
DEA and Machine Learning for Performance Prediction


Abstract
:1. Introduction
2. Related Studies
- They mostly use only DEA and a single neural network approach, especially ANNs in neural networks. Exploration of the combination of other machine learning methods is lacking.
- The existing literature studies mainly use the CCR and BCC models in DEA methods. These two models use the radial distance function. So, these two models for the measurement of the degree of inefficiency only include the part of all inputs (outputs) equal proportional changes, and do not take into account the part of slack improvement. Therefore, there are some shortcomings in the efficiency evaluation.
- After constructing the integrated model, related studies did not further explore how to improve performance prediction in terms of dataset composition and feature index selection.
3. Description of the Methodology
3.1. Data Envelopment Analysis (DEA)
3.1.1. DEA Base Model
3.1.2. SBM Model and Non-Expected Output
3.2. Machine Learning Models
3.2.1. Linear Regression (LR)
3.2.2. Support Vector Regression (SVR)
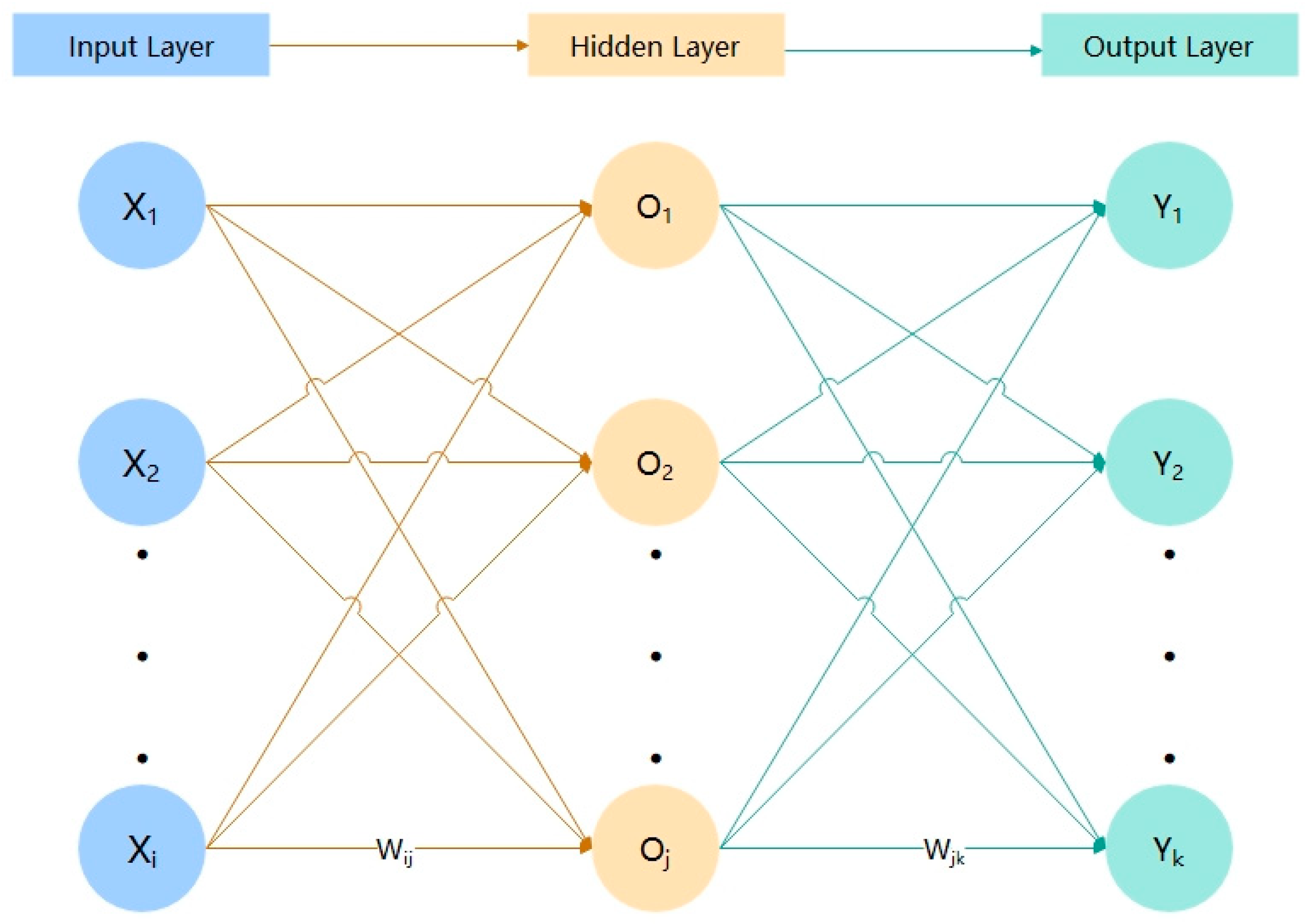
3.2.3. Back Propagation Neural Network (BPNN)
3.2.4. Decision Trees (DT) and Random Forests (RF)
3.2.5. Gradient Boosted Decision Tree (GBDT)
3.2.6. CatBoost, XGBoost, and LightGBM
3.2.7. Adaboost and Bagging
4. Empirical Analysis
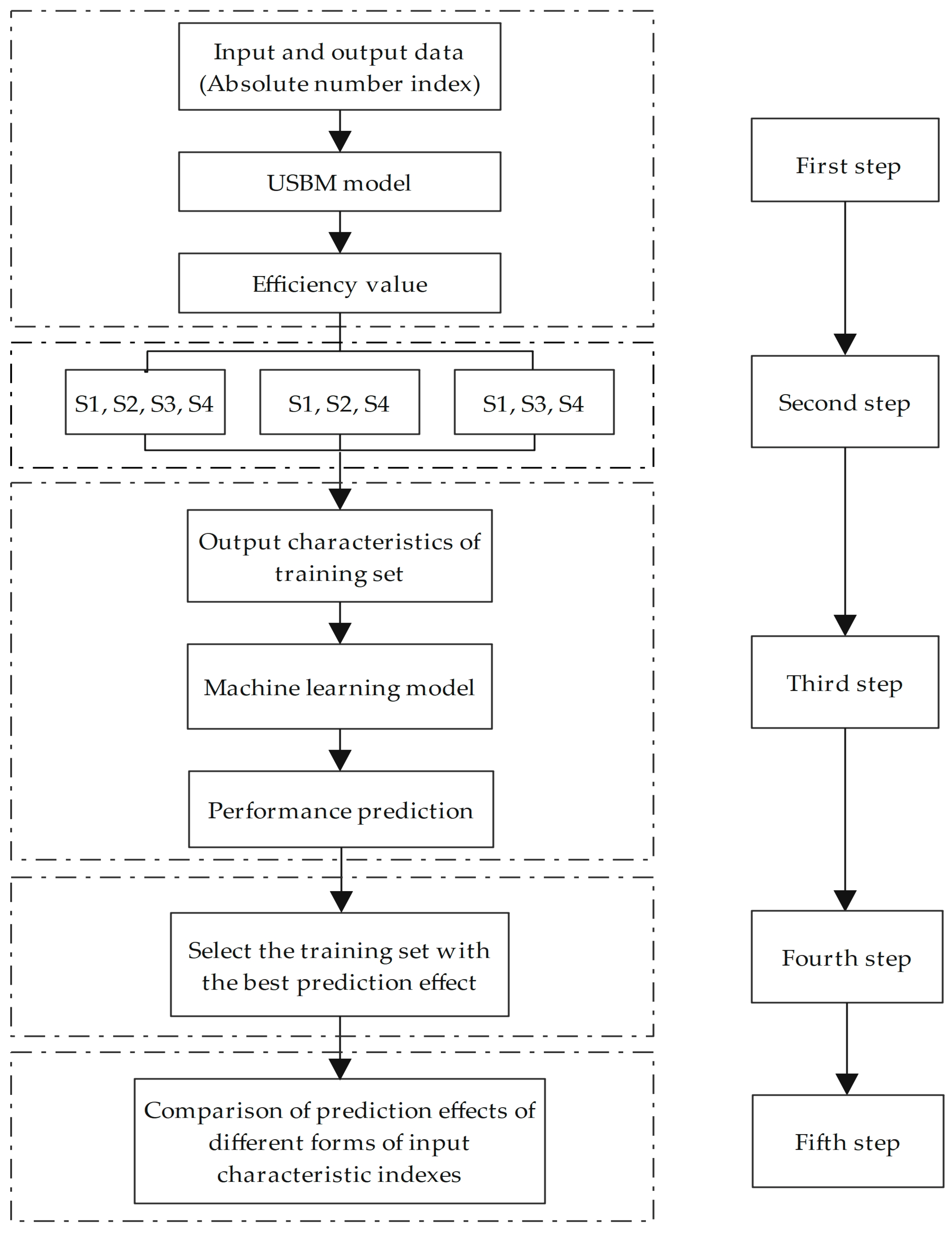
4.1. Design of the Empirical Analysis Process
4.2. Evaluation Index System Construction
4.3. Decision Units and Data Description
4.4. Decision Unit Efficiency Value Measurement
4.5. Evaluation Indicators of the Prediction Effect
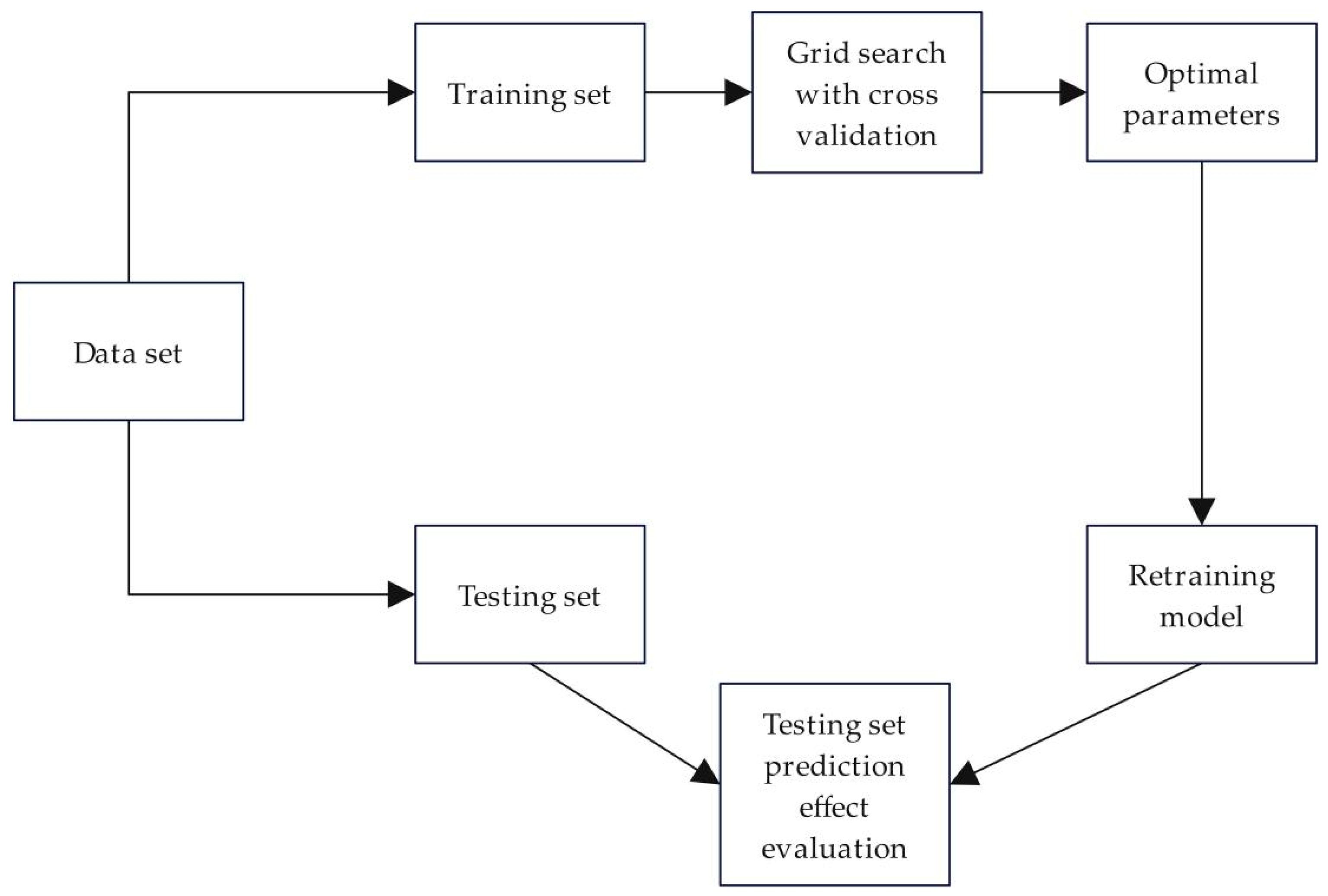
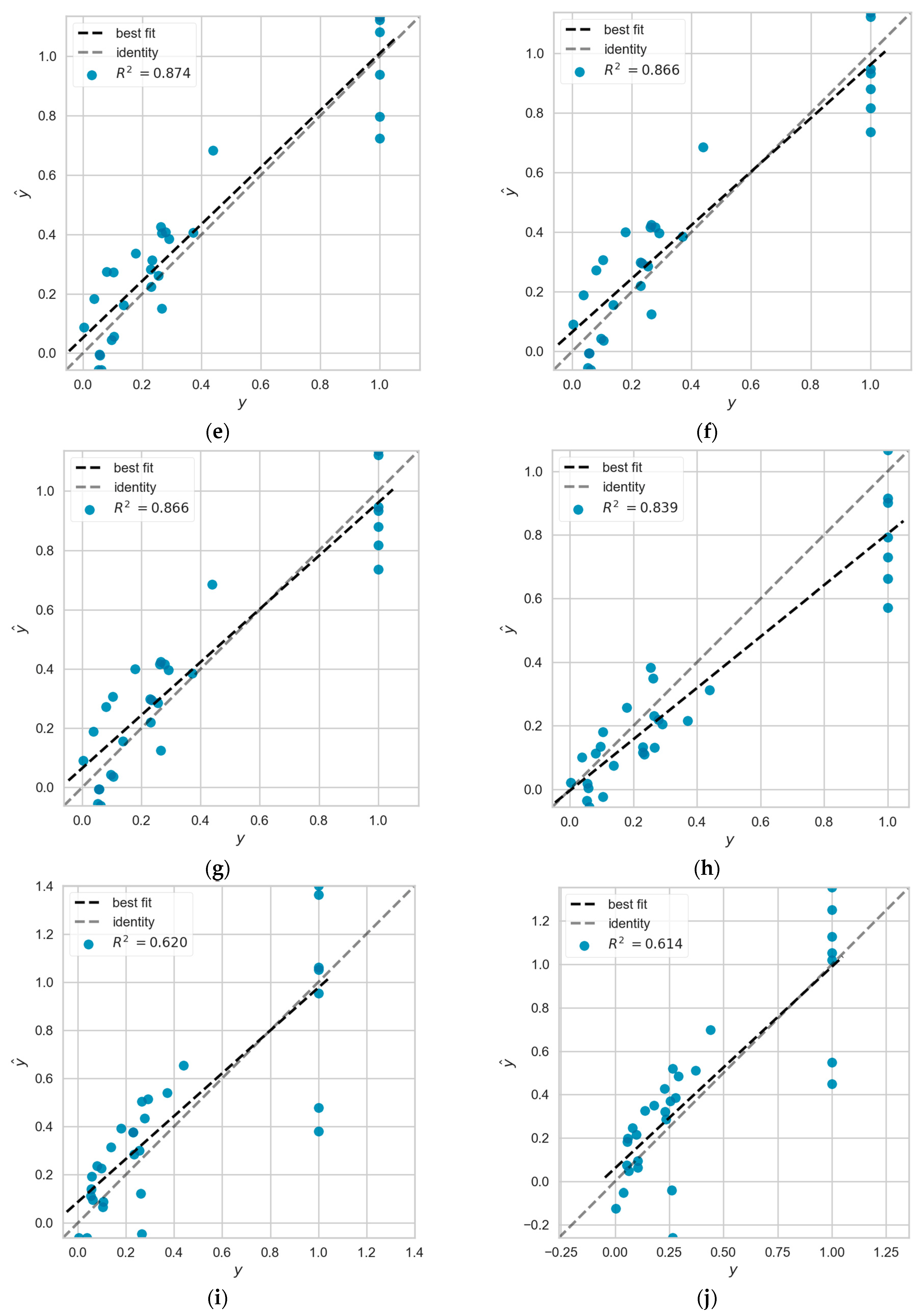
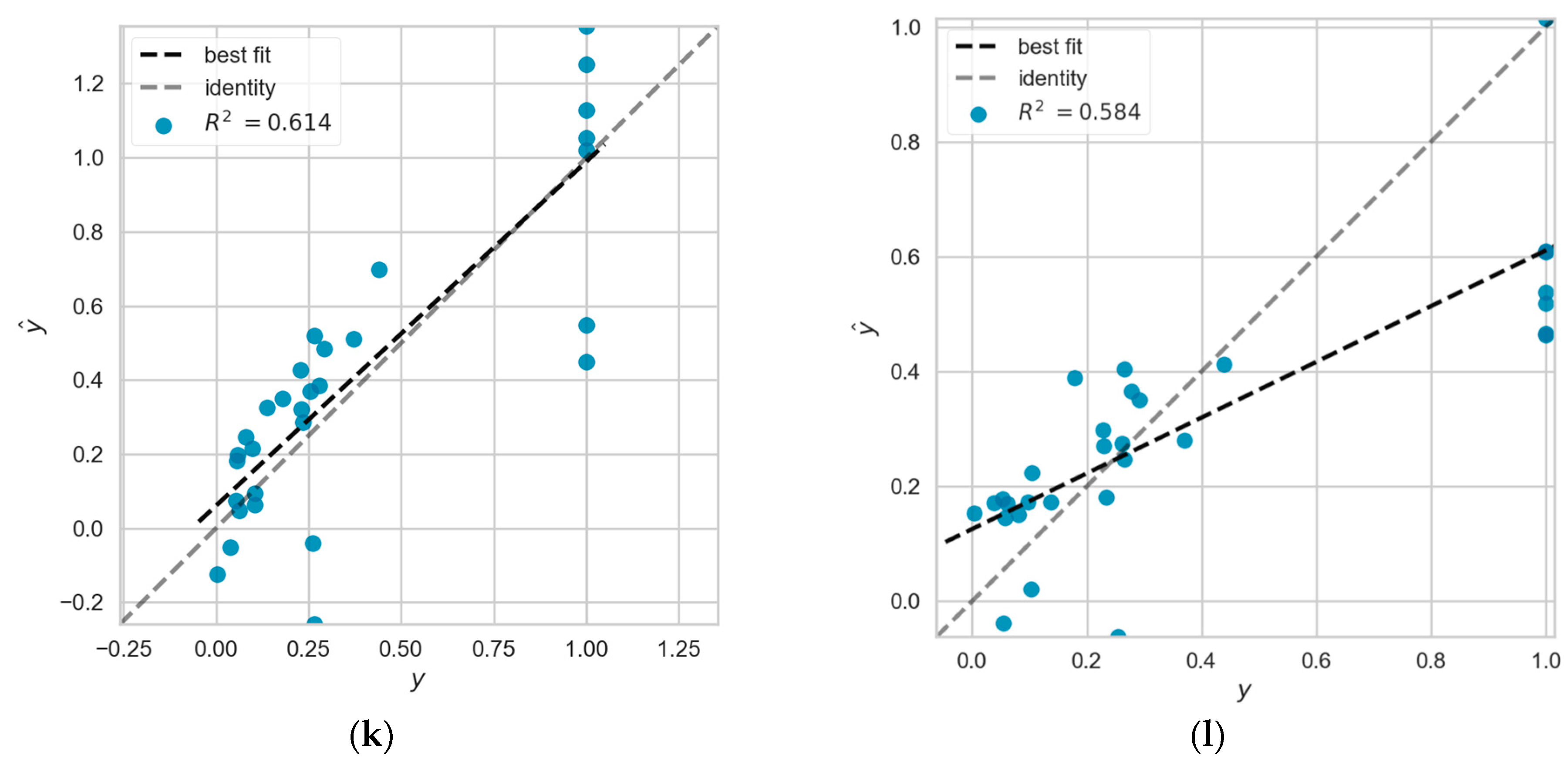
4.6. Performance Prediction Based on DEA and Machine Learning Models
4.7. Results of the Empirical Study Based on the Training Subset of DEA Classification Method
