


Numeral Incorporation as Grammaticalization? A Corpus Study on German Sign Language (DGS)


Abstract
:1. Introduction
2. Theoretical Background
2.1. Numeral Systems in Sign Languanges
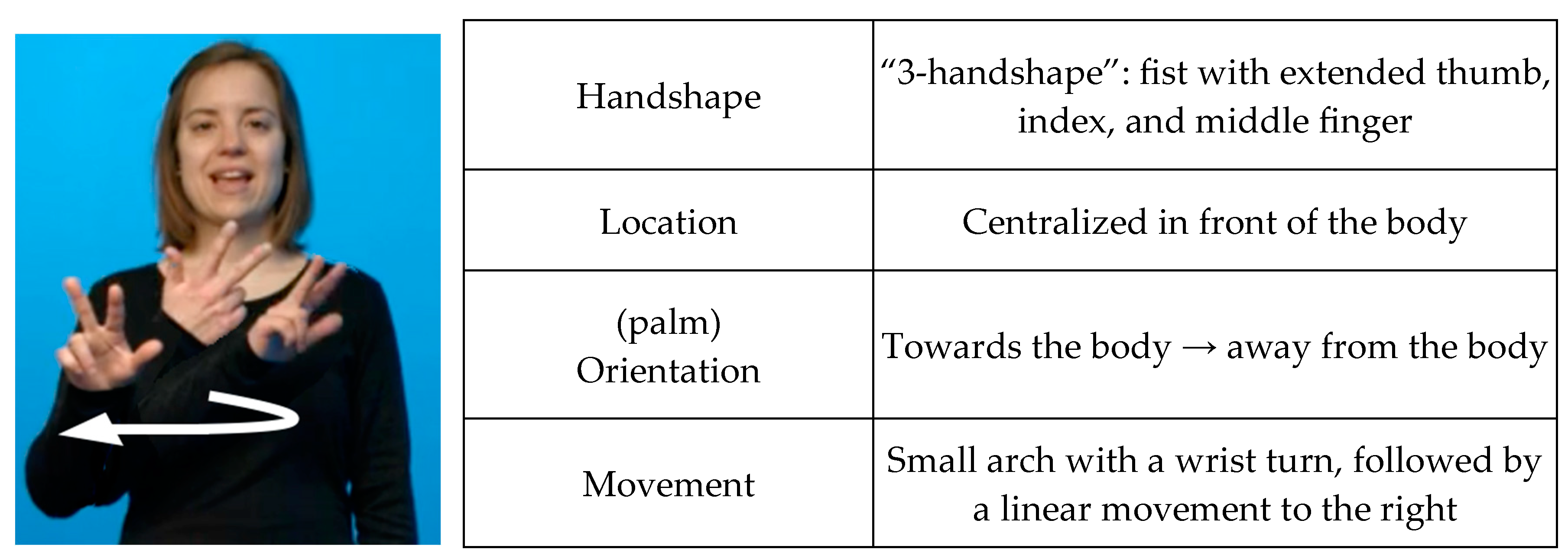
2.2. Numeral Incorporation
2.3. Grammaticalization
3. Materials and Methods
3.1. The DGS Corpus
3.2. Corpus Annotation
3.3. Concept of Study
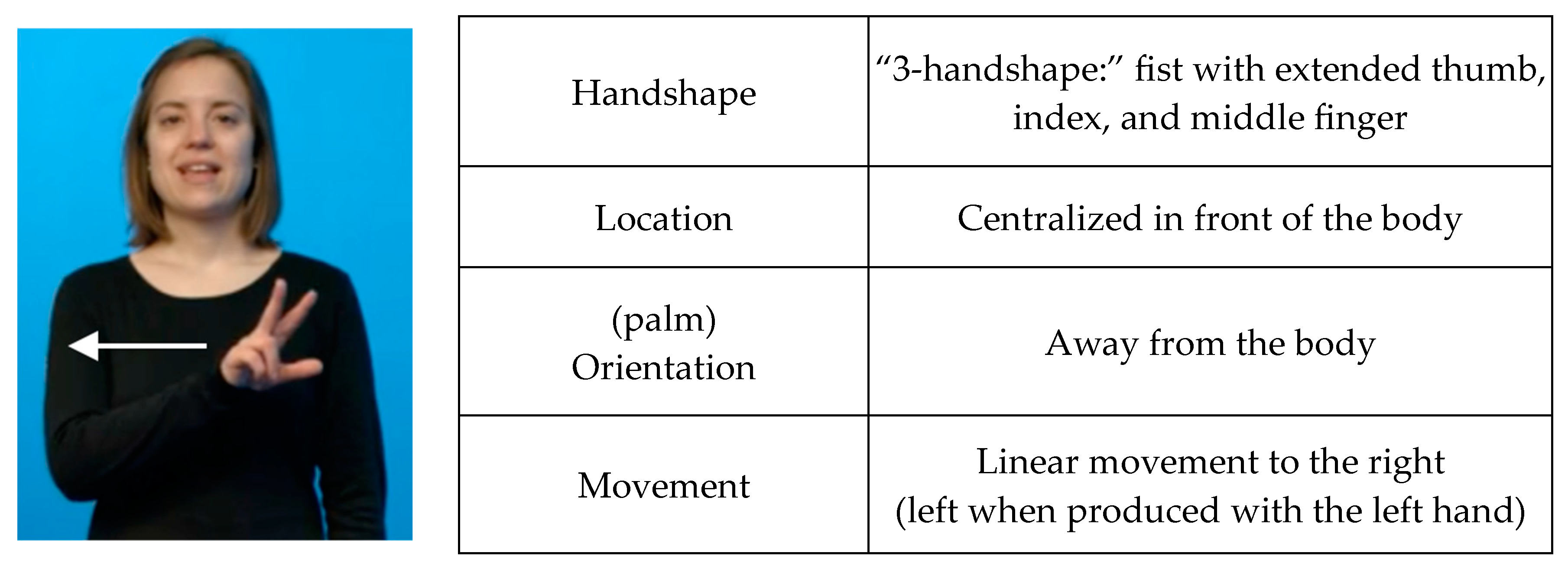
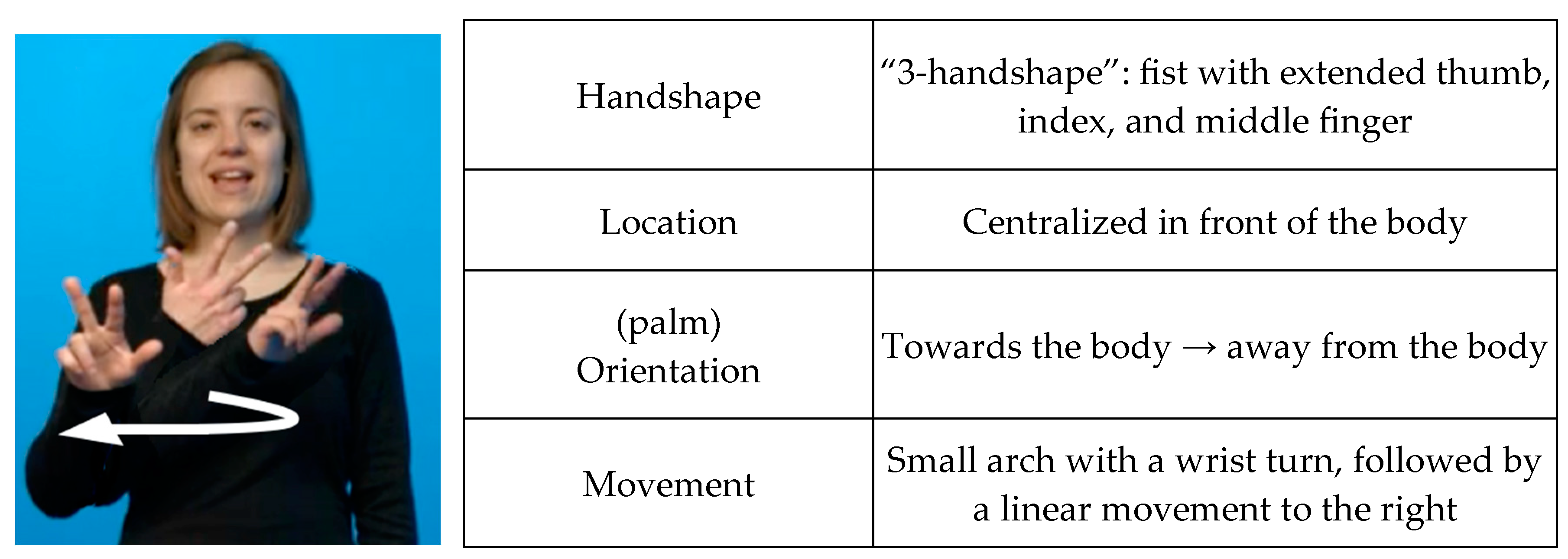
- Phrasal construction: In this construction the two elements are articulated independently from, but adjacent to, one another. The numeral keeps the location and orientation of its unmodified form, and the base is articulated with the handshape of its unmodified form. This is reflected in the corpus through the annotation of a numeral and a lexical base sign (see Appendix C Example (3) for an example featuring the phrasal construction).
- Cliticization: The numeral is still articulated as its own distinguishable sign with its own location and orientation. However, the noun loses its handshape and takes on the numeral handshape instead. The movement of the numeral sign is lost; instead, the movement of the lexical base is extended to accommodate the twist that is needed to match the hand orientations of both signs. This is reflected in the corpus through the annotation of a numeral and a modified lexical base sign (see Appendix C Example (4) for an example featuring the cliticized construction).
- Affixation: Here, the numeral only exists as the numeral handshape of the base sign. The two elements have become one sign. This is reflected in the corpus through the annotation of a single modified lexical base sign (see Appendix C Example (5) for an example featuring the affixed construction).
3.4. Conducting the Study
- $NUM-HUNDREDS1 “hundreds.”
- $NUM-THOUSANDS1 “thousands.”
- Phrasal construction: a numeral from 1 to 10 followed by a lexical sign of the above list without the qualifier q.
- Cliticization: a numeral from 1 to 10 followed by a lexical sign of the above list with qualifier q (specified for the same number value).
- Affixation: a lexical sign of the above list with qualifier q and without a preceding numeral from 1 to 10.
3.5. Hypotheses
3.6. Analysis
4. Results
5. Discussion
5.1. Hypotheses Evaluation
5.2. Numeral Incorporation as Grammaticalization
- Attrition: loss of semantic, phonological, and morphological properties.
