
Distinguishing Sellers Reported as Scammers on Online Illicit Markets Using Their Language Traces


Abstract
:1. Introduction
2. Previous Research
2.1. Digital Traces Left by Trust Mechanisms in Online Trade
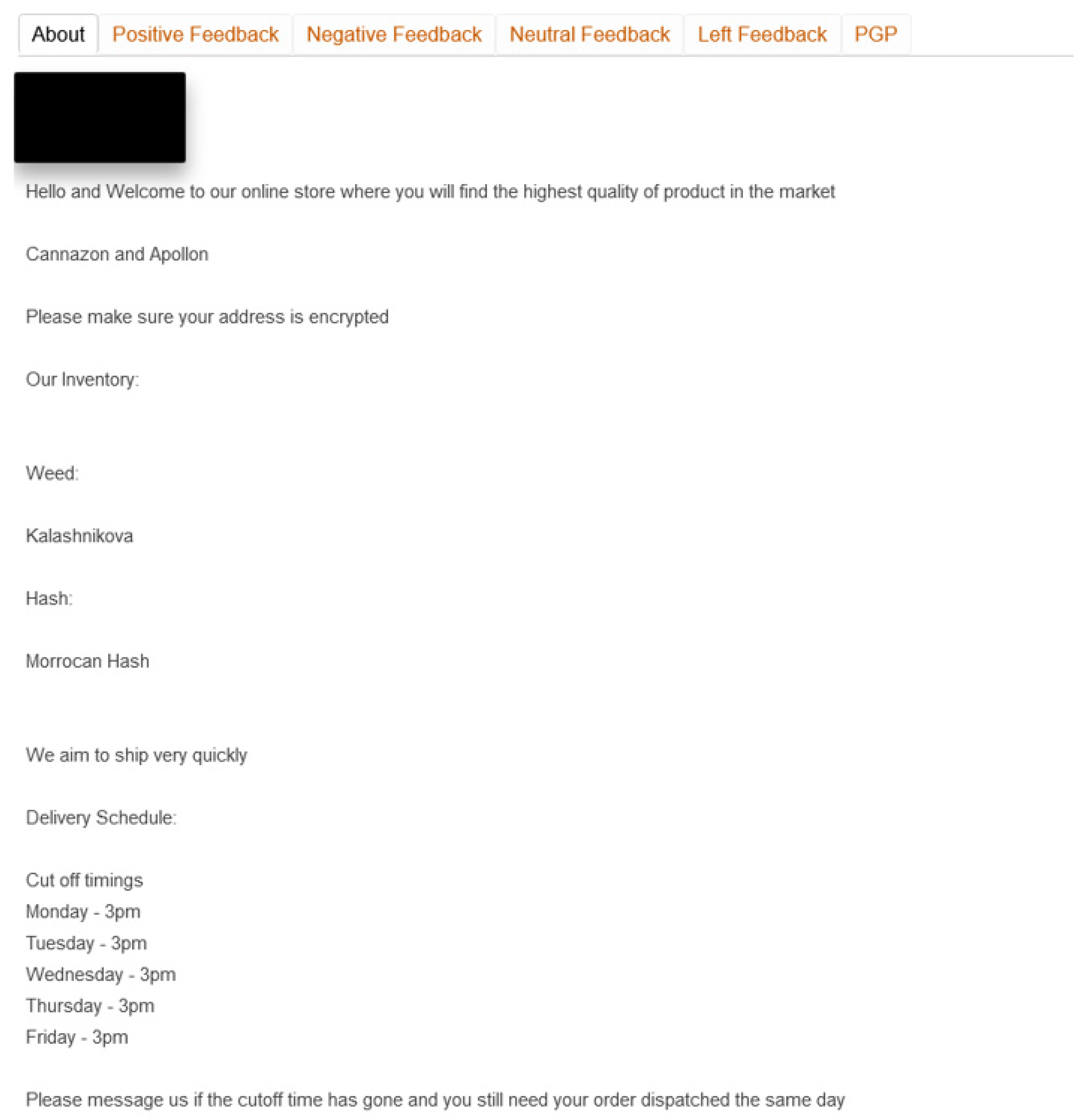
2.1.1. Deceptive Practices in Cryptomarkets
2.1.2. The Informative Value of Feedback
2.1.3. Leveraging Language Traces to Unveil Fraud through Computational Linguistic Analysis
3. Materials and Methods
3.1. Datasets
3.2. The Choice of a Computational Linguistic Approach
3.3. Pretreatment
3.4. Analysis
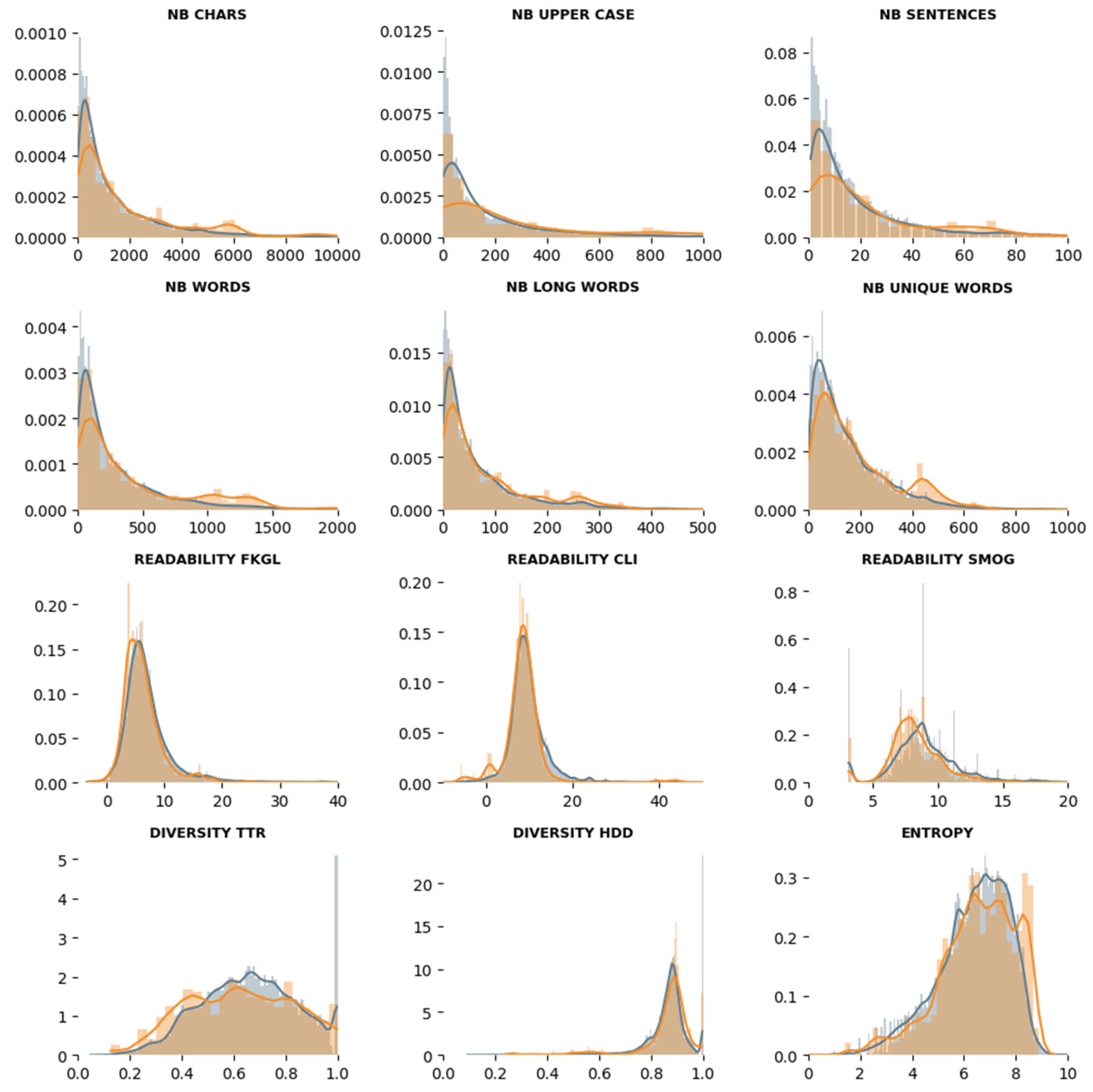
3.4.1. Textometric Analysis of Raw Texts
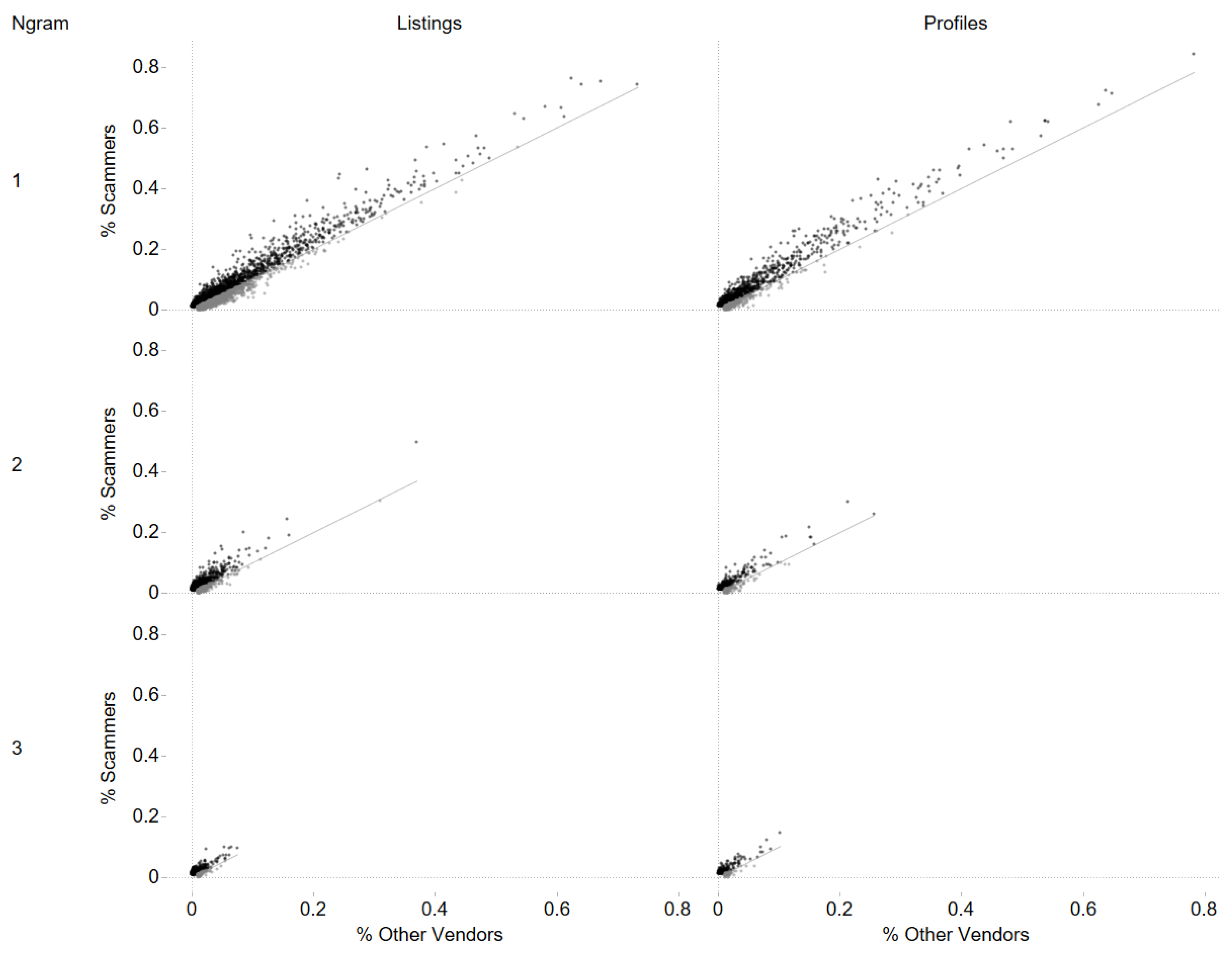
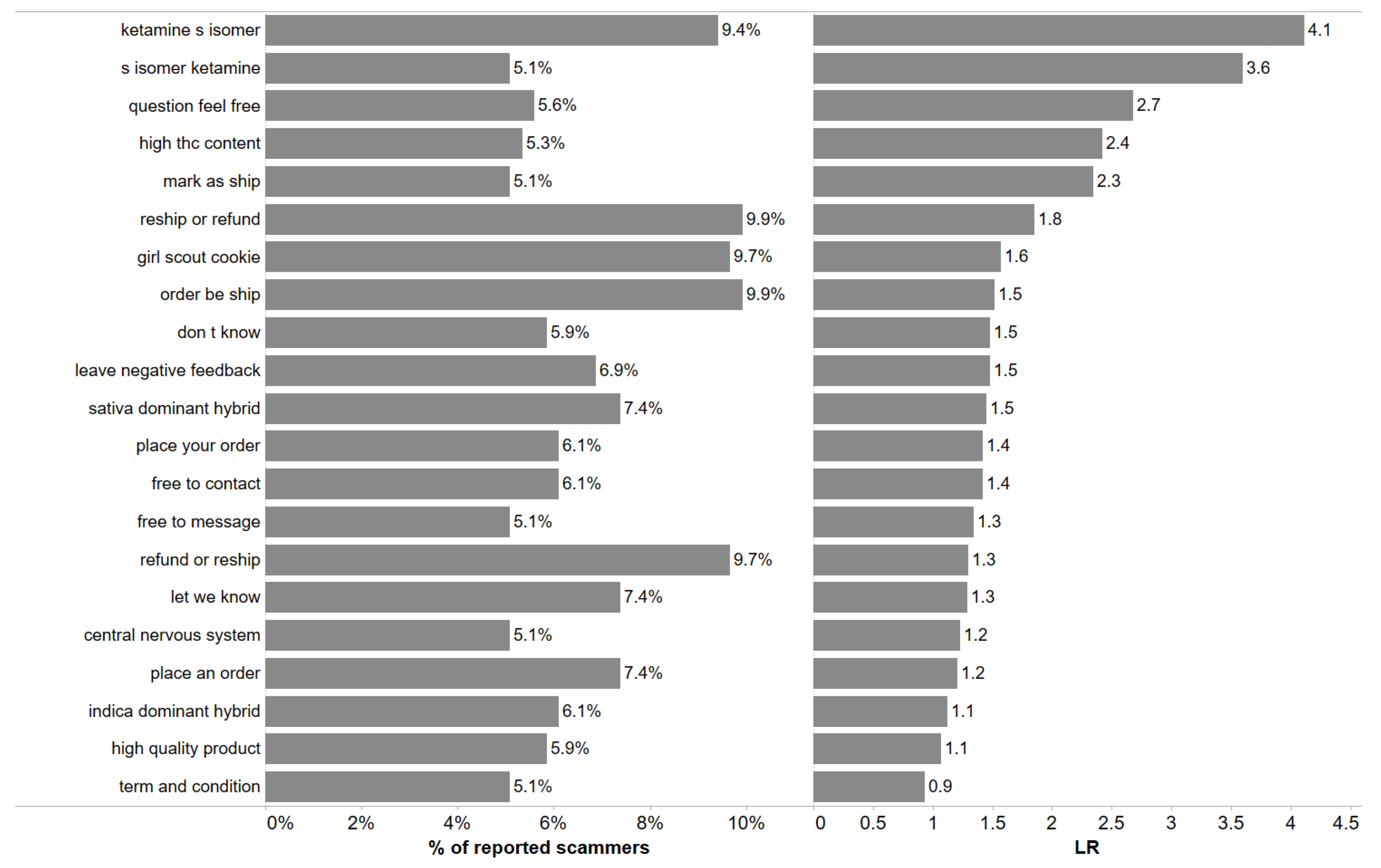
3.4.2. Analysis of the N-Grams
3.4.3. Probabilistic Discrimination
4. Results
4.1. Textometric Analysis of Raw Texts
4.2. Analysis of the N-Grams
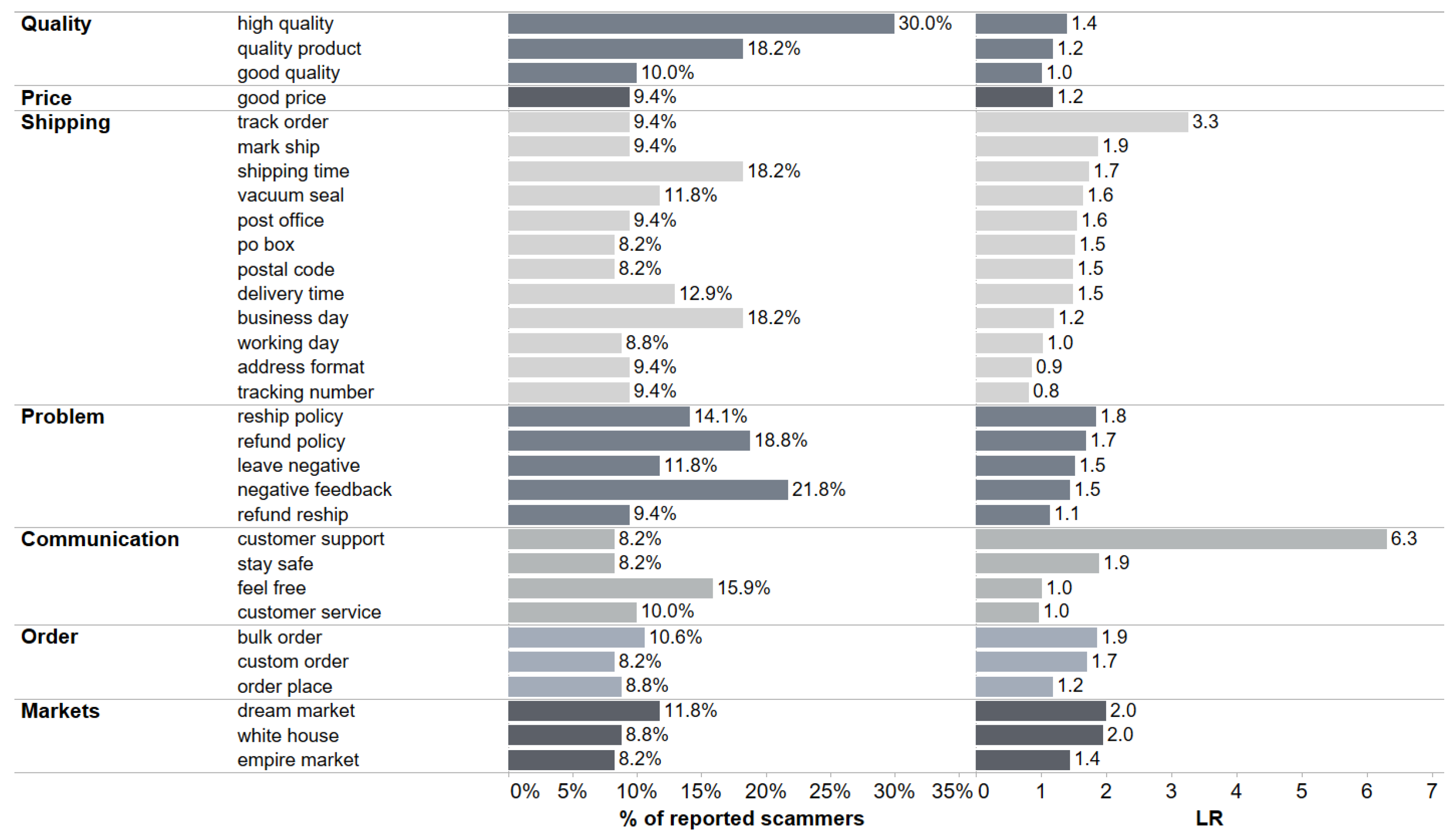
