1. Introduction
In the literature on the syntax–phonology interface, syntactic information is often considered visible in phonology (
Nespor and Vogel 1986;
Selkirk 1984;
Truckenbrodt 1995, et seq.). This is particularly true with respect to sentence-level syntax, as reflected in prosody. For example, the contrast between a statement and question is often made using different intonation patterns. Since Japanese downstep is a process in phrasal phonology, it offers an excellent case for testing the hypothesis that syntactic information is mapped onto prosody. In Japanese downstep, an accented phrase triggers the phrase that follows to be rendered in a lower pitch register (e.g.,
Kubozono 1989;
Pierrehumbert and Beckman 1988;
Poser 1984), as in (1a).
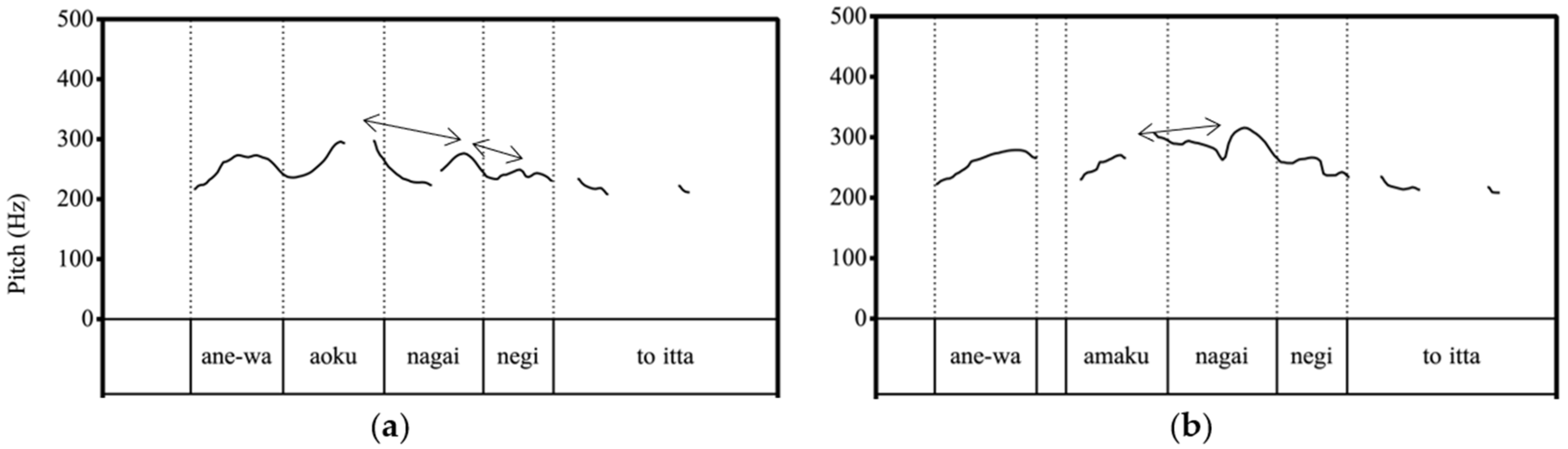
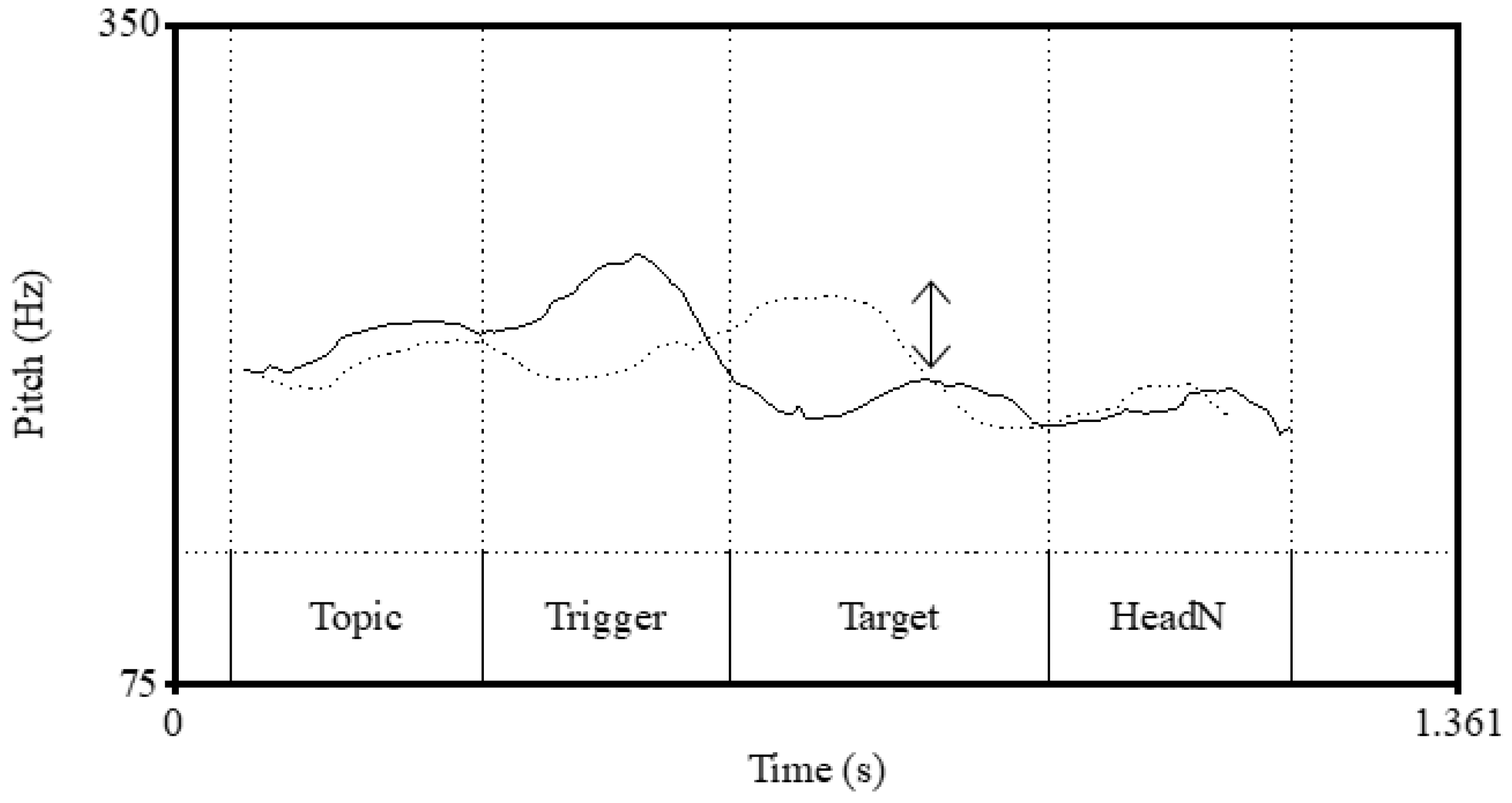
Figure 1a depicts the pitch contour. The accented word
aóku ‘blue’ triggers the word that follows it,
nagái ‘long’, to be rendered in a lower pitch (the acute accent mark indicates a vowel in the accented syllable), and
nagái further triggers the next word,
négi ‘leek’, to be rendered in an even lower-pitched register. In contrast, in (1b), as shown in
Figure 1b, the word
amaku ‘sweet’ does not trigger downstep because it is unaccented; thus, the pitch peak in the word that follows it,
nagái ‘long’, is not as low as the pitch peak of the word in the same position,
nagái, in (1a).