- Paradigmaticization: emergence of morphological paradigms.
- Obligatorification: the new construction becomes obligatory, alternatives disappear.
- Condensation: decrease in the element’s scope.
- Coalescence: increase in bondedness.
- Fixation: loss of variation in positioning.
- Reinterpretation: item is reinterpreted in a given context.
- Extension: item can be used in new contexts.
- Desemanticization/semantic bleaching: meaning components that are not compatible with the new usage are lost.
- Decategorialization: loss of morphosyntactic properties.
- Erosion: Loss of phonetic substance.
5.3. Alternative Approaches
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

Appendix B


Appendix C. DGS Examples with Glosses, Mouthings/Mouth Gestures, Translations, and Sources
| (1) | AND2 | $NUM–TEEN1:5 | CHILD2* | $NUM–ONE–TO–TEN1A:5 | DEAF1A | $NUM–ONE–TO–TEN1A:5 | |||
| Fünfzehn | Kinder | Fünf | Taub | Fünf | |||||
| HEAVY1B* | TO–HEAR2 | $NUM–ONE–TO–TEN1A:5 | CI1* | $GEST–OFF1^ | |||||
| schwerhörig | fünf | ||||||||
| There were 15 kids: 5 were deaf, 5 were hard of hearing, and 5 had a CI. | |||||||||
| Public Corpus transcript: | https://doi.org/10.25592/dgs.corpus-3.0-text-1245390 | Timecode: | 00:10:25:10–00:10:32:31 | ||||||
| (2) | MY1 | FREE1 | TIME5A | TO–BELIEVE2B | $NUM–ONE–TO–TEN1A:6d | $NUM–TENS1:2d | MEMBER4* | |||
| Freizeit | Glaube | Sechsundzwanzig | Mitglied | |||||||
| I think the leisure [bowling] club has about 26 members. | ||||||||||
| Public Corpus transcript: | https://doi.org/10.25592/dgs.corpus-3.0-text-1583950 | Timecode: | 00:09:36:40–00:09:41:07 | |||||||
| (3) | $INDEX1* | ALSO1A | $INDEX1 | TO–TRY–OR–REHEARSAL2* | $NUM–ONE–TO–TEN1A:6d | WEEK1A | |
| Aber | Probe | Sechs | Woche | ||||
| There was a probation period of six weeks. | |||||||
| Public Corpus transcript: | https://doi.org/10.25592/dgs.corpus-3.0-text-1429964 | Timecode: | 00:10:22:37–00:10:24:34 | ||||
| (4) | I1 | TO–THINK1B | OLD8B | TO–THINK1B | BEGINNING1A* | TO–THINK1B |
| alt | anfang | |||||
| $NUM–ONE–TO–TEN1A:3d | OLD8B* | I1 | TO–KNOW–OR–KNOWLEDGE2B^ | NOTHING1B* | ||
| drei | alt | [MG] | ||||
| I think I was three years old, but my memory doesn’t go that far back. | ||||||
| Public Corpus transcript: | https://doi.org/10.25592/dgs.corpus-3.0-text-1428225 | Timecode: | 00:00:01:49–00:00:07:16 | |||
| (5) | MY1 | BOYFRIEND–GIRLFRIEND1 | BEEN1 | MONTH1* | |||
| Mein | Freund | Gewesen | Zwei monat | ||||
| AUSTRALIA1* | $INDEX1 | VACATION8B | BEEN1 | ||||
| Australien | Urlaub | Gewesen | |||||
| My boyfriend spent two months on vacation in Australia. | |||||||
| Public Corpus transcript: | https://doi.org/10.25592/dgs.corpus-3.0-text-1289910 | Timecode: | 00:08:25:07–00:08:28:08 | ||||
| (6) | TO–COME1* | $NUM–CLOCK1A:5 | UNTIL1 | EVENING2* | $NUM–TEEN2B:1d | ||
| mama | fünf uhr | bis | abend | elf uhr | |||
| She [mom] came over around five in the afternoon and stayed until 11:00 at night. | |||||||
| Public Corpus transcript: | https://doi.org/10.25592/dgs.corpus-3.0-text-1176846 | Timecode: | 00:08:39:16–00:08:24:42 | ||||
| (7) | FREIBURG1* | LOCATION1B^ | FAR1* | FROM–TO3* | HOUR2B* | HALF6 | FAR1* | ||
| freiburg | [MG] | drei stunden halb | wei{t} | ||||||
| Yet it [Freiburg] is also quite far away. It took us three [and a half] hours to get there. | |||||||||
| Public Corpus transcript: | https://doi.org/10.25592/dgs.corpus-3.0-text-1184756 | Timecode: | 00:11:28:48–00:11:33:08 | ||||||
Appendix D

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Appendix E
