
Modeling Semiarid River–Aquifer Systems with Bayesian Networks and Artificial Neural Networks

 , , , and
, , , and
Abstract
:1. Introduction
2. Material and Methods
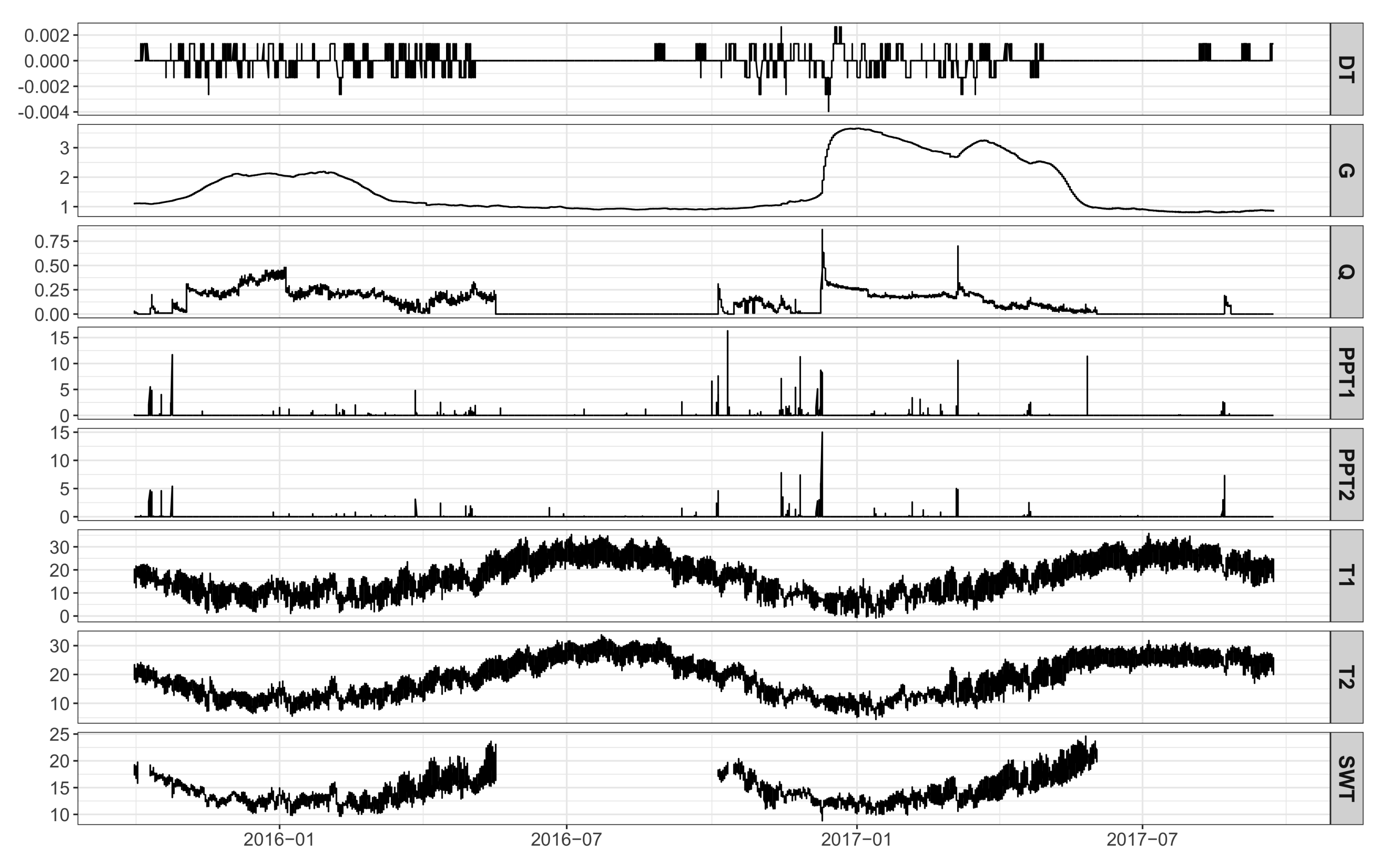
2.1. Study Area and Data Description
2.2. Data Pre-Processing
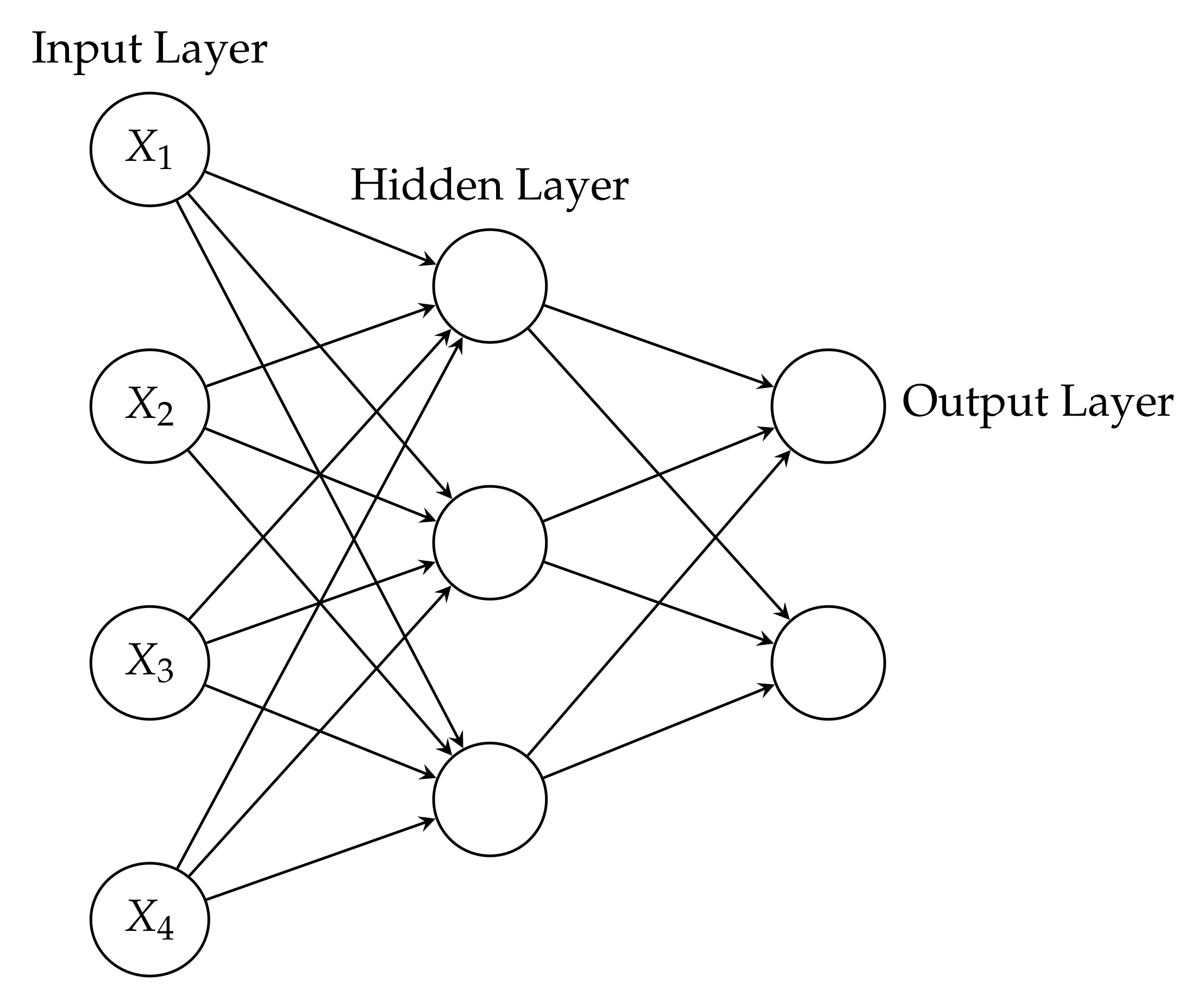
2.3. Artificial Neural Networks and Bayesian Networks
- Classification ACCURACY: ratio of the number of correct predictions to the total number of predictions;
- RECALL or sensitivity: true positive rate, computed as
- PRECISION: ratio of the correctly classified positives to the total classified instances:
- F-SCORE: balance between precision and recall by computing the harmonic mean;
- G-MEAN: geometric mean of the recall and 1−False Positive rate, which tries to measure the equilibrium between the performance on both, classifying the majority and the minority classes;
- AUC: area under the ROC curve, which measures the ability of the classifier to distinguish between both classes.
