
Aircraft Skin Machine Learning-Based Defect Detection and Size Estimation in Visual Inspections

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Data Acquisition and Methods
2.1. Dataset
2.2. Defect Detection
2.2.1. Pre-Trained Models
2.2.2. Loss Functions and Evaluation Protocols
- Classification Loss: measures the difference between predicted class probabilities and the actual class labels and quantifies how well the predictions match the true class labels.
- Localization Loss: measures the discrepancy between the predicted bounding box coordinates and the ground truth bounding box coordinates.
- Regularization Loss: This term is added to the total loss function to prevent overfitting by penalising large weights or complex models and imposes constraints on model parameters to encourage the model to generalise unseen data better.
- Total Loss: represents the overall error, which typically combines various individual loss terms, such as classification, localisation, and regularisation loss, into a single scalar value.
- The COCO detection metrics include:
- Detection Boxes—Precision (mAP). It measures the average precision of object detection across multiple object categories. It evaluates how accurately the model localises and classifies objects within detected bounding boxes.
- Detection Boxes—Recall. It evaluates the model’s ability to detect all relevant objects within an image. It measures the proportion of true positive detections out of all actual positive instances in the dataset.
- Losses (classification, localisation, regularisation and total).
- The PASCAL VOC 2010 detection metrics include:
- Performance per class—Average Precision (AP) is calculated individually for each object class present in the dataset. It provides insights into the model’s performance in detecting and classifying objects of specific categories.
- Precision (mAP)—Mean Average Precision (mAP) evaluates the overall precision of object detection across all object classes. It computes the average AP scores for each class, providing a comprehensive measure of the model’s detection accuracy.
- Open Images V2 Detection
- This metric includes the same metrics (AP and mAP) as the PASCAL VOC 2010 metric. However, the primary distinction lies in the criteria used to classify detected boxes as TP, FP or ignored.
2.2.3. Model Testing
- Confusion MatrixThe Confusion Matrix displays predicted versus expected information, revealing where and how the model becomes confused. This analysis focuses solely on the multiclass classification scenario (Table 5). Before delving into further details, the following terms need to be defined:
