
Forecasting Selected Commodities’ Prices with the Bayesian Symbolic Regression


Abstract
:1. Introduction
2. Literature Review
2.1. Forecasting Methods Challenges
2.2. Crude Oil
2.3. Natural Gas
2.4. Coal
2.5. Metals
2.6. Agricultural Commodities
2.7. General Remarks on Commodity Price Predictors
3. Data
4. Methodology
4.1. Bayesian Symbolic Regression
4.2. Benchmark Models
4.3. Forecast Evaluation
5. Results
5.1. Forecast Accuracy—Measures
5.2. Forecast Accuracy—Testing
5.3. Selection of Parameters for BSR
5.4. Comparision of Models Performances
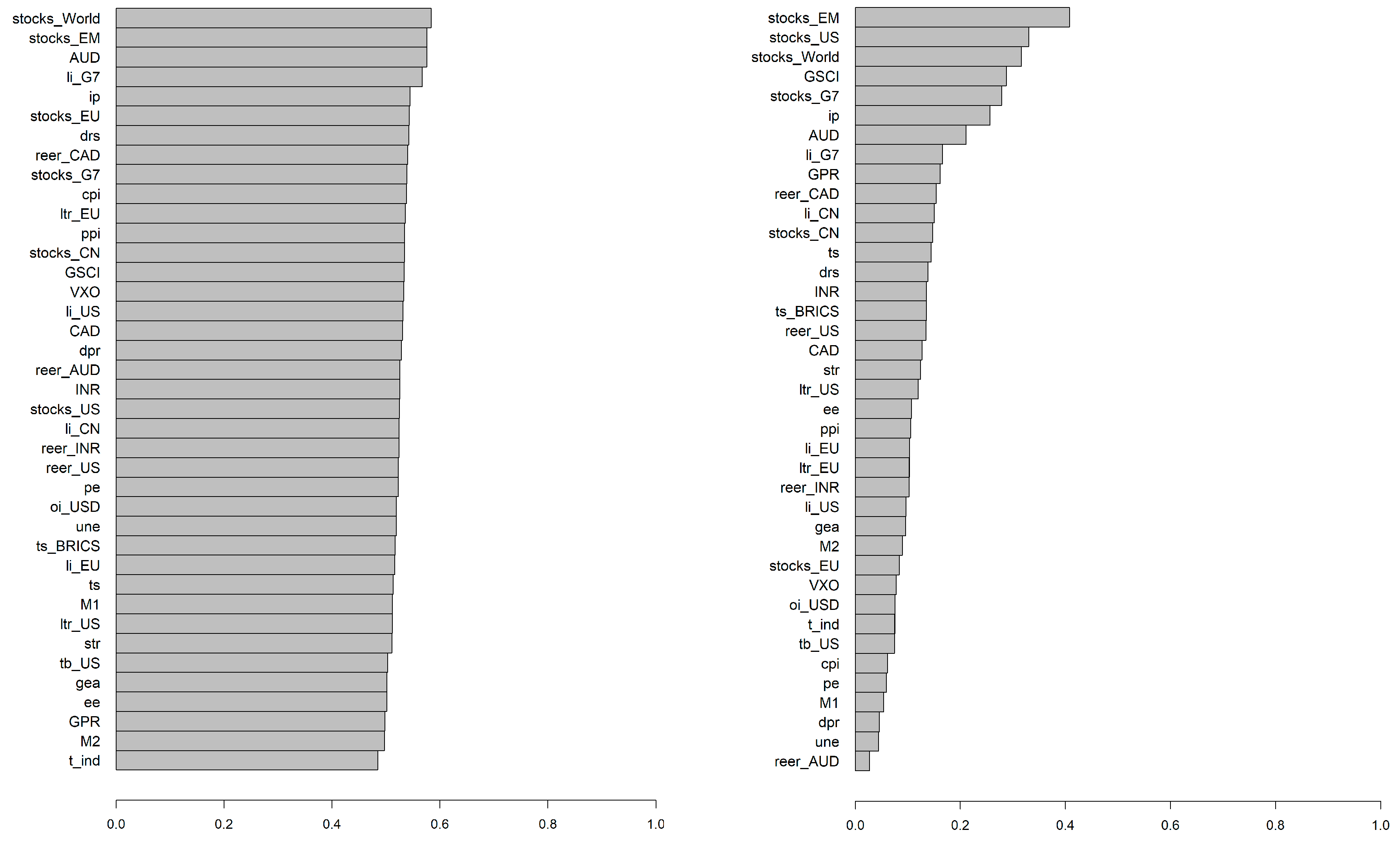
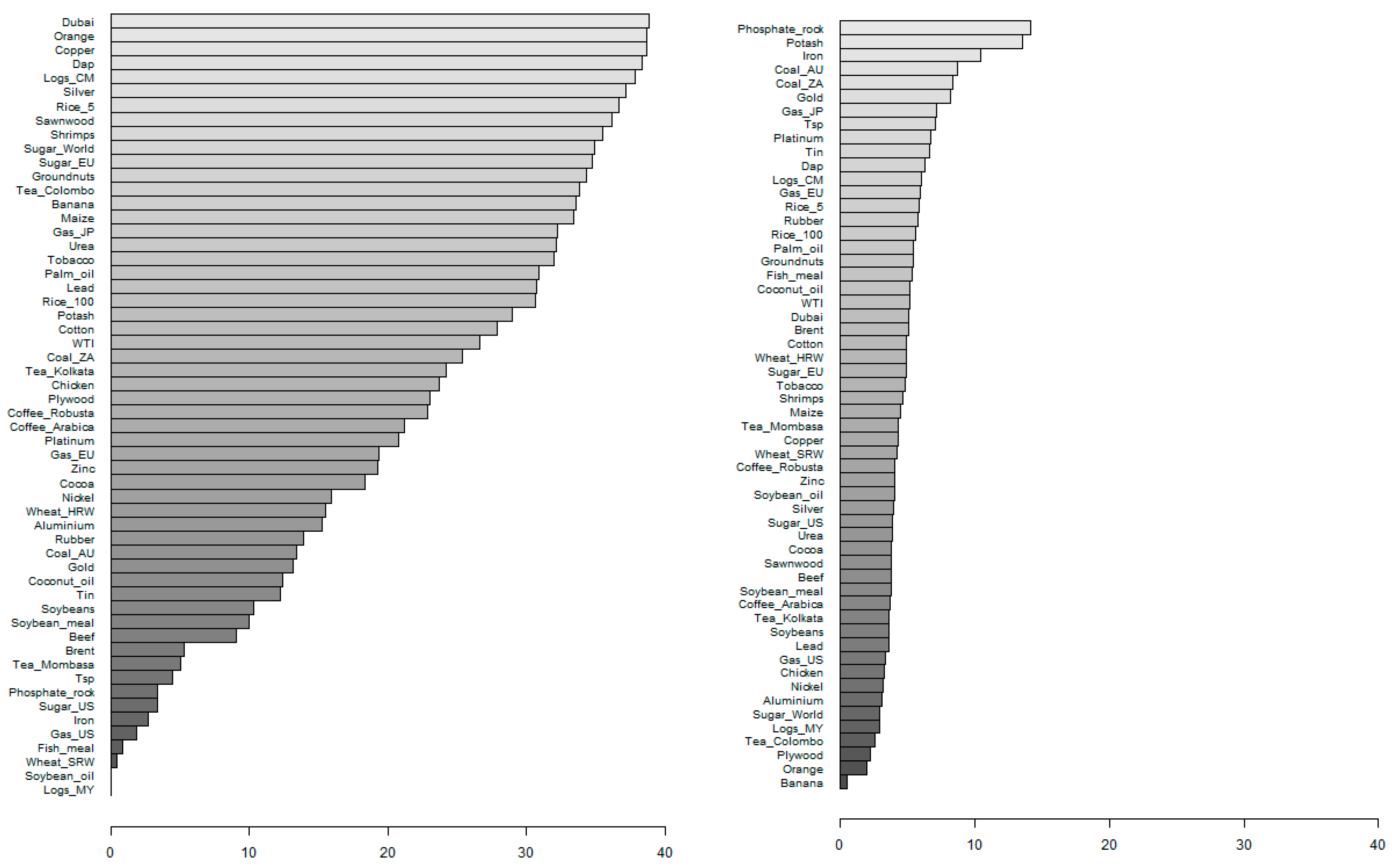
5.5. Time-Varying Importance of Price Predictors
5.6. Overall Importance of Price Predictors
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Description |
|---|---|
| Brent | Brent oil |
| Dubai | Dubai oil |
| WTI | WTI oil |
| Coal_AU | Coal (Australia) |
| Coal_ZA | Coal (South Africa) |
| Gas_US | Gas (U.S.) |
| Gas_EU | Gas (Europe) |
| Gas_JP | Gas (Japan) |
| Cocoa | Cocoa |
| Coffee_Arabica | Coffee Arabic |
| Coffee_Robusta | Coffee Robusta |
| Tea_Colombo | Tea (Colombo) |
| Tea_Kolkata | Tea (Kolkata) |
| Tea_Mombasa | Tea (Mombasa) |
| Coconut_oil | Coconut oil |
| Groundnuts | Groundnuts |
| Fish_meal | Fish meal |
| Palm_oil | Palm oil |
| Soybeans | Soybeans |
| Soybean_oil | Soybean oil |
| Soybean_meal | Soybean meal |
| Maize | Maize |
| Rice_5 | Rice 5% broken |
| Rice_100 | Rice 100% broken |
| Wheat_SRW | U.S. soft red winter wheat |
| Wheat_HRW | U.S. hard red winter wheat |
| Banana | Banana |
| Orange | Orange |
| Beef | Beef |
| Chicken | Chicken |
| Shrimps | Shrimps |
| Sugar_EU | Sugar (Europe) |
| Sugar_US | Sugar (U.S.) |
| Sugar_World | Sugar (world) |
| Tobacco | Tobacco |
| Logs_CM | Logs (Cameroon) |
| Logs_MY | Logs (Malaysia) |
| Sawnwood | Sawnwood |
| Plywood | Plywood |
| Cotton | Cotton |
| Rubber | Rubber |
| Phosphate_rock | Phosphate rock |
| Dap | Diammonium phosphate |
| Tsp | Triple superphosphate |
| Urea | Urea |
| Potash | Potash |
| Aluminium | Aluminium |
| Iron | Iron ore |
| Copper | Copper |
| Lead | Lead |
| Tin | Tin |
| Nickel | Nickel |
| Zinc | Zinc |
| Gold | Gold |
| Platinum | Platinum |
| Silver | Silver |
| Variable | Mean | Standard Deviation | Median | Min | Max | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|
| Brent | 47.49 | 32.21 | 37.72 | 9.80 | 133.90 | 0.82 | −0.48 |
| Dubai | 45.24 | 31.63 | 34.26 | 10.05 | 131.20 | 0.81 | −0.52 |
| WTI | 46.09 | 28.70 | 37.77 | 11.31 | 133.90 | 0.77 | −0.48 |
| Coal_AU | 58.10 | 31.02 | 47.70 | 22.25 | 180.00 | 1.10 | 0.68 |
| Coal_ZA | 54.67 | 29.46 | 46.62 | 21.25 | 167.80 | 0.95 | 0.20 |
| Gas_US | 3.55 | 2.14 | 2.84 | 1.19 | 13.52 | 1.75 | 3.68 |
| Gas_EU | 5.55 | 3.39 | 4.04 | 1.58 | 15.93 | 0.91 | −0.23 |
| Gas_JP | 7.26 | 4.26 | 5.45 | 2.72 | 18.11 | 0.92 | −0.32 |
| Cocoa | 1.92 | 0.70 | 1.69 | 0.86 | 3.53 | 0.48 | −0.90 |
| Coffee_Arabica | 2.88 | 1.10 | 2.84 | 1.17 | 6.62 | 0.70 | 0.53 |
| Coffee_Robusta | 1.65 | 0.61 | 1.68 | 0.50 | 4.03 | 0.35 | 0.36 |
| Tea_Colombo | 2.35 | 0.86 | 1.96 | 1.18 | 4.27 | 0.40 | −1.29 |
| Tea_Kolkata | 2.16 | 0.56 | 2.07 | 1.03 | 4.07 | 0.48 | −0.29 |
| Tea_Mombasa | 1.96 | 0.53 | 1.83 | 1.12 | 3.39 | 0.67 | −0.68 |
| Coconut_oil | 819.90 | 397.80 | 703.00 | 284.00 | 2256.00 | 1.05 | 0.46 |
| Groundnuts | 1192.00 | 405.40 | 1055.00 | 618.20 | 2528.00 | 1.37 | 1.65 |
| Fish_meal | 921.00 | 474.00 | 680.20 | 339.00 | 1926.00 | 0.37 | −1.46 |
| Palm_oil | 618.10 | 252.60 | 576.60 | 234.00 | 1377.00 | 0.80 | 0.08 |
| Soybeans | 343.30 | 119.70 | 307.00 | 183.00 | 684.00 | 0.79 | −0.36 |
| Soybean_oil | 707.50 | 283.80 | 626.00 | 286.90 | 1575.00 | 0.94 | 0.24 |
| Soybean_meal | 307.20 | 117.70 | 270.00 | 144.20 | 651.40 | 0.74 | −0.46 |
| Maize | 148.80 | 59.99 | 124.40 | 75.27 | 333.10 | 1.27 | 0.91 |
| Rice_5 | 354.20 | 126.90 | 321.20 | 163.80 | 907.00 | 0.89 | 0.93 |
| Rice_100 | 288.20 | 126.40 | 232.00 | 120.80 | 762.70 | 0.68 | −0.43 |
| Wheat_SRW | 178.60 | 61.97 | 162.30 | 85.30 | 419.60 | 0.92 | 0.45 |
| Wheat_HRW | 192.50 | 67.55 | 172.70 | 102.20 | 439.70 | 1.03 | 0.35 |
| Banana | 0.71 | 0.28 | 0.65 | 0.25 | 1.30 | 0.32 | −1.18 |
| Orange | 0.67 | 0.23 | 0.64 | 0.23 | 1.43 | 0.60 | −0.26 |
| Beef | 3.05 | 1.08 | 2.69 | 1.63 | 6.18 | 0.65 | −0.65 |
| Chicken | 1.60 | 0.40 | 1.53 | 0.88 | 2.72 | 0.35 | −0.83 |
| Shrimps | 12.09 | 2.14 | 11.88 | 7.50 | 19.25 | 0.64 | 0.43 |
| Sugar_EU | 0.54 | 0.12 | 0.55 | 0.34 | 0.78 | −0.11 | −1.23 |
| Sugar_US | 0.53 | 0.10 | 0.49 | 0.38 | 0.89 | 1.82 | 3.09 |
| Sugar_World | 0.28 | 0.11 | 0.26 | 0.11 | 0.65 | 1.01 | 0.88 |
| Tobacco | 3611.00 | 812.30 | 3400.00 | 2340.00 | 5118.00 | 0.31 | −1.35 |
| Logs_CM | 355.50 | 75.08 | 344.80 | 220.50 | 562.80 | 0.46 | −0.56 |
| Logs_MY | 248.30 | 64.21 | 251.80 | 133.30 | 520.80 | 0.90 | 1.53 |
| Sawnwood | 694.20 | 144.20 | 713.30 | 374.10 | 973.60 | −0.20 | −0.91 |
| Plywood | 497.90 | 93.48 | 499.90 | 310.60 | 751.80 | 0.09 | −0.67 |
| Cotton | 1.64 | 0.49 | 1.61 | 0.82 | 5.06 | 2.82 | 14.46 |
| Rubber | 1.63 | 0.98 | 1.40 | 0.49 | 6.26 | 1.66 | 3.36 |
| Phosphate_rock | 75.95 | 67.49 | 44.00 | 31.00 | 450.00 | 3.08 | 12.69 |
| Dap | 284.20 | 163.50 | 214.80 | 112.80 | 1076.00 | 1.87 | 4.93 |
| Tsp | 258.60 | 165.80 | 198.50 | 105.10 | 1132.00 | 2.36 | 7.90 |
| Urea | 202.80 | 118.20 | 185.80 | 62.75 | 785.00 | 1.46 | 3.31 |
| Potash | 204.80 | 129.90 | 151.20 | 83.00 | 682.50 | 1.46 | 1.61 |
| Aluminium | 1796.00 | 442.90 | 1731.00 | 1040.00 | 3578.00 | 0.82 | 0.34 |
| Iron | 67.32 | 48.40 | 37.90 | 24.30 | 214.40 | 1.18 | 0.31 |
| Copper | 4365.00 | 2472.00 | 3221.00 | 1377.00 | 10,160.00 | 0.45 | −1.25 |
| Lead | 1279.00 | 780.00 | 935.50 | 375.70 | 3720.00 | 0.47 | −1.12 |
| Tin | 12,030.00 | 7412.00 | 8144.00 | 3694.00 | 35,020.00 | 0.71 | −0.64 |
| Nickel | 12,830.00 | 7342.00 | 11,170.00 | 3872.00 | 52,180.00 | 1.86 | 5.14 |
| Zinc | 1702.00 | 762.70 | 1528.00 | 747.60 | 4405.00 | 0.86 | 0.10 |
| Gold | 772.80 | 506.80 | 433.90 | 256.10 | 1969.00 | 0.66 | −1.06 |
| Platinum | 844.10 | 442.30 | 809.80 | 341.20 | 2052.00 | 0.69 | −0.58 |
| Silver | 11.81 | 8.52 | 7.03 | 3.65 | 42.70 | 1.15 | 0.68 |
| dpr | −1.44 | 0.29 | −1.50 | −2.03 | −0.76 | 0.34 | −0.64 |
| pe | 25.58 | 6.77 | 25.41 | 13.32 | 44.20 | 0.68 | 0.22 |
| str | 2.85 | 2.46 | 2.38 | −0.01 | 8.90 | 0.41 | −1.00 |
| ltr_US | 4.58 | 2.21 | 4.46 | 0.62 | 9.36 | 0.29 | −0.90 |
| ltr_EU | 4.83 | 3.03 | 4.25 | −0.09 | 11.14 | 0.39 | −0.78 |
| ts | 1.73 | 1.09 | 1.71 | −0.49 | 3.78 | 0.03 | −1.06 |
| drs | 3.08 | 1.32 | 3.16 | 0.24 | 6.10 | −0.03 | −1.14 |
| cpi | 192.80 | 42.58 | 191.60 | 116.20 | 273.10 | −0.02 | −1.24 |
| ppi | 157.20 | 35.17 | 150.20 | 104.80 | 233.40 | 0.18 | −1.55 |
| ip | 87.46 | 14.13 | 92.35 | 60.59 | 104.20 | −0.76 | −0.90 |
| ee | 16.32 | 4.57 | 15.84 | 9.29 | 26.10 | 0.21 | −1.12 |
| M1 | 1091.00 | 1204.00 | 713.50 | 614.10 | 7230.00 | 4.32 | 17.86 |
| M2 | 3680.00 | 1334.00 | 3335.00 | 2305.00 | 7636.00 | 1.01 | 0.25 |
| gea | 2.47 | 59.50 | −4.90 | −162.40 | 188.60 | 0.73 | 0.86 |
| une | 5.88 | 1.67 | 5.50 | 3.50 | 14.70 | 1.31 | 2.36 |
| AUD | 0.76 | 0.12 | 0.76 | 0.49 | 1.10 | 0.43 | 0.38 |
| CAD | 0.81 | 0.11 | 0.79 | 0.62 | 1.05 | 0.42 | −0.69 |
| INR | 2.55 | 1.28 | 2.22 | 1.32 | 7.69 | 2.17 | 4.62 |
| reer_AUD | 95.05 | 12.43 | 96.64 | 71.32 | 123.90 | 0.22 | −0.60 |
| reer_CAD | 106.10 | 12.08 | 102.90 | 85.69 | 128.40 | 0.20 | −1.32 |
| reer_INR | 90.67 | 12.68 | 88.83 | 64.62 | 128.40 | 0.32 | −0.08 |
| reer_US | 97.58 | 7.57 | 96.89 | 83.93 | 114.60 | 0.28 | −0.99 |
| tb_US | −44,570.00 | 25,260.00 | −48,220.00 | −97,680.00 | −3492.00 | 0.10 | −1.35 |
| GSCI | 3525.00 | 1646.00 | 2990.00 | 1086.00 | 10,560.00 | 1.13 | 1.20 |
| oi_USD | 296,900,000,000.00 | 275,400,000,000.00 | 131,700,000,000.00 | 27,050,000,000.00 | 901,500,000,000.00 | 0.45 | −1.43 |
| t_ind | 1.11 | 0.04 | 1.10 | 1.04 | 1.24 | 0.95 | 0.99 |
| VXO | 19.95 | 8.21 | 18.16 | 7.87 | 61.38 | 1.63 | 3.97 |
| GPR | 98.42 | 48.72 | 88.57 | 39.05 | 512.50 | 4.58 | 29.51 |
| stocks_US | 1330.00 | 859.80 | 1187.00 | 258.90 | 4523.00 | 1.17 | 1.28 |
| stocks_World | 1210.00 | 566.10 | 1149.00 | 423.10 | 3141.00 | 0.76 | 0.33 |
| stocks_G7 | 1080.00 | 515.10 | 1022.00 | 384.30 | 2907.00 | 0.91 | 0.68 |
| stocks_EU | 307.50 | 116.20 | 336.30 | 96.69 | 582.30 | −0.14 | −0.91 |
| stocks_EM | 659.40 | 343.40 | 542.30 | 109.70 | 1376.00 | 0.19 | −1.37 |
| stocks_CN | 44,140.00 | 27,480.00 | 40,970.00 | 2274.00 | 141,100.00 | 0.37 | −0.26 |
| ts_BRICS | 0.00 | 0.01 | 0.00 | −0.04 | 0.05 | −0.68 | 3.74 |
| li_US | 99.77 | 1.33 | 99.91 | 92.31 | 102.20 | −1.59 | 4.55 |
| li_G7 | 99.86 | 1.22 | 100.10 | 92.26 | 102.10 | −1.83 | 6.66 |
| li_EU | 100.00 | 1.68 | 100.10 | 90.44 | 103.20 | −1.09 | 2.99 |
| li_CN | 99.97 | 1.41 | 100.10 | 85.68 | 103.10 | −2.82 | 25.36 |
| Variable | ADF Stat. | ADF p-Val. | PP Stat. | PP p-Val. | KPSS Stat. | KPSS p-Val. |
|---|---|---|---|---|---|---|
| Brent | −7.9953 | <0.01 | −253.6471 | <0.01 | 0.0446 | >0.10 |
| Dubai | −8.2440 | <0.01 | −230.5171 | <0.01 | 0.0436 | >0.10 |
| WTI | −8.0483 | <0.01 | −248.0916 | <0.01 | 0.0400 | >0.10 |
| Coal_AU | −6.5208 | <0.01 | −280.4958 | <0.01 | 0.0801 | >0.10 |
| Coal_ZA | −6.1623 | <0.01 | −266.5725 | <0.01 | 0.0538 | >0.10 |
| Gas_US | −8.7802 | <0.01 | −361.7846 | <0.01 | 0.0348 | >0.10 |
| Gas_EU | −6.4891 | <0.01 | −277.7274 | <0.01 | 0.0560 | >0.10 |
| Gas_JP | −6.7223 | <0.01 | −229.5060 | <0.01 | 0.0636 | >0.10 |
| Cocoa | −7.3658 | <0.01 | −321.8202 | <0.01 | 0.0906 | >0.10 |
| Coffee_Arabica | −6.9581 | <0.01 | −314.2563 | <0.01 | 0.0674 | >0.10 |
| Coffee_Robusta | −6.2083 | <0.01 | −298.5168 | <0.01 | 0.1047 | >0.10 |
| Tea_Colombo | −8.1779 | <0.01 | −348.0611 | <0.01 | 0.0361 | >0.10 |
| Tea_Kolkata | −12.9817 | <0.01 | −282.5993 | <0.01 | 0.0150 | >0.10 |
| Tea_Mombasa | −7.1632 | <0.01 | −313.6262 | <0.01 | 0.0259 | >0.10 |
| Coconut_oil | −6.1340 | <0.01 | −323.9682 | <0.01 | 0.0421 | >0.10 |
| Groundnuts | −7.0198 | <0.01 | −284.0919 | <0.01 | 0.0233 | >0.10 |
| Fish_meal | −7.7946 | <0.01 | −275.7443 | <0.01 | 0.0601 | >0.10 |
| Palm_oil | −7.1712 | <0.01 | −269.1340 | <0.01 | 0.0642 | >0.10 |
| Soybeans | −7.6204 | <0.01 | −331.3422 | <0.01 | 0.0596 | >0.10 |
| Soybean_oil | −6.7782 | <0.01 | −263.4829 | <0.01 | 0.0627 | >0.10 |
| Soybean_meal | −8.0436 | <0.01 | −267.6929 | <0.01 | 0.0425 | >0.10 |
| Maize | −7.6244 | <0.01 | −299.4328 | <0.01 | 0.0389 | >0.10 |
| Rice_5 | −8.7629 | <0.01 | −233.7177 | <0.01 | 0.0488 | >0.10 |
| Rice_100 | −7.7580 | <0.01 | −231.1146 | <0.01 | 0.0521 | >0.10 |
| Wheat_SRW | −8.4273 | <0.01 | −309.6046 | <0.01 | 0.0353 | >0.10 |
| Wheat_HRW | −7.7958 | <0.01 | −304.6156 | <0.01 | 0.0413 | >0.10 |
| Banana | −11.8927 | <0.01 | −388.1070 | <0.01 | 0.0161 | >0.10 |
| Orange | −11.8850 | <0.01 | −268.7407 | <0.01 | 0.0232 | >0.10 |
| Beef | −7.7189 | <0.01 | −228.0717 | <0.01 | 0.1321 | >0.10 |
| Chicken | −10.5157 | <0.01 | −260.6561 | <0.01 | 0.0269 | >0.10 |
| Shrimps | −7.3627 | <0.01 | −196.4938 | <0.01 | 0.0356 | >0.10 |
| Sugar_EU | −7.4501 | <0.01 | −315.1929 | <0.01 | 0.1137 | >0.10 |
| Sugar_US | −6.3475 | <0.01 | −282.7717 | <0.01 | 0.0680 | >0.10 |
| Sugar_World | −7.3141 | <0.01 | −288.5904 | <0.01 | 0.0413 | >0.10 |
| Tobacco | −5.0524 | <0.01 | −287.2056 | <0.01 | 0.1256 | >0.10 |
| Logs_CM | −7.8160 | <0.01 | −292.3322 | <0.01 | 0.0386 | >0.10 |
| Logs_MY | −7.6421 | <0.01 | −255.3297 | <0.01 | 0.0395 | >0.10 |
| Sawnwood | −6.2682 | <0.01 | −333.6141 | <0.01 | 0.0931 | >0.10 |
