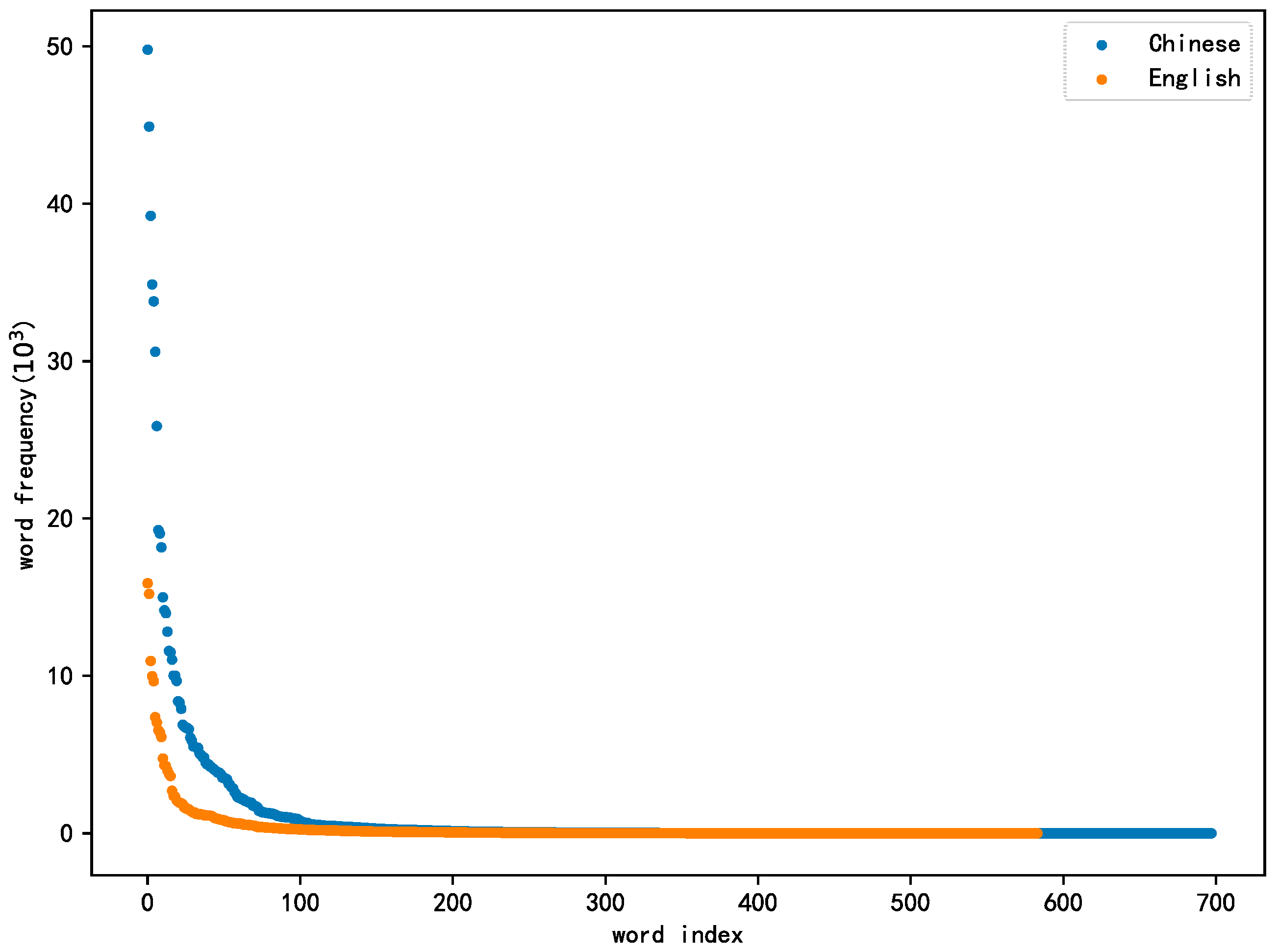
2.6. Vocabulary Imbalance
2.7. Generalization of Unseen Samples
2.8. Ambiguous Word Meaning
- (a)
- Since digits are commonly used in the speech corpus, the distributions or the contextual correlations between digits and other words are extremely similar. This fact reduces the effectiveness of the language model (LM) for text correction to a certain extent for the speech recognition and language understanding task.
- (b)
- For the LU task, it is hard to design a fair and distinct label (slot filling) for digits in the ATC-related corpus. If all the digits are regarded as the same label (i.e., digit), the actual role for different goals (airline number, flight level, altitude, etc.) will be confused. If all the digits are explained as different labels based on their real goal, a large amount of one-to-many relationships will be generated. Both situations have a possibility of degenerating the final performance of the LU model.
2.9. Role Recognition
2.10. Contextual Information
3. Technique
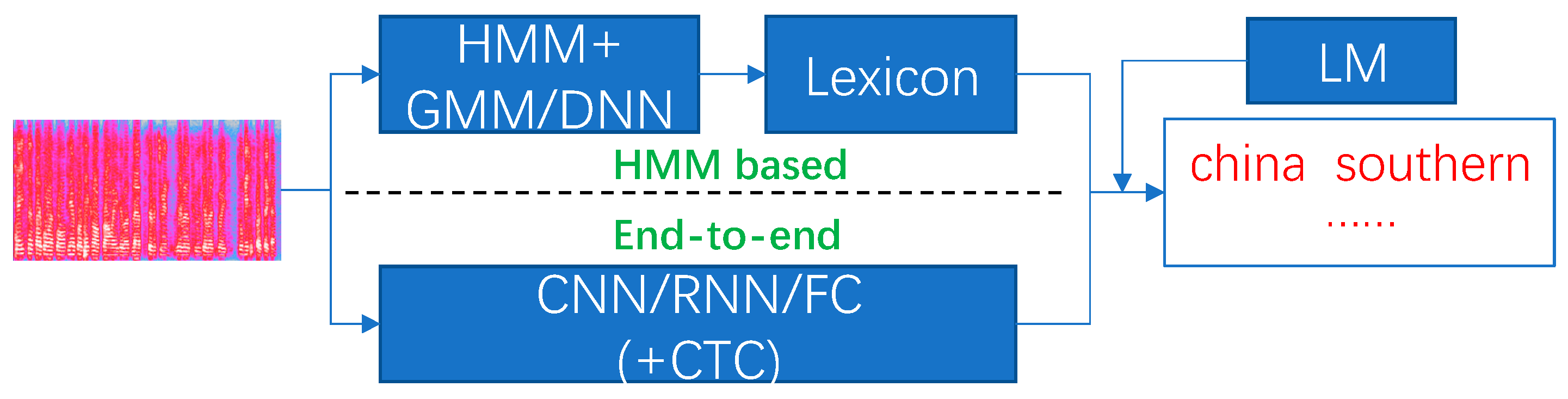
3.1. Automatic Speech Recognition
- (1)
- Statistical models: The introduction of statistical models advanced the first technical peak of the ASR research, which achieves the goal of large vocabulary continuous speech recognition (LVCSR). The hidden Markov model (HMM) [29] was proposed to capture the state transitions among continuous phonemes, while the Gaussian mixture model (GMM) was applied to build the distribution between the state and the vocabulary unit [30]. Currently, the HMM/GMM framework still plays an important role in the ASR research.
