
Grammar Competition and Word Order in a Northern Early Middle English Text


Linguistics and English Language, The University of Edinburgh, Edinburgh EH8 9AD, UK
Languages 2021, 6(2), 59; https://doi.org/10.3390/languages6020059
Submission received: 10 December 2020
/
Revised: 27 February 2021
/
Accepted: 2 March 2021
/
Published: 24 March 2021
(This article belongs to the Special Issue New Empirical Approaches to Grammatical Variation and Change)
Abstract
:The Edinburgh Royal College of Physicians manuscript of Cursor Mundi and the Northern Homilies, a northern Middle English text from the early 14th century, contains unprecedentedly high frequencies of matrix verb-third and embedded verb-second word orders with subject–verb inversion. I give a theoretical account of these word orders in terms of a grammar, the ‘CM grammar’, which differs minimally in its formal description from regular verb-second grammars, but captures these unusual word orders through addition of a second preverbal A-projection. Despite its flexibility, the CM grammar did not spread through the English-speaking population. I discuss the theoretical consequences of this failure to spread for models of grammar competition where fitness is tied to parsing success, and discuss prospects for refining such models.
1. Introduction
This paper has two goals. The first is to describe matrix verb-third and embedded verb-second orders with subject–verb inversion in Old and Early Middle English, with special reference to the Edinburgh Cursor Mundi and Northern Homilies, a northern Middle English document written in three hands from the early–mid 14th century, in which these orders are particularly common. It is particularly noteworthy that matrix verb-third orders with inversion are common in this manuscript, because this contrasts with the matrix verb-second orders found in almost all Germanic languages.
An example of matrix V3 with inversion is given in (1), and an example of embedded V2 with inversion is in (2).1
| (1) [ Sa brad ] [ of hir blis ] es þe wai | ||
| so broad of her bliss is the way | ||
| ‘The way of her bliss is so broad. ’ | (edincmat.1090)2 |
| (2) He wenes [ [ his mak ] mai naman find ] | ||
| he believes his match may no.man find | ||
| ‘He believes that no one may find their equal.’ | (edincmbt.553)3 |
I give a theoretical account of those orders in terms of a grammar that I will call the ‘CM grammar’, which makes two preverbal A-positions available in matrix clauses, and one in embedded clauses. Because the CM grammar can generate these uncommon word orders, in addition to many more common word orders, the CM grammar is more flexible than the northern Middle English described by Kroch and Taylor (1997), or indeed any other grammar described for any variety of English.
The second aim of this paper is to draw out some theoretical implications of this very flexible grammar, which apparently existed in the margins of the history of English, from the perspective of approaches to syntactic change based on grammar competition (Kroch 1989; Yang 2002). These widely adopted approaches model a speaker’s grammatical competence as a distribution over multiple grammars, where the relative weights, or fitness, of the different grammars are determined on Yang’s (2002) model by their success in parsing sentences encountered during language acquisition. On such a model, the flexibility of the CM grammar should lead to that grammar having greater fitness than contemporary grammars and therefore spreading through the population. That, strikingly, did not happen: English word order evolved towards the fixed SVO order found since late Middle English, rather than the more flexible orders generated by the CM grammar. This suggests, contrary to the prediction of Yang (2002), that greater flexibility (more specifically, greater ability to parse sentence structures in the input) does not necessarily yield a selectional advantage, a conclusion that forces a reconsideration of the implementation of grammar competition.
2. Background
I adopt the hypothesis, with its roots in Borer (1983), that syntactic variation reduces to variation in the specification of the properties of functional heads. The models of word order that I describe in this section should therefore ultimately be considered as models of the specification of heads such as C and I. I focus particularly on the uses that different grammars make of the heads which are most directly involved in models of V2 in early English, namely C and a lower head motivated in Haeberli (2000) which I will call F. There are a limited set of possible specifications of these heads, and no single specification is able, on its own, to capture the richness and variation attested in many Old and Middle English texts. However, on a grammar competition approach, we need not expect any single grammar to generate all the observed sentences in a text, because an individual in principle may have access to multiple distinct grammars (that is, multiple distinct sets of specifications of the properties of functional heads).
The rest of this section focuses on grammars that generate V2 and related orders in Old and Middle English. Section 2.1 describes the standard generative model of OE clause structure, deriving from van Kemenade (1987) and Pintzuk (1991). Section 2.2 focuses on the description of northern Middle English word order in Kroch and Taylor (1997), as a point of comparison for the northern Early Middle English of the CM grammar. Finally, in Section 2.3 we identify three grammars that we will compare to the CM grammar in later sections.
2.1. Verb-Second in Old English
Old English (OE) is a verb-second language. This means that in general, a single phrasal constituent precedes the finite verb in matrix clauses. The identity of this constituent ranges over most argumental and adverbial categories. In (3a), an object is in first position; in (3b), a prepositional phrase, and in (3c), an adverbial.
|
(3) a. [ Ðas fif andgitu ] gewisseð seo sawul to hire wyllan the.acc five.acc senses.acc controls the soul to her will ‘The soul controls the five senses according to her will.’ |
| (coaelive,+ALS_[Christmas]:202.161)4 |
| b. [ On manega wisan ] lærð Godes lar þa Cristenan. in many ways teaches God’s lore the.acc christians.acc ‘God’s teaching teaches christians in many ways.’ |
| (coaelhom,+AHom_20:2.2907)5 |
| c. [ Gastlice ] herigen we ures Dryhtnes naman, hælendes Cristes spiritually praise we our.gen Lord.gen name saviour.gen Christ.gen ‘Spiritually, we praise our Lord and saviour Christ’s name.’ |
| (coverhom,HomS_1_[ScraggVerc_5]:203.973)6 |
However, pronominal subjects precede the finite verb, even if there is some other constituent in initial position (van Kemenade 1987; Pintzuk 1991). This means that verb-third word orders like (4) are standard.
| (4) [ Ælc yfel ] he mæg don | |
| each evil he can do | |
| ‘He can do each evil.’ | (cowulf,WHom_4:62.141)7 |
Certain initial elements trigger inversion, though, even when the subject is a personal pronoun. The most important members of this class of elements are the adverbs þa ‘then’ and nu ‘now’, as in (5)—see Pintzuk (1991, pp. 145–50) for a full characterization of this class.
| (5) [ þa ] gemette he sceaðan | |
| then met he robbers | |
| ‘Then he met robbers.’ | (coaelive,+ALS_[Martin]:150.6058) |
Since Pintzuk (1991), these facts have motivated models of OE clause structure which involve multiple subject positions and multiple positions for the finite verb. Assume that the finite verb occupies the same position in (3) and (4). The word order difference between these two examples then indicates that there are two subject positions, one above the finite verb and one below it, with pronominal subjects restricted to the higher position and full NP subjects mainly occurring in the lower position.
The variation between (4) and (5) then reflects variation in the position of the finite verb. In (5), the verb moves higher than in (4), to a position above both subject positions.
A specific implementation of this analysis, from Haeberli (2000), works as follows (for other implementations, see Pintzuk 1991, 1993; Kroch and Taylor 1997, among many others). The top of the clausal functional sequence contains three projections, which I will call CP, FP, and IP (Haeberli uses different labels, but the specific labels are not very important). The higher and lower positions for the finite verb are C and F, respectively. The higher and lower subject positions are Spec,FP and Spec,IP, respectively. Spec,CP is the initial A-position which the preverbal phrase occupies. The three patterns above are then derived as follows.
| (6) a. V2 order with postverbal full NP subject |
 |
| b. V3 order with pronominal subject |
 |
| c. V2 order with pronominal subject and þa/nu |
 |
Subject-initial V2 orders can also be derived by moving the subject to Spec,CP, regardless of the internal syntax of the subject and the position of the verb.8
| (7) |  |
As for word order in subordinate clauses, OE does not typically show embedded V2 effects (Salvesen and Walkden 2017), although we will see some exceptions to this claim in Section 3.5. This means that embedded word order can be taken as a more or less faithful indicator of word order within IP. However, the syntax of the Old English IP is quite variable. It is common to assume, again following Pintzuk (1991, 1993), that there was competition between head-medial and head-final orders for both VP and IP in OE. Variation and change in the structure of IP is not a focus of this paper. However, it will be relevant below that Early Middle English was undergoing a change in progress, the outcome of which was the rigidly head-medial order which has been uniformly attested since late Middle English.
The analysis sketched here is known to undergenerate in that there are several other classes of V3 or V > 3 order in OE (Bech 2001; Haeberli 2002; Speyer 2010; Biberauer and van Kemenade 2011; Bech and Salvesen 2014; Salvesen and Bech 2014; Walkden 2014). However, previous work on V3 and V > 3 order in OE has focused on XSV and SXV orders, where the subject is preverbal. In this paper, I am interested instead in XYVS orders, with two preverbal constituents, neither of them plausibly left-dislocated or left-adjoined, and a postverbal subject. These orders will be particularly relevant in the discussion of the CM grammar in Section 3. They are particularly interesting for the investigation of V2-like patterns, because the classical understanding of V2 puts a lot of explanatory burden on the existence of a single projection, CP, above the subject position, but under an expanded, cartographic view of clause structure, there are potentially several such projections. The greater the number of specifier positions that precede the position of the verb, the greater the number of routes to different varieties of V3 or V > 3 order, potentially including orders where the verb raises past subject position but still has two or more A-positions to its left (see, for instance, discussion of V3 orders in Walkden 2014). Therefore, on the one hand, inversion with multiple preverbal elements speaks against the empirically well-supported notion that second position is somehow special. On the other hand, the proliferation of left-peripheral positions since Rizzi (1997) undermines our theoretical understanding of the special nature of second position. The existence of a verb-third grammar with inversion is informative with respect to this theoretical tension.
2.2. Word Order in Northern Middle English
The earliest Middle English (ME) texts still show the three properties illustrated in (3–5). However, Kroch and Taylor (1997) demonstrate that the late 14th century northern prose Rule of St. Benet, one of the earliest surviving northern prose texts, does not have V3 orders in matrix clauses with subject pronouns. Instead, it shows the inverted order illustrated in (8).
| (8) [ Mi scole ] wil i stablis to godis seruise. | |
| my school will I establish to God’s service | |
| ‘I will establish my school to God’s service.’ | (cmbenrul-m3,4.84)9 |
This means that the grammar of the Rule of St. Benet is like that of many present day Germanic V2 languages: the verb moves to C, a single constituent moves to Spec,CP, and nothing needs to be said about the special status of pronominal subjects (Haeberli 2000).