The major phrase (MaP) is the domain of downstep (see
Igarashi 2015;
Ishihara 2015 for a review). For example, in (1a) and
Figure 1, focusing on the noun phrase
aóku nagái négi ‘green and long leek’, the whole phrase constitutes a single MaP, with each word forming a minor phrase (MiP), a phrase that allows at most one accent: ((
aóku)
MiP (
nagái)
MiP (
négi)
MiP)
MaP.
1 Moreover, as discussed extensively in
Section 2, downstep is reportedly sensitive to certain syntactic information, including whether a given constituent is a maximal projection (i.e., an XP) (
Selkirk and Tateishi 1991), branching structures (e.g.,
Kubozono 1989,
1992;
Ito and Mester 2013), and the part of speech of a given word (
Hirayama and Hwang 2016,
2019;
Hwang and Hirayama 2021;
Selkirk and Tateishi 1991). The left edges of relevant syntactic elements are presumably mapped onto the left edges of MaPs, which then block downstep.
The general question regarding the syntax-prosody interface we are concerned with in this paper is what kinds of syntactic information can affect phrasal phonology. An exploration of the literature on downstep shows that different syntactic structures and different kinds of syntactic boundaries have been discussed. What affects the process and what does not? In what follows, we address one specific aspect of this question on which the literature offers different views, namely whether and how parts of speech affect downstep. The main goal of this paper is to shed new light on this issue.
| 1. | a. | ane-wa | aóku | nagái | négi | to | itta |
| | | big sister-TOP | blue | long | leek | COMP | say.PAST |
| | | ‘My big sister said, “Green and long leek”’. | | | |
| | | | | | |
| | b. | ane-wa | amaku | nagái | négi | to | itta |
| | | big sister-TOP | sweet | long | leek | COMP | say.PAST |
| | | ‘My big sister said, “Sweet and long leek”’. | | | |
This paper is organized as follows.
Section 2 reviews the literature on downstep and factors that reportedly affect it.
Section 3 presents the methodology of the production experiment that we conducted to test whether downstep realization is sensitive to parts of speech, or more specifically, whether adjectives, nouns, and verbs have different effects on the process. The results are reported in
Section 4 and discussed in
Section 5.
Section 6 presents the study’s conclusions.
2. Japanese Downstep and Syntax
Selkirk and Tateishi (
1991) argue that the left edges of maximal projections, or XPs, block downstep. In other words, the left edges of XPs are mapped onto the left edges of MaPs, affecting the realization of downstep by blocking it.
Ishihara (
2019) reports the cumulative effects of XPs on metrical boost with downstep. Metrical boost is a rise of pitch at the beginning of a right-branching structure (
Kubozono 1988,
1989,
1993). For example, between the left-branching phrase [[
náma-no ‘raw-GEN’
áyu-no ‘ayu-GEN’]
niói ‘smell’] ‘smell of raw ayu (fish)’ and right-branching phrase [
kowái ‘terrible’ [
mé-no ‘eye-GEN’
yámai ‘disease’]] ‘terrible eye disease’ (examples from
Kubozono 1989, pp. 33–34), downstep occurs in both phrases. However, metrical boost occurs on
mé-no at the beginning of the right-branching, but not on
áyu-no.
Ishihara (
2019) finds that the effect is larger when there are multiple left edges of XPs, although there is interspeaker variation.
Ishihara (
2016) reports that the left edge of a predicate VP variably blocks downstep, whereas
Hirayama and Hwang (
2019) (and this study) do not find that this particular type of boundary affects downstep in this way.
Clause boundaries have not been intensively studied with downstep, although they have been argued to support the presence of the Intonational Phrase in Japanese (e.g.,
Kawahara and Shinya 2008;
Selkirk 2009;
Ishihara 2019). Furthermore,
Hirayama and Hwang (
2019) tested whether relative clauses would affect downstep, finding that the left edge of the relative clause does not block downstep.
Lexical categories have been reported to affect downstep, but the literature does not agree on how they do this.
Selkirk and Tateishi (
1991) argue that downstep occurs in a phrase in which adjectives (A) are involved, whereas it is blocked when nouns (N) are involved: they find that downstep occurs between the adjectives in [A
1 [A
2 N]] but not between N
1 and N
2 in [N
1 [N
2 N
3]]. They explain this result by postulating that downstep is blocked by XP boundaries and that (a) adjectives do not project XPs while nouns do, and (b) [A
2 N] does not constitute a maximal projection. Downstep is not blocked in [A
1 [A
2 N]] because there is no XP boundary to the left of A
2. However, the process is blocked in [N
1 [N
2 N
3]] because there is an XP boundary to the left of N
2.
The empirical results of
Hirayama and Hwang (
2016),
Hwang and Hirayama (
2021), and
Kubozono (
1992) are opposite to those reported in
Selkirk and Tateishi (
1991).
Kubozono (
1992) reports that downstep occurs in [N
1 [N
2 N
3]].
Hirayama and Hwang (
2016) and
Hwang and Hirayama (
2021), like Selkirk and Tateishi, compared [A
1 [A
2 N]] and [N
1 [N
2 N
3]], and investigated whether downstep occurred. However, they increased the number of speakers in their experiment and adopted the more traditional definition of downstep found in the Japanese literature (e.g.,
Kubozono 1988,
1989,
1993;
Pierrehumbert and Beckman 1988;
Poser 1984).
2 The results suggest that downstep occurred in [N
1 [N
2 N
3]], in particular at N
2, the target of downstep, as in (2), but it was blocked at A
2 in [A
1 [A
2 N]]. The target words/phrases of the process are underlined.
3 Downstepped targets are indicated with ! in (2) to (5) below, although the head nouns are not marked, as that is not the focus of investigation here.
| 2. | a. | An example of [N1 [N2 N3]] | |
| | | nómo-no | !nára-no | mamé |
| | | Nomo-GEN | Nara-GEN | bean |
| | | ‘Nomo’s beans from Nara’ |
| | | | |
| | b. | An example of [A1 [A2 N]] | |
| | | shirói | nagái
| mamé |
| | | white | long | bean |
| | | ‘long white beans’ |
Hirayama and Hwang (
2019) tested adjectives and verbs in their past forms, but retained the right-branching structure, as in (3): [[V
PAST]
RC [[A
PAST]
RC N]]
NP vs. [[V
PAST]
RC [[V
PAST]
RC N]]
NP (RC stands for ‘relative clause’).
