1. Introduction
Mission adaptability is a crucial but challenging capability for small celestial body exploration. In proximity to small celestial bodies, the environment is extremely harsh and unknown. The close approach phase to small celestial bodies faces many uncertainties and even emergencies. In current small celestial body missions [
1,
2], the close approach process is usually highly supervised from the ground [
3,
4], and the ground is always ready to intervene to ensure mission safety.
However, after the close approach process is interfered with by the ground, the original approach trajectory is interrupted, and the original plan is abandoned. A re-approach process and trajectory needs to be re-planned on the ground. This kind of inflexibility reduces the efficiency of temporary task adjustment, and may make it impossible to continue to achieve the set goals after the suspension caused by emergencies. It is urgent to design a spacecraft navigation and guidance strategy to enhance mission adaptability, which will have a promising prospect in small celestial body missions.
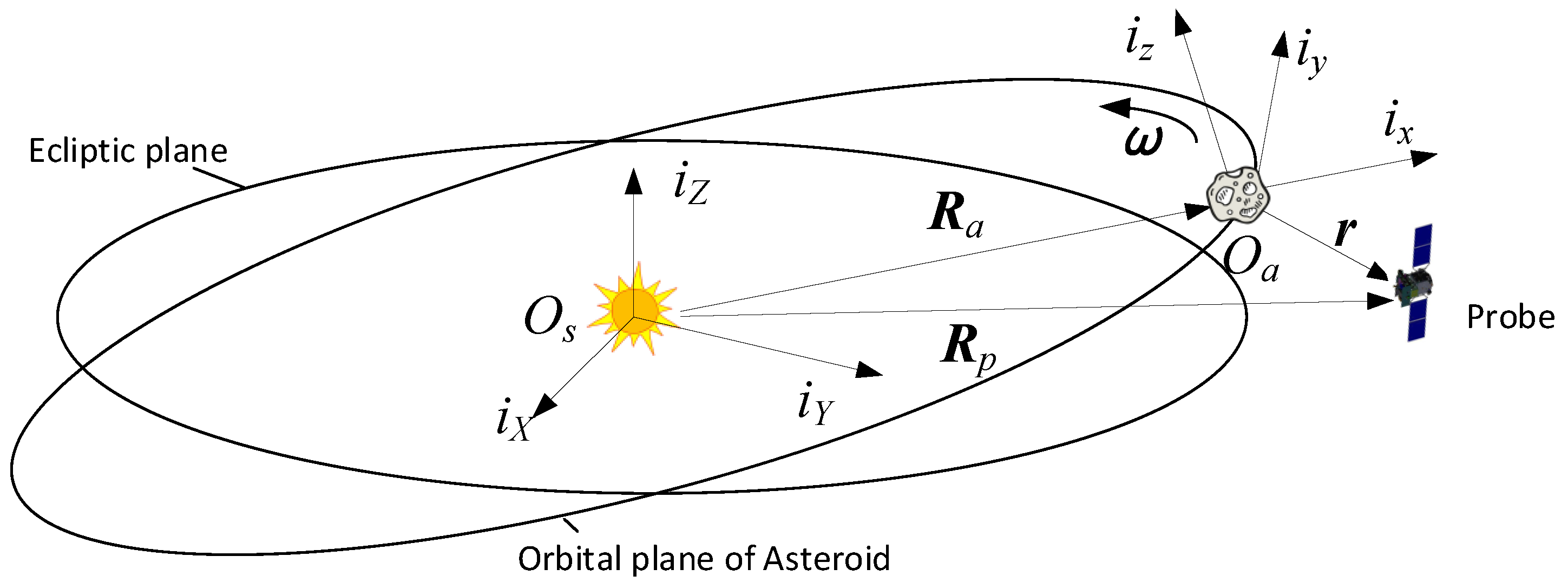
The close approach phase sends the spacecraft to the proximity of asteroids, and then the spacecraft can carry out complex operation tasks. For example, Hayabusa2 started a descent operation from a home position where the distance from the near-Earth asteroid (NEA) Ryugu was 20 km after Hayabusa2 had arrived at the proximity of the asteroid [
5,
6]. Therefore, the close approach phase is vital for mission design [
2,
7,
8]. Specifically, the requirement of the guidance, navigation, and control (GN & C) system is presented very stringently, especially in terms of accuracy and robustness. The terminal accuracy and the robustness to various uncertainty are essential to ensure mission safety and success [
4].
“Robustness” of trajectory or guidance is not a new concept. Research on stochastic optimal control [
9,
10] and stochastic dynamic programming [
11,
12] have been very hot. There is fruitful research on designing robust trajectory, such as chance-constrained optimal control [
13,
14], stochastic differential dynamic programming (SDDP) [
11,
12], evidence theory [
15], and belief-based transcription procedures for stochastic optimal control problems (SOCPs) [
9,
10].
