1. Introduction
On one hand, the massive amounts of data collected in all industries at present provide more specific and valuable information. On the other side, it is more difficult to analyze this data when not all the information is important. Identifying the appropriate aspects of data is a difficult challenge. Dimension reduction is a strategy used to solve classification and regression problems by identifying a subset of characteristics and eliminating duplicate ones. This method is very useful when there are numerous qualities, and not all of them are needed to interpret the data and conduct additional experiments on the attributes. The essential principle of selecting features is that for many pattern classification tasks, a large number of features does not necessarily equal a high classification accuracy. Idealistically, the selected attributes subset will improve classifier performance and provide a quicker, more cost-effective classification, resulting in comparable or even higher classification accuracy than using all of the attributes [
1].
Selecting feature subsets with a powerful and distinctive impact for high-dimensional data analysis is a critical step. High-dimensional datasets have recently become more prevalent in various real-world applications, including genome ventures, data mining, and computer vision. However, the high dimensionality of the datasets may result from unnecessary or redundant features, which can reduce the effectiveness of the learning algorithm or result in data overfitting [
2].
Feature selection (FS) has become a viable data preparation method for addressing the curse of dimensionality. FS strategies focus on selecting feature subsets using various selection criteria while keeping the physical meanings of the original characteristics [
3]. It can make learning models easier to comprehend and perceive. FS has proven its efficiency in various real-world machine learning and data mining problems, such as pattern recognition, information retrieval, object-based image classification, intrusion detection, and spam detection, to name only a few [
4]. The FS process aims to reduce the search space’s dimension to improve the learning algorithm’s efficiency [
5].
The feature selection methodology derives its strength from two main processes, the search and the evaluation. Choosing the most valuable features from the original set with passing all the incoming subsets may face a combinatorial explosion. Therefore, search methodologies are adopted to select the worthy features efficiently. The traditional greedy search strategies such as forward and backward search have been used. The problem with this type of searching is that it may succumb to locally optimal solutions, resulting in non-optimal features. The evaluation function can handle this issue by assessing each feature subset’s overall importance, which may help discover the globally optimal or near-optimal solution. Based on the methods used to evaluate feature subsets, the feature selection algorithms are categorized into three primary approaches: filter, wrapper, and embedding methods [
6].
Since FS seeks out the near-optimal feature subset, it is considered an optimization problem. Thus, exhaustive search methodologies will be unreliable in this situation, as they generate all potential solutions to find only the best one [
7].
Meta-heuristic algorithms gain their superiority from their ability to find the most appropriate solutions in an acceptable, realistic time [
8]. In general, meta-heuristic and evolutionary algorithms can avoid the problem of local-optima better than traditional optimization algorithms [
9]. Recently, nature-inspired meta-heuristic algorithms have been used most frequently to tackle optimization problems [
10].
Typically, the feature selection problem can be mathematically phrased as a multi-objective problem with two objectives: decreasing the size of the selected feature set and optimizing classification accuracy. Typically, these two goals are incompatible, and the ideal answer is a compromise.
Meta-heuristic algorithms are stochastic algorithms that fall into two categories: single-solution-based and population-based. The solution is randomly generated until it reaches the optimum result [
11]. In contrast, the population-based algorithm’s strategy is based on evolving a set of solutions (i.e., population) in a given search space during many iterations until it obtains the best solution. According to the theory of evolutionary algorithms, population-based algorithms are categorized into physics laws-based algorithms, swarm intelligence of particles, and bio-inspired algorithms’ biological behavior. Evolutionary algorithms (EA) are based on the fitness of survival attempts. GA inspires its strategy from natural evolutionary processes (e.g., reproduction, mutation, recombination, and selection). Swarm intelligence (SI) techniques are based on swarms’ mutual intelligence. Finally, the physical processes that motivate the physics law-based algorithms include electrostatic induction, gravitational force, and heating systems of materials [
11].
Several algorithms proved their efficiency in both optimization and feature selection fields. The Genetic Algorithms (GA), especially binary GA approaches, are regarded as leading evolution-based algorithms that have been used to handle FS problems [
12].
The Particle Swarm Optimization (PSO) algorithm, constructed for continuous optimization issues [
13], also has a binary version (BPSO) that was presented for binary optimization problems[
14]. The BPSO has been used, as well, in FS by [
15,
16,
17]. Furthermore, many other optimization algorithms succeeded in solving FS problems, such as the Ant Colony Optimization (ACO) algorithm [
18], Artificial Bee Colony (ABC) algorithm [
19], Binary Gravitational Search Algorithm (BGSA) [
20], Scatter Search Algorithm (SSA) [
21], Archimedes Optimization Algorithm (AOA) [
22], Backtracking Search Algorithm (BSA) [
23], Marine Predators Algorithm (MPA) [
24], and Whale Optimization Algorithm (WOA) [
25].
The common challenge of the previously suggested metaheuristics for FS is the slow convergence rate, bad scalability [
26], and lack of precision and consistency. Moreover, the characteristics of large-scale FS issues with various datasets may differ. As a result, solving diverse large-scale FS issues using an existing approach with only one candidate solution generating process may be inefficient [
27]. Furthermore, identifying an appropriate FS approach and parameter values takes time to efficiently address a large-scale FS issue. This limitation motivates the current study, which proposes a novel algorithm for an FS task using the Heap Based optimizer.
As a result, In this research, we propose an enhancement to a current optimization technique known as the Heap Based Optimizer (HBO), which is a brand-new human behavior-based algorithm [
28]. The HBO is a novel meta-heuristic inspired by corporate rank hierarchy (CRH) and some human behavior. An adaptive opposition strategy is proposed to enable the original algorithm to achieve more precise outcomes with increasingly complex challenges.
HBO displayed incredibly competitive performance. It demonstrates effectiveness in optimization issues. HBO provides numerous benefits, including fewer parameters, a straightforward configuration, simple implementation, and precise calculation. In addition, this method is superior to other algorithms. The HBO algorithm takes fewer iterations. All of these features are really beneficial for resolving the FS issue. It has a straightforward approach, low computational burden, rapid convergence, near-global solution, issue independence, and gradient-free nature [
29,
30].
This paper reports the following main contributions:
An improved Heap Based Optimizer (HBO) algorithm, termed , is proposed for the feature selection problem
The proposed improved version was tested on 20 datasets, in which 8 belong to a considerably high-dimensional class. The performance of the meta-heuristic algorithms on FS problems for such high-dimensional datasets is rarely investigated.
The performance of proposed in terms of fitness, accuracy, precision, sensitivity, F-score, and the number of selected features is compared with some recent optimization methods.
The remainder of the article is as follows:
Section 2 demonstrates the process of reviewing the literature on FS metaheuristic algorithms.
Section 3 introduces Continuous Heap Based Optimizer steps. The binary HBO strategy is detailed in
Section 4. The experiment’s results are discussed in
Section 5. In
Section 6, conclusions and future work are discussed.
2. Related Works
Real-world numerical optimization problems have become increasingly complicated, necessitating efficient optimization approaches. The research direction of evolving and implementing metaheuristics to solve FS problems is still in progress. Generally, identifying prominent feature subsets requires an evaluation that compares subsets and chooses the best. When using a wrapper feature selection model, three performance indicators should be used: a classifier (e.g., Support Vector Machine, k-Nearest Neighbors, Decision Tree), feature selection criteria (e.g., accuracy, area under the ROC curve, and false-positive (FP) elimination rate), and an optimization algorithm to search for the optimal combination of features [
31]. Numerous novel SI optimization algorithms were used as search strategies for several wrapper feature selection techniques. Several studies are interested in converting the continuous optimization methods into binary versions to deal with discrete problems and find the optimal feature subset in classification processes. For instance, different binary versions of PSO have been proposed in [
6,
32,
33]. The authors of [
32] presented an optimization algorithm based on PSO. This study uses the catfish influence to enhance binary particle swarm optimization (BPSO). The proposed algorithm concept is to introduce new particles into the search area that are initialized at the search space’s extreme points, and then substitute particles with the worst fitness if the global best particle’s fitness does not improve after several iterations. The authors used the
k-NN technique with leave-one-out cross-validation (LOOCV) to determine the efficacy of the proposed algorithm’s output.
The authors of [
33] presented a binary PSO algorithm with a mutation operator (MBPSO) to address the spam detection problem and minimize false positives caused by mislabeling non-spam as spam.