4.2.1. Analysis of the Product’s Descriptions
4.2.2. Analysis of the Profile Descriptions
5. Discussion
6. Conclusion and Prospects for Subsequent Research
Author Contributions
Funding
Institutional Review Board Statement
Conflicts of Interest
Appendix A

| 1 | https://en.wikipedia.org/wiki/Dread_(forum), accessed 15 November 2022. |
References
- Addawood, Aseel, Adam Badawy, Kristina Lerman, and Emilio Ferrara. 2019. Linguistic cues to deception: Identifying political trolls on social media. Paper presented at International AAAI Conference on Web and Social Media, Münich, Germany, June 11–14; pp. 15–25. [Google Scholar]
- Aitken, Colin, and Franco Taroni. 2005. Statistics and the Evaluation of Evidence for Forensic Scientists. Significance 2: 40–43. [Google Scholar]
- Arun, Rajkumar, Venkatasubramaniyan Suresh, and CE Veni Madhavan. 2009. Stopword graphs and authorship attribution in text corpora. Paper presented at 2009 IEEE International Conference on Semantic Computing, Berkeley, CA, USA, September 14–16; pp. 192–96. [Google Scholar]
- Bancroft, Angus, Tim Squirrell, Andreas Zaunseder, and Rafanell Irene. 2020. Producing Trust Among Illicit Actors: A Techno-Social Approach to an Online Illicit Market. Sociological Research Online 25: 456–72. [Google Scholar]
- Bozza, Silvia, Claude-Alain Roten, Antoine Jover, Valentina Cammarota, Lionel Pousaz, and Franco Taroni. 2023. A model-independent redundancy measure for human versus ChatGPT authorship discrimination using a Bayesian probabilistic approach. Scientific Reports 13: 19217. [Google Scholar] [CrossRef] [PubMed]
- Button, Mark, Carol McNaughton Nicholls, Jane Kerr, and Rachael Owen. 2014. Online frauds: Learning from victims why they fall for these scams. Australian & New Zealand Journal of Criminology 47: 391–408. [Google Scholar]