In the past few years, machine learning has been very popular in the application of spacecraft guidance, navigation, and control (GN & C). Izzo et al. summarized the development trend of machine learning in the field of spacecraft guidance dynamics and control and predicted future research in 2019 [
16]. Supervised learning, the oldest branch of machine learning, has also shown its robustness to uncertainties [
17]. However, under uncertain environments and complex constraints, a sufficiently large data set of experts is usually required for supervised learning, which needs careful and intricate design to avoid overfitting. Reinforcement learning (RL) has gradually gained more attention [
18], which can autonomously learn control strategies through its interaction with the environment. The trajectory design problem is modeled as a time-discrete Markov decision process (MDP). The learning procedure is realized by maximizing a user-defined function, that is, a reward function. The policy gradient is used to continuously improve the policy, which is used as a baseline as this was later improved through the years. Policy-gradient (PG) algorithms extend deep Q-learning (a finite set of actions) to the field of continuous control (continuous state and action spaces) [
19]. To alleviate the problem of the large variance of a cumulative reward, the actor–critic (AC) method and the advantage actor–critic (A2C) method improve the policy-gradient algorithms based on approximating the Q-function using a second DNN and approximating the advantage function using a generalized advantage estimator [
20]. The proximal policy optimization (PPO) algorithm further stabilizes the update of the policy by introducing a clipped function [
21]. PPO has demonstrated state-of-the-art performances on many benchmark RL problems. PPO is widely used partially because it does not need any ad-hoc reward shaping. In recent years, RL has been applied to spacecraft GN & C, such as low-thrust trajectory design [
22,
23,
24,
25,
26], formation flying [
27], rendezvous or intercept guidance [
28,
29,
30,
31,
32,
33], asteroid hovering [
34,
35], planetary landing [
36,
37,
38,
39,
40,
41], etc. Among them, reinforcement meta learning based on recurrent neural network is used to solve the problems of partially observable Markov decision process (POMDP) and policy extrapolation in the context of continuing learning [
37,
42,
43]. Deep convolutional neural network is used to map the raw observations, such as raw images, to a true inner state [
32,
40], which is also a means to solve the POMDP.
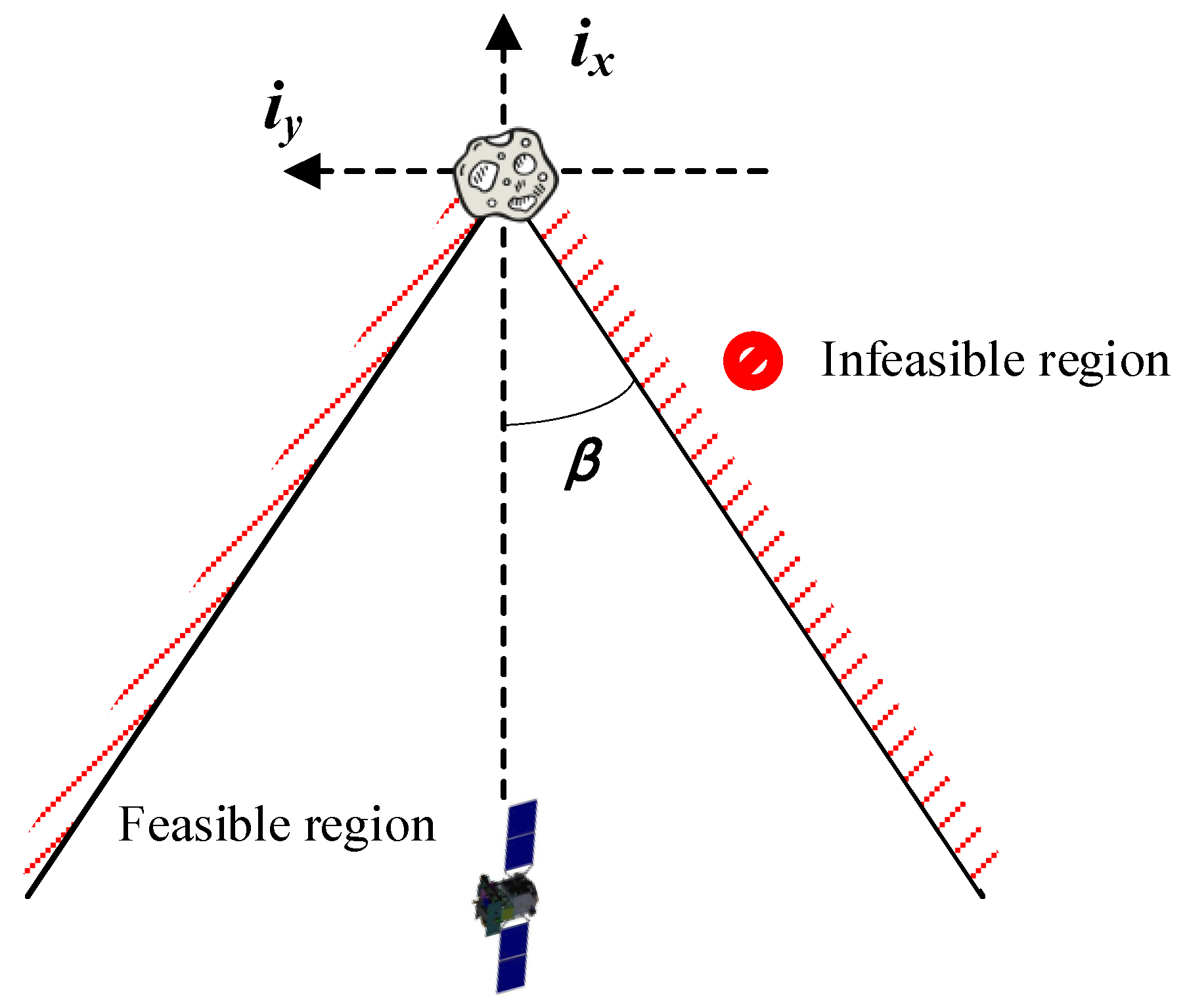
Line of sight (LOS) navigation and AON are heated topics in noncooperative rendezvous [
44], and are also very popular in small celestial body missions, especially those based on CubeSat. On the one hand, AON only needs optical sensors, which can reduce the cost and weight. On the other hand, AON is completely passive and self-contained, working over a wide range of distances. These advantages of AON make it more suitable than microwave radar, laser radar, laser rangefinder, and other sensors. However, AON has a well-known problem of weak range direction observability, and it is necessary to improve the range direction observability by incorporating known orbital maneuvers into the navigation filter [
45,
46,
47]. Several optimal single-step rendezvous guidance methods have been proposed together with different definitions of AON observability [
46,
47]. Moreover, an online guidance framework of multiple maneuvers to obtain optimal observability has also been proposed [
45], which is similar to model predictive control and needs to be solved multiple times online [
48,
49].
