Perceived Phonological Overlap in Second-Language Categories: The Acquisition of English /r/ and /l/ by Japanese Native Listeners


Abstract
:1. Introduction
1.1. The Perceptual Assimilation Model
1.2. PAM-L2
1.3. Perception of English /r/ and /l/ by Japanese Native Listeners
1.4. The Present Study
2. Materials and Methods
2.1. Participants
2.2. Stimuli and Apparatus
2.3. Procedure
3. Results
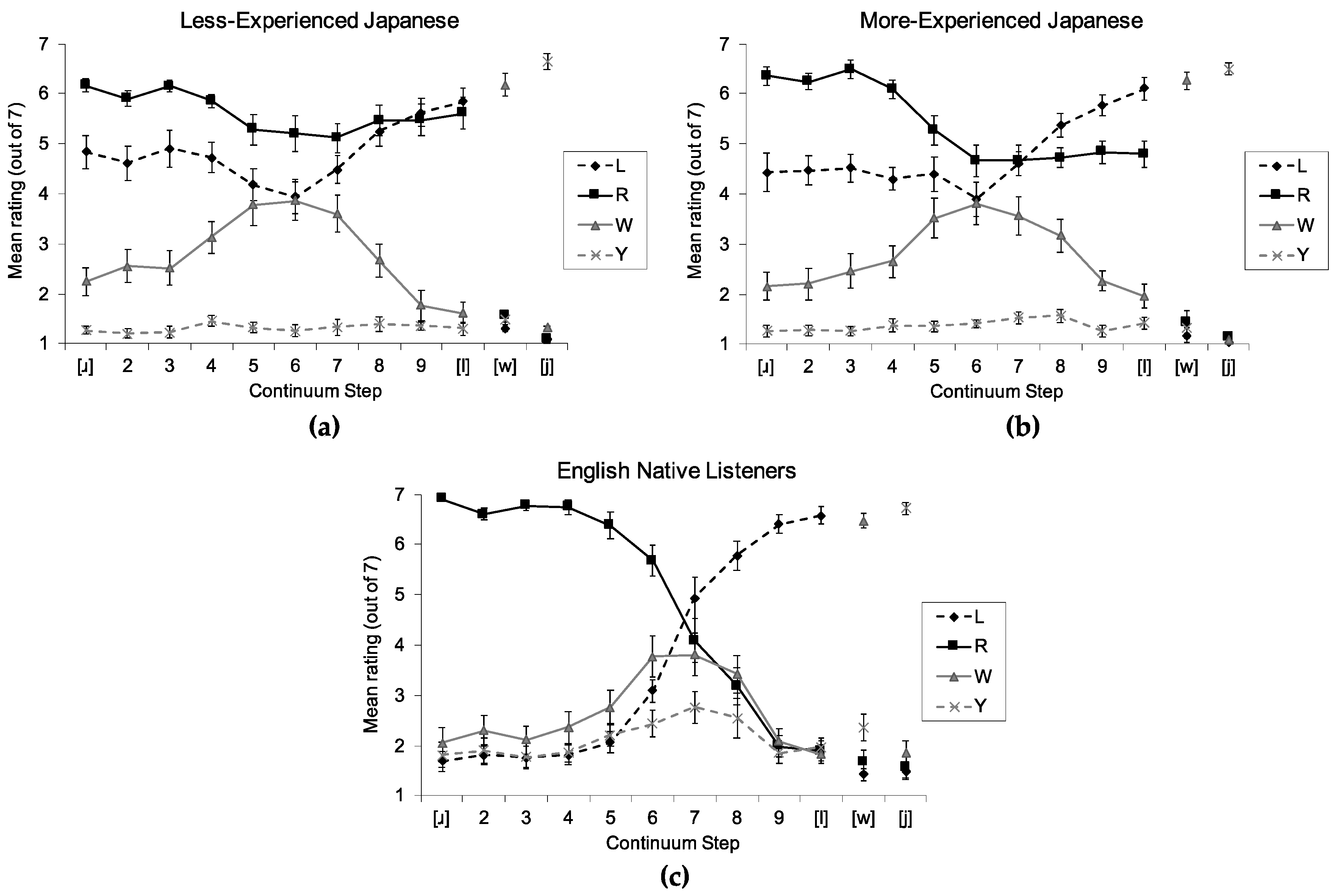
3.1. Forced Category Goodness Rating
3.2. Identification
3.3. Discrimination
4. Discussion
4.1. Identification and Discrimination
4.2. Conflicting Findings between Pre-Lexical and Lexical Tasks
4.3. Methodological Considerations
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Amengual, Mark. 2016. The perception of language-specific phonetic categories does not guarantee accurate phonological representations in the lexicon of early bilinguals. Applied Psycholinguistics 37: 1221–51. [Google Scholar] [CrossRef] [Green Version]
- Antoniou, Mark, Catherine T. Best, and Michael D. Tyler. 2013. Focusing the lens of language experience: Perception of Ma’di stops by Greek and English bilinguals and monolinguals. Journal of the Acoustical Society of America 133: 2397–411. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Antoniou, Mark, Michael D. Tyler, and Catherine T. Best. 2012. Two ways to listen: Do L2-dominant bilinguals perceive stop voicing according to language mode? Journal of Phonetics 40: 582–94. [Google Scholar] [CrossRef] [Green Version]
- Aoyama, Katsura, James E. Flege, Susan G. Guion, Reiko Akahane-Yamada, and Tsuneo Yamada. 2004. Perceived phonetic dissimilarity and L2 speech learning: The case of Japanese /r/ and English /l/ and /r/. Journal of Phonetics 32: 233–50. [Google Scholar] [CrossRef]
- Best, Catherine T. 1994a. The emergence of native-language phonological influences in infants: A perceptual assimilation model. In The Development of Speech Perception: The Transition from Speech Sounds to Spoken Words. Edited by Judith C. Goodman and Howard C. Nusbaum. Cambridge: MIT Press, pp. 167–244. [Google Scholar]
- Best, Catherine T. 1994b. Learning to perceive the sound pattern of English. In Advances in Infancy Research. Edited by C. Rovee-Collier and Lewis P. Lipsitt. Norwood: Ablex, pp. 217–304. [Google Scholar]
- Best, Catherine T. 1995. A direct realist view of cross-language speech perception. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Baltimore: York Press, pp. 171–204. [Google Scholar]
- Best, Catherine T., and Gerald W. McRoberts. 2003. Infant perception of non-native consonant contrasts that adults assimilate in different ways. Language and Speech 46: 183–216. [Google Scholar] [CrossRef] [Green Version]
- Best, Catherine T., Gerald W. McRoberts, and Elizabeth Goodell. 2001. Discrimination of non-native consonant contrasts varying in perceptual assimilation to the listener’s native phonological system. Journal of the Acoustical Society of America 109: 775–94. [Google Scholar] [CrossRef]
- Best, Catherine T., Gerald W. McRoberts, and Nomathemba M. Sithole. 1988. Examination of perceptual reorganization for nonnative speech contrasts: Zulu click discrimination by English-speaking adults and infants. Journal of Experimental Psychology: Human Perception and Performance 14: 345–60. [Google Scholar] [CrossRef]
- Best, Catherine T., and Winifred Strange. 1992. Effects of phonological and phonetic factors on cross-language perception of approximants. Journal of Phonetics 20: 305–30. [Google Scholar] [CrossRef]
