
Data Mining Applied to Decision Support Systems for Power Transformers’ Health Diagnostics

 ,
,  ,
, 



Abstract
:1. Introduction
- Oil-filled power transformers;
- Oil circuit breakers;
- Current and voltage metering oil-filled transformers.
- Transformer oil analysis. The main method for diagnosing the power transformers’ technical state is analysis of dissolved gases, which result from the oil degradation during power transformer operation. The ratio of certain gases’ concentrations allows one to detect the type of equipment damage and its location [9,10,11,12,13];
- Power factor analysis. Power factor measurements and a power transformer’s capacitance are analyzed based on retrospective changes in these values for the particular unit under consideration [14];
- Detection of partial discharges. Partial discharges degrade the properties of a power transformer’s insulation and can cause serious damage. The main methods for determining partial discharges today include acoustic and electromagnetic methods, which identify the discharge location based on the sound and electromagnetic wave analysis [7,19,20], optical methods that capture ultraviolet light from the discharges [21], transient voltage analysis [22], methods for detecting high frequencies [23], etc.;
- Winding displacement identification. These tools are aimed at identifying vibration processes and transformer winding displacement. In this case, the authors propose either using an external vibration sensor, which collects data during transformer operation and by subsequent analysis gives the opportunity to determine the deviations from the normal state [24], or a more common frequency analysis, which is measuring the dependence of power transformer impedance on frequency [25,26,27,28].
2. Materials and Methods
2.1. Data Preprocessing Algorithm
- Data preprocessing, 1st iteration (preliminary data cleaning and preprocessing stage).
- Data preprocessing, 2nd iteration (main stage of data cleaning and preprocessing).
- Building a machine learning-based model.
2.2. Initial Preprocessing
2.3. Gaps and Outliers Processing
2.4. Feature Transformation and Feature Importance Analysis
- Collinearity (correlation) analysis of features based on the Spearman correlation coefficient matrix (cross-correlation of the features);
- Analysis of Spearman’s correlation coefficients of the features in relation to the target variable (class);
- Preliminary training of several machine learning models that evaluate the importance of the features during the solution process.
2.5. Second Iteration of the Algorithm
- Exclude just useless (uninformative) features;
- Reduce the number of samples and features (rows and columns) that will be removed from the original dataset.
2.6. Machine Learning Models
3. Results
3.1. Initial Dataset
3.2. Data Cleaning Iteration I
- Passport data;
- Physical and chemical oil analysis (state of the insulation);
- Oil tank chromatography (general state);
- Magnetic system state;
- Winding state;
- On-load tap changer state.

3.3. Data Cleaning: Iteration II
4. Machine Learning Application to Classify Power Transformers by State
4.1. Taking into Account Dataset Imbalance
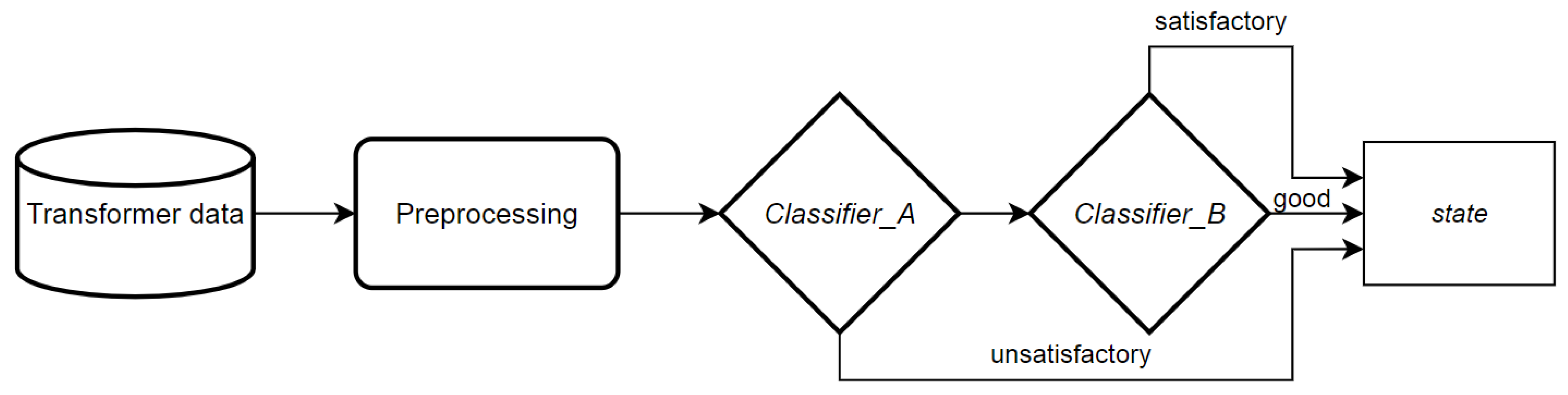
- (1.1)
- apply Classifier_A
- (2.1)
- if Classifier_A predicts “unsatisfactory” then return “unsatisfactory”
- (3.1)
- else apply Classifier_B
- (4.1)
- return Classifier_B prediction.