4.8. Results of the Empirical Study of Proportional Relative and Absolute Number Indicators
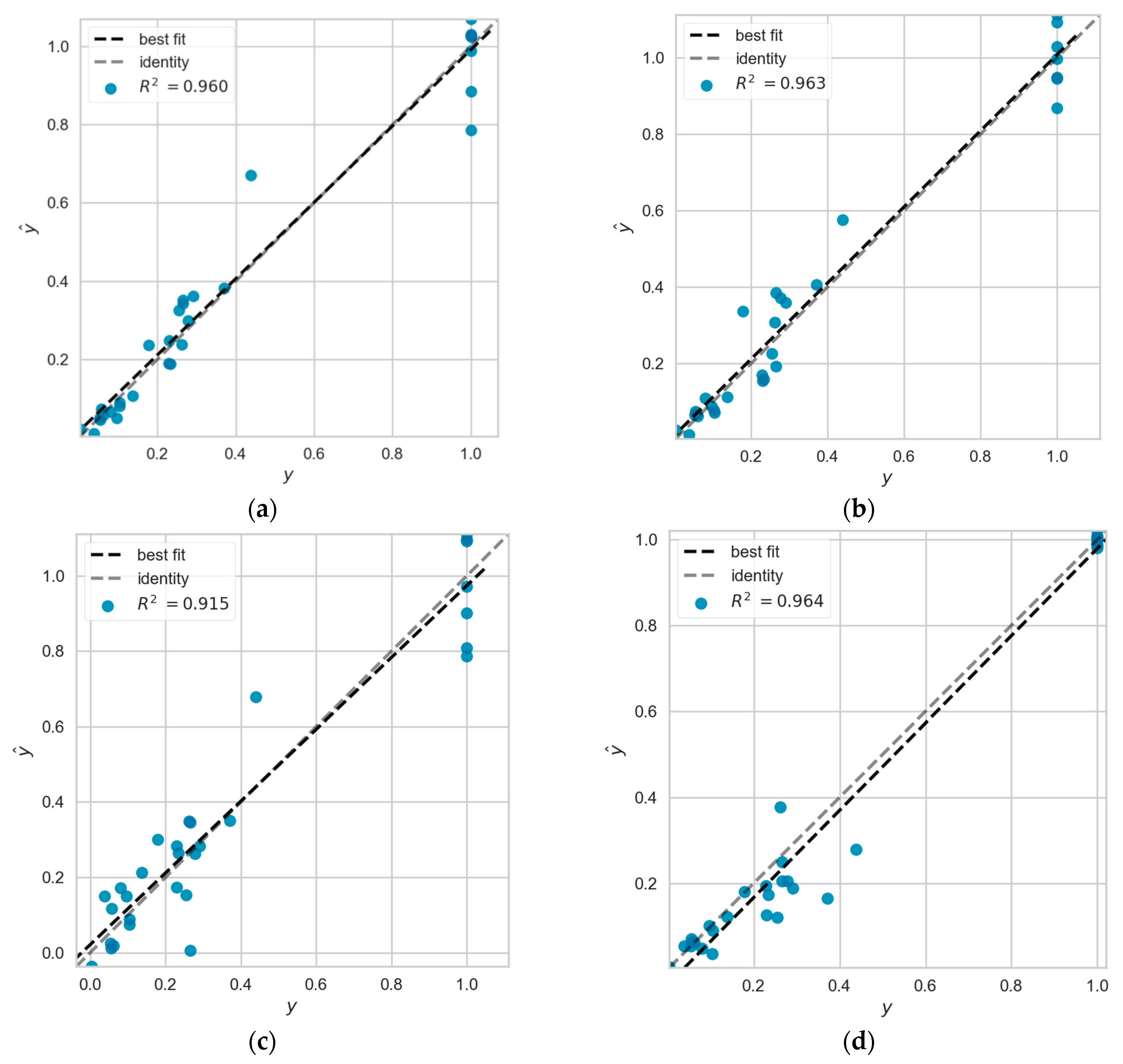
4.9. Analysis of Errors
5. Results and Discussion
- (1)
- In this paper, the absolute efficient frontier is constructed and applied to the performance prediction of a new decision unit. It can break through the limitations of the DEA method, which is based on the input-output index data of the decision unit to constitute the production frontier surface. This frontier surface is relative, and changes as new decision units are added to the frontier surface. The application of the new method allows the addition of new decision units at any time without changing the effective frontier surface and completes a comparative study of the old and new decision units. In addition, the radial or non-radial DEA model measures the efficiency values of each decision unit for each year based on cross-sectional data. Technical efficiency changes and technological progress mainly dominate the variation of efficiency values between years. The radial or non-radial DEA model cannot compare the technical efficiency changes in different years. Using the absolute efficient frontier, the cross-sectional limitation can be broken, and the technical efficiency situation of each decision unit in each year can be compared.
- (2)
- Based on the efficiency scores measured by the DEA method, the efficiency scores are classified by the quartiles method, and then, the different categories are combined and used to train a variety of machine learning models. The trained machine learning models can be used to predict the efficiency scores of new decision units, and the analysis combined with the fitting effect can lead to two conclusions: (i) more effective sample data provide more important feature information; (ii) relatively ineffective sample data will bring the noise to the model learning.
