1. Introduction
Some English varieties are unambiguously considered different ‘dialects’: in settings with a sustained history of institutional and home monolingual English use, e.g., the UK, North America, Australia, New Zealand, and South Africa, regional variation is attributed to distinct historic patterns of language contact [
1]. However, in other non-English settings, language contact between local languages and English—which historically spread through (British) colonialism, e.g., in India and Nigeria [
2], and has recently spread in conjunction with globalization, e.g., in Japan [
3]—has resulted in multiple indigenized World English (WE) language contact varieties. While a growing set are now recognized as distinct English dialects, differing at all structural levels from canonical “standard” English varieties—American English and British Received Pronunciation—these WE settings and the resultant localized English patterns often have a much higher proportion of non-native (L2) speakers compared to canonical English ecologies in North America, the UK, and southern hemispheric majority English settings. WE structures and diachronic trajectories are thus influenced by processes of second language acquisition (SLA) and language contact, among other ecological factors [
4]. WEs are also quantitatively and qualitatively encroaching on indigenous vernacular codes in local settings through processes of language shift, and some have reached the stage of established ideological nativization, such that the local variety surpasses the value of external norms [
2].
However, the status of WEs as distinct dialects of English continues to be contentious, in large part because of their historic or continued majority L2 populations. This debate is also political, rooted in negotiations over the commodification of English(es)—and within that the (de)valuing of some forms of English, L2 and bilingual speakers of English, and non-monolingual English acquisition pathways [
5,
6]. The debate is further influenced by informal notions of mutual intelligibility as a criterion for separating languages: this occludes the reality that codes, while separated at extreme ends as distinct languages, often also have between those extremes a continuum of mutual intelligibility within which codes manifest as dialects. Compounding this, no specific criteria for defining or distinguishing dialects is accepted in academia. Even within WE literature, it is unclear how one could determine at what point and under what conditions a WE ecology has sufficiently developed from L2/SLA history into distinct, nativized WE dialect. Relatedly, it is an open debate how the respective role of socio-historical, ecological, demographic, and communicative factors variably influence evolutionary pathways within processes of dialect focusing and new dialect formation [
2]. Indeed, language contact resulting in dialect focusing and stabilization is an ongoing process which may be (more or only) visible at a global structural level. Building on this perspective, we consider a novel lens for examining WE dialect development, focusing, and stabilization, examining the quantitative frequency characteristics of diachronic WE corpora. We next introduce these quantitative measures, then discuss how they can offer insights for capturing WE dialect development, focusing, and stabilization.
Zipf famously posited that a rank frequency distribution is a property of language, with evidence from a small written corpus (Ulysses) demonstrating that the frequency of an individual word can be derived from its ranked frequency [
7]. Essentially, the distribution of words (
f(
r)) in a corpus of a particular language (where there are, say,
n words), as a function of their rank (
r), can be thought of as a probability mass function,
Following this, Zipf’s postulate is that the distribution follows a power law given by
The
α exponent is essentially the slope of the curve in a log scale, where a larger absolute
α reflects a shorter tail of hapax legomena (frequency = 1) and/or low frequency words. The
C and
α are typically derived from the dataset/corpus in question. Intuitively (assuming
α = 1), what the law says is that the second most frequent word will occur half as many times as the most frequent one, the third most frequent word will occur one third as many times as the most frequent one, and so on. His explanation, formulated as the principle of least effort, argues that non-trivial competing pressures in communication—originally presented as diversification vs. unification, later re-expressed as competition between clarity vs. ease in speaker/hearer interactions [
8]—are the basis for this distributional pattern. Building on this, Mandelbrot proposed a refinement to Zipf’s Law (ZL) which has come to be seen as a more general law regarding lexical frequencies in natural language [
9]. According to Mandelbrot, the frequency distribution of words (
f(
r)) in a corpus of any particular language, as a function of their rank (
r), is given by,
The
β coefficient reflects deviations in the high frequency range, with a larger
β reflecting a larger deviation in the curve from the
α—essentially, all other things being equal, a corpus with a higher
β has comparatively less reliance on higher frequency words, while a corpus with a smaller
β has an increased use of these high frequency words. Thus, in essence, Mandelbrot’s law (ML) better accounts for the higher end of the ranked distribution [
10]. Note in the special case
β = 0, ML reduces to ZL.
Rank frequency distributions are ubiquitous in natural language, and a property of complex communicative systems: communicative optimization can both cause synchronic structural distributions and motivate diachronic statistical patterns [
11,
12,
13,
14,
15,
16,
17]. Rank frequency distributions of language will have a small kernel lexicon of highly ranked words (dominated by function words and high frequency content words) and, at the opposite end, a set of words which occur only once (hapax legomena). In parallel corpora (translations of the same text), the nature of the two ends of the continuum are arguably typologically mediated: languages with more synthetic encoding strategies, i.e., with extensive inflectional systems and morphological compounding processes, will necessarily have more words which appear only once (manifesting as a longer, shallower tail of hapax legomena), while languages which rely more on analytic encoding strategies, i.e., with greater repetition of super frequent words, will have both a shorter, steeper tail of hapax legomena and a shorter, steeper slope in the high frequency range, reflecting the importance of a relatively narrow set of function words in grammatical organization [
18]. These typological patterns are also visible through comparison of the model parameters across corpora: a higher absolute
α exponent arguably reflects a smaller, steeper tail of hapax legomena, while a higher absolute
β exponent arguably reflects a greater relative deviation from the predicted slope [
18]. In comparing two data sets, L
x and L
y with originally predicted slopes
αx and
αy, respectively, a higher
β-value for L
x suggests greater deviation in the high frequency range for L
x than for L
y. However, this difference still requires interpretation with respect to the nature of the deviation of the data from the predicted slope: e.g., for a dataset with a steeper slope in the high frequency range of the rank frequency distribution than the predicted slope, as compared to a dataset with a smaller
β and a flatter, shallower slope in the high frequency range, the former can be interpreted as having comparatively higher frequencies for already high frequency words [
18].