- (2)
- Hybrid neural network models: Thanks to the improvement of the deep neural network (DNN), it was also proposed to the ASR research to replace the GMM, which further generates the HMM/DNN framework [31]. As expected, the HMM/DNN showed desired performance improvements over the HMM/GMM framework, which also promotes the ASR research into the deep learning era.
- (3)
- End-to-end models: Due to the strict requirements of the alignment between speech and vocabulary, Graves et al. proposed a novel loss function called connectionist temporal classification (CTC) [32]. The CTC loss function also formulated a new framework, i.e., it is also known as the end-to-end-based ASR model. The end-to-end ASR model is able to automatically align the speech and text sequence by inserting the blank label, which formulates a more intuitive pipeline [33,34]. The end-to-end framework reduces the requirement of expertise-dependent knowledge and greatly promotes the popularization of the ASR study for common researchers. Many outstanding research outcomes were obtained based on this framework, such as Deep speech 2 (DS2) [35], Jasper [36], CLDNN [37], DeepCNN [38], etc.
- (4)
- Sequence-to-sequence models: Lately, the sequence-to-sequence (S2S) mechanism was also transferred to the ASR research [39,40]. Recently, the attention mechanism [41,42,43,44] and Transformer architecture [45,46,47,48] were also improved to address the ASR issues and showed desired performance improvement.
3.2. Language Understanding
- (1)
- Role recognition: details as illustrated in Section 2.9.
- (2)
- Intent detection: extract the controlling intent (CI) from the text instruction. The CI is a set of predefined ATC-related classes, such as climb, descend, heading, etc.
- (3)
- Slot filling: analyze every word in a text instruction to obtain the contextual types, which are called instruction elements (IE). Similarly, the IE is also a set of predefined ATC-related classes, such as airline, flight number, altitude, speed, etc.
- (1)
- Intent detection: It is a classification task. Various models were proposed and improved to achieve this task, including the generative machine learning models (such as Bayesian [68], HMM [69], etc.), and discriminative models (such as logistic regression [70], maximum entropy [71], conditional random fields (CRF) [72], support vector machine (SVM) [73], etc.). Deep learning models, including recurrent neural network (RNN) [74] and convolutional neural network (CNN) [75], were also introduced to achieve the intent detection.
- (2)
- Slot filling: A maximum entropy Markov model (MEMM) [76] was proposed to achieve the information extraction and segmentation from texts. The CRF was also improved to achieve the slot filling task in [72]. The RNN block [77] and long short-term memory (LSTM) [78] were also applied to improve the performance by building long-term dependencies among the input text sequence.
- (3)
- Joint model: Liu et al. proposed an LSTM-based model to achieve intent detection and the slot-filling task jointly [79]. A combined model based on the CNN and triangular CRF was also improved to jointly achieve the SLU task [75]. The recursive neural networks (RecNN) architecture [80] and gated recurrent unit (GRU) [81] were studied to obtain the semantic utterance classification and slot filling jointly. Recently, the attention mechanism [82,83] and transformer architecture [84,85] were also proposed to address existing issues in the SLU research.
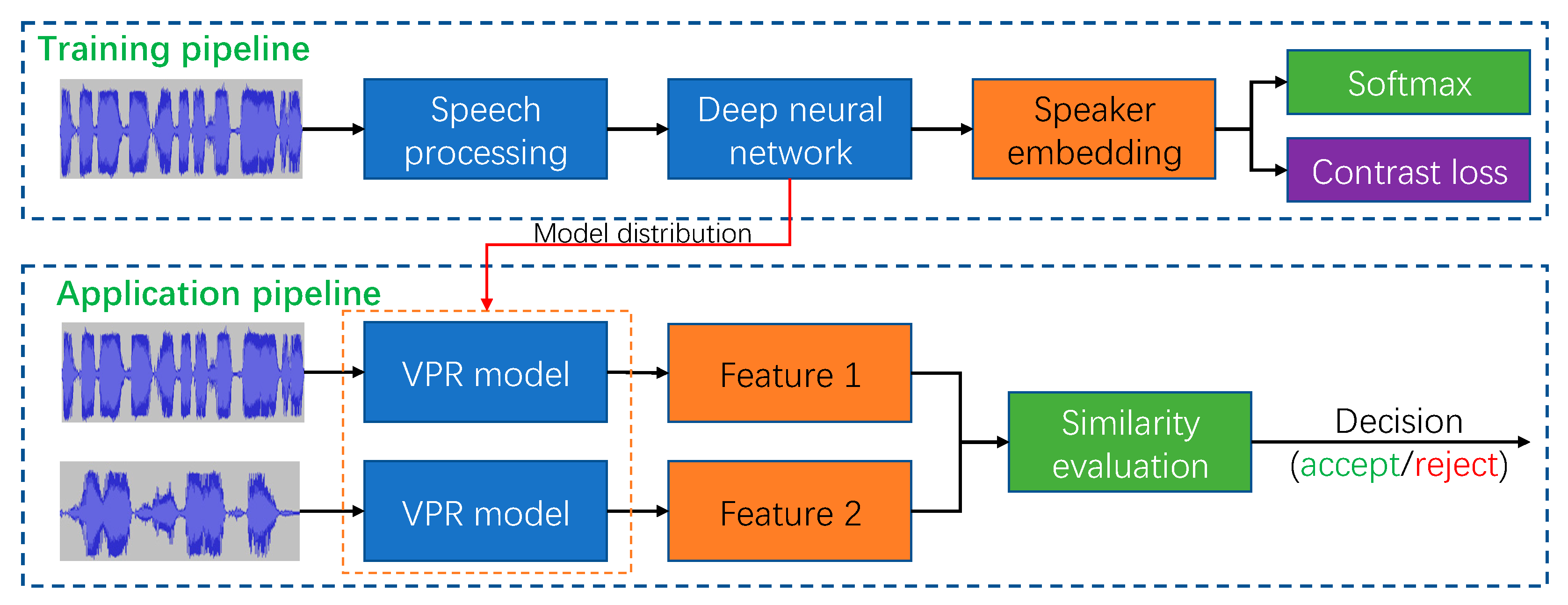
3.3. Voiceprint Recognition
- (1)
- Template matching: In the early stage, the VPR approaches directly calculated the similarity between the time-frequency spectrum to determine whether two utterances come from the same speaker [89]. Then, this type of approach was improved to consider the speech diversity in the temporal dimension, which further generated other approaches, such as the dynamic time warping (DTW) [90] and vector quantization (VQ) [91], etc.
- (2)
- Statistical models: As the GMM model has made great progress in the ASR research, it was also explored to build a robust text-independent VPR system [92]. Moreover, other models were further introduced to improve the performance and robustness, such as the universal background model [93] and support vector machine [94].
- (3)
- (4)
- Deep neural network models: With the d-vector [97] proposed in 2014, DNN-based models showed the ability to directly optimize the discriminations among different speakers. Subsequently, both metric learning and representation learning were also widely used in the VPR research. In this pipeline, the DNN architecture is used to extract high-level abstract embeddings as voiceprint representation features, while metric learning is applied to optimize the networks. Enormous research outcomes were generated based on this core idea, such as Deep Speaker [98], X-vector [99,100], j-vector [101,102], SincNet [103], etc.