- Best, Catherine T., and Michael D. Tyler. 2007. Nonnative and second-language speech perception: Commonalities and complementarities. In Second Language Speech Learning: The Role of Language Experience in Speech Perception and Production. Edited by Murray J. Munro and Ocke-Schwen Bohn. Amsterdam: John Benjamins, pp. 13–34. [Google Scholar]
- Bohn, Ocke-Schwen, Catherine T. Best, Cinzia Avesani, and Mario Vayra. 2011. Perceiving through the lens of native phonetics: Italian and Danish listenerś perception of English consonant contrasts. In Proceedings of the 17th International Congress of Phonetic Sciences, Hong Kong, China, August 17–21. Edited by Wai Sum Lee and Eric Zee. Hong Kong: City University of Hong Kong, pp. 336–39. [Google Scholar]
- Bradlow, Ann R., Reiko Akahane-Yamada, David B. Pisoni, and Yoh‘ichi Tohkura. 1999. Training Japanese listeners to identify English /r/ and /l/: Long-term retention of learning in perception and production. Perception & Psychophysics 61: 977–85. [Google Scholar]
- Bradlow, Ann R., David B. Pisoni, Reiko Akahane-Yamada, and Yoh‘ichi Tohkura. 1997. Training Japanese listeners to identify English /r/ and /l/: IV. Some effects of perceptual learning on speech production. Journal of the Acoustical Society of America 101: 2299–310. [Google Scholar] [CrossRef] [Green Version]
- Bundgaard-Nielsen, Rikke L., Catherine T. Best, Christian Kroos, and Michael D. Tyler. 2012. Second language learners‘ vocabulary expansion is associated with improved second language vowel intelligibility. Applied Psycholinguistics 33: 643–64. [Google Scholar] [CrossRef]
- Bundgaard-Nielsen, Rikke L., Catherine T. Best, and Michael D. Tyler. 2011a. Vocabulary size is associated with second-language vowel perception performance in adult learners. Studies in Second Language Acquisition 33: 433–61. [Google Scholar] [CrossRef]
- Bundgaard-Nielsen, Rikke L., Catherine T. Best, and Michael D. Tyler. 2011b. Vocabulary size matters: The assimilation of second-language Australian English vowels to first-language Japanese vowel categories. Applied Psycholinguistics 32: 51–67. [Google Scholar] [CrossRef] [Green Version]
- Cohen, Jacob. 1988. Statistical Power Analysis for the Behavioral Sciences, 2nd ed. Hillsdale: Lawrence Erlbaum Associates. [Google Scholar]
- Cutler, Anne, Andrea Weber, and Takashi Otake. 2006. Asymmetric mapping from phonetic to lexical representations in second-language listening. Journal of Phonetics 34: 269–84. [Google Scholar] [CrossRef] [Green Version]
- Darcy, Isabelle, Danielle Daidone, and Chisato Kojima. 2013. Asymmetric lexical access and fuzzy lexical representations in second language learners. The Mental Lexicon 8: 372–420. [Google Scholar] [CrossRef]
- Faris, Mona M., Catherine T. Best, and Michael D. Tyler. 2016. An examination of the different ways that non-native phones may be perceptually assimilated as uncategorized. Journal of the Acoustical Society of America 139: EL1–EL5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Faris, Mona M., Catherine T. Best, and Michael D. Tyler. 2018. Discrimination of uncategorised non-native vowel contrasts is modulated by perceived overlap with native phonological categories. Journal of Phonetics 70: 1–19. [Google Scholar] [CrossRef]
- Flege, James E. 1995. Second language speech learning: Theory, findings, and problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Baltimore: York Press, pp. 233–76. [Google Scholar]