| Plywood | −7.3099 | <0.01 | −281.7184 | <0.01 | 0.0430 | >0.10 |
| Cotton | −7.9502 | <0.01 | −194.0813 | <0.01 | 0.0387 | >0.10 |
| Rubber | −6.4845 | <0.01 | −295.2020 | <0.01 | 0.0616 | >0.10 |
| Phosphate_rock | −5.7667 | <0.01 | −381.9933 | <0.01 | 0.0363 | >0.10 |
| Dap | −6.9540 | <0.01 | −203.3954 | <0.01 | 0.0559 | >0.10 |
| Tsp | −7.3063 | <0.01 | −183.7721 | <0.01 | 0.0515 | >0.10 |
| Urea | −8.1881 | <0.01 | −302.8459 | <0.01 | 0.0324 | >0.10 |
| Potash | −6.2091 | <0.01 | −443.6662 | <0.01 | 0.1158 | >0.10 |
| Aluminium | −7.3307 | <0.01 | −337.5590 | <0.01 | 0.0697 | >0.10 |
| Iron | −6.3234 | <0.01 | −271.0289 | <0.01 | 0.0596 | >0.10 |
| Copper | −8.1452 | <0.01 | −233.0640 | <0.01 | 0.0946 | >0.10 |
| Lead | −6.5456 | <0.01 | −310.2747 | <0.01 | 0.0784 | >0.10 |
| Tin | −6.8723 | <0.01 | −298.2957 | <0.01 | 0.1397 | >0.10 |
| Nickel | −6.4269 | <0.01 | −249.7583 | <0.01 | 0.0438 | >0.10 |
| Zinc | −6.3570 | <0.01 | −293.2702 | <0.01 | 0.0385 | >0.10 |
| Gold | −6.6906 | <0.01 | −331.2990 | <0.01 | 0.5126 | 0.0388 |
| Platinum | −8.3714 | <0.01 | −306.8139 | <0.01 | 0.0952 | >0.10 |
| Silver | −7.5172 | <0.01 | −299.9199 | <0.01 | 0.1486 | >0.10 |
| dpr | −2.1808 | 0.5009 | −6.7632 | 0.7318 | 1.8097 | <0.01 |
| pe | −1.8732 | 0.6309 | −5.2990 | 0.8137 | 0.9871 | <0.01 |
| str | −3.5042 | 0.0423 | −9.1229 | 0.5999 | 4.6993 | <0.01 |
| ltr_US | −4.0658 | <0.01 | −31.5982 | <0.01 | 6.2708 | <0.01 |
| ltr_EU | −3.1425 | 0.0979 | −13.4612 | 0.3572 | 6.0577 | <0.01 |
| ts | −3.2958 | 0.0718 | −14.8652 | 0.2787 | 0.2490 | >0.10 |
| drs | −3.1972 | 0.0886 | −11.4279 | 0.4710 | 0.2997 | >0.10 |
| cpi | −6.6089 | <0.01 | −204.7199 | <0.01 | 0.8030 | <0.01 |
| ppi | −6.3383 | <0.01 | −249.5577 | <0.01 | 0.0516 | >0.10 |
| ip | −6.5356 | <0.01 | −298.2689 | <0.01 | 0.2861 | >0.10 |
| ee | −4.9675 | <0.01 | −393.8539 | <0.01 | 0.2569 | >0.10 |
| M1 | −6.9325 | <0.01 | −365.9665 | <0.01 | 0.5329 | 0.0343 |
| M2 | −6.0468 | <0.01 | −156.3054 | <0.01 | 1.3597 | <0.01 |
| gea | −2.4424 | 0.3905 | −22.5739 | 0.0411 | 0.6736 | 0.0159 |
| une | −2.5496 | 0.3451 | −21.1600 | 0.0539 | 0.3989 | 0.0776 |
| AUD | −7.0716 | <0.01 | −393.6667 | <0.01 | 0.0588 | >0.10 |
| CAD | −7.0035 | <0.01 | −413.4559 | <0.01 | 0.0908 | >0.10 |
| INR | −6.4130 | <0.01 | −364.1453 | <0.01 | 0.4552 | 0.0534 |
| reer_AUD | −7.9739 | <0.01 | −275.5769 | <0.01 | 0.0580 | >0.10 |
| reer_CAD | −7.3475 | <0.01 | −307.1186 | <0.01 | 0.0951 | >0.10 |
| reer_INR | −7.3033 | <0.01 | −325.3636 | <0.01 | 0.5238 | 0.0363 |
| reer_US | −7.6200 | <0.01 | −227.4906 | <0.01 | 0.0742 | >0.10 |
| tb_US | −5.7462 | <0.01 | −103.8847 | <0.01 | 0.1607 | >0.10 |
| GSCI | −7.0261 | <0.01 | −316.9545 | <0.01 | 0.2585 | >0.10 |
| oi_USD | −6.8621 | <0.01 | −330.9185 | <0.01 | 0.0850 | >0.10 |
| t_ind | −3.2137 | 0.0858 | −36.2523 | <0.01 | 3.5126 | <0.01 |
| VXO | −3.5502 | 0.0379 | −64.6624 | <0.01 | 0.2472 | >0.10 |
| GPR | −4.7256 | <0.01 | −103.1218 | <0.01 | 0.1747 | >0.10 |
| stocks_US | −6.1733 | <0.01 | −394.0153 | <0.01 | 0.1278 | >0.10 |
| stocks_World | −6.4726 | <0.01 | −374.9809 | <0.01 | 0.0608 | >0.10 |
| stocks_G7 | −6.4349 | <0.01 | −377.8616 | <0.01 | 0.0720 | >0.10 |
| stocks_EU | −6.7591 | <0.01 | −375.6705 | <0.01 | 0.0936 | >0.10 |
| stocks_EM | −7.2645 | <0.01 | −344.3724 | <0.01 | 0.1365 | >0.10 |
| stocks_CN | −6.5398 | <0.01 | −415.8805 | <0.01 | 0.1967 | >0.10 |
| ts_BRICS | −4.9694 | <0.01 | −130.1868 | <0.01 | 0.3909 | 0.0811 |
| li_US | −4.9081 | <0.01 | −29.9440 | <0.01 | 0.0800 | >0.10 |
| li_G7 | −5.2672 | <0.01 | −30.2912 | <0.01 | 0.0946 | >0.10 |
| li_EU | −5.4067 | <0.01 | −25.4211 | 0.0221 | 0.1003 | >0.10 |
| li_CN | −4.1257 | <0.01 | −82.3776 | <0.01 | 0.1147 | >0.10 |
| Commodity | Best | Best vs. ARIMA | Best vs. NAIVE |
|---|---|---|---|
| Brent | DMA | 0.0004 | 0.0002 |
| Dubai | DMA | 0.0001 | 0.0000 |
| WTI | BMA | 0.0004 | 0.0004 |
| Coal_AU | B-RIDGRE | 0.0729 | 0.0246 |
| Coal_ZA | BSR av EW rec | 0.1906 | 0.0006 |
| Gas_US | DMA | 0.0539 | 0.2162 |
| Gas_EU | DMA | 0.4469 | 0.0114 |
| Gas_JP | DMA | 0.4178 | 0.0538 |
| Cocoa | ARIMA | 0.1483 | |
| Coffee_Arabica | DMA | 0.4657 | 0.4603 |
| Coffee_Robusta | ARIMA | 0.1928 | |
| Tea_Colombo | BMA | 0.3237 | 0.3149 |
| Tea_Kolkata | BMA | 0.3972 | 0.1314 |
| Tea_Mombasa | BMA | 0.2629 | 0.3450 |
| Coconut_oil | BMA | 0.1535 | 0.0087 |
| Groundnuts | DMA | 0.2585 | 0.0245 |
| Fish_meal | B-RIDGRE | 0.2576 | 0.4941 |
| Palm_oil | ARIMA | 0.0091 | |
| Soybeans | BMA | 0.1258 | 0.0784 |
| Soybean_oil | DMA | 0.4197 | 0.0387 |
| Soybean_meal | ARIMA | 0.0007 | |
| Maize | BSR av EW rec | 0.2956 | 0.0795 |
| Rice_5 | ARIMA | 0.4718 | |
| Rice_100 | NAIVE | 0.4002 | |
| Wheat_SRW | ARIMA | 0.3001 | |
| Wheat_HRW | BMA | 0.4565 | 0.2907 |
| Banana | DMA | 0.4266 | 0.4133 |
| Orange | ARIMA | 0.3381 | |
| Beef | ARIMA | 0.1138 | |
| Chicken | ARIMA | 0.2135 | |
| Shrimps | ARIMA | 0.0618 | |
| Sugar_EU | RIDGE | 0.0884 | 0.3505 |
| Sugar_US | ARIMA | 0.1307 | |
| Sugar_World | ARIMA | 0.0090 | |
| Tobacco | ARIMA | 0.2881 | |
| Logs_CM | BMA | 0.1138 | 0.0181 |
| Logs_MY | ARIMA | 0.0251 | |
| Sawnwood | DMA | 0.0150 | 0.0824 |
| Plywood | DMA | 0.3120 | 0.2524 |
| Cotton | ARIMA | 0.0036 | |
| Rubber | BMA | 0.4072 | 0.2832 |
| Phosphate_rock | GP fix | 0.0472 | 0.1994 |
| Dap | ARIMA | 0.1316 | |
| Tsp | ARIMA | 0.0446 | |
| Urea | BSR av MSE rec | 0.1435 | 0.0868 |
| Potash | BMA | 0.1253 | 0.4778 |
| Aluminium | DMA | 0.0020 | 0.0010 |
| Iron | RIDGE | 0.1258 | 0.0386 |
| Copper | DMA | 0.1459 | 0.0725 |
| Lead | ARIMA | 0.2022 | |
| Tin | DMA | 0.1651 | 0.1013 |
| Nickel | ARIMA | 0.0693 | |
| Zinc | BMS 1V | 0.4368 | 0.0314 |
| Gold | BMA | 0.1037 | 0.1845 |
| Platinum | BMA | 0.0013 | 0.0034 |
| Silver | DMS 1V | 0.2438 | 0.1263 |
| Commodity | BSR Rec vs. Best | BSR Rec vs. ARIMA | BSR Rec vs. NAIVE |
|---|---|---|---|
| Brent | 0.0000 | 0.0024 | 0.0352 |
| Dubai | 0.0000 | 0.5241 | 0.9577 |
| WTI | 0.0085 | 0.0561 | 0.0825 |
| Coal_AU | 0.0167 | 0.4624 | 0.1947 |
| Coal_ZA | 0.0111 | 0.0017 | 0.1732 |
| Gas_US | 0.1149 | 0.5788 | 0.1229 |
| Gas_EU | 0.0151 | 0.0210 | 0.2298 |
| Gas_JP | 0.0350 | 0.0696 | 0.2353 |
| Cocoa | 0.0010 | 0.0010 | 0.0022 |
| Coffee_Arabica | 0.0003 | 0.0002 | 0.0000 |
| Coffee_Robusta | 0.1578 | 0.1578 | 0.1578 |
| Tea_Colombo | 0.0118 | 0.0106 | 0.0085 |
| Tea_Kolkata | 0.1053 | 0.0368 | 0.2181 |
| Tea_Mombasa | 0.1184 | 0.1287 | 0.1229 |
| Coconut_oil | 0.0557 | 0.0747 | 0.0877 |
| Groundnuts | 0.0041 | 0.0001 | 0.0091 |
| Fish_meal | 0.1584 | 0.1584 | 0.1584 |
| Palm_oil | 0.0968 | 0.0968 | 0.1069 |
| Soybeans | 0.0442 | 0.0516 | 0.0543 |
| Soybean_oil | 0.0605 | 0.0225 | 0.8987 |
| Soybean_meal | 0.0000 | 0.0000 | 0.0000 |
| Maize | 0.0567 | 0.1268 | 0.1653 |
| Rice_5 | 0.1174 | 0.1174 | 0.0821 |
| Rice_100 | 0.0008 | 0.1678 | 0.0008 |
| Wheat_SRW | 0.1148 | 0.1148 | 0.0806 |
| Wheat_HRW | 0.0360 | 0.0586 | 0.0628 |
| Banana | 0.0016 | 0.1621 | 0.0015 |
| Orange | 0.1421 | 0.1421 | 0.1424 |
| Beef | 0.0594 | 0.0594 | 0.1950 |
| Chicken | 0.0310 | 0.0310 | 0.0527 |
| Shrimps | 0.0117 | 0.0117 | 0.0087 |
| Sugar_EU | 0.0590 | 0.3408 | 0.0340 |
| Sugar_US | 0.1120 | 0.1120 | 0.3439 |
| Sugar_World | 0.1591 | 0.1591 | 0.1591 |
| Tobacco | 0.1131 | 0.1131 | 0.1203 |
| Logs_CM | 0.0006 | 0.0232 | 0.0948 |
| Logs_MY | 0.0000 | 0.0000 | 0.0001 |
| Sawnwood | 0.0002 | 0.0432 | 0.0610 |
| Plywood | 0.0056 | 0.0069 | 0.0070 |
| Cotton | 0.0005 | 0.0005 | 0.0164 |
| Rubber | 0.0003 | 0.0182 | 0.0360 |
| Phosphate_rock | 0.0155 | 0.9250 | 0.0061 |
| Dap | 0.1408 | 0.1408 | 0.3374 |
| Tsp | 0.1142 | 0.1142 | 0.8300 |
| Urea | 0.0474 | 0.0868 | 0.2359 |
| Potash | 0.0875 | 0.5945 | 0.1037 |
| Aluminium | 0.0000 | 0.0030 | 0.0073 |
| Iron | 0.2240 | 0.7191 | 0.9356 |
| Copper | 0.0158 | 0.4215 | 0.6329 |
| Lead | 0.0206 | 0.0206 | 0.1275 |
| Tin | 0.1509 | 0.6005 | 0.8598 |
| Nickel | 0.1016 | 0.1016 | 0.4385 |
| Zinc | 0.4096 | 0.5121 | 0.8845 |
| Gold | 0.1634 | 0.6838 | 0.6001 |
| Platinum | 0.0319 | 0.0679 | 0.0675 |
| Silver | 0.0982 | 0.3400 | 0.3480 |
| Commodity | GP Rec vs. Best | GP Rec vs. ARIMA | GP Rec vs. NAIVE |
|---|---|---|---|
| Brent | 0.0000 | 0.0001 | 0.0038 |
| Dubai | 0.0000 | 0.0001 | 0.0005 |
| WTI | 0.0000 | 0.0092 | 0.0405 |
| Coal_AU | 0.1305 | 0.7823 | 0.9500 |
| Coal_ZA | 0.0107 | 0.2715 | 0.7661 |
| Gas_US | 0.1499 | 0.1547 | 0.1528 |
| Gas_EU | 0.0007 | 0.0018 | 0.0083 |
| Gas_JP | 0.0363 | 0.0599 | 0.2664 |
| Cocoa | 0.0000 | 0.0000 | 0.0000 |
| Coffee_Arabica | 0.0004 | 0.0004 | 0.0005 |
| Coffee_Robusta | 0.0301 | 0.0301 | 0.0301 |
| Tea_Colombo | 0.0000 | 0.0000 | 0.0000 |
| Tea_Kolkata | 0.0001 | 0.0000 | 0.0000 |
| Tea_Mombasa | 0.0000 | 0.0000 | 0.0000 |
| Coconut_oil | 0.0000 | 0.0000 | 0.0001 |
| Groundnuts | 0.0000 | 0.0000 | 0.0000 |
| Fish_meal | 0.1590 | 0.1590 | 0.1590 |
| Palm_oil | 0.0009 | 0.0009 | 0.0209 |
| Soybeans | 0.0125 | 0.0125 | 0.0125 |
| Soybean_oil | 0.0011 | 0.0012 | 0.0514 |
| Soybean_meal | 0.0000 | 0.0000 | 0.0002 |
| Maize | 0.0004 | 0.0005 | 0.0005 |
| Rice_5 | 0.1026 | 0.1026 | 0.1026 |
| Rice_100 | 0.0011 | 0.2012 | 0.0011 |
| Wheat_SRW | 0.0000 | 0.0000 | 0.0000 |
| Wheat_HRW | 0.0300 | 0.0448 | 0.0586 |
| Banana | 0.0000 | 0.0000 | 0.0000 |
| Orange | 0.1269 | 0.1269 | 0.1279 |
| Beef | 0.0327 | 0.0327 | 0.0381 |
| Chicken | 0.0762 | 0.0762 | 0.0588 |
| Shrimps | 0.0000 | 0.0000 | 0.0000 |
| Sugar_EU | 0.0012 | 0.0014 | 0.0001 |
| Sugar_US | 0.0746 | 0.0746 | 0.1168 |
| Sugar_World | 0.0000 | 0.0000 | 0.0000 |
| Tobacco | 0.0000 | 0.0000 | 0.0000 |
| Logs_CM | 0.0000 | 0.0003 | 0.0019 |
| Logs_MY | 0.0000 | 0.0000 | 0.0000 |
| Sawnwood | 0.0028 | 0.0029 | 0.0029 |
| Plywood | 0.0000 | 0.0000 | 0.0000 |
| Cotton | 0.0003 | 0.0003 | 0.0007 |
| Rubber | 0.0062 | 0.0493 | 0.0585 |
| Phosphate_rock | 0.2654 | 0.9534 | 0.4070 |
| Dap | 0.0434 | 0.0434 | 0.0293 |
| Tsp | 0.0209 | 0.0209 | 0.4023 |
| Urea | 0.0000 | 0.0002 | 0.0005 |
| Potash | 0.0187 | 0.4791 | 0.0157 |
| Aluminium | 0.0000 | 0.0000 | 0.0001 |
| Iron | 0.1423 | 0.4858 | 0.7309 |
| Copper | 0.0004 | 0.0596 | 0.0722 |
| Lead | 0.0081 | 0.0081 | 0.0111 |
| Tin | 0.0566 | 0.1823 | 0.3743 |
| Nickel | 0.0022 | 0.0022 | 0.0062 |
| Zinc | 0.0001 | 0.0097 | 0.0310 |
| Gold | 0.1449 | 0.4744 | 0.3852 |
| Platinum | 0.0161 | 0.8765 | 0.8434 |
| Silver | 0.4522 | 0.6101 | 0.6420 |
| Commodity | BSR | BSR av MSE | BSR av EW | GP |
|---|---|---|---|---|
| Brent | 0.9997 | 0.0000 | 0.7999 | 0.9982 |
| Dubai | 1.0000 | 0.0000 | 0.0044 | 0.9995 |
| WTI | 0.1591 | 0.8409 | 0.0008 | 0.0005 |
| Coal_AU | 0.3120 | 0.8751 | 0.0000 | 0.0000 |
| Coal_ZA | 0.9830 | 0.0417 | 0.0003 | 0.6665 |
| Gas_US | 0.1963 | 0.1555 | 0.0013 | 0.1225 |
| Gas_EU | 0.1298 | 0.8661 | 0.1405 | 0.0000 |
| Gas_JP | 0.1591 | 0.8409 | 0.0416 | 0.0314 |
| Cocoa | 0.9930 | 0.0000 | 0.0124 | 0.0000 |
| Coffee_Arabica | 0.9999 | 0.0004 | 0.0010 | 0.9980 |
| Coffee_Robusta | 0.1591 | 0.8409 | 0.0000 | 0.9686 |
| Tea_Colombo | 0.7948 | 0.0000 | 0.0000 | 1.0000 |
| Tea_Kolkata | 0.7471 | 0.0000 | 0.8468 | 1.0000 |
| Tea_Mombasa | 0.8812 | 0.0000 | 0.0012 | 0.0000 |
| Coconut_oil | 0.9214 | 0.0000 | 0.0003 | 0.9972 |
| Groundnuts | 0.9960 | 0.0000 | 0.0029 | 0.0000 |
| Fish_meal | 0.8416 | 0.1590 | 0.0301 | 0.8410 |
| Palm_oil | 0.1325 | 0.8768 | 0.0227 | 0.0000 |
| Soybeans | 0.1585 | 0.0125 | 0.8363 | 0.9875 |
| Soybean_oil | 0.3132 | 0.0314 | 0.0712 | 0.0000 |
| Soybean_meal | 1.0000 | 0.0001 | 0.0011 | 0.9940 |
| Maize | 0.9349 | 0.0004 | 0.0005 | 0.0000 |