4.2. Classification Accuracy Metrics
- k-nearest neighbors classifier, kNN;
- Support Vector Machine, SVM (scikit-learn.org);
- Random Forest bagging on decision trees, RF (scikit-learn.org);
- AdaBoost boosting on decision trees, AB (scikit-learn.org);
- XGBoost gradient boosting on decision trees, XGB [36];
- CatBoost gradient boosting on decision trees, CB [37].
5. Discussion
- The initial dataset was 75% filled, where some features had less than 60% of entries, and in the worst case it was 28%. In this context, filling in the gaps would save the amount of data, but would significantly reduce the dataset’s reliability, since a quarter of the data entries would be filled in with synthetic values, not real ones. After excluding the most problematic columns and rows, mean filling was estimated to be 84% and the minimal one for a certain feature was 68%.
- Visualization of dataset using area diagrams made it possible to visually display the observability of the power transformers in the dataset and its dynamics in the course of data cleaning.
- Some features’ distribution asymmetry minimization was performed using logarithmic transformation.
- Spearman correlation analysis made it possible to identify features with high collinearity. From each group of such features, only the one most correlated with the target variable was left. Collinear feature minimization reduces the model’s overfitting risk, while keeping the learning rate at a high level. By training a decision tree ensemble classifier giving the features’ importance, the excluded features were confirmed to be not significant for power transformer technical state assessment.
- By implementing correlation analysis, without affecting the classification accuracy, nine features were excluded. Along with their removal, all the gaps, errors, and outliers for these features were automatically removed, which also increased the initial data quality.
- By implementing the two-iteration procedure, it was possible to save 9% of samples of the “good” class and 5% more in total for all other states. At the same time, after the 2nd iteration’s Step 4, dataset filling was estimated to be 94% with true values, and the minimum filling for individual features was 87%. Due to this, the number of values that were obtained using the data recovery algorithms turned out to be small enough so that the dataset remained as close as possible to the real data and was not a synthetic one.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khalyasmaa, A.I.; Uteuliyev, B.A.; Tselebrovskii, Y.V. Methodology for Analysing the Technical State and Residual Life of Overhead Transmission Lines. IEEE Trans. Power Deliv. 2021, 36, 2730–2739. [Google Scholar] [CrossRef]
- Eltyshev, D.K. Intelligent models for the comprehensive assessment of the technical condition of high-voltage circuit breakers. Inf. Control. Syst. 2016, 5, 45–53. [Google Scholar]
- Metwally, I.A. Failures, Monitoring and New Trends of Power Transformers. IEEE Potentials 2011, 30, 36–43. [Google Scholar] [CrossRef]
- Davidenko, I.V.; Ovchinnikov, K.V. Identification of Transformer Defects via Analyzing Gases Dissolved in Oil. Russ. Electr. Eng. 2019, 4, 338–343. [Google Scholar] [CrossRef]
- Shengtao, L.; Jianying, L. Condition monitoring and diagnosis of power equipment: Review and prospective. High. Volt. IET 2017, 2, 82–91. [Google Scholar]
- Vanin, B.V.; Lvov, Y.; Lvov, N.; Yu, M. On Damage to Power Transformers with a Voltage of 110–500 kV in Operation. Available online: https://transform.ru/articles/html/06exploitation/a000050.article (accessed on 10 February 2022).