Another binary optimization algorithm based on Grasshopper Optimization was developed in [
34]. The authors presented two main methods to produce BGOA. The first method employs Sigmoid and V-shaped transfer functions to convert continuous solutions to binary equivalents. In the second method, a novel strategy, BGOA-M repositions the current solution based on the best solution’s location up to this point. In the same context, the authors of [
35] transformed the continuous version of gray wolf optimization to a binary form (bGWO) to be used in the classification process. Based on the wrapper model, they created two approaches for obtaining the optimal features. The first approach tended to pick the best three solutions, binarize them, and then apply a random crossover. The second approach uses a sigmoid function to smash the continuous position, which is then stochastically thresholded to obtain the modified binary gray wolf position. The results of the proposed approaches outperformed GA and PSO. Another discrete version of GWO, the multi-objective gray wolf optimization algorithm, was presented in [
36]. This proposed algorithm’s goal was to reduce the dimensions of the features for multiclass sentiment classification.
One more neoteric nature-inspired optimization strategy is the Whale optimization algorithm (WOA). WOA is a strategy that emulates the behavioral patterns of a bubble-net hunter. As a binary model based on a sigmoid transfer function, it was adopted in [
10] for feature selection and classification problems (S-shape). BWOA works on the principle of converting any free position of the whale to its binary solutions. This proposed approach forces the search agents to travel in a binary space by implementing an S-shaped transfer function for each dimension.
Likewise, the Ant Lion Optimizer (ALO) algorithm was converted to a binary version by [
35]. This binary version was developed using two approaches. The first just converted the ALO operators to their corresponding binary. The authors used the original ALO and the proper threshold function to threshold its continuous steps after squelching them in the second approach. According to this study, the BALO outperformed the original ALO and other popular optimization algorithms such as GA, PSO, and binary bat algorithm. The authors of [
37] introduced a new version of the Salp Swarm Optimizer (SSA) for feature selection. The SSA’s position wasupdated in the proposed methodology by a type of Sine Cosine Algorithm called sinusoidal mathematical function. This study aimed to improve the exploration process and avoid slumps in a local area.
Furthermore, it tried to enhance the population variety and keep a balance between exploration and exploitation processes using the Disruption Operator. SSA was also used to develop two wrapper-based feature selection models in [
2]. The first model used eight transfer functions to transform the continuous version of SSA. The second model added the crossover operator to improve the swarm behavior with these transfer functions.
Other optimization algorithms, such as the Binary Spotted Hyena Optimizer (BSHO) [
38], Binary bat algorithm (BBA) [
39], Binary dragonfly algorithm [
40], Henry gas solubility optimization algorithm (HGSO) [
41], Gradient-based optimizer (GBO) [
42], Crow search algorithm (CSA) [
43,
44], Equilibrium Optimizer (EO) [
45], and chaotic cuckoo algorithm [
46] are algorithms that have been used to solve feature selection problems and improve classification performance.
One of the recent directions in the literature is using hybrid algorithms to improve performance and efficiency. The authors of [
47] introduced a hybrid algorithm that merges the Flower Pollination Algorithm (FPA) and the Clonal Selection Algorithm to produce a Binary Clonal Flower Pollination Algorithm (BCFA). Their proposed algorithm used the Optimum-Path Forest classifier as an objective function. BCFA was tested on three benchmark datasets and achieved stunning results in selecting the optimal features in less time. A hybrid feature selection algorithm based on the forest optimization algorithm (FOA) and minimization of redundancy and maximum relevance (mRMR) was proposed in [
48]. The results showed that applying
k-NN and NB classifiers with the proposed FOA algorithm outperformed standard classifier algorithms. The authors of [
49] presented a binary swallow swarm optimization (BSSO) algorithm with a fuzzy rule-based classifier to solve the feature selection problem for fuzzy classification. This proposed approach focused on eliminating more potentially noise-inducing features. However, as mentioned in this study, the main drawback of BSSO is the significant number of tunable parameters that must be empirically chosen.
The authors of [
50] combined the GA and PSO to benefit from the exploitation capabilities of GA and the exploration capabilities of PSO. The proposed binary genetic swarm optimization (BGSO) allows GA and PSO to operate independently. Furthermore, BGSO integrated its outcome with the average weighted combination method to generate an intermediate solution to elicit sufficient information from the obtained features. The classifiers used to obtain the final results were
k-NN and MLP.
According to the various mentioned studies, binary versions of optimization algorithms have strengths over traditional feature selection algorithms.
Some other recent notable works of interest which proposed techniques for feature selection based on fuzzy entropy such as in [
51,
52,
53]. Other notable works of interest that proposed metaheuristics for the FS problem are discussed below.
The authors of [
54] proposed an improved multi-objective Salp Swarm Algorithm (SSA) that incorporates a dynamic time-varying strategy and local fittest solutions. The SSA algorithm relies on these components to balance exploration and exploitation. As a result, it achieves faster convergence while avoiding locally optimum solutions. The method is tested on 13 datasets (Nci9, Glioma, Lymphography, PenglungEW, WaveformEW, Zoo, Exactly, Exactly2, HeartEW, SonarEW, SpectEW, Colon, and Leukemia). The authors of [
55] combined monarch butterfly optimizer (MBO) and a KNN classifier wrapper-based FS method. The simulations were made on 18 standard datasets. The suggested method resulted from high classification accuracy of 93% as compared to the related other methods. The authors of [
56] gave two binary versions of the Butterfly Optimization Algorithm (BOA), which were applied to pick the optimal subset of features for classification with the help of a wrapper mode. The methods were assessed on 21 datasets of the UCI repository. The authors of [
57] adopted a binary equilibrium optimizer (EO) motivated by controlled volume mass balance models for determining the dynamic and equilibrium states with a V-shaped transfer function (BEO-V) to choose the optimal subset of features for classification. The anticipated method is tested on 19 UCI datasets to gauge the performance. The authors of [
58] proposed a Social Mimic Optimization (SMO) algorithm based on people’s behavior in society, with the X-shaped transfer function based on crossover operation, to augment the exploration and exploitation credibility of binary SMO. The anticipated method is analyzed using 18 benchmark UCI datasets for performance evaluation. Sigmoid transfer function maps continuous search space into binary space. The authors of [
59] suggested a binary version of Sailfish Optimizer (SFO), called Binary Sailfish (BSF), to deal with FS problems. To promote the exploitation credibility of the BSF algorithm, they combined it with adaptive
-hill climbing. The algorithms are evaluated on 18 UCI benchmark datasets, which were then compared with ten other meta-heuristics applied for FS methods. The authors of [
60] blended GA with the Great Deluge Algorithm (GDA) used in place of mutation operation, thus achieving a high degree of exploitation through perturbation of candidate solutions. The proposed method was evaluated on 15 openly available UCI datasets. The authors of [
61] proffered using a binary Dragonfly Algorithm (BDA) with an improved updating mechanism to capitalize on the survival-of-the-fittest basis by investigating some functions and strategies to revise its five main coefficients for the FS problems. The methods were tested and analyzed with 18 standard datasets, with Sinusoidal-BDA obtaining the best results. The authors of [
62] forwarded a binary symbiotic organism search (SOS) that was used to map continuous-space to a discrete space with the help of an adaptive S-shaped transfer function to obtain the optimal subset of features. The method is assessed on 19 datasets of UCI. The authors of [
63] suggested a multi-objective FS method based on forest optimization algorithm (FOA) with archive, grid, and region-based selection. The performance is evaluated on nine UCI datasets and two microarray datasets. The authors of [
64] proposed an improved Coral Reefs Optimization (CRO) for finding the best subsets of features. The method applied tournament selection to improvize the initial population’s diversity. The method outperforms other algorithms.
To summarize, FS is a binary optimization problem that aims to improve the classification accuracy of machine learning algorithms using a smaller subset of features. To solve the FS problem, many meta-heuristic algorithms were proposed to explore the solution space to determine the optimal or near-optimal solution by belittling the fitness function. However, deciding a specific subset of features through a meta-heuristic algorithm involves a transfer function that can convert the continuous search space to a binary one. Most of the standard datasets from the UCI repository were for evaluation. The literature review results are summarized in
Table 1.
The common challenge of the previously suggested metaheuristics for FS is the slow convergence rate, bad scalability [
26], and lack of precision and consistency. It takes time to identify an appropriate FS approach and parameter values efficiently.
This limitation motivates the current study, which proposes a novel algorithm for an FS task using the Heap Based optimizer. The HBO was selected as an effective optimization engine for a wrapper FS approach because, relative to Si-based optimizers, it showed sufficient efficacy in tackling several optimization difficulties. The HBO is a new optimizer that has not yet been used to solve FS issues. Its distinctive properties make it a suitable search engine for global optimization and FS issues. The HBO is initially efficient, adaptable, simple, and straightforward to deploy. To balance exploration and exploitation, HBO has only one parameter. This parameter is decreased adaptively across successive iterations, enabling the HBO to explore the majority of the search space at the beginning of the searching process and then exploit the promising regions in the final phases, preventing the HBO from becoming trapped at local optima. Therefore, we used an improved and Enhanced algorithm of HBO in this study to select the most optimal features. We proposed a new dimension reduction approach, the bHBO-based one, based on the k-NN classifier, for selecting the optimal set of features.
