
Emerging Lexicon for Objects in Central Taurus Sign Language

Abstract
:1. Introduction
1.1. Iconic Representations in the Manual Systems
1.2. Combination of Signs and İconic Strategies
1.3. The Focus of This Study
1.4. Central Taurus Sign Language
2. Study 1
2.1. Materials and Methods
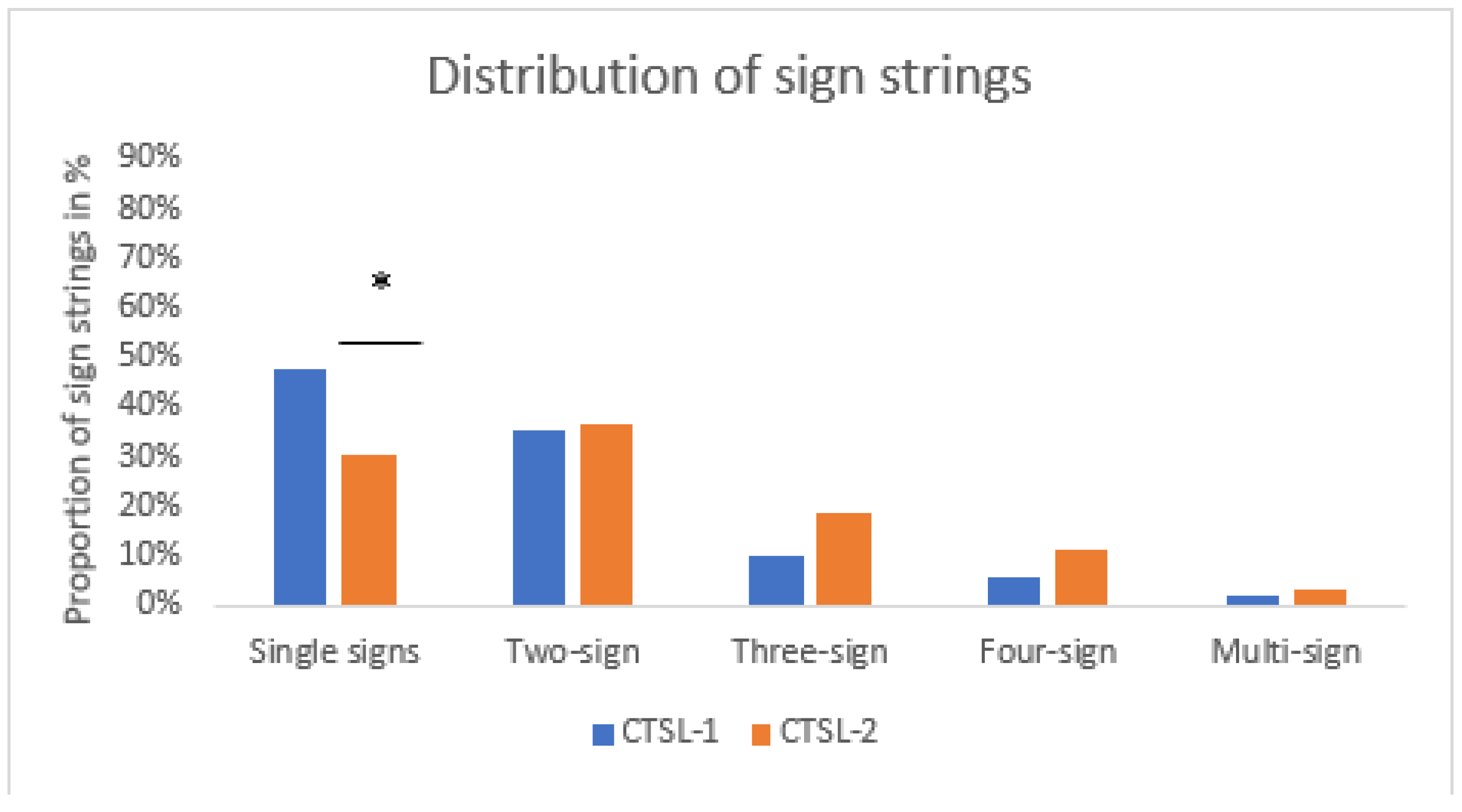
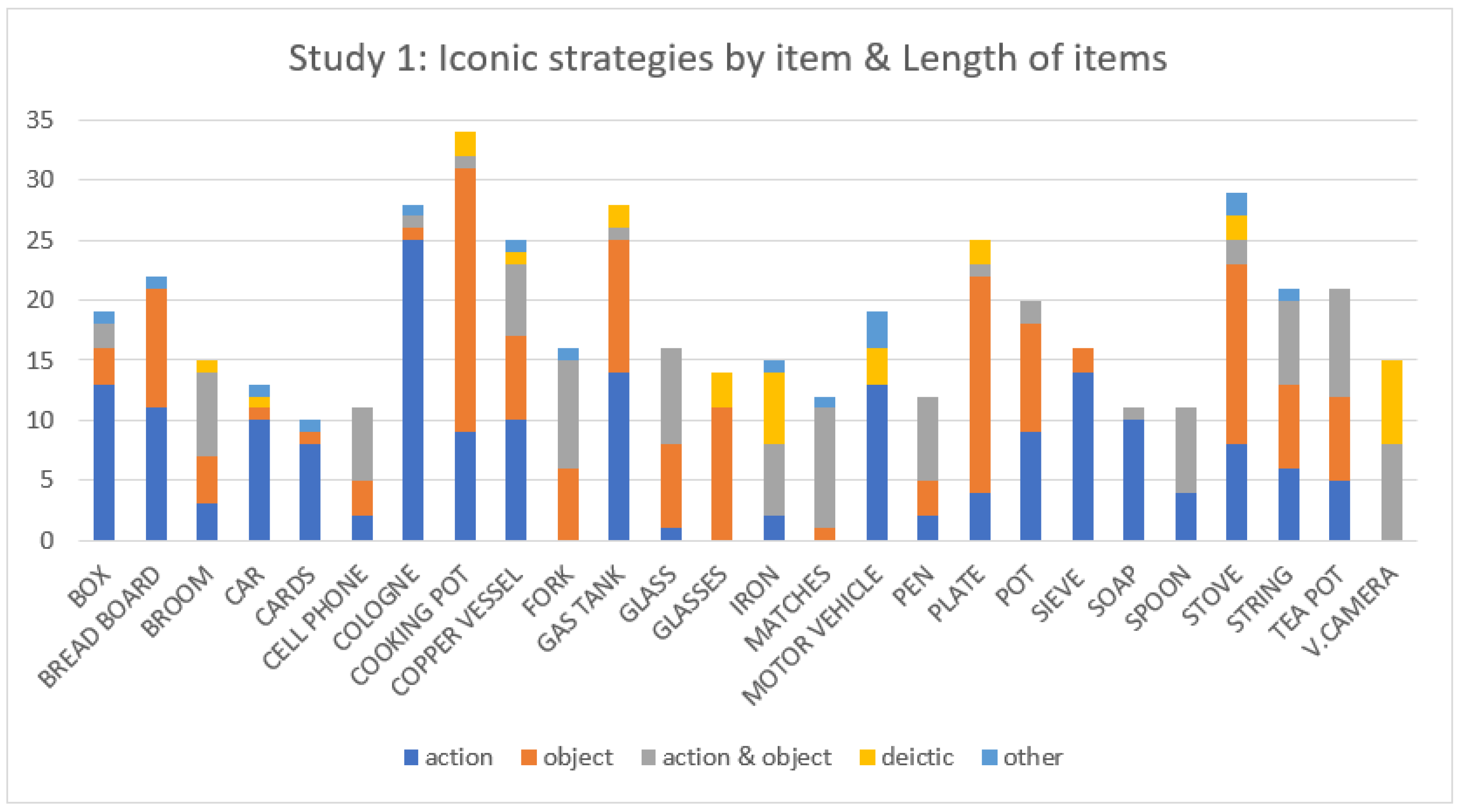
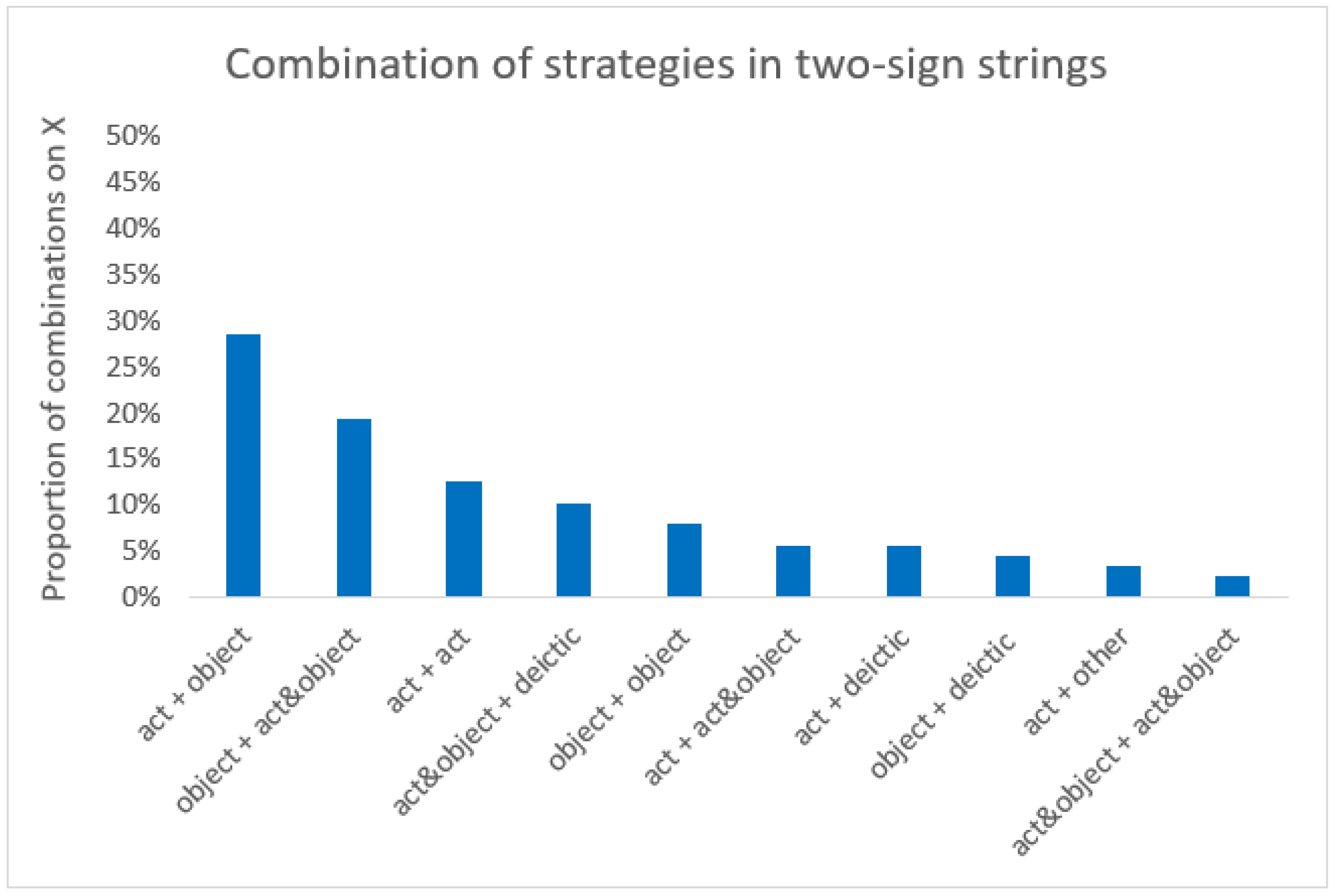
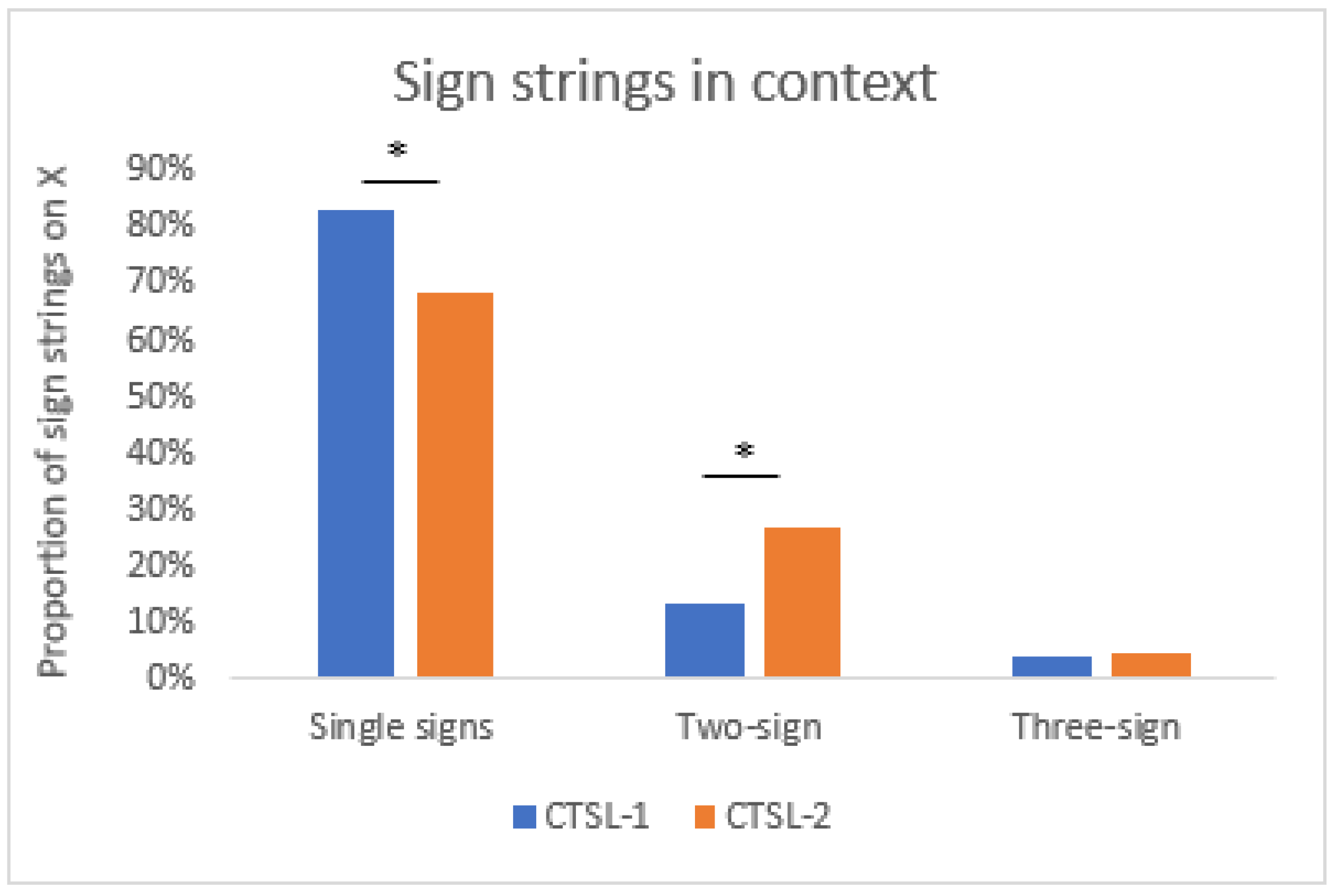
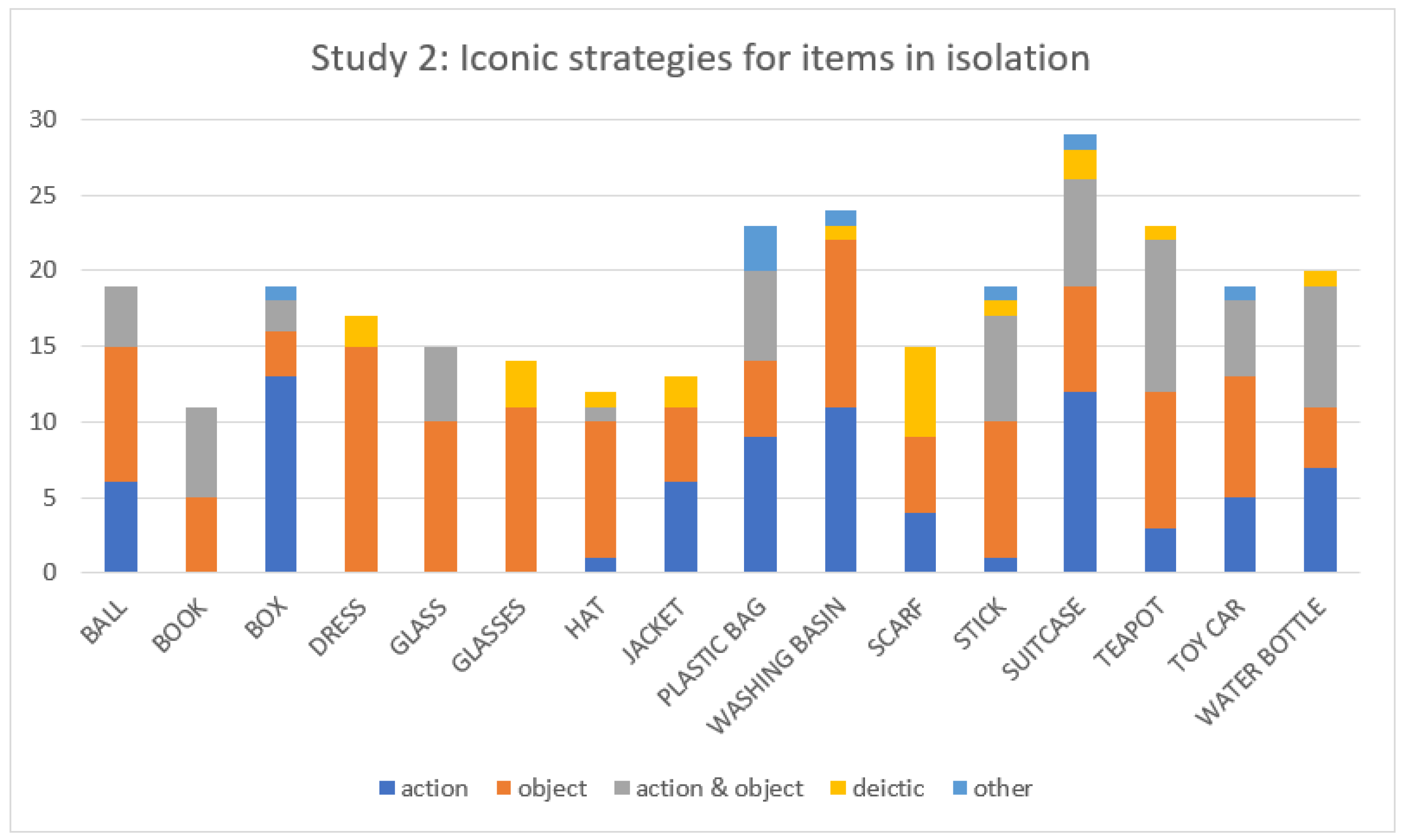
2.2. Results