2.4. Scenarios of Change
3. Results
3.1. Predictive Accuracy Comparison between ANNs and BNs
3.2. Evidence Propagation in Bayesian Networks
4. Discussion
5. Conclusions
Author Contributions
Funding
Dedication
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BN | Bayesian Network |
| ANN | Artificial Neural Network |
| DAG | Directed acyclic graph |
| MLP | Multilayer perceptron |
| RBFN | Radial basis function networks |
| DDA | Dynamic decay adjustment |
| NB | Naive Bayes |
| TAN | Tree augmented network |
| HC | Hill-climbing |
| MLE | Maximum likelihood estimate |
| DT | Difference of groundwater temperature |
| G | Groundwater table |
| Q | Flow volume |
| PPT1 | Precipitation at station 1 |
| PPT2 | Precipitation at station 2 |
| T | Air temperature |
| SWT | Surface water temperature |
References
- Gu, C.; Anderson, W.P., Jr.; Colby, J.D.; Coffey, C.L. Air-stream temperature correlation in forested and urban headwater streams in the Southern Appalachians. Hydrol. Process. 2015, 29, 1110–1118. [Google Scholar] [CrossRef]
- Thornes, J.B. Catchment and Channel Hydrology. In Geomorphology of Desert Environments; Springer: Berlin/Heidelberg, Germany, 1994; pp. 257–287. [Google Scholar] [CrossRef]
- Russo, S.L.; Taddia, G.; Dabove, P.; Abdin, E.C.; Manzino, A.M. Effectiveness of time-series analysis for thermal plume propagation assessment in an open-loop groundwater heat pump plant. Environ. Earth Sci. 2018, 77, 1–11. [Google Scholar] [CrossRef]
- O’Connor, M.T.; Moffett, K.B. Groundwater dynamics and surface water-groundwater interactions in a prograding delta island, louisiana, USA. J. Hydrol. 2015, 524, 15–29. [Google Scholar] [CrossRef]
- Subyani, A.M. Use of chloride-mass balance and environmental isotopes for evaluation of groundwater recharge in the alluvial aquifer, wadi tharad, western saudi arabia. Environ. Geol. 2004, 46, 741–749. [Google Scholar] [CrossRef]
- Stonestrom, D.A.; Constantz, J. Heat as a Tool for Studying the Movement of Ground Water near Streams; US Department of the Interior, US Geological Survey: Charleston, SC, USA, 2003; Volume 1260. [Google Scholar]
- Figura, S.; Livingstone, D.M.; Kipfer, R. Forecasting groundwater temperature with linear regression models using historical data. Groundwater 2015, 53, 943–954. [Google Scholar] [CrossRef]
- Tissen, C.; Benz, S.A.; Menberg, K.; Bayer, P.; Blum, P. Groundwater temperature anomalies in central Europe. Environ. Res. Lett. 2019, 14, 104012. [Google Scholar] [CrossRef] [Green Version]
- Agudelo-Vera, C.; Avvedimento, S.; Boxall, J.; Creaco, E.; de Kater, H.; Di Nardo, A.; Djukic, A.; Douterelo, I.; Fish, K.E.; Iglesias Rey, P.L.; et al. Drinking water temperature around the globe: Understanding, policies, challenges and opportunities. Water 2020, 12, 1049. [Google Scholar] [CrossRef] [Green Version]
- United Nations. Earth Summit: Convention on Desertification. In Proceedings of the ON t.p.: United Nations Conference on Environment and Development, Rio de Janeiro, Brazil, 3–14 June 1992; United Nations: New York, NY, USA, 1994. [Google Scholar]
- Russo, S.L.; Taddia, G.; Gnavi, L.; Verda, V. Neural network approach to prediction of temperatures around groundwater heat pump systems. Hydrogeol. J. 2014, 22, 205–216. [Google Scholar] [CrossRef]
- Rock, G.; Kupfersberger, H. 3D modeling of groundwater heat transport in the shallow Westliches Leibnitzer Feld aquifer, Austria. J. Hydrol. 2018, 557, 668–678. [Google Scholar] [CrossRef]
- Kalbus, E.; Reinstorf, F.; Schirmer, M. Measuring methods for groundwater-surface water interactions: A review. Hydrol. Earth Syst. Sci. 2008, 10, 873–887. [Google Scholar] [CrossRef] [Green Version]
