Abstract
Storage-as-a-service offers cost savings, convenience, mobility, scalability, redundant locations with a backup solution, on-demand with just-in-time capacity, syncing and updating, etc. While this type of cloud service has opened many opportunities, there are important considerations. When one uses a cloud provider, their data are no longer on their controllable local storage. Thus, there are the risks of compromised confidentiality and integrity, lack of availability, and technical failures that are difficult to predict in advance. The contribution of this paper can be summarized as follows: (1) We propose a novel mechanism, En-AR-PRNS, for improving reliability in the configurable, scalable, reliable, and secure distribution of data storage that can be incorporated along with storage-as-a-service applications. (2) We introduce a new error correction method based on the entropy (En) paradigm to correct hardware and software malfunctions, integrity violation, malicious intrusions, unexpected and unauthorized data modifications, etc., applying a polynomial residue number system (PRNS). (3) We use the concept of an approximation of the rank (AR) of a polynomial to reduce the computational complexity of the decoding. En-AR-PRNS combines a secret sharing scheme and error correction codes with an improved multiple failure detection/recovery mechanism. (4) We provide a theoretical analysis supporting the dynamic storage configuration to deal with varied user preferences and storage properties to ensure high-quality solutions in a non-stationary environment. (5) We discuss approaches to efficiently exploit parallel processing for security and reliability optimization. (6) We demonstrate that the reliability of En-AR-PRNS is up to 6.2 times higher than that of the classic PRNS.
1. Introduction
Reliable storage is key for computer systems. Various factors can decrease its reliability and safety: hardware and software malfunctions, integrity violation, unexpected and unauthorized data modifications, data loss, malicious intrusions, falsifications, denial of access, etc.
Multi-cloud storage systems can use both static and dynamic approaches to scaling (Gomathisankaran et al., 2011) [1], (Chervyakov et al., 2019) [2], (Tchernykh et al., 2018) [3], (Tchernykh et al., 2016) [4], (Tchernykh et al., 2020) [5], and (Varghese and Buyya, 2018) [6]. Distributed cloud storage systems are well suited for high-volume data (Tchernykh et al., 2020) [5], (Nachiappan et al., 2017) [7], (Tan et al., 2018) [8], (Sharma et al., 2016) [9], (Li et al., 2016) [10], and (Baker et al., 2015) [11]. They provide a flexible deployment environment for creating the right-sized storage based on capacity, cost, and performance needs. Cloud storage can be adapted to data volume, velocity, variety, and veracity, which is a challenge for traditional storage systems. Modern data storage systems are distributed geographically to reduce disruptions to data centers caused by seismic, hydrogeological, electrical, technogenic, and other catastrophes.
Tchernykh et al. (2019) [12] presented heterogeneous multi-cloud storage based on secret separation schemes (SSS) with data recovery. The authors evaluated its performance, examining the overall coding/decoding speed and data access speed using actual cloud storage providers. A data distribution method with fully homomorphic encryption (FHE) was introduced by Chen and Huang (2013) [13]; however, it has high computational complexity, redundancy, and low reliability. Chervyakov et al. (2019) [14] presented cloud storage based on the redundant residual number system (RRNS). It overcomes several issues of the above approach; however, SSS based on RRNS has a low data coding and decoding speed (Tchernykh et al., 2019 [12]).
The advantage of RRNS is that it has properties of error correction codes, homomorphic encryption (HE), and SSS. It is a non-positional system with no dependence between its shares (i.e., residues). Thus, an error in one share is not propagated to other shares. Therefore, isolation of the faulty residues allows for fault tolerance and facilitates error detection and correction.
Chervyakov et al. (2019) [2] used the Asmuth–Bloom algorithm making the SSS asymptotically ideal. It is effective but inefficient for distributed storage, since it requires redundancy as large as the Shamir scheme. Tchernykh et al. (2018) [3] estimated the risks of cloud conspiracy, DDoS attacks, and errors of cloud providers to find the appropriate moduli and the number of controls and working moduli.
Here, we adapted this approach for a polynomial residue number system (PRNS) to control the computational security of distributed storage. By selecting PRNS moduli, we could also minimize the computational costs associated with the coding–decoding operations. Since they are modular, we had to consider moduli that were irreducible polynomials over the binary field. Parallel execution could be performed as a series of smaller calculations broken down from an overall single, large calculation with horizontal and vertical scalability.
To reduce the decoding complexity from RRNS to a binary representation, Chervyakov et al. (2019) [2] introduced the concept of an approximation of the rank of a number for RRNS (AR-RRNS). This reduces the number of calculated projections and replaces computationally complex long integer division by taking the least significant bits. An approximation of the rank for PRNS (AR-PRNS) was studied by Tchernykh et al. (2019) [15] to avoid the most resource-consuming operations of finding residue from division by a large polynomial. The authors compared the speeds of data coding and decoding of PRNS and RRNS. They also provided a theoretical analysis of data redundancy and mechanisms to configure parameters to cope with different objective preferences.
The contribution of this paper is multifold:
- We propose a novel entropy-based mechanism for improving the reliability of distributed data storage;
- An En-AR-PRNS scheme is proposed that combines the SSS and error correction codes with multiple failure detection/recovery mechanisms. It can detect and correct more errors than the state-of-the-art threshold-based PRNS;
- A theoretical analysis is presented providing the basis for the dynamic storage configuration to deal with varied user preferences and storage properties to ensure high-quality solutions in a non-stationary environment;
- The concept of an AR of the polynomial to improve decoding speed is applied;
- Approaches to efficiently exploit parallel processing to provide fast high-quality solutions for security, reliability, and performance optimization needed in the non-stationary cloud environment are classified.
This paper is organized as follows: Section 2 reviews distributed clouds storage systems and reliability mechanisms. Section 3 introduces notations, basic concepts, and the main properties of the PRNS with error detection mechanisms. Section 4 introduces parameters to configure reliability, data redundancy, coding, and decoding speeds. Section 5 describes the rank of the PRNS number, its approximation, and provides proof of their main properties. Section 6 focuses on a novel En-AR-PRNS entropy-based algorithm to localize and correct errors. Section 7 demonstrates the reliability improvement by analyzing the probability of information loss and the number of detected and corrected errors. Section 8 discusses approaches to efficiently exploit parallel processing for security, reliability, and performance optimization needed in a non-stationary environment. Section 9 presents the conclusion and future work.
2. Related Work
2.1. Security and Privacy
The principal objective of information security is to protect the confidentiality, integrity, and availability of a computer system, named the CIA triad, to prevent data from unauthorized access, use, disclosure, disruption, modification, etc., whether in storage, processing, or transit. Another related direction of extensive study is fault-tolerance, which is the ability to continue operating without interruption when one or more of its components fail, whether due to the fact of failures that are deliberate or not as well as accidents and threats (Srisakthi and Shanthi, 2015) [16].
Confidentiality usually refers to keeping important information secret, which cannot be obtained even by the cloud provider. Data integrity means keeping data unchanged during storage and transmission, ensuring its accuracy and consistency throughout the life cycle. Availability stands for the service being available to the user at any time regardless of hardware, software, or user faults. Privacy implies that there is no unauthorized access to user data. It is centered around proper data handling during collecting, storing, processing, managing, and sharing.
In geographically distributed data centers, cloud providers store several copies of the same data to minimize the impact of natural disasters, fires, floods, technological accidents, etc. However, this solution increases the high costs of storage, backups, and disaster recovery plans. Deliberate threats refer to malicious attempts by an insider or unauthorized person to access information, software cracking, interception, falsification, forgery, etc.
The Cloud Security Alliance announced increased unauthorized access to the information in the clouds (Hubbard and Sutton, 2010) [17]. To reduce this risk, SSS, together with error correction codes, are used. Threads can be reduced by protection systems based on the concept of proactive security (Tchernykh et al., 2018) [18] that incorporates weighted SSS. Data are divided into shares of different sizes, dependent on the reliability of the storage. The secret can be reconstructed even when several shares are modified or unavailable.
2.2. Reliability
Over the past decades, many approaches to ensure reliability have been proposed. The most known are data replication, secret separation schemes (SSS), redundant residual number systems (RRNS), erasure codes (ECs), regenerating codes (RCs), etc. [1,2,3,14,19,20,21,22,23].
Data replication provides for the storage of the same data in multiple locations to improve data availability, accessibility, system resilience, and reliability. This approach becomes expensive with the growing amount of stored data (Ghemawat et al., 2003) [19]. One typical use of data replication is for disaster recovery to ensure that an accurate backup exists in the case of a catastrophe, hardware failure, or a system breach where data are compromised.
Secret Sharing Schemes (SSS) refer to methods for dividing data and distributing shares of the secret between participants in such a way that it can be reconstructed only when a sufficient number of shares are combined (Shamir, Blackly, etc.). They are suitable for securely distributed storage systems (Gomathisankaran et al., 2011) [19]. Asmuth and Bloom (1983) [24] and Mignotte (1982) [25] proposed asymptotically perfect SSS based on RNS.
In RNS, a number is represented by residues—remainders under Euclidean division of the number by several pairwise coprime integers called the moduli. Due to the original number being divided into smaller numbers, operations are carried out independently and concurrently, providing fast computations.
An RRNS is obtained from RNS by adding redundant residues, which bring multiple-error detection and correction capability (Celesti et al., 2016) [14]. With redundant moduli, it can detect and correct errors using projection methods. However, the number of necessary projections grows exponentially with increasing . Significant optimization is required for practical efficiency.
Erasure code (EC) converts length data and produces length data (>) so that the original message can be recovered from a subset of characters. An efficient implementation of EC is complexity (Lin, et al. 2014) [26].
Regenerating codes are designed for providing reliability and efficient repair (reconstruction) of lost coded fragments in distributed storage systems. They overcome the limitations of the traditional codes mentioned above, significantly reducing the traffic (repair-bandwidth) required for repairing. Furthermore, it has reasonable tradeoffs between storage and repair bandwidth (Dimakis et al., 2010) [22]. A special pseudorandom number generator is required to effectively implement RC (Liu et al., 2015) [27].
3. Polynomial Residue Number System
PRNS is used in areas such as digital signal processing (Skavantzos and Taylor, 1991) [28], symmetric block encryption (Chu and Benaissa, 2013) [29], cryptography (Parker and Benaissa, 1995) [30], homomorphic encryption (Chervyakov et al., 2015) [31], wireless sensor networks (Chang et al., 2015) [32], etc. It can support parallel, carry-free, high-speed arithmetic. PRNS over was introduced by (Halbutogullari and Koc, 2000) [33]. Contrary to RRNS, where each modulo is a coprime number, PRNS moduli are irreducible polynomials. The Chinese remainder theorem (CRT) is also applied.
3.1. Basic Definitions
The original data, , can be represented by the polynomial over of the form , for , where the highest exponent of the variable is called the degree of the polynomial. For example, Hence, with a degree of seven.
The PRNS modulo is an n-tuple of irreducible polynomials over the binary field. We denote this n-tuple: ,, …, , where n is the number of moduli and k = n − r is the number of working moduli. di is the degree of the polynomial .
Let be the polynomial of degree that determines the full range of PRNS and be the polynomial with degree that defines the dynamic range of PRNS.
For a unique residue representation of an arbitrary element from , should be greater or equal to and . In PRNS, is represented by an n-tuple of residues , as follows:
where is the residue of the division of the polynomial by .
To convert the residual representation to a polynomial one, the following CRT extension is used:
where and . The quantities are known as the multiplicative inverses of by modulo such that .
Throughout the paper, we introduce notations related to main topics such as PRNS, SSS, cloud storage, coding–decoding, error detection and correction, entropy, and reliability. To facilitate understanding, we summarize the main notations in Table 1.

Table 1.
Main notations.
3.2. Error Detection
PRNS error detection methods are similar to RRNS methods. Adding redundant moduli, we divided the whole representation range into the legitimate (dynamic) range and illegitimate range (Chu and Benaissa, 2013) [29]. An error occurs when the conversion result falls into an illegitimate range.
First, PRNS with the irreducible polynomial k-tuple , , …, which satisfies is defined. Then, one additional polynomial modulo, with the degree , for , where , is added. With the added modulo, , the whole representation range becomes with a degree . An error is detected if polynomials with a degree greater or equal to and smaller than have the illegitimate range.
The proof is as follows:
Let be represented in redundant PRNS as with the legitimate range of the degree being no higher than .
Let us assume that an error occurs in the -th residue:
The can be represented as a sum of and the error as follows:
Since is an element over , its degree is smaller or equal to ; thus, has a legitimate range. Now, let us convert from PRNS back to the polynomial representation using (1) with a full range:
where and .