Although PPCME2 does not contain any other texts which show this pattern so categorically, Kroch and Taylor argue that the distinctive grammar of the Rule of St. Benet is indicative of a longstanding dialect split in English, largely obscured by the uneven distribution of surviving Old and Middle English texts across dialects. They make a convincing claim that this northern V2 grammar was in fact inherited from OE, on the basis of an ingenious analysis of pronominal subjects in northern OE glosses, suggesting that this dialectal variation persisted for several hundred years. Moreover, they hypothesize that the distinctive syntax of the northern dialect could have its origins in contact with Old Norse, a possibility which implies that it could also be useful to compare the Rule of St. Benet to corpus texts from Lincolnshire and East Anglia, areas further south in the Danelaw where there was also signifcant contact with Old Norse.
Our information about this northern grammar remains sparse and fragile, precisely because the only source in PPCME2, for most purposes, is the Rule of St. Benet. An initial goal of the research reported in the present paper was to deepen our understanding of the syntax of northern Early Middle English (EME) by investigating texts not included in PPCME2, so as to better contextualize Kroch and Taylor’s findings about the Rule of St. Benet. As we will see presently, this attempted replication of Kroch and Taylor (1997) is partially successful, but also threw up several unexpected grammatical complexities.
2.3. The Syntactic Context for the CM Grammar
On the basis of the facts above, we identify three different grammars which serve as points of comparison for the CM grammar. These are not complete grammars, but rather specifications of the properties of C, F, and their specifier positions. This reflects the thinking behind Yang’s (2002) ‘Variational Learner’: that competition is between individual parameters (from a Borerian perspective, specifications of properties of functional heads), not between whole grammars.
The first two grammars we will consider have been discussed directly above; the third (the ‘SV grammar’) is a generalization over the non-V2 grammars which have predominated since late ME. Although there is clearly variation with respect to both V-to-I movement and the XV/VX parameter within the class of non-V2 grammars, this variation concerns the lower part of the clause, and we expect the properties of CP and FP to be uniform across all of the non-V2 grammars.
Because we assume a competition-based approach, we do not expect any one grammar to be able to capture all of the linguistic behaviour observed in a text.10 Nevertheless, on Yang’s model, the relative fitness of these grammars in different linguistic environments is determined by their relative parsing success.
The grammars are the following.
1. The non-northern V2 grammar
- V moves to F in matrix clauses.
- V moves to C when Spec,CP is occupied by elements like þa.
- V remains below F in subordinate clauses.
- Spec,CP is an A-position which must be filled in matrix clauses.
- Spec,FP is a position for pronominal subjects.11
- Spec,IP is a position for nonpronominal subjects.
- No adjunction to CP or FP. Adjunction to IP is permitted.12
Word orders generated by the non-northern V2 grammar are the following.
- Matrix clause, full NP subject: SVX, XVS;
- Matrix clause, pronominal subject: SVX, XSV, þa VS;
- Embedded clause: (X*)S(Y*)V(Z*).13
2. The northern V2 grammar
- No FP projection.14
- V moves to C in matrix clauses.
- V remains below C in subordinate clauses.
- Spec,CP is an A-position which must be filled in matrix clauses.
- Spec,IP is a position for all subjects.
- No adjunction to CP. Adjunction to IP is permitted.
Word orders generated by the northern V2 grammar are the following.
- Matrix clause: SVX, XVS;
- Embedded clause: (X*)S(Y*)V(Z*).
3. The SV grammar
- No FP projection.
- V remains below C in all clauses.
- Adjunction to IP permitted.
Word orders generated by the SV grammar are the following.
- Matrix and embedded clauses: (X*)S(Y*)V(Z*).
I now proceed to investigate a well-defined set of word orders which cannot be generated by any of these grammars.
3. Word Order in the Edinburgh Cursor Mundi
In an investigation of grammar competition in historical texts, we have to make careful use of concrete, observable word order to draw inferences about grammars, which are more abstract objects which cannot be observed directly. In what follows, I will distinguish between ‘the Edinburgh manuscript’, a manuscript copy of the Cursor Mundi and the Northern Homilies; certain grammars represented, by hypothesis, in the Edinburgh manuscript; and the observable word orders in the manuscript.
The distinctive word orders identified by Kroch and Taylor in the Rule of St. Benet are also found in the Edinburgh manuscript. In particular, pronouns do not behave differently from full NPs with respect to subject–verb inversion. This is the hallmark of the northern V2 grammar. However, the Edinburgh manuscript is syntactically heterogeneous, and contains orders that cannot be described by the northern V2 grammar, or indeed either of the other grammars identified in Section 2.3. These include matrix V3 orders with subject–verb inversion, and embedded V2 orders. I refer to these two orders as the ‘CM orders’, although we will see presently that they are not unique to Cursor Mundi or the Edinburgh manuscript.
The CM orders motivate a fourth grammar, which I will call the ‘CM grammar’, in addition to the three described in Section 2.3, which can generate these orders. In the CM grammar, Spec,CP and Spec,FP are both preverbal A-positions. Both of these positions are available in the matrix clause, and matrix V3 orders with inversion arise when they are filled by different phrases. Spec,FP also features in embedded clauses, and embedded V2 orders with inversion arise when it is filled by a nonsubject.
Section 3.1 describes the corpus investigation that generated the findings reported here. Section 3.2 describes the word order properties that the Edinburgh manuscript shares with the Rule of St. Benet, and with EME more generally. These word orders do not provide evidence for the CM grammar, though in many cases they are compatible with it. Section 3.3 and Section 3.4 document the two CM orders, embedded verb-second and matrix XYVS, respectively. Finally, Section 3.5 compares word order in the Edinburgh manuscript with other Old and Middle English texts. We will see that the orders uniquely generated by the CM grammar are present across many, but not all, Old and Middle English texts, and can be doubly dissociated from the north/south split identified by Kroch and Taylor. We end with some speculations about why the CM grammar is particularly visible in the Edinburgh manuscript, given that it is not unique to the manuscript.
3.1. Method
All data reported in this paper, unless noted otherwise, come from the York–Toronto–Helsinki parsed corpus of Old English prose (YCOE, Taylor et al. 2003), the Penn–Helsinki Parsed Corpus of Middle English, 2nd edition (PPCME2, Kroch and Taylor 2000), and the Parsed Linguistic Atlas of Early Middle English (PLAEME, Truswell et al. 2019). I ran a series of coding queries in CorpusSearch (http://corpussearch.sourceforge.net, accessed on 12 March 2021) on these corpora. The queries for each corpus were identical except for minor modifications required because of the slightly different annotations in each corpus.
YCOE and PPCME2 are industry-standard parsed corpora of historical English. PLAEME is a new parsed corpus, focusing on the 1250–1325 period, which is underrepresented in PPCME2. It contains texts from the unparsed Linguistic Atlas of Early Middle English (Laing 2013), annotated with information about syntactic structure in the format of PPCME2. The texts contained in PLAEME are arguably of a lower quality, for the purposes of syntactic research, than the texts included in PPCME2: they are mainly in verse, and often short and/or fragmentary. Nevertheless, they have the undeniable virtue of existing: data from this period is particularly sparse, and we must work with what we have, while being sensitive to the limitations of the available evidence. For instance, there are legitimate concerns about the use of verse texts for word order research. However, it is possible to draw inferences about syntax from verse: see Truswell et al. (2019) for discussion, and Trips (2003) for a generative example, discussing Stylistic Fronting in the Ormulum, the only verse text in PPCME2.
Although PLAEME is first and foremost a supplement to PPCME2, it retains some of the functionality of LAEME as a dialect atlas, and the geographical coverage of PLAEME significantly improves on the corresponding M2 period (1250–1350) in PPCME2.
PLAEME contains several texts from within the Danelaw. Most are too short for extensive investigation of word order, but there are two longer texts: an early 14th century verse Genesis and Exodus composed in Norfolk (ms. Cambridge, Corpus Christi College 444), and a major mid-14th century northern manuscript in three hands, the Edinburgh Royal College of Physicians Cursor Mundi and Northern Homilies, composed in Yorkshire in the first half of the 14th century, almost 100 years earlier than the Rule of St. Benet. This manuscript, as transcribed in LAEME and annotated in PLAEME, is our main focus in this paper. Despite some variation between the grammars of the three hands, the text is reasonably uniform with respect to the syntactic properties investigated here, so I will treat the three hands together.
The corpus queries coded each declarative matrix clause, and each finite declarative complement or adverbial clause, for the nature of the subject (full NP or personal pronoun), and the category of the first four constituents in the clause.15 The decision to code only the first four categories reflected a trade-off between practicality and informativity: four categories is sufficient to allow investigation of XYVS orders, and the coding queries were already quite unwieldy, each requiring around a day to run on a standard desktop computer, so there was a practical reason not to code for the category of further constituents.
I excluded several types of parenthetical and/or left-peripheral elements from consideration. These included all constituents tagged with -LFD (‘left-dislocated’) or -PRN (‘parenthetical’), vocatives, and interjections. The exclusion of these elements allowed for a cleaner focus on CP-internal word order. Also excluded were any clause introduced by a coordinating conjunction (because noninitial conjuncts often show subordinate clause word order, even in matrix clauses), and any clause with a null subject, whether coded as expletive, pro, or trace.
These queries permitted a wide-coverage investigation of the presence or absence of inversion in particular contexts. However, there are several special cases that need to be treated separately. These include negation (which in Old and Early Middle English always immediately precedes the finite verb and need not fill the preverbal A-specifier position), pronominal objects (which in many cases are subject to positional restrictions similar to those of pronominal subjects), monosyllabic deictic adverbs such as þa, which have information-structural effects with many subtle consequences for word order (van Kemenade et al. 2008), particles in verb–particle constructions (where the determination of word boundaries is often problematic), participles and other constituents which participate in Stylistic Fronting, and correlative structures such as if … then … or as … so …, which trigger inversion in main clauses in many texts where inversion is not otherwise common. In order to treat the ‘basic’ pattern separately from all these special cases, in this paper I will focus on the order of verb and subject in non-correlative contexts with initial PPs, AdvPs other than those like þa, full NP objects, and less commonly APs, fronted VPs, or fronted infinitival clauses.