- (3)
- Based on the results of the empirical study of the training subset of the DEA classification method, the training subset with the best prediction effect was selected and used to study further the prediction effect of proportional relative indicators and absolute number indicators. After the empirical study, it was found that the proportional relative index has a better prediction effect compared with the absolute number index.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Provincial Area | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Anhui | 0.52 | 0.51 | 0.47 | 0.45 | 0.45 | 0.44 | 0.43 | 0.41 | 0.40 | 0.40 | 0.40 | 0.41 | 0.41 | 0.41 |
| Beijing | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Chongqing | 0.50 | 0.51 | 0.48 | 0.48 | 0.50 | 0.50 | 0.52 | 0.56 | 0.56 | 0.57 | 0.57 | 0.61 | 0.60 | 0.59 |
| Fujian | 0.63 | 0.59 | 0.58 | 0.54 | 0.53 | 0.51 | 0.52 | 0.53 | 0.52 | 0.51 | 0.52 | 0.56 | 0.55 | 0.54 |
| Gansu | 0.40 | 0.40 | 0.39 | 0.39 | 0.39 | 0.40 | 0.41 | 0.41 | 0.42 | 0.43 | 0.43 | 0.43 | 0.44 | 0.44 |
| Guangdong | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Guangxi | 0.49 | 0.47 | 0.22 | 0.44 | 0.39 | 0.31 | 0.31 | 0.32 | 0.32 | 0.32 | 0.32 | 0.32 | 0.35 | 0.31 |
| Guizhou | 0.29 | 0.31 | 0.32 | 0.32 | 0.32 | 0.32 | 0.32 | 0.32 | 0.33 | 0.33 | 0.33 | 0.33 | 0.33 | 0.32 |
| Hainan | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Hebei | 0.37 | 0.25 | 0.28 | 0.28 | 0.28 | 0.28 | 0.28 | 0.29 | 0.29 | 0.30 | 0.31 | 0.28 | 0.35 | 0.28 |
| Henan | 0.46 | 0.44 | 0.44 | 0.41 | 0.39 | 0.38 | 0.39 | 0.31 | 0.39 | 0.40 | 0.40 | 0.43 | 0.44 | 0.47 |
| Heilongjiang | 0.44 | 0.42 | 0.41 | 0.38 | 0.37 | 0.29 | 0.37 | 0.36 | 0.37 | 0.35 | 0.35 | 0.37 | 0.37 | 0.38 |
| Hubei | 0.41 | 0.40 | 0.27 | 0.40 | 0.40 | 0.39 | 0.39 | 0.40 | 0.42 | 0.43 | 0.43 | 0.44 | 0.44 | 0.44 |
| Hunan | 0.47 | 0.45 | 0.44 | 0.43 | 0.41 | 0.40 | 0.41 | 0.42 | 0.43 | 0.44 | 0.44 | 0.46 | 0.35 | 0.49 |
| Jilin | 0.21 | 0.37 | 0.29 | 0.29 | 0.30 | 0.30 | 0.30 | 0.31 | 0.32 | 0.32 | 0.32 | 0.34 | 0.35 | 0.35 |
| Jiangsu | 0.71 | 0.72 | 0.74 | 0.78 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Jiangxi | 0.52 | 0.52 | 0.52 | 0.51 | 0.50 | 0.49 | 0.51 | 0.48 | 0.49 | 0.48 | 0.47 | 0.48 | 0.47 | 0.47 |
| Liaoning | 0.41 | 0.39 | 0.36 | 0.31 | 0.31 | 0.31 | 0.32 | 0.32 | 0.32 | 0.32 | 0.33 | 0.33 | 0.34 | 0.33 |
| Inner Mongolia | 0.40 | 0.38 | 0.37 | 0.35 | 0.31 | 0.32 | 0.32 | 0.32 | 0.33 | 0.33 | 0.34 | 0.34 | 0.34 | 0.35 |
| Ningxia | 0.64 | 0.63 | 1.00 | 0.59 | 0.59 | 0.59 | 0.61 | 0.48 | 0.49 | 0.48 | 0.47 | 0.45 | 0.46 | 0.46 |
| Qinghai | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Shandong | 0.44 | 0.43 | 0.42 | 0.42 | 0.41 | 0.42 | 0.42 | 0.44 | 0.44 | 0.43 | 0.44 | 0.46 | 0.46 | 0.47 |
| Shanxi | 0.40 | 0.39 | 0.28 | 0.28 | 0.29 | 0.29 | 0.29 | 0.30 | 0.30 | 0.30 | 0.31 | 0.29 | 0.35 | 0.30 |
| Shaanxi | 0.41 | 0.40 | 0.27 | 0.39 | 0.38 | 0.37 | 0.36 | 0.36 | 0.35 | 0.35 | 0.35 | 0.35 | 0.35 | 0.35 |
| Shanghai | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Sichuan | 0.43 | 0.40 | 0.38 | 0.38 | 0.39 | 0.41 | 0.42 | 0.43 | 0.43 | 0.45 | 0.45 | 0.48 | 0.48 | 0.48 |
| Tianjin | 0.66 | 0.63 | 0.63 | 0.61 | 0.55 | 0.54 | 0.54 | 0.52 | 0.52 | 0.53 | 0.53 | 0.45 | 0.45 | 0.45 |
| Xinjiang | 0.41 | 0.42 | 0.42 | 0.41 | 0.40 | 0.39 | 0.38 | 0.36 | 0.32 | 0.32 | 0.33 | 0.32 | 0.35 | 0.32 |
| Yunnan | 0.40 | 0.23 | 0.39 | 0.39 | 0.38 | 0.36 | 0.32 | 0.33 | 0.33 | 0.34 | 0.34 | 0.32 | 0.35 | 0.32 |
| Zhejiang | 0.70 | 0.68 | 0.69 | 0.70 | 0.71 | 0.72 | 0.73 | 0.72 | 0.74 | 0.74 | 0.74 | 0.76 | 1.00 | 1.00 |
| R2 | RMSE | MAE | Ranking | |
|---|---|---|---|---|
| Linear Regression | 0.6203 | 0.2231 | 0.1704 | 10 |
| GBDT | 0.9157 | 0.1051 | 0.0612 | 4 |
| XGBoost | 0.9396 | 0.0890 | 0.0630 | 3 |
| LightGBM | 0.9021 | 0.1133 | 0.0812 | 5 |
| CatBoost | 0.9479 | 0.0826 | 0.0611 | 2 |
| AdaBoost | 0.7598 | 0.1774 | 0.1534 | 9 |
| SVR | 0.8743 | 0.1283 | 0.1104 | 7 |
| BPNN | 0.9601 | 0.0723 | 0.0483 | 1 |
| Decision Trees | 0.5877 | 0.2324 | 0.0976 | 11 |
| Random Forest | 0.8875 | 0.1214 | 0.0882 | 6 |
| Bagging | 0.8549 | 0.1379 | 0.1007 | 8 |
| Average Value | 0.8409 | 0.1348 | 0.0941 |
| R2 | RMSE | MAE | Ranking | |
|---|---|---|---|---|
| Linear Regression | 0.6145 | 0.2248 | 0.1754 | 11 |
| GBDT | 0.8696 | 0.1307 | 0.0782 | 5 |
| XGBoost | 0.9401 | 0.0886 | 0.0643 | 2 |
| LightGBM | 0.8738 | 0.1286 | 0.0886 | 4 |
| CatBoost | 0.9401 | 0.0886 | 0.0653 | 3 |
| AdaBoost | 0.7328 | 0.1871 | 0.1609 | 10 |
| SVR | 0.8658 | 0.1326 | 0.1142 | 6 |
| BPNN | 0.9630 | 0.0697 | 0.0550 | 1 |
| Decision Trees | 0.8459 | 0.1421 | 0.0598 | 7 |
| Random Forest | 0.8365 | 0.1464 | 0.1051 | 8 |
| Bagging | 0.8248 | 0.1515 | 0.1110 | 9 |
| Average Value | 0.8461 | 0.1355 | 0.0980 |
| R2 | RMSE | MAE | Ranking | |
|---|---|---|---|---|
| Linear Regression | 0.6145 | 0.2248 | 0.1754 | 11 |
| GBDT | 0.8561 | 0.1373 | 0.0728 | 6 |
| XGBoost | 0.9121 | 0.1073 | 0.0761 | 3 |
| LightGBM | 0.8828 | 0.1239 | 0.0837 | 4 |
| CatBoost | 0.9377 | 0.0903 | 0.0638 | 1 |
| AdaBoost | 0.6692 | 0.2082 | 0.1568 | 10 |
| SVR | 0.8658 | 0.1326 | 0.1142 | 5 |
| BPNN | 0.9148 | 0.1057 | 0.0833 | 2 |
| Decision Trees | 0.6810 | 0.2045 | 0.1129 | 9 |
| Random Forest | 0.8050 | 0.1599 | 0.1105 | 8 |