- Charaudeau, Patrick. 1992. Grammaire du sens et de l’expression. Hachette, epub ahead of print. [Google Scholar]
- Chaski, Carole E. 2005. Who’s At The Keyboard? Authorship Attribution in Digital Evidence Investigations. International Journal of Digital Evidence 4: 14. [Google Scholar]
- Christin, Nicolas. 2013. Traveling the silk road: A measurement analysis of a large anonymous online marketplace. Paper presented at 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, May 13; pp. 213–24. Available online: https://dl.acm.org/doi/10.1145/2488388.2488408 (accessed on 9 November 2023).
- Coleman, Meri, and Ta Lin Liau. 1975. A computer readability formula designed for machine scoring. Journal of Applied Psychology 60: 283–84. [Google Scholar] [CrossRef]
- Degeneve, Clara, Julien Longhi, and Quentin Rossy. 2022. Analysing the digital transformation of the market for fake documents using a computational linguistic approach. Forensic Science International: Synergy 5: 100287. [Google Scholar] [PubMed]
- Décary-Hétu, David, Masarah Paquet-Clouston, Martin Bouchard, and Carlo Morselli. 2018. Patterns in Cannabis Cryptomarkets in Canada in 2018. Ottawa: Public Safety Canada. [Google Scholar]
- Fobbe, Eilika. 2020. Text-Linguistic Analysis in Forensic Authorship Attribution Forensic Linguistics: New Procedures and Standards. International Journal of Language & Law 9: 93–114. [Google Scholar]
- Gibbons, John, and M. Teresa Turell, eds. 2008. Dimensions of Forensic Linguistics. AILA applied linguistics series v. 5. Amsterdam and Philadelphia: John Benjamins Pub. [Google Scholar]
- Hancock, Jeffrey T., Jennifer Thom-Santelli, and Thompson Ritchie. 2004. Deception and design: The impact of communication technology on lying behavior. Paper presented at SIGCHI Conference on Human Factors in Computing Systems, Vienna, Austria, April 24–29; pp. 129–34. [Google Scholar]
- Hauch, Valerie, Iris Blandón-Gitlin, Jaume Masip, and Siegfried L. Sporer. 2015. Are computers effective lie detectors? A meta-analysis of linguistic cues to deception. Personality and Social Psychology Review 19: 307–42. [Google Scholar] [CrossRef] [PubMed]
- Jacquart, Bérangère, Adrien Schopfer, and Quentin Rossy. 2021. Mules financières: Profils, recrutement et rôles de facilitateur pour les escroqueries aux fausses annonces. Revue Internationale de Criminologie et de Police Technique et Scientifique 4/21: 409–26. [Google Scholar]
- Jakupov, Alibek, Julien Mercadal, Besma Zeddini, and Julien Longhi. 2022. Analyzing Deceptive Opinion Spam Patterns: The Topic Modeling Approach. Paper presented at 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI), Macao, China, October 31–November 2; pp. 1251–61. Available online: https://ieeexplore.ieee.org/document/10097994/ (accessed on 1 May 2023).