4| 3. | a. | An example of [[VPAST]RC [[APAST]RC N]]NP | |
| | | [[niránda]RC | [[(!)darúkatta]RC | magó]]NP |
| | | stare.PAST | tired.PAST | grandchild |
| | | ‘a grandchild who stared disfavourably and was tired’ |
| | | |
| | b. | An example of [[VPAST]RC [[VPAST]RC N]]NP | |
| | | [[najínda]RC | [[!niránda]RC | magó]]NP |
| | | get adjusted.PAST | stare.PAST | grandchild |
| | | ‘a grandchild who got adjusted and stared disfavourably’ |
They also tested these parts of speech in the predicative position in non-relative clauses, as in (4): N-
ga A, N-
ga V.
| 4. | a. | An example of N-ga A | |
| | | magó-ga | !nemúi |
| | | grandchild-NOM | sleepy |
| | | ‘‘(Someone’s) grandchild is sleepy’. |
| | | |
| | b. | An example of N-ga V | |
| | | magó-ga | !nirámu |
| | | grandchild-NOM | stare |
| | | ‘(Someone’s) grandchild stares (at someone) disfavourably’. |
| | | | | |
Hirayama and Hwang (
2019) report that downstep occurred in all conditions (i.e., (3) and (4)) but note that in (3), the pattern was much more robust in the verb condition (3b) than in the adjective condition (3a) in that all speakers showed downstep in the former while there was interspeaker variation in the latter.
Hirayama et al. (
2019) extended the investigation of downstep to remaining possibilities researched in
Hirayama and Hwang (
2016,
2019) and
Hwang and Hirayama (
2021), and tested verbs in their nonpast forms in relative clauses, nouns accompanied by the past tense form of a copula in relative clauses, and nouns in the predicative position in non-relative clauses, as in (5): [[V
NONPAST]
RC [[V
NONPAST]
RC N]]
NP, [[V
PAST]
RC [[N Copula
PAST]
RC N]]
NP, N-
ga N. They report having found downstep in all conditions.
| 5. | a. | An example of [[VNONPAST]RC [[VNONPAST]RC N]]NP | |
| | | [[mayóu]RC | [[!nayámu]RC | magó]]NP |
| | | get lost.NONPAST | worry.NONPAST | grandchild |
| | | ‘a grandchild who gets lost and worries’ |
| | | |
| | b. | An example of [[VPAST]RC [[N CopulaPAST]RC N]]NP | |
| | | [[nayánda]RC | [[!dame | datta]RC | magó]]NP |
| | | worry.PAST | no good | Copula | grandchild |
| | | ‘a grandchild who worried and was no good’ |
| | | |
| | c. | An example of N-ga N | |
| | | magó-ga | !námi | |
| | | grandchild-NOM | Nami | |
| | | ‘(My) grandchild is called Nami’. |
Table 1 recapitulates the results obtained in
Hirayama and Hwang (
2016,
2019),
Hirayama et al. (
2019), and
Hwang and Hirayama (
2021) with respect to the presence and absence of downstep and particular parts of speech (nouns, adjectives, and verbs). It can be observed that adjectives may block downstep when they are in attributive use, modifying the head noun, whereas adjectives in predicative use do not block downstep, and nouns and verbs do not block downstep regardless of the type of use (attributive or predicative).
As a source of the different patterning between different lexical categories, or rather, the patterning of adjectives in attributive use thereby blocking downstep,
Hirayama et al. (
2019) consider the (un)naturalness of NPs containing adjectives as used in the experiments. For example, an NP that has two adjectives individually modifying the head noun ([A [A N]]), as in (2b) [
shiroi [
nagai mame]] ‘white, long beans’, does not sound quite natural in Japanese, although it is not ungrammatical. They propose that because of this unnaturalness, (some) speakers inserted a phonological phrase (i.e., MaP) boundary between the two adjectives, which resulted in the downstep being blocked. The same can apply to the other NPs that have an adjective in the past tense form, as in (3a). They point out that when two adjectives are used to modify a noun, the structure where the first one appears in the -
te (or gerundive) form (i.e., [[A-
te A] N]) sounds more natural (e.g., [[
shiroku-te nagai]
mame] ‘white and long beans’).
5To summarize past findings on possible syntactic effects on downstep in Japanese, clause boundaries such as the relative clause boundary do not appear to affect it, whereas phrase-level information (the left edges of XPs) may affect it. Another line of investigation is concerned with parts of speech, although there is debate as to which categories block the process.
5. Discussion
Together with the results of relevant previous studies, the results of this research reveal that adjectives in a particular structure, i.e., [X [A N]], show either the absence of downstep or presence of variable patterns in downstep (see
Table 3). In other words, these results cumulatively suggest that first, the structure [X [
X N]] (where two items independently modify the head noun) is important since downstep may be blocked in this structure, while in others ([[X
X] N] and N-
ga X), downstep occurs irrespective of the parts of speech. Second, adjectives are different from nouns and verbs in that when put in [X [
X N]], they may block downstep. How can these patterns be accounted for? Below, we first discuss the data in relation to the proposals put forward in the literature on Japanese downstep in terms of syntax-prosody mapping. The discussion shows that the mapping from the syntax can account for the contrasting pattern between the left-branching and right-branching structures and contrast between the patterns with adjectives and nouns. However, it still does not explain the difference between adjectives and verbs as seen in
Table 3. We then discuss other areas, i.e., semantics and pragmatics, to explain the data.
Before testing the syntax-prosody mapping proposals against the patterns in
Table 3, we present the prosodic phrasing suggested by the data in
Table 3 based on the assumption that the downstep domain is MaP (
Igarashi 2015;
Ishihara 2015 and references therein). First, the left edge of the intermediate constituent in a right-branching structure (i.e., the left edge of [X X] in [X [X X]]) is variably mapped onto the left edge of a MaP, as shown in (11). When X
2 is an adjective, a MaP boundary can be inserted before it, or the whole phrase makes a single MaP (11a).
10 When X
2 is a noun or verb, the whole phrase makes a MaP (11b).
| 11. | MaP phrasing for [X1 [X2 N]] | |
| | a. | X2 = A |
| | | Variation between ((X1)MiP)MaP ((X2)MiP (N)MiP)MaP and ((X1)MiP (X2)MiP (N)MiP)MaP |
| | | |
| | b. | X2 = N, V |
| | | ((X1)MiP (X2)MiP (N)MiP)MaP |
| | | | |
On the other hand, when no right-branching structure is involved, i.e., in the left-branching structure [[X
1 X2] N] (12a) and [N-
ga X] (12b), the whole phrase makes a single MaP.
| 12. | MaP phrasing for [[X1 X2] N] and [N-ga X] | |
| | a. | [[X1 X2] N] |
| | | ((X1)MiP (X2)MiP (N)MiP)MaP |
| | | |
| | b. | [N-ga X] |
| | | ((N-ga)MiP (X)MiP)MaP |
| | | | |
As reviewed in
Section 2,
Selkirk (
2009) and
Selkirk and Tateishi (
1991) argue in line with Align Theory that the left edge of maximal projections (XPs) is aligned with the left edge of MaP, blocking downstep. This is not readily tenable given the presence of downstep in our data, for example, in the N
2 in [N
1-
no [N
2-
no N
3]] (see
Table 3). A standard syntax would project a maximal projection NP for the N
2. Thus, the left edge of this XP would be mapped onto the left edge of a MaP and downstep would be blocked. However, downstep was robustly found there.