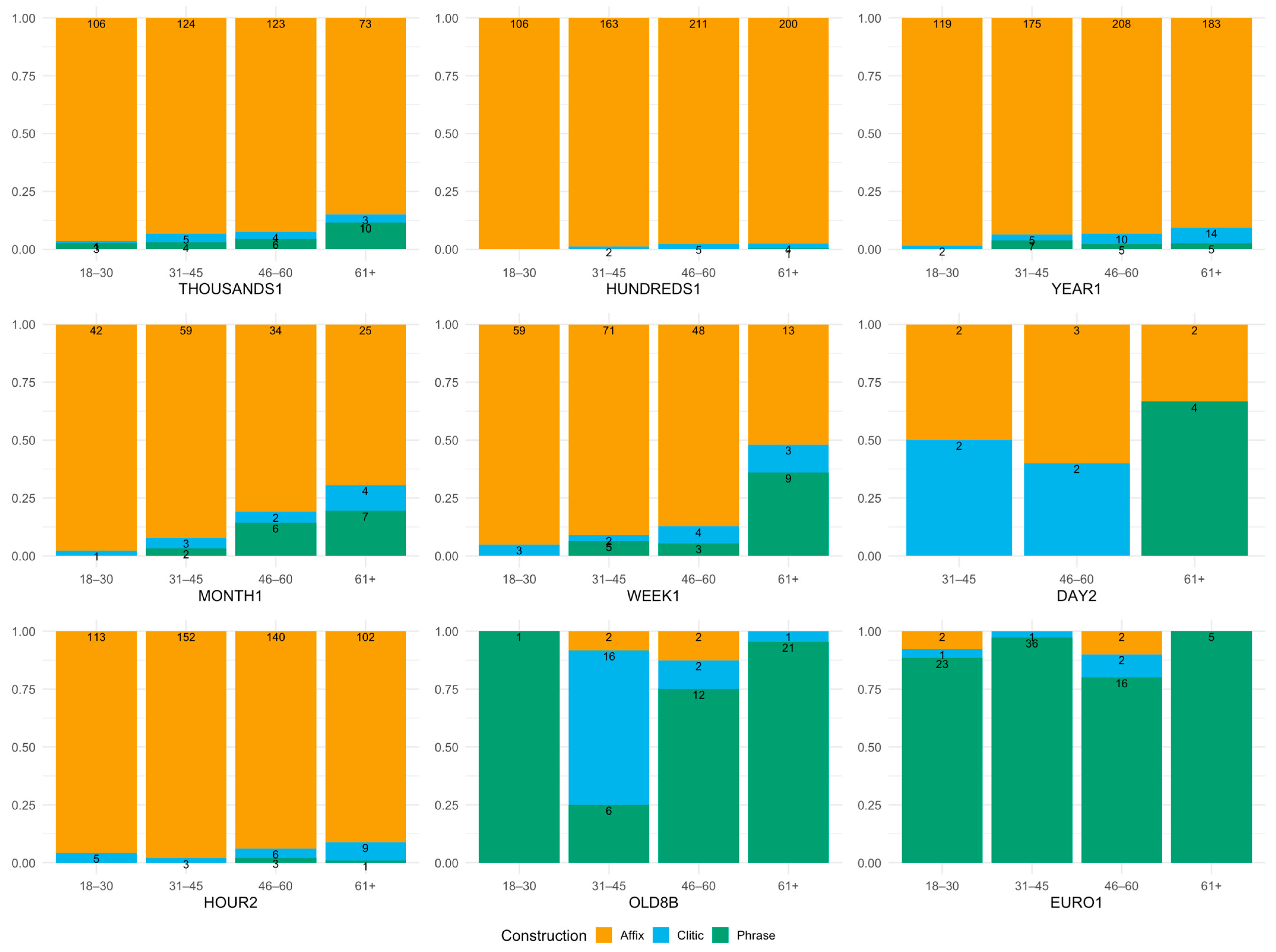
| 18–30 | 31–45 | 46–60 | 61+ | Totals | |
|---|---|---|---|---|---|
| THOUSANDS1 | 110 | 133 | 133 | 86 | 462 |
| HUNDREDS1 | 106 | 165 | 216 | 205 | 692 |
| YEAR1 | 121 | 187 | 223 | 202 | 733 |
| MONTH1 | 43 | 64 | 42 | 36 | 185 |
| WEEK1 | 62 | 78 | 55 | 25 | 220 |
| DAY2 | 0 | 4 | 5 | 6 | 15 |
| HOUR2 | 118 | 155 | 149 | 112 | 534 |
| OLD8B | 1 | 24 | 16 | 22 | 63 |
| EURO1 | 26 | 37 | 20 | 5 | 88 |
| Totals | 587 | 847 | 859 | 699 | 2992 |
| 1 | Depending on the sign, it is possible to form 11 to 19 with a productive movement. However, in general, 11 and 12 have a tendency to be expressed by lexicalized suppletive forms in DGS. |
| 2 | Pfau and Steinbach (2021) claim that in DGS only the numerals 1 to 5 can be incorporated in lexical base signs due to the two-handedness of the numerals from 6 to 10. In our corpus data, the two-handed numerals between 6 to 10 are incorporated. The movement of the lexical base sign is produced by both hands in this case. |
| 3 | It is common in literature on sign languages to refer to specific sign types via labels in capital letters (called glosses). See Section 3.2. for more detail on glosses and the glossing conventions adhered to in the annotation of the DGS corpus. For this introduction, we use a simplified gloss annotation. |
| 4 | Numeral and base sign share the same location in this instance, and the origin of the location in the affixed form is thus opaque. However, analyses of other incorporations show that the location matches the base sign. |
| 5 | The handshape allomorphs for “one” in ASL as well as in DGS are unmarked. It is the selected thumb or index finger as in Figure 2b. |
| 6 | |
| 7 | See Schulder and Hanke (2022) for details on the FAIR and CARE policy within the project. Research on the total of the reference corpus requires an additional license agreement for researchers outside of the DGS–Korpus project. As all authors of this paper are researchers working in the project, we had unrestricted access to the data. |
| 8 | See Konrad et al. (2022, p. 7) for glossing conventions and the definition of the term gloss: “A gloss is a German word that corresponds—on the subtype level—to a core meaning (keyword) of the sign.” |
| 9 | Mouthing refers to the visible mouth movement of silently articulated German words. Mouth gestures are meaningful mouth movements not related to the articulation of a word and are annotated with the label [MG], subsuming all types of mouth gestures. |
| 10 | Deviant in this context is used as a label for tokens whose form in actual execution of the sign differs in some aspect to the form assigned to the type as citation form in iLex. It covers aspects of adaptations due to performance and signed context, such as assimilations, as well as aspects of variation and modification that have not yet been categorized in more detail. The annotation as “deviant” only indicates some difference to the citation form. |
| 11 | HamNoSys, short for Hamburg Notation System for Sign Languages, is a notation system for sign languages (Hanke 2004). |
| 12 | For more information on the prefixes used in the glosses, see Konrad et al. (2022, pp. 14–16). |
| 13 | In the DGS corpus, signs of the category $NUM end by specifying the numeral handshape. This is accomplished by adding a qualifier that includes the numbers 1–10. |
| 14 | The qualifier ′numinc was also included in this study. It occurs only in addition to the qualifier ′q. As the differences between ′q and ′numinc + ′q are minor and irrelevant to our study, they will not be described here. |