- Anibas, C.; Fleckenstein, J.H.; Volze, N.; Buis, K.; Verhoeven, R.; Meire, P.; Batelaan, O. Transient or steady-state? Using vertical temperature profiles to quantify groundwater-surface water exchange. Hydrol. Process. 2009, 23, 2165–2177. [Google Scholar] [CrossRef]
- Keery, J.; Binley, A.; Crook, N.; Smith, J. Temporal and spatial variability of groundwater–surface water fluxes: Development and application of an analytical method using temperature time series. J. Hydrol. 2007, 336, 1–16. [Google Scholar] [CrossRef]
- Langston, G.; Hayashi, M.; Roy, J. Quantifying groundwater-surface water interactions in a proglacial moraine using heat and solute tracers. Water Resour. Res. 2013, 49, 5411–5426. [Google Scholar] [CrossRef]
- Rau, G.; Andersen, M.S.; McCallum, A.; Acworth, R. Analytical methods that use natural heat as a tracer to quantify surface water–groundwater exchange, evaluated using field temperature records. Hydrogeol. J. 2010, 18, 1093–1110. [Google Scholar] [CrossRef]
- Ren, J.; Cheng, J.; Yang, J.; Zhou, Y. A review on using heat as a tool for studying groundwater–surface water interactions. Environ. Earth Sci. 2018, 77, 1–13. [Google Scholar] [CrossRef]
- Goto, S.; Yamano, M.; Kinoshita, M. Thermal response of sediment with vertical fluid flow to periodic temperature variation at the surface. J. Geophys. Res. Solid Earth 2005, 110, B01106. [Google Scholar] [CrossRef]
- Jensen, J.K.; Engesgaard, P. Nonuniform Groundwater Discharge across a Streambed: Heat as a TracerAll rights reserved. No part of this periodical may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or any information storage and retrieval system, without permission in writing from the publisher. Vadose Zone J. 2011, 10, 98–109. [Google Scholar] [CrossRef]
- Taniguchi, M. Evaluation of vertical groundwater fluxes and thermal properties of aquifers based on transient temperature-depth profiles. Water Resour. Res. 1993, 29, 2021–2026. [Google Scholar] [CrossRef]
- Hatch, C.; Fisher, A.; Revenaugh, J.; Constantz, J.; Ruehl, C. Quantifying surface water–groundwater interactions using time series analysis of streambed thermal records: Method development. Water Resour. Res. 2006, 42, W10410. [Google Scholar] [CrossRef] [Green Version]
- Irvine, D.; Briggs, M.A.; Lautz, L.; Gordon, R.; McKenzie, J.M.; Cartwright, I. Using diurnal temperature signals to infer vertical groundwater-surface water exchange. Groundwater 2017, 55, 10–26. [Google Scholar] [CrossRef] [PubMed]
- Vogt, T.; Hoehn, E.; Schneider, P.; Freund, A.; Schirmer, M.; Cirpka, O. Fluctuations of electrical conductivity as a natural tracer for bank filtration in a losing stream. Adv. Water Resour. 2010, 33, 1296–1308. [Google Scholar] [CrossRef]
- Lamontagne, S.; Leaney, F.W.; Herczeg, A. Groundwater–surface water interactions in a large semi-arid floodplain: Implications for salinity management. Hydrol. Process. Int. J. 2005, 19, 3063–3080. [Google Scholar] [CrossRef]
- Westhoff, M.; Bogaard, T.; Savenije, H. Quantifying the effect of in-stream rock clasts on the retardation of heat along a stream. Adv. Water Resour. 2010, 33, 1417–1425. [Google Scholar] [CrossRef]
- Cranswick, R.H.; Cook, P.; Lamontagne, S. Hyporheic zone exchange fluxes and residence times inferred from riverbed temperature and radon data. J. Hydrol. 2014, 519, 1870–1881. [Google Scholar] [CrossRef]
- Xie, Y.; Cook, P.; Shanafield, M.; Simmons, C.; Zheng, C. Uncertainty of natural tracer methods for quantifying river–aquifer interaction in a large river. J. Hydrol. 2016, 535, 135–147. [Google Scholar] [CrossRef]