However, these proposed rendezvous guidance methods are all carried out in a determined manner by building and then solving a deterministic optimal control problem. The robust guidance strategy based on DRL is also usually trained under a fixed number of maneuvers [
31,
33]. Once an optimal guidance or rendezvous trajectory is obtained, the number of maneuvers is fixed. If the number of maneuvers needs to be changed, the problem needs to be solved again. This is one of the reasons for the mentioned inadaptability problem.
We find that the “Stop-and-Go” (SaG) strategy has the ability to increase the number of orbital maneuvers while basically maintaining the geometry of the original trajectory [
3,
50]. The basic idea of SaG is as follows [
3,
50]: a breaking to zero followed by a new impulsive maneuver is performed at a middle waypoint, which is intended to further assist the AON observability in the range direction. However, differential-corrective guidance (fixed-time-of-arrival) is employed in original papers [
3,
50], which can be more sensitive to various uncertainties.
This paper proposes a close approach guidance method with more robustness and adaptability. A good match between SaG strategy and robust DRL-based guidance is used. Specifically, in order to improve the AON observability, the observability term is introduced into the reward function. A flexible SaG strategy is designed to freely insert the SaG point on the close approach trajectory. A framework combining the SaG strategy and the DRL-based guidance is proposed. The advantages of this framework are:
- (1)
The spacecraft can stop at any time during the process of approaching the asteroid to respond to an emergency or avoid hazards, giving the approach process more flexibility;
- (2)
The original robust guidance can still work after the SaG point without the need to solve the guidance policy again, and therefore improve the real-time performance;
- (3)
It can increase the AON observability in the range direction and therefore ensure the terminal accuracy of rendezvous guidance.
The structure of this paper is organized as follows. First, a robust guidance method with enhanced AON observability based on DRL is introduced in
Section 2. Then,
Section 3 introduces the SaG strategy and the framework combining the SaG strategy and the DRL-based guidance. Then, some simulation results in a typical R-bar approaching scenario are given in
Section 4, and the mission adaptability with an onboard application is verified. Finally,
Section 5 concludes with some interesting findings.
3. Flexible SaG Strategy
In the well-known optimal control problem (OCP) of rendezvous guidance, the number of orbital maneuvers is usually fixed, which is usually designed according to the overall goal of the mission [
52]. This means that the solution of OCP for rendezvous guidance is dependent on the number of orbital maneuvers. Once the number of maneuvers changes, the OCP needs to be solved again. This inflexibility means additional computational burden and reduces real-time performance. Nevertheless, the close approach process is very dynamic, and the environment near the asteroid is highly unknown. We hope to overcome this inflexibility. To this end, we consider a SaG strategy.
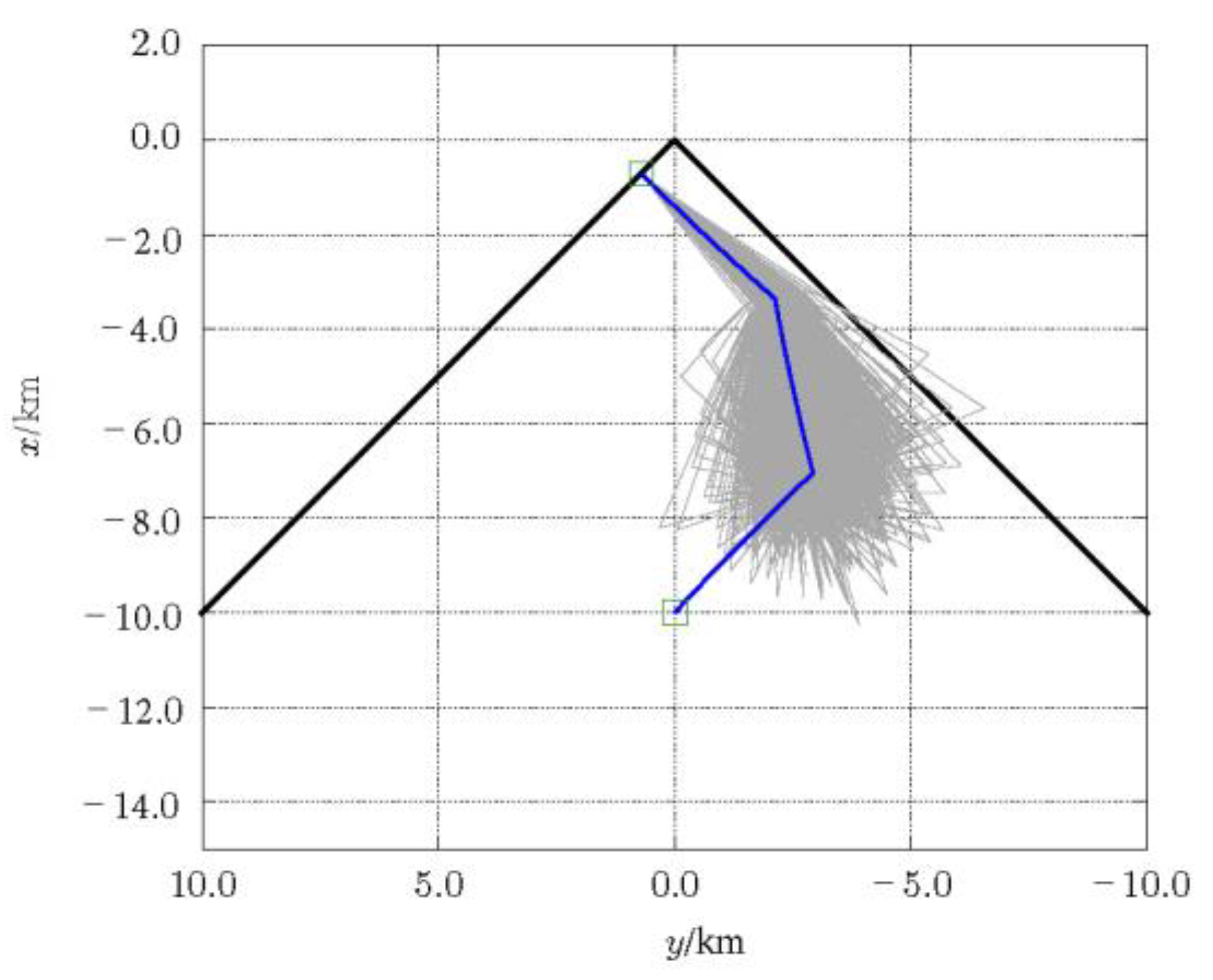
The basic idea of the SaG strategy is to insert a certain number of SaG points into the original trajectory. At the SaG point, the spacecraft obtains the estimation of the current motion state according to the output of the navigation filter, and carries out the “stop” maneuver accordingly. The “stop” maneuver brakes the spacecraft’s velocity to zero, and the motion state just before the stop maneuver is saved. During the “stop” period, the navigation filter continues to work, and the additional “stop” maneuver is used to improve the range observability for AON. After “stopping” for a certain period of time, the spacecraft carries out the “go” maneuver to restore the spacecraft to the motion state before stopping. The navigation filter continues to work, and the additional “go” maneuver is used to improve the range observability again. Assuming that the “stop” time of the spacecraft is not long, other attributes of the mission will not be influenced. Then, the approach trajectory remains relatively unchanged in geometry after the SaG strategy is incorporated, but has a time delay. In this way, the SaG strategy can give some freedom to mission adaption.