Rank frequency distributions are found in contemporary natural language corpora and Swadesh lists [
19,
20,
21], comparisons across multiple languages [
22,
23,
24,
25], in both written and spoken language data [
26], across all English literary texts included in Project Gutenberg [
27], and historic language data that is not yet translated [
28], but, importantly, are not found in random monkey-typing corpora [
14,
29]. Rank frequency research has expanded beyond a narrow focus on adult, monolingual, native speakers to demonstrate distinct rank frequency distributions for corpora of varying levels of L2 proficiency across users of natural language [
30,
31] and artificial command languages [
32], L1 attritors who have lost proficiency in their L1 over their lifespan [
31], different language combinations of spontaneous codeswitching [
33], and in languages with varying proportions of non-native speakers [
34].
One avenue of research in quantitative linguistics is to analyze language evolution through the power law constants. Diachronic analysis of the evolution of a single code uncovers specific patterns for power law constants [
18,
35]. Distinctive patterns have also been found in child vs. adult caregiver speech [
36]: children have a lower
α exponent compared to fully proficient adults. Collectively, rank frequency analysis of diachronic and comparative proficiency language data suggest that the exponent serves as an indicator of linguistic complexity [
31,
34,
35,
36,
37]. Comparisons of the exponent across multiple languages which vary in their degree of synthetic to analytic structural complexity also support the relationship of the exponent to typological differences and/or to processes of typological change [
33,
37,
38,
39]. Based on diachronic data of the same language, rather than across different genres of synchronic data, the exponent has also been interpreted as an indicator of topical homogeneity [
40]. The assimilation of SLA, L1 attrition, diachronic typologically evolving codes, and child vs. adult data collectively presents compelling evidence that comparative differences in the statistical frequency properties of different types of language data (learner vs. proficient speakers, different time periods of the same language) are robust, and can contribute to theorizing and documenting language evolution.
Yet, left unexplored in past research is how these statistical properties manifest in contemporary emerging language contact and new dialect formation, focusing, and stabilization ecologies, now understood to be far more common scenarios for language evolution and diversity than previously thought [
2,
4,
41]. WE data offers an ideal testing ground for this. Specifically, because ZL and ML are quantitative measures of lexical diversity, with an inverse relationship, lower diversity should manifest through higher constants (
C,
α,
β) [
34]. Comparing parallel synchronic corpora, languages with a larger proportion of L2 speakers have higher constants, and less lexical diversity: adult L2 learners provoke a reduction in the number of word forms in the code diachronically [
34]. In tandem, languages with more synthetic properties (more inflected forms of the same dictionary entries and less reliance on discrete function words to show grammatical properties) display lower constants, and hence greater lexical diversity [
18]. However, the three constants should not simply be treated as operating in tandem: we argue that the nature of a linguistic change will affect how these constants each manifest across codes. The diachronic loss of a case system from Old to Modern English, for example, had two effects on the constants: case-marked Old English has a longer tail of hapax legomena which was lost diachronically—visible as a larger
α in modern English— while modern English, relying on analytic syntactic combinations to convey the same grammatical relations, has higher frequencies for very common (typically function) words—visible as a larger
β as compared to Old English [
18]. While both constants increased diachronically, they were provoked by distinct grammatical features within the evolution of English.
Diachronically, we build on this to explore the frequency characteristics of new dialect formation and evolution. For WE varieties, this necessarily starts with more complicated contact between native speakers of multiple dialects of the same code (e.g., British, Scottish, and Irish English varieties) and indigenous English L2 speakers of various proficiency who also command one or more vernacular languages. Over time, WE emergence ecologically demonstrates reduced contact and influence from external English L1 speakers, a rise in the number and proportion of indigenous L2 speakers, and through this, structural changes brought about through the confluence of SLA and sustained language contact/bilingualism (compared to language shift settings) [
2]. Depending on the role(s) that English plays in the local setting, the emergence of indigenous WE L1 speakers (who may or may not also command vernacular codes as bi-/multilinguals) is also possible.
As WE nativization—the development of internal norms and structures—occurs, one can predict both reductions in lexical diversity—in earlier periods process of simplification dominated by L2 speakers with input from multiple English dialects—and increases in lexical diversity—in later periods of nativization within processes of complexification by indigenous L1 speakers [
42]. Pertinent to the first period posited above for WE development, L2 varieties of English and English-based pidgin/creoles commonly demonstrate reduced overt inflectional marking in zero past tense forms of regular verbs, e.g.,
I talk yesterday; a lack of inversion/auxiliaries in
wh-questions, e.g.,
Where you going?; and a lack of number distinction in reflexives, e.g.,
They saw it [
43]. Supporting this prediction, L2 population ratios also correlate with lexical diversity cross-linguistically, with lower lexical diversity in codes with larger non-native populations. Thus, in earlier periods of WE nativization, a larger
α is predicted. However, the second period—of dialect focusing and stabilization—is unexplored in past literature and the focus of the current investigation. In this setting, lexical expansion could occur through processes of borrowing, new word formation, semantic shift or reallocation, and compound word formation [
2]. Growth specifically in the kernel (high frequency) lexicon is also likely in later stages of L2-dominance as new collocational and syntactic patterns become established and are adopted by larger populations and lexical forms become grammaticalized and thus increase in frequency [
44].