| Bagging | 0.8257 | 0.1511 | 0.1104 | 7 |
| Average Value | 0.8150 | 0.1496 | 0.1054 |
| R2 | RMSE | MAE | |
|---|---|---|---|
| Linear Regression | 0.5836 | 0.2336 | 0.1673 |
| GBDT | 0.9359 | 0.0917 | 0.0573 |
| XGBoost | 0.9721 | 0.0553 | 0.0409 |
| LightGBM | 0.9616 | 0.0709 | 0.0491 |
| CatBoost | 0.9674 | 0.0654 | 0.0449 |
| AdaBoost | 0.9246 | 0.0994 | 0.0684 |
| SVR | 0.8394 | 0.1450 | 0.1143 |
| BPNN | 0.9638 | 0.0688 | 0.0438 |
| Decision Trees | 0.9324 | 0.0941 | 0.0640 |
| Random Forest | 0.8875 | 0.1214 | 0.0882 |
| Bagging | 0.9020 | 0.1133 | 0.0792 |
| Average Value | 0.8973 | 0.1054 | 0.0743 |
| Parameter | Affiliation Formula | Formula Belongs to the Model | Parameter Description | Range of Values |
|---|---|---|---|---|
| Equation (1) Equation (2) Equation (3) | CCR model BCC model | Each decision unit has m kind of input | ||
| Equation (1) Equation (2) Equation (3) | CCR model BCC model | Each decision unit has q kind of output | R | |
| Equation (1) | CCR model | The weight of the input | ||
| Equation (1) | CCR model | The weight of the output | ||
| θ | Equation (2) Equation (3) | CCR model BCC model | Efficiency value | |
| λ | Equation (2) Equation (3) | CCR model BCC model | The linear combination coefficient of the decision unit | |
| Equation (4) | SBM model | Objective function | ||
| Equation (4) | SBM model | Input slack variable | ||
| Equation (4) | SBM model | Desired output slack variable | ||
| Equation (4) | SBM model | Non-desired output slack variable | ||
| Equation (5) | Linear Regression | Input vector | R | |
| Equation (5) | Linear Regression | Output vector | R | |
| Equation (5) | Linear Regression | Linear mapping from input to output (Weight matrix) | R | |
| b | Equation (5) | Linear Regression | Offset items | C |
| x | Equation (6) | GBDT model | Input sample | R |
| w | Equation (6) | GBDT model | Weighting factor | R |
| M | Equation (6) | GBDT model | The dataset is divided into M cells | |
| Equation (6) | GBDT model | CART regression tree function | R | |
| α | Equation (6) | GBDT model | Weighting factor for each regression tree | |
| R2 | Equation (7) | Predictive effectiveness evaluation model | Coefficient of determination | |
| Equation (7) Equation (8) Equation (9) | Predictive effectiveness evaluation model | Actual value | R | |
| Equation (7) Equation (8) Equation (9) | Predictive effectiveness evaluation model | Predicted value | R | |
| m | Equation (8) Equation (9) | Predictive effectiveness evaluation model | The number of observations |



References
- Charnes, A.; Cooper, W.W.; Rhodes, E. Measuring the efficiency of decision making units. Eur. J. Oper. Res. 1978, 2, 429–444. [Google Scholar] [CrossRef]
- Staub, R.B.; Souza, G.D.; Tabak, B.M. Evolution of bank efficiency in Brazil: A DEA approach. Eur. J. Oper. Res. 2010, 202, 204–213. [Google Scholar] [CrossRef]
- Holod, D.; Lewis, H.F. Resolving the deposit dilemma: A new DEA bank efficiency model. J. Bank. Financ. 2011, 35, 2801–2810. [Google Scholar] [CrossRef]
- Titko, J.; Stankevičienė, J.; Lāce, N. Measuring bank efficiency: DEA application. Technol. Econ. Dev. Econ. 2014, 20, 739–757. [Google Scholar] [CrossRef]
- Kamarudin, F.; Sufian, F.; Nassir, A.M.; Anwar, N.A.; Hussain, H.I. Bank efficiency in Malaysia a DEA approach. J. Cent. Bank. Theory Pract. 2019, 1, 133–162. [Google Scholar] [CrossRef] [Green Version]
- Azad, M.A.; Talib, M.B.; Kwek, K.T.; Saona, P. Conventional versus Islamic bank efficiency: A dynamic network data-envelopment-analysis approach. J. Intell. Fuzzy Syst. 2021, 40, 1921–1933. [Google Scholar] [CrossRef]
- Micajkova, V. Efficiency of Macedonian insurance companies: A DEA approach. J. Investig. Manag. 2015, 4, 61–67. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Koutmos, D.; Chen, K.; Zhu, J. Using operational and stock analytics to measure airline performance: A network DEA approach. Decis. Sci. 2021, 52, 720–748. [Google Scholar] [CrossRef]
- Dia, M.; Shahi, S.K.; Zéphyr, L. An Assessment of the Efficiency of Canadian Power Generation Companies with Bootstrap DEA. J. Risk Financ. Manag. 2021, 14, 498. [Google Scholar] [CrossRef]
- Jiang, T.; Zhang, Y.; Jin, Q. Sustainability efficiency assessment of listed companies in China: A super-efficiency SBM-DEA model considering undesirable output. Environ. Sci. Pollut. Res. 2021, 28, 47588–47604. [Google Scholar] [CrossRef]
- Ding, L.; Yang, Y.; Wang, W. Regional carbon emission efficiency and its dynamic evolution in China: A novel cross efficiency-malmquist productivity index. J. Clean. Prod. 2019, 241, 118260. [Google Scholar] [CrossRef]
- Iqbal, W.; Altalbe, A.; Fatima, A. A DEA approach for assessing the energy, environmental and economic performance of top 20 industrial countries. Processes 2019, 7, 902. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Wang, Q.; Yao, S. Evaluation and difference analysis of regional energy efficiency in China under the carbon neutrality targets: Insights from DEA and Theil models. J. Environ. Manag. 2021, 293, 112958. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Park, Y.S.; Park, J.D. Evaluating the environmental efficiency of the US airline industry using a directional distance function DEA approach. J. Manag. Anal. 2021, 8, 1–18. [Google Scholar]
