Abstract
In this article we examine the allomorphic variation found in Pennsylvania Dutch plurality. In spite of over 250 years of variable contact with English, Pennsylvania Dutch plural allomorphy has remained largely distinct from English, except for a number of loan words and borrowings from English. Adopting a One Feature-One Head (OFOH) Architecture that interprets licit syntactic objects as spans, we argue that plurality is distributed across different -types, resulting in stored lexical-trees (L-spans) in the bilingual mental lexicon. We expand the traditional feature inventory to be ‘mixed,’ consisting of both semantically-grounded features as well as ‘pure’ morphological features. A key claim of our analysis is that the s-exponent in Pennsylvania Dutch shares a syntactic representation for native and English-origin , although it is distinct from a ‘monolingual’ English representation. Finally, we highlight how our treatment of plurality in Pennsylvania Dutch, and allomorphic variation more generally, makes predictions about the nature of bilingual morphosyntactic representations.
1. Introduction
Processes and phenomena related to word formation—which we take here to be connected with morphology—in contact environments have traditionally been, and continue to be, a topic that garners significant research. In this paper we examine the plural allomorphy of Pennsylvania Dutch (PD), a West Germanic language with strong Palatinate-dialect roots. Today, it is predominantly spoken by conservative Amish and Mennonite groups and has developed and flourished for nearly three centuries in the Eastern US and beyond (Louden 2016). In many respects PD is a remarkable success story of a minoritized language that has not only survived, but has also enjoyed continued growth and expansion. Speakers of PD are best classified as diglossic bilinguals (Grosjean 2008), who use each available language primarily within particular sociolinguistic contexts (for more on this, see Louden 2020). In this article we survey the morphosyntactic and morphophonological realizations of plurality in PD outlined in Fisher et al. (2022), paying close attention to its allomorphic distributions. A key question that we hope to address here is the extent to which syntactic structures associated with the s-exponents in PD are similar or different to their English counterparts, for either ‘native’ PD vocabulary, English loanwords, or both. The PD examples in (1) demonstrate the variety of ways that PD realizes plurality, including in the form of the exponent {s}. In the pages that follow we make the case that any potential differences in PD and English syntax associated with {s} are irrelevant, because the structures of the are identical.
- (1)
- Kissi → Kissi-s ‘pillow/pillows’
- Schnuppi → Schnuppi-s ‘hankie/hankies’
- Hammer → Hammer-s ‘hammer/hammers’
- Mick → Mick-e ‘fly/flies’
- Schtick → Schtick-er ‘piece/pieces’
- Haus → Heis-er ‘house/houses’
- Hand → Hend ‘hand/hands’
- Frein → Frein ‘friend/friends’
Our analysis contributes to and is grounded by a number of theoretical axioms and assumptions. Specifically, we adopt two well-known and well-supported views regarding the bilingual lexicon. The first of these is the hypothesis that the bilingual lexicon—in addition to most other grammatical properties—exists in a combined, integrated cognitive space, in which competition between grammatical elements from each language is inevitable (Aboh 2015; Goldrick et al. 2016; Kroll and Gollan 2014; Marian and Spivey 2003; Putnam et al. 2018). Secondly, in spite of this constant competition of forms and representations in the bilingual lexicon, the general consensus in the language contact literature points towards a strong dispreference for the borrowing of inflectional morphology from one language to another (Matras 2009, 2014; van Coetsem 1988; Winford 2005). Our proposal that s-plurals in PD are structurally identical to their English counterparts for PD speakers adds an interesting wrinkle to this debate of exactly which elements of traditional “inflectional morphology” hinder borrowability in sustained language contact and why this generalization holds true in the majority of cases.
In this article, we adopt the tenets of a late-insertion, realizational approach to morphology within a neo-constructivist model of morphosyntax. Neo-constructivism describes a family of approaches which adhere to a ‘syntax before lexicon’ model of grammar. The building blocks of syntax are thus features, not morphemes. Morphemes are ‘late-inserted’ to realize structure, once it has been assembled. Within neo-constructivism, approaches differ on issues like whether features can be ‘bundled’ in syntactic terminals (Distributed Morphology (DM) (Embick and Noyer 2001; Harley 2009; López 2020; Marantz 2013)) or not (Nanosyntax (NS) (Starke 2009)), whether (and to what extent) multiple operations are required to facilitate the matching and insertion of morphemes (see Caha (2018) for a comprehensive discussion of how DM and NS differ), and whether syntactic categories are axiomatic (DM) or epiphenomenal (Exo-skeletal Syntax (XS) (Borer 2005)). As a consequence of adopting a neo-constructivist approach, morphology is not afforded a unique modular status in our system. Moreover, and in line with a main tenet of NS, we assume a One Feature-One Head (OFOH)-architecture (Kayne 2005; Putnam 2020; Stroik and Putnam 2013), where each feature is a syntactic head, and feature bundling is not possible.
One challenge facing all neo-constructivist approaches, but particularly approaches adhering to an OFOH-architecture, concerns the nature of the features/functional heads (Adger and Svenonius 2011). In privative systems, features cannot take positive or negative values but are simply present or absent. Furthermore, features could be syn(tactico)-sem(antic) in nature, bearing some inherent semantic/C(conceptual)-I(ntentional) content, and thus are interpretable at LF. Alternatively, they could be purely abstract, thus not interpretable at LF. This issue is at the heart of how best to model allomorphic variation and word formation processes. To date, neo-constructivist models have tended to favor feature systems that are either of the syn-sem/C-I kind or purely abstract. The choice, it seems, has been determined in large part by utility and the nature of the linguistic phenomenon under consideration. For example, accounts of structural case, where form is not connected to meaning in any obvious sense, have tended to adopt abstract feature systems (e.g., Caha 2009), whereas studies of spatial expressions and event types have tended to use C-I feature systems (e.g., Svenonius 2010; Ramchand 2019).
We understand allomorphy as the result of any linguistic environment in which the same set of semantic or morphosyntactic features is realized as (at least) two or more phonological representations (or exponents) (Paster 2014). Therefore, we exclude alternations that result from predictable outcomes of phonological operations. Likewise, we understand allomorphy as suppletive, involving multiple underlying forms of the same exponent (see Paster 2014 for discussion).1 Because of the many-to-one correspondence between form and meaning reflected in plural allomorphy, we propose that a system comprising both abstract and C-I features is needed to adequately capture these types of distributions. In a system that only relies on C-I features, the grammar generates only ‘meaningful’ syntactic representations. If morphemes are inserted to express these representations, the expectation is that (i) form will change to express meaning change, and (ii) there may be allosemy, where one form encompasses two or more different structures, each corresponding to a different meaning. It is more challenging, with a purely C-I-based feature system, to account for phenomena that are characterized by a form change without a corresponding meaning change, e.g., structural case morphology, doubling (Barbiers 2008), and indeed allomorphy. The prediction seems to be that ‘pure’ allomorphy, where some forms are not directly associated with C-I-based features, should not exist. This is obviously incorrect, given the various types of empirical evidence to the contrary, including that found in plurality in PD (recall (1)). Instead, accounting for distributions of allomorphs in systems in such a framework requires additional operations, like readjustment rules in DM, where the insertion of some vocabulary items is subject to additional morphosyntactic constraints at PF, and in some instances, deletion post-syntactically.
However, if allomorphy can ostensibly be reduced to the size of syntactic objects, i.e., trees (Caha 2017b, 2018; Starke 2014), we must entertain the notion that not all features are C-I-based. As mentioned above, we explore the possibility that the feature inventory is ‘mixed’, consisting of both C-I-based features and a limited number of abstract features, which we will label as F(eature). To the best of our knowledge, a principled theory of such a mixed inventory of C-I- and abstract F-features has not been extensively investigated within any OFOH-architecture. In the pages that follow we show how a distributive analysis of plurality can account for the allomorphic reflexives of plural marking in PD. In this context, distributive entails the decomposition of number (see Wiltschko (2008, 2021) for recent proposals) into structures containing both C-I- and F-features.
Another key element of our analysis concerns both the structure of and their role in the bilingual mental lexicon. We argue for the existence of unique encoded with syntactic structure. This proposal has two potential advantages: First, it alleviates the necessity of associating with a particular language or origin and anchors this facet of with more salient structure. Second, anchoring syntactic information to particular -types also enables a more straightforward linking between plural allomorphs and particular ‘classes’ of nouns. This simplifies post-syntactic operations and severely restricts the role of PF plays in determining plural exponency. In summary, our distributed treatment of plurality in PD seeks to provide adequate answers to two research questions:
- RQ1: Do the syntactic structures, i.e., spans, that we employ in our analysis explain allomorphy selection in language contact scenarios, particularly by constraining the borrowing of inflectional morphology?
- RQ2: How successful is our spanning-based approach in modeling allomorphy in morphological plural marking in Pennsylvania Dutch?
This paper adheres to the following structure: In Section 2 we provide an overview of the allomorphic variation present in PD plural marking. We turn our attention to theoretical underpinnings of a spanning approach to syntactic structure in Section 3. Here we also establish a view of formal features, building on language-specific oppositions (Hall 2020). We then advance a spanning-analysis of these alternations in the PD plural system in Section 4 that exploits a ‘mixed’ inventory of features. In Section 5, we elaborate on the predictions that a spanning approach to plural allomorphy makes for a bilingual grammar. This paper concludes in Section 6.
2. Plurality in Pennsylvania Dutch: Allomorphic alternations
We now turn to Pennsylvania Dutch, which represents the empirical focus of our analysis. Agreeing with Keiser (2012, p. 1), Pennsylvania Dutch (PD) is a language that has “outgrown its name”. Once a language spoken by only a few thousand in the rural counties of Southeastern Pennsylvania, this Germanic language has spread across North America and is now spoken in many states as well as in Ontario (Louden 2016). The language began forming approximately 250–280 years ago when German-speaking immigrants from Western Europe came to the British colonies in the “New World” seeking economic opportunities and, for some, religious freedom. Because these immigrants came from different parts of the German-speaking world, PD represents a melting pot of mostly Southern German dialects the most influential of which is thought to be Palatinate (Christmann 1950). However, the fact that PD formed in the “New World” also means that it has been in steady contact with English throughout its existence and, remarkably, nearly all speakers are both L1 PD speakers and highly proficient English/PD bilinguals.