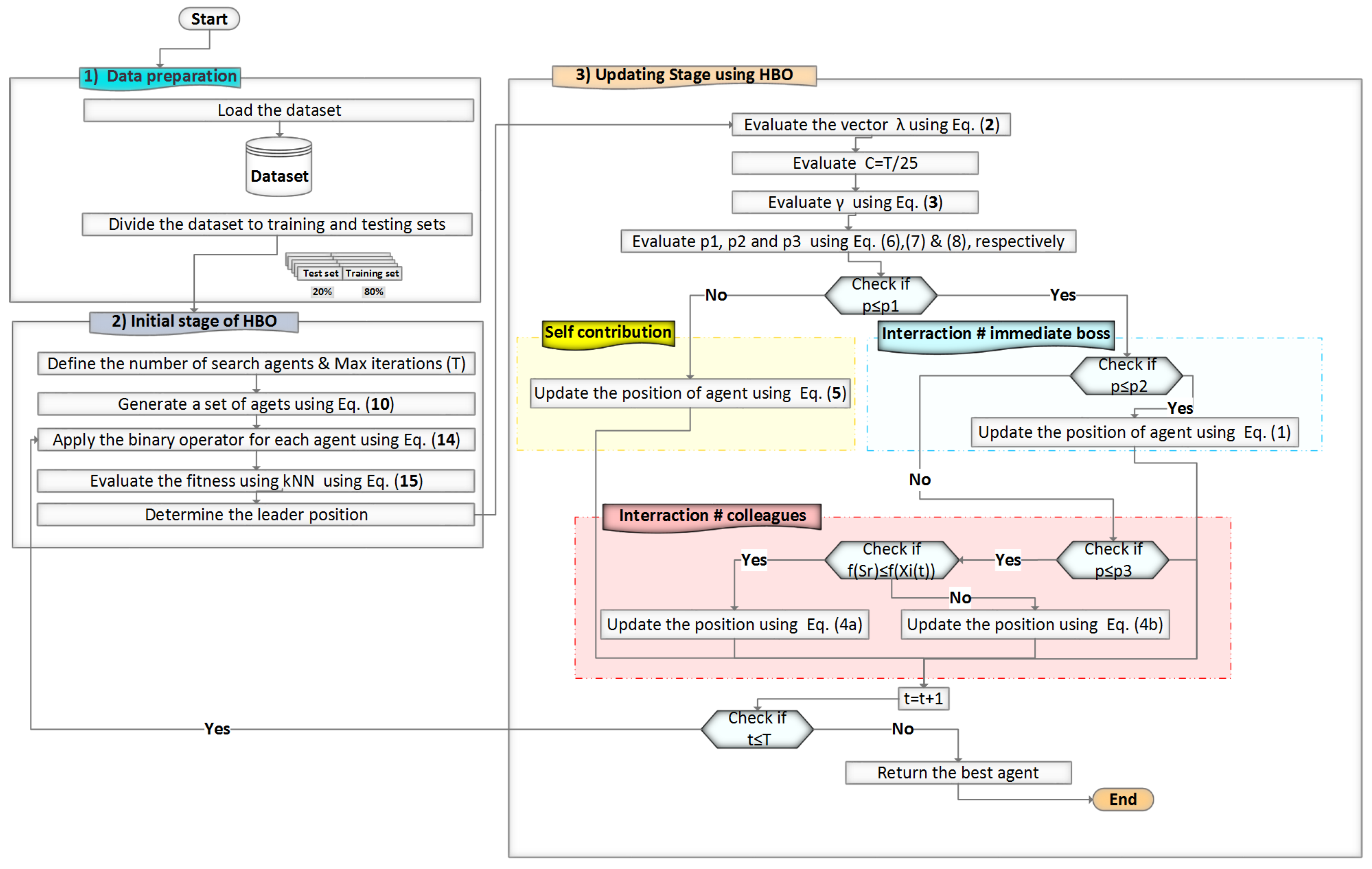
4. The Proposed Binary HBO () for Feature Selection
This section includes the proposed Heap Based Optimizer’s (HBO) steps for solving feature selection using KNN as the classifier. The proposed technique is a mix of the
and KNN algorithms for classification, feature selection, and parameter optimization. In
, KNN parameters are used to identify the best selection accuracy, and the selected features are used for all cross-validation folds.
Figure 1 depicts the suggested
-KNN approach’s flowchart, which depicts the three steps of the proposed method. Algorithm 4 shows the pseudocode for the proposed
with KNN classification algorithm.
| Algorithm 4 The Pseudo code of the proposed based on KNN classifier. |
Inputs: The size of the population, N, and the maximum number of generations T, group classifier G, characteristic X, dataset set D, and a novel fitness function ( fobj). Outputs: The prediction accuracy for each iteration (optimal location) and the highest accuracy value Randomly Initiate the population X i (i = 1, 2, …, N) whiledo New fitness function computed Using the strategy for selecting call features, Call k-NN classifier for ( 1 to T) do is calculated using Equation( 3). is calculated using Equation ( 6) is calculated using Equation ( 7) for ( N down to 2) do heap[I].value ← heap[parent(I)].value ← heap[colleague(I)].value for ( 1 to D) do Calculation of a new fitness function using the call feature selection technique. Call k-NN classifier using Equation ( 9) end for if then end if Heapify_Up(I) end for end for return end while
|
4.1. FS for Classification
Classification is the most important problem in data mining, and its fundamental function is to estimate the class of an unknown object. A dataset (also known as a training set) typically consists of rows (referred to as objects) and columns (referred to as features) that correspond to predetermined classifications (decision features). A significant number of redundant or irrelevant characteristics in the dataset may be the primary factor affecting a classifier’s accuracy and performance. Redundant characteristics may negatively impact the classifier’s performance in various ways; adding more features to a dataset involves adding more examples, which increases the learning time of the classifier. Moreover, a classification that learns from features in the dataset is more accurate than one that learns from irrelevant data. This is because irrelevant features can confuse the classifier, overfitting the data. In addition, the duplicated and irrelevant input will increase the complexity of the classifier, making it more challenging to comprehend the learned results. As was demonstrated previously, the selection of a suitable searching strategy in FS techniques is crucial for optimizing the efficiency of the learning algorithm. FS often aids in detecting redundant and unneeded features and eliminating them to enhance the classifier’s results in terms of learning time and accuracy, as well as simplifying the findings to make them more understandable. By selecting the most informative feature and removing unneeded and redundant features, the dimension of the feature space is decreased, and the convergence rate of the learning algorithm is accelerated.
Because of the above, the HBO was selected as an efficient optimization engine in a wrapper FS method since it has shown sufficient efficacy in solving several optimization issues compared to Si-based optimization techniques. The HBO is a new optimizer that has not yet been used to solve FS issues. Its distinctive properties make it a suitable search engine for global optimization and FS issues. The HBO is initially efficient, adaptable, simple, and straightforward to deploy. To balance exploration and exploitation, HBO has only one parameter.
4.2. The Proposed Binary HBO ()
Searching for the optimal feature subset in FS is a difficult problem, particularly for wrapper-based approaches. This is because the supervised learning (e.g., classifier) must evaluate the selected subset at each optimization step. Consequently, a suitable optimization approach is crucial to minimize the number of evaluations.
The based on comparative of HBO prompted us to suggest using this method as a search strategy in a wrapper-based FS procedure. We proposed a binary version of the HBO to solve the FS problem because the search space may be represented by binary values [0, 1]. Binary operators are believed to be considerably easier than their continuous counterparts. In the continuous form of HBO, each agent’s location is updated depending on its current position, the position of the best solution so far (target), and the positions of all other solutions, as shown in Equations (
1) and (
5). The new solution derived from Equation (
4) is obtained by adding the step vector to the target vector (position vector). However, the addition operator cannot be used in a binary space because the position vector only includes 0 s and 1 s. The next three subsections elaborate on these approaches.
4.3. Proposed for FS Based on KNN
Previous sections demonstrated the significance of an effective search strategy for FS approaches. Another feature of FS techniques is evaluating the selected subset’s quality. Since the suggested method is wrapper-based, an algorithm for learning (such as a classifier) must be incorporated into the evaluation process. This study employs the k-Nearest Neighbor. The classifying quality of the chosen features is integrated into the proposed fitness values because the primary problem of this study is the feature selection problem—not the classification problem—which is tackled by the HBO technique. Each algorithm is executed 51 times with 1000 iterations; the classification is used to select the iteration with the highest accuracy for each run. Therefore, we require the simplicity classifier to reduce each method’s complexity and execution time.
