
Bayesian Decision Making of an Imperfect Debugging Software Reliability Growth Model with Consideration of Debuggers’ Learning and Negligence Factors

Abstract
:1. Introduction
2. Imperfect Debugging Software Reliability Growth Model with Consideration of Debuggers’ Learning and Negligence Factors
2.1. Basic Model Development
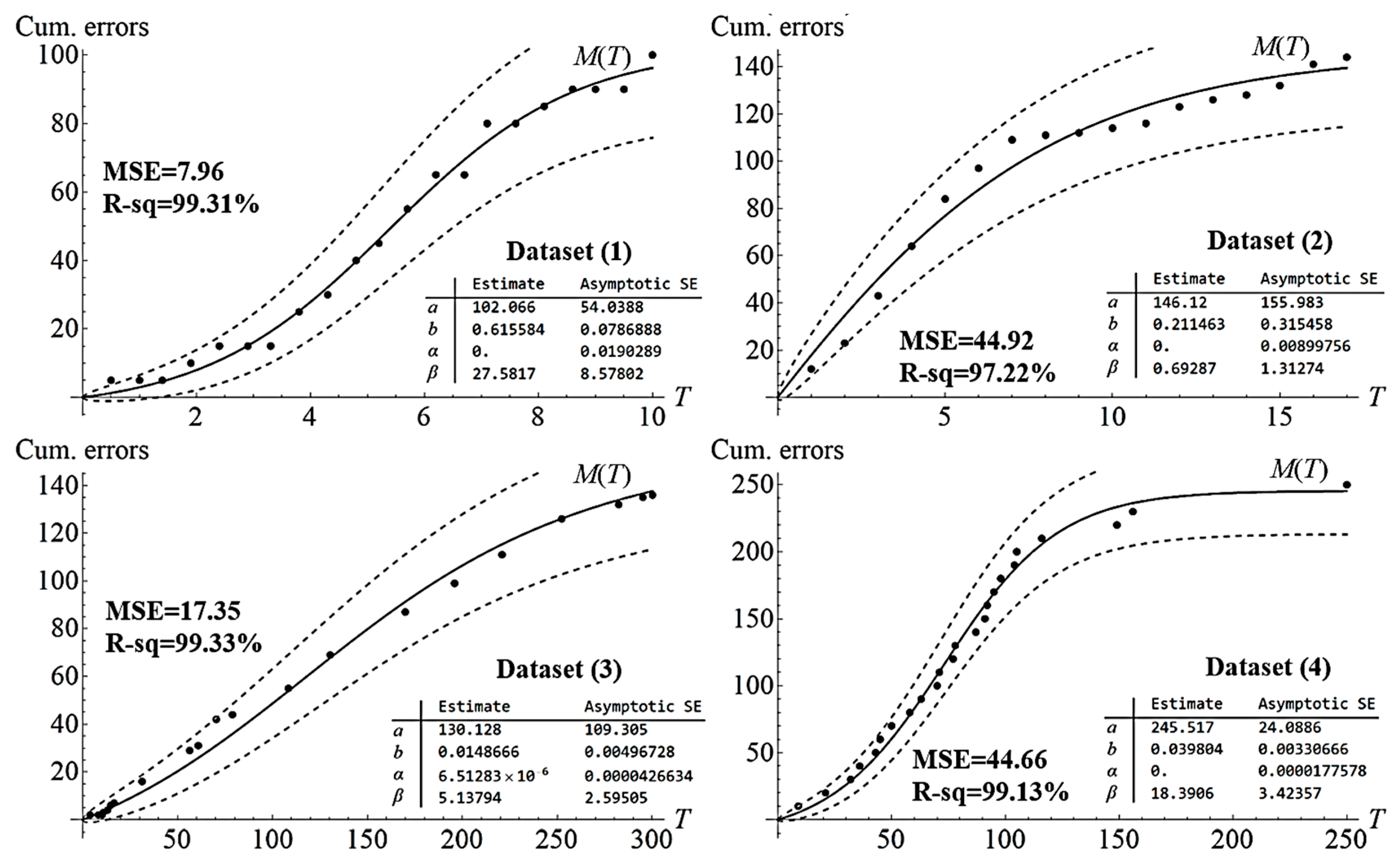
2.2. Parameter Estimation and Models Validation
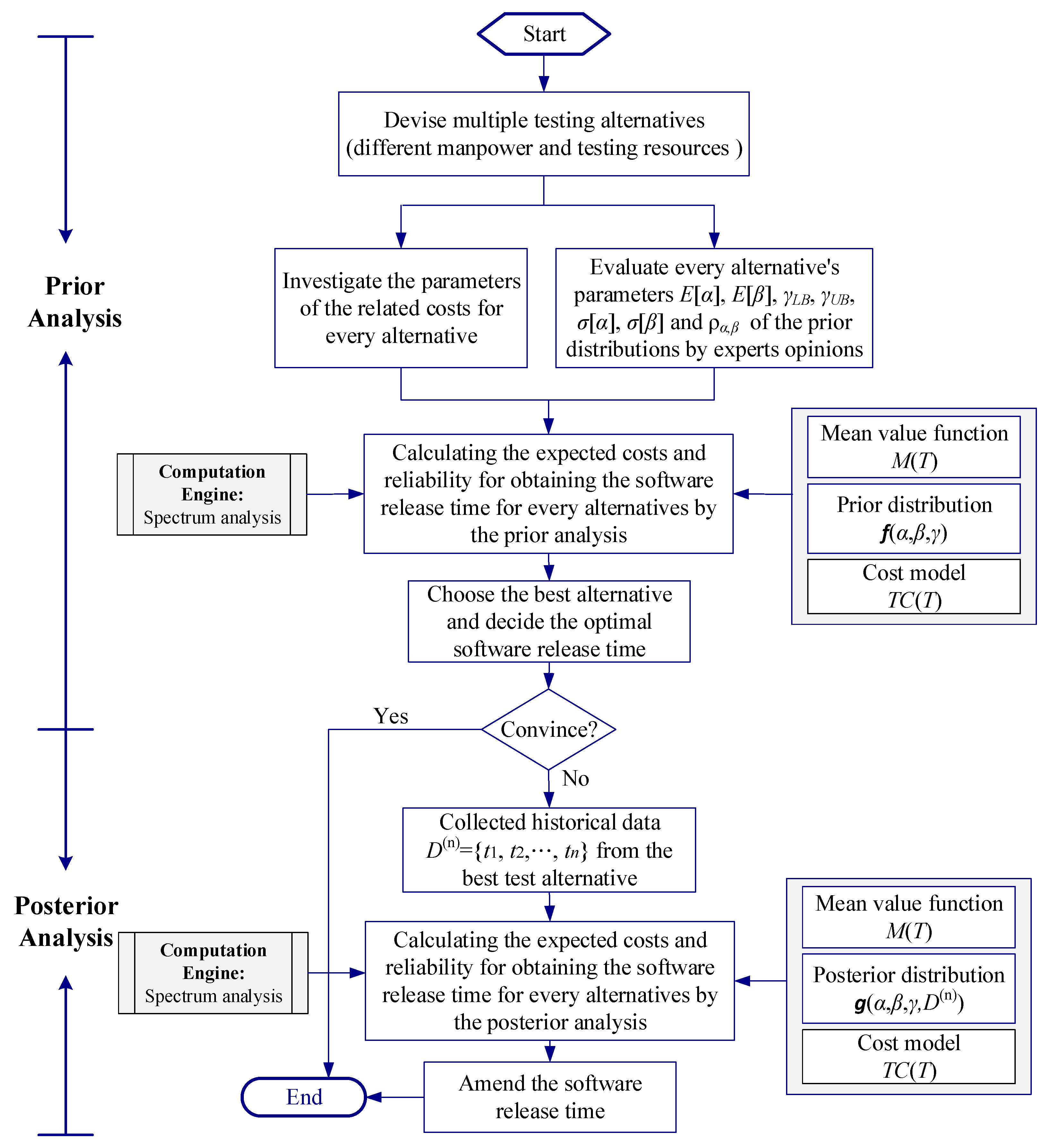
3. Bayesian Analysis for SRGM and Optimal Decision of Software Release
3.1. Bayesian Analysis under Insufficient Historical Data
3.2. Cost Models for Optimal Decision of Software Release
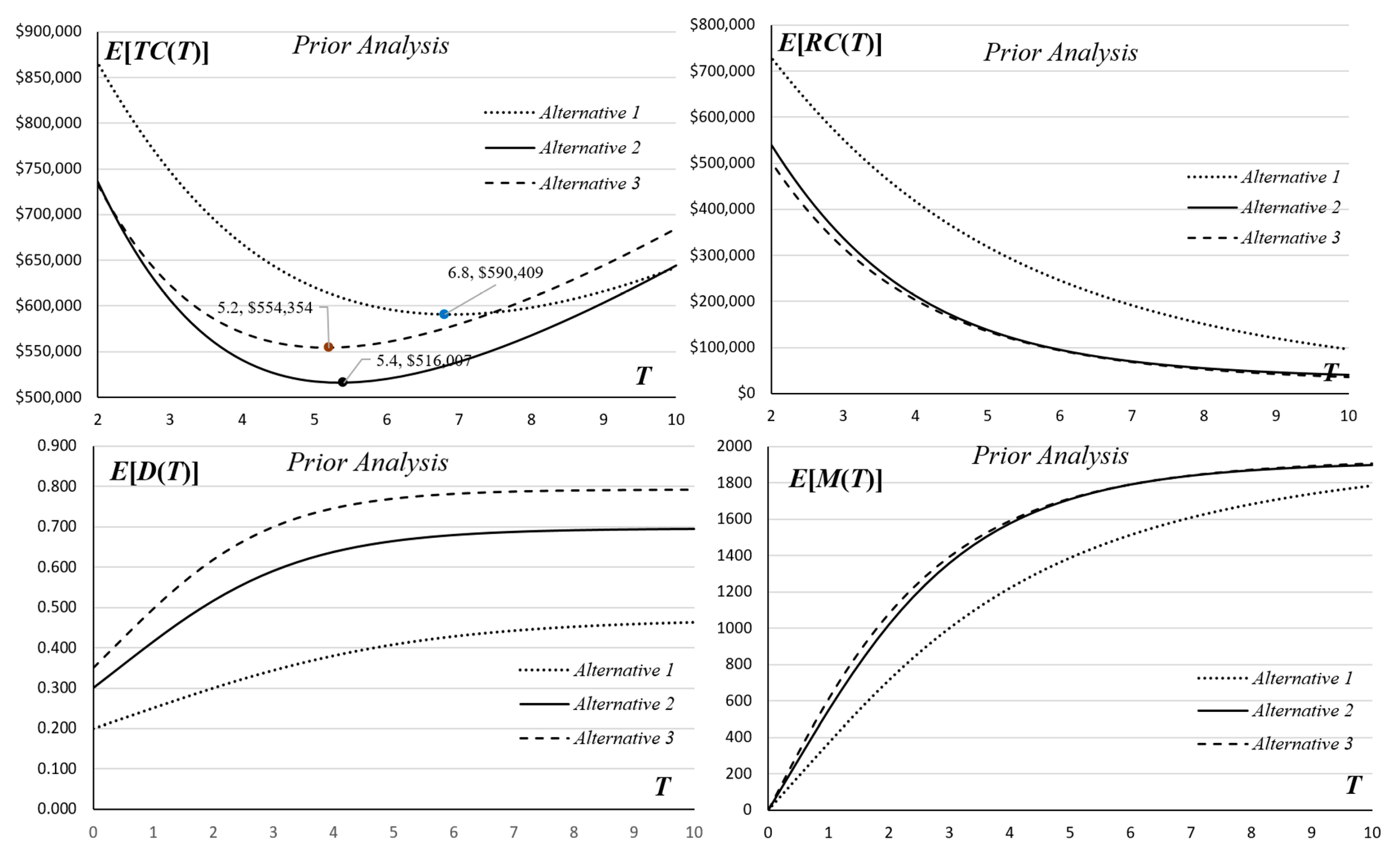
4. Application and Numerical Analysis
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goel, A.L.; Okumoto, K. Time-dependent fault detection rate model for software and other performance measures. IEEE Trans. Reliab. 1979, 28, 206–211. [Google Scholar] [CrossRef]
- Yamada, S.; Ohba, M.; Osaki, S. S-shaped reliability growth modeling for software error detection. IEEE Trans. Reliab. 1983, 32, 475–484. [Google Scholar] [CrossRef]
- Pham, H.; Nordmann, L.; Zhang, X. A general Imperfect software debugging model with S-shaped fault detection rate. IEEE Trans. Reliab. 1999, 48, 169–175. [Google Scholar] [CrossRef]
- Pham, H.; Zhang, X. NHPP Software Reliability and Cost Models with Testing Coverage. Eur. J. Oper. Res. 2003, 145, 443–454. [Google Scholar] [CrossRef]
- Huang, C.Y. Performance analysis of software reliability growth models with testing-effort and change-point. J. Syst. Softw. 2005, 76, 181–194. [Google Scholar] [CrossRef]
- Park, J.Y.; Park, J.H.; Fujiwara, T. Frameworks for NHPP Software Reliability Growth Models. Int. J. Reliab. Appl. 2006, 7, 155–166. [Google Scholar]
- Wu, Y.P.; Hu, Q.P.; Xie, M.; Ng, S.H. Modeling and Analysis of Software Fault Detection and Correction Process by Considering Time Dependency. IEEE Trans. Reliab. 2007, 56, 629–642. [Google Scholar] [CrossRef]
- Ho, J.W.; Fang, C.C.; Huang, Y.S. The Determination of Optimal Software Release Times at Different Confidence Levels with Consideration of Learning Effects. Softw. Test. Verif. Reliab. 2008, 18, 221–249. [Google Scholar] [CrossRef]