2.3. Summary and Conclusions
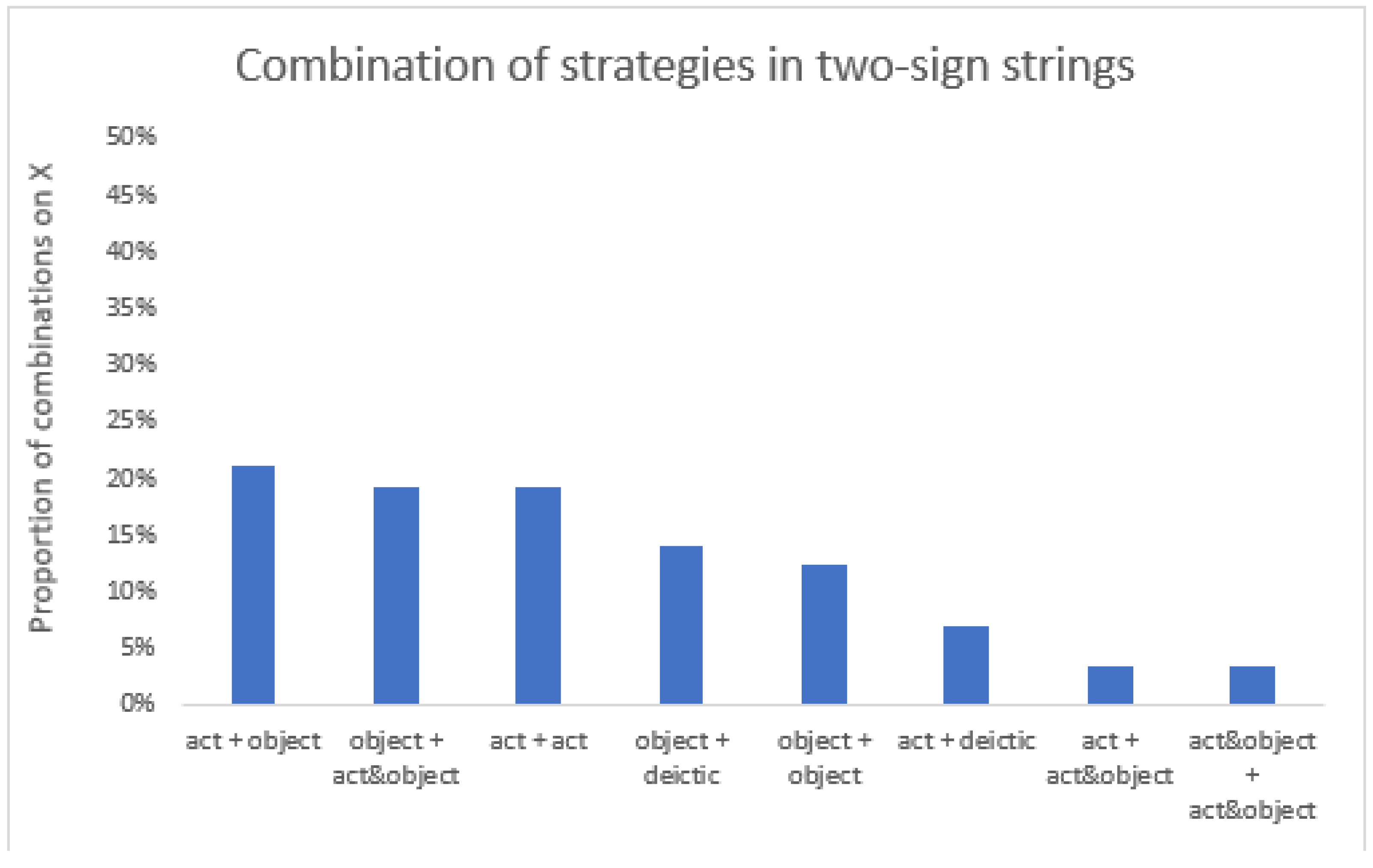
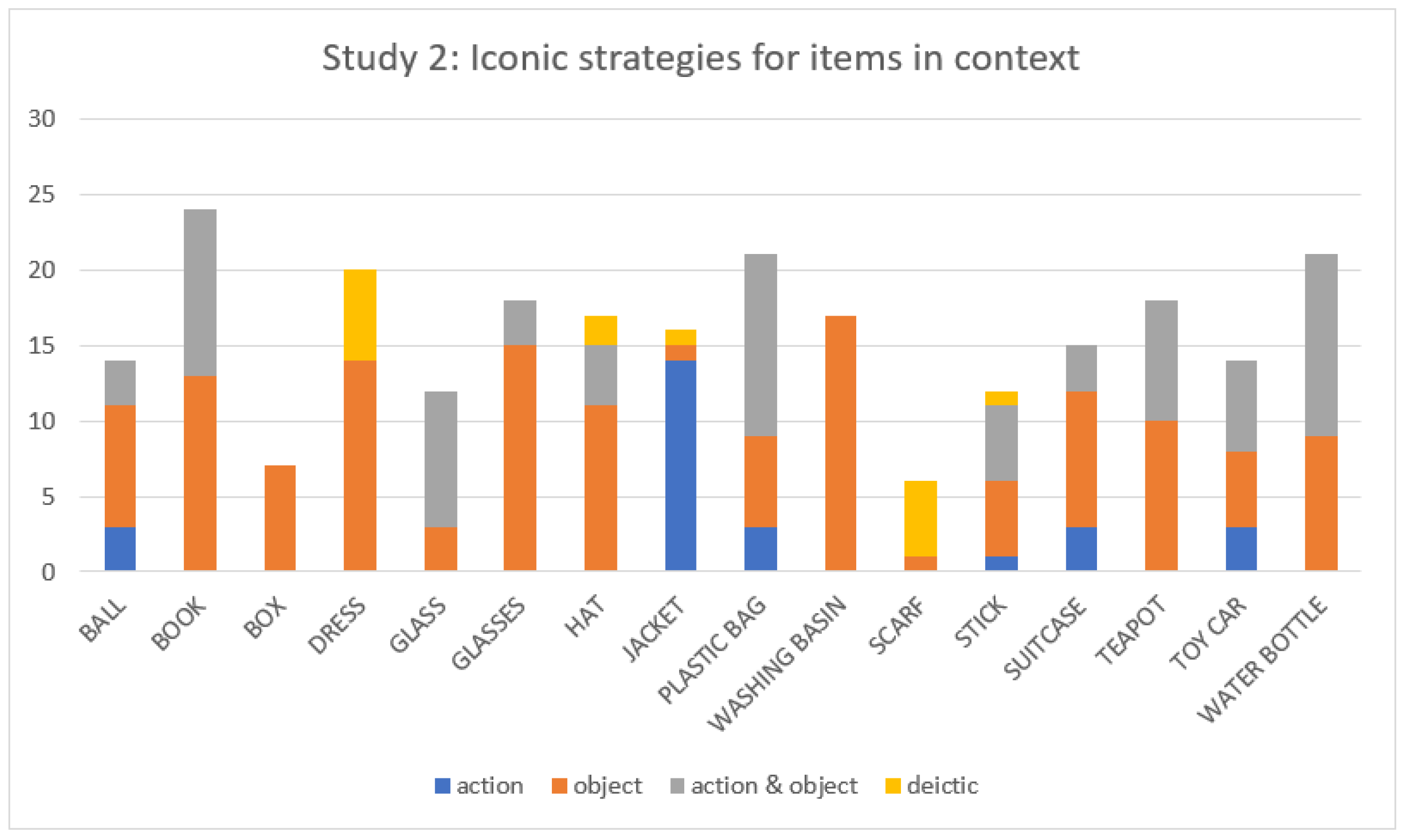
3. Study 2
3.1. Materials and Methods
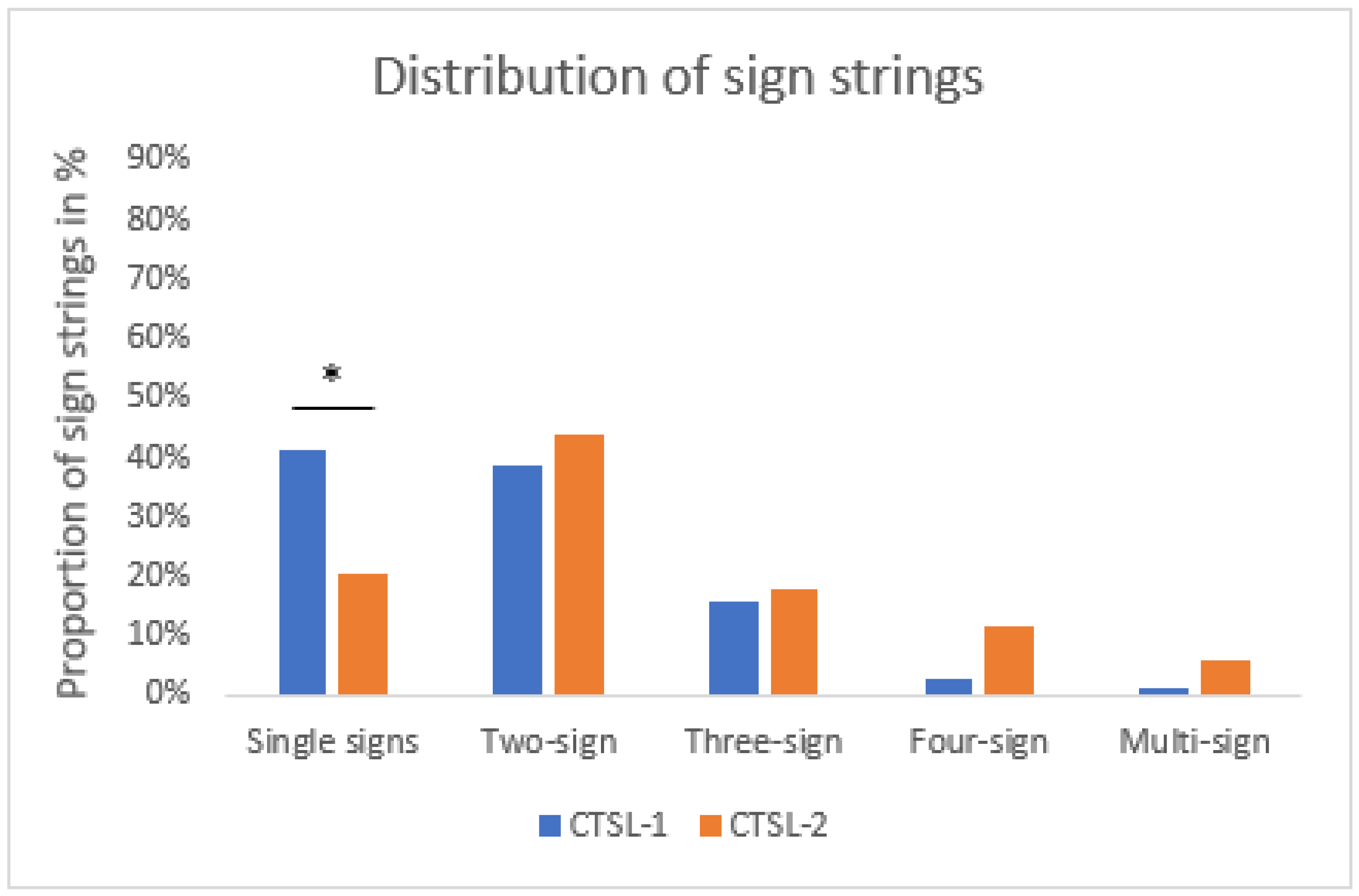
3.2. Results
- (1)
- STICK [=FIRE ^ CUT ^ SIZE]8
- (2)
- STICK [= FIRE ^ CUT] BREAK WOMAN BREAK