| Rice_5 | 0.8793 | 0.1027 | 0.0449 | 0.1594 |
| Rice_100 | 0.9973 | 0.0269 | 0.0904 | 0.9792 |
| Wheat_SRW | 0.9144 | 0.0000 | 0.0135 | 0.9999 |
| Wheat_HRW | 0.9400 | 0.0628 | 0.0000 | 0.0411 |
| Banana | 0.8607 | 0.0000 | 0.2094 | 0.0001 |
| Orange | 0.1591 | 0.8409 | 0.0000 | 0.1117 |
| Beef | 0.8903 | 0.0337 | 0.0658 | 0.0000 |
| Chicken | 0.9754 | 0.1210 | 0.6837 | 0.8680 |
| Shrimps | 0.9739 | 0.0000 | 0.0016 | 0.0001 |
| Sugar_EU | 0.9703 | 0.0002 | 0.1612 | 0.0083 |
| Sugar_US | 0.6617 | 0.1312 | 0.5337 | 0.6361 |
| Sugar_World | 0.8409 | 0.8727 | 0.0491 | 0.0379 |
| Tobacco | 0.8706 | 0.0002 | 0.0403 | 0.9175 |
| Logs_CM | 0.9990 | 0.0002 | 0.0040 | 0.0001 |
| Logs_MY | 0.0227 | 0.9773 | 0.9212 | 1.0000 |
| Sawnwood | 0.6473 | 0.0030 | 0.0906 | 0.0408 |
| Plywood | 0.1648 | 0.8005 | 0.1591 | 0.7624 |
| Cotton | 0.2596 | 0.7893 | 0.0004 | 0.0002 |
| Rubber | 0.9974 | 0.0262 | 0.0000 | 0.9615 |
| Phosphate_rock | 0.9965 | 0.3159 | 0.1899 | 0.7346 |
| Dap | 0.0788 | 0.9212 | 0.0012 | 0.0044 |
| Tsp | 0.5278 | 0.0060 | 0.0758 | 0.6297 |
| Urea | 0.9526 | 0.0000 | 0.0085 | 1.0000 |
| Potash | 0.8955 | 0.0181 | 0.1150 | 0.9811 |
| Aluminium | 0.9999 | 0.0000 | 0.0000 | 0.9998 |
| Iron | 0.5166 | 0.3003 | 0.0374 | 0.0418 |
| Copper | 0.8625 | 0.0029 | 0.0000 | 0.1166 |
| Lead | 0.9535 | 0.0013 | 0.0008 | 0.9830 |
| Tin | 0.4807 | 0.1016 | 0.0806 | 0.0004 |
| Nickel | 0.6666 | 0.0004 | 0.0024 | 0.0010 |
| Zinc | 0.2026 | 0.0004 | 0.0055 | 0.1246 |
| Gold | 0.3883 | 0.3878 | 0.0105 | 0.0000 |
| Platinum | 0.9602 | 0.2326 | 0.0006 | 0.1839 |
| Silver | 0.1561 | 0.8442 | 0.0000 | 0.0000 |
| Commodity | BSR Rec vs. GP Rec | BSR Fix vs. GP Fix |
|---|---|---|
| Brent | 0.0655 | 0.8724 |
| Dubai | 0.0002 | 1.0000 |
| WTI | 0.7229 | 0.0188 |
| Coal_AU | 0.9406 | 0.0000 |
| Coal_ZA | 0.8899 | 0.9977 |
| Gas_US | 0.1541 | 0.0816 |
| Gas_EU | 0.3310 | 1.0000 |
| Gas_JP | 0.6818 | 0.9523 |
| Cocoa | 0.0009 | 0.0000 |
| Coffee_Arabica | 0.2536 | 1.0000 |
| Coffee_Robusta | 0.7545 | 0.9212 |
| Tea_Colombo | 0.0000 | 0.9933 |
| Tea_Kolkata | 0.0000 | 0.9952 |
| Tea_Mombasa | 0.7340 | 0.0000 |
| Coconut_oil | 0.3622 | 0.9736 |
| Groundnuts | 0.0001 | 0.0000 |
| Fish_meal | 0.5007 | 0.9910 |
| Palm_oil | 0.8764 | 1.0000 |
| Soybeans | 0.0125 | 0.9222 |
| Soybean_oil | 0.0269 | 0.0000 |
| Soybean_meal | 0.0347 | 1.0000 |
| Maize | 0.0007 | 0.0000 |
| Rice_5 | 0.1030 | 0.1589 |
| Rice_100 | 0.4754 | 0.9999 |
| Wheat_SRW | 0.0000 | 0.8917 |
| Wheat_HRW | 0.4674 | 0.7429 |
| Banana | 0.0000 | 0.0000 |
| Orange | 0.7725 | 0.1117 |
| Beef | 0.2953 | 0.7829 |
| Chicken | 0.5324 | 0.8318 |
| Shrimps | 0.0000 | 0.0000 |
| Sugar_EU | 0.0031 | 0.0063 |
| Sugar_US | 0.3293 | 0.3542 |
| Sugar_World | 0.8409 | 0.8409 |
| Tobacco | 0.7458 | 1.0000 |
| Logs_CM | 0.0801 | 0.0005 |
| Logs_MY | 0.0001 | 0.0266 |
| Sawnwood | 0.0030 | 0.0000 |
| Plywood | 0.0001 | 0.6267 |
| Cotton | 0.8532 | 0.0008 |
| Rubber | 0.1652 | 1.0000 |
| Phosphate_rock | 0.9117 | 0.7826 |
| Dap | 0.4567 | 0.8416 |
| Tsp | 0.0556 | 0.9980 |
| Urea | 0.0006 | 1.0000 |
| Potash | 0.3157 | 0.9868 |
| Aluminium | 0.0436 | 1.0000 |
| Iron | 0.3080 | 0.1071 |
| Copper | 0.0158 | 0.1789 |
| Lead | 0.0969 | 1.0000 |
| Tin | 0.0972 | 0.0006 |
| Nickel | 0.0027 | 0.0004 |
| Zinc | 0.0008 | 0.2556 |
| Gold | 0.3184 | 0.0001 |
| Platinum | 0.9505 | 1.0000 |
| Silver | 0.7129 | 0.0091 |
Appendix B
References
- Abd Elaziz, Mohamed, Ahmed A. Ewees, and Zakaria Alameer. 2020. Improving adaptive neuro-fuzzy inference system based on a modified salp swarm algorithm using genetic algorithm to forecast crude oil price. Natural Resources Research 29: 2671–86. [Google Scholar] [CrossRef]
- Aguilar-Rivera, Rubén, Manuel Valenzuela-Rendon, and J. Rodriguez-Ortiz. 2015. Genetic algorithms and Darwinian approaches in financial applications: A survey. Expert Systems with Applications 42: 7684–97. [Google Scholar] [CrossRef]
- Ahumada, Hildegart, and Magdalena Cornejo. 2015. Explaining commodity prices by a cointegrated time series-cross section model. Empirical Economics 48: 1667–90. [Google Scholar] [CrossRef]
- Akram, Qaisar Farooq. 2009. Commodity prices, interest rates and the dollar. Energy Economics 31: 838–51. [Google Scholar] [CrossRef]
- Alam, Md Rafayet, and Scott Gilbert. 2017. Monetary policy shocks and the dynamics of agricultural commodity prices: Evidence from structural and factor-augmented VAR analyses. Agricultural Economics 48: 15–27. [Google Scholar] [CrossRef]
- Alameer, Zakaria, Ahmed Fathalla, Kenli Li, Haiwang Ye, and Jianhua Zhang. 2020. Multistep-ahead forecasting of coal prices using a hybrid deep learning model. Resources Policy 65: 101588. [Google Scholar] [CrossRef]
- Alameer, Zakaria, Mohamed Abd Elaziz, Ahmed A. Ewees, Haiwang Ye, and Jianhua Zhang. 2019a. Forecasting copper prices using hybrid adaptive neuro-fuzzy inference system and genetic algorithms. Natural Resources Research 28: 1385–401. [Google Scholar] [CrossRef]
- Alameer, Zakaria, Mohamed Abd Elaziz, Ahmed A. Ewees, Haiwang Ye, and Jianhua Zhang. 2019b. Forecasting gold price fluctuations using improved multilayer perceptron neural network and whale optimization algorithm. Resources Policy 61: 250–60. [Google Scholar] [CrossRef]
- Algieri, Bernardina, Matthias Kalkuhl, and Nicolas Koch. 2017. A tale of two tails: Explaining extreme events in financialized agricultural markets. Food Policy 69: 256–69. [Google Scholar] [CrossRef]
- Aloui, Riadh, Mohamed Safouane Ben Aissa, and Duc Khuong Nguyen. 2013a. Conditional dependence structure between oil prices and exchange rates: A copula-GARCH approach. Journal of International Money and Finance 32: 719–38. [Google Scholar] [CrossRef]
- Aloui, Riadh, Shawkat Hammoudeh, and Duc Khuong Nguyen. 2013b. A time-varying copula approach to oil and stock market dependence: The case of transition economies. Energy Economics 39: 208–21. [Google Scholar] [CrossRef]
- Al-Qudsi, Sulayman. 2010. Oil and commodity price volatility: Origins and impact on the Arab economy and capital markets. Geopolitics of Energy 32: 3–24. [Google Scholar]
- Alquist, Ron, Lutz Kilian, and Robert Vigfusson. 2013. Forecasting the price of oil. In Handbook of Economic Forecasting 2. Edited by Graham Elliott, C. Granger and Allan Timmermann. Amsterdam: Elsevier, pp. 427–507. [Google Scholar]
- Andreasson, Pierre, Stelios Bekiros, Duc Khuong Nguyen, and Gazi Salah Uddin. 2016. Impact of speculation and economic uncertainty on commodity markets. International Review of Financial Analysis 43: 115–27. [Google Scholar] [CrossRef]
- Apergis, Nicholas, and James E. Payne. 2010. Renewable energy consumption and economic growth: Evidence from a panel of OECD countries. Energy Policy 38: 656–60. [Google Scholar] [CrossRef]
- Arango, Luis, Fernando Arias, and Adriana Florez. 2012. Determinants of commodity prices. Applied Economics 44: 135–45. [Google Scholar] [CrossRef]
- Arora, Vipin, and Matthew Tanner. 2013. Do oil prices respond to real interest rates? Energy Economics 36: 546–55. [Google Scholar] [CrossRef]
- Arouri, Mohamed El Hedi, Jamel Jouini, and Duc Khuong Nguyen. 2011. Volatility spillovers between oil prices and stock sector returns: Implications for portfolio management. Journal of International Money and Finance 30: 1387–405. [Google Scholar] [CrossRef]
- Arouri, Mohamed El Hedi, Thanh Huong Dinh, and Duc Khuong Nguyen. 2010. Time-varying predictability in crude-oil markets: The case of GCC countries. Energy Policy 38: 4371–80. [Google Scholar] [CrossRef]
- Arslan-Ayaydin, Özgür, and Inna Khagleeva. 2013. The dynamics of crude oil spot and futures markets. In Energy Economics and Financial Markets. Edited by André Dorsman, John L. Simpson and Wim Westerman. Berlin: Springer, pp. 159–73. [Google Scholar]
- Atil, Ahmed, Amine Lahiani, and Duc Khuong Nguyen. 2014. Asymmetric and nonlinear pass-through of crude oil prices to gasoline and natural gas prices. Energy Policy 65: 567–73. [Google Scholar] [CrossRef]
- Ayres, Joao, Constantino Hevia, and Juan Pablo Nicolini. 2020. Real exchange rates and primary commodity prices. Journal of International Economics 122: 103261. [Google Scholar] [CrossRef]
- Bal, Debi Prasad, and Badri Narayan Rath. 2015. Nonlinear causality between crude oil price and exchange rate: A comparative study of China and India. Energy Economics 51: 149–56. [Google Scholar]
- Banerjee, Debanjan, Arijit Ghosal, and Imon Mukherjee. 2019. Prediction of gold price movement using geopolitical risk as a factor. Advances in Intelligent Systems and Computing 814: 879–86. [Google Scholar]
- Banner, Katharine M., and Megan D. Higgs. 2016. Considerations for assessing model averaging of regression coefficients. Ecological Applications 27: 78–93. [Google Scholar] [CrossRef] [PubMed]
- Barbieri, Maria, and James Berger. 2004. Optimal predictive model selection. The Annals of Statistics 32: 870–97. [Google Scholar] [CrossRef]
- Basher, Syed Abul, Alfred A. Haug, and Perry Sadorsky. 2012. Oil prices, exchange rates and emerging stock markets. Energy Economics 34: 227–40. [Google Scholar] [CrossRef]
- Baumeister, Christiane, and Lutz Kilian. 2015. Forecasting the real price of oil in a changing world: A forecast combination approach. Journal of Business and Economic Statistics 33: 338–51. [Google Scholar] [CrossRef]
- Bekiros, Stelios, Rangan Gupta, and Alessia Paccagnini. 2015. Oil price forecastability and economic uncertainty. Economics Letters 132: 125–28. [Google Scholar] [CrossRef]
- Belmonte, Miguel, and Gary Koop. 2014. Model switching and model averaging in time-varying parameter regression models. Advances in Econometrics 34: 45–69. [Google Scholar]
- Benmoussa, Amor Aniss, Reinhard Ellwanger, and Stephen Snudden. 2020. The New Benchmark for Forecasts of the Real Price of Crude Oil. Working Papers of Bank of Canada 39. Ottawa: Bank of Canada. [Google Scholar]
- Bernabe, Araceli, Esteban Martina, Jose Alvarez-Ramirez, and Carlos Ibarra-Valdez. 2004. A multi-model approach for describing crude oil price dynamics. Physica A: Statistical Mechanics and its Applications 338: 567–84. [Google Scholar] [CrossRef]
- Bernardi, Mauro, and Leopoldo Catania. 2018. The model confidence set package for R. International Journal of Computational Economics and Econometrics 8: 144–58. [Google Scholar] [CrossRef]
- Bhattacharya, Maumita, Rafiqul Islam, and Jemal Abawajy. 2016. Evolutionary optimization: A big data perspective. Journal of Network and Computer Applications 59: 416–26. [Google Scholar] [CrossRef]
- Bistline, John E. 2014. Natural gas, uncertainty, and climate policy in the US electric power sector. Energy Policy 74: 433–42. [Google Scholar] [CrossRef]
- Bloom, Nicholas. 2009. The impact of uncertainty shocks. Econometrica 77: 623–85. [Google Scholar]
- Bloomberg. 2022. S&P GSCI Commodity Total Return Index. Available online: https://www.bloomberg.com/quote/SPGSCITR:IND (accessed on 1 December 2022).
- Borychowski, Michał, and Andrzej Czyzewski. 2015. Determinants of prices increase of agricultural commodities in a global context. Management 19: 152–67. [Google Scholar] [CrossRef]
- Brabazon, Anthony, Michael Kampouridis, and Michael O’Neill. 2020. Applications of genetic programming to finance and economics: Past, present, future. Genetic Programming and Evolvable Machines 21: 33–53. [Google Scholar] [CrossRef]
- Brown, Pablo Pincheira, and Nicolás Hardy. 2019. Forecasting base metal prices with the Chilean exchange rate. Resources Policy 62: 256–81. [Google Scholar] [CrossRef]