- Kapur, P.K.; Gupta, D.; Gupta, A.; Jha, P.C. Effect of introduction of faults and imperfect debugging on release time. Ratio Math. 2008, 18, 62–90. [Google Scholar]
- Chiu, K.C.; Huang, Y.S.; Lee, T.Z. A Study of Software Reliability Growth from the Perspective of Learning Effects. Reliab. Eng. Syst. Saf. 2008, 93, 1410–1421. [Google Scholar] [CrossRef]
- Chiu, K.C.; Ho, J.W.; Huang, Y.S. Bayesian updating of optimal release time for software systems. Softw. Qual. J. 2009, 17, 99–120. [Google Scholar] [CrossRef]
- Inoue, S.; Fukuma, K.; Yamada, S. Two-Dimensional Change-Point Modeling for Software Reliability Assessment. Int. J. Reliab. Qual. Saf. Eng. 2010, 17, 531–542. [Google Scholar] [CrossRef]
- Kapur, P.K.; Pham, H.; Anand, S.; Yadav, K. A unified approach for developing software reliability growth models in the presence of imperfect debugging and error generation. IEEE Trans. Reliab. 2011, 60, 331–340. [Google Scholar] [CrossRef]
- Zachariah, B. Analysis of Software Testing Strategies through Attained Failure Size. IEEE Trans. Reliab. 2012, 61, 569–579. [Google Scholar] [CrossRef]
- Okamura, H.; Dohi, T.; Osaki, S. Software reliability growth models with normal failure time distributions. Reliab. Eng. Syst. Saf. 2013, 116, 135–141. [Google Scholar] [CrossRef]
- Peng, R.; Li, Y.F.; Zhang, W.J.; Hu, Q.P. Testing Effort Dependent Software Reliability Model for Imperfect Debugging Process Considering Both Detection and Correction. Reliab. Eng. Syst. Saf. 2014, 126, 37–43. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Wu, Z.; Shu, Y.; Zhang, Z. An imperfect software debugging model considering log-logistic distribution fault content function. J. Syst. Softw. 2015, 100, 167–181. [Google Scholar] [CrossRef]
- Fang, C.C.; Yeh, C.W. Effective Confidence Interval Estimation of Fault-detection Process of Software Reliability Growth Models. Int. J. Syst. Sci. 2016, 47, 2878–2892. [Google Scholar] [CrossRef]
- Nagaraju, V.; Fiondella, L.; Wandji, T. A heterogeneous single change point software reliability growth model framework. Softw. Test. Verif. Reliab. 2019, 29, e1717. [Google Scholar] [CrossRef]