- Tenbohlen, S.; Coenen, S.; Djamali, M.; Mueller, A.; Samimi, M.H.; Siegel, M. Diagnostic Measurements for Power Transformers. Energies 2016, 9, 347. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, B.; Zhang, X. Research on the Remote Maintenance System Architecture for the Rapid Development of Smart Substation in China. IEEE Trans. Power Deliv. 2017, 33, 1845–1852. [Google Scholar] [CrossRef]
- Duval, M.; Dukarm, J. Improving the reliability of transformer gas-in-oil diagnosis. IEEE Electr. Insul. Mag. 2005, 21, 21–27. [Google Scholar] [CrossRef]
- Faiz, J.; Soleimani, M. Dissolved gas analysis evaluation in electric power transformers using conventional methods a review. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 1239–1248. [Google Scholar] [CrossRef]
- Faiz, J.; Soleimani, M. Assessment of computational intelligence and conventional dissolved gas analysis methods for transformer fault diagnosis. IEEE Trans. Dielectr. Electr. Insul. 2018, 25, 1798–1806. [Google Scholar] [CrossRef]
- Misbahulmunir, S.; Ramachandaramurthy, V.K.; Thayoob, Y.H.M. Improved Self-Organizing Map Clustering of Power Transformer Dissolved Gas Analysis Using Inputs Pre-Processing. IEEE Access 2020, 8, 71798–71811. [Google Scholar] [CrossRef]
- Rao, U.M.; Fofana, I.; Rajesh, K.N.V.P.S.; Picher, P. Identification and Application of Machine Learning Algorithms for Transformer Dissolved Gas Analysis. IEEE Trans. Dielectr. Electr. Insul. 2021, 28, 1828–1835. [Google Scholar] [CrossRef]
- Belanger, M. Transformer Diagnosis: Part 3: Detection Techniques and Frequency of Transformer Testing. Electr. Today 1999, 11, 19–26. [Google Scholar]
- Bucher, M.K.; Franz, T.; Jaritz, M.; Smajic, J.; Tepper, J. Frequency-Dependent Resistances and Inductances in Time-Domain Transient Simulations of Power Transformers. IEEE Trans. Magn. 2019, 55, 7500105. [Google Scholar] [CrossRef]
- Cardoso, A.J.M.; Oliveira, L.M.R. Condition Monitoring and Diagnostics of Power Transformers. Int. J. Comadem. 1999, 2, 5–11. [Google Scholar]
- Zheng, Z.; Li, Z.; Gao, Y.; Yu, Q.Y.S. A New Inspection Method to Diagnose Winding Material and Capacity of Distribution Transformer based on Big Data. In Proceedings of the 2018 IEEE International Conference of Safety Produce Informatization (IICSPI), Chongqing, China, 10–12 December 2018; pp. 346–351. [Google Scholar] [CrossRef]
- Joel, S.; Kaul, A. Predictive Maintenance Approach for Transformers Based On Hot Spot Detection In Thermal images. In Proceedings of the 2020 First IEEE International Conference on Measurement, Instrumentation, Control and Automation (ICMICA), Kurukshetra, India, 24–26 June 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Hussain, M.R.; Refaat, S.S.; Abu-Rub, H. Overview and Partial Discharge Analysis of Power Transformers: A Literature Review. IEEE Access 2021, 9, 64587–64605. [Google Scholar] [CrossRef]
- Meitei, S.N.; Borah, K.; Chatterjee, S. Partial Discharge Detection in an Oil-Filled Power Transformer Using Fiber Bragg Grating Sensors: A Review. IEEE Sens. J. 2021, 21, 10304–10316. [Google Scholar] [CrossRef]
- Gao, K.; Lyu, L.; Huang, H.; Fu, C.; Chen, F.; Jin, L. Insulation Defect Detection of Electrical Equipment Based on Infrared and Ultraviolet Photoelectric Sensing Technology. In Proceedings of the IECON 2019—45th Annual Conference of the IEEE Industrial Electronics Society, Lisbon, Portugal, 14–17 October 2019; pp. 2184–2189. [Google Scholar] [CrossRef]