- Flege, James E. 2003. Assessing constraints on second-language segmental production and perception. In Phonetics and Phonology in Language Comprehension and Production: Differences and Similarities. Edited by Niels O. Schiller and Antje S. Meyer. Berlin: Mouton de Gruyter, pp. 319–55. [Google Scholar]
- Flege, James E. 2009. Give input a chance! In Input Matters in SLA. Edited by Thorsten Piske and Martha Young-Scholten. Bristol: Multilingual Matters, pp. 175–90. [Google Scholar]
- Flege, James E. 2019. A non-critical period for second-language learning. In A Sound Approach to Language Matters—In Honor of Ocke-Schwen Bohn. Edited by Anne M. Nyvad, Michaela Hejná, Anders Højen, Anna B. Jespersen and Mette H. Sørensen. Aarhus: Department of English, School of Communication & Culture, Aarhus University, pp. 501–41. [Google Scholar]
- Flege, James E., Murray J. Munro, and Ian R. A. MacKay. 1995. Factors affecting strength of perceived foreign accent in a second language. Journal of the Acoustical Society of America 97: 3125–34. [Google Scholar] [CrossRef]
- Flege, James Emil, Grace H. Yeni-Komshian, and Serena Liu. 1999. Age constraints on second-language acquisition. Journal of Memory & Language 41: 78–104. [Google Scholar]
- Gibson, James J. 1966. The Senses Considered as Perceptual Systems. Boston: Houghton-Mifflin. [Google Scholar]
- Gibson, James J. 1979. The Ecological Approach to Visual Perception. Boston: Houghton-Mifflin. [Google Scholar]
- Goldstein, Louis, and Carol A. Fowler. 2003. Articulatory phonology: A phonology for public language use. In Phonetics and Phonology in Language Comprehension and Production: Differences and Similarities. Edited by Niels O. Schiller and Antje S. Meyer. Berlin: Mouton de Gruyter, pp. 159–207. [Google Scholar]
- Goto, Hiromu. 1971. Auditory perception by normal Japanese adults of the sounds “l“ and “r“. Neuropsychologia 9: 317–23. [Google Scholar] [CrossRef]
- Guion, Susan G., James E. Flege, Reiko Akahane-Yamada, and Jesica C. Pruitt. 2000. An investigation of current models of second language speech perception: The case of Japanese adults’ perception of English consonants. Journal of the Acoustical Society of America 107: 2711–724. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hallé, Pierre A., Catherine T. Best, and Andrea Levitt. 1999. Phonetic vs. phonological influences on French listeners’ perception of American English approximants. Journal of Phonetics 27: 281–306. [Google Scholar] [CrossRef]
- Hattori, Kota, and Paul Iverson. 2009. English /r/-/l/ category assimilation by Japanese adults: Individual differences and the link to identification accuracy. Journal of the Acoustical Society of America 125: 469–79. [Google Scholar] [CrossRef] [PubMed]
- Iverson, Paul, Patricia K. Kuhl, Reiko Akahane-Yamada, Eugen Diesch, Yoh‘ichi Tohkura, Andreas Kettermann, and Claudia Siebert. 2003. A perceptual interference account of acquisition difficulties for non-native phonemes. Cognition 87: B47–B57. [Google Scholar] [CrossRef]
- Jenkins, James J., Winifred Strange, and Linda Polka. 1995. Not everyone can tell a “rock” from a “lock”: Assessing individual differences in speech perception. In Assessing Individual Differences in Human Behavior: New Concepts, Methods, and Findings. Edited by David J. Lubinski and René V. Dawis. Palo Alto: Davies-Black Publishing, pp. 297–325. [Google Scholar]