| 15 | See Loos and Konrad (2022, p. 20) for a list of all qualifiers, their occurrences, functions, and codes as used in detailed corpus annotation. |
| 16 | The sign EURO1 is a relatively new sign as the Euro was introduced to Germany as a currency in 2002. The sign is produced with the handshape of extended index and middle finger, resembling the two lines of the € symbol. One of the signs used for the previous currency, D–Mark, has no fully specified base form and incorporates numerals from 1 to 10. It is possible that EURO1 started incorporating numerals due to this use of $NUM–GERMAN–MARK1. |
| 17 | The asterisks are commonly used to indicate different levels of significance. They are used as follows: *** for p < 0.001, ** for 0.001 ≤ p < 0.01, and * for 0.01 ≤ p < 0.05. |
References
- Bailey, Guy, Tom Wikle, Jan Tillery, and Lori Sand. 1991. The Apparent Time Construct. Language Variation and Change 3: 241–64. [Google Scholar] [CrossRef]
- Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting Linear Mixed-Effects Models Using Lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Brentari, Diane. 2012. 3. Phonology. In Sign Language. Edited by Roland Pfau, Markus Steinbach and Bencie Woll. Berlin and Boston: De Gruyter Mouton, pp. 21–54. [Google Scholar] [CrossRef]
- Bybee, Joan L. 2006. From Usage to Grammar: The Mind’s Response to Repetition. Language 82: 711–33. [Google Scholar] [CrossRef]
- Bybee, Joan L. 2011. Chapter 6. Usage-based Theory and Grammaticalization. In The Oxford Handbook of Grammaticalization, Online ed. Edited by Bernd Heine and Heiko Narrog. Oxford: Oxford University Press, pp. 69–78. [Google Scholar] [CrossRef]
- Chinchor, Nancy. 1982. Morphological Theory and Numeral Incorporation in American Sign Language. Ann Arbor: Brown University. [Google Scholar]
- Dachkovsky, Svetlana. 2022. Emergence of a Subordinate Construction in a Sign Language: Intonation Ploughs the Field for Morphosyntax. Glossa: A Journal of General Linguistics 7: 1–41. [Google Scholar] [CrossRef]
- Fox, John, and Sanford Weisberg. 2019. An R Companion to Applied Regression, 3rd ed. Thousand Oaks: Sage. [Google Scholar]
- Frishberg, Nancy. 1975. Arbitrariness and Iconicity: Historical Change in American Sign Language. Language 51: 696. [Google Scholar] [CrossRef]
- Hanke, Thomas. 2004. HamNoSys—Representing Sign Language Data in Language Resources and Language Processing Contexts. Paper presented at the LREC2004 Workshop on the Representation and Processing of Sign Languages: From SignWriting to Image Processing. Information Techniques and Their Implications for Teaching, Documentation and Communication, Lisbon, Portugal, May 30; Edited by Oliver Streiter and Chiara Vettori. Paris: ELRA, pp. 1–6. Available online: https://www.sign-lang.uni-hamburg.de/lrec/pub/04001.pdf (accessed on 12 May 2023).
- Hanke, Thomas, and Jakob Storz. 2008. ILex—A Database Tool for Integrating Sign Language Corpus Linguistics and Sign Language Lexicography. Paper presented at the LREC2008 3rd Workshop on the Representation and Processing of Sign Languages: Construction and Exploitation of Sign Language Corpora, Marrakech, Morocco, June 1; Edited by Onno Crasborn, Eleni Efthimiou, Thomas Hanke, Ernst D. Thoutenhoofd and Inge Zwitserlood. Marrakech: European Language Resources Association (ELRA), pp. 64–67. Available online: https://www.sign-lang.uni-hamburg.de/lrec/pub/08011.pdf (accessed on 13 February 2023).