- Brown, Stephen P. A., and Mine K. Yucel. 2008. What drives natural gas prices? The Energy Journal 29: 45–60. [Google Scholar] [CrossRef]
- Buncic, Daniel, and Carlo Moretto. 2015. Forecasting copper prices with dynamic averaging and selection models. The North American Journal of Economics and Finance 33: 1–38. [Google Scholar] [CrossRef]
- Burnham, Kenneth, and David R. Anderson. 2002. Model Selection and Multimodel Inference: A Practical Information. Berlin: Springer. [Google Scholar]
- Buyuksahin, Bahattin, and Michel A. Robe. 2014. Speculators, commodities and cross-market linkages. Journal of International Money and Finance 42: 38–70. [Google Scholar] [CrossRef]
- Byrne, Joseph, Giorgio Fazio, and Norbert Fiess. 2013. Primary commodity prices: Co-movements, common factors and fundamentals. Journal of Development Economics 101: 16–26. [Google Scholar] [CrossRef]
- Byun, Sung. 2017. Speculation in commodity futures markets, inventories and the price of crude oil. Energy Journal 38: 93–113. [Google Scholar] [CrossRef]
- Cade, Brian S. 2015. Model averaging and muddled multimodel inferences. Ecology 96: 2370–82. [Google Scholar] [CrossRef]
- Caginalp, Gunduz, and Mark DeSantis. 2011. Nonlinearity in the dynamics of financial markets. Nonlinear Analysis: Real World Applications 12: 1140–51. [Google Scholar] [CrossRef]
- Caldara, Dario, and Matteo Iacoviello. 2022a. Measuring geopolitical risk. American Economic Review 112: 1194–225. [Google Scholar] [CrossRef]
- Caldara, Dario, and Matteo Iacoviello. 2022b. Measuring Geopolitical Risk. Available online: https://matteoiacoviello.com/gpr.htm (accessed on 1 December 2022).
- Carmona, René. 2015. Financialization of the commodities markets: A non-technical introduction. In Commodities, Energy and Environmental Finance. Edited by R. Aid, M. Ludkovski and R. Sircar. New York: Springer, pp. 3–37. [Google Scholar]
- Cashin, Paul, Luis F. Cespedes, and Ratna Sahay. 2004. Commodity currencies and the real exchange rate. Journal of Development Economics 75: 239–68. [Google Scholar] [CrossRef]
- CBOE. 2022. VIX Historical Price Data. Available online: https://www.cboe.com/tradable_products/vix/vix_historical_data (accessed on 1 December 2022).
- Ceperic, Vladimir, Niko Bako, and A. Baric. 2014. A symbolic regression-based modelling strategy of AC/DC rectifiers for RFID applications. Expert Systems with Applications 41: 7061–67. [Google Scholar] [CrossRef]
- Chai, Jian, Quanying Lu, Yi Hu, Shouyang Wang, Kin Lai, and Hongtao Liu. 2018. Analysis and Bayes statistical probability inference of crude oil price change point. Technological Forecasting and Social Change 126: 271–83. [Google Scholar] [CrossRef]
- Chen, Pei-Fen, Chien-Chiang Lee, and Jhih-Hong Zeng. 2014. The relationship between spot and futures oil prices: Do structural breaks matter? Energy Economics 43: 206–17. [Google Scholar] [CrossRef]
- Chen, Peng. 2015. Global oil prices, macroeconomic fundamentals and China’s commodity sector comovements. Energy Policy 87: 284–94. [Google Scholar] [CrossRef]
- Chen, Qi, Bing Xue, Lin Shang, and Mengjie Zhang. 2016. Improving generalisation of genetic programming for symbolic regression with structural risk minimisation. In Proceedings of the Genetic and Evolutionary Computation Conference GECCO 2016, Denver, CO, USA, July 20–24; Edited by Tobias Friedrich and Frank Neumann. New York: Association for Computing Machinery, pp. 709–16. [Google Scholar]
- Chen, Shiu-Sheng. 2016. Commodity prices and related equity prices. Canadian Journal of Economics 49: 949–67. [Google Scholar] [CrossRef]
- Chen, Shiu-Sheng, and Hung-Chyn Chen. 2007. Oil prices and real exchange rates. Energy Economics 29: 390–404. [Google Scholar] [CrossRef]
- Chen, Yu-Chin, Kenneth Rogoff, and Barbara Rossi. 2010. Can exchange rates forecast commodity prices? The Quarterly Journal of Economics 125: 1145–94. [Google Scholar] [CrossRef]
- Chen, Yu-Chin, Kenneth Rogoff, and Barbara Rossi. 2012. Predicting agri-commodity prices: An asset pricing approach. In Global Uncertainty and the Volatility of Agricultural Commodities Prices. Edited by Bertrand Munier. Amsterdam: IOS Press, pp. 45–71. [Google Scholar]
- Chiou-Wei, Song-Zan, Sheng-Hung Chen, and Zhen Zhu. 2020. Natural gas price, market fundamentals and hedging effectiveness. The Quarterly Review of Economics and Finance 78: 321–37. [Google Scholar] [CrossRef]
- Chipman, Hugh A., Edward I. George, and Robert E. McCulloch. 1998a. BART: Bayesian additive regression trees. The Annals of Applied Statistics 4: 266–98. [Google Scholar] [CrossRef]
- Chipman, Hugh A., Edward I. George, and Robert E. McCulloch. 1998b. Bayesian CART model search. Journal of the American Statistical Association 93: 935–48. [Google Scholar] [CrossRef]
- Ciner, Cetin. 2017. Predicting white metal prices by a commodity sensitive exchange rate. International Review of Financial Analysis 52: 309–15. [Google Scholar] [CrossRef]
- Clark, Todd E., and Michael W. McCracken. 2009. Improving forecast accuracy by combining recursive and rolling forecasts. International Economic Review 50: 363–95. [Google Scholar] [CrossRef]
- Claveria, Oscar, Enric Monte, and Salvador Torra. 2016. Quantification of survey expectations by means of symbolic regression via genetic programming to estimate economic growth in Central and Eastern European economies. Eastern European Economics 54: 171–89. [Google Scholar] [CrossRef]
- Claveria, Oscar, Enric Monte, and Salvador Torra. 2017. Evolutionary computation for macroeconomic forecasting. Computational Economics 51: 1–17. [Google Scholar] [CrossRef]
- Claveria, Oscar, Enric Monte, and Salvador Torra. 2022. A genetic programming approach for economic forecasting with survey expectations. Applied Sciences 12: 6661. [Google Scholar] [CrossRef]
- Clements, Kenneth W., and Renée Fry. 2008. Commodity currencies and currency commodities. Resources Policy 33: 55–73. [Google Scholar] [CrossRef]
- Commodity Futures Trading Commission. 2022. Historical Compressed. Available online: https://www.cftc.gov/MarketReports/CommitmentsofTraders/HistoricalCompressed/index.htm (accessed on 1 December 2022).
- Cornelius, Peter, and Jonathan Story. 2007. China and global energy markets. Orbis 51: 5–20. [Google Scholar] [CrossRef]
- Coulombe, P. G., Maxime Leroux, Dalibor Stevanovic, and Stéphane Surprenant. 2021. Macroeconomic data transformations matter. International Journal of Forecasting 37: 1338–54. [Google Scholar] [CrossRef]
- Cross, Jamie, and Bao Nguyen. 2017. The relationship between global oil price shocks and China’s output: A time-varying analysis. Energy Economics 62: 79–91. [Google Scholar] [CrossRef]
- Cuaresma, Jesus Crespo, Jaroslava Hlouskova, and Michael Obsersteiner. 2018. Fundamentals, speculation or macroeconomic conditions? Modelling and forecasting Arabica coffee prices. European Review of Agricultural Economics 45: 583–615. [Google Scholar] [CrossRef]
- Cuaresma, Jesus Crespo, Jaroslava Hlouskova, and Michael Obsersteiner. 2021. Agricultural commodity price dynamics and their determinants: A comprehensive econometric approach. Journal of Forecasting 40: 1245–73. [Google Scholar] [CrossRef]
- Diaz-Rainey, Ivan, Helen Roberts, and David H. Lont. 2017. Crude inventory accounting and speculation in the physical oil market. Energy Economics 66: 508–22. [Google Scholar] [CrossRef]
- Diebold, Francis X., and Robert S. Mariano. 1995. Comparing predictive accuracy. Journal of Business and Economic Statistics 13: 253–63. [Google Scholar] [CrossRef]
- Dimoulkas, Ilias, Lars Herre, Dina Khastieva, Elis Nycander, Mikael Amelin, and Peyman Mazidi. 2018. A hybrid model based on symbolic regression and neural networks for electricity load forecasting. Paper presented at the 2018 15th International Conference on the European Energy Market (EEM), Lodz, Poland, June 27–29; New York: IEEE, pp. 1–5. [Google Scholar]
- Dogan, Eyup. 2016. The relationship between economic growth, energy consumption and trade. Bulletin of Energy Economics 4: 70–80. [Google Scholar]
- Dong, Baomin, Xuefeng Li, and Boqiang Lin. 2010. Forecasting long-run coal price in China: A shifting trend time-series approach. Review of Development Economics 14: 499–519. [Google Scholar] [CrossRef]
- Downes, John, and Jordan Elliot Goodman. 2018. Dictionary of Finance and Investment Terms. Hauppauge: Barron’s Educational Series, Inc. [Google Scholar]
- Drachal, Krzysztof. 2016. Forecasting spot oil price in a dynamic model averaging framework—Have the determinants changed over time? Energy Economics 60: 35–46. [Google Scholar] [CrossRef]
- Drachal, Krzysztof. 2018a. Determining time-varying drivers of spot oil price in a Dynamic Model Averaging framework. Energies 11: 1207. [Google Scholar] [CrossRef]
- Drachal, Krzysztof. 2018b. Some novel Bayesian model combination schemes: An application to commodities prices. Sustainability 10: 2801. [Google Scholar] [CrossRef]
- Drachal, Krzysztof. 2020. Dynamic Model Averaging in economics and finance with fDMA: A package for R. Signals 1: 47–99. [Google Scholar] [CrossRef]
- Du, Limin, and Yanan He. 2015. Extreme risk spillovers between crude oil and stock markets. Energy Economics 51: 455–65. [Google Scholar] [CrossRef]
- Duc Huynh, Toan Luu Duc, Tobias Burggraf, and Muhammad Ali Nasir. 2020. Financialisation of natural resources & instability caused by risk transfer in commodity markets. Resources Policy 66: 101620. [Google Scholar] [CrossRef]
- EIA. 2020. China’s Crude Oil Imports Surpassed 10 Million Barrels per Day in 2019. Available online: https://www.eia.gov/todayinenergy/detail.php?id=43216 (accessed on 1 December 2022).
- EIA. 2022. U.S. Energy Information Administration. Available online: https://www.eia.gov (accessed on 1 December 2022).
- Eiben, A., and Jim Smith. 2015. Introduction to Evolutionary Computing. Berlin: Springer. [Google Scholar]
- Etienne, Xiaoli L., Scott H. Irwin, and Philip Garcia. 2018. Speculation and corn prices. Applied Economics 50: 4724–44. [Google Scholar] [CrossRef]
- Ewees, Ahmed A., Mohamed Abd Elaziz, Zakaria Alameer, Haiwang Ye, and Jianhua Zhang. 2020. Improving multilayer perceptron neural network using chaotic grasshopper optimization algorithm to forecast iron ore price volatility. Resources Policy 65: 101555. [Google Scholar] [CrossRef]
- Fattouh, Bassam, and Pasquale Scaramozzino. 2011. Uncertainty, expectations, and fundamentals: Whatever happened to long-term oil prices? Oxford Review of Economic Policy 27: 186–206. [Google Scholar] [CrossRef]
- Fattouh, Bassam, Lutz Kilian, and Lavan Mahadeva. 2013. The role of speculation in oil markets: What have we learned so far? The Energy Journal 34: 20–30. [Google Scholar] [CrossRef]
- Fernandez-Diaz, Jose M., and Bruce Morley. 2019. Interdependence among agricultural commodity markets, macroeconomic factors, crude oil and commodity index. Research in International Business and Finance 47: 174–94. [Google Scholar] [CrossRef]
- Fishe, Raymond P.H., and Aaron Smith. 2019. Do speculators drive commodity prices away from supply and demand fundamentals? Journal of Commodity Markets 15: 100078. [Google Scholar] [CrossRef]
- Frankel, Jeffrey, and Andrew K. Rose. 2010. Determinants of Agricultural and Mineral Commodity Prices. Cambridge: Harvard University, John F. Kennedy School of Government. [Google Scholar]
- FRED. 2015. FRED-MD: A Monthly Database for Macroeconomic Research. Journal of Business & Economic Statistics 34: 574–89. [Google Scholar] [CrossRef]
- FRED. 2022. Economic Data. Available online: https://fred.stlouisfed.org (accessed on 1 December 2022).