Although many aspects of its grammar continue to reflect its Palatinate-based heritage (Buffington 1970; Christmann 1950),2 initially, the bulk of research on properties of this language has predominantly focused on the non-sectarian, i.e., individuals who are not members of traditional Anabaptist faith communities, variant of the language. The majority of PD speakers today, however, belong to conservative, separatist Anabaptist groups such as the Amish and Old Order Mennonites. In light of the growing number of these sectarian speakers and the moribund status of non-sectarian PD, linguists have shifted their attention to the former (Knodt 1986; Louden 1989; Louden and Page 2005; Meister Ferré 1994), including work that has begun to investigate linguistic variation based on geographical location and other sociolinguistic variables (Brown 2011, 2019; Keiser 2001, 2012; Louden 2016; Reed and Seifert 1954; Van Ness 1995). The data that we analyze in this paper likewise come from informants who speak sectarian PD.
There has been some more general descriptive work carried out on the morphology of PD, particularly on the gender of English loan words (Page 2011; Reed 1942), however, detailed work on plurals has been limited (see Reed (1948) for a brief treatment). Instructive grammars on PD (e.g., Brown and Madenford 2009; Frey 1985) describe it as having a fairly German-like system of plural formation (see Table 1). These forms draw from the morphemes, or exponents, {e}, {r}, {n}, and {s} (we motivate their phonological content below), along with umlaut and zero plurals. Umlaut refers to a vowel fronting in the stem and can be found in some cases in combination with the {r} exponent as well as without an overt suffix. Our treatment of plural allomorphy in this paper focuses primarily on these morphological reflexives of plural marking in PD. We do not focus on count vs. mass distinctions, other issues related to quantification (such as the structure of quantifiers and cardinals), nor do we explore the relationship between singularity and plurality in the detail it rightfully deserves. In Standard German (SG), prosodic structure plays an important role in the distribution of nominal plurals. In PD, on the other hand, prosody is less rigid for plural formation than in SG, although there are clear tendencies (see Fisher et al. 2022 for details). We turn to a discussion of the prosodic structure in Section 2.1, before elaborating on the particular exponents under investigation in Section 2.2.

Table 1.
Pennsylvania Dutch plural forms.
2.1. Trochaic Structure in (Standard) German vs. Pennsylvania Dutch
Prosody has been shown to figure predominantly in shaping morphological and phonological properties of West Germanic varieties (Booij 1998; Smith 2020). In Dutch and Standard German (SG), for example, prosodic structure plays an important role in the distribution of nominal plurals, such that stem and suffix combinations regularly produce word-final trochees (Booij 1998; Salmons 2018; Schuhmann and Putnam 2021; Schuhmann and Smith 2022; Smith 2020; Wegener 1999; Wiese 2001, 2009). A syllabic trochee is defined as a foot composed of a stressed syllable (ˈ) followed by an unstressed syllable (ˈ#). As is typical in SG, the following nominal plural forms produce word-final, syllabic trochees although each noun uses a different plural allomorph exponent: ˈFrau-en ‘woman-pl’, ˈStift-e ‘pen-pl’, and Geˈsicht-er ‘face-pl’. The suffixes -en, -e, and -er combine with roots that end in a stressed syllable, which are primarily monosyllabic or disyllabic with an initial unstressed syllable. The -n and -∅ forms suffix to trochaic roots, such as ˈTass.e-n ‘cup-pl’ and Comˈpu.ter-∅ ‘computer-pl’, respectively, maintaining the trochee in the plural. Stem vowel alternation, i.e., umlaut, may also occur in combination with {e} and {r}.
Although it is not prudent to classify SG as a direct baseline language for PD (see Polinsky 2018, Section 1.2.2 for discussion), the common ancestry shared by PD and SG warrants an investigation into the degree to which PD shares prosodic tendencies in plural formation with SG. PD does exhibit some German-like traits in the formation of plurals, in particular with respect to employing a trochaic requirement to (some) plural forms (Fisher et al. 2022). We do not treat the morphosemantics and morphophonology of plurality and German separately here, however, when applicable, we make mention of these reflexes in our detailed treatment of PD plurality.
While SG shows a strong tendency for nominal plural forms to end in word-final trochees, not all continental dialects adhere as strictly as SG to this pattern. Wiese (2009) found that Northern Bavarian, for example, is less driven by prosody in plural formation than SG. Regardless of whether this is a pre- or post-contact feature in the U.S., the importance of trochees in underlying representations for the selection of plural alternations seems to be reduced, if not absent, for PD. In their preliminary experimental investigations on PD—using a Wug test (Gleason 1958) and an Acceptability Judgment Task—with sectarian participants from Lancaster County, PA, Fisher et al. (2022) demonstrate that trochees still result from plural formation, primarily through the affixation of the syllabic exponents {e} and {r} to monosyllabic singular stems. Furthermore, {n} is always suffixed to diminutives, which occur as disyllabic singular forms ending in -li and a subset of occurrences of {s} appear in combination with disyllabic roots such as ˈHammer-s ‘hammer-pl’. However, numerous instances abound, where trochees are not present in plurals. These cases are primarily monosyllabic plurals ending in the {s}, primarily loans from English such as ˈFrog-s ‘frog-pl’, and plurals with no suffix, including umlauting plurals, as in ˈFrein ‘friend-pl’ and ˈHend ‘hand-pl’. As there does not appear to be a strict requirement for trochaic plurals (for further details, see Fisher et al. (2022)), we take this to mean that prosodic structures do not directly mediate the distribution of plural allomorphy in PD. Rather, we understand the alternations to result from interactions between the feature composition of plural in PD and the underlying structures of the constituents involved (see Section 4).
2.2. Characteristics of PD Plural Exponents
From the overview presented in Table 1, we direct our focus to four different classes of PD noun plurals. These are based not on stem shape, but on suffix—or exponent—selection. Therefore, we view both umlauting plurals and zero-plurals as belonging to the same morphosyntactic class. The same is the case for all plurals ending in {r}; all nouns with {s} and all nouns with {e} plurals likewise each form their own class. Finally, since PD n-plurals categorically affix to the diminutive suffix -li, we leave these as a topic for further investigation, which will consider representations and interactions beyond plural.3
With respect to s-plurals, Fisher et al. (2022) find that {s} is the most common strategy for lexicalizing plurality when speakers are presented with new lexical content, i.e., nonce items in a Wug test (Gleason 1958). We take this pattern to be consistent with {s} being a type of ‘default’ plural suffix that we find for new PD items, English loanwords, including monosyllabic ones, and a subset of PD stems that have disyllabic roots, particularly those ending in -er and -i, like Baller-s ‘ball-pl’ and Kissi-s ‘pillow-pl’, respectively. It should be noted that {s} has also been proposed as the ‘default’, albeit low-frequency, plural suffix for Standard German in some accounts (see Sonnenstuhl et al. 1999, p. 213; Wiese 1996b, p. 138). We elaborate in Section 4 on the relationship between a potential default status in distribution and the exponent’s underlying syntactic structure in PD.
The plural classes that end in -e and -er, what we respectively adopt as the exponents {e} and {r}, speak to syllabification patterns that illuminate the phonological shapes of both the relevant and exponents. For example, the noun Messer ‘knife’ is disyllabic in both the singular and plural (cf. Messre).4 We see two possibilities for this pattern: (i) with two vowels that undergoes syncope in the plural, or (ii) with a consonant-liquid cluster in the coda, where the liquid is syllabified in the singular. We consider liquid syllabification to be the superior process because an underlying representation such as contrasts the phonological form of divocalic s-plurals like ‘ball’, such that their distinct shapes map neatly to the different syntactic structures presented in Section 4. Liquid syllabification further indicates that there is a unique exponent {r}, not {er}, that does not contain the exponent {e} (for an overview of containment issues see Bobaljik 2012; Caha 2017a; DeClerq and Wyngaerd 2017). Therefore, the surface form of an r-plural like Hemmer ‘shirt-pl’ is derived from the same syllabification mechanisms as the singulars Messer and Hiwwel (see Table 2 for an illustration).
Table 2.
Potential syllabification patterns in consonant-liquid coda clusters.
Accordingly, we consider the forms presented in Table 3 to comprise the core allomorphic variation for PD. In addition to the three classes we elaborated on above, there are again the ∅-plurals, which variably participate in stem alternations. We aim, then, to model the distributions of these four forms through an architecture that pairs an enriched syntactic structure, based on a OFOH-design, to a single, semantic category, namely plural. In the following section, we motivate the theoretical framework we adopt, with consideration to how it defines structures for both exponent selection processes and for C-I interpretation.
Table 3.
Pennsylvania Dutch Plural exponent classes.
3. OFOH-Architecture
In this section we provide an overview of the core theoretical concepts of our analysis. In the subsequent subsections we outline the emergence and content of features (Section 3.1), their distribution in determining the syntax of num(ber) (Section 3.2), and their realization as spans that mediate the insertion of lexical (i.e., morphological) material at the syntax-lexicon interface (Section 3.3).
3.1. Features and Contrast
Feature inventories may differ cross-linguistically due to their primary role in representing language-specific contrasts (Cowper and Hall 2014; Hall 2020). This position contrasts to some degree with cartographic proposals that call for a more rigid organization of features in a ‘universal spine’, or fseq (e.g., Caha 2009; Cinque 1999; Starke 2009; Wiltschko 2014, 2021), even without a particular contrast in a given language system. Grammatical operations in a language are computed using the features that distinguish its relevant oppositions. On our view, which is often referred to as the ‘contrastivist hypothesis’ (Cowper and Hall 2014; Hall 2007), features are not universal or inherent. Instead, they must be postulated based on contrasts, indicated by grammatical operations. Therefore, some type of grammatical activity is the strongest evidence for (an acquirer to postulate) a specific feature (Dresher 2009; Dresher et al. 1994). In our approach, we make use of both C-I-based features, which contribute semantic information, and F-features, which are syntactic features that guide the selection of exponents, but do not contribute semantic information. A C-I-based feature is postulated when a contrast in meaning (and potentially form) is encountered (e.g., locative in vs. directional into). An F-feature, however, is postulated when a contrast in form (but crucially not in meaning) is encountered (e.g., he.nomsang the aria vs. she made him.accsing the aria).
Although this perspective on features was developed in the domain of phonology (Dresher et al. 1994), recent applications of the primacy of grammatical contrast and its relationship to substantive representational content has been extended to (morpho)syntax (esp. Bjorkman and Hall 2020).5 The fundamental difference between the two domains lies in how their properties are related to concrete forms. Specifically, “the features specified on vocabulary items, unlike the features specified on phonemes, are not properties of the vocabulary items [i.e., exponents] themselves; rather, they are specifications of contexts in which the vocabulary items can be inserted” (Hall 2020, p. 262). There are two subtly distinct, important points to made in connection with this statement.