- True Positive (TP) refers to instances where the model correctly detects the target object and the predicted class matches the ground truth class e.g., in the A class, TPA = AA;
- False Positives (FPs) refer to instances where the model correctly detects the target object; however, misclassification occurs e.g., in the A class, FPA = BA + CA + DA + EA;
- False Negative (FN) refers to instances where the model fails to detect the target object (red) or is incorrectly classified e.g., in the A class, FNA = !A + AB + AC + AD + AE;
- True Negative (TN) in multiclass classification is a complex case, and it is computed by summing all instances where the model correctly predicts classes other than the true positive class e.g., in the A class, TNA = BB + CB + DB + EB + BC + CC + DC + EC + BD + CD + DD + ED + BE + CE + DE + EE.
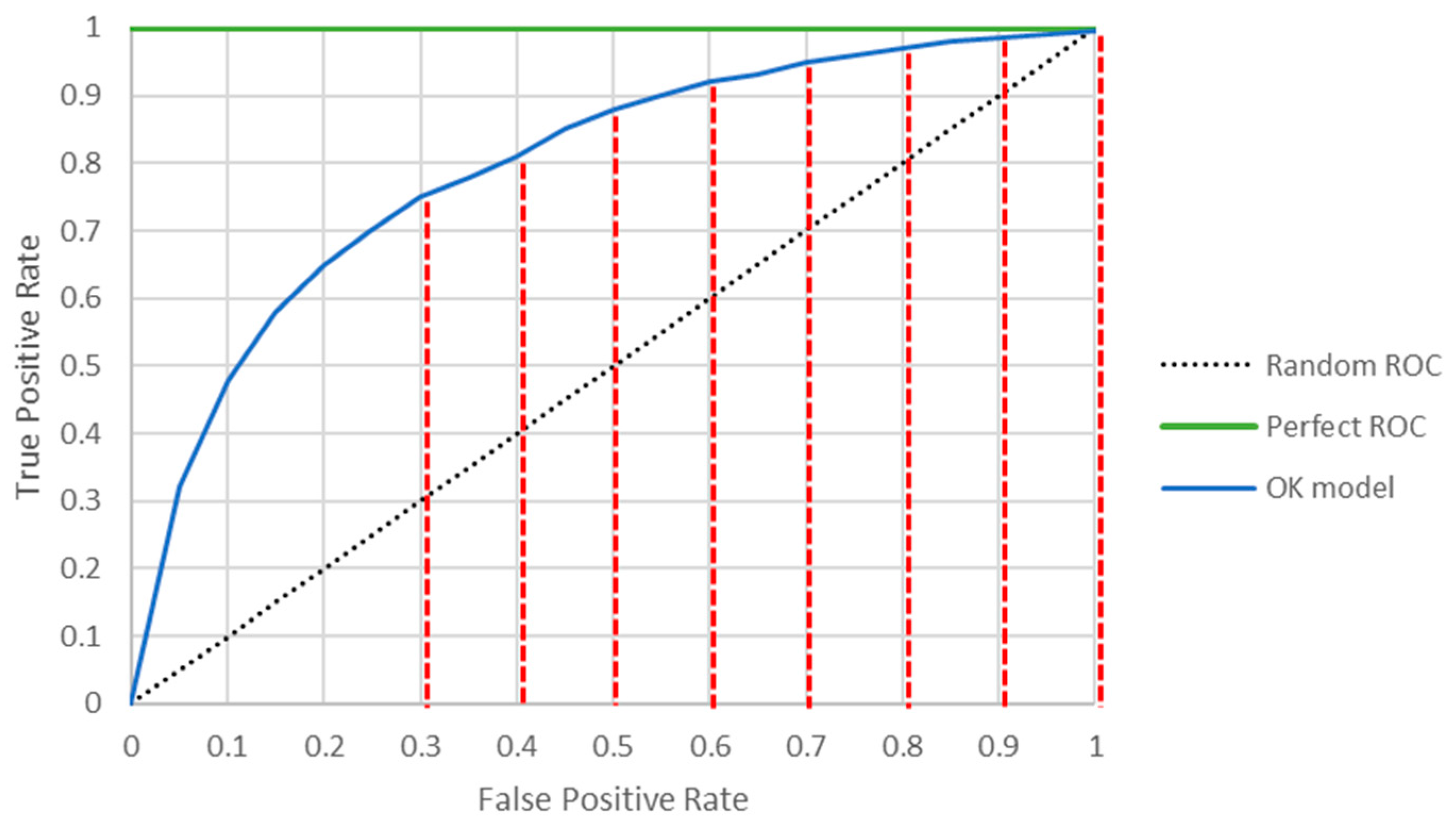
- Receiver Operating Characteristics (ROC) Curve and Area Under the Curve (AUC)
- Intersection over Union
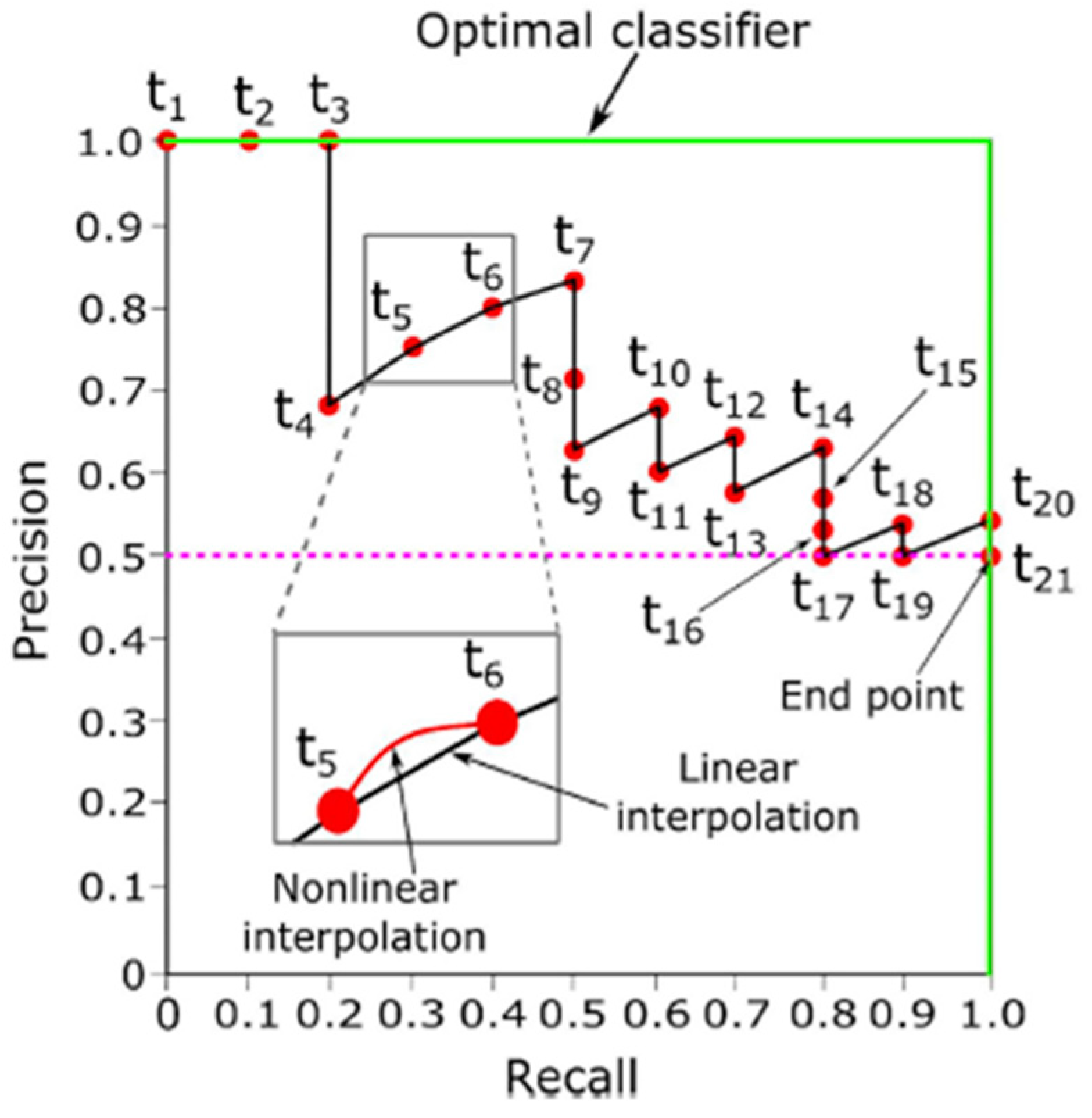
- Precision–Recall (PR)
- F1 score
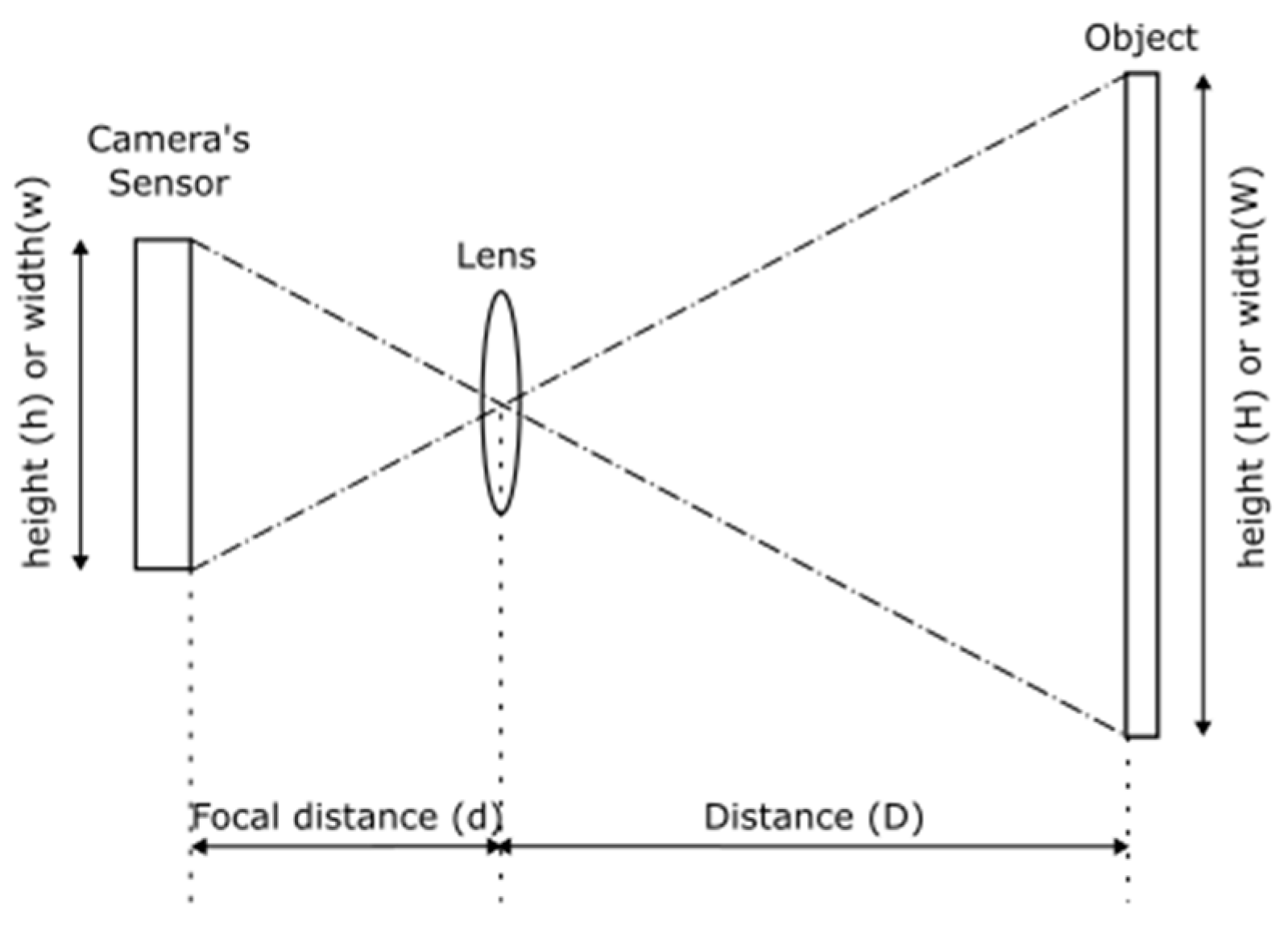
2.3. Defect Size Estimation
3. Discussion
3.1. Defect Detection Results
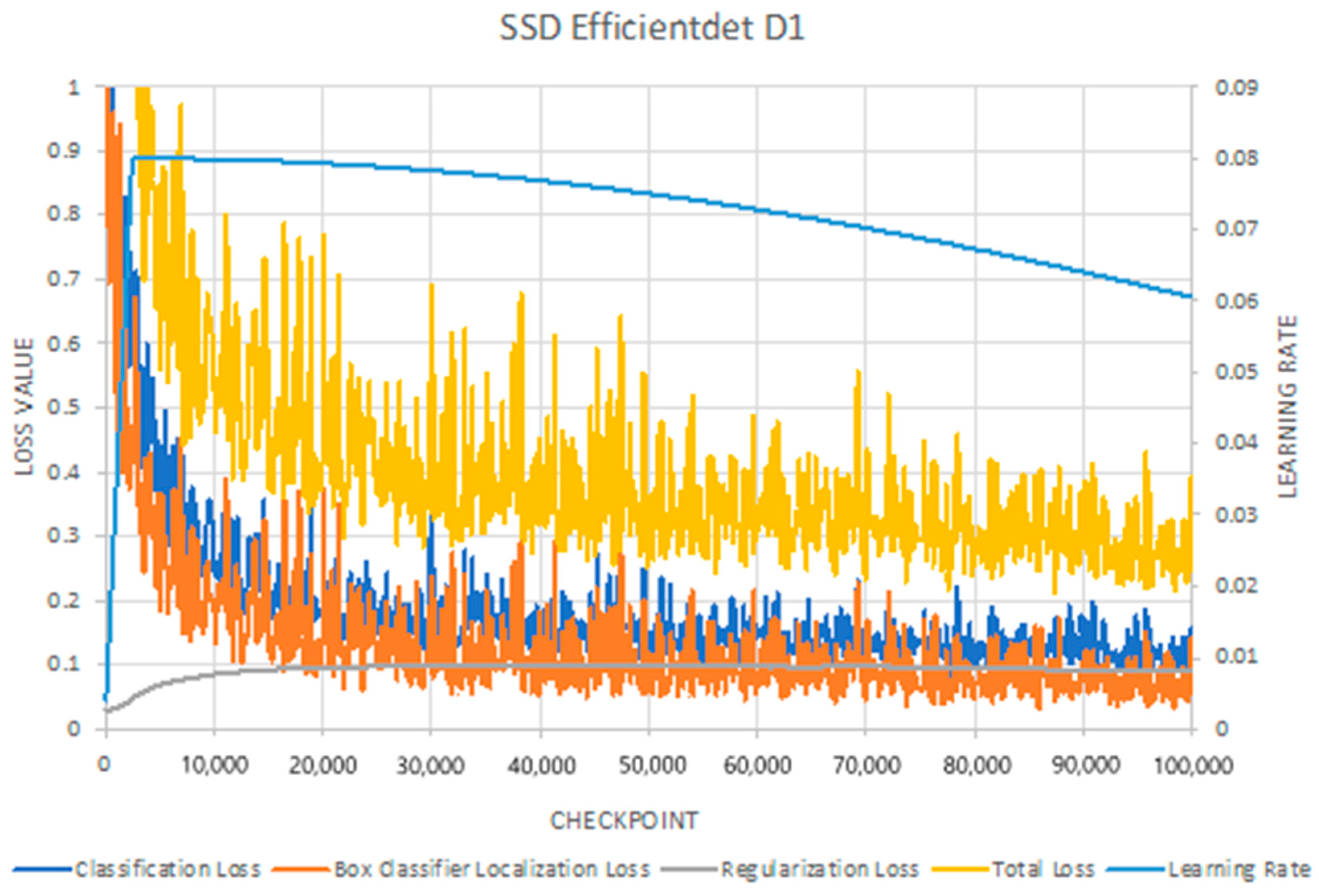
3.1.1. Training Analysis
3.1.2. Validation Results
3.1.3. Testing Results
3.1.4. Limitations and Possible Improvements in Defect Detection
- Increase the number of annotations: This is important for creating a more robust and balanced dataset. Ensuring enough examples of each class helps prevent bias and improves the model’s generalisation ability.
- Consistent image capture: Using the same sensor and shooting conditions helps maintain consistency across the dataset. This reduces variability and ensures the model learns features relevant to the objects rather than environmental factors.
- Capture variations: Taking images of the same object from different angles and under different environmental conditions helps the model learn to recognise objects in various contexts, improving its robustness.
- Image processing: Adjusting exposure levels can help enhance features and remove unnecessary information, making detecting objects more accessible for the model. However, it is essential to ensure that these modifications do not distort the objects or introduce artefacts that could confuse the model.
- Oriented bounding boxes: Oriented bounding boxes can improve localisation accuracy, especially for objects with non-standard orientations. This helps the model better understand the spatial layout of objects in the image.