The degree of is and the degree of can be any number from to . Hence, the degree of , which we denote as , ranges from to .
Since , the following condition is true: if then is correct, otherwise, is not correct.
4. Polynomial Residue Number System
4.1. Coding Speed
For performance analysis, we used an VM Intel Xeon® E5-2673 v.3, 2 GB of RAM, 16 GB SSD hard drive provided by Microsoft Azure [15]. It had bit operations per second, on average, according to the Geekbench Browser site [34].
The PRNS coding complexity was (Chervyakov et al., 2016) [35]. Hence, the calculation of the remainder of the division required roughly bit operations.
To obtain a polynomial of degree , we performed finding the remainder of the division by PRNS moduli times. Hence, the total number of the bit operations was .
The size of the original data was represented by bits. The number of in 1 Mb was . Therefore, to code 1 Mb of data, bit operations were required.
The coding speed, , in MB/s can be calculated by the formula:
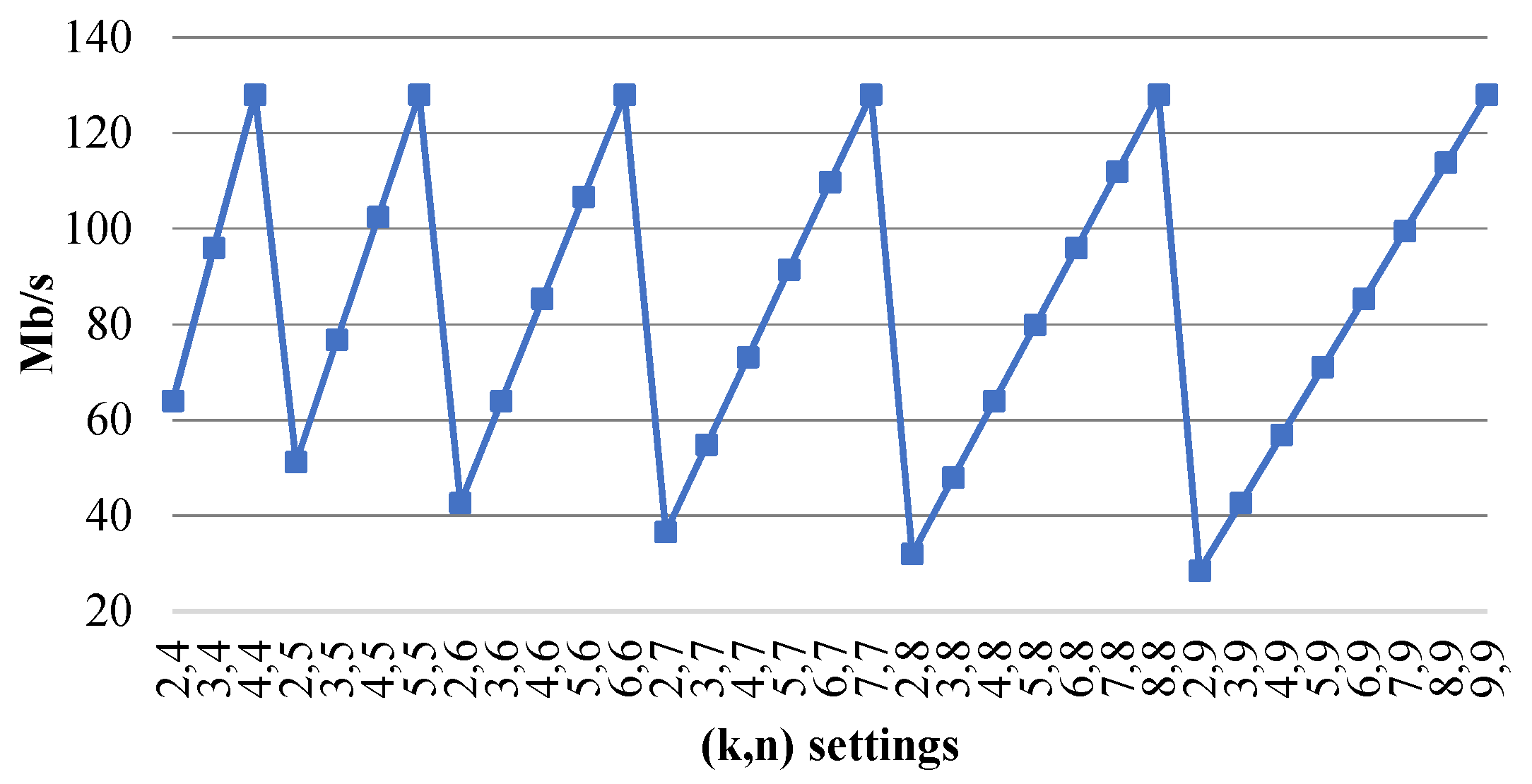
Figure 1 shows that the coding speed, , versus parameters was a saw type. Picks were achieved for the schemes , and minimums were achieved for . The user can select the required parameters to obtain the required speed.
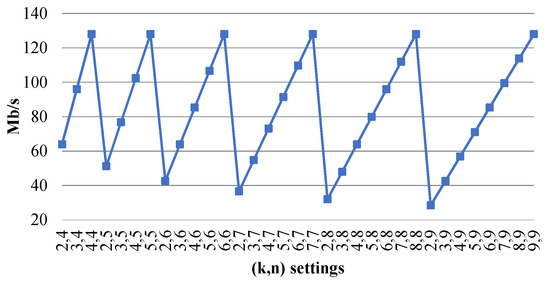
Figure 1.
of a sPRNS versus .
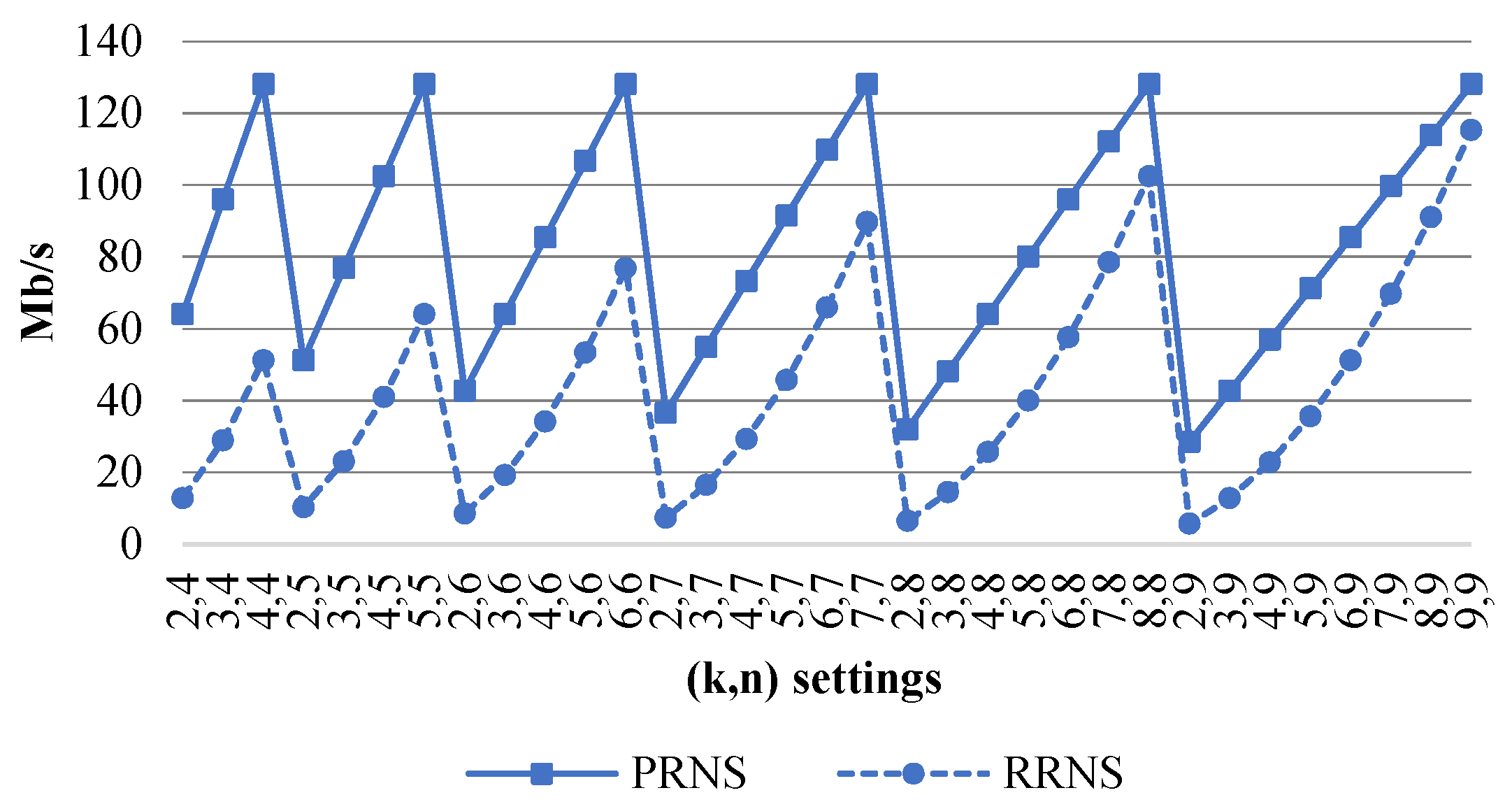
Figure 2 shows the coding speed, , (Mb/s) of PRNS and RRNS. We can see that the coding speed of PRNS was higher than RRNS for all parameters.
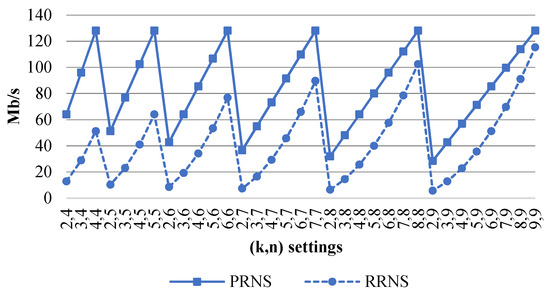
Figure 2.
The of a PRNS and an RRNS versus .
The PRNS operations on did not require the transfer of values from the lowest to the highest term. Consequently, the time complexity of the division remainder decreased compared to the arithmetic operations of RRNS performed over .
4.2. PRNS Decoding Speed with Data Errors
To correct the errors with extra moduli, we used the projection method. To compute a projection, CRT with algorithmic complexity required roughly bit operations. Since the number of projections was , to detect and localize an error, we needed bit operations.
Hence
bit operations were required to code 1 Mb with the worst-case decoding speed, .
Figure 3 shows the data decoding speed, , varying PRNS parameters for .
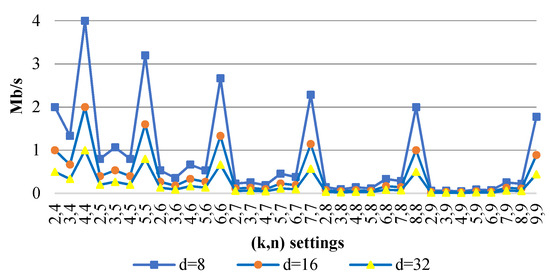
Figure 3.
of a PRNS (Mb/s) versus for .