Firstly, (morpho)syntactic features mediate between exponents and structure. Precisely how this mediating mechanism is modelled has important theoretical consequences. As stated above, our model is based on an OFOH-architecture, where the mediating mechanism is the size and composition of syntactic structure. Specifically, feature trees that are specified on exponents (‘L(exical)-spans’) are matched against feature trees that are generated in syntax (‘S(yntactic)-spans’). As with NS in general, such a mechanism has the advantage over DM of not requiring post-syntactic readjustment rules. We elaborate on (S- and L-)spans in Section 3.3 below.
The second point is that systematic patterns of exponent insertions provide evidence for distinctions in morphosyntactic contexts. In other words, patterns of insertion ought to diagnose (for the acquirer and for the the linguist) the size and content of the spans (i.e., the feature trees). For the acquirer, language-specific morphosyntactic patterns come online once (i) the necessary features are postulated and (ii) those features are generalized to the correct set of grammatical computations governing the relevant morphosyntactic patterns, and (iii) exponents realizing the morphosyntactic patterns have become associated with the features regulating the patterns (see Section 3.2). In our system, (ii) involves the integration of features into S-spans, and (iii) involves the formation of L-spans (i.e., encoding exponents with ‘segments’ of possible S-spans). Again, we elaborate on this in Section 3.3 below.
For bilinguals, we may not only see an expansion or reorientation of relevant oppositions in one language compared to another, but also a more robust set of feature-form mappings and stored feature configurations. Therefore, the allomorphy problem takes on a new shape through potentially asymmetric form-to-feature relationships among exponents. That is, in addition to the possibility that exponents may map to new syntactic configurations, i.e., S-spans, introduced to the grammar via language contact, we may also find homophonous exponents with distinct underlying representations, i.e., multifunctional forms. We explore these competing options with {s} based on its occurrence in two potentially distinct morphophonological environments: as the plural exponent of (i) a disyllabic PD root, i.e., "Ham.mer-s ‘hammer-pl’; "Blum.mi-s ‘flower-(dim)-pl’, and (ii) English-origin lexical items, i.e., Frog-s ‘frog-pl’; Boot-s ‘boot-pl’. However, we argue that {s}, both in PD and in English, is a shared exponent associated to a single underlying structure. Before elaborating on the PD plural paradigm, we motivate the feature primitives we adopt for capturing—and constraining—the distribution of plural allomorphy in PD.
3.2. A Brief Overview of the Syntax of num
To quote Harbour (2014, p. 191): “the challenge for a theory of number is to articulate a set of semantic feature primitives ([C-I-based] features) that apply compositionally to nominal and pronominal lattices alike to yield only attested numbers (e.g., no quadral), and only within attested number systems (e.g., no dual without singular and plural), while at the same time capturing the natural classes attested by morphological compositionality and related diachronic and synchronic phenomena.” The syntax of grammatical number is a rich empirical domain that encompasses diverse theoretical approaches (see Hofherr and Doetjes 2021). Following initial proposals by Ritter (1992) and Borer (2005), realizational, late-insertion models such as DM have proposed that—at least in most cases—plural allomorphy resides ‘outside’ of the structural domain of derivational morphology (which is usually associated with category type-setting functional heads such as n). The only standing exception to this is in connection with lexical plurals, which we do not discuss in this article.6 In this subsection, we provide a motivation for the structure of the functional sequence of heads that exist in the licensing of the syntax of (grammatical) num. The data in the remainder of this subsection are cited from Wiltschko (2021). We will focus strictly on segmental reflexes of plural marking while acknowledging that other distinctions, such as tone, are cross-linguistically employed to indicate plurality.
The basis of Ritter’s (1992) proposal for a separate functional projection for num can be illustrated with possessive constructions in Hebrew. In the construct state (2), the head noun is followed by its possessor, but it cannot be introduced by a determiner.
- (2)
- Hebrew: construct state
- beyt ha-morahouse the-teacher‘the teacher’s house’
- *ha-beyt ha-morathe-house the-teacherIntended: ‘the teacher’s house’
A key contrast is observed when we compare Hebrew construct state DPs in (2) with its free state possessive constructions in (3). Two key differences are worth noting: First, when the determiner ha is absence, the noun phrase is indefinite. Second, the possessor is obligatorily introduced by ʃel, which assigns genitive case. The contrast between these two sets of examples suggests that a functional projection—num exists between the (or n in DM-parlance) and D (see Heycock and Zamparelli (2005) for additional support).
- (3)
- Hebrew: free state
- bayit ʃel ha-morahouse of the-teacher‘a house of the teacher’s’
- ha-bayit ʃel ha-morathe-house of the-teacher‘the teacher’s house’
The observed non-complementarity that exists between number marking and classifiers in languages such as Armenian (see, (4) has led to the proposal that a singleton projection for num is insufficient to account for the syntax of plurality in such languages (Acquaviva 2016; Alexiadou 2011; Dali and Mathieu 2021; Dékány 2021; Mathieu 2012, 2014; Wiltschko 2008). The non-complementarity of number and classifier marker in Armenian can be summarized as follows: nouns can be counted by either a preceding classifier (4a) or by a plural marker (4b), but crucially not by both at the same time (4c).
- (4)
- Armenian
- yergu had hovanoc uni-mtwo cl umbrella have-1s‘I have 2 umbrellas.’
- yergu hovanoc-ner uni-mtwo umbrella-pl have-1s‘I have 2 umbrellas.’
- *yergu had hovanoc-ner uni-mtwo cl umbrella-pl have-1s‘I have 2 umbrellas’ (Borer 2005, p. 39)
The distribution of plural marking also extends beyond the split of number and classifier distinctions. In fact, in some languages, such as Persian, plural distinctions are realized on functional projects as high as D (5).
- (5)
- Persian
- sæg did-æmdog see.past-1sg‘I saw dogs’
- sæg-a-ro did-æmdog-pl-omsee.past-1sg‘I saw the dogs.’ (Gomeshi 2003, p. 48)
Taken together, empirical evidence from typologically diverse languages make an overwhelmingly strong case for the distribution of plural across a domain of functional projections in syntactic structure, which structurally dominate the (Arad 2003, 2005; Wiltschko 2021).
- (6)
- Distributed num projections (Wiltschko 2021, p. 190)

The tree structure in (6) represents structural positions within a functional sequence where number can be realized.7 Working from the bottom up, the categorizing n-head is generally regarded to be the locus idiosyncratic information for the marking of ‘lexical plurals’ (Acuaviva 2008; Alexiadou 2011, 2021). The functional heads, Cl, #, and D represent classifier, num, and determiner respectively. Although different late-insertion models may differ with respect to the exact number and composition of these functional heads, all of them embrace some version of the tree structure represented above in (6). In a OFOH-architecture, these features project as individual heads. As we elaborate on in the remainder of this paper, in our analysis of plural marking in Pennsylvania Dutch, in addition to C-I grounded plural features, such as #, we introduce two abstract (content-free) F-features, see (7). As we explain in our treatment of PD plurals in Section 4, the abstract F-features provide a conceptually appealing way to model the observed allomorphy in this language. Contrasting this structure in (7) with our proposal for English (8; see Section 5) furthermore provides an opportunity to more accurately model instances of plural marking in contact settings.
- (7)
- Syntactic representation for Pennsylvania Dutch plural

- (8)
- Syntactic representation for English plural

3.3. A Spanning Approach to Distributed num
Our neo-constructivist model is based on the premise of an impoverished UG and emergent (natural classes of) formal features that mark language-specific contrasts (Biberauer 2019), as discussed in detail in Section 3.1. We assume that the components of grammar are: (a) a pre-syntactic feature inventory, (b) a syntactic component, (c) a lexicon, (d) a semantic component, and (e) a phonological component. The syntactic component organizes formal features, via the operation Merge, into hierarchical structures called spans.8 More precisely, we refer to the structures generated by the syntactic component as S(yntactic)-spans in order to distinguish them from spans that are encoded on exponents, to which we refer as L(exical)-spans. Blix (2021, p. 7) defines a span as in (9).9
- (9)
- Span:An n-tuple of heads is a span in a syntactic structure S, iff is the complement of Xn in S.
In prose, this means that a span is an uninterrupted sequence of head-complement relations that does not include specifiers. At fixed points in the derivation, the S-span is shipped to the syntax-lexicon interface, where exponents in the lexicon compete to realize (i.e., be inserted into) the structure. This is called ‘spell out’. In line with Svenonius (2020) and Blix (2021), we make the fundamental assumption that spans (and not terminal nodes) are the locus of insertion. Another fundamental assumption that we make about lexicalization is that each node in the S-span must always be associated with an exponent. This is captured by the Exhaustive Lexicalization Principle:
- (10)
- Exhaustive Lexicalization Principle:Every syntactic feature must be lexicalized. (Fábregas 2007, p. 167)
As suggested above, the eligibility of an exponent for insertion into a particular S-span is determined by whether the L-span encoded on that exponent is a match for the S-span. All eligible exponents compete for insertion, and the best-matched candidate is inserted.10 Phenomena like multifunctionality and suppletion indicate that an exponent’s L-span need not match an S-span identically in order for that exponent to ‘win’ the competition for insertion. In our model, like in NS more generally, competition is governed first and foremost by the Superset Principle:
- (11)
- Superset Principle:In case a syntactic span does not have an identical match in the lexical repertoire, select an exponent which contains a superset of the features present in the syntactic span.(Adapted from Fábregas and Putnam 2020, p. 40)
Based on (11), an exponent which qualifies and competes for insertion must have an L-span that contains at least all of the features in the S-span. In other words, the L-span of a qualifying exponent may contain features not present in the S-span. Such ‘irrelevant’ features will simply be underassociated (ignored) in the context of that derivation. According to the Superset Principle, L-spans which do not contain all of the features in the S-span do not qualify to compete for insertion.
Importantly, however, the Superset Principle alone cannot account for all attested patterns of insertion. In particular, as we illustrate below with the contrast between regular and irregular plurals, suppletion suggests an interplay between the Superset Principle and another insertion strategy, which applies if and only if the Superset Principle cannot obtain (i.e., cases in which no exponent at all has an L-span containing a superset of the S-span). We call this secondary insertion strategy Subsect S-span, and provide the definition in (12).11
- (12)
- Subsect S-span:In case no exponent contains a superset of the features present in the S-span,
- select the exponent whose L-span contains as many features present in the S-span as possible, then
- apply (a) until the Exhaustive Lexicalization Principle obtains.