In this proposed approach, the KNN is employed as a classification to guarantee the selected features’ quality. When relevant features are selected from a subset, the classification accuracy will be enhanced. One of the primary goals of FS approaches is to improve classification accuracy; another is to reduce the number of selected features. The superiority of a solution increases as its number of components decreases. In the proposed fitness function, these two contradicting goals are considered. Equation (
16) depicts the fitness function that considers classification accuracy and the number of selected features when evaluating a subset of characteristics across all techniques. In HBO, KNN parameters are used to identify the best selection accuracy, and the selected features are used for all cross-validation folds.
Figure 1 depicts the suggested HBO-KNN approach’s flowchart, which depicts the three steps of the proposed method. The first step is preprocessing, followed by FS and optimization phase, and then the classification and cross-validation phase. Algorithm 4 shows the pseudocode for the proposed
based on the KNN classifier.
4.4. Fitness Function for FS
To define FS as an optimization problem, it is necessary to examine two crucial factors: how to represent a solution and how to evaluate it. A wrapper FS strategy employing HBO as a search algorithm and a
k-NN classifier as an evaluator has been developed. A feature subset is converted into a binary vector with the same length as the number of selected features used for this investigation. If the value of a feature is 1, it has been selected; otherwise, it has not. The quality of a feature subset is determined by the classification accuracy (error rate) and the number of features selected simultaneously. These two contradicting objectives are represented by a single fitness function denoted by Equation (
14).
where
is the number of selected features in a reduct,
is the number of conditional features in the original dataset, and
,
are two main parameters related to the significance of classifying performance and subset length.
The proposed fitness function governs the Accuracy of the selected features. During the iterative process, the solutions HBO finds must be reviewed to verify the performance of each iteration. Before the evaluation of fitness, a binary conversion is realized using Equation (
15) and the HBO fitness function is defined by Equation (
16).
R is the classification error rate computed by
k-NN (80% for training and 20% for testing), where
C denotes the total number of features and
c indicates the relevant selected features.
As illustrated in
Figure 1, HBO is customized to choose the most important and best features.
5. Results and Discussion
In this section, a comparison between the results of the developed FS approach and other methods is performed. The proposed algorithm is compared with eight recent evolutionary feature selection algorithms, such as ALO, AOA, BSA, CSA, LFD, PSO, SMA, and TSA. Each compared algorithm was run 51 times on a population size set to 30 with 1000 iterations. The suggested algorithm was constructed in Matlab using the same interactive environment, which was executed on a computer with an Intel(R) Core i7 2.80 GHz processor and 32 GB RAM.
The experiment is achieved using different datasets with different characteristics. The details of the behavior of datasets are given in the following section.
5.1. Datasets and Parameter Setup
Twenty datasets in
Table 2 from the UCI machine learning repository [
70] are used in the experiments to evaluate the effectiveness of the suggested method. Each dataset’s instances are randomly partitioned into 80% for training and 20% for testing. The provided datasets are arranged from the category of low dimensionality to high dimensionality data. Low-dimensional datasets have less than ten feature sizes, whereas high dimension is greater than ten features. The challenge is finding an optimal subset of features with high accuracy to justify the quality performance. This study employs a wrapper-based method for feature selection based on the KNN classifier, where K = 5 was determined to be the optimal choice for all datasets.
Table 3 presents the settings of parameters of algorithms considered in this work to analyze and assess the performance of the proposed method.
5.2. Performance Metrics
It is imperative to quantify the relevant performance metrics which can guide to analysis of the performance behavior of an anticipated algorithm. As a result, the following evaluation metrics and measures were computed for the proposed method (
), developed to solve the feature selection problem [
71].
Average fitness value: is the best fitness value
obtained when running several algorithms for
N times. It represents decreasing the selection ratio and minimizing the classification error rate. It is calculated by Equation (
17):
Standard Deviation (): It is an indicator of the stability of the used algorithm. It is calculated by (
18):
Average accuracy : The accuracy metric (
) identifies the correct data classification rate. It is calculated by (
19):
In our study, nine different algorithms are running
N times, so it is more suitable to use the
metric, which is calculated by (
20):
Sensitivity or True Positive Rate (TPR): it presents the rate of predicting positive patterns. It is calculated by (
21):
Specificity or True Negative Rate (TNR): it indicates the percentage of actual negatives which are correctly detected. Equation (
22) is used to calculate it:
5.3. Comparison of with Other Metaheuristics
In this section, the comparison of performance of with other well-known meta-heuristic algorithms is performed. The results are discussed in terms of different performance analyses such as:
In terms of fitness: The comparison results between the suggested
and other competing algorithms are shown in
Table 4. It is evident from the obtained results that our
provides results better than the others. For example, it has the smallest results compared with the competitive methods at 17 datasets which represents 85% of the total number of tested datasets. The ALO follows this, which achieved the smallest fitness value in the two datasets, while AOA, BSA, and CSA are the worst algorithms.
In terms of accuracy: The following points can be observed from the results given in
Table 5. First, the
has higher accuracy at nearly 80% of the total number of datasets. In addition, it is more stable than all other tested algorithms. However, it has the worst accuracy of the three datasets. This indicates the high efficiency of the proposed
. This is followed by the ALO, which achieved the second accuracy rank at seven datasets. At the same time, SMA is the worst algorithm. The standard deviation is computed to evaluate the stability of fitness value for each FS method. From the results of Std, it can be seen that the
is more stable than other algorithms in 14 datasets.
In terms of precision: It can be seen from the results presented in
Table 6 that list the precision of the proposed method
with eight wrapper FS algorithms. By examining the average precision values for all 20 datasets, it is evident that
outperforms all advanced competitor algorithms. For example, the average precision has the highest results compared with the competitive methods at eight datasets which represent 40% of the total number of tested datasets. The CSA followed this, achieving the highest precision value in the five datasets, while LFD, BSA, AOA, and TSA are the worst algorithms.
In terms of sensitivity: The results presented in
Table 7 demonstrate the sensitivity of the proposed method
with eight wrapper FS algorithms. Examining the average sensitivity values for each of the 20 Datasets reveals that
outperforms all advanced competitor algorithms. Eight datasets, or 40% of the total number of datasets tested, produce the best results based on the average sensitivity. This was followed by the CSA with the highest value of precision across five datasets. LFD, BSA, AOA, and TSA are the four worst algorithms.
In terms of F-score and number of selected features: In terms of F-score,
Table 8 reveals that the proposed method
outperforms all other competitors. It has the highest results compared with the competitive methods of eight datasets which represent 40% of the total number of tested datasets. The PSO followed this, which achieved the highest F-Score value in five datasets, while LFD, BSA, SMA, and TSA are the worst algorithms.
Based on the results of
Table 9, which depicts
the number of selected features, the proposed method
exhibited excellent performance in selecting relevant features from other competitors. It has the smallest results of the competitive methods at 15 datasets, which represents 75% of the total number of tested datasets. The SMA follows this, achieving the smallest number of selected features at ten datasets.
In this paper, we can see that the performance of the proposed
algorithm for feature selection and classification was investigated using six different statistical metrics (e.g., average fitness value, average accuracy, average sensitivity, average precision, average F_score, and number of selected features over 51 runs for each algorithm)
Table 5 displays the average accuracy for the proposed
and the eight other compared algorithms. As shown, the proposed
recorded the best fitness values in all the used datasets. The findings presented in
Table 5 demonstrate that the suggested
outperformed competing methods in nearly all datasets. Additionally, this method has the highest accuracy rate in 80% of the dataset. ALO is ranked the second algorithm in performance after the proposed
while SMA takes the third rank in performance. The proposed
algorithm achieved the best result for most datasets.
Precision and sensitivity are shown in
Table 6 and
Table 7. The higher the algorithm’s precision and sensitivity, the better its performance. It is easy to see that the proposed
has high precision and sensitivity values in eight datasets. At the same time, the CSA algorithm provides better precision and sensitivity in only six datasets. The ALO algorithm takes the third level in performance in three datasets. Previous results ensure the superiority of the proposed
algorithm over other compared algorithms.
Table 8 shows that the proposed
provides a higher F-score rate than others. The proposed
algorithm provides a higher f-score by 160% than (CSA, PSO) while it is higher by 200% than (ALO). So HBO is ranked the first algorithm in performance, then CSA and PSO came in the second rank followed by ALO ranked the third in performance. We notice that BSA and LFD algorithms ranked last and performed worst.
Table 9 displays the number of selected features for each technique during its evaluation. The results demonstrate that B HBO is highly effective for the FS procedure.