- (3)
- BALL [= CIRCULAR SHAPE ^ BALL THROW]
- (4)
- PLASTIC BAG [= HOLD ^ SPHERICAL SHAPE]
- (5)
- PUT INSIDE WOMAN BALL[= CIRCULAR SHAPE] PUT INSIDE PLASTIC BAG[= HOLD] PUT INSIDE
- (6)
- BALL [= CIRCULAR SHAPE ^ BOUNCE]
- (7)
- PLASTIC BAG [= HOLD ^ PUT INSIDE ^ SIZE]
- (8)
- WOMAN PLASTIC BAG [= PUT INSIDE ^ HOLD ^ SIZE] BALL[= CIRCULAR SHAPE] PUT INSIDE
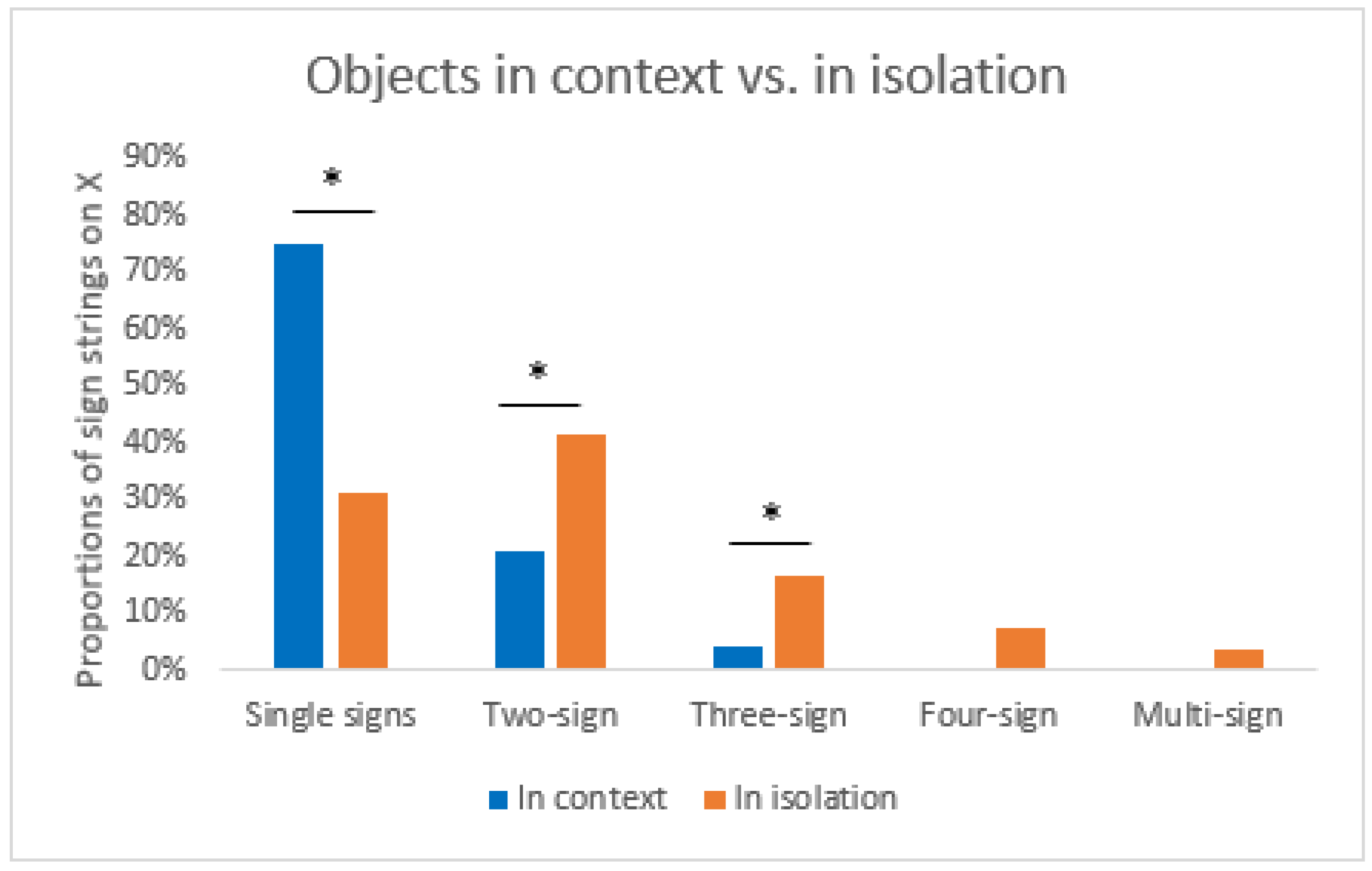
3.3. Summary and Conclusions
4. General Discussion
4.1. Object-Based or Action-Based Iconic Strategies: Which One Is More Salient?
4.2. Is There a Difference across Cohorts of Signers in the Use of Iconic Strategies?
4.3. Is There a Difference in the Use of İconic Strategies and Their Combinations When the Target Objects Are Presented in İsolation vs. Context?