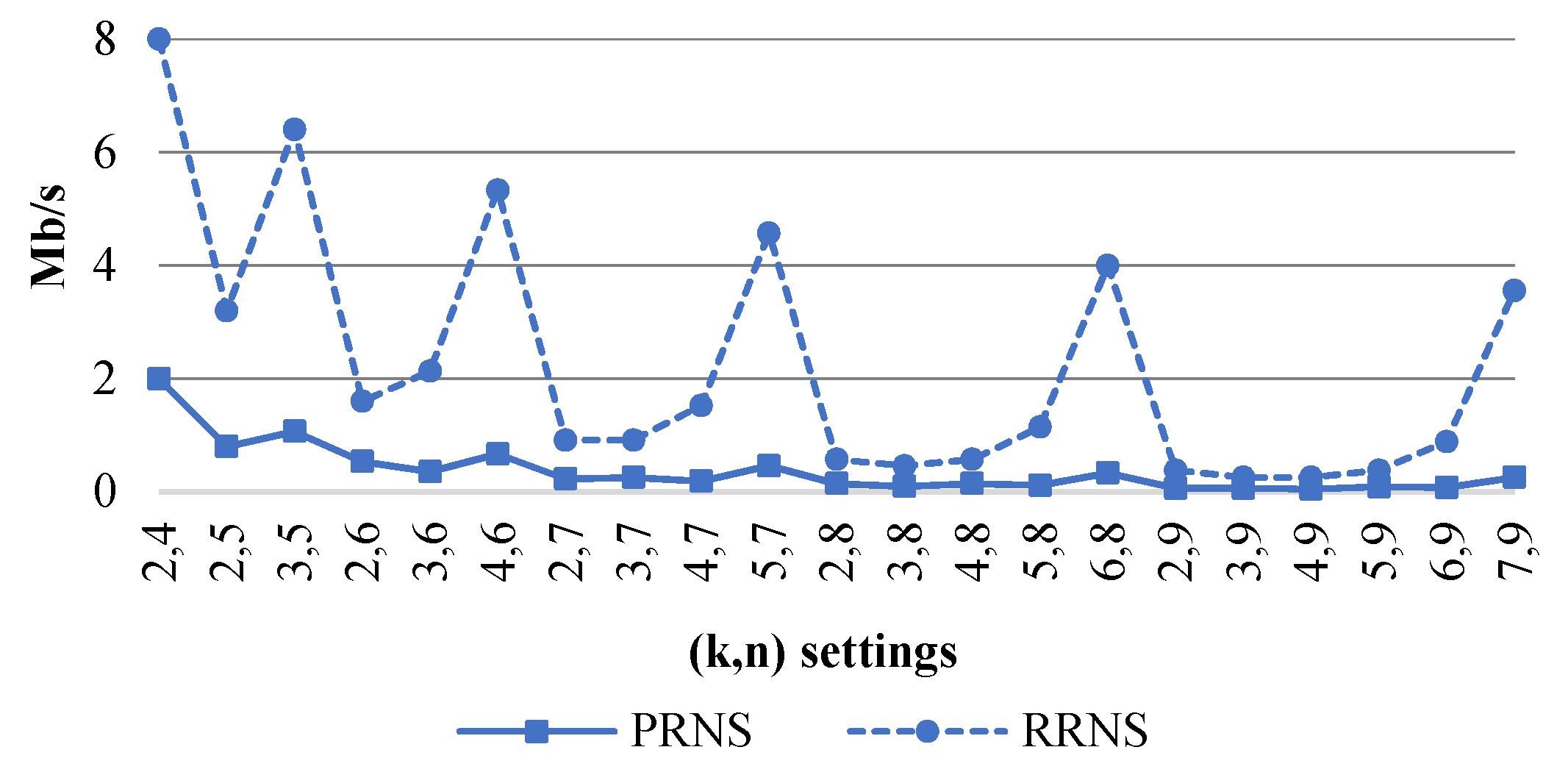
We can see that the computational complexity of PRNS, when an error was localized, was higher than that of RRNS. Hence, the PRNS decoding speed was less than for RRNS.
Figure 4 shows the PRNS and RRNS decoding speeds, (Mb/s), of the worst-case scenario with the maximum number of errors.
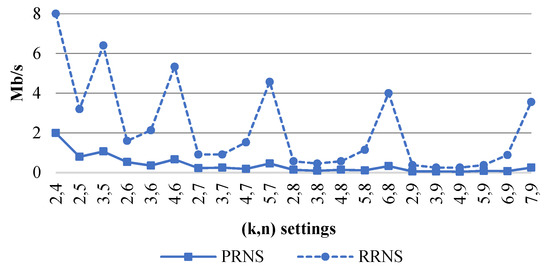
Figure 4.
of a PRNS and an RRNS with the maximum number of errors versus for .
The approximation of the rank of the PRNS number was used to increase this speed (Section 5).
4.3. Data Redundancy
To prevent system operation disruption in the case of technical failures, disasters, and cyber-attacks by maintaining a continuity of service data redundancy is very important.
The input polynomial is , where . Hence, the total input volume approximately equals . The number of bits needed for residues is equal to in the worst case. The data redundancy degradation is the ratio of the coded data size to the original minus 1:
Let us select so that uses at most bits or one word. Hence, the redundancy is roughly .
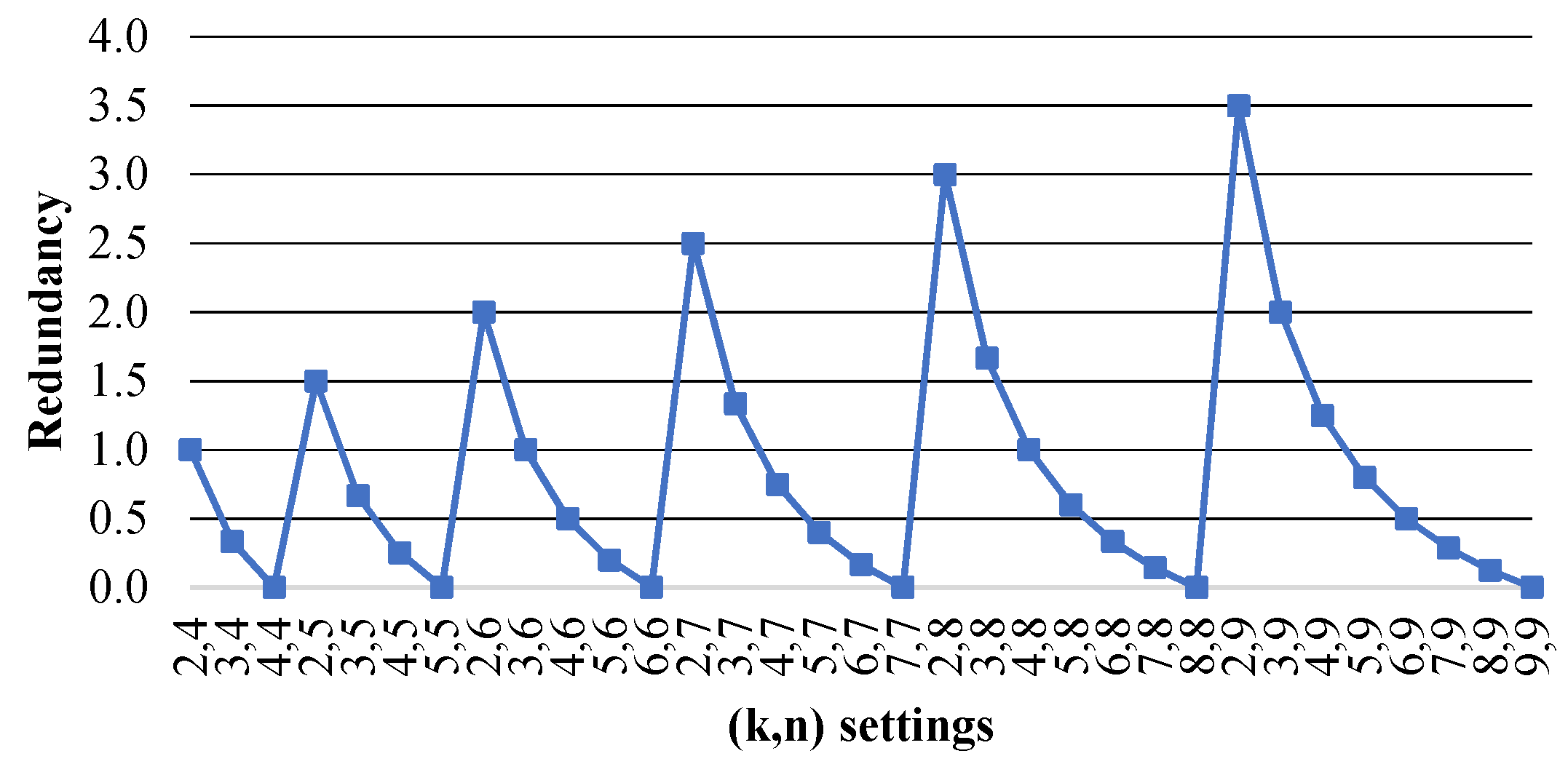
Figure 5 shows the redundancy versus the PRNS parameters. We can see that the minimum values are for , where . These values are less than those of the Bigtable system .
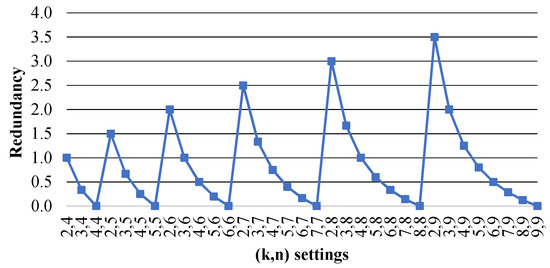
Figure 5.
Data redundancy versus PRNS settings .
PRNS reduces data redundancy compared to numerical RNS, because the degree of the polynomial (residue) is strictly less than the degree of the divisor. We demonstrate this in the following example.
Example 1.
Let us consider a () scheme with PRNS. Let the moduli be , , , and . In this case, the dynamic range is:
Let , and it has 32 bits. has the following representation:
where , , , , , , , and are seventh-degree polynomials of 8 bits.
Therefore, the redundancy degradation is .
5. Approximation of the Rank of the PRNS Number
5.1. Rank
Reducing the computational complexity of the decoding algorithm is of the utmost interest. One possible approach is to approximate the value of the AR [15].
In CRT, the rank of is determined by Equation (2). It is used to restore from residues:
Hence, and for all
is the quotient of dividing by in PRNS representation. Its calculation includes an expensive operation of the Euclidean division. Instead of computing the rank , we calculate an approximation of the rank, , based on the approximate method and modular adder, which decreases the complexity:
where
This method reduces the number of projections and replaces the computationally complex operation of the division of polynomials with the remainder by taking the division of a polynomial by the monomial . The complexity is reduced from to .
Theorem 1 shows that and are equal. It provides the theoretical basis for our approach.
Theorem 1.
If , then .
The proof is described in Appendix A.
The algorithmic complexity of the rank of based on the Theorem 1 is . Since the coefficients are of degree , we can compute efficiently and reduce the computational complexity of the decoding from down to Computation of can be performed in parallel with the computation of .
5.2. AR-PRNS Decoding Speed with Data Errors
In the previous section, we described finding the error using AR to increase the decoding speed.
To detect and localize errors using the syndrome method, it is necessary to pre-compute a table consisting of possible syndromes (rows). The maximum number of bit errors is . Each syndrome indicates the localization of errors. To find the syndrome in the table by binary search, we need bit operations. To code 1 Mb, we need
bit operations. Therefore, the AR-PRNS decoding speed in the worst case is
To detect and correct at least one error, has to satisfy the inequality .