4. Applications
4.1. Information Enhancement
4.2. Communication Error Detection (CED)
- (1)
- The instruction completeness: Confirm whether essential elements are embedded in the ATCO’s instruction based on the ATC rules, such as target altitude for climb instruction. The purpose of this application is to encourage the ATCO to issue standard instructions to eliminate misunderstandings between ATCO and aircrew during the ATC communication.
- (2)
- Resource incursion: Check whether the concerned resources of the ATCO instruction are valid or have conflicted with other operators from temporal and spatial dimensions, such as the closed runway detection, ground obstacle, etc. [104]. In this way, the potential risks can be detected in the stage of instruction issue and greatly improve the operational safety in advance.
- (3)
- Repetition check: Check whether the pilot receives the ATCO’s instruction in a correct and prompt manner. The repetition check error includes no response from aircrew, repetition error (intent or elements), etc. [5]. This application is able to reduce the risks raised by the incorrect transmission and understanding of the pilot instruction, which can eliminate the potential safety risk during the issue of instruction (before changing the aircraft motion states).
4.3. Conflict Detection Considering Intent
4.4. Post Analysis and Processing
- (1)
- Workload measurement: Evaluate the workload of an ATCO from the time and sector dimensions, such as flight peak hours or busy sectors [13,109]. Based on the evaluation results, more efficient and effective designs for the airspace sector are expected to be achieved to balance the ATCO workload, which is also helpful to improve the operational safety of air traffic. For instance, a frequent “correct” instruction may indicate that an ATCO is in a fatigued state, so that too many incorrect instructions appeared in the ATC speech.
- (2)
- Performance evaluation: The ATC speech is a side view of real-time air traffic operation, in which the ATCO performance is enclosed as the conversation speech. Thus, the ATCO performance also deserves to be considered to detect the improper ATC actions and further improve ATCO’s skills. For example, excessive extra instructions for changing aircraft motion state may indicate that the sector always faces potential risk so that the ATCO has to adjust the aircraft motion to resolve the potential conflict. Facing this situation, it is necessary to improve operational safety by enhancing the ATCO skills or designing a more proper standard operating procedure (SOP) during the ATC communication.
- (3)
- Information retrieving: Currently, human hearing is the only way to search the ATC speech for a certain goal. Intuitively, based on the SIU technique, it is easy to search the target information (speech) from a long-duration continuous record speech, such as a certain flight number or a certain ATCO. This is strong support to the post-incident analysis in an automatic manner, since it is laborious and costly work undertaken by human staff.
- (4)
- Event detection: Detect anomaly speech to support other analyses in the ATC domain. For instance, the “confirm” instruction is issued by many speakers in a certain sector or time period and may indicate that the communication condition between ATCO and aircrew in the sector or time period is needed to be improved, such as the infrastructure malfunction or signal interference.
4.5. ATCO Training
5. Future Research
5.1. Speech Quality
- (1)
- Speech enhancement: Facing the inferior speech quality in the ATC domain, an intuitive way is to achieve the speech enhancement to further improve the ASR and VPR performance. With this technique, a high-quality ATC speech is expected to be obtained to support the SIU task and further benefit to achieve the high-performance subsequent ATC applications.
- (2)
- Representation learning: Facing the diverse distribution of speech features raised by different communication conditions, devices, multilingual, unstable speech rate, etc., there are reasons to believe that the handcrafted feature engineering algorithms (such as MFCC) may fail to support the ASR and VPR research to obtain the desired performance. The representation learning, i.e., extracting speech features by a well-optimized neural network, may be a promising way to improve the final SIU performance.
5.2. Sample Scarcity
- (1)
- Transfer learning: Although a set of standardized phraseology has been designed for the ATC procedure, the rules and vocabulary still depend on the flight phases, locations, and control centers. It is urgent to study the transfer learning technique among different flight phases, locations, and control centers to save the sample requirement and formulate a unified global technical roadmap.
- (2)
- Semi-supervised and self-supervised research: Since the data collection and annotation is always an obstacle of applying advanced technology to the ATC domain, the semi-supervised and self-supervised strategies are expected to be a promising way to overcome this dilemma, in which the unlabeled data samples can also be applied to contribute the model optimization based on their intrinsic characteristics, such as that in the common application area.
- (3)
- Sample generation: Similar to the last research topic, sample generation is another way to enhance the sample size and diversity and further improve the task performance, such as text instruction generation.
5.3. Contextual Information
- (1)
- Contextual situational incorporation: As illustrated before, contextual situational information is a powerful way to improve SIU performance. Due to the heterogeneous characteristics of the ATC information, existing works failed to take full advantage of this type of information. Learning from the state-of-the-art studies, the deep neural network may be a feasible tool to fuse the multi-modal input by encoding them as a high-level abstract representation using the learning mechanism and further make contributions to improve the SIU performance.
- (2)
- Multi-turn dialog management: Obviously, the ATC communication in the same frequency is a multi-turn and multi-speaker dialog with a task-oriented goal (ATC safety). During the dialog, the historical information is able to provide significant guidance to current instruction based on the air traffic evolution. Thus, it is important to consider the multi-turn history information to enhance the SIU task of current dialog, similar to what is required in the field of natural language processing.
5.4. Other Research Topics
- (1)
- Joint SIU model: Currently, the ASR and LU tasks are achieved separately, i.e., a cascaded pipeline, which also leads to cascaded errors (reduces the overall confidence). In the future, a joint SIU model for automatic speech recognition understanding (ASRU) deserves to be studied to capture the task compatibility to promote the final performance, similar to that of the joint SLU model. In this way, the SIU task can be achieved in a more intuitive and clear processing paradigm.
- (2)
- On-board SIU system: Currently, all the SIU studies are developed based on the requirements of the ground systems. The computational resource is heavily required due to the applications of the deep learning model. For future development, it is also attractive to achieve the SIU task for the on-board purpose (i.e., cockpit) and further construct a safety monitoring framework for the aircrew. In this way, a bi-directional safety-enhancing system is constructed for both the ATCO and aircrew, which is expected to ensure flight safety in a reinforced manner. To this end, the model transfer from the X86 platform to the embed system (such Jetson, NVIDIA, CA, USA) is the primary research to save the computational resource requirements, such as model compression, power reduction, etc.