In this paper, we empirically address changes in lexical diversity within the second period of WE new dialect focusing and stabilization by comparing diachronic corpora of Indian English (IE) from 1978–2008. India boasts the largest English speaking population in the world, and, as one of the better studied English varieties, IE corpora from different time periods and L1 vs. L2 populations exist and collectively permit exploration of diachronic quantitative frequency patterns. Socially and linguistically, IE has been undergoing nativization since circa 1905 [
2]. Linguistically, features of IE pertinent to exploring lexical diversity diachronically include indigenized discourse and topicalization features which have emerged through semantic reallocation (Examples (1a,b)), lexical hybrids creating compounds (1c,d), the grammaticalization of presentational focus markers (1e,f), innovative extension of transitivity patterns (1g), new verbal complement patterns (1h), different distributions of articles and plural morphemes brought about through the redistribution of the mass/count properties of some classes of nouns and quantifiers (1i–k), changes in preferences for possessive and auxiliary clitics (1l,m), distinct linguistic constraints mediating the form of grammatical case (1.n,o), variation in verb form within subjunctive constructions (1p), and lexico-grammatical innovations resulting in nativized syntactic patterns (1q,r).
| 1. | a. | Non-existential there [45]: Food is there. |
| b. | Invariant isn’t it tag [45,46]: You will eat, isn’t it? |
| c. | Vernacular-English compounds [47]: tiffin-carrier; policewala, lathi-charged |
| d. | English-English compounds [47]: cousin-sister; cow-worship, black money, time-pass; salt giver only focus marker [46]: The sweets are tasty, only. |
| f. | itself focus marker1 [48]: The car was purchased this year, itself. |
| g. | ‘new ditransitives’ like advise occurring with two noun phrase complements in IE [49]: I have advised him some technical changes like using both hands while stopping the ball |
| h. | A markedly lower preference for NP2 + NP complements for the ditransitive give in IE (~22%) vs. British English (~37%) over other complement patterns [49] |
| i. | Zero article [50]: on Ø fifteenth August; Ø lot of X |
| j. | Mass nouns pluralized [51]: litters, furnitures, woods |
| k. | Count nouns not pluralized [52]: One of my relative Ø … |
| l. | Lower use of uncontracted auxiliaries [53]: will vs. ‘ll |
| m. | Lower use of possessive s-genitive [51]: I living next to my memsahib sister Ø house. |
| n. | Dative as ditransitive construction give+NP+NP vs. prepositional construction give+NP+PP |
| o. | Genitive alternation [54]: the party’s position vs. the position of the party |
| p. | Quantitative distinction from other Asian Englishes and British English in was/were/would preferences in conditional if clauses [55] |
| q. | on + if replacing on + whether in conditional if clauses [55]: On if the man, indeed, was the president’s security guard, he said it can be determined only after a probe |
| r. | Innovative ‘intrusive as’ construction [56]: The one who is called as Dr. Sahib… |
This list is not exhaustive: research uncovering IE structural nativization in specific forms and constructions continues, and empirical evidence of IE structural nativization is apparent across the grammar. Structural nativization is also supported by and likely working in tandem with ideological nativization and endonormative stabilization: recent and growing evidence of such, e.g., upper class urban New Delhi IE speakers, recognizes IE as both distinct from external canonical English varieties and ideologically more valuable and appropriate in the local Indian setting [
57]. Given this confluence of evidence, we are interested in what generalizations can be made from a holistic comparison of lexical rank frequency regarding IE dialect focusing, and more broadly, regarding WE nativization. This focus also speaks to a growing methodological reorientation within debates over language contact as processes of both simplification and complexification which are increasingly attending to large scale patterns [
42]. While the emergence of any single new or restructured form or construction may not justify claims of nativization, holistic diachronic differences can be seen as a synthesis of evidence specifically grounded in a larger collection of such restructurings.
Within this setting, we thus ask how a quantitative exploration of power law distributions may diachronically illuminate aspects of WE new dialect focusing and contribute to understanding language contact evolution more broadly. More specifically, we explore whether there is evidence for IE lexical focusing and stabilization (e.g., towards a kernel IE lexicon reflecting increasingly cohesive syntactic and collocational patterns), which we posit will be visible through a reduction in the β diachronically. Lexical expansion, e.g., the creation of new terms, would expand the tail of hapax legomena and manifest in a smaller
α: this is also likely with a diachronically growing population of native and/or fluent IE speakers who are largely speaking to other IE speakers, not to speakers of other English dialects. The goals of this paper are thus to explore, through statistical testing, which rank frequency distribution best fits this data, and to then interpret the patterns in terms of likely IE development pathways, building on previous work on diachronic change in the constants in language data [
33] and the range of restructurings and innovations documented in IE.
This paper expands the scope of power law constants against diachronic language evolution to specifically consider new dialect focusing and stabilization—as such, the descriptive interpretations offered below of changes in the constants should be considered exploratory. Recognizing that language as a sophisticated system is both hierarchical and multi-faceted, we acknowledge that specific patterns within combinatorial structural levels (e.g., syntactic, semantic, pragmatic levels) will necessarily be lost in a single word frequency approach derived from transcriptions of spoken language. This approach, however, still holds value given that it is applied in tandem with and building upon linguistic analyses of other structural levels for IE and other WE varieties. We are not asking how a word frequency rank distribution is *better* than other approaches for testing new dialect stabilization, but, instead, how it may complement them, by considering how semantic, pragmatic, and morpho-syntactic innovations may also be broadly visible in distributional differences between diachronic models of lexical rank frequency within a framework that does not rely on comparison with an external canonical norm.