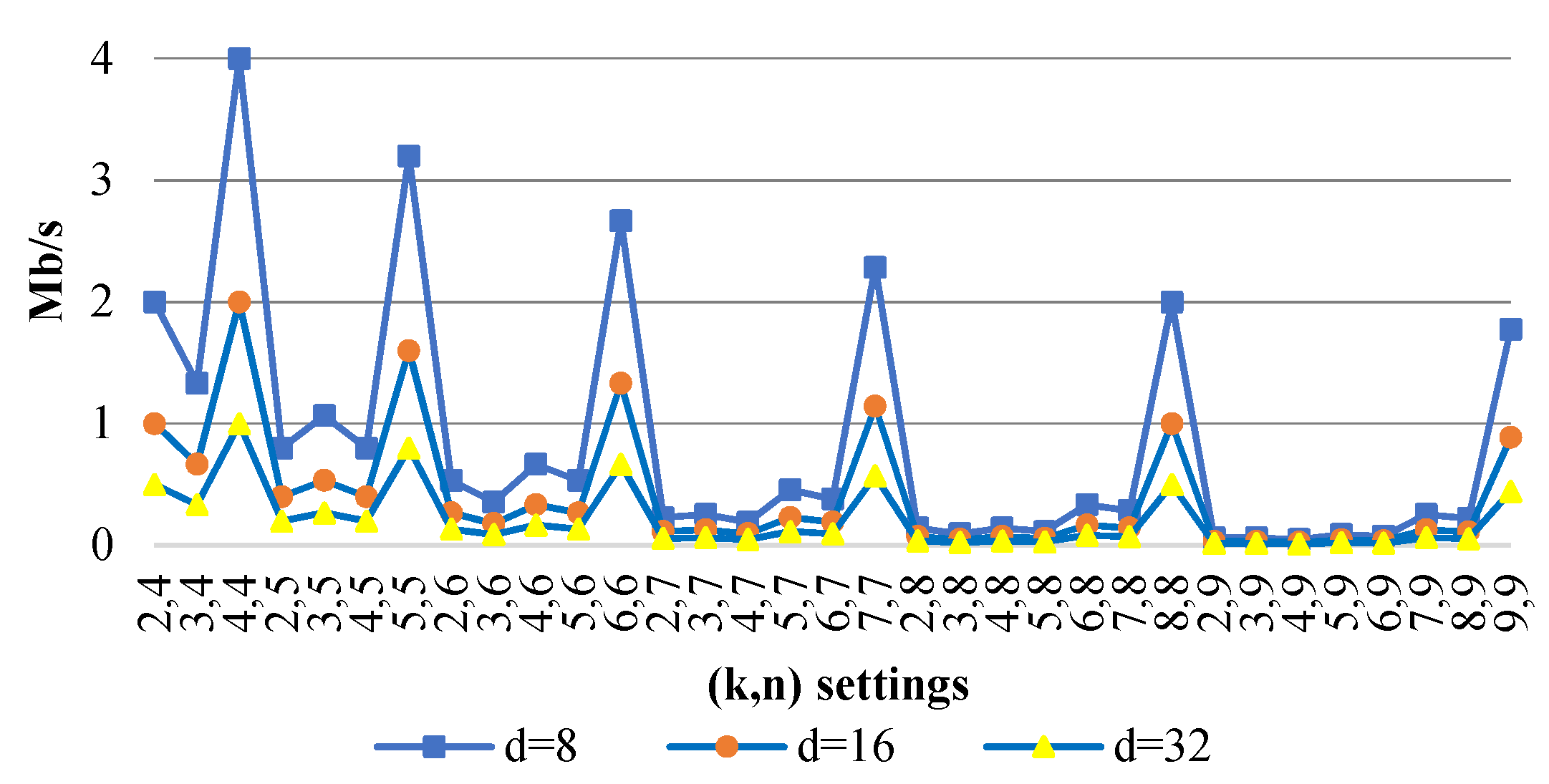
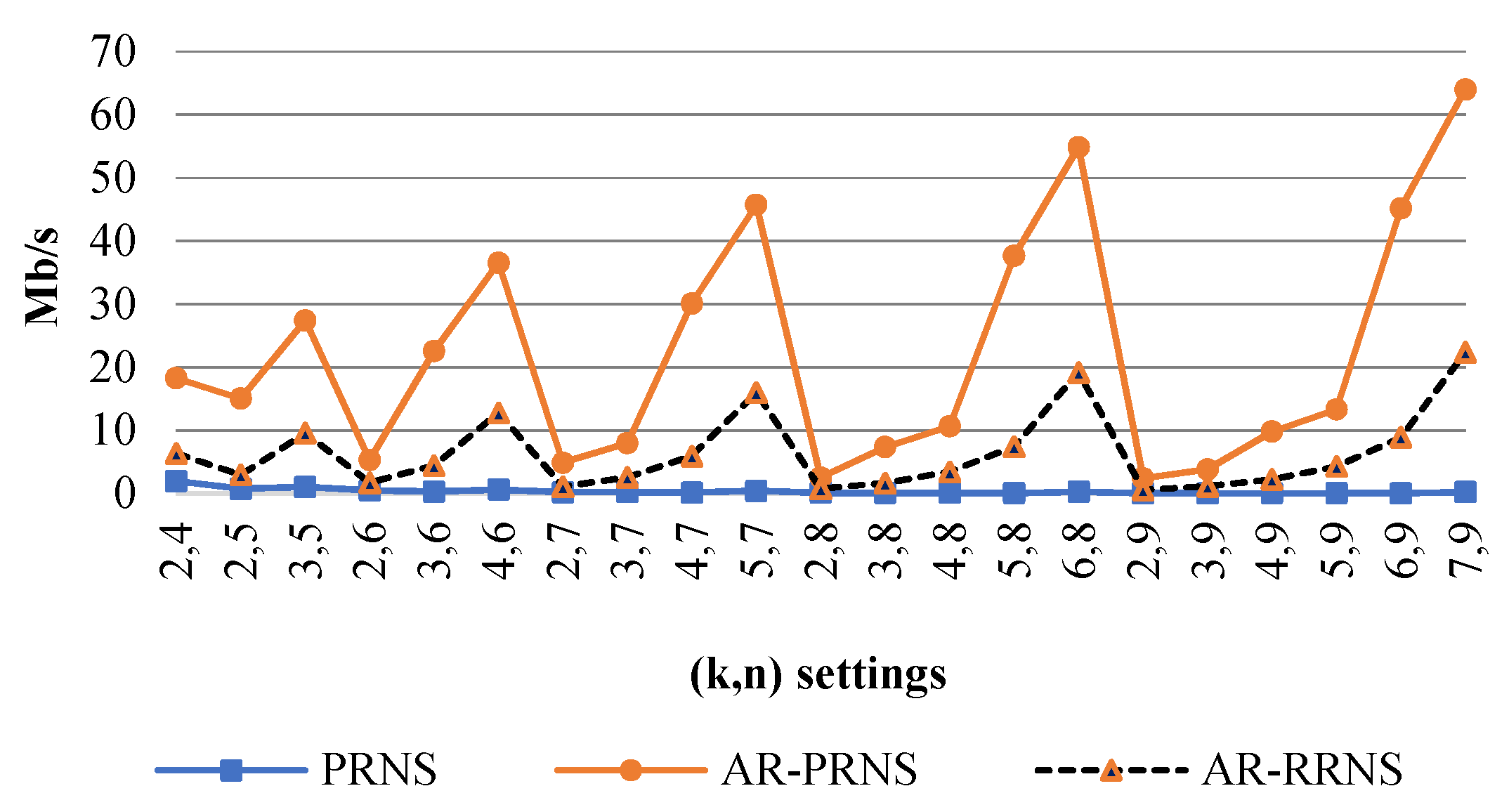
Figure 6 shows the decoding speeds of PRNS, AR-RRNS, and AR-PRNS depending on the parameters that satisfy this condition. We can see that AR-PRNS outperformed the others by almost three times.
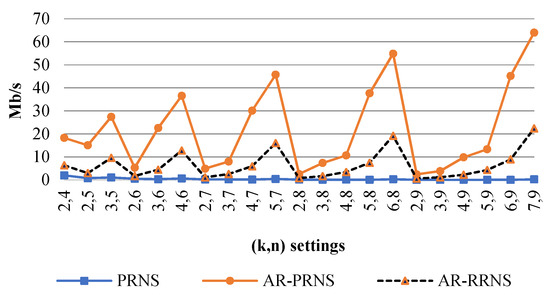
Figure 6.
The decoding speed (Mb/s) of a PRNS, AR-PRNS, and AR-RRNS versus the settings in the worst-case scenario with the maximum number of errors for .
6. Entropy Polynomial Error Correction Code
We propose a novel En-AR-PRNS method for data decoding that uses AR for decoding speed improvement and entropy for reliability improvement. We show that the entropy concept in PRNS can correct more errors than a traditional threshold-based PRNS.
First, can be represented in the form:
Assume that an error has the following form:
Then, instead of , we have .
Using (4), we have:
Without loss of generality, we assume that moduli are in ascending order, i.e., .
Since moduli are included in the dynamic range and is redundant (control moduli), where , Since an error is of the form , where , is a nonzero polynomial, and is the tuple of residues without errors.
If is not an empty tuple and , then an error can be detected, since .
6.1. Entropy in PRNS
According to CRT, is a polynomial over the binary field of degree less than . Therefore, can have different values. Following Kolmogorov (1965) [36] and Ivanov et al. (2019) [37], we can state that the entropy of is equal to:
If and , then the entropy of is equal to :
Hence, the residue carries some information of . If the entropy , the residue does not carry information about . In another extreme, if , the residue equals to . From Equation (5) and Equation (6), it follows that:
If Equation (7) is satisfied, the amount of known information is greater than or equal to the initial information. Hence, we can restore , where is a tuple of residues without error.
From the information theory point of view, the entropy of the residue can be viewed as a measure of how close it is to the minimal entropy case. Hence, it measures the amount of information that carries from . The maximal entropy corresponds to a non-coding–non-secure case.
Using an entropy-based approach, we can verify the obtained result for its correctness using the following theorem.
Theorem 2.
Let be the PRNS moduli n-tuple, , where control moduli,, and is a tuple of residues with an error. If
an error can be detected.
Proof.
Let us consider two cases: when there is an error and when there is no error.
Case 1. If is an empty tuple, then there are no errors and can be calculated using (1).
Case 2. If is not an empty tuple and it satisfies the condition (8), then we show that , where . Due to the fact that where , we have:
Given that , then Equation (9) takes the following form:
Substituting the condition of the theorem into Equation (10), we obtain that satisfies the following inequality:
Because , then Equation (11) takes the following form:
Given that , then from the inequality (12), it follows . Because and , an error is detected. The theorem is proved. □
Example 2.
(see Appendix B) considers the case when the degrees of control moduli are less than the degrees of working moduli so that we can find an error in the remainder of the division by the working moduli.
Example 3 considers the case when one control modulo is used. We can detect two errors unlike one error in the traditional PRNS.
Example 3.
Let PRNS moduli tuple be , , , and , where , and . The dynamic range of PRNS is and .
Let . We consider three cases in which errors occurred on two shares.
Case A. If errors occurred in and , then the error vector had the following form:
Because and , the condition of Theorem 2 (see Equation (8)) is satisfied, and errors can be detected.
Case B. If errors occurred in and , then the error vector is ; hence, . Because and , the condition of Theorem 2 (see Equation (8)) is satisfied, and errors can be detected.
Case C. If an error occurred in and then the error vector is and . Because and , the condition of Theorem 2 (see Equation (8)) is satisfied, and an error can be detected.
Let us show how an error is detected.
First, we calculated the PRNS constants .
Third, we compute , , and , using Equation (1).
Finally, we determine whether , , and have errors.
Case A. Because , then contains an error.
Case B. Because , then contains an error.
Case C. Because , then contains an error.
To detect an error, we use Theorem 2. To localize and correct the error, we modify the maximum likelihood decoding (MLD) method from Goh and Siddiqi (2008) [38].
6.2. MLD Modification
To correct errors, we need tuple residues, where . One of the ways to select them from all correct residues is the MLD method.
In the process of localization and correction of errors, we calculate the tuple of possible candidates, , satisfying the condition . Each of the possible is denoted by , that is:
where is the total number of candidate that fall within the legitimate range, from which is selected.
If their entropies equal , then we can use the Hamming distance, (i.e., Hamming distance between and vector ), of residues. is defined as the number of elements in which two vectors, and , differ.
But if we consider weighted error correction codes in which , then the Hamming distance does not provide correct measurement, since residues carry a different amount of information about .
Let , ,…, be the PRNS moduli tuple:
Let us calculate as the Hamming weight of and using the following Algorithm 1.
| Algorithm 1.. |
| Input: |
| Output. |
| Hamming vector |
| forto |
| then |
| else |
| end if |
| end for |
| Inverse of vector |
| forto |
| then |
| does not contain an error |
| else |
| end if |
| end for |
| Return |
According to Algorithm 1, three steps are used to calculate : First, similar to MLD, calculate the Hamming vector, , where . Second, calculate the inverse of the vector , , where is equal to one if the remainder does not contain an error, otherwise is equal to zero. Third, calculate the amount of entropy, , as a dot product of two vectors, , and vectors consisting of the entropies of the remainders of the division, .
The idea is to calculate the amount of entropy, , but not the number of errors, , as in MLD. If the volume of correct data is greater than , then according to Theorem 2, we can restore the value of .
Now, we can select from all corrected . To this end, traditional MLD picks the candidate with the minimal Hamming distance. In our approach, the best candidate is the with the maximal entropy, .
Example 4.
Let PRNS moduli 4-tuple be , , , and , where , and .
Let the dynamic range and the full range of of PRNS be:
and
Let and , then . There are three possible values of that satisfy the condition .
We present the calculation results in Table 2.
Table 2.
with three candidates of .
If we use the MLD from Kolmogorov (1965) [36], then the tuple of possible recovering candidates consists of two values and with the minimal Hamming distance. The proposed MLD modification for the error correction codes selects for maximal entropy. As we showed above, it allows us to determine the true result, unambiguously and correct the error. In classical PRNS, an error can be detected but not corrected.
7. Reliability
The detection of errors and failures in distributed storage and communication is mainly based on error correction codes, ECs, RCs, and modifications. In contrast to the existing methods, the PRNS method is simple and fast. However, it has one significant drawback: the limitation of detection and localization of errors. To overcome this limitation and increase the reliability, we propose an entropy-based approach to correct errors (see Section 6.1.).
Let be the probability of error of data stored in the -th cloud. It can be seen as the probability of unexpected and unauthorized modifications, falsifications, hardware and software failures, disk errors, integrity violations, denial of access or data loss, etc.
To correct errors, we have to take enough residues without errors. The data access structure is defined as a set of residues without errors allowing correct errors. It is defined as follows: .
Hence, the probability of information loss of an En-AR-PRNS is determined by (13).