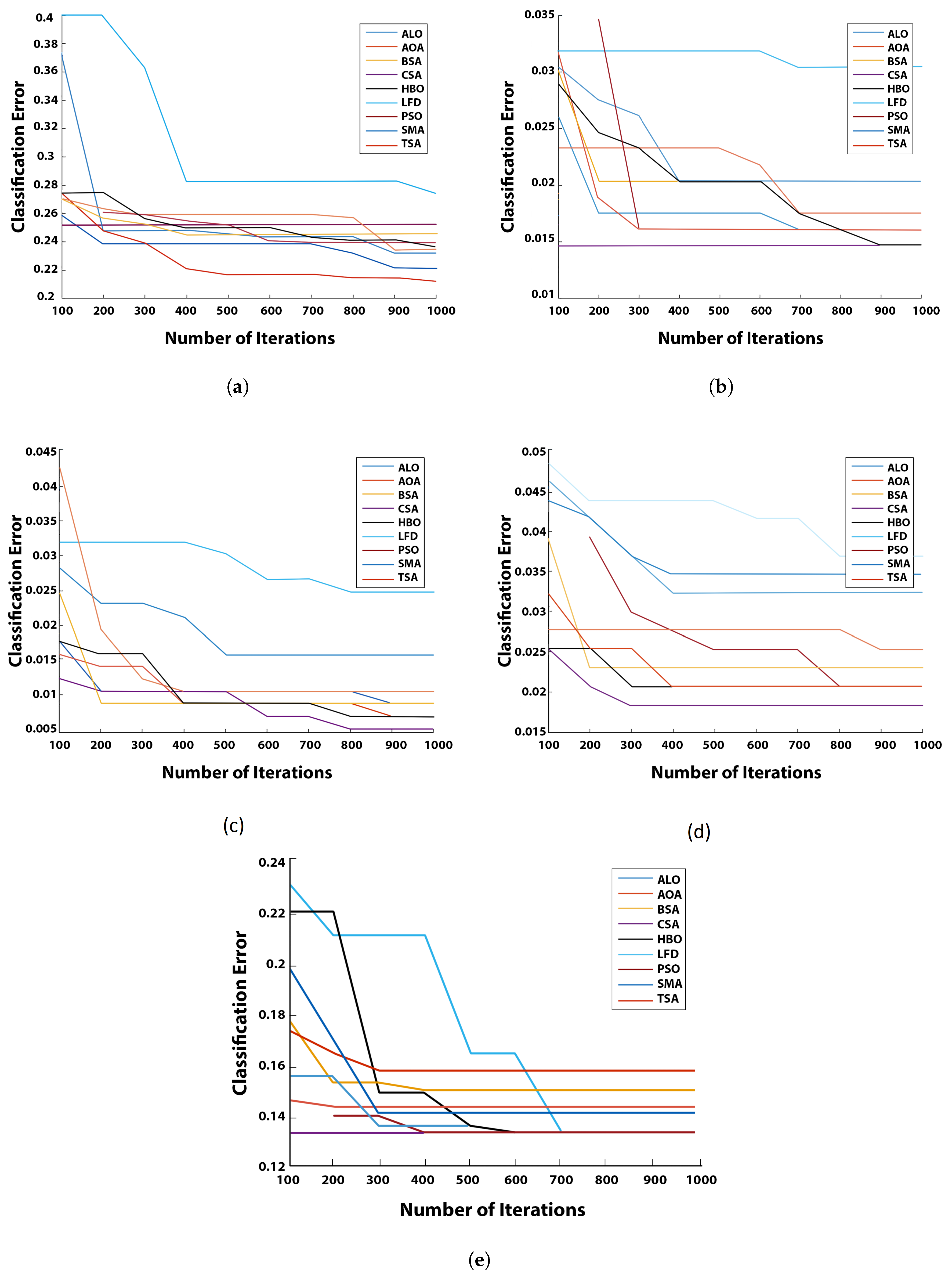
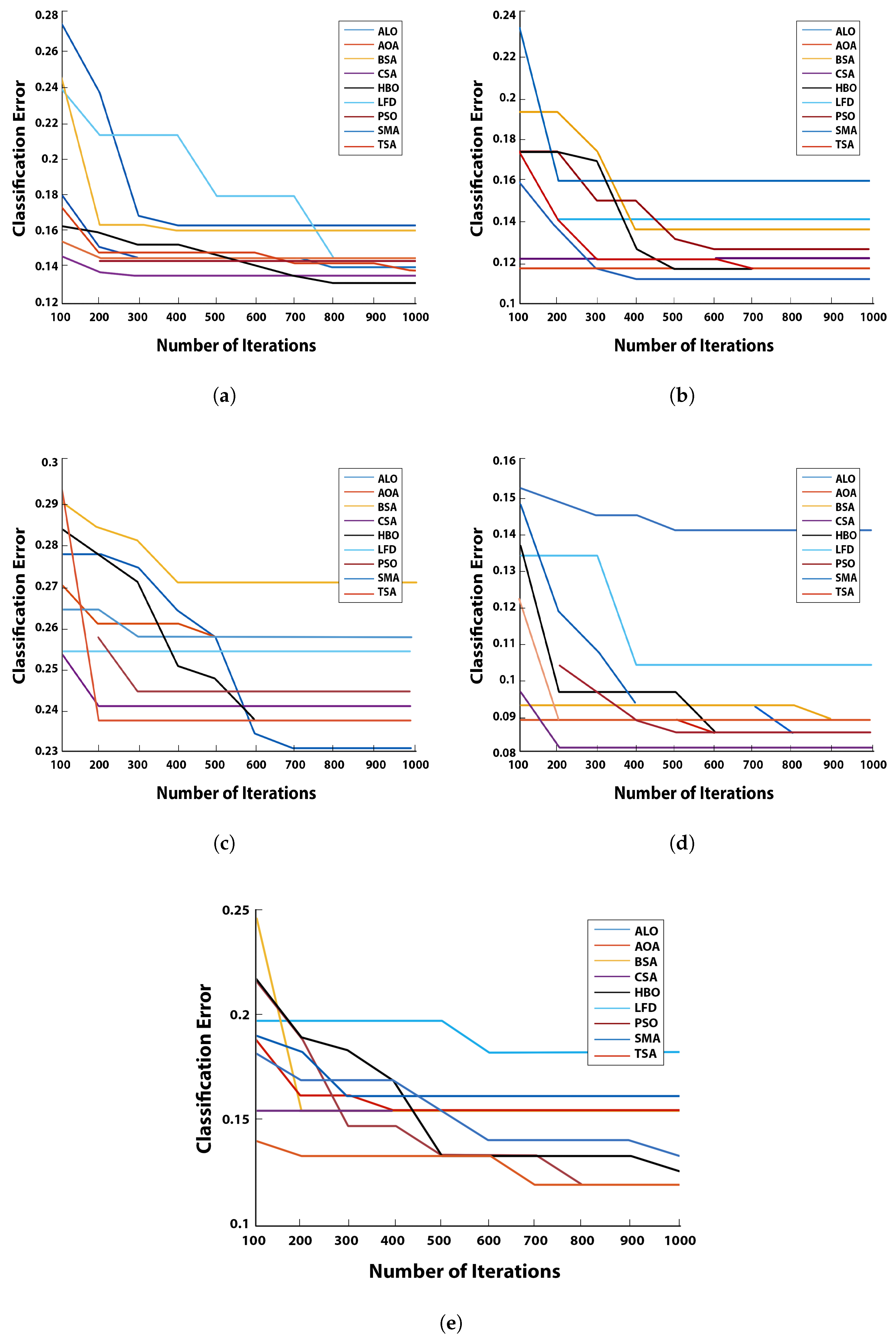
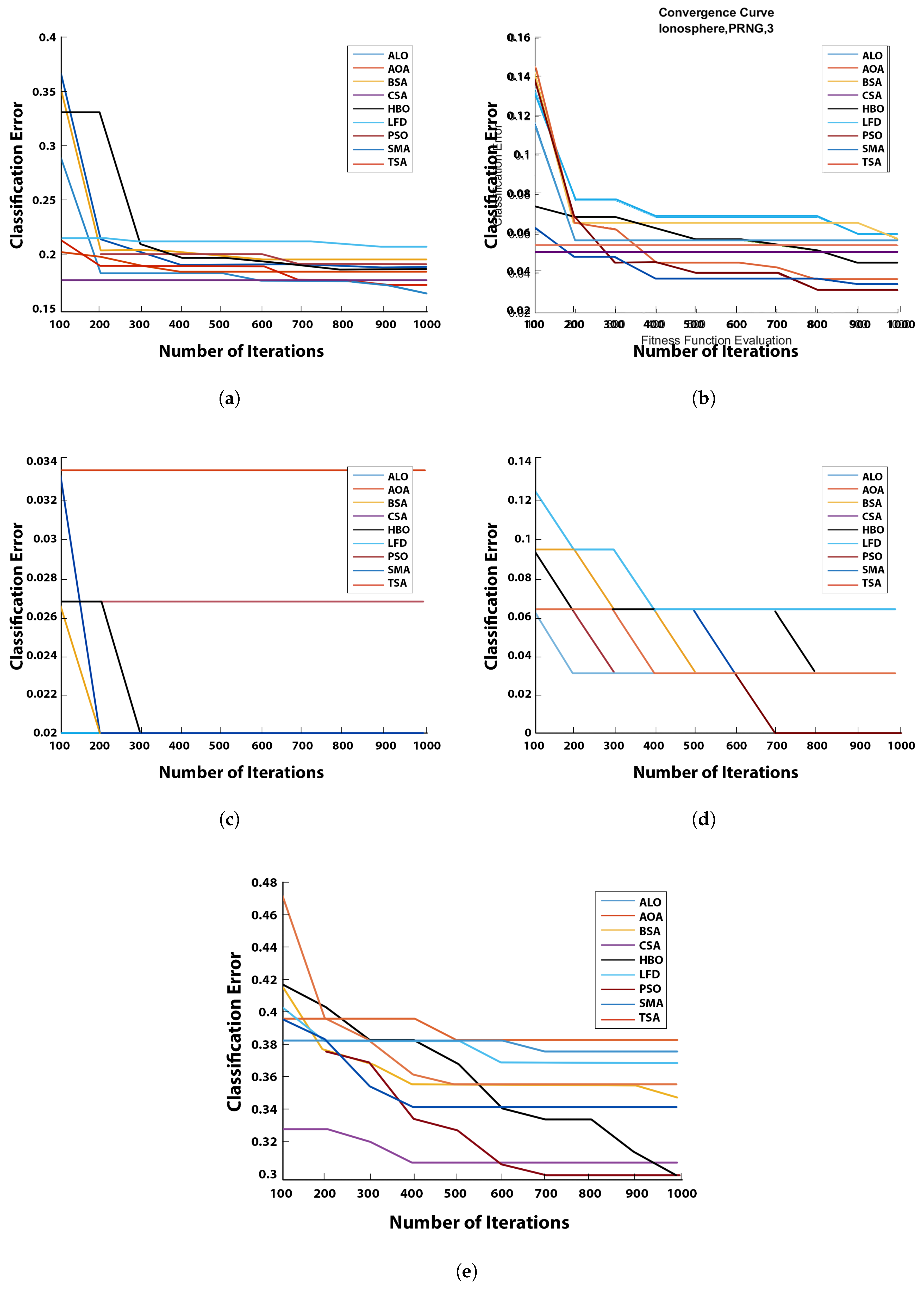
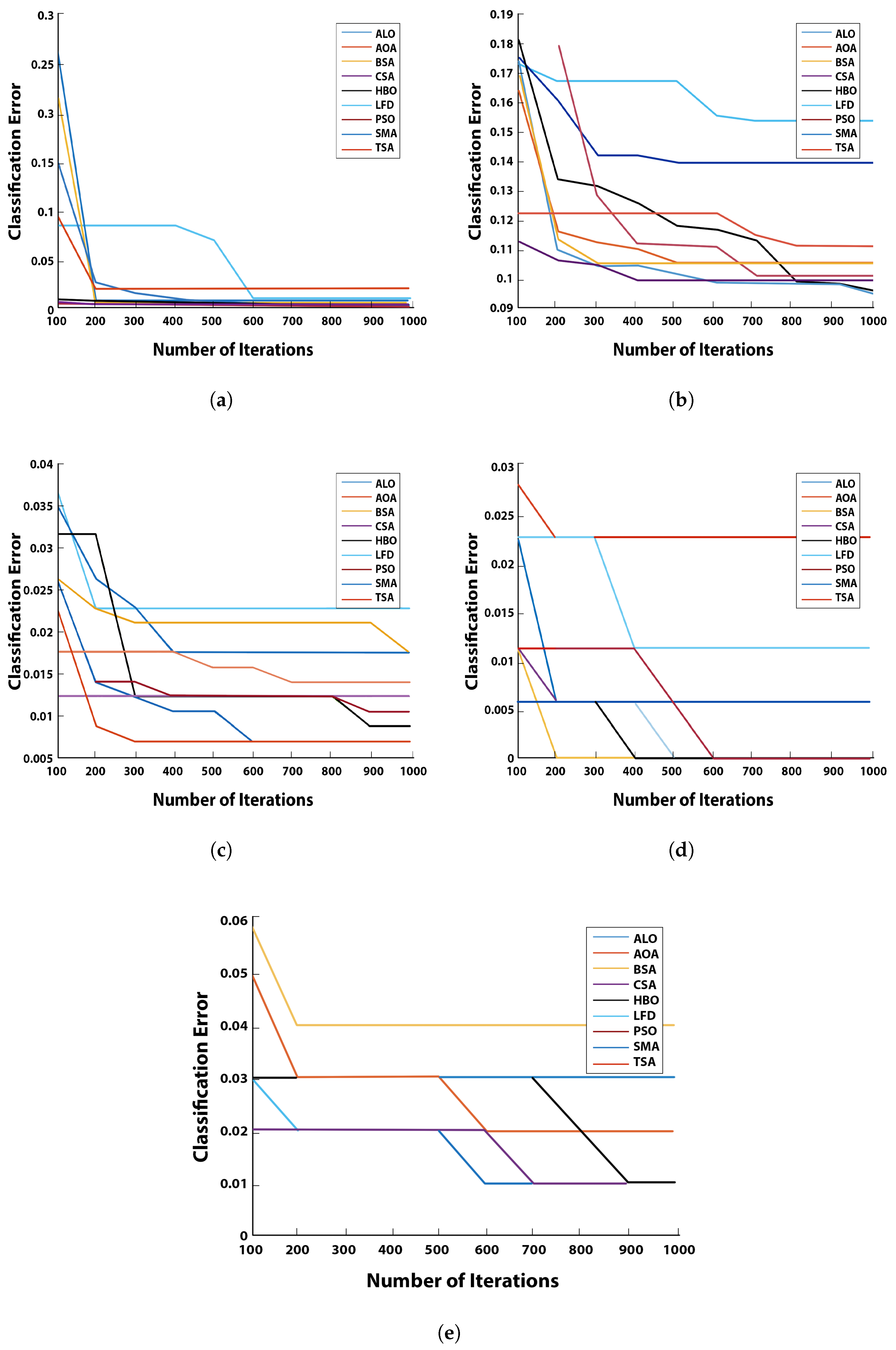
5.4. Convergence Curve
This section is devoted to the asymptotic evaluation of the proposed
algorithm for the FS problem on various carefully chosen datasets. It illustrates the relationship between the number of optimization iterations, the prediction error attained thus far, and the graphical convergence curve of the proposed
technique.The convergence curve of
with varying MHs, such as ALO, AOA, BSA, CSA, LFD, PSO, SMA, and TSA on 20 medical benchmark datasets, is shown in
Figure 2,
Figure 3,
Figure 4 and
Figure 5. It illustrated convergence curves of
with
k-NN.
As can be observed in the graphs, almost every had better outcomes than the others because their curves were higher than the other algorithms. It can be shown that causes an increase in the convergence rate toward the optimal solutions. For example, this can be noticed in the Diabetes, German, Iris, Lymphography, Vowel, Waveform_EW, Wine, and Zoo datasets. Most of these high rates of convergence are obtained at high dimension datasets.