Kubozono (e.g.,
1989, p. 59;
1992, p. 385) proposes a recursive MiP (not MaP) in his prosodic representation, reflecting the syntactic difference between phrases with the left-branching [[X X] N] and right-branching [X [X N]] structures. In his data, downstep occurs in both phrases, and the prosodic representations proposed are (((X)
MiP (X)
MiP)
MiP (N)
MiP)
MaP for [[X X] N] and ((X)
MiP ((X)
MiP (N)
MiP)
MiP)
MaP for [X [X N]]. Note the recursive MiPs in these representations. However, a recursive MiP account does not explain our data as the [X N] in the right-branching [X [X N]] needs to have a MaP boundary to the left of it, as in (11a), to explain the downstep blockage when the second X is A. (Kubozono uses the branching structure in the explanation of the phenomenon called the metrical boost, which he analyzes as occurring in addition to downstep at the beginning of an intermediate constituent in the right-branching structure (
Section 2)).
The idea of recognizing syntactic recursivity as reflected in recursive prosody in Japanese (and other languages) is discussed elsewhere as well (e.g.,
Ito and Mester 2012,
2013). In particular,
Ito and Mester (
2013, p. 34ff.) analyze the prosodic phrasing of left-branching NPs [[N-
no N-
no] N] (containing recursive NPs) and right-branching NPs [N-
no [A-
i N]] as an interaction of the syntax-prosody mapping that uses Match Theory (e.g.,
Selkirk 2009), where syntactic XPs are mapped onto recursive Phonological Phrases (φ), with phonological constraints (such as requirement for binarity for the Phonological Phrase and prohibition of recursivity). In their model, there is a possibility of prosodic phrasing that can assume additional bracketing for the right-branching structure.
11 In fact, in their syntactic bracketing (p. 34ff.), the NP with the right-branching syntax [[X
1] [[X
2] N]] is more complex than the NP with the left-branching one [[[X
1] X
2] N] in that it has more structure (note the additional bracket pair for the former). With this structural difference in mind, their syntax-prosody mapping would yield additional prosodic bracketing for the constituent [[X
2] N] in the right-branching NP: ((X
1)φ
min ((X
2)φ
min (N)φ
min)φ)φ
max. Recursive Phonological Phrases like this may explain the contrast between the left-branching and right-branching difference with downstep as seen in
Table 3. Here, the intermediate Phonological Phrase ((X
2)φ (N)φ)φ, in particular, the left boundary of this prosodic constituent, may block downstep. The variable nature of downstep blocking in
Table 3 can be accounted for if the level of this constituent (intermediate φ) is acknowledged and the claim that prosodic effects become cumulatively strong as more boundaries coincide at higher levels (
Fougeron 2001, et seq.;
Ishihara 2019) is adopted. The boundary here is not as strong as the boundary at the maximal PhPhrase (φ
max), resulting in variable blocking of downstep.
Note, however, that in
Table 3 downstep is not always (variably) blocked at the beginning of an intermediate constituent in a right-branching structure. It is blocked only when A is involved. This can be explained if we explore syntax-prosody mapping and adopt the architecture of prosodic hierarchy where a lower-level constituent is exhaustively contained in an immediately higher-level constituent as in the Strict Layer Hypothesis (e.g.,
Selkirk 1984;
Nespor and Vogel 1986). In
Table 3, the right-branching structure with A may actually involve an embedded clause, here a relative clause: [[X]
RC [[A]
RC N]].
12 A in the past tense form, as in (3a), projects a relative clause. A in the nonpast tense form (with the suffix
-i), as in (2b), may also do so (e.g.,
Kuno 1973;
Yamakido 2005; see
Yamakido 2000 for other references). If embedded clauses are mapped onto Intonational Phrases or PClauses (
Ishihara 2019 and references therein), which is a level higher than the MaP/Phonological Phrase, the left edge of the embedded clause that houses the A is mapped onto the left edge of an Intonational Phrase/PClause. Assuming that the edges of a higher-level prosodic category coincide with those in an immediately lower level prosodic category, the left edge of the Intonational Phrase/PClause is at the left edge of a MaP, which would block downstep. This is also compatible with the fact that the A in the predicate position [N-
ga]
subj [A]
Pred does not block downstep: the left edge of the predicate AP does not coincide with a clause boundary to the exclusion of the subject NP (if we assume a definition of syntactic clause as containing both the subject NP and the predicate); thus, there is no Intonational Phrase/PClause boundary there. This line of account is also compatible with other patterns, especially with [N
1-
no [N
2-
no N
3]], since there is not a clause boundary to the left of N
2, and thus no PClause boundary there.
The above accounts are all based on the syntax-prosody mapping hypotheses. Different syntactic branching structures are mapped onto different recursive PhPhrase structures. A syntactic clause is mapped onto an Intonational Phrase/PClause, and the syntactic difference between A and N in terms of their behaviour in clause projection provides different PClause phrasing. However, the pattern with V in
Table 3 still cannot be explained, since V, having inflection regarding tense, would project a clause just like A if we assume a standard syntax. Then, the abovementioned accounts would predict that downstep would be blocked when V is involved in the right-branching structure [X [V N]], which is not the case in the data and downstep is robust there.
How are the differences in parts of speech, in particular the anomaly of A in the downstep data in
Table 3, explained? The above discussion reveals that syntax may not be enough. That itself is not surprising because there are analyses in the literature on prosody that do not rely on syntax. One example is the information structure: focus is often said to affect prosodic phrasing. Other pragmatic cues have also been argued to be reflected in prosody such as illocutionary force (e.g.,
Selkirk 2009).
13 Below, we explore accounts in terms of semantics, another field that deals with meaning, pragmatics, and an interaction with the baseline condition (i.e., phrases with an unaccented trigger).
N, A, and V differ in terms of their denotation. Placed in the right-branching structure [X
1 [
X2 N]], in which the two Xs individually modify the head noun and thus do not form a constituent, the semantic properties of the categories in X
2 may cause a conflict with X
1 in parsing from X
1 to X
2, in which case a MaP is created beginning with X
2, blocking downstep. If the Xs are verbs, X
1 and X
2 are interpreted to have a certain semantic relation. For example, in [
mayóu [
nayámu magó]] (5a), although
mayóu ‘get lost’ and
nayámu ‘worry’ individually modify
magó ‘(one’s) grandchild’, one can easily identify a causal relation between the actions the verbs denote, i.e., the grandchild gets lost and as a result, gets worried. We can generalize the semantic relation in question as being temporal as the verbs typically denote actions/events: the actions/events conveyed by V
1 and V
2 are interpreted in such a way that one of them temporally precedes the other. This temporally ordered relation ensures a natural flow between the two verbs in [V
1 [
V2 N]], which results in a single phonological phrase (MaP).