- Lee, D.H.; Chang, H.; Pham, H. Software Reliability Model with Dependent Failures and SPRT. Mathematics 2020, 8, 1366. [Google Scholar] [CrossRef]
- Nagaraju, V.; Jayasinghe, C.; Fiondella, L. Optimal test activity allocation for covariate software reliability and security models. J. Syst. Softw. 2020, 168, 110643. [Google Scholar] [CrossRef]
- Huang, Y.S.; Chiu, K.C.; Chen, W.M. A software reliability growth model for imperfect debugging. J. Syst. Softw. 2022, 188, 111267. [Google Scholar] [CrossRef]
- Li, Q.; Pham, H. Software Reliability Modeling Incorporating Fault Detection and Fault Correction Processes with Testing Coverage and Fault Amount Dependency. Mathematics 2022, 10, 60. [Google Scholar] [CrossRef]
- Chang, T.C.; Lin, Y.; Shi, K.; Meen, T.H. Decision Making of Software Release Time at Different Confidence Intervals with Ohba’s Inflection S-Shape Model. Symmetry 2022, 14, 593. [Google Scholar] [CrossRef]
- Kim, Y.S.; Song, K.Y.; Pham, H.; Chang, I.H. A Software Reliability Model with Dependent Failure and Optimal Release Time. Symmetry 2022, 14, 343. [Google Scholar] [CrossRef]
- Mahmood, A.; Siddiqui, S.A.; Sheng, Q.Z. Trust on wheels: Towards secure and resource efficient IoV networks. Computing 2022, 2022, 1–22. [Google Scholar] [CrossRef]
- EI Saddik, A.; Laamarti, F.; Alja’Afreh, M. The Potential of Digital Twins. IEEE Instrum. Meas. Mag. 2021, 24, 36–41. [Google Scholar] [CrossRef]
- Mahmood, A.; Sheng, Q.Z.; Siddiqui, S.A.; Sagar, S.; Zhang, W.E.; Suzuki, H.; Ni, W. When Trust Meets the Internet of Vehicles: Opportunities, Challenges, and Future Prospects. In Proceedings of the 2021 IEEE 7th International Conference on Collaboration and Internet Computing (CIC), Atlanta, GA, USA, 13–15 December 2021. [Google Scholar] [CrossRef]
- Okamura, H.; Dohi, T. Application of EM Algorithm to NHPP-Based Software Reliability Assessment with Generalized Failure Count Data. Mathematics 2021, 9, 985. [Google Scholar] [CrossRef]
- Song, K.Y.; Chang, I.H.; Pham, H. A Testing Coverage Model Based on NHPP Software Reliability Considering the Software Operating Environment and the Sensitivity Analysis. Mathematics 2019, 7, 450. [Google Scholar] [CrossRef] [Green Version]