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, Y.; Deng, L.; Chen, Z.; Wu, X.; Zhang, J.; Yang, B. A Real-Time ATC Safety Monitoring Framework Using a Deep Learning Approach. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4572–4581. [Google Scholar] [CrossRef]
- Rossi, M.A.; Lollini, P.; Bondavalli, A.; Romani de Oliveira, I.; Rady de Almeida, J. A Safety Assessment on the Use of CPDLC in UAS Communication System. In Proceedings of the 2014 IEEE/AIAA 33rd Digital Avionics Systems Conference (DASC), Colorado Springs, CO, USA, 5–9 October 2014; pp. 6B1-1–6B1-11. [Google Scholar]
- Kopald, H.D.; Chanen, A.; Chen, S.; Smith, E.C.; Tarakan, R.M. Applying Automatic Speech Recognition Technology to Air Traffic Management. In Proceedings of the 2013 IEEE/AIAA 32nd Digital Avionics Systems Conference (DASC), East Syracuse, NY, USA, 5–10 October 2013; pp. 6C3-1–6C3-15. [Google Scholar]
- Nguyen, V.N.; Holone, H. Possibilities, Challenges and the State of the Art of Automatic Speech Recognition in Air Traffic Control. Int. J. Comput. Electr. Autom. Control. Inf. Eng. 2015, 9, 1916–1925. [Google Scholar]
- Geacăr, C.M. Reducing Pilot/Atc Communication Errors Using Voice Recognition. In Proceedings of the 27th International Congress of the Aeronautical Sciences, Nice, France, 19–24 September 2010; pp. 1–7. [Google Scholar]
- Glaser-Opitz, H.; Glaser-Opitz, L. Evaluation of CPDLC and Voice Communication during Approach Phase. In Proceedings of the 2015 IEEE/AIAA 34th Digital Avionics Systems Conference (DASC), Prague, Czech, 13–18 September 2015; pp. 2B3-1–2B3-10. [Google Scholar]
- Isaac, A. Effective Communication in the Aviation Environment: Work in Progress. Hindsight 2007, 5, 31–34. [Google Scholar]
- Lin, Y.; Tan, X.; Yang, B.; Yang, K.; Zhang, J.; Yu, J. Real-Time Controlling Dynamics Sensing in Air Traffic System. Sensors 2019, 19, 679. [Google Scholar] [CrossRef]
- Serdyuk, D.; Wang, Y.; Fuegen, C.; Kumar, A.; Liu, B.; Bengio, Y. Towards End-to-End Spoken Language Understanding. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5754–5758. [Google Scholar]
- Helmke, H.; Slotty, M.; Poiger, M.; Herrer, D.F.; Ohneiser, O.; Vink, N.; Cerna, A.; Hartikainen, P.; Josefsson, B.; Langr, D.; et al. Ontology for Transcription of ATC Speech Commands of SESAR 2020 Solution PJ.16-04. In Proceedings of the 2018 IEEE/AIAA 37th Digital Avionics Systems Conference (DASC), London, UK, 23–27 September 2018; pp. 1–10. [Google Scholar]
- De Cordoba, R.; Ferreiros, J.; San-Segundo, R.; Macias-Guarasa, J.; Montero, J.M.; Fernandez, F.; D’Haro, L.F.; Pardo, J.M. Air Traffic Control Speech Recognition System Cross-Task and Speaker Adaptation. IEEE Aerosp. Electron. Syst. Mag. 2006, 21, 12–17. [Google Scholar] [CrossRef]
- Ferreiros, J.; Pardo, J.M.; de Córdoba, R.; Macias-Guarasa, J.; Montero, J.M.; Fernández, F.; Sama, V.; D’Haro, L.F.; González, G. A Speech Interface for Air Traffic Control Terminals. Aerosp. Sci. Technol. 2012, 21, 7–15. [Google Scholar] [CrossRef]
- Helmke, H.; Ohneiser, O.; Muhlhausen, T.; Wies, M. Reducing Controller Workload with Automatic Speech Recognition. In Proceedings of the 2016 IEEE/AIAA 35th Digital Avionics Systems Conference (DASC), Sacramento, CA, USA, 25–29 September 2016; pp. 1–10. [Google Scholar]
- Gurluk, H.; Helmke, H.; Wies, M.; Ehr, H.; Kleinert, M.; Muhlhausen, T.; Muth, K.; Ohneiser, O. Assistant Based Speech Recognition—Another Pair of Eyes for the Arrival Manager. In Proceedings of the 2015 IEEE/AIAA 34th Digital Avionics Systems Conference (DASC), Prague, Czech Republic, 13–18 September 2015; pp. 3B6-1–3B6-14. [Google Scholar]
- Lin, Y.; Li, L.; Jing, H.; Ran, B.; Sun, D. Automated Traffic Incident Detection with a Smaller Dataset Based on Generative Adversarial Networks. Accid. Anal. Prev. 2020, 144, 105628. [Google Scholar] [CrossRef]
- Lin, Y.; Li, Q.; Yang, B.; Yan, Z.; Tan, H.; Chen, Z. Improving Speech Recognition Models with Small Samples for Air Traffic Control Systems. Neurocomputing 2021, 1, 1–21. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR Corpus Based on Public Domain Audio Books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Hernandez, F.; Nguyen, V.; Ghannay, S.; Tomashenko, N.; Estève, Y. TED-LIUM 3: Twice as Much Data and Corpus Repartition for Experiments on Speaker Adaptation. In Proceedings of the 20th International Conference on Speech and Computer, Leipzig, Germany, 18–22 September 2018; pp. 198–208. [Google Scholar]
- Godfrey, J.; Holliman, E. Switchboard-1 Release 2. Available online: https://Catalog.Ldc.Upenn.Edu/LDC97S62 (accessed on 25 January 2021).
- Wang, D.; Zhang, X. THCHS-30: A Free Chinese Speech Corpus. arXiv 2015, arXiv:1512.01882. [Google Scholar]
- Bu, H.; Du, J.; Na, X.; Wu, B.; Zheng, H. AISHELL-1: An Open-Source Mandarin Speech Corpus and a Speech Recognition Baseline. In Proceedings of the 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA), Seoul, Korea, 13 November 2017; pp. 1–5. [Google Scholar]
- Du, J.; Na, X.; Liu, X.; Bu, H. AISHELL-2: Transforming Mandarin ASR Research into Industrial Scale. arXiv 2018, arXiv:1808.10583. [Google Scholar]
- Yang, B.; Tan, X.; Chen, Z.; Wang, B.; Ruan, M.; Li, D.; Yang, Z.; Wu, X.; Lin, Y. ATCSpeech: A Multilingual Pilot-Controller Speech Corpus from Real Air Traffic Control Environment. In Proceedings of the Interspeech 2020, ISCA, Shanghai, China, 25–29 October 2020; pp. 399–403. [Google Scholar]
- Hofbauer, K.; Petrik, S.; Hering, H. The ATCOSIM Corpus of Non-Prompted Clean Air Traffic Control Speech. In Proceedings of the 6th International Conference on Language Resources and Evaluation—LREC, Marrakech, Morocco, 26 May–1 June 2008. [Google Scholar]
- Godfrey, J. Air Traffic Control Complete. Available online: https://catalog.ldc.upenn.edu/ldc94s14a (accessed on 25 January 2021).