Now we will formulate the SaG strategy. Let be the time of stop maneuver, be the spacecraft state output by navigation filter at time , where is the estimated position vector and is the estimated velocity vector. Then, the stop maneuver is , and the time between stop maneuver and go maneuver is . The time of go maneuver is , and the go maneuver is .
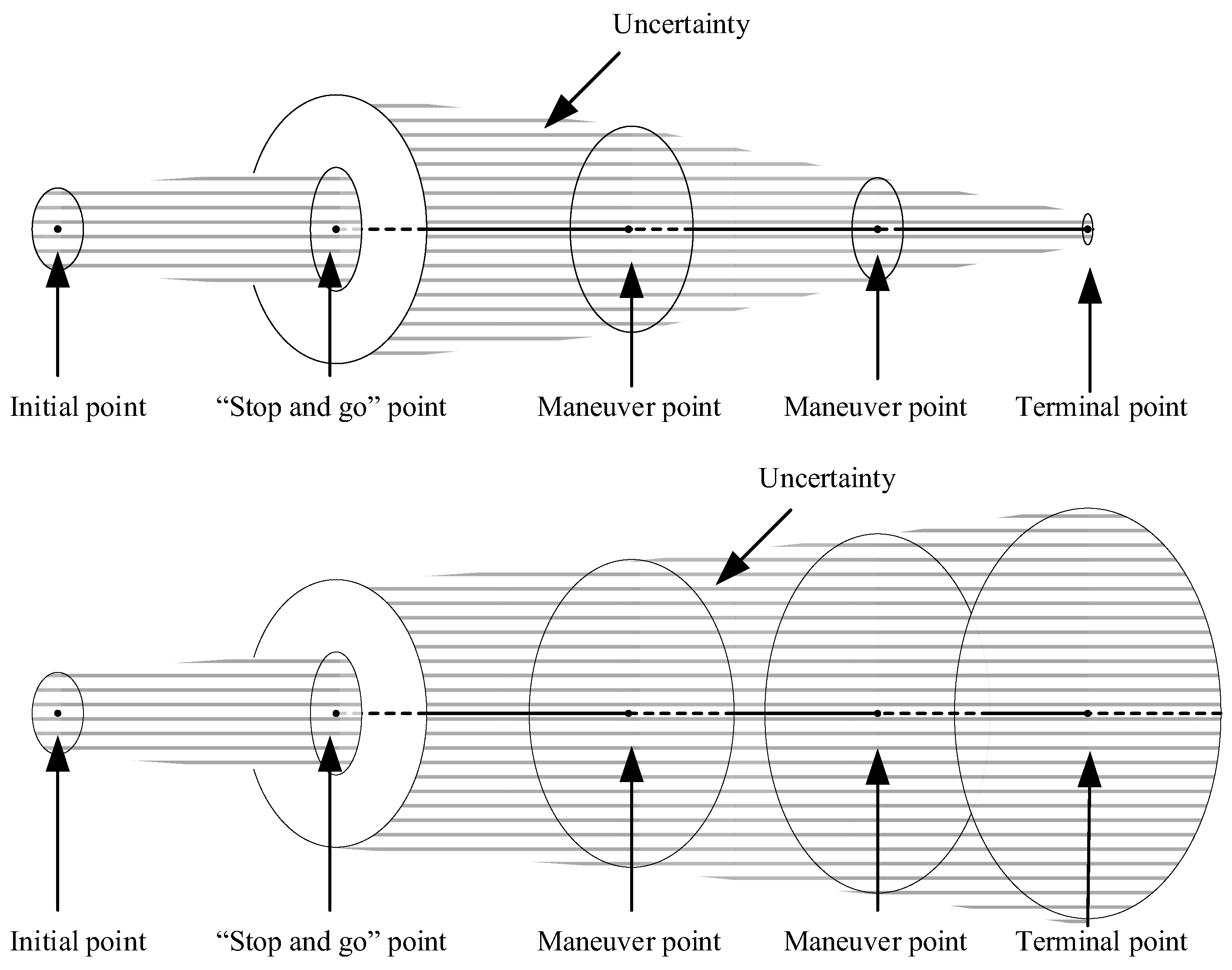
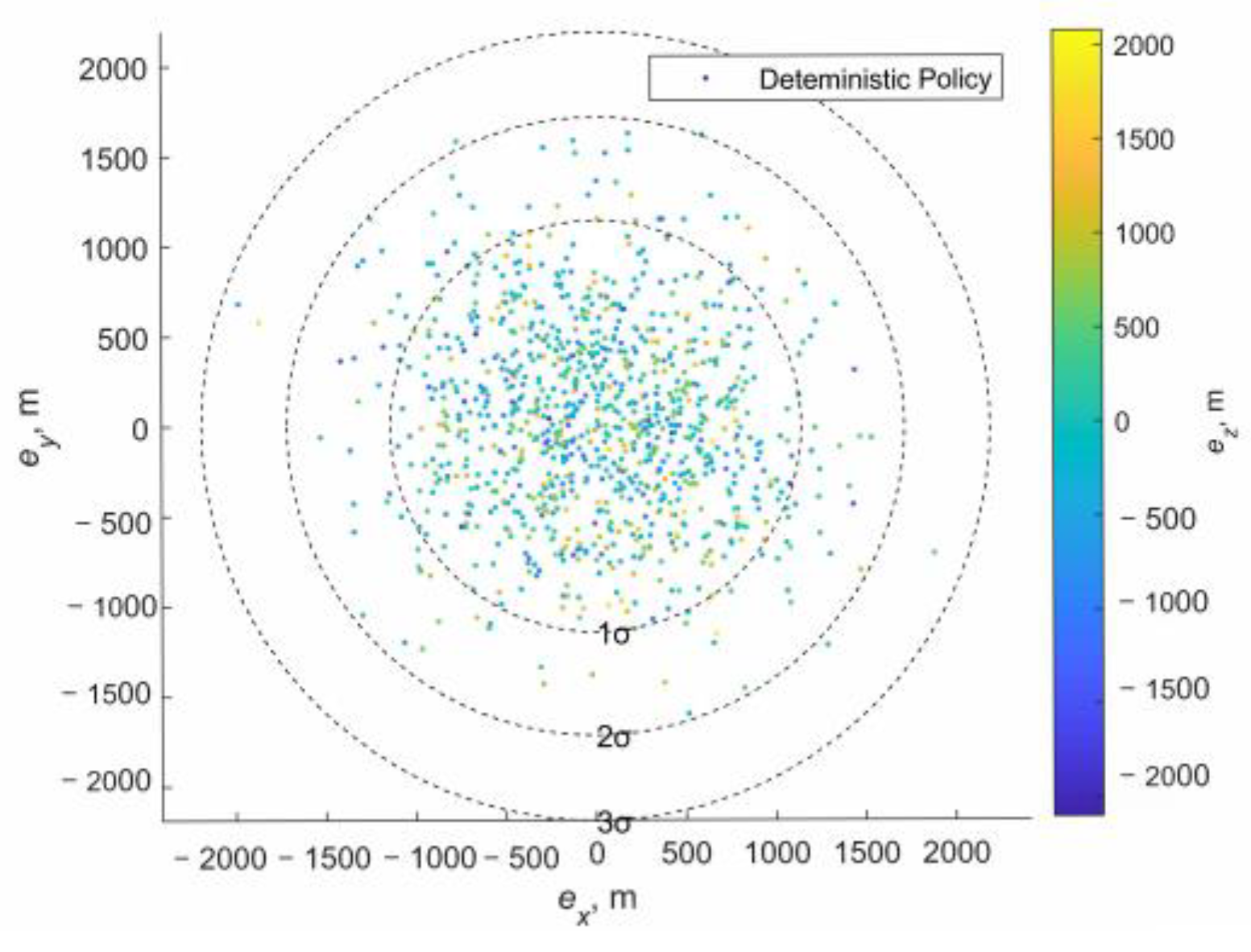