3.2. Unsurprising Word Orders
The most common orders in the Edinburgh manuscript are verb-second orders, with or without inversion. Example (9) shows the uninverted order, while (10) shows inversion in a range of nonsubject-initial orders.16
| (9) Þe erþe sal be al red of hew | |
| the earth shall be all red of hue | |
| ‘The earth shall be all red in hue.’ | (edincmat.20) |
|
(10) a. [ Gret signes ] sal our laud mak ∖ Forto schaw þe wik his wrak great signs shall our Lord make for.to show the sinful His vengeance ‘Our Lord shall make great signs to show the sinful His vengeance.’ | |
| (edincmat.9) | |
| b. [ Wiþin þat t ] was god þīg hid ∖ Þat in þisilke croice es kid within that tree was good thing hidden that in this.same cross is revealed ‘Hidden within that tree was a good thing, that is revealed in this cross.’ | |
| (edincmct.868)17 | |
| c. [ Ful giþeli ] was tat gce te gnt full readily was that grace thee granted ‘That grace was readily granted to thee.’ | (edincmat.1057) |
The Edinburgh manuscript also shows inversion with pronominal subjects, as in (11). As discussed in Section 2.2, this is claimed by Kroch and Taylor (1997) to be a hallmark of northern Old and Middle English dialects. The existence of these orders therefore suggests that the northern V2 grammar is well represented in the Edinburgh manuscript.
|
(11) a. [ His giftes ] gaf he noht ī vaine his gifts gave he not in vain ‘He did not give his gifts in vain.’ | (edincmat.1130) |
| b. [Vnto mirik ] haf ye na riht unto my.kingdom have you no right ‘You have no right to my kingdom.’ | (edincmat.353) |
| c. [ Seldin ] cū we sarmū ner seldom come we sermon near ‘We seldom come near a sermon.’ | (edincmat.656) |
Several kinds of V3 and V > 3 orders discussed by Bech and Salvesen (2014); Salvesen and Bech (2014) are also attested in the Edinburgh manuscript. (12a) shows an SXV order, (12b) an XSV order, and (12c) an XSYV order.
|
(12) a. E(R) þe fulthe of tim was comē ∖ Satenas [ al folk ] aued no ere the fullness of time was come Satan all folk had taken ‘Before the end of the time, Satan had taken all people.’ | (edincmbt.43) |
| b. [ Cristes godhed ] þe fend tok ∖ Als fisce es tan wit bait and hoc Christ’s godhood the fiend took as fish is taken with bait and hook ‘The fiend took Christ’s godhood, as a fish is taken with bait and hook.’ | |
| (edincmbt.101) | |
| c. [ Arli ] þa postlis [ ilke dai ] ∖ Wente to þe tempil forto pie early the apostles each day went to the temple for.to pray ‘Early each day, the apostles went to the temple to pray.’ | (edincmct.24) |
I have not investigated the distribution of these V3 and V > 3 orders without inversion in any detail, so do not know if the factors which Bech (2001) and subsequent authors identify as conditioning these word orders also apply in the Edinburgh manuscript. Section 3.4 focuses instead on V3 orders with inversion, which have not been previously discussed to such an extent.
As for subject positions, Haeberli (2000) argued that there is only a single subject position, Spec,IP, in the northern prose Rule of St. Benet, unlike non-northern V2 grammars with a distinct higher position for subject pronouns. The Edinburgh manuscript is roughly as Haeberli describes for the Rule of St. Benet: pronominal subjects do not generally appear higher than full NP subjects. However, there is a low, typically clause-final, subject position restricted to definite full NPs, illustrated in (13).18
|
(13) a. [ Þarof ] was warnid moyses ∖ Baþe in worde ande eke ī dede thereof was warned Moses both in word and also in deed ‘Moses was warned of it, both in word and in deed.’ | (edincmct.877) |
| b. [ Þan ] sal be herd þe blast of bem then shall be heard the blast of trumpet ‘Then the blast of a trumpet shall be heard.’ | (edincmat.143) |
Pronominal subjects cannot occur in that position: in 81 examples with pronominal subjects where this lower position can be clearly distinguished from the regular subject position between auxiliary and main verb, the pronominal subject always occurs in the higher position, as in (14).
| (14) [ Þus ] was I stikkid al wit stfe | |
| thus was I stabbed all with strife | |
| ‘Thus, I was all stabbed with strife.’ | (edincmat.979) |
However, full NP subjects can also appear in the same position as subject pronouns, whether definite, as in (15a), indefinite, as in (15b), or quantificational, as in (15c).
|
(15) a. [ Þan ] sal þe raynbow decend then shall the rainbow descend ‘Then the rainbow will descend.’ | (edincmat.112) |
| b. [ Forþi ] sal an beded and slain ∖ Þat al þis werd sal qken
therefore shall one be.dead and slain that all this world hall quicken agaī ∖ Þat aman forwit sloh again that a.man forewith slew ‘Therefore, someone shall be dead and slain, who shall bring all this world to life again, that a man previously killed.’ | (edincmat.905) |
| c. [ Þat soru ] mai na tung telle ∖ Þat it sal drey wit fendes felle that sorrow may no tongue tell that it shall suffer with fiends wicked ‘No tongue may tell of the sorrow that it shall suffer with wicked fiends.’ | |
| (edincmbt.679) |
I interpret these facts as implying that there is only one left-peripheral subject position, in Spec,IP, together with a lower rightward subject position whose syntactic status is unclear. Pending further investigation, I will represent the lower position as a rightward specifier of vP, as in (16), but I will restrict attention to the higher subject position in what follows.
| (16) |  |
3.3. Surprising Word Orders: Embedded Verb-Second
The predominant order in embedded clauses is SVO, as in (17), with a minority of SOV orders as in (18).
| (17) He wend [ þat cst war noht bot man ] | |
| he supposed that Christ was naught but man | |
| ‘He supposed that Christ was nothing but a man.’ | (edincmbt.99) |
| (18) Furthermore, [ quē cst [ þair asking ] herd ] ∖ Ful mildely he þaī | |
| and when Christ their asking heard full mildly he them | |
| ansuerd answered | |
| ‘Furthermore, when Christ heard their question, he answered them mildly.’ | |
| (edincmbt.357) |
However, a minority of embedded clauses show nonsubject-initial V2 order. Some examples are given in (19).19,20
|
(19) a. Men wat [ þat [ fu(l) ner ] es som comād ] men know that full near is summer coming ‘Men know that summer is drawing near.’ | (edincmbt.258)21 |
| b. … [ Þat [ rifli ] gere it man þinc mar ∖ Of his bodi … ∖ Þan that commonly makes it man think more of his body than he of his sawel dos ] he of his soul does ‘… that it commonly makes man think more of his body than he does of his soul.’ | |
| (edincmbt.473) | |
| c. … [ Þat [ al to pecis ] sal tai brist ]
that all to pieces shall they burst ‘… that they shall burst all to pieces.’ | (edincmat.131) |
These orders cannot be generated by either of the V2 grammars considered in Section 2.3, because the preverbal A-position for those grammars is Spec,CP, which is ordinarily incompatible with the presence of a complementizer in C. Instead, we will attribute them to the CM grammar, and assume that in the CM grammar, the verb raises to a head lower than C, and that the specifier of that head is an A-position. In the terms used in Section 2.1, a natural interpretation would be that the verb raises to F in the CM grammar, and that Spec,FP is an A-position. Embedded V2 orders then instantiate the structure in (20).
| (20) |  |
At the same time, the Edinburgh manuscript contains a majority of subordinate clauses whose order cannot be derived from this structure. Compared to the 27 tokens of embedded V2, there are 103 examples, like (21), of SXV orders where the X is a full phrase.
|
(21) a. Sin ye [ mi son ] wirkis þis wa … since you my son work this woe ‘Since you bring this misfortune on my son, …’ | (edincmat.825) |
| b. Qn þai [ of pet ] undstode His coming … when they of Peter understood his coming ‘When they heard of His coming from Peter, …’ | (edincmct.527) |
There are also 25 examples, like (22), of XSV orders.
| (22) sinþate [ firste ] þe werde was wȝte … | |
| since.that first the world was wrought | |
| ‘Since the world was first created …’ | (edincmct.857) |
The competition between the embedded V2 orders in (19) and the non-V2 subordinate clause orders in (21–22) implies structural heterogeneity of the sort which is expected under a grammar competition model, as there is no single grammar in this format that I am aware that could generate this diverse range of orders.
For completeness, there are also 547 examples of embedded S–V(–X) orders like (9), which are equally compatible with all four grammars under consideration.
| (23) Of antecst wrang and woch ∖ Me þink [ þat ik haf red | |
| of antichrist wrongness and wickedness me thinks that I have explained
Inoch ] enough | |
| ‘It seems to me that I have explained enough about the wrongness and wickedness of the antichrist.’ | (edincmat.4) |
3.4. Surprising Word Orders: Matrix Verb-Third with Inversion
If one were to couple the CM grammar’s embedded V2 structure with a further A position in matrix Spec,CP, we could derive an alternation between matrix V3 and embedded V2 orders, both permitting inversion. The matrix V3 structure is as in (24).
| (24) |  |
Such matrix V3 orders are in fact attested in the Edinburgh manuscript, as demonstrated in (25).
|
(25) a. [ Of þis twþe ] [ hard ] es twþe to find of this truth hard is truth to find ‘Of this truth, truth is hard to find.’ | (edincmat.180) |
| b. [ Sa brad ] [ of hir blis ] es þe wai so broad of her bliss is the way ‘The way of her bliss is so broad.’ | (edincmat.1090) |
| c. [ A clud ] [ again hī ] sau þai liht a cloud against him saw they alight ‘They saw a cloud descend towards him.’ | (edincmat.152) |
The simplicity and systematicity of the formal description of the CM grammar offers some support for the claim that these matrix V3 orders are a product of the same grammar as embedded V2. The CM grammar differs from the northern V2 grammar in just two respects: the verb moves to F, rather than C; and Spec,FP is an A-position which must be filled. Likewise, it differs from the non-northern V2 grammar in two respects: the A-nature of Spec,FP, as just described, and the fact that subject pronouns are not restricted to preverbal position.22
Because of the flexibility of the structure in (24), with the two A-positions to the left of the verb, very many orders discussed above are compatible with the CM grammar, including all matrix orders with the verb in second or third position, and all embedded verb-second orders. In fact, the matrix word orders that the CM grammar can generate are a proper superset of the orders generated by either of the V2 grammars described in Section 2.3, because a single constituent can move to Spec,FP and then on to Spec,CP, as in (26).23
| (26) |  |
As mentioned above, matrix verb-second orders are common in the Edinburgh manuscript—much more common than matrix XYVS orders. However, this in itself is uninformative about the distribution of the CM grammar, as opposed to a regular V2 grammar, because of the compatibility of the V2 structure in (26) with the CM grammar.