- Friedman, Jerome, Trevor Hastie, and Rob Tibshirani. 2010. Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software 33: 1–22. [Google Scholar] [CrossRef] [PubMed]
- Fuad, Mohd Nazri Mohd, and Mohd Azlan Hussain. 2015. Systematic design of chemical reactors with multiple stages via multi-objective optimization approach. In Computer Aided Chemical Engineering. Edited by K. V. Gernaey, J. K. Huusom and R. Gani. Oxford: Elsevier, vol. 37, pp. 869–74. [Google Scholar]
- Funashima, Yoshito. 2020. Global economic activity indexes revisited. Economics Letters 193: 109269. [Google Scholar] [CrossRef]
- Galipaud, Matthias, Mark A. F. Gillingham, Morgan David, and François-Xavier Dechaume-Moncharmont. 2014. Ecologists overestimate the importance of predictor variables in model averaging: A plea for cautious interpretations. Methods in Ecology and Evolution 5: 983–91. [Google Scholar] [CrossRef]
- Gangopadhyay, Kausik, Abhishek Jangir, and Rudra Sensarma. 2016. Forecasting the price of gold: An error correction approach. IIMB Management Review 28: 6–12. [Google Scholar] [CrossRef]
- Garcia, Diego, and Werner Kristjanpoller. 2019. An adaptive forecasting approach for copper price volatility through hybrid and non-hybrid models. Applied Soft Computing Journal 74: 466–78. [Google Scholar] [CrossRef]
- Gargano, Antonio, and Allan Timmermann. 2014. Forecasting commodity price indexes using macroeconomic and financial predictors. International Journal of Forecasting 30: 825–43. [Google Scholar] [CrossRef]
- Geman, Hélyette, and William Smith. 2013. Theory of storage, inventory and volatility in the LME base metals. Resources Policy 38: 18–28. [Google Scholar] [CrossRef]
- Ghalayini, Latife. 2017. Modeling and forecasting spot oil price. Eurasian Business Review 7: 355–73. [Google Scholar] [CrossRef]
- Ghoshray, Atanu, and Madhavi Pundit. 2021. Economic growth in China and its impact on international commodity prices. International Journal of Finance and Economics 26: 2776–89. [Google Scholar] [CrossRef]
- Giacomini, Raffaella, and Barbara Rossi. 2010. Forecast comparisons in unstable environments. Journal of Applied Econometrics 25: 595–620. [Google Scholar] [CrossRef]
- Golafshani, Emadaldin Mohammadi, and Ashraf Ashour. 2016. Prediction of self-compacting concrete elastic modulus using two symbolic regression techniques. Automation in Construction 64: 7–19. [Google Scholar] [CrossRef]
- Gramacy, Robert B. 2019. Monomvn: Estimation for MVN and Student-t Data with Monotone Missingness. Available online: https://CRAN.R-project.org/package=monomvn (accessed on 1 December 2022).
- Green, Peter J. 1995. Reversible jump Markov chain Monte Carlo computation and Bayesian model determination. Biometrika 82: 711–32. [Google Scholar] [CrossRef]
- Guidolin, Massimo, and Manuela Pedio. 2021. Forecasting commodity futures returns with stepwise regressions: Do commodity-specific factors help? Annals of Operations Research 299: 1317–56. [Google Scholar] [CrossRef]
- Guimera, Roger, Ignasi Reichardt, Antoni Aguilar-Mogas, Francesco A. Massucci, Manuel Miranda, Jordi Pallares, and Marta Sales-Prado. 2020. A Bayesian machine scientist to aid in the solution of challenging scientific problems. Science Advances 6: eaav6971. [Google Scholar] [CrossRef]
- Guzman, Juan Ignacio, and Enrique Silva. 2018. Copper price determination: Fundamentals versus non-fundamentals. Mineral Economics 31: 283–300. [Google Scholar] [CrossRef]
- Haeri, Maryam Amir, Mohammad Mehdi Ebadzadeha, and Gianluigi Folino. 2017. Statistical genetic programming for symbolic regression. Applied Soft Computing 60: 447–69. [Google Scholar] [CrossRef]
- Haider, C., F. O. de Franca, B. Burlacu, and G. Kronberger. 2023. Shape-constrained multi-objective genetic programming for symbolic regression. Applied Soft Computing 132: 109855. [Google Scholar] [CrossRef]
- Haigh, Michael S. 2018. Fundamentals and commodity prices. In Commodities: Markets, Performance, and Strategies. Edited by Kent H. Baker, Greg Filbeck and Jeffrey H. Harris. Oxford: Oxford University Press, pp. 90–108. [Google Scholar]
- Hamid, Mohd Fahmi Abdul, and Ani Shabri. 2017. Palm oil price forecasting model: An autoregressive distributed lag (ARDL) approach. AIP Conference Proceedings 1842: 030026. [Google Scholar] [CrossRef]
- Hamilton, James D. 2009. Causes and consequences of the oil shock of 2007–2008. Brookings Papers on Economic Activity 40: 215–59. [Google Scholar] [CrossRef]
- Hansen, Peter R., Asger Lunde, and James Nason. 2011. The model confidence set. Econometrica 79: 453–97. [Google Scholar] [CrossRef]
- Hara, Akira, Jun-ichi Kushida, and Tetsuyuki Takahama. 2019. Time series prediction using deterministic geometric semantic genetic programming. Paper presented at the 2019 IEEE International Conference on Systems,Man and Cybernetics (SMC), Bari, Italy, October 6–9; New York: IEEE, pp. 1945–49. [Google Scholar]
- Harris, Charles R., K. Jarrod Millman, Stéfan J. Van Der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, and et al. 2020. Array programming with NumPy. Nature 585: 357–62. [Google Scholar] [CrossRef] [PubMed]
- Hartley, Peter, and Kenneth Barry Medlock. 2014. The relationship between crude oil and natural gas prices: The role of the exchange rate. The Energy Journal 35: 25–44. [Google Scholar] [CrossRef]
- Harvey, David I., Neil M. Kellard, Jakob B. Madsen, and Mark E. Wohar. 2018. The resource curse, commodity prices and economic growth. In Global Commodity Markets and Development Economics. Edited by Stephan Pfaffenzeller. London: Routledge, pp. 16–49. [Google Scholar]
- Harvey, David, Stephen Leybourne, and Paul Newbold. 1997. Testing the equality of prediction mean squared errors. International Journal of Forecasting 13: 281–91. [Google Scholar] [CrossRef]
- Hasheminia, Hamed, and Seyed Taghi Akhavan Niaki. 2006. A genetic algorithm approach to find the best regression/econometric model among the candidates. Applied Mathematics and Computation 183: 337–49. [Google Scholar] [CrossRef]
- Hassanat, Ahmad, Khalid Almohammadi, Esra’a Alkafaween, Eman Abunawas, Awni Hammouri, and V. B. Surya Prasath. 2019. Choosing mutation and crossover ratios for genetic algorithms—A review with a new dynamic approach. Information 10: 390. [Google Scholar] [CrossRef]
- Hastie, Trevor, and Brad Efron. 2013. lars: Least Angle Regression, Lasso and Forward Stagewise. Available online: https://CRAN.R-project.org/package=lars (accessed on 1 December 2022).
- Hastie, Trevor, and Robert Tibshirani. 2000. Bayesian backlifting. Statistical Science 15: 196–213. [Google Scholar]
- Hastings, W. Keith. 1970. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 57: 97–109. [Google Scholar] [CrossRef]
- Hatzenbuehler, Patrick L., Philip C. Abbott, and Kenneth A. Foster. 2016. Agricultural commodity prices and exchange rates under structural change. Journal of Agricultural and Resource Economics 41: 204–24. [Google Scholar]
- Herrera, Gabriel Paes, Michel Constantino, Benjamin Miranda Tabak, Hemerson Pistori, Jen-Je Su, and Athula Naranpanawa. 2019. Long-term forecast of energy commodities price using machine learning. Energy 179: 214–21. [Google Scholar] [CrossRef]
- Hong, Harrison, and Motohiro Yogo. 2012. What does futures market interest tell us about the macroeconomy and asset prices? Journal of Financial Economics 105: 473–90. [Google Scholar] [CrossRef]
- Hotelling, Harold. 1931. The economics of exhaustible resources. Journal of Political Economy 39: 137–75. [Google Scholar] [CrossRef]
- Huang, Jianbai, Yingli Li, Hongwei Zhang, and Jinyu Chen. 2021. The effects of uncertainty measures on commodity prices from a time-varying perspective. International Review of Economics and Finance 71: 100–14. [Google Scholar] [CrossRef]
- Huang, Zhixing, Jinghui Zhong, Liang Feng, Yi Mei, and Wentong Cai. 2020. A fast parallel genetic programming framework with adaptively weighted primitives for symbolic regression. Soft Computing 24: 7523–39. [Google Scholar] [CrossRef]
- Hyndman, Rob J., and Anne B. Koehler. 2006. Another look at measures of forecast accuracy. International Journal of Forecasting 22: 679–88. [Google Scholar] [CrossRef]
- Hyndman, Rob J., and Yeasmin Khandakar. 2008. Automatic time series forecasting: The forecast package for R. Journal of Statistical Software 26: 1–22. [Google Scholar]
- Irwin, Scott H., Dwight R. Sanders, and Robert P. Merrin. 2009. Devil or angel? The role of speculation in the recent commodity price boom (and bust). Journal of Agricultural and Applied Economics 41: 377–91. [Google Scholar] [CrossRef]
- Irz, Xavier, Jyrki Niemi, and Xing Liu. 2013. Determinants of food price inflation in Finland—The role of energy. Energy Policy 63: 656–63. [Google Scholar] [CrossRef]
- Jacks, David S., and Martin Stuermer. 2020. What drives commodity price booms and busts? Energy Economics 85: 104035. [Google Scholar] [CrossRef]
- Ji, Qiang, Jiang-Bo Geng, and Ying Fan. 2014. Separated influence of crude oil prices on regional natural gas import prices. Energy Policy 70: 96–105. [Google Scholar] [CrossRef]
- Jin, Ying. 2021. A Bayesian MCMC Based Symbolic Regression Algorithm. Available online: https://github.com/ying531/MCMC-SymReg (accessed on 1 December 2022).
- Jin, Ying, Weilin Fu, Jian Kang, Jiadong Guo, and Jian Guo. 2019. Bayesian symbolic regression. arXiv arXiv:1910.08892. [Google Scholar]
- Juvenal, Luciana, and Ivan Petrella. 2014. Speculation in the oil market. Journal of Applied Econometrics 30: 621–49. [Google Scholar] [CrossRef]
- Kagraoka, Yusho. 2016. Common dynamic factors in driving commodity prices: Implications of a generalized dynamic factor model. Economic Modelling 52: 609–17. [Google Scholar] [CrossRef]
- Kaufmann, Robert K. 2011. The role of market fundamentals and speculation in recent price changes for crude oil. Energy Policy 39: 105–15. [Google Scholar] [CrossRef]
- Kaur, Gursimran, and Babli Dhiman. 2017. Dynamic linkage between Indian stock market and commodity market. International Journal of Applied Business and Economic Research 15: 401–11. [Google Scholar]
- Kaya, H. 2016. Forecasting the price of crude oil with multiple predictors. Siyasal Bilgiler Fakultesi Dergisi (ISMUS) 1: 133–51. [Google Scholar]
- Keijzer, Maarten. 2004. Scaled symbolic regression. Genetic Programming and Evolvable Machines 5: 259–69. [Google Scholar] [CrossRef]
- Kilian, Lutz. 2009. Not all oil price shocks are alike: Disentangling demand and supply shocks in the crude oil market. American Economic Review 99: 1053–69. [Google Scholar] [CrossRef]
- Kilian, Lutz. 2019. Measuring global real economic activity: Do recent critiques hold up to scrutiny? Economic Letters 178: 106–10. [Google Scholar] [CrossRef]
- Kilian, Lutz, and Dan Murphy. 2014. The role of inventories and speculative trading in the global market for crude oil. Journal of Applied Econometrics 29: 454–78. [Google Scholar] [CrossRef]
- Kilian, Lutz, and Xiaoqing Zhou. 2018. Modeling fluctuations in the global demand for commodities. Journal of International Money and Finance 88: 54–78. [Google Scholar] [CrossRef]
- Killian, Lutz, and Bruce Hicks. 2013. Did unexpectedly strong economic growth cause the oil price shock of 2003–2008? Journal of Forecasting 32: 385–94. [Google Scholar] [CrossRef]
- Kim, Soohyeon, J. Baek, and Eunnyeong Heo. 2017. Buffer vs. speculation: A review on the role of crude oil inventory. IAEE Energy Forum 26: 13–14. [Google Scholar]
- Klotz, D., M. Herrnegger, and K. Schulz. 2017. Symbolic regression for the estimation of transfer functions of hydrological models. Water Resources Research 53: 9402–23. [Google Scholar] [CrossRef]
- Koop, G. 2017. Bayesian methods for empirical macroeconomics with big data. Review of Economic Analysis 9: 33–56. [Google Scholar] [CrossRef]
- Koop, Gary, and Dimitris Korobilis. 2011. UK macroeconomic forecasting with many predictors: Which models forecast best and when do they do so? Economic Modelling 28: 2307–18. [Google Scholar] [CrossRef]
- Koop, Gary, and Dimitris Korobilis. 2012. Forecasting inflation using Dynamic Model Averaging. International Economic Review 53: 867–86. [Google Scholar] [CrossRef]
- Koop, Gary, and Dimitris Korobilis. 2013. Large time-varying parameter VARs. Journal of Econometrics 177: 185–98. [Google Scholar] [CrossRef]
- Korns, Michael F. 2011. Accuracy in symbolic regression. In Genetic Programming Theory and Practice IX. Edited by Rick Riolo, Ekaterina Vladislavleva and Jason H. Moore. New York: Springer, pp. 129–51. [Google Scholar]
- Koza, J. 1998. Genetic Programming. Cambridge: MIT Press. [Google Scholar]
- Kronberger, Gabriel, Stefan Fink, Michael Kommenda, and Michael Affenzeller. 2011. Macro-economic time series modeling and interaction networks. In Applications of Evolutionary Computation. Edited by C. Chio, A. Brabazon, G. A. Caro, R. Drechsler, M. Farooq, J. Grahl, G. Greenfield, C. Prins, J. Romero, G. Squillero and et al. Berlin: Springer, pp. 101–10. [Google Scholar]
- Kubalik, Jiří, Erik Derner, and Robert Babuska. 2020. Symbolic regression driven by training data and prior knowledge. In GECCO ‘20: Proceedings of the 2020 Genetic and Evolutionary Computation Conference. New York: Association for Computing Machinery, pp. 958–66. [Google Scholar]
- La Cava, William, Patryk Orzechowski, Bogdan Burlacu, de F. Franca, Marco Virgolin, Ying Jin, Michael Kommenda, and Jason Moore. 2021. Contemporary symbolic regression methods and their relative performance. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks; Edited by J. Vanschoren and S. Yeung. Available online: https://datasets-benchmarks-proceedings.neurips.cc/paper_files/paper/2021/file/c0c7c76d30bd3dcaefc96f40275bdc0a-Paper-round1.pdf (accessed on 1 December 2022).
- Labys, Walter C. 2006. Modeling and Forecasting Primary Commodity Prices. London: Routledge. [Google Scholar]
- Lan, Gongjin, Jakub M. Tomczak, Diederik M.Roijers, and A. E. Eiben. 2022. Time efficiency in optimization with a Bayesian-evolutionary algorithm. Swarm and Evolutionary Computation 69: 100970. [Google Scholar] [CrossRef]
- Landajuela, Mikel, Chak Lee, Jiachen Yang, Ruben Glatt, Claudio P. Santiago, Ignacio Aravena, Terrell Mundhenk, Garrett Mulcahy, and Brenden K. Petersen. 2022. A unified framework for deep symbolic regression. Advances in Neural Information Processing Systems 35: 33985–98. [Google Scholar]
- LaRose, A. 2014. Global Natural Gas Markets Overview. Washington, DC: U.S. Energy Information Administration. [Google Scholar]
- Lee, Geum Yong. 1999. Genetic recursive regression for modeling and forecasting real-world chaotic time series. In Advances in Genetic Programming 3. Edited by L. Spector, W. B. Langdon, U.-M. O’Reilly and P. J. Angeline. Cambridge, MA: MIT Press, pp. 401–23. [Google Scholar]
- Li, Raymond, and Guy C. K. Leung. 2011. The integration of China into the world crude oil market since 1998. Energy Policy 39: 5159–166. [Google Scholar] [CrossRef]
- Li, Raymond, Roselyne Joyeux, and Ronald D. Ripple. 2014. International natural gas market integration. The Energy Journal 35: 159–79. [Google Scholar] [CrossRef]
- Linn, Scott C., and Zhen Zhu. 2004. Natural gas prices and the gas storage report: Public news and volatility in energy futures markets. Journal of Futures Markets 24: 283–313. [Google Scholar] [CrossRef]
- Liu, Li, Yudong Wang, Chongfeng Wu, and Wenfeng Wu. 2016. Disentangling the determinants of real oil prices. Energy Economics 56: 363–73. [Google Scholar] [CrossRef]
- Liu, Yunling, and Yansong Lv. 2020. Commodity price evaluation based on improved data mining methods. Paper presented at the 2020 International Conference on E-Commerce and Internet Technology (ECIT), Zhangjiajie, China, April 22–24; New York: IEEE, pp. 145–48. [Google Scholar]
- Lubbers, Johannes, and Peter Posch. 2016. Commodities’ common factor: An empirical assessment of the markets’ drivers. Journal of Commodity Markets 4: 28–40. [Google Scholar] [CrossRef]
- Mayer, Herbert, Andreas Rathgeber, and Markus Wanner. 2019. Financialization of metal markets: Does futures trading influence spot prices and volatility? Resources Policy 53: 300–16. [Google Scholar] [CrossRef]
- McKinney, Wes. 2010. Data structures for statistical computing in Python. Paper presented at the 9th Python in Science Conference, Austin, TX, USA, June 28–July 3; vol. 445, pp. 56–61. [Google Scholar]
- Medeiros, Marcelo C., Gabriel F. R. Vasconcelos, Álvaro Veiga, and Eduardo Zilberman. 2019. Forecasting inflation in a data-rich environment: The benefits of machine learning methods. Journal of Business &Economic Statistics 39: 98–119. [Google Scholar]
- Mensi, Walid, Makram Beljid, Adel Boubaker, and Shunsuke Managi. 2013. Correlations and volatility spillovers across commodity and stock markets: Linking energies, food, and gold. Economic Modelling 32: 15–22. [Google Scholar] [CrossRef]
- Metropolis, Nicholas, Arianna W. Rosenbluth, Marshall N. Rosenbluth, Augusta H. Teller, and Edward Teller. 1953. Equation of state calculations by fast computing machines. The Journal of Chemical Physics 21: 1087–92. [Google Scholar] [CrossRef]
- Mohammadi, Hassan. 2011. Long-run relations and short-run dynamics among coal, natural gas and oil prices. Applied Economics 43: 129–37. [Google Scholar] [CrossRef]
- Moody’s. 2022. Home. Available online: https://www.moodys.com (accessed on 1 December 2022).