Nevertheless, due to navigation error and maneuver error, the spacecraft has a certain residual velocity after the “stop” maneuver, as shown in
Figure 5. Therefore, during the “stop” period, the residual motion of the spacecraft will cause a certain drift, as shown in
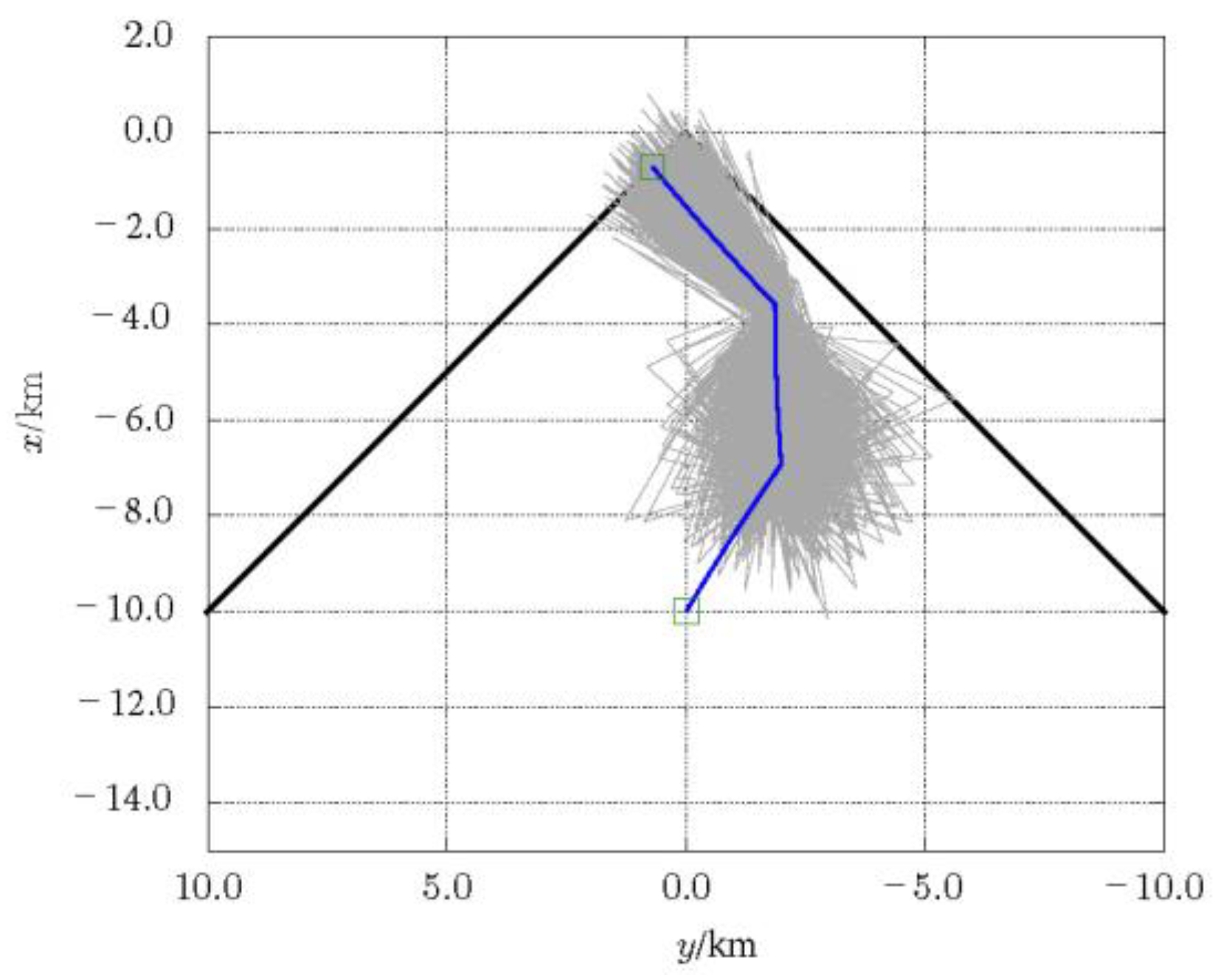
Figure 5. The drift during the “stop” period will cause the subsequent trajectory to deviate from the original