- Pievatolo, A.; Ruggeri, F.; Soyer, R. A Bayesian hidden Markov model for imperfect debugging. Reliab. Eng. Syst. Saf. 2012, 103, 11–21. [Google Scholar] [CrossRef]
- Aktekin, T.; Caglar, T. Imperfect debugging in software reliability: A Bayesian approach. Eur. J. Oper. Res. 2013, 227, 112–121. [Google Scholar] [CrossRef]
- Chatterjee, S.; Shukla, A. Modeling and Analysis of Software Fault Detection and Correction Process Through Weibull-Type Fault Reduction Factor, Change Point and Imperfect Debugging. Comput. Eng. Comput. Sci. 2016, 25, 5009–5025. [Google Scholar] [CrossRef]
- Li, Q.; Pham, H. NHPP software reliability model considering the uncertainty of operating environments with imperfect debugging and testing coverage. Appl. Math. Model. 2017, 51, 68–85. [Google Scholar] [CrossRef]
- Inoue, S.; Yamada, S. Markovian Software Reliability Modeling with Change-Point. Int. J. Reliab. Qual. Saf. Eng. 2018, 25, 1850009. [Google Scholar] [CrossRef]
- Saraf, I.; Iqbal, J. Generalized Multi-release modelling of software reliability growth models from the perspective of two types of imperfect debugging and change point. Qual. Reliab. Eng. Int. 2019, 35, 2358–2370. [Google Scholar] [CrossRef]
- Verma, V.; Anand, S.; Aggarwal, A.G. Software warranty cost optimization under imperfect debugging. Int. J. Qual. Reliab. Manag. 2020, 37, 1233–1257. [Google Scholar] [CrossRef]
- Li, T.; Si, X.; Yang, Z.; Pei, H.; Pham, H. NHPP Testability Growth Model Considering Testability Growth Effort, Rectifying Delay, and Imperfect Correction. IEEE Access 2020, 8, 9072–9083. [Google Scholar] [CrossRef]
- Bai, C.G.; Hu, Q.P.; Xie, M.; Ng, S.H. Software failure prediction based on a Markov Bayesian network model. J. Syst. Softw. 2005, 74, 275–282. [Google Scholar] [CrossRef]
- Melo, A.C.V.; Sanchez, A.J. Software maintenance project delays prediction using Bayesian networks. Expert Syst. Appl. 2008, 34, 908–919. [Google Scholar]
- Lian, Y.; Tang, Y.; Wang, Y. Objective Bayesian analysis of JM model in software reliability. Comput. Stat. Data Anal. 2017, 109, 199–214. [Google Scholar] [CrossRef]