3.2. Defect Size Estimation Results
3.2.1. Lab Tests
3.2.2. Hangar Tests
3.2.3. Limitations and Possible Improvements in Size Estimation
- In some cases, the contour approximation used in the sizing estimation fails to identify dents that are not clearly visible in the photo. If there is a visible colour change that creates an edge, it gives promising results.
- The suggested area of interest (bounding box), which comes from the defect detector, sometimes crops out part of the dent, directly affecting the size estimation. The defect detector works in a stringent IOU (0.9), which is advantageous for the sizing algorithm. The introduction of oriented rounded boxes could further improve the situation.
- There is no solid reference to compare. Trained maintenance engineers perform dent sizing, but the research team lacks this expertise. The manual measurement was not industry-accepted at this stage and introduced uncertainty as it cannot be considered a solid ground truth.
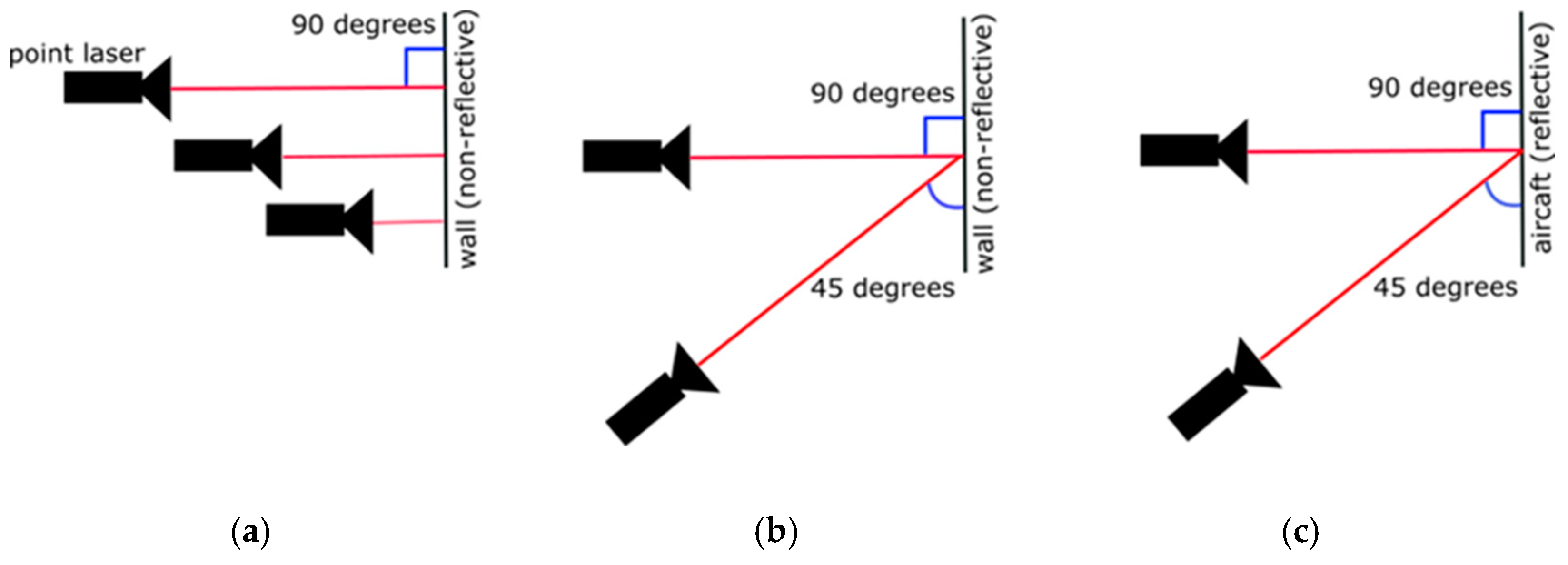
- The distance in the experiments was measured by a laser distance measurer, which, most of the time, did not work because of the reflection on the aircraft’s skin, so instead, a tape measure was used. This procedure is far from perfect. However, in the actual scenario, the UAV has a lidar and flies in a predefined path, maintaining a fixed distance from the aircraft. In addition, since the lidar emits beams on the surface (32 to 128, depending on the model). In this case, an area average can be used, rather than only one measurement utilised in the current experiment.
- If the photo capture is not perpendicular to the defect, perspective distortion may affect the size estimation.
- Lens distortion or image sensor characteristics introduce errors that need to be validated in the representative environment with the camera onboard the UAV.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- IBISWorld. Global Airline Industry Market Size from 2018 to 2023 (in Billions of U.S. Dollars). 2023. Available online: https://www.statista.com/statistics/1110342/market-size-airline-industry-worldwide/ (accessed on 8 February 2024).
- Federal Aviation Administration. Visual Inspection for Aircraft. In Advisory Circular ACNO; 1997; pp. 43–204. Available online: https://www.faa.gov/documentLibrary/media/Advisory_Circular/43-204.pdf (accessed on 9 September 2024).