- Ferreira, R.S.; Ferreira, A.C. Analysis of Turn-to-Turn Transient Voltage Distribution in Electrical Machine Windings. IEEE Lat. Am. Trans. 2021, 19, 260–268. [Google Scholar] [CrossRef]
- Beura, C.P.; Beltle, M.; Tenbohlen, S. Positioning of UHF PD Sensors on Power Transformers Based on the Attenuation of UHF Signals. IEEE Trans. Power Deliv. 2019, 34, 1520–1529. [Google Scholar] [CrossRef]
- Chunlin, G.; Chenliang, Z.; Tao, L.; Kejia, Z.; Huiyuan, M. Transformer Vibration Feature Extraction Method Based on Recursive Graph Quantitative Analysis. In Proceedings of the 2020 IEEE/IAS Industrial and Commercial Power System Asia (I&CPS Asia), Weihai, China, 13–15 July 2020; pp. 1046–1049. [Google Scholar] [CrossRef]
- Jaiswal, G.C.; Ballal, M.S.; Tutakne, D.R.; Doorwar, A. A Review of Diagnostic Tests and Condition Monitoring Techniques for Improving the Reliability of Power Transformers. In Proceedings of the 2018 International Conference on Smart Electric Drives and Power System (ICSEDPS), Maharashtra State, India, 12–13 June 2018; pp. 209–214. [Google Scholar] [CrossRef]
- Denis, R.J.; An, S.K.; Vandermaar, J.; Wang, M. Comparison of Two FRA Methods to Detect Transformer Winding Movement. In Proceedings of the EPRI Substation Equipment Diagnostics Conference VIII, New Orleans, LA, USA, 20–23 February 2000. [Google Scholar]
- Christian, J.; Feser, K. The Transfer Function Method for Detection of Winding Displacements on Power Transformers after Transport. IEEE Trans. Power Deliv. 2004, 19, 214–220. [Google Scholar] [CrossRef]
- Zhao, X.; Yao, C.; Zhao, Z.; Dong, S.; Li, C.X. Investigation of condition monitoring of transformer winding based on detection simulated transient overvoltage response. In Proceedings of the 2016 IEEE International Conference on High Voltage Engineering and Application (ICHVE), Chengdu, China, 19–22 September 2016. [Google Scholar]
- Zhang, L.; Chen, H.; Wang, Q.; Nayak, N.; Gong, Y.; Bose, A.A. Novel On-Line Substation Instrument Transformer Health Monitoring System Using Synchrophasor Data. IEEE Trans. Power Deliv. 2019, 34, 1451–1459. [Google Scholar] [CrossRef]
- Do, T.-D.; Tuyet-Doan, V.-N.; Cho, Y.-S.; Sun, J.-H.; Kim, Y.-H. Convolutional-Neural-Network-Based Partial Discharge Diagnosis for Power Transformer Using UHF Sensor. IEEE Access 2020, 8, 207377–207388. [Google Scholar] [CrossRef]
- Hao, N.; Dong, Z. Condition assessment of current transformer based on multi-classification support vector machine. In Proceedings of the 2011 International Conference on Transportation, Mechanical, and Electrical Engineering, Changchun, China, 16–18 December 2011. [Google Scholar]
- Illias, H.A.; Zhao Liang, W. Identification of transformer fault based on dissolved gas analysis using hybrid support vector machine-modified evolutionary particle swarm optimisation. PLoS ONE 2018, 13, e0191366. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, Q.; Guo, Y.; Shepperd, M. A Comprehensive Investigation of the Role of Imbalanced Learning for Software Defect Prediction. IEEE Trans. Softw. Eng. 2019, 45, 1253–1269. [Google Scholar] [CrossRef] [Green Version]
- Khan, S.H.; Hayat, M.; Bennamoun, M.; Sohel, F.A.; Togneri, R. Cost-Sensitive Learning of Deep Feature Representations from Imbalanced Data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3573–3587. [Google Scholar]