We submit that the principles guiding insertion relate to one another in a heuristic process. This process is given in (13) below.
- (13)
- Insertion Heuristic:When an S-span is spelled out, exponents are inserted according to (a). If (a) cannot obtain, exponents are inserted according to (b). If (b) cannot obtain, then (c) applies:
- Superset Principle
- Subsect S-span
- No insertion
According to (13), the Superset Principle is the first, most desirable insertion strategy, whereas failure to make any insertion is the most costly, least desirable scenario. Thus, in cases where the Superset Principle cannot obtain, we suggest that the Insertion Heuristic activates Subsect S-span, which will cause the S-span to be lexicalized by multiple exponents. In all cases, the competitor whose L-span contains the fewest underassociated features is inserted. Figure 1 offers an illustration.
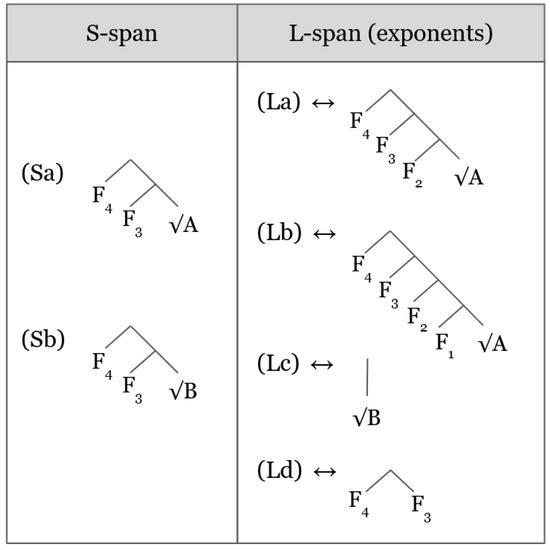
Figure 1.
Spellout: Exponents competing for insertion.
Suppose that (Sa) and (Sb) in Figure 1 are syntactic spans at the syntax-lexicon interface over which the L-spans (La-Ld) compete for insertion. No exponent is a perfect match for either (Sa) or (Sb). In the case of (Sa), both (La) and (Lb) qualify and compete on the basis of the Superset Principle, because they contain all the features comprising (Sa). The L-spans in (Lc) and (Ld) do not qualify since they do not contain all the features comprising (Sa), and the Insertion Heuristic has not been forced to activate Subsect S-span. The winning L-span is (La) since it contains fewer irrelevant features than (Lb) in this scenario, and is therefore the best match to express (Sa). That is, (La) contains the smallest superset of the features in the S-span in (Sa).
In the case of (Sb), there is no single L-span that contains all of its features. Thus, the Superset Principle cannot obtain, and the Insertion Heuristic activates Subsect S-span. Thus, (Lc) and (Ld) in combination spell out the entirety of the S-span in (Sb), via the associated with (Lc) and the feature configurations of (Ld).
More concretely, take the English regular and irregular plurals car-s and mice. Let us assume the S-span for English plural nominals (simplified, for the purposes of this illustration) in (S) in Figure 2. The L-spans associated with the exponents car, mouse, {s}, and mice are also provided in Figure 2.
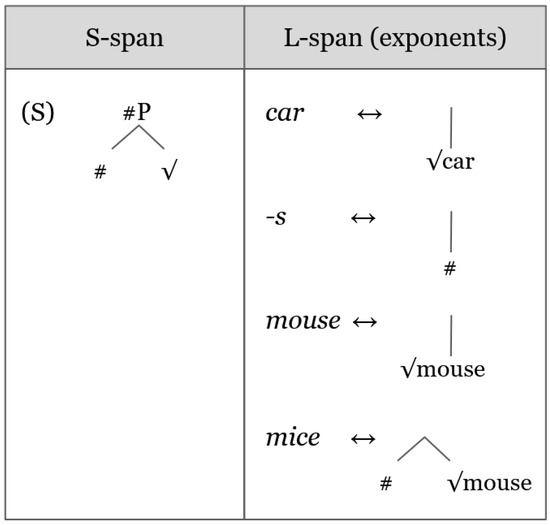
Figure 2.
Spellout: English regular and irregular plurals.
When the in (S) in Figure 2 is , the exponent mice spells out the entire plural S-span, on the basis of the Superset Principle (see (14) below). In fact, so long as the Insertion Heuristic does not activate Subsect S-span, mice is the only candidate for insertion, given that it alone contains a superset of (S). Exponents like mice are what Baunaz and Lander (2018, p. 34) refer to as ‘idiomatic plurals’. When the in (S) is , no exponent has an L-span containing a superset of the nodes. On these grounds, the Insertion Heuristic activates Subsect S-span, on which the exponent car spells out , and the plural suffix {s} spells out the feature [#] (see (15) below). We will follow this basic approach to PD nouns with stem plural changes.
| (14) |  | (15) |  |
In Section 4 we will expand the approach to spelling out plurals which we have outlined here, with particular attention to plural allomorphy in PD. Our proposal is that the syntax creates one S-span for PD plurals, and that this S-span contains the C-I-grounded feature [#], as well as two (content-less) F-features (see (7) above). These F-features, we will argue, play a crucial role in conditioning plural allomorphy in PD. Essentially, the observed patterns of insertion come down to how and plural markers ‘carve up’ the S-span, based on the feature specifications of their L-spans, and whether the Insertion Heuristic has activated the Superset Principle or Subsect S-span.
A key difference between the our model and DM is the locus of underspecification in the grammar, and specifically for our purposes, the implications that follow for bilingual morphosyntactic patterns. In DM, exponents may be underspecified relative to syntactic structures because vocabulary items with the largest subset of features map onto the relevant terminal node (e.g., Embick and Noyer 2001, p. 559). In our model, as for others operationalizing the Superset Principle, syntactic structure may be underspecified relative to vocabulary items since they may contain more features than are built in an S-span (e.g., Baunaz and Lander 2018, p. 32). We view this as an opportunity to model bilingual grammars that share L-span configurations—and even L-span associations with exponents—yet differ in the S-span sizes required to account for language-internal allomorphy. We explore this issue in Section 5 and turn now to our specific proposal for PD plurals.
4. A Distributed Account of Plurality in Pennsylvania Dutch
Based on the patterns discussed in Section 2, we focus our treatment of PD plural allomorphy on the four major classes for exponent selection: {s}, {e}, {r}, and {∅}, of which the latter two may also involve stem alternations. As discussed in Section 3.3, we adopt the position that plurality is not lexicalized as the projection of a single feature, but as a span. In this model, the conceptual category plural consists of one C-I-grounded plural feature (#), i.e., adopting Wiltschko’s (2021) ‘counting’ projection, along with the potential for additional contiguous projections of content-free F-features. The number of features is based on structural requirements for specifying the contexts in which individual plural exponents occur (following Hall 2020), a position that is in harmony with nanosyntactic (Caha 2009; Starke 2009) and other OFOH-approaches. To capture the allomorphy presented in Section 2, we propose two additional F-features in the PD S-span. The plural S-span of a given language is identical for every noun in a plural configuration regardless of which exponent is spelled out at the end of the derivation. We show that an S-span consisting of three features (#, F1, F2), as in (7), repeated in (16), models the plural allomorphy we find in PD. Based on this approach, any language that demonstrates some degree of allomorphy in number distinctions will have this category distributed across a span of projections and anchored in a single C-I feature for plural. This S-span will likely differ in size between languages, owing to language-specific patterns that the acquirer structures and regulates through formal features. We find differences in S-span sizes to be consistent with the distributions of PD and English plural allomorphs (see Section 5).
- (16)
- S-span representing PD distributed plurality, from (7)

As outlined in Section 3.3, the entire plural S-span in (16) must be lexicalized for a noun to be interpreted as plural (see the Exhaustive Lexicalization Principle provided in (10)). The allomorphic patterns observed in PD plurals are a result of how and plural exponents ‘carve up’ the S-span in (16) in accordance with the Insertion Heuristic presented in (13). As Figure 1 and Figure 2 above already suggest, we assume that , just like other exponents, are encoded with L-spans. It is on the basis of the size and feature content of these L-spans that different pair up with different plural allomorphs (or do not combine with a separate plural exponent at all). Specifically, if the L-span of a given does not contain a superset of the PD plural span (in which case the Superset Principle cannot obtain), the Insertion Heuristic will activate Subsect S-span such that the in question ‘shares’ the S-span with an allomorph whose L-span most economically ‘completes’ the lexicalization of the distributed plural S-span.
Consider first nouns that occur with no plural exponent, such as ‘zero’ plurals (e.g., Frein, ‘friend(s)’) and those with only umlaut (e.g., Hand-Hend, ‘hand-hand-pl’). As Figure 3 shows, we propose that such plurals are with L-spans that lexicalize all of the features in the plural S-span.
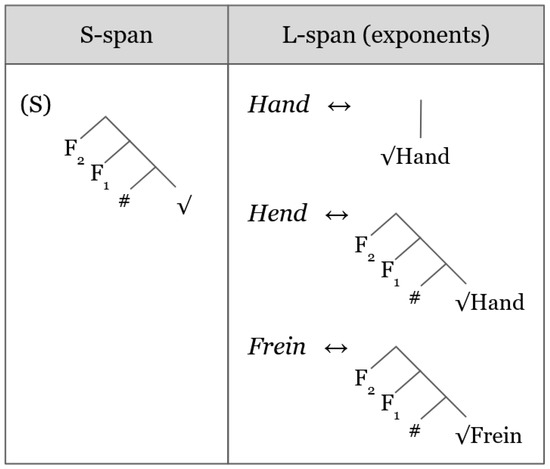
Figure 3.
Spellout of PD ‘zero’ and umlaut plurals.
When the in (S) in Figure 3 is , the exponent Frein is inserted on the basis of the Superset Principle. Should an S-span denoting a singular nominal (i.e., one that does not contain the features {#, }, which we will refer to as ‘bare’ for the sake of convenience) be spelled out, the exponent Frein still constitutes a match on the Superset Principle and, since there is no better-matched exponent in the lexicon, Frein is also inserted into singular contexts.