- Drury, C.G.; Watson, J. Good practices in visual inspection. In Human Factors in Aviation Maintenance-Phase Nine, Progress Report, FAA/Human Factors in Aviation Maintenance; Federal Aviation Administration (FAA): New York, NY, USA, 2002; Available online: https://dviaviation.com/files/45146949.pdf (accessed on 9 September 2024).
- Civil Aviation Authority. CAP 562: Civil Aircraft Airworthiness Information and Procedures. 2020. Available online: http://publicapps.caa.co.uk/modalapplication.aspx?appid=11&mode=detail&id=92 (accessed on 8 February 2024).
- Hrymak, V.; Codd, P. Improving Visual Inspection Reliability in Aircraft Maintenance. Conference Papers. 2021. Available online: https://arrow.tudublin.ie/beschreccon/153 (accessed on 8 February 2024).
- Spencer, F. Visual Inspection Research Project Report on Benchmark Inspections. 1996. Available online: https://rosap.ntl.bts.gov/view/dot/12923 (accessed on 9 September 2024).
- Donecle-Automating your Aircraft Inspections. Available online: https://www.donecle.com/ (accessed on 8 February 2024).
- Mainblades-Drone Aircraft Inspections. Available online: https://mainblades.com/ (accessed on 8 February 2024).
- Holl, J. Hangar of the future. Airbus. Available online: https://www.airbus.com/en/newsroom/news/2016-12-hangar-of-the-future (accessed on 19 June 2024).
- Woodrow, B. EasyJet, Partners Developing UAS Aircraft Inspection Technology-Avionics International0. Avionics International. Available online: https://www.aviationtoday.com/2015/01/20/easyjet-partners-developing-uas-aircraft-inspection-technology/ (accessed on 10 May 2024).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process Syst. 2012, 25. Available online: http://code.google.com/p/cuda-convnet/ (accessed on 10 May 2024). [CrossRef]
- Malekzadeh, T.; Abdollahzadeh, M.; Nejati, H.; Cheung, N.-M. Aircraft Fuselage Defect Detection using Deep Neural Networks. 2017. Available online: https://arxiv.org/abs/1712.09213v2 (accessed on 13 February 2024).
- Doğru, A.; Bouarfa, S.; Arizar, R.; Aydoğan, R. Using Convolutional Neural Networks to Automate Aircraft Maintenance Visual Inspection. Aerospace 2020, 7, 171. [Google Scholar] [CrossRef]
- Bouarfa, S.; Doğru, A.; Arizar, R.; Aydoğan, R.; Serafico, J. Towards automated aircraft maintenance inspection. A use case of detecting aircraft dents using mask r-cnn. AIAA Scitech 2020 Forum 2020, 1. [Google Scholar] [CrossRef]
- Yasuda, Y.D.V.; Cappabianco, F.A.M.; Martins, L.E.G.; Gripp, J.A.B. Automated Visual Inspection of Aircraft Exterior Using Deep Learning. In Proceedings of the Anais Estendidos da Conference on Graphics, Patterns and Images (SIBGRAPI), Gramado, Rio Grande do Sul, Brazil, 18 October 2021; pp. 173–176. [Google Scholar] [CrossRef]
- Avdelidis, N.P.; Tsourdos, A.; Lafiosca, P.; Plaster, R.; Plaster, A.; Droznika, M. Defects Recognition Algorithm Development from Visual UAV Inspections. Sensors 2022, 22, 4682. [Google Scholar] [CrossRef] [PubMed]
- Ren, I.; Zahiri, F.; Sutton, G.; Kurfess, T.; Saldana, C. A Deep Ensemble Classifier for Surface Defect Detection in Aircraft Visual Inspection. Smart Sustain. Manuf. Syst. 2020, 4, 81–94. [Google Scholar] [CrossRef]
- Miranda, J.; Larnier, S.; Herbulot, A.; Devy, M. Uav-based inspection of airplane exterior screws with computer vision. In Proceedings of the VISIGRAPP 2019-Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Prague, Czech Republic, 25–27 February 2019; Volume 4, pp. 421–427. [Google Scholar] [CrossRef]
- Ding, M.; Wu, B.; Xu, J.; Kasule, A.N.; Zuo, H. Visual inspection of aircraft skin: Automated pixel-level defect detection by instance segmentation. Chin. J. Aeronaut. 2022, 35, 254–264. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern. Anal. Mach. Intell. 2017, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Qu, Y.; Wang, C.; Xiao, Y.; Yu, J.; Chen, X.; Kong, Y. Optimization Algorithm for Surface Defect Detection of Aircraft Engine Components Based on YOLOv5. Appl. Sci. 2023, 13, 11344. [Google Scholar] [CrossRef]
- Rice, M.; Li, L.; Ying, G.; Wan, M.; Lim, E.T.; Feng, G.; Ng, J.; Jin-Li, M.T.; Babu, V.S. Automating the Visual Inspection of Aircraft. In Proceedings of the Singapore Aerospace Technology and Engineering Conference (SATEC), Suntec Singapore Convention and Exhibition Centre, Singapore; 2018. Available online: https://oar.a-star.edu.sg/communities-collections/articles/13872?collectionId=20 (accessed on 8 February 2024).