- Zhao, X.; Littlewood, B.; Povyakalo, A.; Strigini, L.; Wright, D. Conservative claims for the probability of perfection of a software-based system using operational experience of previous similar systems. Reliab. Eng. Syst. Saf. 2018, 175, 265–282. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Fei, H.; Yu, Q.; Zhao, W.; Yan, J.; Hong, T. A motifs-based Maximum Entropy Markov Model for realtime reliability prediction in System of Systems. J. Syst. Softw. 2019, 151, 180–193. [Google Scholar] [CrossRef]
- Insua, D.R.; Ruggeri, F.; Soyer, R.; Wilson, S. Advances in Bayesian decision making in reliability. Eur. J. Oper. Res. 2020, 282, 1–18. [Google Scholar] [CrossRef]
- Zarzour, N.; Rekab, K. Sequential procedure for Software Reliability estimation. Appl. Math. Comput. 2021, 402. [Google Scholar] [CrossRef]
- Zhang, X.; Pham, H. Software field failure rate prediction before software deployment. J. Syst. Softw. 2006, 79, 291–300. [Google Scholar] [CrossRef]
- Wang, J.; Wu, Z. Study of the nonlinear imperfect software debugging model. Reliab. Eng. Syst. Saf. 2016, 153, 180–192. [Google Scholar] [CrossRef]
- Singpurwalla, N.D.; Wilson, S.P.; Simon, P. Statistical Analysis of Software Failure Data. In Statistical Methods in Software Engineering; Springer: New York, NY, USA, 1999; pp. 101–167. [Google Scholar]
- Schucany, W.R.; Parr, W.C.; Boyer, J.E. Correlation structure in Farlie-Gumbel-Morgenstern distributions. Biometrika 1978, 65, 650–653. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| : the autonomous errors-detected factor |
| : the learning factor |
| : the negligent factor |
| : the joint prior distribution for ,, |
| : the likelihood function regarding NHPP with the collected dataset |
| : the posterior distribution for ,, |
| : the initial number of all potential errors in the software system |
| : the function of the total errors at time in the software system |
| : the mean value function, which represents the accumulated number of software errors detected during the time interval (0,) |
| : the intensity function that denotes the number of the errors detected at time |
| : the function of the error detection rate |