When the in (S) in Figure 3 is , the exponent Hend is inserted on the basis of the Superset Principle (see (17a) below). Should an S-span denoting a singular nominal (again, one that does not contain the features {#, }) be spelled out, the exponent Hend still constitutes a match on the Superset Principle. However, this time there indeed exists an exponent whose L-span is a better match, namely Hand. Thus, in the context of a singular nominal S-span, Hand ‘wins’ the competition for insertion over Hend (see (17b)). So the difference between zero plurals and umlaut plurals lies in whether or not a distinct L-span for the singular is stored alongside that for the plural. For Frein ‘friend(pl)’, no separate L-span exists.
- (17)
a. 
b. 
Now consider {s}, which appears to behave as a ‘default’ plural exponent (see Section 2). We take this ‘default’ nature of {s}, both for new PD items and for English loanword plurals, to be consistent with a true plural exponent in the sense that it contains in its L-span all of the features required for plural semantics. The , for example Baller (‘ball’), that {s} pairs with lack additional feature specification; they are ‘bare’ roots. This information is captured in Figure 4.
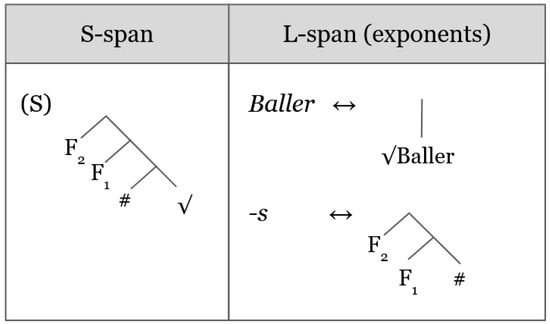
Figure 4.
Spellout of PD {s} plurals.
Notice that, when the in (S) in Figure 4 is , no exponent has an L-span containing a superset of the features in the S-span. In other words, the Superset Principle cannot obtain. Therefore, the Insertion Heuristic will activate Subsect S-span, on which exponents are allowed to lexicalize separate ‘chunks’ of the S-span. Accordingly, the exponent Baller realizes the , and the exponent {s} the features {#, F1, F2} (see (18a)). which take the {s} plural exponent also occur with no stem alternations between singular and plural, which suggests that the same exponent must be mapped to both singular and plural S-spans. This pans out in accordance with the Superset Principle, where exponents of ‘bare’ such as Baller are an identical match for the S-span denoting singular nominals (see (18b)). We furthermore view the shared nature of {s} as a viable exponent for inherited and loaned lexical items to support their bare structure (we elaborate on this point in Section 5).
- (18)
a. 
b. 
In contrast to {s}, we suggest that the L-span of the {e} allomorph is composed only of F1 and F2, and that roots which pair with this allomorph, such as Katz-e (‘cat-pl’), have L-spans which include {#}. This is captured in Figure 5.
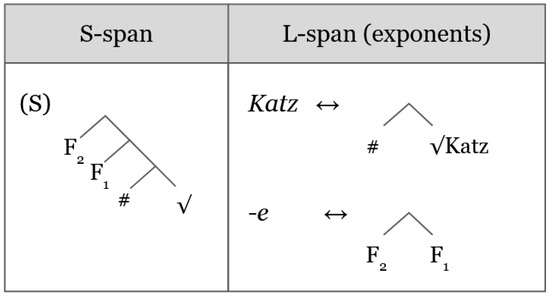
Figure 5.
Spellout of PD {e} plurals.
When the in (S) in Figure 5 is , the first thing to note is again that no exponent has an L-span containing a superset of (S). This again means that the Superset Principle cannot obtain and the Insertion Heuristic activates Subsect S-span. Subsequently, when the exponent Katz maps to the S-span it lexicalizes the and the {#} feature, but leaves F1 and F2 unlexicalized. The exponent {e}, then, spells out the remaining part of the plural span since it’s L-span is an exact match for F1 and F2 (see (19a)).
Because these are ‘regular’ plurals in the sense that the roots do not alternate in phonological shape to express the plural/singular distinction, we may assume that the same exponent which realizes the in a plural S-span also realizes the in the S-span of a singular nominal expression. This is achieved on the Superset Principle, underassociating the C-I feature {#} in the L-span of the (see (19b)).
- (19)
a. 
b. 
The e-plurals and s-plurals both have competing singular and plural -exponents (recall Figure 4 and example (18a) above, and contrast with the umlaut plurals in Figure 3 and (17a), which do have independent plural -exponents). The distinction between -exponents which pair with the {e} allomorph and those of PD origin which pair with the {s} allomorph is signalled to acquirers on the basis of the divocalic structure of the latter. This contrast guides the acquisition (and activation) of -exponents that pair with the {s} allomorph as having L-spans that are bare , rather than being predetermined with any syllabic or prosodic content mapped to them. This approach also avoids labeling or indexing according to language membership and maintaining this distinction also as an emergent property of the bilingual mental lexicon (Johns and Putnam 2019).
Turning to the last class of nouns, the r-plurals, we find that some, but not all, alternate stems between singular and plural, such as Haus-Heiser (‘house-house.pl’). Due to the presence of {r} in the plural, we assume that this exponent lexicalizes part of the PD plural S-span, but that the plural candidate Heis is associated to a larger L-span than its singular counterpart Haus. We therefore propose that the L-spans for alternating nouns that receive {r} in the plural consist of {#} and {F1}, as in Figure 6, but crucially not {F2}, which is then lexicalized by {r} on Subsect S-span under the Insertion Heuristic (see (20a) below), and contrast with the singular nominal expression in (21a).
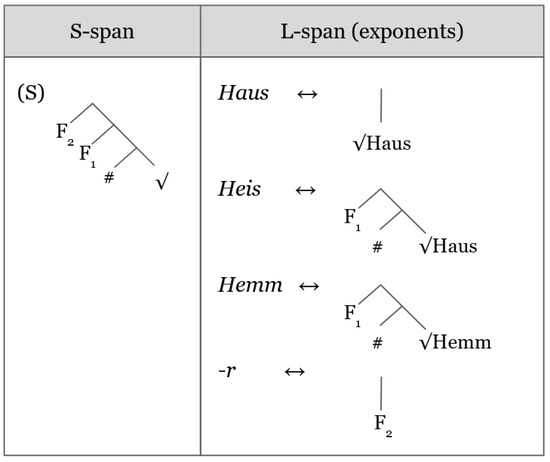
Figure 6.
Spellout of PD {r} plurals.
Figure 6 also shows that, for non-alternating r-plurals like Hemm-Hemmer (‘shirt-shirt.pl’), only one exponent is available. This exponent will map to plural contexts on Subsect S-span (see (21b)), and to singular contexts on the Superset Principle (see (20b)).
- (20)
a. 
b. 
- (21)
a. 
b. 
Table 4 schematizes and summarizes the varying distributions of plural features across exponents that we find in the four major classes of plural nouns that we examined in this section. Where relevant, distinct singular-plural alternations are provided; in instances where there is no independent candidate, cells are shaded in.
Table 4.
Summary of L-spans associated with PD and plural exponents.
In sum, we have captured the broad patterns of PD plural allomorphy by appealing to an OFOH-design and a detailed theory of lexicalization according to which spans are the locus of lexical insertion. We have argued that the S-span underlying all plural expression in PD is invariable and comprised of one C-I-grounded feature {#}, and two contentless F-features, {F1, F2}. The observed allomorphic patterns fall out as a result of how different classes of and plural exponents ‘carve up’ the plural S-span in a quest to lexicalize each and every feature in the S-span (Exhaustive Lexicalization). We demonstrated that an Insertion Heuristic searches first for exponents that map onto S-span in accordance with the Superset Principle. When the Superset Principle cannot obtain, insertion proceeds according the Subsect S-span. In the following section, we operationalize an additional advantage of this architecture, namely its potential for modeling morphosyntactic representations and patterns in an integrated bilingual grammar.
5. Distributed Plurality in a Bilingual Lexicon
The analysis outlined above leads to an interesting and novel view of an integrated bilingual grammar. With respect to shared resources for word formation, L-spans can be interpreted as stored components of a shared lexicon. The construction of new, and sometimes borrowed items are generated through building the required S-spans for the desired semantic interpretation and morphosyntactic alternations. Importantly, this process may be differentiated, depending on language mode (Grosjean 2008), and we propose that the generation of S-spans to capture language-specific patterns is subject to such differentiation. Speaking directly to the combined English-PD lexicon, PD exhibits more plural allomorphy than English. Provided these bilinguals demonstrate knowledge of the requite plural forms/classes, the S-spans that lexicalize plural will be larger in PD than in English.
Expanding on the English plural allomorphy briefly discussed in Section 3.3, we propose that the distributed S-span for English is as in (22). We base this claim on the three English plural allomorphs: {en}, {}, and {s} (e.g., Embick 2015, p. 172),12 with the distributions of L-spans for English and exponents presented in Table 5. Note that although English does not contain F2 in its S-span, the {s} exponent will for PD-English bilinguals. This is represented by leaving the additional feature space unshaded in the table.
Table 5.
Stored features in and exponent L-spans for English plurals.
- (22)
- English distributed plural S-span, from (8)

Our model captures two important aspects regarding an integrated English-PD grammar. The first is that due to its smaller S-span, English only requires the lexicalization of the {# F1} span, meaning that {en} can remain distinct from the PD forms through the specification of F1—i.e., there are no PD exponents with an L-span composed only of F1—while mapping to English that contain # in their L-spans. Secondly, like PD, English s-plurals are stored as ‘bare’ , Our proposal that both PD and English s-plurals lexicalize with the smallest L-spans, along with the fact that English occur with the s-exponent in PD—and not with another plural morpheme—when borrowed, further supports {s} being a shared exponent. Although the English S-span does not project a second abstract feature (F2) like PD, the Superset Principle renders {s} the best match for simple English , although it contains a feature not present in the English S-span.
Based on these representations and principles, we can explain why the s-exponent which appears on the overwhelming majority of English-based loan words in PD is lexicalized as {s}. Importantly, additional knowledge of English will not technically add features to the PD plural S-spans.13 The regular and predictable lexicalization of plural with {s} in English furthermore guides the association of these borrowings, as bare , with the class of PD s-plurals as they become fully incorporated into the PD vocabulary. There is no evidence that English will contain the requisite F-feature(s), and as a result, e-plurals should have larger -spans than PD s-plurals. In our current proposal English with en-plurals and -plurals have the same stored structures as PD e-plurals and r-plurals, respectively. So long as speakers generate the smaller English S-spans while speaking English, the competing PD exponents will not be viable for insertion. However, this model makes the testable prediction that language mixing in plural marking, i.e., PD suffixes on English , will occur through the generation of the PD S-span in English mode and be constrained to {e} for English en-plurals and {r} for English r-plurals. This same prediction hold for instances of borrowing these rather limited English noun classes into PD.