2. Materials and Methods
This analysis draws on two public and one private corpora (
Table 1) to test our hypotheses. The Kolhapur Corpus draws on published written texts largely authored by L2 speakers: it was designed in size and genre coverage to approximately match the Brown and Lancaster-Oslo-Bergen corpora (500 texts spanning 15 categories, 2000 words per text) [
58]. Next, the International Corpus of English (ICE) project has developed matching corpora covering established and new English regional settings across the globe. Each corpus includes ~1 million words spread across 500 texts from a range of registers and genres of spoken and written English. ICE-India [
59] draws dominantly on L2 speakers, within which we consider the frequency characteristics of the ICE-Spoken sub-corpus separately from the ICE-Written sub-corpus. The third, and most recently collected dataset, ENDE (Elite New Delhi English) [
57], draws on transcripts of spontaneous spoken life history interviews with three generations of upper class early Hindi/English bilinguals from New Delhi. ENDE includes the speech of informants (and excludes that of the interviewer), but only includes their English speech (e.g., infrequent Hindi codeswitches are excluded), and only their naturalistic speech (i.e., formal reading passage data was excluded). While the corpora have different transcription protocols for spoken data, all follow standard orthographic practices in terms of spelling conventions (e.g.,
gonna is consistently transcribed as
going to). These corpora collectively permit a diachronic exploration of IE through (a) real-time comparison of written (comparing Kolhapur and ICE-Written) and spoken language data (comparing ICE-Spoken and ENDE); and (b) apparent time comparisons across two modalities (comparing ICE-Written and ICE-Spoken), and by speaker gender and age (separately considering the three age groups and two genders found in the ENDE corpus—discussed below and presented in
Table 2).
Within sociolinguistics, real-time analyses compare data collected at different points in time, while apparent time analyses compare synchronic snapshots of different age groups, genders, or different language modalities (i.e., spoken vs. written language, here), to extrapolate diachronic differences—and hence language change [
60]. Apparent time analyses draw on the assumption that a speaker’s grammar is relatively stable post-adolescence, reflecting the communicative norms from when they were age ~20, such that younger speakers use newer, emerging forms, while older speakers demonstrate older, conservative forms. Such data is less reliable evidence of diachronic change because language patterns can also change across the lifespan such that older speakers also adopt innovations [
61]. However, such changes tend to emerge in forms which gain social meaning, while no lifespan-based changes in quantitative frequency patterns have been documented [
61]. In gender-based apparent time comparisons, women are typically found to lead linguistic change: gender-based differences can thus provide insight into directions of change within data from the same generation [
62]. Linguistic patterns more common to younger females (over older males) are interpreted as innovative, while patterns preferred by older men (over younger women) are interpreted as conservative. Similarly, linguistic innovations are understood to primarily emerge from spoken vernacular language, only later percolating into written language, such that synchronic comparisons of written and spoken data can also provide apparent time evidence of diachronic change [
63]. We thus use these corpora to ask whether apparent time comparisons by gender, age, and modality support or nuance the real-time findings. Given that the ENDE corpus represents three generations of fluent bilinguals, we anticipate focusing of the
β within these three age groups, and a reduced range for constants as compared to the two earlier L2 speaker-dominated corpora of IE. We also anticipate that the synchronic analysis of ICE-India Spoken and Written sub-corpora will mirror the diachronic patterns, because both are derived from L2 populations.
Apart from ZL and ML, we test two other models of rank frequency, namely the Weibull distribution, given by
and the Inverse-Gamma distribution given by
Here, as usual, r denotes the rank, and α, b, and C are free parameters to be inferred from the dataset in question. The Inverse-Gamma distribution is essentially a modification of ZL.
We consider four goodness of fit measures to determine which model of rank frequency distribution best fits the data. Akaike Information Criterion (AIC) [
64] is generated from a fitted model after a log-likelihood value has been obtained, according to the formula: −2·
log-likelihood +
k ·
npar, where
npar represents the number of parameters estimated in the fitted model and
k = 2. Bayesian Information Criterion (BIC) is obtained from the same formula by letting
k = log(
n), where
n is the number of observations used to estimate the parameters. When comparing the models fitted by maximum likelihood to the same data, smaller AIC or BIC values correspond with better fits. We also examine ΔAIC = AIC − AIC
min to capture information lost in alternative models that deviate from the best available amongst those we considered [
65]. These adjusted values are free from the scaling constants incorporated in the criterion value which is highly dependent upon sample size [
65]. The Δ values are ranked such that the best available model would have a Δ value of 0, and any comparable models would be within a small tolerance. A similar analysis and interpretation is provided for ΔBIC values.
Standard error (SE) of the regression model [
64] is obtained by taking the square root of the sum of the squared residual errors over all observation values and dividing the result by the degrees of freedom for the model. The last metric provided, COR(y, ŷ), represents the correlation of the log-transformed relative frequency values with their corresponding fitted values. We would like to point out that SE is not the critical indicator of fit for the power laws considered here. The AIC and BIC are more robust indicators of model fit. We note that the corpora were handled in un-lemmatized form.