- Guo, X.; Wang, X.; Wu, X. Carbon Emission Efficiency and Low-Carbon Optimization in Shanxi Province under “Dual Carbon” Background. Energies 2022, 15, 2369. [Google Scholar] [CrossRef]
- Niu, H.; Zhang, Z.; Xiao, Y.; Luo, M.; Chen, Y. A Study of Carbon Emission Efficiency in Chinese Provinces Based on a Three-Stage SBM-Undesirable Model and an LSTM Model. Int. J. Environ. Res. Public Health 2022, 19, 5395. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, P. Applying the three-stage SBM-DEA model to evaluate energy efficiency and impact factors in RCEP countries. Energy 2022, 241, 122917. [Google Scholar] [CrossRef]
- Bauer, P.W. Recent developments in the econometric estimation of frontiers. J. Econom. 1990, 46, 39–56. [Google Scholar] [CrossRef]
- Stefko, R.; Gavurova, B.; Kocisova, K. Healthcare efficiency assessment using DEA analysis in the Slovak Republic. Health Econ. Rev. 2018, 8, 1–12. [Google Scholar] [CrossRef]
- Wanke, P.; Azad, M.A.; Emrouznejad, A.; Antunes, J. A dynamic network DEA model for accounting and financial indicators: A case of efficiency in MENA banking. Int. Rev. Econ. Financ. 2019, 61, 52–68. [Google Scholar] [CrossRef] [Green Version]
- Kohl, S.; Schoenfelder, J.; Fügener, A.; Brunner, J.O. The use of Data Envelopment Analysis (DEA) in healthcare with a focus on hospitals. Health Care Manag. Sci. 2019, 22, 245–286. [Google Scholar] [CrossRef] [PubMed]
- Blagojević, A.; Vesković, S.; Kasalica, S.; Gojić, A.; Allamani, A. The application of the fuzzy AHP and DEA for measuring the efficiency of freight transport railway undertakings. Oper. Res. Eng. Sci. Theory Appl. 2020, 3, 1–23. [Google Scholar] [CrossRef]
- Yi, L.G.; Hu, M.M. Efficiency Evaluation of Hunan Listed Companies and Influencing Factors. Econ. Geogr. 2019, 6, 154–162. [Google Scholar]
- Emrouznejad, A.; Amin, G.R. DEA models for ratio data: Convexity consideration. Appl. Math. Modeling 2009, 33, 486–498. [Google Scholar] [CrossRef]
- Athanassopoulos, A.D.; Curram, S.P. A comparison of data envelopment analysis and artificial neural networks as tools for assessing the efficiency of decision making units. J. Oper. Res. Soc. 1996, 47, 1000–1016. [Google Scholar] [CrossRef]
- Wang, S. Adaptive non-parametric efficiency frontier analysis: A neural-network-based model. Comput. Oper. Res. 2003, 30, 279–295. [Google Scholar] [CrossRef]
- Santin, D.; Delgado, F.J.; Valino, A. The measurement of technical efficiency: A neural network approach. Appl. Econ. 2004, 36, 627–635. [Google Scholar] [CrossRef]
- Wu, D.D.; Yang, Z.; Liang, L. Using DEA-neural network approach to evaluate branch efficiency of a large Canadian bank. Expert Syst. Appl. 2006, 31, 108–115. [Google Scholar] [CrossRef]
- Azadeh, A.; Ghaderi, S.F.; Sohrabkhani, S. Forecasting electrical consumption by integration of neural network, time series and ANOVA. Appl. Math. Comput. 2007, 186, 1753–1761. [Google Scholar] [CrossRef]
- Emrouznejad, A.; Shale, E. A combined neural network and DEA for measuring efficiency of large scale datasets. Comput. Ind. Eng. 2009, 56, 249–254. [Google Scholar] [CrossRef]
- Samoilenko, S.; Osei-Bryson, K.M. Determining sources of relative inefficiency in heterogeneous samples: Methodology using Cluster Analysis, DEA and Neural Networks. Eur. J. Oper. Res. 2010, 206, 479–487. [Google Scholar] [CrossRef]
- Pendharkar, P.C. A hybrid radial basis function and data envelopment analysis neural network for classification. Comput. Oper. Res. 2011, 38, 256–266. [Google Scholar] [CrossRef]
- Sreekumar, S.; Mahapatra, S.S. Performance modeling of Indian business schools: A DEA-neural network approach. Benchmarking Int. J. 2011, 18, 221–239. [Google Scholar] [CrossRef]
- Tosun, Ö. Using data envelopment analysis–neural network model to evaluate hospital efficiency. Int. J. Product. Qual. Manag. 2012, 9, 245–257. [Google Scholar] [CrossRef]
- Liu, H.H.; Chen, T.Y.; Chiu, Y.H.; Kuo, F.H. A comparison of three-stage DEA and artificial neural network on the operational efficiency of semi-conductor firms in Taiwan. Mod. Econ. 2013, 4, 20–31. [Google Scholar] [CrossRef] [Green Version]
- Kwon, H.B. Exploring the predictive potential of artificial neural networks in conjunction with DEA in railroad performance modeling. Int. J. Prod. Econ. 2017, 183, 159–170. [Google Scholar] [CrossRef]
- Visbal-Cadavid, D.; Mendoza, A.M.; Hoyos, I.Q. Prediction of efficiency in colombian higher education institutions with data envelopment analysis and neural networks. Pesqui. Oper. 2019, 39, 261–275. [Google Scholar] [CrossRef]
- Tsolas, I.E.; Charles, V.; Gherman, T. Supporting better practice benchmarking: A DEA-ANN approach to bank branch performance assessment. Expert Syst. Appl. 2020, 160, 113599. [Google Scholar] [CrossRef]
- Banker, R.D.; Charnes, A.; Cooper, W.W. Some models for estimating technical and scale inefficiencies in DEA. Manag. Sci. 1984, 32, 1613–1627. [Google Scholar] [CrossRef]
- Tone, K. A slacks-based measure of efficiency in data envelopment analysis. Eur. J. Oper. Res. 2001, 130, 498–509. [Google Scholar] [CrossRef] [Green Version]
- Tone, K. Dealing with undesirable outputs in DEA: A slacks-based measure (SBM) approach. Present. NAPW III 2004, 2004, 44–45. [Google Scholar]