This returns us to the discussion of the general tendency not to borrow inflectional morphology in language contact scenarios (Matras 2009, 2014; van Coetsem 1988; Winford 2005). What our analysis seems to suggest is that the size of the —with its accompanying L-span—and the distributed nature of plural offers a working explanation to the limited environments that borrowed inflectional morphology takes place in (intense) contact situations. With respect to PD-English bilinguals, if English has smaller plural S-spans than the recipient language (in this scenario, Pennsylvania Dutch), the exponent associated with the largest L-span in said recipient language will lexicalize as plural due to the distributed nature of the lexicon, provided there are no better matches, mediated by the Superset Principle, in the integrated lexicon.
A final piece of evidence in support of the analysis we put forward here involves the ‘borrowing’ of English-origin into the PD lexicon. When such are borrowed, their allomorphic variation—represented by their F-features in the L-spans—accompany them. What this state of affairs suggests is that these units are stored in the mental lexicon as L-spans (since they don’t inherit any sort of strange leftover F-features). This also adduces support for the Superset Principle by showing that L-spans are the maximum size for PD, too. Having proficiency in both PD and English, some English L-spans for these individuals would have to be different from monolinguals even if their performance is largely indistinguishable from the latter. Our appeal to the different size of (stored) L-spans in the bilingual lexicon impacts how we envisage ‘borrowed’ elements of inflectional morphology (here, plurality) take place. In toto, the analysis set forth here makes the case for the important role that mental representations play in determining the borrowability of (inflectional) morphology in language contact situations by placing limits on the range and domain of potential borrowings reduced in large part to conditions of representational economy (Lohndal and Putnam 2021; Scontras et al. 2018).
6. Conclusions
In the pages above, we sketched out an analysis of plural allomorphy in Pennsylvania Dutch within a late-insertion, realizational model of morphology that adopts a strict OFOH-architecture. Adopting the position recently advanced by Biberauer (2019) and others, our model employs architecture that is both generative and emergent. Our treatment of plurality as being ‘distributed’ across features that are C-I-grounded and features that are abstract (i.e., ‘pure’ F-features) delivers an analysis of the morphological plural allomorphy in PD that is both descriptively adequate and conceptually appealing (thus addressing RQ2). Anchoring syntactic information concerning plurality to particular -types and the features that appear in their spans provides a straightforward association between plural allomorphy and particular ‘classes’ of nouns. A key advantage to this approach in our view is that this system renders many of the additional operations commonly found in DM as superfluous.
Although this analysis of capturing the key morphological alternations in PD plurality shows promise, additional challenges remain—both of a primarily empirical as well as a conceptual nature. Empirically speaking, a detailed analysis must also consider more directly how phonological representations interact with syntactic structures i.e., what is the broader generalization that divocalic in our discussion are s-plurals, whereas the remaining monovocalic belong to one of the other three classes? A second, more conceptually-based challenge returns us to RQ1 posed in the introduction. In spite of the general dispreference of borrowing inflected morphology in language contact, Gardani (2008) observes a difference between what he calls inherent inflection (i.e., plurality) vs. contextual inflection (i.e., agreement). In his assessment, the latter is much less frequent and ‘more difficult’ to borrow than the former. Our proposal that restrictions on the borrowing of inflectional morphology owe to S-span sizes that may be differentiated based on language mode, but mapped with L-span configurations that are shared in an integrated lexicon, shows real promise. Furthermore, our analysis delivers a testable hypothesis that can be applied to other dyads (and triads) of bi/multilingual speakers. In conclusion, the conceptualization of spans guided by the Superset Principle seems well-equipped to address the noted tendency in language contact situations to preserve ‘morphosyntactic subsystem integrity’ (Seifart 2012).
Author Contributions
Conceptualization, D.N., E.P., M.T.P. and K.S.S.; methodology, R.F. and K.S.S.; theoretical analysis D.N., E.P. and M.T.P.; writing—original draft preparation, R.F., D.N., E.P., M.T.P. and K.S.S.; writing—review and editing, R.F., D.N., E.P., M.T.P. and K.S.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Any data obtained from human subjects in connection with this manuscript were conducted according to the guidelines laid out by Institutional Review Board at Penn State University for human subject research (Protocol number: STUDY00002327).
Informed Consent Statement
Informed consent was obtained orally from all informants primary asking them about the acceptability of any linguistic examples.
Data Availability Statement
Due to the fact that the data from this study are based primarily on acceptability judgments and speaker intuitions, the data these judgments are based on are not publicly available.
Acknowledgments
We would like to thank Artemis Alexiadou and Terje Lohndal for the invitation to submit this work for review. The three external reviews posed a series a thoughtful and challenging questions and criticisms that ultimately improved our analysis tremendously, and for this we profusely thank them. We would like to recognize attendees at the SyntaxLab at the University of Cambridge for the invitation to present these ideas for feedback. A special thanks to Theresa Biberauer, Sten Vikner, and Matthew Tyler for their questions. Any remaining shortcomings are our own. Finally, we thank Rob Klosinski for proofreading a final version of this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| C-I | Conceptual-Intentional |
| DM | Distributed Morphology |
| NS | Nanosyntax |
| L-Span | Lexical-span |
| LF | Logical Form |
| OFOH | One Feature One Head |
| PD | Pennsylvania Dutch |
| PF | Phonological Form |
| SG | Standard German |
| S-Span | Syntactic-span |
| XS | Exo-skeletal Syntax |
Notes
| 1 | This is also our understanding of stem vowel alternations such as umlaut patterns. Other treatments, specifically for German, e.g., Wiese (1996a) and more recently Trommer (2021), adopt a phonological analysis via floating features. It is in principle possible in our model to associate features to syntactic structures. For the current discussion, we view alternations of this type as involving distinct candidates (see De Belder (2020) for an allied approach to Dutch plural allomorphy). Yet, for both perspectives the presence vs. absence of umlaut is suppletive in nature. |
| 2 | See Louden (2016) for an extensive historical overview of the language and many of its main grammatical features |
| 3 | While we readily acknowledge that certain tendencies in plural allomorphy in PD may be related to different gender feature values (e.g., {r} plurals tend to be found with historically neuter nouns such as Hemm-er ‘shirt-pl’), we also recognize that these tendencies are not direct indicators of particular plural reflexes. We leave the complex interaction between gender and number features for future research. |
| 4 | In PD, /r/ is typically vocalized as [ɐ] in codas, occurring an approximant [ɹ] elsewhere (Louden and Page 2005). These phonological alternations do not affect the current analysis. |
| 5 | See also Biberauer (2019), for whom such meaningful contrasts in (morpho)syntax include (i) doubling, (ii) silence, (iii) multifunctionality, (iv) movement, and (v) category recursion (e.g., N–N compounds). |
| 6 | See proposals by Lowenstamm (2008), Marantz (2013), Kramer (2016), and Alexiadou (2021) for a treatment of idiosyncratic lexical plural marking based on proximity of this information to the lexical . |
| 7 | An important part of the investigation of number marking in the morphology of language concerns its semantic interpretation and its relation to singular marking. Due to time and space considerations we do not elaborate on these matters here. The reader is referred to Harbour (2014) and Scontras (2022) for a detailed overview. |
| 8 | We do not assume that the order in which features are merged is constrained by UG. Instead, we follow Ramchand and Svenonius (2014) who argue that in principle features can be merged in any order. Well-formed syntactic spans are, however, constrained by interface conditions on the interpretability of such structures, which in fact yields a very limited number of combinatorial possibilities for any given set of features. |
| 9 | See Svenonius (2020) for an alternative definition. |
| 10 | We assume furthermore that each derivation proceeds in a cyclic fashion, meaning that the feature inventory, the syntactic component, and the lexicon are accessed in an iterative manner over the course of constructing one representation. Therefore, once a particular S-span ‘chunk’ has undergone insertion, it may return to the syntactic component to participate in further structure building operations and, subsequently further rounds of spell out. We will not focus on the nature or details of cyclic spell out in this paper, but see no need for representational constraints on the sizes of spans (see Newell (2017) for a similar proposal). |