- Wang, J.; Yang, Y.; Xia, B. A Simplified Cohen’s Kappa for Use in Binary Classification Data Annotation Tasks. IEEE Access 2019, 7, 164386–164397. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Dorogush, A.V.; Gulin, A.; Gusev, G.; Kazeev, N.; Prokhorenkova, L.O.; Vorobev, A. Fighting biases with dynamic boosting. arXiv 2017, arXiv:1706.09516. [Google Scholar]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef]
- Khalyasmaa, A.I.; Senyuk, M.D.; Eroshenko, S.A. Analysis of the State of High-Voltage Current Transformers Based on Gradient Boosting on Decision Trees. IEEE Trans. Power Deliv. 2021, 36, 2154–2163. [Google Scholar] [CrossRef]
- Khalyasmaa, A.I.; Senyuk, M.D.; Eroshenko, S.A. High-voltage circuit breakers technical state patterns recognition based on machine learning methods. IEEE Trans. Power Deliv. 2019, 34, 1747–1756. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Designation | Parameter |
|---|---|
| Output parameters | |
| state | Power equipment state |
| Input parameters (power transformer’s passport data) | |
| n | Transformer number in the database |
| dispatch | Dispatch name |
| trans | Power transformer model |
| volt | Voltage rating, kV |
| winding | Construction, 1—split winding, 2—2 windings, 3—3 windings |
| switching | Voltage regulation, 1—on-load tap changer, 2—no-load tap changer, 3—on-load tap changer and no-load tap changer |
| Input parameters (physical and chemical properties of transformer oil) | |
| TO_year | Oil production year |
| TO_voltage | Breakdown voltage, kV |
| TO_moist | Moisture content, g/t |
| TO_acide | Acid number, mgKOH/g |
| TO_tangent | Oil tangent at 90 °C, % |
| TO_concentr | Ionol additive concentration, % |
| TO_flashpoint | Flash point in a closed cup, °C |
| Input parameters (chromatographic analysis of oil-dissolved gases) | |
| H2 | Hydrogen content H2, % vol. |
| CH4 | Methane content CH4, % vol. |
| C2H4 | Ethylene content C2H4, % vol. |
| C2H6 | Ethane content C2H6, % vol. |
| C2H2 | Acetylene content C2H2, % vol. |
| CO2 | Carbon dioxide content CO2, % vol. |
| CO | Carbon monoxide content CO, % vol. |
| Input parameters (magnetic core characteristics) | |
| NLL_C_a | No-load losses, commissioning tests, short-circuited phase “A,” kW |
| NLL_C_b | No-load losses, commissioning tests, short-circuited phase “B,” kW |
| NLL_C_c | No-load losses, commissioning tests, short-circuited phase “C,” kW |
| NLL_O_a | No-load losses, recent tests, short-circuited phase “A,” kW |
| NLL_O_b | No-load losses, recent tests, short-circuited phase “B,” kW |
| NLL_O_c | No-load losses, recent tests, short-circuited phase “C,” kW |
| Input parameters (winding characteristics) | |
| W_year | Commissioning year |
| W_temp_com | Winding temperature, commissioning tests, °C |
| W_temp_test | Winding temperature, recent tests, °C |
| HV_R60 | High-voltage winding insulation resistance R60, commissioning tests, MOhm |
| HV_tg_c | High-voltage winding insulation tangent, commissioning tests, % |
| HV_R60_test | High-voltage winding insulation resistance R60, recent tests, MOhm |
| HV_tg_test | High-voltage winding insulation tangent, recent tests, % |
| MV_R60 | Medium-voltage winding insulation resistance R60, commissioning tests, MOhm |
| MV_tg_c | Medium-voltage winding insulation tangent, commissioning tests, % |
| MV_R60_test | Medium-voltage winding insulation resistance R60, recent tests, MOhm |
| MV_tg_test | Medium-voltage winding insulation tangent, recent tests, % |
| LV_R60 | Low-voltage winding insulation resistance R60, commissioning tests, MOhm |
| LV_tg_c | Low-voltage winding insulation tangent, commissioning tests, % |