- Pellegrini, T.; Farinas, J.; Delpech, E.; Lancelot, F. The Airbus Air Traffic Control Speech Recognition 2018 Challenge: Towards ATC Automatic Transcription and Call Sign Detection. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 2993–2997. [Google Scholar]
- Lin, Y.; Guo, D.; Zhang, J.; Chen, Z.; Yang, B. A Unified Framework for Multilingual Speech Recognition in Air Traffic Control Systems. IEEE Trans. Neural Netw. Learn. Syst. 2020, 1–13. [Google Scholar] [CrossRef]
- ICAO. Manual on the Implementation of ICAO Language Proficiency Requirements, 2nd ed.; International Civil Aviation Organization: Montréal, QC, Canada, 2010; ISBN 9789292315498. [Google Scholar]
- Benzeghiba, M.; De Mori, R.; Deroo, O.; Dupont, S.; Erbes, T.; Jouvet, D.; Fissore, L.; Laface, P.; Mertins, A.; Ris, C.; et al. Automatic Speech Recognition and Speech Variability: A Review. Speech Commun. 2007, 49, 763–786. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition. IEEE Signal. Process. Mag. 2012. [Google Scholar] [CrossRef]
- Abe, A.; Yamamoto, K.; Nakagawa, S. Robust Speech Recognition Using DNN-HMM Acoustic Model Combining Noise-Aware Training with Spectral Subtraction. In Proceedings of the Annual Conference of the International Speech Communication Association—INTERSPEECH, Dresden, Germany, 6–10 September 2015; pp. 2849–2853. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist Temporal Classification. In Proceedings of the 23rd International Conference on Machine Learning—ICML ’06, Pittsburgh, PA, USA, 25–29 June 2006; ACM Press: New York, NY, USA, 2006; Volume 32, pp. 369–376. [Google Scholar]
- Graves, A.; Mohamed, A.; Hinton, G. Speech Recognition with Deep Recurrent Neural Networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Graves, A.; Jaitly, N. Towards End-to-End Speech Recognition with Recurrent Neural Networks. In Proceedings of the 31st International Conference on Machine Learning—ICML, Beijing, China, 21–26 June 2014. [Google Scholar]
- Amodei, D.; Anubhai, R.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Chen, J.; Chrzanowski, M.; Coates, A.; Diamos, G.; et al. Deep Speech 2: End-to-End Speech Recognition in English and Mandarin. In Proceedings of the 33rd International Conference on Machine Learning—ICML 2016, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Li, J.; Lavrukhin, V.; Ginsburg, B.; Leary, R.; Kuchaiev, O.; Cohen, J.M.; Nguyen, H.; Gadde, R.T. Jasper: An End-to-End Convolutional Neural Acoustic Model. In Proceedings of the Interspeech 2019—ISCA, Graz, Austria, 15–19 September 2019; pp. 71–75. [Google Scholar]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, Long Short-Term Memory, Fully Connected Deep Neural Networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Zeghidour, N.; Xu, Q.; Liptchinsky, V.; Usunier, N.; Synnaeve, G.; Collobert, R. Fully Convolutional Speech Recognition. arXiv 2018, arXiv:1812.06864. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, Attend and Spell: A Neural Network for Large Vocabulary Conversational Speech Recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Chiu, C.-C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-Art Speech Recognition with Sequence-to-Sequence Models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar]
- Watanabe, S.; Hori, T.; Kim, S.; Hershey, J.R.; Hayashi, T. Hybrid CTC/Attention Architecture for End-to-End Speech Recognition. IEEE J. Sel. Top. Signal. Process. 2017, 11, 1240–1253. [Google Scholar] [CrossRef]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-End Attention-Based Large Vocabulary Speech Recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4945–4949. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. arXiv 2015, arXiv:1506.07503. [Google Scholar]
- Pham, N.-Q.; Nguyen, T.-S.; Niehues, J.; Müller, M.; Waibel, A. Very Deep Self-Attention Networks for End-to-End Speech Recognition. In Proceedings of the Interspeech 2019—ISCA, Graz, Austria, 15–19 September 2019; pp. 66–70. [Google Scholar]
- Lian, Z.; Li, Y.; Tao, J.; Huang, J. Improving Speech Emotion Recognition via Transformer-Based Predictive Coding through Transfer Learning. arXiv 2018, arXiv:1811.07691. [Google Scholar]
- Karita, S.; Soplin, N.E.Y.; Watanabe, S.; Delcroix, M.; Ogawa, A.; Nakatani, T. Improving Transformer-Based End-to-End Speech Recognition with Connectionist Temporal Classification and Language Model Integration. In Proceedings of the Annual Conference of the International Speech Communication Association—INTERSPEECH, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Zhou, S.; Dong, L.; Xu, S.; Xu, B. Syllable-Based Sequence-to-Sequence Speech Recognition with the Transformer in Mandarin Chinese. In Proceedings of the Annual Conference of the International Speech Communication Association—INTERSPEECH, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Jiang, D.; Lei, X.; Li, W.; Luo, N.; Hu, Y.; Zou, W.; Li, X. Improving Transformer-Based Speech Recognition Using Unsupervised Pre-Training. arXiv 2019, arXiv:1910.09932. [Google Scholar]
- Toshniwal, S.; Sainath, T.N.; Weiss, R.J.; Li, B.; Moreno, P.; Weinstein, E.; Rao, K. Multilingual Speech Recognition with a Single End-to-End Model. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4904–4908. [Google Scholar]
- Li, B.; Zhang, Y.; Sainath, T.; Wu, Y.; Chan, W. Bytes Are All You Need: End-to-End Multilingual Speech Recognition and Synthesis with Bytes. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5621–5625. [Google Scholar]
- Hu, K.; Bruguier, A.; Sainath, T.N.; Prabhavalkar, R.; Pundak, G. Phoneme-Based Contextualization for Cross-Lingual Speech Recognition in End-to-End Models. In Proceedings of the Interspeech 2019—ISCA, Graz, Austria, 15–19 September 2019; pp. 2155–2159. [Google Scholar]
- Zhang, S.; Liu, Y.; Lei, M.; Ma, B.; Xie, L. Towards Language-Universal Mandarin-English Speech Recognition. In Proceedings of the Interspeech 2019—ISCA, Graz, Austria, 15–19 September 2019; pp. 2170–2174. [Google Scholar]
- Zeng, Z.; Khassanov, Y.; Pham, V.T.; Xu, H.; Chng, E.S.; Li, H. On the End-to-End Solution to Mandarin-English Code-Switching Speech Recognition. In Proceedings of the Interspeech 2019—ISCA, Graz, Austria, 15–19 September 2019; pp. 2165–2169. [Google Scholar]
- Lin, Y.; Yang, B.; Li, L.; Guo, D.; Zhang, J.; Chen, H.; Zhang, Y. ATCSpeechNet: A Multilingual End-to-End Speech Recognition Framework for Air Traffic Control Systems. arXiv 2021, arXiv:2102.08535. [Google Scholar]