- Hanke, Thomas, Marc Schulder, Reiner Konrad, and Elena Jahn. 2020. Extending the Public DGS Corpus in Size and Depth. Paper presented at the LREC2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, Marseille, France, May 16; Paris: European Language Resources Association (ELRA), pp. 75–82. Available online: https://aclanthology.org/2020.signlang-1.12.pdf (accessed on 13 February 2023).
- Hanke, Thomas, Reiner Konrad, and Gabriele Langer. 2023. Chapter 7. Exploring regional variation in the DGS Corpus. In Advances in Sign Language Linguistics. Edited by Ella Wehrmeyer. Amsterdam and Philadelphia: John Benjamins, pp. 192–218. [Google Scholar] [CrossRef]
- Hanke, Thomas, Reiner Konrad, Gabriele Langer, Anke Müller, and Sabrina Wähl. 2017. Detecting Regional and Age Variation in a Growing Corpus of DGS. Paper presented at the Workshop Corpus-Based Approaches to Sign Language Linguistics: Into the Second Decade, Birmingham, UK, July 24. [Google Scholar]
- Heine, Bernd, and Tania Kuteva. 2007. The Genesis of Grammar: A Reconstruction. Oxford and New York: Oxford University Press. [Google Scholar]
- Himmelmann, Nikolaus P. 2004. Lexicalisation and Grammaticalization: Opposite or Orthogonal? In What Makes Grammaticalization? A Look from Its Fringes and Its Components. Edited by Walter Bisang, Nikolaus P. Himmelmann and Björn Wiemer. Berlin and New York: Mouton de Gruyter, pp. 21–44. [Google Scholar] [CrossRef]
- Hopper, Paul J., and Elizabeth C. Traugott. 2003. Grammaticalization, 2nd ed. Cambridge: Cambridge University Press. [Google Scholar] [CrossRef]
- Isard, Amy, and Reiner Konrad. 2022. MY DGS—ANNIS: ANNIS and the Public DGS Corpus. Paper presented at the LREC2022 10th Workshop on the Representation and Processing of Sign Languages: Multilingual Sign Language Resources, Marseille, France, June 25; Edited by Eleni Efthimiou, Stavroula-Evita Fotinea, Thomas Hanke, Julie A. Hochgesang, Jette Kristoffersen, Johanna Mesch and Marc Schulder. Marseille: European Language Resources Association (ELRA), pp. 73–79. Available online: https://www.sign-lang.uni-hamburg.de/lrec/pub/22034.pdf (accessed on 13 February 2023).
- Janzen, Terry. 2012. 34. Lexicalization and Grammaticalization. In Sign Language. An International Handbook. Edited by Roland Pfau, Markus Steinbach and Bencie Woll. Berlin and Boston: De Gruyter Mouton, pp. 816–40. [Google Scholar] [CrossRef]
- Jones, Vanessa L. 2013. Numeral Incorporation in American Sign Language. In Theses and Dissertations. Grand Forks: The University of North Dakota, vol. 1551, Available online: https://commons.und.edu/theses/1551/ (accessed on 11 May 2023).
- Konrad, Reiner, Thomas Hanke, Gabriele Langer, Susanne König, Lutz König, Rie Nishio, and Anja Regen. 2022. Public DGS Corpus: Annotation Conventions/Öffentliches DGS-Korpus: Annotationskonventionen. Working Paper. Version 4.1. Hamburg: DGS-Korpus-Projekt, June 14. [Google Scholar] [CrossRef]
- Ktejik, Mish. 2013. Numeral Incorporation in Japanese Sign Language. Sign Language Studies 13: 186–210. [Google Scholar] [CrossRef]
- Labov, William. 1963. The Social Motivation of a Sound Change. WORD 19: 273–309. [Google Scholar] [CrossRef]
- Lehmann, Christian. 1985. Grammaticalization: Synchronic Variation and Diachronic Change. Lingua e Stile 20: 303–18. [Google Scholar]