- Kato, Misaki, and Melissa M. Baese-Berk. 2020. The effect of input prompts on the relationship between perception and production of non-native sounds. Journal of Phonetics 79: 100964. [Google Scholar] [CrossRef]
- Lively, Scott E., John S. Logan, and David B. Pisoni. 1993. Training Japanese listeners to identify English /r/ and /l/: II. The role of phonetic environment and talker variability in learning new perceptual categories. Journal of the Acoustical Society of America 94: 1242–55. [Google Scholar] [CrossRef]
- Lively, Scott E., David B. Pisoni, and John S. Logan. 1992. Some effects of training Japanese listeners to identify English /r/ and /l/. In Speech Perception, Production and Linguistic Structure. Edited by Yoh‘ichi Tohkura, Eric Vatikiotis-Bateson and Yoshinori Sagisaka. Washington: IOS Press, pp. 175–96. [Google Scholar]
- Lively, Scott E., David B. Pisoni, Reiko A. Yamada, Yoh‘ichi Tohkura, and Tsuneo Yamada. 1994. Training Japanese listeners to identify English /r/ and /l/. III. Long-term retention of new phonetic categories. Journal of the Acoustical Society of America 96: 2076–87. [Google Scholar] [CrossRef]
- Logan, John S., Scott E. Lively, and David B. Pisoni. 1991. Training Japanese listeners to identify English /r/ and /l/: A first report. Journal of the Acoustical Society of America 89: 874–86. [Google Scholar] [CrossRef] [Green Version]
- MacKain, Kristine S., Catherine T. Best, and Winifred Strange. 1981. Categorical perception of English /r/ and /l/ by Japanese bilinguals. Applied Psycholinguistics 2: 369–90. [Google Scholar] [CrossRef] [Green Version]
- McQueen, James M., Michael D. Tyler, and Anne Cutler. 2012. Lexical retuning of children’s speech perception: Evidence for knowledge about words’ component sounds. Language Learning and Development 8: 317–39. [Google Scholar] [CrossRef]
- Miyawaki, Kuniko, James J. Jenkins, Winifred Strange, Alvin M. Liberman, Robert Verbrugge, and Osamu Fujimura. 1975. An effect of linguistic experience: The discrimination of [r] and [l] by native speakers of Japanese and English. Perception & Psychophysics 18: 331–40. [Google Scholar]
- Mochizuki, Michiko. 1981. The identification of /r/ and /l/ in natural and synthesized speech. Journal of Phonetics 9: 283–303. [Google Scholar] [CrossRef]
- Norris, Dennis, James M. McQueen, and Anne Cutler. 2003. Perceptual learning in speech. Cognitive Psychology 47: 204–38. [Google Scholar] [CrossRef]
- Olejnik, Stephen, and James Algina. 2003. Generalized eta and omega squared statistics: Measures of effect size for some common research designs. Psychological Methods 8: 434–47. [Google Scholar] [CrossRef] [Green Version]
- Polka, Linda. 1995. Linguistic influences in adult perception of non-native vowel contrasts. Journal of the Acoustical Society of America 97: 1286–96. [Google Scholar] [CrossRef]
- Reinisch, Eva, Andrea Weber, and Holger Mitterer. 2013. Listeners retune phoneme categories across languages. Journal of Experimental Psychology: Human Perception and Performance 39: 75–86. [Google Scholar] [CrossRef] [Green Version]
- Shinohara, Yasuaki, and Paul Iverson. 2018. High variability identification and discrimination training for Japanese speakers learning English /r/–/l/. Journal of Phonetics 66: 242–51. [Google Scholar] [CrossRef]
- Tyler, Michael D. 2019. PAM-L2 and phonological category acquisition in the foreign language classroom. In A Sound Approach to Language Matters—In Honor of Ocke-Schwen Bohn. Edited by Anne M. Nyvad, Michaela Hejná, Anders Højen, Anna B. Jespersen and Mette H. Sørensen. Aarhus: Dept. of English, School of Communication & Culture, Aarhus University, pp. 607–30. [Google Scholar]