- Srinivasamurthy, A.; Motlicek, P.; Singh, M.; Oualil, Y.; Kleinert, M.; Ehr, H.; Helmke, H. Iterative Learning of Speech Recognition Models for Air Traffic Control. In Proceedings of the Annual Conference of the International Speech Communication Association—INTERSPEECH, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Oualil, Y.; Klakow, D.; Szaszak, G.; Srinivasamurthy, A.; Helmke, H.; Motlicek, P. A Context-Aware Speech Recognition and Understanding System for Air Traffic Control Domain. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU)—IEEE, Sentosa, Singapore, 14–18 December 2017; pp. 404–408. [Google Scholar]
- Srinivasamurthy, A.; Motlicek, P.; Himawan, I.; Szaszák, G.; Oualil, Y.; Helmke, H. Semi-Supervised Learning with Semantic Knowledge Extraction for Improved Speech Recognition in Air Traffic Control. In Proceedings of the Interspeech 2017—ISCA, Stockholm, Sweden, 20–24 August 2017; pp. 2406–2410. [Google Scholar]
- Nguyen, V.N.; Holone, H. N-Best List Re-Ranking Using Syntactic Score: A Solution for Improving Speech Recognition Accuracy in Air Traffic Control. In Proceedings of the 2016 16th International Conference on Control, Automation and Systems (ICCAS)—IEEE, Jeju, Korea, 13–16 October 2016; pp. 1309–1314. [Google Scholar]
- Cordero, J.M.; Dorado, M.; de Pablo, J.M. Automated Speech Recognition in ATC Environment. In Proceedings of the 2nd International Conference on Application and Theory of Automation in Command and Control Systems, London, UK, 29–31 May 2012; pp. 46–53. [Google Scholar]
- Delpech, E.; Laignelet, M.; Pimm, C.; Raynal, C.; Trzos, M.; Arnold, A.; Pronto, D. A Real-Life, French-Accented Corpus of Air Traffic Control Communications. In Proceedings of the LREC 2018—11th International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Zuluaga-Gomez, J.; Motlicek, P.; Zhan, Q.; Veselý, K.; Braun, R. Automatic Speech Recognition Benchmark for Air-Traffic Communications. In Proceedings of the Interspeech 2020—ISCA, Shanghai, China, 25–29 October 2020; pp. 2297–2301. [Google Scholar]
- Hou, N.; Tian, X.; Chng, E.S.; Ma, B.; Li, H. Improving Air Traffic Control Speech Intelligibility by Reducing Speaking Rate Effectively. In Proceedings of the 2017 International Conference on Asian Language Processing (IALP)—IEEE, Singapore, 5–7 December 2017; pp. 197–200. [Google Scholar]
- Šmídl, L.; Švec, J.; Tihelka, D.; Matoušek, J.; Romportl, J.; Ircing, P. Air Traffic Control Communication (ATCC) Speech Corpora and Their Use for ASR and TTS Development. Lang. Resour. Eval. 2019, 53, 449–464. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Veselý, K.; Blatt, A.; Motlicek, P.; Klakow, D.; Tart, A.; Szöke, I.; Prasad, A.; Sarfjoo, S.; Kolčárek, P.; et al. Automatic Call Sign Detection: Matching Air Surveillance Data with Air Traffic Spoken Communications. Proceedings 2020, 59, 14. [Google Scholar] [CrossRef]
- Lin, Y.; Zhang, J.; Liu, H. Deep Learning Based Short-Term Air Traffic Flow Prediction Considering Temporal–Spatial Correlation. Aerosp. Sci. Technol. 2019, 93, 105113. [Google Scholar] [CrossRef]
- Liu, H.; Lin, Y.; Chen, Z.; Guo, D.; Zhang, J.; Jing, H. Research on the Air Traffic Flow Prediction Using a Deep Learning Approach. IEEE Access 2019, 7, 148019–148030. [Google Scholar] [CrossRef]
- Li, L.; Lin, Y.; Du, B.; Yang, F.; Ran, B. Real-Time Traffic Incident Detection Based on a Hybrid Deep Learning Model. Transp. A Transp. Sci. 2020, 1–21. [Google Scholar] [CrossRef]
- Dumais, S.; Platt, J.; Heckerman, D.; Sahami, M. Inductive Learning Algorithms and Representations for Text Categorization. In Proceedings of the Seventh International Conference on Information and Knowledge Management—CIKM ’98, Bethesda, MD, USA, 3–7 November 1998; ACM Press: New York, NY, USA, 1998; pp. 148–155. [Google Scholar]
- Collins, M. Discriminative Training Methods for Hidden Markov Models. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing—EMNLP ’02, Philadelphia, PA, USA, 6–7 July 2002; Association for Computational Linguistics: Morristown, NJ, USA, 2002; Volume 10, pp. 1–8. [Google Scholar]
- Yu, H.-F.; Huang, F.-L.; Lin, C.-J. Dual Coordinate Descent Methods for Logistic Regression and Maximum Entropy Models. Mach. Learn. 2011, 85, 41–75. [Google Scholar] [CrossRef]
- Malouf, R. A Comparison of Algorithms for Maximum Entropy Parameter Estimation. In Proceedings of the 6th Conference on Natural Language Learning—COLING-02, Taipei, Taiwan, 26–30 August 2002; Association for Computational Linguistics: Morristown, NJ, USA, 2002; Volume 20, pp. 1–7. [Google Scholar]
- Raymond, C.; Riccardi, G. Generative and Discriminative Algorithms for Spoken Language Understanding. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Antwerp, Belgium, 27–31 August 2007; Volume 1, pp. 413–416. [Google Scholar]
- Haffner, P.; Tur, G.; Wright, J.H. Optimizing SVMs for Complex Call Classification. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing—ICASSP ’03, Hong Kong, 6–10 April 2003; Volume 1, pp. I-632–I-635. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Xu, P.; Sarikaya, R. Convolutional Neural Network Based Triangular CRF for Joint Intent Detection and Slot Filling. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding—IEEE, Olomouc, Czech Republic, 8–12 December 2013; pp. 78–83. [Google Scholar]
- McCallum, A.; Freitag, D.; Pereira, F. Maximum Entropy Markov Models for Information Extraction and Segmentation. In Proceedings of the Seventeenth International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; pp. 591–598. [Google Scholar]
- Mesnil, G.; Dauphin, Y.; Yao, K.; Bengio, Y.; Deng, L.; Hakkani-Tur, D.; He, X.; Heck, L.; Tur, G.; Yu, D.; et al. Using Recurrent Neural Networks for Slot Filling in Spoken Language Understanding. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 530–539. [Google Scholar] [CrossRef]
- Yao, K.; Peng, B.; Zhang, Y.; Yu, D.; Zweig, G.; Shi, Y. Spoken Language Understanding Using Long Short-Term Memory Neural Networks. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 189–194. [Google Scholar]
- Liu, B.; Lane, I. Joint Online Spoken Language Understanding and Language Modeling with Recurrent Neural Networks. In Proceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Los Angeles, CA, USA, 13–15 September 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 22–30. [Google Scholar]
- Guo, D.Z.; Tur, G.; Yih, W.T.; Zweig, G. Joint Semantic Utterance Classification and Slot Filling with Recursive Neural Networks. In Proceedings of the 2014 IEEE Workshop on Spoken Language Technology, SLT, South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 554–559. [Google Scholar]
- Xiaodong, Z.; Houfeng, W. A Joint Model of Intent Determination and Slot Filling for Spoken Language Understanding. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; Brewka, G., Ed.; AAAI Press: New York, NY, USA, 2016; pp. 2993–2999. [Google Scholar]