4.4. Final Remarks and Future Directions
Supplementary Materials
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1. | Ergin and Brentari (2017) cautiously drew this conclusion as there was only one signer tested for handshape preferences in the first generation. |
| 2. | See also Kimmelman et al. (2018) for unsystematic variation of object vs. handling strategies across European sign languages. |
| 3. | Note that not every two-sign string is a systematic compound in CTSL (see Ergin et al. 2021). |
| 4. | The age range of the participants was reported as they were tested in 2013. |
| 5. | The data in Study 1 and Study 2 were collected in August 2013 and August 2014, respectively. All data were coded by the corresponding author. |
| 6. | These signs are typically referred to as size and shape classifiers in the literature (i.e., SASS; see Supalla 1982). In this study, they are referred to as object-based strategies, as they depict the physical form or an aspect of it, which is in line with the main research question of the current study, aiming to address whether it is the object-based or the action-based strategies that form the building blocks of an emerging lexicon. |
| 7. | Note that the movement involved in tracing forms is not in any way related to the manipulation of an object but describes the properties of size or shape. |
| 8. | The sign strings referring to the target objects are stated in square brackets. “^” is used for combining the signs in each string. |
| 9. | In their coding scheme, Ortega and Özyürek (2020) divided object-based iconic forms into further categories such as representing and drawing, which may have resulted in amplifying the count of action-based iconic forms. |
| 10. | Note that although sign languages are not improvised gestural systems, and there is ample evidence showing complex linguistic organization in sign languages, there is also growing evidence showing that gesturers and signers consistently draw from the same set of iconic strategies to mark the differences across semantic categories when they are asked to express entities in the manual modality (e.g., Hwang et al. 2017; and Ortega et al. 2017). |
References
- Brentari, Diane, Marie Coppola, Laura Mazzoni, and Susan Goldin-Meadow. 2012. When does a system become phonological? Handshape production in gesturers, signers, and homesigners. Natural Language & Linguistic Theory 30: 1–31. [Google Scholar]
- Cook, Susan Wagner, and Michael K. Tanenhaus. 2009. Embodied communication: Speakers’ gestures affect listeners’ actions. Cognition 113: 98–104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Crasborn, Onno, and Han Sloetjes. 2008. Enhanced ELAN functionality for sign language corpora. Paper presented at the LREC 2008, Sixth International Conference on Language Resources and Evaluation, Marrakech, Morocco, May 28–30. [Google Scholar]
- Emmorey, Karen. 2014. Iconicity as structure mapping. Philosophical Transactions of the Royal Society B: Biological Sciences 369: 20130301. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ergin, Rabia. 2017. Central Taurus Sign Language: A Unique Vantage Point into Language Emergence. Ph.D. dissertation, ProQuest Dissertations Publishing, Ann Arbor, MI, USA; p. 10277095. [Google Scholar]
- Ergin, Rabia, Ann Senghas, Ray Jackendoff, and Lila Gleitman. 2020. Structural cues for symmetry, asymmetry, and non-symmetry in Central Taurus Sign Language. Sign Language & Linguistics 23: 171–207. [Google Scholar]
- Ergin, Rabia, and Diane Brentari. 2017. Handshape preferences for objects and predicates in Central Taurus sign language. In Proceedings of the 41st Annual Boston University Conference on Language Development. Edited by Maria LaMendola and Jennifer Scott. Medford: Cascadilla Press, pp. 222–35. [Google Scholar]
- Ergin, Rabia, Irit Meir, Deniz Ilkbaşaran, Carol Padden, and Ray Jackendoff. 2018. The development of argument structure in Central Taurus Sign Language. Sign Language Studies 18: 612–39. [Google Scholar] [CrossRef]
- Ergin, Rabia, Leyla Kürşat, Ethan Hartzell, and Ray Jackendoff. 2021. Central Taurus Sign Language: On the Edge of Conventionalization. Available online: https://psyarxiv.com/x9emd/ (accessed on 20 March 2022).
- Goldin-Meadow, Susan, Diane Brentari, Marie Coppola, Laura Horton, and Ann Senghas. 2015. Watching language grow in the manual modality: Nominals, predicates, and handshapes. Cognition 136: 381–95. [Google Scholar] [CrossRef] [Green Version]
- Haviland, John B. 2013. The emerging grammar of nouns in a first generation sign language: Specification, iconicity, and syntax. Gesture 13: 309–53. [Google Scholar] [CrossRef] [Green Version]
- Hostetter, Autumn B., and Martha W. Alibali. 2008. Visible embodiment: Gestures as simulated action. Psychonomic Bulletin & Review 15: 495–514. [Google Scholar]
- Hou, Lynn. 2018. Iconic Patterns in San Juan Quiahije Chatino Sign Language. Sign Language Studies 18: 570–611. [Google Scholar] [CrossRef]
- Hwang, So-One, Nozomi Tomita, Hope Morgan, Rabia Ergin, Deniz İlkbaşaran, Sharon Seegers, Ryan Lepic, and Carol Padden. 2017. Of the body and the hands: Patterned iconicity for semantic categories. Language and Cognition 9: 573–602. [Google Scholar] [CrossRef] [Green Version]
- Kimmelman, Vadim I., Klezovich G. Anna, and Moroz George. 2018. IPSL: A database of iconicity patterns in sign languages. Creation and use. Paper presented at the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, May 7–12; Edited by Nicoletta Calzolari, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Koiti Hasida and Takenobu Tokunaga. Miyazaki: ELRA. [Google Scholar]
- Kita, Sotaro. 2003. Pointing: A Foundational Building Block of Human Communication. In Pointing: Where Language, Culture, and Cognition Meet. Edited by Sotaro Kita. Mahwah: L. Erlbaum Associates, pp. vii, 339. [Google Scholar]
- Klima, Edward, and Ursula Bellugi. 1979. The Signs of Language. Cambridge: Harvard University Press. [Google Scholar]
- Lepic, Ryan, and Carol Padden. 2017. A-morphous iconicity. In On Looking into Words (and Beyond). Berlin: Language Science Press, vol. 23, p. 489. [Google Scholar] [CrossRef]
- Meir, Irit, Carol Padden, Mark Aronoff, and Wendy Sandler. 2013. Competing Iconicities in the Structure of Languages. Cognitive Linguistics 24. [Google Scholar] [CrossRef] [Green Version]
- Meir, Irit, Mark Aronoff, Wendy Sandler, and Carol A. Padden. 2010. Sign Languages and compounding. In Cross-Disciplinary Issues in Compounding. Edited by Sergio Scalise and Irene Vogel. Amsterdam: John Benjamins Publishing, pp. 301–22. [Google Scholar]
- Morgan, Hope E. 2015. When Does a Word Emerge? Lexical and Phonological Variation in a Young Sign Language. San Diego Linguistic Papers 5: 2–17. [Google Scholar]