- Aust, J.; Shankland, S.; Pons, D.; Mukundan, R.; Mitrovic, A. Automated Defect Detection and Decision-Support in Gas Turbine Blade Inspection. Aerospace 2021, 8, 30. [Google Scholar] [CrossRef]
- Yasuda, Y.D.V.; Cappabianco, F.A.M.; Martins, L.E.G.; Gripp, J.A.B. Aircraft visual inspection: A systematic literature review. Comput. Ind. 2022, 141, 103695. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2021, 17, 168–192. [Google Scholar] [CrossRef]
- See, J.E. Visual Inspection: A Review of the Literature; Sandia National Laoratories: Albuquerque, NM, USA, 2012; p. 87185. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Validation Annotations (%) | Testing Annotations (%) | Training Annotations (%) | Total Annotations (%) |
|---|---|---|---|---|
| Dents | 80 (11.2%) | 131 (14.2%) | 365 (6.9%) | 567 (8.3%) |
| Missing paint | 236 (33%) | 334 (36.1%) | 1723 (33.3%) | 2293 (33.6%) |
| Screw | 230 (32.2%) | 257 (29.8%) | 1724 (33.3%) | 2229 (32.7%) |
| Repair | 112 (15.7%) | 125 (13.5%) | 811 (15.7%) | 1048 (15.4%) |
| Scratch | 57 (8%) | 59 (6.4%) | 563 (10.9%) | 679 (10%) |
| Total Annotations | 715 | 924 | 5177 | 6816 |
| Percentage | 10.5% | 13.6% | 76.0% | 100% |
| Model | Speed (ms) | COCO (mAP) |
|---|---|---|
| SSD MobileNet V1 FPN 640 × 640 | 48 | 29.1 |
| Faster R-CNN ResNet50 V1 640 × 640 | 53 | 29.3 |
| EfficientDet D0 512 × 512 | 39 | 33.6 |
| SSD ResNet50 V1 FPN 640 × 640 (RetinaNet50) | 46 | 34.3 |
| EfficientDet D1 640 × 640 | 54 | 38.4 |
| Model Configuration | Object Detection Model | CNN Feature Extraction | CNN Feature Fusion |
|---|---|---|---|
| SSD MobileNet V1 FPN 640 × 640 | SSD with a Mobilenet v1 + FPN feature extractor | MobileNet V1 backbone | Feature Pyramid Network (FPN) architecture |
| Faster R-CNN ResNet50 V1 640 × 640 | Faster R-CNN with ResNet-50 (v1) | ResNet-50 (v1) backbone | ResNet-50 (v1) backbone |
| EfficientDet D0 512 × 512 | SSD with an EfficientNet-b0 + BiFPN feature extractor | EfficientNet-b0 backbone | BiFPN (Bidirectional Feature Pyramid Network) |
| SSD ResNet50 V1 FPN 640 × 640 (RetinaNet50) | SSD with Resnet 50 v1 FPN feature extractor | ResNet-50 (v1) backbone | Feature Pyramid Network (FPN) architecture |
| EfficientDet D1 640 × 640 | SSD with an EfficientNet-b1 backbone and BiFPN feature extractor | EfficientNet-b1 backbone | BiFPN (Bidirectional Feature Pyramid Network) |
| Training Configuration | Data Augmentation Options |
|---|---|
| SSD MobileNet V1 FPN 640 × 640 | Horizontal flipping and random scale crop |
| Faster R-CNN ResNet50 V1 640 × 640 | Random horizontal flip |
| EfficientDet D0 512 × 512 | Horizontal flipping and random scale crop |
| SSD ResNet50 V1 FPN 640 × 640 (RetinaNet50) | Horizontal flipping and random scale crop |
| EfficientDet D1 640 × 640 | Horizontal flipping and random scale crop |
| Predicted | Expected | |||||
|---|---|---|---|---|---|---|
| A | B | C | D | E | Not Detected | |
| A | AA | BA | CA | DA | EA | !A |
| B | AB | BB | CB | DB | EB | !B |
| C | AC | BC | CC | DC | EC | !C |
| D | AD | BD | CD | DD | ED | !D |
| E | AE | BE | CE | DE | EE | !E |
| Predicted | Expected | |
|---|---|---|
| Positive | Negative | |
| Positive | TP | FP |
| Negative | FN | TN |
| Model | Dent Precision | Dent Recall | Dent F1 | Average AUC | Average Precision | Average F1 |
|---|---|---|---|---|---|---|