To estimate the probability of -th storage error (i.e., failure), , we used data from an analysis of the downtime of public cloud providers presented by CloudHarmony [12]. It monitors the health status of service providers by spinning up workload instances in public clouds and constantly pinging them. It does not present a complete insight into the types of failures due to the limited information obtained by monitoring; however, it serves as a valuable point of reliability analysis.
Table 3 describes the downtime, (in minutes per year), of eight cloud storage providers [39]. We calculated the by the geometric probability definition (ratio of measures) , where is the number of minutes in a year. It included upload and download times (Tchernykh et al., 2018) [18].
Table 3.
Characteristics of the clouds.
Based on these probabilities, we can roughly estimate reliability by calculating the probability of information loss. In threshold PRNS, we lose data when at least storages have errors when we are not able to correct errors. In En-AR-PRNS, as we showed in Section 6, the entropy-based approach allows for correcting more errors.
Let us consider both approaches. Table 4 shows an example of data sharing in eight storages. Column shows the eight moduli we used for coding, ) is the entropy of obtained residues, and the Cloud column is the used storage.
Table 4.
Data allocation based on PRNS.
Due to the entropies and polynomial degrees being equal, the residues could be allocated based on the access speed, trustiness, etc., of the storages. In this case, the reliabilities of both the En-AR-PRNS and PRNS methods had no difference.
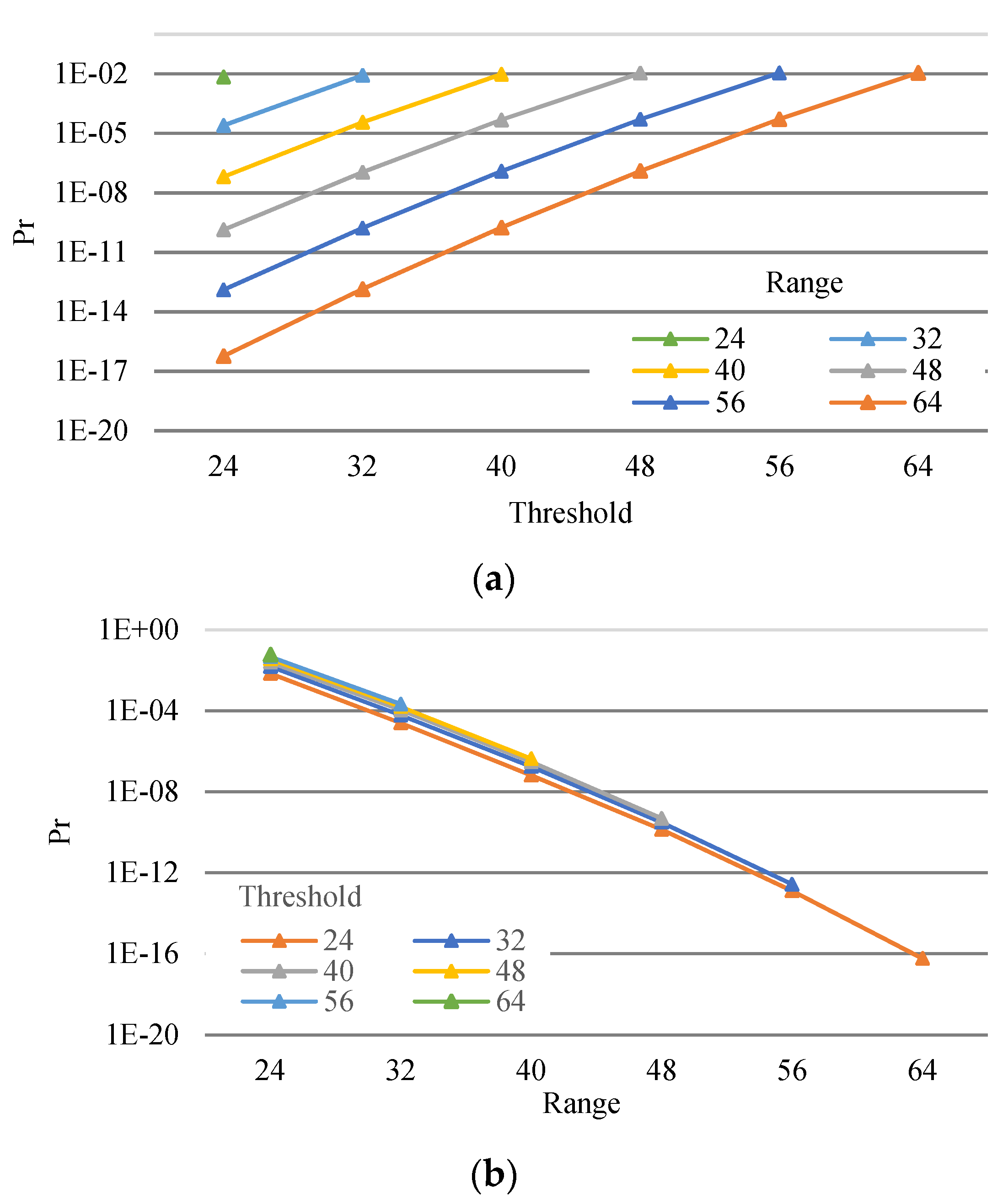
Figure 7 shows the probabilities of information loss. Figure 7a shows that this probability varied ranging from 24 (four storages) to 64 (eight storages) versus the threshold (dynamic range). Figure 7b shows this probability varying threshold from 24 to 64 versus the range.
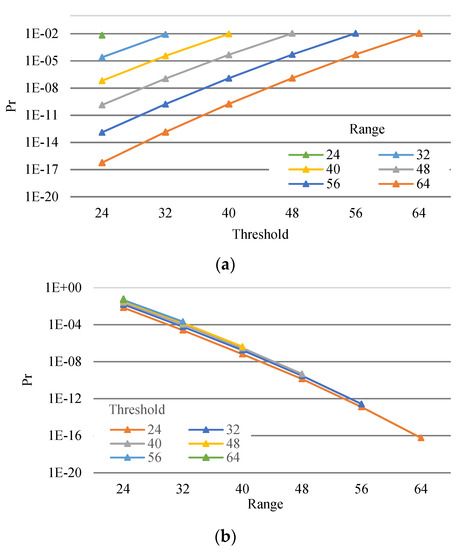
Figure 7.
Probability of information loss of an En-AR-PRNS (a) and a PRNS (b).
We observed that:
- By reducing thresholds (i.e., increasing data redundancy), we reduced the probability of information loss (Figure 7a);
- By increasing the number of clouds (i.e., increasing the range), we reduced the probability of information loss (Figure 7a);
- Reduction in the information loss probability by increasing the range was approximately equal for all thresholds (see Figure 7b).
Example 5.
Let five cloud providers (i.e., Joyent, Azure, Google, Rackspace, and CenturyLink) be used for storage. The probabilities of errors and information loss were calculated using the data presented in [39] (see Table 5).
Table 5.
Data allocation based on En-AR-PRNS.
Table 5 shows an example of the data sharing in these storage systems. The column shows the five used moduli, the column shows the entropy of residues, and the Cloud column shows the storage provider.
Due to the fact that the entropies were different, we allocated the residue with the highest entropy, , on storage with the lowest error probability, . Then, we allocated three shares with entropy four on storages with the next smaller probabilities, . Finally, we allocated the last share with entropy two on storage .
For such an allocation, we used a PRNS with and . The access structures and included combinations of the residues (recovery cases) that could be used to recover original data.
{{1, 2, 3}, {1, 2, 4}, {1, 2, 5}, {1, 3, 4}, {1, 3, 5}, {1, 4, 5}, {2, 3, 4}, {2, 3, 5}, {2, 4, 5}, {3, 4, 5}, {1, 2, 3, 4}, {1, 2, 3, 5}, {1, 2, 4, 5}, {1, 3, 4, 5}, {2, 3, 4, 5}, {1, 2, 3, 4, 5}}.
{{2, 5}, {3, 5}, {4, 5}} .
had nineteen recovery cases and had sixteen cases. As we showed before, to restore data in a PRNS, we can have errors in two residues at most. In an En-AR-PRNS, we showed that, in some cases, we could restore data even with three residues have errors.
The probability of information loss calculated by (13) was and . Therefore, En-AR-PRNS improved the reliability of the storage by about times using the same number of clouds with the same probability of errors for each provider.
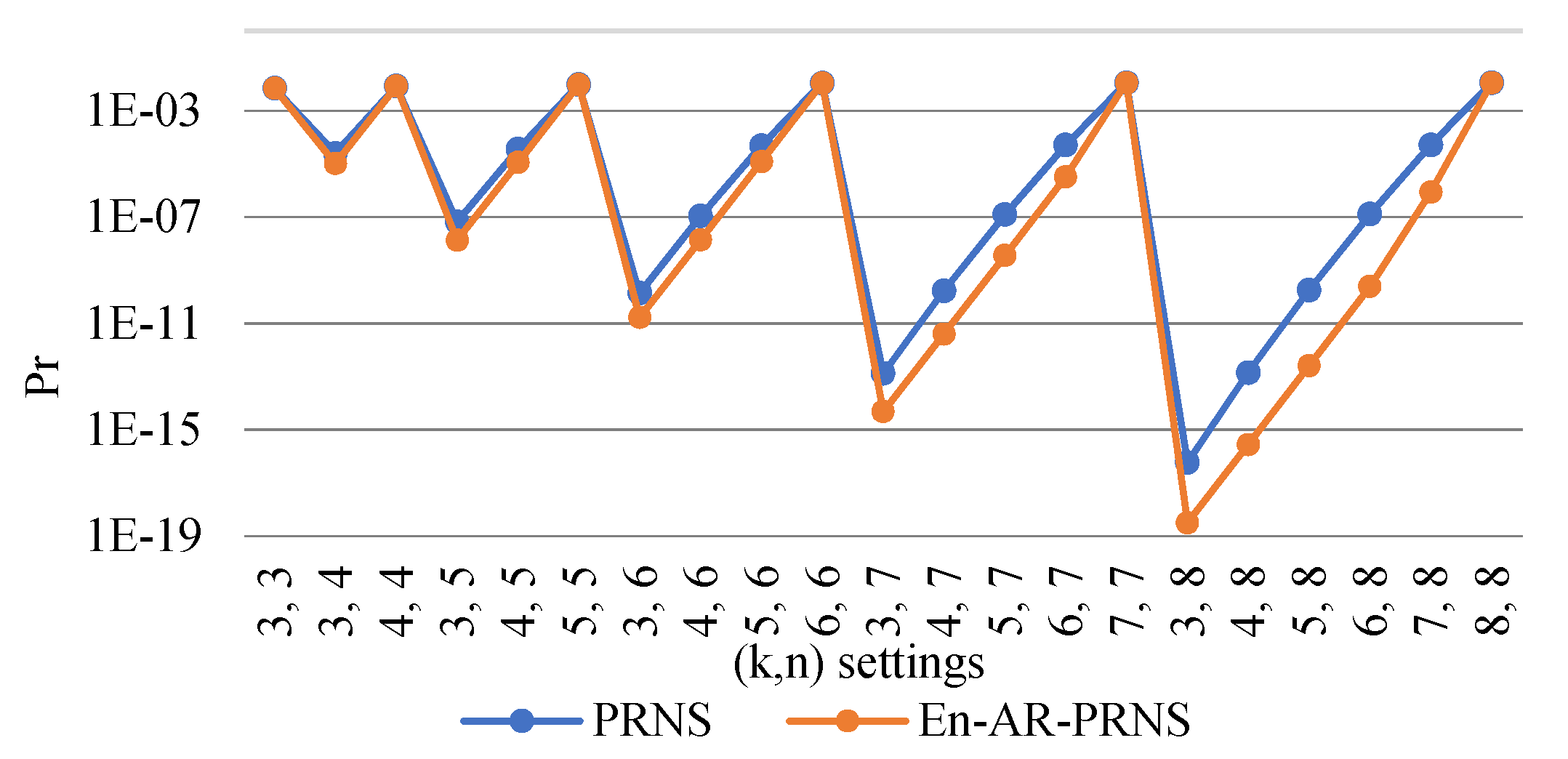
Now, let us compare the reliability of data storages based on PRNS and En-AR-PRNS with various settings. We defined the degree of residues as follows: and . The probabilities of information loss of threshold PRNS and entropy-based PRNS on a logarithmic scale are presented in Figure 8.
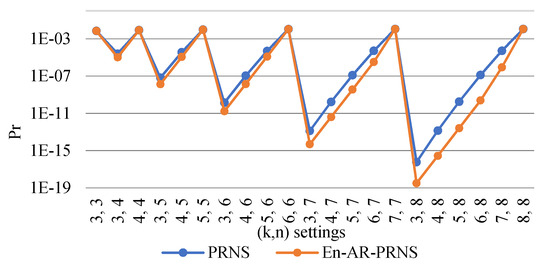
Figure 8.