- Bierkens, M. Modeling water table fluctuations by means of a stochastic differential equation. Water Resour. Res. 1998, 34, 2485–2499. [Google Scholar] [CrossRef]
- Steinschneider, S.; Polebitski, A.; Brown, C.; Letcher, B.H. Toward a statistical framework to quantify the uncertainties of hydrologic response under climate change. Water Resour. Res. 2012, 48, W11525. [Google Scholar] [CrossRef]
- ASCE Task Committee on Application of Artificial Neural Networks in Hydrology. Artificial neural networks in Hydrology. I: Preliminary concepts. J. Hydrol. Eng. 2000, 5, 115–123. [Google Scholar] [CrossRef]
- ASCE Task Committee on Application of Artificial Neural Networks in Hydrology. Artificial Neural Networks in Hydrology. II: Hydrologic applications. J. Hydrol. Eng. 2000, 5, 124–137. [Google Scholar] [CrossRef]
- Coppola, E., Jr.; Szidarovszky, F.; Poulton, M.; Charles, E. Artificial neural network approach for predicting transient water levels in a multilayered groundwater system under variable state, pumping, and climate conditions. J. Hydrol. Eng. 2003, 8, 348–360. [Google Scholar] [CrossRef]
- Daliakopoulos, I.N.; Coulibaly, P.; Tsanis, I.K. Groundwater level forecasting using artificial neural networks. J. Hydrol. 2005, 309, 229–240. [Google Scholar] [CrossRef]
- Nayak, P.C.; Rao, Y.S.; Sudheer, K. Groundwater level forecasting in a shallow aquifer using artificial neural network approach. Water Resour. Manag. 2006, 20, 77–90. [Google Scholar] [CrossRef]
- Krishna, B.; Satyaji Rao, Y.; Vijaya, T. Modelling groundwater levels in an urban coastal aquifer using artificial neural networks. Hydrol. Process. Int. J. 2008, 22, 1180–1188. [Google Scholar] [CrossRef]
- Rajaee, T.; Ebrahimi, H.; Nourani, V. A review of the artificial intelligence methods in groundwater level modeling. J. Hydrol. 2019, 572, 336–351. [Google Scholar] [CrossRef]
- Maier, H.R.; Jain, A.; Dandy, G.C.; Sudheer, K.P. Methods used for the development of neural networks for the prediction of water resource variables in river systems: Current status and future directions. Environ. Model. Softw. 2010, 25, 891–909. [Google Scholar] [CrossRef]
- Kingston, G.B.; Lambert, M.F.; Maier, H.R. Bayesian training of artificial neural networks used for water resources modeling. Water Resour. Res. 2005, 41, W12409. [Google Scholar] [CrossRef] [Green Version]
- Coulibaly, P.; Anctil, F.; Aravena, R.; Bobée, B. Artificial neural network modeling of water table depth fluctuations. Water Resour. Res. 2001, 37, 885–896. [Google Scholar] [CrossRef]
- Humphrey, G.B.; Gibbs, M.S.; Dandy, G.C.; Maier, H.R. A hybrid approach to monthly streamflow forecasting: Integrating hydrological model outputs into a Bayesian artificial neural network. J. Hydrol. 2016, 540, 623–640. [Google Scholar] [CrossRef]
- Ramesh, K.; Anitha, R.; Ramalakshmi, P. Prediction of Lead Seven Day Minimum and Maximum Surface Air Temperature using Neural Network and Genetic Programming. Sains Malays. 2015, 44, 1389–1396. [Google Scholar] [CrossRef]
- Aziz, K.; Rahman, A.; Fang, G.; Shrestha, S. Application of artificial neural networks in regional flood frequency analysis: A case study for Australia. Stoch. Environ. Res. Risk Assess. 2014, 28, 541–554. [Google Scholar] [CrossRef]
- Gong, Y.; Zhang, Y.; Lan, S.; Wang, H. A Comparative Study of Artificial Neural Networks, Support Vector Machines and Adaptive Neuro Fuzzy Inference System for Forecasting Groundwater Levels near Lake Okeechobee, Florida. Water Resour. Manag. 2016, 30, 375–391. [Google Scholar] [CrossRef]