Models were developed to explore various power law fits: we first tested whether rank frequency distributions could be uncovered across the corpora, and what model version provides the best fit. When considering the information loss as tracked by the ΔAIC and ΔBIC values, we see clear evidence that the Mandelbrot model provides the best fit since the Δ value is always 0. We opt to follow the rule of thumb where a model with a Δ > 10 has no support for consideration [
65]. We then compared the exponents across corpora and sub-corpora within the best fitting model version to consider how frequency distributions can provide insight into language evolution and new dialect focusing.
4. Discussion
Each IE corpus demonstrates rank frequency distributions, uniformly best fit by Mandelbrot’s law, supported by each of the goodness of fit measures we considered. Next, we discuss the quantitative characteristics of the exponents in the Mandelbrot model,
α and
β. We follow Bentz et al. [
18] in our interpretation of the constants when possible; however, we are dealing not simply with internal linguistic change, but also with language contact-induced change.
The argument that
α reflects changes in morphological marking (more pervasive inflectional systems linked to a smaller
α and longer tail of hapax legomena [
18]) can be extended to pidgin and other L2 learner contexts where inflections are lost (resulting in a larger
α, or less lexical diversity); however, it is unclear how the
α may relate to the linguistic changes common to later stages of WE dialect focusing. We hypothesize that IE dialect focusing will give rise to hapax legomena within the process of lexical expansion and may be visible in a smaller
α.
In real-time, the
α shrinks diachronically in both spoken (
Table 4, from 1.48 to 1.44) and written (
Table 4, from 1.38 to 1.28) IE modality-based comparisons, while the size of the change is larger for the written corpora. This diachronic increase in the tail of hapax legomena may be related to the increased proficiency of IE L2 speakers, and we interpret this as dialect focusing. While there is not a linear trend across the three generations of speakers in the ENDE corpus, there is minimal deviation in the
α range (0.03291)—the three age groups in the most recently collected ENDE corpus are arguably quite similar and collectively are each quite small, which we interpret as evidence of dialect stabilization. Females from the ENDE corpus have a larger
α than men (1.43 vs. 1.33), indicative of a smaller tail of hapax legomena. However, we note that these sub-corpora are quite small, and not well-balanced: hapax legomena show more distributional variation in smaller and topically varied corpora [
66].
Comparing modalities in apparent time, the ICE- Spoken Corpus has a larger
α (1.48) than the ICE-Written Corpus (1.28): this follows from the more general finding that spoken language, produced online, uses a narrower vocabulary with more high frequency words, manifesting here as a smaller tail of hapax legomena than written language, which permits time for planning and revision [
63]. Overall, we interpret the apparent time modality-based difference in the
α as a further indicator of dialect focusing: natural languages consistently evidence distinct differences between spoken and written language. The apparent time age-based comparison, demonstrating minimal deviation by age, and collectively a very small
α, suggests recent stability and a reduction in the tail of low frequency words. While dialect evolution clearly involves lexical reduction within the establishment of a shared kernel lexicon in early stages of new dialect formation, potentially visible as a diachronic growth in the
α, later stages of dialect stabilization, based on this data, involve the deployment of a larger repertoire of rare lexicon.
Diachronically, an increase in
β can be interpreted as increased syntactic grammaticalization over case-based grammatical systems (a move towards a more analytic over synthetic structure [
18]): while analyses of Old versus Modern English have focused on movement from case markings to periphrastic syntactic constructions, in IE, grammatical changes are evident in new, increasingly grammaticalized syntactic collocational patterns [
67,
68,
69]. Dialect focusing, we hypothesize, has a more distinct kernel lexicon [
70], evidenced in a smaller
β diachronically. The current findings confirm this, and provide diachronic evidence for a reduction in the
β coefficient in real-time in written (Kolhapur 176.9 vs. ICE-Written 91.4) and spoken (ICE-Spoken 88.3 vs. ENDE 14.1) data. We also find apparent time confirmation of this pattern across modalities in the ICE corpus, with a smaller
β visible in the ICE-Spoken corpus (88.3 vs. 91.4), likely reflective of the linguistic conservatism of written language at the lexical level [
71,
72]. Collectively, the real and apparent time data comparing modality suggest that new dialects focus, over time, towards a shared kernel lexicon of high frequency words.
However, the apparent time comparison of ENDE age and gender sub-groups does not confirm that this trend towards grammaticalization is still in effect in the most recent data. Our interpretation rests on the minimally small range of deviance in β across the sub-corpora in concert with how small the ENDE sub-corpora β coefficients are (8.59–12.02) in comparison to the three historic corpora (Kohlapur: 176.9, ICE-Written: 91.4, ICE-Spoken: 88.3). These suggest that contemporary IE, reflected in the three apparent time age groups ENDE draws on, has stabilized after a period of focusing.