14 In contrast, when X
2 in [X
1 [
X2 N]] is an adjective (i.e., [A
1 [
A2 N]], [V.past [
A.past N]]), since adjectives denote a state (or a property) and not an event, X
1 and X
2 cannot forge a temporal relation of the kind observed with verbs. For example, [
shirói [
nagái mamé]] ‘white, long beans’ (2a), an example of [A
1 [
A2 N]], is difficult (if not impossible) to interpret in such a way that the two states described by the adjectives are temporally ordered. Rather, since adjectives convey a state, when the two Xs are adjectives (i.e., [A
1 [
A2 N]]), the states of A
1 and A
2 temporally coexist without being related in terms of any temporal precedence.
15 In order to refer to such a situation (e.g., beans that are white and long), native speakers would probably disfavour the right-branching structure [A
1 [
A2 N]] (2a). They would rather prefer to use another construction, for example, the one in which the first adjective is in the continuative form, [[
shiró-ku nagái ]
mamé], as in (8). The reason for preferring a particular structure over the other could be to avoid a sequence of forms with the same
-i ending (presumably a type of Obligatory Contour Principle (OCP) or identity avoidance). In fact, in a study, wherein we asked 61 Japanese participants their preference among four NPs with two adjective endings [A-
i [A-
i N]], [A-
na [A-
na N]], [A-
i [A-