The probability of information loss of a threshold PRNS and an entropy-based PRNS.
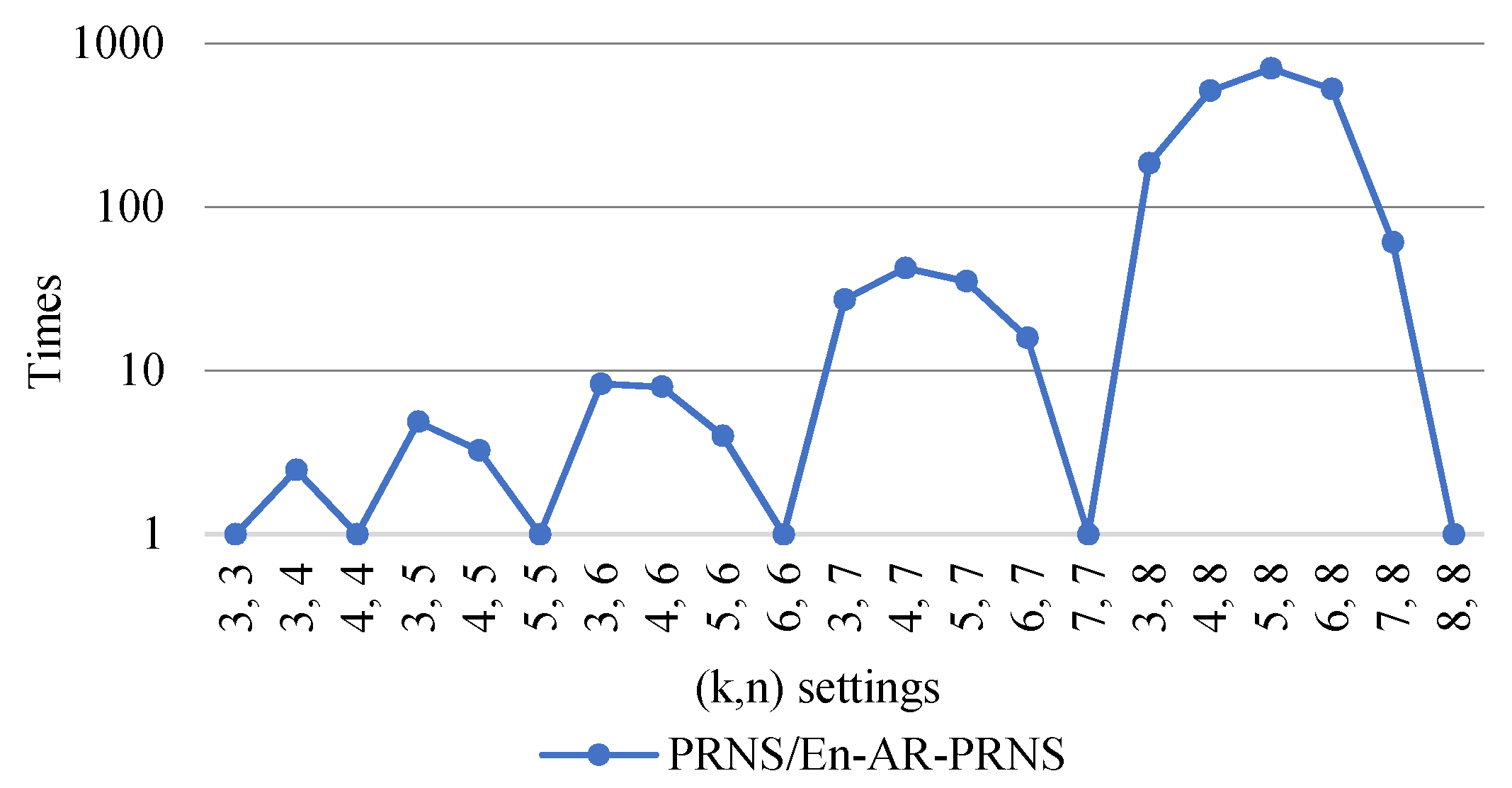
To show the advantage of an entropy-based approach, Figure 9 presents the reliability improvement of En-AR-PRNS over PRNS. We can see that the largest improvement was approximately eighty times for settings. The top improvements were for .
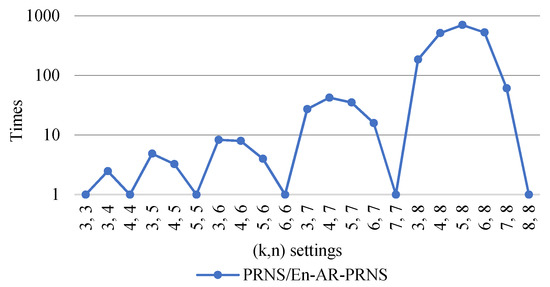
Figure 9.
Reliability improvement of En-AR-PRNS over PRNS.
We can conclude that for the same number of cloud providers, the probability of information loss for En-AR-PRNS was much lower than for PRNS.
Now, we show how many recovery cases can be detected and corrected by both approaches.
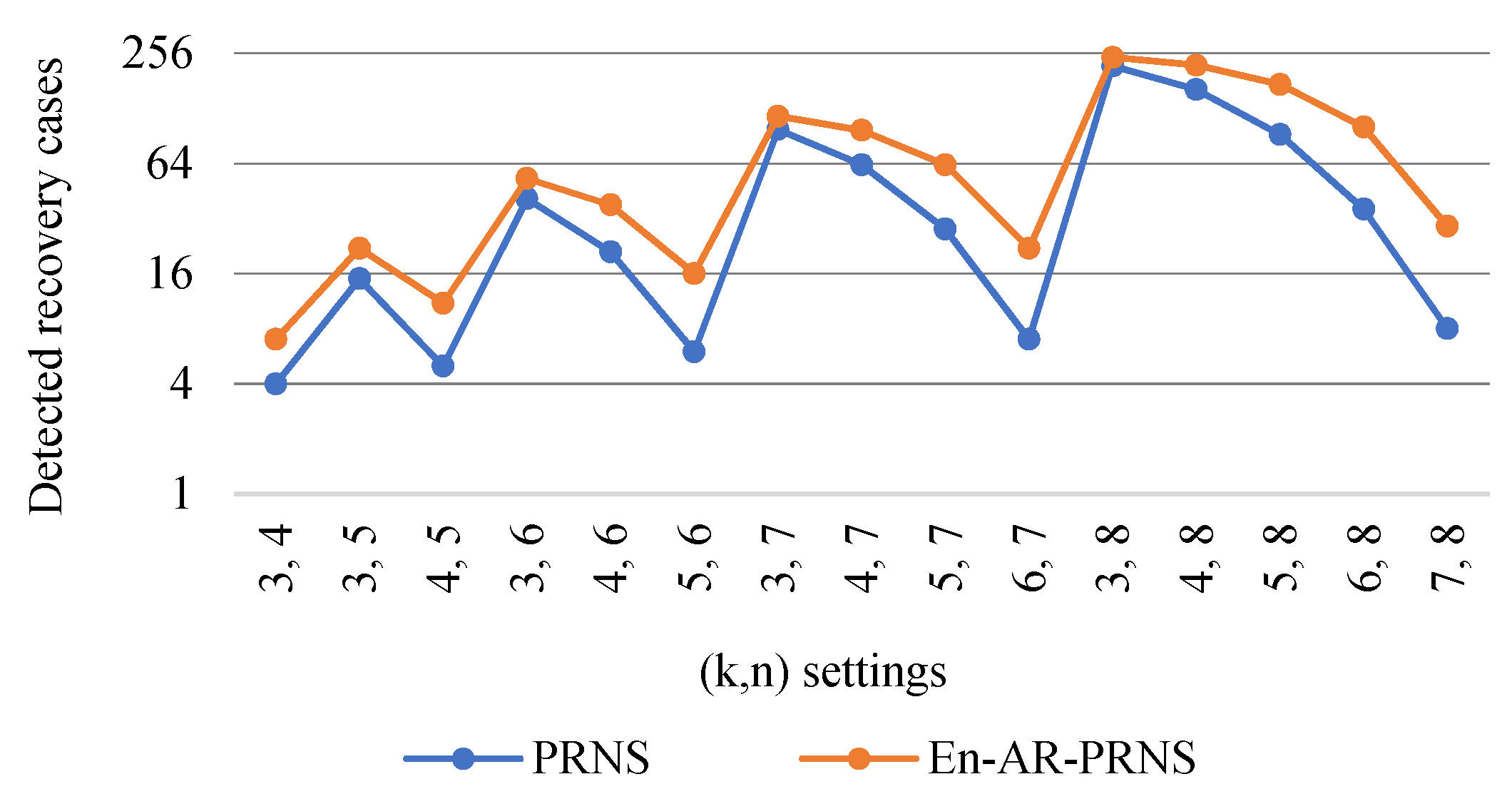
Figure 10 shows the number of recovery cases found by an En-AR-PRNS and a PRNS. For instance, for settings, the PRNS could detect only one error in shares . The En-AR-PRNS could detect the same errors and three more cases when detecting errors in two shares, for a total of seven cases.
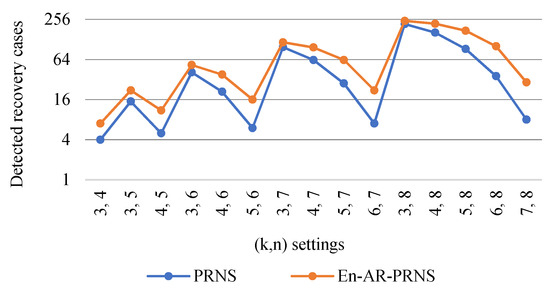
Figure 10.
Number of recovery cases detected by the En-AR-PRNS and the PRNS.
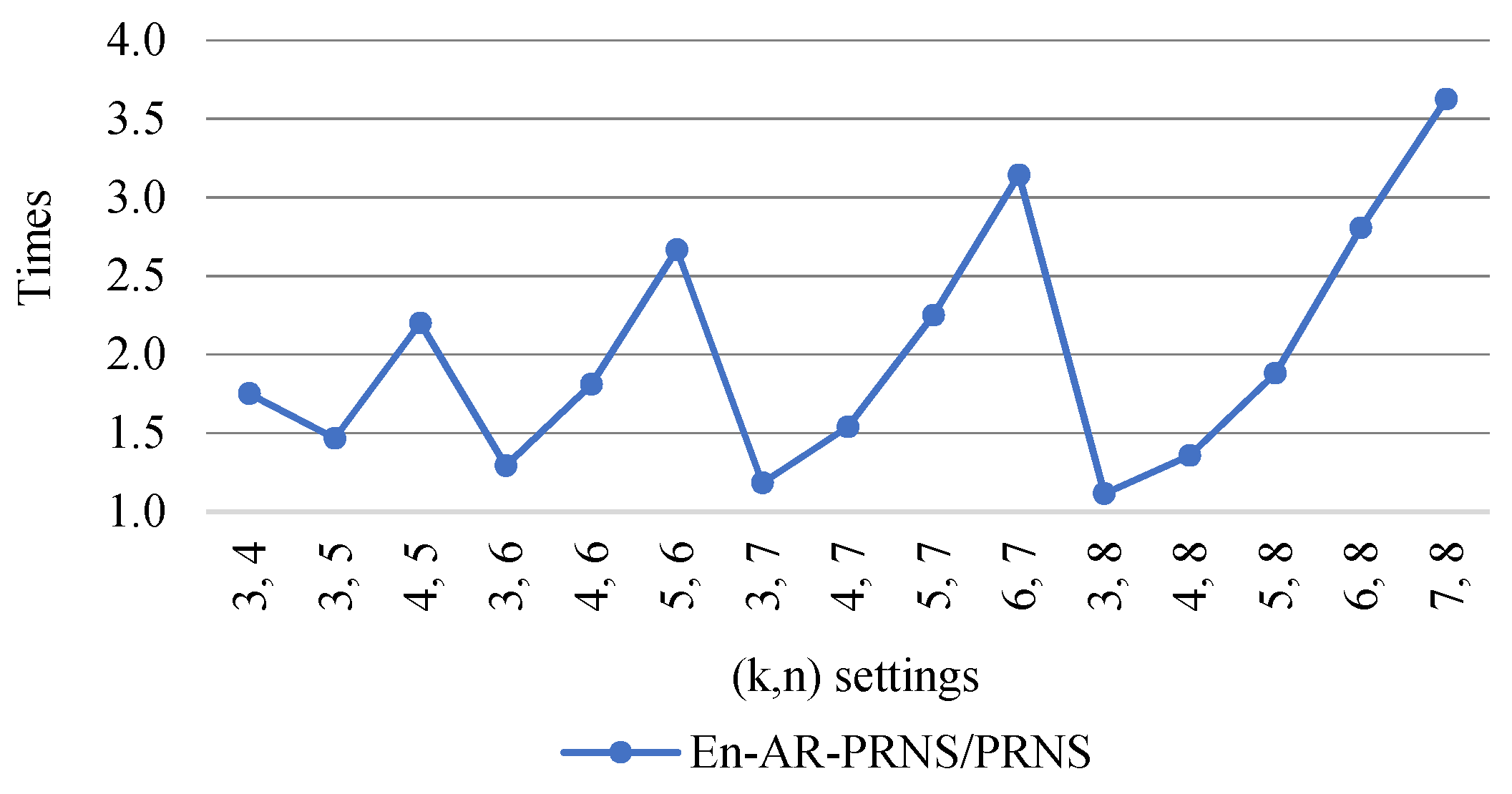
Figure 11 shows how many times the En-AR-PRNS outperformed the PRNS in error detection. We can see that for settings, the En-AR-PRNS outperformed the PRNS by 3.6 times.