- Mostafa, Mohamed M., and Ahmed A. El-Masry. 2016. Oil price forecasting using gene expression programming and artificial neural networks. Economic Modelling 54: 40–53. [Google Scholar] [CrossRef]
- MSCI. 2022. End of Day Index Data Search. Available online: https://www.msci.com/end-of-day-data-search (accessed on 1 December 2022).
- Mu, Xiaoyi. 2007. Weather, storage, and natural gas price dynamics: Fundamentals and volatility. Energy Economics 29: 46–63. [Google Scholar] [CrossRef]
- Narotam, Pradeep K., John F. Morrison, Michael D. Schmidt, and Narendra Nathoo. 2014. Physiological complexity of acute traumatic brain injury in patients treated with a brain oxygen protocol: Utility of symbolic regression in predictive modeling of a dynamical system. Journal of Neurotrauma 31: 630–41. [Google Scholar] [CrossRef]
- Nazlioglu, Saban, and Ugur Soytas. 2012. Oil price, agricultural commodity prices, and the dollar: A panel cointegration and causality analysis. Energy Economics 34: 1098–104. [Google Scholar] [CrossRef]
- Nick, Sebastian, and Stefan Thoenes. 2014. What drives natural gas prices?—A structural VAR approach. Energy Economics 45: 517–27. [Google Scholar] [CrossRef]
- Nicolau, Miguel, and Alexandros Agapitos. 2021. Choosing function sets with better generalisation performance for symbolic regression models. Genetic Programming and Evolvable Machines 22: 73–100. [Google Scholar] [CrossRef]
- Nonejad, Nima. 2019. Crude oil price volatility dynamics and the great recession. Applied Economics Letters 26: 622–27. [Google Scholar] [CrossRef]
- Nonejad, Nima. 2020. A detailed look at crude oil price volatility prediction using macroeconomic variables. Journal of Forecasting 39: 1119–141. [Google Scholar] [CrossRef]
- Nurmakhanova, Mira. 2020. Oil and growth challenge in Kazakhstan. International Journal of Economics and Business Research 20: 100–16. [Google Scholar] [CrossRef]
- Obadi, Saleh Mothana, and Matej Korcek. 2020. Driving fundamentals of natural gas price in Europe. International Journal of Energy Economics and Policy 10: 318–24. [Google Scholar] [CrossRef]
- OECD. 2022. Main Economic Indicators. Available online: https://doi.org/10.1787/data-00052-en (accessed on 1 December 2022).
- Olsen, Kyle, James Mjelde, and David Bessler. 2015. Price formulation and the law of one price in internationally linked markets: An examination of the natural gas markets in the USA and Canada. The Annals of Regional Science 54: 117–42. [Google Scholar] [CrossRef]
- Onorante, Luca, and Adrian Raftery. 2016. Dynamic Model Averaging in large model spaces using dynamic Occam’s window. European Economic Review 81: 2–14. [Google Scholar] [CrossRef] [PubMed]
- Orzechowski, Patryk, William La Cava, and Jason H. Moore. 2018. Where are we now?: A large benchmark study of recent symbolic regression methods. In GECCO ‘18: Proceedings of the Genetic and Evolutionary Computation Conference. Edited by Hernan Aguirre. New York: Association for Computing Machinery, pp. 1183–90. [Google Scholar]
- Osathanunkul, Rossarin, Chatchai Khiewngamdee, Woraphon Yamaka, and Songsak Sriboonchitta. 2018. The role of oil price in the forecasts of agricultural commodity prices. In Predictive Econometrics and Big Data. Edited by V. Kreinovich, S. Sriboonchitta and N. Chakpitak. Berlin: Springer, pp. 422–29. [Google Scholar]
- Ouyang, Ruolan, and Xuan Zhang. 2020. Financialization of agricultural commodities: Evidence from China. Economic Modelling 85: 381–89. [Google Scholar] [CrossRef]
- Pincheira, Pablo, and Nicolás Hardy. 2021. Forecasting aluminum prices with commodity currencies. Resources Policy 73: 102066. [Google Scholar] [CrossRef]
- Pincheira-Brown, Pablo, Andrea Bentancor, Nicolás Hardy, and Nabil Jarsun. 2022. Forecasting fuel prices with the Chilean exchange rate: Going beyond the commodity currency hypothesis. Energy Economics 106: 105802. [Google Scholar] [CrossRef]
- Prates, D. 2007. The recent rise of commodities prices. Revista de Economia Politica 27: 323–44. [Google Scholar]
- R Core Team. 2018. R: A Language and Environment for Statistical Computing; Vienna: R Foundation for Statistical Computing. Available online: https://www.R-project.org (accessed on 1 December 2022).
- Raftery, Adrian E., Miroslav Kárný, and Pavel Ettler. 2010. Online prediction under model uncertainty via Dynamic Model Averaging: Application to a cold rolling mill. Technometrics 52: 52–66. [Google Scholar] [CrossRef]
- Reboredo, Juan. 2012. Modelling oil price and exchange rate co-movements. Journal of Policy Modeling 34: 419–40. [Google Scholar] [CrossRef]
- Reboredo, Juan Carlos, Miguel A. Rivera-Castro, and Gilney F. Zebende. 2014. Oil and US dollar exchange rate dependence: A detrended cross-correlation approach. Energy Economics 42: 132–39. [Google Scholar] [CrossRef]
- Regnier, Eva. 2007. Oil and energy price volatility. Energy Economics 29: 405–27. [Google Scholar] [CrossRef]
- Regolin, Evandro Nunes, and Aurora Trindad Ramirez Pozo. 2005. Bayesian automatic programming. In Genetic Programming. Edited by M. Keijzer, A. Tettamanzi, P. Collet, J. van Hemert and M. Tomassini. Berlin: Springer, pp. 38–49. [Google Scholar]
- Rezitis, Anthony N., and Maria Sassi. 2013. Commodity food prices: Review and empirics. Economics Research International 2013: 694507. [Google Scholar] [CrossRef]
- Ribeiro, Celma O., and Sydnei M. Oliveira. 2011. A hybrid commodity price-forecasting model applied to the sugar-alcohol sector. Australian Journal of Agricultural and Resource Economics 55: 180–98. [Google Scholar] [CrossRef]
- Riggi, Marianna, and Fabrizio Venditti. 2015. The time varying effect of oil price shocks on euro-area exports. Journal of Economic Dynamics and Control 59: 75–94. [Google Scholar] [CrossRef]
- Rubaszek, Michał, and Gazi Salah Uddin. 2020. The role of underground storage in the dynamics of the US natural gas market: A threshold model analysis. Energy Economics 87: 104713. [Google Scholar] [CrossRef]
- Rueda, R., M. P. Cuellar, M. C. Pegalajar, and M. Delgado. 2019a. Straight line programs for energy consumption modelling. Applied Soft Computing Journal 80: 310–28. [Google Scholar] [CrossRef]
- Rueda, R., M. P. Cuellar, M. Molina-Solana, Y. Guo, and M. C. Pegalajar. 2019b. Generalised regression hypothesis induction for energy consumption forecasting. Energies 12: 1069. [Google Scholar] [CrossRef]
- Salisu, Afees A., Kazeem O. Isah, and Ibrahim D. Raheem. 2019. Testing the predictability of commodity prices in stock returns of G7 countries: Evidence from a new approach. Resources Policy 64: 101520. [Google Scholar] [CrossRef]
- Sarradj, Ennes, and Thomas Geyer. 2014. Symbolic regression modeling of noise generation at porous airfoils. Journal of Sound and Vibration 333: 3189–3202. [Google Scholar] [CrossRef]
- Schewe, Jacob, Christian Otto, and Katja Frieler. 2017. The role of storage dynamics in annual wheat prices. Environmental Research Letters 12: 054005. [Google Scholar] [CrossRef]
- Schiller, R. 2000. Irrational Exuberance. Princeton, NJ: Princeton University Press. [Google Scholar]
- Schiller, R. 2022. Online Data. Available online: http://www.econ.yale.edu/~shiller/data.htm (accessed on 1 December 2022).
- Senkerik, Roman, Adam Viktorin, Michal Pluhacek, Tomas Kadavy, and Ivan Zelinka. 2017a. Differential evolution driven analytic programming for prediction. In Artificial Intelligence and Soft Computing. Edited by L. Rutkowski, M. Korytkowski, R. Scherer, R. Tadeusiewicz, L. Zadeh and J. Zurada. Cham: Springer, pp. 676–87. [Google Scholar]
- Senkerik, Roman, Adam Viktorin, Michal Pluhacek, Tomas Kadavy, and Ivan Zelinka. 2017b. Hybridization of analytic programming and differential evolution for time series prediction. In Hybrid Artificial Intelligent Systems. Edited by F. Martinez de Pison, R. Urraca, H. Quintian and E. Corchado. Cham: Springer, pp. 686–98. [Google Scholar]
- Sermpinis, Georgios, Charalampos Stasinakis, Konstantinos Theofilatos, and Andreas Karathanasopoulos. 2015. Modeling, forecasting and trading the EUR exchange rates with hybrid rolling genetic algorithms: Support vector regression forecast combinations. European Journal of Operational Research 247: 831–46. [Google Scholar] [CrossRef]
- Sheta, Alaa, Hossam Faris, and Mouhammd Alkasassbeh. 2013. A genetic programming model for S&P 500 stock market prediction. International Journal of Control and Automation 6: 303–14. [Google Scholar]
- Shilling, Henry. 1996. The International Guide to Securities Market Indices. Chicago: Routledge. [Google Scholar]
- Sinha, Ankur, Pekka Malo, and Timo Kuosmanen. 2015. A multiobjective exploratory procedure for regression model selection. Journal of Computational and Graphical Statistics 24: 154–82. [Google Scholar] [CrossRef]
- Smiech, Sławomir, and Monika Papiez. 2013. Fossil fuel prices, exchange rate, and stockmarket: A dynamic causality analysis on the European market. Economics Letters 118: 199–202. [Google Scholar] [CrossRef]
- Smits, Guido F., and Mark Kotanchek. 2005. Pareto-front exploitation in symbolic regression. In Genetic Programming Theory and Practice II. Edited by Una-May O’Reilly, Tina Yu, Rick Riolo and Bill Worzel. Boston: Springer, pp. 283–99. [Google Scholar]
- Souza, Rodrigo da Silva, Leonardo B. de Mattos, and João E. de Lima. 2021. Commodity prices and the Brazilian real exchange rate. International Journal of Finance and Economics 26: 3152–72. [Google Scholar] [CrossRef]
- Steel, Mark F. 2020. Model averaging and its use in economics. Journal of Economic Literature 58: 644–719. [Google Scholar] [CrossRef]
- Steermer, Martin. 2018. 150 years of boom and bust: What drives mineral commodity prices? Macroeconomic Dynamics 22: 702–17. [Google Scholar] [CrossRef]
- Stephens, T. 2021. Genetic Programming in Python, With a Scikit-Learn Inspired API: Gplearn. Available online: https://github.com/trevorstephens/gplearn (accessed on 1 December 2022).
- Stock, James H., and Mark W. Watson. 2004. Combination forecasts of output growth in a seven-country data set. Journal of Forecasting 23: 405–30. [Google Scholar] [CrossRef]
- Stooq. 2022. Quotes. Available online: https://stooq.com (accessed on 1 December 2022).
- Sukcharoen, Kunlapath, and David Leatham. 2018. Analyzing extreme comovements in agricultural and energy commodity markets using a regular vine copula method. International Journal of Energy Economics and Policy 8: 193–201. [Google Scholar]
- Tan, Xiaofen, and Yongjiao Ma. 2017. The impact of macroeconomic uncertainty on international commodity prices: Empirical analysis based on TVAR model. China Finance Review International 7: 163–84. [Google Scholar] [CrossRef]
- Tapia Cortez, C. A., S. Saydam, J. Coulton, and C. Sammut. 2018. Alternative techniques for forecasting mineral commodity prices. International Journal of Mining Science and Technology 28: 309–22. [Google Scholar] [CrossRef]
- Tashman, Len. 2000. Out-of-sample tests of forecasting accuracy: An analysis and review. International Journal of Forecasting 16: 437–50. [Google Scholar] [CrossRef]
- The Pandas Development Team. 2020. pandas-dev/pandas: Pandas. Available online: https://doi.org/10.5281/zenodo.3509134 (accessed on 1 December 2022).
- The World Bank. 2022. Commodities Markets. Available online: https://www.worldbank.org/en/research/commodity-markets (accessed on 1 December 2022).
- Thiyagarajan, Saloni, G. Naresh, and S. Mahalakshmic. 2015. Forecasting volatility in Indian agri-commodities market. Global Business and Finance Review 20: 95–104. [Google Scholar] [CrossRef]
- Tiwari, Aviral Kumar, Arif Billah Dar, and Niyati Bhanja. 2013. Oil price and exchange rates: A wavelet based analysis for India. Economic Modelling 31: 414–22. [Google Scholar] [CrossRef]
- Uddin, Gazi Salah, Aviral Kumar Tiwari, Mohamed Arouri, and Frédéric Teulon. 2013. On the relationship between oil price and exchange rates: A wavelet analysis. Economic Modelling 35: 502–7. [Google Scholar] [CrossRef]
- UNCTAD. 2012. Don’t Blame the Physical Markets: Financialization Is the Root Cause of Oil and Commodity Price Volatility, Policy Brief 25. Available online: https://unctad.org/system/files/official-document/presspb2012d1_en.pdf (accessed on 1 December 2022).
- United Nations Statistics Division. 2022. Monthly Bulletin of Statistics. Available online: http://comtrade.un.org/api/getmbsdata?series_type=T35.M.V.$&fmt=CSV (accessed on 1 December 2022).
- Van Rossum, G., and F. L. Drake, Jr. 1995. Python Reference Manual. Amsterdam: Centrum voor Wiskunde en Informatica. [Google Scholar]
- Vazquez, Daniel, Roger Guimera, Marta Sales-Prado, and Gonzalo Guillen-Gosalbez. 2022. Automatic modeling of socioeconomic drivers of energy consumption and pollution using Bayesian symbolic regression. Sustainable Production and Consumption 30: 596–607. [Google Scholar] [CrossRef]
- Wagner, Neal, Zbigniew Michalewicz, Moutaz Khouja, and Rob Roy McGregor. 2007. Time series forecasting for dynamic environments: The DyFor genetic program model. IEEE Transactions on Evolutionary Computation 11: 433–52. [Google Scholar] [CrossRef]
- Wang, Qiang, Shuyu Liu, and Rongrong Li. 2018. China’s dependency on foreign oil will exceed 80% by 2030: Developing a novel NMGM-ARIMA to forecast China’s foreign oil dependence from two dimensions. Energy 163: 151–67. [Google Scholar] [CrossRef]
- Wang, Qingfeng, and Xu Sun. 2017. Crude oil price: Demand, supply, economic activity, economic policy uncertainty and wars—From the perspective of Structural Equation Modelling (SEM). Energy 133: 483–90. [Google Scholar] [CrossRef]
- Wang, Shouyang, Lean Yu, and K. K. Lai. 2004. A novel hybrid AI system framework for crude oil price forecasting. Lecture Notes in Computer Science 3327: 233–42. [Google Scholar]
- Wang, Yudong, Bing Zhang, Xundi Diao, and Chongfeng Wu. 2015a. Commodity price changes and the predictability of economic policy uncertainty. Economics Letters 127: 39–42. [Google Scholar] [CrossRef]
- Wang, Yudong, Li Liu, and Chongfeng Wu. 2017. Forecasting the real prices of crude oil using forecast combinations over time-varying parameter models. Energy Economics 66: 337–48. [Google Scholar] [CrossRef]
- Wang, Yudong, Li Liu, Xundi Diao, and Chongfeng Wu. 2015b. Forecasting the real prices of crude oil under economic and statistical constraints. Energy Economics 51: 599–608. [Google Scholar] [CrossRef]
- Weiss, Mark Allen. 2014. Data Structures and Algorithm Analysis in C++. Upper Saddle River: Pearson Education, Inc. [Google Scholar]
- Weng, Futian, Muzhou Hou, Tianle Zhang, Yunlei Yang, Zheng Wang, Hongli Sun, Hao Zhu, and Jianshu Luo. 2018. Application of regularized extreme learning machine based on BIC criterion and genetic algorithm in iron ore price forecasting. In Proceedings of the 2018 3rd International Conference on Modelling, Simulation and Applied Mathematics. Edited by A. Luevanos Rojas, G. Ilewicz, D. J. Jakobczak and K. Weller. Paris: Atlantis Press, pp. 212–17. [Google Scholar]
- Winkler, Stephan M., Gabriel Kronberger, Michael Kommenda, Stefan Fink, and Michael Affenzeller. 2015a. Dynamics of predictability and variable influences identified in financial data using sliding window machine learning. In Computer Aided Systems Theory–EUROCAST 2015. Edited by Roberto Moreno-Díaz, Franz Pichler and Alexis Quesada-Arencibia. Cham: Springer, pp. 326–33. [Google Scholar]
- Winkler, Stephan M., Michael Affenzeller, Gabriel Kronberger, Michael Kommenda, Bogdan Burlacu, and Stefan Wagner. 2015b. Sliding window symbolic regression for detecting changes of system dynamics. In Genetic Programming Theory and Practice XII. Edited by Rick Riolo, William P. Worzel and Mark Kotanchek. Cham: Springer, pp. 91–107. [Google Scholar]
- Working, Holbrook. 1960. Speculation on hedging markets. Food Research Institute Studies 1: 185–220. [Google Scholar]
- WTO. 2022. Statistics on Merchandise Trade. Available online: https://data.wto.org (accessed on 1 December 2022).