Likewise, matrix XSV orders like (12b), which provide a common source of evidence for the loss of V2, are uninformative with respect to the CM grammar, because these are verb-third orders, and so compatible in principle with the CM grammar. Such orders therefore do not lead to a fitness advantage for the SV grammar over the CM grammar. It is, however, possible to find unequivocal evidence in matrix clauses for an SV grammar distinct from both the CM grammar and both V2 grammars. This comes from sentences like those in (27), where the verb occupies fourth (or later) position and is preceded by the subject. There is not space for three preverbal constituents in the structures generated by other grammars, unless any of the constituents are left-dislocated (which seems particularly implausible in the case of (27b), with a particle in first position), so these examples must be generated by a regular SV grammar with left-adjunction to a pre-subject position.
|
(27) a. [ For mi greting ] [ ful sar ] þai gt for my greeting full sore they greeted ‘They wept sorely because of my weeping.’ | (edincmat.1028) |
| b. [ Of ] [ wiþoutin ani wite ] ∖ Herode did their heuid smi(te) off without any blame Herod did their head smite ‘Herod had their head smitten off without blame.’ | (edincmct.772) |
In sum, there is a small amount of examples in matrix clauses in the Edinburgh manuscript which can be generated by an SV grammar but not the CM grammar, a small amount of examples which can be generated by the CM grammar but not the SV grammar, and a very large amount of examples (including all SVX and XSV examples) which are in principle compatible with both grammars.
3.5. Comparisons
Although the influence of the CM grammar is particularly clear in the Edinburgh manuscript, the surprising orders that the CM grammar generates are not unique to that manuscript, and the CM grammar is not the only grammar visible in it. In this section, I investigate the distribution of the CM grammar, and address the question of why it is particularly visible in the Edinburgh manuscript. As well as situating the Edinburgh manuscript and the CM grammar in context, this quantitative investigation actually gives rise to a new argument that the CM orders are the product of a single grammar: the rate of matrix V3 with inversion is positively correlated with the rate of embedded V2 with inversion across texts, as would be expected if these two orders are distinctive products of a single grammar, differently weighted by different individuals.24
As shown in Figure 1, the frequency of matrix XYVS orders is correlated with the frequency of embedded XVS orders across texts, once the special cases described in Section 3.1 are excluded (Spearman’s , , on log-transformed counts for all texts in YCOE, PPCME2, and PLAEME with words). This corroborates the hypothesis laid out in previous sections, that these two word orders are the product of a single grammar: the frequency of both of these orders then correlates with the weight of the CM grammar.
In the following subsections, I ask more focused questions about the spatiotemporal distribution of the CM grammar. In turn, I investigate the CM orders in northern ME, Old English, and late ME.
Before I begin these comparisons, I will briefly dismiss two alternative hypotheses as to why the CM grammar is particularly prominent in the Edinburgh manuscript. Firstly, it is not explanatory to attribute the prominence of the CM grammar in the Edinburgh manuscript to the fact that this text is in verse. The vast majority of PLAEME is in verse, as is the Ormulum in PPCME2, but not all of these texts show the CM orders at the same rate. So to claim that verse is somehow responsible for these word orders in the Edinburgh manuscript, one would have to accept that the creator of this text allowed himself more freedom to bend grammar to meet the metrical constraints of the poem, than other authors did. It seems unlikely that any real explanation could be developed along these lines.
Secondly, it does not seem likely that these word orders could be a product of language contact, or at least not uniquely. The two most plausible contact languages to consider are Old Norse, and Old French, because the Edinburgh manuscript was composed in Yorkshire, within the Danelaw, and some of its material had French sources. However, Old Norse does not display the relevant orders. According to Faarlund (2007), Old Norse is a regular verb-second language, with the only non-V2 matrix clauses being some cases of V1 which Faarlund analyses as having a null initial topic, and therefore actually conforming to the V2 pattern. Moreover, embedded V2 with inversion is limited to a construction where a topic follows complementizer at ‘that’. The details of this construction do not match embedded V2 in the CM grammar, where a range of complementizers and prepositions can introduce the subordinate clause, and where the initial element can belong to categories, such as VP or nominal and adjectival predicates, which cannot be sentence topics. Although this does not rule out the possibility of Old Norse influence on the CM grammar, it rules out any simple story where these structures are borrowed from Old Norse.
Old French is in some respects a more promising source: it shows matrix V3 orders with inversion, like (28), and embedded V2 orders, like (29).
| (28) Car [ ja ] [ bonne ouevre ] ne fera Qui la fin ne resgardera | |
| because never good work neg do.fut who the end neg look.fut | |
| ‘Because someone who does not keep the goal in sight will never do good work.’ | |
| (anonyme_alexandrie,.164)25 |
| (29) Or dit li contes [ que [ .iii. jorz ] fist li preudons Lancelot | |
| now says the story that three days made the prud’homme Lancelot demorer o lui ] stay with him | |
| ‘Now the story tells you that the gentleman made Lancelot stay with him for three days.’ | (Graal, col. 187s, l. 3, Salvesen and Walkden 2017, p. 177) |
However, I will demonstrate in Section 3.5.2 that these orders also existed in OE, before any extensive French influence on English morphosyntax. This suggests that any effect of language contact with French would be more subtle than simple borrowing. At best, the effect of contact with French would be to amplify possibilities that were already present to some extent in English grammar.
3.5.1. Northern Middle English
Although the Edinburgh manuscript is a major northern ME text, there is no reason a priori to expect a direct grammatical relationship between the CM grammar and the northern V2 grammar described by Kroch and Taylor (1997). The two grammars make different claims about the position of the finite verb and about the status of Spec,FP, and are therefore best treated as distinct grammars which both happen to be prominent in northern ME texts.
However, we might still expect a quantitative, indirect relationship between the CM grammar and the northern V2 grammar. The distinctive word orders generated by the CM grammar both involve inversion, and the northern V2 grammar generates a high level of inversion, because northern XVS orders with pronominal subjects correspond to non-northern XSV orders. One would therefore expect the CM grammar to have greater parsing success in northern texts, simply because there is more inversion in northern texts.
In this section, I investigate this possibility by looking at the frequencies of matrix XYVS and embedded XVS orders in relation to the frequency of matrix XVS orders with pronominal subjects, and the status of the Edinburgh manuscript with respect to this relationship.
Firstly, I use data from PLAEME to investigate Kroch and Taylor’s (1997) proposal that inversion with pronominal subjects is a distinctively northern feature. I compare the global frequency of inversion in nonsubject-initial sentences with full NP subjects, to the frequency of inversion in such sentences with pronominal subjects.
Figure 2 shows the rate of inversion in nonsubject-initial sentences with full NP subjects for all PLAEME texts. Each dot on the map represents a text, with the area of the dot proportional to the number of such sentences in the text. The colour of the dot represents the rate of inversion in such sentences. Every large text shows at least 50% inversion in these contexts. This tells us that inversion remains the norm in nonsubject-initial sentences with full NP subjects across the English varieties represented in PLAEME.
In contrast, Figure 3 represents the rate of inversion with pronominal subjects. Although inversion with pronominal subjects is not categorically present in any large text in PLAEME, it is almost completely absent in southwestern texts, and observable to different extents in texts produced in the Danelaw. This suggests that Kroch and Taylor are at least approximately correct in identifying inversion with pronominal subjects as a distinctively northern characteristic. However, this pattern, which they identified in more or less ‘pure’ form in the Rule of St. Benet, is not strictly northern but instead found, to differing extents, in most of the Danelaw.26
The Edinburgh manuscript is visible on these maps as the three large circles just northwest of the Humber (one circle for each hand). The maps show, as already suggested in Section 3.2, that the Edinburgh mansucript makes greater use of Kroch and Taylor’s northern inversion pattern than most PLAEME texts (although not to the same extent as the Rule of St. Benet, which is not plotted on the map as it is not included in PLAEME). In this section, I compare the Edinburgh manuscript to major northern and East Anglian Middle English texts included in PLAEME and PPCME2. From PLAEME, in addition to the three hands of the Edinburgh manuscript, I include the Middle English Genesis and Exodus (visible on the maps as a large dot immediately southeast of the Wash). From PPCME2, I include the Ormulum, the Rule of St. Benet, Richard Rolle’s Prose Treaties and Epistles, and the Thornton ms. Mirror of St. Edmund. The Ormulum is significantly older than the PLAEME texts; the other four PPCME2 texts are significantly younger.
Matrix XYVS and embedded XVS orders are common in the East Anglian Genesis and Exodus, the Rule of St. Benet, and the Thornton Mirror of St. Edmund, as well as the Edinburgh manuscript. (30) gives examples of embedded XVS orders from these other texts, and (31) gives examples of matrix XYVS orders.
|
(30) a. … Til [ ȝure praier ] sal I here … til your prayer shall I hear ‘… until I hear your prayer …’ | (cmbenrul-m3,2.27) |
| b. … þat [ at swylke a tym of þe daye ] dyede þe makere of lyfe that at such a time of the day died the maker of life ‘… that the maker of life died at such a time of day.’ | (cmedthor-m34,44.638)27 |
| c. … ðat [ sister ] ƿore sarra his ƿif that sister was.sbjv Sarah his wife ‘… that Sarah, his wife, was his sister.’ | (genexodt.695)28 |
|
(31) a. Lauerd, þan we haue askid þe, [ þe ancewer ] [ of þe ] sal we here Lord then we have asked thee the answer of thee shall we hear ‘Lord, when we have asked you, we shall hear the answer from you.’ | |
| (cmbenrul-m3,2.43) | |
| b. [ Fro galaad ] [ men ƿið chafare ] ∖ Sag he ðor kumen ƿid from Gilead men with merchandise saw he there come with spices ƿare. species.gen ware ‘He saw men with merchandise come there from Gilead with spices.’ | |
| (genexodt.1211) | |
| c. [ In firme biginig ] [ of nogt ] ∖ ƿas heuene and erðe samen ƿrogt in first beginning of naught was heaven and earth together wrought ‘At the very beginning, heaven and earth were created together from nothing.’ | |
| (genexodt.11) |
In fact, across all texts in YCOE, PPCME2, and PLAEME, there is a positive correlation between frequency of matrix XVS orders with pronominal subjects, and frequency of the two CM orders, taken together (Spearman’s , , on log-transformed counts for all texts in YCOE, PPCME2, and PLAEME with words). This correlation is shown in Figure 4, where northern texts are highlighted in blue. This suggests that the CM orders are distinctively northern to approximately the same extent as Kroch and Taylor’s northern V2 grammar is: there is a cluster of northern texts which show a greater frequency of both the CM orders and the northern V2 pattern than any other text, although some non-northern texts show these variables at almost the same rate.