| Dataset | Reference | Source |
|---|---|---|
| (1) | Zhang & Pham (2006) [46] | Failure data of telecommunication system |
| (2) | Wang et al. (2016) [47] | Medium-scale software project |
| (3) | Peng et al. (2014) [16] | Testing data for the Room Air Development Center |
| (4) | Singpurwalla & Willson (1999) [48] | Failure data of NTDS system |
| Imperfect Debugging SRGMs | |
|---|---|
| Pham et al. (1999) [3] | . |
| Kapur et al. (2008) [9] | . |
| Wang et al. (2015) [17] | . |
| Proposed model | . |
| Alternative 1 | Alternative 2 | Alternative 3 |
|---|---|---|
| Low-Intensity Testing Resource | Medium-Intensity Testing Resource | High-Intensity Testing Resource |
| = 1.9 | ||
| Time T | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | |
| 4 | 1223 | 1575 | 1592 | $667,547 | $540,660 | $570,689 | $417,191 | $212,092 | $202,653 | 0.556 | 0.650 | 0.698 |
| 4.2 | 1260 | 1608 | 1622 | $655,754 | $533,214 | $565,149 | $394,921 | $193,977 | $186,180 | 0.574 | 0.681 | 0.730 |
| 4.4 | 1296 | 1637 | 1649 | $645,163 | $527,293 | $560,886 | $373,985 | $177,704 | $171,304 | 0.591 | 0.710 | 0.760 |
| 4.6 | 1329 | 1663 | 1673 | $635,707 | $522,756 | $557,778 | $354,302 | $163,094 | $157,865 | 0.609 | 0.737 | 0.787 |
| 4.8 | 1360 | 1687 | 1695 | $627,323 | $519,473 | $555,717 | $335,798 | $149,983 | $145,719 | 0.627 | 0.763 | 0.812 |
| 5 | 1390 | 1709 | 1716 | $619,948 | $517,324 | $554,605 | $318,399 | $138,221 | $134,737 | 0.645 | 0.787 | 0.835 |
| 5.2 | 1418 | 1729 | 1734 | $613,527 | $516,201 | $554,354 | $302,037 | $127,670 | $124,801 | 0.663 | 0.809 | 0.855 |
| 5.4 | 1445 | 1746 | 1751 | $608,000 | $516,007 | $554,885 | $286,643 | $118,205 | $115,807 | 0.681 | 0.829 | 0.873 |
| 5.6 | 1470 | 1762 | 1766 | $603,316 | $516,652 | $556,128 | $272,156 | $109,714 | $107,659 | 0.698 | 0.847 | 0.889 |
| 5.8 | 1494 | 1777 | 1780 | $599,428 | $518,059 | $558,021 | $258,518 | $102,094 | $100,275 | 0.715 | 0.864 | 0.903 |
| 6 | 1516 | 1790 | 1793 | $596,289 | $520,155 | $560,507 | $245,675 | $95,255 | $93,578 | 0.732 | 0.879 | 0.916 |
| 6.2 | 1537 | 1802 | 1805 | $593,857 | $522,876 | $563,535 | $233,574 | $89,114 | $87,499 | 0.748 | 0.893 | 0.927 |