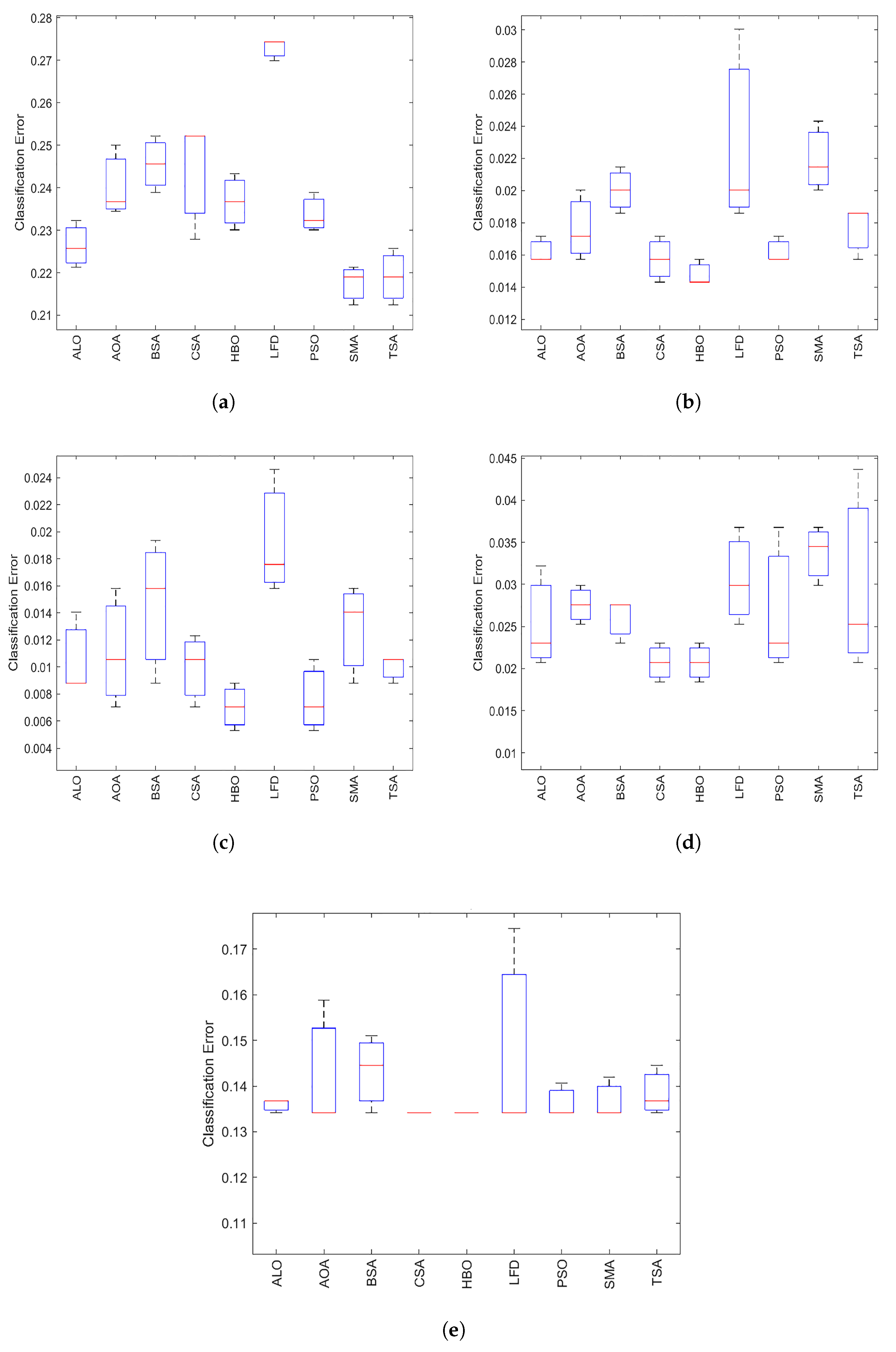
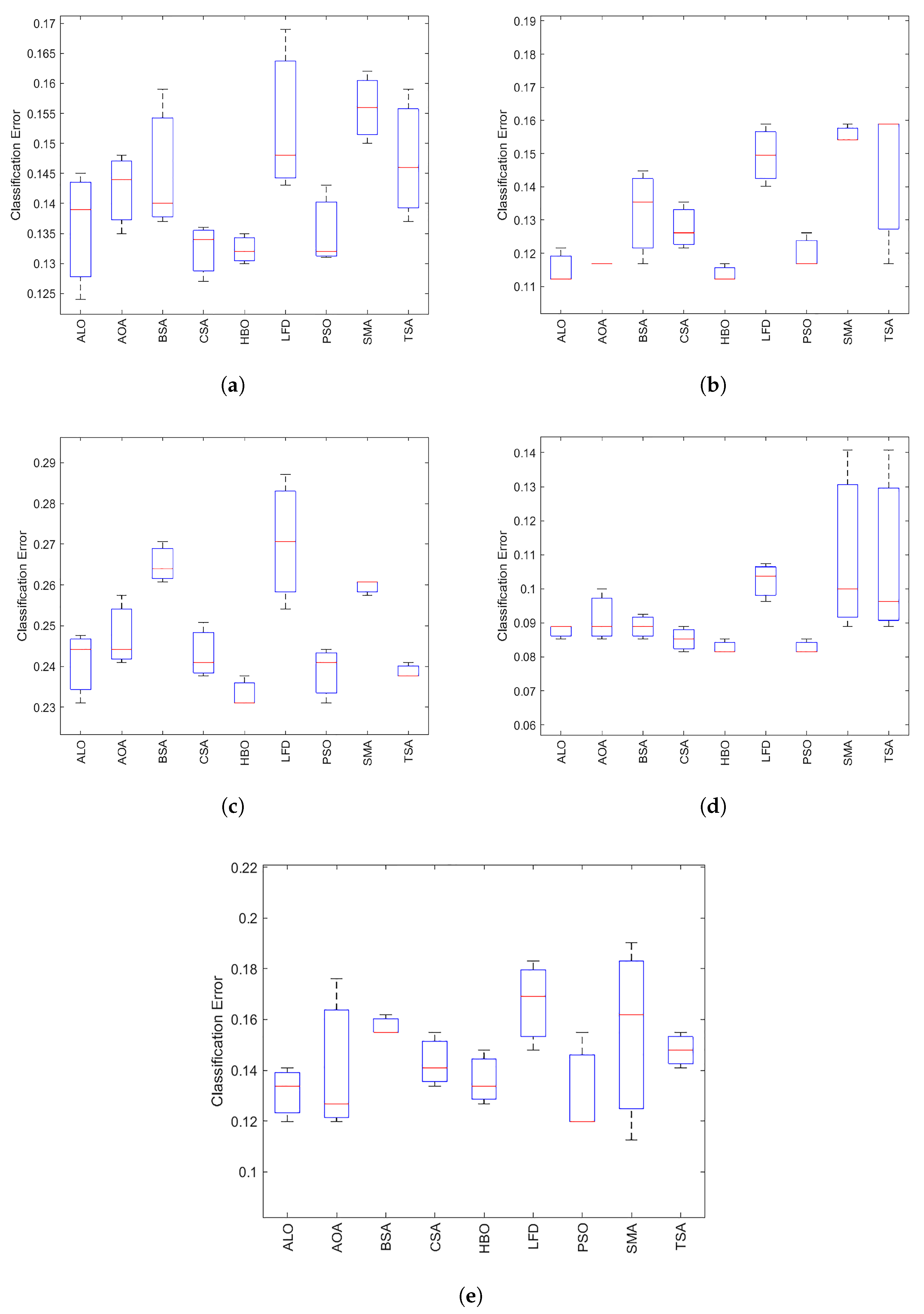
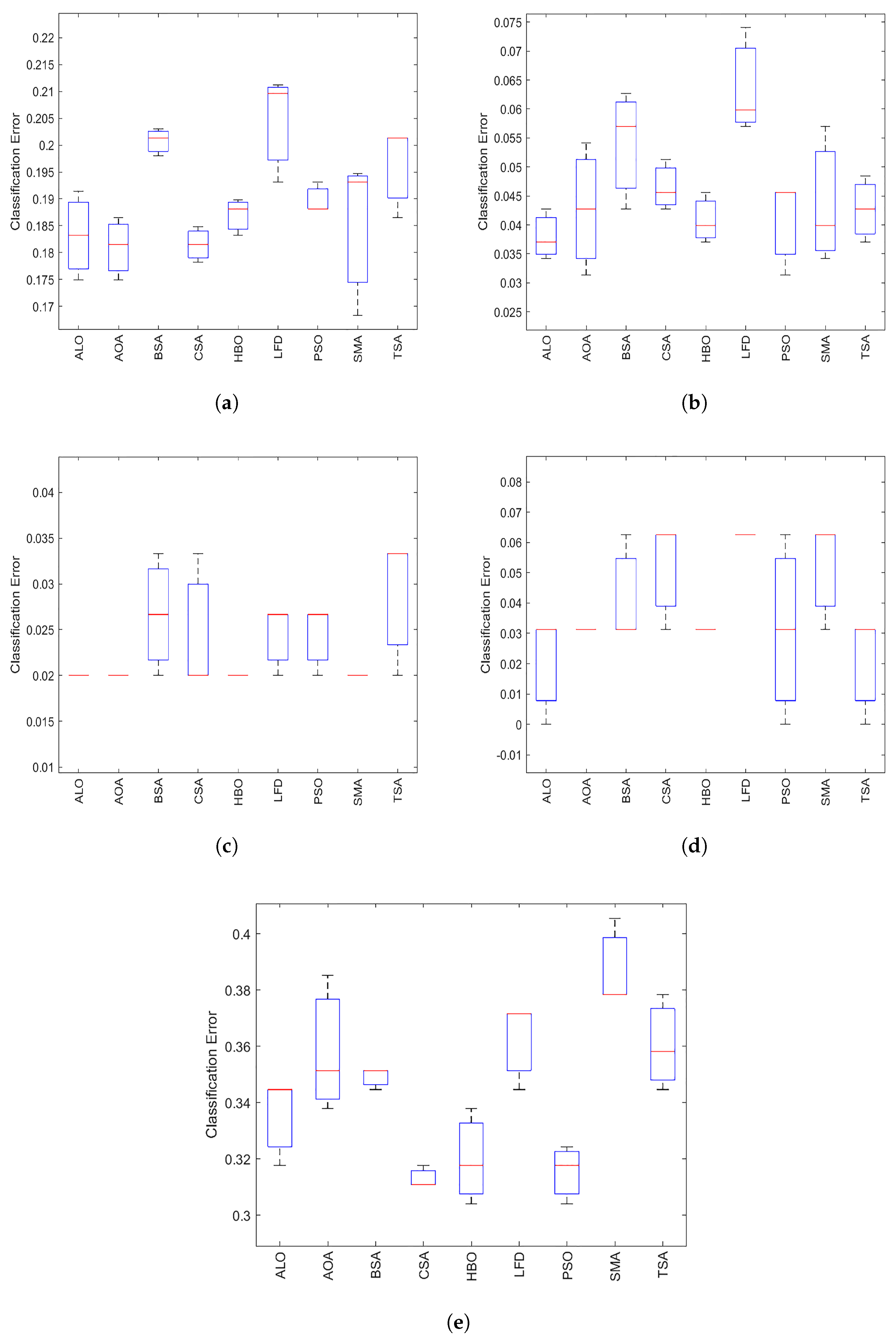
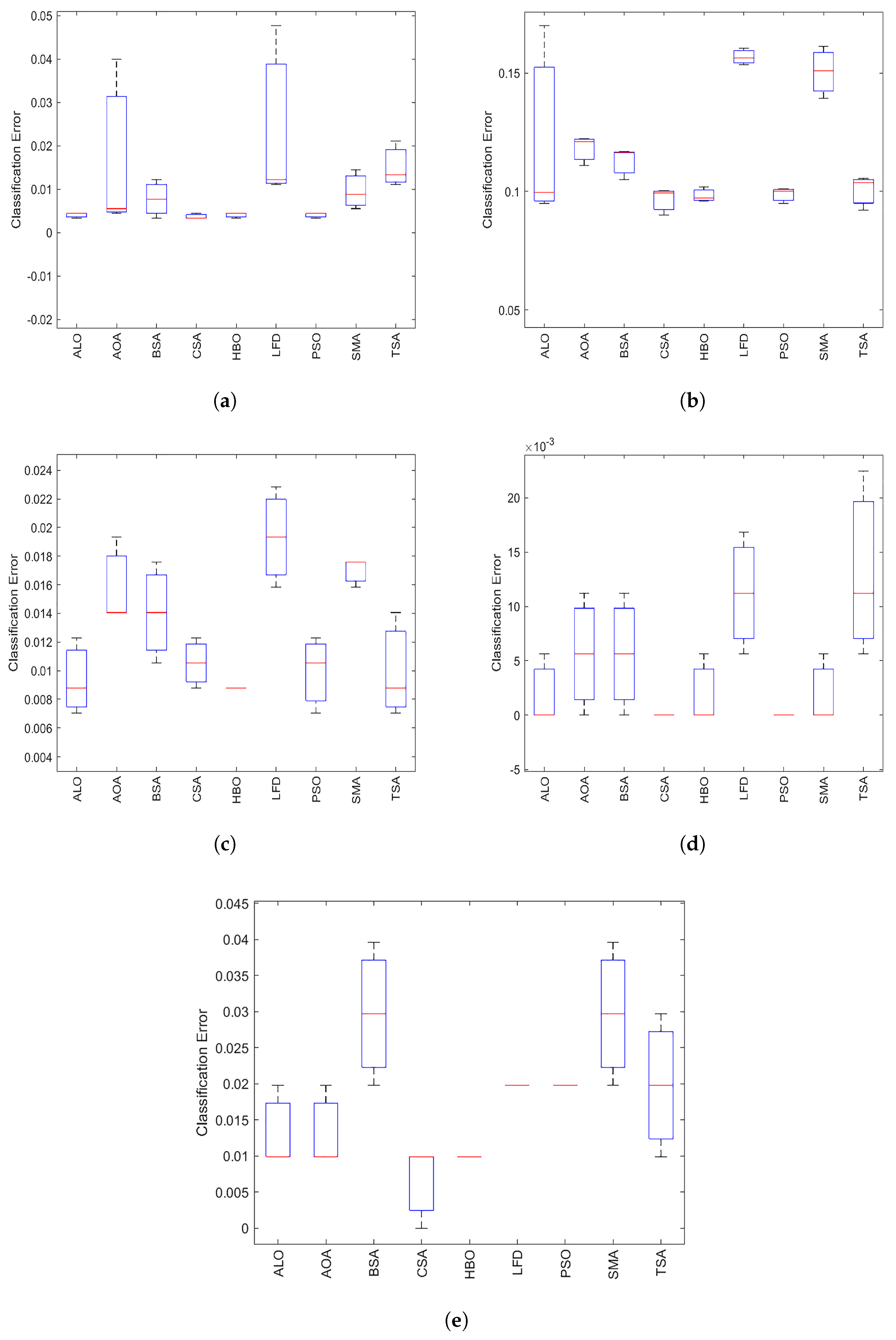
5.5. Boxplot
The boxplot is used to analyze further the behavior of
in terms of different performance measures.
Figure 6,
Figure 7,
Figure 8 and
Figure 9 show boxplots of the accuracies for all datasets achieved by the optimizers; ALO, AOA, BSA, CSA, LFD, PSO, SMA, and TSA on 20 medical benchmark datasets, and the proposed method
with
k-NN. The minimum, maximum, median, first quartile
, and third quartile
of the data are the five elements of a boxplot. In addition, the red line inside the box indicated the median value representing the algorithms’ categorization accuracy. Compared to the other algorithms,
has a higher number of boxplots.
It is evident that the has the lowest boxplot for fitness value in most tested datasets, especially those with high dimensions, except for four datasets (arrhythmia, Hepatitis, Hillvalley, and Lymphography). By analyzing the boxplot results, the following points can be reached: First, the presented has a lower boxplot at 80% of the datasets. In addition, there are some datasets’ boxplot plots that indicate that the competitive FS methods nearly have the same statistical description. In addition, most of the obtained results belong to the first quartile, which indicates that the proposed obtained a small classification error.
We can conclude that the with k-NN has the best boxplots for most datasets compared with the other algorithms. The algorithm’s median has a greater value. Depending on the dataset, the second-best algorithm is ALO.
Finally, it is clear that:
box plots Let us note that outperforms Ant Lion Optimizer (ALO), Archimedes Optimization Algorithm (AOA), Backtracking Search Algorithm (BSA), Crow Search Algorithm (CSA), Levy flight distribution (LFD), Particle Swarm Optimization (PSO), Slime Mold Algorithm (SMA), and Tree Seed Algorithm (TSA) (TSA).