However, the Ormulum and Richard Rolle’s works have a different profile (these are the other blue dots in Figure 4). Examples of the CM orders from these texts, while not nonexistent, are rare. (32) gives two examples of embedded XVS order, the more common of the two CM orders in these texts.
|
(32) a. … Þatt [ Godd allmahhtiȝ cweme ] be Whattse þu dost to gode that God almighty pleasing be what.so thou dost to good ‘… that whatever good you do is pleasing to God.’ | (cmorm-m1,I,255.2075)29 |
| b. … þat [ of all thyng maste ] coveytes God þe lufe of mans hert that of all things most covets God the love of man’s heart ‘… that God covets the love of man’s heart most of all things.’ | |
| (cmrollep-m24,76.203)30 |
These texts therefore support the position outlined at the start of this section, that there is no direct causal link between the distinctive word order of the northern V2 grammar and the CM orders, because they show relatively high rates of northern V2 with relatively low rates of the CM orders. In other words, the statistical correlation between the orders associated with one grammar and the orders associated with the other tolerates exceptions, and these texts are such exceptions.
3.5.2. Old English
The correlation observed in the previous subsection between the CM orders and the northern pattern of inversion with pronominal subjects is overwhelmingly due to ME texts. In Figure 5, Old English texts are coloured red and Middle English texts are coloured blue. It can then be observed that the correlation is particularly strong for the ME texts (Spearman’s , ), but there is no correlation for the OE texts (Spearman’s , ).
The reason for this is plausibly that inversion in matrix clauses with pronominal subjects is almost categorically absent in surviving OE texts.31 Accordingly, the lack of correlation among OE texts in Figure 5 could be a kind of floor effect: matrix inversion with pronominal subjects is so close to completely absent that it only features as noise.
Because of this, OE examples of the CM word orders are restricted to full NP subjects. Such examples are found, but the CM orders are at a lower rate overall than in ME texts, because of this restriction on subject type. Examples of OE embedded V2 orders are given in (33), and OE matrix V3 orders in (34).32
|
(33) a. … þæt [ on hire ] eardode se heofonlica cyning that in her lived the heavenly king ‘… that the heavenly king lived in her.’ | |
| (coblick,HomU_18_[BlHom_1]:11.148.135)33 | |
| b. Witodlice þa þa [ þysne halgan wer ] nydde se deaþes dæg to certainly then then this.acc holy.acc man.acc forced the death.gen day to ðam utgange of lichaman, … the exit of body ‘Certainly, when the day of death forced this holy man to leave his body, …’ | |
| (cogregdC,GDPref_and_4_[C]:20.291.12.4312)34 | |
| c. þonne [ smylte ] blaweð suþanwestan wind, … when gently blows southwesterly wind ‘When a southwesterly wind blows gently, …’ | (coboeth,Bo:9.21.4.343)35 |
|
(34) a. [ Þurh þa oferhygde ] [ of heofonum ] gehreas þæt wundorlice through the pride of heaven fell that wonderful engla gesceaft. angels.gen creation ‘Because of pride, that wonderful creation of the angels fell from heaven.’ | |
| (coverhom,HomS_11.2_[ScraggVerc_3]:23.406) | |
| b. [ Wiþ poccum ], [ swiðe ] sceal mon blod lætan with pocks very.much shall man blood let ‘To treat pocks, one should let a lot of blood.’ | |
| (colaece,Lch_II_[1]:40.1.10.1415)36 | |
| c. [ horse ] [ mete ] is bere þæt he us forgeæf horse.dat food is barley that he us gave ‘Barley that he gave to us is food to a horse.’ | (coaelive,+ALS_[Basil]:214.591) |
Despite the lower frequency of the CM orders in OE texts, I have not discerned any differences in conditions of use of embedded V2 between the Edinburgh manuscript and earlier texts, once the large number of OE examples with þa and similar adverbials are excluded. This suggests that the CM grammar is in fact already present in OE, but that there is less positive evidence for the use of that grammar because of independent facts about OE grammar.
It is also possible that the greater prominence of the CM grammar in later texts reflects the nature of the other competing grammars, and particularly the shift from OV to VO. As is to be expected in a language that is still largely head-final, there are more embedded SXV orders than SVX in OE. These verb-third orders cannot be generated by the CM grammar, if the CM grammar requires V-to-F movement. Accordingly, in OE there is simultaneously less positive evidence in favour of the CM grammar, and more positive evidence in favour of SV grammars.
3.5.3. Late Middle English
The CM orders are present in many late ME texts, but never became widespread, and certain long texts, such as the The Brut or The Chronicles of England, contain no examples at all.
Because the CM orders involve inversion, it is natural to link their decline to the loss of V2. The loss of V2 involves two components: the verb no longer moves to a left-peripheral head position such as C or F, and A-movement to the associated left-peripheral specifier position is no longer required. I assume that the two components of a V2 grammar, even though they are dissociable in principle, were lost together because any grammar which retained one component without the other would generate word orders which would fail to parse large amounts of the input. Loss of the former without the latter would lead to ‘verb-late’ orders, with the verb in V or I and significant freedom in the position of preverbal elements due to A-movement to Spec,CP and/or Spec,FP. Loss of the latter without the former would lead to verb-initial orders, possibly only in matrix clauses.37
To the extent that a text does not show inversion in standard V2 contexts, it should also be expected not to show the CM orders, because the CM grammar would be able to produce standard V2 orders with inversion as well as the CM orders. That expectation is borne out. Figure 6 plots the log-transformed frequency of the CM orders against the frequency of inversion in PP-initial matrix clauses with full NPs, for texts over 10,000 words in length from the 14th and 15th centuries. There is again a positive correlation between the CM orders and the PP-initial V2 orders (Spearman’s , ).
3.5.4. Summary
The CM grammar is present throughout Old and Middle English, but particularly visible in northern ME texts for a variety of reasons. First, OE had a greater rate of OV orders, compared to the preference for VO orders in ME. Because OV orders are less likely to put the verb in second position, this means that there were more OE orders, particularly in embedded clauses, that could not be generated by the CM grammar.
Second, the possibility of inversion with pronominal subjects, coupled with a tendency to use pronominal subjects in the distinctive CM word orders, meant that there was more positive evidence for the CM grammar in northern texts. One must also consider the contingent fact that there are no northern OE texts suitable for investigation of word order.
Finally, because the distinctive CM orders all involve inversion, it is to be expected that the loss of V2, beginning in late ME, effectively reduced the positive evidence for the CM grammar to zero. This claim is supported by a correlation between the rate of inversion and the frequency of the CM orders in Middle English.
4. Implications for Grammar Competition
In this section, I consider the relationships between the two V2 grammars, the SV grammar, and the CM grammar, in the light of the model of grammar competition developed by Yang (2002), in which a grammar’s fitness is determined uniquely by its success in parsing observed input.
The outline of Yang’s model is as follows. There is a finite set of possible grammars (as defined, for instance, by a finite set of parameters). Each grammar is associated with a probability, or a ‘weight’, . When a child encounters an input sentence s, the child picks one grammar to analyse it. The probability that the child will select is . If successfully analyses s, then increases (according to the linear reward–penalty algorithm given Yang 2002, p. 29), and the weights assigned to all other grammars concomitantly decrease. If does not successfully analyse s, then decreases and the weights assigned to all other grammars increase.
Because parsing success increases the weight associated with a grammar, this model favours more flexible grammars, which are capable of parsing a wider variety of input sentences. The CM grammar is interesting in that respect because it is so flexible. The only orders it cannot generate are matrix V ≥ 4 orders and embedded V ≥ 3 orders. In contrast, the SV grammar cannot generate orders with inversion; the northern V2 grammar can generate only V2 orders in matrix clauses and is essentially identical to the SV grammar in embedded clauses; and the non-northern V2 grammar is similar to the northern grammar except for the requirement of matrix V3 orders with subject pronouns.
The greater flexibility of the CM grammar apparently did not give it a competitive advantage, because the CM grammar evidently lost out, in the fullness of time, to the SV grammar. In this section, my aim is to understand why the CM grammar lost out.
I will consider the fitness of the four different grammars discussed in this paper, using all texts in PLAEME as a model of the linguistic environment in England c.1300. All PLAEME texts are dated to within a 75-year window, 1250–1325. I abstract away from temporal differences between these texts and treat them as a single point in the history of English.
It is likely that English around this time had properties which were particularly favourable to the CM grammar. Earlier texts showed greater frequency of embedded SXV orders, which the CM grammar cannot generate because it only generates verb-second orders in embedded clauses. Later texts, as V2 declined, have more frequent XYSV orders, with multiple constituents left-adjoined to the clause and no inversion.
The window occupied by PLAEME texts therefore falls between two sets of less favourable circumstances for the CM grammar. This implies that PLAEME should be a sample of a particularly favourable period for the CM grammar. However, this remains a matter of degree: all grammars other than the CM grammar can generate V≥ 3 orders in embedded clauses, for instance, so there are always cases which are beyond the reach of the CM grammar.
In order to investigate the relative fitness, on Yang’s definition, of the CM grammar, the northern and non-northern V2 grammars, and the SV grammar in ME, I conducted a corpus study on PLAEME using the same technique described in Section 3.1 of coding the category of the first four constituents in the clause. There were some minor improvements to this query compared to the one described above, in the handling of negation, object pronouns, and deictic adverbials like þa. However, the same principles for excluding left-peripheral elements and other special cases were applied to this study. The study included all localized PLAEME texts, regardless of length.
I extracted all finite matrix, complement, and adverbial clauses where the first four positions are occupied by subject, verb, and two other constituents. I then divided these clauses into twelve categories according to the position of the verb and subject, and calculated which categories could be generated by which grammars. These calculations are summarized in Table 1.38
I then calculated, text by text, the proportion of clauses which could be generated by each of the four grammars. The results are plotted in Figure 7, and summarized by region in Table 2.39
These results indicate that the CM grammar has the greatest fitness, on Yang’s model, of the four grammars under consideration across all localized PLAEME texts, considered together. Moreover, the CM grammar has greater fitness in all dialect areas for which data is available in PLAEME. In fact, the CM grammar also has the greatest fitness for the vast majority of individual texts: there were only ten texts (out of 59) in which one of the other grammars had greater parsing success than the CM grammar.
Table 3 shows that this advantage arises because the CM grammar can parse more matrix clauses than the other grammars, while the other grammars can parse more embedded clauses, where they all make identical predictions. Despite this lower parsing success in embedded clauses, the CM grammar has the greatest overall parsing success, simply because there are more matrix than embedded clauses.