- Feigl, M.; Lebiedzinski, K.; Herrnegger, M.; Schulz, K. Machine-learning methods for stream water temperature prediction. Hydrol. Earth Syst. Sci. 2021, 25, 2951–2977. [Google Scholar] [CrossRef]
- Jensen, F.V.; Nielsen, T.D. Bayesian Networks and Decision Graphs; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Fienen, M.N.; Masterson, J.P.; Plant, N.G.; Guitierrez, B.T.; Thieler, E.R. Bridging groundwater models and decision support with a Bayesian network. Water Resour. Res. 2013, 49, 6459–6473. [Google Scholar] [CrossRef] [Green Version]
- de Santa Olalla, F.M.; Dominguez, A.; Ortega, F.; Artigao, A.; Fabeiro, C. Bayesian networks in planning a large aquifer in Easter Mancha, Spain. Environ. Model. Softw. 2007, 22, 1089–1100. [Google Scholar] [CrossRef]
- Molina, J.; Bromley, J.; García-Aróstegui, J.; Sullivan, C.; Benavente, J. Integrated water resources management of overexploited hydrogeological systems using Object-Oriented Bayesian Networks. Environ. Model. Softw. 2010, 25, 383–397. [Google Scholar] [CrossRef] [Green Version]
- Ticehurst, J.L.; Newham, L.T.H.; Rissik, D.; Letcher, R.A.; Jakeman, A.J. A Bayesian network approach for assessing the sustainability of coastal lakes in New South Wales, Australia. Environ. Model. Softw. 2007, 22, 1129–1139. [Google Scholar] [CrossRef]
- Farmani, R.; Henriksen, H.J.; Savic, D. An evolutionary Bayesian belief network methodology for optimum management of groundwater contamination. Environ. Model. Softw. 2009, 24, 303–310. [Google Scholar] [CrossRef]
- Molina, J.L.; Pulido-Velázquez, D.; García-Aróstegui, J.L.; Pulido-Velázquez, M. Dynamic Bayesian Networks as a Decision Support tool for assessing Climate Change impacts on highly stressed groundwater systems. J. Hydrol. 2013, 479, 113–129. [Google Scholar] [CrossRef] [Green Version]
- Paprotny, D.; Morales-Nápoles, O. Estimating extreme river discharges in Europe through a Bayesian network. Hydrol. Earth Syst. Sci. 2017, 21, 2615–2636. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Liang, F.; Yu, B.; Zong, Z. Explicitly integrating parameter, input, and structure uncertainties into Bayesian Neural Networks for probabilistic hydrologic forecasting. J. Hydrol. 2011, 409, 696–709. [Google Scholar] [CrossRef]
- Wu, Y.; Xu, W.; Yu, Q.; Feng, J.; Lu, T. Hierarchical Bayesian network based incremental model for flood prediction. In MultiMedia Modeling; Kompatsiaris, I., Huet, B., Mezaris, V., Gurrin, C., Cheng, W.H., Vrochidis, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 556–566. [Google Scholar]
- Navarro-Martínez, F.; Sánchez-Martos, F.; García, A.S. Identification of groundwater-surface water interaction in the upper basin of the Andarax river by joint use of chemical parameters and the 234U /238U isotopic ratio. Geogaceta 2018, 63, 39–42. [Google Scholar]
- Esteban-Parra, M.J.; Rodrigo, F.S.; Castro-Diez, Y. Spatial and temporal patterns of precipitation in spain for the period 1880–1992. Int. J. Climatol. 1998, 18, 1557–1574. [Google Scholar] [CrossRef]
- Alonso-Sarria, F.; López-Bermúdez, F.; Conesa-García, C. Synoptic Conditions Producing Extreme Rainfall Events along the Mediterranean Coast of the Iberian Peninsula. In Dryland Rivers: Hydrology and Geomorphology of Semi-Arid Channels; John Wiley and Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Riesco Martín, J.; Mora García, M.; de Pablo Dávila, F.; Rivas Soriano, L. Regimes of intense precipitation in the Spanish Mediterranean area. Atmos. Res. 2014, 137, 66–79. [Google Scholar] [CrossRef]
- Martin-Vide, J. Spatial distribution of a daily precipitation concentration index in peninsular spain. Int. J. Climatol. 2004, 24, 959–971. [Google Scholar] [CrossRef]