- Xu, Yang, Liyan Han, Li Wan, and Libo Yin. 2019. Dynamic link between oil prices and exchange rates: A non-linear approach. Energy Economics 84: 104488. [Google Scholar] [CrossRef]
- Yan, Y., and L. Yuan. 2019. Commodity market financialisation, information transmission and driving factors: Research based on environmental intraday high frequency data of China. Journal of Environmental Protection and Ecology 20: 2047–58. [Google Scholar]
- Yang, Chi-Jen, Xiaowei Xuan, and Robert B. Jackson. 2012. China’s coal price disturbances: Observations, explanations, and implications for global energy economies. Energy Policy 51: 720–27. [Google Scholar] [CrossRef]
- Yang, Guangfei, Tao Sun, Jianliang Wang, and Xianneng Li. 2015a. Modeling the nexus between carbon dioxide emissions and economic growth. Energy Policy 86: 104–17. [Google Scholar] [CrossRef]
- Yang, Guangfei, Xianneng Li, Jianliang Wang, Lian Lian, and Tieju Ma. 2015b. Modeling oil production based on symbolic regression. Energy Policy 82: 48–61. [Google Scholar] [CrossRef]
- Yin, Libo, and Qingyuan Yang. 2016. Predicting the oil prices: Do technical indicators help? Energy Economics 56: 338–50. [Google Scholar] [CrossRef]
- Yin, Xuluo, Jiangang Peng, and Tian Tang. 2018. Improving the forecasting accuracy of crude oil prices. Sustainability 10: 454. [Google Scholar] [CrossRef]
- Yousefi, Ayoub, and Tony S. Wirjanto. 2004. The empirical role of the exchange rate on the crude-oil price information. Energy Economics 26: 783–99. [Google Scholar] [CrossRef]
- Yuan, Fong-Ching, Chao-Hui Lee, and Chaochang Chiu. 2020. Using market sentiment analysis and genetic algorithm-based least squares support vector regression to predict gold prices. International Journal of Computational Intelligence Systems 13: 234–46. [Google Scholar] [CrossRef]
- Zegklitz, J., and P. Posik. 2021. Benchmarking state-of-the-art symbolic regression algorithms. Genetic Programming and Evolvable Machines 22: 5–33. [Google Scholar] [CrossRef]
- Zhang, Byong-Tak. 2000. Bayesian methods for efficient genetic programming. Genetic Programming and Evolvable Machines 1: 217–42. [Google Scholar] [CrossRef]
- Zhang, Hui Jun, Jean-Marie Dufour, and John W. Galbraith. 2016. Exchange rates and commodity prices: Measuring causality at multiple horizons. Journal of Empirical Finance 36: 100–20. [Google Scholar] [CrossRef]
- Zhang, Yaojie, M. I. M. Wahab, and Yudong Wang. 2023. Forecasting crude oil market volatility using variable selection and common factor. International Journal of Forecasting 39: 486–502. [Google Scholar] [CrossRef]
- Zhao, Yang, Jianping Li, and Lean Yu. 2017. A deep learning ensemble approach for crude oil price forecasting. Energy Economics 66: 9–16. [Google Scholar] [CrossRef]
- Zhao, Yuan, Weiguo Zhang, Xue Gong, and Chao Wang. 2021. A novel method for online real-time forecasting of crude oil price. Applied Energy 303: 117588. [Google Scholar] [CrossRef]
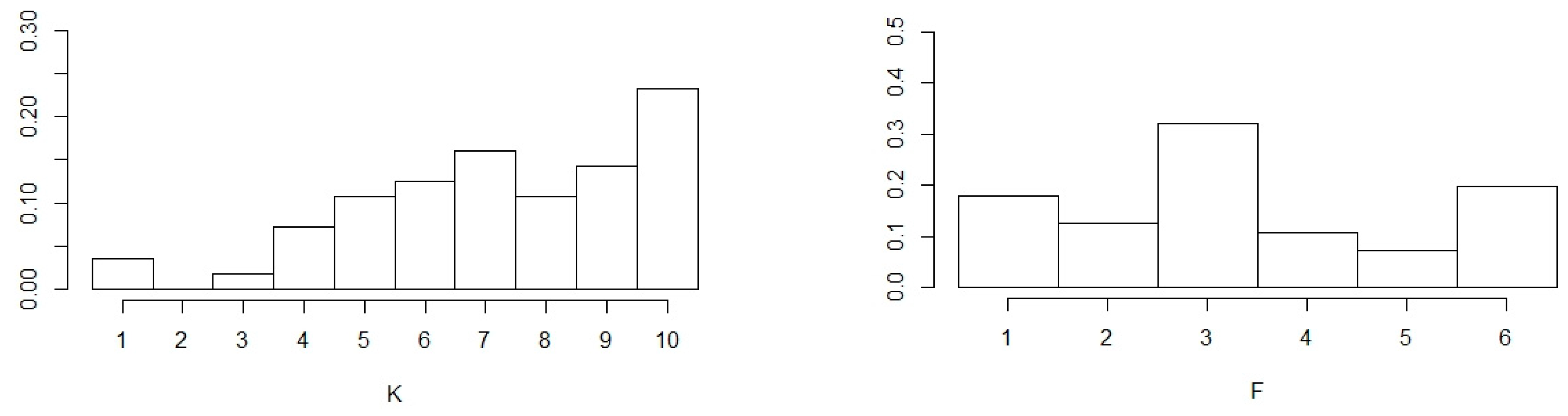






| Crude Oil | Natural Gas | Coal | Metals | Agricultural Commodities |
|---|---|---|---|---|
|
|
|
|
|
| Abbreviation | Description |
|---|---|
| dpr | Dividend-to-price ratio |
| pe | Price earnings ratio |
| str | Short-term interest rate |
| ltr_US | Long-term interest rate for the U.S. |
| ltr_EU | Long-term interest rate for the Euro area |
| ts | Term spread |
| drs | Default return spread |
| cpi | U.S. Consumer Price Index for all urban consumers |
| ppi | U.S. Producer Price Index |
| ip | U.S. industrial production |
| ee | U.S. average hourly earnings of production and nonsupervisory employees |
| M1 | M1 money stock for U.S. |
| M2 | M2 money stock for U.S. |
| gea | Killian’s Index of Global Real Economic Activity |
| une | U.S. unemployment rate |
| AUD | Australian dollar to U.S. dollar exchange rate |
| CAD | Canadian dollar to U.S. dollar exchange rate |
| INR | Indian rupee to U.S. dollar exchange rate |
| reer_AUD | Real effective exchange rate based on manufacturing Consumer Price Index for Australia |
| reer_CAD | Real effective exchange rates based on manufacturing Consumer Price Index for Canada |
| reer_INR | Real effective exchange rates based on manufacturing Consumer Price Index for India |
| reer_US | Real effective exchange rates based on manufacturing Consumer Price Index for U.S. |
| tb_US | U.S. trade balance |
| GSCI | S&P GSCI Commodity Total Return Index |
| oi_USD | Dollar open interest |
| t_ind | Working’s dollar T-index |
| VXO | VXO index (implied volatility based on 30-day S&P 100 index at-the-money options) |
| GPR | Global Geopolitical Risk Index (The Benchmark GPR Index) |
| stocks_US | S&P 500 Index |
| stocks_World | MSCI WORLD for developed markets index |
| stocks_G7 | MSCI G7 index |
| stocks_EU | MSCI EU index |
| stocks_EM | MSCI EM for emerging markets index |
| stocks_CN | Hang Seng Index and Shanghai Composite Index glued and rescaled (in December 1990) |
| ts_BRICS | The share of BRIC countries trade in the total global trade |
| li_US | Leading indicator for U.S. |
| li_G7 | Leading indicator for G7 countries |
| li_EU | Leading indicator for the euro area |
| li_CN | Leading indicator for China |
| Abbreviation | Description |
|---|---|
| BSR rec | Bayesian symbolic regression (recursive) |
| BSR av MSE rec | Bayesian symbolic regression (recursive) with averaging and weights inversely proportional to MSE |
| BSR av EW rec | Bayesian symbolic regression (recursive) with equal weights |
| GP rec | Symbolic regression with genetic programming (recursive) |
| BSR fix | Bayesian symbolic regression (fixed parameters) |
| BSR av MSE fix | Bayesian symbolic regression (fixed parameters) with averaging and weights inversely proportional to MSE |
| BSR av EW fix | Bayesian symbolic regression (fixed parameters) with equal weights |
| GP fix | Symbolic regression with genetic programming (fixed parameters) |
| DMA | Dynamic Model Averaging with Occam window |
| BMA | Bayesian Model Averaging with Occam window |
| DMA 1V | Dynamic Model Averaging over one-variable component models |
| DMS 1V | Dynamic Model Selection over one-variable component models |
| BMA 1V | Bayesian Model Averaging over one-variable component models |
| BMS 1V | Bayesian Model Selection over one-variable component models |
| LASSO | LASSO regression (recursive) |
| RIDGE | RIDGE regression (recursive) |
| EN | Elastic net regression (recursive) |
| B-LASSO | Bayesian LASSO regression (recursive) |
| B-RIDGRE | Bayesian RIDGE regression (recursive) |
| LARS | Least-angle regression |
| TVP | Time-Varying Parameters regression with forgetting factor equal to 1 |
| TVP f | Time-Varying Parameters regression with forgetting factor equal to 0.99 |
| ARIMA | Automatic ARIMA (recursive) |
| HA | Historical average |
| NAÏVE | No-change method |
| BSR rec | BSR av MSE rec | BSR av EW rec | GP rec | BSR fix | BSR av MSE fix | BSR av EW fix | GP fix | DMA | BMA | DMA 1V | DMS 1V | BMA 1V | BMS 1V | LASSO | RIDGE | EN | B-LASSO | B-RIDGRE | LARS | TVP | TVP f | ARIMA | HA | NAIVE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Brent | 0.0992 | 0.0848 | 0.0840 | 0.1099 | 0.0969 | 0.0824 | 0.0882 | 0.0924 | 0.0721 | 0.0738 | 0.0751 | 0.0749 | 0.0742 | 0.0742 | 0.0778 | 0.0815 | 0.0774 | 0.0761 | 0.0781 | 0.0774 | 0.0870 | 0.0875 | 0.0877 | 0.6498 | 0.0925 |
| Dubai | 0.0842 | 0.0761 | 0.0766 | 0.1097 | 0.1576 | 0.0980 | 0.0909 | 0.0908 | 0.0678 | 0.0686 | 0.0707 | 0.0706 | 0.0700 | 0.0700 | 0.0733 | 0.0781 | 0.0743 | 0.0725 | 0.0745 | 0.0815 | 0.0833 | 0.0834 | 0.0843 | 0.6647 | 0.0908 |
| WTI | 0.1113 | 1047.6466 | 0.0937 | 0.1041 | 0.1175 | 3264.9070 | 2771.7826 | 0.1352 | 0.0776 | 0.0755 | 0.0768 | 0.0766 | 0.0760 | 0.0760 | 0.0790 | 0.0837 | 0.0792 | 0.0794 | 0.0816 | 0.0798 | 0.0898 | 0.0928 | 0.0905 | 0.6029 | 0.0947 |
| Coal_AU | 0.1036 | 0.1102 | 0.1087 | 0.0955 | 0.1063 | 4014.9355 | 0.6056 | 0.1565 | 0.0921 | 0.0946 | 0.0994 | 0.1008 | 0.0998 | 0.0998 | 0.0926 | 0.0936 | 0.0925 | 0.0927 | 0.0919 | 0.0983 | 0.1038 | 0.1092 | 0.1027 | 0.5490 | 0.0994 |
| Coal_ZA | 0.0925 | 0.0808 | 0.0786 | 0.0851 | 0.0955 | 0.0893 | 0.0878 | 0.0839 | 0.0855 | 0.0871 | 0.0855 | 0.0851 | 0.0846 | 0.0838 | 0.0810 | 0.0822 | 0.0813 | 0.0815 | 0.0808 | 0.0826 | 0.0885 | 0.0869 | 0.0821 | 0.5423 | 0.0872 |
| Gas_US | 0.1841 | 0.1872 | 1.6213 | 0.4869 | 0.1821 | 41,824.3614 | 71,166.5600 | 1.1844 | 0.1742 | 0.1743 | 0.1790 | 0.1785 | 0.1754 | 0.1752 | 0.1780 | 0.1838 | 0.1786 | 0.1798 | 0.1816 | 0.1785 | 0.2033 | 0.2131 | 0.1854 | 0.5950 | 0.1812 |
| Gas_EU | 0.0874 | 0.1635 | 0.0862 | 0.0894 | 0.5944 | 17.9480 | 36,101.1264 | 0.2850 | 0.0751 | 0.0771 | 0.0806 | 0.0799 | 0.0804 | 0.0802 | 0.0755 | 0.0760 | 0.0755 | 0.0765 | 0.0767 | 0.0788 | 0.0825 | 0.0963 | 0.0756 | 0.5984 | 0.0839 |
| Gas_JP | 0.0607 | 6756.0010 | 6756.0010 | 0.0595 | 0.1355 | 13,511.9823 | 28,114.6024 | 0.1018 | 0.0546 | 0.0552 | 0.0567 | 0.0562 | 0.0585 | 0.0591 | 0.0875 | 0.0590 | 0.0589 | 0.0569 | 0.0583 | 0.0822 | 0.1010 | 0.1058 | 0.0552 | 0.5776 | 0.0586 |
| Cocoa | 0.0617 | 0.0587 | 0.0586 | 0.0704 | 0.1078 | 0.0612 | 0.0611 | 0.3008 | 0.0585 | 0.0574 | 0.0584 | 0.0613 | 0.0581 | 0.0582 | 0.0585 | 0.0594 | 0.0591 | 0.0580 | 0.0579 | 0.0585 | 0.0772 | 0.0849 | 0.0572 | 0.3769 | 0.0578 |
| Coffee_Arabica | 0.0886 | 0.0750 | 0.0740 | 0.0925 | 0.3330 | 0.1368 | 0.0809 | 0.0768 | 0.0738 | 0.0754 | 0.0755 | 0.0808 | 0.0751 | 0.0778 | 0.0758 | 0.0759 | 0.0757 | 0.0742 | 0.0741 | 0.0799 | 0.0858 | 0.0992 | 0.0740 | 0.3818 | 0.0741 |
| Coffee_Robusta | 0.7544 | 35,128.2980 | 60,851.9278 | 0.4188 | 49,684.2213 | 167,366.9005 | 182,580.9262 | 0.0692 | 0.0556 | 0.0597 | 0.0562 | 0.0583 | 0.0566 | 0.0572 | 0.0599 | 0.0576 | 0.0590 | 0.0560 | 0.0568 | 0.0629 | 0.0663 | 0.0656 | 0.0550 | 0.3341 | 0.0559 |
| Tea_Colombo | 0.0559 | 0.0530 | 0.0526 | 0.0906 | 0.0666 | 0.0642 | 0.0666 | 0.0602 | 0.0588 | 0.0502 | 0.0524 | 0.0535 | 0.0511 | 0.0515 | 0.0507 | 0.0518 | 0.0507 | 0.0512 | 0.0514 | 0.0509 | 0.1027 | 0.1349 | 0.0508 | 0.3743 | 0.0508 |
| Tea_Kolkata | 0.1283 | 0.1271 | 0.1260 | 0.1461 | 0.1384 | 0.1207 | 0.1206 | 0.1270 | 0.1510 | 0.1201 | 0.1270 | 0.1288 | 0.1269 | 0.1280 | 0.1266 | 0.1273 | 0.1269 | 0.1264 | 0.1271 | 0.1287 | 0.1518 | 0.6858 | 0.1215 | 0.2654 | 0.1270 |
| Tea_Mombasa | 0.0869 | 0.0676 | 0.0999 | 0.0772 | 0.0763 | 81,392.4276 | 130.0489 | 0.2088 | 0.0687 | 0.0675 | 0.0688 | 0.0695 | 0.0679 | 0.0686 | 0.0681 | 0.0685 | 0.0684 | 0.0681 | 0.0681 | 0.0729 | 0.2347 | 0.2229 | 0.0685 | 0.2842 | 0.0680 |
| Coconut_oil | 0.1117 | 0.0902 | 0.0899 | 0.1168 | 0.1088 | 0.0947 | 0.0954 | 0.0975 | 0.0879 | 0.0870 | 0.0890 | 0.0900 | 0.0890 | 0.0888 | 0.0897 | 0.0901 | 0.0901 | 0.0901 | 0.0906 | 0.0903 | 0.1012 | 0.1043 | 0.0895 | 0.4950 | 0.0910 |
| Groundnuts | 0.0665 | 0.0637 | 0.0643 | 0.0987 | 0.0775 | 0.0821 | 0.0694 | 0.1828 | 0.0582 | 0.0612 | 0.0624 | 0.0628 | 0.0633 | 0.0656 | 0.0631 | 0.0632 | 0.0632 | 0.0630 | 0.0628 | 0.0638 | 0.0790 | 0.0752 | 0.0596 | 0.3458 | 0.0629 |