So, around the time of the Edinburgh manuscript, the CM grammar has a fitness advantage in comparison to other grammars visible in contemporary English texts. Furthermore, yet, the CM grammar never spread, despite this fitness advantage. This suggests that extra flexibility does not always confer a selectional advantage, a lesson familiar from the Subset Principle (Berwick 1985; Manzini and Wexler 1986). However, it does not follow from Yang’s learning model, where fitness is defined directly in terms of parsing success.
This problem can be attributed to the linear reward–penalty algorithm adopted by Yang. Several alternative algorithms are conceivable, and I do not intend to investigate them seriously here. However, I close by pointing out that Bayesian approaches are a widely-used family of algorithms which avoid this problem. Bayesian approaches incorporate Bayes’ rule, in (35).
| (35) |
The utility of Bayes’ rule is that it allows us to infer the probability of a grammar (here, a ‘hypothesis’, h) given a set of some observed phenomena (here, some ‘data’, d). Bayes’ rule tells us that the probability of h given d is proportional to the product of the ‘prior probability’ of h (), and the ‘likelihood’ (, the probability of d given h). This latter term is the most important for our purposes.40
The Subset Principle is closely related to a general principle of Bayesian learning known as the Size Principle (Perfors et al. 2011). The Size Principle is formulated by Tenenbaum (1998) as follows: ‘learners … weight more specific hypotheses higher than more general ones by a factor that increases exponentially with the number of examples used’ (Tenenbaum 1998, p. 64). This follows directly from Bayes’ rule because the posterior probability of a grammar is a function of the prior probability and the likelihood. Because a more flexible grammar can generate more structures, the likelihood of any individual structure being generated is lower. Unlike the Subset Principle, which is stated deterministically, the Size Principle is probabilistic, but approximates the Subset Principle increasingly closely as the amount of input increases.
It is not straightforward to design a Bayesian learning algorithm which is faithful to the spirit of grammar competition. Grammar competition has two components which jointly pose a challenge to typical Bayesian approaches. The first is that grammars are discrete objects: either they generate a sentence or they do not. For a sentence that they do not generate, is literally 0. The second is that individuals display syntactically heterogeneous behaviour. That is, many, or even all individuals have access to grammars and , where can generate some sentences that cannot, and vice versa. This means that, in any representative sample D of linguistic behaviour from such a speaker, there will be some sentences for which and some sentences for which . This has the effect of fixing the posterior probability of and at zero.
It is common in Bayesian learning models to avoid this problem by setting in such cases not at zero, but at some ‘error term’ , slightly above zero. Despite the practical value of this approach, it is not compatible with the spirit of grammar competition. The logic of grammar competition implies that a speaker who assigns a high weight to a grammar may nevertheless generate sentences which cannot generate, simply because a speaker may have access to multiple grammars.
Speculatively, it seems to me that a way round this would be to treat the h term in Bayes’ rule not as an individual grammar, but as the set of grammars accessible to an individual. The Bayesian version of the Subset Principle would still be embodied, because higher likelihoods would be assigned to observed data on more restrictive sets of grammars, and the problem of zeroes disappears: it does not matter if the probability of an observed sentence is zero for any individual grammar, so long as it is not zero for the whole set of grammars accessible to an individual. I hope to develop this speculation in future research.
5. Summary
In this paper, I hope to have demonstrated that the matrix V3 and embedded V2 orders which are prominent in the Edinburgh manuscript should be given a theoretical account in terms of the CM grammar, a grammar which is particularly visible in 14th-century English, but whose effects can be seen already in OE. The argument for treating these apparently exceptional orders as the product of a single grammar rests on the correlation between the frequency of the two orders across texts, suggesting that these orders have a systematic relationship and are not just noise.
The description of that grammar is very simple: it differs from V2 grammars of the period in having two A-positions before the verb, rather than one. That grammatical description is dissociable from the northern/non-northern split uncovered by Kroch and Taylor (1997), and the matrix V3 and embedded V2 orders associated with the CM grammar can be dissociated from Kroch and Taylor’s dialect split in the textual record. Nevertheless, I also demonstrated a correlation, particularly strong in ME, between rates of use of the northern pattern of inversion with pronominal subjects, and rates of use of matrix V3 and embedded V2 orders. This suggests a probabilistic association between the CM grammar and the northern grammar, even if the two grammars should not be considered as one and the same.
The Edinburgh manuscript dates from a time period in which the SXV orders which predominated in OE had largely been replaced by SVX orders, but in which English was still essentially a V2 language, with inversion the norm in nonsubject-initial sentences with full NP subjects. This period is particularly congenial to the CM grammar, because both the earlier SXV orders and the later XYSV orders are incompatible with the CM grammar. Indeed, the CM grammar has greater fitness in the ‘PLAEME window’ of 1250–1325 than any grammar traditionally considered in the generative analysis of ME, on the model of fitness proposed by Yang (2002).
Nevertheless, the CM grammar did not spread, and the distinctive CM orders are only marginally visible in most late 14th- and 15th-century texts. This poses a challenge to Yang’s conception of fitness. In the final section of this paper, I sketched an outline of a way to develop a Bayesian alternative to Yang’s linear reward–penalty algorithm.
This paper is a first attempt at making sense of these orders in texts which have been the subject of little or no prior generative analysis. I will end with three avenues for further research in this area.
The first is simple: I sketched an alternative to the linear reward–penalty algorithm, but did not actually develop it. The paper therefore leaves unfinished business with respect to the theoretical understanding of grammar competition, which should be addressed in future research.
Secondly, there is more empirical work to be done on the Edinburgh manuscript and the CM grammar. In particular, recent work on OE (Bech 2001; van Kemenade et al. 2008; Speyer 2010; Bech and Salvesen 2014) has demonstrated that information structure has a large effect on OE word order, and it would be interesting to investigate similar effects in the time of the Edinburgh manuscript. Of course, a more nuanced understanding of the CM grammar may also affect my assumptions about its relative fitness.
Third, there is the intriguing question of why the CM grammar peaked when it did, and why such grammars are typologically rare. From a theoretical perspective, it is welcome to see a productive V3 grammar like the CM grammar, because there is no theoretical reason why such grammars should not exist, as discussed in Section 2.1. However, V2 grammars are already typologically rare, and it seems likely that the CM grammar is even rarer. As a final speculation, I suggest that transitional periods like English around 1300 are fertile grounds for rare grammars. During a transitional period, the observable linguistic behaviour is more heterogeneous than is usually the case, and this means that there is less pressure from the Subset Principle against more flexible grammars like the CM grammar. The CM grammar can therefore potentially inform us about conditions favouring the emergence of such rare grammars.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article. All scripts used to analyze pre-existing data are publicly available at https://github.com/rtruswell/CM_supplementary.
Acknowledgments
Thanks to Caroline Heycock, Meg Laing, Joel Wallenberg, two anonymous reviewers, and participants in the workshop ‘Multimethodological approaches to synchronic and diachronic variation’ (Potsdam, 2019).
Conflicts of Interest
The author declares no conflict of interest.
References
- Bech, Kristin. 2001. Word Order Patterns in Old and Middle English: A Syntactic and Pragmatic Study. Ph. D. thesis, Universitetet i Bergen, Bergen, Norway. [Google Scholar]
- Bech, Kristin, and Christine Meklenborg Salvesen. 2014. Preverbal word order in Old English and Old French. In Information Structure and Syntactic Change in Germanic and Romance Languages. Edited by Kristin Bech and Kristine Gunn Eide. Amsterdam: John Benjamins, pp. 233–69. [Google Scholar]
- Berwick, Robert. 1985. The Acquisition of Syntactic Knowledge. Cambridge: MIT Press. [Google Scholar]
- Biberauer, Theresa, and Ans van Kemenade. 2011. Subject positions and information-structural diversification in the history of english. Catalan Journal of Linguistics 10: 17–69. [Google Scholar] [CrossRef] [Green Version]
- Borer, Hagit. 1983. Parametric Syntax: Case Studies in Semitic and Romance Languages. Dordrecht: Foris. [Google Scholar]
- Faarlund, Jan Terje. 2007. The Syntax of Old Norse: With a Survey of the Inflectional Morphology and a Complete Bibliography. Oxford: Oxford University Press. [Google Scholar]
- Haeberli, Eric. 2000. Adjuncts and the syntax of subjects in Old and Middle English. In Diachronic Syntax: Models and Mechanisms. Edited by Susan Pintzuk, George Tsoulas and Anthony Warner. Oxford: Oxford University Press, pp. 109–31. [Google Scholar]
- Haeberli, Eric. 2002. Inflectional morphology and the loss of V2 in English. In Syntactic Effects of Morphological Change. Edited by David Lightfoot. Oxford: Oxford University Press, pp. 88–106. [Google Scholar]
- Kroch, Anthony. 1989. Reflexes of grammar in patterns of language change. Language Variation and Change 1: 199–244. [Google Scholar] [CrossRef] [Green Version]
- Kroch, Anthony, and Ann Taylor. 1997. Verb movement in Old and Middle English: Dialect variation and language contact. In Parameters of Morphosyntactic Change. Edited by Ans van Kemenade and Nigel Vincent. Cambridge: Cambridge University Press, pp. 297–325. [Google Scholar]
- Kroch, Anthony, and Ann Taylor. 2000. Penn-Helsinki Parsed Corpus of Middle English, 2nd ed. Available online: https://www.ling.upenn.edu/hist-corpora/PPCME2-RELEASE-4/ (accessed on 11 March 2021).
- Laing, Margaret. 2013. A Linguistic Atlas of Early Middle English, Version 3.2. pp. 1150–325. Available online: http://www.lel.ed.ac.uk/ihd/laeme2/laeme2.html (accessed on 11 March 2021).