- Junger, Marianne, Luka Koning, Pieter Hartel, and Bernard Veldkamp. 2023. In their own words: Deception detection by victims and near victims of fraud. Frontiers in Psychology 14: 1135369. [Google Scholar] [CrossRef]
- Juola, Patrick. 2021. Verifying authorship for forensic purposes: A computational protocol and its validation. Forensic Science International 325: 110824. [Google Scholar] [CrossRef]
- Juola, Patrick, John Sofko, and Patrick Brennan. 2006. A Prototype for Authorship Attribution Studies. Digital Scholarship in the Humanities 21: 169–78. [Google Scholar] [CrossRef]
- Longhi, Julien. 2021. Using digital humanities and linguistics to help with terrorism investigations. Forensic Science International 318: 110564. [Google Scholar] [CrossRef] [PubMed]
- Markowitz, David M. 2023. Deconstructing Deception: Frequency, Communicator Characteristics, and Linguistic Features of Embeddedness. Available online: https://doi.org/10.31234/osf.io/tm629 (accessed on 9 April 2024).
- Markowitz, David M., Jeffrey T. Hancock, Michael T. Woodworth, and Maxwell Ely. 2023. Contextual considerations for deception production and detection in forensic interviews. Frontiers in Psychology 14: 1134052. [Google Scholar] [CrossRef] [PubMed]
- Martin, James. 2013. Lost on the Silk Road: Online drug distribution and the ‘cryptomarket’. Criminology & Criminal Justice 14: 351–67. [Google Scholar]
- Morselli, Carlo, David Décary-Hétu, Masarah Paquet-Clouston, and Judith Aldridge. 2017. Conflict Management in Illicit Drug Cryptomarkets. International Criminal Justice Review 27: 237–54. [Google Scholar] [CrossRef]
- Ott, Myle, Yejin Choi, Claire Cardie, and Jeffrey T. Hancock. 2011. Finding Deceptive Opinion Spam by Any Stretch of the Imagination. Paper presented at 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, June 19–24; pp. 309–19. [Google Scholar]
- Pavlou, Paul A., and Angelika Dimoka. 2006. The Nature and Role of Feedback Text Comments in Online Marketplaces: Implications for Trust Building, Price Premiums, and Seller Differentiation. Information Systems Research 17: 392–414. [Google Scholar] [CrossRef]
- Przepiorka, Wojtek, Lukas Norbutas, and Rense Corten. 2017. Order without Law: Reputation Promotes Cooperation in a Cryptomarket for Illegal Drugs. European Sociological Review 33: 752–64. [Google Scholar] [CrossRef]
- Renaut, Laurène, Laura Ascone, and Julien Longhi. 2017. De la trace langagière à l’indice linguistique: Enjeux et précautions d’une linguistique forensique. Ela. Études de Linguistique Appliquée, 423–42. [Google Scholar]
- Ribaux, Olivier. 2023. De la Police Scientifique à la Traçologie, 2nd ed. Sciences forensiques. Lausanne: EPFL Press. Available online: https://www.epflpress.org/produit/672/9782889155446/de-la-police-scientifique-a-la-tracologie (accessed on 24 October 2023).
- Rossy, Quentin, and David Décary-Hétu. 2017. Internet traces and the analysis of online illicit markets. In The Routledge International Handbook of Forensic Intelligence and Criminology, 1st ed. Edited by Quentin Rossy, David Décary-Hétu, Olivier Delémont and Massimiliano Mulone. London: Routledge, pp. 249–63. Available online: https://www.taylorfrancis.com/books/9781134888955/chapters/10.4324/9781315541945-21 (accessed on 13 February 2021).