trajectory, and the deviation will continue to diverge through error propagation, as shown in
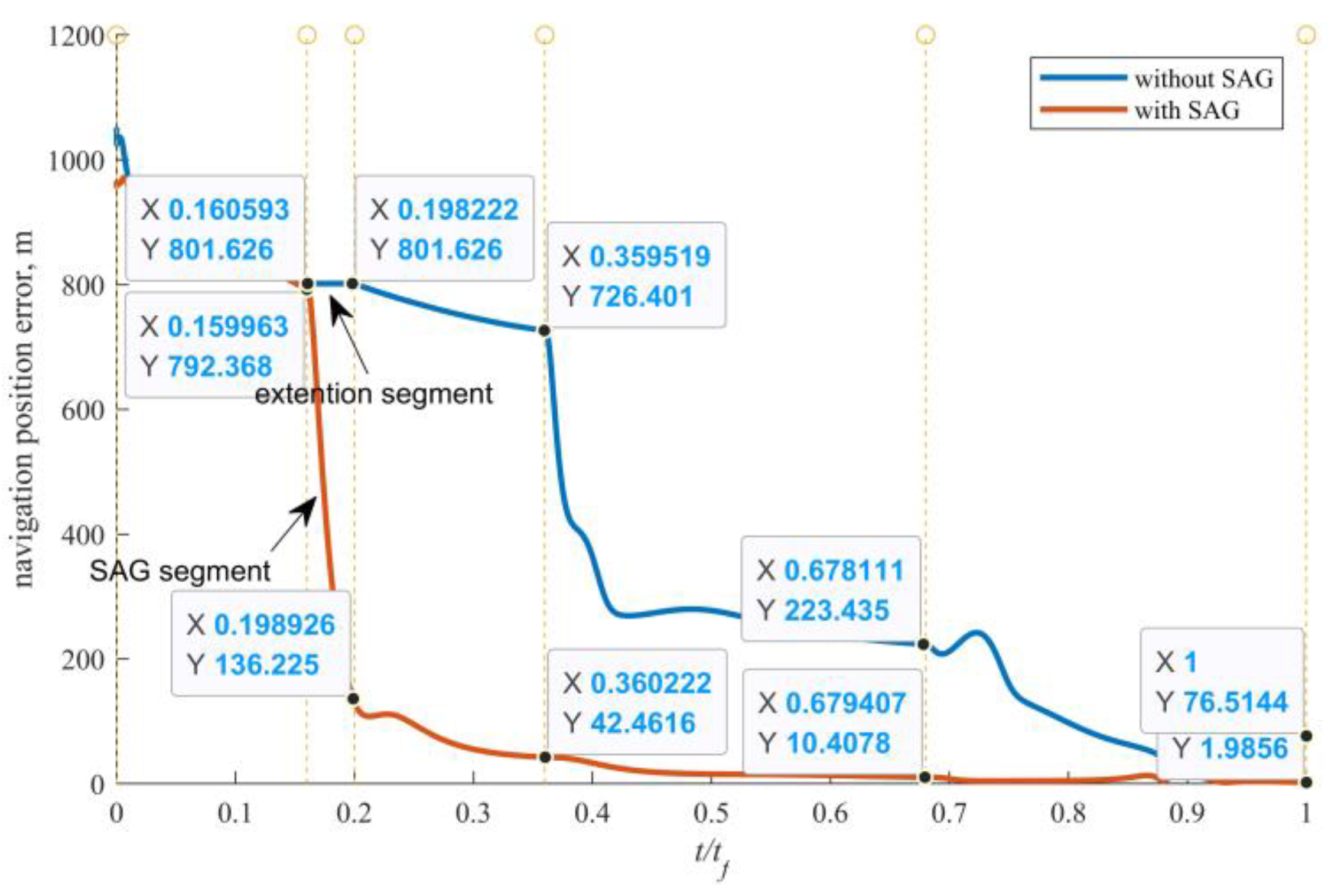
Figure 6. It will eventually lead to a large deviation from the object terminal state. The drift is actually a challenge to the robustness of rendezvous trajectory or rendezvous guidance. It is hard for the deterministic method for solving the OCP of rendezvous guidance to overcome this problem.