- Manzini, M. Rita, and Kenneth Wexler. 1986. Parameters, binding theory, and learnability. Linguistic Inquiry 18: 413–44. [Google Scholar]
- Martineau, France, Paul Hirschbühler, Anthony Kroch, and Yves Charles Morin. 2010. Corpus MCVF annoté syntaxiquement. Ottawa: Université d’Ottawa. [Google Scholar]
- Perfors, Andrew, Joshua Tenenbaum, and Terry Regier. 2011. The learnability of abstract syntactic principles. Cognition 118: 306–38. [Google Scholar] [CrossRef]
- Pintzuk, Susan. 1991. Phrase Structures in Competition: Variation and Change in Old English Word Order. Ph. D. thesis, University of Pennsylvania, Philadelphia, PA, USA. [Google Scholar]
- Pintzuk, Susan. 1993. Verb seconding in Old English: Verb movement to Infl. The Linguistic Review 10: 5–35. [Google Scholar] [CrossRef]
- Rizzi, Luigi. 1997. The fine structure of the left periphery. In Elements of Grammar. Edited by Liliane Haegeman. Dordrecht: Kluwer, pp. 281–337. [Google Scholar]
- Salvesen, Christine Meklenborg, and Kristin Bech. 2014. Postverbal subjects in Old English and Old French. Oslo Studies in Language 6: 201–28. [Google Scholar] [CrossRef]
- Salvesen, Christine Meklenborg, and George Walkden. 2017. Diagnosing embedded V2 in Old English and Old French. In Micro-Change and Macro-Change in Diachronic Syntax. Edited by Éric Mathieu and Robert Truswell. Oxford: Oxford University Press, pp. 168–81. [Google Scholar]
- Speyer, Augustin. 2010. Topicalization and Stress Clash Avoidance in the History of English. Berlin: De Gruyter Mouton. [Google Scholar]
- Taylor, Ann, Anthony Warner, Susan Pintzuk, and Frank Beths. 2003. The York–Toronto–Helsinki Parsed Corpus of Old English prose (YCOE). York: Department of Language and Linguistic Science, University of York, Available online: https://www-users.york.ac.uk/~lang22/YCOE/YcoeHome.htm (accessed on 11 March 2021).
- Tenenbaum, Joshua. 1998. Bayesian modeling of human concept learning. In Advances in Neural Information Processing Systems 11 (NIPS 1998). Edited by Michael Kearns, Sara Solla and David Cohn. Cambridge: MIT Press, pp. 59–68. [Google Scholar]
- Trips, Carola. 2003. Stylistic fronting in the Ormulum: Scandinavian syntactic phenomena in Early Middle English texts. Nordlyd 31: 457–72. [Google Scholar] [CrossRef]
- Truswell, Robert, Rhona Alcorn, James Donaldson, and Joel Wallenberg. 2019. A Parsed Linguistic Atlas of Early Middle English. In Historical Dialectology in the Digital Age. Edited by Rhona Alcorn, Joanna Kopaczyk, Bettelou Los and Benjamin Molineaux. Edinburgh: Edinburgh University Press, pp. 19–38. [Google Scholar]
- van Kemenade, Ans. 1987. Syntactic Case and Morphological Case in the History of English. Dordrecht: Foris. [Google Scholar]
- van Kemenade, Ans. 1997. V2 and embedded topicalization in Old and Middle English. In Parameters of Morphosyntactic Change. Edited by Ans van Kemenade and Nigel Vincent. Cambridge: Cambridge University Press, pp. 326–52. [Google Scholar]
- van Kemenade, Ans, Tanja Milicev, and R. Harald Baayen. 2008. The balance between syntax and discourse in Old English. In English Historical Linguistics 2006: Selected Papers from the Fourteenth International Conference on English Historical Linguistics (ICEHL 14), Bergamo, 21–25 August 2006, Volume I: Syntax and Morphology. Edited by Maurizio Gotti, Marina Dossena and Richard Dury. Amsterdam: John Benjamins, pp. 3–21. [Google Scholar]
- Walkden, George. 2014. Syntactic Reconstruction and Proto-Germanic. Oxford: Oxford University Press. [Google Scholar]
- Yang, Charles. 2002. Knowledge and Learning in Natural Language. Oxford: Oxford University Press. [Google Scholar]
| 1. | In all examples in this paper, I insert brackets around relevant preverbal constituents, boldface the finite verb, and italicize the subject. In examples taken from parsed corpora, I give the token ID from the corpus in lieu of a full citation. For the first example from any corpus text, I also give the text name, date, region, and corpus source in a footnote. See Section 3.1 for further details of the corpus investigation. |
| 2. | Edinburgh Cursor Mundi, Hand A, early 14th century, Northern, PLAEME. |
| 3. | Edinburgh Northern Homilies, Hand B, early 14th century, Northern, PLAEME. |
| 4. | Ælfric, Lives of Saints, c.1000CE, West Saxon, YCOE. |
| 5. | Ælfric, Homilies, supplemental, c.1000CE, West Saxon, YCOE. |
| 6. | Vercelli Homilies, late 10th century, mainly West Saxon, YCOE. |
| 7. | Wulfstan, Homilies, c.1000CE, mainly West Saxon, YCOE. |
| 8. | |
| 9. | Northern prose Rule of St. Benet, early 15th century, Northern, PPCME2. |
| 10. | It is natural to assume that all sentences in a text are generated by some grammar, so the full set of competing grammars to which an individual has access should in principle be able to generate a complete text created by that individual. I do not pay attention to this natural assumption here, for two reasons. First, nothing suggests that these three grammars, plus the CM grammar, are the only grammars of interest. Second, not everything which has been written down is grammatical, for instance because of scribal errors. |
| 11. | |
| 12. | Adjunction to CP or FP would lead us to expect widespread V > 2 orders, contrary to the evidence that OE and EME are predominantly V2 languages. Haeberli (2000) demonstrates that adjuncts can surface between the finite verb and a full NP subject. We model this as IP-adjunction, deviating from Haeberli. |
| 13. | In the study of competition among these grammars in Section 4, X is restricted to adjuncts in embedded clauses in all three grammars described here. That is, I assume that these grammars can generate embedded SVO and SOV orders, but not embedded OSV. |
| 14. | |
| 15. | The following categories were coded: finite verb, subject, direct object, indirect object, other NP argument, NP adjunct, AP, AdvP, PP, VP/infinitive clause, negation, particle, and participle. |
| 16. | PLAEME, following LAEME, transcribes manuscripts more faithfully than YCOE or PPCME2, which are based on edited texts. I have represented examples from PLAEME in the orthography implied by PLAEME’s transcription conventions. As a result, examples in this paper drawn from PLAEME contain several initially unusual-looking abbreviations, not found to the same extent in examples from PPCME2 or YCOE. These include a macron for a following nasal (ī = ‘in’), a superscript vowel for a preceding <r> (gce = ‘grace’), and the <> symbol for <er> (laud = ‘lord’). Linebreaks are represented with ‘∖’. |
| 17. | Edinburgh Cursor Mundi, Hand C, early 14th century, Northern, PLAEME. |
| 18. | There are only two indefinite NPs which are plausibly in this low subject position. One is a there-insertion sentence and the other is an apparent NPI in the scope of negation. It would therefore perhaps be more accurate to claim that indefinite full NPs can only occur in this lower position if they are in the scope of a licensor. However, with only two such examples, it is hard to propose such a generalization with any certainty. |
| 19. | Example (19b) is included in response to a query from an anonymous reviewer. The reviewer noted that van Kemenade (1997) had identified several classes of embedded clause in which inversion was possible in Old English, but which nonetheless should not be analysed as embedded V2, and asked whether all examples of inversion in the Edinburgh manuscript could be analysed along the lines proposed by van Kemenade. The answer is that most examples of inversion in the Edinburgh manuscript do indeed fall into the classes identified by van Kemenade. However, I believe that not all of them do, and (19b) is one of the occasional examples which must be analysed as genuine embedded V2. |
| 20. | There are also at most three examples which may show embedded XYVS order. However, none of them unequivocally do so, and it is not possible to draw any conclusions from such a small number of examples. |
| 21. | The form ‘fu(l)’ is a correction given in LAEME. The manuscript has ‘fur’, which is assumed to be a scribal error. |
| 22. | Walkden (2014) developed an analysis of the Old English V3 orders first described by Bech (2001), according to which the two preverbal constituents occupy A-positions. This is in opposition to the approach in Pintzuk (1991) where the second constituent occupies an A-position. Clearly, Walkden’s analysis is very similar to the analysis developed here. However, it differs in that the second A-posiiton for Walkden was Spec,FamP, restricted to discourse-given constituents. It does not appear that any such restriction is evident in the Edinburgh manuscript. If one were to adopt Walkden’s analysis of OE V3, it would then be possible to claim that the difference between the non-northern V2 grammar and the CM grammar lies in the nature of the second A-position, with this being less restricted in the CM grammar. Such an account must await a better understanding of information structure in the CM grammar. |
| 23. | Alternatively, one could suggest that only Spec,FP needs to be filled on the CM grammar, and Spec,CP can optionally be filled. |
| 24. | I have not investigated word order in other versions of the Cursor Mundi, simply because the Edinburgh manuscript is the only copy in PLAEME. It would be an obvious next step in this research to compare the Edinburgh manuscript to other versions. |
| 25. | |
| 26. | This may in fact corroborate Kroch and Taylor’s hypothesis that this order is related to contact with Old Norse, although it does not address Kroch and Taylor’s specific contact hypothesis. |
| 27. | Mirror of St. Edmund, Thornton ms., c.1440, northern, PPCME2. |
| 28. | Genesis and Exodus, early 14th century, East Anglia, PLAEME. |
| 29. | Ormulum, late 12th century, Lincolnshire, PPCME2. |
| 30. | Richard Rolle, Epistles, 15th century copy of 14th century text, Yorkshire, PPCME2. |
| 31. | This may not be true of the very limited surviving northern OE material, such as the two sets of glosses on which Kroch and Taylor (1997) base their claim that the northern V2 grammar dates back to OE. |
| 32. | One must again bear in mind the demonstration in van Kemenade (1997) that many cases of embedded inversion in OE are not indicative of a V2 grammar. However, it is not clear that all of the examples in (33) fall in the classes that van Kemenade describes. |
| 33. | Blickling Homilies, late 10th century, West Saxon/Anglian, YCOE. |
| 34. | Gregory’s Dialogues (C), late 11th century, West Saxon/Mercian, YCOE. |
| 35. | Boethius, Consolation of Philosophy, mid-10th century, West Saxon, YCOE. |
| 36. | Bald’s Leechbook, mid-10th century, West Saxon/Anglian, YCOE. |
| 37. | Inversion has of course not fully disappeared from the grammar of English, surviving in a number of relatively fixed ‘residual V2’ contexts, including matrix questions, locative inversion, and quotative inversion. |
| 38. | The coding in Table 1 is too coarse to represent all the grammatical subtleties discussed above. For instance, I have claimed that XP–V–YP–S orders are possible in the Edinburgh manuscript, and so presumably in the CM grammar, only when the subject is a definite full NP. The results reported here are sufficiently robust for coding decisions in these respects not to affect the results presented below. |
| 39. | I considered three regions, corresponding to the clusters of texts visible on the maps. The southwestern region was defined as below N and between W. The northern region was defined as above N and less than W. The East Anglian region was defined as between N and less than W. A handful of smaller texts, particularly in the northwest and on the south coast, are not in any of these regions. For this reason, the ‘Total’ row in Figure 2 slightly exceeds the sum of the other three rows. |
| 40. | The final term, , is treated as a normalizing term to ensure that the probabilities sum to 1, and does not have a straightforward interpretation in its own right. |
Figure 1.