- Liddell, Scott K. 1996. Number Incorporating Roots & Non-Incorporating Prefixes in American Sign Languages. Sign Language Studies 92: 201–26. [Google Scholar]
- Liddell, Scott K., and Robert E. Johnson. 1986. American Sign Language Compound Formation Processes, Lexicalization, and Phonological Remnants. Natural Language and Linguistic Theory 4: 445–513. [Google Scholar] [CrossRef]
- Loos, Cornelia, and Reiner Konrad. 2022. Detailed Annotation and Qualifiers. Working Paper. Version 1. Hamburg: DGS-Korpus-Projekt, April 4. [Google Scholar] [CrossRef]
- Mathur, Gaurav, and Christian Rathmann. 2011. Two Types of Nonconcatenative Morphology in Signed Languages. In Deaf around the World, Online ed. Edited by Gaurav Mathur and Donna Jo Napoli. Oxford: Oxford University Press, pp. 54–82. [Google Scholar] [CrossRef]
- Meir, Irit. 2012. 5. Word Classes and Word Formation. In Sign Language. Edited by Roland Pfau, Markus Steinbach and Bencie Woll. Berlin and Boston: De Gruyter Mouton, pp. 77–111. [Google Scholar] [CrossRef]
- Pfau, Roland, and Markus Steinbach. 2011. Grammaticalization in Sign Languages. In The Oxford Handbook of Grammaticalization, Online ed. Edited by Bernd Heine and Heiko Narrog. Oxford: Oxford University Press, pp. 683–95. [Google Scholar] [CrossRef]
- Pfau, Roland, and Markus Steinbach. 2021. Number in Sign Languages. In The Oxford Handbook of Grammatical Number. Edited by Patricia Cabredo Hofherr and Jenny Doetjes. Oxford: Oxford University Press, pp. 644–60. [Google Scholar] [CrossRef]
- Quer, Josep, Carlo Cecchetto, Caterina Donati, Carlo Geraci, Meltem Kelepir, Roland Pfau, and Markus Steinbach, eds. 2017. Part 2: Phonology. In SignGram Blueprint. A Guide to Sign Language Grammar Writing. Berlin and Boston: De Gruyter Mouton, pp. 17–68. [Google Scholar] [CrossRef]
- Sagara, Keiko, and Ulrike Zeshan. 2016. Semantic Fields in Sign Languages—A Comparative Typological Study. In Semantic Fields in Sign Languages: Colour, Kinship and Quantification. Edited by Ulrike Zeshan and Keiko Sagara. Berlin and Boston: De Gruyter Mouton, pp. 3–38. [Google Scholar] [CrossRef]
- Schulder, Marc, and Thomas Hanke. 2022. How to Be FAIR When You CARE: The DGS Corpus as a Case Study of Open Science Resources for Minority Languages. Paper presented at the 13th International Conference on Language Resources and Evaluation (LREC 2022), Marseille, France, June 20–25; Edited by Nicoletta Calzolari, Frédéric Béchet, Philippe Blache, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Hitoshi Isahara, Bente Maegaard, Joseph Mariani and et al. Paris: European Language Resources Association (ELRA), pp. 164–73. Available online: http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.18 (accessed on 13 February 2023).
- Schulder, Marc, Dolly Blanck, Thomas Hanke, Ilona Hofmann, Sung-Eun Hong, Olga Jeziorski, Lutz König, Susanne König, Reiner Konrad, Gabriele Langer, and et al. 2021. Data Statement for the Public DGS Corpus. Working Paper. Version 2. Hamburg: DGS-Korpus-Projekt, November 11. [Google Scholar] [CrossRef]
- Semushina, Nina, and Rachel I. Mayberry. 2019. Numeral Incorporation in Russian Sign Language: Phonological Constraints on Simultaneous Morphology. Sign Language Studies 20: 83–131. [Google Scholar] [CrossRef] [PubMed]