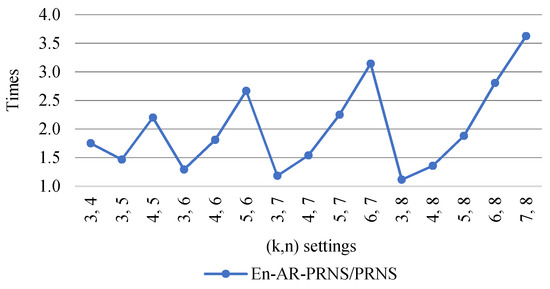
Figure 11.
Improvement of number of recovery cases detected by En-AR-PRNS over PRNS.
An En-AR-PRNS detects and corrects more errors than classical methods in a PRNS. Table 6 shows the comparative analysis of the methods.
Table 6.
Comparison of multiple residue digit error detection and correction algorithms.
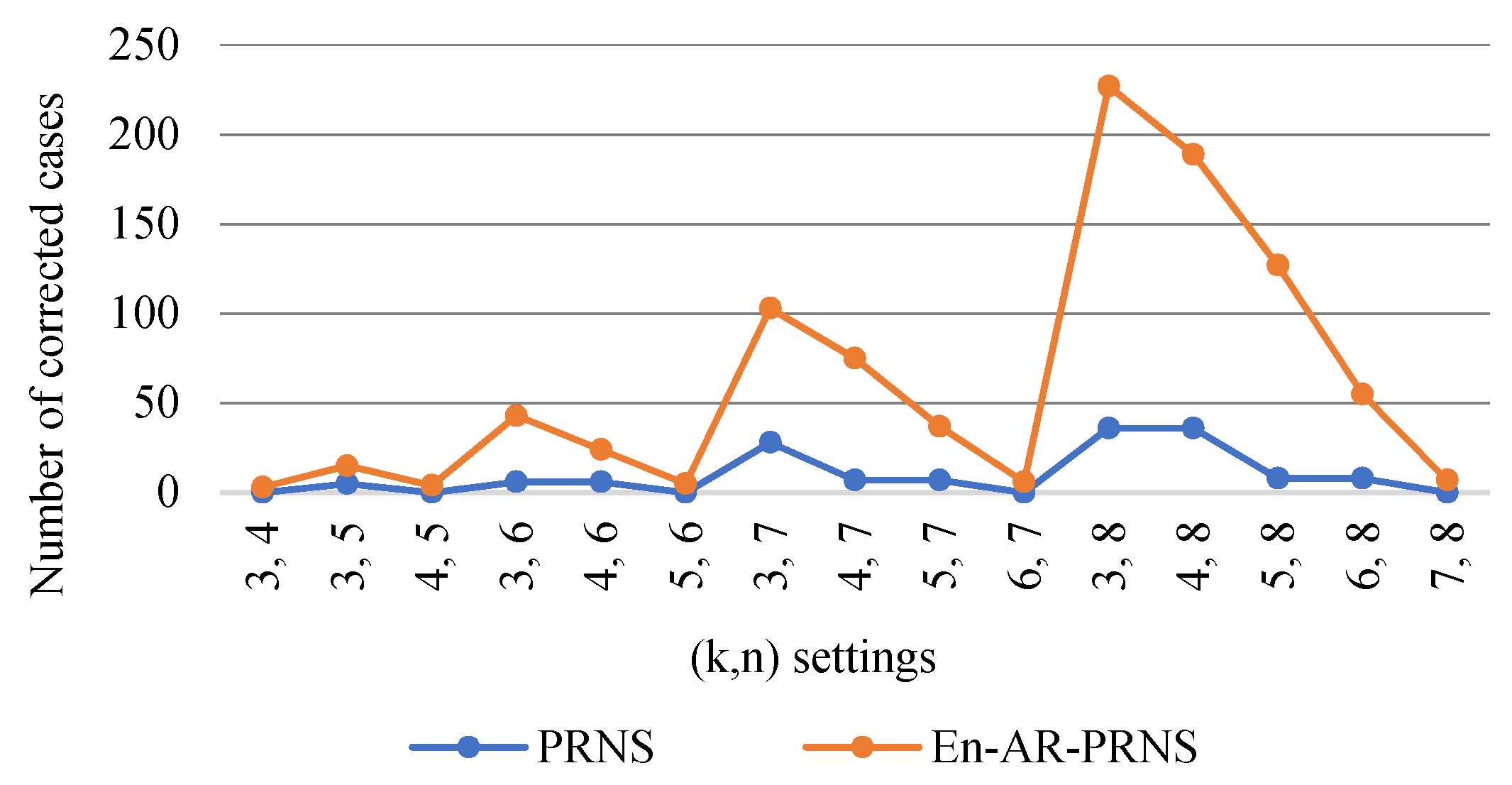
Figure 12 shows the number of recovery cases corrected by En-AR-PRNS and PRNS. We see that for settings, the En-AR-PRNS corrected errors in 227 cases and PRNS in 36 cases.
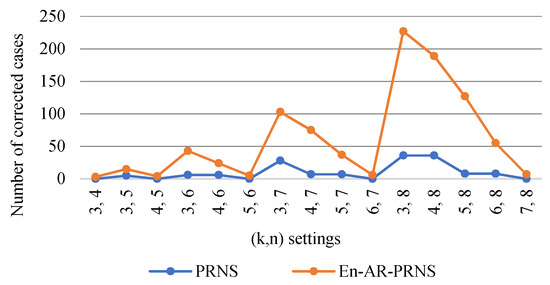
Figure 12.
Number of recovery cases corrected by En-AR-PRNS and PRNS.
Example 6 explains the results shown in Figure 12.
Example 6.
Let PRNS moduli 4-tuple be , , , and , where , and . The number of recovery cases found by PRNS is zero and by En-AR-PRNS it was three: , , and .
8. Discussion
The complexity of the presented algorithm motivates the usage of parallel computing. The inherent properties of PRNS attract much attention from both the scientific community and industry. Special interest is paid to the parallelization of the following algorithms:
- Coding: data conversion from conventional representation to PRNS;
- Decoding: data conversion from PRNS to conventional representation;
- Homomorphic computing: processing encrypted information without decryption;
- PRNS-based communication: transmitting shares;
- Computational intelligence: Estimating and classifying the security and reliability levels and finding adequate settings.
Coding. Since the computation of the residue for each modulo is independent, polynomial-to-PRNS conversion can be efficiently parallelized: independent calculation of residues ; parallel calculation of each residue based on a neural-like network approach to finite ring computations.
Decoding. Despite En-AR-PRNS performance improvement for PRNS-residues-to-polynomial conversion, presented in this paper, this conversion still significantly impacts the performance limitation of the whole system. It is one of the most difficult PRNS operations, and parallel computing can significantly improve it.
The following parallelization options are exploited:
- Parallel syndrome table search;
- Independent generation of the candidates, , with data recovery from all possible tuples of residues;
- Parallel calculation of and to generate the candidate ;
- Independent calculation of the entropy, , for each candidate. PRNS offers an important source of parallelism for addition, subtraction, and multiplication operations;
- Data are converted to many smaller polynomials (residues). Operations on initial data are substituted by faster operations on residuals executed in parallel. The complexity of operations is reduced;
- These features are used by the cryptography (RSA) community (Yen et al., 2003) [40], (Bajard and Imbert, 2004) [41], homomorphic encryption (Cheon et al., 2019) [42], and Microsoft SEAL (Laine, 2017) [43];
- Errors in a faulty computational logic element are localized in the corresponding residue without impacting other residues. This property is used in the algorithm for detecting errors in the AES cipher (Chu and Benaissa, 2013) [29] and control calculation results with encrypted data (Chervyakov et al., 2019) [2].
- Operations are based on fractional representations. Regardless of word sizes, they can be performed on bits without carrying in a single clock period. This improves computational efficiency, which has been proven to be especially useful in digital signal processing (Chang et al., 2015) [32], cryptography: RSA (Bajard and Imbert, 2004) [41], elliptic curve cryptography (Schinianakis et al., 2009 [44]; Guillermin, 2010) [45]), homomorphic encryption (Cheon et al., 2019 [42]; Laine, 2017 [43]), etc. This property is a way to approach a famous bound of speed at which addition and multiplication can be performed (Flynn, 2003) [46]. This bound, called Winograd’s bound, determines a minimum time for arithmetic operations and is an important basis for determining the comparative value of the various implementations of algorithms.
Other optimization criteria can also be considered, for instance, power consumption. Using small arithmetic units for the PRNS processor reduces the switching activities in each channel and dynamic power (Wang et al., 2000) [47]. The enhanced speed and low power consumption make the PRNS very encouraging in applications with intensive operations.
9. Conclusions
In this paper, we studied data reliability based on a polynomial residual number system and proposed a configurable, reliable, and secure distributed storage scheme, named En-AR-PRNS. We provided a theoretical analysis of the dynamic storage configurations.
Our main contributions were multi-fold:
- We proposed a novel decoding technique based on entropy to increase reliability. We showed that it can detect and correct more errors than the classical threshold-based PRNS;
- We provided a theoretical analysis of the reliability, redundancy, and coding/decoding speed, depending on configurable parameters to dynamically adapt the current configuration to various changes in the storage that are difficult to predict in advance;
- We reduced the computational complexity of the decoding from down to using the concept of an approximation of the rank of a polynomial.
The main idea of adaptive optimization is to set PRNS parameters, moduli, and storages and dynamically change them to cope with different objective preferences and current properties. To this end, the past characteristics can be analyzed for a certain time interval to determine appropriate parameters. This interval should be set according to the dynamism of the characteristics and storage configurations.
This reactive approach deals with the uncertainty and non-stationarity associated with unauthorized data modifications, hardware and software malfunctions, disk errors, loss of data, malicious intrusions, denial of access for a long time, data transmission failures, etc. To detect changes, estimate, and classify the security and reliability levels, and violations of confidentiality, integrity, and availability, multi-objective techniques using computational intelligence and artificial intelligence can be applied. Future work will center on a comprehensive experimental study to assess the proposed mechanism’s efficiency and effectiveness in real dynamic systems under different types of errors and malicious attacks.
Author Contributions
Conceptualization, A.T., M.B., A.A. and A.Y.D.; Data curation, A.Y.D.; Formal analysis, A.T. and M.B.; Investigation, M.B., A.A. and A.Y.D.; Methodology, A.T., A.A. and A.Y.D.; Project administration, A.A.; Writing—Original draft, A.T. and M.B. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Ministry of Education and Science of the Russian Federation (Project: 075-15-2020-915).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
The proof of Theorem 1.
If , then .
Proof .
Let , then can be represented as , where .
Let us compute the value of :
Computing by substituting Equation (A1) into Equation (3), we obtain:
From Equation (A2) and Equation (2), it follows that:
The sufficient condition is:
Since:
then is sufficient to hold the inequality . The theorem is proved. □
Appendix B
Example A1.
Let PRNS moduli tuple be , , , and , where , , and . The dynamic range of PRNS is:
and
and , then:
Because and , the condition of Theorem 2 is satisfied (see Equation (8)) and an error is detected.
In the following, we show how the error is detected.
First, we calculate the PRNS constants.
Second, to calculate , we compute the sum:
Using Equation (3), we obtain:
Finally, we compute using Equation (2) and Theorem 1.
Because , contains an error.