- Martín-Rosales, W.; Pulido-Bosch, A.; Vallejos, A.; Gisbert, J.; Andreu, J.M.; Sánchez-Martos, F. Hydrological implications of desertification in southeastern Spain. Hydrol. Sci. J. 2007, 52, 1146–1161. [Google Scholar] [CrossRef] [Green Version]
- Voermans, F.; Baena Pérez, J. Memoria y Hoja Geológica de Alhama de Almería (1:50.000). In MAGNA (1044); Instituto Geológico y Minero de España: Madrid, Spain, 1983. [Google Scholar]
- ITGE. Atlas Hidrogeológico de Andalucía; Technical Report; Instituto Tecnológico Geominero de España: Madrid, Spain, 1998; p. 216. [Google Scholar]
- Velando Muñoz, F.; Navarro Vázquez, D. Memoria y Hoja Geológica de Gérgal (1:50.000). In MAGNA (1029); Instituto Geológico y Minero de España: Madrid, Spain, 1979. [Google Scholar]
- Martin-Rojas, I.; Somma, R.; Delgado, F.; Estévez, A.; Iannace, A.; Perrone, V.; Zamparelli, V. Triassic continental rifting of pangaea: Direct evidence from the alpujarride carbonates, betic cordillera, SE spain. J. Geol. Soc. 2009, 166, 447–458. [Google Scholar] [CrossRef]
- Sanchez Martos, F.; Bosch, A.P.; Calaforra, J.M. Hydrogeochemical processes in an arid region of europe (almeria, SE spain). Appl. Geochem. 1999, 14, 735–745. [Google Scholar] [CrossRef]
- Casas, P. funModeling: Exploratory Data Analysis and Data Preparation Tool-Box Book; 2020; R Package Version 1.9.4. Available online: https://CRAN.R-project.org/package=funModeling (accessed on 4 October 2021).
- Castillo, E.; Gutiérrez, J.M.; Hadi, A.S. Expert Systems and Probabilistic Network Models; Springer: New York, NY, USA, 1997. [Google Scholar]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems; Morgan-Kaufmann: San Mateo, CA, USA, 1988. [Google Scholar]
- Scanagatta, M.; Salmerón, A.; Stella, F. A survey on Bayesian network structure learning from data. Prog. Artif. Intell. 2019, 8, 425–439. [Google Scholar] [CrossRef]
- Russell Stuart, J.; Norvig, P. Artificial Intelligence: A Modern Approach; Prentice Hall: Hoboken, NJ, USA, 2009. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; Wiley Interscience: Hoboken, NJ, USA, 2001. [Google Scholar]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian Network Classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef] [Green Version]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall: Hoboken, NJ, USA, 1998. [Google Scholar]
- Berthold, M.R.; Diamond, J. Boosting the performance of rbf networks with dynamic decay adjustment. Adv. Neural Inf. Process. 1995, 7, 8. [Google Scholar]
- Bergmeir, C.N.; Benítez Sánchez, J.M. Neural Networks in R Using the Stuttgart Neural Network Simulator: RSNNS; American Statistical Association: Boston, MA, USA, 2012. [Google Scholar]
- Scutari, M. Learning Bayesian Networks with the bnlearn R Package. J. Stat. Softw. Artic. 2010, 35, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B Methodol. 1974, 36, 111–133. [Google Scholar] [CrossRef]
- Madsen, A.L.; Jensen, F.V. Lazy propagation in junction trees. In Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence, Madison, WI, USA, 24–26 July 1998; pp. 362–369. [Google Scholar]
- Shenoy, P.P.; Shafer, G. Axioms for probability and belief functions propagation. In Uncertainty in Artificial Intelligence, 4; Shachter, R., Levitt, T., Lemmer, J., Kanal, L., Eds.; North Holland: Amsterdam, The Netherlands, 1990; pp. 169–198. [Google Scholar]
- Zhang, N.L.; Poole, D. Exploiting causal independence in Bayesian network inference. J. Artif. Intell. Res. 1996, 5, 301–328. [Google Scholar] [CrossRef] [Green Version]