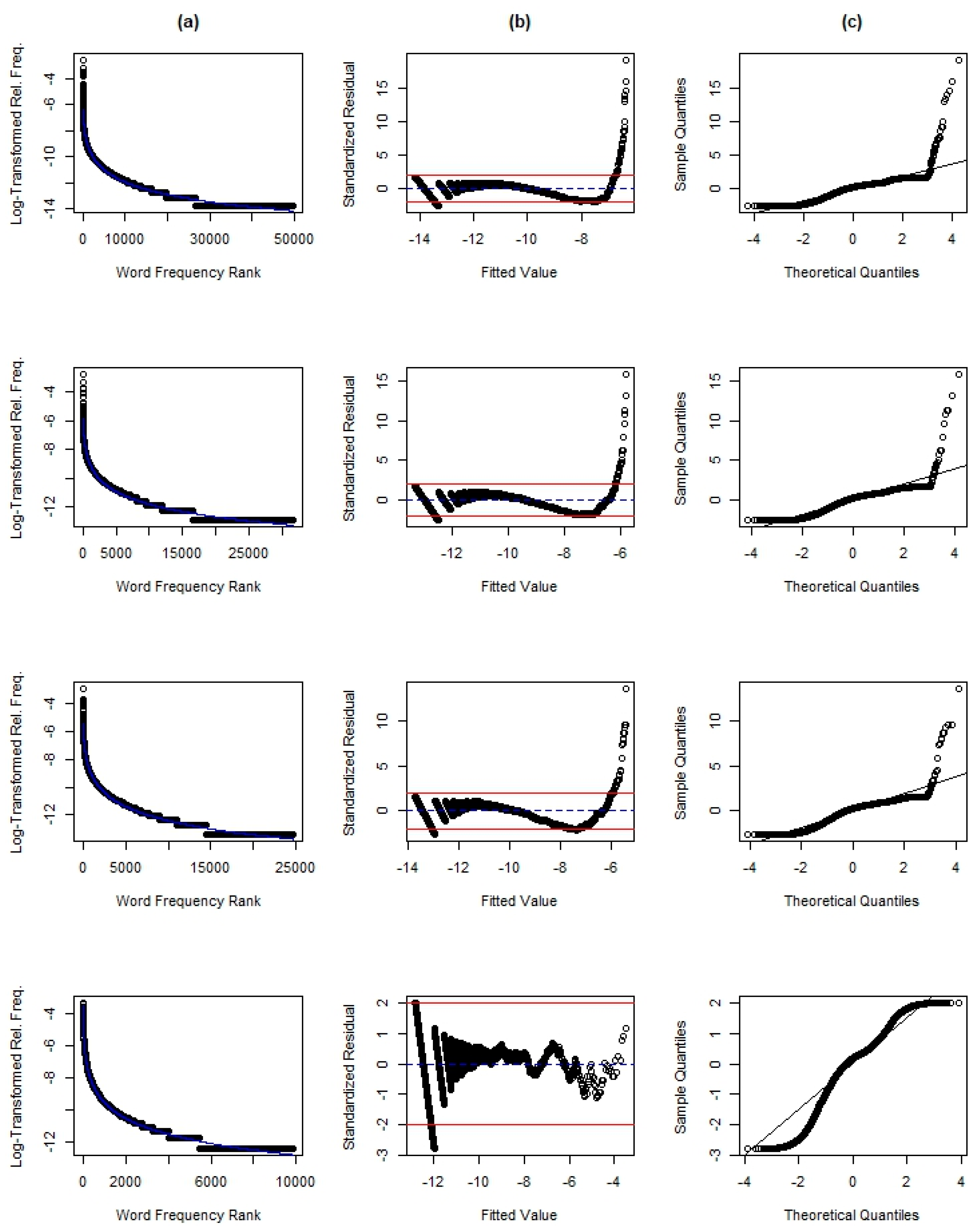
Graphically, in
Figure 1, we see that the ENDE corpus has the best fit to Mandelbrot’s Law, as visible by a narrower range and smaller absolute values for residuals. From
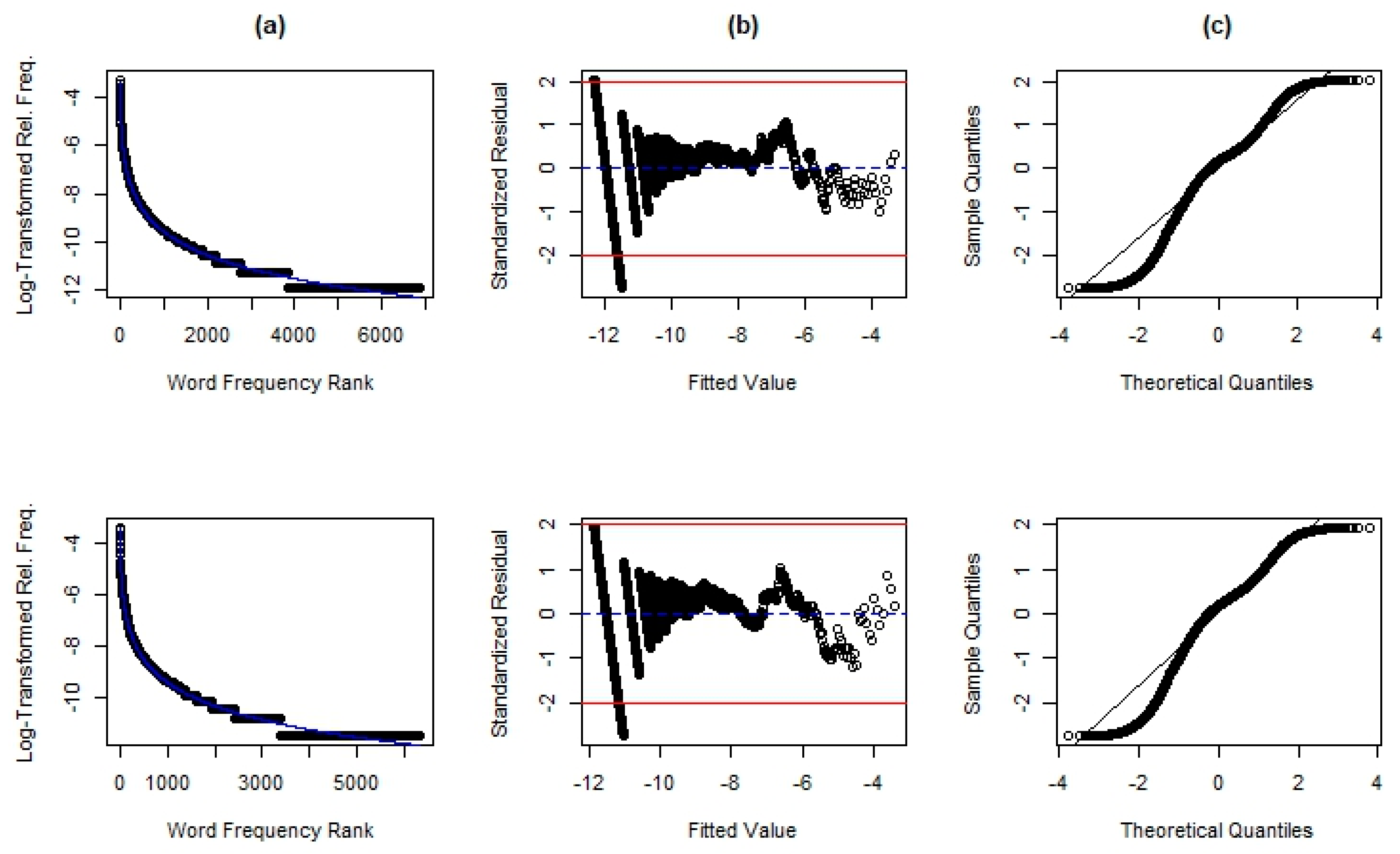
Figure 2 comparing genders within the ENDE corpus, we see, for females, a more random scatter of residuals (reflected in the relatively