References
- Gomathisankaran, M.; Tyagi, A.; Namuduri, K. HORNS: A homomorphic encryption scheme for Cloud Computing using Residue Number System. In Proceedings of the 2011 45th Annual Conference on Information Sciences and Systems, Baltimore, MD, USA, 23–25 March 2011; pp. 1–5. [Google Scholar] [CrossRef]
- Chervyakov, N.; Babenko, M.; Tchernykh, A.; Kucherov, N.; Miranda-López, V.; Cortés-Mendoza, J.M. AR-RRNS: Configurable reliable distributed data storage systems for Internet of Things to ensure security. Futur. Gener. Comput. Syst. 2019, 92, 1080–1092. [Google Scholar] [CrossRef]
- Tchernykh, A.; Babenko, M.; Chervyakov, N.; Miranda-López, V.; Kuchukov, V.; Cortés-Mendoza, J.M.; Deryabin, M.; Kucherov, N.; Radchenko, G.; Avetisyan, A. AC-RRNS: Anti-collusion secured data sharing scheme for cloud storage. Int. J. Approx. Reason. 2018, 102, 60–73. [Google Scholar] [CrossRef]
- Tchernykh, A.; Schwiegelshohn, U.; Talbi, E.-G.; Babenko, M. Towards understanding uncertainty in cloud computing with risks of confidentiality, integrity, and availability. J. Comput. Sci. 2019, 36, 100581. [Google Scholar] [CrossRef]
- Tchernykh, A.; Babenko, M.; Chervyakov, N.; Miranda-Lopez, V.; Avetisyan, A.; Drozdov, A.Y.; Rivera-Rodriguez, R.; Radchenko, G.; Du, Z. Scalable Data Storage Design for Nonstationary IoT Environment with Adaptive Security and Reliability. IEEE Internet Things J. 2020, 7, 10171–10188. [Google Scholar] [CrossRef]
- Varghese, B.; Buyya, R. Next generation cloud computing: New trends and research directions. Future Gener. Comput. Syst. 2018, 79, 849–861. [Google Scholar] [CrossRef] [Green Version]
- Nachiappan, R.; Javadi, B.; Calheiros, R.N.; Matawie, K.M. Cloud storage reliability for Big Data applications: A state of the art survey. J. Netw. Comput. Appl. 2017, 97, 35–47. [Google Scholar] [CrossRef]
- Tan, C.B.; Hijazi, M.H.A.; Lim, Y.; Gani, A. A survey on Proof of Retrievability for cloud data integrity and availability: Cloud storage state-of-the-art, issues, solutions and future trends. J. Netw. Comput. Appl. 2018, 110, 75–86. [Google Scholar] [CrossRef]
- Sharma, Y.; Javadi, B.; Si, W. Sun, Reliability and energy efficiency in cloud computing systems: Survey and taxonomy. J. Netw. Comput. Appl. 2016, 74, 66–85. [Google Scholar] [CrossRef]
- Li, S.; Cao, Q.; Wan, S.; Qian, L.; Xie, C. HRSPC: A hybrid redundancy scheme via exploring computational locality to support fast recovery and high reliability in distributed storage systems. J. Netw. Comput. Appl. 2016, 66, 52–63. [Google Scholar] [CrossRef]
- Baker, T.; Mackay, M.; Shaheed, A.; Aldawsari, B. Security-Oriented Cloud Platform for SOA-Based SCADA. In Proceedings of the 2015 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Shenzhen, China, 4–7 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 961–970. [Google Scholar] [CrossRef]
- Tchernykh, A.; Miranda-López, V.; Babenko, M.; Armenta-Cano, F.; Radchenko, G.; Drozdov, A.Y.; Avetisyan, A. Performance evaluation of secret sharing schemes with data recovery in secured and reliable heterogeneous multi-cloud storage. Clust. Comput. 2019, 22, 1173–1185. [Google Scholar] [CrossRef]
- Chen, X.; Qiming, H. The data protection of mapreduce using homomorphic encryption. In Proceedings of the 2013 IEEE 4th International Conference on Software Engineering and Service Science, Beijing, China, 23–25 May 2013; pp. 419–421. [Google Scholar] [CrossRef]
- Celesti, A.; Fazio, M.; Villari, M.; Puliafito, A. Adding long-term availability, obfuscation, and encryption to multi-cloud storage systems. J. Netw. Comput. Appl. 2016, 59, 208–218. [Google Scholar] [CrossRef]
- Tchernykh, A.; Babenko, M.; Kuchukov, V.; Miranda-Lopez, V.; Avetisyan, A.; Rivera-Rodriguez, R.; Radchenko, G. Data Reliability and Redundancy Optimization of a Secure Multi-cloud Storage Under Uncertainty of Errors and Falsifications. In Proceedings of the 2019 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Rio de Janeiro, Brazil, 20–24 May 2019; pp. 565–572. [Google Scholar] [CrossRef]
- Srisakthi, S.; Shanthi, A.P. Towards the Design of a Secure and Fault Tolerant Cloud Storage in a Multi-Cloud Environment. Inf. Secur. J. Glob. Perspect. 2015, 24, 109–117. [Google Scholar] [CrossRef]
- Hubbard, D.; Sutton, M. Top Threats to Cloud Computing V1.0, Cloud Security Alliance, 2010, (n.d.). Available online: https://ioactive.com/wp-content/uploads/2018/05/csathreats.v1.0-1.pdf. (accessed on 24 April 2021).
- Tchernykh, A.; Babenko, M.; Miranda-Lopez, V.; Drozdov, A.Y.; Avetisyan, A. WA-RRNS: Reliable Data Storage System Based on Multi-cloud. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Vancouver, BC, Canada, 21–25 May 2018; pp. 666–673. [Google Scholar] [CrossRef]
- Ghemawat, S.; Gobioff, H.; Leung, S.-T. The Google file system. ACM SIGOPS Oper. Syst. Rev. 2003, 37, 29. [Google Scholar] [CrossRef]
- Miranda-Lopez, V.; Tchernykh, A.; Babenko, M.; Avetisyan, A.; Toporkov, V.; Drozdov, A.Y. 2Lbp-RRNS: Two-Levels RRNS With Backpropagation for Increased Reliability and Privacy-Preserving of Secure Multi-Clouds Data Storage. IEEE Access 2020, 8, 199424–199439. [Google Scholar] [CrossRef]
- Lin, H.-Y.; Tzeng, W.-G. A Secure Erasure Code-Based Cloud Storage System with Secure Data Forwarding. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 995–1003. [Google Scholar] [CrossRef]
- Dimakis, A.G.; Godfrey, P.B.; Wu, Y.; Wainwright, M.J.; Ramchandran, K. Network Coding for Distributed Storage Systems. IEEE Trans. Inf. Theory 2010, 56, 4539–4551. [Google Scholar] [CrossRef] [Green Version]
- Gentry, C. Computing arbitrary functions of encrypted data. Commun. ACM 2010, 53, 97. [Google Scholar] [CrossRef] [Green Version]
- Asmuth, C.; Bloom, J. A modular approach to key safeguarding. IEEE Trans. Inf. Theory 1983, 29, 208–210. [Google Scholar] [CrossRef]
- Mignotte, M. How to Share a Secret. In Cryptography. EUROCRYPT 1982; Lecture Notes in Computer Science; Beth, T., Ed.; Springer: Berlin/Heidelberg, Germany, 1982; Volume 149. [Google Scholar] [CrossRef]
- Lin, S.-J.; Chung, W.-H.; Han, Y.S. Novel Polynomial Basis and Its Application to Reed-Solomon Erasure Codes. In Proceedings of the 2014 IEEE 55th Annual Symposium on Foundations of Computer Science, Philadelphia, PA, USA, 18–21 October 2014; pp. 316–325. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Huang, K.; Rong, H.; Wang, H.; Xian, M. Privacy-Preserving Public Auditing for Regenerating-Code-Based Cloud Storage. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1513–1528. [Google Scholar] [CrossRef]
- Skavantzos, A.; Taylor, F.J. On the polynomial residue number system (digital signal processing). IEEE Trans. Signal Process. 1991, 39, 376–382. [Google Scholar] [CrossRef]
- Chu, J.; Benaissa, M. Error detecting AES using polynomial residue number systems. Microprocess. Microsyst. 2013, 37, 228–234. [Google Scholar] [CrossRef]
- Parker, M.G.; Benaissa, M. GF(pm) multiplication using polynomial residue number systems. IEEE Trans. Circuits Syst. II Analog. Digit. Signal Process 1995, 42, 718–721. [Google Scholar] [CrossRef]
- Chervyakov, N.I.; Babenko, M.G.; Kucherov, N.N. Development of Homomorphic Encryption Scheme Based on Polynomial Residue Number System. Sib. Electron. Math. Rep.-Sib. Elektron. Mat. Izv. 2015, 12, 33–41. [Google Scholar]
- Chang, C.-H.; Molahosseini, A.S.; Zarandi, A.A.E.; Tay, T.F. Residue Number Systems: A New Paradigm to Datapath Optimization for Low-Power and High-Performance Digital Signal Processing Applications. IEEE Circuits Syst. Mag. 2015, 15, 26–44. [Google Scholar] [CrossRef]
- Halbutogullari, A.; Koc, C.K. Parallel multiplication in GF(2k) using polynomial residue arithmetic. Des. Codes Cryptogr. 2000, 20, 155–173. [Google Scholar] [CrossRef]
- Geekbench Browser. Available online: https://browser.geekbench.com (accessed on 24 April 2021).
- Chervyakov, N.I.; Lyakhov, P.A.; Babenko, M.G.; Garyanina, A.I.; Lavrinenko, I.N.; Lavrinenko, A.V.; Deryabin, M.A. An efficient method of error correction in fault-tolerant modular neurocomputers. Neurocomputing 2016, 205, 32–44. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Three approaches to the definition of the concept “quantity of information”. Probl. Peredači Inf. 1965, 1, 3–11. [Google Scholar]
- Ivanov, M.; Sergiyenko, O.; Mercorelli, P.; Hernandez, W.; Tyrsa, V.; Hernandez-Balbuena, D.; Rodriguez Quinonez, J.C.; Kartashov, V.; Kolendovska, M.; Iryna, T. Effective informational entropy reduction in multi-robot systems based on real-time TVS. In Proceedings of the 2019 IEEE 28th International Symposium on Industrial Electronics (ISIE), Vancouver, BC, Canada, 12–14 June 2019; LNCS; Volume 11349, pp. 1162–1167. [Google Scholar] [CrossRef]
- Goh, V.T.; Siddiqi, M.U. Multiple error detection and correction based on redundant residue number systems. IEEE Trans. Commun. 2008, 56, 325–330. [Google Scholar] [CrossRef]
- Research and Compare Cloud Providers and Services. Available online: https://cloudharmony.com/status (accessed on 26 November 2021).
- Yen, S.-M.; Kim, S.; Lim, S.; Moon, S.-J. RSA speedup with chinese remainder theorem immune against hardware fault cryptanalysis. IEEE Trans. Comput. 2003, 52, 461–472. [Google Scholar] [CrossRef] [Green Version]
- Bajard, J.C.; Imbert, L. a full RNS implementation of RSA. IEEE Trans. Comput. 2004, 53, 769–774. [Google Scholar] [CrossRef]
- Cheon, J.H.; Han, K.; Kim, A.; Kim, M.; Song, Y. A Full RNS Variant of Approximate Homomorphic Encryption, in LNCS; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11349, pp. 347–368. [Google Scholar] [CrossRef]
- Laine, K. Simple Encrypted Arithmetic Library 2.3.1., Microsoft Res. 2017. Available online: https://www.microsoft.com/en-us/research/uploads/prod/2017/11/sealmanual-2-3-1.pdf (accessed on 17 April 2021).
- Schinianakis, D.M.; Fournaris, A.P.; Michail, H.E.; Kakarountas, A.P.; Stouraitis, T. An RNS Implementation of an Fp Elliptic Curve Point Multiplier. IEEE Trans. Circuits Syst. I Regul. Pap. 2009, 56, 1202–1213. [Google Scholar] [CrossRef]
- Guillermin, N. A High Speed Coprocessor for Elliptic Curve Scalar Multiplications over Fp. In International Workshop on Cryptographic Hardware and Embedded Systems; Springer: Berlin/Heidelberg, Germany, 2010; pp. 48–64. [Google Scholar] [CrossRef]
- Flynn, M.J.; Oberman, S. Advanced Computer Arithmetic Design; Wiley: Hoboken, NJ, USA; p. 344.
- Wang, W.; Swamy, M.N.S.; Ahmad, M.O. An area-time-efficient residue-to-binary converter. In Proceedings of the 43rd IEEE Midwest Symposium on Circuits and Systems (Cat.No.CH37144), Lansing, MI, USA, 8–11 August 2000; Volume 2, pp. 904–907. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).