na N]], and [A-
na [A-
i N]] in terms of the naturalness scale from 1 (not sounding Japanese) to 6 (natural as Japanese), [A-
i [A-
i N]] sounded least natural to them to a statistically significant degree compared to others.
16 In [V.past [
A.past N]] (e.g., [
niránda [
darúkatta magó]] ‘a grandchild who stared disfavourably and was tired’ (3a)), since verbs are involved, a temporal relation is expected between the verb action/event and adjective state. However, [V.past [
A.past N] fails to be interpreted in such a way that the state of A begins after the event of V (begins and) ends or that the event of V begins after the state of A (begins and) ends. Crucially, however, it can be interpreted to mean that the event of V begins after the state of A has begun. For example, in (3a), the event of the grandchild staring disfavourably began after the start of their state of being tired. In this interpretation, there is no temporal precedence relation between the event of V and state of A in a strict sense, but it is still possible to claim that there is a partial temporal precedence relation between the two. The existence of this relation can be the source of the interspeaker variation in the presence of downstep in [V.past [
A.past N]] (see
Table 3): Some speakers needed a strict temporal precedence relation between the two Xs in [X
1 [X
2 N]] in order to make a single MaP over them. As such, they inserted a MaP boundary at the left edge of A in [V [
A N]]. If a noun appears in X
2 in [X
1 [X
2 N]] (i.e., [N
1-
no [
N2-
no N]], [V.past [
N datta N]]) when a verb is involved, i.e., in [V.past [
N datta N]], a semantic relation similar to the one found in verbs exists between the two Xs. When accompanied by
datta, the past tense form of a copular, a noun can denote an event (e.g.,
dame-datta can mean ‘failed’), and thus it is verb-like, which creates a certain temporal precedence relation between the V and N. In [N
1-
no [
N2-
no N]], the semantically underspecified nature of the particle -
no and frequency may play a role. It has been argued (e.g., in
den Dikken and Singhapreecha 2004) that Japanese -
no, like, for example, English
of and Spanish
de, is a linker that encodes a variety of semantic relations for the nouns it links. Because of this, and presumably with the help that the construction N-
no N is very frequent in Japanese, speakers can smoothly parse from N
1 to N
2 in [N
1-
no [
N2-
no N]], creating a single downstep domain.
Another possible factor for the MaP boundary to the left of A in [X [A N]] is focus.
17 One possible interpretation of the blocking of downstep is that the speakers somehow emphasized the A, which resulted in placing the focus on that element. (The source of the focus placement could be the unnaturalness created by the structure and category A as discussed above.) Since focus can be realized even when the item is downstepped (e.g.,