flatter slope to the right of the fitted value of −5) for the highest ranked words, suggesting a slightly better model over the one for males. In
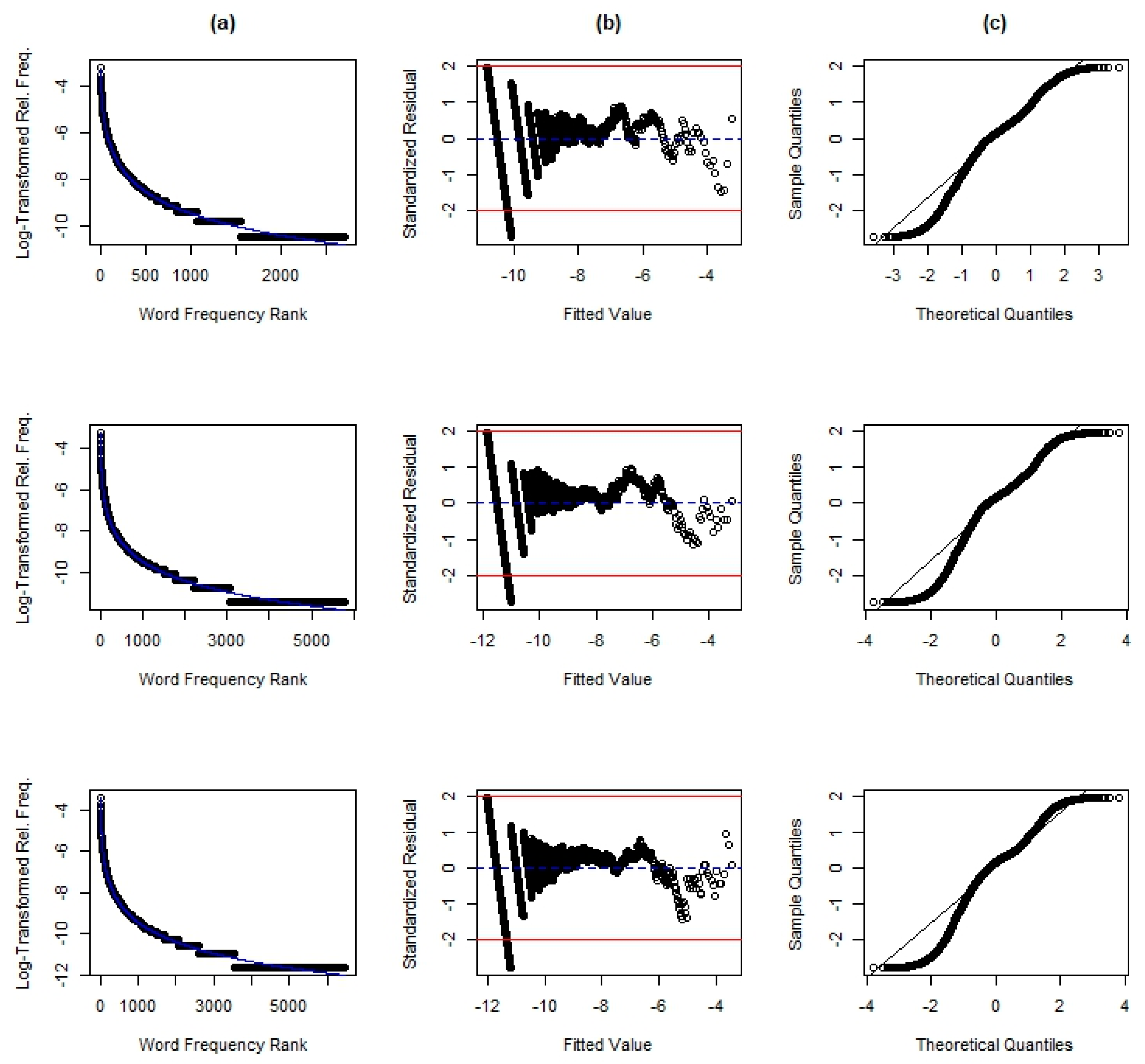
Figure 3, comparing apparent time age groups within the ENDE corpus, the theoretical quantile range is notably smaller for youths, but that is most likely due to the much smaller sub-corpus size.