- Rossy, Quentin, and Olivier Ribaux. 2020. Orienting the Development of Crime Analysis Processes in Police Organisations Covering the Digital Transformations of Fraud Mechanisms. European Journal on Criminal Policy and Research, Epub ahead of print. [Google Scholar] [CrossRef]
- Roux, Claude, Rebecca Bucht, Frank Crispino, Peter De Forest, Chris Lennard, Pierre Margot, Michelle D. Miranda, Niamh NicDaeid, Olivier Ribaux, Alastair Ross, and et al. 2022. The Sydney declaration—Revisiting the essence of forensic science through its fundamental principles. Forensic Science International 332: 111182. [Google Scholar]
- Soska, Kyle, and Nicolas Christin. 2015. Measuring the Longitudinal Evolution of the Online Anonymous Marketplace Ecosystem. 24th USENIX Security Symposium, Epub ahead of print. [Google Scholar]
- Taroni, Franco, Paolo Garbolino, Silvia Bozza, and Colin Aitken. 2022. The Bayes’ factor: The coherent measure for hypothesis confirmation. Law, Probability and Risk 20: 15–36. [Google Scholar] [CrossRef]
- Titus, Richard M., Fred Heinzelmann, and John M. Boyle. 1995. Victimization of persons by fraud. Crime & Delinquency 41: 54–72. [Google Scholar]
- Tzanetakis, Meropi, Gerrit Kamphausen, Bernd Werse, and Roger von Laufenberg. 2016. The transparency paradox. Building trust, resolving disputes and optimising logistics on conventional and online drugs markets. International Journal of Drug Policy 35: 58–68. [Google Scholar] [CrossRef] [PubMed]
- van Deursen, K. 2021. The Effect of Feedback Polarity on the Sales and Prices on Cryptomarket AlphaBay. Bachelor thesis, Utrecht University, Utrecht, The Netherlands. [Google Scholar]
- Vidros, Sokratis, Constantinos Kolias, Georgios Kambourakis, and Leman Akoglu. 2017. Automatic Detection of Online Recruitment Frauds: Characteristics, Methods, and a Public Dataset. Future Internet 9: 6. [Google Scholar] [CrossRef]
- Wright, David. 2014. Stylistics Versus Statistics: A Corpus Linguistic Approach to Combining Techniques in Forensic Authorship Analysis Using Enron Emails. Leeds: University of Leeds. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N of Unique Ads | N of Unique Description | Crawling Period | Nb Crawls | |
|---|---|---|---|---|
| EM | 87′543 | 61′346 | 2020.06–2020.08 | 8 |
| DM | 88′640 | 45′432 | 2020.07–2021.01 | 17 |
| WHM | 83′524 | 56′739 | 2020.04–2021.03 | 30 |
| Total | 259′707 | 163′517 |
| Thread | Number of Posts Containing ‘Scam’ |
|---|---|
| White House Market | 261 |
| Empire Market | 1967 |
| DarkMarket | 678 |
| Total | 2906 |
| Reported Scammer N Profiles > N Distinct Descriptions | Others N Profiles > N Distinct Descriptions | Reported Scammer N Ads > N Distinct Descriptions | Others N Ads > N Distinct Descriptions | |
|---|---|---|---|---|
| DarkMarket | 33 > 52 | 809 > 813 | 717 > 906 | 33′465 > 39′645 |
| Empire Market | 83 > 153 | 804 > 936 | 2099 > 2537 | 43′536 > 48′767 |
| White House Market | 73 > 142 | 2036 > 3240 | 2632 > 3308 | 42′464 > 49′326 |
| Total | 189 > 347 | 3647 > 4925 | 5448 > 6751 | 119′465 > 137′272 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Degeneve, C.; Longhi, J.; Rossy, Q. Distinguishing Sellers Reported as Scammers on Online Illicit Markets Using Their Language Traces. Languages 2024, 9, 235. https://doi.org/10.3390/languages9070235
Degeneve C, Longhi J, Rossy Q. Distinguishing Sellers Reported as Scammers on Online Illicit Markets Using Their Language Traces. Languages. 2024; 9(7):235. https://doi.org/10.3390/languages9070235
Chicago/Turabian StyleDegeneve, Clara, Julien Longhi, and Quentin Rossy. 2024. "Distinguishing Sellers Reported as Scammers on Online Illicit Markets Using Their Language Traces" Languages 9, no. 7: 235. https://doi.org/10.3390/languages9070235