| LV_R60_test | Low-voltage winding insulation resistance R60, recent tests, MOhm |
| LV_tg_test | Low-voltage winding insulation tangent, recent tests, % |
| Input parameters (on-load tap changer) | |
| OLTC_year | Commissioning year |
| OLTC_volt | Breakdown voltage of the oil from the on-load tap changer tank, kV |
| Model | Parameters |
|---|---|
| kNN | distance metric = Manhattan, number of neighbors = 3 |
| SVM | C = 1.0, degree = 3, kernel = radial basis function |
| RF | maximum tree depth = 3, learning rate = 0.1, number of trees = 7, criterion = Gini |
| AB | maximum tree depth = 3, learning rate = 0.1, number of trees = 7, criterion = Gini |
| XGBoost | maximum tree depth = 3, learning rate = 0.1, number of trees = 7, booster = GBTree |
| CatBoost | maximum tree depth = 3, learning rate = 0.1, number of trees = 7 |
| Model | PPV | TPR | F1 | TNR | kappa |
|---|---|---|---|---|---|
| kNN | 1.00 | 0.90 | 0.95 | 1.00 | 0.94 |
| SVM | 0.82 | 0.90 | 0.86 | 0.97 | 0.83 |
| RF | 1.00 | 0.80 | 0.89 | 1.00 | 0.88 |
| AB | 1.00 | 0.90 | 0.95 | 1.00 | 0.94 |
| XGBoost | 1.00 | 0.90 | 0.95 | 1.00 | 0.94 |
| CatBoost | 1.00 | 0.90 | 0.95 | 1.00 | 0.94 |
| Model | Parameters |
|---|---|
| kNN | distance metric = Manhattan, number of neighbors = 3 |
| SVM | C = 0.1, degree = 3, kernel = radial basis function |
| RF | maximum tree depth = 3, learning rate = 0.1, number of trees = 35, criterion = gini |
| AB | maximum tree depth = 3, learning rate = 0.1, number of trees = 35, criterion = gini |
| XGB | maximum tree depth = 3, learning rate = 0.1, number of trees = 35, booster = gbtree |
| CB | maximum tree depth = 3, learning rate = 0.1, number of trees = 35 |
| Model | PPV | TPR | F1 | TNR | Cohen’s Kappa |
|---|---|---|---|---|---|
| kNN | 0.77 | 0.89 | 0.82 | 0.85 | 0.71 |
| SVM | 0.64 | 1.0 | 0.78 | 0.69 | 0.56 |
| RF | 0.78 | 0.96 | 0.86 | 0.85 | 0.76 |
| AB | 0.83 | 0.84 | 0.84 | 0.90 | 0.74 |
| XGB | 0.88 | 0.82 | 0.85 | 0.94 | 0.77 |
| CB | 0.70 | 1.00 | 0.83 | 0.76 | 0.67 |
| Transformer State | PPV (1) | PPV (2) | TPR (1) | TPR (2) | F1 (1) | F1 (2) |
|---|---|---|---|---|---|---|
| good | 0.79 | 0.70 | 0.55 | 0.80 | 0.65 | 0.75 |
| satisfactory | 0.79 | 0.87 | 0.83 | 0.83 | 0.81 | 0.85 |
| unsatisfactory | 0.69 | 1.00 | 1.00 | 0.90 | 0.82 | 0.95 |
| average | 0.76 | 0.83 | 0.79 | 0.83 | 0.76 | 0.83 |
| weighted average | 0.78 | 0.78 | 0.77 | 0.84 | 0.76 | 0.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khalyasmaa, A.I.; Matrenin, P.V.; Eroshenko, S.A.; Manusov, V.Z.; Bramm, A.M.; Romanov, A.M. Data Mining Applied to Decision Support Systems for Power Transformers’ Health Diagnostics. Mathematics 2022, 10, 2486. https://doi.org/10.3390/math10142486
Khalyasmaa AI, Matrenin PV, Eroshenko SA, Manusov VZ, Bramm AM, Romanov AM. Data Mining Applied to Decision Support Systems for Power Transformers’ Health Diagnostics. Mathematics. 2022; 10(14):2486. https://doi.org/10.3390/math10142486
Chicago/Turabian StyleKhalyasmaa, Alexandra I., Pavel V. Matrenin, Stanislav A. Eroshenko, Vadim Z. Manusov, Andrey M. Bramm, and Alexey M. Romanov. 2022. "Data Mining Applied to Decision Support Systems for Power Transformers’ Health Diagnostics" Mathematics 10, no. 14: 2486. https://doi.org/10.3390/math10142486
APA StyleKhalyasmaa, A. I., Matrenin, P. V., Eroshenko, S. A., Manusov, V. Z., Bramm, A. M., & Romanov, A. M. (2022). Data Mining Applied to Decision Support Systems for Power Transformers’ Health Diagnostics. Mathematics, 10(14), 2486. https://doi.org/10.3390/math10142486