5. Conclusions
Responding to our broader research agenda, to explore WE evolution through frequency distributions, we next discuss how these real and apparent time comparisons of frequency distributions relate to new dialect formation, focusing, and stabilization within the context of language contact evolution. We found that IE does follow power law frequency distributions, based on three different corpora and considering both spoken and written language. This is a novel finding, and offers a new avenue for exploring WE dialect evolution. While innovations and restructurings in language contact settings are dominantly contrasted with canonical patterns and ‘standard’ codes, the current approach permits an exploration of IE diachronically without reference to an external standard. Expanding on a growing body of literature documenting discrete instances of innovation and restructuring within IE and across the cline of English contact ecologies more broadly, we examine WE nativization and focusing from a holistic lexical rank frequency perspective.
Our second interest was towards capturing and measuring diachronic dialect focusing and stabilization within language contact ecologies. In IE, we found a real-time diachronic decrease in the β coefficient for both spoken and written data and an apparent time reduction in the β from the linguistically conservative ICE-Written corpus to the innovative ICE-Spoken corpus. These changes in the β coefficient illustrate that IE has undergone lexical focusing towards a kernel lexicon and is now stable based on three generations of apparent time data. This pattern merits exploration in other WE and new dialect formation settings. Of particular interest, IE evolution (specifically, later stage focusing and stabilization) is visible over a relatively short time period (1978 to 2008), and can be captured quantitatively without unduly relying on the examination of any single or small group of linguistic features within the new dialect. These quantitative characteristics of new dialect focusing are visible in both spoken and written data, and are also visible through apparent time comparison of spoken vs. written data, while dialect stabilization is visible in the apparent time comparison of three generations of speakers in the most recent corpus.
The analysis revealed that Mandelbrot’s Law provides the best fit for every corpus explored here. We see this through the AIC and BIC. We would like to point out that SE is not the critical indicator of fit for the power laws considered here.
While previous diachronic frequency research has not posited a specific explanation for changes in
α, here, a real-time reduction within both spoken (
Table 4, from 1.48 to 1.44) and written (
Table 4, from 1.38 to 1.28) language—linguistically, longer tails of hapax legomena diachronically—arguably relates to growth in IE speakers’ proficiency, one aspect of which is an increasing lexicon. This evidence further suggests that later stages of dialect stabilization involve the deployment of a larger repertoire of rare lexicon. Apparent time modality-based differences in
α, with a smaller tail of hapax legomena in spoken language, are meanwhile consistent with earlier research on spoken versus written language, while this evidence extends the finding to diachronic contact situations.
Given that Mandelbrot’s Law provides a better fit than Zipf’s Law for these IE corpora, optimization is interpreted as an increasingly smaller
β, but not specifically a
β idealized as zero. We interpret this diachronic reduction of
β as an indicator of internal language optimization in high frequency words. The real and apparent time evidence for a shrinking
β complements previous discrete analyses encompassing a range of IE syntactic, pragmatic, and discourse-functional innovations which include the development of verb-particle collocational patterns, novel focus particles and invariant tags, and the grammaticalization of a range of lexical items [
46]. These documented IE features have developed through the reshaping of individual words and structures by increasingly larger groups of fluent English speakers in India (L1 or otherwise), and we argue that their collective impact on contemporary IE is visible through frequency characteristics.
Importantly, these widespread structural changes in IE are not centered around the development or loss of a case system or specifically through a change along the cline from synthetic to analytical inflectional encoding, and instead reflect widespread individual innovations in syntactic collocational patterns, syntactic reconfigurations, and the concurrent grammaticalization of specific lexical forms to take on discourse-pragmatic functions. Based on the real and apparent time quantitative characteristics which accompany the development of these innovative and restructured IE forms, we extend previous interpretations of diachronic changes in
β as reflecting a grammatical fingerprint of the inflectional state of a language [
18] to argue that
β also reflects the innovative functional grammaticalization of new collocational patterns. This research could profitably be extended to fit two regime models [
73,
74], to explicitly test whether better fits are possible, and more directly speak to distinct patterns for high versus low frequency lexicon.
This analysis also contributes to understanding how synchronic comparisons by age and gender (within ENDE), and modality (within ICE-India) can support and nuance real-time findings based on a comparison of diachronic corpora. Broadly, the ENDE sub-corpora comparisons show minimal deviation in comparison to the diachronic and modality-based comparisons. This may be because there is more genre- and register-based homogeneity within the ENDE-based oral history interviews, but it may also relate to the smaller size of the ENDE sub-corpora—future research will resolve this.
Broadly, this quantitative exploration of power law distributions in synchronic and diachronic IE data provides the first frequency characteristics for a WE. These comparisons offer evidence of language contact-based evolution and new dialect focusing and stabilization in IE which does not rely on small sets of discrete structural patterns or innovations, and also does not compare IE to external ‘standard’ reference points. Future analyses of additional WEs and pidgin/creoles will refine our understanding of how quantitative frequency characteristics contribute to theorizing language contact evolution.








{kind=link}
{kind=link}
{kind=link}