- Tyler, Michael D. 2021. Phonetic and phonological influences on the discrimination of non-native phones. In Second Language Speech Learning: Theoretical and Empirical Progress. Edited by Ratree Wayland. Cambridge: Cambridge University Press, pp. 157–74. [Google Scholar]
- Tyler, Michael D., Catherine T. Best, Alice Faber, and Andrea G. Levitt. 2014a. Perceptual assimilation and discrimination of non-native vowel contrasts. Phonetica 71: 4–21. [Google Scholar] [CrossRef]
- Tyler, Michael D., Catherine T. Best, Louis M. Goldstein, and Mark Antoniou. 2014b. Investigating the role of articulatory organs and perceptual assimilation in infants’ discrimination of native and non-native fricative place contrasts. Developmental Psychobiology 56: 210–27. [Google Scholar] [CrossRef]
- Weber, Andrea, and Anne Cutler. 2004. Lexical competition in non-native spoken-word recognition. Journal of Memory and Language 50: 1–25. [Google Scholar] [CrossRef] [Green Version]
- Werker, Janet F., and John S. Logan. 1985. Cross-language evidence for three factors in speech perception. Perception & Psychophysics 37: 35–44. [Google Scholar]
- Winer, Benjamin J., Donald R. Brown, and Kenneth M. Michels. 1991. Statistical Principles in Experimental Design, 3rd ed. New York: McGraw-Hill. [Google Scholar]
| 1 | |
| 2 | Note that square brackets are used here to denote a phonetic category rather than a specific phone. |
| 3 | Although participants had no difficulty using this scale, the scale is reversed in the results section to assist the reader in interpreting the data patterns. That is, 7 is reported as highly similar and 1 is reported as highly dissimilar. |
| 4 | Generalized eta squared (η2G) is a measure of effect size that is appropriate for mixed designs (Olejnik and Algina 2003). It is compatible with Cohen’s (1988) benchmarks for interpreting eta squared (small = 0.01, medium = 0.06, and large = 0.14). |



{kind=link}
{kind=link}
{kind=link}
| Group | Step | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| [ɹ] | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | [l] | ||
| Less experienced | t(17) | −3.43 | −3.84 | −3.65 | −4.30 | −2.66 | −4.81 | −2.84 | −1.37 | 0.75 | 0.71 |
| p | 0.003 | 0.001 | 0.002 | <0.001 | 0.016 | <0.001 | 0.011 | 0.190 | 0.462 | 0.488 | |
| More experienced | t(18) | −6.22 | −4.42 | −5.58 | −5.02 | −2.53 | −2.40 | −0.19 | 2.07 | 2.34 | 4.11 |
| p | <0.001 | <0.001 | <0.001 | <0.001 | 0.021 | 0.028 | 0.850 | 0.054 | 0.031 | 0.001 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tyler, M.D. Perceived Phonological Overlap in Second-Language Categories: The Acquisition of English /r/ and /l/ by Japanese Native Listeners. Languages 2021, 6, 4. https://doi.org/10.3390/languages6010004
Tyler MD. Perceived Phonological Overlap in Second-Language Categories: The Acquisition of English /r/ and /l/ by Japanese Native Listeners. Languages. 2021; 6(1):4. https://doi.org/10.3390/languages6010004
Chicago/Turabian StyleTyler, Michael D. 2021. "Perceived Phonological Overlap in Second-Language Categories: The Acquisition of English /r/ and /l/ by Japanese Native Listeners" Languages 6, no. 1: 4. https://doi.org/10.3390/languages6010004
APA StyleTyler, M. D. (2021). Perceived Phonological Overlap in Second-Language Categories: The Acquisition of English /r/ and /l/ by Japanese Native Listeners. Languages, 6(1), 4. https://doi.org/10.3390/languages6010004