- Cano, A.; Moral, S.; Salmerón, A. Lazy evaluation in Penniless propagation over join trees. Networks 2002, 39, 175–185. [Google Scholar] [CrossRef] [Green Version]
- Chee, Y.E.; Wilkinson, L.; Nicholson, A.E.; Quintana-Ascensio, P.F.; Fauth, J.E.; Hall, D.; Ponzio, K.J.; Rumpff, L. Modelling spatial and temporal changes with GIS and Spatial and Dynamic Bayesian Networks. Environ. Model. Softw. 2016, 82, 108–120. [Google Scholar] [CrossRef]
- Højsgaard, S. Graphical Independence Networks with the gRain Package for R. J. Stat. Softw. 2012, 46, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Bogan, T.; Mohseni, O.; Stefan, H.G. Stream temperature-equilibrium temperature relationship. Water Resour. Res. 2003, 39, 1245. [Google Scholar] [CrossRef] [Green Version]
- Foulquier, A.; Malard, F.; Barraud, S.; Gibert, J. Thermal influence of urban groundwater recharge from stormwater infiltration basins. Hydrol. Process. Int. J. 2009, 23, 1701–1713. [Google Scholar] [CrossRef]
- Mishkin, F.S.; Schmidt-Hebbel, K. Does Inflation Targeting Make a Difference? Doc. Trab. Banco Cent. Chile; Working Paper 12876; NBER Working Paper Series; NBER: Cambridge, MA, USA, 2007. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Abbreviation |
|---|---|
| Groundwater temperature, measured as the difference of two consecutive time steps | DT |
| Groundwater table | G |
| Flow volume | Q |
| Precipitation at Station 1 | PPT1 |
| Precipitation at Station 2 | PPT2 |
| Air temperature at Station 1 | T1 |
| Air temperature at Station 2 | T2 |
| Surface water temperature | SWT |
| Predictive Variable | Lag (in Hours) |
|---|---|
| Groundwater table (G) | 0 |
| Flow volume (Q) | 48 |
| Precipitation at Station 1 (PPT1) | 72 |
| Precipitation at Station 2 (PPT2) | 70 |
| Air temperature at Station 1 (T1) | 5 |
| Air temperature at Station 2 (T2) | 5 |
| Surface water temperature (SWT) | 5 |
| Network | Best Configuration | ACCURACY | AUC | G-MEAN | PRECISION | RECALL | FSCORE |
|---|---|---|---|---|---|---|---|
| MLP (1 HL) | 5 | ||||||
| MLP (2 HL) | (3,4) | ||||||
| MLP (3 HL) | (4,4,4) | ||||||
| MLP (4 HL) | (4,3,1,4) | ||||||
| MLP (5 HL) | No discrimination skill | ||||||
| RBFN with DDA algorithm | |||||||
| Naive Bayes | |||||||
| TAN | |||||||
| HC | |||||||
| ACCURACY | AUC | G-MEAN | PRECISION | RECALL | FSCORE |
|---|---|---|---|---|---|
| 0.8809 | 0.8071 | 0.7841 | 0.8871 | 0.9474 | 0.931 |
| Evidence on PPT2 | Posterior Probability Distribution of DT | |
|---|---|---|
| D | N | |
| L | 0.1737 | 0.8263 |
| M | 0.3192 | 0.6809 |
| H | 0.8333 | 0.1667 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maldonado, A.D.; Morales, M.; Navarro, F.; Sánchez-Martos, F.; Aguilera, P.A. Modeling Semiarid River–Aquifer Systems with Bayesian Networks and Artificial Neural Networks. Mathematics 2022, 10, 107. https://doi.org/10.3390/math10010107
Maldonado AD, Morales M, Navarro F, Sánchez-Martos F, Aguilera PA. Modeling Semiarid River–Aquifer Systems with Bayesian Networks and Artificial Neural Networks. Mathematics. 2022; 10(1):107. https://doi.org/10.3390/math10010107
Chicago/Turabian StyleMaldonado, Ana D., María Morales, Francisco Navarro, Francisco Sánchez-Martos, and Pedro A. Aguilera. 2022. "Modeling Semiarid River–Aquifer Systems with Bayesian Networks and Artificial Neural Networks" Mathematics 10, no. 1: 107. https://doi.org/10.3390/math10010107
APA StyleMaldonado, A. D., Morales, M., Navarro, F., Sánchez-Martos, F., & Aguilera, P. A. (2022). Modeling Semiarid River–Aquifer Systems with Bayesian Networks and Artificial Neural Networks. Mathematics, 10(1), 107. https://doi.org/10.3390/math10010107