| Fish_meal | 53.4523 | 0.1942 | 25.4774 | 53.3846 | 0.1465 | 106.7756 | 141.3178 | 0.0563 | 0.0563 | 0.0557 | 0.0560 | 0.0583 | 0.0555 | 0.0563 | 0.0556 | 0.0553 | 0.0555 | 0.0550 | 0.0550 | 0.0593 | 0.0627 | 0.0705 | 0.0570 | 0.5068 | 0.0550 |
| Palm_oil | 0.1380 | 0.1923 | 84.1373 | 0.0753 | 382.0911 | 188.1413 | 0.2427 | 0.1500 | 0.0636 | 0.0660 | 0.0663 | 0.0660 | 0.0668 | 0.0674 | 0.0679 | 0.0686 | 0.0693 | 0.0675 | 0.0682 | 0.0728 | 0.0780 | 0.0806 | 0.0634 | 0.4160 | 0.0685 |
| Soybeans | 0.0894 | 1.5004 | 12.5538 | 346.5396 | 0.0902 | 1.7229 | 219.1701 | 0.0620 | 0.0584 | 0.0577 | 0.0595 | 0.0607 | 0.0588 | 0.0597 | 0.0586 | 0.0588 | 0.0585 | 0.0589 | 0.0597 | 0.0590 | 0.0669 | 0.0687 | 0.0593 | 0.3699 | 0.0598 |
| Soybean_oil | 0.0558 | 0.0561 | 0.0560 | 0.0622 | 0.0590 | 0.0566 | 0.0563 | 0.2619 | 0.0522 | 0.0541 | 0.0543 | 0.0553 | 0.0554 | 0.0558 | 0.0556 | 0.0550 | 0.0550 | 0.0550 | 0.0554 | 0.0553 | 0.0622 | 0.0718 | 0.0526 | 0.4172 | 0.0568 |
| Soybean_meal | 0.0695 | 0.0615 | 0.0613 | 0.0773 | 0.0965 | 0.0676 | 0.0688 | 0.0664 | 0.0622 | 0.0622 | 0.0624 | 0.0634 | 0.0623 | 0.0634 | 0.0624 | 0.0622 | 0.0622 | 0.0620 | 0.0622 | 0.0634 | 0.0738 | 0.0905 | 0.0583 | 0.3990 | 0.0622 |
| Maize | 0.0752 | 0.0713 | 0.0710 | 0.1380 | 0.1018 | 0.0796 | 0.0822 | 0.2767 | 0.0711 | 0.0714 | 0.0720 | 0.0729 | 0.0722 | 0.0726 | 0.0713 | 0.0712 | 0.0714 | 0.0718 | 0.0718 | 0.0722 | 0.0784 | 0.0860 | 0.0718 | 0.4252 | 0.0725 |
| Rice_5 | 0.0866 | 0.0786 | 0.0782 | 1.0294 | 0.1064 | 0.0882 | 0.0871 | 10.5696 | 0.0844 | 0.0774 | 0.0776 | 0.0782 | 0.0768 | 0.0783 | 0.0780 | 0.0774 | 0.0777 | 0.0767 | 0.0757 | 0.0873 | 0.0870 | 0.0914 | 0.0749 | 0.3829 | 0.0755 |
| Rice_100 | 0.0878 | 0.0793 | 0.0780 | 0.0882 | 0.1555 | 0.0844 | 0.0864 | 0.0784 | 0.0827 | 0.0780 | 0.0788 | 0.0797 | 0.0781 | 0.0798 | 0.0819 | 0.0794 | 0.0800 | 0.0792 | 0.0800 | 0.0866 | 0.0889 | 0.1108 | 0.0793 | 0.4523 | 0.0768 |
| Wheat_SRW | 0.0823 | 0.0805 | 0.0806 | 0.1056 | 0.1118 | 0.0832 | 0.0828 | 0.0830 | 0.0809 | 0.0797 | 0.0812 | 0.0829 | 0.0810 | 0.0814 | 0.0809 | 0.0811 | 0.0808 | 0.0809 | 0.0809 | 0.0819 | 0.0885 | 0.0925 | 0.0795 | 0.3694 | 0.0804 |
| Wheat_HRW | 0.0781 | 0.0751 | 0.0750 | 0.0784 | 0.0895 | 0.0844 | 0.0926 | 0.0863 | 0.0775 | 0.0742 | 0.0753 | 0.0757 | 0.0751 | 0.0756 | 0.0754 | 0.0752 | 0.0752 | 0.0749 | 0.0752 | 0.0782 | 0.0824 | 0.0867 | 0.0744 | 0.3714 | 0.0746 |
| Banana | 0.0961 | 0.0947 | 0.0944 | 0.1677 | 0.1030 | 0.0976 | 0.1085 | 0.4457 | 0.0912 | 0.0917 | 0.0930 | 0.0972 | 0.0923 | 0.0938 | 0.0924 | 0.0918 | 0.0922 | 0.0922 | 0.0917 | 0.0922 | 0.1210 | 0.1249 | 0.0919 | 0.3993 | 0.0915 |
| Orange | 0.5287 | 77,708.5698 | 109,896.5186 | 0.2958 | 0.1121 | 495,972.8294 | 544,551.3422 | 747.4920 | 0.1114 | 0.1119 | 0.1133 | 0.1155 | 0.1127 | 0.1127 | 0.1136 | 0.1124 | 0.1138 | 0.1124 | 0.1121 | 0.1144 | 0.1358 | 0.1511 | 0.1106 | 0.3571 | 0.1120 |
| Beef | 0.0497 | 0.0485 | 0.0488 | 0.0507 | 0.1451 | 0.0506 | 0.0496 | 0.0859 | 0.0476 | 0.0478 | 0.0484 | 0.0486 | 0.0483 | 0.0485 | 0.0483 | 0.0487 | 0.0487 | 0.0487 | 0.0489 | 0.0494 | 0.0526 | 0.0550 | 0.0456 | 0.3768 | 0.0487 |
| Chicken | 0.0484 | 0.0465 | 0.0460 | 0.0483 | 0.0474 | 0.0455 | 0.0456 | 0.0465 | 0.0457 | 0.0454 | 0.0461 | 0.0463 | 0.0458 | 0.0457 | 0.0460 | 0.0462 | 0.0461 | 0.0465 | 0.0469 | 0.0469 | 0.0482 | 0.0521 | 0.0435 | 0.2619 | 0.0460 |
| Shrimps | 0.0445 | 0.0434 | 0.0432 | 0.0522 | 0.0476 | 0.0467 | 0.0478 | 0.0719 | 0.0421 | 0.0426 | 0.0429 | 0.0439 | 0.0431 | 0.0434 | 0.0429 | 0.0430 | 0.0430 | 0.0428 | 0.0429 | 0.0469 | 0.0535 | 0.0531 | 0.0392 | 0.1930 | 0.0428 |
| Sugar_EU | 0.0346 | 0.0323 | 0.0323 | 0.0401 | 0.0385 | 0.0345 | 0.0333 | 0.0784 | 0.0326 | 0.0322 | 0.0342 | 0.0339 | 0.0339 | 0.0339 | 0.0322 | 0.0321 | 0.0322 | 0.0328 | 0.0328 | 0.0331 | 0.0392 | 0.0387 | 0.0340 | 0.2482 | 0.0325 |
| Sugar_US | 0.0417 | 0.0413 | 0.0416 | 0.0422 | 0.0417 | 0.0415 | 0.0413 | 0.0419 | 0.0430 | 0.0406 | 0.0417 | 0.0422 | 0.0410 | 0.0408 | 0.0421 | 0.0416 | 0.0421 | 0.0417 | 0.0415 | 0.0435 | 0.0440 | 0.0444 | 0.0400 | 0.2106 | 0.0413 |
| Sugar_World | 162.3136 | 0.1653 | 0.2684 | 0.1072 | 195,035.8825 | 283,162.9708 | 516,035.5325 | 0.6007 | 0.0825 | 0.0818 | 0.0828 | 0.0866 | 0.0824 | 0.0828 | 0.0821 | 0.0826 | 0.0824 | 0.0822 | 0.0822 | 0.0819 | 0.0933 | 0.0981 | 0.0780 | 0.4136 | 0.0821 |
| Tobacco | 0.0242 | 0.0171 | 0.0171 | 0.0202 | 0.0458 | 0.0296 | 0.0255 | 0.0201 | 0.0167 | 0.0178 | 0.0166 | 0.0171 | 0.0171 | 0.0174 | 0.0186 | 0.0178 | 0.0184 | 0.0168 | 0.0171 | 0.0182 | 0.0216 | 0.0226 | 0.0162 | 0.2379 | 0.0165 |
| Logs_CM | 0.0342 | 0.0316 | 0.0318 | 0.0361 | 0.0384 | 0.0371 | 0.0370 | 0.0594 | 0.0320 | 0.0304 | 0.0320 | 0.0324 | 0.0318 | 0.0322 | 0.0320 | 0.0326 | 0.0322 | 0.0317 | 0.0321 | 0.0344 | 0.0368 | 0.0434 | 0.0317 | 0.2294 | 0.0328 |
| Logs_MY | 0.0661 | 458.1314 | 323.9475 | 0.1741 | 0.0370 | 0.1722 | 0.0354 | 0.0461 | 0.0319 | 0.0337 | 0.0332 | 0.0338 | 0.0333 | 0.0336 | 0.0334 | 0.0332 | 0.0334 | 0.0331 | 0.0330 | 0.0444 | 0.0428 | 0.0461 | 0.0308 | 0.2390 | 0.0330 |
| Sawnwood | 0.0271 | 0.0269 | 0.0269 | 0.1205 | 0.0427 | 0.0348 | 0.0306 | 0.1523 | 0.0244 | 0.0248 | 0.0260 | 0.0277 | 0.0260 | 0.0264 | 0.0263 | 0.0260 | 0.0261 | 0.0262 | 0.0266 | 0.0268 | 0.0352 | 0.0352 | 0.0259 | 0.2006 | 0.0258 |
| Plywood | 0.0284 | 0.0759 | 0.1058 | 0.0384 | 0.0389 | 112.6283 | 424.0129 | 0.0379 | 0.0219 | 0.0224 | 0.0227 | 0.0239 | 0.0229 | 0.0236 | 0.0233 | 0.0224 | 0.0230 | 0.0223 | 0.0223 | 0.0280 | 0.0310 | 0.0348 | 0.0222 | 0.1541 | 0.0222 |
| Cotton | 0.0844 | 0.0934 | 5.7991 | 0.0806 | 0.0889 | 116,060.2346 | 267.7386 | 0.1411 | 0.0778 | 0.0790 | 0.0782 | 0.0787 | 0.0778 | 0.0779 | 0.0808 | 0.0791 | 0.0807 | 0.0784 | 0.0789 | 0.0793 | 0.0816 | 0.0845 | 0.0638 | 0.3293 | 0.0769 |
| Rubber | 0.1118 | 0.0995 | 0.1003 | 0.1199 | 0.2225 | 0.1372 | 0.1098 | 0.1014 | 0.1043 | 0.0983 | 0.1022 | 0.1055 | 0.1013 | 0.1011 | 0.1022 | 0.1007 | 0.1014 | 0.1016 | 0.1027 | 0.1027 | 0.1103 | 0.1102 | 0.0995 | 0.6144 | 0.1016 |
| Phosphate_rock | 0.2018 | 0.1923 | 0.1918 | 0.1943 | 0.1935 | 0.1930 | 0.1924 | 0.1915 | 0.2253 | 0.1951 | 0.1925 | 0.1925 | 0.1925 | 0.1925 | 0.1989 | 0.1954 | 0.1954 | 0.1989 | 0.2047 | 0.2331 | 0.2076 | 0.2502 | 0.2393 | 0.8601 | 0.1934 |
| Dap | 0.1093 | 250.0493 | 0.5955 | 0.1107 | 1.8048 | 532.8508 | 569.0750 | 0.2111 | 0.0998 | 0.1010 | 0.1011 | 0.1020 | 0.1019 | 0.1014 | 0.1002 | 0.0977 | 0.0972 | 0.0999 | 0.1010 | 0.1027 | 0.1024 | 0.1020 | 0.0942 | 0.5790 | 0.1042 |
| Tsp | 0.1079 | 0.1075 | 0.1059 | 0.1157 | 0.1399 | 0.1186 | 0.1192 | 0.1140 | 0.1024 | 0.1137 | 0.1102 | 0.1099 | 0.1139 | 0.1127 | 0.1067 | 0.1044 | 0.1053 | 0.1062 | 0.1058 | 0.1100 | 0.1110 | 0.1109 | 0.0947 | 0.6395 | 0.1147 |
| Urea | 0.1559 | 0.1424 | 0.1469 | 0.2334 | 0.2902 | 0.1812 | 0.2412 | 0.1426 | 0.1487 | 0.1445 | 0.1529 | 0.1504 | 0.1520 | 0.1537 | 0.1522 | 0.1523 | 0.1520 | 0.1510 | 0.1526 | 0.1533 | 0.1722 | 0.1762 | 0.1483 | 0.5829 | 0.1524 |
| Potash | 0.1239 | 0.1151 | 0.1149 | 0.1277 | 0.1266 | 0.1166 | 0.1153 | 0.1148 | 0.1170 | 0.1142 | 0.1151 | 0.1151 | 0.1145 | 0.1145 | 0.1153 | 0.1157 | 0.1161 | 0.1151 | 0.1147 | 0.1218 | 0.1165 | 0.1196 | 0.1271 | 0.6299 | 0.1142 |
| Aluminium | 0.0570 | 0.0471 | 0.0472 | 0.0631 | 0.0663 | 0.0646 | 0.0540 | 0.0515 | 0.0439 | 0.0456 | 0.0466 | 0.0463 | 0.0469 | 0.0480 | 0.0459 | 0.0468 | 0.0460 | 0.0463 | 0.0468 | 0.0461 | 0.0557 | 0.0568 | 0.0499 | 0.2351 | 0.0508 |
| Iron | 0.1112 | 0.1111 | 0.1106 | 0.1127 | 0.1147 | 0.1140 | 0.1139 | 0.1206 | 0.1186 | 0.1218 | 0.1190 | 0.1189 | 0.1201 | 0.1201 | 0.1149 | 0.1097 | 0.1115 | 0.1113 | 0.1108 | 0.1144 | 0.1621 | 0.1215 | 0.1126 | 0.6999 | 0.1148 |
| Copper | 0.0709 | 0.0692 | 0.0696 | 0.0765 | 0.1273 | 0.0852 | 0.0820 | 0.2231 | 0.0666 | 0.0675 | 0.0687 | 0.0707 | 0.0683 | 0.0679 | 0.0686 | 0.0695 | 0.0686 | 0.0686 | 0.0695 | 0.0722 | 0.0768 | 0.0797 | 0.0702 | 0.5706 | 0.0718 |
| Lead | 0.0899 | 0.0831 | 0.0836 | 0.0978 | 0.1803 | 0.1050 | 0.1081 | 0.0861 | 0.0847 | 0.0821 | 0.0839 | 0.0852 | 0.0830 | 0.0825 | 0.0846 | 0.0849 | 0.0842 | 0.0839 | 0.0852 | 0.0835 | 0.0933 | 0.0989 | 0.0818 | 0.5983 | 0.0845 |
| Tin | 0.0711 | 0.0711 | 0.0709 | 0.0743 | 0.0762 | 0.0755 | 0.0763 | 0.1300 | 0.0683 | 0.0703 | 0.0710 | 0.0716 | 0.0709 | 0.0712 | 0.0720 | 0.0711 | 0.0710 | 0.0707 | 0.0714 | 0.0717 | 0.0742 | 0.0813 | 0.0717 | 0.6120 | 0.0735 |
| Nickel | 0.1114 | 0.1106 | 0.1106 | 0.1297 | 0.1128 | 0.1168 | 0.1172 | 0.2589 | 0.1048 | 0.1105 | 0.1108 | 0.1124 | 0.1107 | 0.1107 | 0.1100 | 0.1106 | 0.1101 | 0.1097 | 0.1098 | 0.1125 | 0.1187 | 0.1150 | 0.1040 | 0.5837 | 0.1110 |
| Zinc | 0.0737 | 0.0751 | 0.0754 | 0.0814 | 0.1548 | 0.0786 | 0.0792 | 0.2273 | 0.0743 | 0.0743 | 0.0742 | 0.0742 | 0.0738 | 0.0734 | 0.0768 | 0.0752 | 0.0769 | 0.0746 | 0.0750 | 0.0783 | 0.0877 | 0.0935 | 0.0738 | 0.4652 | 0.0761 |
| Gold | 0.0415 | 0.0418 | 0.0421 | 0.0422 | 0.0447 | 0.0443 | 0.0436 | 0.0584 | 0.0413 | 0.0406 | 0.0412 | 0.0427 | 0.0418 | 0.0424 | 0.0464 | 0.0467 | 0.0464 | 0.0413 | 0.0419 | 0.0448 | 0.0522 | 0.0490 | 0.0421 | 0.6476 | 0.0418 |
| Platinum | 0.0819 | 0.0633 | 0.0628 | 0.0644 | 0.0949 | 0.0676 | 0.0689 | 0.0664 | 0.0656 | 0.0620 | 0.0639 | 0.0636 | 0.0642 | 0.0643 | 0.0625 | 0.0626 | 0.0628 | 0.0628 | 0.0629 | 0.0655 | 0.0712 | 0.0714 | 0.0664 | 0.5191 | 0.0664 |
| Silver | 0.0926 | 1.0462 | 0.1473 | 0.0895 | 0.2114 | 21,752.5782 | 8168.0694 | 0.2819 | 0.0900 | 0.0890 | 0.0897 | 0.0890 | 0.0896 | 0.0895 | 0.0900 | 0.0901 | 0.0899 | 0.0897 | 0.0908 | 0.0907 | 0.1178 | 0.1043 | 0.0912 | 0.6978 | 0.0915 |
| Model | Frequency |
|---|---|
| ARIMA | 65.45% |
| DMA | 60.00% |
| BMA | 56.36% |
| NAIVE | 25.45% |
| BMS 1V | 18.18% |
| BMA 1V | 16.36% |
| BSR av MSE rec | 14.55% |
| BSR av EW rec | 14.55% |
| B-LASSO | 14.55% |
| B-RIDGRE | 14.55% |
| RIDGE | 12.73% |
| EN | 12.73% |
| BSR rec | 10.91% |
| BSR av EW fix | 10.91% |
| DMA 1V | 10.91% |
| DMS 1V | 10.91% |
| LASSO | 9.09% |
| LARS | 9.09% |
| GP fix | 7.27% |
| GP rec | 5.45% |
| BSR av MSE fix | 5.45% |
| TVP | 3.64% |
| TVP f | 3.64% |
| BSR fix | 0.00% |
| HA | 0.00% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Drachal, K.; Pawłowski, M. Forecasting Selected Commodities’ Prices with the Bayesian Symbolic Regression. Int. J. Financial Stud. 2024, 12, 34. https://doi.org/10.3390/ijfs12020034
Drachal K, Pawłowski M. Forecasting Selected Commodities’ Prices with the Bayesian Symbolic Regression. International Journal of Financial Studies. 2024; 12(2):34. https://doi.org/10.3390/ijfs12020034
Chicago/Turabian StyleDrachal, Krzysztof, and Michał Pawłowski. 2024. "Forecasting Selected Commodities’ Prices with the Bayesian Symbolic Regression" International Journal of Financial Studies 12, no. 2: 34. https://doi.org/10.3390/ijfs12020034
APA StyleDrachal, K., & Pawłowski, M. (2024). Forecasting Selected Commodities’ Prices with the Bayesian Symbolic Regression. International Journal of Financial Studies, 12(2), 34. https://doi.org/10.3390/ijfs12020034