- Müller, Cornelia. 2013. Gestural modes of representation as techniques of depcition. In Body–Language–Communication: An International Handbook on Multimodality in Human Interaction. Edited by Cornelia Müller, Alan J. Cienki, Ellen Fricke, Silva H. Ladewig, David McNeill and Sedinha Tessendorf. Berlin: De Gruyter Mouton, pp. 1687–701. [Google Scholar]
- Müller, Cornelia, Jana Bressem, and Silva H. Ladewig. 2013. Towards a Grammar of Gestures: A Form-Based View. In Body–Language–Communication: An International Handbook on Multimodality in Human Interaction. Berlin: De Gruyter Mouton, vol. 1, pp. 707–33. [Google Scholar]
- Nyst, Victoria, Marta Morgado, Timothy Hadjah, Marco Nyarko, Mariana Martins, Lisa van der Mark, Evans Burichani, Tano Angoua, Moustapha Magassouba, Dieydi Sylla, and et al. 2021. Object and handling handshapes in 11 sign languages: Towards a typology of the iconic use of the hands. Linguistic Typology. [Google Scholar] [CrossRef]
- Ortega, Gerardo, Annika Schiefner, and Asli Özyürek. 2017. Speakers’ gestures predict the meaning and perception of iconicity in signs. Paper presented at the 39th Annual Conference of the Cognitive Science Society (CogSci 2017), London, UK, July 16–29; pp. 889–94. [Google Scholar]
- Ortega, Gerardo, and Asli Özyürek. 2020. Systematic mappings between semantic categories and types of iconic representations in the manual modality: A normed database of silent gesture. Behavior Research Methods 52: 51–67. [Google Scholar] [CrossRef] [Green Version]
- Ortega, Gerardo, Beyza Sumer, and Asli Ozyurek. 2014. Type of iconicity matters: Bias for action-based signs in sign language acquisition. Paper presented at the 36th Annual Meeting of the Cognitive Science Society (CogSci 2014), Quebec City, QC, Canada, July 23–26; pp. 1114–19. [Google Scholar]
- Padden, Carol A. 2016. Interaction of Morphology and Syntax in American Sign Language. London: Routledge. [Google Scholar]
- Padden, Carol, Irit Meir, So-One Hwang, Ryan Lepic, Sharon Seegers, and Tory Sampson. 2013. Patterned iconicity in sign language lexicons. Gesture 13: 287–305. [Google Scholar] [CrossRef]
- Padden, Carol, So-One Hwang, Ryan Lepic, and Sharon Seegers. 2015. Tools for language: Patterned iconicity in sign language nouns and verbs. Topics in Cognitive Science 7: 81–94. [Google Scholar] [CrossRef]
- Perniss, Pamela M. 2007. Space and Iconicity in German Sign Language (DGS). [Sl]: MPI Series in Psycholinguistics. Available online: http://www.pernipa.eu/papers/Perniss_MPI_dissertation.pdf (accessed on 20 March 2022).
- Perniss, Pamela, Robin Thompson, and Gabriella Vigliocco. 2010. Iconicity as a general property of language: Evidence from spoken and signed languages. Frontiers in Psychology 1: 227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pietrandrea, Paola. 2002. Iconicity and arbitrariness in Italian sign language. Sign Language Studies 2: 296–321. [Google Scholar] [CrossRef]
- Pizzuto, Elena, and Virginia Volterra. 2000. Iconicity and transparency in Sign Languages: A cross-linguistic cross-cultural view. In The Signs of Language Revisited: An Anthology to Honor Ursula Bellugi and Edward Klima. Edited by Karen Emmorey and Harlan L. Lane. Mahwah: Lawrence Erlbaum Associates, pp. 229–250. [Google Scholar]
- Sandler, Wendy, Mark Aronoff, Irit Meir, and Carol Padden. 2011. The gradual emergence of phonological form in a new language. Natural Language & Linguistic Theory 29: 503–43. [Google Scholar]
- Schembri, Adam, Jones Caroline, and Burnham Denis. 2005. Comparing action gestures and classifier verbs of motion: Evidence from Australian Sign Language, Taiwan Sign Language, and nonsigners’ gestures without speech. Journal of Deaf Studies and Deaf Education 10: 272–90. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Senghas, Ann, Sotaro Kita, and Aali Özyürek. 2004. Children creating core properties of language: Evidence from an emerging sign language in Nicaragua. Science 305: 1779–82. [Google Scholar] [CrossRef] [Green Version]
- Supalla, Ted R. 1982. Structure and Acquisition of Verbs of Motion and Location in American Sign Language. Ph.D. dissertation, University of California, San Diego, CA, USA. [Google Scholar]
- Taub, Sarah. 2001. Language from the Body: Iconicity and Metaphor in American Sign Language. Cambridge: Cambridge University Press. [Google Scholar]
- Tkachman, Oksana, and Wendy Sandler. 2013. The noun-verb distinction in two young sign languages. Gesture 13: 253–86. [Google Scholar] [CrossRef]
- Vermeerbergen, Myriam. 2006. Past and current trends in sign language research. Language & Communication 26: 168–92. [Google Scholar]
- Wilbur, Ronnie. 2003. Representations of telicity in ASL. Paper presented at the Proceedings from the Annual Meeting of the Chicago Linguistic Society, Atlanta, GA, USA, January 2–5; vol. 39, pp. 354–68. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| box | fork | motor vehicle | spoon |
| bread board | gas tank | pen | stove |
| broom | game cards | plate | string |
| car | glass | pot | telephone |
| cologne | glasses | sieve | teapot |
| cooking pot | iron | soap | video camera |
| copper vessel | matches |
| ball | dress | glasses | washing basin |
| box | hat | plastic bag | suitcase |
| book | jacket | scarf | teapot |
| bottle | glass | stick | toy car |
| Woman puts the ball inside the plastic bag | Woman puts the glass on the table |
| Man puts the onion in the plastic bag | Man puts the glasses on woman’s face |
| Man puts the teapot into the box | The woman drops the glasses |
| Man throws the hat | Man is sewing the jacket |
| Man puts the hat on woman’s head | Man takes off the jacket |
| Man picks up the small book on the table | Man takes the bottle from the woman |
| Toy car hits the book | Bottle falls on the woman |
| Man irons dress | Woman is trying to break the stick |
| Woman is washing the dress in the washing basin | Man is trying to open the suitcase |
| Woman is washing the scarf in the washing basin |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ergin, R. Emerging Lexicon for Objects in Central Taurus Sign Language. Languages 2022, 7, 118. https://doi.org/10.3390/languages7020118
Ergin R. Emerging Lexicon for Objects in Central Taurus Sign Language. Languages. 2022; 7(2):118. https://doi.org/10.3390/languages7020118
Chicago/Turabian StyleErgin, Rabia. 2022. "Emerging Lexicon for Objects in Central Taurus Sign Language" Languages 7, no. 2: 118. https://doi.org/10.3390/languages7020118
APA StyleErgin, R. (2022). Emerging Lexicon for Objects in Central Taurus Sign Language. Languages, 7(2), 118. https://doi.org/10.3390/languages7020118