| 11 | Crucially, although Subsect S-span does involve an exponent spelling out the largest possible subset of the features in an S-span, there are two reasons why it does not straightforwardly equate to the Subset Principle of DM. Firstly, insertion according to Subsect S-span, works on the basis of overspecified exponents (i.e., L-spans on competing exponents may contain features not present in the S-span), whereas insertion according to the Subset Principle involves underspecified exponents (i.e., competing exponents cannot contain features that are not present in the syntactic structure). Secondly, Subsect S-span is driven by the Exhaustive Lexicalization Principle (on which every syntactic feature must be lexicalized), whereas the Subset Principle does not require every syntactic feature to be lexicalized. |
| 12 | The English {s} plural is in fact /z/, which is unspecified for laryngeal features, rather than ‘voiced’ (Iverson and Salmons 1995). Because PD lacks a contrast between /s/ and /z/ (there is no specification required) and because PD speakers tend to pronounce English /z/ as [s] (Louden and Page 2005), we are confident in viewing English /z/ and PD {s} as referring to the same phonological category. |
| 13 | Of course, with this statement we arrive at an interesting open question as to whether or not all S-spans here are similar in structure and content. Can the conceptualization of ‘language mode’ mediate where the exact cut-off point would be for lexicalization, or is this an instance of highly variable behavior which is subject to individual ‘proficiency’? |
References
- Aboh, Enoch Oladé. 2015. The Emergence of Hybrid Grammars: Language Contact and Change. Cambridge: Cambridge University Press. [Google Scholar]
- Acquaviva, Paolo. 2016. Structures for plurals. Lingvisticœ Investigationes 39: 217–33. [Google Scholar] [CrossRef]
- Acuaviva, Paolo. 2008. Lexical Plurals: A Morphosemantic Approach. Oxford: Oxford University Press. [Google Scholar]
- Adger, David, and Peter Svenonius. 2011. Features in minimalist syntax. In The Oxford Handbook of Linguistic Minimalism. Edited by Cedric Boeckx. Oxford: Oxford University Press, pp. 27–51. [Google Scholar]
- Alexiadou, Artemis. 2011. Plural mass nouns and the morpho-syntax of number. In Proceedings of the 28th West Coast Conference on Formal Linguistics (WCCFL28). Somerville: Cascadilla Proceedings Project, vol. 33, p. 41. [Google Scholar]
- Alexiadou, Artemis. 2021. Lexical plurals. In The Oxford Handbook of Grammatical Number. Edited by Patricia Cabredo Hofherr and Jenny Doetjes. Oxford: Oxford University Press, pp. 242–56. [Google Scholar]
- Arad, Maya. 2003. Locality constraints in the interpretation of roots: The case of Hebrew denominal verbs. Natural Language & Linguistic Theory 21: 737–78. [Google Scholar]
- Arad, Maya. 2005. Roots and Patterns: Hebrew Morpho-Syntax. Dordrecht: Springer. [Google Scholar]
- Barbiers, Sjef. 2008. Microvariation in syntactic doubling—An introduction. In Microvariation in Syntactic Doubling. Edited by Sjef Barbiers, Olaf Koeneman, Marika Lekakou and Margreet van der Ham. Leiden: Brill, pp. 1–34. [Google Scholar]
- Baunaz, Lena, and Eric Lander. 2018. Nanosyntax: The basics. In Exploring Nanosyntax. Edited by Lena Baunaz, Karen De Clerq, Liliane Haegeman and Eric Lander. Oxford: Oxford University Press, pp. 3–56. [Google Scholar]
- Biberauer, Theresa. 2019. Factors 2 and 3: Towards a principled approach. Catalan Journal of Linguistics, 45–88. [Google Scholar] [CrossRef]
- Bjorkman, Bronwyn M., and Daniel Currie Hall, eds. 2020. Contrast and Representations in Syntax. Oxford: Oxford University Press. [Google Scholar]
- Blix, Hagen. 2021. Spans in South Caucasian agreement: Revisiting the pieces of inflection. Natural Language & Linguistic Theory 39: 1–55. [Google Scholar]
- Bobaljik, Jonathan. 2012. Universals in Comparative Morphology: Suppletion, Superlatives, and the Structure of Words. Cambridge: MIT Press. [Google Scholar]
- Booij, Geert. 1998. Phonological output constraints in morphology. In Phonology and Morphology of the Germanic Languages. Edited by Wolfgang Kehrein and Richard Wiese. Tübingen: Max Niemeyer Verlag, pp. 143–63. [Google Scholar]
- Borer, Hagit. 2005. Structuring Sense: Volume I: In Name Only. Oxford: Oxford University Press. [Google Scholar]
- Brown, Joshua R. 2011. Religious Identity and Language Shift among Amish-Mennonites in Kishacoquillas Valley, Pennsylvania. Ph.D. thesis, The Pennsylvania State University, State College, PA, USA. [Google Scholar]
- Brown, Joshua. 2019. The changing sociolinguistic identities of the Beachy Amish-Mennonites. Journal of Amish and Plain Anabaptist Studies 7: 19–31. [Google Scholar]
- Brown, Joshua R., and Douglas J. Madenford. 2009. Schwetz mol Deitsch! An Introductory Pennsylvania Dutch Course. Morgantown: Masthof Press. [Google Scholar]
- Buffington, Albert F. 1970. Similarities and dissimilarities between Pennsylvania German and the Rheinish Palatinate dialects. Pennsylvania German Society 3: 91–116. [Google Scholar]
- Caha, Pavel. 2009. The Nanosyntax of Case. Ph.D. thesis, University of Tromsø, Tromsø, Norway. [Google Scholar]
- Caha, Pavel. 2017a. How (not) to derive *ABA: The case of Blansitt’s generalisation. Glossa: A Journal of General Lingusitics 2: 84. [Google Scholar] [CrossRef][Green Version]
- Caha, Pavel. 2017b. Suppletion and morpheme order: A unified account. Journal of Linguistics 53: 865–96. [Google Scholar] [CrossRef]
- Caha, Pavel. 2018. Notes on insertion in Distributed Morphology and Nanosyntax. In Exploring Nanosyntax. Oxford: Oxford University Press, pp. 57–88. [Google Scholar]
- Christmann, Ernst. 1950. Das Pennsylvaniadeutsch als pfälzische Mundart. Rheinisches Jahrbuch für Volkskunde 1: 47–82. [Google Scholar]
- Cinque, Guglielmo. 1999. Adverbs and Functional Heads: A Cross-Linguistic Perspective. Oxford: Oxford University Press. [Google Scholar]
- Cowper, Elizabeth, and Daniel Currie Hall. 2014. Reductiō ad discrīmen: Where features come from. Nordlyd 41: 145–64. [Google Scholar] [CrossRef]
- Dali, Myriam, and Éric Mathieu. 2021. A Theory of Distributed Number. Amsterdam: John Benjamins. [Google Scholar]
- De Belder, Marijke. 2020. A split approach to the selection of allomorphs: Vowel length alternating allomorphy in Dutch. Glossa: A Journal of General Linguistics 5: 42. [Google Scholar] [CrossRef]
- DeClerq, Karen, and Guido Vanden Wyngaerd. 2017. * ABA revisited: Evidence from Czech and Latin degree morphology. Glossa: A Journal of General Lingusitics 2: 69. [Google Scholar]
- Dékány, Éva. 2021. The Hungarian Nominal Functional Sequence. New York: Springer. [Google Scholar]
- Dresher, B. Elan. 2009. The Contrastive Hierarchy in Phonology. Oxford: Oxford University Press. [Google Scholar]
- Dresher, B. Elan, Glyne Piggott, and Keren Rice. 1994. Contrast in Phonology: Overview. In Toronto Working Papers in Linguistics. Edited by Carrie Dyck. Toronto: Department of Linguistics, University of Toronto, Number 13. pp. iii–xvii. [Google Scholar]
- Embick, David. 2015. The Morpheme: A Theoretical Introduction. Berlin: De Gruyter Mouton. [Google Scholar]
- Embick, David, and Rolk Noyer. 2001. Movement operations after syntax. Linguisitic Inquiry 32: 555–95. [Google Scholar] [CrossRef]
- Fábregas, Antonio. 2007. The exhaustive lexicalization principle. Nordlyd 34: 130–60. [Google Scholar] [CrossRef]
- Fábregas, Antonio, and Michael T. Putnam. 2020. Passives and Middles in Mainland Scandinavian: Microvariation through Exponency. Berlin: Mouton. [Google Scholar]
- Fisher, Rose, Katharina S. Schuhmann, and Michael T. Putnam. 2022. Reducing the role of prosody: Plural allomorphy in Pennsylvania Dutch. In WILA 12 Proceedings. Edited by Kelly Biers and Joshua R. Brown. Somerville: Cascadilla Proceedings Project, pp. 1–10. [Google Scholar]
- Frey, J. William. 1985. A Simple Grammar of Pennsylvania Dutch. Lancaster: John Baers & Son. [Google Scholar]
- Gardani, Francesco. 2008. Borrowing of Inflectional Morphemes in Language Contact. Frankfurt: Peter Lang. [Google Scholar]
- Gleason, Jean Berko. 1958. The Wug Test. Cambridge: Larchwood Press. [Google Scholar]
- Goldrick, Matthew, Michael T. Putnam, and Laura S. Schwarz. 2016. Co-activation in bilingual grammars: A computational account of code mixing. Bilingualism: Language an Cognition 19: 857–76. [Google Scholar] [CrossRef]
- Gomeshi, Jila. 2003. Plural marking, indefiniteness, and the noun phrase. Studia Linguistica 57: 47–74. [Google Scholar] [CrossRef]
- Grosjean, François. 2008. Studying Bilinguals. Oxford: Oxford University Press. [Google Scholar]
- Hall, Daniel Currie. 2007. The Role and Representation of Contrast in Phonological Theory. Ph.D. thesis, University of Toronto, Toronto, ON, Canada. [Google Scholar]
- Hall, Daniel Currie. 2020. Contrast in syntax and contrast in phonology: Same difference? In Contrast and Representations in Syntax. Edited by Bronwyn M. Bjorkman and Daniel Currie Hall. Oxford: Oxford University Press, pp. 247–71. [Google Scholar]
- Harbour, Daniel. 2014. Paucity, abundance, and the theory of number. Language 90: 185–229. [Google Scholar] [CrossRef]
- Harley, Heidi. 2009. Compounding in Distributed Morphology. In The Oxford Handbook of Compounding. Edited by Rochelle Lieber and Pavol Štekauer. Oxford: Oxford University Press, pp. 129–44. [Google Scholar]
- Heycock, Caroline, and Roberto Zamparelli. 2005. Friends and colleagues: Plurality, coordination, and the structure of DP. Natural Language Semantics 13: 201–70. [Google Scholar] [CrossRef]
- Hofherr, Patricia Cabredo, and Jenny Doetjes, eds. 2021. The Oxford Handbook of Grammatical Number. Oxford: Oxford University Press. [Google Scholar]
- Iverson, Gregory K., and Joseph Salmons. 1995. Aspiration and laryngeal representations in Germanic. Phonology 12: 369–96. [Google Scholar] [CrossRef]
- Johns, Michael A., and Michael T. Putnam. 2019. Language membership as a gradient emergent feature. Bilingualism: Language and Cognition 22: 701–2. [Google Scholar] [CrossRef]
- Kayne, Richard S. 2005. Movement and Silence. Oxford: Oxford University Press. [Google Scholar]