- Taub, Sarah F. 2001. Language from the Body: Iconicity and Metaphor in American Sign Language. Cambridge and New York: Cambridge University Press. [Google Scholar]
- Traugott, Elizabeth Closs, and Graeme Trousdale. 2013. Constructionalization and Constructional Changes. Oxford: Oxford University Press. [Google Scholar] [CrossRef]
- von Mengden, Ferdinand. 2010. Chapter I. Linguistic Numeral Systems. In Cardinal Numerals: Old English from a Cross-Linguistic Perspective. Berlin and New York: De Gruyter Mouton, pp. 12–71. [Google Scholar] [CrossRef]
- Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy McGowan, Romain François, Garrett Grolemund, Alex Hayes, Lionel Henry, Jim Hester, and et al. 2019. Welcome to the Tidyverse. Journal of Open Source Software 4: 1686. [Google Scholar] [CrossRef] [Green Version]
- Zeshan, Ulrike, Cesar Ernesto Escobedo Delgado, Hasan Dikyuva, Sibaji Panda, and Connie de Vos. 2013. Cardinal Numerals in Rural Sign Languages: Approaching Cross-Modal Typology. Linguistic Typology 17: 357–96. [Google Scholar] [CrossRef] [Green Version]






| Category | Annotation Scheme and Example ‘Three Weeks’ | |
|---|---|---|
| Phrasal Construction | Scheme | $NUM-ONE-TO-TEN′q:n BASE-SIGN |
| Example | $NUM-ONE-TO-TEN′q:3d WEEK1 | |
| Cliticization | Scheme | $NUM-ONE-TO-TEN′q:n BASE-SIGN’q:n |
| Example | $NUM-ONE-TO-TEN′q:3d WEEK1’q:3d | |
| Affixation | Scheme | BASE-SIGN’q:n |
| Example | WEEK1’q:3d |
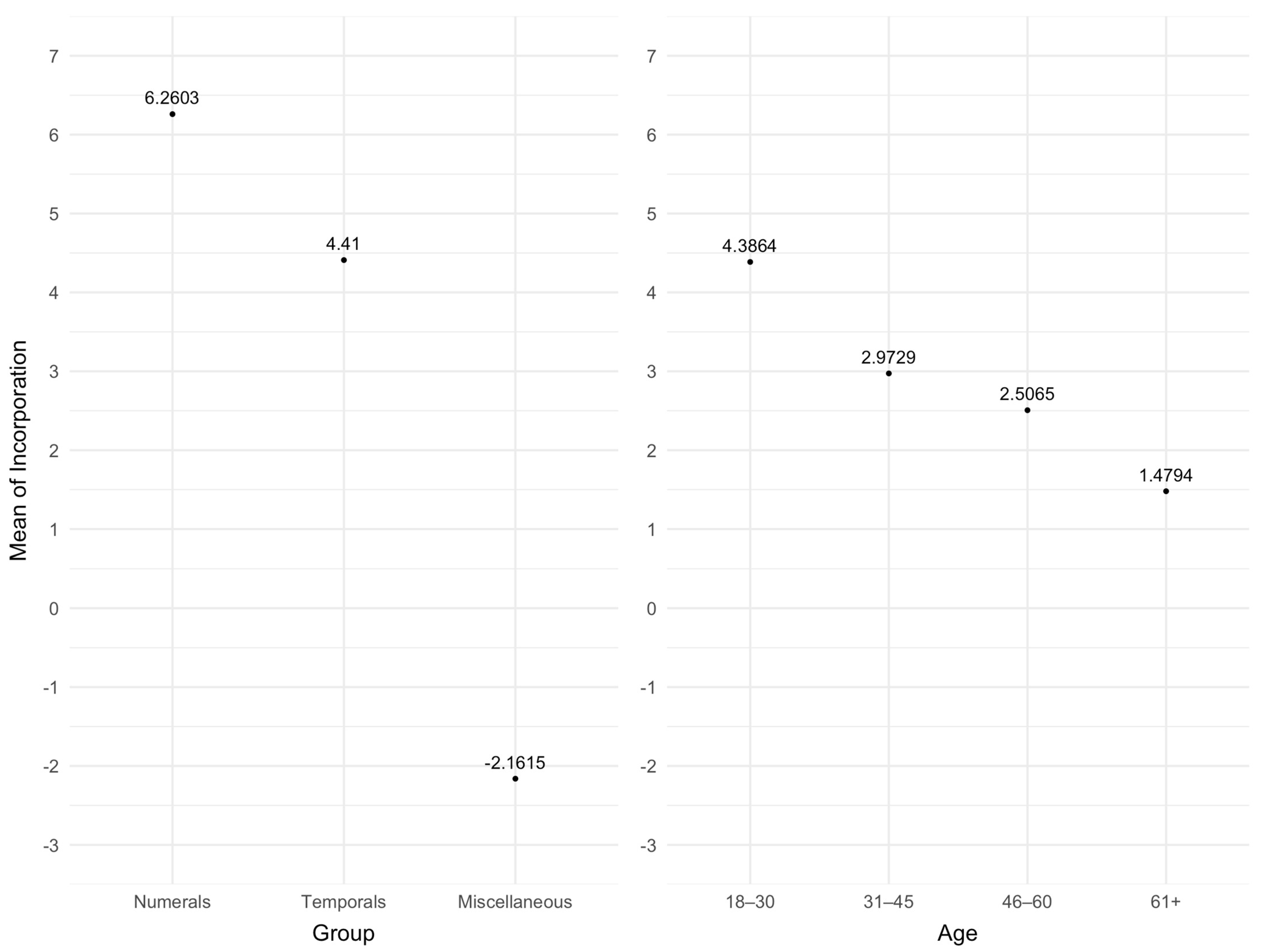
| β | Standard Deviation | z-Value | p-Value | |
|---|---|---|---|---|
| Intercept | 7.8104 | 1.2794 | 6.105 | p < 0.001 ***17 |
| Temporals | −1.8503 | 1.2491 | −1.481 | 0.13853 |
| Miscellaneous | −8.4218 | 1.5581 | −5.405 | p < 0.001 *** |
| β | Standard Deviation | z-Value | p-Value | |
|---|---|---|---|---|
| Intercept | 7.8104 | 1.2794 | 6.105 | p < 0.001 *** |
| 31–45 | −1.4134 | 0.6745 | −2.095 | 0.03613 * |
| 46–60 | −1.8799 | 0.6819 | −2.757 | 0.00584 ** |
| 61+ | −2.9070 | 0.6982 | −4.163 | p < 0.001 *** |
| Degrees of Freedom | Pr (>Chisq) | ||
|---|---|---|---|
| Sign Group | 33.845 | 2 | p < 0.001 *** |
| Age Group | 19.135 | 3 | p < 0.001 *** |
| β | Standard Error | Degrees of Freedom | z.Ratio | p.Value | |
|---|---|---|---|---|---|
| (18–30)–(31–45) | 1.413 | 0.675 | Inf | 2.095 | 0.1545 |
| (31–45)–(46–60) | 0.466 | 0.500 | Inf | 0.933 | 0.7873 |
| (46–60)–61+ | 1.027 | 0.497 | Inf | 2.066 | 0.1644 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Otte, F.; Müller, A.; Wähl, S.; Langer, G. Numeral Incorporation as Grammaticalization? A Corpus Study on German Sign Language (DGS). Languages 2023, 8, 153. https://doi.org/10.3390/languages8020153
Otte F, Müller A, Wähl S, Langer G. Numeral Incorporation as Grammaticalization? A Corpus Study on German Sign Language (DGS). Languages. 2023; 8(2):153. https://doi.org/10.3390/languages8020153
Chicago/Turabian StyleOtte, Felicitas, Anke Müller, Sabrina Wähl, and Gabriele Langer. 2023. "Numeral Incorporation as Grammaticalization? A Corpus Study on German Sign Language (DGS)" Languages 8, no. 2: 153. https://doi.org/10.3390/languages8020153
APA StyleOtte, F., Müller, A., Wähl, S., & Langer, G. (2023). Numeral Incorporation as Grammaticalization? A Corpus Study on German Sign Language (DGS). Languages, 8(2), 153. https://doi.org/10.3390/languages8020153