| EfficientDet D1 | 0.712 | 0.439 | 0.543 | 0.657 | 0.279 | 0.526 |
| EfficientDet D0 | 0.652 | 0.450 | 0.533 | 0.641 | 0.261 | 0.473 |
| Faster R-CNN ResNet50 V1 | 0.565 | 0.357 | 0.438 | 0.608 | 0.229 | 0.444 |
| SSD ResNet50 V1 FPN | 0.710 | 0.407 | 0.518 | 0.590 | 0.214 | 0.411 |
| Faster R-CNN ResNet50 V1 | 0.500 | 0.290 | 0.367 | 0.607 | 0.228 | 0.407 |
| Predicted | Expected | |||||
|---|---|---|---|---|---|---|
| Dent | Missing Paint | Screw | Repair | Scratch | Not Detected | |
| Dent | 47 | 5 | 3 | 8 | 3 | 50 |
| Missing paint | 4 | 81 | 11 | 3 | 13 | 93 |
| Screw | 1 | 10 | 79 | 10 | 4 | 86 |
| Repair | 5 | 4 | 8 | 62 | 0 | 25 |
| Scratch | 0 | 6 | 4 | 3 | 17 | 23 |
| Predicted Dent | Expected Dent | |
|---|---|---|
| Positive | Negative | |
| Positive | 47 | 19 |
| Negative | 60 | 542 |
| Class Name | TRP | FPR | Precision | Recall | AP | F1 | AUC | CL-Min | CL-Avg | CL-Max |
|---|---|---|---|---|---|---|---|---|---|---|
| Dent | 0.44 | 0.03 | 0.71 | 0.44 | 0.44 | 0.54 | 0.69 | 20 | 59 | 98 |
| Average | 0.28 | 0.53 | 0.66 |
| Object | Actual (mm) | Measured (mm) | Abs Difference (mm) |
|---|---|---|---|
| object 1 width | 88.5 | 88.5 | 0.0 |
| object 1 height | 53.5 | 53.6 | 0.1 |
| object 2 width | 150.0 | 147.9 | 2.1 |
| object 2 height | 70.0 | 72.7 | 2.7 |
| object 3 width | 150.0 | 149.2 | 0.8 |
| object 3 height | 62.0 | 62.2 | 0.2 |
| object 4 width | 8.0 | 8.2 | 0.2 |
| object 4 height | 7.4 | 8.1 | 0.7 |
| object 5 width | 23.6 | 21.1 | 2.5 |
| object 5 height | 23.1 | 21.0 | 2.1 |
| object 6 width | 79.5 | 79.0 | 0.5 |
| object 6 height | 76.2 | 79.0 | 2.8 |
| Object | Actual (mm) | Measured (mm) | Abs Difference (mm) |
|---|---|---|---|
| defect 1 width | 73 | 60.5 | 12.5 |
| defect 1 height | 94 | 74.1 | 19.9 |
| defect 2 width | 130 | 113.9 | 16.1 |
| defect 2 height | 90 | 74.7 | 15.3 |
| defect 3 width | 110 | 143.9 | 33.9 |
| defect 3 height | 75 | 95.9 | 20.9 |
| defect 4 width | 65 | 80.1 | 15.1 |
| defect 4 height | 75 | 106.7 | 31.7 |
| defect 5 width | 190 | 145.5 | 44.5 |
| defect 5 height | 65 | 94.3 | 29.3 |
| Distance (cm) | Distance Measured (cm) | Difference (cm) |
|---|---|---|
| 30 | 34 | 4 (close to dead zone) |
| 60 | 60 | 0 |
| 100 | 100 | 0 |
| 250 | 250 | 0 |
| 400 | 402 | 2 |
| 500 | 501 | 1 |
| Distance (cm) | Angle (Degrees) | Material | Distance Measured (cm) | Difference (cm) |
|---|---|---|---|---|
| 100 | 90 | non-reflective | 100 | 0 |
| 100 | 45 | non-reflective | 101 | 1 |
| 100 | 90 | reflective | 101 | 1 |
| 100 | 45 | reflective | 135 | 35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Plastropoulos, A.; Bardis, K.; Yazigi, G.; Avdelidis, N.P.; Droznika, M. Aircraft Skin Machine Learning-Based Defect Detection and Size Estimation in Visual Inspections. Technologies 2024, 12, 158. https://doi.org/10.3390/technologies12090158
Plastropoulos A, Bardis K, Yazigi G, Avdelidis NP, Droznika M. Aircraft Skin Machine Learning-Based Defect Detection and Size Estimation in Visual Inspections. Technologies. 2024; 12(9):158. https://doi.org/10.3390/technologies12090158
Chicago/Turabian StylePlastropoulos, Angelos, Kostas Bardis, George Yazigi, Nicolas P. Avdelidis, and Mark Droznika. 2024. "Aircraft Skin Machine Learning-Based Defect Detection and Size Estimation in Visual Inspections" Technologies 12, no. 9: 158. https://doi.org/10.3390/technologies12090158