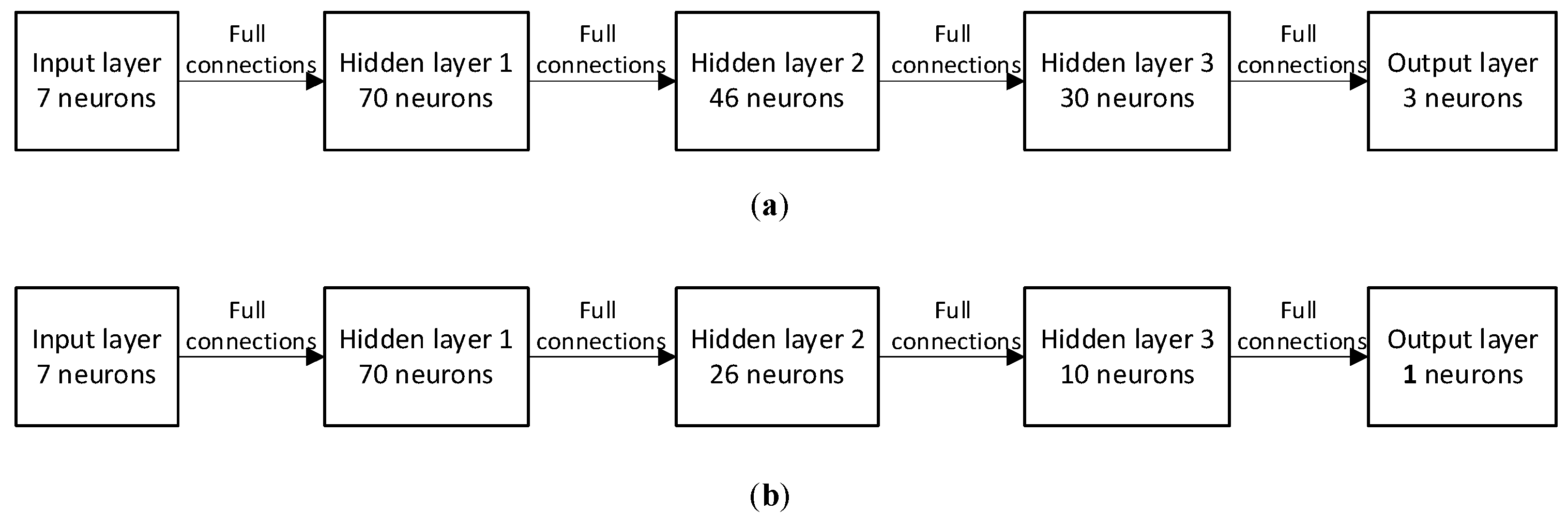
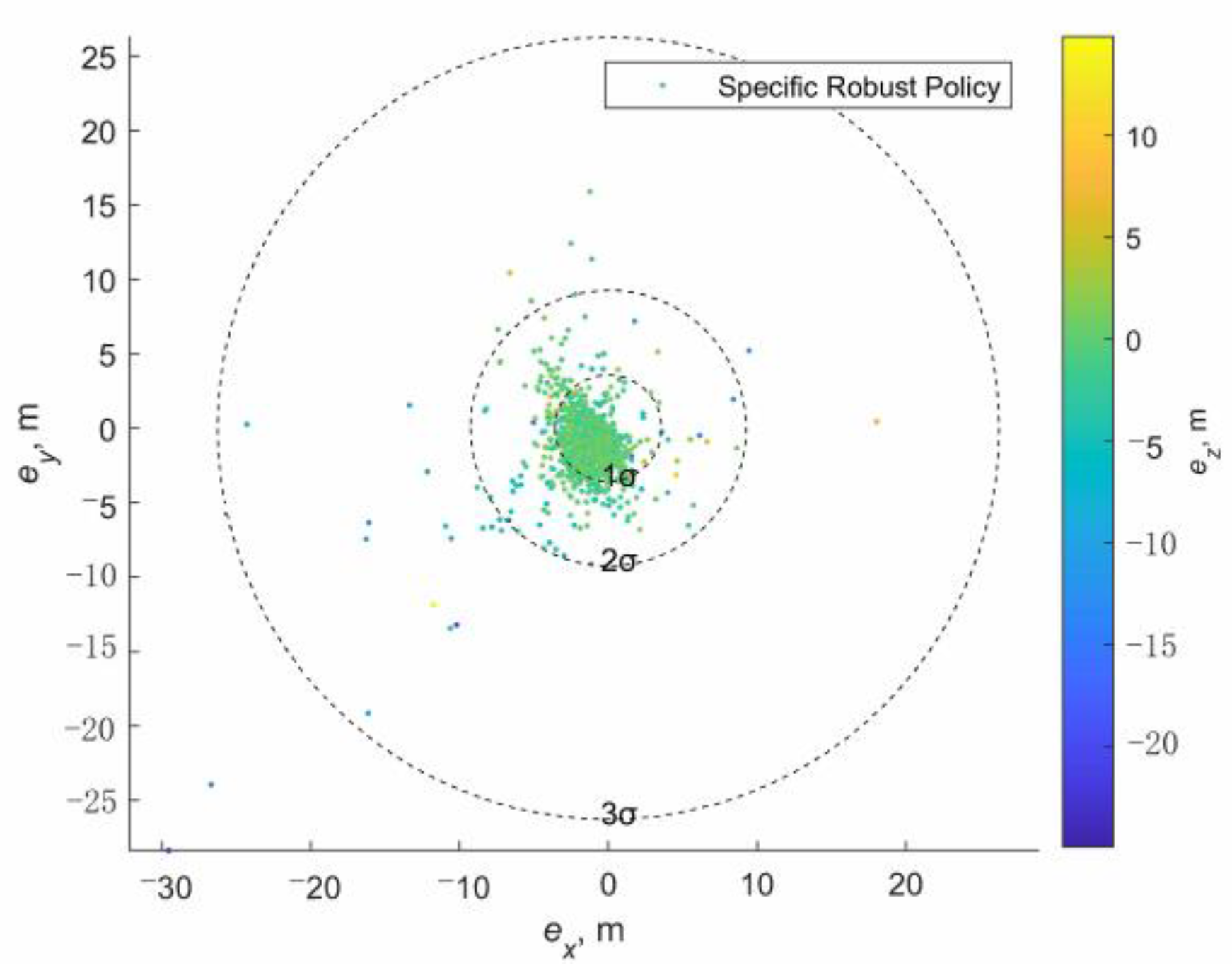
It is worth noting that the time delay and motion state drift caused by the SaG strategy can be well solved by a special design with the robust DRL-based guidance strategy. First, the input of the strategy network is a seven-dimensional vector composed of relative position, velocity, and left time. Therefore, it is only necessary to suspend the SaG strategy during the stop period, and then continue to execute the DRL-based guidance by inputting the output of the navigation filter into the strategy network, so that the whole process of navigation and guidance will be consistent. Second, as mentioned above, after the “stop” maneuver, the spacecraft does not actually stand still, but retains a small residual speed. Therefore, there will be a small residual motion during the SaG period, resulting in a certain spatial deviation between the starting state and the end state of the SaG period, as shown in
Figure 6. Note that the spatial deviation will be small and bounded if there is a closed-loop station-keeping controller (such as the box control), general in asteroid missions [