| 6.4 | 1558 | 1812 | 1815 | $592,090 | $526,167 | $567,061 | $222,167 | $83,597 | $81,978 | 0.763 | 0.905 | 0.937 |
| 6.6 | 1577 | 1822 | 1825 | $590,953 | $529,975 | $571,044 | $211,410 | $78,638 | $76,961 | 0.778 | 0.916 | 0.945 |
| 6.8 | 1595 | 1830 | 1834 | $590,409 | $534,257 | $575,448 | $201,260 | $74,180 | $72,397 | 0.792 | 0.926 | 0.953 |
| 7 | 1612 | 1838 | 1842 | $590,427 | $538,970 | $580,240 | $191,680 | $70,168 | $68,243 | 0.806 | 0.935 | 0.959 |
| 7.2 | 1628 | 1845 | 1850 | $590,976 | $544,081 | $585,393 | $182,631 | $66,556 | $64,460 | 0.819 | 0.943 | 0.965 |
| 7.4 | 1644 | 1852 | 1856 | $592,028 | $549,555 | $590,880 | $174,081 | $63,303 | $61,011 | 0.831 | 0.949 | 0.969 |
| 7.6 | 1658 | 1858 | 1863 | $593,558 | $555,366 | $596,678 | $165,999 | $60,370 | $57,866 | 0.843 | 0.955 | 0.974 |
| 7.8 | 1672 | 1863 | 1868 | $595,540 | $561,487 | $602,766 | $158,353 | $57,725 | $54,995 | 0.854 | 0.961 | 0.977 |
| 8 | 1685 | 1868 | 1874 | $597,952 | $567,896 | $609,125 | $151,119 | $55,337 | $52,373 | 0.864 | 0.966 | 0.980 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Q.; Yeh, C.-W.; Fang, C.-C. Bayesian Decision Making of an Imperfect Debugging Software Reliability Growth Model with Consideration of Debuggers’ Learning and Negligence Factors. Mathematics 2022, 10, 1689. https://doi.org/10.3390/math10101689
Tian Q, Yeh C-W, Fang C-C. Bayesian Decision Making of an Imperfect Debugging Software Reliability Growth Model with Consideration of Debuggers’ Learning and Negligence Factors. Mathematics. 2022; 10(10):1689. https://doi.org/10.3390/math10101689
Chicago/Turabian StyleTian, Qing, Chun-Wu Yeh, and Chih-Chiang Fang. 2022. "Bayesian Decision Making of an Imperfect Debugging Software Reliability Growth Model with Consideration of Debuggers’ Learning and Negligence Factors" Mathematics 10, no. 10: 1689. https://doi.org/10.3390/math10101689
APA StyleTian, Q., Yeh, C.-W., & Fang, C.-C. (2022). Bayesian Decision Making of an Imperfect Debugging Software Reliability Growth Model with Consideration of Debuggers’ Learning and Negligence Factors. Mathematics, 10(10), 1689. https://doi.org/10.3390/math10101689