- Keiser, Steven H. 2001. Language Change across Speech Islands: The Emergence of a Midwestern Dialect of Pennsylvania German. Ph.D. thesis, The Ohio State University, Columbus, OH, USA. [Google Scholar]
- Keiser, Steven H. 2012. Pennsylvania German in the American Midwest. Durham: Duke University Press. [Google Scholar]
- Knodt, Thomas. 1986. Quantitative aspects of lexical borrowing into Pennsylvania German. In Studies on the Languages and Verbal Behavior of the Pennsylvania Germans I. Edited by Werner Enninger. Stuttgart: Steiner Verlag, pp. 53–60. [Google Scholar]
- Kramer, Ruth. 2016. A split analysis of plurality: Number in Amharic. Linguistic Inquiry 47: 527–59. [Google Scholar] [CrossRef]
- Kroll, Judith F., and Tamar H. Gollan. 2014. Speech planning in two languages: What bilinguals tell us about language production. In The Oxford Handbook of Language Production. Edited by Matthew Goldrick, Victor Ferreira and Michele Miozzo. Oxford: Oxford University Press, pp. 165–81. [Google Scholar]
- Lohndal, Terje, and Michael T. Putnam. 2021. A tale of two lexicons: Decomposing complexity across a distributed lexicon. Heritage Language Journal 18: 1–29. [Google Scholar] [CrossRef]
- López, Luis. 2020. Bilingual Grammar: Towards an Integrated Model. Cambridge: Cambridge University Press. [Google Scholar]
- Louden, Mark L. 1989. Bilingualism and Syntactic Change in Pennsylvania German. Ph.D. thesis, Cornell University, Ithaca, NY, USA. [Google Scholar]
- Louden, Mark L. 2016. Pennsylvania Dutch: The Story of an American Language. Baltimore: John Hopkins. [Google Scholar]
- Louden, Mark L. 2020. Minority Germanic languages. In The Cambridge Handbook of Germanic Linguistics. Edited by B. Richard Page and Michael T. Putnam. Cambridge: Cambridge University Press, pp. 807–32. [Google Scholar]
- Louden, Mark L., and B. Richard Page. 2005. Stable bilingualism and phonological (non)convergence in Pennsylvania German. In ISB4 Proceedings of the 4th International Symposium on Bilingualism. Edited by James Cohen, Kara T. McAlister, Kellie Rolstad and Jeff MacSwan. Somerville: Cascadilla Press, pp. 1384–92. [Google Scholar]
- Lowenstamm, Jean. 2008. On little n, √, and types of nouns. In Sounds of Silence: Empty Elements in Syntax and Phonology. Edited by Jutta Hartmann, Veronika Hegedus and Henk van Riemsdijk. Amsterdam: Elsevier, pp. 105–43. [Google Scholar]
- Marantz, Alec. 2013. Locality domains for contextual allomorphy across the interfaces. In Distributed Morphology Today. Edited by Ora Matushansky and Alec Marantz. Cambridge: MIT Press, pp. 95–115. [Google Scholar]
- Marian, Virorica, and Michael Spivey. 2003. Competing activation in bilingual language processing: Within-and between-language competition. Bilingualism: Language and Cognition 6: 97–116. [Google Scholar] [CrossRef]
- Mathieu, Éric. 2012. Flavors of division. Linguistic Inquiry 43: 650–79. [Google Scholar] [CrossRef]
- Mathieu, Éric. 2014. Many a plural. In Weak Referentiality. Edited by Ana Aguilar-Guevara, Bert Le Bruyn and Joost Zwarts. Amsterdam: John Benjamins, pp. 157–81. [Google Scholar]
- Matras, Yaron. 2009. Language Contact. Cambridge: Cambridge University Press. [Google Scholar]
- Matras, Yaron. 2014. Why is borrowing of inflectional morphology dispreferred? In Borrowed Morphology. Edited by Francesco Gardani, Peter Arkadiev and Nino Amiridze. Berlin: Mouton, pp. 41–80. [Google Scholar]
- Meister Ferré, Barbara. 1994. Stability and Change in the Pennsylvania German Dialect of an Old Order Amish Community in Lancaster County. Stuttgart: Franz Steiner Verlag. [Google Scholar]
- Newell, Heather. 2017. Nested phase interpretation and the PIC. In The Structure of the Words at the Interfaces. Edited by Heather Newell, Máire Noonan, Glyne Piggott and Lisa deMena Travis. Oxford: Oxford University Press, pp. 20–40. [Google Scholar]
- Page, B. Richard. 2011. Gender assignment of English loanwords in Pennsylvania German: Is there a feminine tendency? In Studies on German-Language Islands. Edited by Michael T. Putnam. Amsterdam: John Benjamins, pp. 151–63. [Google Scholar]
- Paster, Mary. 2014. Allomorphy. In The Oxford Handbook of Derivational Morphology. Edited by Rochelle Lieber and Pavol Štekauer. Oxford: Oxford University Press, pp. 219–34. [Google Scholar]
- Polinsky, Maria. 2018. Heritage Languages and Their Speakers. Cambridge: Cambridge University Press. [Google Scholar]
- Putnam, Michael T. 2020. One Feature—One Head: Features as functional heads in language acquisition and attrition. In New Trends in Language Acquisition within the Generative Perspective. Edited by Pedro Guijarro-Fuentes and Cristina Suárez-Gómez. Dordrecht: Springer, pp. 1–23. [Google Scholar]
- Putnam, Michael T., Matthew Carlson, and David Reitter. 2018. Integrated, not isolated: Defining typological proximity in an integrated multilingual architecture. Frontiers in Psychology 8: 2212. [Google Scholar] [CrossRef]
- Ramchand, Gillian. 2019. Event structure and verbal decomposition. In Oxford Handbook of Event Structure. Edited by Robert Truswell. Oxford: Oxford University Press, pp. 314–41. [Google Scholar]
- Ramchand, Gillian, and Peter Svenonius. 2014. Deriving the functional hierarchy. Language Sciences 46: 152–74. [Google Scholar] [CrossRef]
- Reed, Carroll E. 1942. The gender of English loan words in Pennsylvania German. American Speech 17: 25–29. [Google Scholar] [CrossRef]
- Reed, Carroll E. 1948. The adaptation of English to Pennsylvania German morphology. American Speech 23: 239–44. [Google Scholar] [CrossRef]
- Reed, Carroll E., and Lester W. J. Seifert. 1954. A Linguistic Atlas of Pennsylvania German. Marburg: Becker. [Google Scholar]
- Ritter, Elizabeth. 1992. Cross-linguistic evidence for Number Phrase. Canadian Journal of Linguistics 37: 197–218. [Google Scholar] [CrossRef]
- Salmons, Joseph. 2018. A History of German: What the Past Reveals about Today’s Language. Oxford: Oxford University Press. [Google Scholar]
- Schuhmann, Katharina S., and Michael T. Putnam. 2021. Relativized prosodic domains: A late-insertion account of German plural allomorphy. Languages 6: 142. [Google Scholar] [CrossRef]
- Schuhmann, Katharina S., and Laura C. Smith. 2022. Practical prosody: New hope for teaching German plurals. Unterrichtspraxis/Teaching German 55. [Google Scholar]
- Scontras, Gregory. 2022. On the semantics of number morphology. Linguistics and Philosophy Online. , 1–32. [Google Scholar] [CrossRef]
- Scontras, Gregory, Maria Polinsky, and Zuzanna Fuchs. 2018. In support of representational economy: Agreement in heritage Spanish. Glossa 3: 1–29. [Google Scholar] [CrossRef]
- Seifart, Frank. 2012. The principle of morphosyntactic subsystem integrity in language contact: Evidence from morphological borrowing in Resígaro (Arawakan). Diachronica 29: 471–504. [Google Scholar] [CrossRef]
- Smith, Laura Catharine. 2020. The role of foot structure in Germanic. In The Cambridge Handbook of Germanic Linguistics. Edited by Michael T. Putnam and B. Richard Page. Cambridge: Cambridge University Press, pp. 49–72. [Google Scholar]
- Sonnenstuhl, Ingrid, Sonja Eisenbeiss, and Harald Clahsen. 1999. Morphological priming in the German mental lexicon. Cognition 72: 203–36. [Google Scholar] [CrossRef]
- Starke, Michel. 2009. Nanosyntax: A short primer to a new approach to language. Nordlyd 36: 1–6. [Google Scholar]
- Starke, Michal. 2014. Towards an elegant solution to language variation: Variation reduces to the size or lexically stored trees. In Linguistic Variation in the Minimalist Framework. Edited by M. Carme Picalo. Oxford: Oxford University Press, pp. 140–53. [Google Scholar]
- Stroik, Thomas S., and Michael T. Putnam. 2013. The Structural Design of Language. Cambridge: Cambridge University Press. [Google Scholar]
- Svenonius, Peter. 2010. Spatial P in English. In Mapping Spatial PPs: The Cartography of Syntactic Structure. Edited by Guglielmo Cinque and Luigi Rizzi. Oxford: Oxford University Press, pp. 127–60. [Google Scholar]
- Svenonius, Peter. 2020. A span is a thing: A span-based theory of words. In Proceedings of NELS 50—Volume 3. Edited by Mariam Asatryan, Yixiao Song and Ayana Whitmal. Cambridge: MIT Press, pp. 193–206. [Google Scholar]
- Trommer, Jochen. 2021. The subsegmental structure of German pluralallomorphy. Natural Language & Linguistic Theory 39: 601–56. [Google Scholar]
- van Coetsem, Frans. 1988. Loan Phonology and the Two Transfer Types in Language Contact. Dordrecht: Foris. [Google Scholar]
- Van Ness, Silke. 1995. Ohio Amish women in the vanguard of a language change: Pennsylvania German in Ohio. American Speech 70: 69–80. [Google Scholar] [CrossRef]
- Wegener, Heide. 1999. Die Pluralbildung im Deutschen - ein Versuch im Rahmen der Optimalitätstheorie. Linguistik Online 4: 1–55. [Google Scholar] [CrossRef]
- Wiese, Richard. 1996a. Phonological versus morphological rules: On German umlaut and ablaut. Journal of Linguistics 32: 113–35. [Google Scholar] [CrossRef]
- Wiese, Richard. 1996b. The Phonology of German. Oxford: Oxford University Press. [Google Scholar]
- Wiese, Richard. 2001. How prosody shapes German words and morphemes. Marburger Arbeiten zur Linguistik 5: 155–84. [Google Scholar]
- Wiese, Richard. 2009. The grammar and typology of plural noun inflection in varieties of German. Journal of Comparative Germanic Linguistics 12: 137–73. [Google Scholar] [CrossRef]
- Wiltschko, Martina. 2008. The syntax of non-inflectional plural marking. Natural Language & Linguistic Theory 26: 639–94. [Google Scholar]
- Wiltschko, Martina. 2014. The Universal Structure of Categories: Towards a Formal Typology. Cambridge: Cambridge University Press. [Google Scholar]
- Wiltschko, Martina. 2021. The syntax of number markers. In The Oxford Handbook of Grammatical Number. Edited by Patricia Cabredo Hofherr and Jenny Doetjes. Oxford: Oxford University Press, pp. 164–96. [Google Scholar]
- Winford, Donald. 2005. Contact-induced changes: Classification and processes. Diachronica 22: 373–427. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).