Frequency of matrix XYVS and embedded XVS orders in Old and Middle English texts of words length.
Figure 1.
Frequency of matrix XYVS and embedded XVS orders in Old and Middle English texts of words length.
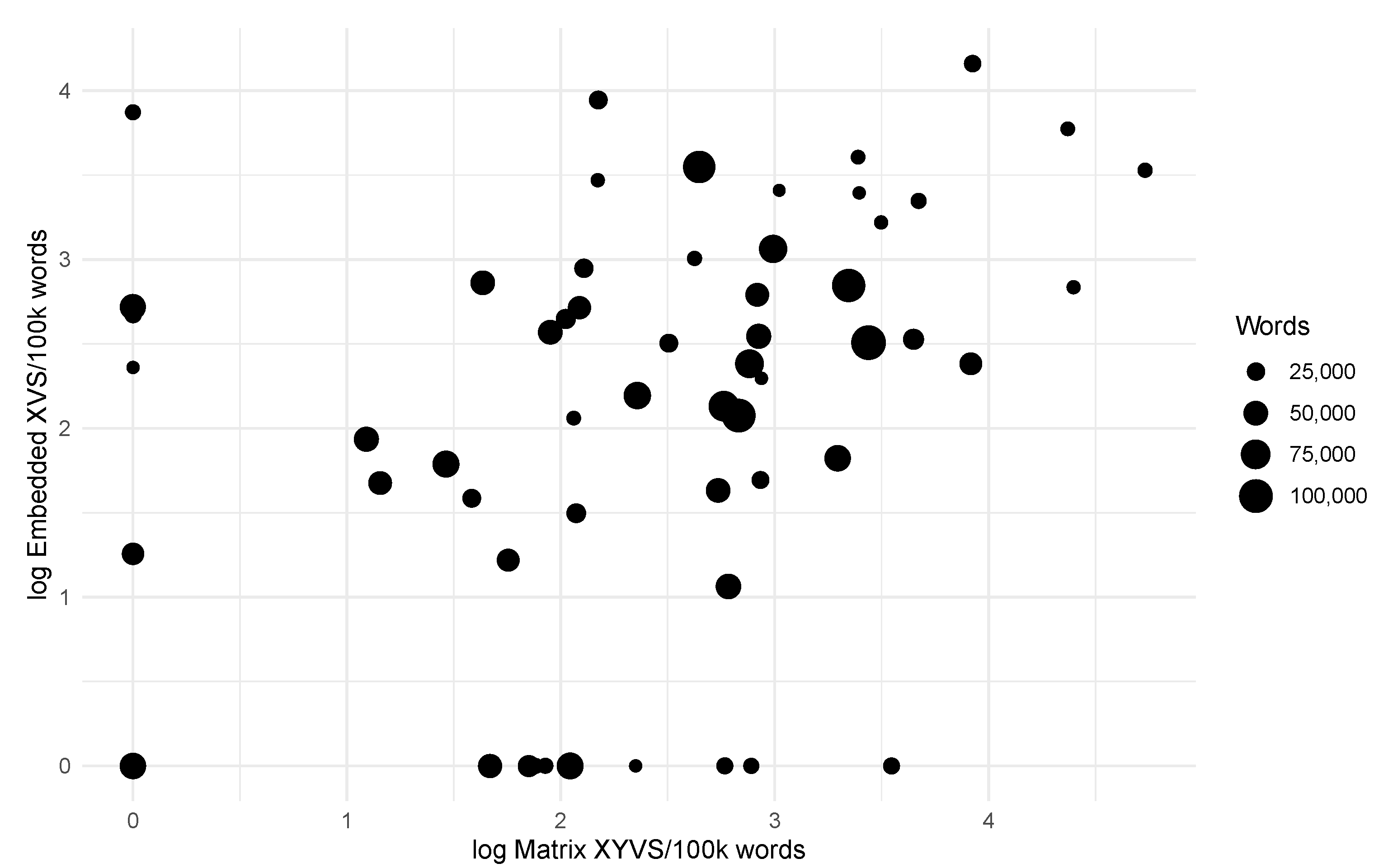
Figure 2.
Rate of inversion in nonsubject-initial sentences with full NP subjects, all PLAEME texts.
Figure 2.
Rate of inversion in nonsubject-initial sentences with full NP subjects, all PLAEME texts.

Figure 3.
Rate of inversion in nonsubject-initial sentences with pronominal subjects, all PLAEME texts.
Figure 3.
Rate of inversion in nonsubject-initial sentences with pronominal subjects, all PLAEME texts.

Figure 4.
Frequency of the CM orders, and of matrix XVS orders with pronominal subjects, in Old and Middle English texts of >10,000 words length. Major northern texts are highlighted in blue.
Figure 4.
Frequency of the CM orders, and of matrix XVS orders with pronominal subjects, in Old and Middle English texts of >10,000 words length. Major northern texts are highlighted in blue.

Figure 5.
The data in Figure 4 split into Old English (red) and Middle English (blue) texts.
Figure 5.
The data in Figure 4 split into Old English (red) and Middle English (blue) texts.

Figure 6.
Correlation of the CM orders with inversion in PP-initial matrix clauses with full NP subjects, 14th–15th-century texts of words. The major northern texts are highlighted in blue.
Figure 6.
Correlation of the CM orders with inversion in PP-initial matrix clauses with full NP subjects, 14th–15th-century texts of words. The major northern texts are highlighted in blue.

Figure 7.
Proportion of clauses in each text in PLAEME which can be generated by the northern V2 grammar (top left), the non-northern V2 grammar (top right), the CM grammar (bottom left), and the SV grammar (bottom right). Each dot corresponds to a text; the size of the dot corresponds to the amount of clauses included from that text; the colour indicates the proportion of clauses in the text that can be generated by the grammar in question.
Figure 7.
Proportion of clauses in each text in PLAEME which can be generated by the northern V2 grammar (top left), the non-northern V2 grammar (top right), the CM grammar (bottom left), and the SV grammar (bottom right). Each dot corresponds to a text; the size of the dot corresponds to the amount of clauses included from that text; the colour indicates the proportion of clauses in the text that can be generated by the grammar in question.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Orders which can be generated by the northern and non-northern V2 grammars, the CM grammar, and the SV grammar.
Table 1.
Orders which can be generated by the northern and non-northern V2 grammars, the CM grammar, and the SV grammar.
| Full NP, Matrix | Full NP, Embedded | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Northern | Non-Northern | CM | SV | Northern | Non-Northern | CM | SV | ||
| XP YP S V | * | * | * | √ | XP YP S V | √ | √ | * | √ |
| XP YP V S | * | * | √ | * | XP YP V S | * | * | * | * |
| XP V YP S | * | √ | √ | * | XP V YP S | * | * | * | * |
| V XP YP S | * | * | * | * | V XP YP S | * | * | * | * |
| XP S YP V | * | * | * | √ | XP S YP V | √ | √ | * | √ |
| XP S V YP | * | * | √ | √ | XP S V YP | √ | √ | * | √ |
| XP V S YP | √ | √ | √ | * | XP V S YP | * | * | √ | * |
| V XP S YP | * | * | * | * | V XP S YP | * | * | * | * |
| S XP YP V | * | * | * | √ | S XP YP V | √ | √ | * | √ |
| S XP V YP | * | * | √ | √ | S XP V YP | √ | √ | * | √ |
| S V XP YP | √ | √ | √ | √ | S V XP YP | √ | √ | √ | √ |
| V S XP YP | * | * | * | * | V S XP YP | * | * | * | * |
| Pronoun, Matrix | Pronoun, Embedded | ||||||||
| Northern | Non-Northern | CM | SV | Northern | Non-Northern | CM | SV | ||
| XP YP S V | * | * | * | √ | XP YP S V | √ | √ | * | √ |
| XP YP V S | * | * | √ | * | XP YP V S | * | * | * | * |
| XP V YP S | * | * | * | * | XP V YP S | * | * | * | * |
| V XP YP S | * | * | * | * | V XP YP S | * | * | * | * |
| XP S YP V | * | * | * | √ | XP S YP V | √ | √ | * | √ |
| XP S V YP | * | √ | √ | √ | XP S V YP | √ | √ | * | √ |
| XP V S YP | √ | * | √ | * | XP V S YP | * | * | √ | * |
| V XP S YP | * | * | * | * | V XP S YP | * | * | * | * |
| S XP YP V | * | * | * | √ | S XP YP V | √ | √ | * | √ |
| S XP V YP | * | * | √ | √ | S XP V YP | √ | √ | * | √ |
| S V XP YP | √ | √ | √ | √ | S V XP YP | √ | √ | √ | √ |
| V S XP YP | * | * | * | * | V S XP YP | * | * | * | * |
Table 2.
Parsing success of four competing grammars in three different regions.
| Region | # Clauses | Northern V2 | Non-Northern V2 | SV | CM |
|---|---|---|---|---|---|
| Southwest | 2074 | 863 (42%) | 1384 (67%) | 1365 (66%) | 1490 (72%) |
| North | 1412 | 828 (59%) | 840 (59%) | 797 (56%) | 1045 (74%) |
| East Anglia | 696 | 383 (55%) | 462 (66%) | 446 (64%) | 514 (74%) |
| Total | 4251 | 2126 (50%) | 2739 (64%) | 2657 (63%) | 3107 (73%) |
Table 3.
Parsing success of four competing grammars in matrix and embedded clauses.
| Clause Type | # Clauses | Northern V2 | Non-Northern V2 | SV | CM |
|---|---|---|---|---|---|
| Matrix | 3132 | 1307 (42%) | 1915 (61%) | 1838 (59%) | 2510 (80%) |
| Embedded | 1119 | 819 (73%) | 819 (73%) | 819 (73%) | 597 (53%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Truswell, R. Grammar Competition and Word Order in a Northern Early Middle English Text. Languages 2021, 6, 59. https://doi.org/10.3390/languages6020059
AMA Style
Truswell R. Grammar Competition and Word Order in a Northern Early Middle English Text. Languages. 2021; 6(2):59. https://doi.org/10.3390/languages6020059
Chicago/Turabian StyleTruswell, Robert. 2021. "Grammar Competition and Word Order in a Northern Early Middle English Text" Languages 6, no. 2: 59. https://doi.org/10.3390/languages6020059