





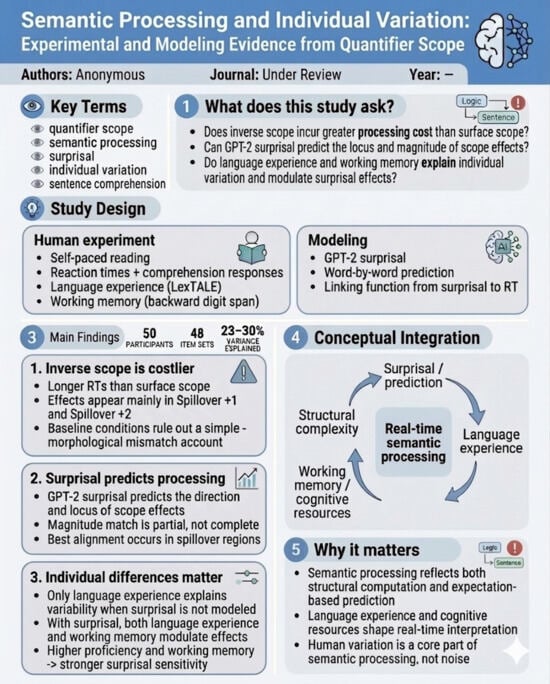
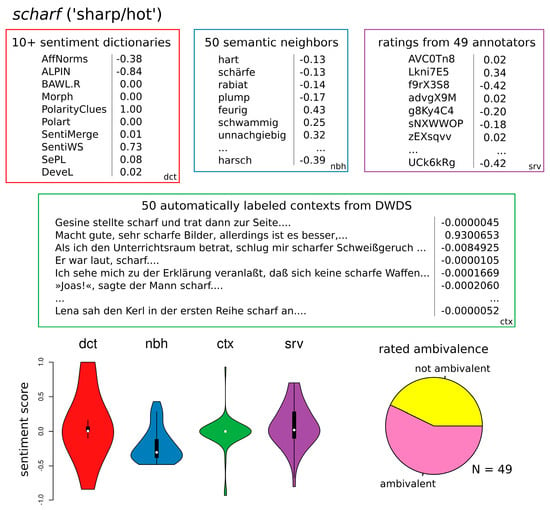
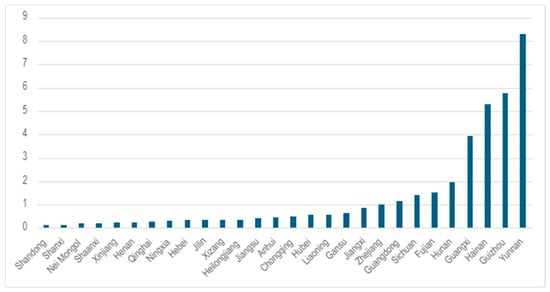
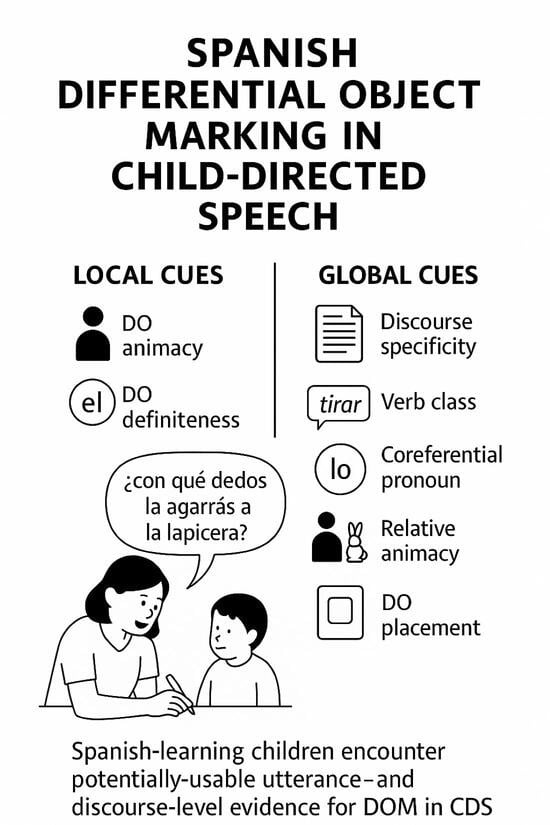
Languages 2026, 11(6), 130; https://doi.org/10.3390/languages11060130 (registering DOI) - 22 Jun 2026
Abstract
This study examines the linguistic landscape of northern Lesbos at the turn of the 20th century through the lens of historical sociolinguistics. The research focuses on the scientific intersection and subsequent controversy between the native scholar Spyridon Anagnostou and the renowned German linguist
[...] Read more.
This study examines the linguistic landscape of northern Lesbos at the turn of the 20th century through the lens of historical sociolinguistics. The research focuses on the scientific intersection and subsequent controversy between the native scholar Spyridon Anagnostou and the renowned German linguist Paul Kretschmer. Methodologically, the study employs archival research, biographical analysis, and a comparative study of Anagnostou’s original manuscripts held at the Research Center for Modern Greek Dialects (KENDI) against published editions. The results include the identification of 36 unpublished fairy tales and an analysis of phonetic and morphological phenomena, such as kappacism and rare feminine endings, which are largely absent from contemporary records. Comparative analysis further reveals significant “dialectal normalization” and ideological interventions in both scholars’ transcriptions. We conclude that Anagnostou’s manuscripts serve as a vital “linguistic fossil” and a proxy for unrecorded spontaneous speech, recovering diachronic depth lost to dialect leveling. Ultimately, the study highlights the importance of marginal local scholarship in reconstructing a “language history from below” and addressing epistemic injustice and the ideology of transcriptions in the history of dialectology.
Full article
(This article belongs to the Special Issue The Modern Dialect of Lesbos: Selected Topics)














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}