- Li, C.; Li, L.; Qi, J. A Self-Attentive Model with Gate Mechanism for Spoken Language Understanding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing—EMNLP 2018, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Liu, B.; Lane, I. Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, San Francisco, CA, USA, 8–12 September 2016; pp. 685–689. [Google Scholar]
- Radfar, M.; Mouchtaris, A.; Kunzmann, S. End-to-End Neural Transformer Based Spoken Language Understanding. In Proceedings of the Interspeech 2020—ISCA, Shanghai, China, 25–29 October 2020; pp. 866–870. [Google Scholar]
- Huang, C.-W.; Chen, Y.-N. Adapting Pretrained Transformer to Lattices for Spoken Language Understanding. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Sentosa, Singapore, 14–18 December 2019; pp. 845–852. [Google Scholar]
- Nguyen, V.N.; Holone, H. N-Best List Re-Ranking Using Semantic Relatedness and Syntactic Score: An Approach for Improving Speech Recognition Accuracy in Air Traffic Control. In Proceedings of the 2016 16th International Conference on Control, Automation and Systems (ICCAS)—IEEE, Gyeongju, Korea, 16–19 October 2016; pp. 1315–1319. [Google Scholar]
- Oualil, Y.; Schulder, M.; Helmke, H.; Schmidt, A.; Klakow, D. Real-Time Integration of Dynamic Context Information for Improving Automatic Speech Recognition. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Dresden, Germany, 6–10 September 2015; ISCA: Dresden, Germany, 2015; pp. 2107–2111. [Google Scholar]
- Kersta, L.G. Voiceprint Identification. Nature 1962, 196, 1253–1257. [Google Scholar] [CrossRef]
- Pruzansky, S. Pattern-Matching Procedure for Automatic Talker Recognition. J. Acoust. Soc. Am. 1963, 35, 354–358. [Google Scholar] [CrossRef]
- Furui, S. Cepstral Analysis Technique for Automatic Speaker Verification. IEEE Trans. Acoust. 1981, 29, 254–272. [Google Scholar] [CrossRef]
- Soong, F.; Rosenberg, A.; Rabiner, L.; Juang, B. A Vector Quantization Approach to Speaker Recognition. In Proceedings of the ICASSP ’85, IEEE International Conference on Acoustics, Speech, and Signal Processing, Tampa, FL, USA, 26–29 March 1985; Volume 10, pp. 387–390. [Google Scholar]
- Reynolds, D.A.; Rose, R.C. Robust Text-Independent Speaker Identification Using Gaussian Mixture Speaker Models. IEEE Trans. Speech Audio Process. 1995, 3, 72–83. [Google Scholar] [CrossRef]
- Reynolds, D.A.; Quatieri, T.F.; Dunn, R.B. Speaker Verification Using Adapted Gaussian Mixture Models. Digit. Signal. Process. 2000, 10, 19–41. [Google Scholar] [CrossRef]
- Campbell, W.M.; Sturim, D.; Reynolds, D.A. Support Vector Machines Using GMM Supervectors for Speaker Verification. IEEE Signal. Process. Lett. 2006, 13, 308–311. [Google Scholar] [CrossRef]
- Kenny, P.; Ouellet, P.; Dehak, N.; Gupta, V.; Dumouchel, P. A Study of Interspeaker Variability in Speaker Verification. IEEE Trans. Audio. Speech. Lang. Process. 2008, 16, 980–988. [Google Scholar] [CrossRef][Green Version]
- Dehak, N.; Kenny, P.J.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-End Factor Analysis for Speaker Verification. IEEE Trans. Audio, Speech Lang. Process. 2011. [Google Scholar] [CrossRef]
- Variani, E.; Lei, X.; McDermott, E.; Moreno, I.L.; Gonzalez-Dominguez, J. Deep Neural Networks for Small Footprint Text-Dependent Speaker Verification. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Florence, Italy, 4–9 May 2014. [Google Scholar]
- Li, C.; Ma, X.; Jiang, B.; Li, X.; Zhang, X.; Liu, X.; Cao, Y.; Kannan, A.; Zhu, Z. Deep Speaker: An End-to-End Neural Speaker Embedding System. arXiv 2017, arXiv:1705.02304. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Povey, D.; Khudanpur, S. Deep Neural Network Embeddings for Text-Independent Speaker Verification. In Proceedings of the Interspeech 2017—ISCA, Stockholm, Sweden, 20–24 August 2017; pp. 999–1003. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-Vectors: Robust DNN Embeddings for Speaker Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Liu, Y.; Qian, Y.; Chen, N.; Fu, T.; Zhang, Y.; Yu, K. Deep Feature for Text-Dependent Speaker Verification. Speech Commun. 2015. [Google Scholar] [CrossRef]
- Chen, N.; Qian, Y.; Yu, K. Multi-Task Learning for Text-Dependent Speaker Verification. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Dresden, Germany, 6–10 September 2015; pp. 185–189. [Google Scholar]
- Ravanelli, M.; Bengio, Y. Speaker Recognition from Raw Waveform with SincNet. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 1021–1028. [Google Scholar]
- Kopald, H.; Chen, S. Design and Evaluation of the Closed Runway Operation Prevention Device. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2014, 58, 82–86. [Google Scholar] [CrossRef]
- Lin, Y.; Zhang, J.; Liu, H. An Algorithm for Trajectory Prediction of Flight Plan Based on Relative Motion between Positions. Front. Inf. Technol. Electron. Eng. 2018, 19, 905–916. [Google Scholar] [CrossRef]
- Lin, Y.; Yang, B.; Zhang, J.; Liu, H. Approach for 4-D Trajectory Management Based on HMM and Trajectory Similarity. J. Mar. Sci. Technol. 2019, 27, 246–256. [Google Scholar] [CrossRef]
- Chen, Z.; Guo, D.; Lin, Y. A Deep Gaussian Process-Based Flight Trajectory Prediction Approach and Its Application on Conflict Detection. Algorithms 2020, 13, 293. [Google Scholar] [CrossRef]
- Yepes, J.L.; Hwang, I.; Rotea, M. New Algorithms for Aircraft Intent Inference and Trajectory Prediction. J. Guid. Control. Dyn. 2007, 30, 370–382. [Google Scholar] [CrossRef]
- Cordero, J.M.; Rodríguez, N.; Miguel, J.; Pablo, D.; Dorado, M. Automated Speech Recognition in Controller Communications Applied to Workload Measurement. In Proceedings of the Third SESAR Innovation Days, Stockholm, Sweden, 26–28 November 2013; pp. 1–8. [Google Scholar]
- ICAO. Manual on Air Traffic Controller Competency-Based Training and Assessment, 1st ed.; International Civil Aviation Organization: Montréal, QC, Canada, 2016. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Corpus | Language | Domain | Size (Hour) | Access |
|---|---|---|---|---|---|
| 1 | LibriSpeech [17] | English | novels | 960 | public |
| 2 | TED-LIUM3 [18] | English | TED talks | 452 | public |
| 3 | Switchboard [19] | English | Telephone | 260 | public |
| 4 | THCHS30 [20] | Chinese | newspapers | 30 | public |
| 5 | AISHELL-V1 [21] | Chinese | multidomain | 500 | public |
| 6 | AISHELL-V2 [22] | Chinese | multidomain | 1000 | application |
| 7 | ATCSpeech [23] | Chinese/English | real ATC | 59 | application |
| 8 | ATCOSIM [24] | English | simulated ATC | 11 | public |
| 9 | LDC94S14 [25] | English | airport | 70 | paid |
| 10 | Airbus [26] | English | pilot | 40 | unavailable |
| Language | Corpus | Mean (w/s) | Standard Deviation (w/s) |
|---|---|---|---|
| Chinese | ATCSpeech [23] | 5.15 | 1.10 |