Ishihara 2016), a study is necessary to test this account in which we carefully control for focus in examining downstep in [X [A N]].
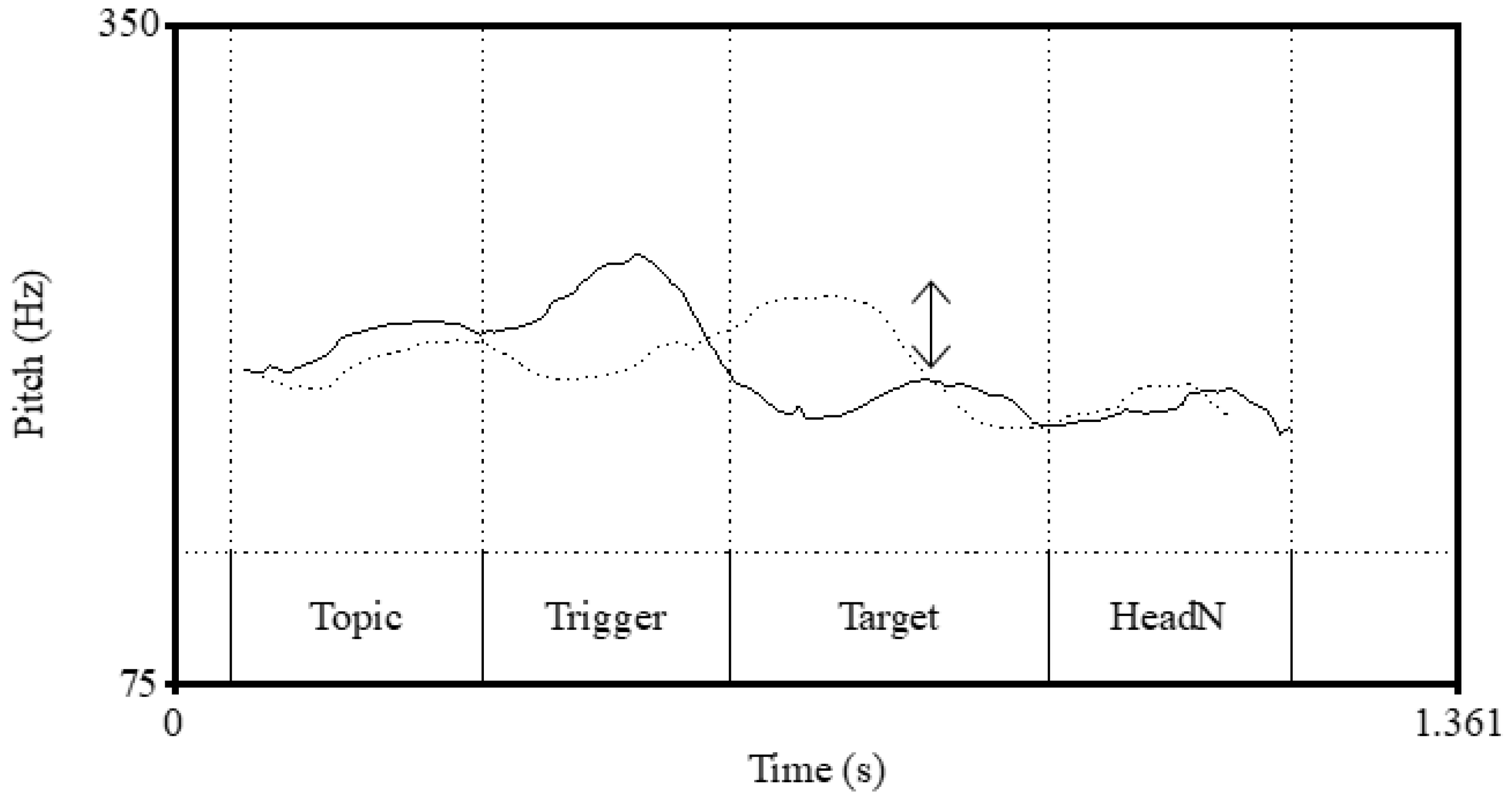
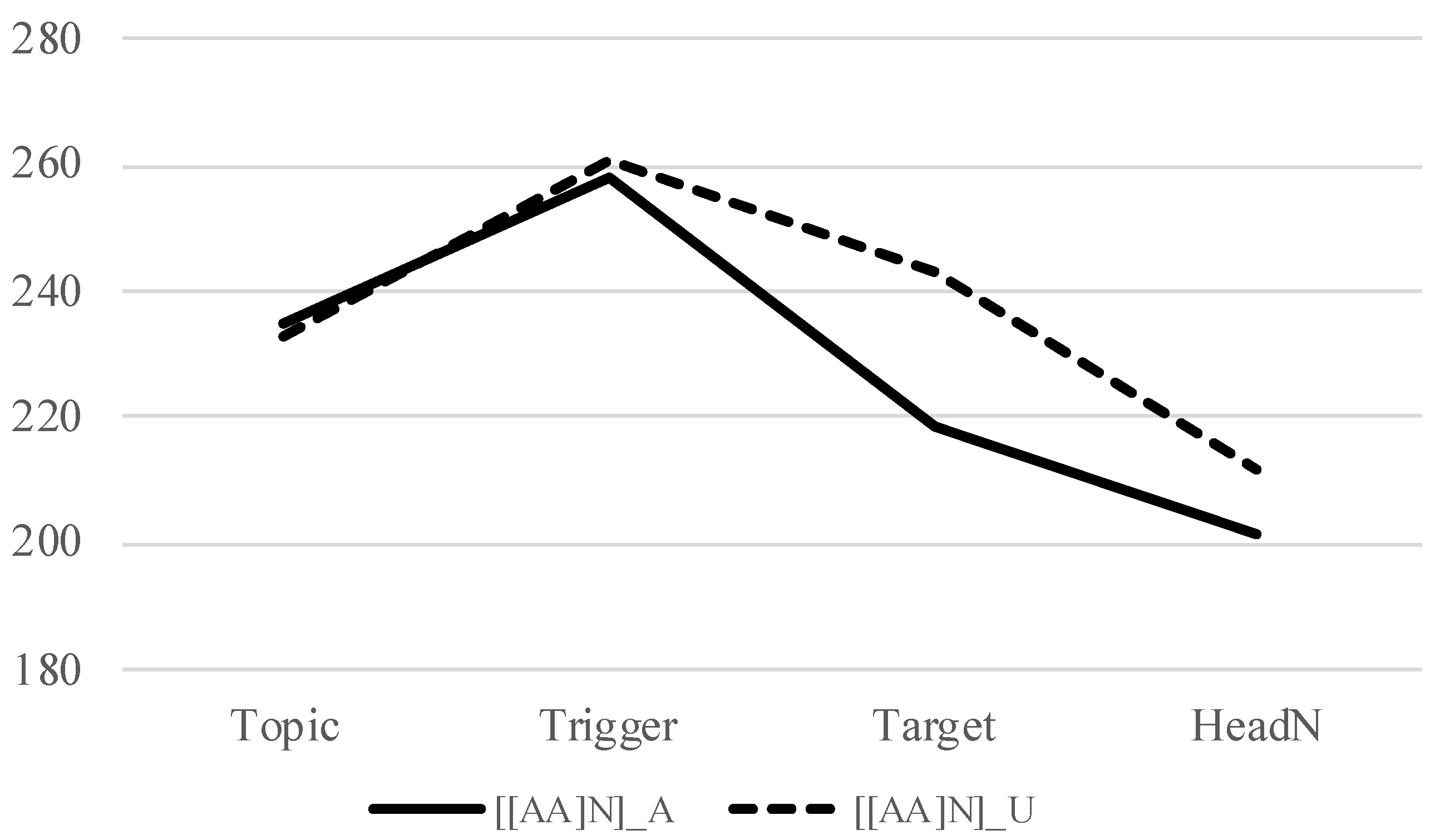
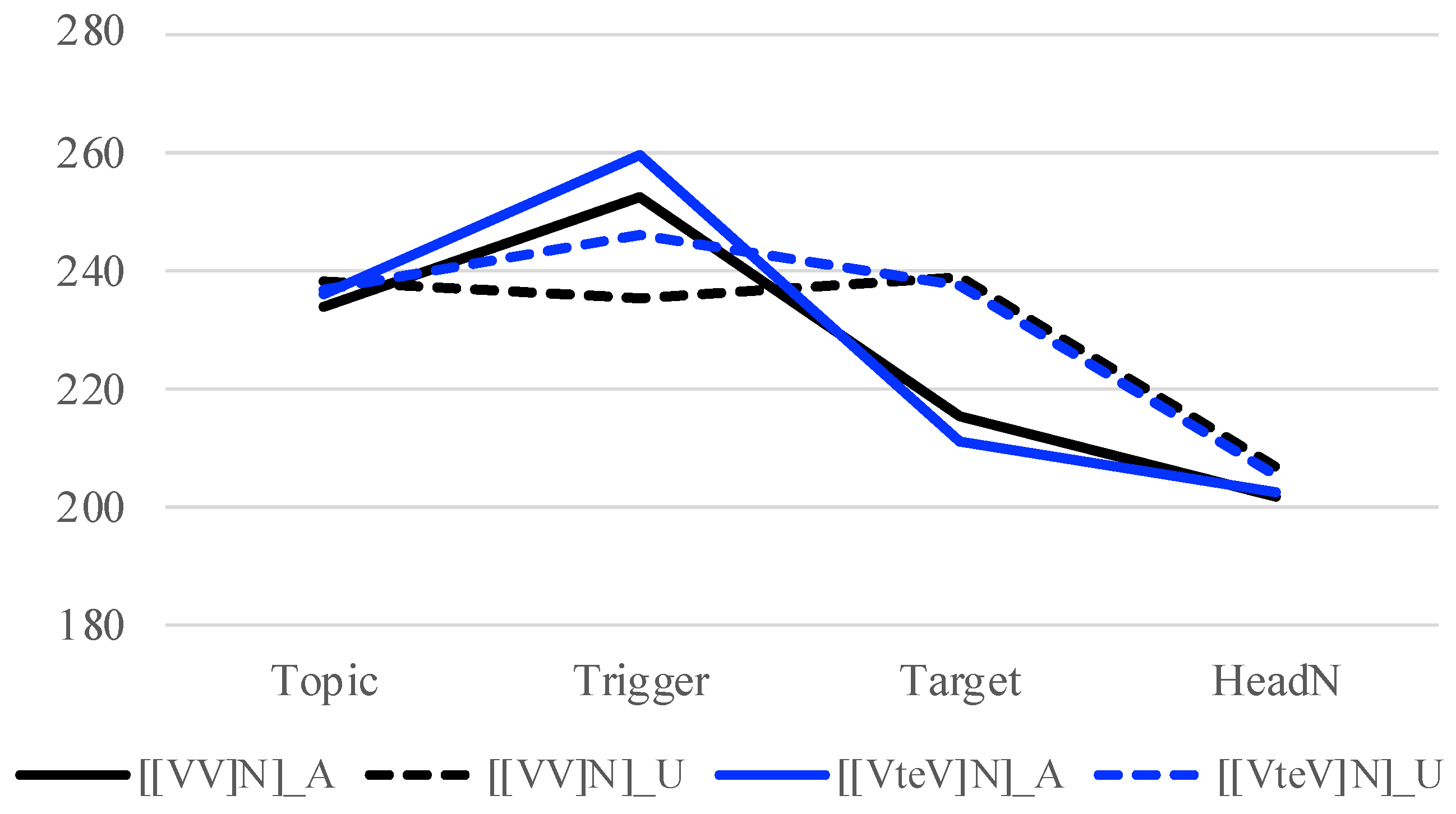
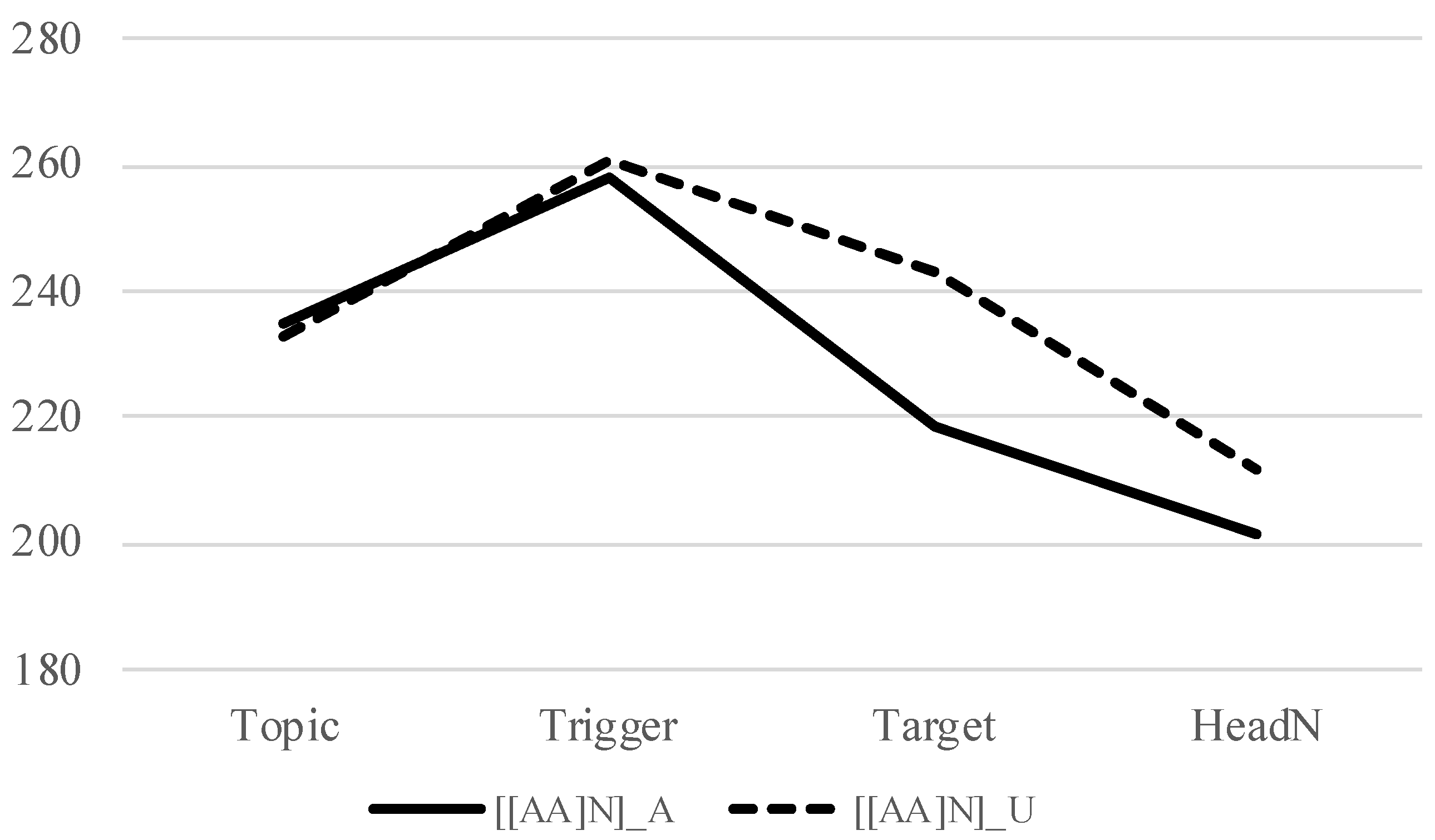
Another possible line of explanation for the absence of downstep in [X [A N]] is based on variable phrasings in the baseline condition, i.e., phrases with an unaccented trigger. In
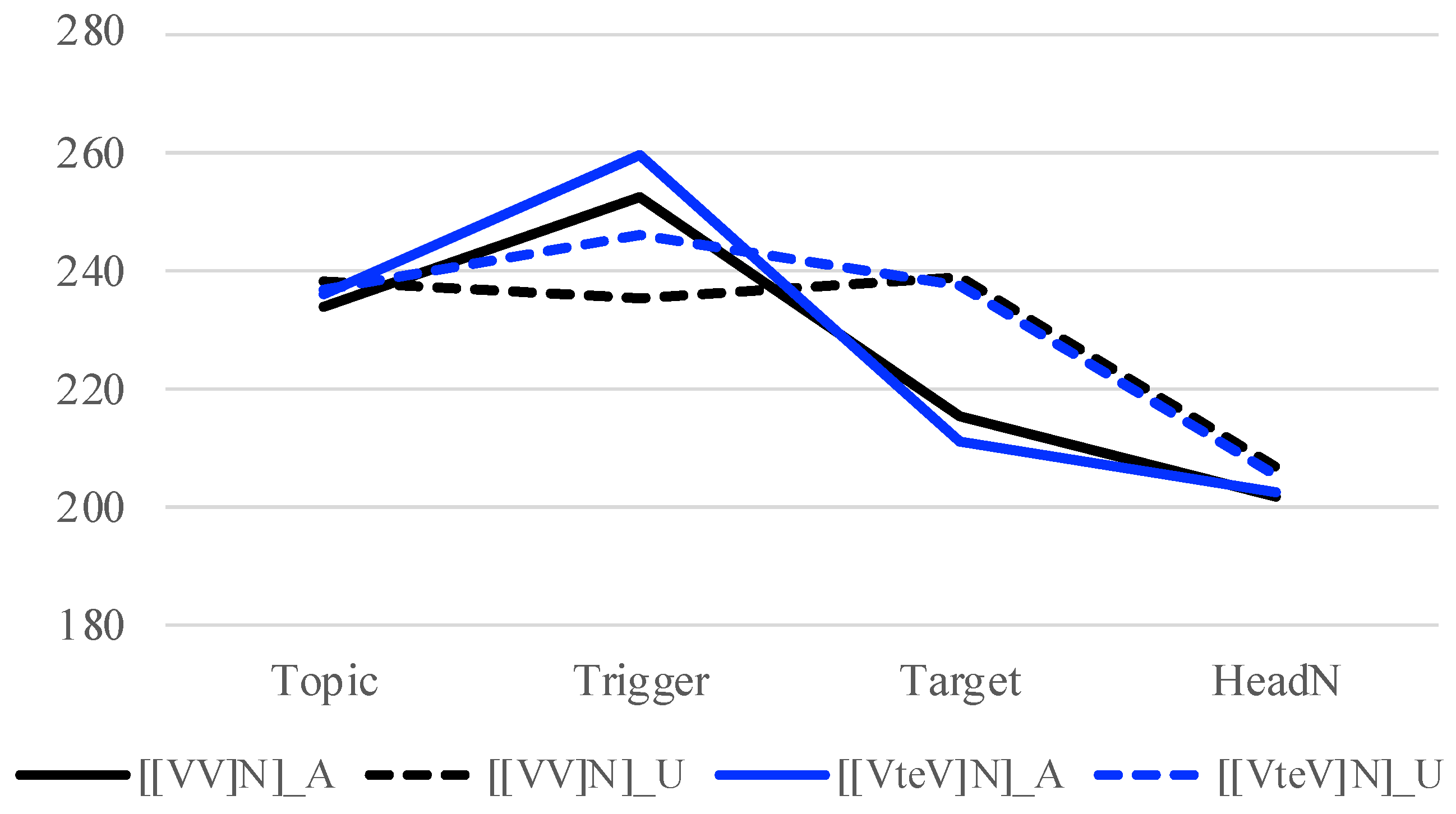
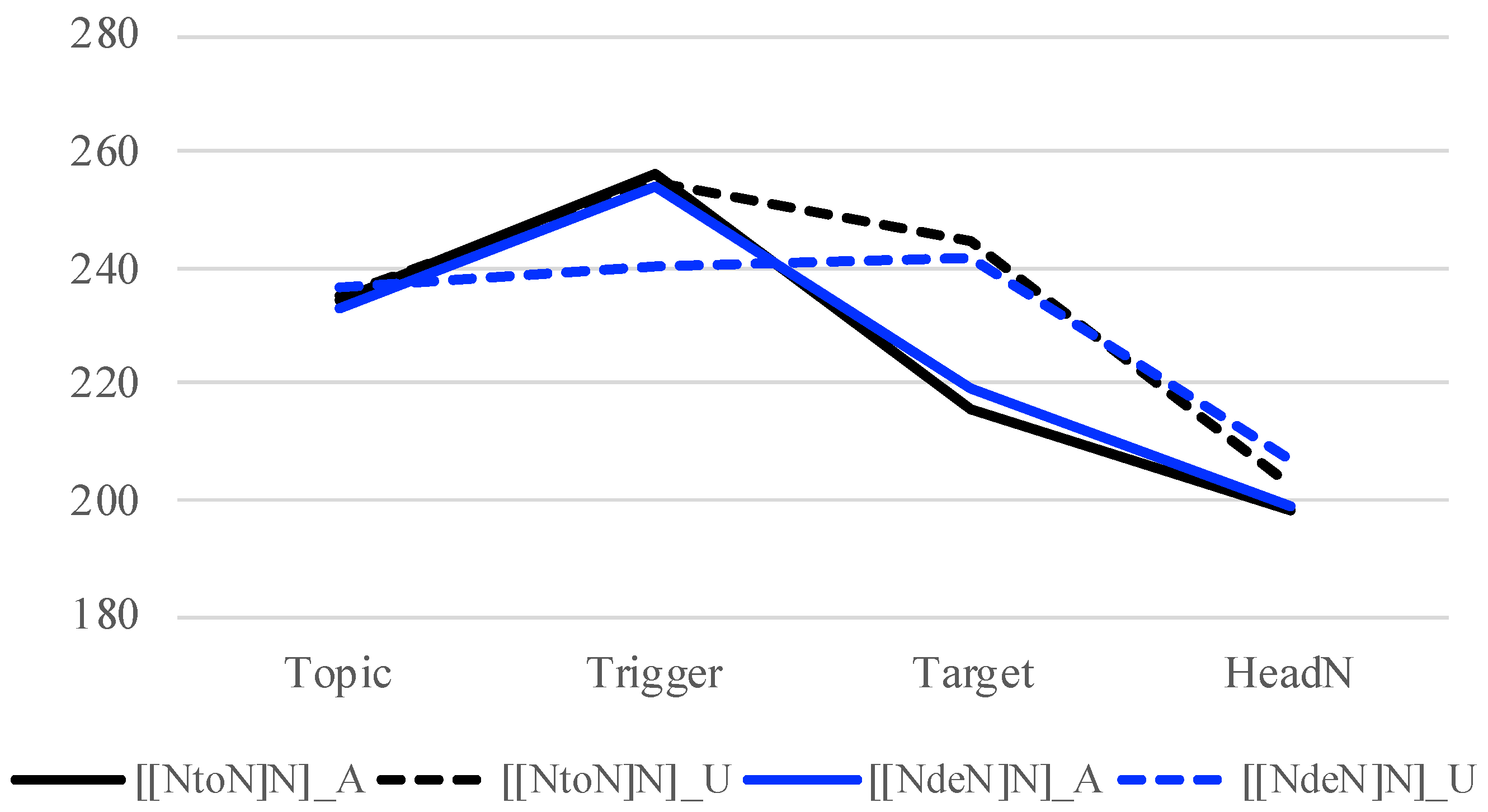
Figure 3, the f0 peaks from the Trigger to Target show a downtrend in the baseline condition ([[AA] N] U), which is not observed, at least not to the same degree, in
Figure 4 (verb) and
Figure 5 (noun). This can suggest that there is a MiP boundary between X
1 and X
2 in [[X
1 X
2] N] when X
1 is unaccented and adjectives are involved, while this is usually not the case and the two Xs would make a single MiP when X
1 is unaccented. If there is indeed a MiP boundary with adjectives but not with verbs and nouns, this may partly explain the different patterns that adjectives demonstrate compared to nouns and verbs. This should also be further investigated.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}