- Charnes, A.; Cooper, W.W. Programming with linear fractional functional. Nav. Res. Logist. Q. 1962, 9, 181–186. [Google Scholar] [CrossRef]
- Vapnik, V.N. The nature of statistical learning theory. Nat. Stat. Learn. Theory 1995, 20, 273–297. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Breiman, L.I.; Friedman, J.H.; Olshen, R.A. Classification and Regression Trees Wadsworth. Biometrics 1984, 40, 358. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]




| Authors/Year | Research Findings |
|---|---|
| Athanassopoulos and Curram (1996) [25] | For the first time, it is demonstrated that DEA and neural networks are justified as non-parametric models with a combination. This is the first attempt in this field. |
| Wang (2003) [26] | The combination of DEA and ANNs can help decision makers construct a stable and effective boundary. |
| Santin et al. (2004) [27] | By comparing the application of DEA and ANNs in efficiency analysis, it is demonstrated that the two methods have some similarity and provide a basis for the combination of both. |
| Wu et al. (2006) [28] | The article applies a combination of DEA and ANNs to the performance evaluation of Canadian banks. The empirical study shows that the method facilitates the construction of a stronger frontier surface and addresses the shortcomings of a purely linear DEA approach. |
| Azadeh et al. (2007) [29] | Combining DEA and ANNs is a good complement to help in predicting efficiency. |
| Emrouznejad and Shale (2009) [30] | The integrated model of DEA and neural network methods can be a useful tool for measuring the efficiency of large datasets. |
| Samoilenko and Osei-Bryson (2010) [31] | This paper proposed that neural networks should be able to assist DEA. |
| Pendharkar (2011) [32] | This paper propose a hybrid radial basis function network-DEA. The model shows good results on the dichotomous classification problem. |
| Sreekumar and Mahapatra (2011) [33] | The main objective of this research is to formulate an integrated approach combining DEA and neural network for assessing and predicting the performance of B-schools in India for effective decision making as the errors and biases generated as a result of human intervention in decision making would be significantly reduced. |
| Tosun (2012) [34] | The article combines DEA and ANN methods and applies them to the efficiency evaluation of hospitals. Results show that well-trained ANNs perform good classification and even gives better solutions than DEA. |
| Liu et al. (2013) [35] | The study measured the technical efficiency of 29 semiconductor companies in Taiwan using a three-stage radial DEA model combined with ANNs. According to the empirical results, the ANNs approach yielded a more robust frontier and identifies more efficient units since more good performance patterns are explored. |
| Kwon (2017) [36] | The study used DEA models to evaluate the efficiency of each decision unit. Based on these efficiency results, the back propagation neural network in ANNs model was subsequently used to predict the efficiency score and target output of each decision unit. This is a new attempt to extend the back propagation neural network model for purposes of best performance prediction. |
| Visbal-Cadavid et al. (2019) [37] | The paper presents the results of a study on the application of DEAs and ANNs to data from Colombian higher education institutions and points out that in the future different machine learning techniques should be used instead of just neural networks. |
| Tsolas et al. (2020) [38] | Integration of DEA and ANNs to test the efficiency classification of Greek bank branches. According to the empirical results, the integrated model shows a satisfactory classification capability. |
| Indicator Type | Variables | Unit |
|---|---|---|
| Input indicator 1 | Workforce | 10,000 people |
| Input indicator 2 | Capital stock | Billion |
| Input indicator 3 | Energy | Million tons of standard coal |
| Desired Output Indicators | Gross regional product | Billion |
| Non-desired output indicators | Carbon dioxide emissions | Ton |
| Variables | Average Value | Standard Deviation | Minimum Value | Maximum Value |
|---|---|---|---|---|
| Labor force (10,000 people) | 35,043.40 | 29,119.78 | 1711.90 | 158,345.80 |
| Capital stock (billion yuan) | 2649.41 | 1736.99 | 294.19 | 6995.00 |
| Energy (million tons of standard coal) | 13,636.75 | 8569.33 | 920.45 | 41,390.00 |
| Gross regional product (billion yuan) | 14,625.58 | 13,309.65 | 560.83 | 78,346.04 |
| Carbon dioxide emissions (ton) | 331.45 | 272.61 | 14.61 | 1700.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Xiao, Y.; Niu, H. DEA and Machine Learning for Performance Prediction. Mathematics 2022, 10, 1776. https://doi.org/10.3390/math10101776
Zhang Z, Xiao Y, Niu H. DEA and Machine Learning for Performance Prediction. Mathematics. 2022; 10(10):1776. https://doi.org/10.3390/math10101776
Chicago/Turabian StyleZhang, Zhishuo, Yao Xiao, and Huayong Niu. 2022. "DEA and Machine Learning for Performance Prediction" Mathematics 10, no. 10: 1776. https://doi.org/10.3390/math10101776
APA StyleZhang, Z., Xiao, Y., & Niu, H. (2022). DEA and Machine Learning for Performance Prediction. Mathematics, 10(10), 1776. https://doi.org/10.3390/math10101776