| THCHS-30 [20] | 3.48 | 0.47 | |
| English | ATCSpeech [23] | 3.28 | 0.75 |
| Librispeech [17] | 2.73 | 0.47 |
| Language | Common | ATC |
|---|---|---|
| English | three | tree |
| five | fife | |
| nine | niner | |
| thousand | tousand | |
| Chinese | ling | dong |
| yi | yao | |
| er | liang | |
| qi | guai |
| Papers | Technique Details | Challenges Concerned |
|---|---|---|
| [1] | Independent end-to-end models, DS2, ASR, ATC safety monitoring | Section 2.4 and Section 2.5 |
| [27] | An integrated cascaded model, DS2+S2S, multilingual ASR | Section 2.2, Section 2.3, Section 2.4, Section 2.5, Section 2.6 and Section 2.7 |
| [16] | Independent end-to-end models, DS2, ASR, pretraining, transfer learning | Section 2.1, Section 2.4, Section 2.5 and Section 2.6 |
| [8] | Cascaded model, DS2+S2S, SIU, multi-level LMs | Section 2.2, Section 2.4, Section 2.5, Section 2.8 and Section 2.9 |
| [54] | Complete end-to-end model, representation learning, multilingual, pretraining | Section 2.1, Section 2.2, Section 2.3, Section 2.4, Section 2.5 and Section 2.6 |
| [55] | HMM/DNN, data augmentation, iterative training using unlabeled samples | Section 2.1 and Section 2.7 |
| [56] | HMM/DNN, context-aware rescoring, SIU task | Section 2.5, Section 2.7, Section 2.8 and Section 2.10 |
| [57] | Semi-supervised for transfer learning, DNN based models | Section 2.1, Section 2.2, Section 2.5 and Section 2.7 |
| [14] | AcListant® based traffic dynamic sensing, Arrival Managers (AMAN) | Section 2.7 and Section 2.8 |
| [11] | Cross-task adaption, HMM framework, transfer learning | Section 2.2, Section 2.3 and Section 2.7 |
| [58] | N-best list re-ranking, ATCOSIM, syntactic knowledge | Section 2.10 |
| [59] | traffic dynamic sensing | - |
| [12] | HMM-based framework, Spanish and English ATC speech, SIU task | Section 2.4 and Section 2.5 |
| [60] | French-accented English ATC speech, Time Delay Deep Neural Network (TDNN) | Section 2.1, Section 2.2, Section 2.4 and Section 2.5 |
| [61] | 170 h of ATCO speech, TDNN-based benchmark | Section 2.2, Section 2.4 and Section 2.7 |
| [62] | Improve intelligibility by reducing speech rate | Section 2.2 and Section 2.3 |
| [63] | Speech corpus for ASR and text-to-speech task | Section 2.2, Section 2.3 and Section 2.5 |
| [64] | Callsign correlation between ATC speech and surveillance data | Section 2.1, Section 2.5 and Section 2.10 |
| Text | CCA | 4012 | Turn Left | Heading 330 | Climb to | 1200 m |
|---|---|---|---|---|---|---|
| Slot filling | B-AL | B-CS | B-TL | I-TL | B-CL | I-CL |
| Intent | Turn left and climb | |||||
| Papers | Technique Details |
|---|---|
| [1] | Joint S2S model, 26 controlling intent, safety monitoring |
| [8] | Joint S2S model, 26 controlling intents, 55 instruction elements |
| [10] | SESAR 2020 Solution PJ.16-04, extra qualifier, conjunction |
| [86] | 10 ontologies for ATC command extraction |
| [57] | More label classes (such as QNH), conditional clearances |
| [87] | Command definition for ASR rescoring |
| Section | Item | Findings | Conclusions or Future Research Topics |
|---|---|---|---|
| Challenges | Data collection and annotation | English corpus [24,26] Chinese/English corpus [23] | More corpora are required to build large-scale SIU systems in the ATC domain. |
| Volatile background noise and inferior intelligibility | Multi-scale CNN [27] | Representation learning may be a promising way to overcome the mentioned issue. | |
| Unstable speech rate | Multi-scale CNN [27] | ||
| Multilingual and accented speech | Cascaded pipeline [8,27] Independent system [1,23] | The end-to-end multilingual framework. | |
| Code switching | Language model [27] | The author believes that the most efficient way is to build sufficient training samples. | |
| Vocabulary imbalance | Phoneme-based vocabulary [8,27] Data augmentation [1,26] | Sub-word-based vocabulary is a better tradeoff between the vocabulary size and sequence length. | |
| Generalization of unseen samples | Transfer learning [16] | Transfer learning from other domains is a feasible way to address this issue. | |
| Ambiguous word meaning | Currently, no literature is for this issue. | An intuitive way is to build a dictionary for synonyms pairs. | |
| Role recognition | Text-dependent SLU model [1,8] | VPR is a powerful text-independent way to achieve this task. | |
| Contextual information | Enumeration of possible information [56,87]. | Deep information fusion using neural network is expected to improve the performance of this issue. | |
| Techniques | Automatic speech recognition | Monolingual: HMM-based [26], deep learning based [1,16,23,60]. Multilingual: deep learning based [8,27,54]. | Great efforts deserve to be made to promote the ASR task into an industrial level, including speech quality, contextual information, etc. |
| Language understanding | Concept extraction [10], deep learning based SLU model [1,8]. | More concept classes are required to cover the ATC-related elements, especially for the rarely used terms. | |
| Voiceprint recognition | Currently, there is no literature for this issue. | Building a corpus for the ATC environment is the key to train a qualified VPR system. | |
| Applications | Information enhancement | Electronic strip system [10]. | More applications are expected to be achieved based on the SIU task. |
| Communication error detection | Studies based on ASR tools [5,12,14,60,62]. | A way to improve the air traffic safety. | |
| Conflict detection considering intent | Flight trajectory considering intent [107]. | Conflict detection considering intent should be studied to provide more warning time for ATCO. | |
| Post analysis and processing | (1) Workload measurement and performance evaluation [13,109]. (2) Currently, there is no literature on the information retrieving and event detection. | More applications are required to be explored to take full advantage of the SIU research outcomes. | |
| ATCO training | There is no literature for this issue. | It is very important to emphasize the SIU task in the ATC domain. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y. Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application. Aerospace 2021, 8, 65. https://doi.org/10.3390/aerospace8030065
Lin Y. Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application. Aerospace. 2021; 8(3):65. https://doi.org/10.3390/aerospace8030065
Chicago/Turabian StyleLin, Yi. 2021. "Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application" Aerospace 8, no. 3: 65. https://doi.org/10.3390/aerospace8030065
APA StyleLin, Y. (2021). Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application. Aerospace, 8(3), 65. https://doi.org/10.3390/aerospace8030065