53], or the SaG period is small, and that the spatial deviation can be large if the station-keeping controller does not work and the SaG period is large. Nevertheless, the robustness of the DRL-based guidance will work in this situation. It can ensure the accuracy of terminal position and velocity state in the presence of initial motion state deviation. In this way, the SaG strategy can further improve the range observability. This also better explains the term “SaG point”, which means that in the framework of DRL-based robust guidance, the drift motion during the “stop” period can be ignored and can be regarded as a stationary point. We expect that when incorporating the SaG strategy, robust guidance will achieve better terminal accuracy than the open-loop guidance will do, as shown in
Figure 7.
The number of SaG points is flexible. The SaG point can be triggered in different ways. For example, it can be triggered by the internal conditions of the navigation filter. For example, it can be triggered by the covariance matrix of the navigation filter to help accelerate the convergence. In addition, the SaG point can be triggered by an external trigger signal. Under the framework of online guidance, we propose an externally triggered SaG strategy, as shown in
Figure 8.
Figure 9 shows the online guidance framework obtained from AON and DRL-based guidance combined with the SaG strategy.






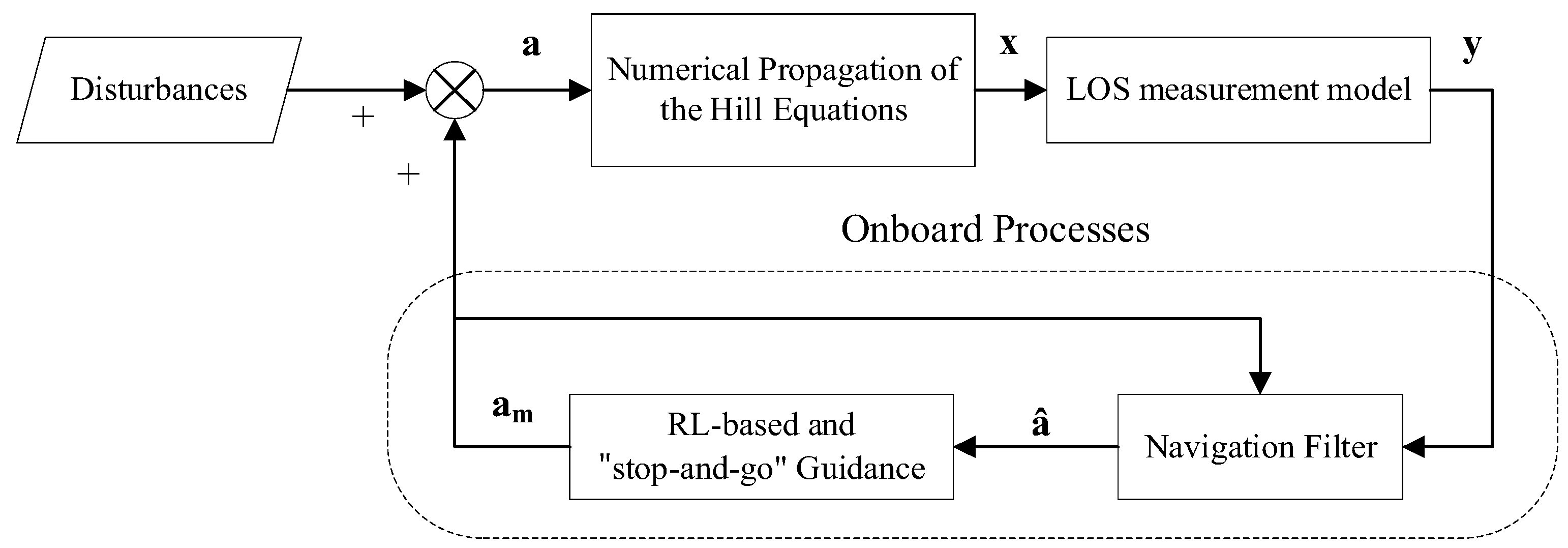



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}