In final, it is easy to note that:
The performance of the proposed method is compared to the performance of eight different algorithms. The results reveal the higher categorization, accuracy, number of selected characteristics, sensitivity, and specificity of our proposed method.
5.6. The Wilcoxon Test
Statistical analysis is necessary to compare the efficiency of
to that of other competitive algorithms. Wilcoxon’s test assesses the superiority of the presented
over the other FS methods. The main aim of using Wilcoxon’s test is to determine whether there is a significant difference between
(as control group) and each of the tested FS methods. Since Wilcoxon’s test is the pair-wise non-parametric statistical test, in this test, there are two hypotheses: the first one is called null and supposes there is no significant difference between the
and other methods. The second hypothesis is called the alternative, and it assumes there is a significant difference. The alternative hypothesis is accepted if the
p-value is less than 0.05.
Table 10 shows the
p-value obtained using Wilcoxon’s rank-sum test for the accuracy. From the results, it can be seen that
has a significant difference in accuracy value with ALO, AOA, BSA, CSA, LFD, PSO, SMA, and TSA at 17 datasets. In most cases, there is a significant difference with other methods, with nearly more than 14 datasets. The combination of MRFO and SCA enhances the performance of determining the relevant features with increasing classification accuracy. Following this criterion,
outperforms all other algorithms to varying degrees, indicating that
benefits from extensive exploitation. In general,
is statistically significant with 85% of algorithms. Therefore, we can conclude that
has a high exploration capability to investigate the most promising regions of the search space and provides superior results compared to competing algorithms.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}